1 PREDIKSI PRESTASI AKADEMIK MAHASISWA FMIPA UNIVERSITAS RIAU
MENGGUNAKAN ALGORITMA K-NEAREST NEIGHBOR BERBASIS WEB
Zakyatul Lattivah, Zaiful Bahri
Mahasiswa Program Studi S1 Sistem Informasi Jurusan Ilmu Komputer
Fakultas Matematika dan Ilmu Pengetahuan Alam Kampus Bina Widya Pekanbaru, 28293, Indonesia
[email protected] ABSTRACT
This study aims to predict the academic achievement of FMIPA Riau University students using the K-Nearest Neighbor algorithm. The results of the predictions are achievement in terms of the category of cumulative grade point average (IPK) "High" or "Low", this is because new students cannot know their estimated future achievements, so with this prediction system new students can see their achievement predictions. in the future (sixth semester) by looking at the school of origin majors, the average national exam, college motivation, and work at the beginning of college which can be used as a reference and motivation for maximum achievement. The system is designed using the PHP programming language and the database server uses MySQL and the system design uses UML. The comparison of training data and test data is 70%: 30%. The results obtained from this study get an average level of accuracy of 80%.
Keywords: K-Nearest Neighbor, Prediction, Academic Achievement, Data Mining.
ABSTRAK
Penelitian ini bertujuan untuk memprediksi prestasi akademik mahasiswa FMIPA Universitas Riau menggunakan algoritma K-Nearest Neighbor. Hasil dari prediksi yaitu prestasi dalam hal kategori nilai indeks prestasi kumulatif (IPK) “Tinggi” atau “Rendah”, hal ini dikarenakan mahasiswa baru tidak bisa mengetahui perkiraan prestasinya di masa mendatang, sehingga dengan adanya sistem prediksi ini mahasiswa baru dapat melihat prediksi prestasi nya dimasa mendatang (semester enam) dengan melihat jurusan sekolah asal, rata-rata ujian nasional, motivasi kuliah, dan status kerja ketika awal masuk perkuliahan yang mana hal ini bisa dijadikan sebagai acuan dan motivasi untuk berprestasi dengan maksimal. Sistem dirancang menggunakan bahasa pemrograman PHP dan database server menggunakan MySQL serta perancangan desain sistem menggunakan UML. Perbandingan data latih dan data uji adalah 70%:30%. Hasil yang diperoleh dari penelitian ini mendapatkan rata-rata tingkat akurasi sebanyak 80%.
Kata Kunci: K-Nearest Neighbor, Prediksi, Prestasi Akademik, Data Mining.
2 PENDAHULUAN
Pendidikan merupakan hal yang sangat penting dan merupakan hak dari setiap orang.
Pendidikan bertujuan untuk mengembangkan potensi peserta didik secara umum khususnya mahasiswa, mencerdaskan mahasiswa agar menjadi manusia yang beriman dan bertakwa kepada Allah SWT, berilmu, kreatif, cakap, dan kritis dalam menghadapai permasalahan.
Perguruan tinggi merupakan salah satu penyelenggara pendidikan akademik bagi mahasiswa.
Mahasiswa dapat dijadikan sebagai acuan untuk menunjukkan keberhasilan dari proses pendidikan di perguruan tinggi salah satunya dengan cara melihat prestasi akademik mahasiswa. Prestasi mahasiswa merupakan suatu bentuk hasil pencapaian mahasiswa selama mengikuti kegiatan akademik di Perguruan Tinggi. Keberhasilan mahasiswa dalam bidang akademik ditandai dengan prestasi akademik yang dicapai.
Prestasi akademik mahasiswa diukur dengan indeks prestasi kumulatif (IPK). Nilai IPK menjadi salah satu indikator mutu kelulusan mahasiswa. Institusi pendidikan bisa dikatakan berhasil dalam melaksanakan proses pendidikan, jika lulusannya berkualitas dan berprestasi (Rasyid, 2014).
Mahasiswa yang baru masuk ke perguruan tinggi, tidak bisa mengetahui perkiraan atau prediksi prestasinya dalam hal kategori nilai IPK di masa mendatang, mahasiswa mengetahui IPK-nya ketika sudah mengikuti perkuliahan selama satu tahun. Oleh karena itu perlu dibangun suatu sistem yang dapat memprediksi prestasi akademik mahasiswa. Penelitian ini bertujuan untuk memprediksi prestasi akademik mahasiswa FMIPA Universitas Riau menggunakan algorima K-Nearest Neighbor sehingga dapat membantu memberikan informasi mengenai kategori prestasi mahasiswa baru di semester enam mendatang, hal ini dapat membantu mencegah ataupun memotivasi untuk berprestasi dengan maksimal dikarenakan IPK tidak hanya memiliki kemungkinan untuk naik atau bertahan, tetapi dapat turun dengan signifikan. Sistem prediksi prestasi akademik ini sudah pernah diteliti menggunakan metode berbeda, yaitu “Sistem Prediksi Prestasi Akademik Mahasiswa Menggunakan Metode Decision Tree C4.5” (Rasyid, 2014)
Penelitian lainnya berjudul “Algoritma K-Nearest Neighbor Classification Sebagai Sistem Prediksi Predikat Prestasi Mahasiswa” yang diteliti oleh Mustakim dan Giantika Oktaviani F tahun 2016. Penelitian ini memprediksi predikat mahasiswa pujian, sangat memuaskan, memuaskan, atau cukup. Proses prediksi menggunakan algoritma K-Nearest Neighbor Classification (K-NN) dan menghasilkan pengujian akurasi sebesar 82%
(Mustakim and Oktaviani, 2016).
METODE PENELITIAN
a. Teknik Pengumpulan Data
Teknik pengumpulan data pada penelitian ini menggunakan kuisioner online, wawancara, dan studi literatur. Data yang digunakan pada penelitian ini adalah data mahasiswa FMIPA Universitas Riau angkatan 2016 dan 2017 jenjang S1 yang didapat melalui kuisoner. Wawancara dilakukan dengan bagian akademis FMIPA Universitas Riau.
Studi literatur yaitu dilakukan dengan mengambil informasi untuk dijadikan sebagai referensi yang terdapat pada jurnal, buku ataupun media eletronik lainnya yang memiliki
3 keterkaitan dengan materi penelitian.
b. Data Mining
Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Mustakim and Oktaviani, 2016).
Definisi lain diantaranya adalah pembelajaran berbasis induksi (induction-based learning) adalah proses pembentukan definisi-definisi konsep umum yang dilakukan dengan cara mengobservasi contoh-contoh spesifik dari konsep-konsep yang akan dipelajari.
Data mining berisi pencarian trend atau pola yang diinginkan dalam database besar untuk mengambil keputusan diwaktu yang akan datang. Pola-pola ini dikenali oleh perangkat tertentu yang dapat memberikan suatu analisa data yang berguna dan berwawasan yang kemudian dapat dipelajari lebih teliti, yang mungkin saja menggunakan perangkat pendukung keputusan yang lainnya.
Data mining merupakan suatu langkah dalam Knowledge Discoverying Database (KDD). Proses KDD secara garis besar dapat dijelaskan sebagai berikut (Mutiara, 2015).
1. Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-processing/Cleaning
Sebelum proses data mining, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang tidak konsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak.
3. Transformation
Data yang telah dipilih ditransformasi, sehingga data tersebut sesuai untuk proses data mining. Proses transformasi dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Interpretation Evaluation
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
c. Algoritma K-Nearest Neighbor
K-Nearest Neighbours merupakan sebuah metode untuk melakukan klasifikasi terhadap objek berdasarkan data latih yang jaraknya paling dekat dengan titik objek tersebut.
Algoritma K-NN merupakan algoritma supervised, yang bertujuan untuk menemukan pola baru dalam data dengan menghubungkan pola data yang sudah ada dengan data yang baru.
Nilai k yang terbaik untuk algoritma ini tergantung pada data, secara umumnya, nilai k yang tinggi akan mengurangi efek noise pada klasifikasi, tetapi membuat batasan antara klasifikasi menjadi lebih kabur (Dina and Marjianto, 2018).
4 Algoritma K-NN adalah salah satu metode yang digunakan untuk analisis klasifikasi, namun beberapa dekade terakhir metode K-NN juga digunakan untuk prediksi.
Langkah-langkah untuk menghitung algoritma K-NN adalah (Suwirmayanti, 2017):
1. Menentukan nilai k
K artinya jumlah tetangga terdekat. Syarat nilai k adalah tidak boleh lebih besar dari jumlah data latih dan nilai k harus ganjil dan lebih dari satu. Nilai k yang terbaik untuk algoritma ini tergantung pada data. Secara umum, nilai k yang tinggi akan mengurangi efek noise pada klasifikasi, tetapi membuat batasan antara setiap klasifikasi menjadi semakin kabur. Menentukan k yaitu yaitu :
k = √𝑛 (1)
dimana:
k = jumlah tetangga terdekat n = jumlah data latih.
2. Menghitung kuadrat jarak (euclidean distance) masing-masing objek terhadap data latih yang diberikan.
d = √∑𝑝𝑖=1(𝑥2𝑖− 𝑥1𝑖)² (2) dimana:
𝑥1 = data sampel 𝑥2 = data uji i = variabel data d = jarak
p = dimensi data
3. Mengurutkan objek-objek tersebut ke dalam kelompok yang mempunyai jarak euclid terkecil.
4. Mengumpulkan label class Y (Klasifikasi Nearest Neighbour).
5. Menggunakan kategori Nearest Neighbour yang paling mayoritas maka dapat diprediksikan nilai query instance yang telah dihitung.
d. Rumus Slovin
Berdasarkan sejarahnya, rumus ini pertama kali diperkenalkan pada tahun 1960 oleh Slovin. Rumus Slovin merupakan rumus yang digunakan untuk menentukan ukuran sampel minimal (n) jika diketahui ukuran populasi (N). Rumus Slovin sebagai berikut (Tullah and Hanafri, 2014):
n = 𝑁
1+𝑁𝑒2 (3)
Dimana : n : jumlah sampel N : jumlah populasi
e : batas toleransi kesalahan (error tolerance)
e. Normalisasi Min-max
Data mentah yang telah didapat ditransformasikan terlebih dahulu sehingga data tersebut sesuai atau cocok untuk proses mining. Data yang telah ditransformasi selanjutnya dinormalisasi. Salah satu metode normalisasi adalah min-max normalization dimana atribut diskalakan dalam range yang lebih kecil seperti 0.0 sampai 1.0. Kelebihan metode ini adalah
5 keseimbangan nilai perbandingan antara data ketika sebelum dan sesudah proses normalisasi.
Persamaan normalisasi min-max ditunjukkan dengan persamaan (Junaedi et al., 2011):
v' = 𝑣−𝑚𝑖𝑛𝐴
𝑚𝑎𝑥𝐴−𝑚𝑖𝑛𝐴 (new_𝑚𝑎𝑥𝐴 – new_𝑚𝑖𝑛𝐴 ) + new_𝑚𝑖𝑛𝐴 (4) dimana :
v' = nilai data yang sudah dinormalisasi v = nilai data yang belum dinormalisasi
𝑚𝑎𝑥𝐴 = nilai maksimum data dari atribut ke-A 𝑚𝑖𝑛𝐴 = nilai minimum data dari atribut ke-A
new_𝑚𝑎𝑥𝐴 = nilai maksimum data baru dari atribut ke-A new_𝑚𝑖𝑛𝐴 = nilai minimum data baru dari atribut ke-A f. Split Validation
Split Validation adalah teknik validasi yang membagi data menjadi dua bagian secara acak, sebagian sebagai data training dan sebagian lainnya sebagai data testing. Dengan menggunakan Split Validation akan dilakukan percobaan training berdasarkan split ratio yang telah ditentukan sebelumnya, untuk kemudian sisa dari split ratio data training akan dianggap sebagai data testing. Data training adalah data yang akan dipakai dalam melakukan pembelajaran sedangkan data testing adalah data yang belum pernah dipakai sebagai pembelajaran dan akan berfungsi sebagai data pengujian kebenaran atau keakurasian hasil pembelajaran. Ilustrasi split validation dapat dilihat pata tabel 1 (Dwi Untari, 2010).
Tabel 1. ilustrasi Split Validation
g. Akurasi
Perhitungan akurasi dapat dilihat pada persamaan berikut (Mustakim and Oktaviani, 2016):
Akurasi = jumlah pengujian yang diprediksi benar
jumlah data yang diuji x 100% (5)
HASIL DAN PEMBAHASAN
a. Data Yang Digunakan
Data yang digunakan adalah data sampel. Untuk mendapatkan jumlah sampel, data populasi dihitung menggunakan Rumus Slovin. Populasi mahasiswa FMIPA jenjang S1 adalah 1153 mahasiswa, untuk mendapatkan jumlah data sampel digunakan Rumus Slovin sebagai berikut:
6 n = 𝑁
1+𝑁𝑒2
n = 1153
1+1153 (0,05)2
= 296,97
= 297 (dibulatkan) dimana:
n : jumlah sampel N : jumlah populasi (1153)
e : batas toleransi kesalahan/error tolerance (0,05)
Sehingga diperoleh data sampel sebanyak 297 data. 297 data sampel ini di-cleaning dikarenakan dari pengumpulan data melalui kuisoner online terdapat data yang kosong atau tidak lengkap, kemudian data akan diproses lagi sesuai dengan tahapan dalam data mining.
b. Tahapan Proses Data Mining
Proses data mining tahap pertama (data preprocessing) terdiri dari selection yaitu memilih data yang sesuai dengan variabel yang dibutuhkan dalam penelitian terdiri dari jurusan sekolah (asal), rata-rata ujian nasional, status kerja (status pekerjaan mahasiswa ketika awal masuk kuliah), motivasi pilihan kuliah (pihak yang memotivasi mahasiswa dalam memilih progam studi kuliah) dan IPK (IPK mahasiswa hingga disemester enam). IPK menjadi label kelas atau kelas tujuan yang nantinya dikategorikan menjadi kategori “tinggi”
atau “rendah”. Dari 297 data yang telah disampel menggunakan Rumus Slovin, hanya tersedia 253 data dan selebihnya merupakan data kosong atau tidak lengkap.
Selanjutnya data di-cleaning untuk menghilangkan data yang tidak digunakan dalam proses data mining sistem diantaranya membuang data yang kosong/tidak lengkap, menghilangkan duplikasi data, memeriksa data yang tidak konsisten, dan memperbaiki kesalahan pada data. sehingga total data setelah di-cleaning menjadi 249.
Kemudian data ditranformasi data untuk merubah tipe data menjadik numerik agar dapat dihitung menggunakan algoritma K-NN. Dalam transformasi, terdapat beberapa pendekatan/teknik untuk melakukan transformasi data, salah satunya adalah normalisasi.
Setelah data ditransformasi kemudian data di normalisasi dengan normalisasi min-max (Junaedi et al., 2011). Pada tahap normalisasi ini data latih dan data uji akan dibagi secara otomatis oleh sistem dan dipisah tiap program studi.
c. Perhitungan K-NN
Selanjutnya data yang siap diproses menggunakan algoritma K-NN adalah data yang telah dinormalisasi. Perhitungan dibawah untuk program studi sistem informasi. Cara yang sama juga dilakukan untuk Program Studi Biologi, Kimia, Fisika, Matematika, dan Statistika.
hasil normalisasi dapat dilihat pada tabel 2.
Tabel 2. Dataset hasil normalisasi
No Nama NIM Prodi Jurusan
sekolah
Rata-
rata UN Motivasi Status
kerja IPK
1 Dea ika saskia 1603111451 Sistem Informasi 0,4 0 0,5 0 Tinggi
2 Deviani Sinaga 1603122971 Sistem Informasi 0 0 0,5 0 Tinggi
. .
249 Dira Andriani 1603115429 Sistem Informasi 0 0,5 0 0 Tinggi
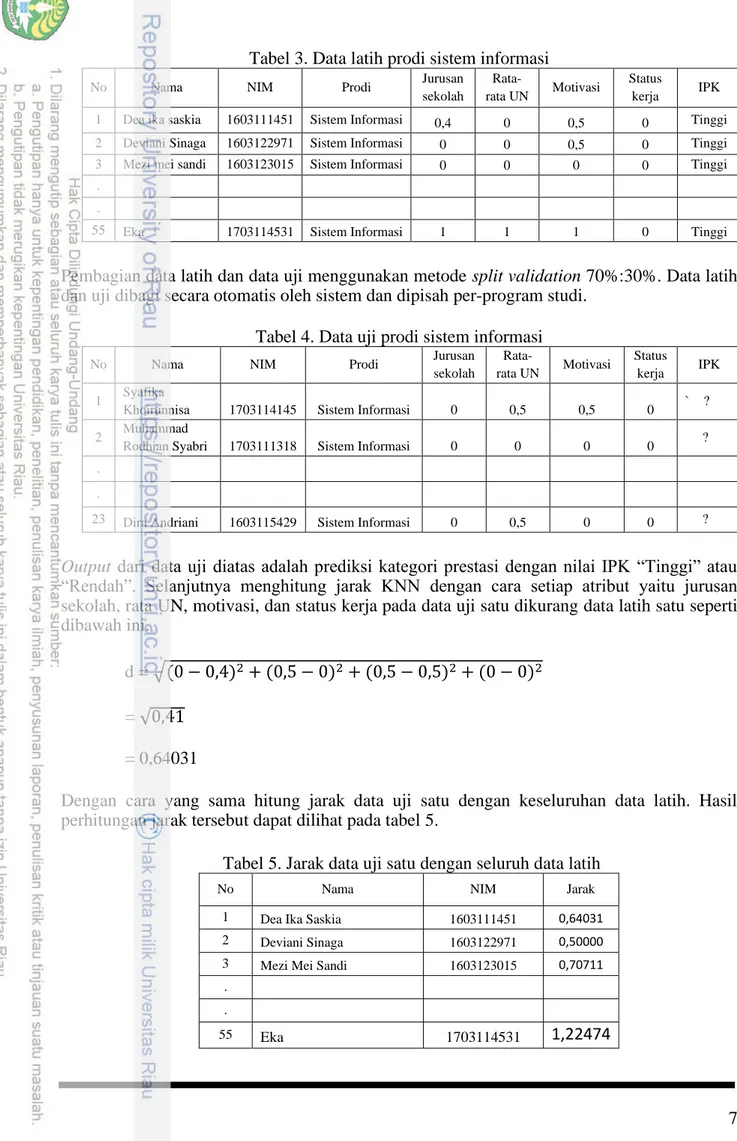
7 Tabel 3. Data latih prodi sistem informasi
No Nama NIM Prodi Jurusan
sekolah
Rata-
rata UN Motivasi Status
kerja IPK
1 Dea ika saskia 1603111451 Sistem Informasi 0,4 0 0,5 0 Tinggi
2 Deviani Sinaga 1603122971 Sistem Informasi 0 0 0,5 0 Tinggi
3 Mezi mei sandi 1603123015 Sistem Informasi 0 0 0 0 Tinggi
. .
55 Eka 1703114531 Sistem Informasi 1 1 1 0 Tinggi
Pembagian data latih dan data uji menggunakan metode split validation 70%:30%. Data latih dan uji dibagi secara otomatis oleh sistem dan dipisah per-program studi.
Tabel 4. Data uji prodi sistem informasi
No Nama NIM Prodi Jurusan
sekolah
Rata-
rata UN Motivasi Status
kerja IPK 1 Syafika
Khoirunnisa 1703114145 Sistem Informasi 0 0,5 0,5 0 ` ?
2 Muhammad
Rodhian Syabri 1703111318 Sistem Informasi 0 0 0 0 ?
. .
23 Dira Andriani 1603115429 Sistem Informasi 0 0,5 0 0 ?
Output dari data uji diatas adalah prediksi kategori prestasi dengan nilai IPK “Tinggi” atau
“Rendah”. Selanjutnya menghitung jarak KNN dengan cara setiap atribut yaitu jurusan sekolah, rata UN, motivasi, dan status kerja pada data uji satu dikurang data latih satu seperti dibawah ini.
d = √(0 − 0,4)2+ (0,5 − 0)2+ (0,5 − 0,5)2+ (0 − 0)2
= √0,41
= 0,64031
Dengan cara yang sama hitung jarak data uji satu dengan keseluruhan data latih. Hasil perhitungan jarak tersebut dapat dilihat pada tabel 5.
Tabel 5. Jarak data uji satu dengan seluruh data latih
No Nama NIM Jarak
1 Dea Ika Saskia 1603111451 0,64031
2 Deviani Sinaga 1603122971 0,50000
3 Mezi Mei Sandi 1603123015 0,70711
. .
55 Eka 1703114531 1,22474
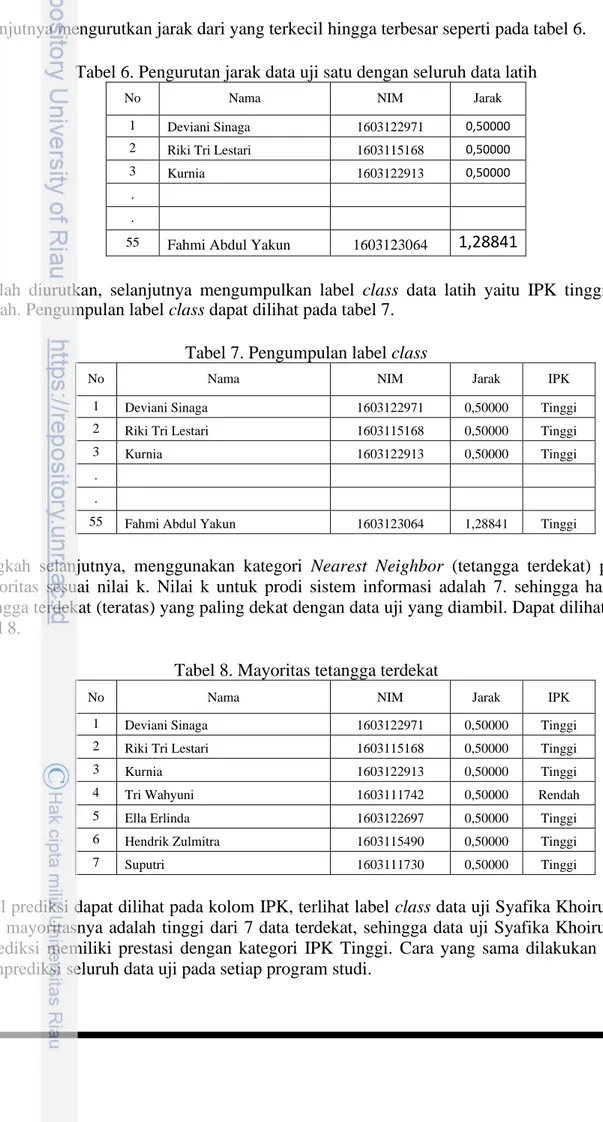
8 Selanjutnya mengurutkan jarak dari yang terkecil hingga terbesar seperti pada tabel 6.
Tabel 6. Pengurutan jarak data uji satu dengan seluruh data latih
No Nama NIM Jarak
1 Deviani Sinaga 1603122971 0,50000
2 Riki Tri Lestari 1603115168 0,50000
3 Kurnia 1603122913 0,50000
. .
55 Fahmi Abdul Yakun 1603123064 1,28841
Setelah diurutkan, selanjutnya mengumpulkan label class data latih yaitu IPK tinggi atau rendah. Pengumpulan label class dapat dilihat pada tabel 7.
Tabel 7. Pengumpulan label class
No Nama NIM Jarak IPK
1 Deviani Sinaga 1603122971 0,50000 Tinggi
2 Riki Tri Lestari 1603115168 0,50000 Tinggi
3 Kurnia 1603122913 0,50000 Tinggi
. .
55 Fahmi Abdul Yakun 1603123064 1,28841 Tinggi
Langkah selanjutnya, menggunakan kategori Nearest Neighbor (tetangga terdekat) paling mayoritas sesuai nilai k. Nilai k untuk prodi sistem informasi adalah 7. sehingga hanya 7 tetangga terdekat (teratas) yang paling dekat dengan data uji yang diambil. Dapat dilihat pada tabel 8.
Tabel 8. Mayoritas tetangga terdekat
No Nama NIM Jarak IPK
1 Deviani Sinaga 1603122971 0,50000 Tinggi
2 Riki Tri Lestari 1603115168 0,50000 Tinggi
3 Kurnia 1603122913 0,50000 Tinggi
4 Tri Wahyuni 1603111742 0,50000 Rendah
5 Ella Erlinda 1603122697 0,50000 Tinggi
6 Hendrik Zulmitra 1603115490 0,50000 Tinggi
7 Suputri 1603111730 0,50000 Tinggi
Hasil prediksi dapat dilihat pada kolom IPK, terlihat label class data uji Syafika Khoirunnisa nilai mayoritasnya adalah tinggi dari 7 data terdekat, sehingga data uji Syafika Khoirunnisa diprediksi memiliki prestasi dengan kategori IPK Tinggi. Cara yang sama dilakukan untuk memprediksi seluruh data uji pada setiap program studi.
9 Hasil perhitungan akurasi dengan menggunakan perbandingan data latih dan data uji 70%:30% setiap program studi, kinerja algoritma K-NN pada sistem memperoleh 100% pada program studi Sistem Informasi, 95% Biologi, 75% Kimia, 80% Fisika, 66% Matematika, dan 66% Statistika. Setelah mendapatkan persentase akurasi, didapatkan rata-rata akurasi sebanyak 80%.
d. Perancangan Sistem
Dalam perancangan sistem prediksi prestasi akademik mahasiswa FMIPA Universitas Riau, sistem dirancang dengan pemodelan Unified Modelling Language (UML) yang terdiri dari use case diagram, activity diagram, class diagram, dan sequence diagram.
KESIMPULAN
Berdasarkan penelitian yang dilakukan, didapatkan bahwa hasil prediksi prestasi akademik mahasiswa FMIPA Universitas Riau menggunakan algoritma K-NN memperoleh akurasi 100% untuk Program Studi Sistem Informasi, 95% Biologi, 75% Kimia, 80% Fisika, 66% Matematika, dan 66% Statistika, kemudian rata-rata akurasi diperoleh sebanyak 80%.
Persentase yang cukup tinggi, tetapi hal ini disebabkan karena sebaran label/class data yang tidak seimbang, dan data yang sedikit variatifnya, sehingga data latih dan data uji banyak yang memiliki kemiripan, sedangkan label seluruh datanya tidak seimbang. Sistem akan mengambil hasil sesuai dengan data latih dan data uji yang tersedia, sehingga menghasilkan peluang prediksi relatif tepat.
SARAN
1. Sistem Prediksi Prestasi Akademik Mahasiswa menggunakan algoritma K-Nearest Neighbor ini dapat dikembangkan lagi dengan mengambil data yang seimbang (persentase labelnya memiliki jumlah yang seimbang, karena pada penelitian ini jumlah label data yang memiliki kategori prestasi (IPK) tinggi lebih banyak daripada yang rendah), akan lebih baik jika labelnya memiliki nilai yang seimbang sehingga sistem akan terprediksi dengan baik.
2. Sistem Prediksi Prestasi Akademik Mahasiswa menggunakan algoritma K-Nearest Neighbor ini dapat dikembangkan lagi dengan menambah cakupan data yang digunakan, sehingga mampu menambah kompleksitas untuk hasil prediksi serta keakurasiannya.
3. Sistem Prediksi Prestasi Akademik Mahasiswa menggunakan algoritma K-Nearest Neighbor ini dapat dikembangkan lagi dengan algoritma data mining lainnya, sehinggga mendapatkan hasil yang lebih optimal.
4. Sistem Prediksi Prestasi Akademik Mahasiswa menggunakan algoritma K-Nearest Neighbor ini dapat dikembangkan lagi dengan berbasis mobile.
UCAPAN TERIMA KASIH
Penulis mengucapkan banyak terima kasih kepada bapak Zaiful Bahri, S.Si., M.Kom selaku dosen pembimbing skripsi yang telah membimbing, meluangkan waktu, memotivasi, dan membantu dalam penelitian serta penulisan karya ilmiah ini.
10 DAFTAR PUSTAKA
Dina, N. Z. and Marjianto, R. S. 2018. Prediksi Penentuan Penerima Besasiswa Dengan Metode Knearest Neighbour, Jurnal Nasional Informatika dan Teknologi Jaringan, 2, pp. 135–139.
Dwi Untari. 2010. Data Mining untuk Menganalisa Prediksi Mahasiswa Berpotensi Non- Aktif Menggunaka Metode Decision Tree C4.5, Fakultas Ilmu Komputer Universitas Dian Nuswantoro.
Hermawati, Fajar Astuti. 2013. Data Mining.Yogyakarta : Penerbit Andi.
Junaedi, H. et al. 2011. Data Transformation pada Data Mining, Prosiding Konferensi Nasional Inovasi dalam Desain dan Teknologi-IDeaTech, 7, pp. 93–99.
Mustakim, F. and Oktaviani, G. 2016. Algoritma K-Nearest Neighbor Classification, 13(2), pp. 195–202.
Mutiara, I. dan A. 2015. Penerapan K-Optimal Pada Algoritma Knn Untuk Prediksi Kelulusan Tepat Waktu Mahasiswa Program Studi Ilmu Komputer Fmipa Unlam Berdasarkan Ip Sampai Dengan Semester 4, Klik - Kumpulan Jurnal Ilmu Komputer, 2(2), pp. 159–173.
Rasyid, Aunur. 2014. PREDICTION SYSTEM OF STUDENT ACADEMIC ACHIEVEMENT USING DECISION TREE C4 . 5 pp. 621.
Suwirmayanti, N. L. G. P. 2017. Penerapan Metode K-Nearest Neighbor Untuk Sistem Rekomendasi Pemilihan Mobil, Techno.Com, 16(2), pp. 120–131.
Tullah, R. and Hanafri, M. I. 2014. Evaluasi Penerapan Sistem Informasi Pada Politeknik LP3I Jakarta Dengan Metode Pieces’, Jurnal Sisfotek Global, 4(1), pp. 22–28.