9
LANDASAN TEORI
2.1 Kecerdasan Buatan (Artificial Intelligence)
Berikut adalah beberapa definisi dari Artificial Intelligence, yang digolongkan ke dalam 4 (empat) kategori (Russell dan Norvig, 1995):
1. Sistem yang berpikir seperti manusia
a. “The exciting new effort to make computers think … machines with minds, in the full and literal sense.” (Haugeland, 1985)
b. “[The automation of] activities that we associate with human thinking, activities such as decision-making, problem solving, learning ...”
(Bellman, 1978)
2. Sistem yang berpikir secara rasional
a. “The study of mental faculties through the use of computational models.”
(Charniak and McDermott, 1985)
b. “The study of computations that make it possible to perceive, reason, and act.” (Winston, 1992)
3. Sistem yang bertindak seperti manusia
a. “The art of creating machines that perform functions that require intelligence when performed by people.” (Kurzweil, 1990)
b. “The study of how to make computers do things at which, at the moment, people are better.” (Rich dan Knight, 1991)
4. Sistem yang bertindak secara rasional
a. “Computational Intelligence is the study of the design of intelligence agents.” (Poole et al., 1998)
b. “AI ... is concerned with intelligence behavior in artifacts.” (Nilsson, 1998)
Secara garis besar, Artificial Intelligence merupakan sebuah studi tentang bagaimana membuat komputer mengerjakan sesuatu yang dapat dikerjakan manusia (Elaine Rich, 1991). Jika dibandingkan dengan kecerdasan alami (Natural Intelligence), atau kecerdasan yang dimiliki oleh manusia, kecerdasan buatan memiliki beberapa keuntungan secara komersial antara lain (Sri Kusumadewi, 2003):
a. Kecerdasan buatan lebih bersifat permanen. Kecerdasan alami akan cepat mengalami perubahan. Hal ini dimungkinkan karena sifat manusia yang pelupa.
Kecerdasan buatan tidak akan berubah sepanjang sistem komputer dan program tidak mengubahnya.
b. Kecerdasan buatan lebih mudah diduplikasi dan disebarkan. Mentransfer pengetahuan manusia dari satu orang ke orang lain membutuhkan proses yang sangat lama; dan juga suatu keahlian itu tidak akan pernah dapat diduplikasi dengan lengkap. Oleh karena itu, jika pengetahuan terletak pada suatu sistem komputer, pengetahuan tersebut dapat disalin dari komputer tersebut dan dapat dipindahkan dengan mudah ke komputer yang lain.
c. Kecerdasan buatan jauh lebih murah dibanding dengan kecerdasan alami.
Menyediakan layanan komputer akan lebih mudah dan lebih murah
dibandingkan dengan harus mendatangkan seseorang untuk mengerjakan sejumlah pekerjaan dalam jangka waktu yang sangat lama.
d. Kecerdasan buatan bersifat konsisten. Hal ini disebabkan karena kecerdasan buatan adalah bagian dari teknologi komputer. Sedangkan kecerdasan alami akan senantiasa berubah-ubah.
e. Kecerdasan buatan dapat didokumentasi. Keputusan yang dibuat oleh komputer dapat didokumentasi dengan mudah dengan cara melacak setiap aktivitas dari sistem tersebut. Kecerdasan alami sangat sulit untuk direproduksi.
f. Kecerdasan buatan dapat mengerjakan pekerjaan lebih cepat dibanding dengan kecerdasan alami.
g. Kecerdasan buatan dapat mengerjakan pekerjaan lebih baik dibanding dengan kecerdasan alami.
Namun ada juga beberapa keuntungan dari kecerdasan alami yang tidak dimiliki oleh kecerdasan buatan, yaitu (Sri Kusumadewi, 2003):
a. Kreatif. Kemampuan untuk menambah ataupun memenuhi pengetahuan itu sangat melekat pada jiwa manusia. Pada kecerdasan buatan, untuk menambah pengetahuan harus dilakukan melalui sistem yang dibangun.
b. Kecerdasan alami memungkinkan orang untuk menggunakan pengalaman secara langsung. Sedangkan pada kecerdasan buatan harus bekerja dengan input-input simbolik.
c. Pemikiran manusia dapat digunakan secara luas, sedangkan kecerdasan buatan sangat terbatas.
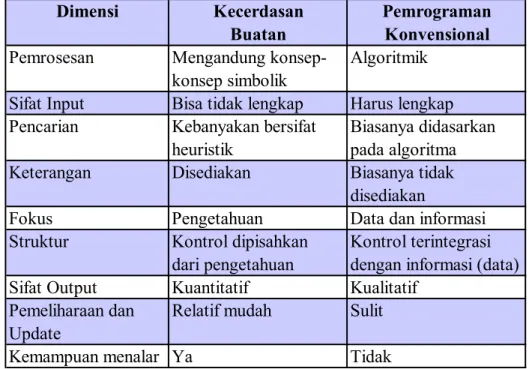
Perbedaan komputasi kecerdasan buatan dengan komputasi konvensional dapat dilihat pada tabel berikut (Sri Kusumadewi, 2003).
Dimensi Kecerdasan Pemrograman
Buatan Konvensional Pemrosesan Mengandung konsep- Algoritmik
konsep simbolik
Sifat Input Bisa tidak lengkap Harus lengkap Pencarian Kebanyakan bersifat Biasanya didasarkan
heuristik pada algoritma
Keterangan Disediakan Biasanya tidak
disediakan
Fokus Pengetahuan Data dan informasi
Struktur Kontrol dipisahkan Kontrol terintegrasi dari pengetahuan dengan informasi (data) Sifat Output Kuantitatif Kualitatif
Pemeliharaan dan Relatif mudah Sulit Update
Kemampuan menalar Ya Tidak
Tabel 2.1 Perbedaan Kecerdasan Buatan dan Pemrograman Konvensional
Pada tahun 1950, seorang berkebangsaan Inggris, Alan Turing, mengembangkan suatu pengujian kecerdasan mesin yang disebut dengan Turing Test. Berdasarkan pengujian ini, suatu komputer dinyatakan cerdas apabila telah dapat membuat seorang pewawancara manusia (human interrogator), setelah mengajukan beberapa pertanyaan, tidak dapat menebak apakah jawaban yang didapatkan berasal dari seorang manusia atau bukan. Untuk dapat lulus tes ini, komputer harus memiliki kemampuan-kemampuan berikut (Russell dan Norvig, 1995):
• Natural Language Processing (Pengolahan Bahasa Alami), untuk dapat berkomunikasi dalam bahasa sehari-hari manusia,
• Knowledge Representation (Representasi Pengetahuan), untuk menyimpan apa yang diketahui atau didengarnya,
• Automated Reasoning, untuk menggunakan informasi yang telah disimpan untuk menjawab pertanyaan-pertanyaan dan mengambil kesimpulan baru,
• Machine Learning, untuk beradaptasi dengan keadaan yang baru dan untuk mendeteksi serta meramalkan kemungkinan pola,
• Computer Vision, untuk perceive obyek, dan
• Robotics, untuk memanipulasi obyek dan berpindah tempat atau bergerak.
Sampai saat ini, kecerdasan buatan banyak diterapkan untuk menangani berbagai macam persoalan, antara lain (Russell dan Norvig, 1995):
• Autonomous planning and scheduling, untuk membuat perencanaan dan penjadwalan otomatis. Program yang pernah dibuat adalah untuk mengontrol penjadwalan operasi pesawat luar angkasa (Jonsson et al., 2000 ) pada NASA.
• Game playing, untuk mengikutsertakan komputer dalam suatu permainan. Salah satu program yang berhasil adalah Deep Blue Sea dari IBM, karena mampu mengalahkan juara dunia catur Garry Kasparov dengan skor akhir 3,5 – 2,5 (Goodman and Keene, 1997).
• Autonomous control, untuk sistem pengaturan otomatis pada suatu benda.
Contohnya adalah ALVINN Computer Vision System, yang telah dilatih untuk dapat mengendarai mobil dan tetap berada di jalurnya, namun masih memerlukan bantuan manusia sebesar 2%. Penelitian terbaru telah berhasil dilakukan oleh General Motors dalam menciptakan driverless car pada awal tahun 2008 ini.
Mobil tersebut dapat berjalan dan memarkirkan dirinya tanpa bantuan manusia sama sekali.
• Diagnosis, untuk melakukan diagnosa pada bidang kedokteran. Sebuah program pernah diciptakan untuk menangani diagnosa penyakit pada jaringan limfa dan mendapatkan pengakuan dari para pakar kedokteran (Heckerman, 1991).
• Logistics Planning, untuk membuat perencanaan logistik. Salah satu program yang pernah diciptakan adalah DART (Dynamic Analysis and Replanning Tool), untuk membuat perencanaan dan penjadwalan logistik otomatis untuk transportasi (Cross dan Walker, 1994).
• Robotics, untuk membuat robot. Sampai saat ini, banyak dokter bedah yang menggunakan asisten robot dalam microsurgery (pembedahan mikro). Salah satunya adalah HipNapf (DiGioia et al., 1996).
• Language understanding and problem solving, untuk dapat memahami bahasa manusia sehari-hari. Program yang pernah dibuat untuk menangani persoalan ini adalah PROVERB (Littman et al., 1999). Program ini dapat menyelesaikan teka- teki silang (crossword puzzle) lebih baik daripada kebanyakan orang.
Berdasarkan bidang persoalan yang dapat ditanganinya, kecerdasan buatan (Artificial Intelligence) dapat dipilah menjadi sejumlah sub disiplin ilmu, antara lain (Elaine Rich, 1991):
a. Expert System (Sistem Pakar)
Di sini komputer digunakan sebagai sarana untuk menyimpan pengetahuan para pakar. Dengan demikian komputer akan memiliki keahlian untuk menyelesaikan permasalahan dengan meniru keahlian yang dimiliki oleh pakar.
b. Natural Language Processing (Pengolahan Bahasa Alami)
Dengan pengolahan bahasa alami ini, diharapkan user dapat berkomunikasi dengan komputer menggunakan bahasa sehari-hari.
c. Speech Recognition (Pengenalan Ucapan)
Melalui pengenalan ucapan, diharapkan manusia dapat berkomunikasi dengan komputer menggunakan suara (speech).
d. Robotics and Sensory Systems (Robotika dan Sistem Sensor)
Algoritma cerdas diprogramkan ke dalam kontroler robot, contohnya adalah penerapan pada robot AIBO dan ASIMO dari Jepang.
e. Computer Vision
Mencoba untuk dapat menginterpretasikan gambar atau obyek-obyek tampak melalui komputer.
f. Intelligent Computer-Aided Instruction
Komputer dapat digunakan sebagai tutor yang dapat melatih dan mengajar.
g. Machine Learning (Pembelajaran Mesin)
Memberikan kesempatan bagi komputer untuk belajar, dan memperbaiki diri atau melakukan improvisasi berdasarkan pengalaman. Bidang-bidang yang menggunakan machine learning di antaranya adalah: Artificial Neural Network (Jaringan Saraf Tiruan), Fuzzy Logic, dan Genetic Algorithm (Algoritma Genetika).
h. Game Playing
Implementasi kecerdasan buatan pada games atau permainan, misalnya catur, Othello, Tic-tac-toe, dan sebagainya.
2.2 Neural Network (NN)
2.2.1 Jaringan Saraf Tiruan (Artificial Neural Network)
“Artificial neural network adalah sistem pemrosesan informasi yang memiliki karakteristik yang secara umum sangat menyerupai sistem jaringan saraf pada otak manusia (biological neural network)” (Laurene Fausett, 1994, p3).
Ide utama dari ANN (Artificial Neural Network) adalah untuk mengadopsi mekanisme kerja pada otak manusia, yaitu:
1. jumlah processing element/node/neuron yang sangat banyak, 2. neuron-neuron (processing element) bekerja secara paralel, dan 3. adanya sifat Fault Tollerance (toleransi kesalahan).
Adapun neural network memiliki karakteristik sebagai berikut (Laurene Fausett, 1994, p3):
1. pola hubungan antara neuron-neuron atau disebut topologi jaringan,
2. metode penentuan bobot dalam hubungan antar neuron yang disebut proses pelatihan atau training, dan
3. fungsi aktivasi.
Sampai saat ini, ANN sudah banyak diterapkan pada berbagai macam aplikasi, seperti: pemrosesan sinyal (signal processing), controlling, pengenalan pola (pattern recognition), diagnosa penyakit, speech production, speech recognition, dan prediksi bisnis.
2.2.2 Jaringan Saraf Manusia (Biological Neural Network)
Otak manusia mempunyai sifat yang sangat unik, sehingga terkadang ada masalah yang dapat dipecahkan oleh otak manusia, sedangkan tidak dapat dipecahkan oleh komputer. Otak manusia terdiri atas jaringan sistem saraf yang sangat kompleks.
Neural berasal dari kata neuron, yaitu sel-sel penyusun sistem saraf di dalam otak manusia yang memiliki fungsi utama mengumpulkan, memproses, dan menyebarkan sinyal-sinyal elektris. Kapasitas pemrosesan informasi otak muncul terutama dari jaringan-jaringan neuron.
Biological neuron memiliki tiga komponen utama, yaitu dendrit, soma, dan axon.
Dendrit bertugas menerima sinyal dari neuron-neuron yang lain. Sinyal merupakan rangsangan elektris yang ditransmisikan melalui celah sinapsis (synaptic gap) yang
disebabkan oleh proses kimiawi tubuh. Proses transmisi secara kimiawi ini mengubah sinyal yang masuk atau sinyal input (dengan mengukur besarnya frekuensi dari sinyal yang diterima). Cara inilah yang diadopsi oleh proses perubahan bobot dalam Artificial Neural Network.
Soma, atau badan sel, bertugas menjumlahkan sinyal-sinyal input. Apabila input yang diterima telah mencukupi, maka sel akan menembakkan atau mentransmisikan sinyal melalui axon ke sel yang lainnya.
Gambar 2.1 Neuron Biologis Pada Manusia
Otak manusia mengandung kurang lebih 1010 – 1011 atau 100 milyar neuron dan terdapat 1000 sampai dengan 10000 sambungan sinapsis dalam satu neuron yang terkoneksi ke neuron-neuron lainnya sehingga terdapat kurang lebih 1015 sinapsis pada otak manusia.
2.2.3 Arsitektur Neural Network
Pengaturan neuron ke dalam layer-layer serta pola hubungan di dalam dan di antara layer-layer disebut arsitektur jaringan (net architecture). Masing-masing layer pada arsitektur jaringan memiliki input dan output. Pada umumnya, neural network digolongkan ke dalam single layer atau multilayer. Dalam menentukan jumlah layer, unit input tidak dihitung sebagai layer, karena tidak melakukan komputasi atau perhitungan. Jadi, jumlah layer dalam suatu jaringan dapat ditentukan dengan menghitung banyaknya layer yang memiliki bobot. Sudut pandang ini dimotivasi dengan adanya fakta bahwa bobot dalam suatu jaringan mengandung informasi yang sangat penting.
Secara umum, dikenal 3 jenis arsitektur jaringan pada Artificial Neural Network, yaitu: Single Layer Network, Multi Layer Network, dan Recurrent Network.
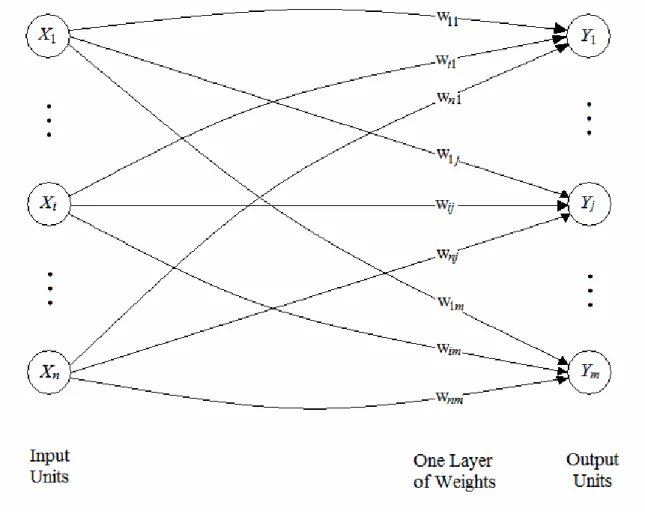
2.2.3.1 Single Layer Network
Topologi jaringan pada Single Layer Network terdiri dari 1 input layer dan 1 output layer. Pada input layer dan output layer terdapat beberapa node yang jumlahnya tergantung pada aplikasi program yang akan dibuat (karakteristik pola pada input dan output).
Gambar 2.2 Arsitektur Single Layer Network
Kelebihan Single Layer Network antara lain (Laurene Fausett, 1994):
• sederhana / mudah untuk diimplementasikan, dan
• proses training cepat.
Kelemahan Single Layer Network antara lain (Laurene Fausett, 1994):
• tidak dapat memecahkan masalah yang rumit, dan
• tidak mampu menyelesaikan XOR dan parity check (Marvin Minsky, 1969).
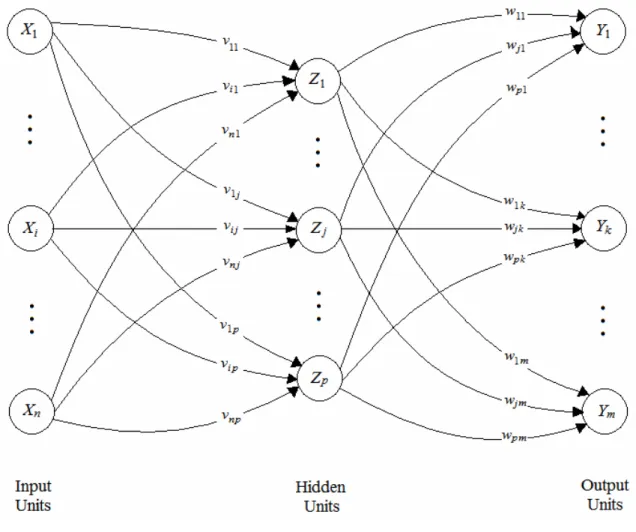
2.2.3.2 Multi Layer Network
Topologi jaringan pada Multi Layer Network terdiri dari 1 input layer, 1 atau lebih hidden layer, dan 1 output layer. Hidden layer terletak di antara input layer dan output layer yang jumlahnya bisa lebih dari 1 lapisan. Pada umumnya, banyaknya node pada hidden layer dihitung melalui rumus:
∑ node hidden = (2/3 * ∑ node input) + ∑ node output
Gambar 2.3 Arsitektur Multi Layer Network
Kelebihan Multilayer Network (Laurene Fausett, 1994):
• mampu menyelesaikan masalah yang lebih kompleks Kelemahan Multilayer Network (Laurene Fausett, 1994):
• proses training lebih lama, dan
• lebih rumit
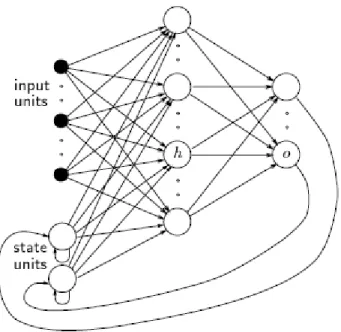
2.2.3.3 Recurrent Network
Pada Single Layer Network dan Multilayer Network tidak terdapat koneksi timbal balik, yaitu koneksi yang melalui output suatu layer menuju ke input dari layer yang sama atau layer sebelumnya, sehingga disebut non-recurrent atau feed forward network.
Secara umum, network yang memiliki koneksi timbal balik tersebut dinamakan recurrent network. Non-recurrent network tidak memiliki memori, di mana outputnya ditentukan oleh input dan nilai-nilai dari bobot (weight). Dalam beberapa konfigurasi, recurrent network memutar kembali outputnya menjadi input.
Dengan demikian, output dari recurrent network ditentukan oleh input dari output sebelumnya. Dengan alasan ini, recurrent network memiliki sifat-sifat serupa dengan short-turn memory (memori jangka pendek).
Gambar 2.4 Arsitektur Recurrent Network
2.2.4 Fungsi Aktivasi
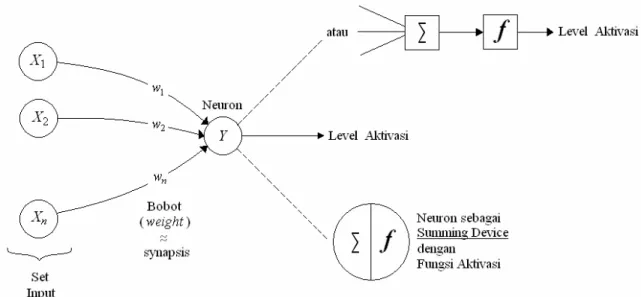
Pada ANN, setiap neuron menerima satu set input, setiap input dikalikan dengan bobot (weight) sesuai dengan kekuatan sinapsis. Jumlah seluruh input berbobot tersebut menentukan kemungkinan neuron untuk menembakkan sinyal. Nilai ini yang disebut dengan level aktivasi (activation level).
Secara matematis, untuk suatu neuron, setiap input x , yang dimodulasikan oleh i
sebuah bobot w , sehingga jumlah total input adalah i
∑
= n i xiwi
1
, atau dalam bentuk vektor
W
X ⋅ , di mana X =(x1,x2,...,xn) dan W =(w1,w2,...,wn).
Model komputasi dari ANN yang dimaksud, secara skematis adalah sebagai berikut:
Gambar 2.5 Model Komputasi Artificial Neural Network
Total sinyal input, y=x1w1+x2w2 +...+xnwn, selanjutnya diproses oleh sebuah fungsi aktivasi (activation function) untuk menghasilkan sinyal output, yang jika tidak sama dengan nol, akan ditransmisikan sebagai keluaran (level aktivasi atau activation level).
Beberapa fungsi aktivasi yang lazim digunakan dalam Neural Network antara lain adalah:
a. Fungsi Identitas
Fungsi ini umumnya digunakan pada neuron-neuron yang berada pada unit input.
x x
f( )= untuk semua x
Gambar 2.6 Kurva Fungsi Identitas
b. Fungsi Tangga Biner (Binary Step Function)
Fungsi ini disebut juga sebagai Threshold Function atau Heaviside Function.
⎩⎨
⎧
<
= ≥
θ θ x jika
x x jika
f 0
) 1 (
dimana θ adalah suatu nilai threshold.
Gambar 2.7 Kurva Fungsi Tangga Biner
Fungsi ini digunakan pada Single Layer Network (jaringan lapis tunggal).
Biasanya digunakan untuk mengubah input yang merupakan variabel kontinyu menjadi input yang bernilai biner (0 atau 1).
Nilai threshold (θ ) menjadi garis pemisah antara daerah dengan respon aktivasi positif dan daerah dengan respon aktivasi negatif.
c. Fungsi Tangga Bipolar (Bipolar Step Function)
⎩⎨
⎧
<
−
= ≥
θ θ x jika
x x jika
f 1
) 1 (
dimana θ adalah suatu nilai threshold.
Gambar 2.8 Kurva Fungsi Tangga Bipolar
Fungsi Tangga Bipolar serupa dengan Fungsi Tangga Biner, hanya saja daerah hasilnya {-1, 1}.
d. Fungsi Sigmoid Biner
Fungsi ini mencakup fungsi-fungsi kurva S, yang mana fungsi ini juga menyerupai sifat-sifat sinyal pada human brain.
Contoh-contoh yang sering digunakan adalah fungsi logistik, dimana fungsi ini memiliki kelebihan dalam melatih Neural Network dengan model Back Propagation, karena memiliki hubungan sederhana antara nilai fungsi pada suatu titik dengan nilai turunannya, sehingga meminimumkan biaya komputasi selama pembelajaran. Yang dimaksud biaya komputasi dalam hal ini adalah waktu (time).
e
xx
f
−σ= − 1 ) 1 (
dimana σ merupakan parameter kecuraman yang diberikan, dan umumnya nilai ini dipilih σ =1. Fungsi ini memiliki turunan pertama:
[
1 ( )]
) ( )
(x f x f x
f ′ =σ⋅ −
dimana daerah hasilnya berada pada interval 0 sampai dengan 1.
Gambar 2.9 Kurva Fungsi Sigmoid Biner
Fungsi ini khususnya digunakan sebagai aktivasi untuk Neural Network dimana outputnya terletak pada interval 0 – 1.
e. Fungsi Sigmoid Bipolar
Fungsi Sigmoid Biner dapat diskalakan sehingga memiliki daerah hasil pada sembarang interval sesuai dengan permasalahan yang diberikan. Yang paling umum adalah daerah hasil dari -1 sampai dengan 1.
Fungsi yang merupakan hasil dari proses skala tersebut dinamakan Fungsi Sigmoid Bipolar, sesuai dengan daerah hasilnya. Jika f(x) adalah Fungsi Sigmoid Biner dimana:
e
xx
f
−= − 1 ) 1 (
maka )g(x adalah Fungsi Sigmoid Bipolar sebagai berikut:
x x x
e x e
g x e g
x f x
g
−
−
−
+
= − + −
=
−
=
1 ) 1 (
1 1 ) 2 (
1 ) ( 2 ) (
Sedangkan turunan pertama dari g(x) adalah:
[
1 ( )][
1 ( )]
)
(x 2 g x g x
g′ = σ + −
Gambar 2.10 Kurva Fungsi Sigmoid Bipolar
Fungsi Sigmoid Biner dan Fungsi Sigmoid Bipolar beserta turunannya umumnya digunakan dalam algoritma training pada model Neural Network Back Propagation.
Sedangkan Fungsi Tangga Biner dan Fungsi Tangga Bipolar digunakan pada Neural Network Bidirectional Associative Memory (BAM).
2.2.5 Paradigma Pembelajaran
Untuk dapat menyelesaikan suatu permasalahan, Jaringan Saraf Tiruan (Artificial Neural Network) memerlukan algoritma pembelajaran mesin (Machine Learning), supaya dari suatu set input dapat dihasilkan set output yang diinginkan. Menurut Russell dan Norvig (2003), dalam bidang machine learning, pada umumnya dikenal 3 (tiga) macam metode pembelajaran: supervised learning (learning with a teacher),
unsupervised learning (learning without a teacher), dan reinforcement learning (learning with a critic).
Gambar 2.11 Paradigma Pembelajaran dalam Machine Learning
2.2.5.1 Supervised Learning
Dalam supervised learning (learning with a teacher), proses pembelajaran dilakukan di bawah naungan guru. “Guru” yang dimaksudkan di sini adalah seseorang yang memiliki pengetahuan tentang suatu lingkungan, dalam hal ini pengetahuan tersebut direpresentasikan dalam contoh input – output. Supervised learning memerlukan pasangan setiap input dengan output yang diinginkan. Pasangan ini disebut dengan training pair.
Pada umumnya jaringan akan di-training menggunakan sejumlah training pair.
Satu input vektor diaplikasikan, kemudian output-nya dihitung dan dibandingkan dengan target output. Selisihnya akan dikembalikan ke jaringan dan sekaligus bobotnya disesuaikan berdasarkan suatu algoritma yang cenderung meminimumkan error (kesalahan). Setelah itu, vektor-vektor dari training set diaplikasikan seluruhnya secara berurutan, error dihitung, dan bobotnya disesuaikan kembali sampai seluruh training set menghasilkan error sekecil-kecilnya.
Supervised learning biasanya digunakan untuk pengelompokan pola (pattern classification). Sebuah jaringan neural network yang di-training untuk menghubungkan satu set vektor input dengan satu set vektor output yang sesuai disebut associative memory. Jika vektor output yang diinginkan sama dengan vektor input, jaringan itu disebut auto-associative memory. Jika vektor target output berbeda dengan vektor input, jaringan itu disebut hetero-associative memory. Setelah training, sebuah associative memory dapat memanggil kembali (recall) pola yang telah disimpan ketika diberikan vektor input yang serupa atau hampir sama dengan vektor yang telah dipelajari. Metode pembelajaran ini salah satunya digunakan pada Back Propagation.
2.2.5.2 Unsupervised Learning
Supervised learning dalam konsep human-brain dianggap tidak tepat. Pada paradigma unsupervised learning (learning without a teacher), sebagaimana namanya, tidak ada guru yang mengawasi proses pembelajaran. Dengan kata lain, target output tidak diberikan. Training set hanya terdiri dari vektor-vektor input, tanpa pasangan output. Sejauh ini, paradigma ini dianggap sebagai model dalam konsep sistem biologis.
Pada unsupervised learning atau self-organized learning, proses pembelajaran dilakukan tanpa adanya external supervisor atau external teacher yang mengawasi proses pembelajaran atau dengan kata lain tidak adanya target output untuk dibandingkan dengan vector output sebagai hasil komputasi dari vector input seperti pada supervised learning. Secara garis besar, unsupervised learning mencoba untuk mengambil fitur-fitur yang umum atau paling mewakili dari suatu input data. Jaringan
akan mengubah bobot sehingga beberapa vektor input yang memiliki kesamaan fitur akan dikelompokan ke dalam output yang sama.
Keuntungan dari unsupervised learning adalah kemampuannya untuk mengelompokkan input data yang hilang atau mengandung error (noise) dengan baik.
Sistem dapat menggunakan fitur yang telah diambil dan dipelajari dari training data, untuk membangun kembali pola input data dari input data yang rusak (corrupted).
2.3 Reinforcement Learning (RL)
Reinforcement learning (learning with a critic) adalah suatu pembelajaran tentang bagaimana suatu agen dapat belajar apa yang akan dilakukan, khususnya ketika tidak ada guru yang mengarahkan agen itu untuk mengambil tindakan yang benar dalam setiap situasi (Sutton dan Barto, 1998).
Kebalikan dari supervised learning, pada reinforcement learning, agen diberikan evaluasi atas tindakan yang telah dilakukan, namun dengan tidak memberitahukan tindakan apa yang benar dan harus dilakukan. Agen akan diberikan penghargaan (reward) atau hukuman (punishment) atas tindakannya. Penghargaan dan hukuman inilah yang disebut dengan reinforcement.
Sebagai contohnya, suatu agen dapat belajar bagaimana cara bermain catur dengan supervised learning – dengan memberikan contoh dari situasi-situasi permainan dan bagaimana cara terbaik untuk mengatasi situasi seperti itu. Dalam reinforcement learning, dimana tidak ada guru yang menyediakan contoh-contoh situasi atau keadaan, agen akan mencoba mengatasi situasi yang dihadapi dengan gerakan secara acak (random moves). Dengan mencoba gerakan secara acak tersebut, agen dapat
membangun model perkiraan dari lingkungannya: apa yang akan terjadi apabila dia melakukan suatu tindakan dan bahkan bagaimana lawan akan menanggapi tindakannya tersebut. Masalahnya adalah, tanpa masukan-masukan tentang bagaimana suatu hal dikatakan baik dan bagaimana suatu hal dikatakan buruk, agen tidak dapat memperoleh gambaran langkah apa selanjutnya yang akan diambil. Agen harus mengetahui bahwa memenangkan permainan adalah suatu hal yang baik dan bahwa kalah dalam permainan adalah hal yang buruk. Jenis masukan seperti ini dinamakan reward atau reinforcement.
Dalam permainan seperti catur, reinforcement hanya diberikan pada saat akhir permainan. Dalam permainan lain seperti tenis meja, setiap poin yang dicetak dapat dipertimbangkan sebagai reward. Dalam belajar untuk merangkak, perpindahan ke arah depan dinyatakan sebagai suatu prestasi. Walaupun reward diberikan sebagai suatu input, agen harus dapat membedakan antara reward dengan input-input yang lainnya.
Sebagai contoh, hewan-hewan dapat mengenali rasa sakit dan lapar sebagai reward yang bersifat negatif, serta kesenangan dan makanan sebagai reward yang bersifat positif.
Reinforcement telah dipelajari dengan teliti oleh psikolog hewan selama lebih dari 60 tahun.
Salah satu tantangan terbesar yang muncul dalam reinforcement learning dan tidak muncul pada metode learning yang lain adalah bagaimana menyeimbangkan (trade-off) antara eksplorasi dan eksploitasi (Sutton dan Barto, 1998). Untuk mendapatkan reward yang besar, agen reinforcement learning harus memilih action yang telah dicoba sebelumnya dan telah terbukti efektif untuk menghasilkan reward yang besar. Tetapi untuk menemukan action-action tersebut, agen harus mencoba action yang belum pernah dipilih sebelumnya. Agen harus melakukan eksploitasi terhadap apa
yang telah diketahui dalam mendapatkan reward, tetapi agen juga harus melakukan eksplorasi untuk menghasilkan pilihan action yang lebih baik di masa yang akan datang.
Dilema yang terjadi adalah bahwa eksplorasi maupun eksploitasi tidak dapat semata- mata dikejar tanpa menyebabkan kegagalan pada tugas yang dilakukan. Agen harus mencoba berbagai macam action dan lebih memilih action-action yang kelihatannya terbaik. Dalam sebagian besar kasus, setiap action harus dicoba berkali-kali untuk dapat mencapai perkiraan expected reward yang handal (reliable).
Ada dua karakteristik dari reinforcement learning yang membedakan dari metode learning yang lain, yaitu trial-and-error search dan delayed reward (Sutton dan Barto, 1998). Di dalam reinforcement learning, trainer / teacher hanya menyediakan nilai reward yang bersifat langsung (immediate) yang diperoleh agen ketika mengeksekusi suatu action. Oleh karena itu agen menghadapi masalah temporal credit assignment: menentukan action yang mana dalam urutannya yang harus dijalankan untuk menghasilkan reward akhir yang lebih besar.
2.3.1 Elemen-elemen Dasar Reinforcement Learning
Berdasarkan Sutton dan Barto (1998), terdapat 4 (empat) elemen dalam sistem Reinforcement Learning, yaitu: policy, reward function, value function, dan model of environment.
1. Policy
Policy menentukan cara berperilaku learning agent pada suatu waktu. Secara singkat, policy merupakan pemetaan dari state tertentu pada suatu environment ke dalam action yang harus dilakukan ketika berada di state tersebut. Dalam
beberapa kasus, policy dapat berupa function sederhana atau lookup table, namun dalam kasus lain policy melibatkan proses komputasi yang luas seperti halnya pada proses pencarian (search process). Policy adalah inti dari Reinforcement Learning dalam menentukan perilaku dari learning agent.
2. Reward function
Reward function mendefinisikan tujuan (goal) dalam suatu permasalahan reinforcement learning. Secara singkat, reward function memetakan setiap pasangan state-action dalam suatu lingkungan ke dalam reward yang dapat diukur dengan angka, yang mengindikasikan nilai intrinsik dari suatu state.
Tujuan utama agent reinforcement learning adalah untuk memaksimalkan total reward yang diterima dalam jangka panjang. Reward function menentukan event mana yang baik ataupun buruk untuk agent. Dalam sistem biologi, reward diidentifikasikan dengan kesenangan (pleasure) dan rasa sakit (pain). Kedua hal ini adalah ciri-ciri yang menentukan masalah yang dijumpai oleh agen. Oleh karena itu, reward function harus tidak dapat diubah oleh agen. Namun, agen dapat menyediakan basis atau dasar untuk mengubah policy. Sebagai contoh, apabila suatu action yang dipilih oleh policy diikuti dengan reward yang kecil, maka policy dapat diubah untuk memilih action yang lain pada situasi yang sama di masa selanjutnya.
3. Value function
Berbeda dengan reward function yang dapat mengindikasikan action apa yang baik dalam immediate reward (reward langsung), sebuah value function dapat menspesifikasikan action apa yang baik dalam jangka panjang (long run). Secara singkat, nilai dari sebuah state adalah jumlah keseluruhan reward yang diharapkan oleh agen untuk diakumulasikan di masa yang akan datang, dimulai dari state tersebut. Apabila reward menentukan nilai intrinsik dari environmental state secara langsung (immediate) maka value mengindikasikan nilai jangka panjang dari suatu state setelah memperhitungkan state-state berikutnya dan reward yang tersedia pada state-state tersebut. Sebagai contoh, suatu state dapat saja selalu menghasilkan reward yang rendah secara langsung tetapi masih mempunyai value yang tinggi karena state tersebut secara tetap diikuti oleh state- state lain yang menghasilkan reward yang tinggi, atau sebaliknya. Dalam analogi manusia, reward yang tinggi adalah seperti kesenangan (pleasure) dan reward yang rendah seperti rasa sakit (pain), sedangkan value berhubungan dengan penilaian lebih lanjut mengenai bagaimana senang atau tidaknya kita pada saat lingkungan kita berada dalam state tertentu.
Tanpa reward tidak akan ada value, dan tujuan satu-satunya dari memperkirakan value adalah untuk mendapatkan reward yang lebih besar. Pemilihan action dilakukan berdasarkan penilaian value. Dalam reinforcement learning, action yang dicari adalah yang menghasilkan state dengan value tertinggi, bukan reward tertinggi, karena action-action ini menghasilkan jumlah reward terbesar
dalam jangka panjang. Dalam pengambilan keputusan dan perencanaan, value adalah satu-satunya hal yang harus diperhatikan.
4. Model of environment
Model of environment adalah sesuatu yang menggambarkan perilaku dari environment. Model of environment ini sangat berguna untuk mendesain dan merencanakan perilaku yang tepat pada situasi mendatang yang memungkinkan sebelum agent sendiri mempunyai pengalaman dengan situasi itu. Saat masa- masa awal RL dikembangkan, model of environment yang ada berupa trial and error. Namun modern RL sekarang sudah mulai menjajaki spektrum dari low- level, trial and error menuju high-level, deliberative planning.
2.3.2 Kerangka Kerja Reinforcement Learning
“Permasalahan pada reinforcement learning sebenarnya merupakan permasalahan pada pembelajaran (learning) melalui interaksi untuk mencapai goal.”
(Sutton and Barto, 1998). Menurut Sutton dan Barto, pada reinforcement learning yang disebut dengan agen adalah si pembelajar dan pembuat keputusan (learner and decision- maker), sedangkan yang dimaksud dengan environment adalah segala sesuatu yang berinteraksi dengan agen dan berada di luar agen. Proses interaksi berlangsung secara terus-menerus, dimana agen memilih action yang tersedia dan environment memberikan respon terhadap action tersebut serta memberikan situasi (state) baru kepada agen.
Environment juga memberikan reward, berupa angka-angka numerik, kepada agen ketika agen memilih sebuah action.
Secara lebih spesifik, agen dan lingkungannya berinteraksi pada urutan waktu (time steps), t 0, 1, 2, 3, dst. Setiap time step t, agen menerima beberapa reperesentasi = dari kondisi lingkungannya (state), st∈ , dimana S merupakan kumpulan state-state S yang mungkin, dan berdasarkan state-state yang mungkin tersebut, agen memilih sebuah action, at∈A
( )
st , dimana A( )
st merupakan kumpulan action-action yang tersedia pada state tersebut (s ). Sebagai akibat dari pemilihan action tersebut, agen menerima sebuah t reward, rt+1∈R, dan agen pindah ke state yang baru st+1.Gambar 2.12 Metode Pembelajaran Reinforcement Learning
Setiap proses transisi antara agen dengan lingkungannya (state) disebut juga dengan agent’s policy dan dinotasikan πt, dimana πt
( )
s,a adalah kemungkinan daria
at = jika st = . Metode reinforcement learning dapat menentukan bagaimana agen s merubah policy-nya sebagai hasil dari pengalamannya selama proses interaksi dengan lingkungannya. Secara garis besar, tujuan agen adalah untuk memaksimalkan total reward yang diterimanya selama proses interaksi dalam jangka waktu yang lama (long
run). Framework ini bersifat abstrak dan fleksibel serta dapat diaplikasikan ke dalam permasalahan yang berbeda-beda dengan berbagai cara.
2.3.3 Markov Decision Process (MDP)
Menurut Sutton dan Barto (1998), dalam reinforcement learning, environment direpresentasikan sebagai MDP yang didefinisikan sebagai berikut:
- S → kumpulan state dari environment s∈S - A(s) → kumpulan action yang mungkin ketika
- P(s, s’ ,a) → probabilitas transisi dari s ke s’ akibat dari a
- R(s, s’, a) → reward yang didapat ketika transisi s ke s’ akibat dari a - γ → discount rate untuk delayed reward
Gambar 2.13 Markov Decision Process
γ adalah suatu konstanta yang mempunyai nilai di antara 0 dan 1 (0 < γ < 1), yang menunjukkan hubungan antara delayed reward dengan immediate reward. Jika nilai γ semakin mendekati 0, maka agen akan lebih mempertimbangkan immediate reward, sedangkan apabila nilai γ semakin mendekati 1, maka delayed reward atau future reward yang akan lebih menjadi pertimbangan bagi agen. Menurut Mance E.
Harmon dan Stephanie S. Harmon (1996), pada MDP yang memiliki state akhir, t
. . . s
ta
r
t +1s
t +1a
t +1r
t +2s
t +2t +2
a r
t +3s
t +3. . .
a
t +3discount rate tidak mutlak untuk digunakan karena tidak memiliki pengaruh yang berarti, akan tetapi discount rate dibutuhkan pada MDP yang tidak memiliki state akhir.
Menurut Sutton dan Barto (1998), berdasarkan transisi state-action, MDP dapat dikelompokkan menjadi 2 (dua) jenis, yaitu :
- Deterministic MDP / finite MDP, transisi dari state x setelah melakukan action a selalu menghasilkan state x' dengan probabilitas 1.
- Nondeterministic MDP, terdapat fungsi distribusi probabilitas P
(
x|'x,a)
yang memberikan probabilitas (kemungkinan) melakukan action a ketika di state x akan menghasilkan state x'.2.3.4 Action Value Menggunakan Metode ε-greedy
Metode ε-greedy merupakan salah satu cara untuk menyeimbangakan antara proses eksplorasi dengan eksploitasi agen terhadap lingkunganya. ε dalam metode ε- greedy menandakan probabilitas dari eksplorasi dalam setiap trial, dimana ε memiliki range nilai dari 0 sampai 1. jika ε = 1, maka algoritma ε-greedy sepenuhnya mengarah kepada eksplorasi, sedangkan jika ε = 0, maka algoritma ε-greedy sepenuhnuya mengarah kepada eksploitasi, agen akan memillih action dengan nilai estimasi tertinggi.
Berikut diberikan algoritma ε-greedy dalam bentuk pseudocode:
Set parameter ε
] 1 , 0 [ random i=
IF i < ε THEN
) (a A random
a= ∈ //eksplorasi ELSE
) , ( max arg Q s a
a= a∈A //eksploitasi
2.3.5 Q-Learning
“Permasalahan yang mendasar yang terjadi pada proses pembelajaran agen terhadap lingkungannya adalah kesulitan untuk mengetahui optimal policy π*:S →A, karena training data yang tersedia tidak meyediakan contoh pasangan
( )
s,a yang benar untuk mencapai kondisi optimal” (Tom M. Mitchell, 1997, p.373). Namun, training information yang tersedia untuk agen hanya berupa serangkaian immediate reward(
si ai)
r , untuk i = 0, 1, 2, 3, dst. Berdasarkan informasi training (training information) ini, akan lebih mudah untuk mempelajari fungsi evaluasi numerik (numerical evaluation function) yang ditentukan berdasarkan state-action, dibandingkan mengimplementasi optimal policy di dalam fungsi evaluasi ini.
Evaluation function yang harus dipelajari oleh agen adalah V . Melalui * evaluation function ini, agen dapat memilih state-state yang dapat memberikan cumulative reward yang lebih besar. Misalkan agen sedang menghadapi dua kemungkinan state s1 dan s2. Agen harus memilih state s1 karena V*
( )
s1 >V*( )
s2 , karena cumulative reward yang akan dihasilkan oleh s1 akan lebih besar daripada s2. Evaluation function ini merupakan perilaku agen (agent’s policy) dalam mengambil setiap action yang tersedia untuk setiap state. optimal action pada state s adalah action a yang memaksimalkan jumlah dari immediate reward r ,( )
s a ditambah nilai V dari * immediate successor state, didiskon dengan parameter γ.( )
s[
r( )
s a V( ( )
s a) ]
a
, ,
max
arg *
* γ δ
π = +
di mana:
( )
s,aδ → memberikan state baru hasil dari action a terhadap state s
Berdasarkan persamaan di atas, agen dapat memperoleh optimal policy dengan mempelajari V , dengan kondisi agen memiliki pengetahuan yang sempurna terhadap * fungsi immediate reward r dan fungsi trasisi state δ. Akan tetapi, pada awalnya agen tidak memiliki pengetahuan apapun tentang fungsi-fungsi tersebut, sehingga agen tidak dapat memilih action yang optimal. Oleh karena itu, dibutuhkanlah sebuah evaluation function Q, guna mendapatkan evalutation function yang optimal (V ). *
2.3.5.1 Q-Function
Q-function dinotasikan sebagai Q(s,a) dan nilai dari Q adalah reward yang diterima secara langsung ketika agen mengeksekusi action a terhadap state s, ditambah nilai (didiskon oleh γ) dari optimal policy setelah action-state tersebut dipilih.
( ) ( )
s a r s a V( ( )
s a)
Q , ≡ , +γ * δ ,
Berdasarkan persamaan di atas, maka dapat ditulis kembali persamaan π* menjadi:
( )
s Q( )
s aa
, max
* =arg π
Persamaan di atas menunjukkan bahwa agen mempelajari Q-function bukan mempelajari fungsi V . Dengan mempelajari Q-function, agen dapat memilih optimal * action ketika agen tidak memiliki pengetahuan apapun tentang fungsi r dan δ.
Persamaan di atas juga memperjelas bahwa untuk mendapatkan optimal policy, agen harus memilih action a terhadap state s yang dapat memaksimalkan Q ,
( )
s a .2.3.5.2 Algoritma Q-Learning
Q-learning adalah suatu bentuk dari reinforcement learning yang di dalamnya agen belajar untuk menetapkan value untuk pasangan state-action (Watkins 1989).
Dengan mempelajari Q-function, maka agen akan belajar untuk mendapatkan optimal policy. Sebelumnya dapat dilihat hubungan antara Q dengan V , *
( )
max( )
, ''
* s Q s a
V = a
sehingga dapat ditulis kembali persamaan
( )
s[
r( )
s a V( ( )
s a) ]
a
, ,
max
arg *
* γ δ
π = +
menjadi:
( ) ( )
, , max( ( )
, , ')
' Q s a a
a s r a s
Q = +γ a δ
Untuk menjelaskan algoritma ini, digunakan simbol Q yang menunjukkan ∧ estimasi agen (learner’s estimate) atau hipotsesis dari fungsi Q yang sebenarnya. Dalam algoritma ini, agen merepresentasikan hipotesisnya pada tabel yang berukuran besar dengan setiap masukan yang berbeda untuk setiap pasangan state-action. Pada awalnya, tabel ini berisikan nilai 0, artinya agen pada awal pembelajaran tidak memiliki pengetahuan apapun. Secara iteratif, agen akan belajar mengobservasi lingkungannya
dengan melihat kemungkinan-kemungkinan action yang tersedia, kemudian dengan menggunakan action value ε-greedy, action tersebut akan dipilih dan dijalankan. Akibat dari pemilihan action tersebut agen akan mendapatkan reward langsung (immediate
reward) dan mengobservasi state selanjutnya s' serta meng-update tabel Q ,∧
( )
s a dengan rumus berikut:( )
, max(
,' ')
' Q s a
r a s
Q a
∧
∧ ← +γ
Secara lebih rinci, berikut adalah pseudocode untuk algoritma Q-learning:
1. Set parameter γ, and environment reward (reward function) 2. Initialize the table entry Qˆ(s,a) to zero
3. For each episode:
a. Select random initial state b. Do while not reach goal state:
• Select action a from s using ε-greedy strategy for the current state
• Receive immediate reward r
• Observe the new state s′
• Update the table entry for Qˆ(s,a) as follows:
) , ˆ( max )
,
ˆ(s a r Q s a
Q ← + a ′ ′
γ ′
• Set the next state as the current state End Do
End For
2.3.5.3 Contoh Kasus Menggunakan Q-Learning
Untuk memperjelas mengenai konsep Q-learning, akan diberikan suatu contoh kasus yang sederhana namun cukup merepresentasikan konsep tersebut. Pada kasus ini terdapat 6 buah state (s1, s2, s3, s4, s5,dan s6) yang direpresentasikan dalam bentuk grid world dan sebuah action.
Gambar 2.14 Contoh Kasus Menggunakan Q-Learning
Dari gambar di atas, s6 merupakan goal state, sehingga reward yang didapatkan oleh agen ketika mencapai goal state (s6) adalah 100, sedangkan yang menuju state lainnya (s1, s2, s3, s4, dans5) mendapatkan reward 0. Parameter γ yang digunakan adalah 0.5. Mula-mula function table Q∧ diinisialisasikan dengan nilai 0 (agen belum memiliki
pengetahuan). Selama proses training, agen akan meng-update function table Q∧ untuk merekam pengalaman agen dalam setiap episode sehingga pada akhirnya agen dapat memperoleh optimal policy. Dalam setiap episode, agen akan memilih state awal secara acak (random) dan diperbolehkan untuk memilih action sampai mencapai goal state.
Sebelum proses training dijalankan, semua nilai Q-value diinisialisasi dengan nol. Seiring dengan berlangsungnya training, nilai-nilai ini akan terus di-update sehingga nantinya akan menghasilkan nilai Q-value yang konvergen.
1. Episode ke-1
Posisi awal : s1
Pilihan action yang tersedia dari s1 : a12 dan a14
Action yang dipilih : a12
s1, a12 0 s1, a14 0
s2, a21 0
s2, a23 0
s2, a25 0 s3, a32 0 s3, a36 0 s4, a41 0 s4, a45 0 s5, a54 0 s5, a52 0 s5, a56 0
s1, a12 0 s1, a14 0
s2, a21 0 s2, a23 0 s2, a25 0
s3, a32 0 s3, a36 0 s4, a41 0 s4, a45 0 s5, a54 0 s5, a52 0 s5, a56 0
Posisi sekarang : s2
Pilihan action yang tersedia dari s2 : a21, a25, dan a23
Update Q
(
s1, a12)
∧ :
( ) ( ) ( ) ( )
⎟⎠
⎜ ⎞
⎝ + ⎛
= ∧ ∧ ∧
∧
23 2 25 2 21 ' 2
12
1,a r max Qs ,a ,Qs ,a ,Q s ,a
s Q
a
γ
(
1, 12)
=0+0.5*0∧
a s Q
(
1, 12)
=0∧
a s Q
Action yang dipilih : a23
Posisi sekarang : s3
Pilihan action yang tersedia : a31, dan a36
Update Q
(
s2, a23)
∧ :
( ) ( ) ( )
⎟⎠
⎜ ⎞
⎝ + ⎛
= ∧ ∧
∧
36 3 32 ' 3
23
2,a r max Q s ,a ,Qs ,a
s
Q γ a
(
2, 23)
=0+0.5*0∧
a s Q
s1, a12 0 s1, a14 0
s2, a21 0 s2, a23 0
s2, a25 0 s3, a32 0 s3, a36 0 s4, a41 0 s4, a45 0 s5, a54 0 s5, a52 0 s5, a56 0
(
2, 23)
=0∧
a s Q
Action yang dipilih : a36
Posisi sekarang : s6
Update Q
(
s3, a36)
∧ :
(
3, 36)
=100∧
a s Q
s1, a12 0 s1, a14 0
s2, a21 0 s2, a23 0 s2, a25 0
s3, a32 0 s3, a36 100 s4, a41 0 s4, a45 0 s5, a54 0 s5, a52 0 s5, a56 0
2. Episode ke-2
Posisi awal : s2
Pilihan action yang tersedia dari s2 : a21, a25, dan a23
Action yang dipilih : a23
Posisi sekarang : s3
Pilihan action yang tersedia : a31, dan a36
s1, a12 0 s1, a14 0
s2, a21 0 s2, a23 0 s2, a25 0
s3, a32 0 s3, a36 100 s4, a41 0 s4, a45 0 s5, a54 0 s5, a52 0 s5, a56 0
s1, a12 0 s1, a14 0
s2, a21 0 s2, a23 50 s2, a25 0 s3, a32 0 s3, a36 100 s4, a41 0 s4, a45 0 s5, a54 0 s5, a52 0 s5, a56 0
Update Q∧
(
s2, a23)
:( ) ( ) ( )
⎟⎠
⎜ ⎞
⎝ + ⎛
= ∧ ∧
∧
36 3 32 ' 3
23
2,a r max Q s ,a ,Qs ,a
s
Q γ a
(
2, 23)
=0+0.5*100∧ s a
Q
(
2, 23)
=50∧ s a
Q
Action yang dipilih : a36
s
1s
2s
3s
4s
5 a56s
6a12
a21
a23
a32
a45
a54
a14 a41 a25 a52 a36
Posisi sekarang : s6
Update Q∧(s3, a36) :
(
3, 36)
=100∧ s a
Q
s1, a12 0 s1, a14 0
s2, a21 0 s2, a23 50 s2, a25 0
s3, a32 0 s3, a36 100 s4, a41 0 s4, a45 0 s5, a54 0 s5, a52 0 s5, a56 0
Setelah sekian banyaknya iterasi, maka function table Q∧ yang terbentuk adalah:
s1, a12 25 s1, a14 25
s2, a21 12.5 s2, a23 50 s2, a25 25
s3, a32 25 s3, a36 100 s4, a41 12.5 s4, a45 50 s5, a54 25 s5, a52 25 s5, a56 100
Kondisi terjadinya proses konvergensi antara function table Q∧ dengan true / optimal function table Q adalah jika setiap pasangan state-action telah dikunjungi sebanyak mungkin sampai nilainya sudah tidak berubah lagi (tetap).
2.4 Produk dan Promosi 2.4.1 Pengertian Produk
Dalam bidang pemasaran, produk didefinisikan sebagai segala sesuatu yang dapat ditawarkan ke pasar untuk diperhatikan, dimiliki, digunakan, atau dikonsumsi yang dapat memuaskan keinginan atau kebutuhan (Kotler dan Armstrong, 1989).
Kepuasan pelanggan adalah suatu tingkatan di mana perkiraan kinerja produk sesuai dengan harapan pembeli (Kotler dan Armstrong, 1989). Kepuasan konsumen bukan hanya mengacu pada bentuk fisik dari produk, melainkan satu paket kepuasan yang didapat dari pembelian produk. Kepuasan tersebut merupakan akumulasi dari kepuasan fisik, psikis, simbolis, sampai kepada pelayanan yang diberikan oleh produsen.
“Produk dapat mencakup benda fisik, jasa, prestise, tempat, organisasi, maupun ide.” (Kotler dan Armstrong, 1989). Produk yang berwujud disebut barang, sedangkan yang tidak berwujud disebut sebagai jasa. Dalam manajemen produk, identifikasi dari produk adalah barang dan jasa yang ditawarkan kepada konsumen. Kata produk digunakan untuk mempermudah pengujian pasar dan daya serap pasar, yang akan sangat berguna bagi tenaga pemasaran (marketing), manajer, dan bagian pengendalian kualitas (quality control).
2.4.1.1 Pengembangan Produk Baru
Pada saat salah satu ataupun beberapa produk yang sedang dipasarkan berada pada tahap yang disebut “kedewasaan”, maka pengusaha mulai memanfaatkan keuntungan yang diperolehnya dari produk tersebut untuk mengembangkan ide penciptaan produk baru. Produk baru inilah yang diharapkan nantinya akan dapat menggantikan produk tersebut. Produk baru dapat diartikan sebagai berikut (Kotler dan Armstrong, 1989):
1. Produk asli, yaitu benar-benar produk baru.
2. Produk yang disempurnakan atau diperbaiki.
3. Produk yang dimodifikasi.
4. Produk dengan merk baru yang dikembangkan perusahaan melalui berbagai upaya penelitian dan pengembangannya sendiri.
2.4.1.2 Product Bundling
“Product bundling is the practice of selling two or more different products (or services) in a fixed proportion and at an explicit or implicit price” (Carlton dan Perloff, 1994, p470).
Secara singkat, product bundling dapat diartikan sebagai strategi untuk menggabungkan penjualan beberapa produk menjadi satu paket penjualan. Strategi ini sangat umum digunakan dalam bisnis software. Sebagai contohnya, Microsoft memaketkan software pengolah kata, spreadsheet, dan database ke dalam satu paket Office Suite yang disebut sebagai Microsoft Office Suite. Dalam industri masakan cepat saji (fast food), beberapa item produk ditawarkan dalam satu paket khusus.
Strategi ini akan memiliki tingkat keberhasilan tinggi apabila:
1. biaya produksi rendah, 2. pangsa pasar cukup besar,
3. konsumen berminat karena ada unsur penyederhanaan dalam proses pembelian produk dan dapat mengambil manfaat dari pembelian produk,
4. rata-rata marginal cost rendah, dan 5. customer acquisition cost tinggi.
Product bundling sangat tepat untuk produk yang memiliki volume penjualan dan tingkat keuntungan yang tinggi. Menurut riset Bakos dan Brynjolfsson (1999), product bundling sangat tepat dan efektif apabila diterapkan pada produk informasi digital yang memiliki marginal cost nyaris nol.
Product bundling dibedakan menjadi 2 (dua) jenis (Bram Foubert, 1999), yaitu:
1. Pure bundling, terjadi apabila konsumen hanya bisa membeli keseluruhan paket (tidak ada pilihan lain).
2. Mixed bundling, terjadi apabila konsumen bisa memilih antara membeli keseluruhan paket atau dapat membeli secara terpisah.
2.4.2 Pengertian Pemasaran
Pemasaran adalah terjemahan dari kata marketing, yang mempunyai pengertian yang sangat luas sesuai dengan perkembangan ekonomi dan teknologi. Terdapat beberapa definisi dari pemasaran:
1. Menurut W.Y. Stanton
“Pemasaran adalah sesuatu yang meliputi seluruh sistem yang berhubungan dengan tujuan untuk merencanakan dan menentukan harga sampai dengan mempromosikan dan mendistribusikan barang dan jasa yang bisa memuaskan kebutuhan pembeli aktual maupun potensial.”
2. Menurut H. Nystrom
“Pemasaran merupakan suatu kegiatan penyaluran barang atau jasa dari tangan produsen ke tangan konsumen.”
3. Menurut Kotler dan Armstrong
“Pemasaran adalah suatu proses sosial dan manajerial yang membuat individu dan kelompok memperoleh apa yang mereka butuhkan dan inginkan lewat penciptaan dan pertukaran timbal balik produk dan nilai dengan orang lain..”
4. Menurut Asosiasi Pemasaran Amerika Serikat (American Marketing Association)
“Pemasaran adalah pelaksanaan kegiatan usaha perdagangan yang diarahkan pada aliran barang dan jasa dari produsen ke konsumen.”
Dari keseluruhan definisi di atas, maka dapat ditarik kesimpulan bahwa pemasaran adalah rangkaian penyampaian barang dan jasa dari produsen kepada konsumen yang berhubungan erat dengan kepuasan yang akan diperoleh konsumen setelah membeli hasil produksi perusahaan.
2.4.3 Pengertian Promosi
Sebagian besar orang menganggap bahwa promosi dan pemasaran mempunyai pengertian yang sama, dimana sebenarnya promosi hanya merupakan salah satu bagian dari kegiatan pemasaran. Walaupun promosi sering dihubung-hubungkan dengan penjualan, namun pada kenyataannya promosi mempunyai arti yang lebih luas dari penjualan, karena penjualan hanya berhubungan dengan pertukaran hak milik yang dilakukan oleh tenaga penjual kepada pembeli, sedangkan promosi adalah setiap aktivitas yang ditujukan untuk memberitahukan, membujuk, atau mempengaruhi konsumen untuk menggunakan produk yang dihasilkan oleh suatu perusahaan.
Pengertian promosi yang dikemukakan oleh Kotler dan Armstrong (1989) adalah sebagai berikut: “Promotion encompasses all the tools in the marketing mix whose mayor is persuasive communication.”
Secara keseluruhan, promosi dapat disimpulkan sebagai usaha-usaha yang dilakukan oleh perusahaan untuk mempengaruhi konsumen supaya membeli produk yang dihasilkan ataupun untuk menyampaikan berita tentang produk tersebut dengan jalan mengadakan komunikasi dengan para pendengar (audience) yang sifatnya membujuk (persuasif). Sedangkan promosi penjualan menurut Kotler dan Armstrong (1989) adalah “insentif jangka pendek untuk mendorong pembelian atau penjualan dari suatu produk atau jasa”.
Jadi tujuan dasar dilaksanakannya promosi adalah untuk mempengaruhi konsumen supaya membeli suatu produk. Suatu promosi yang dilaksanakan tanpa mempunyai tujuan tertentu sama saja dengan melakukan pekerjaan yang sia-sia. Tujuan promosi merupakan dasar dalam membuat keseluruhan program promosi yang akan dijalankan oleh perusahaan dalam rangka mencapai apa yang diinginkannya, kemudian baru menyusul langkah-langkah selanjutnya.
Pengertian supermarket adalah “toko besar, berbiaya rendah, bermarjin rendah, bervolume tinggi, dan swalayan yang menjual variasi bahan makanan, laundry, dan produk rumah tangga yang sangat beragam” (Kotler dan Armstrong, 1989).
Supermarket merupakan salah satu perusahaan yang sangat sering melakukan kegiatan promosi. Ketatnya persaingan mendorong supermarket berlomba-lomba memberikan promosi yang menarik.
Menurut Kotler dan Armstrong (1989), secara garis besar, promosi suatu perusahaan dapat berupa:
1. Sampel, yaitu sejumlah kecil produk yang ditawarkan kepada konsumen untuk dicoba.