THE PRONUNCIATION OF ENGLISH VOICED AND
VOICELESS OBSTRUENTS IN THE MEDIAL POSITION:
A CASE STUDY IN SMA YOS SUDARSO SOKARAJA
AN UNDERGRADUATE THESIS
Presented as Partial Fulfillment of the Requirements for the Degree of Sarjana Sastra
in English Letters
By
MARIA SEKAR SATITI Student Number: 134214019
ENGISH LETTERS STUDY PROGRAM DEPARTEMENT OF ENGLISH LETTERS
FACULTY OF LETTERS SANATA DHARMA UNIVERSITY
ii
THE PRONUNCIATION OF ENGLISH VOICED AND
VOICELESS OBSTRUENTS IN THE MEDIAL POSITION:
A CASE STUDY IN SMA YOS SUDARSO SOKARAJA
AN UNDERGRADUATE THESIS
Presented as Partial Fulfillment of the Requirements for the Degree of Sarjana Sastra
in English Letters
By
MARIA SEKAR SATITI Student Number: 134214019
ENGISH LETTERS STUDY PROGRAM DEPARTEMENT OF ENGLISH LETTERS
FACULTY OF LETTERS SANATA DHARMA UNIVERSITY
vii
YOU’LL
NEVER KNOW IF YOU
NEVER TRY
viii
ACKNOWLEDGEMENTS
Firstly, I thank Jesus Christ and Mother Marry for the unconditional love and blessing to me.
I give my deepest appreciation and gratitude to my thesis advisor, Anna Fitriati, S.Pd., M.Hum, for the patience and the wisdoms while guiding me in the preparation of this thesis. I also owe my gratitude to my co-advisor, Adventina Putranti, S.S., M.Hum, for the valuable guidance. I thank the headmaster of SMA Yos Sudarso Sokaraja, Dra. Ch. Retno Indriastuti, and the English teacher for eleven-grade students in SMA Yos Sudarso, Alexander Karyadi, S.Pd., for letting me to do my observation and share a little of my knowledge of English to the students.
This thesis is dedicated to my family (Papa, Mama, Mas Beny, Mba Kunthi, and Deandra) who always give me endless support in every condition and become a light when I am in the dark. I thank my other families (RF, The Homer, PSM Cantus Firmus, Geng Wanita Ular, SLP Batch 9, and Sasing A 2013) that always make me happy when I am down.
ix
CHAPTER II: REVIEW OF LITERATURE ... 6
A. Review of Related Studies ... 6
B. Review of Related Theories ... 8
1. English Phonetics ... 8
2. English Phonology ... 13
3. Indonesian Phonetics and Phonology... 15
4. Error Analysis ... 17
CHAPTER IV: ANALYSIS (RESULTS AND DICUSSION) ... 24
A. The Result of Voiced and Voiceless Obstruents Pronunciation Among the Students of SMA Yos Sudarso Sokaraja ... 24
1. Voiced ... 25
2. Voiceless ... 28
B. Analysis of the Errors... 32
1. Phonological Analysis ... 33
a. The sound [p] in the word repairs ... 33
x
c. The sound [k] in the word firecrackers ... 34
d. The sound [ɡ] in the word ago... 35
e. The sound [v] in the word never ... 36
f. The sound [θ] in the word anything ... 36
g. The sound [ð] in the word others... 37
h. The sound [s] in the word thesis ... 38
i. The sound [z] in the word lazy ... 38
j. The sound [ʃ] in the word washing ... 39
k. The sound [ʒ] in the word leisure ... 40
l. The sound [ʤ] in the word apologize ... 41
2. Error Analysis of Interference Errors ... 42
CHAPTER V: CONCLUSION ... 51
BIBLIOGRAPHY ... 54
APPENDICES ... 56
A. Data Material ... 56
B. List of Question ... 57
C. Data Result ... 58
D. Data Transcription ... 59
E. Interview Result ... 63
F. The List of Respondents... 67
xi
LIST OF TABLES
Table 1 English Consonants ... 13
Table 2 Indonesian Consonants ... 16
Table 3 Result of Respondents’ Pronunciations ... 25
Table 4 The Sound Change Summary ... 31
xii
ABSTRACT
SATITI, MARIA SEKAR. The Pronunciation of English Voiced and Voiceless Obstruents in the Medial Position: A Case Study in SMA Yos Sudarso Sokaraja. Yogyakarta: Department of English Letters, Faculty of Letters, Sanata Dharma University, 2017.
In pronunciation, differentiating one sound and other sounds is important because it can change the meaning of a word. In English phonology, sounds are differentiated by distinctive features. One of the distinctive features is voicing feature. Voicing feature is very important in English sounds especially obstruent sounds. Unfortunately, voicing feature Is often forgotten by English learners. For that reason, the purpose of this thesis is to find out how English learners in Indonesia pronounce voiced and voiceless obstruent sounds, and analyze the errors that appear. The respondents of this thesis are the students of SMA Yos Sudarso Sokaraja. The data in this thesis are the students’ pronunciations of voiced and voiceless obstruent sounds.
There are two problems that are formulated in this thesis. Firstly, how do the students of SMA Yos Sudarso Sokaraja pronounce the voiced and voiceless obstruent sounds? Secondly, what is the cause of the errors that appear in their pronunciations?
The method that is used in this thesis is qualitative method with the case study strategy. This method is used to observe how the students pronounce voiced and voiceless obstruent sounds. The data are analyzed using English phonetics and phonology, Indonesian phonetics and phonology, and error analysis of interference errors.
As the result, the students have difficulties in pronouncing voiced sounds [v] and [ʒ], and voiceless sounds [θ] and [ʃ]. The students fail to apply voicing feature in pronouncing those sounds. The students pronounce the sound [v] and [ʒ] as voiceless sound, while the sounds [θ] and [ʃ] is pronounced as other sounds which are also voiceless. Some errors that are made by the students are caused by the influences of how Indonesian or Javanese words are read.
xiii
ABSTRAK
SATITI, MARIA SEKAR. The Pronunciation of English Voiced and Voiceless Obstruents in the Medial Position: A Case Study in SMA Yos Sudarso Sokaraja. Yogyakarta: Program Studi Sastra Inggris, Fakultas Sastra, Universitas Sanata Dharma, 2017.
Di dalam pelafalan, membedakan satu suara dengan yang lain adalah hal yang penting karena hal tersebut dapat merubah makna suatu kata. Dalam fonologi Bahasa Inggris, bunyi dibedakan oleh beberapa ciri pembeda. Salah satuya adalah ciri penyuaraan. Ciri penyuaraan sangat penting dalam bunyi pada Bahasa Inggris terutama bunyi obstruen. Sayangnya, ciri penyuaraan sering dilupakan oleh orang yang belajar Bahasa Inggris. Oleh Karena itu, tujuan dari tesis ini adalah untuk menemukan bagaimana cara orang Indonesia yang belajar Bahasa Inggris melafalkan bunyi obstruen bersuara dan tak bersuara, dan menganalisis kesalahan-kesalahan yang muncul. Responden dalam tesis ini adalah para siswa SMA Yos Sudarso Sokaraja. Data dalam tesis ini adalah pengucapan bunyi obstruen bersuara dan tak bersuara oleh para siswa.
Ada dua rumusan masalah dalam tesis ini. Pertama, bagaimana para siswa SMA Yos Sudarso Sokaraja melafalkan bunyi obstruen bersuara dan tak bersuara? Kedua, apa penyebab dari kesalahan yang muncul dalam pelafalan?
Metode penelitian yang digunakan dalam skripsi ini adalah metode kualitatif dengan strategi studi kasus. Metode ini digunakan untuk meneliti bagaimana para siswa mengucapkan bunyi obstruen bersuara dan tak bersuara. Data dalam tesis ini dianalisis menggunakan teori fonetik dan fonologi Bahasa Inggris, fonetik dan fonologi Bahasa Indonesia, dan analisis kesilapan pada kesalahn interferen.
1
CHAPTER I INTRODUCTION
A. Background of the Study
In verbal communication, speaking is one of many ways to deliver a message. In speaking, pronunciation is very important in delivering the meaning. Mispronunciation can cause misunderstanding of the meaning of every word which is said. For example, a listener will misunderstand the word van if the speaker mispronounces it as fan.
Mispronunciation is very common among non-English speakers. It is also very common among English learners. English learners have to follow the pronunciation rules of English words. It means that they also have to follow the English phonetics and phonology. English phonetics and phonology help the learners to pronounce every English word correctly, then they would not make any mispronunciation which will cause any misunderstanding.
Pronouncing a word means pronouncing sounds, and a sound is different from one and other. Sounds consist of consonants and vowels. What the writer would like to observe in this undergraduate thesis is English consonant sounds. The writer would like to observe consonant sounds because there are many cases of consonant sound mispronunciations among English learners in Indonesia.
place of articulation. They are labiodental sounds. Yet, they are still different. What makes them different is the manner of articulation. They are different in voicing, that [v] is voiced and [f] is voiceless.
Voicing in English phonology is a distinctive feature. It means that voicing can make a different meaning of one word and the other word. An example about voicing as distinctive feature is
The phonetic feature of voicing therefore distinguishes the two words. Voicing also distinguishes feel and veal [f]/[v] and cap and cab [p]/[b]. When a feature distinguishes one phoneme from another, hence one word from another, it is a distinctive feature… (Fromkin, Rodman, and Hyams, 2011: 238).
The example shows that if sound [v] or [b] as voiced sounds are pronounced as voiceless sounds, there will be misunderstanding among the listeners.
It is important to pronounce English consonants differently in terms of voicing because some English consonants like [f] and [v] have a big difference in voicing. It is also stated that “The voiced/voiceless distinction is very important in English,” (Fromkin, Rodman, and Hyams, 2011: 218). It means that voicing in English has a big role to differentiate one sound from the other sounds.
Looking at that background, the writer is interested in observing the pronunciation of voiced and voiceless English consonants among English learners in Indonesia. The writer observes obstruent sounds only because the voicing feature has an important part in distinguishing one obstruent sound with the other obstruent
sounds like Ranford said that “Voicing is a distinctive feature for English obstruents, in that it serves to distinguish one phoneme from another,” (2000: 95). The writer only observes obstruent sounds in the medial position because all obstruent sounds appear in the medial position in the English book that is used by the respondents.
The writer would like to observe the students of SMA Yos Sudarso Sokaraja. The writer chooses high school students because they are English learners who have learned English longer than elementary students or junior high school students. The writer hopes this thesis can be very useful for the teachers and the students as an evaluation of their study in speaking English in the future if the students do not continue to learn English.
The other reason is most of the students of SMA Yos Sudarso Sokaraja come from Banyumas. People in Banyumas have strong accent which is called
ngapak. Most of the students come from Banyumas and they have strong ngapak
B. Problem Formulation
Related to the topic, the problems are formulated as follows:
1. How do the students of SMA Yos Sudarso Sokaraja pronounce the voiced and voiceless obstruent sounds?
2. What is the cause of the errors that appear in their pronunciations?
C. Objectives of the Study
There are two aims of the observation that are represented by the problem formulation. The first is to observe how the students’ pronunciation in pronouncing voiced and voiceless obstruent sounds in the medial position. The students potentially make sound changes in their pronunciation. The changes of the sounds are called errors. Then, the second aim is to see the reasons behind the errors that they make in pronouncing voiced and voiceless obstruent sounds.
D. Definition of Terms
In communication, people say the words that they want to delivers to the listener. They pronounce the words. Therefore, the term pronunciation means the way people say a word, or in the smaller unit of a word is sound, because “When
you know a word, you know its sound (pronunciation) and its meaning,” (Fromkin
et al, 2011: 37).
(2010: 91). Therefore, there are voiced and voiceless sounds. According to them
“Sounds produced with vibrating vocal folds (see Figure 1) are said to be voiced;” (2010: 91) and voiceless sounds are “those produced without vocal cord vibration,” (2010: 91).
Consonants are divided into specific and major classes. One of the major classes is obstruent. The sounds are called obstruents “because their production
obstructs the airflow,” (Radford, Atkinson, Britain, Clahsen, and Spencer, 2000: 37). There are some specific classes that belong to obstruents. According to
Fromkin, “The non-nasal stops, the fricatives, and the affricates form a major class of sounds called obstruents,” (2011: 210). It means that obstruents is a major class which consists of three specific classes. They are non-nasal stops, the fricatives, and the affricates.
6
CHAPTER II
REVIEW OF LITERATURE
A. Review of Related Studies
In the thesis, the writer focuses on phonetics and phonology because the writer would like to observe the English learners’ pronunciations of voiced and voiceless obstruent sounds. There are some studies about phonetics and phonology which the writer would like to relate to this thesis.
Keating (1984) in her journal concerns on phonetics and phonology. Keating observes the voicing feature not only in English, but also in another language. The similarity between Keating’s paper and this thesis is both of them talk about voicing feature. She concludes that voicing feature is one of many features to contrast sounds. In this thesis, the writer would like to observe voicing feature deeper, which is important to differentiate sounds, and how English learners pronounce it.
Another study of voicing feature is a paper by Heselwood (1997). He talks about the voicing feature of English consonant cluster in the final position. Related
thesis, the writer would like to observe consonant sounds which are obstruent in the medial position.
There is also an undergraduate thesis done by Simatupang (2015). Her thesis discusses how Javanese people pronounce voiced consonant. She chooses the tour guides in Keraton Yogyakarta as the respondents. She discusses how Javanese as
the respondents’ mother tongue influences their pronunciation on English voiced consonants.
The similarity of Simatupang’s thesis and this thesis is both of them discuss
voiced consonants, but this thesis only focus on obstruents. This thesis also not only focus on voiced sound, but also in voiceless sounds.
The data of this undergraduate thesis are English learners’ pronunciations. Because of that, the writer relates the thesis with other studies about pronunciation especially English learner pronunciation.
The paper by O’Brien (2004) discusses pronunciation. It discusses German
pronunciation by American students who learns German. O’Brien focuses on the stress, rhythm, and intonation. O’Brien finds what sounds which are nativelike and what sounds are not through the students’ pronunciation.
An undergraduate thesis done by Daho (2015) discuss pronunciation errors produced by a Papuan ELESP students. Daho’s thesis and this thesis is similar. Both of them use case study strategy and both of them discuss pronunciation errors. However, the focus and the respondents are different.
B. Review of Related Theories 1. English Phonetics
Phonetics is about sounds. Phonetics is “The study of speech sounds,” (Fromkin et al, 2011: 219). The square brackets [ ] is used to represent phonetic transcription while the slashes / / is represented phonemic transcription. According to Fromkin, “The phonemic representation of speech sounds using phonetic symbols, ignoring phonetic details that are predictable by rule, usually given between slashes,” (2011: 597), while “The representation of speech sounds using phonetic symbols between square brackets,” (2011: 597).
The phonetics which is discussed is English phonetics because the writer talks about English sounds. English sounds are divided into two, they are consonant and vowel.
a. English Consonant
There are 24 English consonants. They are classified by some ways. One of the ways is place of articulation.
i. Place of Articulation
1) Bilabial
Consonants which are produced by “bringingboth lips together,” (Fromkin
et al, 2011: 196) are called bilabial. They are [p], [b], and [m]. 2) Labiodental
Consonants are called labiodental when they are pronounced by “touching the bottom lip to the upper teeth,” (Fromkin et al, 2011: 196). The consonants which are labiodental are [f] and [v].
3) Interdental
When consonant is articulated by “inserting the tip of the tongue between the teeth,” (Fromkin et al, 2011: 196), it is called interdental. Consonants which are interdental are [θ] and [
ð].
4) Alveolar
There are seven consonants which are pronounced “with the tongue raised in various ways to the alveolar ridge,” (Fromkin et al, 2011: 197). There are [t], [d], [n], [s], [z], [l], and [r].
5) Palatal
The sounds [ʃ], [ʒ], [ʧ], [ʤ], and [j] are palatal because they are produced
by “raising the front part of the tongue to the palate” (Fromkin et al, 2011: 197). 6) Velar
7) Glottal
The sounds which belong to Glottal class are [h] and [ʔ]. Glottal sounds are explained as:
The sound of [h] is from the flow of air through the open glottis, and past the tongue and lips as they prepare to pronounce a vowel sound, which always follows [h]. If the air is stopped completely at the glottis by tightly closed vocal cords, the sound upon release of the cords is a glottal stop [ʔ] (Fromkin et al, 2011: 197).
ii. Manner of Articulation
English consonants are classified not only by place of articulation. English consonants are also classified by manner of articulation as Fromkin states
Speech sounds also vary in the way the airstream is affected as it flows from the lungs up and out of the mouth and nose. It may be blocked or partially blocked; the vocal cords may vibrate or not vibrate. We refer to this as the manner of articulation. (2011: 198).
Based on the way the airstream, they are classified into some following classes: 1) Stops
According to Fromkin “Stops are consonants in which the airstream is completely blocked in the oral cavity for a short period (tens of milliseconds). All
other sounds are continuants” (2011: 201). The stop consonants are the sounds [p], [b], and [m] as bilabial stops, the sounds [t], [d], and [n] as alveolar stops, the sounds [k], [g], and [ŋ] as velar stops, and the sound [ʔ] as glottal stop.
2) Fricatives
fricatives, the sounds [s] and [z] as alveolar fricatives, the sounds [ʃ] and [ʒ] as palatal fricatives, and the sound [h] as glottal fricative.
3) Affricates
Consonants which are affricates because they are produced “by a stop closure followed immediately by a gradual release of the closure that produces an effect characteristic of a fricative,” (Fromkin et al, 2011: 202). There are two English consonants which are affricates, they are [ʧ] and [ʤ].
4) Liquids
Liquids are produced when “there is some obstruction of the airstream in the mouth, but not enough to cause any real constriction or friction,” (Fromkin et al, 2011: 202). Liquids sounds are [l] and [r].
5) Glides
Glides are produced “with little obstruction of the airstream,” (Fromkin et al, 2011: 203) and “They are always followed directly by a vowel and do not occur at the end of words,” (Fromkin et al, 2011: 203). The glide consonants are [j] and [w].
iii. Voicing Feature
The condition of vocal cord also becomes a way to distinguish English consonants, whether it vibrates or not. Therefore, English consonants are also classified as voiced and voiceless sounds.
1) Voiceless
Consonant sound is voiceless if the vocal cord does not vibrate in the
vocal cords are apart so that air flows freely through the glottis into the oral cavity,” (2011: 198). The consonants which are voiceless are shown in table 1.
2) Voiced
Consonant sound is voiced when the vocal cord vibrates in the production
of the sound. Fromkin states “If the vocal cords are together, the airstream forces its way through and causes them to vibrate. Such sounds are voiced,” (2011: 198). The examples of voiced consonant are shown in table 1.
iv. Nasalization
The other way to distinguish English consonants is by using nasalization. Consonants are also distinguished as nasal sounds and oral sounds. Nasal sound and oral sound are produced because of the influence of velum.
1) Nasal
According to Fromkin, nasal sound is produced “when the velum is not in its raised position, air escapes through both the nose and the mouth,” (2011: 199). The nasal consonants are shown in table 1.
2) Oral
v. Obstruents
English consonants are also classified into some classes which is called major classes, the more general classes. One of the major classes is obstruent. It is called obstruents because “the airstream may be fully obstructed,” (Fromkin et al,
2011: 210) in the production of the sound. According to Fromkin “The non-nasal stops, the fricatives, and the affricates form a major class of sounds called obstruents,” (2011: 210). The other sounds which are not classified as obstruent are classified as sonorant.
English consonants are classified by some classes and they are different one another. For the summary from Fromkin, English consonant can be seen as the following table.
Table 1: English Consonants
2. English Phonology
English phonology is “the study of how speech sounds form pattern,”
The pattern of the sounds when they are pronounced can be seen through phonology.
Sounds are different from one another. In phonology, something that differ one sound and the other sounds is called distinctive feature. Fromkin explains that
“when a feature distinguishes one phoneme from another, hence one word from another, it is a distinctive feature,” (2011: 238).
There are some features that become distinctive the feature of English consonants. One of them is voicing feature. Kreidler states that “Speech has melody
– different melodies or intonation patterns – as a result of these different frequencies of vibration,” (2004: 21). A good example of voicing feature as a distinctive feature for English consonants from Fromkin is
The minimal pairs seal [sil] and zeal [zil] show that [s] and [z] represent two contrasting phonemes in English. They cannot be allophones of one phoneme because one cannot replace the [s] with the [z] without changing the meaning of the word…. We know that [s] and [z] differ in voicing: [s] is voiceless and [z] is voiced. The phonetic feature of voicing therefore distinguishes the two words. (2011: 238).
Voicing feature is an important feature to differentiate obstruent sounds because they are really different in terms of voicing. It is stated that “Voicing is a distinctive feature for English obstruents, in that it serves to distinguish one phoneme from another,” (Radford et al, 2000: 95). According to him
It is useful to distinguish the plosives, affricates and fricatives, which usually come in voiced/voiceless pairs from the nasals and approximants, which are intrinsically voiced. The former are called obstruent (because their production obstruct the airflow) and the latter are called sonorants (because they involve a greater degree of resonance) (2000: 37).
3. Indonesian Phonetics and Phonology
Indonesian Phonetics is similar with English phonetics. Dardjowidjojo
states that “The mechanism for the production of the Indonesian sounds is the same
as that for english,” (2009: 36). Indonesian phonetics also differs sounds into consonants and vowel.
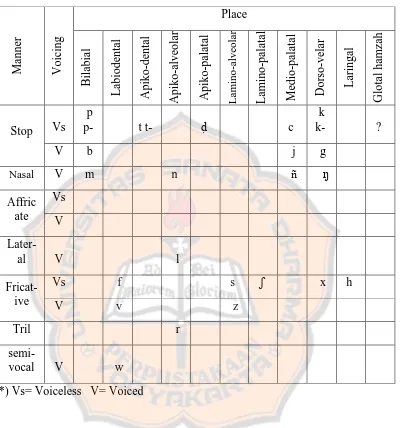
a. Indonesian Consonants
Indonesian consonants are similar with English. Indonesian consonants are produced by considering the point of articulation, the manner of articulation, the connection between active and passive articulator, and the voicing feature (Marsono, 2008: 60). Indonesian consonants can be seen in the table 2 according to Marsono.
Although Indonesian consonants look similar with English consonants, but there are some differences between them. The first difference is that there is no sound [ñ] in English consonants. The sound only appears in beginning of the word or in the medial position as the beginning of the syllable (Marsono, 2008: 77). The sound is represented by the letter ny.For examples are the word nyewa for initial position and punya for middle position.
Table 2: Indonesian Consonants
*) Vs= Voiceless V= Voiced
There are sound [ʧ] and [ʤ] in English, but there are no those sounds Indonesian. However, there are two sounds which are similar with those sounds. The sound [ʧ] is similar with the sound [c] and the sound [ʤ] is similar with [j]. the sound [c] and [j] in Indonesian are medio-palatal sounds.
In terms of position and voicing rules, there are also some differences between Indonesian consonants and English consonants. The differences are first,
the sound [z] in English is found in initial, medial, and final position (Marsono, 2008: 88), while in Indonesian the sound only appears in initial and medial position (Marsono, 2008: 88). The second is that according to Marsono, there is sound [v] in Indonesian. However, Dardjowidjojo says that the letter v Indonesian word is pronounced as [f] (2009:41). The letter v on Indonesian words only appears in the beginning of a syllable, while in English the sound [v] appears in the beginning, middle, and final position of a word.
4. Error Analysis
English learners often make mistakes when pronouncing English words. The mistakes which are systematic are considered as errors and error analysis (EA)
is used “as a tool for investigating how learners acquire a second language (L2),”
(Ellis, 2012: 45) which in this case is English learners.
There are eight types of production errors in speech. They are anticipations, persevations, addition and deletion, metathesis, spoonerism, shifts, substitutions, and blends.
immortal soul is pronounced as his immoral soul. Metathesis is the switching of two unit which each unit taking place of the other. For example, the phrase fill the pool is pronounced as fool the pill. Spoonerism is the error when a metathesis involves the first sounds of two separate words. For example, the phrase dear old queen is pronounced as queer old dean. Shift occurs when a unit is moved from one location to another location. When the sentence she decides to hit it is pronounced as she decide to hits it becomes the example of shift error. Substitution occur when one unit is replaced with another, and blends occur when two words
“fuse” into a single term. The example of substitution is when the phrase it’s hot
here is pronounced as it’s cold here, and the example of blends is when the phrase
grizzly/ghastly is pronounced as grastly (Dawson, 2016: 376).
C. Theoretical Framework
In this thesis, the writer would like to observe how English learners pronounce obstruent sounds. English phonetics help the writer to identify their pronunciation. The writer observes how English learners produce obstruent sounds in their pronunciation.
In this thesis, the writer also tries to find the causes of the errors that appear
in English learners’ pronunciation. The respondents in this thesis are Indonesian people. Because the respondents are Indonesian, Indonesian phonetics and phonology are needed to support the phonological analysis.
20
CHAPTER III METHODOLOGY
A. Object of the Study
The data that are analyzed in this thesis are voiced and voiceless obstruent sounds in the medial position pronounced by students of SMA Yos Sudarso Sokaraja. The voiced obstruent sounds are [b], [d], [g], [v], [ð], [z], [ʒ], and [ʤ], while the voiceless one are [p], [t], [k], [f], [θ], [s], [ʃ], and [ʧ]. All of those sounds are provided in the Diktat Bahasa Inggris as their English textbook in the speaking part. The writer does not find the sound [h] and [ʔ] which is in the medial position in the book. Therefore, the writer does not focus on those sounds.
Because the writer would like to observe English learners, the place where the writer gains the data is a school. The school is SMA Yos Sudarso Sokaraja. SMA Yos Sudarso Sokaraja is located in Jl. Letjend Supardjo Rustam, Desa Sokaraja Kulon RT03/RW10, Sokaraja, Banyumas, Central Java, (http://ysbs.or.id/id/portfolio_post/sma-yos-sudarso-sokaraja/).
There are nineteen respondents of thirty nine students in the eleven grade from two classes. There are eleven students come from social class, and eight students come from science class. The students are chosen based on the agreement of the writer and the English teacher. At first, there are twenty respondents, but there is one respondent who does not fulfill the requirements. Therefore, the writer choses nineteen respondents.
B. Approach of the Study
Phonological approach is used to analyze the sound pattern in human language. According to Gussmann “the theory of phonology reflects our current understanding of the organisation and the working of the sound system of languages,” (2002: 19). Since the data are sounds, phonological approach is used to analyze the data. Error analysis approach is also used to analyze the errors which are produced by the respondents.
C. Method of the Study 1. Data Collection
The writer uses the qualitative method with case study strategy in this thesis. According to Stake in Creswell
The writer observes the students of SMA Yos Sudarso Sokaraja in a time, means that the writer observes particular people in particular place and time. Therefore, case studies strategy is used in this thesis.
The first thing that is done by the writer is studying the English book that is used by the students. Then, the writer decides to observe voiced and voiceless obstruent sounds in the medial position because almost all obstruent sounds appears in the medial position except for the sound [h] and [ʔ].
In the qualitative method, the data is collected in some procedures. Creswell states that
The data collection steps include setting the boundaries for the study, collecting information through unstructured (or semi-structured) observation and interviews, documents, and visual materials, as well as establishing the protocol for recording information (2003: 185).
In this thesis, the data are audio recording of the respondents’ pronunciations and
information about respondents’ background. The writer uses a sound recorder to collect the audio material and do the interview to the respondents in order to get further information about their background. Therefore, the next step is preparing the instruments including the list of sentences, the list of questions, and the sound recorder.
To gain the audio material of pronunciation, the respondents are asked to read some sentences which have been prepared by the writer that are pick from the
In order to know further information about respondents’ background, the writer asks them some questions through an interview. The writer asks every respondent, one by one, some questions related to their living background, language background, and educational background right after the writer gets the audio material of the pronunciations. The writer records the answers using hand writing and sound recorder.
2. Data Analysis
First step of analyzing the data is transcribing the audio material of the
students’ pronunciations. The writer transcribes every word that becomes the
writer’s focus whichis pronounced by the respondents. The words’ transcriptions
are transcribed based on Oxford Advance Learner’s Dictionaryand IPA. Then, the transcriptions are categorized into some groups based on how the respondents pronounce voiced and voiceless obstruent sounds in the medial position. The transcription helps the writer to know the errors that are made by the respondents. The writer also transcribes the result of the interview with the respondents. The writer can see the similarity and the difference of one respondent and other respondents from the interview transcription.
Then, the writer analyzes the errors using phonology and error analysis theory. The result of the interview also helps the writer in analyzing the errors. By
24
CHAPTER IV
ANALYSIS RESULT AND DISCUSSION
This chapter consists of two subchapters. The first subchapter is the result of the respondents’ pronunciations. The second sub-chapter is the analysis of the errors that appears in the respondents’ pronunciations which consist of phonological analysis and error analysis. The first subchapter answers the first question. The second subchapter answer the second question in the problem formulation.
A. The Result of Voiced and Voiceless Obstruents Pronunciation Among the Students of SMA Yos Sudarso Sokaraja
There are nineteen students who become the respondents in this thesis. In pronouncing voiced and voiceless obstruent sounds in the medial position, the
Table 3: Result of Respondents’ Pronunciations
1. Voiced
There are eight voiced obstruent sounds that become the writer’s focus in this thesis. The respondents do not pronounce all of the eight voiced obstruent sounds successfully. Only two of eight sounds are pronounced successfully by the respondents, and there is one sound that is unsuccessfully pronounced by all respondents. The table 4.1 shows that the respondents tend to make more errors in pronouncing voiced obstruent sounds in the medial position rather than the voiceless sounds.
unsuccessfully pronounced by all respondents. The sound [v] in the word never
becomes the most unsuccessfully pronounced after the sound [ʒ]. The sound [ʤ] in the word apologize become the third most unsuccessfully pronounced by the respondents after the sound [ʒ] and [v].
a. Sound [b]
To gain the data of pronunciation of the sound [b] in the medial position, the writer uses the word about. The respondents have no difficulties in pronouncing the sound [b] in the word about. There is no mispronunciation found by the writer. b. Sound [d]
The writer uses the word reading for the sound [d] in the medial position pronunciation. All of the respondents successfully pronounce the sound [d] in the word reading. There is no mispronunciation found by the writer.
c. Sound [g]
The respondents are asked to pronounce the word ago. Most of the respondents have no problem in pronouncing the sound [g] in the word ago. Only one incorrect pronunciation is made. It is made by the fourteenth respondent who pronounces it as [kɔ].
d. Sound [v]
it as [nefər] and one respondent pronounce it as [nefə]. However, those incorrect pronunciations have the same error, that the sound [v] is pronounced as [f].
e. Sound [ð]
To gain the data of the sound [ð] in the medial position, the writer uses the word others. There are five incorrect pronunciations found by the writer. The seventh and sixteenth respondents pronounce the word others as [ɔdər]. The nineteenth respondent pronounces it as [ʌdər]. The eighteenth respondent pronounces it as [ʌtəs], and the eight respondent pronounces it as [ɔldərs].
f. Sound [z]
The word lazy is chosen to be pronounced by the respondents in order to gain the data of the sound [z] in the medial position. There are four respondents who pronounce the word incorrectly. The first is the fourth respondent who pronounces it as [les]. The second is the eighth respondent who pronounces the word as [lets]. The third is the fourteenth respondent who pronounces it as [lesi]. The last is the eighteenth respondent who pronounces the word as [lesən].
g. Sound [ʒ]
h. Sound [ʤ]
In order to gain the data of the sound [ʤ], the writer uses the word apologize
in this thesis. There are three medial consonants in this word. Yet, the writer only focuses on the sound [ʤ] in the word. There are six respondents who pronounce the word correctly. There are eight respondents who pronounce the sound [ʤ] in the word as [ɡ]. There is one respondent who pronounces the word as [əpɔlɪŋsi]. There is also one respondent who pronounces the word as [ʌblɔk], one respondent pronounces the word as [əpɔŋsɪŋ], one respondent pronounces the word as [pɔlbɪs], and one respondent pronounces it as [əpɔlɪs].
2. Voiceless
There are eight voiceless obstruent sounds that become the writer’s focus in
this thesis. Not all voiceless obstruent sounds in the medial position are successfully pronounced by the respondents. There are only two sounds which are successfully pronounced by all respondents, and there is one sound that is unsuccessfully pronounced by all respondents. However, the table 4.1 shows that the respondents make more correct pronunciations in voiceless obstruent sounds rather than in voiced obstruent sounds. The respondents have less difficulties in pronouncing voiceless obstruent sounds in the medial position.
The sound [f] in the word office and the sound [ʧ] in the word teacher are pronounced successfully by all respondents. There is no mispronunciation found in the two sounds. The sound [θ] in the word anything becomes the most unsuccessfully pronounced by the respondents. All respondents mispronounce that
pronounced after the sound [θ]. There are only two respondents who successfully
pronounce the sound [ʃ]. The other sounds are quite successfully pronounced by the student with the number of correct pronunciation are above ten.
a. Sound [p]
The writer uses the word repairs to gain the data of the pronunciation of sound [p] in the medial position. In pronouncing the sound [p], the writer finds three incorrect pronunciations. The first respondent pronounces it as [rɪpres], the eighth respondent pronounces it as [rɪprens], and the nineteenth respondent pronounces it as [rɪpreɪs].
b. Sound [t]
The word attempt is used for the sound [t] pronunciation in the medial position. There are three incorrect pronunciations made by the respondents. The three incorrect pronunciations are made by the second respondent, the fourth respondent, and the nineteenth respondent. The second respondent pronounces the word as [etmen], the fourth respondent pronounces it as [eðəm], and the nineteenth respondent pronounces it as [mpɪt].
c. Sound [k]
fourth respondent who pronounces it as [freskres]. The fourth is made by the eighth respondent who pronounces it as [frenskən]. The last is made by the fourteenth respondent who pronounces it as [faərkreks].
d. Sound [f]
The writer uses the word office to gain the data of the sound [f] in the medial position. There is no incorrect pronunciation found by the writer. All respondents correctly pronounce the sound [f] in the word office.
e. Sound [θ]
The word anythingis chosen to gain the data of the sound [θ] in the medial
position. All respondents pronounce the word incorrectly. Most of them pronounce the sound [θ] as the sound [t], but there is a respondent who pronounces the word as [endir].
f. Sound [s]
To gain the data of the sound [s] in the medial position, the writer uses the word thesis. There are three respondents who pronounce the word thesis incorrectly. The first and ninth respondent pronounce it as [tis] and the fourth respondent pronounce it as [ðes].
g. Sound [ʃ]
h. Sound [ʧ]
The writer uses the word teacher in order to gain data of the sound [ʧ] in the medial position. The respondents have no any difficulty in pronouncing the word. There is no incorrect pronunciation that is found by the writer.
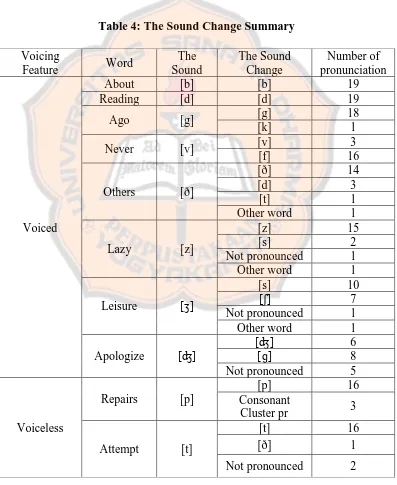
From the explanation above, the change of the sounds that are pronounced by the respondents can be summarized as the table 4 below.
Table 4: The Sound Change Summary
Most of the sound changes that are made by the students have similarity with the sounds that become the writer focus. There are some sound changes that similar in place of articulation, but different in voicing feature like in the case of [v] pronunciation. There are also some sound changes that are similar in voicing feature, but different in place of articulation like in the case of [θ] pronunciation. Most of the changes that are similar in voicing feature come from the neighbor of
the focus sounds’ place articulation. For example, the sound [θ] changes from interdental into alveolar which is the near interdental. However, interdental and alveolar are similar because they are coronal. In the case of the hissing sounds like
[ʒ] and [ʃ], the sounds change into the other hissing sounds because they are come from the same class, it is sibilants.
B. Analysis of the Errors
In this sub-chapter, the errors made by the respondents are analyzed by using phonology and error analysis theory. In this analysis, the writer only focuses
on the voiced and voiceless obstruent sounds in the medial position. However, there is no error found in the word about, reading, office, and teacher. Therefore, the writer does not discuss those words in this sub-chapter.
1. Phonological Analysis
a. Sound [p] in the word repairs
The errors that are made in the word repairs are there are three respondents mispronounce the word from /rɪˈpeə(r)s/ into [rɪpres], [rɪprens], and [rɪpreɪs]. All of those mispronunciations are that the respondents mispronounce the sound [p] into consonant cluster pr. The three respondents experience slip of the tongue. Slip of
the tongue is “an involuntary deviation of intended utterance,” (2011: 593).
There is no consonant cluster occurs in the final position of a syllable or a word in Indonesian (Dardjowidjojo, 2009: 55). The consonant cluster in the errors are all in the beginning of the syllable. The respondents mispronounce the word because it is easier to pronounce consonant cluster in the beginning of a syllable as they have in Indonesian word like pria or pramugari.
b. Sound [t] in the word attempt
[e] instead of [ə]. This condition make the consonant [t] become flap. The flap occurs between a stressed vowel and unstressed vowel (Fromkin, 2011: 235). Yet, the respondent does not pronounce the flap but the voiced sound [ð] because the two sounds are similar.
The respondent who makes error [etmen] mispronounces the word. The sound [t] supposed to be the onset of tempt as the second syllable of the word, but the respondent mispronounces it. The respondent’s mispronunciation is et as the first syllable and men as the second syllable. The respondent pronounces the sound [t] as the coda of the first syllable of the word.
It also explains the respondent who pronounces the word as [mpɪt]. In this case, the respondent mispronounces the word into one syllable only. The respondent also pronounces the sound [t] as the coda of the syllable.
c. Sound [k] in the word firecrackers
The errors which are found are [frikrekrɪs], [frikəʧərs], [freskres], [frenskən], [faerkreks]. The respondent who mispronounces the word into [frikrekrɪs] experiences slip of the tongue. The respondent is influenced by the previous syllable kre which has consonant cluster as the onset of the syllable. Therefore, the respondent also pronounces the sound [k] in the final syllable as cluster kr.
way most of Indonesian and Javanese words are read. Most of Indonesian and Javanese words are read as the same as the spelling. There is the letter c in the word
firecrackers. Therefore, the respondent pronounces the sound [k] as the sound [c]. In the case of errors [freskres] and [frenskən], the respondents unfinish to pronounce the word. The respondents do not pronounce the sound [k] in the last
syllable which becomes the writer’s focus.
The respondent who makes the error [faerkreks] does not pronounce the vowel [ə] in the last syllable. The word which has three syllables becomes having two syllables only. The first syllable is faer and the second is kreks. The sound [k] which supposed to be the onset of the third syllable becomes consonant cluster and coda of the second syllable. Since the vowel is not pronounced, the third syllable is gone. The respondent also does not pronounce the sound [k] because it becomes cluster ks.
d. Sound [ɡ] in the word ago
e. Sound [v] in the word never
There are only three respondents from nineteen respondents who successfully pronounce the sound [v] in the word never. The other respondents pronounce the sound [v] as the sound [f]. The sounds [v] and [f] come from the same place of articulation. They are labiodental. However, they are different in terms of voicing feature. The sound [v] is voiced and the sound [f] is voiceless. All errors are about the respondents who make error pronounce the voiced sound [v] as voiceless sound [f]. It shows that they are failed to pronounce voiced obstruent sound in this case the sound [v].
The respondents have difficulty in pronouncing the sound [v] because according to Dardjowidjojo (2009, 41), the letter v Indonesian word is pronounced as [f] like in the word aktivitas and devisa. Therefore, most of the respondents have difficulty in pronouncing the sound [v] because they do not use that sound in everyday life.
f. Sound [θ] in the word anything
All of the respondents pronounce the word sound [θ] incorrectly. Eighteen respondents pronounce the sound [θ] as the sound [t]. According to Marsono (1999:
85), the sound [θ] does not exist in Indonesian. Dardjowidjojo also said that
Indonesian people have difficulty in pronouncing the sound [θ] because Indonesian
people does not have that sound in their language (2009: 76). Therefore, the
respondents tend to pronounce the sound [θ] as the sound [t] because they are
sound [t] is produced by the tongue and alveolar ridge which is near upper teeth. In addition, there is letter t in the word anything that makes the respondents tend to
pronounce the sound [θ] as the sound [t].
There is also one respondent who pronounces the word as [endir]. The error is very different from the correct pronunciation. The error only has two syllables instead of three syllables. The sound [d] in the error represents how the respondent
pronounce the sound [θ]. The respondent incorrectly pronounces the voiceless sound [θ] because it becomes voiced. The error shows that the respondent is failed in pronouncing the sound [θ] and the whole word.
g. Sound [ð] in the word others
There are five errors made by five respondents. Two respondents make the same error, it is [ɔdər]. There are also [ɔldərs], [ʌtəs], and [ʌdər] which are each error is made by one respondent.
In the case of [ɔdər] and [ʌdər], the respondents are unsuccessful in pronouncing the voiced sound [ð]. They pronounce it as the sound [d] which is also a voiced sound. However, the sound [ð] and the sound [d] come from different place of articulation. According to Marsono (1999: 84), there is no sound [ð] in Indonesian. Therefore, it is difficult to be pronounce by Indonesian people. In this case the respondents replace the sound [ð] with the sound [d] which is similar. Dardjowidjojo also says that, “Indonesians tendto replace it with /d/,” (2009: 77).
is pronounced as voiceless. The respondent is not accustomed to pronounce the sound [ð] in daily language. Therefore, the respondent pronounces it as the sound [t] which is more often used in daily language. In addition, there is the letter t in the word others that make the respondent tends to pronounce the sound [t] instead of [ð].
In the case [ɔldərs], the respondent misreads the word. The error sounds like the respondent pronounce the word olders. In fact, the word others and olders are different in meaning.
h. Sound [s] in the word thesis
There are three errors made by the respondents. There are [tis], [ðes], and [tis]. All of the errors are the same. The respondents make an unfinished pronunciation in pronouncing the word. The word thesis has two syllables with the sound [s] in the medial position and the final position of the word. The sound [s] in
the medial position of the word become the writer’s focus. Yet, the error shows that
the respondents only pronounce one syllable of the word and the sound [s] only appears in the final position. It means that the respondents who mispronounce the word do not pronounced the sound [s] in the medial position which becomes the
writer’s focus.
i. Sound [z] in the word lazy
It shows that the respondents who make this error are failed to follow voicing feature for the sound [z].
The respondents who make errors [les] and [lets] misread the word. Their pronunciations show that they pronounce the word less and lets. The meaning of
less and lets are different from the word lazy. The errors show that they are failed
to pronounce the sound [z] which is the writer’s focus.
j. Sound [ʃ] in the word washing
There are only two respondents from nineteen respondents who successfully pronounce the sound [ʃ] in the middle of the word. Fifteen respondents pronounce the sound [ʃ] as the sound [s]. Basically, both sounds [ʃ] and [s] are voiceless. However, they come from different place articulation. In Indonesian, the sound [ʃ] is similar with the sound the word asyik which is represented by the letter sy
(Marsono, 1999: 90). Yet, in this case almost all respondents are failed to pronounce the sound [ʃ]. The respondents do not pronounce it as sy in the word asyik because the word washing uses the letter sh not sy. Therefore, they tend to pronounce it as [s] not the sound of sy. In addition, according to Djardjowidjojo (2009, 42) that in pronouncing the sound of letter sy, people often pronounce it as the sound [s]. for example, the word asyik is often read as asik and the word syukur is often read as
sukur. However, the sound [ʃ] and [s] are pronounced similarly.
There is also one respondent who pronounces the word as [walhɪŋ]. In this error, the respondent does not pronounce the sound [ʃ]. The sound [ʃ] is replaced by the sound [h] which come from different place articulation and they do not sound similar.
k. Sound [ʒ] in the word leisure
Another error about voicing feature is that there are seven respondents who mispronounce the word leisure. In the word leisure, there is sound [ʒ] in the middle of the word that become the writer’s focus. These seven respondents who mispronounce the sound [ʒ] into [ʃ]. The sound [ʒ] and [ʃ] come from the same place of articulation, but the voicing feature differs those two sounds. The error is that seven respondents pronounce the voiceless sound [ʃ] instead of the voiced sound [ʒ]. It shows that the seven respondents are failed in applying voicing feature in their pronunciation of the sound [ʒ]. In addition, they are influenced by the letter
sure in the word. The word sure itself is pronounce /ʃɔ:(r)/. Therefore, they tend to pronounce the sound [ʒ] as [ʃ]. However, the word sure and the letter sure in the word leisure is different in pronunciation.
The other errors are that there are two respondents who mispronounce the word into [lɔʊs] and [leɪs]. The respondents who make these errors do unfinished pronunciation in pronouncing the word. The word leisure has two syllable which has the sound [ʒ] in the middle of the word that becomes the writer’s focus. In this case, the two respondents mispronounce the word that make it become has one syllable only and the sound [ʒ] in the medial that becomes the writer’s focus position is gone. It shows that the two respondents are unsuccessful in pronouncing the sound [ʒ] in the medial position.
l. Sound [ʤ] in the word apologize
There are eight respondents from nineteen respondents who mispronounce the sound [ʤ] in the word apologize. They pronounce it as the sound [ɡ]. Both sound [ʤ] and [ɡ] are voiced, but they come from different place of articulation. The respondents who make this error are influenced by the letter g in the word. Since Indonesian people pronounce most of the Indonesian word the same with the spelling, the eight respondents tend to pronounce the sound [ʤ] as [ɡ].
The other errors are [əpɔlɪŋsi], [ʌblɔk], [əpɔŋsɪŋ], [pɔlbɪs], and [əpɔlɪs]. The respondents who make these errors do not pronounce the sound [ʤ]. The respondents who mispronounce the word into [ʌblɔk], [əpɔŋsɪŋ], [pɔlbɪs], and [əpɔlɪs] do unfinished pronunciation of the word. All of these errors are really different from it supposed to be.
some English sounds like the sounds in Indonesian because they do not use some English consonants in daily conversation. Therefore, they tend to make errors in pronouncing some sounds.
2. Error Analysis
This sub-chapter discusses the errors that appear using error analysis theory. To support the analysis, there are some data about the respondents that are got from interview. There are thirteen respondents from nineteen respondents who have Indonesian as their mother tongue and there are six respondents who have Javanese as their mother tongue. Seventeen respondents come from region where the people use Javanese ngapak like Banyumas, Cilacap, and Purbalingga. All the respondents do not get English courses outside the school while they are studying in senior high school, but eleven of them have ever got English courses when they were in elementary school or junior high school. All respondents have never studied phonology, so they do not know about voicing feature in phonology.
One type of the errors is metathesis that is the switching of two unit which each unit taking place of the other (Dawson, 2016: 376). Some errors that are considered as metathesis made by the respondents are the mispronunciation of the final consonant cluster.
(2008: 71), the sound order of Indonesian consonant cluster which consists of two consonants can be explained like this:
a. The first consonant is around [p], [b], [t], [d], [k], [ɡ], [f], and [s]. b. The second consonant is around [l], [r], [w], [s], [m], [n], and [k].
Those sound is the element of Indonesian consonant cluster. For example, consonant cluster pl in the word plagiat and consonant cluster br in the word bromo. Because of this sound order, many respondents make metathesis errors in pronouncing final consonant cluster by switching the position of the sounds that make them do not pronounce the final consonant cluster.
In the word repairs, the three errors that are made is that the respondents pronounce the sound [p] into the consonant cluster pr. The consonant cluster of the word repairs is cluster rs that appears in the final position. All respondents who make that errors have Indonesian as their mother tongue. Since there is no consonant cluster that appears in the final position of Indonesian word, the respondents tend to pronounce the cluster in the initial position of the second syllable. They pronounce the consonant cluster pr because there is consonant cluster pr in Indonesian like in the word pria or pramugari.
syllable. Consonant cluster kr appears in the Indonesian words like kronologi and
akrab.
All of those errors happen because most of the respondents have Indonesian as their mother tongue. Some of them have Javanese as their mother tongue. They also use Indonesian or Javanese in daily communication. Most of the Indonesian and Javanese words are read the same as the spelling especially for the consonants. Because of that reasons, the respondents potentially make that errors because they tend to use the way how Indonesian and Javanese words are pronounced in pronouncing English words.
There are some respondents who do not pronounce the obstruent sounds that
become the writer’s focus. Some respondents do not pronounce some obstruent
sounds in the medial positions because they mispronounce the whole word or do unfinished pronunciation. This kind of error appears in the word attempt, firecrackers, thesis, washing, leisure, and apologize.
In the word attempt, there are two respondents who do not pronounce the
respondent only read the last three letters of the word which are m, p, and t. Then, the respondent insert the sound [ɪ] among the three letters because those letters need a vowel as the nucleus of the syllable.
In the word firecrackers, there are two respondents who pronounce the word as [freskres] and [frenskəns]. They do not know how to pronounce the word, but
they try to pronounce it by guessing the pronunciation. They guess the word’s
pronunciation based on the letters of the word. There are the letters f, r, e, and k. They pronounce the first syllable as fre because they see the letter f, r, and e appears in sequence. They are influenced by the way how Indonesian words are read. Therefore, they pronounce the first syllable as fre. The following syllable, the letter
k appears in sequence with the letter e. In Indonesian phonology, the letter e can be pronounced as [e] like in the word ekor or [ə] like in the word elang (Marsono, 2008: 37). Therefore, the respondents pronounce the following syllable as a syllable that contains of the letter k and e.
In the word thesis, there are three respondents who do not pronounce the
In the word washing, there is a respondent who do not pronounce the sound
[ʃ] that becomes the writer’s focus. The respondent mispronounces it as [walhɪŋ]. The respondent does not know how to pronounce the letter sh in the word, but the respondent try to pronounce it by guessing the pronunciation. Since the
respondent’s mother tongue is Javanese and the respondent’s daily language is
Javanese with ngapak dialect, the respondent is influenced by the way how Javanese words are read. Most of Javanese words are read the as the spelling. Therefore, the respondent mispronounces the word as [walhɪŋ] because there are the letters w, a, h, i, and ng in the word washing. The respondent guesses the pronunciation by pronouncing the word as same as the spelling and replaces the pronunciation of the letter sh into the sound [l] and [h].
There is a respondent who does not pronounce the sound [ʒ] in the word
leisure. The respondent mispronounces it as [lɔʊs]. The respondent does not know how to pronounce it correctly, but the respondent try to pronounce it by guessing the pronunciation. The respondent is influenced by the letter l and s in the word, and the pronunciation of the word sure that appears in the word. It makes the respondent pronounces the word by using the sound [l] and [s] as the consonants and the vowel which is similar with the vowel in the word sure. Therefore, the respondent pronounces the word as [lɔʊs].
guessing the correct pronunciation. They pronounce the first two syllable correctly, but the following syllables are incorrect. Since all respondents who make that errors have Indonesian as their mother tongue, they are influenced by how Indonesian words are read. They pronounce the following syllable based on the letter in the word apologize. Since the sound [z] does not appear in the final position of an Indonesian word and the letter z in the final position of an Indonesian word is pronounced as [s] (Marsono, 2008: 88), the three respondents pronounce the sound [s] in the following syllable.
In the word apologize, the letter i and z appears in sequence. It makes the three respondents tend to pronounce the sound [ɪ] and [s] in sequence. The letter g
also influenced two respondents who pronounce the word as [əpɔlɪŋsi], [əpɔŋsɪŋ]. The letter g usually appears in sequence with the letter n that is pronounce as [ŋ]. Therefore, there are two respondents pronounce the sound [ŋ] in the medial position because the letter g in the word apologize also appears in the medial position.
There is also a respondent who do not pronounce the word apologize
correctly by pronouncing it as [pɔlbɪs]. Since the respondent’s mother tongue and daily language is Indonesian, the respondent is influenced by the way of how Indonesian words are read in guessing the pronunciation of the word apologize. The respondent pronounces the word as [pɔlbɪs] because there are the letters p, o, l, i,
and z. Since the sound [z] does not appears in the final position of Indonesian words, the respondent pronounce it as the sound [s]. The respondent also inserts the sound [b] between the sound [l] and [ɪ] because there is a consonant between the letter l
and I in the word apologize. Then, the respondent guesses that the pronunciation of the word apologize is [pɔlbɪs].
The respondents who do not pronounce some obstruent sounds that become
the writer’s focus because they do not know the correct pronunciations and try to guess the pronunciation of the words. In their guessing, they are influenced by the way of how Indonesian or Javanese words are read. They guess the pronunciation based on the letters that appears in the words.
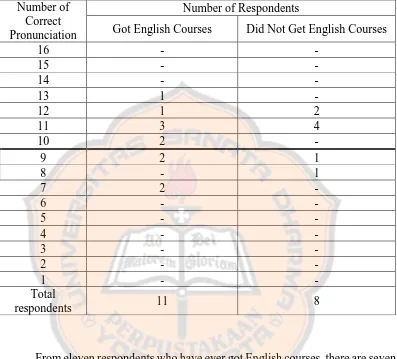
Table 5: The Respondents’ Correct Pronunciation Result Based on Their Background
From eleven respondents who have ever got English courses, there are seven respondents who get ten correct pronunciations, and four respondents get below ten correct pronunciations. More than a half of the respondents who have ever got English courses get score ten and above for the correct pronunciation. The higher score is achieved by the fifteenth respondent who got English courses when she was at elementary school. It shows that English courses can a factor that help the respondents to have good pronunciation. English courses also can be a factor that
Number of Correct Pronunciation
Number of Respondents
Got English Courses Did Not Get English Courses
51
CHAPTER V CONCLUSION
Error is common among English learners. Indonesian people who learn English commonly make errors in pronouncing English sounds or words. Students of SMA Yos Sudarso Sokaraja, as English learners also make some errors in their pronunciations.
The students of SMA Yos Sudarso Sokaraja make many errors in pronouncing voiced obstruent sounds. There are 93 of correct pronunciations that are made. From eight sounds, there is one sound that is mispronounced by all students. The sound is [ʒ] in the word leisure. The sound [ʒ] is voiced sound, but all students pronounce it as voiceless sound [ʃ].
The students also mispronounce the sound [v] in the word never. There are only three students who pronounce it correctly. Most of the students pronounce the voiced sound [v] as the sound [f] which is voiceless.
In pronouncing voiceless obstruent sounds, the students make more correct pronunciations. There are 102 correct pronunciations that are made by the students. All students fail to pronounce the sound [θ]. The students mispronounce the sound [θ] into the sound [t]. The two sounds are voiceless. However, they are different because they are produced differently.
it as the sound [s]. Both sounds are voiceless, but they are different in the production of the sounds.
From the data above, the students of SMA Yos Sudarso Sokaraja have more difficulties in pronouncing voiced obstruent sounds in the medial position because they make more errors in pronouncing voiced obstruent sounds in the medial position than the voiceless one. They have big difficulties in pronouncing the sound [ʒ] and [v] in the medial position. They tend to pronounce the two sounds as the voiceless sounds.
In pronouncing the voiceless sounds, the students do not really have difficulties in pronouncing voiceless obstruent sounds in the medial position because they make more correct pronunciations rather than in pronouncing the voiced obstruent sounds in the medial position. Yet, they have big difficulties in pronouncing the sound [θ] and [ʃ]. However, their difficulties are not in the voicing feature but in the production of the sound because they still pronounce the two sounds as voiceless.
The errors that are made by the students is not only about voicing feature, but also the other errors like slip of the tongue, production of some words which have no meaning, and misreading. From those errors, there are some errors that are considered as metathesis errors.
The students tend to guess the pronunciation of the words when they do not know how to pronounce them. The result is that they produce the new words that have no meaning and their pronunciations are very different from the correct one. They are influenced by the way of Indonesian or Javanese words are read in guessing the pronunciation of the words that they do not know.