OPTIMASI PEMILIHAN THRESHOLD DAN OPERATOR
FUZZY LOCAL BINARY PATTERN MENGGUNAKAN MULTI
OBJECTIVE GENETIC ALGORITHM
GIBTHA FITRI LAXMI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2012
iii
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa disertas berjudul Optimasi Pemilihan
Threshold dan Operator Fuzzy Local Binary Pattern Menggunakan Multi Objective Genetic Algorithm adalah benar karya saya dengan arahan dari komisi
pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir disertasi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Desember 2012
Gibtha Fitri Laxmi
v
ABSTRACT
GIBTHA FITRI LAXMI. Optimization of Fuzzy Local Binary Pattern in Threshold and Operator Selection using Multi Objective Genetic Algorithm. Supervised by YENI HERDIYENI and YANDRA ARKEMAN.
This research proposes multi-objective genetic algorithm non-dominated-sorting (MOGA NSGA-II) of fuzzy local binary pattern to optimize LBP operator and fuzzy threshold for identification of Indonesia medicinal plant. Multi-objective genetic algorithm (MOGA) is genetic algorithm (GA) which developed specifically for problems with multiple objectives. We evaluated 1,440 medicinal plant leaf images which are belonging to 30 species. The images was taken from Biofarmaka IPB, Cikabayan Farm, Green house Center Ex-Situ Conservation of Medicinal Plant Indonesia Tropical Forest and Gunung Leutik. FLBP is used to handle uncertainty on images with various patterns. FLBP approach is based on the assumption that a local image neighbourhood may be characterized by more than a single binary pattern. The experimental results show that the correct selection of FLBP operator and threshold can improve the identification from 66.44% to 85%. It can be concluded that this propose method is capable to improve medicinal plants identification species efficiently and accurately.
Keywords: Fuzzy Local Binary Pattern, Multi-Objective Genetic Algorithm,
vii
RINGKASAN
GIBTHA FITRI LAXMI. Optimasi Pemilihan Threshold dan Operator
Fuzzy Local Binary Pattern Menggunakan Multi Objective Genetic Algorithm.
Dibimbing oleh YENI HERDIYENI dan YANDRA ARKEMAN.
Indonesia sebagai negara tropis memiliki keanekaragaman hayati yang sangat tinggi. Hal tersebut dapat dilihat dari beragamnya jenis flora di Indonesia dan masuknya Indonesia ke dalam sepuluh negara yang kekayaan keanekaragaman hayatinya tertinggi atau dikenal dengan megadiversity country. Keanekaragaman hayati di Indonesia memiliki lebih dari 38.000 spesies tanaman dan di antaranya hanya 2.039 spesies tanaman obat yang memiliki informasi dasar hanya 0.05% dari jenis tanaman yang ada di Indonesia. Jenis tanaman lainnya sekitar 99.95% tidak diketahui apakah dapat digunakan sebagai tanaman obat, maka dari itu perlu dilakukan identifikasi pada tanaman obat tersebut. Proses identifikasi tanaman obat dapat dilakukan dengan berbagai cara, di antaranya melalui taksonomi dengan bantuan herbarium dan text book. Cara tersebut dapat dilakukan dengan membandingkan ciri dari herbarium terhadap objek aslinya, misalnya dengan identifikasi manual menggunakan organ generatif buah dan bunga akan diperoleh hasil dalam waktu yang cukup lama. Teknologi identifikasi secara otomatis diperlukan untuk mempercepat proses identifikasi tersebut menggunakan organ vegetatif seperti daun yang paling mudah untuk ditemukan.
Penelitian sebelumnya telah membuat teknologi indentifikasi otomatis dengan melakukan ekstraksi ciri tanaman hias menggunakan Local Binary Pattern (LBP) descriptor dan proses klasifikasi menggunakan Probabilistic Neural
Network (PNN), dan juga telah melakukan penelitian dengan mencoba beragam
operator Local Binary Pattern (LBP) hingga menggabungkan operator tersebut. Metode LBP memiliki kelemahan dalam thresholding pada nilai keabuan piksel yang membuat penyajian teksturnya sensitif terhadap noise. Hasil threshold pada original LBP terkadang menghasilkan pengodean pola biner yang tidak sesuai dengan kandungan nilai pikselnya. Hal ini dikarenakan adanya ketidakpastian yang diakibatkan oleh adanya keragaman tekstur pada daun. Penelitian sebelumnya yang dilakukan oleh Iakovidis dan tim penelitinya ialah menggunakan fuzzy logic untuk mengatasi ketidakpastian pada representasi tekstur LBP, yang dikenal sebagai metode Fuzzy Local Binary Pattern (FLBP). Akan tetapi Fuzzy Local Binary Pattern dalam pengidentifikasian tanaman obat pada prosesnya mengharuskan mencoba setiap nilai threshold FLBP yang mengontrol derajat ketidakpastian serta operator LBP untuk menentukan sampling
point dan radius yang cocok untuk semua data citra uji yang dimiliki sehingga
memiliki akurasi yang baik. Operator LBP dan nilai threshold FLBP memiliki pengaruh terhadap komputasi. Semakin besar rentang nilai threshold, semakin banyak piksel yang harus diproses dalam perhitungan fuzzy. Oleh karena itu akan lebih baik jika dalam prosesnya FLBP memiliki operator LBP dan nilai threshold FLBP yang minimum dengan akurasi yang tinggi. Banyaknya perbedaan tujuan dari nilai operator LBP, nilai threshold FLBP, dan akurasi inilah yang menjadikan awal penerapan Multi-Objective Genetic Algorithm (MOGA) dalam penelitian.
MOGA akan digunakan untuk menentukan Operator LBP dan nilai threshold FLBP yang cocok dalam identifikasi citra sehingga memiliki akurasi yang tinggi.
Objek penelitian yang digunakan pada penelitian ini ialah citra tanaman obat. Jumlah citra daun tumbuhan obat yang digunakan adalah 1.440 yang terdiri dari 30 spesies daun, depan dan belakang (masing-masing kelas berjumlah 48 citra).
Tahapan dalam penelitian ini dilakukan dengan cara membagi data latih dan data uji. Data latih akan diekstraksi menggunakan kombinasi nilai threshold FLBP dan operator LBP. Kemudian data uji akan dimasukan ke dalam sistem, dimana data uji atau disebut citra kueri akan dilakukan ekstraksi menggunakan fungsi obyektif pertama dan kedua yang berupa nilai threshold FLBP dan operator LBP. Fungsi obyektif pertama dan kedua didapatkan dari inisialisai populasi yang berupa nilai biner yang kemudian akan diubah menjadi desimal. Hasil perubahan itu akan dilanjutkan fungsi ekstraksi. Hasil ekstraksi citra kueri akan dilakukan proses klasifikasi menggunakan Probabilistic Neural Network (PNN). Nilai PNN yang dihasilkan akan dijadikan acuan obyektif ketiga pada konsep NSGA-II.
Ketiga obyektif yang dihasilkan akan dilakukan fungsi non-dominated
sorted untuk menentukan urutan perangkinan pada setiap individu. Fungsi crowding distance dilakukan agar solusi yang dihasilkan tidak berada dalam satu
titik yang sama, sehingga memiliki kumpulan solusi sebanyak individu dalam populasi. Urutan pertama dari kumpulan solusi NSGA-II akan dijadikan parameter untuk proses identifikasi menggunakan metode ekstraksi FLBP. Pemilihan nilai threshold dan operator FLBP yang didapat dari NSGA-II memiliki kontribusi yang baik dalam peningkatan akurasi yaitu sebesar 16% dari metode identifikasi FLBP tanpa NSGA-II.
Berdasarkan hasil penelitian dapat disimpulkan bahwa metode FLBP menggunakan NSGA-II memberikan peningkatan akurasi dari 66.44% menjadi 85%. Dari hasil evaluasi dapat disimpulkan bahwa NSGA-II mampu memilih nilai
threshold dan operator LBP yang tepat untuk identifikasi citra tumbuhan obat.
NSGA-II menghasilkan nilai threshold tiap kelas citra tumbuhan obat bervariasi. Besarnya nilai threshold didapatkan dari citra yang memiliki perubahan kandungan nilai piksel yang besar dan kontras, begitupun sebaliknya. NSGA-II dapat memilih operator yang berukuran besar untuk citra yang memiliki warna yang seragam, sedangkan citra yang memiliki tekstur yang kompleks membutuhkan operator LBP yang lebih kecil. PNN digunakan sebagai klasifikasi citra tumbuhan obat, dimana kinerja klasifikasi yang baik akan menghasilkan identifikasi yang benar.
Analisa ujicoba statistika menggunakan uji-t menunjukan bahwa peningkatan akurasi hasil identifikasi menggunakan FLBP+NSGA-II berbeda nyata dengan FLBP tanpa NSGA-II. Nilai signifikansi yang digunakan ialah lebih kecil dari α = 0.05 dan menghasilkan nilai 4.88 x 10-5, sehingga FLBP+NSGA-II
memiliki metode yang lebih baik dari FLBP tanpa NSGA-II.
Kata kunci: Fuzzy Local Binary Pattern, Multi-Objective Genetic Algorithm,
ix
© Hak Cipta milik IPB, tahun 2012 Hak Cipta dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan,
penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan yang wajar IPB.
Dilarang mengumumkan dan memperbanyak sebagian atau seluruh Karya tulis dalam bentuk apapun tanpa izin IPB.
xi
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Ilmu Komputer
OPTIMASI PEMILIHAN THRESHOLD DAN OPERATOR
FUZZY LOCAL BINARY PATTERN MENGGUNAKAN MULTI
OBJECTIVE GENETIC ALGORITHM
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2012
xiii
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 12 Juli 1986, dari pasangan Suroso dan Yulinar. Penulis merupakan putri kedua dari dua bersaudara.
Pada tahun 1997, penulis lulus dari SD Negeri Panaragan 1 Bogor, lalu pada tahun yang sama melanjutkan pendidikan di SLTP NEGERI 1 Bogor. Pada tahun 2000, penulis lulus dari SLTP dan melanjutkan sekolah di SMU Negeri 2 Bogor hingga tahun 2003. Pada tahun yang sama penulis berkesempatan untuk melanjutkan studinya di Institut Pertanian Bogor (IPB) melalui jalur USMI (Undangan Seleksi Masuk IPB) sebagai mahasiswa S1 Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam. Pada tahun 2008 Penulis lulus S1 Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam. Penulis pernah bekerja menjadi Guru ICT di SMP Negeri 4 Bogor dari tahun 2009-2011. Dan saat ini Penulis bekerja sebagai Staff Pengajar di Universitas Ibn Khaldun dan Universitas Pakuan Bogor.
ii xv
PRAKATA
Alhamdulillahi Rabbil ‘alamin, puji dan syukur penulis panjatkan kepada
Allah SWT atas segala curahan rahmat dan karunia-Nya sehingga tugas akhir ini dapat diselesaikan. Tugas akhir ini berjudul Optimasi Pemilihan Threshold dan Operator Fuzzy Local Binary Pattern Menggunakan Multi-Objective Genetic
Algorithm.
Dalam menyelesaikan tugas akhir ini penulis mendapatkan banyak sekali bantuan, bimbingan dan dorongan dari berbagai pihak. Oleh karena itu, penulis ingin mengucapkan terima kasih kepada semua pihak yang telah membantu dalam penyelesaian tugas akhir ini, antara lain:
1 Kedua orangtua tercinta, papa Suroso dan mama Yulinar atas segala do’a, kasih sayang, dan dukungannya,
2 Uning Gibthi Ihda Suryani, S.P, Audrey, Kakak Ipar Listio Nugroho, S.E.,Etek Melly, Om Yudi, Maudi Meilutfa, Alm. Dwiki Maulana Akbar, dan Luna Latifah yang selalu memberikan motivasi dalam selama masa perkuliahan dan penyelesaian tugas akhir ini,
3 Ibu Dr. Yeni Herdiyeni, S.Si, M.Kom selaku pembimbing pertama atas bimbingan dan arahannya selama pengerjaan tugas akhir ini,
4 Bapak Dr. Ir. Yandra Arkeman, M.Eng. selaku pembimbing kedua atas bimbingan dan arahannya selama pengerjaan tugas akhir ini,
5 Bapak Mushthofa, S.Kom, M.Sc selaku moderator dalam seminar dan penguji dalam sidang,
6 Imam Abu Daud atas cinta kasih, bantuan, perhatian, dan motivasinya selama pengerjaan tugas akhir ini,
7 Pak Rico, Mega, Kadek, Ryanti, Siska, Fanny Valerina, Fani R, Oki dan Iyos, atas bantuan dan kebersamaan selama konsultasi bersama dan kebersamaan di LAB CI,
8 Mba Mila, Mba Yudith, Bu Kania, Bu Anna, Bu Dian, Bu Husna, Pak Dedi, Mr. Ghani, yang selalu bersama penulis dalam suka dan duka,
9 Semua teman seperjuangan Pasca Ilkom 12,
10 Dila, Tyas, Ulya, Sigit, Dyah, dan pastinya ACEM sejati yang selalu bersemangat bersama penulis untuk membangun Laladon menjadi lebih maju, 11 Teman-teman Lab CI yang akan memulai perjuangannya,
12 Pak Yadi, Pak Pendi, Pak Soleh, dan Mas Irvan, yang selalu membantu penulis dari awal masuk ilkom sampai sekarang,
Penulis juga mengucapkan terima kasih kepada semua pihak yang telah membantu selama pengerjaan penyelesaian tugas akhir ini yang tidak dapat disebutkan satu-persatu. Semoga penelitian ini dapat memberi manfaat.
Bogor, September 2012
ii xvii
DAFTAR ISI
Halaman
DAFTAR ISI ... xvii
DAFTAR TABEL ... xix
DAFTAR GAMBAR ... xxi
DAFTAR LAMPIRAN ... xxiii
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Tujuan Penelitian ... 2
1.3 Manfaat Penelitian ... 2
1.4 Ruang Lingkup Penelitian ... 3
BAB II TINJAUAN PUSTAKA ... 4
2.1 Fuzzy Local Binary Pattern (FLBP) ... 5
2.2 Probabilistic Neural Network (PNN) ... 8
2.3 Algoritme Genetika ... 9 2.3.1 Inisialisasi Populasi ... 11 2.3.2 Fungsi Evaluasi ... 11 2.3.3 Seleksi ... 11 2.3.4 Pindah Silang ... 11 2.3.5 Mutasi ... 12
2.4 Multi Objective Genetic Algorithm (MOGA) ... 12
2.5 Pareto Optimality ... 13
2.6 Elite Strategy ... 13
3.1 Data Citra Tumbuhan ... 16
3.2 Praproses ... 16
ii
3.4 Klasifikasi dengan Probabilistic Neural Network (PNN) ... 17
3.5 Multi Objective Genetic Algorithm (MOGA) ... 17
3.6 Pengujian Sistem ... 21
3.7 Perangkat Keras dan Perangkat Lunak ... 21
BAB IV HASIL DAN PEMBAHASAN ... 23
4.1 Hasil Praproses ... 23 4.2 Ekstraksi Tekstur FLBP ... 23 4.3 Algoritme Genetika ... 24 4.3.1 Inisialisasi Populasi ... 24 4.3.2 Fungsi Evaluasi ... 25 4.3.3 Tournament Selection ... 26 4.3.4 Pindah Silang ... 26 4.3.5 Mutasi ... 27
4.3.6 Non-Dominated Sorted dan Crowding Distance ... 27
4.3.7 Iterasi Algoritme Genetika ... 32
4.4 Pengujian Data ... 33
4.5 Analisa Hasil Uji ... 41
4.5.1 Uji Signifkansi Metode (Uji Statistik T) ... 41
4.5.2 Analisa Waktu Komputasi ... 43
BAB 5 SIMPULAN DAN SARAN ... 44
5.1 Simpulan ... 45
5.2 Saran ... 45
DAFTAR TABEL
Halaman
1 Operator LBP ... 16
2 Sorting tabel jumlah dominated setiap individu ... 29
3 Hasil perhitungan nilai crowding distance setiap individu ... 30
4 Ilustrasi sebaran front pada populasi awal. ... 31
5 Hasil NSGA-II ... 31
6 Spesifikasi GA pada penelitian ini ... 32
7 Rataan peluang citra setiap kelas ... 33
8 Jumlah Citra Uji Tiap Kelas ... 33
9 Nilai threshold FLBP dan jumlah yang diidentifikasi NSGA-II pada setiap kelas citra ... 35
10 Contoh hasil variabel obyektif nilai threshold FLBP NSGA-II ... 37
11 Nilai operator LBP yang berbeda dalam kelas yang sama. ... 39
12 Contoh kelas 9 (Kemangi) yang diidentifikasi ... 40
13 Contoh kelas 13 (Gadung China) yang diidentifikasi ... 40
14 Kombinasi hasil NSGA-II ... 41
15 Hasil Uji t berpasangan nilai akurasi setiap kelas ... 42
ii xxi
DAFTAR GAMBAR
Halaman
1 Membership function m0() dan m1() sebagai fungsi dari Δpi. ... 5
2 Skema komputasi FLBP dengan F=19 (Valerina 2012). ... 7
3 Hasil akurasi klasifikasi citra menggunakan FLBP. ... 8
4 Struktur PNN. ... 8
5 Ilustrasi pindah silang dua titik potong (two point crossover) ... 12
6 Proses mutasi kromosom. ... 12
7 Pareto Optimality (Goldberg 1989) ... 13
8 Metode Penelitian ... 15
9 Kombinasi operator LBP dan nilai threshold FLBP pada Kelas 1 ... 17
10 Proses algoritme genetika multi-obyektif. ... 18
11 Diagram alur proses pindah silang. ... 20
12 Diagram alur proses mutasi. ... 21
13 Hasil praproses citra. ... 23
14 Histogram FLBP pada tumbuhan obat. ... 24
15 Proses NSGA-II ... 24
16 Ilustrasi Kromosom ... 25
17 Proses pemilihan orangtua menggunakan metode turnamen seleksi ... 26
18 Pseudo code non-dominated sorted dan crowding distance pada NSGA-II (Watchareeruetai et.al 2009) ... 28
19 Contoh hasil kalkulasi menggunakan non-dominated ... 28
20 Ilustrasi non-dominated dan crowding distance ... 30
21 Nilai threshold LBP dan Δpi , (a) nilai threshold FLBP kecil, nilai selisih kecil (b) nilai threshold FLBP besar, nilai selisih besar ... 34
ii
23 Citra Kelas 11 Jeruk Nipis (Citrus aurantifolia Swingle) ... 38 24 Citra homogen dengan nilai threshold besar. ... 38 25 Jenis tumbuhan obat kelas 23 Remak Daging. ... 38 26 Kelas citra menggunakan dominan operator LBP (8,2) ... 39
ii xxiii
DAFTAR LAMPIRAN
1 Kelas Citra ... 51 2 Antarmuka Sistem ... 54
BAB I PENDAHULUAN 1.1 Latar Belakang
Indonesia sebagai negara tropis memiliki keanekaragaman hayati yang sangat tinggi. Hal tersebut dapat dilihat dari beragamnya jenis flora di Indonesia dan masuknya Indonesia ke dalam sepuluh negara yang kekayaan keanekaragaman hayatinya tertinggi atau dikenal dengan megadiversity country. Keanekaragaman hayati di Indonesia memiliki lebih dari 38.000 spesies tumbuhan (Bappenas 2003) dan di antaranya hanya 2.039 spesies tumbuhan obat yang memiliki informasi dasar (Zuhud 2009) hanya 0.05% dari jenis tumbuhan yang ada di Indonesia. Jenis tumbuhan lainnya sekitar 99.95% tidak diketahui apakah dapat digunakan sebagai tumbuhan obat, maka dari itu perlu dilakukan identifikasi pada tumbuhan obat tersebut. Proses identifikasi tumbuhan obat dapat dilakukan dengan berbagai cara, di antaranya melalui taksonomi dengan bantuan herbarium dan text book. Cara tersebut dapat dilakukan dengan membandingkan ciri dari herbarium terhadap objek aslinya, misalnya dengan identifikasi manual menggunakan organ generatif buah dan bunga akan diperoleh hasil dalam waktu yang cukup lama. Teknologi identifikasi secara otomatis diperlukan untuk mempercepat proses identifikasi tersebut menggunakan organ vegetatif seperti daun yang paling mudah untuk ditemukan.
Kulsum (2010) telah membuat teknologi indentifikasi otomatis dengan melakukan ekstraksi ciri tanaman hias menggunakan Local Binary Pattern (LBP)
descriptor dan proses klasifikasi menggunakan Probabilistic Neural Network
(PNN). Kusmana (2011) telah melakukan penelitian dengan mencoba beragam operator Local Binary Pattern (LBP) hingga menggabungkan operator tersebut.
Metode LBP memiliki kelemahan dalam thresholding pada nilai keabuan piksel yang membuat penyajian teksturnya sensitif terhadap noise. Hasil threshold pada original LBP terkadang menghasilkan pengodean pola biner yang tidak sesuai dengan kandungan nilai pikselnya. Hal ini dikarenakan adanya ketidakpastian yang diakibatkan oleh adanya keragaman tekstur pada daun. Iakovidis et al.(2008) menggunakan fuzzy logic untuk mengatasi ketidakpastian pada representasi tekstur LBP, yang dikenal sebagai metode Fuzzy Local Binary
Pattern (FLBP). Akan tetapi Fuzzy Local Binary Pattern dalam
pengidentifikasian tumbuhan obat yang dilakukan oleh Valerina (2012), pada prosesnya mengharuskan mencoba setiap nilai threshold FLBP yang mengontrol derajat ketidakpastian serta operator LBP untuk menentukan sampling point dan
radius yang cocok untuk semua data citra uji yang dimiliki sehingga memiliki
akurasi yang baik. Menurut Valerina (2012), operator LBP dan nilai threshold FLBP memiliki pengaruh terhadap komputasi. Semakin besar rentang nilai
threshold, semakin banyak piksel yang harus diproses dalam perhitungan fuzzy.
Oleh karena itu akan lebih baik jika dalam prosesnya FLBP memiliki operator LBP dan nilai threshold FLBP yang minimum dengan akurasi yang tinggi. Banyaknya perbedaan tujuan dari nilai operator LBP, nilai threshold FLBP, dan akurasi inilah yang menjadikan awal penerapan Multi-Objective Genetic
Algorithm (MOGA) dalam penelitian. MOGA akan digunakan untuk menentukan
Operator LBP dan nilai threshold FLBP yang cocok dalam identifikasi citra sehingga memiliki akurasi yang tinggi seperti yang dilakukan Zavaschi et al. (2012).
Objek penelitian yang digunakan pada penelitian ini ialah citra tumbuhan obat. Ciri dari citra tumbuhan obat tersebut akan dilakukan proses klasifikasi. Proses Klasifikasi yang akan digunakan ialah Probabilistic Neural Network (PNN)yang memiliki struktur yang sederhana dan proses training yang cepat tanpa harus memperbarui nilai bobot (Wu et al. 2007).
1.2 Tujuan Penelitian
Tujuan penelitian ini adalah mengoptimasi pemilihan nilai threshold FLBP dan operator LBP menggunakan Multi-Objective Genetic Algorithm untuk meningkatkan hasil akurasi identifikasi tumbuhan obat.
1.3 Manfaat Penelitian
Manfaat dari penelitian ini adalah meningkatkan akurasi identifikasi tumbuhan berbasiskan citra dan dapat dilakukan identifikasi secara otomatis.
3
1.4 Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah:
1. Objek citra adalah data citra daun tumbuhan obat di Indonesia. 2. Menggunakan operator LBP (8,1), dan (8,2).
BAB II TINJAUAN PUSTAKA
2.1 Fuzzy Local Binary Pattern (FLBP)
Fuzzifikasi pada pendekatan LBP meliputi transformasi variabel input menjadi variabel fuzzy, berdasarkan pada sekumpulan fuzzy rule. Dalam hal ini, digunakan dua fuzzy rule untuk mendapatkan nilai biner dan nilai fuzzy, berdasarkan deskripsi relasi antara nilai pada circular sampling 𝑝! dan piksel pusat 𝑝!"#$"% (Iakovidis 2008), yaitu :
Rule R0: Semakin negatif nilai ∆𝑝! maka nilai kepastian terbesar dari 𝑑! adalah 0. Rule R1 : Semakin positif nilai ∆𝑝! maka nilai kepastian terbesar dari 𝑑! adalah 1.
Gambar 1 Membership function m0() dan m1() sebagai fungsi dari Δpi. Dari rules R0 dan R1, dua membership function 𝑚!( ) dan 𝑚!( ) dapat ditentukan. Fungsi m0() mendefinisikan derajat dimana 𝑑! adalah 0. Membership
function 𝑚!( ) adalah fungsi menurun (Gambar 1) yang didefinisikan sebagai berikut : 𝑚! 𝑖 = 0 𝑖𝑓 ∆𝑝! ≥ 𝐹 !!!!! ! .! 𝑖𝑓 − 𝐹 < ∆𝑝! < 𝐹 1 𝑖𝑓 ∆𝑝! ≤ −𝐹 (1)
Sementara, membership function 𝑚!( ) mendefinisikan derajat dimana 𝑑! adalah 1. Fungsi 𝑚!( ) didefinisikan sebagai berikut (Gambar 1) :
𝑚! 𝑖 = 1 𝑖𝑓 ∆𝑝! ≥ 𝐹 !!!!! ! .! 𝑖𝑓 − 𝐹 < ∆𝑝! < 𝐹 0 𝑖𝑓 ∆𝑝! ≤ −𝐹 (2)
dimana 𝐹 𝜖 (0,255] merepresentasikan threshold FLBP yang akan mengontrol derajat ketidakpastian.
Metode LBP original hanya menghasilkan satu kode LBP saja, sedangkan dengan metode FLBP akan menghasilkan satu atau lebih kode LBP. Gambar 7 menyajikan contoh pendekatan FLBP, dimana dua kode LBP (A,B) mencirikan ketetanggaan 3x3. Masing-masing nilai LBP yang dihasilkan memiliki tingkat kontribusi (CA, CB) yang berbeda, bergantung pada nilai-nilai fungsi keanggotaan m0() dan m1() yang dihasilkan. Untuk ketetanggaan 3×3, kontribusi CLBP dari setiap kode LBP pada histogram FLBP didefinisikan sebagai berikut (Keramidas 2008):
𝐶!"# = 𝑚!" !
!!!
(𝑖)
Total kontribusi ketetanggaan 3×3 ke dalam bin histogram FLBP yaitu :
𝐶!"# !""
!"#!!
= 1
Pada Gambar 2 yang menunjukan matriks hasil nilai LBP menggunakan fuzzifikasi. Proses fuzzifikasi satu daerah ketetanggaan 3x3 akan menghasilkan 1 sampai 2n nilai LBP, dimana n merupakan banyaknya nilai Δpi (selisih antara piksel pusat dan piksel tetangga) yang masuk kedalam rentang fuzzy. Proses tersebut dapat mengatasi masalah representasi tekstur yang dihasilkan oleh metode original LBP, yang cenderung memiliki perbedaan rentang nilai LBP yang jauh antara tetangganya.
( 4)
( 3)
7
Gambar 2 Skema komputasi FLBP dengan F=19 (Valerina 2012).
Valerina (2012) melakukan percobaan setiap nilai threshold FLBP (F) untuk identifikasi tumbuhan, sehingga mendapatkan akurasi identifikasi yang beragam (Gambar 3), akurasi yang tertinggi didapat terlihat pada nilai threshold FLBP, F = 4. Pengambilan nilai threshold FLBP dilihat dalam hal adanya pengaruh besarnya nilai threshold FLBP terhadap komputasi. Semakin besar rentang nilai parameter, semakin banyak piksel yang harus diproses.
0 10 20 30 40 50 60 70 80 90 100 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Akurasi (%) Parameter fuzzifikasi F FLBP (8,1) 247 251 253 251 252 240 190 152 211 250 159 130 114 158 219 104 85 96 107 160 74 69 80 89 117 Nilai FLBP 15; 31; 143; 159 135; 143; 151; 159; 167; 175; 183; 191; 199; 207; 215; 223; 231; 239; 247; 255 5; 7; 13; 15;21; 23; 29;31; 37;39;45; 47;53; 55; 61;63; 133; 135; 141;143;149; 151; 157; 159; 165; 167;173; 175; 181; 183;189; 191 135 143; 159 15; 31 135; 143 143; 159; 15; 31; 175; 191; 47; 63 14; 15; 30; 31
Jatropha curcas Linn.
Nilai keabuan piksel
Gambar 3 Hasil akurasi klasifikasi citra menggunakan FLBP.
2.2 Probabilistic Neural Network (PNN)
PNN merupakan Artificial Neural Network (ANN) yang menggunakan teorema probabilitas klasik (pengklasifikasian Bayes). PNN diperkenalkan oleh Donald Specht pada tahun 1990. PNN menggunakan pelatihan (training)
supervised. Training data PNN mudah dan cepat. Bobot bukan merupakan hasil training melainkan nilai yang dimasukkan (tersedia) (Wu et al. 2007).
Gambar 4 Struktur PNN.
Struktur PNN pada Gambar 4 terdiri atas empat lapisan, yaitu lapisan masukan, lapisan pola, lapisan penjumlahan, dan lapisan keputusan/keluaran. Lapisan masukan merupakan objek 𝑥 yang terdiri atas 𝑘 nilai ciri yang akan diklasifikasikan pada 𝑛 kelas. Proses-proses yang terjadi setelah lapisan masukan adalah: 0 10 20 30 40 50 60 70 80 90 100 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Akurasi (%) Parameter fuzzifikasi F FLBP (8,2)
9
1. Lapisan pola (pattern layer)
Lapisan pola menggunakan 1 node untuk setiap data pelatihan yang digunakan. Setiap node pola merupakan perkalian titik (dot product) dari vektor masukan 𝑥 yang akan diklasifiksikan dengan vektor bobot 𝑥!", yaitu 𝑍! = 𝑥 . 𝑥!", 𝑍! kemudian dibagi dengan bias tertentu σ dan selanjutnya dimasukkan ke dalam fungsi radial basis, yaitu 𝑟𝑎𝑑𝑏𝑎𝑠 𝑛 = exp (−𝑛)!. Dengan demikian, persamaan yang digunakan pada lapisan pola adalah. 𝑓 𝑥 = 𝑒𝑥𝑝 −(!!!!")!(!!!!")
!!!
!
(5)
𝑘𝑒𝑡 ∶ 𝑥, 𝑚𝑒𝑟𝑢𝑝𝑎𝑘𝑎𝑛 𝑚𝑎𝑡𝑟𝑖𝑘𝑠 𝑜𝑏𝑗𝑒𝑘 𝑑𝑒𝑛𝑔𝑎𝑛 𝑖 𝑏𝑎𝑟𝑖𝑠 𝑑𝑎𝑛 𝑗 𝑘𝑜𝑙𝑜𝑚 2. Lapisan penjumlahan (summation layer)
Menerima masukan dari node lapisan pola yang terkait dengan kelas yang ada. Persamaan yang digunakan pada lapisan ini adalah:
𝑝 𝑥 = ! (!!)!!!! ! exp(− (!!!!")!(!!!!") !!! )! ! !!! (6)
3. Lapisan keluaran (output layer)
Menentukan kelas dari input yang diberikan. Input x akan masuk ke Y jika nilai 𝑝! 𝑥 paling besar dibandingkan kelas lainnya.
2.3 Algoritme Genetika
Algoritme genetika atau genetic algorithm (GA) adalah pengoptimasian dan teknik pencarian berdasarkan prinsip genetik dan seleksi alam (Haupt & Haupt 2004). GA dapat diaplikasikan untuk menyelesaikan permasalahan optimasi kombinasi, yaitu dengan mendapatkan suatu nilai solusi optimal terhadap suatu permasalahan yang mempunyai banyak kemungkinan solusi (Hermawanto 2003).
GA digunakan untuk menemukan solusi dalam masalah yang kompleks melalui kumpulan-kumpulan metode atau teknik seperti fungsi evaluasi (fitness
GA dikarakterisasi dengan 5 komponen dasar yaitu :
1 Representasikan kromosom untuk memudahkan penemuan solusi dalam masalah pengoptimasian.
2 Inisialisasi populasi.
3 Fitness function yang mengevaluasi setiap solusi.
4 Proses genetik yang menghasilkan sebuah populasi baru dari populasi yang ada.
5 Parameter genetika seperti ukuran populasi, probabilitas proses genetik, banyaknya generasi, dan lain-lain.
Gen dan Cheng (2000) menjelaskan bahwa algoritme genetika memelihara populasi dari individu (Pi) pada setiap generasi ke-i. Setiap individu merepresentasikan sebuah solusi potensial yang kemudian dievaluasi untuk dinilai
fitness-nya dan setiap individu menjalani transformasi stokastik menggunakan
operasi genetik untuk membentuk individu baru.
Ada dua jenis transformasi yang digunakan yaitu mutasi dan pindah silang (crossover). Transformasi tersebut akan menghasilkan individu baru C(i) yang akan dievaluasi kembali. Setelah beberapa generasi dilakukan pada setiap individu, hasil akhir yang didapat menjadi konvergen dan terbaik. Individu terbaik inilah yang diharapkan menjadi solusi optimal atau suboptimal dari masalah. Struktur umum dari algoritme genetika dijelaskan sebagai berikut:
Prosedur: Algoritme Genetika
begin i ← 0;
inisialisasi P(i); evaluasi P(i);
while (i <= maksimum iterasi) do begin
rekombinasi P(i);
evaluasi C(i);
pilih P(i+1) dari P(i) dan C(i);
i ← i + 1;
end end
11
2.3.1 Inisialisasi Populasi
Algoritme Genetika (GA) dimulai dengan sebuah group dari kromosom yang disebut populasi. Populasi memiliki Npop kromosom dan berbentuk matriks dengan ukuran Npop x Nbits serta diisi dengan bilangan acak (Bagchi 1999).
2.3.2 Fungsi Evaluasi
Fungsi Evaluasi atau fitness function adalah ukuran kinerja atau fungsi yang mengevaluasi seberapa baik nilai setiap solusi yang terjadi (Klabbankoh 1999). Nilai evaluasi dari sebuah kromosom tergantung seberapa baik kromosom tersebut memecahkan masalah yang ada (Mitchell 1998).
2.3.3 Seleksi
Seleksi adalah proses memilih individu pada populasi yang memiliki nilai evaluasi baik untuk dilanjutkan ke proses pindah silang dan mutasi (Cox 2005). Proses seleksi harus terjadi disetiap iterasi agar kromosom dalam populasi dapat berkembang sehingga mendapatkan anggota kromosom yang paling sesuai dengan fungsi tujuannya (Haupt & Haupt 2004).
2.3.4 Pindah Silang
Pindah silang dikenal sebagai recombination dimana dalam prosesnya terjadi pertukaran informasi antara induk dalam mating pool sehingga menghasilkan individu baru yang merupakan solusi (Bagchi 1999). Pindah silang merupakan komponen paling penting dalam GA pada proses genetik (Gen & Cheng 1997). Pindah silang ini bisa juga berakibat buruk jika ukuran populasi sangat kecil. Dalam suatu populasi yang sangat kecil, suatu kromosom dengan gen-gen yang mengarah ke solusi akan sangat cepat menyebar ke kromosom-kromosom lainnya. Probabilitas pindah silang Pc digunakan untuk mengatasi masalah penyebaran tersebut.
Teknik pindah silang dapat dilakukan dalam berbagai cara mulai dari one
point crossover atau disebut satu titik potong, sampai multiple-point crossover
(Klabbankoh 1999). Jika struktur direpresentasikan sebagai string biner, crossover dapat diimplementasikan dengan memilih titik secara acak, titik potong yang dipilih akan menyebabkan antar gen dari kromosom induk saling bertukar.
Sebagai contoh dua kromosom induk melakukan pindah silang antar posisi 5 sampai posisi 11 (Gambar 5).
1 0 1 1 1 1 1 1 0 0 1 1 1 0 1
1 0 0 1 1 0 0 1 1 1 1 0 0 0 0
Hasil pindah silang menghasilkan kromosom baru
1 0 1 1 1 0 0 1 1 1 1 1 1 0 1
1 0 0 1 1 1 1 1 0 0 1 0 0 0 0
Gambar 5 Ilustrasi pindah silang dua titik potong (two point crossover)
2.3.5 Mutasi
Mutasi adalah operator genetik kedua yang digunakan dalam GA. Kromosom yang dihasilkan memiliki kemungkinan bernilai lebih baik atau lebih buruk dari kromosom sebelumnya. Jika kromosom yang terpilih lebih buruk dari kromosom sebelumnya maka kromosom yang terpilih memiliki peluang tereliminasi pada proses seleksi. Mutasi berguna untuk mengembalikan kerusakan akibat proses genetik (Aly 2007).
Proses mutasi diimplementasikan pada setiap gen dengan besar probabilitas mutasi Pm. Semakin besar nilai Pm maka proses terjadinya mutasi pada populasi akan semakin banyak. Contoh proses mutasi diperlihatkan pada Gambar 6.
Gambar 6 Proses mutasi kromosom.
2.4 Multi Objective Genetic Algorithm (MOGA)
Algoritme genetika multi obyektif merupakan metode baru Algoritme Genetika (GA) dengan tujuan memecahkan permasalahan multi obyektif (Yandra & Tamura 2007). Permasalah optimasi multi obyektif memiliki beberapa fungsi obyektif, misalnya seperti meminimumkan atau memaksimumkan, dengan bentuk umum sebagai berikut:
Minimize/Maximize : fm (x), m = 1, 2, …, M; Ketentuan : gj (x) ≥ 0, j = 1, 2, …, J;
13
hk(x) = 0, k = 1, 2, …, K;
xi(L)≤ xi ≤ xi(U), i = 1, 2, …, N;
Kumpulan kendala akhir disebut variable batas, yang membatasi setiap variabel keputusan xi untuk mengambil nilai di dalam xi(L) batas bawah dan x i-(U)batas atas.
2.5 Pareto Optimality
Optimasi multi-obyektif tidak mungkin memiliki solusi optimal tunggal yang secara bersamaan mengoptimalkan semua tujuan. Hasil yang dihasilkan adalah seperangkat solusi yang optimal dengan tingkat yang bervariasi dari nilai tujuan yang disebut solusi Pareto Optimality (Goldberg 1989).
Sifat Pareto ditunjukan pada Gambar 7 dan dapat diformalkan menggunakan hubungan dominasi antara solusi alternatif. Solusi yang ditemukan melalui konsep ini bukan berupa satu titik melainkan kumpulan beberapa titik disebut pareto frontier atau pareto set. Pareto set adalah kumpulan titik-titik yang kesemuanya memenuhi konsep pareto optimality.
Gambar 7 Pareto Optimality (Goldberg 1989)
2.6 Crowding Distance
Crowding distance merupakan cara untuk membandingkan antara solusi
dengan urutan/rank non-domination yang sama. Crowding distance dilakukan dengan sebuah estimasi parameter yang berbentuk kubus antara front solusi sama dan terdekat. Fungsi crowding distance melibatkan fm(i-1) dan fm(i+1) untuk setiap fungsi objektif m dari setiap solusi i dengan fm(i-1) ≤ fmi≤ fm(i+1), fmmax dan fmmin merupakan nilai maksimum dan minimum fungsi objektif m dan M adalah total
jumlah objektif. Crowding distance untuk setiap solusi i dihitung menggunakan rumus :
(7)
CD(i) = ∞, jika solusi i adalah batas semua solusi dari setiap fungsi objektif.
Sebuah solusi i dikatakan mendominasi solusi j dalam ukuran crowding distance jika : rank(i) < rank(j) or (rank(i) = rank(j) and CD(i) > CD(j)) (Deb et. al 2002).
2.7 Elite Strategy
Elite Strategy memiliki sejumlah nE individu anggota populasi baru yang
akan diganti dengan sejumlah nE anggota himpunan solusi optimal pareto. Individu yang dibuang dari populasi dipilih secara acak dengan ketentuan individu yang dibuang adalah individu solusi yang tidak ikut menjadi anggota himpunan solusi optimal pareto. Populasi yang sudah mengalami elite strategy siap untuk kembali menjalani proses evaluasi dan seleksi.
BAB III METODE PENELITIAN
Penelitian ini menggunakan kombinasi dari operator LBP, nilai threshold FLBP dan nilai klasifikasi PNN. Kombinasi operator LBP dan nilai threshold FLBP akan diproses menggunakan MOGA sehingga menghasilkan kumpulan kombinasi. Hasil kumpulan kombinasi tersebut memiliki operator LBP minimum dan nilai threshold FLBP minimum, serta nilai peluang PNN yang maksimum. Metode penelitian yang akan dilakukan dapat dilihat pada Gambar 8.
Gambar 8 Metode Penelitian Citra Tumbuhan Obat Citra Grayscale Ekstraksi Ciri Fuzzy LBP Threshold 1-10 Operator(8,1) Operator(8,2) Klasifikasi PNN Model Klasifikasi Hasil Identifikasi Citra Tumbuhan Obat Ekstraksi Citra Ekstraksi Ciri Multi-Objective Genetic Algorithm
3.1 Data Citra Tumbuhan
Akuisisi citra daun tumbuhan obat dilakukan dengan pemotretan tiga puluh jenis tumbuhan obat di kebun Biofarmaka IPB dan di rumah kaca Pusat Konservasi Ex-Situ Tumbuhan Obat Hutan Tropika Indonesia, Fahutan, IPB. Pemotretan dilakukan menggunakan lima kamera digital yang berbeda (DSC-W55, 7210 Supernova, Canon Digital Axus 95 IS, Samsung PL100, dan EX-Z35).
Total citra daun tumbuhan obat yang digunakan adalah 1.440 yang terdiri atas 30 spesies daun (Lampiran 1), depan dan belakang (masing-masing kelas 48 citra) dimbil beberapa pada waktu yang berbeda (pagi, siang dan sore). Citra daun berformat JPG dan berukuran 270 × 240 piksel.
3.2 Praproses
Pada tahap awal praproses, dilakukan perbaikan data tumbuhan obat dengan mengganti latar belakang citra daun dengan latar belakang berwarna putih, dan dari setiap objek data tersebut hanya terdiri dari satu daun serta memperkecil ukuran citra menjadi 270x240 piksel. Kemudian mode warna citra diubah menjadi
grayscale untuk proses ekstraksi selanjutnya.
3.3 Ekstraksi Tekstur dengan Fuzzy Local Binary Pattern
Ekstraksi tektur pada citra tumbuhan obat hanya dilakukan pada piksel yang menyusun citra tersebut. Citra dikonversi ke mode warna grayscale. Selanjutnya membagi citra ke dalam beberapa local region sesuai dengan sampling points dan
radius yang digunakan.
Tabel 1 Operator LBP Operator LBP (P,R) Ukuran Blok (piksel) Kuantisasi Sudut (8,1) 3 x 3 45 derajat (8,2) 5 x 5 45 derajat
Ekstraksi tekstur dilakukan dengan konvolusi menggunakan Operator LBP yang disajikan pada Tabel 1. Hasil perhitungan FLBP pun direpresentasikan dalam bentuk histogram degan total bin yang dihasilkan sebanyak 256.
17
3.4 Klasifikasi dengan Probabilistic Neural Network (PNN)
Setelah proses ekstraksi citra dilakukan, akan diperoleh hasil vektor histogram dengan operator LBP beserta nilai threshold FLBP. Tahap selanjutnya adalah mengklasifikasi vektor-vektor histogram tersebut dengan PNN. Klasifikasi dilakukan pada vektor histogram untuk menentukan akurasi identifikasi tumbuhan obat. Klasifikasi dilakukan dengan membagi data latih dan data uji dengan komposisi masing-masing 80% dan 20% untuk data daun. Data latih tiap kelas citra berjumlah 38 citra, sedangkan data uji tiap kelas berjumlah 10 citra.
Data latih yang dimiliki merupakan kombinasi gabungan operator LBP dan nilai threshold FLBP sehingga jumlah data latih tiap kelas menjadi 38 citra x 2 operator x 10 nilai threshold FLBP. Contoh ilustrasi data dapat dilihat pada Gambar 9. Selanjutnya akan diperoleh model klasifikasi dari hasil pelatihan data.
Kelas 1 , operator(8,1), F= 1 Kelas 1 , operator(8,1), F= 2 … operator(8,2), Kelas 1 , F= 10 1 2 3 … 256 1 2 3 … 256 1 2 3 … 256 1 2 … 38
Gambar 9 Kombinasi operator LBP dan nilai threshold FLBP pada Kelas 1
3.5 Multi Objective Genetic Algorithm (MOGA)
Algoritme genetika multi obyektif (MOGA) merupakan suatu metode optimasi dengan fungsi tujuan lebih dari satu (ganda) yang dimana antara tujuan-tujuan ini terjadi konflik. Proses MOGA pada umumnya sama dengan seperti
single objective GA akan tetapi ditambahkannya fungsi non-dominated sort serta crowding distance. Proses tersebut dapat dilihat pada Gambar 9. Ide dari tujuan
MOGA adalah mencari front dari pareto optimal yang merupakan semua kemungkinan solusi yang tidak terdominasi oleh kemungkinan solusi lainnya. Bagaimanapun juga penentuan pareto yang optimal bisa dikatakan sulit untuk mencapai semua solusi berada dalam satu front. Maka dari itu lebih memilih
non-dominated front untuk mendapatkan front pareto optimality, yang dimana
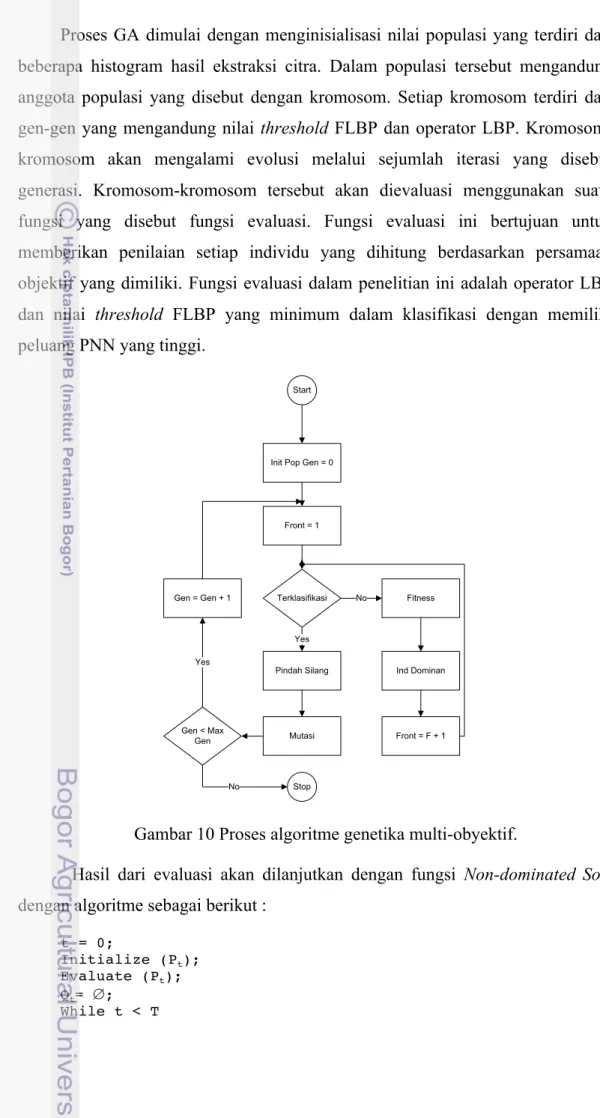
Proses GA dimulai dengan menginisialisasi nilai populasi yang terdiri dari beberapa histogram hasil ekstraksi citra. Dalam populasi tersebut mengandung anggota populasi yang disebut dengan kromosom. Setiap kromosom terdiri dari gen-gen yang mengandung nilai threshold FLBP dan operator LBP. Kromosom-kromosom akan mengalami evolusi melalui sejumlah iterasi yang disebut generasi. Kromosom-kromosom tersebut akan dievaluasi menggunakan suatu fungsi yang disebut fungsi evaluasi. Fungsi evaluasi ini bertujuan untuk memberikan penilaian setiap individu yang dihitung berdasarkan persamaan objektif yang dimiliki. Fungsi evaluasi dalam penelitian ini adalah operator LBP dan nilai threshold FLBP yang minimum dalam klasifikasi dengan memiliki peluang PNN yang tinggi.
Gambar 10 Proses algoritme genetika multi-obyektif.
Hasil dari evaluasi akan dilanjutkan dengan fungsi Non-dominated Sort dengan algoritme sebagai berikut :
t = 0; Initialize (Pt); Evaluate (Pt); Qt= ∅; While t < T Start
Init Pop Gen = 0
Front = 1 Terklasifikasi Pindah Silang Mutasi Fitness Ind Dominan Front = F + 1 Gen = Gen + 1 Gen < Max Gen Yes No Yes Stop No
19 Rt = Pt∪ Qt; F = Non_dominated_sort(Rt) Pt+1 = ∅, i = 1; While |Pt+1| + |Fi| > N Crowding_distance_assigment (Fi) Pt+1 = Pt+1 ∪F1 ; i = i+1; End While Sort(Fi, <n); Pt+1 = Pt+1 ∪ Fi [1:(N - |Pt+1|)] ; Qt+1= make_new_population(Pt+1); t = t+1; End While
Fungsi crowding distance memiliki algoritme sebagai berikut :
l = |L|;
for each i ∈ L L[i]distance = 0; For each objective m L = sort(L,m);
L[1]distance = L[l]distance = ∞ ; For I = 2 to (l-1);
𝐿[𝑖]!"#$%&'( = 𝐿[𝑖]!"#$%&'! + !!"# !!!!! !!!!!!
!! !"# !!
Hasil evaluasi lainnya menentukan kualitas individu yang akan digunakan untuk proses seleksi induk. Proses seleksi yang digunakan pada penelitian ini adalah tournament selection. Tournament selection dapat menyesuaikan dan dapat beradaptasi dari perbedaan domain. Prosesnya dengan cara melakukan turnamen antar s pesaing, dengan s merupakan ukuran turnamen. Pengukuran antar pesaing dilihat dari nilai rank kemudian nilai crowding distance yang dimiliki antar pesaing. Pemenang dari turnamen akan dimasukan ke dalam mating pool untuk proses genetik. Semakin banyak individu yang memiliki nilai fitness yang lebih tinggi maka akan semakin banyak individu yang akan dipilh.
Populasi baru hasil dari proses seleksi dilanjutkan ke proses genetika selanjutnya yaitu pindah silang dan mutasi. Pindah silang dan mutasi berguna untuk menciptakan populasi baru yang lebih baik dari populasi sebelumnya.
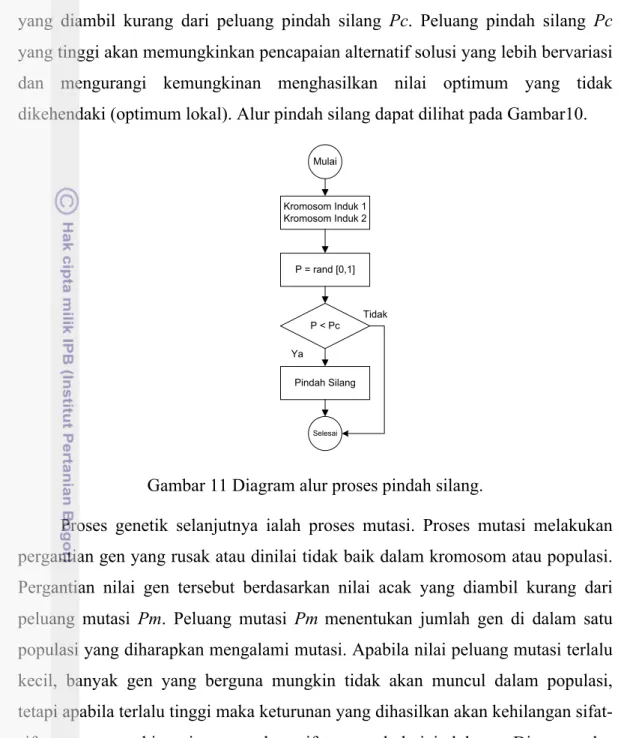
Proses pindah silang merupakan proses lanjutan dari proses seleksi yang menghasilkan calon-calon kromosom yang akan dipindahsilangkan. Proses pindah silang memerlukan dua kromosom induk dari hasil seleksi. Proses ini dilakukan dengan menggantikan semua nilai alele dari kromosom induk. Kromosom dalam satu populasi yang dipindahsilangkan berdasarkan nilai acak
yang diambil kurang dari peluang pindah silang Pc. Peluang pindah silang Pc yang tinggi akan memungkinkan pencapaian alternatif solusi yang lebih bervariasi dan mengurangi kemungkinan menghasilkan nilai optimum yang tidak dikehendaki (optimum lokal). Alur pindah silang dapat dilihat pada Gambar10.
Gambar 11 Diagram alur proses pindah silang.
Proses genetik selanjutnya ialah proses mutasi. Proses mutasi melakukan pergantian gen yang rusak atau dinilai tidak baik dalam kromosom atau populasi. Pergantian nilai gen tersebut berdasarkan nilai acak yang diambil kurang dari peluang mutasi Pm. Peluang mutasi Pm menentukan jumlah gen di dalam satu populasi yang diharapkan mengalami mutasi. Apabila nilai peluang mutasi terlalu kecil, banyak gen yang berguna mungkin tidak akan muncul dalam populasi, tetapi apabila terlalu tinggi maka keturunan yang dihasilkan akan kehilangan sifat-sifat yang mungkin saja merupakan sifat-sifat unggul dari induknya. Diagram alur mutasi dapat dilihat pada Gambar 11.
Mulai Kromosom Induk 1 Kromosom Induk 2 P = rand [0,1] Pindah Silang P < Pc Selesai Tidak Ya
21
Gambar 12 Diagram alur proses mutasi.
Hasil populasi baru akan dievaluasi kembali dan diurutkan untuk mengetahui kromosom yang yang memiliki nilai terbaik selanjutnya.
3.6 Pengujian Data
Pengujian data dilakuan oleh sistem dengan penilaian tingkat keberhasilan klasifikasi terhadap citra kueri. Evaluasi dari kinerja model klasifikasi didasarkan pada banyaknya data uji yang diprediksi secara benar atau salah oleh model. Hal ini dapat dihitung menggunakan akurasi yang didefinisikan sebagai berikut:
𝑎𝑘𝑢𝑟𝑎𝑠𝑖 =!"#$"%#$" !"#$%&'% !"#$ !"#$%
!"!#$ !"#$"%#$" !!"#$%&$ ×100% (11)
3.7 Perangkat Keras dan Perangkat Lunak
Perangkat keras yang digunakan dalam penelitian ini adalah Processor intel® Corei3-2100 3.16 GHz, memori DDR3 RAM 8.00 GB dan hardisk 650 GB. Perangkat lunak yang digunakan adalah Sistem Operasi Windows 7,
MATLAB 2010a. Mulai Kromosom P = rand [0,1] P < Pm Gen(r) dimutasi R = random Selesai Tidak Ya
BAB IV HASIL DAN PEMBAHASAN
4.1 Hasil Praproses
Valerina (2012) melakukan praproses data citra tumbuhan obat dengan menyeleksi objek satu daun dan memperkecil ukuran citra menjadi 270x240 piksel. Mode warna citra keseluruhan dan citra daun kemudian diubah menjadi
grayscale untuk proses ekstraksi selanjutnya. Hasil praproses data bertujuan
mengurangi waktu pemrosesan data (running time). Hasil praproses data dapat dilihat pada Gambar 12.
Psidium guajava L.
Gambar 13 Hasil praproses citra.
4.2 Ekstraksi Tekstur FLBP
Citra hasil praproses digunakan sebagai masukan pada proses ekstraksi dengan FLBPP,R. Ekstraksi FLBPP,R dilakukan menggunakan ukuran circular
neighborhood yang tertera pada Tabel 1. Ciri FLBP yang dihasilkan diekstrak
menggunakan nilai threshold FLBP fuzzifikasi (F) yang berbeda. Nilai threshold FLBP fuzzifikasi yang digunakan mulai dari F = 1 sampai F = 10. Dimana nilai
threshold FLBP fuzzifikasi menentukan nilai biner yang dihasilkan. Jika terdapat
sejumlah 𝑚 nilai ∆𝑝! yang berada dalam rentang fuzzy maka akan menghasilkan nilai biner sebanyak 2!. Sehingga semakin besar nilai threshold FLBP fuzzifikasi maka akan memberikan nilai rentang yang semakin besar yang berbanding lurus dengan nilai biner dan waktu komputasi dalam pembacaan nilai piksel.
Ekstraksi FLBP menghasilkan histogram frekuensi yang ditunjukan Gambar 13, dimana histogram merupakan pertambahan CLBP dari nilai LBP yang dihasilkan. Panjang bin yang dihasilkan pada histogram FLBPP,R bergantung pada
P yang digunakan adalah 8 sehingga jumlah bin pada histogram FLBPP,R
sebanyak 28 = 256 bin.
Gambar 14 Histogram FLBP pada tumbuhan obat.
4.3 Algoritme Genetika
Algoritme Genetika merupakan dasar dari pembentukan Algoritme Genetika Multi-Objektif. Tahapan proses genetika yang dilakukan sama dengan fungsi tujuan yang lebih dari satu atau disebut multi objective. Algoritme Genetika Multi Obyektif pada penelitian ini menggunakan NSGA-II dengan skema prosesnya dapat dilihat pada Gambar 14.
Gambar 15 Proses NSGA-II
4.3.1 Inisialisasi Populasi
Inisialisasi Populasi merupakan tahap awal yang dilakukan untuk menentukan kombinasi variabel keputusan. Kombinasi populasi yang akan
0 50 100 150 200 250 300 350 400 450 500 0 7 14 21 28 35 42 49 56 63 70 77 84 91 98 105 112 119 126 133 140 147 154 161 168 175 182 189 196 203 210 217 224 231 238 245 252 Fr ekuensi Nilai LBP Histogram FLBP Begin : Initialize Population (N) Evaluate Objective Function Non-Dominated Sorting Tournament Selection
Crossover & Mutation
Combine Parent and Child Population, Non-Dominating Sorting Evaluate Objective Function Stopping Criteria met? Select N individuals
Report Final Population and Stop No
25
dibentuk berupa nilai binary string 0 dan 1. Banyaknya populasi yang digunakan sebanyak 20 individu yang dapat diubah sesuai keinginan pengguna.
Setiap individu memiliki jumlah gen sebanyak 15 bit, dengan 10 bit pertama adalah variabel x1 (parameter) dan 5 bit berikutnya ialah variabel x2 (operator LBP), dan memiliki ketentuan dibawah ini :
𝑥!, 1 ≤ 𝑥! ≤ 10 𝑥!, 1 ≤ 𝑥! ≤ 2
Sebuah kromosom yang terdiri dari bilangan biner akan dilakukan dekode nilai biner menjadi nilai desimal berdasarkan ketentuan di atas. Ilustrasi bentuk sebuah kromosom dan dekode nilai kromosom pada penelitian ini terdapat pada Gambar 15.
1 0 1 1 1 1 1 1 0 0 1 1 1 0 1
8
2
Ket : Kueri citra akan di ekstraksi menggunakan FLBP dengan operator LBP = 2 dengan arti (8,2) dan nilai threshold FLBP, F=8
Gambar 16 Ilustrasi Kromosom
4.3.2 Fungsi Evaluasi
Fungsi Evaluasi merupakan dimensi tujuan dari suatu keputusan, dimana terdapat 3 fungsi tujuan yang digunakan dalam penelitian ini yaitu, meminimalkan fungsi pertama dan kedua, serta memaksimalkan fungsi yang ketiga. Fungsi pertama, kedua dan ketiga masing-masing digunakan untuk menentukan nilai
threshold FLBP, operator LBP, dan nilai peluang klasifikasi menggunakan fungsi
PNN.
Fungsi evaluasi yang digunakan pada penelitian ini adalah : 𝑀𝑖𝑛𝑖𝑚𝑖𝑧𝑒 ∶ 𝑓! 𝑥 = 𝑥!
𝑀𝑖𝑛𝑖𝑚𝑖𝑧𝑒 ∶ 𝑓! 𝑥 = 𝑥! 𝑀𝑎𝑥𝑖𝑚𝑖𝑧𝑒 ∶ 𝑓! 𝑥 = 𝑚𝑎 𝑥 1 𝑛! 𝑒 ! !!!!!!" ! !! !!! , 𝑥 = 𝑘𝑢𝑒𝑟𝑖 𝑓𝑖𝑡𝑢𝑟, 𝑥! = 𝑑𝑎𝑡𝑎 𝑙𝑎𝑡𝑖ℎ
Peluang dengan nilai tertinggi itulah akan menentukan bahwa individu fitur yang dibentuk menggunakan operator LBP dan threshold FLBP sesuai yang digunakan. Ketentuan fungsi objektif dalam sistem yang digunakan sebagai berikut :
[prob] = oPNN(x_uji(i),data_latih,bias); [maxprob idx] = max(prob);
f(3) =maxprob;
4.3.3 Tournament Selection
Tournament Selection merupakan proses pemilihan orang tua untuk
dilakukan proses genetik. Ukuran untuk melakukan tournament ialah sebanyak 2 individu. Pemilihan orangtua dilakukan berdasarkan persaingan dengan 2 kriteria yaitu rank/front dan nilai crowding distance. Proses pemilihan orangtua pada sistem dapat dilihat pada Gambar 17 yang kemudian orangtua yang terpilih akan dimasukan kedalam mating pool. Ukuran mating pool yang merupakan tempat penyimpanan untuk orang tua sebanyak setengah dari jumlah populasi.
front CD front CD mating pool
indv 1 1 ∞ indv 1 1 ∞ pilih orangtua
indv 1 indv 2 1 0.3 random indv 4 2 0.5 front <<
indv 3 1 1 indv indv 2 1 0.3 CD >> indv 3
indv 4 2 0.5 indv 3 1 1
Gambar 17 Proses pemilihan orangtua menggunakan metode turnamen seleksi
4.3.4 Pindah Silang
Proses pindah silang yang digunakan pada penelitian ini adalah konsep
one point crossover. Prosesnya memerlukan dua kromosom induk dari hasil
seleksi. Nilai alele antar kromosom induk akan digantikan secara keseluruhan dari titik potong. Jumlah kromosom dalam satu populasi yang dipindahsilangkan
27
bergantung pada nilai acak yang diambil kurang dari peluang pindah silang Pc. Peluang pindah silang (Pc) yang tinggi akan memungkinkan pencapaian alternatif lebih bervariasi.
4.3.5 Mutasi
Proses mutasi yang digunakan pada penelitian ini yaitu fungsi binary bit
flip. Proses mutasi merupakan proses pengubahan nilai gen pada kromosom yang
telah dipilih sebelumnya. Pemilihan gen tersebut ialah dengan cara mengambil nilai acak [0,1] yang kemudian nilai acak akan dibandingkan dengan peluang mutasi. Setelah itu alele dari setiap individu yang terpilih akan dimutasi dengan ketentuan sebagai berikut :
if rand< pm if gen(i) == 1 gen(i) = 0; else gen(i) = 1; end end
Banyaknya gen yang dimutasi berdasarkan peluang mutasi Pm yang ditentukan berdasarkan banyaknya fungsi tujuan yang digunakan. Peluang Pm yang digunakan pada penelitian ini sebesar 0.333. Ilustrasi mutasi pada penelitian ini dapat dilihat pada Gambar 11.
4.3.6 Non-Dominated Sorted dan Crowding Distance
Non-dominated Sorting Genetic Algorithm (NSGA-II) yang digunakan dalam penelitian ini mengunakan konsep tidak terdominasi satu sama lain dalam grup, dan perangkingan terdapat dalam tiap solusi kemudian dijadikan sebagai
front. Pseudocode proses non-dominated sorted dan crowding distance pada
Gambar 18 Pseudo code non-dominated sorted dan crowding distance pada NSGA-II (Watchareeruetai et.al 2009)
Di dalam front setiap solusi akan memiliki sebuah pengukuran jarak yang relatif disebut crowding distance, yang menghitung jarak rata-rata (di dalam ruang tujuan) dari dirinya sendiri ke adjacent solusi yang lain.
Contoh hasil kalkulasi menggunakan non-dominated dan crowding distance dapat dilihat pada Gambar 19.
indv 1 indv 2 result
F1 5 < 7 1 0
F2 1 < 1 1 1
F3 0.89 > 0.92 0 1
Jika hasil indv(1) = indv(2) , maka non-inferior / equal dominated Jika hasil indv(1) > indv(2) , maka dominated
Jika hasil indv(1) < indv(2) , maka non-dominated
indv 1 indv 2 indv 3 indv 4 indv 5
5 < 7 10 4 9
1 < 1 2 2 1
0.89 0.92 0.93 0.89 0.95
equal dominated equal equal
Gambar 19 Contoh hasil kalkulasi menggunakan non-dominated
Individu 1 akan dilakukan perbandingan objektif dengan semua individu yang ada, terlihat bahwa individu 3 terdominasi oleh individu 1, sedangkan individu lainnya memiliki nilai yang dominasi yang sama.
Sehingga bisa mendapatkan jumlah dominated hasil dari perbandingan antar individu.
29
indv(1) = {....} = 0 indv(2) = {....} = 0
indv(3) = { indv(1) , indv(4) , indv(5) } = 3 indv(4) = {....} = 0
indv(5) = { indv(4) } = 1
Jumlah dominated akan dilakukan sorting berdasarkan jumlah yang paling sedikit sehingga didapatkan individu hasil nondominated-sort (Tabel 2).
Tabel 2 Sorting tabel jumlah dominated setiap individu
F(x1) F(x2) F(x3) Rank indv(1) 5 1 0.89 1 indv(2) 7 1 0.92 1 indv(4) 4 2 0.89 1 indv(5) 9 1 0.95 2 indv(3) 10 2 0.93 3
Proses crowding distance dilakukan pada setiap individu yang memiliki rank/ yang sama. Berdasarkan frontier pada Gambar 1 didapat bahwa indv(4) berada pada posisi pertama crowding distance, sedangkan indv(2) merupakan posisi terakhir. Indv(4) dan indv(2) memiliki jarak infinitif (∞), sedangkan indv(1) memiliki nilai 2. Rumus crowding distance sebagai berikut :
𝑖!.! = 𝑓 𝑖 + 1 !− 𝑓 𝑖 − 1 ! 𝑓!!"# − 𝑓
!!"# !
dimana perhitungan manual crowding distance sebagai berikut : m = 1, yaitu fungsi f(x1) 1!.! = 0.88 − 0.5 0.88 − 0.5= 1 dan m = 2, yaitu fungsi f(x2) 1!.! = 0.69 − 0.4 0.69 − 0.4= 1
1C.D = 1 + 1 = 2
sehingga crowding distance untuk indv(1) ialah 2.
Hasil perhitungan nilai crowding distance setiap individu dapat dilihat pada Tabel 3.
Tabel 3 Hasil perhitungan nilai crowding distance setiap individu F(x1) F(x2) Rank C.D indv(1) 0.87 0.41 1 2 indv(2) 0.88 0.4 1 ∞ indv(3) 0.5 0.69 1 ∞ indv(4) 0.57 2.35 2 ∞ indv(5) 0.87 11.2 3 ∞
Non-dominated dan crowding distance akan menghasilkan konsep
kumpulan beberapa titik yang merupakan solusi dari permasalahan. Ilustrasi peranan non-dominated dan crowding distance pada penelitian pada saat generasi pertama dan generasi terakhir terdapat pada Gambar 20.
Gambar 20 Ilustrasi non-dominated dan crowding distance
Waktu yang dibutuhkan untuk membentuk populasi pertama serta identifikasi citra kueri membutuhkan waktu 16,5 detik dimana sebaran individu terbagi ke dalam 4 front. Beberapa individu dalam populasi mendominasi individu yang lainnya. Proses NSGA-II membutuhkan waktu 120 detik dengan 50 generasi menghasilkan sebaran individu ke dalam front yang sama yaitu dalam front 1. Ilustrasi pembagian front dapat dilihat pada Tabel 4. Pembentukan front yang
31
sama serta jarak sebaran yang merata antar titik solusi merupakan pembentukan akhir dari NSGA-II yang ilustrasi sebaran hasil dapat dilihat pada Tabel 5.
Tabel 4 Ilustrasi sebaran front pada populasi awal.
Threshold FLBP Operator LBP Nilai PNN Front 5 2 0.970035 1 5 2 0.970035 1 4 2 0.969156 1 2 2 0.96169 1 4 2 0.969156 1 5 2 0.970035 1 6 1 0.97262 1 7 2 0.972108 2 6 2 0.97082 2 8 2 0.972552 2 8 2 0.972552 2 7 2 0.972108 2 8 2 0.972552 2 7 2 0.972108 2 6 2 0.97082 2 9 2 0.972473 3 9 2 0.972473 3 10 2 0.972196 4 10 2 0.972196 4 10 2 0.972196 4
Tabel 5 Hasil NSGA-II
Ind X1 X2 Threshold FLBP Operator LBP Nilai PNN
1 0 0 0 1 0 1 0 0 1 1 0 0 0 0 1 2 1 0.96 2 1 1 0 1 0 1 0 0 1 1 0 0 0 0 1 9 1 0.98 3 0 0 0 1 0 1 0 0 1 1 0 0 0 0 1 2 1 0.96 4 0 0 1 1 1 1 0 0 0 1 0 0 0 0 1 4 1 0.97 5 0 0 1 1 0 1 0 0 1 1 0 0 0 0 1 3 1 0.97 6 0 0 1 1 0 1 0 0 1 1 0 0 0 0 1 3 1 0.97 7 1 0 1 0 0 1 1 0 1 1 0 0 0 0 1 7 1 0.97 8 0 0 1 1 1 1 0 0 0 1 0 0 0 0 1 4 1 0.97 9 0 1 1 0 0 1 0 0 1 1 0 0 0 0 1 5 1 0.97 10 1 1 0 1 0 1 0 0 1 1 0 0 0 0 1 9 1 0.97 11 0 0 0 1 0 1 0 0 1 1 0 0 0 0 1 2 1 0.96 12 1 0 1 1 0 1 0 1 1 0 0 0 0 0 1 8 1 0.98
Ind X1 X2 Threshold FLBP Operator LBP Nilai PNN 13 1 0 1 1 0 1 0 1 1 1 0 0 0 0 1 8 1 0.98 14 0 0 0 1 0 1 0 0 1 1 0 0 0 0 0 2 1 0.96 15 0 1 1 1 1 1 0 0 1 1 0 0 0 0 1 6 1 0.97 16 0 0 0 1 0 1 0 0 1 1 0 0 0 0 1 2 1 0.96 17 1 1 0 1 0 1 0 0 1 1 0 0 0 0 1 9 1 0.98 18 1 1 0 1 0 1 0 0 1 1 0 0 0 0 1 9 1 0.98 19 1 1 0 1 0 1 1 0 1 1 0 0 0 0 1 9 1 0.98 20 1 0 1 0 0 1 0 0 1 1 0 0 0 0 1 7 1 0.98
Hasil NSGA-II pada Tabel 2 merupakan kumpulan solusi untuk minimasi operator LBP dan threshold FLBP serta memiliki nilai peluang yang tinggi. Untuk identifikasi pada sistem menggunakan fungsi objektif individu pertama yaitu menggunakan operator LBP (8,1) dan nilai threshold FLBP F = 2. Kumpulan solusi lainnya dapat dijadikan alternatif dalam penentuan operator LBP dan nilai
threshold FLBP identifikasi dari citra kueri.
4.3.7 Iterasi Algoritme Genetika
Jumlah iterasi yang digunakan dalam penelitian ini. Jika iterasi telah mencapai maksimum, maka proses genetik pada penelitian ini akan selesai dan menghasilkan populasi yang lebih baik dengan keseragaman front.
Spesifikasi GA secara sederhana yang digunakan dalam penelitian ini dijelaskan pada Tabel 6.
Tabel 6 Spesifikasi GA pada penelitian ini
Spesifikasi GA Keterangan
Jumlah Kromosom atau besarnya populasi N = 20, random binary string
Nilai evaluasi f(x1) = x1 , f(x2)= x2 , f(x3) = Probabilistic
Neural Network
Jumlah gen 15 bit biner, x1 = 10 bit, x2 = 5 bit.
Peluang pindah silang 0.9
Peluang mutasi 1/n (jumlah obyektif) = 0.333
Metode Seleksi Tournament Selection
Pindah Silang One Point Crossover
Mutasi Binary bit flip mutation
33
4.4 Pengujian Data
Identifikasi kueri citra dilakukan menggunakan NSGA-II yang memiliki tujuan/obyektif sebanyak 3 tujuan, yaitu meminimasi operator LBP dan nilai
threshold FLBP serta memaksimalkan peluang klasifikasi menggunakan fungsi Probabilistic Neural Network (PNN). Hasil MOGA berupa nilai operator LBP
dan nilai threshold FLBP akan digunakan untuk melakukan identifikasi kueri citra.
Data yang digunakan untuk pengujian adalah data berdasarkan nilai peluang tiap citra. Nilai peluang antar citra akan dihitung rata-rata citra yang kemudian dijadikan nilai threshold rataan untuk mengeliminasi citra yang memiliki peluang lebih kecil. Rataan peluang tiap kelas dapat dilihat pada Tabel 7 di bawah ini. Tabel 7 Rataan peluang citra setiap kelas
Kelas Rataan Kelas Rataan Kelas Rataan
1 0.96 11 0.85 21 0.90 2 0.86 12 0.87 22 0.87 3 0.91 13 0.85 23 0.86 4 0.93 14 0.80 24 0.89 5 0.86 15 0.88 25 0.79 6 0.93 16 0.84 26 0.85 7 0.89 17 0.85 27 0.93 8 0.97 18 0.86 28 0.96 9 0.93 19 0.87 29 0.94 10 0.89 20 0.92 30 0.91
Citra yang memiliki nilai peluang lebih kecil dari nilai peluang kelasnya tidak akan terpilih untuk dijadikan data latih dan data uji. Data latih yang digunakan masing-masing kelas digunakan sebanyak 29 citra. Data uji yang digunakan masing-masing kelas memiliki jumlah yang berbeda dapat dilihat pada Tabel 8.
Tabel 8 Jumlah Citra Uji Tiap Kelas
Kelas Jumlah Citra Kelas Jumlah Citra Kelas Jumlah Citra
1 7 11 5 21 5
2 7 12 5 22 4
3 9 13 8 23 6
4 5 14 4 24 6
Kelas Jumlah Citra Kelas Jumlah Citra Kelas Jumlah Citra 6 6 16 6 26 7 7 6 17 5 27 4 8 3 18 9 28 5 9 5 19 7 29 2 10 6 20 5 30 7
Data citra uji yang telah ditentukan akan dilakukan optimasi menggunakan NSGA-II untuk mendapatkan nilai threshold FLBP dan operator LBP. NSGA-II menghasilkan nilai threshold FLBP dan operator LBP yang berbeda-beda walaupun dalam kelas citra yang sama.
Nilai threshold FLBP yang digunakan ialah dari 1 sampai dengan 10. Nilai
threshold FLBP merupakan nilai Δpi (selisih antara piksel pusat dan piksel tetangga) dimana jika Δpi besar maka nilai threshold FLBP akan bernilai besar dan sebaliknya (Gambar 21).
1 -F 0 F ΔPi 1 -F 0 F ΔPi M0 M1 M0 M1 (a) (b)
Gambar 21 Nilai threshold FLBP dan Δpi , (a) nilai threshold FLBP kecil, nilai selisih kecil (b) nilai threshold FLBP besar, nilai selisih besar Operator LBP merupakan obyektif berikutnya yang menjadi pertimbangan tujuan minimalisasi dalam penentuan nilai akhir NSGA-II. Menurut Ojala (2002) operator LBP (8,1) memiliki akurasi yang lebih baik dibandingkan dengan operator LBP (16,2), hal tersebut menyatakan bahwa operator LBP (8,1) dapat mengekstrak fitur dengan baik. Kecilnya ukuran blok yang digunakan pada operator LBP (8,1) membuat proses pembacaan tekstur menjadi lebih detail sehingga bisa lebih membedakan tekstur antar kelas dan memiliki waktu komputasi yang lebih kecil.