Supervised Learning
Misalkan kita ingin membuat suatu program komputer yang ketika diberi gambar seseorang, dapat menentukan apakah orang dalam gambar tersebut pria atau wanita. Program yang kita buat tersebut adalah yang disebut sebagai classifier, karena program tersebut berusaha menetapkan kelas (yaitu pria atau wanita) ke sebuah objek (gambar). Tugas supervised learning adalah untuk membangun sebuah classifier dengan memberikan sekumpulan contoh training yang sudah diklasifikasi (pada kasus ini, contohnya adalah gambar yang telah dimasukkan ke kelas yang tepat).
Tantangan utama pada supervised learning adalah generalisasi: Setelah menganalisa beberapa contoh gambar, supervised learning harus menghasilkan suatu classifier yang dapat digunakan dengan baik pada semua gambar.
Pasangan objek, dan kelas yang menunjuk pada objek tersebut adalah suatu contoh yang telah diberi label. Himpunan contoh yang telah diberi label akan menghasilkan suatu algoritma pembelajaran yang disebut training set. Misalkan kita menyediakan suatu training set kepada algoritma pembelajaran, dan algoritma tersebut menghasilkan output yang berupa classifier. Bagaimana cara mengukur kualitas classifier ini? Solusi yang umumnya digunakan adalah dengan menggunakan himpunan contoh berlabel yang lain yang disebut sebagai test set. Kita dapat mengukur persentase contoh yang diklasifikasi dengan benar atau persentase contoh yang mengalami kesalahan klasifikasi.
Pendekatan yang dilakukan untuk menghitung persentase mengasumsikan bahwa setiap klasifikasi adalah independen, dan setiap klasifikasi sama pentingnya. Asumsi ini sering sekali dilupakan.
Asumsi bahwa setiap kelas adalah independen seringkali dilanggar bila ada suatu ketergantungan sementara pada data. Contohnya, seorang dokter pada suatu klinik mengetahui bahwa suatu wabah penyakit sedang terjadi. Oleh karena itu, setelah melihat beberapa pasien yang kesemuanya terserang flu, ada kemungkinan besar kalau dokter akan menganggap pasien berikutnya mengidap penyakit yang sama, walaupun pasien tidak menunjukkan gejala sejelas gejala penyakit pasien sebelumnya.
Asumsi bahwa semua klasifikasi sama pentingnya seringkali dilanggar bila ada perubahan resiko yang berhubungan dengan perbedaan perhitungan kesalahan. Contoh: classifier harus menentukan suatu apakah seorang pasien terserang kanker atau tidak berdasarkan perhitungan laboratorium. Ada dua macam kesalahan. Yang pertama disebut, kesalahan false positive, yaitu kesalahan yang muncul ketika classifier mengklasifikasi orang yang sehat sebagai orang yang mengidap kanker. False negative muncul ketika classifier mengklasifikasi orang yang mengidap kanker sebagai orang yang sehat. Umumnya, false negative lebih sering beresiko daripada false positive, sehingga kita harus menggunakan algoritma pembelajaran yang dapat menimbulkan false negative lebih sedikit, walaupun hasilnya akan menimbulkan lebih banyak false positive.
Supervised learning tidak hanya mempelajari classifier, tetapi juga mempelajari fungsi yang dapat memprediksi suatu nilai numerik. Contoh: ketika diberi foto seseorang, kita ingin memprediksi umur, tinggi, dan berat orang yang ada pada foto tersebut. Tugas ini sering disebut sebagai regresi. Pada kasus ini, setiap contoh training yang terlah diberi label berisi sebuah objek, dan nilai yang dimilikinya. Kualitas dari fungsi prediksi biasanya diukur sebagai kuadrat perbedaan nilai pemprediksi.
Ada banyak algoritma pembelajaran yang dikembangkan dari supervised learning. Algoritma-algoritma tersebut tersebut adalah:
decision
trees (pohon keputusan)
, artificial neural networks, support vector machine.Latar Belakang Pohon Keputusan
Di dalam kehidupan manusia sehari-hari, manusia selalu dihadapkan oleh berbagai macam masalah dari berbagai macam bidang. Masalah-masalah yang dihadapi oleh manusia memiliki tingkat kesulitan dan kompleksitas yang sangat bervariasi, mulai dari masalah yang teramat
sederhana dengan sedikit faktor-faktor yang terkait, sampai dengan masalah yang sangat rumit dengan banyak sekali faktor-faktor yang terkait dan perlu untuk diperhitungkan.
Untuk menghadapi masalah-masalah ini, manusia mulai mengembangkan sebuah sistem yang dapat membantu manusia agar dapat dengan mudah mampu untuk menyelesaikan masalah-masalah tersebut. Adapun pohon keputusan ini adalah sebuah jawaban akan sebuah sistem yang manusia kembangkan untuk membantu mencari dan membuat keputusan untuk masalah-masalah tersebut dan dengan memperhitungkan berbagai macam faktor yang ada di dalam lingkup masalah tersebut. Dengan pohon keputusan, manusia dapat dengan mudah mengidentifikasi dan melihat hubungan antara faktor-faktor yang mempengaruhi suatu masalah dan dapat mencari penyelesaian terbaik dengan memperhitungkan faktor-faktor tersebut. Pohon keputusan ini juga dapat menganalisa nilai resiko dan nilai suatu informasi yang terdapat dalam suatu alternatif pemecahan masalah.
Peranan pohon keputusan sebagai alat bantu dalam mengambil keputusan (decision support tool) telah dikembangkan oleh manusia sejak perkembangan teori pohon yang dilandaskan pada teori graf. Kegunaan pohon keputusan yang sangat banyak ini membuatnya telah dimanfaatkan oleh manusia dalam berbagai macam sistem pengambilan keputusan.
Pengertian Pohon Keputusan
Pohon dalam analisis pemecahan masalah pengambilan keputusan adalah pemetaan mengenai alternatif-alternatif pemecahan masalah yang dapat diambil dari masalah tersebut. Pohon tersebut juga memperlihatkan faktor-faktor kemungkinan/probablitas yang akan mempengaruhi alternatif-alternatif keputusan tersebut, disertai dengan estimasi hasil akhir yang akan didapat bila kitamengambil alternatif keputusan tersebut.
Manfaat Pohon Keputusan
Pohon keputusan adalah salah satu metode klasifikasi yang paling populer karena mudah untuk diinterpretasi oleh manusia. Pohon keputusan adalah model prediksi menggunakan struktur pohon atau struktur berhirarki. Konsep dari pohon keputusan adalah mengubah data menjadi pohon keputusan dan aturan-aturan keputusan. Manfaat utama dari
penggunaan pohon keputusan adalah kemampuannya untuk mem-break down proses pengambilan keputusan yang kompleks menjadi lebih simpel sehingga pengambil keputusan akan lebih menginterpretasikan solusi dari permasalahan. Pohon Keputusan juga berguna untuk mengeksplorasi data, menemukan hubungan tersembunyi antara sejumlah calon variabel input dengan sebuah variabel target. Pohon keputusan memadukan antara eksplorasi data dan pemodelan, sehingga sangat bagus sebagai langkah awal dalam proses pemodelan bahkan ketika dijadikan sebagai model akhir dari beberapa teknik lain. Sering terjadi tawar menawar antara keakuratan model dengan transparansi model.
Dalam beberapa aplikasi, akurasi dari sebuah klasifikasi atau prediksi adalah satu-satunya hal yang ditonjolkan, misalnya sebuah perusahaan direct mail membuat sebuah model yang akurat untuk memprediksi anggota mana yang berpotensi untuk merespon permintaan, tanpa memperhatikan bagaimana atau mengapa model tersebut bekerja.
Kelebihan Pohon Keputusan
Kelebihan dari metode pohon keputusan adalah:
1. Daerah pengambilan keputusan yang sebelumnya kompleks dan sangat global, dapat diubah menjadi lebih simpel dan spesifik.
2. Eliminasi perhitungan-perhitungan yang tidak diperlukan, karena ketika menggunakan metode pohon keputusan maka sample diuji hanya berdasarkan kriteria atau kelas tertentu.
3. Fleksibel untuk memilih fitur dari internal node yang berbeda, fitur yang terpilih akan membedakan suatu kriteria dibandingkan kriteria yang lain dalam node yang sama. Kefleksibelan metode pohon keputusan ini meningkatkan kualitas keputusan yang dihasilkan jika dibandingkan ketika menggunakan metode penghitungan satu tahap yang lebih konvensional.
4. Dalam analisis multivariat, dengan kriteria dan kelas yang jumlahnya sangat banyak, seorang penguji biasanya perlu untuk mengestimasikan baik itu distribusi dimensi tinggi ataupun parameter tertentu dari distribusi kelas tersebut. Metode pohon keputusan dapat menghindari munculnya permasalahan ini dengan menggunakan kriteria yang jumlahnya lebih sedikit pada setiap node internal tanpa banyak mengurangi kualitas keputusan yang dihasilkan.
Kekurangan Pohon Keputusan
Beberapa kekurangan dari pohon keputusan yaitu:
1. Terjadi overlap terutama ketika kelas-kelas dan kriteria yang digunakan jumlahnya sangat banyak. Hal tersebut juga dapat menyebabkan meningkatnya waktu pengambilan keputusan dan jumlah memori yang diperlukan.
2. Pengakumulasian jumlah eror dari setiap tingkat dalam sebuah pohon keputusan yang besar.
3. Kesulitan dalam mendesain pohon keputusan yang optimal.
4. Hasil kualitas keputusan yang didapatkan dari metode pohon keputusan sangat tergantung pada bagaimana pohon tersebut didesain.
Skema Pohon Keputusan
Struktur Dasar Pohon
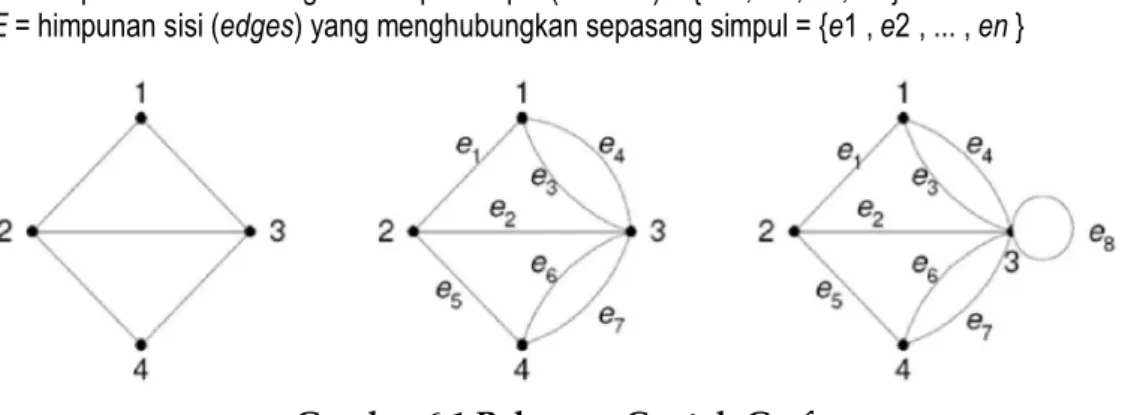
Berdasarkan teori Graf, definisi pohon adalah “sebuah graf, tak-berarah, terhubung, yang tidak mengandung sirkuit”. Graf adalah suatu representasi visual dari objek-objek diskrit yang dinyatakan dengan noktah, bulatan, atau titik, serta hubungan yang ada antara objek-objek tersebut. Secara matematis, graf didefinisikan sebagai pasangan himpunan (V,E) yang dalam hal ini : V = himpunan tidak-kosong dari simpul-simpul (vertices) = { v1 , v2 , ... , vn }
E = himpunan sisi (edges) yang menghubungkan sepasang simpul = {e1 , e2 , ... , en }
Gambar 6.1 Beberapa Contoh Graf
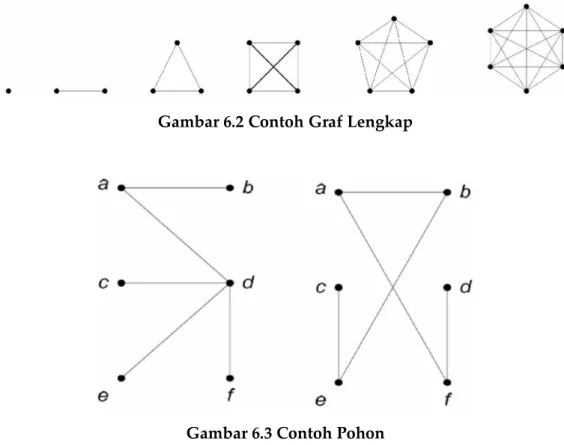
Suatu titik (.) juga dapat disebut sebagai graf, graf tersebut disebut sebagai graf trivial, yaitu suatu graf yang terdiri dari sebuah titik tanpa sisi. Ada juga beberapa graf khusus, salah satunya adalah graf lengkap (complete graph) yaitu graf sederhana yang setiap simpulnya mempunyai sisi ke semua
simpul lainnya. Graf lengkap dengan n buah simpul dilambangkan dengan Kn. Jumlah sisi pada graf lengkap yang terdiri dari n buah simpul adalah n(n – 1)/2.
Gambar 6.2 Contoh Graf Lengkap
Gambar 6.3 Contoh Pohon
Selain itu, sebuah pohon juga memenuhi salah satu dari pernyataan-pernyataan yang ekuivalen di bawah ini:
Misal G adalah sebuah pohon.
~ Setiap pasang simpul di dalam G terhubung dengan lintasan tunggal. ~ G terhubung dan memiliki m = n – 1 buah sisi.
~ G tidak mengandung sirkuit dan memiliki m = n –1 buah sisi.
~ G tidak mengandung sirkuit dan penambahan satu sisi pada graf akan membuat hanya satu sirkuit.
~ G terhubung dan semua sisinya adalah jembatan.
Adapun permodelan pohon yang biasa dipakai dalam pohon keputusan adalah rooted tree (pohon berakar), pohon yang satu buah
simpulnya diperlakukan sebagai akar dan sisi-sisinya diberi arah sehingga menjadi graf berarah.
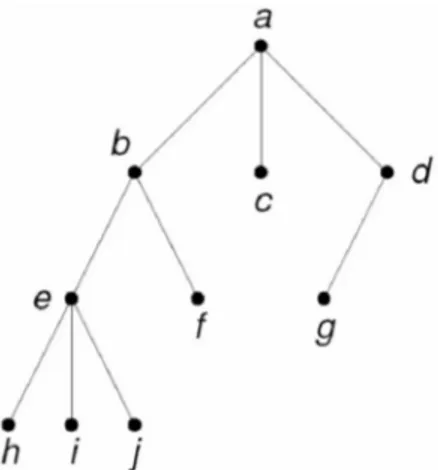
Gambar 6.4 Contoh Pohon Berakar
Beberapa terminologi dalam pohon berakar:
~ Anak/Child atau Orangtua/Parent: b,c, dan d adalah anak dari a dan a adalah orangtua dari b,c, dan d.
~ Lintasan/Path: lintasan dari a ke j adalah a,b,e,j. Panjang lintasan dari a ke j adalah jumlah sisi yang dilalui, yaitu 3.
~ Saudara kandung/Sibling: b,c,dan d adalah saudara kandung sebab mempunyai orangtua yang sama yaitu a.
~ Derajat: derajat adalah jumlah anak yang ada pada simpul tersebut. A berderajat 3, dan b berderajat 2. Derajat suatu pohon adalah derajat maksimum dari semua simpul yang ada. Pohon pada gambar 3 berderajat 3.
~ Daun: daun adalah simpul yang tidak mempunyai anak. c,f,g,h,i,dan j adalah daun.
~ Simpul dalam/Internal nodes: simpul yang mempunyai anak. Simpul a,b, dan d adalah simpul dalam.
~ Tingkat/Level: adalah 1 + panjang lintasan dari simpul teratas ke simpul tersebut. Simpul teratas mempunyai tingkat = 1.
~ Pohon n-ary: pohon yang tiap simpul cabangnya mempunyai banyaknya n buat anak disebut pohon n-ary. Jika n=2, pohonnya disebut pohon binary (binary/biner).
Struktur Pohon Keputusan
Secara umum, pohon keputusan dalah suatu gambaran permodelan dari suatu persoalan yang terdiri dari serangkaian keputusan yang mengarah ke solusi. Tiap simpul dalam menyatakan keputusan dan daun menyatakan solusi.
Permodelan pohon keputusan di sini berupa permodelan pohon n-ary, dengan jumlah anak yang dapat berbeda-beda tiap simpulnya.
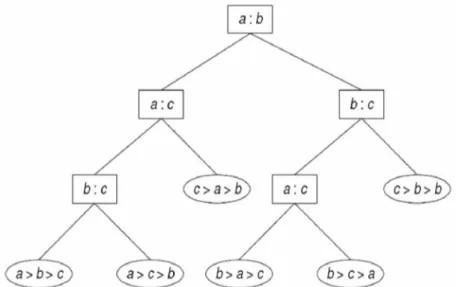
Gambar 6.6 Pohon keputusan untuk mengurutkan 3 buah bilangan a, b, dan c
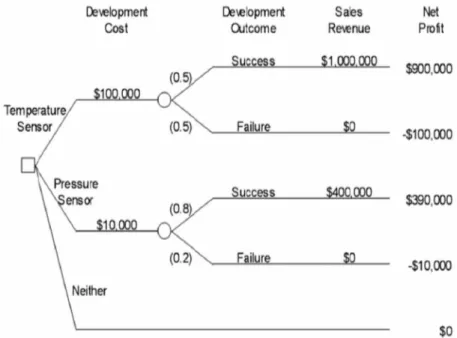
Pohon keputusan pada gambar 6.5 dibaca dari atas ke bawah. Simpul paling atas pada pohon keputusan ini adalah simpul akar. Simpul yang ditandai dengan tanda kotak di simpul tersebut disebut dengan simpul keputusan. Cabang-cabang yang mengarah ke kanan dan kekiri dari sebuah cabang keputusan merepresentasikan kumpulan dari alternatif keputusan yang bisa diambil. Hanya satu keputusan yang dapat diambil dalam suatu waktu.
Dalam beberapa pohon keputusan, juga sering disertakan simpul tambahan, yaitu simpul probabilitas. simpul ini biasa ditandai dengan gambar lingkaran kecil yang disertai dengan angka pada cabang-cabang yang mengakar pada simpul probabilitas itu. Angka-angka yang terletak pada cabang-cabang tersebut merupakan probalitas kesempatan akan munculnya keputusan yang ada di cabang tersebut dalam pilihan.
Sebagai sebuah catatan, pohon keputusan tidak hanya dapat ditulis secara vertikal, namun juga dapat secara horizontal. Pada penulisan secara horizontal, pembacaan pohon keputusan dimulai dari kiri ke kanan.
Selain itu, di posisi paling bawah sebuah pohon keputusan juga dapat ditambahkan sebuah titik akhir (endpoint), yang merepresentasikan hasil akhir dari sebuah lintasan dari akar pohon keputusan pohon tersebut sampai ke titik akhir itu.
Gambar 6.7 Pohon keputusan horizontal dan mengandung simpul probabilitas
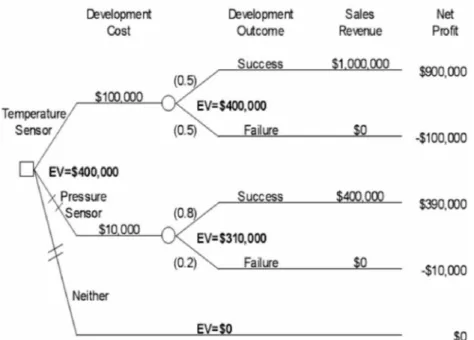
Expected value/hasil estimasi adalah sebuah estimasi hasil dari sebuah keputusan tertentu. Hasil ini didapatkan dari mengkalikan setiap kemungkinan peluang terjadinya suatu kemungkinan lalu menambahkan hasilnya menhadi suatu jumlah.
Expected value decision criterion/kriteria keputusan hasil estimasi adalah suatu seleksi agar dapat memilih sebuah alternatif keputusan yang mempunyai hasil estimasi yang paling baik/yang paling diinginkan. Dalam situasi bila “more is better” atau lebih banyak itu lebih baik, maka pilihan keputusan dengan hasil estimasi paling tinggi adalah yang terbaik, sedangkan dalam situasi bila ”less is better”, maka pilihan keputusan dengan hasil estimasi paling rendah adalah yang terbaik.
Gambar 6.8 Pohon keputusan dengan expected value/hasil estimasi
Di dalam pohon keputusan pada gambar 6.8, cabang pohon keputusan yang mengandung alternatif pilihan yang kurang disarankan/kurang baik menurut kriteria hasil estimasi ditandai dengan tanda ‘//’ pada cabang tersebut. Hasil estimasi pada setiap simpul probabilitas ditandai dengan tanda ‘EV’. Hasil estimasi yang terdapat pada simpul keputusan bernilai sama dengan hasil estimasi bila kita mengkuti cabang tersebut sampai mencapai keputusan akhir.
Decision tree rollback adalah suatu teknik untuk menghitung selama suksesif hasil estimasi yang ada dari simpul keputusan di akhir pohon sampai kembali ke akar pohon keputusan tersebut.
Decision strategy/strategi pengambilan keputusan adalah semua spesifikasi lengkap dari semua kemungkinan pilihan yang sesuai dengan kriteria hasil dari sebuah pengambilan keputusan suatu masalah secara sekuensial dengan menggunakan sebuah pohon keputusan.
Dalam decision analysis, pohon keputusan dapat diartikan sebagai sebuah alat untuk membuat ide yang secara umum dapat mengacu kepada sebuah graf atau sebuah model dari keputusan-keputusan dan akibat-akibat yang dapat muncul dari keputusan-keputusan tersebut, termasuk peluang terjadinya suatu kejadian, biaya yang dibutuhkan, dan utilitas. Melalui
pohon ini strategi terbaik untuk menyelesaikan suatu masalah dapat diketahui. Pohon keputusan juga digunakan untuk mengkalkulasikan peluang kondisi-kondisi yang mungkin akan terjadi desertai dengan analisis-analisis faktor-faktor yang mempengaruhi keputusan yang diambil dengan menggunakan pohon keputusan tersebut.
Contoh Aplikasi
A. Identifikasi Pembeli Komputer
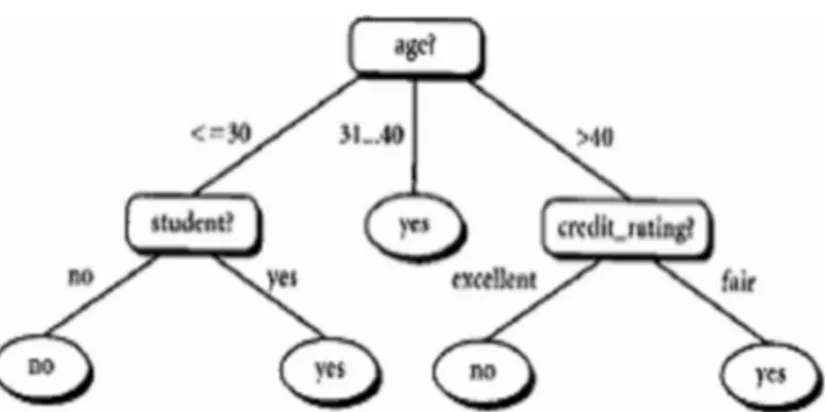
Gambar 6.9 Contoh Aplikasi Pohon Berakar untuk Identifikasi Pembeli Komputer Sumber: Pramudiono (2008)
Disini setiap percabangan menyatakan kondisi yang harus dipenuhi dan tiap ujung pohon menyatakan kelas data. Contoh di Gambar 6.9 adalah identifikasi pembeli komputer, dari pohon keputusan tersebut diketahui bahwa salah satu kelompok yang potensial membeli komputer adalah orang yang berusia di bawah 30 tahun dan juga pelajar. Setelah sebuah pohon keputusan dibangun maka dapat digunakan untuk mengklasifikasikan record yang belum ada kelasnya. Dimulai dari node root, menggunakan tes terhadap atribut dari record yang belum ada kelasnya tersebut lalu mengikuti cabang yang sesuai dengan hasil dari tes tersebut, yang akan membawa kepada internal node (node yang memiliki satu cabang masuk dan dua atau lebih cabang yang keluar), dengan cara harus melakukan tes lagi terhadap atribut atau node daun. Record yang kelasnya tidak diketahui kemudian diberikan kelas yang sesuai dengan kelas yang ada pada node daun. Pada pohon keputusan setiap simpul daun menandai label kelas. Proses dalam pohon
keputusan yaitu mengubah bentuk data (tabel) menjadi model pohon (tree) kemudian mengubah model pohon tersebut menjadi aturan (rule).
B. Keputusan untuk Bermain Tenis atau Tidak
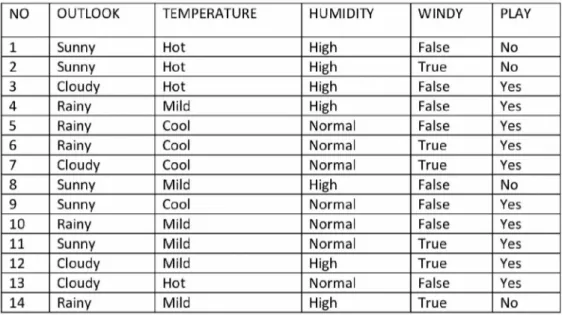
Tabel 6.1 Keputusan Bermain Tenis
Dalam kasus yang tertera pada Tabel 6.1, akan dibuat pohon keputusan untuk menentukan main tenis atau tidak dengan melihat keadaan cuaca (outlook), temperatur, kelembaban (humidity) dan keadaan angin (windy).
Secara umum algoritma untuk membangun pohon keputusan adalah sebagai berikut:
1. Pilih atribut sebagai akar
2. Buat cabang untuk masing-masing nilai 3. Bagi kasus dalam cabang
4. Ulangi proses untuk masing-masing cabang sampai semua kasus pada cabang memiliki kelas yang sama.
Untuk memilih atribut sebagai akar, didasarkan pada nilai gain tertinggi dari atribut-atribut yang ada. Untuk menghitung gain digunakan rumus seperti tertera dalam Rumus 1.
Sedangkan perhitungan nilai entropy dapat dilihat pada rumus 2 berikut:
Berikut ini adalah penjelasan lebih rinci mengenai masing-masing langkah dalam pembentukan pohon keputusan dengan menggunakan algoritma untuk menyelesaikan permasalahan.
a. Menghitung jumlah kasus, jumlah kasus untuk keputusan Yes, jumlah kasus untuk keputusan No, dan Entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut OUTLOOK, TEMPERATURE, HUMIDITY dan WINDY. Setelah itu lakukan penghitungan Gain untuk masing-masing atribut. Hasil perhitungan ditunjukkan oleh Tabel 2. Baris TOTAL kolom Entropy pada Tabel 6.2 dihitung dengan rumus 2, sebagai berikut:
Sedangkan nilai Gain pada baris OUTLOOK dihitung dengan menggunakan rumus 1, sebagai berikut:
Sehingga didapat Gain(Total, Outlook) = 0.258521037
Tabel 6.2 Perhitungan Node 1
Dari hasil pada Tabel 6.2 dapat diketahui bahwa atribut dengan Gain tertinggi adalah HUMIDITY yaitu sebesar 0.37. Dengan demikian HUMIDITY dapat menjadi node akar. Ada 2 nilai atribut dari HUMIDITY yaitu HIGH dan NORMAL. Dari kedua nilai atribut tersebut, nilai atribut NORMAL sudah mengklasifikasikan kasus menjadi 1 yaitu keputusan-nya Yes, sehingga tidak perlu dilakukan perhitungan lebih lanjut, tetapi untuk nilai atribut HIGH masih perlu dilakukan perhitungan lagi.
Dari hasil tersebut dapat digambarkan pohon keputusan sementara seperti Gambar 6.10 di halaman berikutnya.
Gambar 6.10 Pohon Keputusan Hasil Perhitungan Node 1
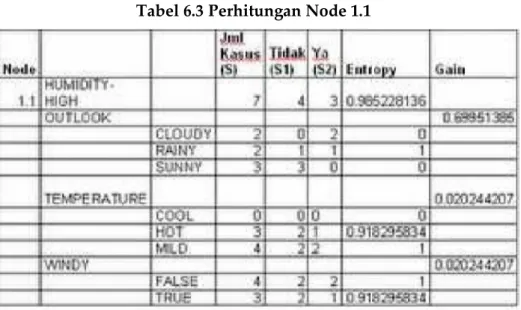
b. Menghitung jumlah kasus, jumlah kasus untuk keputusan Yes, jumlah kasus untuk keputusan No, dan Entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut OUTLOOK, TEMPERATURE dan WINDY yang dapat menjadi node akar dari nilai atribut HIGH. Setelah itu lakukan penghitungan Gain untuk masing-masing atribut. Hasil perhitungan ditunjukkan oleh Tabel 6.3.
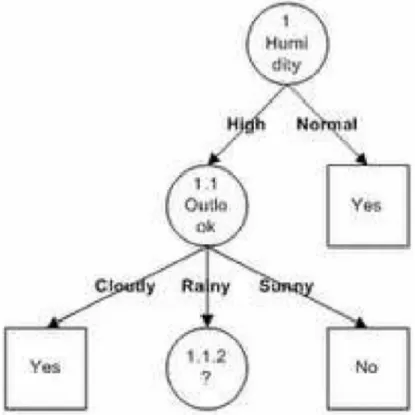
Dari hasil pada Tabel 6.3 dapat diketahui bahwa atribut dengan Gain tertinggi adalah OUTLOOK yaitu sebesar 0.67. Dengan demikian OUTLOOK dapat menjadi node cabang dari nilai atribut HIGH. Ada 3 nilai atribut dari OUTLOOK yaitu CLOUDY, RAINY dan SUNNY. Dari ketiga nilai atribut tersebut, nilai atribut CLOUDY sudah mengklasifikasikan kasus menjadi 1 yaitu keputusannya Yes dan nilai atribut SUNNY sudah mengklasifikasikan kasus menjadi satu dengan keputusan No, sehingga tidak perlu dilakukan perhitungan lebih lanjut, tetapi untuk nilai atribut RAINY masih perlu dilakukan perhitungan lagi. Pohon keputusan yang terbentuk sampai tahap ini ditunjukkan pada gambar 6.11.
c. Menghitung jumlah kasus, jumlah kasus untuk keputusan Yes, jumlah kasus untuk keputusan No, dan Entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut TEMPERATURE dan WINDY yang dapat menjadi node cabang dari nilai atribut RAINY. Setelah itu lakukan penghitungan Gain untuk masing-masing atribut. Hasil perhitungan ditunjukkan oleh Tabel 6.4.
Tabel 6.4 Perhitungan Node 1.1.2
Dari hasil pada tabel 6.4 dapat diketahui bahwa atribut dengan Gain tertinggi adalah WINDY yaitu sebesar 1. Dengan demikian WINDY dapat menjadi nodecabang dari nilai atribut RAINY. Ada 2 nilai atribut dari WINDY yaitu FALSE dan TRUE. Darikedua nilai atribut tersebut, nilai atribut FALSE sudah mengklasifikasikan kasus menjadi 1 yaitu keputusannya Yes dan nilai atribut TRUE sudah mengklasifikasikan kasus menjadi satu dengan keputusan No, sehingga tidak perlu dilakukan perhitungan lebih lanjut untuk nilai atribut ini.
Pohon keputusan yang terbentuk sampai tahap ini ditunjukkan pada Gambar 6.12 di halaman berikutnya.
Gambar 6.12 Pohon Keputusan Hasil Perhitungan Node 1.1.2
Dengan memperhatikan pohon keputusan pada Gambar 6.12, diketahui bahwa semua kasus sudah masuk dalam kelas. Dengan demikian, pohon keputusanpada Gambar 6.12 merupakan pohon keputusan terakhir yang terbentuk.
Referensi:
Kusrini & Emha Taufiq Luthfi. 2009. Algoritma Data Mining. Penerbit Andi Offset, Yogyakarta. Larose, Daniel T. 2005. Discovering Knowledge ini Data: An Introduction to Data Mining.
Wiley.
Pramudiono, Iko. 2008. Pengantar Data Mining: Menambang Permata Pengetahuan di Gunung
Data. http://www.ilmukomputer.com.
Santosa, Budi. 2007. Data Mining : Teknik Pemanfaatan Data untuk keperluan Bisnis. Graha Ilmu. Yogyakarta.