BAB 2
TINJAUAN PUSTAKA
3.1 Dasar Teori Particle Swarm Optimization (PSO)
Particle Swarm Optimization (PSO) diperkenalkan oleh Dr. Eberhart dan Dr. Kennedy pada tahun 1995, merupakan algoritma optimasi yang meniru proses yang terjadi dalam kehidupan populasi burung (flock of bird) dan ikan (school of fish) dalam bertahan hidup. Sejak diperkenalkan pertama kali, algoritma PSO berkembang cukup pesat, baik dari sisi aplikasi maupun dari sisi pengembangan metode yang digunakan pada algoritma tersebut (Haupt, R.L. & Haupt, S.E. 2004). Oleh sebab hal tersebut, mereka mengategorikan algoritma sebagai bagian dari kehidupan rekayasa/buatan Artificial Life. Algoritma ini juga terhubung dengan komputasi evolusioner, algoritma genetik dan pemrograman evolusionari (Jatmiko et al. 2010).
Dalam Particle Swarm Optimization (PSO), kawanan diasumsikan mempunyai ukuran tertentu dengan setiap partikel posisi awalnya terletak disuatu lokasi yang acak dalam ruang multidimensi. Setiap partikel diasumsikan memiliki dua karakteristik yaitu posisi dan kecepatan. Setiap partikel bergerak dalam ruang atau space tertentu dan mengingat posisi terbaik yang pernah dilalui atau ditemukan terhadap sumber makanan atau nilai fungsi objektif. Setiap partikel menyampaikan informasi atau posisi terbaiknya kepada partikel yang lain dan menyesuaikan posisi dan kecepatan masing masing berdasarkan informasi yang diterima mengenai posisi yang bagus tersebut. Particle Swarm Optimization (PSO) adalah salah satu dari teknik komputasi evolusioner, yang mana populasi pada PSO didasarkan pada penelusuran algoritma dan diawali dengan suatu populasi yang random yang disebut dengan particle. Berbeda dengan teknik komputasi evolusioner lainnya, setiap particle di dalam PSO juga berhubungan dengan suatu velocity. Partikel-partikel tersebut bergerak melalui penelusuran ruang dengan velocity yang dinamis yang disesuaikan menurut perilaku historisnya. Oleh karena itu, partikel-partikel mempunyai kecenderungan untuk
bergerak ke area penelusuran yang lebih baik setelah melewati proses penelusuran. Particle Swarm Optimization (PSO) mempunyai kesamaan dengan genetic algorithm yang mana dimulai dengan suatu populasi yang random dalam bentuk matriks. Namun PSO tidak memiliki operator evolusi yaitu crossover dan mutasi seperti yang ada pada genetic algorithm. Baris pada matriks disebut particle atau dalam genetic algorithm sebagai kromosom yang terdiri dari nilai suatu variable. Setiap particle berpindah dari posisinya semula ke posisi yang lebih baik dengan suatu velocity.
Pada algoritma PSO vektor velocity di update untuk masing-masing partikel kemudian menjumlahkan vektor velocity tersebut ke posisi particle. Update velocity dipengaruhi oleh kedua solusi yaitu global best yang berhubungan dengan biaya yang paling rendah yang pernah diperoleh dari suatu particle dan solusi local best yang berhubungan dengan biaya yang paling rendah pada populasi awal. Jika solusi local best mempunyai suatu biaya yang kurang dari biaya solusi global yang ada, maka solusi local best menggantikan solusi global best. Kesederhanaan algoritma dan performansinya yang baik, menjadikan PSO telah menarik banyak perhatian di kalangan para peneliti dan telah diaplikasikan dalam berbagai persoalan optimisasi. PSO telah populer menjadi optimisasi global dengan sebagian besar permasalahan dapat diselesaikan dengan baik di mana variabel-variabelnya adalah bilangan riil. Menurut Wati (2011), beberapa istilah umum yang biasa digunakan dalam Particle Swarm Optimization dapat didefinisikan sebagai berikut:
1. Swarm : populasi dari suatu algoritma.
2. Particle: anggota (individu) pada suatu swarm. Setiap particle merepresentasikan suatu solusi yang potensial pada permasalahan yang diselesaikan. Posisi dari suatu particle adalah ditentukan oleh representasi solusi saat itu.
3. Pbest (Personal best): posisi Pbest suatu particle yang menunjukkan posisi particle yang dipersiapkan untuk mendapatkan suatu solusi yang terbaik. 4. Gbest (Global best) : posisi terbaik particle pada swarm atau posisi terbaik
5. Velocity (v): vektor yang menggerakkan proses optimisasi yang menentukan arah di mana suatu particle diperlukan untuk berpindah (move) untuk memperbaiki posisinya semula atau kecepatan yang menggerakkan proses optimasi yang menentukan arah dimana particle diperlukan untuk berpindah dan memperbaiki posisinya semula.
6. Inertia weight (θ): inertia weight di simbolkan w, parameter ini digunakan untuk mengontrol dampak dari adanya velocity yang diberikan oleh suatu particle.
7. Learning Rates (c1 dan c2) : suatu konstanta untuk menilai kemampuan particle (c1) dan kemampuan sosial swarm (c2) yang menunjukkan bobot dari particle terhadap memorinya.
Menurut Chen & Shih (2013) posisi dari tiap partikel dapat dianggap sebagai calon solusi (candidate solution) bagi suatu masalah optimisasi. Tiap-tiap partikel diberi suatu fungsi fitness merancang sesuai dengan menunjuk masalah yang yang bersesuaian. Ketika masing-masing partikel bergerak ke suatu posisi baru didalam ruang pencarian, itu akan mengingat sebagai personal best (Pbest). Sebagai tambahan
terhadap ingatan informasi sendiri, masing-masing partikel akan juga menukar informasi dengan partikel yang lain dan mengingat global best (Gbest). Kemudian
masing-masing partikel akan meninjau kembali arah dan percepatannya sesuai dengan Pbest dan Gbest untuk bergerak ke arah yang optimal dan menemukan solusi yang optimal.
Dengan keuntungan dari aplikasi yang mudah dan sederhana, lebih sedikit parameter yang diperlukan, dan hasil yang baik, PSO telah diadopsi didalam banyak bidang, seperti TSP, flowshop, VRP, task-resource assignment, penjadwalan khusus dan lain lain. Sebab itu PSO telah pula diterapkan dalam membentuk penjadwalan yang optimal untuk university cources. Seperti halnya dengan algoritma evolusioner yang lain, algoritma PSO adalah sebuah populasi yang didasarkan penelusuran inisialisasi partikel secara random dan adanya interaksi diantara partikel dalam populasi. Di dalam PSO setiap partikel bergerak melalui ruang solusi dan mempunyai kemampuan untuk mengingat posisi terbaik sebelumnya dan dapat bertahan dari generasi ke generasi. Menurut Kennedy & Eberhart (1995) Algoritma PSO dikembangkan dengan berdasarkan pada model berikut:
1. Ketika seekor burung mendekati target atau makanan (atau bisa minimum atau maximum suatu fungsi tujuan) secara cepat mengirim informasi kepada burung-burung yang lain dalam kawanan tertentu.
2. Burung yang lain akan mengikuti arah menuju ke makanan tetapi tidak secara langsung.
3. Ada komponen yang tergantung pada pikiran setiap burung, yaitu memorinya tentang apa yang sudah dilewati pada waktu sebelumnya.
Menurut Bai (2010) keuntunggan dari Algoritma PSO adalah:
1. PSO berdasar pada kecerdasan (intelligence). Ini dapat diterapkan ke dalam kedua penggunaan dalam bidang teknik dan riset ilmiah.
2. PSO tidak punya overlap dan kalkulasi mutasi. Pencarian dapat dilakukan oleh kecepatan dari partikel. Selama pengembangan beberapa generasi, kebanyakan hanya partikel yang optimis yang dapat mengirim informasi kepartikel yang lain, dan kecepatan dari pencarian adalah sangat cepat.
3. Perhitungan didalam Algoritma PSO sangat sederhana, menggunakan kemampuan optimisasi yang lebih besar dan dapat diselesaikan dengan mudah. 4. PSO memakai kode/jumlah yang riil, dan itu diputuskan langsung dengan
solusi, dan jumlah dimensi tetap sama dengan solusi yang ada.
Lebih lanjut Bai (2010) menjelaskan beberapa kerugian dari Algoritma PSO adalah:
1. Metode mudah mendapatkan optimal parsial (sebagian), yang mana menyebabkan semakin sedikit ketepatannya untuk peraturan tentang arah dan kecepatan.
2. Metode tidak bisa berkembang dari permasalahan sistem yang tidak terkoordinir, seperti solusi dalam bidang energi dan peraturan yang tidak menentu didalam bidang energy.
Model Algoritma PSO ini akan disimulasikan dalam ruang dengan dimensi tertentu dengan sejumlah iterasi sehingga di setiap iterasi, posisi partikel akan semakin mengarah ke target yang dituju (minimasi atau maksimasi fungsi). Ini dilakukan hingga maksimum iterasi dicapai atau bisa juga digunakan kriteria penghentian yang lain. Hal ini disebabkan, PSO merupakan algoritma optimasi yang mudah dipahami, cukup sederhana, dan memiliki unjuk kerja yang sudah terbukti handal. Algoritma PSO dapat
digunakan pada berbagai masalah optimasi baik kontinyu maupun diskrit, linier maupun nonlinier. PSO memodelkan aktivitas pencarian solusi terbaik dalam suatu ruang solusi sebagai aktivitas terbangnya kelompok partikel dalam suatu ruang solusi tersebut. Dengan demikian, awal penelusuran pada algoritma PSO dilakukan dengan populasi yang random (acak) yang disebut dengan partikel dan jika suatu partikel atau seeokor burung menemukan jalan yang tepat atau pendek menuju sumber makanan, maka sisa kelompok yang lain juga akan segera mengikuti jalan tersebut meskipun lokasi mereka jauh di kelompok tersebut. Posisi partikel dalam ruang solusi tersebut merupakan kandidat solusi yang berisi variabel-variabel optimasi. Setiap posisi tersebut akan dikaitkan dengan sebuah nilai yang disebut nilai objektif atau nilai fitness yang dihitung berdasarkan fungsi objektif dari masalah optimasi yang akan diselesaikan.
3.2 Proses Algoritma PSO
Menurut Chen & Shih (2013) untuk memulai algoritma PSO, kecepatan awal (velocity) dan posisi awal (position) ditentukan secara random. Kemudian proses pengembangannya sebagai berikut:
1. Asumsikan bahwa ukuran kelompok atau kawanan (jumlah partikel) adalah N. Kecepatan dan posisi awal pada tiap partikel dalam N dimensi ditentukan secara random (acak).
2. Hitung kecepatan dari semua partikel. Semua partikel bergerak menuju titik optimal dengan suatu kecepatan. Awalnya semua kecepatan dari partikel diasumsikan sama dengan nol, set iterasi i = 1.
3. Nilai fitness setiap partikel ditaksir menurut fungsi sasaran (objective function) yang ditetapkan. Jika nilai fitness setiap partikel pada lokasi saat ini lebih baik dari Pbest, maka Pbest diatur untuk posisi saat ini.
4. Nilai fitness partikel dibandingkan dengan Gbest. Jika Gbest yang terbaik maka Gbest yang diupdate.
5. Persamaan (2.1) dan (2.2) ditunjukkan di bawah ini untuk memperbaharui (update) kecepatan (velocity) dan posisi (position) setiap partikel.
𝑉𝑖𝑑𝑘+1= 𝑤 × 𝑉𝑖𝑑𝑘 + 𝑐1 × 𝑟𝑎𝑛𝑑1 × (𝑃𝑖𝑑− 𝑋𝑖𝑑) + 𝑐2 × 𝑟𝑎𝑛𝑑2 × (𝐺𝑖𝑑− 𝑋𝑖𝑑) (2.1)
𝑋𝑖𝑑𝑘+1= 𝑋
Dimana:
Vid = komponen kecepatan individu ke i pada d dimensi Xid = posisi individu i pada d dimensi
𝜔 = parameter inertia weight
𝑐1 𝑐2 = konstanta akselerasi (learning rate), nilainya antara 0 sampai 1 rand1, rand2 = parameter random antara 0 sampai 1
𝑃𝑖d= Pbest (local best) individu i pada d dimensi 𝐺id= Gbest (global best) pada d dimensi
6. Cek apakah solusi yang sekarang sudah konvergen. Jika posisi semua partikel menuju ke satu nilai yang sama, maka ini disebut konvergen. Jika belum konvergen maka langkah 2 diulang dengan memperbarui iterasi i = i + 1, dengan cara menghitung nilai baru dari Pbest,j dan Gbest. Proses iterasi ini
dilanjutkan sampai semua partikel menuju ke satu titik solusi yang sama. Biasanya akan ditentukan dengan kriteria penghentian (stopping criteria), misalnya jumlah selisih solusi sekarang dengan solusi sebelumnya sudah sangat kecil.
7. Menurut Engelbrecht (2006) ada 2 aspek penting dalam memilih kondisi berhenti yaitu:
a. Kondisi berhenti tidak menyebabkan PSO convergent premature (memusat sebelum waktunya) dimana solusi tidak optimal yang didapat.
b. Kondisi berhenti harus melindungi dari kondisi oversampling pada nilainya, jika kondisi berhenti memerlukan perhitungan yang terus menerus maka kerumitan dari proses pencarian akan meningkat.
Beberapa kondisi berhenti yang dapat dipakai dalam Particle Swarm Optimization menurut Engelbrecht (2006) adalah:
- Berhenti ketika jumlah iterasi telah mencapai jumlah iterasi maksimum yang diperbolehkan, berhenti ketika solusi yang diterima ditemukan, Berhenti ketika tidak ada perkembangan setelah beberapa iterasi.
3.3 Menentukan Parameter Algoritma PSO
Menurut Hsieh et al. (2007) menentukan kombinasi parameter terbaik Algoritma PSO dengan kondisi yang berbeda yaitu:
1. Jumlah partikel (number of particle)
Rangenya adalah 20 - 40, tetapi 10 partikel akan mendapatkan hasil yang lebih baik.
2. Kecepatan maksimum (maximum velocity)
Kecepatan maksimum (v) diatur untuk perpindahan partikel. Jika kecepatan Vid diantara -10, 10. Kemudian kecepatan maksimum adalah pada 20.
3. Learning factors
Learning factor (c1 dan c2) pada umumnya mempunyai nilai 2. Berbeda masalah juga akan berbeda nilainya dan rangenya adalah 0 - 4.
4. Kondisi berhenti (stop condition)
Termasuk jumlah iterasi maksimum dari Algoritma PSO dan syarat error mencapai minimal. Kondisi berhenti tergantung masalah yang dioptimalkan. 5. Inertia weight
Shi & Eberhart (1998) menemukan Algoritma PSO dengan Inertia weight (w) dengan range antara 0.8 – 1.2.
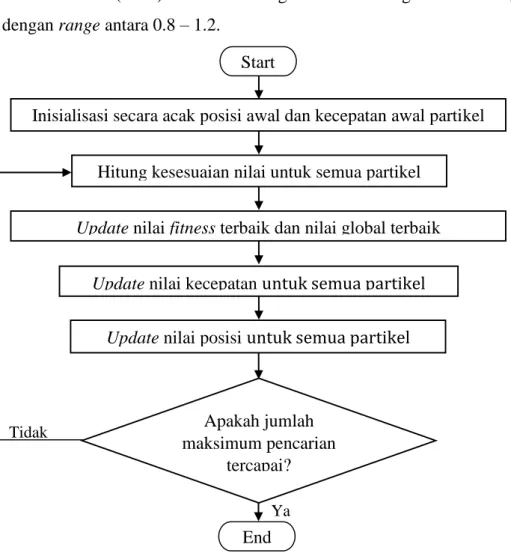
Gambar 2.1 Flowchart Algoritma PSO
Inisialisasi secara acak posisi awal dan kecepatan awal partikel
Hitung kesesuaian nilai untuk semua partikel
Apakah jumlah maksimum pencarian
tercapai? Start
Update nilai fitness terbaik dan nilai global terbaik
Update nilai kecepatan untuk semua partikel Update nilai posisi untuk semua partikel
End Tidak
3.6 Algoritma Genetika
Algoritma ini ditemukan di Universitas Michigan, Amerika Serikat oleh John Holland (1975) melalui sebuah penelitian dan dipopulerkan oleh salah satu muridnya, David Goldberg (Haupt R.L. & Haupt S.E. 2004). Algoritma genetika adalah algoritma pencarian heuristik yang didasarkan atas seleksi alamiah dan evolusi. Teori seleksi alamiah dan evolusi pertama sekali diperkenalkan oleh Charles Darwin. Algoritma ini didasari oleh konsep evaluasi biologi, dan dapat memberikan solusi alternatif atas suatu masalah yang hendak diselesaikan. Algoritma genetika menawarkan suatu solusi pemecahan masalah yang terbaik, dengan memanfaatkan metode seleksi, crossover, dan mutasi. Solusi terbaik yang diinginkan dapat dicapai dengan terus mengulang proses pencarian keturunan (Ferdian et al. 2013).
Proses pencarian solusi diawali dengan tahap pembangkitan populasi awal secara acak. Populasi ini terdiri dari kromosom-kromosom dan setiap kromosom merupakan gambaran solusi atas pemecahan masalah. Populasi yang telah dipilih tersebut akan menghasilkan keturunan baru yang sifatnya diharapkan lebih baik dari populasi sebelumnya. Populasi yang baik sifatnya akan memiliki peluang untuk terus dikembangkan agar menghasilkan keturunan populasi yang lebih baik selanjutnya. Pendekatan yang diambil oleh algoritma ini adalah dengan menggabungkan secara acak berbagai pilihan solusi terbaik di dalam suatu kumpulan untuk mendapatkan generasi solusi terbaik berikutnya yaitu pada suatu kondisi yang memaksimalkan kecocokannya atau biasa disebut fitness. Generasi ini akan merepresentasikan perbaikan-perbaikan pada populasi awalnya. Dengan melakukan proses ini secara berulang, algoritma ini diharapkan dapat mensimulasikan proses evolusioner. Pada akhirnya, akan didapatkan solusi-solusi yang paling tepat bagi permasalahan yang dihadapi. Dengan demikian algoritma genetika dapat menggunakan metode seleksi, pindah silang dan mutasi dalam membentuk populasi baru, dengan memaksimalkan fungsi fitness yang diharapkan akan lebih baik dari populasi sebelumnya. Algoritma genetika adalah algoritma yang berusaha menerapkan pemahaman mengenai evolusi alamiah pada pemecahan-masalah (problem solving).
Untuk menggunakan algoritma genetika, solusi permasalahan direpresentasikan sebagai kromosom. Tiga aspek yang penting untuk penggunaan algoritma genetika:
1. Definisi fitness function.
3. Definisi dan implementasi operasi genetika.
Jika ketiga aspek di atas telah didefinisikan, algoritma genetika akan bekerja dengan baik. Algoritma genetika cukup baik untuk digunakan dalam penjadwalan mata kuliah di sebuah perguruan tinggi dan merupakan salah satu jalan untuk memecahkan masalah yang cukup besar dengan solusi yang cukup baik meskipun masalah tersebut membutuhkan waktu eksekusi yang lama bila dilakukan secara manual (Jain et al. 2010). Algoritma genetika diilhami oleh ilmu genetika, karena itu istilah yang digunakan dalam algoritma genetika banyak diadopsi dari ilmu tersebut. Menurut Michalewicz (1996) apabila dibandingkan dengan prosedur pencarian dan optimasi biasa, algoritma genetika berbeda dalam beberapa hal sebagai berikut:
1. Manipulasi dilakukan terhadap kode dari himpunan parameter (biasa disebut chromosome), tidak secara langsung terhadap parameternya sendiri.
2. Proses pencarian dilakukan dari beberapa titik dalam satu populasi, tidak dari satu titik saja.
3. Proses pencarian menggunakan informasi dari fungsi tujuan.
4. Pencariannya menggunakan unsur peluang (stochastic operators) yang bersifat probabilistik, tidak menggunakan aturan deterministik.
Kelebihan Algoritma genetika sebagai metode optimasi adalah sebagai berikut: 1. Algoritma genetika merupakan algoritma yang berbasis populasi yang
memungkinkan digunakan pada optimasi masalah dengan ruang pencarian (search space) yang sangat luas dan kompleks. Properti ini juga memungkinkan Algoritma genetika untuk melompat keluar dari daerah lokal optimum (Gen & Cheng, 1997).
2. Individu yang ada pada populasi bisa diletakkan pada beberapa sub-populasi yang diproses pada sejumlah komputer secara paralel. Hal ini bisa mengurangi waktu komputasi pada masalah yang sangat kompleks (Defersha & Chen, 2010). Penggunaan sub-populasi juga bisa dilakukan pada hanya satu komputer untuk menjaga keragaman populasi dan meningkatkan kualitas hasil pencarian.
3. Algoritma genetika menghasilkan himpunan solusi optimal yang sangat berguna pada peyelesaian masalah dengan banyak obyektif (Mahmudy & Rahman, 2011).
4. Algoritma genetika dapat digunakan untuk menyelesaikan masalah yang kompleks dengan banyak variabel. Variabel tersebut bisa kontinyu, diskrit atau campuran keduanya (Haupt, R.L & Haupt, S.E, 2004).
5. Algoritma genetika menggunakan chromosome untuk mengkodekan solusi sehingga bisa melakukan pencarian tanpa memperhatikan informasi derivatif yang spesifik dari masalah yang diselesaikan (Gen & Cheng, 1997; Haupt, R.L & Haupt, S.E 2004).
6. Algoritma genetika bisa diimplementasikan pada berbagai macam data seperti data yang dibangkitkan secara numerik atau menggunakan fungsi analitis (Haupt, R.L & Haupt, S.E, 2004).
7. Algoritma genetika cukup fleksibel untuk dihibridisasikan dengan algoritma lainnya (Gen & Cheng, 1997). Beberapa penelitian membuktikan bahwa hybrid GA (HGA) sangat efektif untuk menghasilkan solusi yang lebih baik (Mahmudy et al. 2013d).
8. Algoritma genetika bersifat ergodic, sembarang solusi bisa diperoleh dari solusi yang lain dengan hanya beberapa langkah. Hal ini memungkinkan eksplorasi pada daerah pencarian yang sangat luas dilakukan dengan lebih cepat dan mudah (Marian, 2003).
2.5 Proses Algoritma Genetika
Proses dalam algoritma genetika diawali dengan inisialisasi, yaitu menciptakan individu-individu secara acak yang memiliki susunan gen (chromosome) tertentu. Chromosome ini mewakili solusi dari permasalahan yang akan dipecahkan. Reproduksi dilakukan untuk menghasilkan keturunan (offspring) dari individu-individu yang ada pada populasi. Evaluasi digunakan untuk menghitung kebugaran (fitness) setiap chromosome. Semakin besar fitness maka semakin baik chromosome tersebut untuk dijadikan calon solusi. Seleksi dilakukan untuk memilih individu dari himpunan populasi dan offspring yang dipertahankan hidup pada generasi berikutnya. Fungsi probabilistis digunakan untuk memilih individu yang dipertahankan hidup, karena individu yang lebih baik mempunyai nilai fitness lebih besar dan mempunyai peluang lebih besar untuk terpilih (Gen & Cheng, 1997). Oleh karena itu setiap individu akan dievaluasi dengan fitness function dan individu yang mempunyai nilai fitness yang lebih besar merupakan individu yang terbaik.
Setelah melewati sekian iterasi (generasi) akan didapatkan individu terbaik. Individu terbaik ini mempunyai susunan chromosome yang bisa dikonversi menjadi solusi yang terbaik (paling tidak mendekati optimum). Dari sini bisa disimpulkan bahwa algoritma genetika menghasilkan suatu solusi optimum dengan melakukan pencarian di antara sejumlah alternatif titik optimum berdasarkan fungsi probabilistic (Michalewicz, 1996). Dalam siklus perkembangan algoritma genetika mencari solusi (chromosome) terbaik terdapat beberapa proses sebagai berikut:
1. Inisialisasi
Inisialisasi dilakukan untuk membangkitkan himpunan solusi baru secara acak/random yang terdiri atas sejumlah string chromosome dan ditempatkan pada penampungan yang disebut populasi. Dalam tahap ini harus ditentukan ukuran populasi (popSize). Nilai ini menyatakan banyaknya individu/ chromosome yang ditampung dalam populasi. Panjang setiap string chromosome (stringLen) dihitung berdasarkan presisi variabel solusi yang kita cari.
2. Reproduksi
Reproduksi dilakukan untuk menghasilkan keturunan dari individu-individu yang ada di populasi. Himpunan keturunan ini ditempatkan dalam penampungan offspring. Dua operator genetika yang digunakan dalam proses ini adalah pindah silang (crossover) dan mutasi (mutation). Ada banyak metode crossover dan mutation yang telah dikembangkan oleh para peneliti dan biasanya bersifat spesifik terhadap masalah dan representasi chromosome yang digunakan. Crossover dilakukan dengan memilih dua induk (parent) secara acak dari populasi. Metode crossover yang digunakan adalah metode one-cut-point, yang secara acak memilih satu titik potong dan menukarkan bagian kanan dari tiap induk untuk menghasilkan offspring. Mutasi dilakukan dengan memilih satu induk secara acak dari populasi. Metode mutasi yang digunakan adalah dengan memilih satu titik acak kemudian mengubah nilai gen pada titik tersebut.
3. Evaluasi
Evaluasi digunakan untuk menghitung kebugaran (fitness) setiap chromosome. Semakin besar fitness maka semakin baik chromosome tersebut untuk
dijadikan calon solusi. Evaluasi dilakukan terhadap keseluruhan individu dengan cara:
a. Mengubah/memetakan setiap string biner menjadi variabel x1 dan x2.
b. Menghitung nilai fungsi obyektive f(x1,x2).
c. Konversi nilai f(x1,x2) menjadi nilai fitness. Karena masalah ini adalah
pencarian nilai maksimum, maka nilai fitness untuk tiap individu bisa dihitung secara langsung sebagai berikut:
fitness = f (x1,x2) (2.3)
Untuk masalah pencarian nilai minimum maka bisa digunakan persamaan 2.4 atau 2.5. Nilai C pada persamaan 2.4 merupakan nilai konstan yang harus ditetapkan sebelumnya. Penggunaan persamaan 2.5 harus dilakukan secara hati-hati untuk memastikan tidak terjadi pembagian dengan nol.
fitness = C – f (X) (2.4)
𝑓𝑖𝑡𝑛𝑒𝑠𝑠 = 1
𝑓(𝑋)
4. Seleksi
Seleksi dilakukan untuk memilih individu dari himpunan populasi dan offspring yang dipertahankan hidup pada generasi berikutnya. Semakin besar nilai fitness sebuah chromosome maka semakin besar peluangnya untuk terpilih. Hal ini dilakukan agar terbentuk generasi berikutnya yang lebih baik dari generasi sekarang. Metode seleksi yang sering digunakan adalah roulette wheel, binary tournament, dan elitism.
Langkah-langkah membentuk roulette wheel berdasarkan probabilitas kumulatif adalah:
- Misalkan fitness(Pk) adalah nilai fitness individu ke-k. Maka bisa dihitung
total fitness sebagai berikut:
𝑡𝑜𝑡𝑎𝑙 𝑓𝑖𝑡𝑛𝑒𝑠𝑠 = ∑ 𝑓𝑖𝑡𝑛𝑒𝑠𝑠 (𝑃𝑘) 𝑝𝑜𝑝 𝑠𝑖𝑧𝑒
𝑘=1
Hitung nilai probabilitas seleksi (prob) tiap individu: 𝑝𝑟𝑜𝑏𝑘 = 𝑓𝑖𝑡𝑛𝑒𝑠𝑠 (𝑃𝑘)
𝑡𝑜𝑡𝑎𝑙 𝑓𝑖𝑡𝑛𝑒𝑠𝑠 , 𝑘 = 1,2 … , 𝑝𝑜𝑝𝑠𝑖𝑧𝑒
Hitung nilai probabilitas kumulatif (probCum) tiap individu: 𝑝𝑟𝑜𝑏𝐶𝑢𝑚𝑘 = ∑ 𝑝𝑟𝑜𝑏𝑗 𝑘 𝑗=1 , 𝑘 = 1,2 … , 𝑝𝑜𝑝𝑠𝑖𝑧𝑒 dimana:
Pk : probabilitas terpilihnya individu k dalam populasi
pk : nilai fitted value dari individu k
pj : nilai fitted value dari individu ke- j, dimana j = 1, 2, ..., pop size
pop size : jumlah seluruh individu dalam populasi
2.5.1 Kondisi Berhenti (Termination Condition)
Iterasi GA diulang terus sampai kondisi berhenti tercapai. Beberapa kriteria bisa dipakai untuk hal ini sebagai berikut:
1. Iterasi berhenti sampai generasi n. Nilai n ditentukan sebelumnya berdasarkan beberapa eksperimen pendahuluan. Semakin tinggi ukuran dan kompleksitas masalah maka nilai n semakin besar. Nilai n ditentukan sedemikian rupa sehingga konvergensi populasi tercapai dan akan sulit didapatkan solusi yang lebih baik setelah n iterasi (Yogeswaran et al. 2009).
2. Iterasi berhenti setelah n generasi berurutan tidak dijumpai solusi yang lebih baik (Mahmudy et al. 2012a). Kondisi ini menunjukkan bahwa GA sulit mendapatkan solusi yang lebih baik dan penambahan iterasi hanya membuang waktu.
3. Iterasi berhenti setelah t satuan waktu tercapai. Ini biasa digunakan jika diinginkan untuk membandingkan performa dari beberapa algoritma (Mahmudy, 2013). Dalam implementasi praktis, kombinasi kondisi (1) dan (2) bisa dipakai (Mahmudy et al. 2013e).
3.7.2 Penggunaan Algoritma Genetika
Algoritma genetik dimulai dengan sekumpulan set status yang dipilih secara random yang disebut populasi. Algoritma ini mengkombinasikan dua populasi induk. Setiap status atau individual direpresentasikan sebagai sebuah string.
1. Fitness function
Setiap individual dievaluasi dengan fitness function. Sebuah fitness function mengembalikan nilai tertinggi untuk individual yang terbaik. Individu akan diurutkan berdasarkan nilai atau disebut dengan selection.
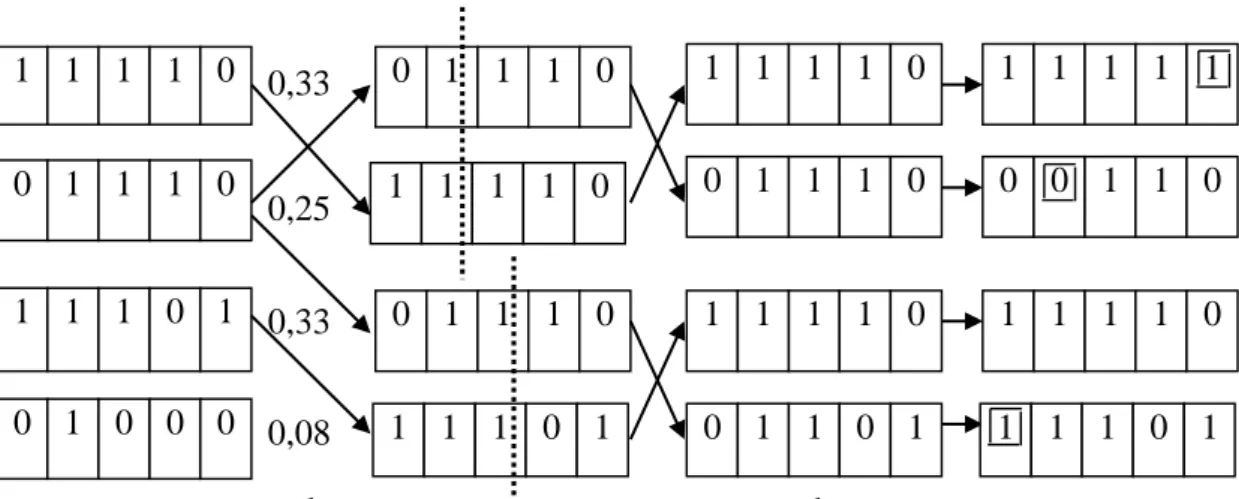
2. Crossover
Untuk setiap pasang induk, sebuah titik crossover akan dipilih secara random dari posisi dalam string. Pada gambar titik crossover terletak pada indeks ketiga dalam pasangan pertama dan setelah indeks kelima pada pasangan kedua.
3. Mutation
Pada mutation atau mutasi, tiap lokasi menjadi sasaran mutasi acak, dengan probabilitas independen yang kecil. Sebuah digit dimutasikan pada anak pertama, ketiga, dan keempat. Algoritma genetika mengkombinasikan suatu kecenderungan menaik dengan pengeksplorasian acak diantara urutan pencarian paralel. Keuntungan utamanya, bila ada datang dari operasi crossover. Namun, secara matematis dapat tunjukkan bahwa bila posisi dari kode genetik di permutasikan di awal dengan urutan acak, crossover tidak memberikan keunggulan. Secara intuisi, keuntungannya didapat dari kemampuan crossover untuk menggabungkan blok-blok huruf berukuran besar yang telah berevolusi secara independen untuk melakukan fungsi yang bermanfaat sehingga dapat menaikkan tingkat pencarian.
4. Schema
Teori dari algoritma genetika menjelaskan cara kerjanya menggunakan ide dari suatu schema, suatu substring di mana beberapa posisi tidak disebutkan. Dapat ditunjukkan bahwa, bila fitness rata-rata dari schema berada di bawah mean maka jumlah instansiasi dari schema di dalam populasi akan bertambah seiring bertambaahnya waktu. Jelas sekali bahwa efek ini tidak akan signifikan bila bit-bit yang bersebelahan sama sekali tidak berhubungan satu sama sekali, karena akan ada beberapa blok kontinyu yang memberikan keuntungan yang konsisten. Algoritma genetika paling efektif dipakai bila schema-schema berkorespondensi menjadi komponen berati dari sebuah solusi. Sebagai contoh, bila string adalah representasi dari sebuah antena, maka schema merepresentasikan komponen-komponen dari antena, seperti reflector dan
deflector. Sebuah komponen yang baik cenderung akan berkerja baik pada rancangan yang berbeda. Ini menunjukkan bahwa penggunaan algoritma genetika yang benar memerlukan rekayasa yang baik pada representasinya.
Gambar 2.2 Contoh Penggunaan Algoritma Genetika
2.5.3 Istilah dalam Algoritma Genetika
Terdapat beberapa definisi penting dalam Algoritma genetika yang perlu diperhatikan, yaitu:
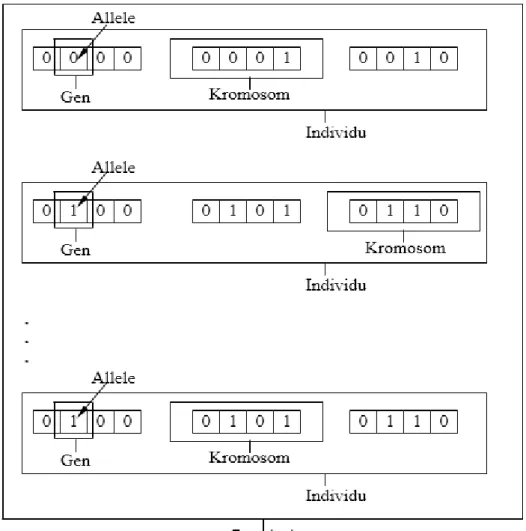
1. Genotype (Gen), sebuah nilai yang menyatakan satuan dasar yang membentuk suatu arti tertentu dalam satu kesatuan gen yang dinamakan kromosom. Dalam algoritma genetika, gen ini bisa berupa biner, float, interger maupun karakter, elemen permutasi atau kombinasi.
2. Allele, merupakan nilai dari gen
3. Individu atau kromosom, gabungan gen-gen yang membentuk nilai tertentu dan merupakan salah satu solusi yang mungkin dari permasalahan yang diangkat.
4. Populasi, merupakan sekumpulan individu yang akan diproses bersama dalam satu siklus proses evalusi.
5. Generasi, menyatakan satu siklus proses evolusi atau satu iterasi di dalam algoritma genetika. 1 1 1 1 0 0 1 1 1 0 1 1 1 0 1 0 1 0 0 0 0,33 0,25 0,33 0,08 1 1 1 1 0 0 1 1 1 0 0 1 1 1 0 1 1 1 0 1 1 1 1 1 0 0 1 1 1 0 1 1 1 1 0 0 1 1 0 1 1 1 1 1 1 0 0 1 1 0 1 1 1 1 0 1 1 1 0 1 a. Inisialisasi Populasi c. Seleksi b. Fungsi Fitness d. Crossover e. Mutasi
Gambar 2.3 Ilustrasi Istilah dalam Algoritma Genetika
2.6 Komponen-komponen Utama Algoritma Genetika
Menurut Suyanto (2005), terdapat beberapa komponen dalam algoritma genetika yaitu: 2.6.1 Teknik Pengkodeaan
Teknik pengkodean adalah bagaimana mengkodekan gen dari kromosom, gen merupakan bagian dari kromosom. Satu gen akan mewakili satu variabel. Agar dapat diproses melalui algoritma genetik, maka alternatif solusi tersebut harus dikodekan terlebih dahulu kedalam bentuk kromosom. Masing-masing kromosom berisi sejumlah gen yang mengodekan informasi yang disimpan didalam individu atau kromosom. Gen dapat direpresentasikan dalam bentuk: string bit, bilangan real, daftar aturan, gabungan dari beberapa kode, elemen permutasi, pohon (tree), elemen program atau representasi
lainnya yang dapat diimplementasikan untuk operator genetika. Kromosom dapat direpresentasikan dengan menggunakan:
a. String bit: 10011, 11101, dst b. Bilangan Real: 65.65, 562.88, dst c. Elemen Permutasi: E2, E10, dst d. Daftar Aturan: R1, R2, R3, dst
e. Elemen Program: pemrograman genetika f. Elemen Kombinasi dan Struktur lainnya.
2.6.2 Membangkitkan Populasi Awal dan Kromosom
Membangkitkan populasi awal adalah proses membangkitkan sejumlah individu atau kromosom secara acak atau melalui prosedur tertentu. Ukuran untuk populasi tergantung pada masalah yang akan diselesaikan dan jenis operator genetika yang akan diimplementasikan. Setelah ukuran populasi ditentukan, kemudian dilakukan pembangkitan populasi awal. Teknik dalam pembangkitan populasi awal pada penelitian ini menggunakan metode random search, pencarian solusi dimulai dari suatu titik uji tertentu secara acak titik uji tersebut dianggap sebagai alternatif solusi yang disebut sebagai populasi. Apabila ukuran populasi terlalu besar, maka waktu akan banyak terbuang karena berkaitan dengan besarnya jumlah data yang dibutuhkan dan waktu ke arah konvergensi akan lebih lama (Goldberg, 1989).
2.6.3 Seleksi
Seleksi digunakan untuk memilih individu-individu mana saja yang akan dipilih untuk proses crossover dan mutasi. Seleksi digunakan untuk mendapatkan calon individu yang baik. Semakin tinggi nilai fitness suatu individu semakin besar kemungkinannya untuk terpilih. Terdapat beberapa metode seleksi yaitu:
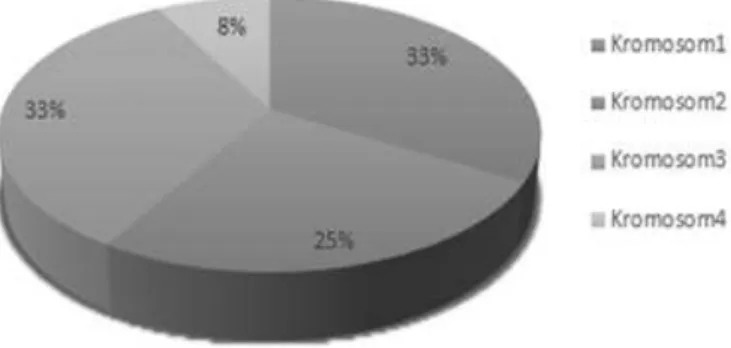
1. Roulette Wheel
Calon induk yang akan dipilih berdasarkan nilai fitness yang dimilikinya, semakin baik individu tersebut yang ditunjukkan dengan semakin besar nilai fitnessnya akan mendapatkan kemungkinan yang lebih besar untuk terpilih sebagai induk. Misalkan saja roulette wheel merupakan tempat untuk menampung seluruh kromosom dari tiap populasi, maka besarnya tempat dari roulette wheel tersebut menunjukkan seberapa besar nilai fitness yang dimiliki
oleh suatu kromosom, semakin besar nilai fitness tersebut, maka semakin besar pula tempat yang tersedia. Ilustrasinya dapat digambarkan sebagai berikut:
Gambar 2.4 Ilustrasi Seleksi dengan Roulette Wheel 2. Steady State
Metode ini tidak banyak digunakan dalam proses seleksi karena dilakukan dengan mempertahankan individu yang terbaik. Pada setiap generasi, akan dipilih beberapa kromosom dengan nilai fitnessnya yang terbaik sebagai induk, sedangkan kromosom-kromosom yang memiliki nilai fitness terburuk akan digantikan dengan offspring yang baru. Sehingga pada generasi selanjutnya akan terdapat beberapa populasi yang bertahan.
3. Tournament
Dalam metode seleksi tournament sejumlah N individu dipilih secara acak dan kemudian menentukan fitnessnya. Kebanyakan metode seleksi ini digunakan pada binary, dimana hanya dua individu yang dipilih.
4. Ranking
Seleksi ini memperbaiki proses seleksi yang sebelumnya yaitu roulette wheel karena pada seleksi tersebut kemungkinan salah satu kromosom mempunyai nilai fitness yang mendominasi hingga 90% bisa terjadi, sehingga nilai fitness yang lain akan mempunyai kemungkinan yang sangat kecil sekali untuk terpilih. Sehingga dalam seleksi ranking, dilakukan perumpamaan sesuai dengan nilai fitnessnya, nilai fitness terkecil diberi nilai 1, yang terkecil kedua diberi nilai 2, dan begitu seterusnya sampai yang terbagus diberi nilai N (jumlah kromosom dalam populasi). Nilai tersebut yang akan diambil sebagai presentasi tepat yang tersedia.
2.6.4 Crossover
Salah satu komponen yang paling penting dalam algoritma genetika adalah pindah silang atau crossover. Sebuah kromosom yang mengarah pada solusi yang baik dapat diperoleh dari proses memindah-silangkan dua buah kromosom. Pindah silang juga dapat berakibat buruk jika ukuran populasinya sangat kecil. Dalam suatu populasi yang sangat kecil, suatu kromosom dengan gen-gen yang mengarah pada solusi terbaik akan sangat cepat menyebar ke kromosom-kromosom lainnya. Untuk mengatasi masalah ini digunakan suatu aturan bahwa pindah silang hanya bisa dilakukan dengan suatu probabilitas tertentu, artinya pindah silang bisa dilakukan hanya jika suatu bilangan random yang dibangkitkan kurang dari probabilitas yang ditentukan tersebut. Pada umumnya probabilitas tersebut diset mendekati 1.
Ada beberapa cara yang bisa digunakan untuk melakukan crossover sesuai dengan encodingnya yang dijelaskan sebagai berikut:
1. Crossover satu titik
Memilih satu titik tertentu, selanjutnya nilai biner sampai titik crossovernya dari induk pertama digunakan dan sisanya dilanjutkan dengan nilai biner dari induk kedua.
Contoh: 11001011 11011111
2. Crossover Dua Titik
Memilih dua titik tertentu, lalu nilai biner sampai titik crossover pertama pada induk pertama digunakan, dilanjutkan dengan nilai biner dari titik pertama sampai titik kedua dari induk kedua, kemudian sisanya melanjutkan nilai biner dari titik kedua pada induk pertama lagi.
Contoh: 11001011 11011111
3. Uniform Crossover
Nilai biner yang digunakan dipilih secara random dari kedua induk. Contoh:
11001111 (child-1) 11011011 (child-2)
11011011 (child-1) 11001111 (child-2)
11001011 + 11011101 = 11011111 4. Crossover Aritmatik
Crossover aritmatik digunakan untuk representasi kromosom berupa bilangan float (pecahan). Crossover ini dilakukan dengan menentukan nilai r sebagai bilangan random lebih dari 0 dan kurang dari 1. Selain itu juga ditentukan posisi dari gen yang dilakukan crossover menggunakan bilangan random. Suatu operasi aritmetika digunakan untuk menghasilkan offspring yang baru. Contoh:
11001011 + 11011111 = 11001001 (AND) 5. Crossover Permutasi
Memilih satu titik tertentu, nilai permutasi sampai titik crossover pada induk pertama digunakan lalu sisanya dilakukan scan terlebih dahulu, jika nilai permutasi pada induk kedua belum ada pada offspring nilai tersebut ditambahkan.
Contoh :
(123456789) + (453689721) = 12345689
2.6.5 Mutasi
Mutasi merupakan proses mengubah nilai dari satu atau beberapa gen dalam suatu kromosom. Mutasi ini berperan untuk menggantikan gen yang hilang dari populasi akibat seleksi yang memungkinkan munculnya kembali gen yang tidak muncul pada inisialisasi populasi. Metode mutasi yang digunakan adalah mutasi dalam pengkodean nilai. Proses mutasi dalam pengkodean nilai dapat dilakukan dengan berbagai cara berdasarkan encodingnya terdapat beberapa macam, diantaranya adalah sebagai berikut :
1. Binary Encoding
Melakukan inversi pada bit yang terpilih, 0 menjadi 1 dan sebaliknya, 1 menjadi 0.
Contoh : 11001001 10001001 2. Permutation Encoding
Memilih dua nilai dari gen dan menukarnya. Contoh : (1 2 3 4 5 8 9 7) (1 8 3 4 5 6 2 9 7)
Ada beberapa operator mutasi untuk representasi permutasi, seperti metode inversion, insertion, displacement, dan reciprocal exchange mutation.
a. Inversion Mutation
Inversion mutation memilih dua posisi dalam sebuah kromosom dengan cara acak dan kemudian menginversikan substring di antara dua posisi tersebut.
b. Insertion Mutation
Insertion Mutation memilih sebuah gen dengan cara acak dan memasukkan ke dalam kromosom dengan cara acak pula.
c. Displacement Mutation
Displacement Mutation memilih sebuah sub/sekelompok gen dengan cara acak kemudian memasukkan ke dalam kromosom dengan cara acak. d. Reciprocal Exchange Mutation (REM)
Reciprocal Exchange Mutation memilih dua posisi secara acak, kemudian menukar dua gen dalam posisi tersebut.
3. Value Encoding
Menentukan sebuah nilai kecil yang akan ditambahkan atau dikurangkan pada salah satu gen dalam kromosom.
Contoh : (1.29 5.68 2.86 4.11 5.55) (1.29 5.68 2.73 4.22 5.55) 4. Tree Encoding
Node yang terpilih akan diubah. Karena proses mutasi juga merupakan salah satu operator dasar dalam algoritma genetika, sehingga sama dengan crossover, mutasi juga memerlukan probabilitas dengan proses yang sama seperti pada probabilitas crossover. Individu dengan nilai probabilitas yang lebih kecil dari probabilitas yang telah ditentukan yang akan melewati proses mutasi. Nilai probabilitas mutasi ini menunjukkan seberapa sering gen tertentu dari kromosom yang telah diproses dengan crossover akan melewati mutasi. Jika tidak ada proses mutasi, maka offspring yang dihasilkan akan sama dengan hasil individu setelah proses crossover, tanpa ada perubahan sedikitpun. Proses mutasi ini biasanya dilakukan untuk mencegah terjadinya lokal optimum, proses mutasi ini sebaiknya tidak terlalu sering dilakukan karena proses algoritma genetika akan cepat berubah menjadi random search. Pada probabilitas mutasi, jika terlalu rendah akan mengakibatkan banyak gen
yang berguna tidak sempat untuk dimanfaatkan dan jika terlalu besar akan menyebabkan offspring kehilangan sifat dari induknya dan tidak akan dapat memanfaatkan lagi proses evolusi alamiah.
2.6.6 Elitisme
Karena seleksi dilakukan secara acak (random), maka tidak ada jaminan bahwa suatu individu bernilai fitness tertinggi akan selalu terpilih. Kalaupun individu bernilai fitness tertinggi terpilih, mungkin saja individu tersebut akan rusak (nilai fitnessnya menurun) karena proses pindah silang. Untuk menjaga agar individu bernilai fitness tertinggi tersebut tidak hilang selama evolusi, maka perlu dibuat satu atau beberapa salinannya. Prosedur ini dikenal sebagai Elitisme.
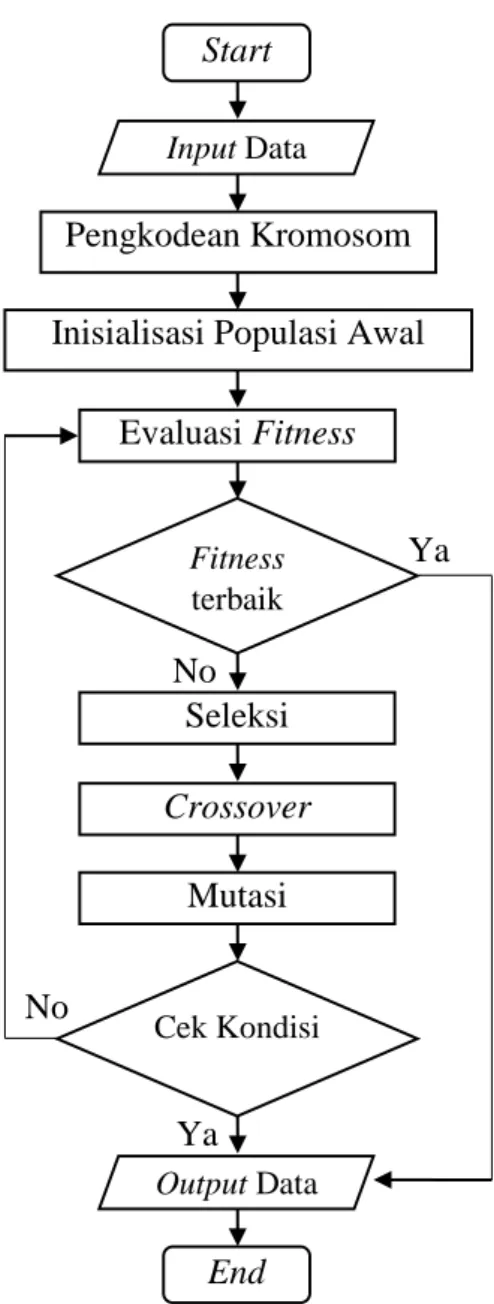
Gambar 2.5 Flowchart Algoritma Genetika Start Input Data Pengkodean Kromosom Evaluasi Fitness Seleksi Cek Kondisi
Inisialisasi Populasi Awal
Fitness terbaik No Ya Crossover Mutasi Output Data No Ya End
2.7 Penjadwalan
Penjadwalan memegang peran yang sangat penting di industri manufaktur maupun industry jasa (Pinedo, 2012). Permasalahan penjadwalan merupakan permasalahan kombinatorial yang rumit karena memiliki daerah alternative solusi yang luas dan banyak dijumpai lokal optimal (Yu, 2006). Permasalahan tersebut menjadi salah satu permasalahan kombinatorial yang mendapatkan banyak perhatian dari para peneliti (Amirthagadeswaran & Arunachalam, 2006). Beberapa diantaranya membuktikan bahwa permasalahan tersebut bertipe NP-hard (non deterministic polynomial-time hard) atau tipe permasalahan yang sulit untuk diselesaikan untuk ukuran yang besar (Xia & Wu, 2006). Dalam kasus penjadwalan perkuliahan, diperlukan algoritma yang lebih baik yaitu algoritma yang dapat menyelesaikan masalah kriteria dan multi-objektif. Salah satu algoritma yang dapat digunakan adalah algoritma genetika (Hanita, 2011).
Penjadwalan didefinisikan oleh Chu & Fang (1999) sebagai perencanaan berbasis waktu dan combinational optimization yang diselesaikan dengan kerjasama antara pencarian dan heuristik, yang biasanya mengarah pada solusi yang memuaskan tetapi suboptimal. Terdapat banyak jenis problem penjadwalan dalam kehidupan sehari-hari, seperti ujian, perkuliahan, pelajaran jadwal transportasi, dan lain-lain. selanjutnya dikatakan oleh Chu bahwa masalah penjadwalan yang paling umum adalah University Course Timetabling Problem (UCTP) dan Exam Timetabling Problem (ETP). Dengan demikian penjadwalan merupakan pengalokasian satu set event (kegiatan) ke dalam sejumlah ruangan dan timeslot dimana sejumlah batasan (constraints) harus dipenuhi. Banyak jenis masalah penjadwalan yang ada dalam kehidupan sehari-hari, contohnya adalah penjadwalan matakuliah, ujian, transportasi, mesin pabrik, dan lain-lain.
Tabel 2.1 Contoh Jadwal Perkuliahan HARI/
PUKUL
Ruang A Ruang B Ruang C Ruang D
SENIN 09.00 – 11.45 13.00 – 15.45 16.00 – 17.50 MK1 MK2 MK24 - - MK25 MK4 MK6 - MK8 - SELASA 09.00 – 11.45 13.00 – 15.45 16.00 – 17.50 MK5 - MK26 - MK3 MK27 - - - - - -
RABU 09.00 – 11.45 13.00 – 15.45 16.00 – 17.50 - - - MK7 MK10 - MK11 - MK28 - - MK29 KAMIS 09.00 – 11.45 13.00 – 15.45 16.00 – 17.50 MK12 - - MK13 - - - - MK30 MK14 MK16 MK31 JUMAT 09.00 – 11.45 13.00 – 15.45 16.00 – 17.50 - - MK32 MK15 - MK33 MK17 - - - MK18 MK34 SABTU 09.00 – 11.45 13.00 – 15.45 16.00 – 17.50 - MK19 - - MK20 MK36 MK22 MK21 - MK23 - -
Penjadwalan perkuliahan menjadi salah satu masalah kompleks yang selalu dihadapi oleh setiap kampus. Penjadwalan perkuliahan merupakan penyusunan dan pengaturan jadwal perkuliahan pada slot waktu yang tersedia selama satu minggu beserta pembagian ruang kelasnya seperti ditunjukkan pada Tabel 2.1. Penjadwalan tersebut harus memperhatikan beberapa hal seperti kapasitas ruang, dosen, mahasiswa, dan waktu setiap perkuliahan. Masalah penjadwalan meliputi optimasi beberapa kriteria termasuk batasan-batasan seperti kebijakan program studi/kurikulum, pemilihan ruang kelas yang sesuai, dan ketersediaan dosen pengajar (Oner, et al. 2011). Dalam penjadwalan perkuliahan, terdapat dua kategori batasan yaitu batasan yang bersifat harus atau disebut batasan mutlak (hard constraint) dan batasan yang bersifat prioritas atau disebut batasan lunak (soft constraint) (Oner, et al. 2011). Batasan yang bersifat mutlak (hard constraint) yang wajib dipenuhi, yaitu:
1. Seorang dosen tidak dapat mengajar lebih dari satu perkuliahan dalam waktu yang sama
2. Sekelompok mahasiswa (dengan tingkatan/semester yang sama) tidak dapat dijadwalkan mengikuti pelajaran lebih dari satu dalam waktu yang sama 3. Hanya satu perkuliahan yang dapat diselenggarakan di suatu ruang kelas pada
slot waktu yang ada.
4. Jumlah alokasi slot waktu setiap perkuliahan harus sesuai dengan beban jam pelajaran perkuliahan tersebut.
5. Kapasistas ruang belajar harus mampu menampung sejumlah mahasiswa yang akan mengambil suatu perkuliahan.
6. Beberapa perkuliahan harus dijadwalkan pada ruang kelas tertentu seperti laboratorium komputer
Sedangkan batasan lunak (soft constraint) yang bersifat “prioritas” merupakan batasan yang boleh dilanggar jika perlu, yaitu:
1. Prioritas dosen pengajar perkuliahan dan prioritas mahasiswa seharusnya dipertimbangkan, prioritas ini dapat dinyatakan dengan bilangan numerik yang merupakan tingkat ketidakpuasan mahasiswa atau dosen.
2. Perkuliahan dengan beban 4 JP/Sks dapat dilaksanakan dalam satu sesi atau dalam dua sesi masing-masing 2 JP/Sks, tergantung prioritas dosen.
3. Dosen sebaiknya memiliki hari libur mengajar.
Jamnezhad et al. (2011) menambahkan batasan lunak sebagai berikut :
1. Waktu jeda antar perkuliahan dalam satu hari bagi mahasiswa seharusnya diminimalkan.
2. Ruang kelas untuk mahasiswa semester yang sama sebaiknya menggunakan ruang yang sama.
Berbagai tujuan penyusunan jadwal perkuliahan seperti dihasilkannya jadwal yang efisien, jumlah kelas yang berurutan sedikit dari seorang dosen, dan sebagainya menyebabkan persoalan penjadwalan perkuliahan sebagai persoalan optimasi multi-objektif (Aldasht, et al. 2005). Dalam penjadwalan kuliah, akan dibahas tentang pembagian jadwal untuk tiap mahasiswa pada kuliah tertentu sekaligus dosen pengajarnya, kemudian dalam penjadwalan perkuliahan akan dibahas tentang pembagian jadwal kuliah untuk tiap-tiap kelas beserta dosen pengajar, dalam penjadwalan ujian akan dibahas pengaturan dosen yang menjaga ujian dan mahasiswa atau murid yang menempati ruang ujian, sedangkan pada penjadwalan karyawan, dilakukan pengaturan karyawan yang akan bekerja pada waktu tertentu di bagian tertentu. Proses tersebut tentu saja dibuat berdasarkan permasalahan yang ada (Ariani, et al. 2011). Oleh karena itu penjadwalan merupakan proses untuk menyusun suatu jadwal atau urutan proses yang diperlukan dalam sebuah persoalan. Persoalan penjadwalan biasanya berhubungan dengan penjadwalan kelas dalam kampus/sekolah dan juga dalam lingkup yang tidak jauh berbeda seperti penjadwalan mata kuliah/mata
pelajaran, penjadwalan ujian, atau bisa juga penjadwalan karyawan, baik dalam suatu perusahaan, rumah sakit, dan sebagainya.
2.8 Penelitian yang terkait
Ada beberapa penelitian yang terkait dengan penelitian yang penulis buat, yaitu:
Tahun Penulis Penjelasan Penelitian
2010 Bai, Qinghai PSO adalah sebuah metode heuristic baru yang berdasarkan pada swarm intelligence, dibandingkan dengan algoritma lain, metodenya sangat sederhana, mudah diselesaikan, dan memerlukan lebih sedikit parameter,
yang membutuhkan banyak
pengembangan. Bagaimanapun penelitian PSO masih permulaan dan masih banyak permasalahan yang bisa
dipecahkan dan
memadukan/mencampurkan keuntungan algoritma PSO dengan algoritma optimasi cerdas lainnya akan menghasilkan algoritma cerdas campuran yang mempunyai nilai optimasi yang lebih praktis.
2010 Isabella L.S & Herry C.P Membandingkan algoritma PSO, Simulated Annealing (SA) dan Genetic Algorithm (GA) untuk memecahkan permasalah tata letak fasilitas pada perusahaan. Berdasarkan hasil percobaan untuk setiap kasus, momen terkecil selalu dicapai oleh GA-SA II, diikuti oleh PSO dan GA-SA I. Setelah dilakukan pengujian yang sama dengan studi kasus sebelumnya, didapatkan bahwa nilai momen yang dihasilkan ketiga algoritma berbeda secara signifikan. Kemudian mengusulkan penggunaan algoritma kombinasi antara algoritma genetika dan simulated annealing dalam permasalahan tata letak fasilitas yang berbeda bentuk. 2010 Rahayuningsih, D.A Menggunakan algoritma genetika dalam
penjadwalan dosen akan lebih efektif dari pada menggunakan cara manual karena dapat mencapai optimisasi, algoritma genetika lebih mudah digunakan jika digabungkan dengan cara manual,
parameter dapat di atur sesuai dengan kebutuhan.
2012 Raisha, A.R. et al. Algoritma Particle Swarm Optimization (PSO) sebagai algoritma untuk penyelesaian masalah optimasi dengan proses pembangkitan posisi dan velocity awal, update velocity dan update posisi sebagai 3 tahapan utamanya sehingga didapatkan solusi berupa jadwal kuliah. 2013 Simamora, P. Menggunakan algoritma genetika untuk
penjadwalan kuliah studi kasus Fakultas Teknik USU, metode tanpa algoritma penjadwalan tidak bisa mengatasi pelanggaran waktu yang terjadi sedangkan metode dengan algoritma penjadwalan pelanggaran waktu dapat dihindari hingga 0 (nol) bahkan tidak terjadi pelanggaran. Metode dengan algoritma penjadwalan lebih cepat dibandingkan metode tanpa menggunakan algoritma penjadwalan