ANALISIS PERBANDINGAN ALGORITMA
DISTANCE-WEIGHTED KNN DAN ALGORITMA KNN PADA
PREDIKSI MASA STUDI MAHASISWA
Wenie Hardianti1, Fatma Indriani2, Radityo Adi Nugroho3123Prodi Ilmu Komputer FMIPA Universitas Lambung Mangkurat
Jl. A. Yani Km 36 Banjarbaru, Kalimantan Selatan Email: weniehardianti@gmail.com
Abstract
The amount of data owned by a college will increase every year. Prediction of student study period can be extracted using the data using KNN Algorithm and Distance-Weighted KNN Algorithm. The KNN algorithm is done by searching the k group of objects in the closest training data (similar) to objects in new data or data testing. Distance-Weighted KNN is an algorithm that serves to assign different weights to the nearest neighbor by distance, and the nearest neighbor has a greater weight. There are things that affect the performance of DWKNN algorithm is the selection of k values, therefore we need to know the value of k and its accuracy. Confusion matrix is used to determine the accuracy of both algorithms. Both algorithms can produce an accuracy of 83.3%, but in stability the accuracy of DWKNN algorithm is better than KNN algorithm. The k-optimal values generated by the DWKNN algorithm for student study duration are 1, 3, and 9.
Keywords: K-Nearest Neighbor, Distance-Weighted KNN, Data Mining, Confusion Matrix,
Student Study Period.
Abstrak
Jumlah data yang dimiliki oleh sebuah perguruan tinggi akan mengalami peningkatan setiap tahunnya. Prediksi masa studi mahasiswa dapat digali menggunakan data tersebut menggunakan Algoritma KNN dan Algoritma Distance-Weighted KNN. Algoritma KNN dilakukan dengan mencari kelompok k objek dalam data training yang paling dekat (mirip) dengan objek pada data baru atau data testing. Distance-Weighted KNN merupakan algoritma yang berfungsi untuk memberi bobot yang berbeda ke tetangga terdekat sesuai jaraknya, dan tetangga terdekat memiliki bobot yang lebih besar. Ada hal yang mempengaruhi kinerja algoritma DWKNN yaitu pemilihan nilai k, oleh karena itu perlu diketahui nilai k dan tingkat akurasinya. Confusion matrix digunakan untuk mengetahui tingkat akurasi pada kedua algoritma. Kedua algoritma sama-sama dapat menghasilkan akurasi sebesar 83.3%, namun dalam kestabilan akurasi algoritma DWKNN lebih baik daripada algoritma KNN. Nilai k-optimal yang dihasilkan algoritma DWKNN untuk prediksi masa studi mahasiswa adalah 1, 3, dan 9.
Kata kunci: K-Nearest Neighbor, Distance-Weighted KNN, Data Mining, Confusion Matrix,
Masa Studi Mahasiswa. 1. PENDAHULUAN
Jumlah data yang dimiliki oleh sebuah perguruan tinggi akan mengalami peningkatan setiap tahunnya. Namun, terkadang data tersebut dibiarkan begitu saja tanpa ada proses
lebih lanjut. Padahal, jika diolah dan digali menggunakan data mining maka akan menghasilkan sebuah informasi dan pengetahuan yang dapat digunakan oleh pihak akademik untuk masa depan.
Salah satu fungsi data mining yaitu klasifikasi. Klasifikasi merupakan proses pengklasifikasian sebuah himpunan obyek/data ke dalam kelas tertentu berdasarkan atribut-atributnya. Dalam klasifikasi, terdapat target kategori. Sebagai contoh penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan tinggi, pendapatan sedang dan pendapat rendah [12].
Algoritma KNN adalah merupakan salah satu algoritma yang digunakan untuk klasifikasi, selain itu juga dapat digunakan untuk estimasi dan prediksi [12]
Algoritma K-Nearest Neighbor (KNN) termasuk kelompok instance-base learning. KNN dilakukan dengan mencari kelompok k objek dalam data training yang paling dekat (mirip) dengan objek pada data baru atau data testing [8]
Algoritma Distance-weighted KNN adalah pengembangan algoritma berdasarkan algoritma KNN. Awal dikembangkannya
Distance-Weighted KNN dilakukan oleh Dudani
(1976) dalam jurnal penelitiannya yang berjudul Distance-Weighted K-NN rule.
Distance-Weighted K-NN merupakan
algoritma yang berfungsi untuk memberi bobot yang berbeda ke tetangga terdekat sesuai jaraknya, dan tetangga terdekat memiliki bobot yang lebih besar.
Distance-Weighted K-NN dirancang untuk mengurangi
pengaruh sensitivitas pemilihan ukuran nilai k dan menghasilkan kinerja yang baik dalam proses klasifikasi [7].
Ada hal yang mempengaruhi kinerja algoritma KNN yaitu pemilihan nilai K. jika nilai k terlalu kecil, maka hasil klasifikasi akan berpengaruh noise yang dapat mengurangi tingkat akurasi. Di sisi lain, jika nilai k terlalu besar, maka hasil klasifikasi akan mengurangi efek noise, namun membuat batasan setiap klasifikasi menjadi lebih kabur serta mempengaruhi tingkat akurasi juga [19]. Penentuan nilai k terbaik tergantung pada data yang dipilih.
Maka perlu adanya penelitian tentang analisis perbandingan algoritma KNN dan
Distance-weighted KNN pada prediksi masa
studi mahasiswa. Berdasarkan atribut nilai IP semester satu dan semester dua, akreditasi sekolah, nilai UN, dan jalur masuk ke perguruan tinggi Unlam. Data yang digunakan merupakan data akademik, data alumni, dan biodata mahasiswa Prodi Ilmu Komputer angkatan 2008-2012. Selanjutnya akan diklasifikasi yang menghasilkan prediksi
“tepat” atau “terlambat”. Jika mahasiswa tersebut menjalani masa studi <=5 tahun maka hasil klasifikasi adalah “tepat”, dan jika mahasiswa tersebut menjalani masa studi >5 tahun maka hasil klasifikasi adalah “terlambat”.
2. METODOLOGI PENELITIAN 2.1. Tahapan Penelitian
Pada penelitian ini terdapat tahap
Knowledge Discovery in Database sebagai
berikut:
a) Pengumpulan Data
Data akademik mahasiswa dan data alumni mahasiwa Program Studi Ilmu Komputer Fmipa Unlam angkatan 2008-2012 yang di peroleh dari bidang akademik FMIPA UNLAM Banjarbaru dan database SIMARI ULM.
b) Pencarian Literatur
Pencarian literatur merupakan suatu metode pengumpulan data yang diperoleh dari buku-buku literatur maupun referensi tentang masa studi mahasiswa, algoritma distance-weighted k-nn, dan klasifikasi. Selain buku, karya-karya ilmiah maupun jurnal, artikel juga dijadikan referensi dalam penelitian ini.
c) Data selection
Tahap ini adalah tahap menyeleksi data dari database yang akan digunakan dalam penelitian. Data yang digunakan dalam penelitian ini berasal dari database Sistem Informasi Akademik di Program studi Ilmu Komputer FMIPA UNLAM Banjarbaru yang sudah ada dan terbentuk. Atribut yang digunakan pada database SIA yaitu Nama, NIM, IP semester satu dan dua, jalur masuk UNLAM, lama masa studi. Serta untuk untuk menambah data yang kurang lengkap di database SIA seperti atribut nilai UN yang diperoleh dari bidang kemahasiswa FMIPA UNLAM Banjarbaru dan nilai akreditasi sekolah yang diperoleh dari BAN SMA/MA Kalsel.Penelitian ini berkaitan dengan IP semester mahasiswa mulai dari satu sampai dengan semester 2, nilai akreditasi sekolah, nilai UN, dan jalur masuk PN. d) Data integration
Data integration merupakan tahapan untuk menggabungkan antar data yang terkait menjadi satu kesatuan. Di dalam database SIA tidak tersedia data mahasiswa angkatan tahun 2008, dan nilai akreditasi sekolah sedangkan nilai UN kurang lengkap, sehingga di buatlah tabel
baru yang nanti akan di gabung menjadi satu kesatuan menggunakan queri.
e) Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses
cleaning pada data yang menjadi fokus Knowledge Discovery in Database (KDD).
Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak atau terdapat nilai yang kosong. Untuk proses pada data yang kosong, maka dilakukan teknik missing value menggunakan SPSS yaitu operator Series
Mean.
Missing value adalah informasi yang tidak tersedia untuk sebuah objek(kasus). Hal tersebut terjadi karena informasi untuk sesuatu tentang objek tidak diberikan, sulit dicari, atau memang informasi terebut tidak ada [17].
Missing value pada dasarnya tidak bermasalah bagi keseluruhan data, apalagi jika jumlahnya hanya sedikit, misal hanya 1 % dari seluruh data. Namun jika persentase data yang hilang tersebut cukup besar, maka perlu dilakukan pengujian apakah data yang mengandung banyak missing tersebut masih layak diproses lebih lanjut ataukah tidak [17]
f) Transformation
Pada tahap ini berguna untuk mempresentasikan data yang sesuai dengan tujuan yang ingin dicapai. Tahap ini adalah proses transformasi data yang telah dipilih, menjadi data yang diolah sehingga menghasilkan pola sesuai dengan proses data mining. Salah satunya mengubah data kategorik menjadi data numerik menggunakan metode binari. g) Data mining
Proses untuk mengklasifikasi data yang telah ditetapkan dengan menggunakan rumus algoritma KNN dan
Distance Weighted K-NN (DWKNN).
Sehingga dapat menghasilkan prediksi masa studi mahasiswa dan nilai k-optimal. h) Presentasi pengetahuan
Pengetahuan yang didapat akan di analisis dan dijelaskan yaitu seperti nilai akurasi yang dihasilkan untuk meprediksi masa studi mahasiswa, dan nilai k-optimal. Pada tahap presentasi pengetahuan, pengukuran tingkat akurasi menggunakan confusion matrix. Omary, 2010 mendefinikasi akurasi sebagai bagian dari
jumlah prediksi yang benar terhadap jumlah prediksi. Jumlah prediksi dalam klasifikasi didasarkan pada jumlah pengujian dengan hasil klasifikasi secara benar atau salah yang telah diprediksi oleh model klasifikasi. Hasil prediksi dituliskan ke dalam confusion matrix dimana nilai kelas sebenarnya disajikan dalam baris, sedangkan kelas hasil prediksi disajikan dalam kolom tabel [6] . Berikut ini tabel dari confusion matrix:
confusion matrix predicted class actual class class= yes class= no class= yes a b class= no c d
Tabel 1. Confusion matrix Keterangan:
a =TP (true positive) b= FN (false negative) c= FP(false positive) d= TN (true negative)
True Positives menunjukkan jumlah kelas positif yang tepat diprediksi sebagai kelas positif oleh model. True Negatives menunjukkan jumlah kelas negatif yang tepat diprediksi sebagai kelas negatif oleh model. False Positives menunjukkan jumlah kelas negatif yang keliru diprediksi sebagai kelas positif oleh model. False Negatives menunjukkan jumlah kelas positif yang keliru diprediksi sebagai kelas negatif oleh model [14]
2.2. Bahan Penelitian
Bahan yang diperlukan adalah data yang mendukung dalam penelitian ini. Penelitian ini menggunakan database simari Universitas Lambung Mangkurat. Data yang digunakan adalah IP mahasiswa Ilmu Komputer FMIPA Unlam angkatan 2008-2012, asal sekolah, nilai UN, jalur masuk, masa studi dan nilai akreditasi sekolah.
3. HASIL DAN PEMBAHASAN 3.1. Pengumpulan Data
Data yang dikumpulkan berupa
database sistem informasi akademik
mahasiswa yang diperoleh dari UPT PPTIK UNLAM Banjarbaru. Serta data nilai akreditasi sekolah dari BAN-SMA/MA Kalsel.
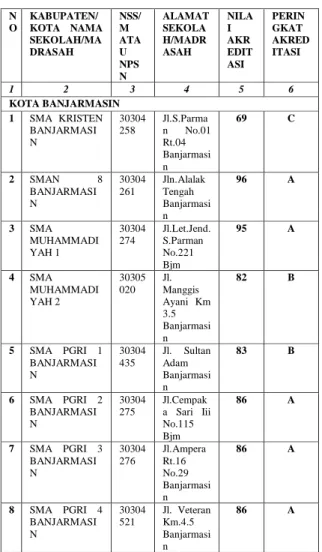
Gambar 1. Sampel tabel pada batabase Simari. Tabel 2. Sampel data akreditasi sekolah
N O KABUPATEN/ KOTA NAMA SEKOLAH/MA DRASAH NSS/ M ATA U NPS N ALAMAT SEKOLA H/MADR ASAH NILA I AKR EDIT ASI PERIN GKAT AKRED ITASI 1 2 3 4 5 6 KOTA BANJARMASIN 1 SMA KRISTEN BANJARMASI N 30304 258 Jl.S.Parma n No.01 Rt.04 Banjarmasi n 69 C 2 SMAN 8 BANJARMASI N 30304 261 Jln.Alalak Tengah Banjarmasi n 96 A 3 SMA MUHAMMADI YAH 1 30304 274 Jl.Let.Jend. S.Parman No.221 Bjm 95 A 4 SMA MUHAMMADI YAH 2 30305 020 Jl. Manggis Ayani Km 3.5 Banjarmasi n 82 B 5 SMA PGRI 1 BANJARMASI N 30304 435 Jl. Sultan Adam Banjarmasi n 83 B 6 SMA PGRI 2 BANJARMASI N 30304 275 Jl.Cempak a Sari Iii No.115 Bjm 86 A 7 SMA PGRI 3 BANJARMASI N 30304 276 Jl.Ampera Rt.16 No.29 Banjarmasi n 86 A 8 SMA PGRI 4 BANJARMASI N 30304 521 Jl. Veteran Km.4.5 Banjarmasi n 86 A 3.2. Pencarian Literatur
Pencarian literatur merupakan suatu metode pengumpulan data yang diperoleh dari buku-buku literatur maupun referensi tentang masa studi mahasiswa, algoritma k-nn, algoritma distance-weighted k-nn, dan klasifikasi. Selain buku, karya-karya ilmiah maupun jurnal, artikel juga dijadikan referensi dalam penelitian ini.
3.3. Data Selections
Pada tahap data selections yaitu melakukan persiapan terhadap data yang telah dipilih untuk diolah menjadi data penelitian. Hal ini dilakukan karena tidak semua data dan atribut didalamnya akan digunakan, sehingga hanya data yang berhubungan dengan kepentingan penelitian yang akan digunakan. Data yang digunakan dalam penelitian ini berasal dari database Sistem Informasi Akademik di Program studi Ilmu Komputer FMIPA UNLAM Banjarbaru yang sudah ada dan terbentuk. Atribut yang digunakan pada database SIA yaitu Nama, NIM, IP semester satu dan dua, jalur masuk UNLAM, lama masa studi. Serta untuk untuk menambah data yang kurang lengkap di database SIA seperti atribut nilai UN yang diperoleh dari bidang kemahasiswa FMIPA UNLAM Banjarbaru dan nilai akreditasi sekolah yang diperoleh dari BAN SMA/MA Kalsel.
a. Database SIMARI Program Studi Ilmu Komputer FMIPA UNLAM Banjarbaru Pada database ini peneliti menggunakan beberapa tabel yang berhubungan dengan penelitian saja. Tabel-tabel tersebut terdiri dari: tabel sia_m_mahasiswa, tabel sia_m_matakuliah_kurikulum, tabel sia_m_kurikulum, tabel sia_m_prodi, tabel sia_t_kelas, tabel sia_t_krs, tabel sia_t_krs_detail, tabel sia_t_semester, tabel sia_t_keluar.
b. Data mahasiswa Program Studi Ilmu Komputer FMIPA UNLAM Banjarbaru tahun 2008 sampai 2012 untuk mengambil nilai UN.
c. Data akreditasi tahun 2008 sampai dengan 2012 untuk mengambil atribut nilai akreditasi sekolah.
3.3. Data Integration
Data yang telah dipilih dalam data selection tersebuat akan dilanjutkan ke tahap data integration. Data integration merupakan tahapan untuk menggabungkan antar data yang terkait menjadi satu kesatuan. Di dalam database SIA tidak tersedia data mahasiswa
angkatan tahun 2008, dan nilai akreditasi sekolah sedangkan nilai UN kurang lengkap, sehingga di buatlah tabel baru yang nanti akan di gabung menjadi satu kesatuan menggunakan query.
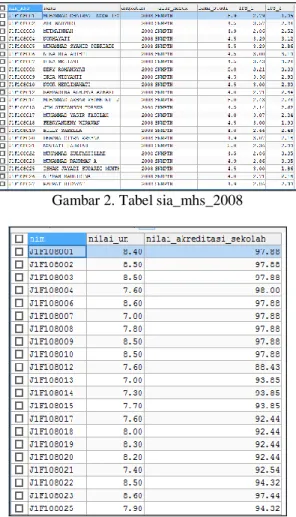
Gambar 2. Tabel sia_mhs_2008
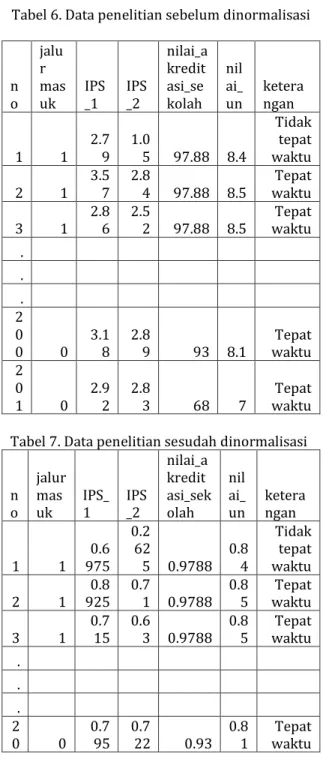
Gambar 3. Tabel sia_nila_un_akreditasi 3.4. Cleaning
Setelah melakukan tahap penggabungan data menjadi satu kesatuan maka akan diproses pada tahap cleaning. Tahap cleaning merupakan tahapan untuk menghapus data yang noise, membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak atau terdapat nilai yang kosong. Untuk proses mengisi nilai yang kosong, maka dilakukan teknis missing value menggunakan aplikasi statistika SPSS yaitu operator series Mean.
Untuk atribut nilai UN, nilai akreditasi sekolah terdapat nilai yang masih kosong. Sehingga untuk mengisi nilai kosong tersebut digunakanlah operator series mean pada SPSS.
Tabel 3. Missing value
ATRIBUT MISSING VALUE DALAM PERSEN
NILAI AKREDITASI 70 35%
NILAI UN 85 43%
Setelah melakukan pengisian nilai maka untuk mengisi atribut nilai UN yaitu 8.52 sedangkan untuk nilai akreditasi sekolah yaitu bervariasi. Seperti tabel dibawah ini:
Tabel 4. Hasil perhitungan untuk mengisi Nilai UN menggunakan Mean
Tabel 5. Hasil perhitungan untuk mengisi Nilai Akreditasi Sekolah menggunakan Mean
92.44 92.44 92.44 #NULL! 370.8934 93.315 89.09 89.09 89.09 #NULL! 370.8934 94.3225 #NULL! 370.8934 94.3225 97.88 97.88 97.88 97.88 97.88 97.88 97.88 97.88 97.88 #NULL! 370.8934 97.44 #NULL! 370.8934 97.44 96 96 96 #NULL! 370.8934 97.44 3.5. Transformasi
Pada tahap ini berguna untuk mempresentasikan data yang sesuai dengan tujuan yang ingin dicapai. Tahap ini adalah proses transformasi data yang telah dipilih, menjadi data yang diolah sehingga menghasilkan pola sesuai dengan proses data mining. Pada penelitian ini terdapat dua tahap transformasi, yang pertama ada transformasi atribut jalur masuk menjadi binner yaitu nol dan satu, transformasi kedua adalah
6.7 6.7 8.3 8.3 #NULL! 8.515937 #NULL! 8.515937 7.9 7.9 7.7 7.7 #NULL! 8.515937 #NULL! 8.515937 #NULL! 8.515937
mengubah atribut lama studi menjadi dua kategori yaitu tepat waktu dan tidak tepat waktu.
3.6. Data Mining
Pada penelitian “Analisis Perbandingan Algoritma Distance-Weighted KNN Dan Algoritma KNN Pada Prediksi Masa Studi Mahasiswa” ini dilakukan dua kali tahapatan proses algoritma, yakni algoritma Distance-Weighted KNN dan algoritma KNN. Data yang akan diproses berjumlah 201 data yang terdiri dari data alumni lulus tepat waktu sebanyak 163 data dan data alumni lulus tidak tepat waktu sebanyak 38 data. Untuk proses data training menggunakan data sebanyak 201 dan untuk data testing menggunakan 30 data yang diambil secara acak pada keseluruhan data.
a. K-Nearest Neighbor (KNN)
Algoritma KNN adalah merupakan salah satu algoritma yang digunakan untuk klasifikasi, selain itu juga dapat digunakan untuk estimasi dan prediksi [12]. Algoritma K-Nearest Neighbor (KNN) termasuk kelompok instance-base learning. KNN dilakukan dengan mencari kelompok k objek dalam data training yang paling dekat (mirip) dengan objek pada data baru atau data testing [2]). Sehingga klasifikasi untuk record baru yang tidak diklasifikasi didapatkan dengan membandingkannya dengan record yang paling mirip dengan training set [12] .Teknik K-Nearest Neighbor melakukan langkah-langkah yaitu, mulai input: Data training, label data training, k, data testing (Santoso, 2007). 1. Untuk semua data testing, hitung
jaraknya ke setiap data training
2. Tentukan k data training yang jaraknya paling dekat dengan data
3. Testing
4. Periksa label dari k data ini
5. Tentukan label yang frekuensinya paling banyak
6. Masukan data testing ke kelas dengan frekuensi paling banyak
7. Berhenti
8. Label untuk semua data testing didapat. Untuk menghitung jarak antara dua titik x dan y bisa menggunakan jarak Euclidean sebagai berikut:
Yang mana X1,1= 1,2, adalah atribut kategori, dan n1i, n1 mewakili frekuensi yang sesuai (Santoso, 2007).
Dalam subbab ini yang akan dibahas yaitu tahapan proses perhitungan menggunakan algoritma K-Nearest Neighbor (KNN). Hasil yang didapat dalam perhitungan algoritma ini adalah proses perhitungan pada data training dan data testing yang menghasilkan klasifikasi masa studi tepat waktu dan tidak tepat waktu. Untuk proses perhitungan algoritma KNN digunakan 200 data sebagai data training yang terdiri dari kelas tepat waktu sebanyak 163 data dan kelas tidak tepat waktu sebanyak 38 data.
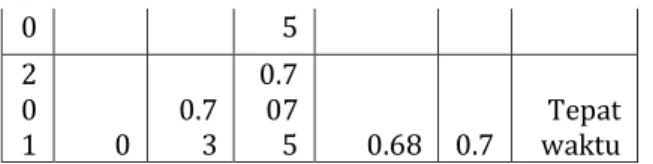
Tabel 6. Data penelitian sebelum dinormalisasi
n o jalu r mas uk IPS_1 IPS_2 nilai_a kredit asi_se kolah nil ai_ un keterangan 1 1 2.79 1.05 97.88 8.4 Tidak tepat waktu 2 1 3.57 2.84 97.88 8.5 waktu Tepat 3 1 2.86 2.52 97.88 8.5 waktu Tepat . . . 2 0 0 0 3.18 2.89 93 8.1 waktu Tepat 2 0 1 0 2.92 2.83 68 7 waktu Tepat Tabel 7. Data penelitian sesudah dinormalisasi
n o jalur mas uk IPS_1 IPS_2 nilai_a kredit asi_sek olah nil ai_ un keterangan 1 1 975 0.6 0.2 62 5 0.9788 0.84 Tidak tepat waktu 2 1 925 0.8 0.71 0.9788 0.85 waktu Tepat 3 1 0.715 0.63 0.9788 0.85 waktu Tepat . . . 2 0 0 0.795 0.722 0.93 0.81 waktu Tepat
0 5 2 0 1 0 0.73 0.7 07 5 0.68 0.7 waktu Tepat b. Distance-Weighted KNN Algoritma Distance-weighted KNN adalah pengembangan algoritma berdasarkan algoritma KNN. Awal dikembangkannya Distance-Weighted KNN dilakukan oleh Dudani (1976) dalam jurnal penelitiannya yang berjudul Distance-Weighted NN rule. Distance-Distance-Weighted K-NN merupakan algoritma yang berfungsi untuk memberi bobot yang berbeda ke tetangga terdekat sesuai jaraknya, dan tetangga terdekat memiliki bobot yang lebih besar. Distance-Weighted K-NN dirancang untuk mengurangi pengaruh sensitivitas pemilihan ukuran nilai k dan menghasilkan kinerja yang baik dalam proses klasifikasi[3].
Fungsi untuk pembobotan berdasarkan jarak weighted k-nn menggunakan distance weighted k-nn (Dudani 1976 dalam Gou et al. 2012).
kemudian, hasil klasifikasi data uji didapatkan dengan pemilihan bobot terbesar.
= arg max
dengan:
T= = kumpulan data latih = vector data latih
= label kelas data latih yang berkorespondensi dengan vector
x = data uji
d = jarak Euclidean antara x’ dan (jarak terbesar)
d = jarak Euclidean antara x’ dan (jarak data ke-i)
d = jarak Euclidean antara x’ dan (jarak terkecil)
y’ = label kelas data uji yang belum diketahui
y = label kelas (tepat atau terlambat)
= label kelas untuk ke-i tetangga di antara k tetangga terdekatnya
= fungsi Dirac delta, bernilai 1 jika y= dan bernilai 0 jika selainnya.
3.7. Presentasi Pengetahun
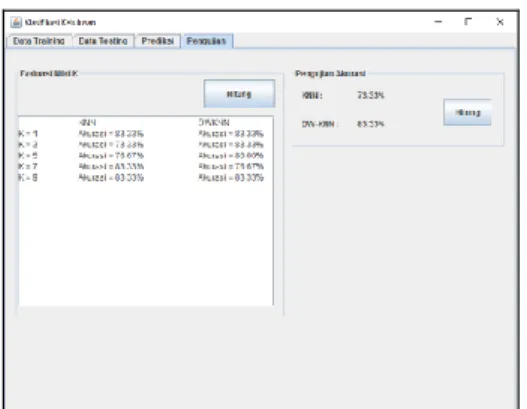
Tabel 8. Hasil akurasi algoritma DWKN dan KNN Perbandinga n algoritma K=1 K=3 K=5 K=7 K=9 KNN 83. 33 % 73. 33 % 76. 67 % 83. 33 % 83. 33 % DWKNN 83. 33 % 83. 33 % 80. 00 % 76. 67 % 83. 33 % Pada saat algoritma KNN dan DWKNN menggunakan k=1 menghasilkan tingkat akurasi yang sama yaitu 83.3%, namun pada saat menggunakan k=3 terjadi penurunan tingkat akurasi pada algoritma KNN yaitu 73.3% sedangkan pada algoritma DWKNN masih stabil dengan akurasi sebesar 83.3%. Selanjutnya ketika menggunakan k=5, pada algoritma KNN akurasi yang dihasilkan cenderung meningkat yaitu 76.67% sedangkan algoritma DWKNN mengalami penurunan akurasi yaitu 80.0%, namun tetap algoritma DWKNN lebih besar akurasinya daripada algoritma KNN. Berbeda saat menggunakan k=7, algoritma KNN lebih besar akurasinya yaitu 83.3% sedangkan algoritma DWKNN mengalami penurunan akurasi menjadi 76.67%. Dan terakhir menggunakan k=9 kedua algoritma menghasilkan akurasi yang sama yaitu 83.3%.
Dengan demikian, dalam kasus penelitian ini kedua algoritma sama-sama bisa menghasilkan akurasi sebesar 83.3%. Selain itu terjadinya fluktuasi akurasi terhadap algoritma KNN karena sensitivitas ukuran nilai k. Namun, dalam hal kestabilan akurasi algoritma DWKNN lebih baik daripada algoritma KNN dan dapat mengurangi sensitivitas pemilihan ukuran nilai k.
Tabel 9. Hasil akurasi algoritma DWKNN DWK NN K=1 K=3 K=5 K=7 K=9 83.33 % 83.33 % 80.00 % 76.67 % 83.33 % Nilai akurasi yang paling tinggi adalah nilai k 1, 3, dan 9 sebesar 83.3% sedangkan nilai k=5 sebesar 80.0% dan nilai k=7 sebesar 76.7%. Akurasi yang dihasilkan algoritma DWKNN cenderung stabil dan mengurangi sensitivitas terhadap nilai k.
3.8. Implementasi
Pada penelitan “Analisis Perbandingan Algoritma Distance-Weighted Knn Dan Algoritma Knn Pada Prediksi Masa Studi Mahasiswa” akan menampilkan hasil klasifikasi berupa implementasi. Berikut ini merupakan form penginputan data yang menghasilkan prediksi masa studi mahasiswa menggunakan algoritma KNN dan algoritma DWKNN.
Gambar 4. Tab pada data training
Gambar 5. Tab pada data testing
Gambar 6. Tab pada data prediksi untuk hasil algoritma KNN
Gambar 7. Tab pada data prediksi untuk hasil algoritma KNN
Gambar 8. Tab pada data prediksi untuk hasil algoritma DWKNN
Gambar 9. Tab pada data prediksi untuk hasil algoritma DWKNN
Gambar 10. Tab pada data pengujian untuk hasil algoritma
4. SIMPULAN
Kesimpulan yang dapat diambil dari penelitian ini adalah:
a. Untuk algoritma Distance-Weighted KNN diperoleh nilai akurasi sebesar 83.3% pada nilai k 1, 3, dan 9. Selain itu pada nilai k=5 diperoleh akurasi sebesar 80.0% dan pada nilai k=7 diperoleh akurasi sebesar 76.7%. Sedangkan untuk algoritma K-nearest Neighbor (KNN) diperoleh nilai akurasi sebesar 83.3% pada nilai k 1, 7, dan 9. Selain itu pada nilai k=3 diperoleh akurasi sebesar 73.3% dan pada nilai k=5 diperoleh akurasi sebesar 76.7% . Dengan demikian, kedua algoritma sama-sama dapat menghasilkan akurasi sebesar 83.3%, dan dalam hasil kestabilan akurasi algoritma DWKNN lebih baik.
b. Nilai k-optimal pada algoritma DWKNN untuk prediksi masa studi mahasiswa adalah k 1, 3, dan 9 dengan hasil akurasi sebesar 83.3%. Dengan demikian dalam penelitian ini algoritma DWKNN cocok di implementasikan untuk memprediksi masa studi mahasiswa.
DAFTAR PUSTAKA
[1]. Asnawi, Hamdan, Adi, Radityo N., Budiman, Irwan. 2017. Perancangan Database Sistem Informasi Akademik Universitan Lambung Mangkurat. Kumpulan jurnal Ilmu Komputer, Vol. 04, No. 01 : 09
[2]. Ayu, M.B, Budiman Irwan,H, Farmadi, Andi. 2015. Penerapan K-optimal Pada Algoritma Knn Untuk Prediksi Kelulusan Tepat Waktu Mahasiswa Program Studi Ilmu Komputer Fmipa Unlam Berdasarkan IP Sampai Dengan
Semester 4, Kumpulan jurnal Ilmu Komputer, Vol. 02, No. 02 : 51-54
[3]. BAN-PT. 2008. Buku VI Matriks Penilaian Instrumen Akreditasi Program Studi Sarjana. Badan Akreditasi Nasional Perguruan Tinggi, Jakarta. [4]. Bertalya. 2009. Konsep Data Mining,
Klasifikasi: Pohon Keputusan. Jakarta: Universitas Gunadarma.
[5]. Dudani SA. 1976. The distance-weighted k-nearest neighbor rule. IEEE Transactions on System, Man, and Cybernetics. SMC-6(4): 325-327.
[6]. Fiastantyo, Gian. 2013. Perbandingan Kinerja Metode Klasifikasi Data Mining Menggunakan Naïve Bayes Dan Algoritma C4.5 Untuk Prediksi Ketepatan Waktu. Teknik Informatika Fakultas Ilmu Komputer. Semarang. [7]. Gou J, Du L, Zhang Y, Xiong T. 2012. A new
distance-weighted k-nearest neighbor classifier. School of Computer Science and Engineering, University of Electronic Science and Technology of China. China. College of Engineering and Computer Science, the Australian National University Canberra. Australia.
[8]. Han, J, Kamber, M, & Pei, J. 2006. Data Mining: Concept and Techniques, Second Edition. Waltham: Morgan Kaufmann Publishers.
[9]. Hechenbichler, Klaus., Schliep, Klaus.2004.Weighted K-Nearest-Neighbor Techniques And Ordinal Classification. Paper institut fur statistic sonderforschungsbereich 386. Germany., New Zealand.
[10]. Hermawati, L., Safriandono, A.N. 2016 Penggabungan Algoritma Forward Selection dan K-Nearest Neighbor untuk Mendiagnosis Penyakit Diabetes di Kota Semarang. Teknik Informatika Universitas Sultan Fatah. Demak.
[11]. Indriati, Ridok, A., 2016. Sentiment Analysis For Review Mobile Applications Using Neighbor Method Weighted K-Neares Neighbor (NKWNN). Informatics Department Faculty Of Computer Science Universitas Brawijaya. [12]. Larose, Daniel T. 2005. Discovering
Data mining. New Jersey: JohnWilley& Sons. Inc.
[13]. Liu, B., 2007 . Web Data mining: Exploring Hyperlinks, Contents, dan Usage Data. Berlin: Springer.
[14]. Omary, Z. dan Fredrick Mtenzi. 2010. Machine Learning Approach to Identifying the Dataset Threshold for the Performance Estimators in Supervised Learning. International Journal for Infonomics (IJI), Volume 3, Issue 3 : 314-325.
[15]. Santoso, B. (2007). Data Mining Teknik Pemanfaatan Data Untuk Keperluan Bisnis (1 ed). Yogyakarta: Graha Ilmu. [16]. Syahidah,A. 2014. Klasifikasi
Imbalanced Data Menggunakan Weighted K-Nearest Neighbor Pada Data Debitur Kartu Kredit Bank. Skripsi. Fakultas MIPA. ITB. Bogor.
[17]. Wahyu, Arif N., 2011. Modul Analisis Missing Value & Outlier. https://www.scribd.com/doc/46229573/ Modul-Analisis-Missing-Value-Outlier (diakses tanggal 19 agustus 2017)
[18]. Windarti, Mariana. 2016. Prediksi Studi Mahasiswa Menggunakan Kombinasi Algoritma Bayesian Network Dan K-Nearest Neighbor. Tesis Program Pascasarjana, Universitas Atma Jaya, Yogyakarta.
[19]. Wu X, Kumar V. 2009. The Top Ten Algorithms in Data Mining. New York: CRC Pres.