Jurnal Teknologi Informasi dan Komunikasi Vol.1 No.2, Desember 2012
28 Pembentukan Pola Kalimat
Pada Forum Konsultasi Kesehatan Wiwin Suwarningsih Pusat Penelitian Informatika LIPI
Komplek LIPI Gd. 20 Lt.3. Jl. Sangkuriang Bandung
wiwin@informatika.lipi.go.id,
Abstrak
Aplikasi berbasis web dibidang kesehatan saat ini sudah banyak yang menyediakan sarana untuk konsultasi dengan dokter. Proses konsultasi antara dokter dengan pasien ini dibuat secara terbuka dengan tujuan dapat dibaca dan dijadikan informasi bagi pembaca lainnya. Hasil konsultasi ini merupakan teks bahasa Indonesia yang bersifat alami. Pada makalah ini akan diuraikan bagaimana membentuk pola kalimat bahasa Indoensia yang berasal dari teks konsultasi menjadi sebuah informasi berupa pengetahuan baru yang dapat dimanfaatkan oleh pengunjung web. Metoda yang akan digunakan adalah maximum entrop.
Kata Kunci : text mining, teks konsultasi, analisa leksikal, maximum entrhopy, ekstraksi pengetahuan. Abstract
Web-based applications in the health sector are now widely that provides a means for consultation with a physician. The process of consultation between doctor and patient is made openly in order to be read and used as information for other readers. The results of this consultation are the text of the Indonesian language is natural. This paper will describe how a pattern language of Indonesia sentences from the text information such as consultation into a new knowledge that can be used by web visitors. The method to be used is the maximum Entrop.
Keywoard: text mining, consulting texts, lexical analysis, maximum entrhopy, knowledge extraction
1. Pendahuluan
Aplikasi berbasis web dibidang kesehatan saat ini sudah banyak yang menyediakan sarana untuk konsultasi dengan pakar[1]. Kepakaran yang disediakan oleh aplikasi tersebut terdiri dari dokter spesialis diantaranya spesialis orthopedi, spesialis THT, spesialis saraf, spesialis anak dan banyak lagi.
Sarana konsultasi ini disediakan dengan tujuan memudahkan pasien untuk mendapatkan informasi secara cepat tanpa harus bertatap muka dengan dokter yang bersangkutan. Proses konsultasi antara dokter dengan pasien ini dibuat secara terbuka dengan tujuan hasil konsultasi yang bersifat umum dapat dibaca dan dijadikan informasi bagi pengunjung web.
Tujuan lainnya dibuat menjadi konsultasi terbuka agar pembaca bila mengalami hal yang sama tidak perlu bertanya dua kali. Hasil konsultasi yang diberika oleh para dokter ini diharapkan dapat memberikan kontribusi yang positif ke masyarakat dan secara tidak langsung
menambah pengetahuan masyarakat akan pentingnya menjaga kesehatan.
Berdasarkan hal tersebut, sekarang bagaimana caranya dari teks konsultasi tersebut dapat diperoleh sebuah pengetahuan baru yang dapat dijadikan sebagai tindakan preventif yang harus dilakukan oleh masyarakat bila mengalami kondisi yang sama seperti informasi yang ada di teks konsultasi tersebut. Pada makalah ini akan diuraikan cara mengekstraksi pengetahuan dari teks konsultasi dengan menggunakan metoda text mining. Proses ekstraksi yang akan dilakukan adalah dengan cara menganlisa leksikal dan analisa sintaks dari teks konsultasi[1][2].
Hasil akhir dari penelitian ini diharapkan memperoleh sebuah pengetahuan baru berupa tindakan preventif
2. PENAMBANGAN TEKS (TEXT
MINING)
Penambangan teks (text
Jurnal Teknologi Informasi dan Komunikasi Vol.1 No.2, Desember 2012
29
berkembang yang berusaha untuk mengumpulkan informasi yang berarti dari teks bahasa alami. Dibandingkan dengan jenis data yang disimpan dalam basisdata, teks tidak terstruktur dan sulit untuk menangani algoritmanya.
Namun demikian, dalam budaya modern, teks adalah kendaraan yang paling umum untuk pertukaran informasi formal. Bidang
penambangan teks biasanya berkaitan dengan teks yang fungsinya adalah komunikasi informasi faktual atau pendapat, dan motivasi untuk mencoba untuk mengekstrak informasi dari teks tersebut secara otomatis.
Penambangan Teks dan pengolahan bahasa alami.
Penambangan teks muncul untuk merangkul seluruh pengolahan bahasa alami dan otomatis, analisis struktur seperti kutipan dalam literatur akademik dan hyperlink dalam literatur Web, kedua sumber informasi tersebut berguna untuk pengolahan tradisional domain bahasa alami. Tapi, pada kenyataannya, upaya pertambangan teks menghindari aspek yang lebih dalam, kognitif, pengolahan bahasa alami klasik yang mendukung teknik lebih mirip dengan yang digunakan dalam pengambilan informasi praktis.
Gambar 1. Modul Pertambangan Teks[1] Modul pertambangan teks berisi nilai data berdasarkan analisis historis dari kemungkinan bentuk konsultasi, kepuasan pelanggan terhadap layanan dan lain-lain. Algoritma yang dikembangkan dapat berdasarkan teks yang dimasukkan dalam laporan klaim pemeriksa dan detail berdasarkan klaim. Contoh model pertambangan teks yang dikembangkan khusus untuk klien dengan DWreview (lihat gambar.1). Model penambangan data dapat memberikan
klien keunggulan kompetitif dan rincian teknis disimpan sebagai rahasia perusahaan yang dijaga ketat.
Entropi Maksimum (Maximum Entropy) Kerangka entropi maksimum memperkirakan probabilitas didasarkan pada prinsip membuat asumsi sesedikit mungkin, selain kendala yang
dikenakan. demikian
kendala biasanya berasal dari data pelatihan, mengungkapkan beberapa hubungan antara fitur dan hasil. Distribusi probabilitas yang memenuhi properti di atas adalah salah satu dengan entropi tertinggi.
Gambar 2. Probabilitas Distribusi Maksimum Entropi[2]
Probabilitas distribusi ini adalah unik, sesuai dengan distribusi kemungkinan maksimum, dan memiliki bentuk eksponensial.
Gambar 3. Algoritma Maksimum-Entropi.[2][3]
Untuk meringkas prosedur pelatihan secara keseluruhan maksimum entropi, pertama membagi data kedalam dua bagian yaitu data percobaan dan data untuk pengujian yang berasal dari stiap pasang stste yang relevan dengan transisi dari masing-masing state.
Input : Sebuah urutan pengamatan 01 ...0m, urutan sesuai
label l1 ... lm, sejumlah state dari masing-masing label, dan
berpotensi memiliki struktur transisi terbatas. Tentukan urutan state yang terkait dengan urutan label pengamatan. (Bila hal ini ambigu, dapat ditentukan probalistik dengan iterasi dua langkah berikutnya). Deposit state pengamatan pasang (s,0) menjadi state s’ yang berhubungan sebelumnya sebagai data pelatihan untuk
masing-masing fungsi state transisi Ps’(s|0).
Temukan solusi maximum entropi untuk fungsi diskriminatif
masing-masing state dengan menemukan iteratif λa
nilai-nilai yang membentuk solusi entropi maksimum untuk setiap fungsi transisi
Output : Maksimal-entropi berbasis Markov Model yang
mengambil urutan labelnya tidak diketahui dari pengamatan dan memprediksi label yang berhubungan
Jurnal Teknologi Informasi dan Komunikasi Vol.1 No.2, Desember 2012
30
3. METODA PENELITIAN
Metoda penelitian yang digunakan padamakalah ini adalah metoda maximum
entrophy yaitu metoda penambangan teks (text mining) yang meliputi identifikasi struktur
elemen dengan cara analisa leksikal; segmentasi informasi; pembentukan template pola kalimat.
4. HASIL DAN PEMBAHASAN
4.1 Identifikasi Struktur Elemen
Sumber data teks adalah teks konsultasi antara dokter dan pasien. Teks yang digunakan adalah teks yang diambil dari forum konsultasi kesehatan dalam bentuk bahasa Indonesia (contoh teks lihat gambar 2).
Gambar 4. Sumber Teks Hasil Konsultasi dengan menggunakan Bahasa Indonesia. Elemen struktur pada sumber teks terdiri dari pertanyaan dan jawaban. Bahasa Indonesia belum memiliki pola seperti bahasa Inggris, sehingga identifikasi struktur elemen pada teks konsultasi ini menggunakan cara yang diberikan oleh metoda entropi maksimum. Hasil dari identifikasi strukur elemen dapat dilihat pada tabel 1.
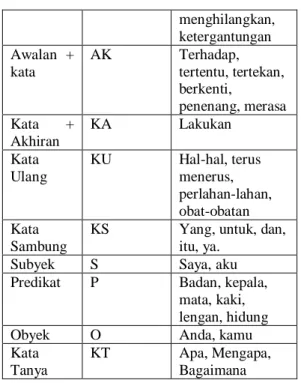
Tabel1. Identifikasi Struktur Elemen Struktur Elemen Kata Kodefikasi Contoh Kelompok Kata KK Setiap saat, rumah sakit. Awalan + Kata + Akhiran AKA Kecemasan, pengehentian, menimbulkan, membutuhkan, menghilangkan, ketergantungan Awalan + kata AK Terhadap, tertentu, tertekan, berkenti, penenang, merasa Kata + Akhiran KA Lakukan Kata Ulang KU Hal-hal, terus menerus, perlahan-lahan, obat-obatan Kata Sambung
KS Yang, untuk, dan,
itu, ya.
Subyek S Saya, aku
Predikat P Badan, kepala,
mata, kaki, lengan, hidung
Obyek O Anda, kamu
Kata Tanya
KT Apa, Mengapa,
Bagaimana
Identifikasi elemen kata ini dibuat sebagai cara kita membentuk suatu konsep dari klasifikasi kata dalam bahasa Indonesia. Konsep ini dibentuk berdasarkan data teks konsultasi kesehatan. Pembuatan konsep ini berdasarkan pda pendekatan kata kunci, hubungan kata dengan kamus dan pendekatan statistik penggunaan bahasa alami. Bahasa alami dalam bahasa Indoensia terkadang ada penambahan imbuhan yang berasal dari dialek bahasa daerah. Pada makalah ini imbuhan lkata yang berasal dari bahasa daerah diabaikan.
4.2 Proses Analisa Leksikal
Pada tahap analisa leksikal ini proses yang dilakukan adalah pengenalan token untuk membentuk sebuah kata dari rangkaian huruf. Setelah kata terbentuk maka dilakukan pengenalan batas kata, dalam bahasa Indonesia terdiri dari kata dasar, kata dasar yang diberi imbuhan awalan dan akhiran, kata ulang dan pengenalsan berdasarkan kata-kata yang sesuai dengan kamus bahasa indonesia. Apabila terdapat kata yang bukan berasal dari kamus bahasa Indonesia maka kata ini akan diabaikan.
Normalisasi kata dilakukan untuk mencari kata dasar dari kata yang menggunakan awalan dan imbuhan, hal ini dilakukan untuk memudahkan membangun sebuah pola bahasa yang berasal dari kata yang terbentuk dari proses
Pertanyaan : Badan terasa tak enak dan perut terasa
seolah kejang terus menerus, kenapa dokter ya ? Jawab : Kecemasan terhadap suatu masalah tertentu atau tertekan karena stres yang menumpuk, dapat membuat anda merasa tak enak badan.
Pertanyaan : Saya hampir setiap saat merasa cemas, hal
itu timbul sejak berhenti merokok, minum alkohol atau obat-obatan penenang atau obat tidur . Apa yang harus saya lakukan dokter ?
Jawab : Penghentian mendadak hal-hal semacam itu memang dapat menimbulkan perasaan tidak tenang dan cemas. Penanggulangannya anda membutuhkan terapi untuk perlahan-lahan menghilangkan ketergantungan pada alkohol dan obat-obatan penenang.
Jurnal Teknologi Informasi dan Komunikasi Vol.1 No.2, Desember 2012
31
analisa sintkas. Algoritma untuk analisis leksikal dapat dilihat pada gambar 3.
public class AnalisisLeksikal {
private String[] KataKunci = { "badan", "rasa", "enak", "tak",
"perut", "kejang", "hampir", "timbul", "tekant", "stress", "tumpuk", "buat", "rokok", "henti", "obat", "tidur", "tenang", "minum","alkohol”, "mendadak", "hilang", "ketergantungan”, "pada", "perasaan","perlahan-lahan",“setiap saat","terapi", "ya", "dokter", "terus menerus","lakukan", "harus", "saya", "tertekan", "karena", "membuat" }; HashMap<String, ArrayList<Integer>> TabelKataKunci; HashMap<String, ArrayList<Integer>> otherWords = new HashMap<String, ArrayList<Integer>>(); public AnalisisLeksikal(String NamaFile){ Scanner kb = null; int lineNumber = 0; try { kb = new Scanner(new File(NamaFile)); } catch (FileNotFoundException e) { e.printStackTrace(); }
TabelKataKunci = new HashMap<String, ArrayList<Integer>>(); for(int i = 0; i < 47; i++) { TabelKataKunci.put(keywords[i], new ArrayList<Integer>()); } while(kb.hasNextLine()) { lineNumber++;
String line = kb.nextLine(); String[] lineparts =line.split("\\s+|\\.+|\\; + |\\(+|\\)+|\\\"+|\\:+|\\[+|\\]+"); for(String x: lineparts) { ArrayList<Integer> list = keywordsTable.get(x); if(list == null) { list = otherWords.get(x); if(list == null) { ArrayList<Integer> temp = new ArrayList<Integer>(); temp.add(lineNumber); otherWords.put(x,temp); } Else { otherWords.remove(x); ArrayList<Integer> temp = new ArrayList<Integer>();
temp.add(lineNumber); otherWords.put(x, temp); } } Else { TabelKataKunci.remove(x); ArrayList<Integer>
temp = new ArrayList<Integer>();
temp.add(lineNumber); keywordsTable.put(x, temp); } } } } System.out.println("KataKunci :"); printMap(TabelKataKunci); System.out.println(); System.out.println("Kata Yang Lain :"); printMap(otherWords); }
public static void main(String args[])
{
new Analisis Leksikal("LeksiUji.txt"); }
Gambar 3. Algoritma Analisis Leksikal Pada gambar 3 dapat dilihat algoritma analisis leksikal ini diambil dari token yang telah terbentuk, kemudian token tersebut dijadikan sebagai kata kunci untuk analisa teks yang akan dibaca. Hasil dari proses analisis leksikal ini akan disimpan dalam file LeksiUji.txt.
4.3 Segmentasi Informasi
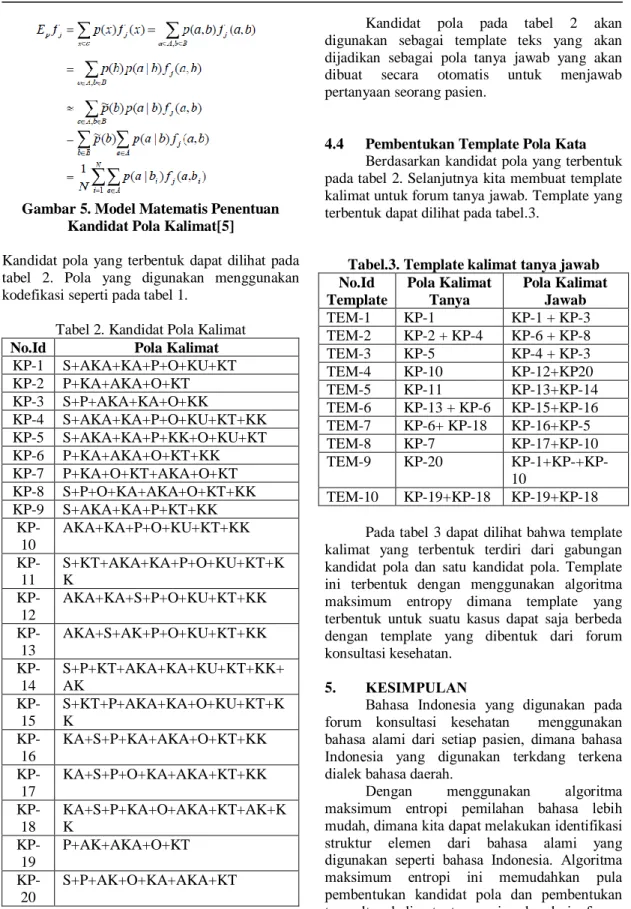
Tujuan tahap ini adalah memperoleh kandidat pola bahasa untuk menemukan pengetahuan baru. Kandidat pola bahasa akan digunakan untuk membuat template dari forum konsultasi. Pembentukan pola ini menggunakan metoda maksimum entropy dengan uraian penggunaan rumus sebagai berikut :
Jurnal Teknologi Informasi dan Komunikasi Vol.1 No.2, Desember 2012
32 Gambar 5. Model Matematis Penentuan
Kandidat Pola Kalimat[5]
Kandidat pola yang terbentuk dapat dilihat pada tabel 2. Pola yang digunakan menggunakan kodefikasi seperti pada tabel 1.
Tabel 2. Kandidat Pola Kalimat
No.Id Pola Kalimat
KP-1 S+AKA+KA+P+O+KU+KT KP-2 P+KA+AKA+O+KT KP-3 S+P+AKA+KA+O+KK KP-4 S+AKA+KA+P+O+KU+KT+KK KP-5 S+AKA+KA+P+KK+O+KU+KT KP-6 P+KA+AKA+O+KT+KK KP-7 P+KA+O+KT+AKA+O+KT KP-8 S+P+O+KA+AKA+O+KT+KK KP-9 S+AKA+KA+P+KT+KK KP-10 AKA+KA+P+O+KU+KT+KK KP-11 S+KT+AKA+KA+P+O+KU+KT+K K KP-12 AKA+KA+S+P+O+KU+KT+KK KP-13 AKA+S+AK+P+O+KU+KT+KK KP-14 S+P+KT+AKA+KA+KU+KT+KK+ AK KP-15 S+KT+P+AKA+KA+O+KU+KT+K K KP-16 KA+S+P+KA+AKA+O+KT+KK KP-17 KA+S+P+O+KA+AKA+KT+KK KP-18 KA+S+P+KA+O+AKA+KT+AK+K K KP-19 P+AK+AKA+O+KT KP-20 S+P+AK+O+KA+AKA+KT
Kandidat pola pada tabel 2 akan digunakan sebagai template teks yang akan dijadikan sebagai pola tanya jawab yang akan dibuat secara otomatis untuk menjawab pertanyaan seorang pasien.
4.4 Pembentukan Template Pola Kata Berdasarkan kandidat pola yang terbentuk pada tabel 2. Selanjutnya kita membuat template kalimat untuk forum tanya jawab. Template yang terbentuk dapat dilihat pada tabel.3.
Tabel.3. Template kalimat tanya jawab No.Id Template Pola Kalimat Tanya Pola Kalimat Jawab TEM-1 KP-1 KP-1 + KP-3 TEM-2 KP-2 + KP-4 KP-6 + KP-8 TEM-3 KP-5 KP-4 + KP-3 TEM-4 KP-10 KP-12+KP20 TEM-5 KP-11 KP-13+KP-14 TEM-6 KP-13 + KP-6 KP-15+KP-16 TEM-7 KP-6+ KP-18 KP-16+KP-5 TEM-8 KP-7 KP-17+KP-10 TEM-9 KP-20 KP-1+KP-+KP-10 TEM-10 KP-19+KP-18 KP-19+KP-18 Pada tabel 3 dapat dilihat bahwa template kalimat yang terbentuk terdiri dari gabungan kandidat pola dan satu kandidat pola. Template ini terbentuk dengan menggunakan algoritma maksimum entropy dimana template yang terbentuk untuk suatu kasus dapat saja berbeda dengan template yang dibentuk dari forum konsultasi kesehatan.
5. KESIMPULAN
Bahasa Indonesia yang digunakan pada forum konsultasi kesehatan menggunakan bahasa alami dari setiap pasien, dimana bahasa Indonesia yang digunakan terkdang terkena dialek bahasa daerah.
Dengan menggunakan algoritma maksimum entropi pemilahan bahasa lebih mudah, dimana kita dapat melakukan identifikasi struktur elemen dari bahasa alami yang digunakan seperti bahasa Indonesia. Algoritma maksimum entropi ini memudahkan pula pembentukan kandidat pola dan pembentukan tempalte kalimat tanya jawab dari forum konsultasi kesehatan.
Jurnal Teknologi Informasi dan Komunikasi Vol.1 No.2, Desember 2012
33
Penelitian yang dapat dilakukan selanjutnya adalah mencari dan menemukan pola untuk pengetahuan baru dengan memanfaatkan dari template pola kalimat yang telah dibentuk.
6. PUSTAKA
[1] Andrew McCallum, Dayne Freitag, Fernando Pereira, 2002, “ Maximum Entropy Markov Models For Informatioan Extraction and Segmentation”, AAAI-02 Proceedings. Copyright © 2002, AAAI (www.aaai.org). All rights reserved [2] Soderland, S. 2001, “ Building a Machine
Learning Based Text Understanding System”. In Proceedings of IJCAI
Workshop on Adaptive Text Extraction and Mining, 64-70.
[3] Taira, R. K. and Soderland, S. 2000, “A Statistical Natural Language Processor for Medical Reports” . In Proceedings of the
International Conference on Mathematics and Engineering Techniques in Medicine and Biological Sciences
[4] Jong Hwan Suh, Chung Hoon Park, Si Hyun Jeon, 2010, “Applying text and data mining techniques to forecasting the trend of petitions filed to e-People”, Expert Systems with Applications 37, P: 7255– 7268
[5] G. Koteswara Rao1 and Shubhamoy Dey, 2011, “DECISION SUPPORT FOR E-GOVERNANCE: A TEXT MINING APPROACH” International Journal of Managing Information Technology (IJMIT) Vol.3, No.3, August 2011DOI : 10.5121/ijmit.2011.3307 73
[6] Muhlberger, P., Webb, N., & Stromer-Galley, J., 2008, “The Deliberative E Rulemaking Project (DeER) : Improving Federal Agency Rulemaking Via Natural Language Processing and Citizen Dialogue", ACM International Conference Proceeding Series: Proceedings of the 9th Annual International Digital Government Research Conference, p. 403, vol. 289
![Gambar 1. Modul Pertambangan Teks[1]](https://thumb-ap.123doks.com/thumbv2/123dok/1948955.3511677/2.918.190.454.635.836/gambar-modul-pertambangan-teks.webp)