SELEKSI PEUBAH DALAM PEMODELAN PDRB SEKTOR
PERTANIAN DENGAN METODE REGRESI KUADRAT
TERKECIL PARSIAL
ASTUTI DEWI WARAWATI
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2017
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul Seleksi Peubah dalam
Pemodelan PDRB Sektor Pertanian dengan Metode Regresi Kuadrat Terkecil
Parsial adalah benar karya saya dengan arahan dari komisi pembimbing dan belum
diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber
informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak
diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam
Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut
Pertanian Bogor.
Bogor, Januari 2017
Astuti Dewi Warawati
RINGKASAN
ASTUTI DEWI WARAWATI. Seleksi Peubah dalam Pemodelan PDRB Sektor
Pertanian dengan Metode Regresi Kuadrat Terkecil Parsial. Dibimbing oleh BUDI
SUSETYO dan UTAMI DYAH SYAFITRI.
Produk Domestik Regional Bruto (PDRB) merupakan indikator penting yang
berguna untuk mengetahui kondisi perekonomian di suatu daerah. Nilai PDRB
diperoleh dari selisih output dengan biaya antara. Banyaknya komoditas yang
terlibat dalam perhitungan tersebut lebih dari tiga ratus komoditas pertanian. Secara
ekonomi, biaya yang diperlukan dalam pengumpulan ke-300 peubah tersebut relatif
besar, sedangkan secara statistik dimungkinkan PDRB dapat dihitung hanya dengan
sebagian dari 300 peubah yang berpengaruh. Penelitian ini bertujuan melakukan
pemodelan untuk menentukan peubah penjelas yang memiliki pengaruh besar
terhadap PDRB provinsi pada sektor pertanian.
Penelitian ini menggunakan data sekunder yang terdiri dari data PDRB sektor
pertanian tahun 2013 dan data Sensus Pertanian 2013 (ST2013). Data PDRB
diperoleh dari publikasi yang dikeluarkan oleh Badan Pusat Statistik (BPS),
sedangkan data Sensus Pertanian 2013 (ST2013) diunduh dari situs ST2013 yang
dikelola oleh BPS. Data ST2013 tersusun atas subsektor tanaman pangan, tanaman
hortikultura, perikanan, tanaman perkebunan, peternakan, dan tanaman kehutanan
sejumlah 590 peubah. Amatan yang digunakan adalah semua provinsi di Indonesia.
Penelitian ini menggunakan data ST2013 sebagai matriks peubah penjelas
(X) dan data PDRB sebagai vektor peubah respon (
yyyy). Metode analisis yang
biasanya digunakan dalam pemodelan adalah Metode Kuadrat Terkecil (MKT).
Terdapat beberapa asumsi yang perlu dipenuhi pada MKT, salah satunya adalah
tidak adanya multikolinieritas di antara peubah penjelas. Multikolinieritas terjadi
ketika terdapat korelasi yang tinggi di antara peubah penjelas. Kondisi
multikolinieritas juga terjadi pada data berdimensi tinggi, yaitu ketika banyaknya
peubah penjelas jauh lebih besar dibandingkan dengan banyaknya amatan yang
digunakan. Kondisi multikolinieritas membuat matriks informasi (X
''''X) tidak
memiliki matriks kebalikan. Hal ini berakibat pendugaan dengan MKT, yaitu
y=X(X'X)
-1X
''''y tidak dapat dilakukan. Oleh karena itu, perlu digunakan metode lain,
salah satunya adalah metode Regresi Kuadrat Terkecil Parsial (RKTP).
Metode RKTP memiliki kemampuan untuk mereduksi dimensi (komponen)
dari matriks data yang berdimensi lebih besar dan saling berkorelasi. Pereduksian
dimensi tidak mempengaruhi banyaknya peubah penjelas yang terlibat dalam
model. Hal ini dikarenakan komponen adalah kombinasi linier dari peubah penjelas
dengan peubah respon pada model RKTP. Metode RKTP merupakan metode
regresi yang bertujuan untuk menghasilkan dugaan peubah respon dengan
memanfaatkan semua peubah penjelas. Meskipun demikian, penelitian ini akan
memilih peubah penjelas yang berpengaruh besar terhadap peubah respon.
Metode pemilihan peubah penjelas dilakukan dengan dua strategi, yaitu
dengan regresi Least Absolute Shrinkage and Selection Operator (LASSO) dan
statistik Variable Importance in the Projection (VIP). Strategi pertama dilakukan
dengan penerapan regresi LASSO sebelum analisis RKTP. Regresi LASSO dipilih
sebagai metode seleksi karena koefisien regresi dapat disusutkan hingga bernilai
nol. Peubah penjelas yang bersesuaian dengan koefisien regresi LASSO yang
bernilai selain nol adalah peubah penjelas yang berpengaruh terhadap peubah
respon. Peubah-peubah tersebut selanjutnya dimasukan ke dalam analisis RKTP.
Strategi kedua dilakukan dengan penerapan satistik VIP setelah analisis RKTP.
Pengambilan keputusan peubah penjelas yang berpengaruh terhadap peubah respon
diambil berdasarkan kriteria ambang batas sebesar VIP=0.8 dan VIP=1.0. Suatu
peubah penjelas dinyatakan memiliki pengaruh terhadap peubah respon jika VIP
dari peubah penjelas tersebut melebihi nilai ambang batas yang digunakan.
Berdasarkan analisis yang dilakukan, diperoleh beberapa model yang
selanjutnya dipilih model terbaik. Kriteria seleksi yang digunakan dalam pemilihan
peubah penjelas adalah nilai korelasi, Root Mean Square Error (RMSE), dan
kemampuan model dalam menjelaskan peubah respon. Di samping itu, banyaknya
peubah penjelas dan komponen yang digunakan dalam model juga
dipertimbangkan. Hasil analisis menunjukan bahwa model RKTP dengan LASSO
sebagai kriteria pemilihan peubah dan menggunakan dua komponen merupakan
model terbaik.
SUMMARY
ASTUTI DEWI WARAWATI. Variable Selection on Agricultural GRDP
Modelling using Partial Least Square Regression Method. Supervised by BUDI
SUSETYO and UTAMI DYAH SYAFITRI.
Gross Regional Domestic Product (GRDP) is an important indicator which
can be used to measure the economic status on certain area. GRDP is calculated by
deducting the output by the marginal cost of certain commodities. The number of
commodities used are more than three hundred commodities. Economically, the
cost needed to collect 300 variables is expensive, but statistically it is possible to
calculate GRDP by using some of 300 influential variables. The aim of this research
is to build model and to select the important variables which have effect towards
Agricultural GRDP at province level.
This research used secondary data consisting the Agricultural GRDP 2013
and the Agricultural Census 2013. The Agricultural GRDP 2013 data was acquired
from publication which was released by Badan Pusat Statistik (BPS), meanwhile
the Agricultural Census 2013 data was downloaded from Sensus Pertanian 2013
(ST2013) site under BPS. The independent variables consisted of the variables from
crops subsector, horticultures subsector, fisheries subsector, plantations subsector,
live stocks subsector, and forestries subsector to the number of 590 variables. The
observations used were all the provinces of Indonesia.
This research used ST2013 data as the independent variables matrix (X) and
the GRDP as the dependent variable vector (y). Ordinary Least Square is one of
methods usually used in modelling. There are several assumptions needed to be
fulfilled, for instance there is not multicollinearity among the independent variables.
Multicollinearity happens when the independent variables have high correlation
among the independent variables. Multicollinearity also happens in data with high
dimensionality, i.e. when the number of independent variables is much larger than
the number of observations. The multicollinearity makes information matrix (X
''''X)
does not have the inverse, so the OLS estimation, y=X(X'X)
-1X
''''y cannot be applied.
The alternative method is needed, e.g. Partial Least Square Regression (PLSR).
The PLSR method reduces the dimensions (components) based on high
dimensionality on data matrix and its intercorelation. The dimension reduction does
not have influence towards the number of the independent variables used in the
model. This is because the dimension is linear combination of the independent and
the dependent variables of PLSR model. The purpose of PLSR is to predict the
dependent variable using all independent variables. Nevertheless, this research
would like to select the independent variables which had important effect towards
the dependent variable.
The independent variables selection used two strategies, first by applying
Least Absolute Shrinkage and Selection Operator (LASSO) and the second, by
applying Variable Importance in the Projection (VIP). The first strategy was
proceeded by applying LASSO before the PLSR analysis. LASSO regression was
chosen as variables selection because LASSO was able to shrink the regression
coefficient towards zero. The independent variables which had important effect
towards the dependent variable were the ones with non-zero coefficient. Thus, those
selected independent variables were used to build model GRDP using PLSR. The
second selection method was by applying VIP after PLSR analysis. The decision
used to decide which independent variables had important effect towards the
response was by using VIP=0.8 and VIP=1.0 as the cut-off. An independent
variable had important effect towards the dependent variable if the VIP is larger
than the cut-off.
The next analysis was to select the best model from the built models from
previous analysis. The best model was decided based on correlation, Root Mean
Square Error (RMSE) and the model ability to explain the variability of response
variable. The number of independent variables and components used in model were
also considered to decide the best model. The result showed that the PLSR model
using LASSO regression as the independent variables selector on two dimensions
was the best model.
© Hak Cipta Milik IPB, Tahun 2017
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau
menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan,
penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau
tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Dilarang mengumumkan dan memperbanyak sebagian atau seluruh karya tulis ini
dalam bentuk apa pun tanpa izin IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar
Magister Sains
pada
Program Studi Statistika
SELEKSI PEUBAH DALAM PEMODELAN PDRB SEKTOR
PERTANIAN DENGAN METODE REGRESI KUADRAT
TERKECIL PARSIAL
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2017
Judul Tesis : Seleksi Peubah dalam Pemodelan PDRB Sektor Pertanian dengan
Metode Regresi Kuadrat Terkecil Parsial
Nama
: Astuti Dewi Warawati
NIM
: G151140271
Disetujui oleh
Komisi Pembimbing
Dr Ir Budi Susetyo, MS
Ketua
Dr Utami Dyah Syafitri, SSi, MSi
Anggota
Diketahui oleh
Ketua Program Studi
Statistika
Dr Ir I Made Sumertajaya, MS
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala rahmat dan
karuniaNya sehingga karya ilmiah ini dapat diselesaikan. Tema yang dipilih dalam
penelitian yang dilakukan sejak bulan April 2016 adalah makroekonomi dengan
judul Seleksi Peubah dalam Pemodelan PDRB Sektor Pertanian dengan Metode
Regresi Kuadrat Terkecil Parsial.
Terima kasih penulis ucapkan kepada bapak Dr Ir Budi Susetyo, MS selaku
ketua komisi pembimbing dan ibu Dr Utami Dyah Syafitri, SSi, MSi selaku anggota
komisi pembimbing atas arahan, bimbingan dan saran kepada penulis. Penulis juga
mengucapkan terima kasih kepada ibu Dr Ir Erfiani, MSi selaku penguji luar komisi
dan bapak Dr Ir I Made Sumertajaya, MS selaku ketua penguji pada ujian sidang
yang telah memberikan saran dan masukan sehingga penulis dapat menghasilkan
karya tulis yang lebih baik. Selanjutnya penulis mengucapkan terima kasih kepada
Direktorat Jenderal Pendidikan Tinggi (DIKTI) atas beasiswa Fresh Graduate (FG)
yang diberikan, seluruh dosen serta staf Departemen Statistika IPB atas bimbingan
dan bantuannya, dan teman-teman yang selalu mengingatkan dan memberikan
semangat kepada penulis. Penghargaan setinggi-tingginya penulis sampaikan
kepada bapak Rebani, ibu Lestari Yuli Astuti, adik Lalan Agung Prasetyo dan serta
seluruh keluarga atas segala pengorbanan, doa, dan kasih sayang kepada penulis.
Semoga karya ilmiah ini dapat bermanfaat bagi khalayak luas.
Bogor, Januari 2017
DAFTAR ISI
DAFTAR TABEL
vi
DAFTAR GAMBAR
vi
DAFTAR LAMPIRAN
vi
1
PENDAHULUAN
1
Latar Belakang
1
Tujuan Penelitian
2
2
TINJAUAN PUSTAKA
2
Regresi Kuadrat Terkecil Parsial (RKTP)
2
Validasi Silang
3
Pemilihan Peubah
4
Kriteria Pemilihan Model
6
3
METODOLOGI PENELITIAN
7
Data
7
Metode Analisis
8
4
HASIL DAN PEMBAHASAN
12
Data Cleaning
12
Eksplorasi Data
12
RKTP
13
Pemilihan Model Terbaik
20
5
SIMPULAN DAN SARAN
21
Simpulan
21
Saran
22
DAFTAR PUSTAKA
23
LAMPIRAN
25
DAFTAR TABEL
1
Nilai RMSE yang dihasilkan pada proses validasi silang model
L-RKTPK32
14
2
Nilai RMSE yang dihasilkan pada proses validasi silang model
RKTP-VIPK32
16
3
Kriteria kebaikan model
20
DAFTAR GAMBAR
1
Skema pembagian kelompok pada validasi silang
4
2
Diagram alir pada metode analisis
9
3
Diagram kotak garis PDRB pada sektor pertanian 2013
12
4
Diagram scree dari model RKTP dengan LASSO sebagai kriteria
penentu peubah penjelas yang berpengaruh terhadap peubah respon
14
5
Diagram korelasi loadings antara peubah penjelas dengan dua komponen
yang digunakan pada model L-RKTPK02
15
6
Diagram nilai loadings pada model L-RKTPK02
15
7
Diagram scree model RKTP dengan VIP sebagai kriteria pemilihan
peubah penjelas
16
8
Diagram pencar 590 peubah penjelas dengan batas VIP=0.8 (
-
-
) dan
VIP=1.0 (
─
)
17
9
Diagram pencar 326 peubah penjelas dengan batas VIP=0.8
17
10
Diagram beban korelasi antara peubah penjelas dengan dua komponen
yang digunakan pada model RKTP-VIP08K02
18
11
Diagram pencar 271 peubah penjelas dengan batas VIP=1.0
19
12
Diagram beban korelasi antara peubah penjelas dengan dua komponen
yang digunakan pada model RKTP-VIP10K02
19
DAFTAR LAMPIRAN
1
Daftar peubah yang digunakan dalam penelitian
25
2
Daftar peubah penjelas yang digunakan pada model RKTP dengan
1
PENDAHULUAN
Latar Belakang
Produk Domestik Regional Bruto (PDRB) merupakan indikator penting yang
berguna untuk mengetahui kondisi perekonomian di suatu daerah. Angka ini
diperoleh dari nilai tambah bruto seluruh barang dan jasa yang dihasilkan pada
suatu wilayah sebagai akibat aktivitas ekonomi dalam periode tertentu (BPS 2015).
Angka PDRB diukur pada dua level pemerintahan, yaitu pada tingkat kabupaten
dan tingkat provinsi. Fokus penelitian ini adalah PDRB pada tingkat provinsi.
Angka PDRB memiliki beberapa kegunaan, antara lain untuk melihat
pergeseran struktur ekonomi, mengetahui pertumbuhan ekonomi di suatu daerah
dari tahun ke tahun, dan untuk melihat struktur perekonomian atau peranan setiap
lapangan usaha dalam menunjukan basis perekonomian pada suatu daerah.
Berkaitan dengan manfaat yang terakhir, informasi tersebut dapat diperoleh dari
angka PDRB berdasarkan lapangan usaha. Badan Pusat Statistik (BPS)
mengelompokkan PDRB berdasarkan lapangan usaha ke dalam 17 kategori, salah
satunya adalah Kategori A yang merupakan sektor pertanian. Sektor ini diperinci
menjadi subsektor pertanian, peternakan, perburuan, dan jasa pertanian; subsektor
perikanan; serta subsektor kehutanan dan penebangan kayu.
Perhitungan angka PDRB pada sektor pertanian dilakukan dengan
pendekatan produksi yang dihitung berdasarkan selisih antara output dengan biaya
antara yang digunakan untuk proses produksi pada suatu sektor/subsektor (BPS
Provinsi Maluku Utara 2015). Output adalah nilai barang atau jasa yang dihasilkan
dalam suatu periode tertentu, sedangkan biaya antara adalah barang dan jasa tidak
tahan lama yang digunakan dalam proses produksi. Perhitungan PDRB pada sektor
pertanian melibatkan lebih dari 300 komoditas pertanian. Secara ekonomi, biaya
yang diperlukan dalam pengumpulan ke-300 peubah tersebut relatif besar,
sedangkan secara statistik dimungkinkan PDRB dapat dihitung hanya dengan
sebagian dari 300 peubah yang berpengaruh. Salah satu metode statistika yang
dapat digunakan dalam penentuan peubah yang berpengaruh tersebut adalah
metode regresi.
Metode regresi yang biasanya digunakan dalam analisis adalah Metode
Kuadrat Terkecil (MKT). Analisis pemodelan dengan MKT memerlukan gugus
peubah penjelas dan peubah respon. Ada beberapa asumsi yang perlu dipenuhi
dalam MKT, salah satunya adalah tidak adanya multikolinieritas di antara peubah
penjelas (X)
. Multikolinieritas merupakan kondisi ketika peubah-peubah penjelas
memiliki korelasi yang relatif tinggi. Kondisi multikolinieritas juga terjadi pada
data berdimensi tinggi, yaitu ketika banyaknya peubah penjelas jauh lebih besar
dibandingkan dengan banyaknya amatan yang digunakan. Kondisi multikolinieritas
membuat matriks informasi (X
''''X) tidak memiliki matriks kebalikan sehingga tidak
dapat melakukan pendugaan terhadap parameter regresi dan pengujian parameter
regresi. Oleh karena itu, perlu digunakan metode lain, salah satunya adalah metode
Regresi Kuadrat Terkecil Parsial (RKTP).
Metode RKTP merupakan metode yang mampu mereduksi dimensi. Metode
ini hampir mirip dengan metode Regresi Komponen Utama (RKU), hanya saja
RKTP melibatkan keragaman peubah penjelas dan peubah respon dalam
2
membangun skor komponen (Mevik & Wehrens 2007). Ada beberapa algoritme
RKTP, yaitu Non-linear Iterative Partial Least Square (NIPALS), Straight
Forward Implementation of Statistically Inspired Modification (SIMPLS), dan
algoritme kernel.
Metode RKTP biasanya diterapkan pada bidang kemometrika, ekologi,
kedokteran, klimatologi, dan biologi. Penerapan RKTP pada bidang kimia
dilakukan oleh Wold et al. (2001) dalam analisis data enzim. Penerapan lain dalam
bidang kemometrika dilakukan oleh Wigena & Aunuddin (1998) pada analisis yang
bertujuan menduga kandungan protein dalam gandum. Wigena (2011) menerapkan
metode RKTP pada bidang klimatologi untuk menduga curah hujan pada beberapa
stasiun curah hujan di Indramayu berdasarkan data Global Circulation Model
(GCM). Metode RKTP diterapkan oleh Carascal et al. (2009) pada data ekologi
karena amatan lebih sedikit dibandingkan dengan peubah yang digunakan.
Tondel
et al. (2011) menggunakan RKTP pada salah satu tahapan analisisnya untuk
memodelkan data genetik.
Metode RKTP dapat menghasilkan dugaan peubah respon dengan
memanfaatkan semua peubah penjelas. Meskipun demikian, penelitian ini akan
memilih peubah penjelas yang benar-benar berpengaruh terhadap respon. Proses
pemilihan peubah penjelas dilakukan dengan metode regresi Least Absolute
Shrinkage and Selection Operator (LASSO) dan statistik Variable Importance in
the Projection (VIP).
Tujuan Penelitian
Tujuan dari penelitian ini adalah sebagai berikut:
1.
Mengaplikasikan RKTP untuk mengatasi data berdimensi tinggi (jumlah
peubah penjelas yang lebih banyak dari pada jumlah amatan yang digunakan).
2.
Menyeleksi peubah penjelas yang berpengaruh terhadap PDRB sektor pertanian
dengan LASSO dan VIP.
2
TINJAUAN PUSTAKA
Regresi Kuadrat Terkecil Parsial (RKTP)
Metode RKTP merupakan metode regresi yang tidak memerlukan asumsi
sebaran. Metode ini memiliki dua persamaan linier sehingga disebut sebagai model
bilinier. Berikut ini adalah model bilinier RKTP:
X=TP
'+E
y=Uc'+f
dengan X (n×k) merupakan matriks peubah penjelas, T adalah matriks skor peubah
penjelas berukuran n×a yang kolom-kolomnya berisikan vektor t
a. P (k×a) adalah
matriks loading dari matriks X yang kolom-kolomnya berisikan vektor loading
matriks peubah penjelas p
a
. Matriks E merupakan matriks sisaan yang berukuran
n×k . Vektor y (n×1) adalah vektor peubah respon, U merupakan matriks skor
3
adalah vektor weight bagi vektor y. Vektor f merupakan vektor sisaan y berukuran
n×1
. Indeks n menunjukan banyaknya amatan, a merupakan banyaknya
komponen (peubah laten) pada model RKTP, dan indeks k menunjukan banyaknya
peubah penjelas.
Komponen merupakan kombinasi linier dari peubah penjelas yang memiliki
koragam tinggi dengan peubah respon (Akarachantachote et al. 2014). Sifat
komponen tersebut saling bebas sehingga kondisi multikolinieritas dari data
berdimensi tinggi dapat teratasi. Penentuan banyaknya komponen yang digunakan
pada data dapat diputuskan dengan diagram scree, yaitu ketika garis pada diagram
pada suatu titik lebih curam ke kiri namun landai ke kanan. Diagram scree diperoleh
dari statistik tertentu yang digunakan pada proses validasi silang.
Validasi Silang
Banyaknya komponen yang terlibat di dalam analisis RKTP ditentukan
dengan validasi silang. Metode ini mampu memprediksi kesalahan pendugaan
dalam pemodelan dengan melibatkan komponen dengan jumlah tertentu. Ada dua
metode dalam validasi silang, yaitu validasi lipat-K (K-fold validation) dan metode
leave-one-out (LOO) (Hastie et al. 2008).
Validasi lipat-K dilakukan dengan membagi data sebanyak K kelompok
dengan ukuran yang relatif sama. Sebanyak K-1 kelompok bertugas untuk
membangun model dan gugus data ini disebut sebagai gugus data pemodelan. Satu
kelompok sisanya digunakan sebagai gugus data validasi. Simpangan hasil
pemodelan dihitung berdasarkan kedua gugus tersebut. Proses ini diulangi hingga
semua kelompok data telah digunakan sebagai gugus data validasi. Proses iterasi
tersebut akan menghasilkan K buah nilai simpangan yang selanjutnya digunakan
untuk menghitung kesalahan prediksi pada validasi silang. Ilustrasi proses validasi
silang lipat-K ditampilkan pada Gambar 1.
Metode validasi LOO biasa digunakan pada data dengan jumlah amatan yang
relatif kecil. Konsep metode validasi LOO hampir mirip dengan metode lipat-K
dengan perbedaan yang terletak pada banyaknya kelompok validasi. Metode LOO
membagi data sebanyak amatan yang terlibat, sehingga kelompok validasi yang
terbentuk adalah sejumlah n. Amatan sejumlah n-1 digunakan sebagai gugus
pemodelan dan satu amatan yang tidak termasuk ke dalam gugus data pemodelan
digunakan sebagai data validasi. Proses ini dilakukan n kali hingga semua amatan
pernah digunakan gugus validasi. Proses validasi silang diakhiri dengan
perhitungan kesalahan prediksi pada validasi silang.
Metode validasi silang yang digunakan pada penelitian ini adalah metode
LOO. Kesalahan prediksi akan dihitung dengan Root Mean Square Error of
Prediction (RMSEP). Berikut ini adalah persamaan RMSEP yang digunakan dalam
validasi silang.
RMSEP =
∑ y
i -i-y
i 2 n i=1n
4
dengan y
i-imerupakan prediksi peubah respon ke-i tanpa mengikutsertakan amatan
ke-i dan y
imenyatakan nilai peubah respon yang sesungguhnya pada amatan
ke-i,
i=1, 2, …, n (Esbensen et al. 2002).
Pemilihan Peubah
LASSO
Metode Least Absolute Shrinkage and Selection Operator (LASSO) adalah
metode regresi yang diajukan oleh Tibshirani pada tahun 1996. Metode ini
merupakan solusi untuk memperbaiki hasil dugaan koefisien regresi yang
dihasilkan oleh MKT (Tibshirani 1996). Nilai dugaan yang dihasilkan oleh MKT
cenderung memiliki bias yang rendah namun memiliki ragam tinggi. Keakuratan
dugaan parameter regresi tersebut dapat ditingkatkan dengan penyusutan beberapa
koefisien regresi LASSO.
Regresi LASSO memiliki asumsi bahwa amatan bersifat saling bebas dan
peubah penjelas memiliki kondisi yang terbakukan. Peubah penjelas yang
digunakan dalam regresi LASSO perlu ditransformasi dengan persamaan berikut
Gambar 1 Skema pembagian kelompok pada validasi silang
Kelompok 1 Kelompok 2 … Kelompok K-1 Kelompok K Iterasi ke-1 Gugus data
validasi Gugus data pemodelan
Kelompok 1 Kelompok 2 … Kelompok K-1 Kelompok K Iterasi ke-2 Gugus data validasi
Gugus data pemodelan Gugus data pemodelan Kelompok 1 Kelompok 2 … Kelompok K-1 Kelompok K Iterasi ke-K-1
Gugus data pemodelan
Kelompok 1 Kelompok 2 … Kelompok K-1 Kelompok K Iterasi ke-K Gugus data validasi Gugus data pemodelan
Gugus data validasi
Gugus data pemodelan
5
z
ij=
x
ij- x
js
jdengan z
ijadalah data dalam kondisi terbakukan, x
jadalah rataan peubah penjelas
ke-j, dan s
jadalah simpangan baku pada peubah ke-j. Data yang sudah mengalami
proses transformasi memiliki nilai harapan nol dan ragam satu.
Ide dasar regresi LASSO dalam menghasilkan dugaan parameter regresi
adalah dengan menambahkan kendala pada solusi MKT. Misalkan terdapat gugus
data dengan n amatan
zzzz
i,y
i, i=1,2,…, n, dan
zzzz
i= z
i1,…,z
ik Tmerupakan peubah
penjelas sebanyak k peubah. Persamaan regresi yang digunakan adalah
y
i= β
0+
z
ijβ
jk
j=1
+ ε
idengan ε
imerupakan dugaan sisaan. Solusi untuk dugaan persamaan regresi
dengan MKT diperoleh dengan meminimumkan jumlah sisaan kuadrat atau dapat
dituliskan sebagai
β
min
ε
i2 k j=1=
min
y
i-y
i 2 n i=1dengan
iadalah dugaan peubah respon yang diperoleh dari y
= β
0-
∑ z
ijβ
j k
j=1
.
Sehingga persamaan diperoleh jumlah kuadrat sisaan yang diminimumkan sebagai
berikut
β
min
ε
i2 k j=1=
min
y
i- β
0-
z
ijβ
j k j=1 2 n i=1Solusi LASSO diperoleh dari persamaan bagi solusi MKT ditambahkan kendala
∑ β
kj=1 j≤
t
dan t
≥0, dengan t adalah parameter tuning yang berpengaruh terhadap
besarnya penyusutan. Sehingga solusi bagi regresi LASSO
β
lasso=
arg min
β
y
i-β
0-
z
ijβ
j k j=1 2 n i=1dengan kendala
∑ β
kj=1 j≤
t
dan t
≥0. Persamaan tersebut juga dapat dituliskan
dalam bentuk berikut
β
lasso= arg min
β
y
i-β
0-
z
ijβ
j k j=1 2+λ
β
j k j=1 n i=1, λ ≥ 0
dengan λ adalah parameter kompleksitas yang mengatur besarnya penyusutan.
Fungsi
tersebut
mencari
nilai
β
sehingga
fungsi
∑
ni=1y
i-β
0-∑ z
kj=1 ijβ
j 2+λ
∑ β
kj=1 jmencapai minimum. Fungsi ∑
ni=1y
i-β
0-
∑ z
kj=1 ijβ
j 2akan
selalu bernilai positif, sehingga fungsi λ
∑ β
pj=1 jyang dapat mengatur agar fungsi
6
∑ β
k jj=1
adalah nol, sehingga konstanta λ yang memegang kendali agar fungsi
∑
y
i-β
0-
∑ z
ijβ
j k j=1 2+λ
∑ β
j k j=1 ni=1
menjadi minimum. Nilai terkecil dari λ adalah
nol dan jika λ
0, maka solusi yang dihasilkan sama dengan solusi yang dihasilkan
MKT. Sehingga semakin tinggi nilai λ maka parameter LASSO yang diperoleh
akan semakin mendekati nol.
Metode LASSO merupakan metode regresi yang dapat menyusutkan
beberapa dugaan parameter regresi sehingga menjadi nol. Koefisien regresi LASSO
yang mencapai nilai nol menunjukan bahwa peubah penjelas terkait tidak memiliki
pengaruh penting terhadap peubah respon. Kemampuan regresi LASSO yang dapat
menyusutkan dugaan koefisien regresi tersebut dapat digunakan sebagai metode
seleksi peubah penjelas.
Solusi persamaan LASSO tidak memiliki bentuk tertutup dan hanya dapat
diperoleh dengan pemrograman kuadratik (Tibshirani 1996). Ada beberapa
algoritme yang dapat digunakan pada analisis regresi LASSO, salah satunya adalah
dengan memodifikasi algoritme Least Angle Regression (LARS). Hastie et al.
(2008) menyebutkan bahwa algoritme LARS merupakan algoritme yang efisien
untuk kasus
k
≫
n
.
Variable Importance in the Projection
Variable importance in the projection (VIP) adalah salah satu metode yang
digunakan untuk pemilihan peubah. Statistik ini biasanya digunakan pada
pemilihan peubah dengan RKTP. Pemilihan peubah tersebut akan didasarkan atas
nilai VIP yang dihitung berdasarkan persamaan berikut
VIP
j= k
#
c
i2t
'it
iw
ji/
‖w
i‖
2 a i=1%
c
i2t
i't
i a i=1&
dengan k menunjukan banyaknya peubah penjelas yang digunakan, i=1, 2, …, a
menunjukan komponen yang digunakan, c
imenunjukan bobot pada vektor respon
untuk komponen ke-i, dan w
jimenunjukan bobot matriks peubah penjelas ke-j pada
komponen ke-i. Ada beberapa nilai ambang batas (cut-off) yang dapat digunakan
dalam RKTP. Chong & Jun (2004) berpendapat bahwa suatu peubah penjelas
memberikan pengaruh yang signifikan jika nilai VIP-nya melebihi 1.0, sedangkan
Wold (1994) berpendapat bahwa suatu peubah penjelas memberikan pengaruh yang
penting terhadap peubah respon jika nilai VIP-nya di atas 0.8.
Kriteria Pemilihan Model
Model terbaik dipilih berdasarkan beberapa kriteria, di antaranya kemampuan
model dalam menghasilkan nilai dugaan peubah respon, tingkat kesalahan, dan
kesederhanaan model. Statistik yang dapat digunakan dalam pengukuran
kemampuan prediksi model di antaranya adalah korelasi dan Root Mean Square
Error (RMSE). Model terbaik ditunjukan dengan nilai korelasi yang paling besar
namun nilai RMSE yang paling kecil.
Kekuatan hubungan linier antara dua peubah dapat diukur dengan nilai
korelasi. Semakin mirip hasil dugaan peubah penjelas dengan data aslinya, maka
7
nilai korelasinya mendekati satu. Berikut ini adalah formula untuk menghitung nilai
korelasi
r
YY'=
∑ y
i-y
y
i-y
n i=1
(∑ y
ni=1 i-y
2(∑ y
ni=1 i-y
2dengan y
imenyatakan nilai sesungguhnya dan
y
imerupakan hasil prediksi data
pemodelan pada amatan ke- i, i=1,2,…,n
. Notasi y menyatakan rataan peubah
respon yang sesungguhnya dan y menyatakan rataan dugaan peubah respon.
RMSE adalah statistik yang dapat digunakan untuk mengukur kesalahan hasil
prediksi dengan data aslinya. Berikut ini adalah rumus perhitungan RMSE (Chen
& Wei 2006)
RMSE
=
1
n
y
i-y
i 2 n i=1dengan i=1,
2, …, n.
3
METODOLOGI PENELITIAN
Data
Data yang digunakan dalam penelitian ini adalah data sekunder yang terdiri
dari data PDRB sektor pertanian tahun 2013 dan data Sensus Pertanian 2013
(ST2013). Data PDRB diperoleh dari publikasi yang dikeluarkan oleh BPS
sedangkan data Sensus Pertanian 2013 (ST2013) diunduh dari situs ST2013 yang
dikelola oleh BPS. Data PDRB digunakan sebagai peubah respon sedangkan data
ST2013 digunakan sebagai peubah penjelas. Data tersebut dikumpulkan pada skala
provinsi sehingga banyaknya amatan yang digunakan adalah 34 provinsi.
Data yang digunakan untuk memodelkan PDRB berbeda dengan data dalam
perhitungan PDRB secara konvensional. Perhitungan PDRB selama ini
memerlukan data harga dan kuantitas suatu komoditas. Sementara itu, penelitian ini
tidak melibatkan harga namun melibatkan informasi lain terkait komoditas tersebut.
Semua informasi yang terkandung di dalam data ST2013 diikutsertakan dalam
pemodelan, yaitu sejumlah 590 peubah. Data ST2013 terdiri dari 85 peubah
mencakup informasi umum berkaitan pertanian Indonesia, 162 peubah berasal dari
subsektor tanaman pangan, 31 peubah berasal dari subsektor tanaman hortikultura,
46 peubah berasal dari subsektor perikanan, 214 peubah berasal dari subsektor
perkebunan, 33 peubah berasal dari subsektor peternakan, dan 19 peubah berasal
dari subsektor kehutanan. Daftar peubah yang digunakan pada penelitian ini
terdapat pada Lampiran 1.
Kegiatan ST2013 dilakukan dalam tiga tahap, yaitu pencacahan lengkap
usaha pertanian yang dilakukan pada Mei 2013, survei pendapatan rumah tangga
usaha pertanian yang dilakukan pada November 2013, dan survei struktur ongkos
komoditas pertanian strategis dalam setiap subsektor pertanian yang dilakukan dari
bulan Mei hingga Oktober 2014. Pendekatan PDRB yang digunakan adalah
pendekatan produksi sehingga data dari survei yang terakhir tidak diikutsertakan
dalam analisis.
8
Metode Analisis
Gambar 2 menunjukan diagram alir metode analisis pada penelitian ini.
Tahapan analisis adalah sebagai berikut:
1.
Mengumpulkan data ST2013 dan data PDRB provinsi atas dasar harga berlaku
menurut lapangan usaha pada sektor pertanian tahun 2013.
2.
Melakukan data cleaning.
3.
Melakukan eksplorasi data.
4.
Melakukan pembakukan data dengan transformasi berikut
Z
ij=
X
ij- µ
j
σ
j, i=1,2,…, 34; dan j=1,2,…,590;
dengan Z
ijadalah data yang sudah dibakukan pada amatan ke-i dan peubah
penjelas ke-j,
μ
jadalah rataan peubah penjelas ke-j,
σ
jmerupakan simpangan
baku pada peubah penjelas ke-j.
5.
Melakukan analisis data.
Analisis RKTP pada penelitian ini menggunakan algoritme NIPALS
(Wold et al. 2001), yaitu dengan tahapan sebagai berikut:
1)
Melakukan inisialisasi vektor u dengan memanfaatkan vektor peubah
respon, u=y.
2)
Menghitung pembobot matriks peubah penjelas X
, yaitu w=
X 'u u'u
dan
mengubah vektor w menjadi otonormal, w=
w, ,, ,(w'w)
.
3)
Menduga skor pada matriks X, yaitu t=Xw.
4)
Menghitung pembobot peubah respon, yaitu c=y
't/(t
't).
5)
Memperbarui skor pada vektor peubah respon, yaitu u=yc/(c
'c).
6)
Menguji kekonvergenan berdasarkan perubahan t dengan menggunakan
‖tlama-tbaru‖ ‖tbaru)‖
<ε , dengan ε merupakan batas kekonvergenan yang nilainya
sangat kecil. Jika kondisi tersebut tidak tercapai, maka iterasi dikembalikan
ke langkah 2), namun jika kondisi tersebut tercapai maka iterasi dilanjutkan
ke langkah 7). Kesimpulan yang dihasilkan pada data dengan satu peubah
respon bersifat konvergen sehingga analisis dapat dilanjutkan ke tahapan
berikutnya.
7)
Menyederhanakan matriks X dan vektor y.
p=X
't/(t't)
X=X-tp
'y=y-tc
'8)
Mengulangi proses iterasi pada komponen selanjutnya (dari langkah 1)
hingga validasi silang mengindikasikan bahwa tidak terdapat informasi
penting di dalam X yang berkaitan dengan
yyyy.
Parameter regresi yang dihasilkan oleh analisis RKTP dengan
algoritme NIPALS dapat diduga dengan persamaan berikut
9
Analisis RKTP digunakan sebagai analisis utama dan dikombinasikan
dengan metode pemilihan peubah yang terbagi ke dalam dua strategi. Strategi
pertama dilakukan dengan penerapan regresi LASSO sebelum analisis RKTP
sedangkan strategi kedua dilakukan dengan statistik VIP setelah analisis RKTP.
Gambar 2 Diagram alir pada metode analisis
Data Eksplorasi Data Pemilihan model terbaik Data Cleaning Transformasi X ke Z - . / 01 Transformasi balik dari Z ke X pada model terbaik Regresi LASSO Z terhadap Y RKTP Analisis model berdasarkan hasil seleksi peubah dengan
regresi LASSO
Seleksi komponen berdasarkan validasi
silang Pemeriksaan kebebasan antar sisaan
dengan uji runtunan
Y dan Z terpilih dari Regresi LASSO Analisis RKTP antara Z dengan Y Seleksi peubah Analisis dengan peubah penjelas yang memiliki p engaruh penting terhadap peubah respon Seleksi komponen berdasarkan validasi silang Analisis dengan peubah penjelas yang memiliki pengaruh p enting terhadap p eubah respon Seleksi komponen berdasarkan validasi silang S t r a t e g i 1 S t r a t e g i 2 VIP = 0.8 VIP = 1.0
10
a.
Strategi 1.
Melakukan pengujian asumsi pada pada regresi LASSO sebelum
melakukan analisis dengan RKTP. Berikut adalah algoritme LARS (Hastie
et al. 2008) yang digunakan pada penelitian ini:
1)
Melakukan inisialisasi e=y-y
2 dan β
j=0, j=1,2,…,
k, dengan notasi e
merupakan vektor sisaan dan k adalah banyaknya peubah penjelas.
2)
Menemukan peubah penjelas z
jyang memiliki korelasi yang paling kuat
dengan e.
3)
Memperbarui β
jdari nilai 0 bergerak menuju koefisien kuadrat terkecil
〈zzzz
j,
eeee〉, hingga peubah kompetitor z
klain memiliki korelasi sebesar
korelasi antara z
jdengan sisaan saat ini.
4)
Mengubah β
j
dan β
kke arah yang didefinisikan oleh koefisien kuadrat
terkecil bersama dari sisaan sekarang pada z
j,z
k, hingga beberapa
peubah kompetitor
zzzz
lmemiliki korelasi dengan sisaan sekarang dengan
besaran yang sama.
5)
Mengulangi langkah-langkah tersebut hingga semua peubah penjelas k
telah masuk. Solusi model penuh untuk model penuh kuadrat terkecil
diperoleh setelah min (n-1,
k
) langkah.
Algoritme LASSO memodifikasi langkah 4 dengan mengeluarkan
peubah penjelas jika terdapat koefisien regresi yang nilai awalnya bukan
nol mencapai nilai nol dan menghitung kembali arah kuadrat terkecil
bersama.
Regresi LASSO menghasilkan nilai dugaan peubah respon. Selisih
antara peubah respon dengan dugaannya akan menghasilkan sisaan. Nilai
tersebut selanjutnya diuji kebebasan dengan uji runtunan. Pengujian
terhadap sisaan dilakukan karena terdapat asumsi pada regresi LASSO,
yaitu berkaitan dengan kebasan antar amatan. Sisaan digunakan dalam
pengujian karena keragaman data berasal dari sisaan dan peubah penjelas
diasumsikan bersifat tetap. Hal ini berakibat keragaman peubah respon
dapat diukur berdasarkan keragaman sisaan model. Hipotesis yang
digunakan pada uji runtunan adalah sebagai berikut.
H
6: sisaan saling bebas
H
8: sisaan tidak saling bebas.
Peubah penjelas yang terpilih dari regresi LASSO selanjutnya
digunakan sebagai peubah penjelas pada analisis RKTP. Model yang
dihasilkan disebut sebagai model L-RKTPKAA. Notasi L menunjukan
bahwa model tersebut menggunakan regresi LASSO sebagai metode
pemilihan peubah. Posisi notasi L yang terletak sebelum notasi RKTP
berarti proses pemilihan peubah dilakukan sebelum analisis RKTP. Notasi
KAA menunjukan banyaknya komponen yang terlibat di dalam model,
dengan AA berupa angka yang terdiri dari dua digit. Analisis dilakukan
dengan semua komponen yang mungkin diikutsertakan pada model dan
dengan jumlah komponen yang lebih sedikit.
b.
Strategi 2.
Melakukan analisis RKTP pada 590 peubah penjelas dan satu peubah
respon. Analisis dilanjutkan dengan dengan pemilihan peubah penjelas
11
berdasarkan nilai VIP. Jika nilai VIP suatu peubah penjelas di atas nilai
ambang batas, yaitu VIP=0.8 dan VIP=1.0, peubah penjelas tersebut
memiliki pengaruh penting terhadap peubah respon.
Notasi model yang dihasilkan analisis RKTP Strategi 2 dinyatakan
dengan RKTP-VIPBBKAA. Notasi VIP yang terletak di belakang RKTP
berarti bahwa proses pemilihan peubah dilakukan setelah analisis RKTP.
Notasi BB menunjukan nilai VIP yang digunakan sebagai batas dan KAA
menunjukan banyaknya komponen yang terlibat di dalam model. Analisis
dilakukan dengan semua komponen yang mungkin diikutsertakan pada
model dan dengan jumlah komponen yang lebih sedikit.
Perangkat lunak yang digunakan dalam penelitian ini adalah perangkat
lunak R dan dengan bantuan beberapa paket. Analisis RKTP dilakukan dengan
paket pls. Pemilihan peubah dengan regresi LASSO menggunakan paket lars
sedangkan statistik VIP tidak menggunakan paket. Nilai VIP diperoleh dari
fungsi yang dikembangkan oleh Bjørn & Mevik (2007) dan fungsi tersebut
berhubungan dengan paket pls.
6.
Melakukan pemilihan model terbaik hasil analisis dengan Strategi 1 dan
Strategi 2 berdasarkan tiga kriteria.
Kriteria yang pertama adalah kemampuan model dalam menghasilkan
nilai dugaan peubah respon. Statistik yang digunakan dalam kriteria ini adalah
nilai korelasi dan RMSE. Suatu model semakin baik jika nilai korelasinya
semakin mendekati satu namun nilai RMSEnya kecil. Nilai korelasi antara
peubah respon dengan dugaannya yang mendekati berarti nilai dugaan yang
dihasilkan semakin mirip dengan nilai aslinya. Sementara nilai RMSE yang
semakin kecil menandakan bahwa kesalahan model dalam menghasilkan nilai
dugaan juga semakin kecil.
Kriteria kedua dalam penentuan model terbaik adalah kemampuan model
dalam menjelaskan keragaman peubah respon dan peubah penjelas. Metode
RKTP merupakan metode analisis regresi yang menghasilkan nilai dugaannya
dengan memanfaatkan proses penguraian peubah dan transformasi. Proses
penguraian peubah dapat dilihat dari persamaan RKTP yang merupakan model
bilinier. Peubah penjelas diuraikan menjadi persamaan yang terpisah dari
peubah respon. Kedua peubah tersebut mengandung komponen yang nilainya
diperoleh dari kombinasi linier antara peubah penjelas dan peubah respon.
Sehingga, kemampuan RKTP dalam menjelaskan peubah penjelas dan peubah
respon menjadi salah satu kriteria penentu kebaikan model.
Kriteria terakhir yang digunakan sebagai penentu model terbaik adalah
banyaknya peubah dan komponen di dalam model yang terbentuk. Hal tersebut
berkaitan dengan kesederhanaan model. Model sederhana merupakan model
yang melibatkan sedikit peubah penjelas dan komponen.
12
4
HASIL DAN PEMBAHASAN
Data Cleaning
Proses data cleaning dilakukan pada data ST2013. Banyaknya peubah yang
diperoleh dari situs Sensus Pertanian 2013 adalah sejumlah 1278 peubah. Data
tersebut mengandung informasi mengenai subsektor penyusun pertanian Indonesia
dan jasa pertanian. Perhitungan PDRB dengan pendekatan produksi tidak
mengikutsertakan data terkait jasa pertanian, sehingga peubah-peubah tersebut
dikeluarkan dari calon peubah penjelas.
Jumlah calon peubah penjelas setelah peubah jasa pertanian dikeluarkan
adalah 606 peubah. Proses data cleaning dilanjutkan dengan pemeriksaan calon
peubah penjelas agar tidak muncul sebanyak dua kali atau lebih. Setelah diperiksa,
banyaknya peubah penjelas yang digunakan dalam analisis berjumlah 590 peubah.
Eksplorasi Data
Pemeriksaan pada peubah respon dilakukan pada data yang belum dibakukan
dan dilakukan dengan bantuan diagram kotak garis. Berdasarkan Gambar 3,
diperoleh informasi bahwa terdapat pencilan pada data PDRB sektor pertanian
tahun 2013. Kriteria batas pencilan yang digunakan adalah 1.5× Jangkauan Antar
Kuartil 1.5× JAK
, sehingga suatu provinsi tergolong sebagai pencilan jika
memiliki nilai PDRB di luar selang
9Kuartil
1-1.5× JAK, Kuartil
3+1.5× JAK
: atau
tidak berada di antara selang [-36821.5, 86446.5]. Provinsi yang memiliki nilai
PDRB di luar selang tersebut adalah provinsi Jawa Timur, Jawa Tengah, Jawa
Barat, Sumatera Utara, dan Riau. Kelima provinsi ini memiliki nilai PDRB yang
relatif lebih tinggi dibandingkan provinsi lain.
200000 150000 100000 50000 0 P D R B S e k t o r P e r t a n ia n 2 0 1 3 Jawa Timur Jawa Tengah Jawa Barat Riau Sumatera Utara
13
Proses eksplorasi data pada peubah penjelas tidak menggunakan diagram
kotak garis. Hal ini dikarenakan terdapat 590 peubah sehingga pemeriksaan
dilakukan dengan nilai terbakukan provinsi pada masing-masing peubah. Provinsi
Jawa Timur, Jawa Tengah, Jawa Barat, Sumatera Utara, dan Riau memiliki nilai
terbakukan yang relatif jauh dari nilai nol pada hampir semua peubah penjelas. Nilai
peubah penjelas pada kelima provinsi tersebut relatif lebih tinggi dibandingkan
provinsi lain. Hal ini berarti kelima provinsi tersebut menghasilkan komoditas
pertanian yang relatif lebih tinggi dibandingkakn provinsi lain.
Tingginya nilai PDRB pada Jawa Timur, Jawa Tengah, Jawa Barat, Sumatera
Utara, dan Riau dapat dikaitkan dengan tingginya peubah penjelas pada provinsi
yang bersangkutan. Karena sesuai dengan pendapat Frank & Bernanke (2004) dan
Mankiw (2007), PDRB diperoleh dari hasil kali kuantitas produk dengan harganya.
Berdasarkan hal ini, dapat disimpulkan bahwa semakin tinggi produk pertanian
maka PDRB sektor pertanian pada wilayah tersebut akan semakin tinggi.
RKTP
L-RKTP
Nilai-p yang dihasilkan uji runtunan pada sisaan yang dihasilkan model
regresi LASSO adalah sebesar 0.696. Kesimpulan yang diambil dengan taraf nyata
5% adalah tidak tolak H0 yang artinya sisaan LASSO bersifat saling bebas. Karena
asumsi regresi LASSO sudah terpenuhi, maka analisis dilanjutkan dengan RKTP.
Analisis dengan regresi LASSO menunjukan bahwa terdapat 33 peubah
penjelas yang memiliki pengaruh terhadap peubah respon. Ke-33 peubah tersebut
merupakan peubah dengan koefisien regresi LASSO yang nilainya tidak nol.
Peubah-peubah tersebut tersusun dari 2 peubah dari subsektor pertanian umum, 5
peubah dari subsektor tanaman pangan, 4 peubah dari subsektor tanaman
hortikultura, 2 peubah dari subsektor peternakan, 13 peubah dari subsektor tanaman
perkebunan, 6 peubah dari subsektor perikanan, dan 1 peubah dari subsektor
kehutanan. Peubah penjelas terpilih ini selanjutnya digunakan untuk memodelkan
peubah respon dengan metode RKTP.
Analisis dengan RKTP menunjukan bahwa terdapat 32 komponen yang
terbentuk dari 33 peubah penjelas. Model ini selanjutnya disebut sebagai model
L-RKTPK32. Model L-RKTPK32 mampu menjelaskan 99.99% keragaman peubah
penjelas dan seluruh keragaman pada peubah respon. Korelasi yang dihasilkan
antara PDRB dugaan model dengan data asli PDRB sektor pertanian tahun 2013
adalah sebesar 0.997. Besarnya kesalahan yang dihasilkan model diukur dengan
RMSE, yaitu sebesar 21556.08.
Analisis dilanjutkan dengan pembentukan model yang lebih sederhana, yaitu
dengan melibatkan jumlah komponen yang lebih sedikit. Tabel 1 menunjukan nilai
RMSEP yang dihasilkan. Nilai tersebut selanjutnya digunakan untuk membangun
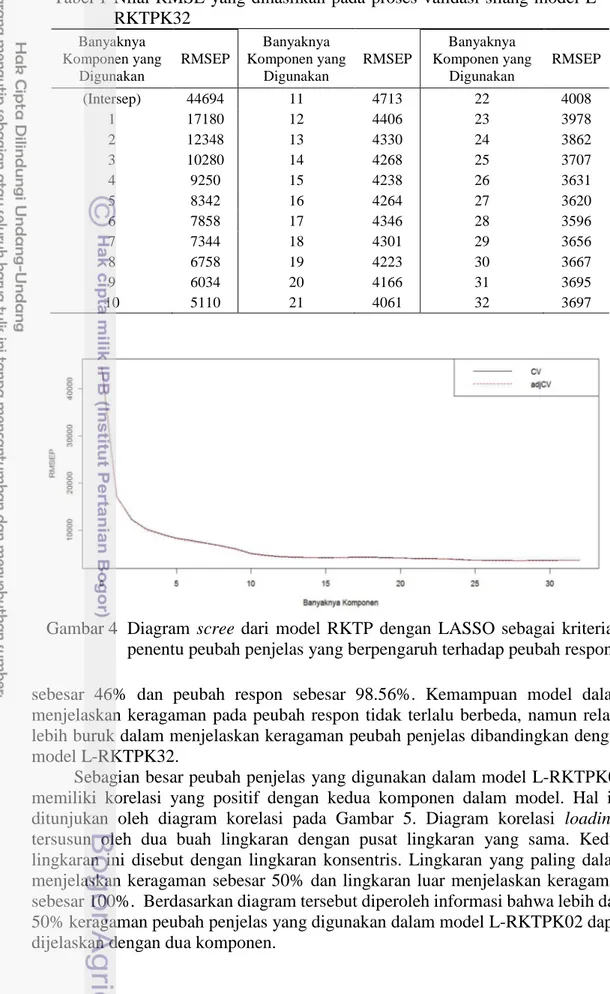
diagram scree pada Gambar 4. Berdasarkan Gambar 4, banyaknya dimensi yang
digunakan adalah sebanyak dua dimensi karena garis yang terletak pada sisi kiri
pada titik komponen kedua relatif curam dan garis sebelah kanan relatif landai.
Model RKTP dengan dua komponen ini selanjutnya disebut sebagai model
L-RKTPK02 dengan K02 menunjukan banyaknya komponen yang digunakan,
yaitu dua komponen. Model ini mampu menjelaskan keragaman peubah penjelas
14
sebesar 46% dan peubah respon sebesar 98.56%. Kemampuan model dalam
menjelaskan keragaman pada peubah respon tidak terlalu berbeda, namun relatif
lebih buruk dalam menjelaskan keragaman peubah penjelas dibandingkan dengan
model L-RKTPK32.
Sebagian besar peubah penjelas yang digunakan dalam model L-RKTPK02
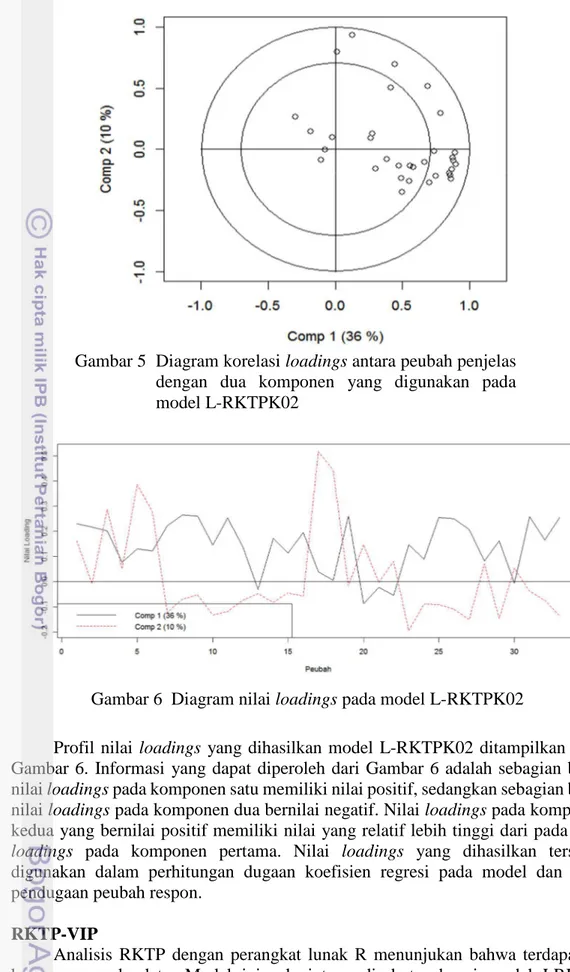
memiliki korelasi yang positif dengan kedua komponen dalam model. Hal ini
ditunjukan oleh diagram korelasi pada Gambar 5. Diagram korelasi loadings
tersusun oleh dua buah lingkaran dengan pusat lingkaran yang sama. Kedua
lingkaran ini disebut dengan lingkaran konsentris. Lingkaran yang paling dalam
menjelaskan keragaman sebesar 50% dan lingkaran luar menjelaskan keragaman
sebesar 100%. Berdasarkan diagram tersebut diperoleh informasi bahwa lebih dari
50% keragaman peubah penjelas yang digunakan dalam model L-RKTPK02 dapat
dijelaskan dengan dua komponen.
Tabel 1 Nilai RMSE yang dihasilkan pada proses validasi silang model
L-RKTPK32
Banyaknya Komponen yang Digunakan RMSEP Banyaknya Komponen yang Digunakan RMSEP Banyaknya Komponen yang Digunakan RMSEP (Intersep) 44694 11 4713 22 4008 1 17180 12 4406 23 3978 2 12348 13 4330 24 3862 3 10280 14 4268 25 3707 4 9250 15 4238 26 3631 5 8342 16 4264 27 3620 6 7858 17 4346 28 3596 7 7344 18 4301 29 3656 8 6758 19 4223 30 3667 9 6034 20 4166 31 3695 10 5110 21 4061 32 3697Gambar 4 Diagram scree dari model RKTP dengan LASSO sebagai kriteria
penentu peubah penjelas yang berpengaruh terhadap peubah respon
15
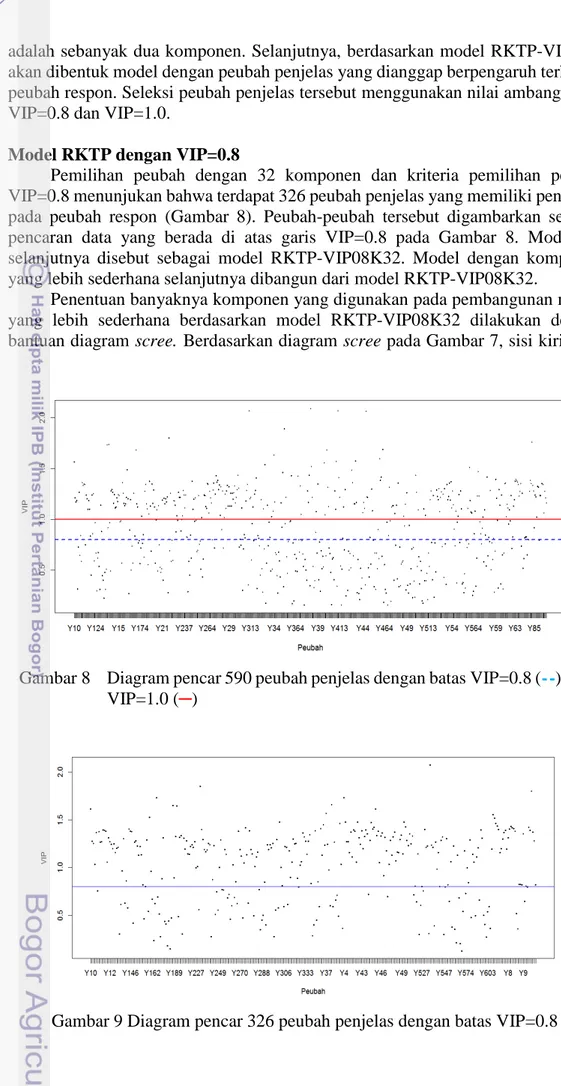
Profil nilai loadings yang dihasilkan model L-RKTPK02 ditampilkan pada
Gambar 6. Informasi yang dapat diperoleh dari Gambar 6 adalah sebagian besar
nilai loadings pada komponen satu memiliki nilai positif, sedangkan sebagian besar
nilai loadings pada komponen dua bernilai negatif. Nilai loadings pada komponen
kedua yang bernilai positif memiliki nilai yang relatif lebih tinggi dari pada nilai
loadings pada komponen pertama. Nilai loadings yang dihasilkan tersebut
digunakan dalam perhitungan dugaan koefisien regresi pada model dan pada
pendugaan peubah respon.
RKTP-VIP
Analisis RKTP dengan perangkat lunak R menunjukan bahwa terdapat 32
komponen pada data. Model ini selanjutnya disebut sebagai model
LRKTP-Gambar 5 Diagram korelasi loadings antara peubah penjelas
dengan dua komponen yang digunakan pada
model L-RKTPK02
16
VIPK32. Model ini mampu menjelaskan keragaman peubah penjelas sebesar
99.39% dan peubah respon sebesar 100%. Kemiripan hasil prediksi peubah penjelas
yang diukur dengan korelasi adalah 0.881, sedangkan kesalahan prediksi yang
diukur dengan RMSE adalah sebesar 122520.67
Tabel 2 menunjukan hasil validasi silang pada model RKTP-VIPK32. Nilai
RMSEP yang dihasilkan tabel tersebut digunakan pada diagram scree yang terlihat
pada Gambar 7. Selisih nilai RMSEP antara komponen pertama dan komponen
kedua relatif lebih besar dibandingkan dengan selisih nilai RMSEP antara
komponen kedua dengan komponen ketiga. Nilai RMSEP pada komponen ketiga
hingga komponen terakhir relatif sama. Kondisi ini terlihat pada Gambar 7 yang
menunjukan kondisi garis yang curam pada sisi kiri titik komponen kedua dan sisi
yang relatif lebih landai pada sisi kanannya. Berdasarkan hal ini, banyaknya
komponen yang digunakan pada model yang dibangun dari model RKTP-VIPK32
Tabel 2 Nilai RMSE yang dihasilkan pada proses validasi silang model
RKTP-VIPK32
Banyaknya Komponen yang Digunakan RMSEP Banyaknya Komponen yang Digunakan RMSEP Banyaknya Komponen yang Digunakan RMSEP (Intersep) 44694 11 20874 22 21012 1 24663 12 20916 23 21012 2 20729 13 20952 24 21012 3 20267 14 20990 25 21012 4 20624 15 20986 26 21012 5 20988 16 20998 27 21012 6 20902 17 21004 28 21012 7 20959 18 21009 29 21012 8 20881 19 21010 30 21012 9 20857 20 21012 31 21012 10 20836 21 21012 32 21012Gambar 7 Diagram scree model RKTP dengan VIP sebagai kriteria pemilihan
peubah penjelas
17
adalah sebanyak dua komponen. Selanjutnya, berdasarkan model RKTP-VIPK32
akan dibentuk model dengan peubah penjelas yang dianggap berpengaruh terhadap
peubah respon. Seleksi peubah penjelas tersebut menggunakan nilai ambang batas
VIP=0.8 dan VIP=1.0.
Model RKTP dengan VIP=0.8
Pemilihan peubah dengan 32 komponen dan kriteria pemilihan peubah
VIP=0.8 menunjukan bahwa terdapat 326 peubah penjelas yang memiliki pengaruh
pada peubah respon (Gambar 8). Peubah-peubah tersebut digambarkan sebagai
pencaran data yang berada di atas garis VIP=0.8 pada Gambar 8. Model ini
selanjutnya disebut sebagai model RKTP-VIP08K32. Model dengan komponen
yang lebih sederhana selanjutnya dibangun dari model RKTP-VIP08K32.
Penentuan banyaknya komponen yang digunakan pada pembangunan model
yang lebih sederhana berdasarkan model RKTP-VIP08K32 dilakukan dengan
bantuan diagram scree. Berdasarkan diagram scree pada Gambar 7, sisi kiri pada
Gambar 8 Diagram pencar 590 peubah penjelas dengan batas VIP=0.8 (
-
-
) dan
VIP=1.0 (
─
)
18
titik komponen kedua menunjukan kondisi yang curam namun landai pada sisi
kanannya. Sehingga banyaknya komponen yang digunakan pada model yang
dibangun dari model RKTP-VIP08K32 adalah dua komponen. Model ini disebut
sebagai model RKTP-VIP08K02.
Berdasarkan model RKTP-VIP08K02, terdapat 218 dari 326 peubah penjelas
yang memiliki pengaruh yang dianggap penting terhadap peubah respon. Ke-218
peubah tersebut merupakan pencaran data yang terletak di atas garis horizontal
VIP=0.8 pada Gambar 9. Tebaran data yang berada di bawah garis tersebut
dianggap tidak memberikan pengaruh yang penting terhadap peubah respon.
Model RKTP-VIP08K02 mampu menjelaskan keragaman peubah penjelas
sebesar 72.55% dan peubah respon sebesar 95.95%. Kemampuan model dalam
penjelasan keragaman peubah penjelas dan peubah respon lebih banyak
dipengaruhi oleh komponen pertama, yaitu sebesar 65.3%. Sebagian besar peubah
penjelas pada model RKTP-VIP08K02 memiliki korelasi positif yang relatif kuat
dengan komponen pertama, sedangkan peubah penjelas yang memiliki nilai
korelasi mendekati nol dengan komponen pertama cenderung memiliki nilai
korelasi positif yang cukup kuat dengan komponen kedua (Gambar 10).
Model RKTP dengan VIP=1.0
Pemilihan peubah dengan nilai batas VIP=1.0 dari model RKTP-VIP32
menunjukan bahwa terdapat 271 peubah penjelas yang berpengaruh terhadap
peubah respon. Berdasarkan Gambar 8, ke-271 peubah tersebut merupakan tebaran
data yang berada di atas garis horizontal yang menunjukan nilai VIP=1.0. Model
ini selanjutnya akan disebut sebagai model RKTP-VIP10K32. Berdasarkan model
RKTP-VIP10K32 akan dibangun model baru dengan banyaknya komponen yang
Gambar 10 Diagram beban korelasi antara peubah penjelas dengan dua
19
terlibat lebih sedikit sehingga dihasilkan model yang lebih sederhana. Sesuai
dengan informasi yang diperoleh dari Gambar 7, banyaknya komponen yang
dilibatkan pada model yang baru adalah dua. Hal ini dikarenakan sisi kiri dari
komponen dua bersifat curam dan landai di sisi kanannya. Model yang dihasilkan
selanjutnya disebut sebagai model RKTP-VIP10K02.
Model RKTP-VIP10K02 menunjukan bahwa terdapat 172 peubah penjelas
yang mempengaruhi peubah respon. Ke-172 peubah tersebut merupakan tebaran
data yang berada di atas garis VIP=1.0 pada Gambar 11. Peubah-peubah tersebut
terdiri dari 56 peubah berisikan informasi umum berkaitan pertanian Indonesia, 46
peubah berasal dari subsektor tanaman pangan, 10 peubah berasal dari subsektor
hortikultura, 14 peubah berasal dari subsektor peternakan, 29 peubah berasal dari
tanaman perkebunan, 9 peubah dari subsektor perikanan, dan 8 peubah dari
subsektor kehutanan.
Gambar 11 Diagram pencar 271 peubah penjelas dengan batas VIP=1.0
Gambar 12 Diagram beban korelasi antara peubah penjelas dengan dua
komponen yang digunakan pada model RKTP-VIP10K02
20
Gambar 12 menunjukan hubungan antara 271 peubah penjelas dengan dua
komponen. Sebagian besar peubah penjelas berada di luar lingkaran konsentris 50%.
Hal ini berarti keragaman yang mampu dijelaskan oleh komponen pertama hampir
100%. Sementara sebagian kecil peubah penjelas mampu dijelaskan keragamannya
oleh komponen kedua. Kemampuan model RKTP-VIP10K02 dalam menjelaskan
keragaman peubah penjelas dengan dua komponen adalah sebesar 77.79%.
Sementara itu, kemampuan model dalam menjelaskan keragaman peubah respon
adalah sebesar 96.16%.
Pemilihan Model Terbaik
Tiga kriteria yang digunakan dalam pemilihan peubah ditampilkan pada
Tabel 3. Berdasarkan kriteria pertama, yaitu kemampuan model dalam
menghasilkan nilai dugaan peubah respon, model L-RKTPK32. Hal ini dikarenakan
model ini memiliki nilai korelasi yang paling tinggi dan RMSE yang paling rendah.
Selain itu, model L-RKTPK32 merupakan model terbaik berdasarkan kriteria kedua.
Model L-RKTPK32 mampu menjelaskan dengan paling berkaitan keragaman
peubah penjelas dan peubah respon. Sementara itu, berdasarkan kriteria terakhir,
yaitu kesederhanaan model, model terbaik adalah model L-RKTPK02. Meskipun
banyaknya peubah penjelas yang digunakan dalam model L-RKTPK32 sama
dengan model L-RKTPK02. Model L-RKTPK02 menggunakan komponen yang
lebih sedikit dibandingkan model L-RKTPK32, sehingga model L-RKTPK02 lebih
sederhana dari pada model L-RKTPK32.
Kemampuan model L-RKTPK02 dalam menghasilkan nilai dugaan relatif
hampir sama dengan model L-RKTPK32. Hal tersebut terlihat dari nilai korelasi
kedua model yang relatif hampir sama. Namun kemampuan model L-RKTPK02
dalam menjelaskan keragaman peubah penjelas kurang baik, yaitu hanya sebesar
46%. Karena fokus dari penelitian ini adalah mendapatkan model model yang
mampu menghasilkan nilai dugaan peubah respon dengan baik, kriteria
kemampuan model dalam menjelaskan peubah respon tidak begitu diperhatikan.
Kemampuan model L-RKTPK02 dalam menjelaskan keragaman peubah penjelas
mendekati 100% dan nilai tersebut relatif dekat dengan model L-RKTPK32.
Kemampuan model L-RKTPK02 yang dapat menjelaskan keragaman peubah
respon sebesar 98.56% hanya dengan dua komponen mebuat model ini terpilih
sebagai model terbaik.
Tabel 3 Kriteria kebaikan model
Model Korelasi RMSE
Kemampuan dalam
Menjelaskan Keragaman Banyaknya X yang Terpilih X Y L-RKTPK32 0.997 21556.08 99.99% 100% 33 L-RKTPK02 0.969 72000.08 46% 98.56% 33 RKTP-VIPK32 0.881 122520.67 99.39% 100% RKTP-VIP08K32 RKTP-VIP10K32 RKTP-VIP08K02 0.920 103066.86 72.55% 95.93% 218 RKTP-VIP10K02 0.928 97616.36 77.79% 96.16% 172