EVALUASI PENILAIAN KINERJA PENYELESAIAN KLAIM PADA ASURANSI KESEHATAN DENGAN
MENGGUNAKAN METODE SIMPLE ADDITIVE WEIGHTING
Fahrul Nurzaman 1)
1)
Teknik Informatika Universitas Persada Indonesia Y.A.I Jl. Salemba Raya 7/9A Jakarta Pusat
email : fnurzaman@gmail.com
ABSTRACT
The level of customer’s satisfaction in a Health Insurance can be seen from the costumer’s satisfaction to the service provided by the Health Insurance Company. One of the most important things in the health insurance service is a claim settlement which is in accordance with Service Level Agreement (SLA).
The claim settlement which is in accordance with Service Level Agreement (SLA) can give a guarantee to the costumer’s satisfaction so it influences the level of customer confidence in the Company. The high competition in a health insurance business is very important to pay attention to the settlement of claims in order to comply with Service Level Agreement (SLA), it can even be faster than the Service Level Agreement (SLA) that has been agreed. Performance of claims settlement must be improved to achieve satisfying expectations of customer. Therefore the evaluation of the claims settlement assessment is done to the verifier team that has the tasks on resolving the case of health insurance claims. The assessments are made with the purpose to evaluate the performance by looking at the rating of verifier team in resolving the claims in every month. To get the calculation on the assessment of the claims settlement performance evaluation is performed data mining process on the warehouse data system using Simple Addictive Weighting Method (SAW). There are five criteria as a benchmark assessment which is used for such methods, some of them are benefits type, payment method type, action items, great value and the amount of the claims settlement days. The result of research is data presentation which is in form of a verifier ranking can be used by company management as knowledge.
Keywords
Data mining, Simple Additive Weighting (SAW), Verifier, Service Level Agreement (SLA)
1. Pendahuluan
Tingkat kepuasan pelanggan dalam Asuransi Kesehatan salah satu nya dapat dilihat dari kepuasan
Pelanggan terhadap pelayanan yang diberikan Perusahaan Asuransi Kesehatan. Salah satu hal yang terpenting dalam pelayanan Asuransi Kesehatan adalah penyelesaian klaim yang sesuai dengan Service Level Agreement (SLA). Penyelesaian klaim yang sesuai dengan Service Level Agreement (SLA) dapat memberi jaminan terhadap kepuasan Pelanggan, sehingga mempengaruhi tingkat kepercayaan Pelanggan terhadap Perusahaan. Dengan tingginya persaingan dalam bisnis bidang Asuransi Kesehatan sangat penting untuk memperhatikan penyelesaian klaim agar selalu sesuai dengan Service Level Agreement (SLA), bahkan dapat lebih cepat dari Service Level Agreement (SLA) yang sudah disepakati. Kinerja penyelesaian klaim harus ditingkatkan demi tercapai harapan memuaskan pelanggan. Penyelesaian klaim tidak lepas dari kinerja tim verifikator. Verifikator adalah orang yang mempunyai tugas untuk memverifikasi klaim yang diajukan oleh pelanggan Asuransi kesehatan. Dalam hal ini perusahaan ingin meningkatkan pelayanan terutama dalam penyelesaian klaim. Untuk itu dilakukan evaluasi penilaian kinerja tim verifikator dengan melihat tingkat kesulitan klaim dan jumlah hari penyelesaian klaim. Tingkat kesulitan klaim terdiri dari 4 kriteria yaitu jenis manfaat, jenis metode pembayaran , jumlah item tindakan dan besar nilai klaim. Setiap kriteria memiliki bobot nilai sendiri dimana nantinya akan diketahui rangking verifikator yang memiliki nilai yang paling besar. Evaluasi penilaian kinerja tim verifikator dilakukan tiap bulan.
Dari latar belakang di atas terdapat permasalahan yaitu bagaimana mendapatkan rangking verifikator pada tiap bulannya , sehingga dari rangking tersebut diketahui verifikator yang memiliki kinerja yang baik di setiap bulan. Untuk menyelesaikan permasalahan di atas maka dibuat proses Data mining untuk mendukung pengambilan keputusan dengan menggunakan Metode Simple Additive Weighting Method (SAW). Konsep dasar metode Simple Additive Weighting (SAW) adalah mencari penjumlahan terbobot dari rating kinerja pada setiap alternatif pada semua atribut. Metode Simple Additive Weighting (SAW) membutuhkan proses
normalisasi matriks keputusan (X) ke suatu skala yang dapat diperbandingkan dengan semua rating alternatif yang ada. Simple Additive Weighting (SAW) merupakan metode yang dapat digunakan dalam menghadapi situasi Multi Attribute Decision Making (MADM). Tujuan penelitian ini adalah implementasi Data mining untuk mendukung keputusan dalam evaluasi penilaian kinerja penyelesaian klaim Asuransi Kesehatan menggunakan Metode Simple Additive Weighting (SAW). Hasil dari penelitian adalah penyajian data rangking verifikator setiap bulan yang merupakan hasil dari proses perhitungan sehingga dengan data yang disajikan dapat menjadi pengetahuan yang dapat membantu pihak manajemen perusahaan untuk menganalisa dan mengambil keputusan berkaitan dengan proses penyelesaian klaim Asuransi Kesehatan.
2. Landasan Teori
2.1 Sistem Pendukung Keputusan
2.1.1 Pengertian DSS (Decision Support System)
Decision Support System adalah salah satu jenis aplikasi teknologi informasi yang mendominasi perusahaan-perusahaan modern yang ingin meningkatkan kualitas manajemen dalam menunjang proses pengambilan keputusan. Decision Support System adalah sistem berbasis komputer interaktif, DSS membantu manajer atau pengambil keputusan dalam menggunakan dan memanipulasi data, menggunakan daftar periksa (¢hecklist), dan membuat serta menggunakan model matematika untuk menyelesaikan masalah-masalah yang terstruktur [4].
Decision Support System adalah sistem informasi yang membantu untuk mengidentifikasikan kesempatan pengambil keputusan atau menyediakan informasi untuk membantu pengambil keputusan [1]. Definisi awal Decision Support System menunjukan bahwa Decision Support System sebagai sebuah sistem yang dimaksudkan untuk mendukung para pengambil keputusan manajerial dalam situasi keputusan semiterstruktur [7]. Decision Support System adalah sistem informasi yang membantu untuk mengidentifikasikan kesempatan pengambilan keputusan atau penyediaan informasi untuk membantu pengambilan keputusan. Pada dasarnya Decision Support System hampir sama dengan Sistem Informasi Manajemen karena menggunakan basis data sebagai sumber data. Decision Support System bermula dari Sistem Informasi Manajemen karena menekankan pada fungsi pendukung pembuat keputusan di seluruh tahap- tahap nya, meskipun keputusan aktual tetap wewenang eksklusif pembuat keputusan.
2.1.2 Tujuan Decision Support System
Dalam Decision Support System terdapat tiga tujuan harus dicapai , yaitu :
1. Membantu manajer dalam pembuatan keputusan untuk memecahkan masalah semi terstruktur.
2. Mendukung keputusan manajer dalam pembuatan keputusan, dan bukan mengubah atau mengganti keputusan tersebut.
3. Meningkatkan efektifitas manajer dalam pembuatan keputusan, dan bukan meningkatkan.
Tujuan ini berkaitan dengan tiga prinsip dasar dari konsep Decision Support System, yaitu struktur masalah, dukungan masalah, dukungan keputusan, dan efektifitas keputusan [4].
2.1.3 Dukungan Keputusan
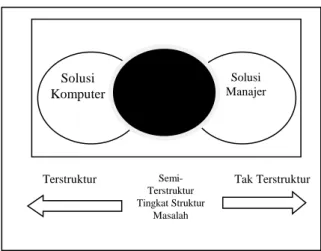
Decision Support System tidak dimasukkan untuk menggantikan manajer. Gambar 2.1 menggambarkan hubungan ini antara struktur masalah dengan tingkat dukungan yang disediakan oleh komputer. Komputer dapat diterapkan pada bagian masalah yang terstruktur, tetapi manajer bertanggung jawab atas bagian yang tak terstruktur menerapkan penilaian atau intuisi, dan melakukan analisis [4].
Gambar 1 Decision Support System Fokus Masalah Semi Terstruktur
2.1.4 Komponen Decision Support System
Komponen Decision Support System terdiri dari beberapa subsistem, yaitu subsistem manajemen data, subsistem manajemen model, subsistem atarmuka pengguna, dan subsistem manajemen berbasis pengetahuan [7].2.2 Data Mining
Secara sederhana data mining adalah penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar [3]. Data mining juga disebut sebagai serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data [1]. Data mining,
Solusi Komputer
Solusi Manajer
Terstruktur Semi- Tak Terstruktur Terstruktur
Tingkat Struktur Masalah
sering juga disebut sebagai Knowledge Discovery In Database (KDD). KDD adalah kegiatan yang meliputi pengumpulan, pemakaian data, histori untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar [5].
Data mining adalah kegiatan menemukan pola yang menarik dari data dalam jumlah besar, data dapat disimpan dalam database, data warehouse, atau penyimpanan informasi lainnya. Data mining berkaitan dengan bidang ilmu-ilmu lain, seperti database system, data warehouse, statistic, machine learning, information retrieval, dan komputasi tingkat tinggi.
Selain itu, data mining didukung oleh ilmu lain seperti neural network, pengenalan pola, spatial data analysis, image database, signal processing [6].
Data mining didefinisikan sebagai proses menemukan pola-pola dalam data. Proses ini otomatis atau seringnya semiotomatis [6]. Pola yang ditemukan harus penuh arti dan pola tersebut memberikan keuntungan, biasanya keuntungan secara ekonomi.
Karakteristik data mining sebagai berikut:
1. Data mining berhubungan dengan penemuan sesuatu yang tersembunyi dan pola data tertentu yang tidak diketahui sebelumnya.
2. Data mining biasa menggunakan data yang sangat besar. Biasanya data yang besar digunakan untuk membuat hasil lebih dipercaya.
3. Data mining berguna untuk membuat keputusan yang kritis, terutama dalam Strategi [3].
Berdasarkan beberapa pengertian tersebut dapat ditarik kesimpulan bahwa data mining adalah suatu teknik menggali informasi berharga yang terpendam atau tersembunyi pada suatu kleksi data (database) yang sangat besar sehingga ditemukan suatu pola yang menarik yang sebelumnya tidak diketahui. Data mining sendiri berarti usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar. Karena itu data mining sebenarnya memiliki akar yang panjang dari bidang ilmu seperti kecerdasan (Artifical Intelligent), Machine Learning, Statistik dan Database.
Beberapa metode yang sering disebut-sebut dalam literature data mining antara lain Clustering, Classification, Association Rules Mining, Neural Network, Generic Algorithm dan lain-lain [1].
2.2.1 Tahap-tahap Data Mining
Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi beberapa tahap. Tahap-tahap tersebut bersifat interaktif, pemakai terlibat langsung atau dengan perantaraan knowledge base.
Tahap-tahap data mining ada 6 yaitu : 1. Pembersihan Data (Data Cleansing)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan. Pada umumnya data yang diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen, memiliki isian-isian yang tidak
sempurna seperti data yang hilang, data yang tidak valid atau juga hanya sekedar salah ketik. Selain itu, ada juga atribut-atribut data yang tidak relevan dengan hipotesa data mining yang dimiliki. Data-data yang tidak relevan itu juga lebih baik dibuang.
Pembersihan data juga akan mempengaruhi performansi dari teknik data mining karena data yang ditangani akan berkurang jumlah kompleksitasnya.
2. Intergasi Data (Data Integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru. Tidak jarang data yang diperlukan untuk data mining tidak hanya berasal dari satu database tetapi juga berasal dari beberapa database atau file teks.
Intergrasi data dilakukan pada atribut-atribut yang mengidentifikasikan entitas-entitas yang unik seperti atribut nama, jenis produk, nomor pelanggan dan lainnya. Intergasi data perlu dilakukan secara cermat karena kesalahan pada intgrasi data bisa menghasilkan hasil yang menyinpang dan bankan menyesatkan pengambilan aksi nantinya.
3. Seleksi Data (Data Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database.
4. Transformasi Data (Data Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam data mining. Beberapa metode data mining membutuhkan format data yang khusus sebelum bisa diaplikasikan. Sebagai contoh beberapa metode standar seperti analisis asosiasi dan clustering hanyabisa menerima input data kategorikal.
Karenanya data berupa angka numeric yang berlanut perlu dibagi-bagi menjadi beberapa interval. Proses ini sering disebut transformasi data.
5. Proses Mining
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
6. Evaluasi Pola (Pattern Evaluation)
Untuk mengidentifikasi pola-pola menarik kedalam knowledge based yang ditemukan. Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai. Bila ternyata hasil yang diperoleh tidak sesuai hipotesa ada beberapa alternative yang dapat diambil seperti menjadikannya umpan balik untuk memperbaiki proses data mining, mencoba metode data mining lain yang lebih sesuai, atau menerima hasil ini sebagai suatu hasil yang di luar dugaan yang mungkin bermanfaat.
7. Presentasi Pengetahuan (Knowledge Presentation) Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna. Tahap terakhir
dari proses data mining adalah bagaimana memformulasikan keputusan aksi dari hasil analisi yang didapat. Ada kalanya hal ini harus melibatkan orang-orang yang tidak memahami data mining.
Karenanya prsentasi hasil data mining dalam bentuk pengetahuan yang bisa dipahami semua orang adalah satu tahapan yang diperlukan dalam proses data mining.
Dalam presentasi ini, visualisasi juga bisa membantu mengkomunikasikan hasil Data Mining [6].
2.3 Metode Simple Additive Weighting (SAW)
Merupakan metode penjumlahan terbobot.Konsep dasar metode SAW adalah mencari penjumlahan terbobot dari rating kinerja pada setiap alternatif pada semua kriteria [2]. Metode SAW membutuhkan proses normalisasi matrik keputusan (X) ke suatu skala yang dapat diperbandingkan dengan semua rating alternatif yang ada.Metode SAW mengenal adanya 2 (dua) atribut yaitu kriteria keuntungan (benefit) dan kriteria biaya (cost).
Perbedaan mendasar dari kedua kriteria ini adalah dalam pemilihan kriteria ketika mengambil keputusan.
Adapun langkah penyelesaian dalam menggunakannya adalah:
1. Menentukan alternatif, yaitu Ai.
2. Menentukan kriteria yang akan dijadikan acuan dalam pengambilan keputusan, yaitu Cj
3. Memberikan nilai rating kecocokan setiap alternatif pada setiap kriteria.
4. Menentukan bobot preferensi atau tingkat kepentingan (W) setiap kriteria.
W = [ W1,W2,W3,…,WJ]
5. Membuat tabel rating kecocokan dari setiap alternatif pada setiap kriteria.
6. Membuat matrik keputusan (X) yang dibentuk dari tabel rating kecocokan dari setiap alternatif pada setiap kriteria. Nilai X setiap alternatif (Ai) pada setiap kriteria (Cj) yang sudah ditentukan, dimana, i=1,2,…m dan j=1,2,…n.
7.
8. Melakukan normalisasi matrik keputusan dengan cara menghitung nilai rating kinerja ternomalisasi (rij) dari alternatif Ai pada kriteria Cj.
9.
Keterangan :
a. Kriteria keuntungan apabila nilai memberikan keuntungan bagi pengambil keputusan, sebaliknya kriteria biaya apabila menimbulkan biaya bagi pengambil keputusan.
b. Apabila berupa kriteria keuntungan maka nilai dibagi dengan nilai dari setiap kolom, sedangkan untuk kriteria biaya, nilai dari setiap kolom dibagi dengan nilai.
10. Hasil dari nilai rating kinerja ternomalisasi (rij) membentuk matrik ternormalisasi (R)
11.
12. Hasil akhir nilai preferensi (Vi) diperoleh dari penjumlahan dari perkalian elemen baris matrik ternormalisasi (R) engan bobot preferensi (W) yang bersesuaian eleman kolom matrik (W).
Hasil perhitungan nilai Vi yang lebih besar mengindikasikan bahwa alternatif Ai merupakan alternatif terbaik [2].
Keuntungan Simple Additive Weighting (SAW) Di bawah ini ada beberapa keuntungan Simple Additive Weighting (SAW) [1] :
1. Memberikan suatu model yang mudah dimengerti, luwes untuk bermacam-macam persoalan yang tidak terstruktur.
2. Mencerminkan cara berpikir alami untuk memilah- milih elemen-elemen dari suatu system ke dalam berbagai tingkat berlainan dan mengelompokan unsur yang serupa dalam setiap tingkat.
3. Memberikan suatu skala pengukuran dan memberikan metode untuk menetapkan prioritas.
4. Memberikan penilaian terhadap konsistensi logis dari pertimbangan-pertimbangan yang digunakan dalam menentukan prioritas.
5. Menuntun ke suatu pandangan menyeluruh terhadap alternatif yang muncul untuk masalah yang dihadapi.
6. Memberikan suatu sarana untuk penilaian yang tidak dipaksakan tetapi merupakan penilaian yang sesuai pandangan masing-masing.
7. Memungkinkan setiap orang atau kelompok untuk mempertajam kemampuan logic dan intuisinya terhadap persoalan yang dipetakan melalui Simple Additive Weighting (SAW).
3. Hasil dan Pembahasan
3.1 Analisis Kebutuhan Data
Data yang dibutuhkan sebagai masukkan dalan proses perhitungan Metode Simple Additive Weighting (SAW) adalah tahun dan bulan pengerjaan klaim, petugas verifikasi klaim, jenis manfaat klaim, jenis
pembayaran klaim, nomor klam , jumlah item tindakan, besar nilai klaim dan jumlah SLA berdasarkan hari kerja.
Dari data tersebut akan diberi bobot masing-masing berdasarkan tingkat kesulitan dalam penyelesaian klaim dan baik tidak nya jumlah SLA penyelesaian klaim berdasarkan hari kerja. Untuk Nilai jumlah SLA berdasarkan hari kerja dalah Nilai SLA diambil dari selisih jumlah hari kerja dari tanggal terima dokumen klaim dengan tanggal penyelesaian klaim.
Sumber data berasal dari Basis Data Transaksional atau Basis Data Operasional yang akan dimasukkan ke dalam Sistem Datawarehouse atau Basis Data Staging.
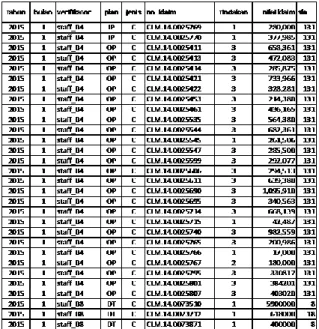
Proses Data mining dan proses perhitungan akan menggunakan data yang terdapat pada Sistem Datawarehouse atau Basis Data Staging sebagai sumber data. Sumber data digunakan untuk mendapatkan data nilai seleksi yang merupakan data awal untuk acuan perhitungan rangking verifikator dengan menggunakan Metode Simple Additive Weighting (SAW). Di bawah ini adalah contoh Sumber data :
Gambar 2 Sumber Data Yang Digunakan
3.2 Analisis Sistem Arsitektur Basis Data
Sumber Data yang digunakan untuk proses data mining dan proses perhitungan data adalah Sistem Datawarehouse atau Basis Data Staging. Data di Basis data transaksional atau Basis Data operasional secara otomatis diambil sesuai dengan data yang dibutuhkan menggunakan implementasi kode query dimasukkan ke dalam Sistem Datawarehouse atau Basis Data Staging.Server Sistem Operasional
Database Transaksional/Operasional
Database Staging/
Datawarehouse Server Sistem Datawarehouse
Gambar 3 Arsitektur Basis Data Stagin
3.3 Analisis Skema Basis Data Transaksional
Data yang dibutuhkan untuk menjadi data masukkan proses data mining dan proses perhitungan berasal dari database transaksional yang melibatkan banyak tabel. Tabel-tabel itu diantaranya Tabel master petugas verifikator, Tabel master jenis manfat klaim, Tabel transaksi klaim dan Tabel master tindakan . Berikut di bawah ini adalah Skema Basis Data Transaksional untuk Operasional Klaim :Gambar 4 Skema Basis Data Operasional Klaim
3.4 Analisis Perhitungan Data
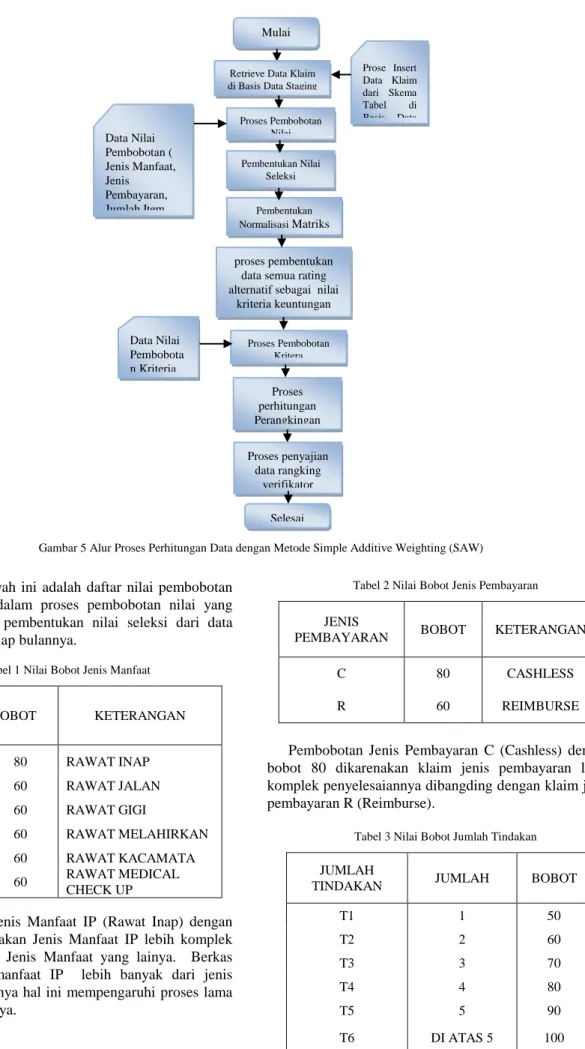
Proses Perhitungan data dimulai dari pengambilan data dari tabel klaim di Sistem Datawarehouse atau Basis Data Staging. Data Tabel klaim didapat dari proses insert data klaim dari Basis data transaksional ke dalam Sistem Datawarehouse atau Basis Data Staging. Dari Tabel data klaim di Basis Data staging, dilakukan proses pembobotan nilai untuk mendapatkan nilai seleksi data klaim dari tiap verifikator. Terdapat 5 kriteria untuk dilakukan pembobotan nilai untuk mendapatkan nilai seleksi data nya, yaitu diantaranya jenis manfaat, jenis pembayaran, jumlah item tindakan, besar nilai klaim dan jumlah hari kerja Service Level Agreement (SLA). Dari Nilai Seleksi data akan menghasilkan Matriks Rating Kinera verifikator.
Setelah mendapatkan Matriks Rating Kinera verifikator , maka dilakukan proses pembentukan data semua rating alternatif sebagai nilai kriteria keuntungan.
Setelah mendapatkan data semua rating alternatif, maka dilakukan proses pembentukan data normalisasi matriks keputusan. Dari data normalisasi matriks keputusan dilakukan proses perangkingan dengan menjumlahkan setiap alternatif dari data normalisasi matriks keputusan setiap baris di kalikan bobot kriteria yang sudah ditentukan Dari data perangkingan yang dihasilkan dibuat proses penyajian data untuk mendukung pengambil keputusan dalam proses penyelesaian klaim. Di bawah ini adalah Alur Proses Perhitungan data :
Gambar 5 Alur Proses Perhitungan Data dengan Metode Simple Additive Weighting (SAW)
Berikut di bawah ini adalah daftar nilai pembobotan yang digunakan dalam proses pembobotan nilai yang digunakan dalam pembentukan nilai seleksi dari data klaim verifikator tiap bulannya.
Tabel 1 Nilai Bobot Jenis Manfaat
JENIS
MANFAAT BOBOT KETERANGAN
IP 80 RAWAT INAP
OP 60 RAWAT JALAN
DT 60 RAWAT GIGI
MT 60 RAWAT MELAHIRKAN
GL 60 RAWAT KACAMATA
MC 60 RAWAT MEDICAL
CHECK UP
Pembobotan Jenis Manfaat IP (Rawat Inap) dengan Bobot 80 dikarenakan Jenis Manfaat IP lebih komplek dibanding dengan Jenis Manfaat yang lainya. Berkas Dokumen jenis manfaat IP lebih banyak dari jenis manfaat yang lainnya hal ini mempengaruhi proses lama pengerjaan klaimnya.
Tabel 2 Nilai Bobot Jenis Pembayaran
JENIS
PEMBAYARAN BOBOT KETERANGAN
C 80 CASHLESS
R 60 REIMBURSE
Pembobotan Jenis Pembayaran C (Cashless) dengan bobot 80 dikarenakan klaim jenis pembayaran lebih komplek penyelesaiannya dibangding dengan klaim jenis pembayaran R (Reimburse).
Tabel 3 Nilai Bobot Jumlah Tindakan
JUMLAH
TINDAKAN JUMLAH BOBOT
T1 1 50
T2 2 60
T3 3 70
T4 4 80
T5 5 90
T6 DI ATAS 5 100
Mulai
Retrieve Data Klaim di Basis Data Staging
Proses Pembobotan Nilai
Pembentukan Nilai Seleksi
Pembentukan Normalisasi Matriks
keputusan
Prose Insert Data Klaim dari Skema Tabel di Basis Data
Transaksi onal Data Nilai
Pembobotan ( Jenis Manfaat, Jenis Pembayaran, Jumlah Item Tindakan , Nilai Besar Klaim , Jumlah Hari Kerja SLA)
proses pembentukan data semua rating alternatif sebagai nilai
kriteria keuntungan
Proses Pembobotan Kritera
Proses perhitungan Perangkingan
Selesai Data Nilai
Pembobota n Kriteria (W)
Proses penyajian data rangking
verifikator
Pembobotan jumlah tindakan dilihat dari banyak tindakan yang dianalisa dalam klaim tersebut. Dimana Bobot terbesar adalah 100 dan terendah adalah 50.
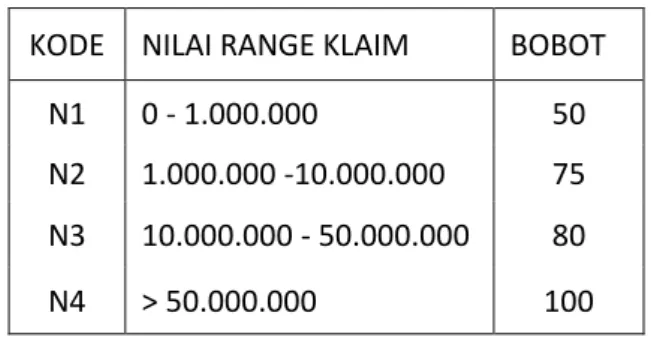
Tabel 4 Nilai Bobot Nilai Klaim
KODE NILAI RANGE KLAIM BOBOT
N1 0 - 1.000.000 50
N2 1.000.000 -10.000.000 75 N3 10.000.000 - 50.000.000 80
N4 > 50.000.000 100
Pembobotan nilai klaim didasarkan pada besarnya nilai klaim , bobot yang paling tinggi adalah besarnya nilai klaim yang mencapat lebih dari 50.000.000 hal ini dikarenakan penyelesaian klaim semakin rumit
Tabel 5 Nilai Bobot Jumlah Hari Kerja SLA
JENIS SLA BOBOT
CASHLESS 0-7 100
CASHLESS 7-14 80
CASHLESS 14-30 70
CASHLESS 30-60 50
CASHLESS > 60 30
REIMBURSE 0 - 7 100
REIMBURSE 7 - 14 80 REIMBURSE > 14 50
Pembobotan SLA merupakan pembobotan menurut penyelesaian klaim yang disepakati berdasarkan jumlah hari kerja. Dimana SLA di bawah 7 Hari kerja, merupakan bobot yang tertinggi baik untuk jenis pembayaran Cashless maupun Reimburse.
Tabel 6 Nilai Bobot Kriteria KOMPONE
N BOBOT KETERANGAN
W1 0.15 JENIS MANFAAT W2 0.10 JENIS PEMBAYARAN W3 0.15 JUMLAH TINDAKAN W4 0.25 BESAR NILAI KLAIM W5 0.35 JUMLAH HARI KERJA
SLA
Pembobotan KriteriaPenilaian Verifikator dilihat dari waktu penyelesaian klaim dan tingkat kesulitan atau kompleksitas dari klaim tersebut. Waktu penyelesaian
klaim dapat diukur dengan jumlah hari kerja SLA.
Dimana jumlah hari kerja SLA didapat dari jumlah hari kerja dari Tanggal dokumen diterima sampai tanggal klaim selesai diproses. Tingkat kesulitan klaim dilihat dari besar nilai klaim, jumlah tindakan, jenis manfaat dan jenis pembayaran. Jumlah Hari Kerja SLA (W5) diberi bobot tertinggi diantara empat kriteria yang lainnya dikarenakan SLA hal yang paling penting dalam penilaiain Evaluasi Verifikator, maka diberi bobot 0.35 (35 %) , untuk besar nilai klaim (W4) menjadi urutan yang pertama tingkat kesulitan dalam menyelesaikan klaim sehubungan dengan akan menimbulkan nilai resiko yang cukup besar pula sehingga dengan itu diberi bobot 0.25 (25%), selanjutnya Jumlah tindakan (W1) dan jenis manfaat (W3) yang memiliki bobot yang sama dikarenakan tingkat kesulitan yang sama yaitu dengan bobot 0.15 (15%) dan jumlah Pembayaran (W2) yang memiliki tingkat kesulitan rendah dengan bobot 0.10 (10%).
3.5 Perancangan Basis Data
Untuk kebutuhan Basis Data Staging maka dibuat Tabel yang menampung data dari Basis Data Transaksional dan Tabel yang menampung data dari hasil proses perhitungan. Berikut di bawah ini daftar Tabel yang digunakan untuk proses implementasi Data mining :
Gambar 6 Struktur Data Tabel
3.6 Implementasi Data mining
Untuk mendapatkan nilai seleksi pada tiap verifikator dan tiap bulannya maka dibuat implementasi kode query seperti di bawah ini :
select tahun,bulan,verifikator,nilai_A/n_item as nilai_A,nilai_B/n_item as nilai_B,
nilai_C/n_item as nilai_C,nilai_D/n_item as nilai_D,nilai_E/n_item as nilai_E
from (
select tahun,bulan,verifikator, count(*) as n_item, sum(nilai_plan) as nilai_A,
sum(nilai_jns_pembayaran) as
nilai_B,sum(nilai_tindakan) as nilai_C,
sum(nilai_nilaiklaim) as nilai_D, sum(nilai_sla) as nilai_E from (
SELECT *,case when nama_plan='IP' then 80 else 60 end as nilai_plan,
case when jns_klaim='C' then 80 else 60 end as nilai_jns_pembayaran,
case when item_tindakan=1 then 50 else case when item_tindakan=2 then 60 else case when item_tindakan=3 then 70 else case when item_tindakan=4 then 80 else case when item_tindakan=5 then 90 else 100 end end end end end as nilai_tindakan, case when nilai_klaim > 0 and nilai_klaim
<=1000000 then 50 else
case when nilai_klaim > 1000000 and nilai_klaim
<=10000000 then 75 else
case when nilai_klaim > 10000000 and nilai_klaim <=50000000 then 80 else
100 end end end as nilai_nilaiklaim,
case when jns_klaim = 'C' and sla > 0 and sla <
=7 then 100 else
case when jns_klaim = 'C' and sla > 7 and sla <
=14 then 80 else
case when jns_klaim = 'C' and sla > 14 and sla
< =30 then 70 else
case when jns_klaim = 'C' and sla > 30 and sla
< =60 then 50 else
case when jns_klaim = 'C' and sla > 60 then 30 else
case when jns_klaim = 'R' and sla > 0 and sla <
=7 then 100 else
case when jns_klaim = 'R' and sla > 7 and sla <
=14 then 80 else
case when jns_klaim = 'R' and sla > 14 then 50 end end end end end end end end as nilai_sla FROM (
select tahun,
bulan,verifikator,nama_plan,jns_klaim, no_klaim,count(*) as item_tindakan, sum(nilai_klaim) as nilai_klaim, sla
from tt_klaim group by tahun, bulan,verifikator,nama_plan,jns_klaim,
no_klaim,count(*) as item_tindakan having sum(nilai_klaim)>0 ) AS TBLa ) as tblB group by tahun,bulan,verifikator ) as tblC order by tahun , bulan,verifikator
Dari hasil kode query tersebut didapat data nilai seleksi sebagai berikut :
Tabel 7 Contoh Data Nilai Seleksi Data nilai seleksi tersebut dimasukkan ke dalam tabel
ts_nilai_seleksi untuk diproses ke tahap berikut nya.
Untuk mendapatkan data semua rating alternatif sebagai nilai kriteria keuntungan tiap bulannya maka dibuat implementasi kode query seperti di bawah ini : select tahun,bulan,max(max_A) as max_A, max(max_B) as max_B,max(max_C) as
max_C,max(max_D) as max_D, max(max_E) as max_E
from ts_nilai_seleksi
group by tahun,bulan order by tahun,bulan
Dari hasil kode query tersebut didapat data semua rating alternatif sebagai nilai kriteria keuntungan tiap bulannya sebagai berikut :
tahun bulan verifikator nilai_A nilai_B nilai_C nilai_D nilai_E
2015 1 staff_04 61 80 65 50 30
2015 1 staff_08 61 80 62 51 85
2015 1 staff_11 61 73 60 51 83
2015 1 staff_12 60 78 60 50 79
2015 1 staff_13 61 77 58 50 85
2015 1 staff_14 61 78 59 50 82
2015 1 staff_17 62 80 61 50 30
2015 1 staff_18 60 77 59 50 85
2015 2 staff_01 62 61 64 50 49
2015 2 staff_06 60 60 50 50 50
2015 2 staff_08 61 79 61 51 78
2015 2 staff_11 61 76 59 51 86
2015 2 staff_12 60 79 61 50 78
2015 2 staff_13 61 75 59 50 85
2015 2 staff_14 60 79 61 50 82
2015 2 staff_17 80 80 70 50 30
Tabel 8 Contoh Data Rating Alternatif
tahun bulan max_A max_B max_C max_D max_E
2015 1 62 80 65 51 85
2015 2 80 80 70 51 86
2015 3 65 80 62 52 86
2015 4 80 80 64 52 85
2015 5 65 80 64 55 84
2015 6 62 80 64 52 93
2015 7 63 80 68 51 96
2015 8 63 80 67 53 91
2015 9 62 80 61 51 86
2015 10 61 80 63 51 88
2015 11 62 80 62 52 84
2015 12 62 80 62 51 92
Data nilai rating Alternatif tersebut dimasukkan ke dalam tabel ts_nilai_rating_alternatif untuk diproses ke tahap berikut nya.
Untuk mendapatkan data Normalisasi Matriks Keputusan pada tiap bulannya maka dibuat implementasi kode query seperti di bawah ini :
select tahun,bulan, nilai_A/(select maxA from
ts_nilai_rating_alternatif t1 where t1.tahun=tA.tahun and t1.bulan=tA.bulan) as N_A,
nilai_B/(select maxB from
ts_nilai_rating_alternatif t2 where t2.tahun=tA.tahun and t2.bulan=tA.bulan) as N_B,
nilai_C/(select maxC from
ts_nilai_rating_alternatif t3 where t3.tahun=tA.tahun and t3.bulan=tA.bulan) as N_C,
nilai_D/(select maxD from
ts_nilai_rating_alternatif t4 where t4.tahun=tA.tahun and t4.bulan=tA.bulan) as N_D,
nilai_E/(select maxE from
ts_nilai_rating_alternatif t5 where t5.tahun=tA.tahun and t5.bulan=tA.bulan) as N_E
from ts_nilai_seleksi tA order by tahun,bulan
Dari hasil kode query tersebut didapat data Normalisasi Matriks keputusan tiap bulannya sebagai berikut :
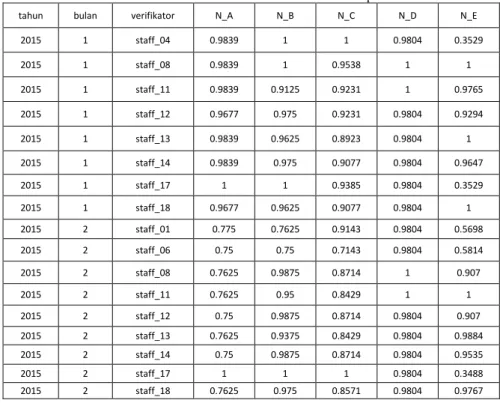
Tabel 9 Contoh Data Normalisai Matriks keputusan
tahun bulan verifikator N_A N_B N_C N_D N_E
2015 1 staff_04 0.9839 1 1 0.9804 0.3529
2015 1 staff_08 0.9839 1 0.9538 1 1
2015 1 staff_11 0.9839 0.9125 0.9231 1 0.9765
2015 1 staff_12 0.9677 0.975 0.9231 0.9804 0.9294
2015 1 staff_13 0.9839 0.9625 0.8923 0.9804 1
2015 1 staff_14 0.9839 0.975 0.9077 0.9804 0.9647
2015 1 staff_17 1 1 0.9385 0.9804 0.3529
2015 1 staff_18 0.9677 0.9625 0.9077 0.9804 1
2015 2 staff_01 0.775 0.7625 0.9143 0.9804 0.5698
2015 2 staff_06 0.75 0.75 0.7143 0.9804 0.5814
2015 2 staff_08 0.7625 0.9875 0.8714 1 0.907
2015 2 staff_11 0.7625 0.95 0.8429 1 1
2015 2 staff_12 0.75 0.9875 0.8714 0.9804 0.907
2015 2 staff_13 0.7625 0.9375 0.8429 0.9804 0.9884
2015 2 staff_14 0.75 0.9875 0.8714 0.9804 0.9535
2015 2 staff_17 1 1 1 0.9804 0.3488
2015 2 staff_18 0.7625 0.975 0.8571 0.9804 0.9767
Data Normalisai Matriks keputusan tersebut dimasukkan ke dalam tabel ts_normalisasi_matriks untuk diproses ke tahap berikut nya.
Untuk mendapatkan data perangkingan verifikator tiap bulannya maka dibuat implementasi kode query seperti di bawah ini :
select tahun,bulan,verifikator,
(N_A*0.15)+(N_B*0.10)+(N_C*0.15)+(N_D*
0.25)+(N_E*0.35) as Total_nilai from ts_normalisasi_matriks order by tahun,bulan
Dari hasil kode query tersebut didapat data perangkingan verifikator tiap bulannya sebagai berikut :
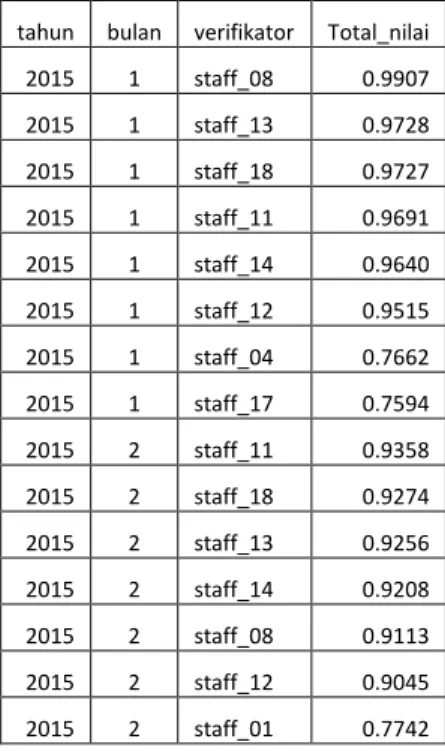
Tabel 10 Contoh Data Perangkingan Verifikator
tahun bulan verifikator Total_nilai 2015 1 staff_08 0.9907 2015 1 staff_13 0.9728 2015 1 staff_18 0.9727 2015 1 staff_11 0.9691 2015 1 staff_14 0.9640 2015 1 staff_12 0.9515 2015 1 staff_04 0.7662 2015 1 staff_17 0.7594 2015 2 staff_11 0.9358 2015 2 staff_18 0.9274 2015 2 staff_13 0.9256 2015 2 staff_14 0.9208 2015 2 staff_08 0.9113 2015 2 staff_12 0.9045 2015 2 staff_01 0.7742
Data perangkingan verifikator tersebut dimasukkan ke dalam tabel ts_rangking_verifikator untuk diproses ke tahap berikut nya.
Data perangkingan verifikator merupakan hasil akhir proses perhitungan menggunakan Metode Simple Additive Weighting (SAW). Dari hasil akhir tersebut maka dibuat penyajian data agar dapat digunakan untuk menganalisa dan mendukung keputusan dalam proses penyelesaian klaim. Penyajian data tersebut diantaranya adalah Data verifikator yang memiliki nilai yang terbesar di tiap bulannya, Data verifikator yang memiliki nilai yang terkecil di tiap bulannya dan Nilai yang dimiliki verifikator di tiap bulannya.
Berikut di bawah ini adalah contoh penyajian data untuk Peringkat Tertinggi untuk tiap bulannya di Tahun 2015 dan 2016.
Gambar 7 Penyajian Data Peringkat Tertinggi Verifikator Berikut di bawah ini adalah contoh penyajian data untuk Peringkat Terendah untuk tiap bulannya di Tahun 2015 dan 2016.
Gambar 8 Penyajian Data Peringkat Terendah Verifikator
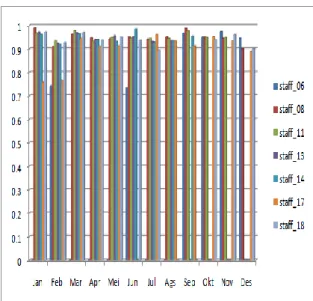
Berikut di bawah ini adalah contoh penyajian data untuk Nilai yang dimiliki verifikator untuk Tahun 2015.
Gambar 9 Penyajian Data Nilai Verifikator Tahun 2015
4. Kesimpulan
Dari hasil dan pembahasan Evaluasi Penilaian Kinerja Penyelesaian Klaim Pada Asuransi Kesehatan dengan menggunakan Metode Simple Additive Weighting, dapat diambil kesimpulan sebagai berikut : 1. Terdapat lima kriteria sebagai seleksi penentuan
penilaian Kinerja Penyelesaian klaim yaitu Jenis Manfaat (C1), Jenis Pembayaran (C2), Jumlah Tindakan (C3), Besar nilai Klaim (C4), dan Jumlah hari Kerja SLA (C5).
2. Nilai bobot pada lima kriteria adalah W1 bobot untuk Jenis Manfaat dengan nilai 0.15, W2 bobot untuk Jenis Pembayaran dengan nilai 0.10, W3 bobot untuk Jumlah Tindakan dengan nilai 0.15, W4 bobot untuk Besar nilai klaim dengan nilai 0.25, W5 bobot untuk Jumlah hari kerja SLA dengan nilai 0.35.
3. Sumber Data yang digunakan dalam proses pengolahan Data mining berasal dari Sistem Datawarehouse atau Basis Data Staging dimana datanya didapat dari Basis Data Transaksional.
4. Data perangkingan verifikator merupakan hasil akhir proses perhitungan menggunakan Metode Simple Additive Weighting (SAW), yang disajikan berupa Tabel Data peringkat Tertinggi dan Terendah untuk setiap bulannya serta Grafik Nilai Verifikator untuk tiap bulannya.
Terdapat beberapa saran untuk pengembangan penelitian tersebut diantaranya :
1. Analisa perhitungan dapat menggunakan Metode lain untuk digunakan sebagai pembanding hasil penilaian dan kecepatan proses.
2. Penyajian data dibuat sebanyak mungkin dalam rangka mendukung pihak manajemen dalam mengambil keputusan kebijakan proses penyelesaian klaim.
REFERENSI
[1] Kusrini, Emha Taufiq Lutfhi, 2009, “Algoritma Data Mining”, Penerbit Andi, Yogyakarta.
[2] Kusumadewi, Sri, 2006, “Fuzzy Multi-Attribute Decision Making (Fuzzy MADM)”, Graha Ilmu,Yogyakarta.
[3] Larose, Daniel T., 2005, “Discovering Knowledge in Data: An Introduction to Data Mining”, John Willey &
Sons, Inc, New Jersey.
[4] McLeod, Raymond, 1995, “Sistem Informasi Manajemen”, PT. Tema Baru, Klaten
[5] Santosa, Budi, 2007, “Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis”, Graha Ilmu,Yogyakarta.
[6] Susanto, Sani, dan Suryadi, Dedy, 2010, “Pengantar Data Mining” , Penerbit Andi Yogyakarta, Yogyakarta.
[7] Turban, Efraim., Aronso, Jay., Liang Peng Ting, 2005,
“Decision Support System and Intelligence System (Versi Bahasa Indonesia), Edisi Ke-7”, ANDI Offset, Yogyakarta.
Fahrul Nurzaman, memperoleh gelar ST dan MTI dari STT TELKOM Bandung dan Universitas Indonesia Jakarta tahun 2004 dan 2009. Saat ini sebagai Staf Pengajar program studi Teknik Informatika Universitas Persada Indonesia YAI.