BAB III
ANALISIS DAN PERANCANGAN
SISTEM PAKAR KESEHATAN
Berikut ini adalah diagram proses pengembangan sistem pakar kesehatan ini:
Gambar III-1 Proses pengembangan sistem pakar kesehatan
Pada Gambar III-1, dapat dilihat bahwa proses pengembangan sistem pakar diawali dengan analisis awal, kemudian terbagi menjadi tiga proses secara paralel, yaitu analisis data, analisis
shell Induct/MCRDR, dan analisis dan perancangan program. Analisis data mencakup
tahapan-tahapan yang dilalui untuk memperoleh data digital yang siap digunakan oleh sistem pakar. Analisis shell Induct/MCRDR mencakup analisis kelemahan dan perubahan yang dilakukan pada shell Induct/MCRDR agar dapat menangani permasalahan diagnosis penyakit dan pemberian terapi. Analisis dan perancangan program mencakup perancangan sistem pakar, termasuk pembuatan format dataset yang digunakan pada analisis data.
3.1 Analisis Awal
Ada dua hal utama yang perlu diperhatikan dalam pembangunan sistem pakar: 1. Ranah masalah
Karakteristik dari ranah masalah diagnosis penyakit umum dan pemberian terapinya adalah sebagai berikut:
a. Gejala yang dialami pasien dapat lebih dari satu.
b. Diagnosis yang dihasilkan dapat lebih dari satu (misalnya seorang pasien didiagnosis menderita typhoid fever dan cystitis pada saat yang sama).
c. Terapi/obat yang diberikan pakar dapat lebih dari satu.
III-1
2. Sumber daya dan manajemen
Sumber daya yang terlibat dalam pengembangan sistem pakar ini adalah penulis (perekayasa pengetahuan) dan seorang pakar, dr. Frans Sukardi.
Berikut adalah evaluasi kelayakan proyek sistem pakar: 1. Pengguna dan Manajemen
Pengguna sistem pakar ini adalah pakar sendiri, tetapi tidak tertutup kemungkinan bahwa sistem pakar ini dapat digunakan oleh masyarakat awam. Sistem ini melibatkan interaksi dengan pengguna, di mana pengguna diminta untuk memasukkan gejala-gejala maupun alergi untuk dianalisis. Sistem pakar ini dapat digunakan oleh masyarakat awam tanpa harus mengetahui pengetahuan spesifik tertentu.
2. Task
Sistem pakar ini akan melakukan diagnosis terhadap gejala masukan pengguna, dan menghasilkan terapi yang sesuai dengan gejala masukan tersebut.
3. Pakar
Pakar dalam ranah permasalahan sistem pakar ini ada, dan dapat diajak bekerja sama. Walaupun demikian, pengetahuan pakar tidak didapatkan secara langsung dari pakar yang bersangkutan, melainkan melalui media berupa kartu pasien.
3.1.1 Spesifikasi
Kebutuhan Sistem
Sistem pakar kesehatan ini termasuk sistem pakar berskala kecil, dan memiliki spesifikasi sebagai berikut:
1. Mampu menerima masukan dataset dengan format tertentu. Format dataset ini dapat dilihat pada Subbab 3.4.3.
2. Mampu membangkitkan pengetahuan secara otomatis dari masukan dataset yang telah diterima sebelumnya.
3. Mampu menampilkan diagnosis penyakit dan terapi dari gejala-gejala penyakit masukan.
4. Memiliki antarmuka yang mudah dipahami dan mudah digunakan oleh penggunanya.
3.1.2
Pengembangan Sistem Pakar
Berikut adalah analisis masalah-masalah yang harus diperhatikan dalam pengembangan sistem pakar kesehatan:
1. Bagaimana format dataset masukan sehingga dapat diproses oleh sistem pakar kesehatan.
2. Bagaimana proses pembangunan basis pengetahuan dari sistem pakar kesehatan ini. 3. Bagaimana menangani kasus-kasus tertentu yang hanya dialami perempuan atau
laki-laki saja.
4. Batasan apa saja yang dimiliki oleh sistem pakar kesehatan ini. 5. Bagaimana proses inferensi pengetahuan untuk setiap kasus masukan.
3.2 Analisis Data
3.2.1
Masalah Diagnosis Penyakit dan Pemberian Terapi
Masalah diagnosis penyakit oleh pakar terdiri dari dua bagian besar, yaitu diagnosis penyakit itu sendiri, dan penentuan terapi dari hasil diagnosis. Agar dapat mendiagnosis penyakit, pakar melakukan anamnesis, pemeriksaan umum, dan pemeriksaan fisik terhadap pasien. Setelah seorang pasien didiagnosis penyakitnya, pakar akan memberikan terapi untuk mengobati penyakit tersebut. Pemberian terapi ini juga dipengaruhi data hasil anamnesis dan pemeriksaan. Seluruh proses ini dicatat pakar pada kartu pasien yang bersangkutan. Berikut ini adalah contoh kartu pasien yang telah diisi oleh pakar.
Gambar III-2 Contoh kartu pasien.
Diagnosis penyakit oleh pakar merupakan permasalahan klasifikasi, di mana pakar menentukan penyakit apa saja yang diderita pasien. Seorang pasien dapat mengalami multiple
diseases (menderita lebih dari satu penyakit dalam waktu yang bersamaan), termasuk
komplikasi penyakit, sehingga hasil diagnosis pakar dapat berjumlah lebih dari satu. Misalnya, seorang pasien memiliki gejala demam dan anyang-anyangan didiagnosis
menderita typhoid fever (tifus) dan cystitis (radang kandung kemih). Oleh karena itu, permasalahan ini termasuk ke dalam permasalahan klasifikasi majemuk.
Pemberian obat/terapi sama seperti diagnosis penyakit. Pakar memilih obat yang dirasa cocok untuk pasien berdasarkan penyakit yang dideritanya. Proses pemilihan ini juga merupakan proses klasifikasi, di mana obat untuk pasien dipilih dari sekian banyak obat yang tersedia, dengan berbagai pertimbangan berdasarkan data medis pasien dan hasil diagnosis pakar. Selain itu, obat yang diberikan pakar dapat lebih dari satu, maka pemberian obat/terapi juga merupakan permasalahan klasifikasi majemuk.
Masalah diagnosis penyakit dan pemberian terapi ini dapat ditangani dengan metode Induct/MCRDR. Selain merupakan permasalahan klasifikasi majemuk, masalah ini juga melibatkan data klasifikasi majemuk dalam jumlah besar.
3.2.2
Seleksi dan Ekstraksi Data
Data tentang diagnosis penyakit dan pemberian terapi diperoleh dari seorang pakar, yaitu dr. Frans Sukardi. Selain itu, data juga didapatkan dari berbagai referensi tertulis berupa buku, yaitu [MIM08].
Dalam proses pengembangan perangkat lunak, data didapatkan melalui media tertulis berupa kartu pasien.
3.2.2.1 Pengambilan Data
Untuk mendapatkan data mentah, dilakukan pembacaan kartu pasien serta wawancara dengan pakar. Tidak semua data yang tertulis pada kartu pasien digunakan sebagai data dari tugas akhir ini. Data diambil secara acak dengan frekuensi 3-5 kasus untuk setiap kartu pasien. Adapun data yang diambil memiliki ketentuan sebagai berikut:
1. Pada Subbab 1.4 telah diasumsikan bahwa kedatangan pasien hanya untuk satu kali kedatangan saja, maka antara data yang satu dengan yang lain diasumsikan tidak berhubungan (saling lepas). Dengan demikian, data “tanggal kedatangan” tidak perlu digunakan.
2. Jika ada beberapa kasus yang sama pada orang yang sama (misalkan 5 kali mengalami rheumatism), maka akan diambil 1-2 kasus saja dan sisanya diabaikan. Hal ini dilakukan agar jumlah jenis kasus yang diperoleh seimbang.
3. Berat badan pada umumnya hanya digunakan untuk menentukan dosis obat yang sesuai. Karena dosis obat tidak ditangani sistem pakar ini, maka data “berat badan” diabaikan.
Dari pembacaan kartu pasien tersebut, didapatkan data sebagai berikut:
1. Nama pasien (tidak digunakan dalam tugas akhir ini karena bersifat rahasia) 2. Jenis kelamin pasien
3. Umur pasien
4. Riwayat penyakit dulu 5. Tanggal kedatangan 6. Tekanan darah 7. Suhu tubuh
8. Berat badan (jika diperlukan)
9. Keluhan pasien / gejala yang dialami pasien 10. Hasil diagnosis dokter
11. Terapi yang diberikan (obat & anjuran)
Contoh data mentah dapat dilihat pada Lampiran D.
3.2.2.2 Penentuan Atribut Diagnosis Penyakit dan Pemberian Terapi
Setelah data mentah diperoleh, dilakukan analisis atribut-atribut yang mempengaruhi diagnosis dan pemberian terapi. Berdasarkan batasan masalah pada Tugas Akhir ini, atribut yang berhubungan dengan hasil diagnosis, antara lain:
1. Jenis kelamin 2. Umur
3. Suhu tubuh 4. Tekanan darah
5. Riwayat penyakit dulu 6. Keluhan/gejala/tanda-tanda
Berikut ini adalah atribut yang berhubungan dengan pemberian terapi: 1. Jenis kelamin
2. Umur 3. Suhu tubuh 4. Tekanan darah
6. Keluhan/gejala/tanda-tanda 7. Hasil diagnosis
3.2.2.3 Abstraksi dan Pengolahan Data
Untuk memperoleh data siap pakai, dilakukan abstraksi data dengan ketentuan sebagai berikut:
1. Umur dibedakan menjadi dua:
a. Anak-anak (di bawah sama dengan 12 tahun) b. Dewasa (di atas 12 tahun)
2. Tekanan darah dibedakan menjadi tiga:
a. Rendah (tekanan darah atas lebih rendah dari 110 mmHg atau tekanan darah bawah lebih rendah dari 70 mmHg)
b. Normal (tekanan darah atas antara 110 mmHg sampai dengan 120 mmHg dan tekanan darah bawah antara 70 mmHg sampai dengan 80 mmHg)
c. Tinggi (tekanan darah atas lebih besar dari 120 mmHg atau tekanan darah bawah lebih besar dari 80 mmHg)
3. Suhu tubuh dibedakan menjadi tiga: a. Rendah (di bawah 36° C)
b. Normal (antara 36° C sampai dengan 37° C) c. Tinggi (lebih besar dari 37° C)
Selanjutnya dilakukan pengolahan data sebagai berikut:
1. Berdasarkan batasan masalah dalam Tugas Akhir ini, keterangan waktu yang terkait dengan keluhan pasien (misalnya demam 2 hari, batuk-batuk selama 5 hari, dll) diabaikan.
2. Karena satu penyakit bisa diobati dengan bermacam-macam merk obat, maka dilakukan penyederhanaan solusi obat. Data obat yang diperoleh diubah menjadi data jenis obat. Sebagai contoh, Panadol, Frisium, Dumolit berturut-turut merupakan jenis obat Analgesic (antisakit), Tranqualizer (obat tenang), dan Somnil (obat tidur). Data jenis obat diperoleh dari tanya jawab dengan pakar.
3. Riwayat penyakit dulu yang tidak mempengaruhi keadaan sekarang dihilangkan (misalnya operasi). Penyakit yang pada umumnya terus diderita pasien tetap ditulis (asma, maag, diabetes, dll).
4. Melakukan penyederhanaan keluhan. Sebagai contoh, jika ada keluhan “nyeri pada lutut kanan”, maka akan disederhanakan menjadi “nyeri pada lutut” saja.
Contoh data setelah abstraksi dan pengolahan data dilakukan dapat dilihat pada Lampiran D. Selanjutnya, data ini disimpan dalam format teks digital (txt) untuk dilakukan penyesuaian dengan format dataset rancangan.
3.3 Analisis Shell Induct/MCRDR
Shell Induct/MCRDR pada [ARM07] akan digunakan sistem pakar ini sebagai kakas bantu
utama dalam membentuk basis pengetahuan. Dalam penggunaannya, shell ini memiiki beberapa keterbatasan, yaitu:
1. Ketidakmampuan menghasilkan solusi majemuk
Shell Induct/MCRDR ini akan menghasilkan sebuah pohon n-ary dengan
kondisi-kondisi yang sangat spesifik, dan penelusuran solusi pada pohon tersebut tidak menghasilkan solusi yang majemuk. Hal ini disebabkan oleh banyaknya stopping rule yang dihasilkan. Dari 138 data diagnosis yang digunakan, dihasilkan kurang lebih 2900 buah rule dan 2800 buah stopping rule (lebih dari 90% rule merupakan stopping
rule). Contoh kasus dapat dilihat pada Lampiran E, di mana solusi yang dihasilkan
sistem selalu merupakan solusi tunggal. Untuk mengatasi permasalahan di atas, pembentukan stopping rule diabaikan. Dengan tidak adanya stopping rule, sistem dapat menghasilkan solusi majemuk.
2. Kemungkinan node akar tidak keluar menjadi node solusi
Pengabaian stopping rule menimbulkan masalah baru, yaitu kemungkinan tidak pernah terpilihnya node akar sebagai solusi. Dengan demikian, maka kelas solusi terbanyak menjadi jarang terpilih. Hal ini biasanya terjadi pada penelusuran pohon dari atribut masukan yang berjumlah banyak dan memenuhi kondisi pada satu node di bawah akar atau lebih (solusi node akar hanya muncul jika semua kondisi tidak terpenuhi). Untuk mengatasi masalah tersebut, maka node akar dalam pohon Induct/MCRDR akan diturunkan menjadi node anak yang berada satu di bawah node akar sehingga kelas terbanyak dapat keluar sebagai solusi majemuk bersama solusi lainnya. Kondisi untuk Hal ini mengacu pada teori MCRDR sendiri, di mana node akar pada pohon MCRDR merupakan kelas default atau kasus normal.
3. Penurunan akurasi jika menggunakan kelas default
Penggunaan kelas default atau kasus normal sebagai node akar menurunkan akurasi sistem sekitar 10%. Hal ini disebabkan perhitungan kondisi setiap node yang berada di bawah node akar merupakan perhitungan untuk solusi selain kelas kemunculan terbanyak sehingga banyak kondisi yang tidak dipenuhi dan node akar muncul sebagai solusi. Untuk mengatasi hal tersebut, maka kelas solusi pada node akar tetap diisi dengan kelas solusi yang paling banyak kemunculannya.
4. Ketidakpraktisan jika menggunakan atribut majemuk
Shell ini tidak praktis dalam penggunaan atribut majemuk, misalnya atribut “keluhan
pasien” yang bisa mengandung lebih dari satu nilai. Penulisan atribut majemuk ini tidak praktis, karena setiap nilai dari atribut majemuk harus ditulis secara manual menjadi satu atribut dengan nilai “yes” dan “no”.
5. Tidak mampu membedakan kasus-kasus tertentu dalam konteks kesehatan
Dalam konteks kesehatan, shell ini tidak dapat membedakan kasus-kasus khusus tertentu, misalnya keluhan atau penyakit yang hanya dapat diderita oleh perempuan seperti terlambat datang bulan. Oleh karena itu, dilakukan optimasi terhadap pohon yang terbentuk dengan menambahkan stopping rule. Kondisi dari stopping rule merupakan jenis kelamin dengan atribut laki-laki atau perempuan, dan kelas solusi
null.
Solusi pada poin nomor 4 dapat dilihat dari dataset masukan sistem pakar, di mana atribut majemuk dipisahkan dengan tanda titik koma (;). Pada gambar di bawah, dapat dilihat contoh data masukan sistem pakar: Maag, asma, wasir merupakan atribut majemuk dari riwayat penyakit dulu, sedangkan sakit kepala dan susah tidur merupakan atribut majemuk dari diagnosis.
perempuan, dewasa, normal, normal, maag;asma;wasir, sakit kepala;susah tidur, tension headache
Gambar III-3 Contoh data masukan sistem pakar setelah dilakukan perubahan pada shell Induct/MCRDR.
Solusi poin nomor 1, 2, 3, dan 5 dapat dilihat pada pohon pengetahuan yang terbentuk di bawah ini:
R0: ... => diagnosis = psikosomatis
| R1: (keluhan-anyang-anyangan = yes) => diagnosis = cystitis | R2: (keluhan-mual = yes) => diagnosis = dispepsia
| R8: (keluhan-anyang-anyangan = yes) => none
| R3: (keluhan-demam = yes) & (tekanan_darah = tinggi) => diagnosis = faringitis | R9: (keluhan-anyang-anyangan = yes) => none
| R10: (keluhan-mual = yes) => none
| R4: (keluhan-batuk = yes) => diagnosis = ispa | R11: (keluhan-anyang-anyangan = yes) => none | R12: (keluhan-mual = yes) => none
| R13: (keluhan-demam = yes) & (tekanan_darah = tinggi) => none | R5: (keluhan-nyeri pinggang = yes) => diagnosis = lumbago
| R14: (keluhan-anyang-anyangan = yes) => none | R15: (keluhan-mual = yes) => none
| R16: (keluhan-demam = yes) & (tekanan_darah = tinggi) => none | R17: (keluhan-batuk = yes) => none
| R6: (keluhan-sakit kepala = yes) => diagnosis = tension headache | R18: (keluhan-anyang-anyangan = yes) => none
| R19: (keluhan-mual = yes) => none
| R20: (keluhan-demam = yes) & (tekanan_darah = tinggi) => none | R21: (keluhan-batuk = yes) => none
| R22: (keluhan-nyeri pinggang = yes) => none
| R7: (jenis_kelamin = laki-laki) => diagnosis = cystitis | R23: (keluhan-mual = yes) => none
| R24: (keluhan-demam = yes) & (tekanan_darah = tinggi) => none | R25: (keluhan-batuk = yes) => none
| R26: (keluhan-nyeri pinggang = yes) => none | R27: (keluhan-sakit kepala = yes) => none
Gambar III-4 Contoh pohon pengetahuan sebelum perbaikan shell Induct/MCRDR.
R0: ... => diagnosis = psikosomatis
| R1: (tekanan_darah = tinggi) & (suhu_tubuh = normal) & (keluhan-nyeri pinggang = no) => diagnosis = psikosomatis
| R2: (keluhan-anyang-anyangan = yes) => diagnosis = cystitis | R3: (keluhan-mual = yes) => diagnosis = dispepsia
| R9: (jenis_kelamin = laki-laki) => diagnosis = none
| R4: (keluhan-demam = yes) & (tekanan_darah = tinggi) => diagnosis = faringitis | R5: (keluhan-batuk = yes) => diagnosis = ispa
| R6: (keluhan-nyeri pinggang = yes) => diagnosis = lumbago | R7: (keluhan-sakit kepala = yes) => diagnosis = tension headache | R8: (jenis_kelamin = laki-laki) => diagnosis = cystitis
Gambar III-5 Contoh pohon pengetahuan sesudah perbaikan shell Induct/MCRDR.
Dari kedua gambar di atas, dapat dilihat perbedaan yang terjadi pada shell Induct/MCRDR. Poin nomor 1 ditunjukkan dengan hilangnya stopping rule dari pohon yang terbentuk. Contoh
stopping rule dapat dilihat pada R8, R9, R10 pada Gambar III-4. Poin nomor 2 ditunjukkan
pada Gambar III-5, tanpa R1. Jika dimasukkan sejumlah atribut yang banyak memenuhi kondisi pada node bukan akar, maka sistem akan jarang sekali menghasilkan node akar sebagai solusi. Poin nomor 3 ditunjukkan pada Gambar III-5 tanpa R0. Tidak adanya R0 menyebabkan akurasi turun sekitar 10%. Terakhir, poin nomor 5 ditunjukkan oleh R9 pada Gambar III-5. R9 menjamin bahwa yang menderita dispepsia hanya perempuan.
Algoritma Induct/MCRDR setelah dilakukan perubahan di atas adalah sebagai berikut: BuildMCRDR(Default_Class,Attrs,Training_Set)
{Menghasilkan pohon pengetahuan MCRDR dengan simpul bernilai T} type T = {Class: nilai kelas
Clause: nilai klausa
Cov: pohon perkecualian positif NotCov: pohon perkecualian negatif}
for Class = (set of class values) if Class = Default_Class
TempClause ← BestClause(Class,Attr,Training_Set)
if r(TempClause) < r(T.Clause)
T.Clause ← TempClause T.Class ← Class
Bentuk simpul akar dengan klausa true dan solusi Default_Class
Bentuk simpul di bawah akar dengan klausa T.Clause dan solusi Default_Class Covered ← himpunan semua entitas e dalam Training_Set dengan
T.Clause(e) bernilai benar
NotCovered ← himpunan semua entitas e dalam Training_Set dengan T.Clause(e) bernilai salah
if e berada dalam Covered dan e.Class = Class
T.Cov ← BuildMCRDR(Class,Attrs,Covered) ;pada level selanjutnya
if e berada dalam NotCovered dan e.Class = Class
T.NotCov ← BuildMCRDR(Class,Attrs,NotCovered) ;pada level sama
end BuildMCRDR
3.4 Analisis dan Perancangan Program
Sistem pakar ini dibangun berdasarkan shell Induct/MCRDR pada [ARM07] dan akan menggunakan package lib.JSci untuk melakukan operasi distribusi binomial yang digunakan dalam penghitungan nilai r. JSci merupakan kependekan dari Java Objects for Science.
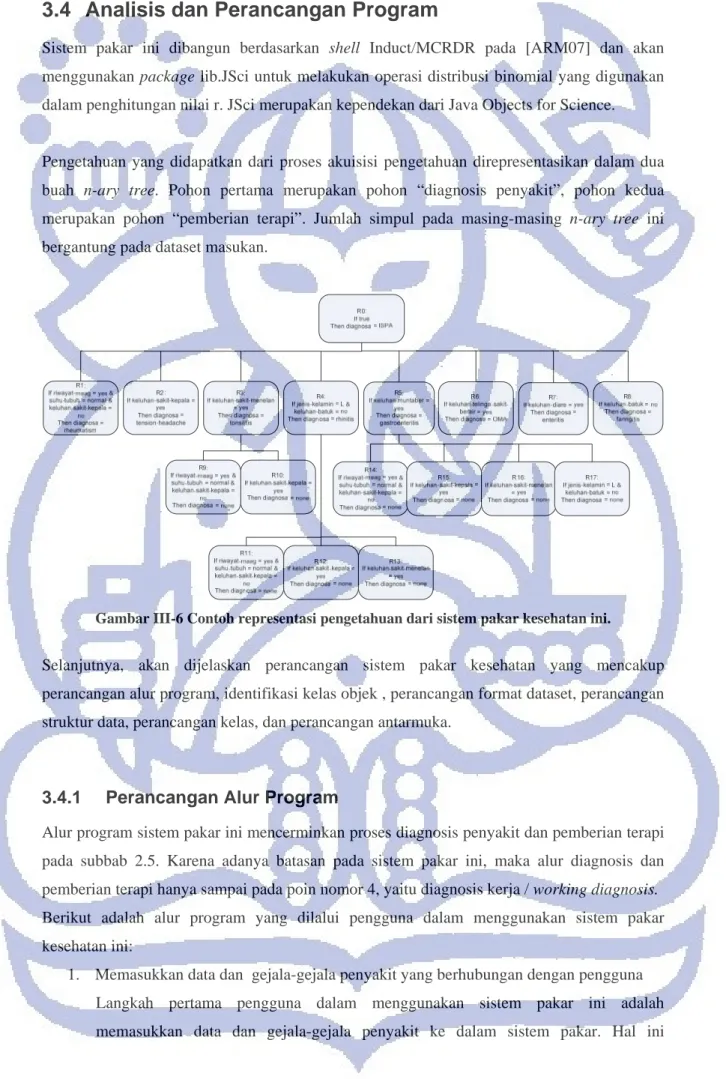
Pengetahuan yang didapatkan dari proses akuisisi pengetahuan direpresentasikan dalam dua buah n-ary tree. Pohon pertama merupakan pohon “diagnosis penyakit”, pohon kedua merupakan pohon “pemberian terapi”. Jumlah simpul pada masing-masing n-ary tree ini bergantung pada dataset masukan.
Gambar III-6 Contoh representasi pengetahuan dari sistem pakar kesehatan ini.
Selanjutnya, akan dijelaskan perancangan sistem pakar kesehatan yang mencakup perancangan alur program, identifikasi kelas objek , perancangan format dataset, perancangan struktur data, perancangan kelas, dan perancangan antarmuka.
3.4.1
Perancangan Alur Program
Alur program sistem pakar ini mencerminkan proses diagnosis penyakit dan pemberian terapi pada subbab 2.5. Karena adanya batasan pada sistem pakar ini, maka alur diagnosis dan pemberian terapi hanya sampai pada poin nomor 4, yaitu diagnosis kerja / working diagnosis. Berikut adalah alur program yang dilalui pengguna dalam menggunakan sistem pakar kesehatan ini:
1. Memasukkan data dan gejala-gejala penyakit yang berhubungan dengan pengguna Langkah pertama pengguna dalam menggunakan sistem pakar ini adalah memasukkan data dan gejala-gejala penyakit ke dalam sistem pakar. Hal ini
merepresentasikan proses anamnesis, pemeriksaan umum, dan pemeriksaan khusus pada subbab 2.5.
2. Menjalankan diagnosis sistem pakar
Setelah memasukkan gejala penyakit, pengguna menekan tombol “Diagnosis”. Sistem pakar kemudian akan menampilkan kemungkinan penyakit yang diderita dan solusi terapi yang diberikan. Hal ini merepresentasikan diagnosis kerja pada subbab 2.5.
3. Kembali ke awal
Jika pengguna ingin menjalankan sistem pakar dari awal, pengguna dapat menekan tombol ‘Ulangi’ yang disediakan.
Tahapan yang dilalui sistem pakar dalam membentuk basis pengetahuan adalah sebagai berikut:
1. Sistem pakar membaca file dataset diagnosis dan dataset obat (diperoleh dari ekstraksi data pada kartu pasien), kemudian membentuk file lain dengan format tertentu yang dapat diterima oleh sistem pakar. Isi dari file yang dibentuk ini adalah daftar kemunculan atribut dan nilainya beserta dengan datasetnya.
2. Sistem pakar membaca file yang baru dibentuk ini, dan menuliskan kemunculan setiap nilai atribut “riwayat penyakit” dan atribut “keluhan” pada list yang terdapat di jendela utama dari sistem pakar ini.
3. Sistem pakar mengubah setiap dataset yang dibaca ke dalam format struktur data tertentu.
4. Dari struktur data yang sudah terbentuk, sistem pakar membangun basis pengetahuan dengan metode Induct/MCRDR.
3.4.2
Identifikasi Kelas Objek
Identifikasi kelas objek dari pengembangan sistem pakar ini adalah: 1. Kelas ListAtribut
Kelas ini menyimpan daftar atribut dan kelas yang mungkin muncul dalam pembangunan suatu pengetahuan. Penyimpanan dilakukan dengan membaca file dataset masukan yang mengandung daftar atribut dan kelas.
2. Kelas ListData
Kelas ini menyimpan dataset masukan dengan membaca file dataset masukan ke dalam struktur data yang ditentukan.
3. Kelas Condition
4. Kelas Rules
Kelas ini menyimpan format dari suatu rule, yang terdiri dari kondisi dan solusi. Karena suatu rule mengandung kondisi, maka kelas Rules ini akan mengandung atribut kelas Condition.
5. Kelas Node
Kelas ini menyimpan bentuk simpul dari suatu pohon. Setiap simpul memiliki sebuah
rule karena itu kelas Node ini memiliki atribut kelas Rules.
6. Kelas MainMCRDR
Kelas ini adalah kelas utama yang melakukan operasi pembacaan file dataset masukan, pembangunan pengetahuan, dan penelusuran pengetahuan untuk mencari solusi dari kasus masukan.
7. Kelas MainFrame
Kelas ini adalah antarmuka dari sistem pakar. 8. Kelas Inisialisasi
Kelas ini adalah kelas pembentuk thread saat membangun basis pengetahuan.
3.4.3 Perancangan
Format
Dataset
Dalam pengembangan sistem pakar ini, digunakan 2 jenis dataset, yaitu dataset untuk diagnosis penyakit dan dataset obat. Kedua dataset ini berupa file. Dataset diagnosis penyakit berisi atribut-atribut yang mempengaruhi diagnosis dan diagnosis yang muncul dalam pengetahuan beserta nilai atribut dan nilai kelas majemuknya, sedangkan dataset obat berisi solusi obat dari dataset diagnosis. Atribut yang mempengaruhi dapat dilihat pada subbab 3.2.2.2.
Sebelum dapat digunakan oleh sistem pakar, dilakukan pemrosesan terhadap dataset terlebih dahulu. Pemrosesan ini bertujuan untuk mempermudah pendaftaran nilai atribut yang muncul pada dataset. Berikut adalah format dataset masukan sebelum dapat diproses sistem pakar:
#datadiagnosis
nilai_jenis_kelamin_1, ..., nilai_riwayat_penyakit_1a;...;nilai_riwayat_penyakit_1z, nilai_keluhan_1a;...;nilai_keluhan_1z, nilai_diagnosis_1a, ..., nilai diagnosis_1z ...
nilai_jenis_kelamin_n, ..., nilai_riwayat_penyakit_na;...;nilai_riwayat_penyakit_nz, nilai_keluhan_na;...;nilai_keluhan_nz, nilai_diagnosis_na, ..., nilai diagnosis_nz
#dataobat
nilai_jenis_kelamin_1, ..., nilai_riwayat_penyakit_1a;...;nilai_riwayat_penyakit_1z, nilai_keluhan_1a;...;nilai_keluhan_1z, nilai_diagnosis_1a;...;nilai diagnosis_1z, nilai_obat_1a, ..., nilai_obat_1z
...
nilai_jenis_kelamin_n, ..., nilai_riwayat_penyakit_na;...;nilai_riwayat_penyakit_nz, nilai_keluhan_na;...;nilai_keluhan_nz, nilai_diagnosis_na;...;nilai diagnosis_nz, nilai_obat_na, ..., nilai_obat_nz
Gambar III-8 Format file dataset pemberian terapi sebelum diproses sistem pakar
Kedua dataset di atas merupakan file teks biasa. Dataset diagnosis sebelum dapat diproses sistem pakar diawali dengan identitas dataset #datadiagnosis diikuti dengan penulisan data di bawahnya. Setiap baris setelah identitas dataset merupakan sebuah dataset. Urutan penulisan sebuah dataset adalah sebagai berikut: jenis kelamin, umur, suhu tubuh, tekanan darah, riwayat penyakit, keluhan, dan diagnosis. Masing-masing jenis data dipisahkan dengan separator koma (,). Jenis kelamin, umur, suhu tubuh, dan tekanan darah hanya dapat mempunyai sebuah nilai, sedangkan riwayat penyakit, keluhan, dan diagnosis dapat mempunyai lebih dari satu nilai. Atribut riwayat penyakit dan keluhan yang masing-masing memiliki lebih dari satu nilai dipisahkan dengan tanda titik koma (;), sedangkan untuk nilai diagnosis yang lebih dari satu dipisahkan dengan tanda koma (,).
Penulisan dataset obat hampir sama dengan dataset diagnosis. Perbedaannya terletak pada identitas dataset #dataobat, kelas diagnosis yang menjadi atribut sehingga nilai diagnosis yang satu dengan yang lain dipisahkan dengan separator titik koma (;), dan kelas solusi merupakan obat.
Kedua dataset tersebut akan diproses terlebih dahulu ke dalam format yang dapat digunakan oleh sistem pakar. Tujuan dari pemrosesan ini adalah mendapatkan nilai-nilai dari masing-masing atribut yang muncul pada dataset. Berikut ini adalah format dataset diagnosis setelah pemrosesan:
#induct/MCRDR #names
attribute jenis_kelamin {nilai_jenis_kelamin_a, ..., nilai_jenis_kelamin_z} attribute umur {nilai_umur_1, ..., nilai_umur_z}
attribute suhu_tubuh {nilai_suhu_tubuh_a, ..., nilai_suhu_tubuh_z}
attribute tekanan_darah {nilai_tekanan_darah_a, ..., nilai_tekanan_darah_z}
mattribute riwayat_penyakit {nilai_riwayat_penyakit_a, ... , nilai_riwayat_penyakit_z} mattribute keluhan {nilai_keluhan_a, ..., nilai_keluhan_z}
class diagnosis {nilai_diagnosis_1, ..., nilai_diagnosis_100} #data
nilai_jenis_kelamin_1, ..., nilai_riwayat_penyakit_1a;...;nilai_riwayat_penyakit_1z, nilai_keluhan_1a;...;nilai_keluhan_1z, nilai_diagnosis_1a, ..., nilai diagnosis_1z ...
nilai_jenis_kelamin_n, ..., nilai_riwayat_penyakit_na;...;nilai_riwayat_penyakit_nz, nilai_keluhan_na;...;nilai_keluhan_nz, nilai_diagnosis_na, ..., nilai diagnosis_nz
Format file dataset diagnosis penyakit terdiri dari identitas file dataset yang ditandai dengan #induct/MCRDR. Awal penulisan daftar atribut dan kelas ditandai dengan #names. Urutan penulisan harus diawali dengan atribut dan diakhiri dengan penulisan daftar kelas diagnosis yang dihasilkan. Format daftar atribut ditandai dengan penulisan attribute, dilanjutkan dengan nama atribut, dan diakhiri dengan nilai-nilai atribut yang dipisahkan koma dan dibatasi dengan kurung kurawal. Atribut yang dapat memiliki lebih dari satu nilai ditandai dengan penulisan mattribute. Aturan yang sama berlaku untuk penulisan nama kelas dan nilai-nilai kelas. Perbedaan hanya terdapat pada penanda yang diawali dengan penulisan class.
Selanjutnya dilakukan pendaftaran atas dataset yang diawali dengan tanda #data. Setiap penulisan sebuah dataset harus mengikuti urutan kemunculan atribut dan kelas yang telah ditulis sebelumnya. Pemisah antara nilai satu dengan yang lainnya dilakukan dengan penggunaan separator koma. Atribut yang memiliki lebih dari satu nilai (misalnya gejala demam, batuk-batuk) dipisahkan dengan tanda titik koma tanpa spasi (;). Isi dari bagian ini sama dengan isi pada dataset sebelum pemrosesan, tanpa #datadiagnosis atau #dataobat
#induct/MCRDR #names
attribute jenis_kelamin {nilai_jenis_kelamin_a, ..., nilai_jenis_kelamin_z} attribute umur {nilai_umur_1, ..., nilai_umur_z}
attribute suhu_tubuh {nilai_suhu_tubuh_a, ..., nilai_suhu_tubuh_z}
attribute tekanan_darah {nilai_tekanan_darah_a, ..., nilai_tekanan_darah_z}
mattribute riwayat_penyakit {nilai_riwayat_penyakit_a, ... , nilai_riwayat_penyakit_z} mattribute keluhan {nilai_keluhan_a, ..., nilai_keluhan_z}
mattribute diagnosis {nilai_diagnosis_1, ..., nilai_diagnosis_100} class obat {nilai_obat_1, ..., nilai_obat_100}
#data
nilai_jenis_kelamin_1, ..., nilai_riwayat_penyakit_1a;...;nilai_riwayat_penyakit_1z, nilai_keluhan_1a;...;nilai_keluhan_1z, nilai_diagnosis_1a;...;nilai diagnosis_1z, nilai_obat_1a, ..., nilai_obat_1z
...
nilai_jenis_kelamin_n, ..., nilai_riwayat_penyakit_na;...;nilai_riwayat_penyakit_nz, nilai_keluhan_na;...;nilai_keluhan_nz, nilai_diagnosis_na;...;nilai diagnosis_nz, nilai_obat_na, ..., nilai_obat_nz
Gambar III-10 Format file dataset obat
Perbedaan mendasar antara dataset diagnosis dengan dataset obat hanya terletak pada kelas solusi (obat) dan kelas diagnosis pada dataset sebelumnya menjadi sebuah matttribute. Aturan penulisan dataset obat sama dengan aturan penulisan pada dataset diagnosis.
3.4.4
Perancangan Struktur Data
Struktur data yang digunakan sistem pakar ini sama dengan struktur data pada shell Induct/MCRDR [ARM07]. Penjelasan mengenai struktur data ini dapat dilihat pada subbab 2.4.2.
Pada struktur data ListData, atribut yang memiliki lebih dari satu nilai akan mempunyai jumlah kolom nilai atribut sebanyak jumlah nilai atribut itu. Misalnya, jika atribut gejala_penyakit mempunyai nilai demam, batuk, dan pilek, maka akan terdapat 3 kolom pada ListData. Setiap kemunculan nilai atribut (khusus atribut yang dapat memiliki lebih dari satu nilai), maka pada kolom yang bersesuaian akan diisi dengan ‘yes’, sebaliknya jika nilai tersebut tidak muncul, maka akan ditandai dengan ‘no’. Jumlah kolom nilai kelas berukuran sama dengan jumlah nilai kelas pada ListAtribut. Bila suatu data mengandung nilai_kelas_1, maka ListData akan mengisi kolom kelas pertama dengan nilai ’yes’, sebaliknya jika tidak mengandung nilai_kelas_1, maka akan diisi dengan nilai ‘no’.
3.4.5 Perancangan
Kelas
Package dan kelas yang digunakan oleh sistem pakar ini sama dengan package dan kelas
yang digunakan oleh shell Induct/MCRDR, ditambah dengan kelas “Inisialisasi” untuk menjaga agar program tetap responsif saat pembentukan basis pengetahuan dalam jumlah besar.
Berikut adalah daftar pembagian kelas berdasarkan package yang digunakan:
Tabel III-1 Daftar kelas untuk tiap package yang digunakan sistem pakar kesehatan
No Nama Package Deskripsi Daftar Kelas
1. gui Berisi kelas-kelas antarmuka MainFrame.java
2. lib.jdots Berisi kelas-kelas pada library JDOTS Kelas-kelas dalam library JDOTS
3. lib.JSci Berisi kelas-kelas pada library JSci
(Java Objects for Science)
Kelas-kelas dalam library JSci
4. util Berisi kelas-kelas utama sistem
Induct/MCRDR TwoDimArrList.java ListAttrb.java ListData.java Condition.java Rules.java Node.java MainMCRDR.java Inisialisasi.java
3.4.6 Perancangan
Antarmuka
Antarmuka sistem pakar ini memiliki 2 jendela utama, yaitu:
a. Jendela untuk menerima masukan pengguna berupa data pasien dan keluhannya, sekaligus untuk menampilkan solusinya.
b. Jendela untuk melihat pohon pengetahuan yang terbentuk dan melakukan validasi terhadap pohon tersebut.
Gambar III-11 Rancangan antarmuka utama sistem pakar
Pada Gambar III-11, antarmuka sistem pakar memiliki 3 bagian utama, yaitu data dan keluhan pasien, hasil diagnosis, dan anjuran obat. Pemilihan jenis kelamin, umur, suhu tubuh, dan tekanan darah dapat dilakukan dengan menekan radio button yang tersedia. Riwayat penyakit dan keluhan pasien merupakan list yang pilihannya dapat dipilih lebih dari satu (list majemuk). Daftar riwayat penyakit dan keluhan bergantung kepada data latih yang digunakan. Sesudah pengguna memasukkan data yang diperlukan, ia dapat melihat solusi yang diberikan sistem dengan menekan tombol “Diagnosis”. Untuk mengulangi proses memasukkan data, pengguna dapat menekan tombol “Ulangi”.
Gambar III-12 Rancangan antarmuka untuk melihat pohon pengetahuan dan melakukan validasi
Rancangan antarmuka pada Gambar III-12 mempunyai 3 bagian utama, yaitu TextArea untuk menampilkan pohon pengetahuan maupun hasil pengujian, bagian validasi untuk melakukan pengujian terhadap pohon pengetahuan yang terbentuk, dan yang terakhir adalah tombol untuk membersihkan layar (TextArea).