BIOSTATISTIK
“STATISTIK DESKRIPTIF”
DISUSUN OLEH :
NAMA : Ns. Enok Sureskiarti.,M.Kep NIDN : 1119108202
Fakultas Ilmu Kesehatan dan Farmasi
Universitas Muhammadiyah Kalimantan Timur
ii Puji syukur alhamdulillah penulis panjatkan kehadirat Allah Subhanahu watta “alla yang telah melimpahkan rahmat dan karunia-Nya, sehingga pada akhirnya penulis dapat menyelesaikan Modul Statistik Deskriptif ini dengan baik.
Modul Statistik Deskriptif ini penulis sajikan dalam bentuk buku yang sederhana dan tujuan penulisan modul Statistik Deskriptif adalah untuk memudahkan mahasiswa dan menjadi tambahan referensi untuk menyusun tugas akhir
Akhir kata semoga modul Statistik Deskriptif ini dapat bermanfaat bagi penulis khususnya dan bagi para pembaca yang berminat pada umumnya.
Balikpapan, 2019
3
KATA PENGANTAR ... ii
DAFTAR ISI... iii
BAB I PENDAHULUAN ... 1
A. Pengertian Statistik... 1
B. Pengumpulan dan Pengolahan Data ... 1
C. Cara Pengambilan Sampel ... 2
D. Pembagian Data... 3
E. Skala Pengukuran Data ... 4
F. Penyajian Data... 4
BAB II DASAR-DASAR STATISTIK DESKRIPTIF ... 9
A. Distribusi Frekuensi ... 9
B. Ukuran Pemusatan... 12
BAB III UKURAN GEJALAPUSAT DATA YANG DIKELOMPOKKAN DAN UKURAN DISPERSI ... 16
A. Ukuran Gejala Pusat Data Yang Dikelompokkan... 16
B. Ukuran Dispersi... 19
BAB IV KEMIRINGAN, KERUNCINGAN DISTRIBUSI DATA DAN ANGKA INDEKS ... 23
A. Kemiringan Distribusi Data ... 23
B. Ukuran Keruncingan Kurva (Kurtosis) ... 24
C. Angka Indeks... 25
BAB V REGRESI DAN KORELASI SEDERHANA ... 33
A. Pengertian Regresi dan Korelasi ... 33
B. Analisa Regresi Sederhana... 35
C. Analisa Korelasi Sederhana ... 36
4
B. Pengertian Data Berkala... 39 C. Ciri-Ciri Trend Sekuler ... 40 DAFTAR PUSTAKA ... 45
BAB I PENDAHULUAN
A. Pengertian Statistika
Statistic atau ilmu statistik atau statitika adalah sebuah ilmu yang mempelajari teknik-teknik pengumpulan, pengorganisasian, analisis dan interpretasi atau informasi data. Metode statistik adalah prosedur-prosedur yang digunakan dalam pengumpulan, penyajian, analisis dan penafsiran data. Metode – metode tersebut dikelompokan menjadi dua kelompok yaitu
1. Statistik Dekriptif adalah metode-metode yang berkaitan dengan pengumpulan dan penyajian suatu gugus data sehingga memberikan informasi yang berguna.
2. InferensiaStatistik mencakup semua metode yang berhubungan dengan analisis sebagian data untuk kemudian sampai pada peramalan atau penarikan kesimpulan mengenai keseluruhan gugus data.
Dalam memecahkan masalah dengan cara statistik, lebih tepat jika mengikuti tahapan yang lebih ilmiah. Langkah-langkah dasar dalam pemecahan masalah secara statistik adalah
1. Mengidentifikasikan masalah atau peluang 2. Mengumpulkan fakta yang tersedia
3. Mengumpulkan data orisinil yang baru
4. Mengklasifikasikan dan mengikhtisarkan data 5. Menyajikan data
6. Menganalisis data
Dalam menggunakan data sebagai dasar dalam pembuatan keputusan harus memenuhi persyaratan data yang baik yaitu objektif , representatif (mewakili) dan kesalahan kecil.
B. Pengumpulan Dan Pengolahan Data
Data statistik yang diharapkan adalah data yang dapat dipercaya dan tepat waktu. Sebelum pengumpulan data dilakukan terlebih dahulu harus diketahui untuk apa data itu dikumpulkan. Apapun tujuan pengumpulan data adalah untuk mengetahui :
1. Jenis elemen atau objek yang akan diteliti. Elemen adalah unit terkecil dari objek penelitian.
2. Karateristik adalah sifat-sifat, ciri-ciri atau hal-hal yang dimiliki oleh elemen. Nilai karateristik suatu elemen merupakan nilai variabel. Variabel atau peubah ialah sesuatu yang nilainya dapat berubah atau berbeda. Metode pengumpulan data dalam statistik ada dua cara yaitu
1. Sensus adalah cara pengumpulan data apabila seluruh elemen populasi diselidiki satu persatu
2. Sampling adalah cara pengumpulan data apabila yang diselidiki hanya elemen sampel dari suatu populasi.
Populasi adalah kumpulan dari seluruh elemen sejenis tetapi dapat dibedakan satu sama lain karena karateristiknya. Misalnya seluruh karyawan perusahaan.
Sampel adalah bagian dari populasi. Jika n adalah banyaknya elemen sampel dan N adalah banyaknya elemen populasi maka n < N .
C. Cara Pengambilan Sampel
Ada 2 cara pengambilan sampel, cara acak (random) dan bukan acak (nonrandom). Cara acak adalah syatu cara pemilihan sejumlah elemen dari populasi untuk menjadi anggota sampel, dimana pemilihannya dilakukan sedemikian rupa sehingga setiap elemen populasi mendapat kesempatan yang sama untuk dipilih menjadi anggota sampel. Cara ini dianggap objektif karena netral. Samplingnya disebut probability sampling.
Cara bukan acak adalah suatu cara pemilihan elemen-elemen dari populasi untuk menjadi anggota sampel diaman setiap elemen tidak mendapat kesempatan yang sama untuk dipilih. Cara bukan acak ini lebih bersifat subjektif dan samplingnya disebut nonprobability sampling.
Jenis-jenis pengambilan sampel :
1. Simple random sampling ialah sampling dimana pemilihan elemen populasi dilakukan sedemikian rupa sehingga setiap elemen tersebut mempunyai kesempatan yang sama untuk terpilih. Metode ini tepat dipergunakan apabila populasi homogen atau relatif homogen
2. Stratified random sampling ialah sampling dimana pemilihan elemen anggota sampel dilakukan sebagai berikut :
a. Populasi dipecah menjadi populasi di pecah /dibagi menjadi populasi yang lebih kecil disebut SRATUM. Pembuatan stratum harus homogen Atau relatif homogen. Misalnya menjadi k stratum (k = 2,3 atau lebih) b. Setia[ stratum diambil sampel secara acak, kemudian dibuat perkiraan
untuk mewakili stratum yang bersangkutan
3. Multistage random sampling yaitu sampling dimana pemilihan elemen anggota sampel dilakukan secara bertahap (by stages)
Contoh :
Penelitian untuk mengetahui rata-rata upah karmatan yawan restoran padang di seluruh ibukota propinsi.
Tahap 1. Memilih sampel Kota
Tahap 2. Memilih sampel restoran, dari kota yang terpilih Tahap 3. Memilih sampel karyawan dari restoran yang terpilih Xijk = upah karyawan ke k , restoran ke j dan kota ke i
Misalnya Salim dari arestoran SAIYO , kota Jakarta
4. Cluster Random Sampling ialah sampling dimana elemen terdiri dari elemen- elemen yang lebih kecil disebut klaster (cluster). Contoh : Suatu penelitian
untuk mengetahui rata-rata kebutuhan modal pemilik toko di Jakarta. Pusat pebelanjaan (mal) seperti pasar Baru, Glodok, PIM , Plaza Senayan, Mangga Dua, dianggap sebagai klaster. Apabila Pasar Baru terpilih sebagai sampel maka semua toko diteliti, pemiliknya ditanya jumlah modal yang dibutuhkan. 5. Systematic Random Sampling ialah sampling dimana pemilihan elemen
pertama dipilih secara acak (random) sedangkan elemen berikutnya dipilih secara sistematis berjarak k, dimana k = N/n.
D. Pembagian Data 1. Menurut Sifatnya
a. Data Kualitatif adalah data yang tidak bisa dihitung dalam angka, tetapi dapat diukur atau dikatagorikan dalam berbagai golongan
b. Data Kuantitatif adalah data yang berujud angka, terdiri dari data distrik yaitu data yang berupa bilangan bulat yang biasanya berhubungan dengan proses penghitungan. Sementara data kontinyu adalah data numerik yang meliputi baik bilangan bulat maupun pecahan, dan biasanya berhubungan dengan proses pengukuran.
2. Menurut Waktunya
a. Data silang (Cross Section) aialah data yang dikumpulkan pada suatu waktu tertentu yang bisa menggambarkan keadaan pada waktu tersebut, misalnya jumlah warga DKI Jakarta menurut asal dan agama pada tahun 2016
b. Data Berkala (Time Series) adalah data yang dikumpulkan dari waktu ke waktu , misalnya data angka kematiandan kelahiran dari tahun ke tahun di Indonesia yang cenderung membesar dan mengecil.
3. Cara Memperoleh
a. Data primer ialah data yang didapatkan langsung dari responden misalnya data pegawai negeri sipil di BAKN
b. Data sekunder ialah data yang diambil dari dari data primer yang telah diolah, untuk tujuan lain. Misalkan dara perkawinan antara umur 10 s/d 20 tahun diIndonesia yang diambil dari Kementrian Agama untuk tujuan analisa perkawinan setiap suku bangsa di Indonesia.
4. Sumbernya
a. Data Internal adalah data yang dikumpulkan dari dalam perusahaan atau suatu unit kegiatan ekonomi itu sendiri, yang pada umumnya meliputi berbagai informasi seperti tingkat produksi, biaya produksi atau volume penjualan
b. Data Eksternal adalah data yang dihasilkan dari luar perusahaan misalnya data penjualan tingkat industri.
Syarat data yang baik adalah 1. Benar/Obyektif
3. Dipercaya, kesalahan bakunya kecil 4. Tepat waktu
5. Relevan, data yang dikumpulkan ada hubungannya dengan permasalahan
E. Skala Pengukuran Data
Empat macam skala pengukuran dan data terdiri dari
1. Skala Nominal adalah skala yang diterapkan pada data yang hanya bisa dibagi ke dalam kelompok-kelompok tertentu dan pengelompokan tersebut hanya dilakukan untuk tujuan identifikasi. Misalnya kita bisa membuat kode numerik untuk tiap kelompok terhadap data seperti sedan = 1, truk = 2, dan bus = 3
2. Skala Ordinal adalah skala yang diterapkan pada data-data yang dapat dibagi kedalam berbagai kelompok dan kita bisa membuat peringkat diantara kelompok-kelompok tersebut. Misalnya kita bisa membuat kode untuk masing-masing skala pengukuran seperti sangat bagus = 1, bagus = 2 dan kurang bagus = 3. Kita tahu bahwa 1 memiliki peringkat lebih tinggi dari 2 dan 2 memiliki peringkat lebih tinggi dari 3.
3. Skala interval adalah skala yang diterapkan pada data yang dapat dirangking atau diperingkat dan dengan peringkat tersebut kita bisa mengetahui perbedaan diantara peringkat-peringkat tersebut dan kita bisa menghitung besarnya perbedaan
4. Skala Rasio adalah skala yang diterapkan pada data-data yang dapat diranking atau diperingkat dan untuk peringkat-peringkat tersebut kita bisa menjalankan operasi aritmetik. Contohnya Harga beras di Batam Rp 5.000 dan harga beras dijakarta Rp. 2.500
F. Penyajian Data Cross Section Tabel Penyajian dengan Tabel
Tabel merupakan kumpulan angka-angka yang disusun menurut katagori-katagori. 1. Tabel satu arah ialah tabel yang memuat keterangan mengenai satu hal atau
satu karateristik. Misalnya Produksi menurut varietasnya atau menurut hasil panennya. Tabel dibawah ini adalah contohnya.
Sumber : (Supranto, 2016)
2. Tabel dua arah tabel yang menunjukan hubungan dua hal atau dua karateristik
Sumber : (Supranto, 2016)
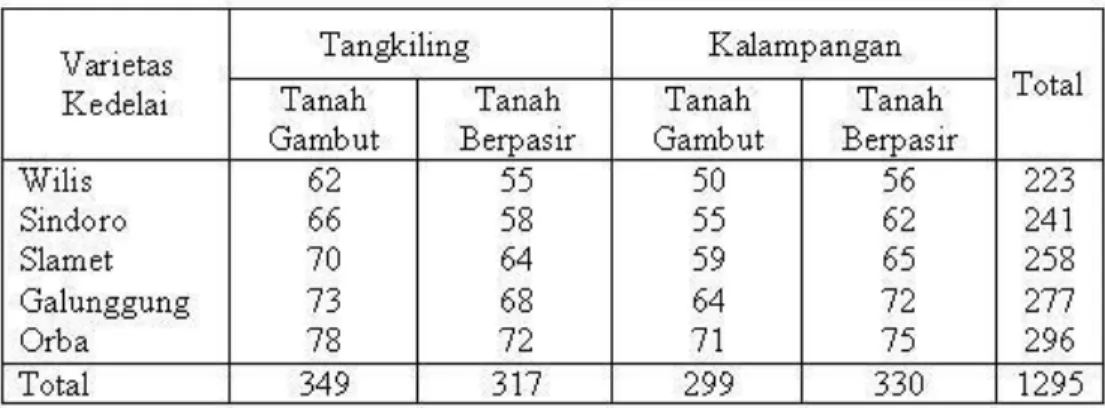
Tabel diatas adalah contoh tabel dua arah. Data produksi kedelai menurut jenis varietas dan daerah panen
3. Tabel tiga arah ialah tabel uang menunjukkan tiga hal atau tiga karateristik.
Sumber : (Supranto, 2016)
Tabel diatas adalah contoh tabel tiga arah. Produksi kedelai menurut jenis varietas, daerah panen dan jenis tanah.
Bentuk Grafik
Data berkala (time series data) yaitu data yang dikumpulkan dari waktu ke waktu untuk mengetahui perkembangan suatu hal.
1. Grafik garis tunggal (single line chart) adalah grafik yang terdiri dari satu garis untuk menggambarkan perkembangan (trend) dari suatu karateristik.
Sumber : (Supranto, 2016)
Gambar : Grafik Garis Tunggal Varietas Kedelai
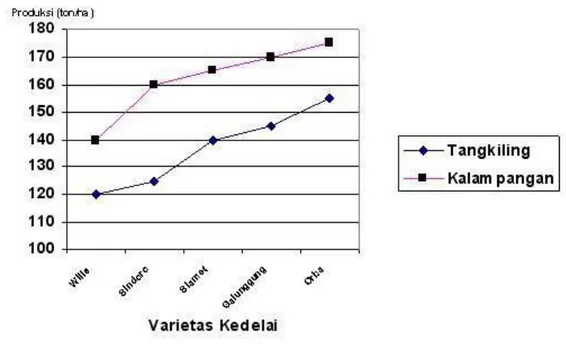
2. Grafik garis berganda (multiple line chart) grafik yang terdiri dari beberapa garis untuk menggambarkan perkembangan beberapa hal kejadian sekaligus.
Varietas
Sumber : (Supranto, 2016)
Gambar : Grafik Garis Berganda Varietas Kedelai 3. Grafik batangan
a. Grafik batangan tunggal (Single bar chart) adalah grafik yang terdiri satu batangan untuk menggambarkan perkembangan (trend) dari satu karateristk.
Sumber : (Supranto, 2016)
Gambar : Grafik Batang Varietas Kedelai
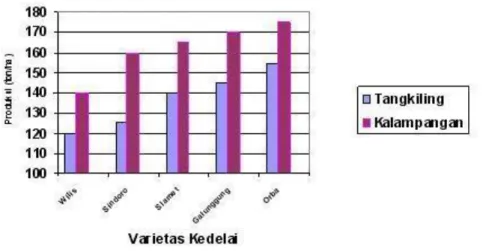
b. Grafik Batangan berganda (multiple bar chart) adalah grafik yang terdiri beberapa batangan untuk menggambarkan beberapa kejadian
. Sumber : (Supranto, 2016)
Gambar : Grafik Batang Varietas Kedelai
4. Grafik lingkaran , penggambaran ini akan lebih tepat, apabila hendak mengetahui perbandingan nilai-nilai karateristik yang satu dengan yang lain dan dengan keseluruhan
Sumber : (Supranto, 2016)
Gambar : Grafik lingkaran Varietas Kedelai
Latihan Soal-Soal 1. Berikan lima contoh populasi
2. Apa yang anda ketahui tentang sampel? Dari contoh no 1 berikan contoh sampelnya
3. Terangkan perbedaan antara data primer dan data sekunder
4. Baik sampling bertingkat (Stratified sampling) mauoun sampling berkelompok (clustered sampling) mengelompokan data-data dari suatu polulasi. Jelaskan perbedaan utama diantara kedua metode sampling tersebut!
BAB II
DASAR-DASAR STATISTIKA DESKRIPTIF
A. Distribusi Frekuensi
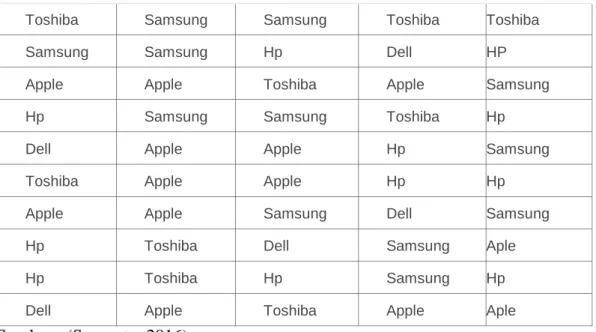
Distribusi Frekuensi yaitu pengelompokan data ke dalam beberapa kelompok (kelas) dan kemudian dihitung banyaknya data yang masuk kedalam tiap kelas. 1. Distribusi Frekuensi Kualitatif
Tabel 2.1 Data mengenai 50 orang pembeli Komputer
Toshiba Samsung Samsung Toshiba Toshiba
Samsung Samsung Hp Dell HP
Apple Apple Toshiba Apple Samsung
Hp Samsung Samsung Toshiba Hp
Dell Apple Apple Hp Samsung
Toshiba Apple Apple Hp Hp
Apple Apple Samsung Dell Samsung
Hp Toshiba Dell Samsung Aple
Hp Toshiba Hp Samsung Hp
Dell Apple Toshiba Apple Aple
Sumber : (Supranto, 2016)
Data pada tabel 2.1 merupakan data kualitatif 50 orang paembeli komputer dari lima jenis perusahaan komputer. Dari data tersebut kesulitan untuk mengetahui dengan cepat, jenis komputer, mana yang paling banyak diminati pembeli. Untuk itu perlu disajikan dalam distribusi frekuensi.
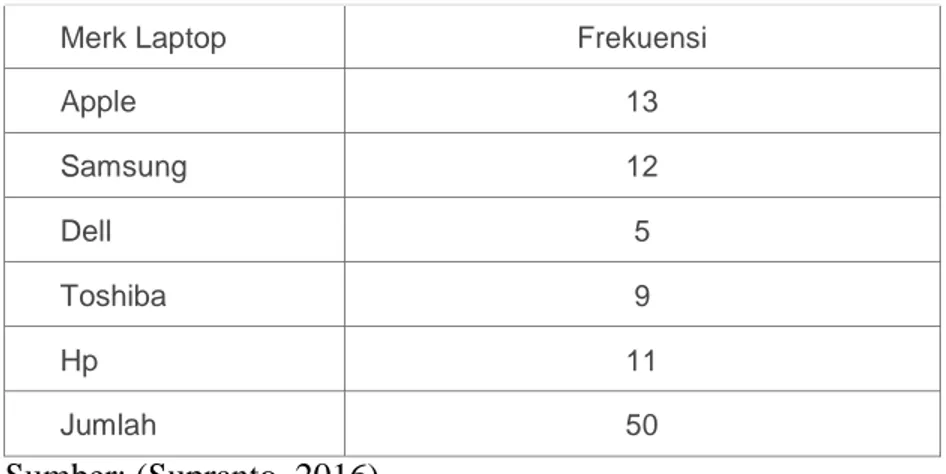
Tabel 2.2 Dsitribusi Frekuensi Pembelian Komputer dari 5 merk
Merk Laptop Frekuensi
Apple 13 Samsung 12 Dell 5 Toshiba 9 Hp 11 Jumlah 50 Sumber: (Supranto, 2016)
Tabel 2.2 menyajikan hasil distribusi frekuensi yang dilakukan. Dari tampilan tabel 2.2 dapat diketahui dengan cepat bahwa Apple merupakan jenis komputer yang paling banyak peminatnya.
2. Distribusi Frekuensi data kuantitatif
Ada tiga hal yang perlu di perhatikan dalam menentukan kelas bagi distribusi frekuensi untuk data kuantitatif, yaitu jumlah kelas, lebar kelas dan batas kelas.
a. Jumlah kelas
Jumlah kelas sebaiknya antara 7 dan 15 . Rumus untuk menentukan banyaknya kelas sebagai berikut :
k = 1 + 3,322 log n dimana k = banyak nya kelas
n = banyaknya nilai observasi
Rumus tersebut diberi nama Kriterium Sturge dan merupakan suatu perkiraan tentang banyaknya kelas. Misalnya, data dengan n = 100, maka banyaknya kelas k adalah sebagi berikut :
k = 1 + 3,322 log 100 = 1 + 3, 322 (2) = 7,644
Jadi, banyaknya kelas sebaiknya 7 b. Interval Kelas
Disarankan interval atau lebar kelas adalah sama untuk setiap kelas. Untuk menentukan besarnya kelas (panjang interval) digunakan rumus :
c = Xn – X1 k
Dimana : c = perkiraan besarnya (class width, class size, class length) k = banyaknya kelas
Xn = Nilai observasi terbesar X1 = Nilai observasi terkecil
75 86 66 86 50 78 66 79 68 60 80 83 87 79 80 77 81 92 57 52 58 82 73 95 66 60 84 80 79 63 80 88 58 84 96 87 72 65 79 80 86 68 76 41 80 40 63 90 83 94 76 66 74 76 68 82 59 75 35 34 65 63 85 87 79 77 76 74 76 78 75 60 96 74 73 87 52 98 88 64 76 69 60 74 72 76 57 64 67 58 72 80 72 56 73 82 78 45 75 56 Jumlah kelas k = 1 + 3,322 log 100 = 1 + 3, 322 (2) = 7,644
Jadi, banyaknya kelas sebaiknya 7 interval kelas c = 98 – 34
7 c = 9,14 (9) Menentukan Batas Kelas (Class Limits)
Batas Kelas adalah nilai-nilai terluar (terendah) atau tertinggi dari suatu kelas. Langkah pertama dalam pembentukan kelas adalah menentukan batas-batas kelas dari kelas terbawah (kelas pertama). Kelas-kelas yang akan kita buat dalam distribusi frekuensi tersebut harus memuat seluruh data observasi yaitu nilai observasi terendah akan masuk dalam kelas pertama dan nilai tertinggi dari observasi tersebut akan masuk dalam kelas terakhir dari distribusi frekuensi
Kelas ke Batas Kelas Modal (Jumlah Rp) Frekuensi
1 30 – 39 2 2 40 – 49 3 3 50 – 59 11 4 60 – 69 20 5 70 – 79 32 6 80 – 89 25 7 90 – 99 7
Pembatas-pembatas Kelas (Class Boundaries)
Pembatas-pembatas kelas adalah nilai nilai khusus sepanjang sebuah skala pengukuran yang memisahkan dua kelas yang berdampingan.
Tbk = bbk – 0,5 (skala terkecil) Tak = bak + 0,5 (skala terkecil) Tbk = Tepi batas kelas
Bbk = batas bawah kelas Tak = Tepi atas kelas Bak = Batas atas kelas
Kelas ke Batas Kelas Modal (Jumlah Rp) Pembatas-pembatas kelas
1 30 – 39 29,5 – 39,5 2 40 – 49 39,5 – 49,9 3 50 – 59 49,5 – 59,5 4 60 – 69 59,5 – 69,5 5 70 – 79 69,5 – 79,5 6 80 – 89 79,5 – 89,5 7 90 – 99 89,5 – 99,5
Jenis Distribusi Frekuensi
1. Distribusi Frekuensi Kumulatif
Adalah suatu daftar yang memuat frekuensi-frekuensi kumulatif, jika ingin mengetahui banyaknya observasi yang ada diatas atau dibawah suatu nilai tertentu
2. Distribusi Frekuensi Relatif
Adalah perbandingan daripada frekuensi masing-masing kelas dan jumlah frekuensi seluruhnya dan dinyatakan dalam persen.
Distribusi Frekuensi komulatif kurang dari (dari atas) adalah suatu total frekuensi dari semua nilai-nilai yang lebih kecil dari tepi bawah kelas pada masing-masing interval kelasnya
Distribusi Frekuensi komulatif lebih dari (dari bawah) adalah suatu total frekuensi dari semua nilai-nilai yang lebih besar dari tepi bawah kelas pada masing-masing interval kelasnya
Distribusi Frekuensi komulatif relatifType equation here.
Adalah suatu total frekuensi dengan menggunakan presentasi
1. Rata-rata Hitung
Apabila kita mempunyai nilai variabel X1, sebagai hasil pengamatan atau observasi sebanyak N kali yatu X1, X2....,Xn, maka
X = = 1/N x1 = 1/N x1+x2 +...+xN
2. Rata-rata Ukur/Geometri dari sejumlah N nilai data adalah akar pangkat N dari hasil kali masing-masing nilai dari kelompok tersebut.
G = N √ X1,X2,...Xn atau Log G = ( log x1)/N
3. Rata-rata Harmonis dari seperangkat data X1, X2, ..., Xn adalah kebalikan rata-rata hitung dari kebalikan nilai-nilai data.
RH = N (1/Xi)
4. Rata-rata tertimbang, jika nilai data X1 mempunyai timbangan Wi, adalah 𝑛 ∑ �𝑖�1 ��=1 X = 𝑛 ∑ �1 ��=1 5. Median
Apabila ada sekelompok nilai sebanyak n diurutkan mulai dari yang terkecil X1 sampai dengan yang terbesar Xn , maka nilai yang ada ditengah disebut median (Med). Setengah (=50%) dari nilai lebih kecil atau sama dengan median, tengah lainnya lebih besar atau sama dengan median.
Untuk n ganjil : N = 2k + 1 Untuk n genap : N = 2k Contoh :
Ada 7 karyawan dengan upah perbulan masing-masing Rp.20.000, Rp. 80.000, Rp.75.000, Rp.60.000, Rp.50.000, Rp.85.000 dan Rp. 45.000. Tentukan median upah karyawan tersebut!
Urutkan dahulu nilai terkecil sampai terbesar.
X1 = 20.000 X2 = 45.000 X3 = 50.000 X4 = 60.000 X5 = 75.000 X6 = 80.000 Dan X7 = 85.000
Tentukan nilai k dari 7 = 2k + 1 k= 3
Jadi Median = Med = Xk-1 = X4 = 60.000 Untuk n genap
X1 = 20.000 X2 = 45.000 X3 = 50.000 X4 = 60.000 X5 = 75.000 X6 = 80.000 X7 = 85.000 dan X9 = 90.000
Tentukan nilai k dari 8 = 2k K = 4
Jadi Median = Med = 1 (X4 +X5) 2
= 1 (60.000 + 75.000) 2
= 67.500 6. Modus
Adalah nilai kelompok tersebut yang mempunyai frekuensi tertinggi atau nilai yang paling banyak terjadi didalam suatu kelompok nilai (Mod).
X F 2 2 5 1 7 1 9 3 10 2 11 1 12 1 18 1
Modus (Mod) = 9 sebab nilai observasi ini yang paling banyak atau mempunyai frekuensi terbesar.
7. Kuartil
Adalah Fraktil yang membagi seperangkat data menjadi empat bagian yang sama.
Kuartil :Q1 = nilai yang ke i(n+1) / 4 , i = 1,2,3 8. Desil
Adalah fraktil yang membagi seperangkat data menjadi sepuluh bagian yang sama.
Desil : Di = nilai yang ke i(n+1)/10, i= 1,2,...,9 9. Persentil
Adalah fraktil yang membagi seperangkat data menjadi seratus bagian yang sama
LATIHAN SOAL-SOAL
1. Apa yang dimaksud dengan distribusi frekuaensi?
2. Terdapat 40 orang yang ikut dalam paket wisata dengan informasi umur mereka sebagai berikut :
77 68 63 84 58 64 59 69 70 77 71 65 71 55 65 60 60 61 58 72 78 71 84 62 55 57 56 80 76 69 66 71 72 70 69 64 58 67 79 68
a. Berapa jumlah kelas yang Anda sarankan
b. Berapa panjang/interval kelas yang baik menurut Anda c. Berapa batas kelas bawah yang Anda rekomendasikan d. Buatlah distribusi frekuensinya
3. Apa yang dimaksud dengan median dan modus? 4. Hitunglah rata-rata ukur (geometrik) dari data berikut
107, 132, 120, 110, 130, 126, 116, 122
5. Diperoleh data gaji pada saat pertama kali masuk kerja sebagai berikut (dalam ribuan rupiah)
700 600 725 500 770 750 525 690 770 780 800 575 680 700 650 785 800 580 695 650 650 750 550 750 700 a. Berapa rata-rata gaji pada saat masuk? b. Berapa median dari gaji pada saat masuk? c. Berapa modusnya?
d. Berapa kuartil pertamanya? e. Berapa kuartil ketiganya?
BAB III
UKURAN GEJALA PUSAT DATA YANG DIKELOMPOKKAN DAN UKURAN DISPERSI
A. Ukuran Gejala Pusat Data yang Dikelompokkan 1. Rata-rata hitung Rumusnya : x = ∑fiMi ∑ fi f = frekuensi m = titik tengah contoh :
Berat badan 100 orang mahasiswa Fakultas Ekonomi Universitas tahun 2013 disajikan dalam tabel berikut :
Berat Badan (kg) Banyaknya Mahasiswa (f)
60 – 62 5 63 – 65 18 66 – 68 42 69 – 71 27 72 – 74 8 Sumber : (Supranto, 2016)
Hitunglah rata-rata perkiraan berat per mahasiswa.
Berat Badan (kg) M f Mf 60 - 62 61 5 305 63 - 65 64 18 1.152 66 - 68 67 42 2.814 69 - 71 70 27 1.890 72 - 74 73 8 584 Jumlah ∑f = 100 ∑Mf = 6.745 Sumber : (Supranto, 2016) M1 = 60 + 62 = 61, ..., M5 = 72 + 74 = 73 2 2 x = ∑fiMi ∑ fi = 6.745
100 = 67,45
Jadi rata-rata perkiraan berat permahasiswa adalah 67,45 kg.
2. Median
Med = Lm + (N/2 - ∑f) . c Fm Keterangan :
Med = Median data kelompok Lm = Tepi bawah kelas median N = Jumlah frekuensi
∑f = Frekuensi kumulatif diatas kelas median fm = frekuensi kelas median
c = interval kelas median
Hitunglah nilai median dari data berikut :
Kelas f 30 – 39 4 40 – 49 6 50 – 59 8 60 – 69 12 70 – 79 9 80 – 89 7 90 – 99 4 Jumlah 50 Sumber : (Supranto, 2016) Penyelesaian : N/2 = 50/2 = 25
f1 + f2 + f3 = 4 + 6 + 8 = 18 , dan untuk mencapai 25 masih kurang 7, sehingga perlu ditambah dengan frekuensi kelas keempat. Jadi median terletak pada kelas ke 4 yaitu kelas 60 – 69 setelah dikoreksi menjadi 59,5 – 69,6 c = 69,9 – 59,9 = 10 Lm = 59,5 N/2 = 25 (∑f1) = 18 fm = 12 Med = 59,5 +10(25 – 18) 12 Med = 65,33
3. Modus
Mod = Lmo + c{ f1)0 } (f1)0 + (f2)0 dimana,
Lo = nilai batas bawah sebenarnya, dari kelas yang memuat modus fmo = frekuensi kelas yang memuat modus
(f1)o = fmo – f(mo-1) {selisih frekuensi kelas yang memuat modus dengan frekuensi kelas sebelumnya (bawahnya) }
(f2)0 = fmo – f(mau+1) {selisih frekuensi kelas yang memuat modus dengan frekuensi kelas sesudahnya (atasnya) }
c = besarnya jarak antara suatu kelas dengan kelas sebelumnya, misalnya antara kelas kedua dengan kelas kesatu, kelas ketiga dengan kelas kedua
Cari modus dari tabel frekuensi berikut :
Kelas f 30 – 39 4 40 – 49 6 50 – 59 8 60 – 69 12 70 – 79 9 80 – 89 7 90 – 99 4 Jumlah 50 Sumber: (Supranto, 2016) Penyelesaian :
fmo = 12 merupakan frekuensi dari kelas yang memuat modus (nilai tertinggi).
Kelas interval yang memuat modus, mempunyai nilai batas bawah ½ (59+60) = 59,5
Nilai batas atas ½ (69 + 70) = 69,5
Jadi antara 59,5 – 69,5 terdapat observasi fmo = 12 C = 69,5 – 59,5 = 10 Lo = 59,5 f(mo-1) = 8 f(mo+1) = 9 (f1)o = 12 – 8 = 4 (f2)o = 12 – 9 = 3 Mod = Lmo + c{ f1)0 } (f1)0 + (f2)0
mod = 59,5 + 10 ( 4 ) 4 + 3 = 65,214 4. Kuartil Q1 = Lo + c{iN/4 -(f1)0 }, i = 1,2,3 Fq
Lo = nilai batas bawah dari kelas yang memuat kuartil ke i n = banyaknya observasi = jumlah semua frekuensi
(∑fi)o = jumlah frekuensi dari semua kelas sebelum kelas yang mengandung kuartil
fq = frekuensi dari kelas yang mengandung kuartil ke i
c = besarnya keklas yang mengandung kuartil ke i atau jarak nilai batas bawah (atas) dari suatu kelas terhadap nilai batas bawah (atas) kelas berikutnya i = 1,2,3
in = i kali n B. Ukuran Dispersi
Merupakan ukuran penyebaran suatu kelompok data terhadap pusat data. 1. Nilai Jarak
Apabila suatu kelompok nilai (data) sudah disusun menurut urutan yang terkecil (X1) sampai dengan yang terbesar (Xn), maka untuk menghitung nilai jarak dipergunakan rumus berikut :
Nilai Jarak = NJ = Xn – X1 atau Nilai Maksimum – Nilai Minimum Untuk data dikelompokan, dapat dihitung dengan dua cara :
a. NJ = Nilai tengah kelas terakhir – Nilai tengah kelas pertama b. NJ = Batas atas kelas terakhir – batas bawah kelas pertama
Berat badan 100 orang mahasiswa Fakultas Ekonomi Universitas tahun 2013 disajikan dalam tabel berikut :
Berat Badan (kg) Banyaknya Mahasiswa (f)
60 – 62 5 63 – 65 18 66 – 68 42 69 – 71 27 72 – 74 8 Sumber : (Supranto, 2016)
Penyelesaian:
Cara 1 : Nilai tengah kelas terakhir = 72 + 74 = 73 kg 2
Nilai tengah kelas pertama = 60 + 62 = 61 kg 2
Maka : NJ = 73 – 61 = 12 kg
Cara 2 : Batas atas kelas terakhir = 74,5 Batas bawah kelas pertama = 59.5 NJ = 74,5 – 59,5
= 15 kg
2. Rata-Rata Simpangan
Merupakan jumlah nilai mutlak dari selisih semua nilai dengan nilai rata-rata dibagi banyaknya data
RS = 1/n ∑ | Xi - �| Keterangan :
RS = Simpangan Rata-Rata X = Nilai data
� = Nilai rata-rata hitung 𝑓 = frekuensi kelas 𝑛 = Banyaknya data 3. Variansi (Variance)
Merupakan rata-rata kuadrat selisih atau kuadrat simpangan dari semua nilai data terhadap rata-rata hitung.
a. Data tidak berkelompok ��2 = 1 ∑ ( X - � )2 𝑛 − 1 b. Data berkelompok ��2 = 1 ∑f ( X - � )2 𝑛 − 1 Keterangan : ��2 = Variansi X = Nilai data
� = Nilai rata-rata hitung
f = Frekuensi kelas (data berkelompok) n = Banyaknya data
4. Simpangan baku
5. Jangkauan kuartil JK = ½ (Q3 – Q1) Q1 = Kuartil pertama Q3 = Kuartil ketiga 6. Jangkauan Persentil 𝐽𝑃10−90 = 𝑃90 - 𝑃10 P10 = persentil kesepuluh P90 = persentil kesemblanpuluh LATIHAN SOAL-SOAL
1. Dengan menggunakan distribusi frekuensi berikut :
Kelas Frekuensi 0 – 4 2 5 – 9 7 10 - 13 12 15 - 19 6 20 - 24 3 a. Tentukan jaraknya
b. Hitung deviasi standarnya c. Berapa Variannya
2. Umur pekerja yang baru dipekerjakan dan belum mempunyai keahlian dikelompokkan ke dalam distribusi berikut :
Umur (tahun) Banyaknya Pekerja
18 - 21 7
22 - 25 11
26 - 29 20
30 - 34 12
a. Hitung median umur pekerja b. Apa arti nilai tersebut
3. Nilai hasil ujian statistik mahasiswa AMIK BSI dikelompokkan sebagai berikut : Nilai kelas f 30 - 39 2 40 - 49 5 50 - 59 8 60 - 69 15 70 - 79 20 80 - 89 16 90 - 99 10
Hitung rata-rata, median dan modus
4. Dengan data soal No. 3 Hitung kuartil pertama, ketiga 5. Hitung desil kelima
23
BAB IV
KEMIRINGAN, KERUNCINGAN DISTRIBUSI DATA DAN ANGKA INDEKS
A. Kemiringan Distribusi Data
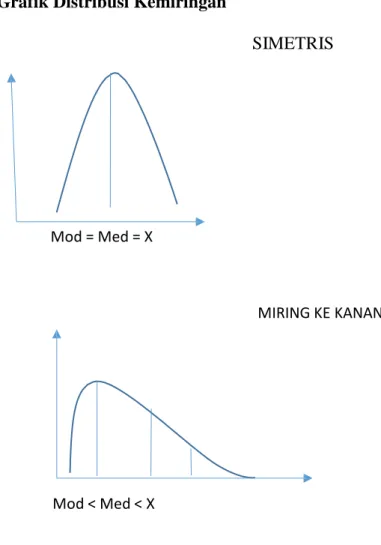
Merupakan derajat ukuran dari ketidaksimetrisan (Asimetri) suatu distribusi data. Kemiringan distribusi data terdapat 3 jenis, yaitu :
a. Simetris : menunjukkan letak nilai rata-rata hitung, median dan modus berhimpit (berkisar disatu titik)
b. Miring ke kanan : mempunyai nilai modus paling kecil dan rata-rata hitung paling besar
c. Miring kekiri : mempunyai nilai modus paling besar dan rata-rata hitung paling kecil
Grafik Distribusi Kemiringan
SIMETRIS
Mod = Med = X
MIRING KE KANAN
24 MIRING KE KIRI
X < Med < Mod
Rumus untuk menghitung derajat kemiringan distribusi data Ukuran Tingkat Kemencengan (TK) menurut Pearson TK = � - mod atau TK = 3 ( � -
med) S S
Dimana :
� = rata-rata hitung mod = modus S = simpangan baku
Ukuran Tingkat Kemencengan (TK) berdasarkan Momen ketiga Data tidak berkelompok
��3 = 1 Σ (X1 - � )3 n� �3 Data berkelompok ��3 = 1 Σfi (mi - � )3 n� �3 Keterangan :
𝛼3 = Ukuran tingkat kemencengan S = Simpangan baku
Xi = Nilai data ke – i � = Nilai rata-rata hitung fi = Frekuensi kelas ke i
mi = nilai titik tengah kelas ke i S = Simpangan baku
25
Jika 𝛼3 = 0 distribusi data simetris 𝛼3 < 0 distribusi data miring ke kiri 𝛼3 > 0 distribusi data miring ke kanan Rumus Bowley, menggunakan nilai kuartil : 𝛼3 = Q3 + Q1 – 2Q2 Q3 – Q1 Keterangan : Q1 = Kuartil pertama Q2 = Kuartil kedua Q3 = Kuartil ketiga
Cara menentukan kemiringannya :
Jika Q3 – Q2 = Q2 – Q1 sehingga Q3 + Q1 – 2Q2 = 0 yang mengakibatkan 𝛼3 = 0, sebaliknya jika distribusi miring maka ada dua kemungkinan yaitu Q1 = Q2 atau Q2 = Q3 dalam hal ini Q1 = Q2 maka 𝛼3 = 1 dan untuk Q2 = Q3 maka 𝛼3 = -1
B. Ukuran Keruncingan Kurva (Kurtosis)
Merupakan derajat atau ukuran tinggi rendahnya puncak suatu distribusi data terhadap distribusi normalnya data. Ada 3 jenis derajat keuncingan, yaitu :
1. Leptokurtis : distribusi data yang puncaknya relatif tinggi
26
3. Platikurtis : distribusi data yang puncaknya terlalu rendah dan terlalu mendatar.
Derajat keruncingan distribusi data 𝛼4 dapat dihitung berdasarkan rumus berikut : Data tidak berkelompok
��4 = 1 Σ (X1 - � )4 n� �4 Data berkelompok ��4 = 1 Σ ���(mi - � )4 n��4 Keterangan : ��4 = Derajat keruncingan Xi = Nilai data ke – i � = nilai rata-rata hitung fi = frekuensi kelas ke -i
mi = nilai titik tengah kelas ke –i S = Simpangan baku
n = banyaknya data
Jika 𝛼4 = 3 distribusi keruncingan data disebut mesokurtis Jika 𝛼4 > 3 distribusi keruncingan data disebut leptokurtis Jika 𝛼4 < 3 distribusi keruncingan data disebut platikurtis
C. Angka Indeks
1. Pengertian Angka Indeks
Adalah suatu angka yang dibuat sedemikian rupa sehingga dapat dipergunakan untuk melakukan perbandingan antara kegiatan yang sama (produksi, ekspor, hasil penjualan, jumlah uang yang beredar dll).
28
a. Waktu dasar (Baase Period) yaitu dimana suatu kegiatan (kejadian) dipergunakan untuk dasar perbandingan
b. Waktu yang bersangkutan atau sedang berjalan (current period) yaitu waktu dimana suatu kegiatan akan diperbandingkan terhadap kegiatan pada waktu dasar.
Beberapa syarat yang perlu diperhatikan dalam menentukan atau memilih waktu dasar adalah
1. Waktu sebaiknya menunjukkan keadaan perekonomian yang stabil, dimana harga tidak berubah dengan cepat sekali
2. Waktu sebaiknya usahakan paling lama 10 tahun atau lebih baik kurang dari 5 tahun
3. Waktu di mana terjadi peristiwa penting
4. Waktu dimana tersedia data untuk keperluan pertimbangan, hal ini tergantung pada tersedianya biaya untuk penelitian ( pengumpulan data)
SISTEMATIKA ANGKA INDEKS
ANGKA INDEKS
ANGKA INDEKS SEDERHANA ✓ Bentuk Relatif ✓ Bentuk Agregat ANGKA INDEKS TERTIMBANG ✓ Bentuk Relatif ✓ Bentuk Agregat✓ Angka Indeks Harga ✓ Angka Indeks Kuantitas ✓ Angka Indeks Nilai
✓ Angka Indeks Harga ✓ Angka Indeks Kuantitas ✓ Angka Indeks Nilai
29
Angka Indeks Sederhana Relatif Harga
Jika Pn adalah harga dari komoditas tunggal dalam periode tertentu dan Po adalah harga komoditas tersebut dalam periode dasar, rumus umum untuk menghitung indeks harga sederhana atau haga relatif adalah
It,o = �� �𝑡 X 100%
Data harga dan kuantitas yang di konsumsi dari tiga komoditas disuatu kota tahun 2010 dan 2015
Komoditas Unit Kuota Harga rata2 Rp 2010 Harga rata2 2015 Konsumsi perkapita (juta)2010 Konsumsi perkapita (juta) 2015 Rokok 1 bungkus 2.500 3.000 11,6 10,1 Gula 1 kg 1.200 1.500 50,2 60,3 Beras 1 kg 2.600 3.200 35,9 50,2
Tabel diatas mencatat harga rata-rata dan konsumsi perkapita dati tiga komoditas padatahun 2010 dan tahun 2015 dengan tahun 2010 sebagai tahun perbandingan. Indeks harga sederhana untuk rokok dengan dasar data tersebut adalah :
I 2010/2015 = �� �� X 100% = 3.000 X 100 = 120 2.500
Indeks harga 120 mengindikasikan bahwa harga 1 bungkus rokok adalah 20 persen lebih tinggipada tahun 2015 dibandingkan tahun 2010. Begitu juga untuk Indkes harga produk Gula dan Beras.
Angka Indeks Kuantitas Sederhana
Dengan tabel diatas indkes kuantitas sederhana untuk beras I2015/2010 = ��� 𝑞� X 100% = 50,2 X 100 = 140
35,9
Indeks kuantitas 140 ini mengindikasikan bahwa tahun 2015 jumlah konsumsi beras adalah 140 persen dari jumlah konsumsi beras tahun 2010 atau mengalami kenaikan sebesar 40 %. Kita juga bisa menghitung bahwa indeks kuantitas sederhana untuk rokok dan gula.
30
Indeks Agregat Tidak Tertimbang
Indeks agregat tidak tertimbang digunakan untuk unit-unit yang mempunyai satuan yang sama. Indkes ini diperoleh dengan jalan membagi hasil penjumlahan harga pada waktu yang bersangkutan dengan hasil penjumlahan harga pada waktu dasar. It,o = ∑�𝑡
∑�� X 100%
Rumus ini dapat dipergunakan bila barang-barang mempunyai satuan yang sama. Sehingga tidak bisa untuk menghitung angka indkes produksi untuk 9 macam bahan pokok karena satuannya berbeda.
Harga Barang menurut Jenisnya selama tahun 2005 – 2007 (dalam satuan)
Jenis barang Harga
2005 2006 2007 A 100 150 200 B 200 250 300 C 500 600 700 D 400 500 600 Jumlah 1.200 1.500 1.800
Indeks harga agregat tidak tertimbang untuk tahu 2006 dan 2007 dengan waktu dasar 2005. I06/05 = ∑�𝑡 ∑�� X 100% = 1.500 X 100% 1.200 = 125 %
Rumus Angka Indkes Sederhana Kuantitas Agregatif It,o = ∑�𝑡
∑�� X 100% Indeks Tertimbang
Indeks Agregat Tertimbang Indeks Harga Agregat Tertimbang
31 L = ∑�𝑡� � ∑���� X 100% 2. Indeks Pasche P = ∑�𝑡� 𝑡 ∑���𝑡 X 100%
Indeks Produksi Agregat Tertimbang 1. Indeks Laspeyres L = ∑�� � 𝑡 ∑���� X 100% 2. Indeks Pasche P = ∑�𝑡� 𝑡 ∑�𝑡�� X 100%
Hitunglah indeks harga agregatif tertimbang dengan menggunakan rumus Laspeyres dan Paasche
Jenis barang Harga Produksi dalam satuan
2005 2006 2005 2006 A 691 2.020 741 937 B 310 661 958 1.499 C 439 1.000 39 30 D 405 989 278 400 E 568 1.300 2.341 3.242 Penyelesaian : L06/05 = ∑� 06 � 05 ∑�05�05 X 100% = (2.020)(741)+(661)(958)+(1.000)(39)+(989)(278)+(1.300)(2.341) x 100% (691)(741)+(310)(958)+(439)(39)+(405)(278)+(568)(2.341) = 241,90% P06/05 = ∑� 06 � 06 ∑�05�0 6 X 100% = (2.020)(937)+(661)(1.499)+(1.000)(30)+(989)(400)+(1.300)(3.242) x 100% (691)(937)+(310)(1.499)+(439)(30)+(405)(400)+(568)(3.242) = 240,46%
32
Variasi dari Indeks HargaTertimbang
1. Indeks Fischer I = √𝐿ℎ𝑎��𝑎 � 𝑃ℎ𝑎��𝑎 2. Ndeks Drobisch I = ½ (L harga + P Harga) Variasi dari Indeks Produksi Tertimbang
1. Indeks Fischer I = √𝐿���𝑑��𝑘�𝑖 � 𝑃���𝑑��𝑘�𝑖
2. Indeks Drobisch I = ½ (L produk + P Produk)
Dengan menggunakan data dari data diatas maka L = 241, 90%
P = 240,47%
Dengan menggunakan rumus fischer
1. Indeks Fischer I = √𝐿ℎ𝑎��𝑎 � 𝑃ℎ𝑎��𝑎 = √241,90% � 240, 47% = 241,18%
2. Indeks Drobisch I = ½ (L produk + P Produk) = ½ ( 241,90 + 240,47) = 241,18%
Kesimpulannya adalah bahwa ternyata rumus Fisher dan Dronbisch memberikan hasil yang sama.
33
LATIHAN SOAL
Nilai hasil Ujian statistik mahasiswa dikelompokkan
Kelas Nilai F 30 - 39 2 40 – 49 5 50 – 59 8 60 – 69 15 70 – 79 20 80 – 89 16 90 - 99 10
1. Hitung rata-rata, median dan modus
2. Hitung tingkat kemencengan dan arah kemencengannya 3. Hitung tingkat keruncingannya.
Jenis barang Harga Produksi dalam satuan
2005 2006 2005 2006
A 300 315 35 25
B 100 125 4 10
C 500 600 1 2
4. Hitunglah indeks harga dan Produksi sederhana barang A, B dan C untuk tahun 2006 dengan waktu dasar tahun 2005
5. Hitung indeks harga dan produksi agregatif tahun 2006 dengan waktu dasar tahun 2005
34
BAB V
REGRESI DAN KORELASI SEDERHANA
A. Pengertian Regresi dan Korelasi
Regresi dan korelasi di gunakan untuk mempelajari pola dan mengukur hubungan statistik antara dua atau lebih variabel. Jika digunakan hanya dua variabel disebut regresi dan korelasi sederhana. Sedangkan bila digunakan lebih dari dua variabel disebut regresi dan korelasi berganda.
Variabel yang akan diduga disebut variabel terikat (tidak bebas) atau dependent variable, biasa dinyatakan dengan variabel Y. Sedangkan variabel yang menerangkan perubahan variabel terikat disebut variabel bebas atau independent variabel, biasa dinayatakn dengan variabel X. Apabila dua variabel X dan Y mempunyai hubungan, maka nilai variabel X yang sudah diketahui dapat dipergunakan untuk memperkirakan/ menaksir Y. Ramalan pada dasarnya merupakan perkiraan mengenai terjadinya suatu kejadian .
Persamaan regresi (perkiraan/peramalan) dibentuk untuk menerangkan pola hubungan variabel-variabel. Analisa korelasi di gunakan untuk mengukur keeratan hubungan antara variabel-variabel.
Untuk menetukan persamaan hubungan antarvariabel , langkah-langkahnya adalah: 1. Mengumpulkan data dari variabel yang dibutuhkan misalnya X sebagai
variabel bebas dan Y adalah variabel tidak bebas
2. Menggmbarkan titik-titik pasangan (x,y) dalam sebuah sistem koordinat bidang. Hasil dari gambar itu disebut Diagram Pencar
35
Sumber : (Supranto, 2016)
Pola hubungan dari grafik-grafik tersebut. Pada Grafik a, b, c terlihat bahwa peningkatan nilai y sejalan dengan peningkatan nilai x. Apabila nilai x meningkat, maka nilai y pun meningkat, dan sebaliknya. Dari Grafik a sampai c, sebaran titik- titik pasangan data semakin mendekati bentuk garis lurus yang menunjukkan bahwa keeratan hubungan antara variabel x dan y semakin kuat (sinergis).
Hal yang sebaliknya terjadi pada Grafik d, e, dan f. Peningkatan nilai y tidak sejalan dengan peningkatan nilai x .Peningkatan salah satu nilai menyebabkan penurunan nilai pasangannya. Sekali lagi tampak bahwa kekuatan hubungan antara
36
kedua variabel dari d menuju f semakin kuat.
Berbeda dengan grafik sebelumnya, pada Grafik g tidak menunjukkan adanya pola hubungan linier antara kedua variabel. Hal ini menandakan bahwa tidak ada korelasi di antara kedua variabel tersebut. Terkahir, pada Grafik h kita bisa melihat adanya pola hubungan di antara kedua variabel tersebut, hanya saja polanya bukan dalam bentuk hubungan linier, melainkan dalam bentuk kuadratik.
Kegunaan dari diagram pencar adalah :
1. Membantu menunjukkan apakah terdapat hubungan yang bermanfaat antara dua variabel
2. Membantu menetapkan tipe persamaan yang menunjukkan hubungan antara kedua variabel tersebut.
3. Menentukan persamaan garis regresi atau mencari nilai-nilai konstan B. Analisa Regresi Sederhana
Analisa regresi linier sederhana adalah hubungan secara linier antara satu variabel dependen yang digunakan untuk memprediksi atau meramalkan suatu nilai variabel dependen berdasarkan variabel independen.
Persamaan garis regresi linier sederhana untuk sampel dengan menggunakan metode Kuadrat Terkecil
y = a + bx b = n∑XY - ∑X. ∑Y n∑�2 - (∑X)2 � = ∑X n � = ∑Y n a = � - b�
y = nilai yag diukur/dihitung pada variabel tidak bebas x = nilai tertentu dari variabel bebas
a = intersep / perpotongan garis regresi dengan sumbu y
b = koefisien regresi / kemiringan dari garis regresi/ untuk mengukur kenaikan atau penurunan y untuk setiap perubahan satu-satuan x/ untuk mengukur besarnya pengaruh x terhadap y kalau x naik satu unit
Contoh soal
Misalnya X adalah persenyase kenaikan biaya periklanan dan Y adalah persentasi kenaikan hasil penjualan. Berapakah besarnya ramalan persentase (%) kenaikan penjualan kalau biaya iklan dinaikkan menjadi 15% (X=15)
37 X Y �2 XY 1 2 1 2 2 4 4 8 4 5 16 20 5 7 25 35 7 8 49 56 9 10 81 90 10 12 100 120 12 14 144 168 ∑X = 50 � = 6,25 � = 7,75 ∑Y = 62 ∑� 2 = 420 ∑XY = 499 b = n∑XY - ∑X. ∑Y n∑�2 - (∑X)2 = 8(499) – 50 (62) 8(420) –(50)2 = 1,04 a = � - b� = 7,75 – 1,04 (6,25) = 1,25 Y = a + bX = 1,25 + 1,04X
Kalau X = 15, ramalan % kenaikan penjualan Y = 1,25 + 1,04 (15) = 16,85
C. Analisa Korelasi Sederhana
Analisa korelasi digunakan untuk mengukur kekuatan keeratan hubungan antara dua variabel melalui sebuah bilangan yang disebut koefisien korelasi. Koefisien korelasi linier (r) adalah ukuran hubungan linier antara dua variabel /peubah acak X dan Y untuk mengukur sejauh mana titik-titik menggerombol sekitar sebuah garis lurus regresi.
r = n∑XY - ∑X∑Y
√{�∑�2 − (∑�)2}{�∑�2 − (∑�)2}
Jika b positif maka r positif dan jika b negatif maka r negatif.
Jika nilai r terletak Di -1≤ r ≤+1 , jika r mendekati +1 dan -1 maka terjadi korelasi tinggi dan terjadi hubungan linier yang sempurna antara X dan Y. Jika r mendekati 0 hubungan liniernya sangat lemah atau tidak ada. Misalnya r = - 0,6 , menunjukkan arah yang berlawanan , jika nilai X naik maka nilai Y turun, begitu pula sebaliknya. Jika r = +0,6 menunjukkan arah yang sama , jika nilai X naik maka nilai Y juga naik.
38
D. Koefisien Determinasi
Nilai koefisien determinasi antara 0 dan 1. Koefisien determinasi adalah untuk menyatakan proporsi keragaman total nilai-nilai peubah Y yang dapat dijelaskan oleh nilai-nilai peubah X melalui hubungan linier tersebut. Contohnya r = 0,6 �2= 0,36 artinya 36% besarnya sumbangan X terhadap naik turunnya Y adalah 36 % sedangkan 64% disebabkan oleh faktor lain.
X = Pendapatan perkapita (ribuan milliar rupiah)
Y = Pengeluaran konsumsi rumah tangga (ribuan milliar rupiah)
X Y �2 � 2 XY 19 15 361 225 285 27 20 719 400 540 39 28 1.521 784 1.092 47 36 2.209 1.296 1.692 52 42 2.704 1.764 2.184 66 45 4.356 2.025 2.970 78 51 6.084 2.601 3.978 85 55 7.225 3.025 4.675 ∑X = 413 ∑Y = 292 ∑�2 = 25.189 ∑�2= 12.120 ∑XY = 17.416 r = n∑XY - ∑X∑Y √{�∑�2 − (∑�)2}{�∑�2 − (∑�)2} r = 8(17.416) – (413)(292) √{8(25.189) − (413)2}{8(12.120) − (292)2} = 0,98
Kesimpulannya : Hubungan X dan Y sangat kuat dan positif. Besarnya sumbangan pendapatan perkapita terhadap naik/turunnya pengeluaran konsumsi adalah
39
LATIHAN SOAL
1. Tentukan apakah hubungan variabel X dan Y berikut (positif atau negatif)
X 2 4 3 8 9 10 13
Y 1 2 5 7 8 11 14
2. Hitung r dan �2 nya. Intrepretasikan hasilnya 3. X = Nilai ujian matematika mahasiswa
Y = Nilai ujian statistik mahasiswa
X 7 6 8 9 10 5 4 9 7 3
Y 6 8 9 7 9 6 5 8 8 4
Dengan menggunakan persamaan regresi, berapa nilai satistik yang diperoleh kalau nilai matematika yang dicapai sebesar 8,5?
4. Hitung �2 dan apa artinya
5. Tulis persamaan regresi linier sederhana, berapa besarnya nilai regresi? Apa arti nilai ini?
40
BAB VI
ANALISA DATA BERKALA
A¶ Pengertian Analisa Data Berkala
Data yang dikumpulkan dari waktu ke waktu untuk menggambarkan perkembangan suatu kegiatan (perkembangan produksi, harga, hasil penjualan, jumlah penduduk, jumlah kecelakaan, jumlah kejahatan). Merupakan serangkaian nilai-nilai variabel yang disusun berdasarkan waktu.
Data berkala adalah serangkaian data yang terdiri dari variabel Yi yang merupakan serangkaian hasil obsevasi dan fungsi dari variabel Xi yang merupakan variabel waktu yang bergerak secara seragam dan kearah yang sama, dari waktu yang lampau ke waktu yang mendatang.
B¶ Komponen Data Berkala
Gerakan/ variasi data berkala terdiri dari empat macam sebagai berikut :
1. Gerakan Tren Jangka Panjang yaitu suatu gerakan yang menunjukkan arah perkembangan secara umum (kecenderungan menaik/menurun). Contohnya tren sekuler umumnya meliputi gerakan yang lamanya sekitar 10 tahun atau lebih.
2. Gerakan/variasi siklis adalah gerakan jangka panjang di sekitar garis trend (berlaku untuk data tahunan).
3. Gerakan/variasi musiman adalah gerakan yang mempunyai pola tetap dari waktu kewaktu, misalnya meningkatnya harga makanan dan pakaian menjelang hari raya Idul Fitri
4. Gerakan/variasi yang tidak teratur adalah gerakan/variasi yang sifatnya sporadis, contohnya naik turunnya produksi akibat banjir yang datangnya tidak teratur.
Kemakmuran resesi
Pemulihan Depresi
41
C. Ciri-ciri Tren Sekuler
Pengertian Trend ialah gerakan dalam deret berkala yang berjangka panjang, lamban dan berkecenderungan menuju ke satu arah, arah menaik atau menurun. Umumnya meliputi gerakan yang lamanya 10 tahun atau lebih.
Trend digunakan dalam melakukan peramalan (forecasting). Metode yang basanya dipakai, antara lain adalah Metode Semi Average dan Metode Least Square
1. Metode Semi Average
Langkah-langkahnya sebagai berikut :
a. Data dikelompokkan menjadi dua, masing-masing kelompok harus mempunyai jumlah data yang sama. Kalau datanya ganjil hilangkan satu, yaitu yang berada di tengah,
b. Masing-masing kelompok dicari rata-ratanya
c. Titik absis harus dipilih dari variabel X yang berada di tengah masing- masing kelompok (tahun atau waktu yang di tengah
d. Untuk menentukan nilai trend linier untuk tahun-tahun tertentu dapat dirumuskan sebagai berikut :
Y = a + bX
a = �1 , Jika periode dasar berada pada kelompok 1 b = �2 , Jika periode dasar berada pada
kelompok 2 b = � 2 -
� 1 n
y = data berkala (time series) = taksiran nilai tren ao = nilai trend pada tahun dasar
b = rata-rata pertumbuhan nilai tren tiap tahun x = variabel waktu (hari, minggu, bulan atau tahun) n = jumlah data tiap kelompok
Tahun X Y’ Rata rata
2002 0 10.164,9 2003 1 11.169,2 �1 = 45.714,1 = 11.428 2004 2 12.054,6 4 2005 3 12.325,4 2006 4 12.842,2 2007 5 13.511,5 �2 = 55.384,6 = 13.846,2 2008 6 14.180,8 4 2009 7 14.850,1 Y = a + bX 11.428,5 = a + b(1,5) ... (1) 13.846,2 = a + b(5,5) ... (2) a = 11.428,5 – 1,5b
42 13.846,2 = 11.428,5 – 1,5b + 5,5b 13.846,2 = 11.428,5 + 4b 4b = 2.417,7 b = 604,42 a = 11.428,5 – 1,5 (604,42) a = 10 .521,87
sehingga Y = 10.521,89 + 604,42X (X = variabel waktu)
Dari persamaan di atas, diramalkan PDB untuk tahun 2010 dan 2011 sebagai berikut :
PDB 2010 (X = 8) Y = 10.521,89 + 604,42 (8) = 15.357,23
PDB 2011 (X = 9) Y = 10.521,89 + 604,42 (9) = 15.961,65
2. Rata-rata Bergerak Tertimbang
a. Umumnya timbangan yang digunakan bagi rata-rata bergerak ialah koefisien Binomial. Rata-rata bergerak per 3 tahun harus diberi koefisien Binomial. Rata- rata bergerak per 3 tahun harus diberi koefisien 1, 2, 1 sebagai timbangannya. b. Prosedur menghitung rata-rata bergerak tertimbang per 3 tahun sebagai berikut
:
1) Jumlahkan data tersebut selama 3 tahun berturut-turut secara tertimbang 2) Bagilah hasil penjumlahan tersebut dengan faktor pembagi 1+2+1 = 4.
Hasilnya diletakkan di tengah tengah tahun tersebut. Data Penjualan PT. Malvinas
Tahun Y (= jutaan rupiah) Rata-rata bergerak 4 tahun Rata-rata bergerak 5 tahun 1997 50,0 1998 36,5 1999 43,0 43,5 2000 44,5 40,7 42,6 2001 38,9 41,1 40,2 2002 38,1 38,5 39,4 2003 32,6 37,1 39,6 2004 38,7 37,8 38,0 2005 41,7 38,5 38,4 2006 41,1 38,8 37,6 2007 33,8
43
3. Metode Kuadrat Terkecil
Metode yang sering digunakan untuk meramalkan Y, karena perhitungannya lebih teliti. Garis tren linier dapat ditulis sebagai persamaan garis lurus :
Y = a + bX a = (∑Y) /2 b = (∑XY) / ∑�2
Y = data berkala (time series data) X = waktu (hari, minggu, bulan, tahun)
a = bilangan konstan/ nilai tren pada tahun dasar
b = koefisien arah (slope) = rata-rata kenaikan /pertumbuhan nilai tren tiap tahun Untuk melakukan perhitungan, maka diperlukan niali tertentu pada variabel waktu (X) sehingga jumlah nilai variabel waktu adalah nol atau ∑X = 0
Untuk n = 3, maka X1, X2, X3 -1 0 1 Untuk n = 4, maka X1, X2, X3, X4
-3 -1 1 3 Untuk n ganjil maka n = 2k + 1
2k = n – 1 k = n - 1 2 X2 + 1 = 0 n = 3 k = 3 – 1 = 2/2 = 1 2 Xk + 1 = X2 = 0 Untuk n genap maka n = 2k
k = n/2 Xk +(k+1) = 0 X (k +(k+1)) = X5/2
2
= X 2,5 Yang dibagi 2 adalah (k +(k + 1))
n = 4 --- k = n/2
44 Tahun X Y XY �2 2002 -7 10.164,9 -71.154,3 49 2003 -5 11.169,2 -55.846,0 25 2004 -3 12.054,6 -36.163,8 9 2005 -1 12.325,4 -12.325,4 1 2006 1 12.842,2 12.842,2 1 2007 3 13.511,5 40.534,5 9 2008 5 14.180,8 70.904,0 25 2009 7 14.850,1 103.950,7 49 ∑Y =101.098,7 � = 12.637,34 ∑XY = 52.741,9 ∑�2 = 168
Persamaan garis tren dengan menggunakan metode kuadrat terkecil a = � = 12.637,34
b = (∑XY) / ∑�2 = 52.741,9
168 = 313,94
45
LATIHAN SOAL
Tahun 1 2 3 4 5 6 7
Y 123 130 137 147 158 172 189
1. Dengan menggunakan rata-rata semi (semi average) caru trend nya Produksi tahunan kayu berukuran besar dari sebuah perusahan kayu sejak tahun 2000 adalah sebagai berikut :
Tahun Produksi (000 ton)
2000 4 2001 8 2002 5 2003 8 2004 11 2005 9 2006 11 2007 14
2. Dari tabel diatas tentukan persamaan garis lurus (trend linier) dengan metode kuadrat terkecil
3. Jika digunakan persamaan yang diperoleh berapa nilai perkiraan tahun 2008
Produksi tahunan perusahaan kayu yang diproduksi oleh perusahaan Woody sejak tahun 2000
Tahun Produksi (000 ton)
2000 4 2001 8 2002 5 2003 8 2004 11 2005 9 2006 11 2007 14 2008 12 2009 15 2010 16 2011 19
4. Berdasarkan data tabel diatas tentukan rata-rata bergerak 3 tahunan 5. Berdasarkan data tabel diatas tentukan rata-rata bergerak 4 tahunan
46
DAFTAR PUSTAKA
Hadi, D. A. (2012). ANALISIS HUBUNGAN CITRA IKLAN, CITRA MEREK,
DAN KEPRIBADIAN MEREK SABUN MANDI. BOGOR: IPB.
Hakim, Abdul. 2010. Statistika Deskriptif Untuk Ekonomi dan Bisnis. Ekonisia. Yogyakarta
Priyatno, Dwi. 2012. Belajar Cepat Olah Data Statistik dengan SPSS. ANDI OFFSET. Yogyakarta
Sanusi, Anwar (2011). Metode Penelitian Bisnis, Jakarta: Salemba Raya
Sarwono, Jonathan. 2013. Strategi Melakukan Riset Kuantitatif, Kualitatif,
Gabungan. Yogyakarta: Andi Offset.
Sugiyono. (2017). Metode Penelitian Kuantitatif Kualitatif dan R & D (Cetakan ke- 26). Bandung: Penerbit Alfabeta. Halaman x + 334. ISBN 979-8433-64-0 Supranto, J.2016. Statistik Teori dan Aplikasi. Penerbit Erlangga. Jakarta