1
KASUS PADA JST CELL CIKARANG
SKRIPSI
Diajukan Sebagai Salah Satu Syarat Untuk Kelulusan Program Studi -1 (S1) Program Studi Teknik Informatika
Oleh :
SIDIK AZIS PURWADI 311421132
PROGRAM STUDI TEKNIK INFORMARIKA SEKOLAH TINGGI TEKNOLOGI PELITA BANGSA
BEKASI 2018
ii
PREDIKSI PRODUK TERLARIS UNTUK MENGELOLA MODAL USAHA MENGGUNAKAN ALGORITMA DECISION TREE
BERBASIS WEB STUDI KASUS PADA JST CELL CIKARANG
Yang disusun oleh : Sidik Azis Purwadi
311421132
Telah disetujui oleh dosen pembimbing skripsi pada tanggal 09 November 2018
Dosen Pembimbing I Dosen Pembimbing II
Suherman, S.Kom., M.Kom. Giri Nurpribadi, S.TP., M.M.
NIDN : 0308086805 NIDN : 0413086804
Mengetahui
Kaprodi Teknik Informatika
Aswan S. Sunge. S.E, M.Kom. NIDN : 0426018003
iii
PREDIKSI PRODUK TERLARIS UNTUK MENGELOLA MODAL USAHA MENGGUNAKAN ALGORITMA DECISION TREE
BERBASIS WEB STUDI KASUS PADA JST CELL CIKARANG
Yang disusun oleh : Sidik Azis Purwadi
311421132
Telah dipertahankan di depan Dewan Penguji pada tanggal 14 November 2018
Susunan Dewan Penguji
Dosen Penguji I Dosen Penguji II
Elkin Rilvani, S.Kom.,M.M. Tyas Ismi Thrialfhiyanti, S.Pi., M.Sc.
NIDN : 0426078401 NIDN : 0412029103
Mengetahui
Kaprodi Teknik Informatika Ketua STT Pelita Bangsa
Aswan S. Sunge. S.E, M.Kom Dr.Ir. Supriyanto, M.P
iv
Nama : Sidik Azis Purwadi
NIM : 311421132
Perguruan Tinggi : STT Pelita Bangsa Program Studi : Teknik Informatika
Alamat Kampus : Jl. Inspeksi Kalimalang – Tegal Danas Cikarang Selatan,Bekasi-jawa Barat 17530
Alamat Rumah : Ds.Kemiri RT.04/RW.02, Kec.Sumpiuh. Kab.Banyumas Jawa tengah.
Dengan ini menyatakan bahwa skripsi yang telah saya buat dengan judul
“
PREDIKSI PRODUK TERLARIS UNTUK MENGELOLA MODAL
USAHA MENGGUNAKAN ALGORITMA DECISION TREE
BERBASIS WEB STUDI KASUS PADA JST CELL CIKARANG
”adalah asli (orisinil) atau tidak plagiat (menjiplak) dan belum pernah diterbitkan/dipublikasikan dimanapun dan dalam bentuk apapun. Demikianlah surat pernyataan ini saya buat dengan sebenar-benarnya tanpa ada paksaan dari pihak manapun. Apabila dikemudian hari ternyata saya memberikan keterangan palsu dan atau ada pihak lain yang mengklaim skripsi yang telah saya buat adalah hasil karya milik seseorang atau badan tertentu,saya bersedia diproses baik secara pidana maupun perdata dan kelulusan saya dari Sekolah Tinggi Teknologi Pelita Bangsa dicabut/dibatalkan.
Bekasi, November 2018 Yang meyatakan,
v
wirausahawan untuk mengembangkan usahanya. JST Cell merupakan sebuah toko yang bergerak di bidang elektronik dan aksesoris terutama handphone. Penggunaan modal usaha yang kurang baik dan tidak tepat akan menimbulkan banyak kerugian bagi JST Cell diantaranya adalah perputaran uang modal usaha menjadi terganggu yang berdampak pada penghasilan. Prediksi Produk Terlaris Untuk Mengelola Modal Usaha Menggunakan Algoritma Decision Tree Berbasis Web Studi Kasus Pada JST Cell Cikarang, adalah sebuah sistem prediksi untuk menentukan apakah produk tersebut laris atau tidak laris. Metode decision tree atau pohon keputusan merupakan salah satu metode klasifikasi pada data mining. Metode ini mengubah data fakta menjadi data aturan yang digambarkan seperti pohon yang disebut pohon keputusan. Decision tree dapat memprediksi suatu kejadian yang akan datang berdasarkan data sebelumnyaDengan menginplementasikan data mining menggunakan algoritma decision tree C4.5 yang dapat memprediksi suatu kejadian yang akan datang berdasarkan data sebelumnya. Penelitian ini menghasilkan sebuah sistem yang dapat membantu memprediksi produk terlaris sesuai dengan kebutuhan JST Cell. Dengan adanya sistem tersebut, maka JST Cell dapat memprediksi produk mana yang akan menjadi produk terlaris dan JST Cell dapat menyediakan stok produk yang diprediksi terlaris. Penggunaan sistem melalui OS android akan lebih fleksibel dan UI yang dihasilkan juga akan lebih bagus. Sistem yang dihasilkan masih bisa dikembangkan lebih lanjut dengan fitur yang belum tersedia sehingga bisa ditambah sesuai kebutuhan seperti import dan eksport dataset, perhitungan prediksi secara otomatis berdasarkan dataset yang ada, sehingga sistem ini bisa diaplikasikan pada semua kasus tidak hanya pada JST Cell. Kata kunci : Algoritma, Decision Tree, C4.5, Data Mining, Prediksi.
vi
electronics and accessories, especially mobile phones. The use of business capital that is not good and not right will cause a lot of losses for JST Cell, including the turnover of business capital money to be disrupted which has an impact on income. Predictions of Best-Selling Products for Managing Business Capital Using Web-Based Decision Tree Algorithms Case Study In JST Cell Cikarang, is a prediction system to determine whether the product is in demand or not in demand. The decision tree method or decision tree is one of the classification methods in data mining. This method converts fact data into rule data that is described as a tree called a decision tree. Decision tree can predict an upcoming event based on previous data By implementing data mining using C4.5 decision tree algorithm that can predict an upcoming event based on previous data. This research produces a system that can help predict the best-selling products according to JST Cell needs. With the existence of this system, JST Cell can predict which product will be the best-selling product and JST Cell can provide the best-selling product stock predicted. The use of the system through the Android OS will be more flexible and the resulting UI will also be better. The resulting system can still be further developed with features that are not yet available so that they can be added according to needs such as import and export datasets, automatic prediction calculations based on existing datasets, so that this system can be applied in all cases not only on JST Cell.
vii
berkat dan karunia-Nya kepada penulis, serta kepada semua pihak yang telah turut dalam membantu penyelesaian laporan skripsi ini. Penulis memberi judul :
PREDIKSI PRODUK TERLARIS UNTUK MENGELOLA MODAL USAHA MENGGUNAKAN ALGORITMA
DECISION TREE BERBASIS WEB STUDI KASUS PADA JST CELL CIKARANG
Maksud dari penulisan ini adalah untuk memenuhi persyaratan dan syarat ujian untuk mendapatkan gelar sarjana komputer. Penulis sadar bahwa penulisan laporan ini masih jauh dari kesempurnaan , baik secara alamiah maupun secara teknik, oleh karena itu penulis sangat mengharapkan adanya kritikan dan saran yang bersifat membangun, sebagai bahan pertimbangan bagi penulis di masa mendatang. Selama penelitian dan penyelesaikan laporan ini, penulis telah banyak menerima bimbingan, pengarahan, petunjuk, dan saran, serta fasilitas yang membantu. Untuk itu penulis menyampaikan ucapan terima kasih yang sebesar-besarnya kepada :
1. Bapak Dr. Ir. Supriyanto, M.P, selaku ketua STT Pelita Bangsa.
2. Bapak Aswan S. Sunge, S.E., M.Kom, selaku ketua program studi Teknik Informatika STT Pelita Bangsa.
3. Bapak Suherman, S.Kom., M.Kom, selaku Dosen Pembimbing 1 4. Bapak Giri Nurpribadi,S.TP., M.M. selaku Dosen Pembimbing 2
5. Kepada seluruh Dosen, staf dan karyawan prodi Teknik Informatika Sekolah Tinggi Teknologi Pelita Bangsa
6. Kepada kedua orang tua saya yang tercinta, dan adik-adikku tercinta yang selalu mendoakan dan membimbing demi keberhasilan anaknya, dan telah memberikan dukungan baik moril maupun material yang tidak terhitung jumlahnya.
menyusun laporan skripsi ini serta kepada semua pihak yang telah memberikan dukungannya yang tidak dapat disebutkan satu persatu sehingga penelitian ini dapat diselesaikan.
8. Untuk semua teman-teman perantauan yang ada di Cikarang ini, yang senantiasa selalu men-support dan mengingatkan saya agar cepat menyelesaikan skripsi ini.
Akhirnya semoga Allah SWT memberikan balasan pahala kebaikan atas segala bantuan yang telah diberikan kepada penulis. Penulis berharap semoga laporan ini bermanfaat bagi semua pihak yang membantu,meskipun dalam laporan ini masih banyak kekurangan. Oleh karena itu, kritik dan saran yang membangun tetap penulis harapkan.
Cikarang, November 2018 Penulis
HALAMAN PERSEMBAHAN
Yang Utama Dari Segalanya...
Sembah sujud serta syukur kepada Allah SWT. Taburan cinta dan kasih sayang-Mu telah memberikanku kekuatan, membekaliku dengan ilmu serta memperkenalkanku dengan cinta. Atas karunia serta kemudahan yang Engkau berikan akhirnya skripsi yang sederhana ini dapat terselesaikan. Sholawat dan salam selalu terlimpahkan keharibaan Rasullah Muhammad SAW.
Kupersembahkan karya sederhana ini kepada orang yang sangat kukasihi dan kusayangi :
Ibunda dan Ayahanda Tercinta
Sebagai tanda bakti, hormat, dan rasa terima kasih yang tiada terhingga kupersembahkan karya tulis ini kepada Ibu dan Ayah yang telah memberikan kasih sayang, segala dukungan, dan cinta kasih yang tiada terhingga yang tiada mungkin dapat kubalas hanya dengan selembar kertas yang bertuliskan kata cinta dan persembahan. Semoga ini menjadi langkah awal untuk membuat Ibu dan Ayah bahagia karna kusadar, selama ini belum bisa berbuat yang lebih. Terima Kasih Ibu.... Terima Kasih Ayah...
Adik - Adiku
Untuk adik-adikku, tiada yang paling mengharukan saat kumpul bersama kalian, walaupun sering bertengkar tapi hal itu selalu menjadi warna yang tak akan bisa tergantikan, terima kasih atas doa dan bantuan kalian selama ini, hanya karya tulis ini yang dapat aku persembahkan. Maaf belum bisa menjadi panutan seutuhnya, tapi aku akan selalu menjadi yang terbaik untuk kalian semua.
Dosen Pembimbing Tugas Akhirku
Bapak Suherman dan Bapak Giri Nurpribadi selaku dosen pembimbing 1 dan 2 tugas akhir saya, terima kasih banyak pak, saya sudah dibantu selama ini, sudah dinasehati, sudah diajari, saya tidak akan lupa atas bantuan dan kesabaran dari bapak.
Terima kasih banyak untuk semua ilmu, didikan dan pengalaman yang sangat berarti yang telah kalian berikan kepada saya.
Teman-Teman angkatan 2014 :
Terima kasih banyak untuk bantuan dan kerja samanya selama ini, Serta semua pihak yg sudah membantu selama penyelesaian Tugas Akhir ini.
xi
bergerak dan masa depanmu dibentuk oleh apa yang kamu lakukan hari ini. Percayalah bahwa usaha tidak akan menghianati hasil.
“Hai orang-orang yang beriman, mintalah pertolongan (kepada Allah) dengan sabar dan (mengerjakan) sholat sesungguhnya Allah beserta orang-orang yang sabar” ( Al-Baqoroh:153 ).
xii
Persetujuan ... ii
Pengesahan ... iii
Surat Pernyataan Keaslian Skripsi ... iv
Abstraksi ... v
Abstract ... vi
Kata Pengantar ... vii
Halaman Persembahan ... ix
Motto ... xi
Daftar Isi... xii
Daftar Tabel ... xv
Daftar Gambar ... xvi
Daftar Lampiran ... xviii
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Identifikasi Masalah dan Pembatasan Masalah... 2
1.2.1 Identifikasi Masalah ... 2 1.2.2 Pembatasan Masalah ... 3 1.3 Rumusan Masalah ... 3 1.4 Tujuan Penelitian ... 3 1.5 Manfaat Penelitian ... 3 1.5.1 Bagi Penulis ... 3 1.5.2 Bagi JST Cell ... 4 1.6 Sistematika Penulisan ... 4
BAB II TINJAUAN PUSTAKA ... 5
2.1 Penelitian Terdahulu ... 5
2.2 Definisi Judul ... 6
2.2.2 Pengertian Produk ... 6
2.2.3 Pengertian Modal Usaha ... 7
2.2.4 Pengertian Algoritma ... 7
2.3 Data Mining ... 8
2.3.1 Pengertian Data Mining ... 8
2.3.2 Tahap-Tahap Data Mining ... 8
2.3.3 Tugas-Tugas Data Mining... 10
2.3.4 Manfaat Data Mining ... 11
2.3.5 Jenis atau Teknik Data Mining ... 11
2.4 Decision Tree ... 12
2.4.1 Pengertian Decision Tree ... 12
2.4.2 Entropy Dan Information Gain ... 15
2.5 Pemograman WEB ... 17
2.5.1 Pengertian WEB ... 17
2.5.2 HyperText Markup Language (HTML) ... 17
2.5.3 PHP (Hypertext Preprocesseor) ... 18
2.5.4 CSS (Cascading Style Sheet) ... 18
2.6 Teknik Pengembangan Sistem ... 18
2.7 Rapid Miner ... 23
2.8 Database ... 24
2.8.1 Pengertian Database ... 24
2.8.2 Database Management System (DBMS) ... 24
2.8.3 MySQL ... 25
2.8 XAMPP ... 26
2.9 Kerangka Pemikiran ... 27
2.10 Hipotesis ... 28
2.11 Waktu Penelitian ... 28
BAB III METODE PENELITIAN ... 29
3.1 Metode Penelitian ... 29
3.2 Analisis Data Knowledge Discovery in Database (KDD) ... 30
3.4 Kebutuhan Software dan Hardware ... 36
BAB IV HASIL DAN PEMBAHASAN ... 37
4.1 Hasil Penelitian ... 37
4.1.1 Perhitungan Manual Decision Tree ... 37
4.1.2 Perhitungan Menggunakan RapidMiner ... 42
4.1.3 Pemodelan Sistem ... 48
4.1.4 User Interface Prediksi Produk Terlaris ... 56
4.2 Pembahasan ... 59 BAB V PENUTUP ... 60 5.1 Kesimpulan ... 60 5.2 Saran ... 60 DAFTAR PUSTAKA ... 61 LAMPIRAN ... 64
xv
Tabel 3.2 Klasifikasi Kuota internet ... 31
Tabel 3.3 Klasifikasi Nominal Pulsa ... 32
Tabel 3.4 Klasifikasi Jenis Produk ... 32
Tabel 3.5 Klasifikasi Harga... 33
Tabel 3.6 Tabel Terjual ... 33
Tabel 3.7 Data Testing Penjualan Produk JST Cell ... 34
Tabel 3.8 Data Training Penjualan Produk JST Cell ... 34
Tabel 4.1 Skenario Use Case Diagram Prediksi Produk Terlaris ... 48
xvi
Gambar 2.3 Contoh Decision Tree... 13
Gambar 2.4 Tahapan Membangun Pohon Keputusan... 15
Gambar 2.5 Rumus Menghitung Entrophy ... 16
Gambar 2.6 Rumus Menghitung Gain ... 16
Gambar 2.7 Notasi Use case diagram... 19
Gambar 2.8 Contoh Use case diagram ... 19
Gambar 2.9 Notasi Class diagram ... 20
Gambar 2.10 Contoh Class Diagram ... 20
Gambar 2.11 Notasi Sequence Diagram ... 21
Gambar 2.12 Contoh Sequence Diagram... 21
Gambar 2.13 Notasi Activity Diagram ... 22
Gambar 2.14 Contoh Activity Diagram ... 22
Gambar 2.15 Tampilan Utama StarUML ... 23
Gambar 2.16 Halaman Utama Rapid Miner ... 24
Gambar 2.17 Tampilan Utama XAMPP ... 27
Gambar 2.18 Tampilan Utama XAMPP ... 27
Gambar 2.19 Tabel Waktu Penelitian ... 28
Gambar 3.1 Statistik Data Tidak Lengkap ... 30
Gambar 3.2 Tahapan Penelitian ... 36
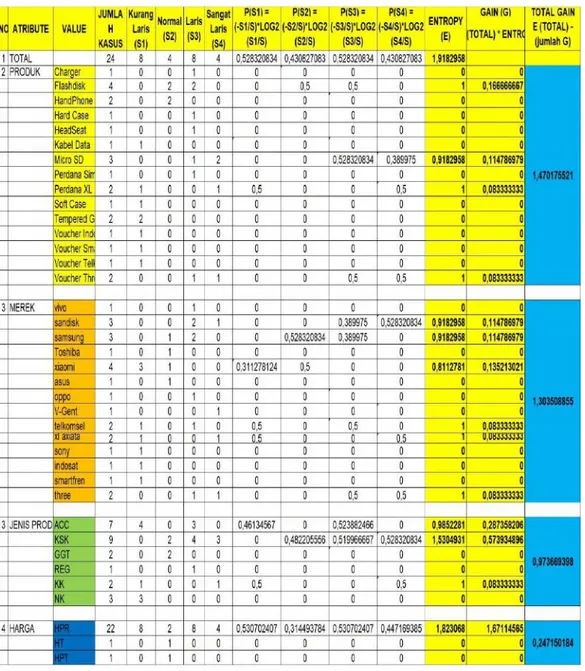
Gambar 4.1 Tabel Perhitungan node 1.0 ... 38
Gambar 4.2 Perhitungan Node 1.1 ... 39
Gambar 4.3 Perhitungan Node 1.2 ... 39
Gambar 4.4 Perhitungan Node 1.3 ... 39
Gambar 4.5 Perhitungan Node 1.4 ... 40
Gambar 4.6 Perhitungan Node 1.5 ... 40
Gambar 4.7 Perhitungan Node 1.6 ... 40
Gambar 4.9 Halaman Utama RapidMiner 8.0 ... 43
Gambar 4.10 Kotak Dialog select the cell to import ... 43
Gambar 4.11 Kotak Dialog format your columns ... 44
Gambar 4.12 Process Validation ... 44
Gambar 4.13 Tabel Hasil Akurasi Data Testing ... 45
Gambar 4.14 Tabel Hasil Recall Data Testing ... 45
Gambar 4.15 Tabel Hasil Precision Data Testing ... 45
Gambar 4.16 Tree View Rapidminer ... 46
Gambar 4.17 Rule Tree ... 46
Gambar 4.18 Desain Akurasi Prediksi Data Testing Dan Training ... 47
Gambar 4.19 Hasil Akurasi Prediksi Data Testing Dan Training ... 47
Gambar 4.20 Use Case Diagram Prediksi Produk Terlaris ... 48
Gambar 4.21 Activity Diagram Login ... 49
Gambar 4.22 Activity Diagram Dataset ... 50
Gambar 4.23 Activity Diagram Tambah Data ... 50
Gambar 4.24 Activity Diagram Prediksi ... 51
Gambar 4.25 Activity Diagram Tentang Saya ... 51
Gambar 4.26 Activity Diagram Logout ... 52
Gambar 4.27 Sequence Diagram Login ... 52
Gambar 4.28 Sequence Diagram Dataset ... 53
Gambar 4.29 Sequence Diagram Tambah Data ... 53
Gambar 4.30 Sequence Diagram Prediksi ... 54
Gambar 4.31 Sequence Diagram Tentang Saya ... 54
Gambar 4.32 Sequence Diagram Logout ... 55
Gambar 4.33 Class Diagram Prediksi Produk Terlaris ... 55
Gambar 4.34 User Interface Halaman Login ... 56
Gambar 4.35 User Interface Halaman Menu Utama ... 57
Gambar 4.36 User Interface Menu Dataset ... 57
Gambar 4.37 User Interface Menu Tambah Data ... 58
Gambar 4.38 User Interface Menu Prediksi ... 58
xviii
Lampiran 2 Interview JST Cell ... Lampiran 3 Surat Ijin Penelitian ... Lampiran 4 Dataset Penjualan JST Cell Bulan Agustus – Oktober 2018 ... Lampiran 5 Data Testing ... Lampiran 6 Data Training ... Lampiran 7 Form Kendali Bimbingan ... Lampiran 8 Biodata Mahasiswa ...
1 1.1 Latar Belakang Masalah
Seiring dengan kemajuan zaman, kemajuan teknologi informasi pun tak urung juga menjadi suatu terobosan baru yang sudah banyak digunakan oleh para informan demi mencapai tujuan mereka. Perkembangan teknologi informasi dapat memudahkan manusia untuk beraktivitas melihat berita dan mencari berbagai informasi yang beredar di dunia maya. Semua tergantung dari bagaimana kita menggunakan teknologi yang dapat bermanfaat bagi kita dan orang lain, namun disatu sisi ada juga dampak negatif yaitu banyak remaja yang memanfaatkan teknologi informasi hanya untuk hal-hal yang tidak bertanggung jawab atas apa yang mereka kerjakan. Apabila kita menggunakan teknologi dengan benar kita dapat melakukan pekerjaan, penjualan, dan lainnya, sehingga kita dapat memperoleh keuntungan dari teknologi tersebut. Kebutuhan akan adanya informasi sekarang ini sangat penting bagi pengguna informasi itu sendiri, dengan pemanfaatan informasi yang optimal, akan memberikan banyak keuntungan bagi penggunanya. Informasi dapat menjadi pertimbangan dalam mengambil keputusan, dapat juga mengetahui keadaan atau situasi dilingkungan sekitar, dan mengetahui disaat kita tidak tahu.
JST Cell merupakan sebuah toko yang bergerak di bidang elektronik dan aksesoris terutama handphone dan berdiri pada tahun 2009. Nama JST Cell diambil dari tiga nama depan pendiri nya yaitu Johari, Saepul, dan Teguh, tetapi pada tahun 2012 status toko sepenuhnya sudah menjadi hak milik Johari, JST Cell sendiri beralamat di Jl.Industri Pasir Gombong RT 01 / RW 05, Kec.Cikarang Utara, Kab.Bekasi. Meski tokonya bisa dikatakan kecil yaitu hanya berukuran 3x4 𝑚2, pemilik toko mengaku dia bisa mengambil sebuah perumahan di daerah Cibarusah dan kebutuhan hidup lebih dari cukup terpenuhi. Untuk mendapatkan hasil atau keuntungan yang besar kita harus mengetahui produk mana saja yang paling
dicari oleh konsumen ditambah lagi persaingan harga yang semakin ketat antar toko dan semakin banyak orang-orang yang berwirausaha dibidang yang sama. Penggunaan modal usaha untuk pembelian produk yang akan dijual nantinya harus sangat diperhatikan dan hati-hati dalam menggunakannya, dalam masalah yang dihadapi JST Cell ini adalah terlalu sering melakukan kesalahan dalam menggunakan modal untuk pembelian produk yang akan dijual, pemilik toko terkadang membeli sebuah produk yang belum tentu laris dipasaran dengan jumlah yang banyak sehingga uang modal pun habis dan perputarannya menjadi terganggu. Kalau di biarkan terus menerus seperti ini maka akan menimbulkan banyak kerugian bagi pemilik toko, dan dampak terburuknya adalah JST Cell bisa gulung tikar / bangkrut.
Metode decision tree atau pohon keputusan merupakan salah satu metode klasifikasi pada data mining. Metode ini mengubah data fakta menjadi data aturan yang digambarkan seperti pohon yang disebut pohon keputusan. Decision tree dapat memprediksi suatu kejadian yang akan datang berdasarkan data sebelumnya. Dengan menggunakan algoritma decision tree penulis bermaksud membuat sebuah sistem prediksi yang dapat membantu pemilik toko dalam menentukan produk mana yang memang pantas di beli dengan jumlah yang banyak dan mana yang sedikit agar modal dapat dikelola dan digunakan dengan semaksimal mungkin. Berdasarkan latar belakang diatas, maka penulis menyusun tugas akhir dengan judul “Prediksi Produk Terlaris Untuk Mengelola Modal Usaha Menggunakan Algoritma Decision Tree Berbasis Web Studi Kasus Pada JST Cell Cikarang”.
1.2 Identifikasi Masalah dan Pembatasan Masalah 1.2.1 Identifikasi Masalah
Dari permasalahan latar belakang yang disebutkan diatas maka ada beberapa permasalahan yang timbul antara lain :
1. Perputaran uang modal usaha terganggu yang berdampak pada penghasilan. 2. Banyak stok produk lama belum terjual yang rusak dimakan waktu.
3. Banyak produk yang sudah kadaluwarsa seperti kartu perdana regular dan kuota internet.
1.2.2 Pembatasan Masalah
Agar tidak melenceng dari pokok pembahasan, maka penulis membatasi permasalahan hanya pada penerapan algoritma decision tree untuk memprediksi produk yang sangat laris, dan kurang laris untuk mengontrol penggunaan uang modal usaha, data yang di pakai hanya data penjualan pada JST cell agar bisa dipergunakan dengan maksimal dan mendapat keuntungan yang besar.
1.3 Rumusan Masalah
Dalam penggunaan uang modal usaha pemilik toko terkadang membeli produk yang belum tentu laris dipasaran dengan jumlah yang banyak sehingga uang modal akan habis dan perputarannya menjadi terganggu. Berdasarkan rumusan masalah di atas, penulis mengajukan pertanyaan riset sebagai berikut :
1. Mengapa sering melakukan kesalahan dalam menggunakan uang modal usaha? 2. Bagaimana cara membuat sistem yang dapat mengontrol penggunaan uang
modal usaha?
3. Bagaimana cara menerapkan algoritma decision tree untuk memprediksi produk terlaris untuk mengontrol uang modal usaha?
1.4 Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah sebagai berikut:
1. Menemukan konsep solusi yang tepat dari permasalahan pada JST cell. 2. Memberikan kontribusi yang baik bagi JST Cell agar bisa lebih bersaing di
bidangnya.
3. Menemukan rule tree sebagai acuan untuk memprediksi produk pada jst cell.
1.5 Manfaat Penelitian 1.5.1 Bagi Penulis
Adapun manfaat yang dapat diambil oleh penulis antara lain:
1. Menerapkan ilmu yang di dapat dari bangku perkuliahan dan menerapkannya langsung di lapangan.
3. Memperluas wawasan, keterampilan yang nantinya menjadi bekal untuk siap terjun ke lapangan pekerjaan.
1.5.2 Bagi JST Cell
Adapun manfaat yang dapat di ambil oleh pemilik toko antara lain :
1. Dengan mengetahui produk mana yang paling laris pemilik toko bisa membelinya lebih banyak dengan begitu modal usaha dapat dipergunakan dengan sebaik-baiknya.
2. Produk yang rusak dan produk kadaluwarsa bisa diminimalisir.
3. Keuntungan dari hasil penjualan dengan sistematika tertentu akan meningkat.
1.6 Sistematika Penulisan
Sistematika penulisan ini dibuat untuk memberikan gambaran mengenai permasalahan yang ditulis dalam penyusunan skripsi ini pada setiap bab. Adapun bentuk dari sistematika penulisan ini adalah:
BAB I PENDAHULUAN
Menguraikan tentang Latar belakang, identifikasi, Batasan, Rumusan Masalah, Tujuan , Manfaat, dan Metode serta Sistematika Penulisan. BAB II TINJAUAN PUSTAKA
Bab ini akan membahas mengenai penjelasan tentang beberapa teori yang dijadikan landasan berfikir dalam penelitian.
BAB III METODE PENELITIAN
Semua prosedur, proses penelitian sejak persiapan hingga berakhirnya penelitian akan di bahas pada bab ini.
BAB IV HASIL DAN PEMBAHASAN
Bab ini menyorot tentang hasil akhir dari penelitian dan pembahasannya. BAB V PENUTUP
Berisi tentang kesimpulan yang diambil dari hasil penelitian yang telah dilariskan serta saran-saran yang dapat diberikan oleh penulis kepada pemilik toko.
BAB II
TINJAUAN PUSTAKA
2.1 Penelitian Terdahulu
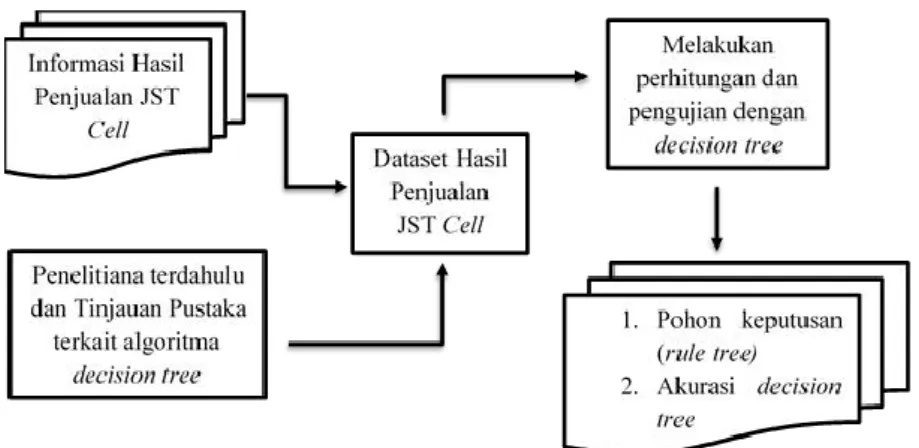
Penelitian terdahulu menjelaskan tentang penelitian-penelitian serupa yang akan dilakukan oleh Peneliti. Maka pada penelitian ini Peneliti telah merangkum beberapa penelitian terdahulu yang berkaitan dengan penelitian yang akan Peneliti lakukan. Gambar 2.1 adalah beberapa penelitian terdahulu yang telah dirangkum dalam bentuk tabel :
Gambar 2.1 Tabel Penelitian Terdahulu Sumber : Azwanti (2018), Harahap (2015), Faradillah (2013)
No Nama Peneliti Tahun Judul Hasil
1 Nurul Azwanti 2018
ANALISA ALGORITMA C4.5 UNTUK MEMPREDIKSI PENJUALAN MOTOR PADA PT.
CAPELLA DINAMIK NUSANTARA CABANG MUKA
KUNING
Dari dua hasil pengujian yang telah dilakukan yaitu proses secara manual dan menggunakan software WEKA 3.8.1 dapat kita ambil sebuah kesimpulan bahwa hasil pengujian sangat baik karena rule yang dihasilkan hampir sama. Perbedaannya hanya terletak pada atribut tahun produksi yang masuk ke dalam WEKA, namun tidak megubah hasil keputusan. Akurasi data testing yang dihasilkan adalah sebesar 75.00%
2 Fitriana Harahap 2015
PENERAPAN DATA MINING DALAM MEMPREDIKSI
PEMBELIAN CAT
pembelian cat dengan menggunakan metode Data Mining khususnya Algoritma C4.5 akan bermanfaat sekali dalam proses pengambilan keputusan dalam pembelian cat pada Home Smart Medan.
1. Yang menjadi faktor tertinggi yang mempengaruhi pembelian cat pada Home Smart adalah faktor kompetisi supplier dalam memasarkan produknya.
2. Faktor kedua yang mempengaruhi pembelian cat Home Smart adalah Kualitas cat dan Animo Masyarakat untuk mengetahui dan membeli produk cat yang dipasarkan dengan berbagai cara yang dilakukan pihak produsen cat tersebut.
3. Faktor Harga tidak mempengaruhi pembelian pada
3 Sarah Faradillah 2013
IMPLEMENTASI DATA MINING UNTUK PENGENALAN KARAKTERISTIK TRANSAKSI
CUSTOMER DENGAN MENGGUNAKAN ALGORITMA
C4.5
Setelah mengimplementasikan data mining dengan algoritma C4.5 maka karakteristik transaksi customer sudah dapat dikenali sehingga pihak PD. Cipta Sari Mandiri Tanjung Morawa bisa mengambil keputusan yang berkaitan dengan menyiapkan atau menyediakan stock produk yang digunakan untuk masa yang akan datang. Dan untuk bagian pemasaran harus meningkatkan penawaran-penawaran dengan memberikan hal-hal yang baru pada produk untuk menarik perhatian para customer menggunakan produk yang ditawarkan.
2.2 Definisi Judul 2.2.1 Pengertian Prediksi
Menurut Nugroho (2016:46), prediksi merupakan “kegiatan yang dilakukan oleh seorang peneliti dalam memperkirakan kejadian di masa yang akan datang dengan menggunakan pendekatan ilmu tertentu”.
Menurut Hay’s, dkk (2017:29), Prediksi adalah “pemikiran terhadap suatu besaran, misalnya permintaan terhadap satu atau beberapa produk pada periode yang akan datang. Pada hakekatnya prediksi hanya merupakan suatu perkiraan (forecast), tetapi dengan menggunakan teknik-teknik tertentu, maka prediksi menjadi lebih dari sekedar perkiraan. Prediksi dapat diartikan perkiraan yang ilmiah (educated forecast)”.
Menurut Hidayatsyah (2013:II-2), prediksi adalah “satu-satunya hal yang ditonjolkan, misalnya sebuah perusahaan directmail membuat sebuah model yang akurat untuk memprediksi anggota mana yang berpotensi untuk merespon permintaan, tanpa memperhatikan bagaimana atau mengapa model tersebut bekerja”.
Berdasarkan pengertian diatas maka penulis dapat menyimpulkan bahwa prediksi adalah sebuah teknik pemikiran untuk memperkirakan apa yang akan terjadi berdasarkan data masa lalu.
2.2.2 Pengertian Produk
‘Produk juga dapat didefinisikan sebagai atribut fisik, psikologi, dan simbolis yang bisa menghasilkan kepuasan maupun manfaat bagi konsumen’. (Keegan 2007:76 dalam Maria dan Anshori 2013:2).
(Supranto & Limakrisna 2011:125 dalam Zulaicha dan Irawati 2016:125), mengemukakan suatu produk ialah “apa saja yang dibutuhkan dan diinginkan seorang konsumen, untuk memenuhi kebutuhan yang dipersepsikan”.
Menurut Tengor, dkk (2016:369), “Produk adalah segala sesuatu yang dapat memenuhi dan memuaskan kebutuhan dan keinginan manusia, baik yang dapat diraba atau nyata maupun tidak dapat diraba atau jasa layanan”.
Dari Pengertian diatas maka dapat disimpulkan bahwa produk adalah segala sesuatu yang dapat memuaskan pemakainya.
2.2.3 Pengertian Modal Usaha
Sarwanti, dkk (2016), “Modal usaha adalah pengeluaran perusahaan untuk membeli barang-barang modal dan perlengkapan-perlengkapan produksi untuk menambah kemampuan memproduksi barang yang tersedia dalam perekonomian. Indikatornya adalah pembelanjaan pokok dan penunjang dinyatakan dengan satuan rupiah”.
‘Modal usaha merupakan kebutuhan utama bagi seorang pengusaha dalam menjalankan usaha baik pada saat memulai, pengembangan maupun pada saat penurunan usaha’. (Wulaningsih, 2005:14 dalam Feriansyah, dkk ,2015:29).
Saryawan, dkk (2015), “Modal adalah seluruh pengeluaran untuk membeli barang-barang modal (modal tetap dan modal variabel) yang terdiri atas: mesin-mesin, bangunan, kendaraan, (mobil dan sepeda motor), peralatan komunikasi dan informasi, peralatan non mesin, listrik, air, alat-alat tulis, dan keperluan kantor, suku cadang/pergantian peralatan, bahan baku”.
Jadi dapat disimpulkan bahwa modal usaha adalah pengeluaran baik berupa uang, benda, ataupun kemampuan yang dimiliki seseorang untuk menjalankan suatu kegiatan yang menghasilkan keuntungan.
2.2.4 Pengertian Algoritma
Ritayani (2013:72), “Algoritma adalah langkah-langkah yang disusun secara tertulis dan berurutan untuk menyelesaikan suatu masalah.”
Maulana, (2017:69), Algoritma adalah metode efektif yang diekspresikan sebagai rangkaian terbatas. Algoritma juga merupakan kumpulan perintah untuk menyelesaikan suatu masalah. Perintah-perintah ini dapat diterjemahkan secara bertahap dari awal hingga akhir. Masalah tersebut dapat berupa apa saja, dengan syarat untuk setiap permasalahan memiliki kriteria kondisi awal yang harus dipenuhi sebelum menjalankan sebuah algoritma
Vidyarsih, dkk (2016:8), “Algoritma merupakan langkah-langkah yang digunakan untuk menyelesaikan suatu permasalahan dengan pendekatan secara matematis”.
Dari pengertian diatas maka dapat disimpulkan bahwa algoritma adalah langkah-langkah berurutan guna menyelesaikan masalah.
2.3 Data Mining
2.3.1 Pengertian Data Mining
Azwanti (2018:34), “Data mining adalah suatu rangkaian proses, data mining dapat dibagi menjadi beberapa tahap. Tahap-tahap tersebut bersifat interaktif di mana pemakai terlibat langsung atau dengan perantaraan knowledge base”.
Harahab (2015:856), “Data mining adalah proses yang mengunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar”.
Faradillah (2013:64), “Data mining adalah suatu istilah yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan yang terkait dari berbagai database besar”. Berdasarkan pengertian data mining diatas maka dapat disimpulkan data mining adalah Tahapan proses yang bersifat interaktif untuk mengidentifikasi informasi dari database.
2.3.2 Tahap-Tahap Data Mining
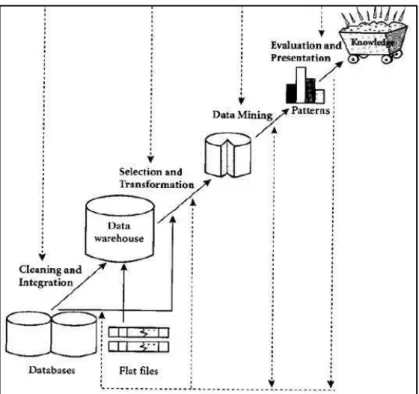
Istilah data mining memiliki hakikat sebagai disiplin ilmu yang tujuannya adalah untuk menemukan, menggali, atau menambang pengetahuan dari data atau informasi yang kita miliki. Data mining, sering juga disebut sebagai Knowledge Discovery in Database (KDD). Knowledge Discovery in Database KDD adalah kegiatan yang meliputi pengumpulan, pemakaian data, historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. Dan salah satu tahapan dalam keseluruhan proses Knowledge Discovery in Database KDD adalah data mining. Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi beberapa tahapan yang bersifat interaktif, pemakai terlibat langsung atau dengan perantaraan knowledge base. Adapun tahap-tahap data mining dapat dilihat pada gambar berikut :
Gambar 2.2 Tahapan Data Mining Sumber : Azwanti (2018).
Keterangan gambar :
1. Pembersihan data (data cleaning) pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan. 2. Integrasi data (data integration) integrasi data merupakan penggabungan data
dari berbagai database ke dalam satu database baru.
3. Seleksi data (data selection) data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database.
4. Transformasi data (data transformation) data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam data mining.
5. Proses mining merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data. Beberapa metode yang dapat digunakan berdasarkan pengelompokan data mining. 6. Evaluasi pola (pattern evaluation) Untuk mengidentifikasi pola-pola menarik
7. Presentasi pengetahuan (knowledge presentation) merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna.
2.3.3 Tugas-Tugas Data Mining
Tugas-tugas yang biasa dilakukan oleh data mining antara lain: 1. Klastering
Mengelompokkan obyek ke dalam beberapa kelompok berdasarkan kemiripan antar obyek, dimana dalam satu klaster harus berisi obyek yang saling mirip dan antar klaster obyek salin tidak mirip. Klastering ini tidak memerlukan data pelatihan yang sudah diberi label.
2. Klasifikasi
Klasifikasi data merupakan suatu proses yang menemukan properti-properti yang sama pada sebuah himpunan obyek di dalam sebuah basis data dan mengklasifikasikannya ke dalam kelas-kelas yang berbeda menurut model klasifikasi yang ditetapkan. Tujuan dari klasifikasi adalah untuk menemukan model dari training set yang membedakan atribut ke dalam kategori atau kelas yang sesuai, model tersebut kemudian digunakan untuk mengklasifikasikan atribut yang kelasnya belum diketahui sebelumnya. Beberapa metode klasifikasi umum digunakan dalam data mining adalah: pengklasifikasi pohon keputusan, pengklasifikasi Bayesian, pengklasifikasi k-nearest neighbour, penalaran berbasis kasus, algoritma genetika dan teknik logika fuzzy. (Azwanti, 2018:34).
3. Regresi
Regresi pada dasarnya mirip dengan klasifikasi, yakni memerlukan data pelatihan yang sudah diberi label. Bedanya, output klasifikasi adalah nilai diskrit, sedangkan output dari regresi adalah nilai kontinyu. Regresi ini mencari model hubungan antara atribut predictor dan atribut depedent, dimana atribut dependent nya juga berupa nilai kontinyu.
4. Asosiasi
Melakukan asosiasi antar obyek dalam suatu set data, biasanya data franksaksional. Asosiasi dilakukan dengan menghitung berapa kali dalam
suatu set data suatu transaksi yang mengandung dua item atau lebih yang berhubungan. Sering ada yang menyebut Market Basket.
2.3.4 Manfaat Data Mining
Data mining juga bisa dimanfaatkan untuk menyelesaikan masalah dalam kebutuhan dibidang bisnis, misalnya :
1. Mengetahui hilangnya pelanggan dikarenakan adanya pesaing.
2. Mengetahui item suatu produk yang memiliki kesamaan karakteristik. 3. Mengidentifikasi produk-produk yang sudah terjual dengan produk lainnya. 4. Untuk memprediksi dari tingkat penjualan.
5. Menilai tingkat resiko dalam menentukan jumlah produksi pada suatu item. 6. Memprediksi perilaku bisnis dimasa depan.
2.3.5 Jenis atau Teknik Data Mining
Teknik yang digunakan dalam data mining erat kaitanya dengan “penemuan” (discovery) dan “pembelajaran” (learning) yang terbagi dalam tiga metode utama pembelajaran yaitu :
1. Supervised Learning
adalah teknik yang paling banyak digunakan. Teknik ini sama dengan “programing by example”. Teknik ini melibatkan fase pelatihan dimana data pelatihan historis yang karakter – karakternya dipetakan ke hasil – hasil yang telah diketahui diolah dalam algoritma data mining. Proses ini melatih algoritma untuk mengenali variabel – variabel dan nilai – nilai kunci yang nantinya akan digunakan sebagai dasar dalam perkiraan – perkiraan ketika di berikan data baru.
2. Unsupervised Learning
Teknik pembelajaran ini tidak melibatkan fase pelatihan seperti yang terdapat pada supervised learning. Teknik ini bergantung pada penggunaan algoritma yang mendeteksi semua pola, seperti associations dan sequences, yang muncul dari kriteria penting yang spesifik dalam data masukan. Pendekatan ini mengarah pada pembuatan banyak aturan (rules) yang mengkarakterisasikan penemuan associations, clusters, dan segments. Aturan – aturan ini kemudian dianalisis untuk menemukan hal – hal penting.
3. Reinforcement Learning
Teknik pembelajaran ini jarang digunakan dibandingkan dengan dua teknik lainya, namun memiliki peranan – peranan yang terus dioptimalkan dari waktu ke waktu memiliki control adaptif. Teknik ini sangat menyerupai kehidupan nyata yaitu seperti “on – job training”, dimana seorang pekerja diberikan sekumpulan tugas yang membutuhkan keputusan – keputusan. Pada beberapa titik waktu kelak diberikan penilaian atas performace pekerja tersebut kemudian pekerja diminta mengevaluasi keputusan – keputusan yang telah dibuatnya sehubungan dengan hasil performace pekerja tersebut. Reinformace learning sangat tepat digunakan untuk menyelesaikan masalah – masalah yang sulit bergantung pada waktu.
2.4 Decision Tree
2.4.1 Pengertian Decision Tree
Azwanti (2018:34), Pohon keputusan menggunakan representasi struktur pohon (tree) di mana setiap node merepresentasikan atribut, cabangnya merepresentasikan nilai dari atribut dan daun merepresentasikan kelas. Node yang paling atas dari pohon keputusan disebut sebagai root. Salah satu keuntungan yang paling signifikan dari pohon keputusan adalah kenyataan bahwa pengetahuan dapat diekstrak dan direpresentasikan dalam bentuk klasifikasi aturan if-then. Pohon keputusan merupakan metode klasifikasi yang paling popular digunakan. Selain karena pembangunannya relatif cepat, hasil dari model yang dibangun mudah untuk dipahami. Pohon keputusan bekerja dengan membentuk pohon keputusan yang dapat disimpulkan aturan-aturan klasifikasi tertentu, salah satunya adalah C4.5.
Anggarwal (2015:293), “Decision trees are a classification methodology, wherein the classification process is modeled with the use of a set of hierarchical decisions on the feature variables, arranged in a tree-like structure.” Yang diartikan ke dalam bahasa indonesia sebagai berikut : “Pohon keputusan adalah metodologi klasifikasi, dimana proses klasifikasi dimodelkan dengan menggunakan satu set keputusan hirarkis pada variabel fitur, diatur dalam bentuk seperti pohon struktur.”
Barros, el al (2015:1), “decision tree is a classifier represented by a flowchart-like tree structure that has been widely used to represent classification models, specially due to its comprehensible nature that resembles the human reasoning”. Yang diartikan ke dalam bahasa indonesia sebagai berikut : “
pohon keputusan adalah penggolong yang diwakili oleh struktur pohon seperti alur alur yang memiliki telah banyak digunakan untuk merepresentasikan model klasifikasi, khususnya karena dapat dipahami alam yang menyerupai penalaran manusia”.
Gambar 2.3 Contoh Decision Tree
Sumber : Faradillah (2013:66).
Dari pengertian para pakar diatas maka dapat disimpulkan decision tree merupakan sebuah metode berdasarkan data set atau data training yang berisi aturan-aturan tertentu dan berbentuk seperti pohon untuk menyelesaikan permasalahan terkait. Beberapa model decision tree yang sudah dikembangkan antara lain :
A. CART (Classification And Regression Tree)
CART adalah singkatan dari classification and regression tree. Dalam CART, ada dua langkah penting yang harus diikuti untuk mendapatkan tree dengan
performansi yang optimal. Classification and Regression Tree (CART) dikembangkan oleh Breiman dkk (1993) merupakan metodologi statistika nonparametrik berdasarkan kaidah pohon keputusan, baik untuk peubah respon kategorik maupun kontinyu. Apabila variabel respon data berupa kontinyu maka akan diperoleh model pohon regresi, sedangkan apabila data variabel respon berskala kategorik maka akan diperoleh model pohon klasifikasi.
Adapun beberapa kelebihan metode klasifikasi pohon antara lain :
1. Metode ini bersifat nonparametrik sehingga tidak memerlukan asumsi-asumsi yang mengikat seperti asumsi distribusi normal untuk variabel prediktor. 2. Struktur data dapat dilihat secara visual sehingga memudahkan eksplorasi dan
pengambilan keputusan berdasarkan model yang diperoleh.
3. Tidak hanya memberikan klasifikasi, namun juga estimasi probabilitas kesalahan pengklasifikasian.
4. Mampu mengidentifikasi interaksi antar variabel prediktor yang berpengaruh secara lokal akibat diterapkannya pengambilan keputusan secara bertahap dalam himpunan-himpunan bagian data pengukuran yang kompleks.
5. Hasil klarifikasi akhir berbentuk sederhana dan mengklarifikasikan data baru secara efisien.
6. Kemudahan dalam interpretasi hasil.
Pembentukan pohon klasifikasi pada dasarnya hampir sama dengan pembentukan pohon regresi di mana simpul utama dipilah menjadi simpul anak kiri (left child node) dan simpul anak kanan (right child node), demikian seterusnya hingga didapatkan suatu simpul akhir (terminal node). Tujuan utama pembentukan pohon klasifikasi adalah menghasilkan pengklasifikasian yang akurat dan menentukan prediksi struktur data (Breiman dkk,1993). Pengklasifikasian dengan metode klasifikasi pohon terdiri dari empat komponen. Komponen pertama yaitu variabel respon yang berbentuk kategori, variabel ini akan diprediksi berdasarkan variabel prediktor. Komponen kedua yaitu variabel prediktor yang berskala kategori, kontinyu atau campuran. Komponen ketiga yaitu data learning yang terdiri dari variabel respon dan prediktor. Komponen ke empat yaitu data testing untuk keakuratan hasil prediksi. Santosa dan Umam (2018).
B. ID3 (Iterative Dichotomiser 3) Dan C4.5
ID3 adalah model decision tree yang lain, dalam ID3 kita gunakan kriteria information gain untuk memilih atribut yang akan digunakan untuk pemisahan proyek. Atribut yang mempunyai information gain paling tinggi dibandingkan dengan atribut lainnya dipilih untuk melakukan pemecahan. Sedangkan C4.5 merupakan pengembangan dari ID3, dengan perbaikan dilakukan dalam beberapa hal sebagai berikut :
Bisa mengatasi missing data. Bisa mengatasi data continue. Prining.
Aturan.
Mrnggunakan gain ratio sebagai kriteria pemecahan.
Algoritma C4.5 yaitu sebuah algoritma yang digunakan untuk membangun decision tree (pengambilan keputusan). Algoritma C.45 adalah salah satu algoritma induksi pohon keputusan yaitu ID3 (Iterative Dichotomiser 3). Untuk memilih atribut akar, didasarkan pada nilai gain tertinggi dari atribut-atribut yang ada.
Gambar 2.4 Tahapan Membangun Pohon Keputusan Sumber : Azwanti, 2018.
2.4.2 Entropy Dan Information Gain A. Entropy
Entropy digunakan dalam salah satu algoritma klasifikasi paling awal, disebut sebagai ID3. Entropi E (S) untuk set S dapat dihitung menurut Persamaan pada distribusi kelas p1. . . pk poin data pelatihan di node. Entropi ini akan
Pilih atribut sebagai akar
Buat cabang untuk tiap-tiap
nilai
Bagi kasus dalam cabang
Ulangi proses yang sama sampai memiliki kelas yang sama
digunakan untuk menentukan percabangan pohon keputusan. Misalnya ada data dengan atribut usia, pelajar, income, dan credit rating yang menentukan seseorang membeli barang. Pertama-tama dihitung entropi atribut-atribut itu untuk mencari information gained berdasarkan entropi itu, jadi logikanya makin rendah entropi-nya maka makin kuat atribut itu menjadi akar. Sementara itu, perhitungan nilai entrophy dapat dilihat pada persamaan berikut :
Gambar 2.5 Rumus Menghitung Entrophy Sumber : Azwanti, 2018.
Dimana :
S : Himpunan kasus A : Atribut
N : Jumlah partisi S
Pi : Proporsi dari Si terhadap S B. Information Gain
Information gain adalah salah satu atribute selection measure yang digunakan untuk memilih test atribute tiap node pada tree. Atribut dengan information gain tertinggi dipilih sebagai tes atribut dari suatu node. Untuk menghitung gain digunakan rumus seperti yang tertera dalam persamaan berikut :
Gambar 2.6 Rumus Menghitung Gain Sumber : Azwanti, (2018).
Dimana :
S : Himpunan kasus A : Atribut
N : Jumlah partisi kasus A
|Si| : Jumlah kasus pada partisi ke-i |S| : Jumlah kasus dalam S
2.5 Pemograman WEB 2.5.1 Pengertian WEB
“Definisi kata web adalah Web sebenarnya penyederhanaan dari sebuah istilah dalam dunia komputer yaitu WORLD WIDE WEB yang merupakan bagian dari tekhnologi Internet. World wide Web atau disingkat dengan nama www, merupakan sebuah sistem jaringan berbasis Client-Server yang mempergunakan protokol HTTP (Hyperteks Transfer Protocol) dan TCP/IP (Transmisson Control Protocol / Internet Protocol) sebagai medianya. Karena kedua sistem ini mempunyai hubungan yang sangat erat, maka untuk saat ini sulit untuk membedakan antara HTTP dengan WWW”. (Hastanti, dkk 2015:1-2)
2.5.2 HyperText Markup Language (HTML)
Menurut Harison dan Syarif (2016:43) “HTML adalah sebuah bahasa markup yang digunakan untuk membuat sebuah halaman web, menampilkan berbagai informasi di dalam sebuah Penjelajah web Internet dan formating hypertext sederhana yang ditulis kedalam berkas format ASCII agar dapat menghasilkan tampilan wujud yang terintegerasi. Dengan kata lain, berkas yang dibuat dalam perangkat lunak pengolah kata dan disimpan kedalam format ASCII normal sehingga menjadi home page dengan perintah-perintah HTML. Bermula dari sebuah bahasa yang sebelumnya banyak digunakan di dunia penerbitan dan percetakan yang disebut dengan SGML(Standard Generalized Markup Language), HTML adalah sebuah standar yang digunakan secara luas untuk menampilkan halaman web. HTML saat ini merupakan standar internet yang didefinisikan dan dikendalikan penggunaannya oleh World Wide Web Consortium(W3C). HTML dibuat oleh kolaborasi Caillau TIM dengan Berners-lee Robert tahun 1989”.
2.5.3 PHP (Hypertext Preprocesseor)
“PHP adalah sebuah bahasa pemograman yangberjalan dalam sebuah web-server. (PHP diciptakan oleh programmer unix dan Perl yang bernama Rasmus Lerdoft pada bulan Agustus-September1994. Script PHP adalah bahasa program yang berjalanpada sebuah web server, atau sering disebut server-side. Oleh karena itu, PHP dapat melakukan apa saja yang bisadilakukan program CGI lain, yaitu mengolah data dengan tipe apapun, menciptakan halaman web yang dinamis,serta menerima dan menciptakan cookies, dan bahkan PHP bisa melakukan lebih dari itu”. (Harison dan Syarif 2016:42).
2.5.4 CSS (Cascading Style Sheet)
Menurut Winarno dan Utomo (2010:106) dalam Prayitno dan Safitri (2015:2) menerangkan bahwa “CSS merupakan bahasa pemrograman web yang digunakan untuk mengatur style-style yang ada di tagtag HTML”.
Menurut Simarmata (2010:148) dalam Firmansyah dan Udi (2018:185) Mendefinisi-kan bahwa “PHP (Hypertext Preprocessor) adalah PHP mengijinkan pengembang untuk menempelkan kode didalam HTML dengan menggunakan bahasa yang sama seperti perl dan UNIX shells.”
2.6 Teknik Pengembangan Sistem A. UML (Unified Modelling Language)
Menurut Windu Gata, Grace (2013:4) dalam Hendini (2016:108), “Unified Modeling Language (UML) adalah bahasa spesifikasi standar yang dipergunakan untuk mendokumentasikan, menspesifikasikan dan membangun perangkat lunak. UML merupakan metodologi dalam mengembangkan sistem berorientasi objek dan juga merupakan alat untuk mendukung pengembangan sistem”.
Dengan menggunakan UML kita dapat membuat model untuk semua jenis aplikasi piranti lunak, dimana aplikasi tersebut dapat berjalan pada piranti keras, sistem operasi dan jaringan apapun, serta ditulis dalam bahasa pemrograman apapun. Tetapi karena UML juga menggunakan class dan operation dalam konsep dasarnya, maka ia lebih cocok untuk penulisan piranti lunak dalam bahasa-bahasa berorientasi objek seperti C++, Java, C# atau VB.NET.
B. Behavioral Diagram 1. Use Case Diagram
Use case diagram merupakan pemodelan untuk kelakuan (behavior) sistem informasi yang akan dibuat. Use case digunakan untuk mengetahui fungsi apa saja yang ada di dalam sistem informasi dan siapa saja yang berhak menggunakan fungsi-fungsi tersebut. Gambar dibawah ini adalah gambar notasi dari use case diagram :
Gambar 2.7 Notasi Use case diagram Sumber : Hendini (2016:108).
Berikut ini adalah Contoh Use Case Diagram :
Gambar 2.8 Contoh Use case diagram Sumber : Hendini (2016:108).
2. Class Diagram
Merupakan hubungan antar kelas dan penjelasan detail tiap-tiap kelas di dalam model desain dari suatu sistem, juga memperlihatkan aturan-aturan dan tanggung jawab entitas yang menentukan perilaku sistem. Class Diagram juga menunjukkan atribut-atribut dan operasi-operasi dari sebuah kelas dan constraint yang berhubungan dengan objek yang dikoneksikan. Gambar dibawah ini adalah gambar notasi dari class diagram :
Gambar 2.9 Notasi Class diagram Sumber : Hendini (2016:108).
Berikut ini adalah contoh dari Class Diagram :
Gambar 2.10 Contoh Class Diagram Sumber : Hendini (2016:108).
3. Sequence Diagram
Sequence Diagram menggambarkan kelakuan objek pada use case dengan mendeskripsikan waktu hidup objek dan pesan yang dikirimkan dan diterima antar objek. Simbol-simbol yang digunakan dalam Sequence Diagram yaitu:
Gambar 2.11 Notasi Sequence Diagram Sumber : Hendini (2016:108).
Contoh Squence Diagram :
Gambar 2.12 Contoh Sequence Diagram Sumber : Hendini (2016:108).
4. Activity Diagram
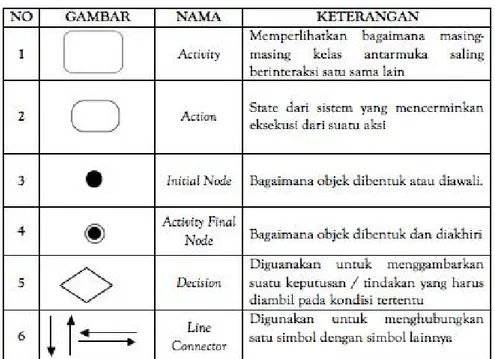
Activity Diagram menggambarkan workflow (aliran kerja) atau aktivitas dari sebuah sistem atau proses bisnis. Simbol-simbol yang digunakan dalam activity diagram yaitu :
Gambar 2.13 Notasi Activity Diagram Sumber : Hendini (2016:108).
Contoh Activity Diagram :
Gambar 2.14 Contoh Activity Diagram Sumber : Hendini (2016:108).
C. Modeling Tools StartUML
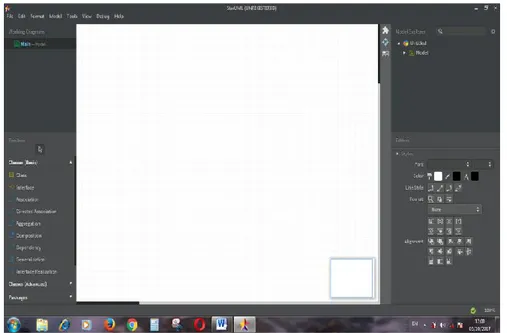
StarUML adalah software permodelan yang mendukung UML (Unified Modeling Language). Berdasarkan pada UML version 2.0 dan dilengkapi 14 macam diagram yang berbeda, mendukung notasi UML 2.0 dan juga mendukung
pendekatan MDA (Model Driven Architecture) dengan dukungan konsep UML. StarUML dapat memaksimalkan produktivitas dan kualitas dari suatu software project. (Triandini dan I Gede Suardika, 2012). Dibawah ini adalah tampilan halaman depan dari StarUML :
Gambar 2.15 Tampilan Utama StarUML Sumber : Data Primer, 2018
2.7 Rapid Miner
Rapid Miner merupakan perangkat lunak yang dibuat oleh Dr. Markus Hofmann dari Institute of Technologi Blanchardstown dan Ralf Klinkenberg dari rapid-i.com dengan tampilan GUI (Graphical User Interface) sehingga memudahkan pengguna dalam menggunakan perangkat lunak ini.
Perangkat lunak ini bersifat open source dan dibuat dengan menggunakan program Java di bawah lisensi GNU Public Licence dan Rapid Miner dapat dijalankan di sistem operasi manapun. Dengan menggunakan Rapid Miner, tidak dibutuhkan kemampuan koding khusus, karena semua fasilitas sudah disediakan. Rapid Miner dikhususkan untuk penggunaan data mining. Model yang disediakan juga cukup banyak dan lengkap, seperti Model Bayesian, Modelling, Tree Induction, Neural Network dan lain-lain.
Banyak metode yang disediakan oleh Rapid Miner mulai dari klasifikasi, klustering, asosiassi dan lain lain. Jika tidak ada model atau model algoritma yang
tidak ada dalam Weka, pengguna boleh menambahkan modul lain, karena weka bersifat open source, jadi siapapun dapat ikut mengembangkan perangkat lunak ini.
Gambar 2.16 Halaman Utama Rapid Miner Sumber : Data Primer, 2018.
2.8 Database
2.8.1 Pengertian Database
Basis data atau database merupakan kumpulan informasi yang disimpan dalam komputer secara sistematik sehingga dapat diperiksa menggunakan suatu program komputer untuk memperoleh informasi dari basis data tersebut. Sebuah basis data mempunyai penjelasan terstruktur dari jenis fakta yang tersimpan di dalamnya yang disebut sebagai skema basis data. Skema menggambarkan objek yang diwakili suatu basis data dan hubungan di antara objek tersebut. Model yang umum digunakan sekarang adalah model relasional yang mewakili semua informasi dalam bentuk tabel-tabel yang saling berhubungan dimana setiap tabel terdiri dari baris dan kolom. (Sumadya, dkk 2016:A552).
Basis data didefinisikan sebagai kumpulan data yang terintegrasi dan diatur sedemikian rupa sehingga data tersebut dapat dimanipulasi, diambil, dan dicari secara cepat. Selain berisi data, database juga berisi meta data. (Gat, 2015:305). 2.8.2 Database Management System (DBMS)
Sistem manajemen database atau database management system (DBMS) adalah merupakan suatu sistem software yang memungkinkan seorang user dapat
mendefinisikan, membuat, dan memelihara serta menyediakan akses terkontrol terhadap data. Database sendiri adalah sekumpulan data yang berhubungan dengan secara logika dan memiliki beberapa arti yang saling berpautan. Keuntungan dari Database Management System adalah:
1. Pengulangan Data Berkurang.
Pengulangan data atau repetisi berarti bahwa kolom data yang sama (misal: alamat seseorang) muncul berkali-kali dalam file yang berbeda dan terkadang dalam format yang berbeda. Dalam sistem pemrosesan yang lama, file - file yang berbeda akan mengulang data yang sama sehingga memboroskan ruang penyimpanan.
2. Intregitas Data Meningkat.
Integritas tidak akurat. dalam DBMS, berkurangnya pengulangan berarti meningkatkan kesempatan integritas data, karena semua perubahan hanya dilakukan di satu tempat.
3. Keamanan Data Meningkat.
Meskipun berbagai departemen bisa berbagi pakai data, Namun akses ke informasi bisa dibatasi hanya untuk pengguna tertentu. Hanya dengan menggunakan password maka informasi finansial, medis, dan nilai mahasiswa dalam database sebuah universitas tersedia hanya bagi mereka yang memiliki hak untuk mengetahuinya.
4. Kemudahan Pemeliharaan Data.
DBMS menawarkan prosedur standar untuk menambahkan, mengedit dan menghapus rekaman, juga untuk memvalidasi pemeriksaan untuk memastikan bahwa data yang tepat sudah dimasukkan dengan benar dan lengkap ke dalam masing – masing jenis kolom. (Prasetyo,dkk 2015:13).
2.8.3 MySQL
Mysql adalah salah satu jenis database server yang sangat terkenal. Kepopulerannya disebabkan MySQL menggunakan SQL sebagai bahasa dasar untuk mengakses database nya. MySQL bersifat free dengan lisensi GNU General Public License (GPL). Dengan adanya keadaan ini maka anda dapat meggunakan software ini dengan bebas tanpa perlu harus takut dengan lisensi yang ada. MySQL
termasuk jenis RDBMS (Relational Database Management System). Itulah sebabnya istilah table, baris, kolom digunakan pada MySQL. Pada MySQL sebuah database mengandung satu atau sejumlah table. (Prasetyo,dkk 2015:13).
MySQL adalah sebuah database manajemen system (DBMS) popular yang memiliki fungsi sebagai relational database manajemen system (RDBMS). Selain itu MySQL software merupakan suatu aplikasi yang sifatnya open source serta server basis data MySQL memiliki kinerja sangat cepat, reliable, dan mudah untuk digunakan serta bekerja dengan arsitektur client server atau embedded systems. Dikarenakan faktor open source dan popular tersebut maka cocok untuk mendemontrasikan proses replikasi basis data. (Yuliansyah, 2014:827).
MySQL adalah database server open source yang cukup popular keberadaannya. Dengan berbagai keunggulan yang dimiliki, membuat software database ini banyak digunakan oleh praktisi untuk membangun suatu project.Adanya fasilitas API (Application Programming Interface) yang dimiliki oleh MySQL, memungkinkan bermacam – macam aplikasi komputer yang ditulis dengan berbagai Bahasa pemrograman dapat mengakses basis data MySQL. (Wahana Komputer 2010:21, dalam Firman, dkk, 2016:30)
2.8 XAMPP
Menurut Palit, dkk, (2015:2-3), XAMPP adalah perangkat lunak bebas, yang mendukung banyak sistem operasi, merupakan kompilasi dari beberapa program. Fungsinya adalah sebagai server yang berdiri sendiri (localhost), yang terdiri atas program Apache HTTP Server, MySQL database, dan penerjemah bahasa yang ditulis dengan bahasa pemrograman PHP dan Perl. Nama XAMPP merupakan singkatan dari X (empat sistem operasi apapun), Apache, MySQL, PHP dan Perl. Program ini tersedia dalam GNU (General Public License) dan bebas, merupakan web server yang mudah digunakan yang dapat melayani tampilan halaman web yang dinamis. Untuk mendapatkanya dapat mendownload langsung dari web resminya.
Terdapat beberapa folder penting yang perlu diketahui. Untuk lebih memahami setiap fungsinya, terdapat beberapa penjelasan sebagai berikut :
1. apache adalah folder utama dari Apache Web Server.
2. htdocs adalah folder utama untuk menyimpan data-data latihan web, baik PHP maupun HTML biasa. Pada folder ini dapat membuat subfolder sendiri untuk mengelompokkan file latihannya. Semua folder dan file program di htdocs bisa diakses dengan mengetikkan alamat http://localhost/ di browser.
Gambar 2.17 Tampilan Utama XAMPP Sumber : Data Primer, 2018.
2.9 Kerangka Pemikiran
Kerangka pemikiran merupakan alur pikir penulis yang dijadikan sebagai skema pemikiran atau dasar-dasar pemikiran untuk memperkuat indikator yang melatar belakangi penelitian ini. Dalam kerangka pemikiran ini penulis mencoba menjelaskan masalah pokok penelitian.
Gambar 2.18 Tampilan Utama XAMPP Sumber : Data Primer, 2018.
2.10 Hipotesis
Hipotesis merupakan jawaban sementara dari pertanyaan penelitian, yang berfungsi untuk menentukan arah pembuktian yang harus dibuktikan pada proses penelitian. Pada hipotesis penelitian ini adalah, diduga bahwa penggunaan decision tree pada konsep data mining dapat menyelesaikan masalah pada prediksi produk terlaris untuk mengelola modal usaha JST Cell Cikarang menggunakan algoritma C4.5 dengan hasil akurasi yang optimal.
2.11 Waktu Penelitian
BAB III
METODE PENELITIAN
3.1 Metode Penelitian
Dilihat dari jenis informasi yang dikelola maka jenis penelitian ini terbagi menjadi :
1. Pendekatan Penelitian
Pada penelitian ini dibangun dengan pendekatan kuantitatif dimana pendekatan penelitian ini berbasis pola alur Kumpulkan teori, Hasilkan konsep, Rumuskan hipotesis, Uji hipotesis, dan Tarik Kesimpulan.
2. Jenis Penelitian
Dalam penelitian ini termasuk kedalam penelitian ekperimental karena merupakan penelitian yang bersifat uji coba, mempengaruhi hal-hal yang terkait dengan seluruh variabel atau atribut dan melibatkan pengembangan dan evaluasi.
Untuk melaksanakan dan menunjang keberhasilan penelitian yang akan dilakukan, penulis dalam mencari data atau informasi yang dibutuhkan dengan menggunakan pendekatan sebagi berikut :
1. Interview
Penulis bermaksud mendapatkan sumber data primer Yaitu prosedur pengumpulan data yang dilakukan dengan cara tanya jawab atau interview secara lisan maupun tulisan dengan pihak yang terkait, dalam hal ini yakni pemilik toko JST Cell.
2. Observasi
Penulis melakukan pengamatan secara langsung atau tinjauan langsung ke lapangan, serta melakukan pengamatan langsung terhadap objek permasalahan yang diteliti untuk memperoleh informasi yang lebih real.
3. Daftar Pustaka
Sumber data sekunder sebagai pelengkap data primer yaitu mengkaji, mengkutip, dan mempelajari berbagai jenis buku, jurnal, dan artikel dari
internet yang berhubungan dengan permasalahan yang diteliti, dimana teori-teori yang dipergunakan dijadikan sebagai referensi dalam penyusunan skripsi tersebut.
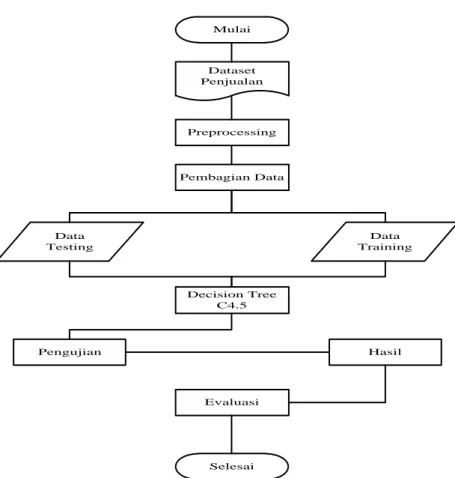
3.2 Analisis Data Knowledge Discovery in Database (KDD)
Dalam pengumpulan data terdapat sebanyak 121 data dan memiliki 5 atribut. Setelah data di dapatkan maka ada beberapa tahapan preparation data. Preparation data merupakan tahapan untuk mendapatkan data yang berkualitas dan mempermudah proses perhitungan data mining, maka dapat dilakukan beberapa teknik sebagai berikut :
A. Data Cleaning
Pada tahap ini dilakukan proses pembersihan data untuk memastikan data yang telah dipilih layak atau tidak dalam proses permodelan data mining. Dalam penelitian ini dilakukan pembersihan data dengan cara menghilangkan data yang tidak lengkap dan mengisi nilai-nilai yang hilang, data yang tidak lengkap (missing value).
Gambar 3.1 Statistik Data Tidak Lengkap Sumber : Data Primer , 2018.
Pada Gambar 3.1 tidak ditemukan adanya data yang tidak lengkap ataupun nilai yang hilang, maka proses cleaning tidak perlu dilakukan.
B. Data Selection
Berikut adalah tabel 3.1 yang merupakan tabel atribut yang akan digunakan dalam proses perhitungan decision tree C4.5.
Tabel 3.1 Atribut yang digunakan
No Atribut Tipe
1 Produk Text
2 Merek Text
3 Jenis Produk Text
4 Harga Currency
5 Terjual Numeric
Sumber : Data Primer, 2018. C. Data Transformation
Setelah data sudah dipilih maka dilakukan tahapan untuk melakukan transformasi terhadap atribut, transformasi akan dilakukan untuk memodifikasi sumber data ke format yang berbeda yang dapat diterima oleh proses data mining pada tahap selanjutnya. Transformasi nilai-nilai dari dari atribut juga perlu dilakukan sehingga dapat mengakibatkan proses pengenalan pola data dan pembentukan keputusan menjadi lama. Berikut ini adalah tranformasi yang dilakukan oleh penulis :
1. Klasifikasi Jenis Produk
Pada atribut jenis produk terdapat empat value yaitu aksesoris, regular, nominal, dan kuota. Untuk melakukan klasifikasi pada value nominal dan kuota dapat menggunakan rumus sturgess yaitu :
Klasifikasi kuota internet, jumlah kelas = 1 + 3.3 log 44 = 6,423393832 dibulatkan menjadi 6. Range = (50 – 1) / 6 = 8,166666667, dibulatkan menjadi 8.
Tabel 3.2 Klasifikasi Kuota internet Klasifikasi Kuota Internet
1 - 9 Kuota Sangat Kecil KSK
17,2 - 25,2 Kuota Sedang KS
25,3 - 33,3 Kuota Besar KB
33,4 - 41,4 Kuota Besar Sekali KBS
41,5 - 50 Kuota Sangat Besar Sekali KSBS
Klasifikasi nominal voucher pulsa jumlah kelas = 1 + 3.3 log 25 = 5,613202029 dibulatkan menjadi 6. Range = (100.000 – 5.000) / 6 = Rp15.833.
Tabel 3.3 Klasifikasi Nominal Pulsa
Nominal pulsa Klasifikasi
Rp5.000 - Rp20.833 Nominal Sangat Kecil NKS
Rp20.834 - Rp36.668 Nominal Kecil NK
Rp36.669 - Rp52.502 Nominal Sedang NS
Rp52.503 - Rp68.336 Nominal Besar NB
Rp68.337 - Rp84.171 Nominal Besar Sekali NBS
Rp84.172 - Rp100.000 Nominal Sangat Besar Sekali NSBS
Setelah klasifikasi kuota dan nominal telah di lakukan maka didapat klasifikasi jenis produk sebagai berikut :
Tabel 3.4 Klasifikasi Jenis Produk
Jenis Produk Klasifikasi
1 - 9 Kuota Sangat Kecil KSK
9,1 - 17,1 Kuota Kecil KK
17,2 - 25,2 Kuota Sedang KS
25,3 - 33,3 Kuota Besar KB
33,4 - 41,4 Kuota Besar Sekali KBS 41,5 - 50 Kuota Sangat Besar Sekali KSBS Rp5.000 - Rp20.833 Nominal Sangat Kecil NKS
Rp20.834 - Rp36.668 Nominal Kecil NK
Rp36.669 - Rp52.502 Nominal Sedang NS
Rp52.503 - Rp68.336 Nominal Besar NB
Rp68.337 - Rp84.171 Nominal Besar Sekali NBS Rp84.172 - Rp100.000 Nominal Sangat Besar Sekali NSBS
Aksesoris ACC
Gadget GGT