PROPOSAL PENELITIAN
DANA ITS TAHUN 2020
Pengembangan Metode Vector Support Machine
(SVM) untuk klasifikasi Data Multinomial
menggunakan preprocessing Reduksi Dimensi
Tim Peneliti :R Mohamad Atok, SSi, MSi, PhD (Departemen Aktuaria-FSAD) Imam Safawi Ahmad SSi, MSi (Departemen Aktuaria- FSAD)
LEMBAGA PENELITIAN DAN PENGABDIAN KEPADA MASYARAKAT
INSTITUT TEKNOLOGI SEPULUH NOPEMBER
2
Daftar Isi
BAB I RINGKASAN
7
BAB II PENDAHULUAN
7
A Rumusan Masalah
8
B Tujuan
9
C Manfaat Penelitian
9
BAB III TINJAUAN PUSTAKA
9
A Support Vector Machine
9
B Support Vector Machine pada Kasus Bisa dibagi secara linear
10
C Support Vector Machine pada Kasus tidak Bisa dibagi secara linear
13
D Kernels
15
E Evaluasi Performansi
17
BAB IV METODOLOGI
18
A Sumber Data
18
B Variabel
18
C Langkah Kajian
20
BAB V JADWAL
21
A Jadwal Penelitian
21
B Rencana Anggaran Belanja
22
BAB VI DAFTAR PUSTAKA
23
3
A Biodata Ketua Peneliti
24
B Biodata Anggota Peneliti
25
4
Daftar Tabel
Tabel 1 Confusion Matrix
17
Tabel 2 Variabel Penelitian
18
Tabel 3 Jadwal Penelitian
21
5
Daftar Gambar
Gambar 1 Peta Jalan Penelitian
8
Gambar 2 Ilustrasi two mapping dalam support vector machine
10
Gambar 3 Ilustrasi hyperplane yang mungkin pada suatu pengklasifikasian
10
Gambar 4 Ilustrasi hyperplane x^T w+b=0, margin untuk bisa dibagi secara
6
Daftar Lampiran
A Biodata Ketua Peneliti
24
B Biodata Anggota Peneliti
25
7
Pengembangan Metode Vector Support Machine (SVM) untuk klasifikasi
Data Multinomial menggunakan preprocessing Reduksi Dimensi
Studi kasus: Klasifikasi Data Pelanggan Listrik Rumah Tangga bersubsidi Kota Surabaya
BAB I. RINGKASAN
Klasifikasi data menggunakan SVM relatif lebih baik dibandingkan beberapa metode lain, baik klasik maupun yang menggunakan Machine Learning. Salah satu masalah dalam SVM adalah proses yang dilakukan sangat lama. Hal itu menyebabkan klasifikasi yang mensyaratkan kecepatan waktu kadang mengabaikan metode ini. Salah satu masalah adalah pada kasus multinomial yang biasa diselesaikan dengan cara one-versus-one (OVO) atau one-versus-all (VOA) semakin membuat SVM semakin memakan waktu. Usulan perbaikan dari segi reduksi dimensi menjadi salah satu pilihan untuk mengurangi waktu proses klasifikasi. Disisi lain masalah reduksi menggunakan metode unsupervised dan data non metrik menjadi kendala tersendiri. Kasus Pelanggan Listrik PLN segmen Rumah Tangga merupakan salah satu kasus menarik untuk klasifikasi multinomial.
Kata-kata kunci: Support Vector Machine (SVM), Klasifikasi, Multinomial
BAB II. PENDAHULUAN
Salah satu upaya pemerintah Indonesia dalam membantu penyediaan listrik yang merata yaitu dengan adanya pemberian bantuan subsidi listrik untuk masyarakat yang kurang mampu, sebagaimana yang telah diatur dalam Undang-Undang Nomor 30 Tahun 2007 yang membahas mengenai energi dan Undang-Undang Nomor 30 Tahun 2009 yang membahas tentang ketenagalistrikan. Menurut Kementrian Energi dan Sumber Daya Mineral (2017) ketentuan pemberian bantuan subsidi listrik kepada seluruh sektor rumah tangga dengan daya 450 VA dan 900 VA yang berupa penetapan tarif listrik yang lebih rendah berdasarkan status ekonomi sosial dalam rangka memenuhi kebutuhan penggunaan listrik bagi masyarakat yang kurang mampu atau tergolong miskin. Namun dalam pelaksanaannya, program pemberian bantuan subsidi listrik masih terdapat kendala yaitu berupa pemberian bantuan yang tidak tepat sasaran, khususnya pada sektor rumah tangga dengan daya 900 VA.
Menurut data Badan Pusat Statistik (2018) menyatakan bahwa persentase rumah tangga yang menggunakan listrik dari PLN sebagai sumber penerangan adalah sebesar 99,74 persen, sedangkan persentase penduduk miskin pada Maret 2018 mencapai 4,88 persen atau terdapat sebanyak 140,81 ribu penduduk miskin di kota Surabaya. Seperti yang sudah diketahui bahwa penduduk miskin berhak untuk menerima subsidi listrik sebagai bentuk bantuan pemerintah dalam meningkatkan kesejahteraan perekonomian, sehingga semakin tinggi persentase penduduk miskin maka akan semakin besar pula anggaran yang dibutuhkan.
Penelitian terkait dilakukan oleh Somantri, Sungkar, & Sasmito (2015) yaitu berupa perbandingan hasil klasifikasi menggunakan metode C.45, k-NN, Naïve Bayes (NB), dan Support Vector Machine (SVM) terhadap penanganan gangguan jaringan distribusi listrik 20 KV. Widiawati dan Atok (2017) membandingkan SVM dan Naïve Bayes Classifier untuk analisis pelanggan PLN segmen rumah tangga. Kedua penelitian menunjukkan bahwa SVM memberikan kinerja relatif lebih baik tetapi dengan catatan masalah waktu pemodelan yang sangat lama. Sedangkan Astuti, Purnami dan Atok (2019) menggunakan kombinasi SVM
8
dengan Estreme Learning Machine (ELM) dengan preprocessing Discrete Wavelett Transform (DWT) untuk optimalisasi pengenalan pola gelombang otak.
Metode SVM adalah salah satu metode dalam machine learning yang bisa melakukan prediksi secara baik untuk kasus klasifikasi dan regresi (Vapnik, 1998). Prinsip SVM diawali dengan klasifikasi linear yang selanjutnya dikembangkan dalam kasus non-linear dengan menggunakan konsep kernel trick pada ruang kerja berdimensi tinggi (Cortes dan Vapnik, 1995). Pada kasus klasifikasi biner, konsep kerja dari SVM yaitu mencari hyperplane optimum dengan meghasilkan nilai maksimum margin yang memisahkan antara dua kategori kelas (Karpagachelvi et al., 2012).
Pada kasus data non metrik biner, secara umum SVM lebih unggul dibandingkan beberapa metode lain. Sedangkan penggunaan data multinomial dengan lebih dari dua kelas diselesaikan menggunakan one-versus-one atau one-versus-all (rest). Penyelesaian ini mengakibatkan pembuatan variabel baru sebanyak kelas yang ada dalam variabel tersebut. Penambahan jumlah variabel yang diakibatkan oleh pemecahan variabel multinomial menjadi variabel bertipe biner menyebabkan kelambatan dalam pengklasifikasian. Penggunaan reduksi dimensi pada data multinomial dimungkinan untuk mempercepat konvergensi dengan menjaga kualitas atau cakupan informasi yang dikandung dalam data.
Gambar 1: Peta jalan penelitian
A. Rumusan Masalah
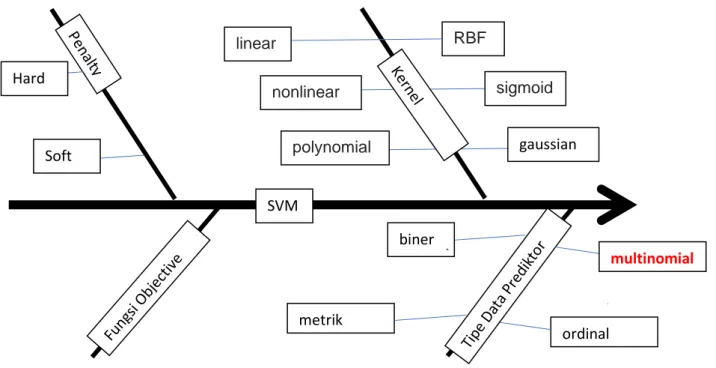
Berdasarkan tipe tujuan SVM dibagi dalam dua bagian, SVM dengan respon berskala pengukuran metrik (interval/rasio) yang sering disebut dengan SVM untuk Regresi atau Support Vector Regression (SVR) dan respon berskala pengukuran non metrik yang sering disebut SVM untuk klasifikasi atau SVM saja. Dari skala pengukuran predictor ada beberapa tipe yaitu biner (tidak memandang ordinal atau nominal), nominal lebih dari 2, ordinal lebih
SVM biner multinomial ordinal metrik Hard Soft linear radial basis funct ion ( RBF), and sigmo id nonlinear radial basis func tion (RBF ), and sigmoid polynomial RBF gaussian sigmoid
9
dari 2 dan metrik (interval/rasio). Dalam penelitian ini difokuskan pada tipe data multinomial untuk variabel prediktor.
B. Tujuan penelitian
1. Mencari teknik reduksi dimensi variabel predictor multinomial untuk preprocessing metode SVM, khususnya menggunakan teknik Principal Component Analysis (PCA) 2. Pembandingan Metode reduksi data multinomial dengan beberapa metode yang sudah
ada (OVO dan OVA) untuk ketepatan klasifikasi.
3. Penerapan SVM dengan reduksi dimensi prediktor pada data Pelanggan Listrik Rumah Tangga bersubsidi Kota Surabaya.
C. Manfaat Penelitian
Manfaat dari penelitian ini adalah pencarian metode paling efisien untuk klasifikasi multi class untuk data nominal dan implementasinya pada identifikasi kelas pelanggan listrik rumah tangga bersubsidi berdasarkan factor-faktor kemiskinan.
BAB III. TINJAUAN PUSTAKA
A. Support Vector Machine (SVM)
Support Vector Machine (SVM) pertama kali diperkenalkan oleh vapnik pada tahun 1960s sebagai metode klasifikasi dan sampai saat ini menjadi metode yang sering digunakan dalam penelitian karena perkembangannya dalam teknik dan teori ditambah dengan eksistensinya dalam regresi dan estimasi. SVM telah menjadi alternatif metode penyelesaian permasalahan klasifikasi dalam machine learning dan data mining. Metode statistika klasik akan menekan residual secara empirik. Berbeda dengan itu, SVM bertujuan meminimalkan batas error dengan memaksimalkan margin hyperplane untuk mengelompokkan suatu data (Purnami et al., 2009). Penerapan SVM telah diterapkan secara meluas di berbagai bidang antara lain text categorization, speech recognition, remote sensing image analysis, time series forecasting, information security (Deng et al.,2013).
SVM merupakan metode yang digunakan untuk mengelompokkan kasus linier dan nonlinier. Algoritma dari SVM bekerja meggunakan mapping nonlinier untuk mentransformasikan data training ke dimensi baru yang lebih tinggi. SVM akan mencari hyperplane yang optimal untuk memisahkan label kelas yang satu dengan yang lainnya (Han et al., 2012). SVM mencari hyperplane menggunakan support vector dan margins dijelaskan oleh support vector. Hyperplane merupakan garis pembatas antar kelas sementara margin merupakan jarak terpendek dari hyperplane dengan kedua sisi kelas (Han et al., 2012).
10
Pada dasarnya, SVM melakukan dua operasi matematika utama ketika memisahkan suatu kelas yaitu sebagai berikut (Haykin, 2009) :
1. Nonlinear mapping dengan ruang sampel ditransformasi ke ruang feature yang berdimensi tinggi yang disembunyikan dari input dan output.
2. Membentuk hyperplane untuk memisahkan titik-titik pada step pertama seperti pada gambar
Gambar Error! No text of specified style in document.. Ilustrasi two mapping dalam support vector machine. Sumber: Haykin. (2009)
B. Support Vector Machine pada Kasus Bisa dibagi secara linear
Misalkan suatu kasus terdiri dari dua kelas yang bisa dibagi secara linear, diberikan sebuah data set D dengan 𝑆 = {(𝒙1, 𝑦1), (𝒙2, 𝑦2), … , (𝒙𝑛, 𝑦𝑛)}, dimana 𝒙𝑖 himpunan data yang memiliki hubungan dengan 𝑦𝑖 (𝒙𝒊∈ 𝐑𝑛). Setiap 𝑦𝑖 dikategorikan +1 atau − 1 dengan kata
lain 𝑦𝑖 ∈ {+1, −1} dan (𝑦𝒊 ∈ 𝐑𝑛). Berikut adalah ilustrasi gambar dari dua kelas yang
berbeda yang dipisahkan oleh hyperplane.
Gambar 3 Ilustrasi hyperplane yang mungkin pada suatu pengklasifikasian Sumber: Han et al. (2012)
Berdasarkan Gambar 3 terlihat bahwa terdapat dua pilihan hyperplane yang bisa digunakan. Kedua bentuk hyperplane tersebut dapat menghasilkan nilai error yang berbeda, tetapi tidak ada garansi bahwa kedua bentuk hyperplane tersebut akan menunjukkan hasil yang
11
sama baiknya saat memisahkan data baru (Tan dkk., 2005). Formula untuk menghitung hyperplane dapat ditulisakan sebagai berikut (Han dkk., 2012).
𝒙𝑻𝒘 + 𝑏 = 0
Gambar 4 Ilustrasi hyperplane 𝑥𝑇𝑤 + 𝑏 = 0, margin untuk bisa dibagi secara linear (kiri) dan tidak bisa dibagi secara linear (kanan)
Sumber: Hardle et al. (2014)
𝒘 adalah vektor bobot (weight vector) dengan 𝒘 = [𝑤1, 𝑤2, … , 𝑤𝑛]; dimana 𝑛 adalah jumlah variabel dan 𝑏 adalah sebuah scalar yang sering disebut bias. Misalkan terdapat dua training data 𝒙𝑻= (𝑥
1, 𝑥2). Apabila 𝑏 atau bias dituliskan sebagai 𝑤0, maka formula yang
diperoleh adalah sebagai berikut.
𝑤0+ 𝑤1𝑥1+ 𝑤2𝑥2 = 0
Formula yang yang membatasi hyperplane pada batas atas adalah sebagai berikut. 𝑤0+ 𝑤1𝑥1+ 𝑤2𝑥2 > 0
Formula yang yang membatasi hyperplane pada batas bawah adalah sebagai berikut.
𝑤0+ 𝑤1𝑥1+ 𝑤2𝑥2 < 0 )
Fase training dari mtode SVM termasuk melakukan estimasi parameter 𝑏 dan 𝒘 dari data training. Parameter harus dipilih sedemikian mungkin sehingga dua kondisi berikut terpenuhi. Penentuan vektor pendukung membutuhkan margin yang maksimal, margin merupakan koridor diantara batas pemisah. Sehingga hyperplane yang menjelaskan kedua sisi dari margin dengan setiap observasi 𝑖 = 1,2, ⋯ , 𝑛 dapat dituliskan sebagai berikut.
𝑤0+ 𝑤1𝑥1+ 𝑤2𝑥2 ≥ 1 untuk 𝑦𝑖 = +1 1 𝑤0+ 𝑤1𝑥1+ 𝑤2𝑥2 ≤ 1 untuk 𝑦𝑖 = −1 2
Kondisi pada Gambar mengharuskan bahwa semua pengamatan yang dari kelas 𝑦𝑖 =
+1 pada Gambar harus berlokasi di atas hyperplane, sementara kelas 𝑦𝑖 = −1 pada Gambar harus berlokasi di bawah hyperplane.
12
Setiap training tuples yang berada diantara persamaan 1 dan persamaan 2 disebut support vector. Menentukan support vector dengan memilih nilai dari 𝒘 dan 𝑏 yang dapat membuat margin menjadi maksimal. Margin dilambangkan dengan 𝑑− dan 𝑑+, dengan (+)
dan (−) menandakan kedua daerah dipisahkan oleh hyperplane (Hardle dkk., 2014). ‖𝐰‖ merupakan panjang vektor dari w atau dapat didefinisikan ‖𝐰‖ = √𝐰𝑇𝒘 =
√𝑤12+ 𝑤
12+ ⋯ + 𝑤𝑝2. Nilai dari margin (d) dapat dihitung dengan mengurangi jarak tegak
lurus bidang pembatas kelas positif dari titik asal dengan jarak tegak lurus bidang pembatas kelas negatif dari titik asal. Sehingga bidang pemisah (separating hyperplane) optimum diperoleh dengan memaksimalkan persamaan 3, atau secara ekuivalen meminimalkan fungsi obyektif berikut.
𝑑 =(1 − 𝑏) − (−1 − 𝑏)
‖𝒘‖ =
2
‖𝒘‖ 3
Dari persamaan 3 dapat mengoptimumkan bidang pemisah (separating hyperplane) sama dengan meminimalkan norm euclidean dari vektor bobot 𝒘 (Haykin, 2009). Optimasi kuadratik untuk mencari hyperplane yang optimal dapat menggunakan fungsi lagrange multipliers, berikut adalah fungsi lagrange multipliers.
𝐿𝑝(𝒘, 𝑏) =1 2‖𝒘‖ 2− ∑ 𝜶 𝒊[𝒚𝑖(𝒙𝑖𝑇𝒘 + 𝑏) − 1] 𝑛 𝑖=1 4
dimana 𝛼𝑖 disebut Lagrange multipliers, solusi untuk masalah optimasi ditentukan oleh titik pelana dari fungsi Lagrange multipliers 𝐽(𝒘, 𝑏, 𝛼). Meminimalkan Langrangian dengan cara mencari turunan pertama dari fungsi lagrange multipliers terhadap 𝒘 dan 𝑏 (Hardle dkk., 2014). 𝜕𝐿𝑝(𝒘, 𝑏) 𝜕𝒘 = 0 𝒘 − ∑𝑛𝑖=1𝛼𝑖𝑦𝑖𝒙𝑖 = 0 sehingga diperoleh 𝒘 = ∑𝑛𝑖=1𝛼𝑖𝑦𝑖𝒙𝑖 5 𝜕𝐿𝑝(𝒘,𝑏) 𝜕𝑏 = 0 sehingga diperoleh ∑ 𝛼𝑖𝑦𝑖 𝑛 𝑖=1 = 0
Setelah mencari turunan pertama terhadap 𝒘 seperti pada persamaan 5Error! Reference source not found., kemudian persamaan tersebut disubstitusikan ke persamaan 4 untuk 𝒘 = ∑𝑛𝑖=1𝛼𝑖𝑦𝑖𝒙𝒊, hasilnya sebagai berikut.
1 2‖𝒘‖ 2 = 1 2∑ ∑ 𝛼𝑖 𝑛 𝑗=1 𝑛 𝑖=1 𝛼𝑗𝑦𝑖𝑦𝑗𝒙𝒊𝑻𝒙𝒋 ∑ 𝛼𝑖[𝑦𝑖(𝒙𝑖𝑇𝒘 + 𝑏) − 1] 𝑛 𝑖=1 =1 2∑ 𝛼𝑖𝑦𝑖𝒙𝒊 𝑻∑ 𝛼 𝑗𝑦𝑖𝒙𝑗 𝑛 𝑗=1 𝑛 𝑖=1 − ∑ 𝛼𝑖 𝑛 𝑗=1
13 = 1 2∑ 𝛼𝑖𝑦𝑖𝒙𝒊 𝑻∑ 𝛼 𝑗𝑦𝑖𝒙𝑗 𝑛 𝑗=1 𝑛 𝑖=1 − ∑ 𝛼𝑖 𝑛 𝑗=1
Sehingga diperoleh lagrangian untuk dual problem adalah sebagai berikut. max 𝛼 𝐿𝐷(𝜶) = ∑ 𝛼𝑖 𝑛 𝑗=1 −1 2∑ ∑ 𝛼𝑖 𝑛 𝑗=1 𝑛 𝑖=1 𝛼𝑗𝑦𝑖𝑦𝑗𝒙𝒊𝑻𝒙𝒋
Dengan 𝜶 vektor lagrange multiplier Setelah menyelesaikan dual problem, langkah berikutnya yaitu melakukan klasifikasi objek dengan menggunakan formula berikut:
𝑔̂(𝑥) = 𝑠𝑖𝑔𝑛(𝒙𝑇𝒘̂ + 𝑏̂) dengan 𝒘̂ = ∑𝑛𝑖=1𝛼̂𝑖𝑦𝑖𝒙𝒊
C. Support Vector Machine pada Kasus Tidak bisa dibagi secara linear
Sebelumnya sudah dibahas mengenai kasus yang memiliki pola bisa dibagi secara linear, maka pada sub bab ini akan dilanjutkan dengan membahas kasus yang lebih rumit yaitu pola tidak bisa dibagi secara linear. Pada dasarnya, SVM merupakan metode yang digunakan untuk menyelesaikan permasalahan bisa dibagi secara linear, namun seiring berjalannya waktu SVM dapat menyelesaikan kasus tidak bisa dibagi secara linear. Ilustrasi dari kasus tidak bisa dibagi secara linear ditunjukan pada Gambar 4 sebelumnya.
Pada kasus tidak bisa dibagi secara linear terdapat penambahan variabel slack yang dilambangkan dengan tanda "𝜉𝑖". Penambahan variabel slack untuk menunjukkan pinalti terhadap ketelitian pemisahan yang memungkinkan suatu titik berada dalam margin error 0 ≤ 𝜉𝑖 ≤ 1 (Hardle dkk., 2014). Selanjutnya formula yang didapat adalah sebagai berikut.
𝒙𝑇𝒘 + 𝑏 ≥ 1 − 𝜉
𝑖 for 𝑦𝑖 = 1
𝒙𝑇𝒘 + 𝑏 ≥ −(1 − 𝜉
𝑖) for 𝑦𝑖 = −1
𝜉𝑖 ≥ 0
Persamaan diatas dapat digabungkan menjadi fungsi constrain seperti berikut ini. 𝑦𝑖(𝒙𝑇𝒘 + 𝑏) ≥ 1 − 𝜉𝑖
𝜉𝑖 ≥ 0
Hukuman untuk kesalahan dalam pengelompokan yaitu berhubungan dengan jarak titik kesalahan klasifikasi 𝑥𝑖 dari batas hyperplane. Apabila 𝜉𝑖 ≥ 0, kemudian terjadi kesalahan dalam pemisahan kelas yang ada. Formula yang dapat digunakan untuk memaksimalkan margin adalah sebagai berikut (Hardle dkk., 2014).
min 𝒘,𝜉 1 2‖𝒘‖ 2+ 𝐶 ∑ 𝜉 𝑖 𝑛 𝑖=1
14
Fungsi lagrange yang digunakan untuk menyelesaikan permasalahan primal adalah sebagai berikut. Lp(𝒘, 𝑏, 𝝃) =1 2‖𝒘‖ 2+ 𝐶 ∑ 𝜉 𝑖 𝑛 𝑖=1 − ∑ 𝛼𝑖 𝑛 𝑖=1 {𝑦𝑖(𝒙𝑇𝒘 + 𝑏) − 1 + 𝜉 𝑖} − ∑ 𝜇𝑖𝜉𝑖 𝑛 𝑖=1
dimana 𝛼𝑖 ≥ 0 dan 𝜇𝑖 ≥ 0 adalah lagrange multipliers. Masalah primal dirumuskan dengan meminimumkan fungsi langrange dengan mencari turunan pertama terhadap 𝒘, 𝑏, dan 𝝃. Berikut adalah kondisi first-order:
𝜕𝐿𝑝(𝒘, 𝑏, 𝝃) 𝜕𝒘 = 0; 𝒘 − ∑ 𝛼𝑖𝑦𝑖𝒙𝒊 𝑛 𝑖=1 = 0 6 𝜕𝐿𝑝(𝒘, 𝑏, 𝝃) 𝜕𝑏 = 0; ∑ 𝛼𝑖𝑦𝑖 𝑛 𝑖=1 = 0 7 𝜕𝐿𝑝(𝒘, 𝑏, 𝝃) 𝜕𝜉𝑖 = 0; 𝐶 − 𝛼𝑖 − 𝜇𝑖 = 0 8
Berdasarkan persamaan 6, 7, dan 8 diperoleh fungsi constraints sebagai berikut: 𝛼𝑖 ≥ 0,
𝜇𝑖 ≥ 0,
𝛼𝑖{𝑦𝑖(𝒙𝑖𝑇𝒘 + 𝑏) − 1 + 𝜉
𝑖} = 0,
𝜇𝑖𝜉𝑖 = 0
Sama dengan kasus bisa dibagi secara linear, apabila diketahui bahwa ∑𝑛𝑖=1𝛼𝑖𝑦𝑖𝑏 = 0, maka
dari permasalahan primal dibawa kedalam penyelesaian permasalahan dual maka akan diperoleh penyelesaian sebagai berikut (Hardle dkk., 2014).
𝐿𝐷(𝜶) = 1 2∑ ∑ 𝛼𝑖𝛼𝑗𝑦𝑖𝑦𝑗𝒙𝑖 𝑇𝒙 𝑗− 𝑛 𝑗=1 𝑛 𝑖=1 ∑ 𝛼𝑖𝑦𝑖𝒙𝑖𝑇 𝑛 𝑖=1 ∑ 𝛼𝑗𝑦𝑗𝒙𝑗𝑇 𝑛 𝑗=1 + 𝐶 ∑ 𝜉𝑖 𝑛 𝑖=1 + ∑ 𝛼𝑖 𝑛 𝑖=1 − ∑ 𝛼𝑖 𝑛 𝑖=1 𝜉𝑖− ∑ 𝜇𝑖 𝑛 𝑖=1 𝜉𝑖 = ∑ 𝛼𝑖 𝑛 𝑖=1 −1 2∑ ∑ 𝛼𝑖𝛼𝑗𝑦𝑖𝑦𝑗𝒙𝑖 𝑇𝒙 𝑗 𝑛 𝑗=1 𝑛 𝑖=1 + ∑ 𝜉𝑖 𝑛 𝑖=1 (𝐶 − 𝛼𝑖 − 𝜇𝑖) ⏟ 0 max 𝛼 𝐿𝐷(𝜶) = ∑ 𝛼𝑖 𝑛 𝑖=1 −1 2∑ ∑ 𝛼𝑖𝛼𝑗𝑦𝑖𝑦𝑗𝒙𝑖 𝑇𝒙 𝑗 𝑛 𝑗=1 𝑛 𝑖=1
15
dimana fungsi constrain untuk permasalahan dual yaitu 0 ≤ 𝛼𝑖 ≤ 𝐶 dan ∑ 𝛼𝑛1 𝑖𝑦𝑖 = 0. Persamaan dual dapat diselesaikan dengan menggunakan quadratic programming secara numerik untuk mencari nilai dari 𝛼𝑖. Pengamatan 𝑥𝑖 untuk 𝛼𝑖 > 0 merupakan suatu titik (support vector) yang berada diatas atau didalam margin ketika soft margin digunakan (Scholkopf, 2002).
D. Kernels
Klasifikasi linier tidak cocok digunakan untuk beberapa permasalahan klasifikasi, sehingga perlu dilakukan transformasi terhadap data yang ada. Transformasi linearly separation ke nonlinearly separation dilambangkan dengan simbol Φ, melakukan transfomasi dari n-dimensi pada vektor 𝑥 ke m dimensi vektor 𝑧 pada ruang Euclidean 𝑅𝑚, dapat di ilustrasikan seperti berikut ini.
Φ: { 𝑅
𝑛 → ℋ
𝒙 = ([𝑥]1, . . , [𝑥]𝑛)𝑇 → 𝒛 = (𝑧
1, 𝑧2, … )T = Φ(𝑥) 9
dimana data training awal dan training setelah dilakukan transfomasi diberikan seperti persamaan berikut.
Training awal: T = {(𝑥1, 𝑦1), … , (𝑥𝑛, 𝑦𝑛)}
Training setelah transformasi: TΦ = {(𝑧1, y1), … , (𝑧𝑛, y𝑛)}
dimana 𝑥𝑖 ∈ 𝑅𝑛, 𝑦𝑖 ∈ 𝑌 = {+1, −1}, 𝑖 = 1,2, … , 𝑛. Algoritma dari proses klasifikasi SVM untuk kasus nonlinear separation adalah sebagai berikut.
1) Masukkan data training dengan T = {(𝑥1, 𝑦1), … , (𝑥𝑛, 𝑦𝑛)}, dimana 𝑥𝑖 ∈ 𝑅𝑛, 𝑦𝑖 ∈ 𝑌 =
{+1, −1}, 𝑖 = 1,2, … , 𝑛.
2) Memilih sebuah map yang tepat Φ: 𝒙 = Φ(𝒙) dari space 𝑅𝑛 ke dalam Hilbert space dan parameter penalty 𝐶 > 0.
3) Menyusun dan menyelesaikan permasalahan convex quadratic programming dengan menggunakan persamaan berikut.
min 𝜶 1 2∑ ∑ 𝛼𝑖𝛼𝑗𝑦𝑖𝑦𝑗(Φ(𝒙𝒊). Φ(𝒙𝒋)) − ∑ 𝛼𝑗 𝑛 𝑗=1 𝑛 𝑗=1 𝑛 𝑖=1 ∑ 𝛼𝑖𝑦𝑖 = 0 𝑛 𝑖=1 0 ≤ 𝛼𝑖 ≤ 𝐶, 𝑖 = 1,2, ⋯ , 𝑛
16 dengan 𝛼∗ = (𝛼
1∗, ⋯ , 𝛼𝑛∗)𝑇
4) Menghitung nilai 𝑏∗: memilih komponen 𝛼∗, 𝛼𝑗∗ ∈ (0, 𝐶) 𝑏∗ = ∑ 𝑦𝑖 𝑛 𝑖=1 − ∑ 𝑦𝑖𝛼𝑖∗ 𝑛 𝑖=1 (Φ(𝒙𝒊). Φ(𝒙𝒋)) ;
5) Menyusun fungsi keputuasn dengan menggunakan persaman berikut 𝑓(𝒙) = 𝑠𝑖𝑔𝑛(𝑔(𝒙))
𝑔(𝒙) = ∑ 𝑦𝑖𝛼𝑖∗
𝑛
𝑖=1
(Φ(𝒙𝒊) ∙ Φ(𝒙𝒋)) + 𝑏∗.
Pada kasus nonlinear, membutuhkan sebuah kernel yang berbeda untuk membentuk suatu hyperplane. Fungsi kernel didefinisikan sebagai 𝑅𝑛× 𝑅𝑛 yang dipanggil dengan kernel
𝑅𝑛× 𝑅𝑛 seperti pada persamaan 9. Berikut adalah fungsi dasar kernel (Deng dkk., 2013).
𝐾(𝒙, 𝒙′) = (Φ(𝒙) ∙ Φ(𝒙′)) (2.1)
dimana (∙) merupakan inner product dari Hilbert space, untuk setiap 𝑥𝑖, ⋯ , 𝑥𝑛 ∈ 𝑅𝑛,
berdasarkan gram matrix (𝐾(𝒙𝒊, 𝒙𝒋))
𝑛×𝑛 untuk 𝐾(𝒙, 𝒙
′) = 𝑓(𝒙)𝑓(𝒙′), dengan 𝑓(∙) fungsi real
pada 𝑅𝑛. Setiap vektor 𝛼 = (𝛼
1, ⋯ , 𝛼𝑙)𝑇𝜖𝑅𝑛, dari uraian tersebut fungsi kernel yang didapat
adalah sebagai berikut (Deng dkk., 2013).
𝜶𝑇(𝐾(𝒙, 𝒙′))𝑛×𝑛𝜶 = ∑ ∑ 𝛼𝑖𝛼𝑗𝐾(𝒙𝒊, 𝒙𝒋) 𝑛 𝑗=1 𝑛 𝑖=1 = ∑ ∑ 𝛼𝑖𝛼𝑗𝑓(𝒙𝒊)𝑓(𝒙𝒋) 𝑛 𝑗=1 𝑛 𝑖=1 = ∑ 𝛼𝑖𝑓(𝒙𝒊) ∑ 𝛼𝑗𝑓(𝒙𝒋) 𝑛 𝑗=1 𝑛 𝑖=1 = (∑ 𝛼𝑖𝑓(𝒙𝒊) 𝑛 𝑖=1 ) 2 ≥ 0.
Matrik gram merupakan matrik positive semidefinite, oleh karena itu 𝐾(𝒙, 𝒙′) adalah kernel. Terutama berlaku untuk 𝑓(𝒙) = √𝜶.
Berikut adalah beberapa fungsi kernel yang sering digunakan (Deng dkk., 2013; Scholkopf, 2002).
1) Kernel Linier
𝐾(𝒙, 𝒙′) = 𝒙′𝒙
17 𝐾(𝒙, 𝒙′) = (𝒙′𝒙 + 1)𝑑
3) Kernel Gaussian Radial Basis Function 𝐾(𝒙, 𝒙′) = 𝑒𝑥𝑝 (−‖𝒙 − 𝒙
′‖2
2𝜎2 )
E. Evaluasi Performasi
Evaluasi performa dari suatu metode dalam menyelesaikan suatu kasus harus dilakukan untuk melihat seberapa besar kemampuan dari metode tersebut dalam menyelesaikan permasalahan yang ada.
Tabel 1 Confusion matrix
Predicted Positive Predicted Negative
Actual Positive TP FN
Actual Negative FP TN
Sumber: Han et al. (2012) Keterangan:
TP : True Positive (jumlah prediksi benar pada kelas positif) TN : True Negative (jumlah prediksi benar pada kelas negatif) FP : False Positive (jumlah prediksi salah pada kelas positif) FN : False Negative (jumlah prediksi salah pada kelas negatif)
Tabel diatas merupakan tabel confusion matrix, confusion matrix merupakan suatau alat untuk melakukan analisa seberapa baik metode klasifikasi dalam mengenali tuples dalam kelas yang berbeda (Han dkk., 2012). Beberapa metode yang sering digunakan yaitu akurasi, sensitivitas, spesifisitas, dan Area Under the Curve (AUC).
Akurasi merupakan suatu alat yang digunakan untuk menghitung ketepatan klasifikasi. Sensitivitas merupakan ukuran performansi kelas positif, sedangkan spesifitas merupakan ukuran performansi kelas negatif. Berikut adalah beberapa rumus yang digunakan untuk menghitug akurasi, sensitivitas, spesifisitas, dan Area Under the Curve (Han dkk., 2012; Sokolova dkk., 2006).
Akurasi = 𝑇𝑃 + 𝑇𝑁
𝑇𝑃 + 𝐹𝑃 + 𝐹𝑁 + 𝑇𝑁 (2.2)
Sensitivitas = 𝑇𝑃
18 Spesifisitas = 𝑇𝑁
𝑇𝑁 + 𝐹𝑃 (2.4)
𝐴𝑈𝐶 =1
2(Sensitivitas + Spesitifitas) (2.5)
BAB IV. METODOLOGI
A. Sumber Data
Pada penelitian ini data yang digunakan adalah data sekunder yang diperoleh dari PT. PLN (Persero) Distribusi Jawa Timur yaitu berupa data pelanggan rumah tangga dengan daya listrik 900 VA yang menerima subsidi listrik di Kota Surabaya sebanyak 27.555 pelanggan, dan data yang rumah tangga miskin dengan penggunaan daya listrik 900 VA menurut BAPPEKO yaitu sebanyak 70.195 rumah tangga.
B. Variabel Penelitian
Variabel penelitian yang digunakan pada penelitian ini ditampilkan pada Tabel 1. Tabel 2. Variabel Penelitian
Variabel Nama variabel Keterangan Jenis
data Y Status pelanggan listrik rumah
tangga miskin daya 900 VA
1. Tidak menerima subsidi
2. Penerima subsidi Nominal
X1 Status kepemilikan bangunan tempat
tinggal 1. Milik sendiri 2. Kontrak/sewa 3. Bebas sewa/dinas Lainnya Nominal
X2 Status kepemilikan lahan tempat
tinggal
1. Milik sendiri 2. Milik orang lain 3. Milik negara 4. Lainnya
Nominal
X3 Luas lantai Luas lantai rumah dalam
satuan m2 Rasio
X4 Jenis lantai terluas
1. Tanah 2. Semen/bata merah 3. Ubin/tegel 4. Keramik 5. Marmer/granit 6. Lainnya Nominal
X5 Jenis dinding terluas
1. Bambu 2. Kayu 3. Tembok 4. Lainnya
Nominal
19
2. Asbes
3. Genteng tanah liat 4. Genteng metal 5. Genteng keramik 6. Genteng beton 7. Lainnya
X7 Jumlah kamar tidur Jumlah kamar tidur yang
dimiliki Rasio
X8 Sumber air minum
1. Sumur terlindung 2. Sumur bor/pompa 3. Leding eceran 4. Leding meteran 5. Air isi ulang
6. Air kemasan bermerk 7. Lainnya
Nominal
X9 Kualitas atap terluas 1. Kualitas rendah
2. Kualitas tinggi Ordinal X10 Cara memperoleh air minum
1. Tidak membeli 2. Membeli eceran 3. Langganan
Nominal
X11 Penggunaan fasilitas buang tinja
1. Tidak ada 2. Bersama 3. Umum 4. Pribadi
Nominal
X12 Bahan bakar memasak
1. Kayu bakar 2. Minyak tanah 3. Gas kota/biogas 4. Gas 3 kg 5. Gas >3 kg 5. Listrik Nominal X13 Kepemilikan lahan 1. Ya 6. Tidak Nominal
X14 Kepemilikan pemanas air (water
heater)
1. Ya
2. Tidak Nominal
X15 Kepemilikan sambungan telepon 1. Ya
20
Tabel 2.. Variabel Penelitian (Lanjutan)
Variabel Nama variabel 1. Keterangan Jenis
data X16 Kepemilikan lemari es 2. Ya 2. Tidak Nominal X17 Kepemilikan televisi 1. Ya 3. Tidak Nominal X18 Kepemilikan komputer/laptop 1. Ya 2. Tidak Nominal X19 Kepemilikan AC 1. Ya 2. Tidak Nominal
X20 Kepemilikan sepeda motor 1. Ya
2. Tidak Nominal
X21 Peserta program raskin 1. Tidak
2. Ya Ordinal
X22 Peserta PKH (Program
Keluarga Harapan)
1. Tidak
2. Ya Ordinal
X24 Kepemilikan Kartu Indonesia
Pintar
1. Tidak
2. Ya Ordinal
X25 Kepemilikan emas 10 gr 1. Ya
2. Tidak Ordinal
X26 Jumlah anggota keluarga 2. Jumlah anggota keluarga Rasio
X27 Status kesejahteraan (desil)
1. Kondisi kesejahteraan 10% terendah 2. Kondisi kesejahteraan 11% hingga 20% terendah 3. Kondisi kesejahteraan 21% hingga 30% terendah 3. Kondisi kesejahteraan 31% hingga 40% terendah Ordinal C. Langkah Kajian
1. Preprocessing data menggunakan reduksi dimensi
2. Eksplorasi data variabel tingkat status kesejahteraan rumah tangga miskin di Surabaya 3. Melakukan pemetaan persebaran penerima subsidi listrik di Surabaya.
4. Tahapan dalam Menyusun Algoritma SVM sebagai berikut: 1) Menentukan jumlah hidden neuron dan nilai constraint (C).
2) Menentukan fungsi aktivasi, misalkan menggunakan Gaussian sehingga diperoleh 𝑔(𝑥) = exp(−𝑥2), persamaan untuk 𝑔(𝑥).
3) Membangkitkan hidden node (vektor pembobot input) secara random dengan menggunakan fungsi aktivasi.
21 5) Membangkitkan nilai Eϕ.
6) Menghitung nilai output. 7) Melakukan klasifikasi data.
8) Menghitung nilai akurasi, sensitivitas, spesifisitas dan AUC.
9) Mengulangi (1) sampai (8) sampai memperoleh nilai yang optimum.
BAB V. JADWAL DAN RANCANGAN ANGGARAN BIAYA
A. Jadwal Penelitian
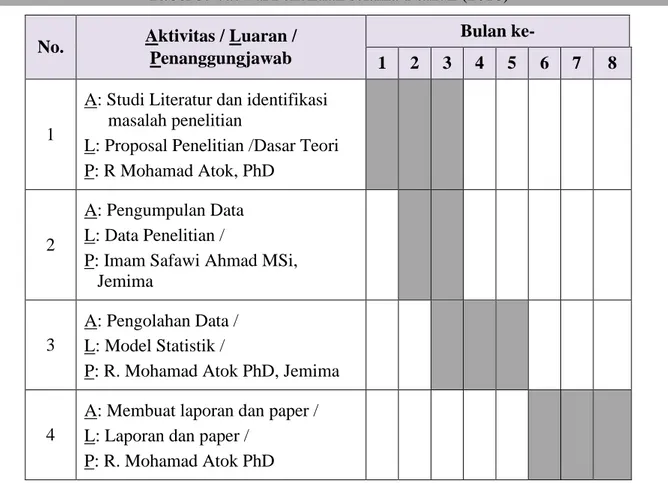
Rencana penelitian akan dilakukan di Laboratorium Statistika Ekonomi, Finansial dan Aktuaria, Jurusan Statistika selama delapan bulan (April-November 2020). Jadwal rencana kegiatan penelitian, luaran dan penanggungjawab selengkapnya disajikan pada Tabel 3.
Tabel 3. Jadwal Penelitian selama 1 tahun (2018)
No. Aktivitas / Luaran / Penanggungjawab
Bulan ke-
1 2 3 4 5 6 7 8
1
A: Studi Literatur dan identifikasi masalah penelitian
L: Proposal Penelitian /Dasar Teori P: R Mohamad Atok, PhD
2
A: Pengumpulan Data L: Data Penelitian /
P: Imam Safawi Ahmad MSi, Jemima
3
A: Pengolahan Data / L: Model Statistik /
P: R. Mohamad Atok PhD, Jemima
4
A: Membuat laporan dan paper / L: Laporan dan paper /
22
B. Rencana Anggaran Biaya
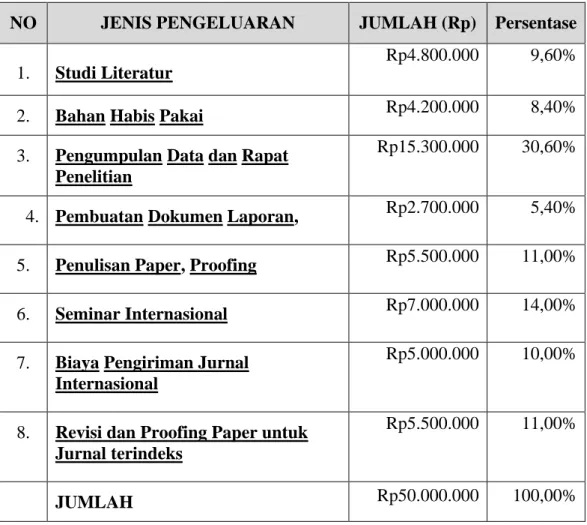
Daftar anggaran biaya untuk pelaksanaan penelitian selama satu (1) tahun disajikan pada Tabel 4
Tabel 4. Anggaran biaya untuk 1 tahun pelaksanaan penelitian
NO JENIS PENGELUARAN JUMLAH (Rp) Persentase
1. Studi Literatur
Rp4.800.000 9,60%
2. Bahan Habis Pakai Rp4.200.000 8,40%
3. Pengumpulan Data dan Rapat Penelitian
Rp15.300.000 30,60%
4. Pembuatan Dokumen Laporan, Rp2.700.000 5,40% 5. Penulisan Paper, Proofing Rp5.500.000 11,00%
6. Seminar Internasional Rp7.000.000 14,00%
7. Biaya Pengiriman Jurnal Internasional
Rp5.000.000 10,00%
8. Revisi dan Proofing Paper untuk Jurnal terindeks
Rp5.500.000 11,00%
23
BAB VI. RUJUKAN
Astuti, B.S.F, Purnami, S.W., dan Atok, R.M., Classify Epileptic EEG Signals using Extreme Support Vector Machine for Ictal and Muscle Artifact Detection, Proceeding of International Conference on Imaging, Signal Processing and Communication, Singapore, 2019.
Badan Pusat Statistik (BPS), "Berita Resmi Statistik : Profil Kemiskinan di Kota Surabaya Tahun 2018," BPS Kota Surabaya, Surabaya, 2018.
Cortes, C. dan Vapnik, V. (1995), ""Support Vector Networks"", Machine Learning, Vol. 20, No. 3, pp. 273-297.
Han, J., Kamber, M. dan Pei, J. (2012), Data Mining : Concepts and Technique 3rd edition, Morgan Kaufman, USA.
Hardle, W.K., Prastyo, D.D. dan Hafner, C.M. (2014), ""Support Vector Machines with Evolutionary Feature Selection for Default Pradiction"",dalam The Oxford Handbook of Aplpied Nonparametric and Semiparametric Econometrics and Statistics, J. Racine, A.S.d.A.U. , Oxford University Press, pp. 346-373.
Haykin, S. (2009), Neural Networks and Learning Machines, Perarson Education, Inc., Upper Saddle River, New Jersey.
Karpagachelvi, S., Arthanari, M. dan Sivakumar, M. (2012), "Classification of Electrocardiogram Signals with Support Vector Machines and Extreme Learning Machine", Neural Comput & Applic, Vol. 21, pp. 1331-1339.
Kementrian Energi dan Sumber Daya Mineral, “Kebijakan Subsidi Listrik Tepat Sasaran Rumah Tangga Daya 900 VA”, Direktorat Jendral Ketenagalistrikan, Jakarta, 2017.
Larose, D.T., Discovering Knowledge in Data : An Introduction to Data Mining, New York: John Willey & Sons Inc, 2005.
Purnami, S.W., Embong, A., Zain, J.M. dan Rahayu, S.P. (2009), "A New Smooth Support Vector Machine and Its Applications in Diabetes Disease Diagnosis", Journal of Computer Science 5, Vol. 5, No. 12, pp. 1003-1008.
Scholkopf, B..d.S.A.J. (2002), "Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond, MIT Press, Massachusetts.
Sokolova, M., Japkowicz, N. dan Szpakowicz, S. (2006), "Beyond Accuracy, F-score and ROC: a Family of Discriminant Measures for Performance Evaluation", American Association for Artificial Intelligence.
Somantri, O., M. S. Sungkar dan G. W. Sasmito, "Neural Network Untuk Klasifikasi
Penanganan Gangguan Jaringan Distribusi Listrik 20 KV," Konferensi Nasional Informatika (KNIF) , Bandung, 2015.
Tan, P.-N., Steinbach, M. dan Kumar, V. (2005), Introduction to Data Mining, Person, Boston. Widiawati, W.Y., dan, Atok, R.M., Analisis Klasifikasi Pelanggan Listrik Rumah Tangga bersubsidi Surabaya Menggunakan SVM dan Naïve Bayes, 2017
24
BAB VII. LAMPIRAN
C. Biodata Ketua Tim Peneliti
1. Nama Lengkap : R. Mohamad Atok, M.Si., Ph.D
2. NIP : 197109151997021001
3. Fungsional/Pangkat/Gol. : Lektor / Penata / IIIc
4. Bidang Keahlian : Analisis data, time series, komputasi statistika, penyelesaian data outlier, neural network 5. Departemen/Fakultas : Aktuaria/Sains dan Analitika Data
6. Alamat Rumah & No. Telp. : Perumahan Dosen ITS T27, Jl Hidrodinamika II, Keputih, Sukolilo, Surabaya. Telp: 081331551312 7. Pengalaman Penelitian :
a. Kajian Metode Pengelompokan Big Data Berbasis Model untuk penentuan Subsidi dengan implementasi Konsumen Listrik se Surabaya, 2018 (Ketua)
b. Pengelompokan Penduduk Miskin Surabaya berdasar Profil sosial ekonomi, 2019 (Ketua)
8. Publikasi
a. Classify Epileptic EEG Signals using Extreme Support Vector Machine for Ictal and Muscle Artifact Detection
9. Tugas Akhir Bimbingan
a. Analisis Klasifikasi Pelanggan Listrik Rumah Tangga bersubsidi Surabaya Menggunakan SVM dan Naïve Bayes (Widiawati)
b. Analisis Pemilihan Model Klasifikasi Pelanggan Listrik Rumah Tangga Penerima Subsidi di Kota Surabaya Menggunakan Metode CART, Naïve Bayes, dan Regresi Logistik (Lestari)
10. Tesis Bimbingan
a. Extreme Support Vector Machine untuk Deteksi Artifact pada Perekaman Sinyal EEG Penderita Epilepsi (Astuti)
Demikian biodata ini saya buat dengan sebenarnya untuk memenuhi persyaratan sebagai salah satu syarat pengajuan hibah penelitian.
Surabaya, 07 Maret 2020 Ketua Peneliti,
(R. Mohamad Atok, M.Si., Ph.D) NIP. 197109151997021001
25
D. Biodata Anggota Tim Peneliti
1. Nama Lengkap : Imam Safawi Ahmad, S.Si., M.Si
2. NIP : 198102242014041001
3. Fungsional/Pangkat/Gol. : Asisten Ahli/Penata Muda/IIIb
4. Bidang Keahlian : Statistika Ekonomi, Finansial dan Aktuaria 5. Departemen/Fakultas : Aktuaria/Sains dan Analitika Data
6. Alamat rumah dan Telp : Jl. Karangrejo Sawah III No. 40 Wonokromo Surabaya/ 081330066446
7. Pengalaman Penelitian :
a. Kajian Metode Pengelompokan Big Data Berbasis Model untuk penentuan Subsidi dengan implementasi Konsumen Listrik se Surabaya, 2018 (Anggota)
b. Pengelompokan Penduduk Miskin Surabaya berdasar Profil sosial ekonomi, 2019 (Anggota)
8. Publikasi :
a. Spatial Simultaneous Equation Model: Case Study Empirical Analysis of Regional Economic Growth in Central Java
b. Forecasting of monthly inflow and outflow currency using time series regression and ARIMAX: The Idul Fitri effect.
Surabaya, 07 Maret 2020 Anggota Peneliti
26
E. Surat Pernyataan Kesediaan Anggota Tim Penelitian
Yang bertanda tangan di bawah ini kami:
Nama : Imam Safawi Ahmad, SSi, MSi.
NIP : 19810224 201404 1 001
Jurusan / Fakultas : Statistika/FMIPA
menyatakan bersedia untuk melaksanakan tanggung jawab sebagai anggota tim penelitian:
Judul Penelitian : Pengembangan Metode Vector Support Machine (SVM) untuk klasifikasi Data Multinomial menggunakan preprocessing Reduksi Dimensi . Ketua Tim Peneliti : R Mohamad Atok, Ph.D
dengan tugas: membantu membuat proposal, Eksplorasi Data, Membuat program R,
membantu membuat jurnal internasional dan makalah seminar, membantu membuat laporan akhir
Surat pernyataan ini kami buat dengan sebenarnya untuk digunakan seperlunya.
Surabaya, 07 Maret 2020
Yang membuat pernyataan