BAB 2
TINJAUAN PUSTAKA
2.1. Data Mining (DM)
Data mining adalah proses menambang (mining) pengetahuan dari sekumpulan data yang sangat besar (Han & Kamber 2006). Menurut Connolly dan Begg, 2005. Data mining adalah proses pengolahan informasi dari sebuah database yang besar, meliputi proses ekstraksi, pengenalan, komprehensif, dan penyajian informasi sehingga dapat digunakan dalam pengambilan keputusan bisnis yang krusial”. Sedangkan Menurut Berry dan Linoff (2004), “Data mining adalah mengeksplorasi dan menganalisis data dalam jumlah besar untuk menemukan pola dan rule yang berarti”. Data mining merupakan suatu langkah dalam knowledge discovery in database (KDD).
Alasan-alasan utama dalam penggunaan data mining adalah :
1. Banyaknya jumlah data yang ada dan akan terus meningkatnya jumlah data.
2. Kebutuhan untuk menginterpretasikan data.
Data mining tidak hanya berhubungan dengan masalah basis data, tetapi merupakan suatu “titik temu” dari berbagai macam ilmu pengetahuan yang dapat digunakan untuk membangun suatu informasi dalam memperoleh pengetahuan yang baru ataupun penting. Disiplin ilmu tersebut dapat meliputi basis data, statistik, probabilistik, jaringan saraf tiruan, data visual, dan sebagainya.
2.1.1. Data Cleaning
Data cleaning adalah suatu teknik yang digunakan untuk menangani data yang tidak lengkap. Proses data cleaning ini juga mencakup antara lain membuang duplikasi data, memeriksa data yang tidak konsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi) (Kurniawati, 2015).
Pada proses ini juga dilakukan proses enrichment, yaitu proses memperkaya data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
Untuk melakukan proses data cleaning dapat menggunakan teknik remove incomplete data. Pada teknik remove incomplete data, data yang tidak lengkap dihilangkan (remove) di record/baris data pada masing-masing variabel sampel data tersebut.
Dalam teknik remove incomplete data dilakukan pemilahan atau penentuan data yang tidak lengkap / komplit untuk dihilangkan dalam satu record / baris data pada masing-masing variabel data yang ada, seperti pada tabel 2.1 :
Tabel 2.1. Data Tidak Lengkap
Dari Tabel 2.1 diatas dapat dilihat bahwa terdapat data tidak lengkap yaitu pada record 3 dan 7. Untuk menjadikannya sebagai data lengkap, dengan teknik remove incomplete data maka nama peserta 003 dan 007 akan dihapus dari database. Dari hasil yang didapat maka tabel data lengkapnya adalah seperti pada tabel 2.2
Tabel 2.2. Data Lengkap
Pasien Gejala
001 Demam, sakit perut, muntah, sakit kepala
002 Demam, keringat malam hari, sakit kepala, muntah, sakit perut
003 -
004 Demam, sakit kepala, muntah, sakit perut 005 Demam, sakit kepala, muntah, sakit perut 006 Demam, sakit perut, sakit kepala, muntah
007 -
Pasien Gejala
001 Demam, sakit perut, muntah, sakit kepala
002 Keringat malam hari, sakit kepala, muntah, badan lemas 004 Demam, sakit kepala, muntah, sakit perut
005 Demam, sakit kepala, muntah, sakit perut 006 Demam, sakit perut, sakit kepala, muntah
2.1.2. Data Transformation
Data transformation adalah suatu teknik yang digunakan untuk mentransformasikan data mentah ke dalam data yang ditransformasikan. Untuk melakukan data transformasi, dapat digunakan dengan berbagai macam cara, salah satunya adalah Algoritma Fungsi Interval.
Algoritma data transformation dengan cara algoritma fungsi interval ini, adalah dengan langkah-langkah seperti yang dijelaskan pada algoritma berikut ini: Algoritma
Input : Data lengkap
Output : Data yang ditransformasikan
Berdasarkan nilai diatas, maka tabel 3.3 dapat ditransformasikan ke dalam tabel 2.3.
Tabel 2.3. Data Transformasi
Atribut Nilai
Demam 0 = Tidak, 1 = Ya
Sakit kepala 0 = Tidak, 1 = Ya Sakit perut 0 = Tidak, 1 = Ya
Muntah 0 = Tidak, 1 = Ya
Diagnosa 1 = Positif, 2 = Negatif
Tabel 2.4. Hasil Data Transformasi
2.2. Teori Rough Set
Teknik Rough Set merupakan sebuah teknik matematik yang dikembangkan oleh Pawlack pada tahun 1982 dan digunakan untuk analisis klasifikasi data dalam bentuk tabel (Thangavel, et al. 2006). Data yang digunakan biasanya data diskret. Tujuan dari
Pasien Demam Sakit kepala Sakit perut Muntah
001 1 1 1 1
002 0 1 0 1
004 1 1 1 1
005 1 1 1 1
analisis Rough Set adalah untuk mendapatkan perkiraan rule yang singkat dari suatu tabel. Hasil dari analis Rough Set dapat digunakan dalam proses data mining dan knowledge discovery. Teknik ini digunakan untuk menangani masalah uncertainly, missing data, uncompleted, inconsistency data, imprecision, dan vagueness (tidak pasti, data hilang, tidak lengkap, tidak selaras, ketidaktepatan, ketidakjelasan).
Teori ini memberikan pendekatan matematika baru untuk permasalahan dengan tingkat ketidakpastian yang tinggi. Teori ini menjadi dasar penting untuk kecerdasan buatan, pembelajaran mesin, perolehan informasi, analisis keputusan, data mining, sistem pakar, hingga pengenalan pola. Kelebihan teori ini adalah tidak diperlukannya preliminary dan juga informasi tambahan mengenai data dalam melakukan analisis suatu data. Tetapi teori rough set ini tidak dapat menyelesaikan permasalahan dengan atribut yang bernilai kontinu. Sedangkan yang ada dalam kasus di dunia nyata selalu mengandung variabel – variabel yang bernilai kontinu.
Filosofi rough set didirikan pada asumsi bahwa dengan setiap objek wacana alam semesta kita mengasosiasikan beberapa informasi (data, pengetahuan). Sebagai contoh, jika objek adalah pasien yang menderita penyakit tertentu, gejala dari penyakit tersebut merupakan informasi tentang pasien. Objek ditandai oleh informasi yang sama yang indiscernible (similar) mengingat informasi yang tersedia pada objek tersebut. Hubungan indiscernibility yang dihasilkan dengan cara ini adalah dasar matematika teori rough set. Himpunan dari seluruh obyek indiscernible (similar) yang disebut elementary set, dan membentuk granul dasar (atom) dari pengetahuan tentang alam semesta. serikat pekerja dari beberapa elementary set dirujuk sebagai satu set crisp (tepat) dengan kata lain set tersebut rough. Setiap rough set memiliki masalah garis batas (boundary-line), yaitu objek yang tidak dapat diklasifikasikan dengan pasti, dengan menggunakan pengetahuan yang ada, karena member dari set tersebut atau objek complement. Tentunya rough set, berbeda dengan precise set, tidak dapat dicirikan dalam hal informasi tentang elemen mereka. Dengan rough set, sepasang precise set menyebutkan aproksimasi bawah dan atas dari rough set berasosiasi. Aproksimasi bawah (lower approximation) terdiri dari semua objek yang tentu saja termasuk set dan upper approximation berisi semua objek yang mungkin termasuk set. Perbedaan antara aproksimasi atas dan bawah membentuk daerah batas (boundary region) rough set. Aproksimasi adalah dua operasi dasar pada teori rough set.
Pendekatan rough set tampaknya menjadi dasar yang penting untuk AI dan ilmu kognitif, khususnya pada area machine learning, akuisisi pengetahuan, decision analysis, penemuan pengetahuan dari database, sistem pakar, penalaran induktif dan pengenalan pola. Teori rough set telah berhasil diterapkan dalam banyak masalah kehidupan nyata dalam kedokteran, farmakologi, teknik, perbankan, keuangan, analisis pasar, pengelolaan lingkungan dan lain-lain.
Pendekatan rough set untuk analisis data memiliki banyak kelebihan utama. diantaranya adalah:
1. Menyediakan algoritma efisien untuk menemukan pola yang tersembunyi dalam data.
2. Menemukan set minimal data (reduksi data). 3. Mengevaluasi signifikansi data.
4. Menghasilkan set decision rule dari data.
5. Menawarkan interpretasi langsung dari hasil yang diperoleh.
6. Sebagian besar algoritma didasarkan pada teori rough set sangat cocok untuk pemrosesan paralel.
7. Mudah untuk dipahami.
Rough Set merupakan teknik yang efisien untuk knowledge discovery in database (KDD) proses dan data mining. Secara umum teori Rough Set telah digunakan dalam banyak aplikasi seperti medicine, pharmacology, business, banking, engineering design, image processing dan decision analysis.
Beberapa konsep dasar yang harus dilakukan untuk melakukan knowledge discovery in database (KDD) dengan teknik rough set, antara lain:
1. Information system dan Decision system, representasikan data atau objek. 2. Indicernibility Relation, menghubungankan antar atribut yang tidak dapat
dipisahkan.
3. Equivalence Class, mengelompokkan objek-objek yang memiliki atribut kondisi yang sama.
4. Discernibility Matrix / discernibility matrix modulo, sekumpulan atribut yang berbeda antara objek.
5. Reduction, penyelesaian atribut minimal dari sekumpulan atribut kondisi dengan menggunakan prime implicant fungsi boolean.
6. Generating Rules, membangkitkan aturan-aturan (rules) dari pengetahuan yang didapat dalam proses ekstrak data.
Dalam sebuah pengambilan keputusan, teknik Artificial Intelligence (AI) Rough Set merupakan salah satu teknik yang tepat digunakan, dengan teknik ini nantinya akan didapat suatu hasil knowledge / pattern yang dapat digunakan dalam mengambil suatu keputusan, yaitu dengan melakukan tahapan-tahapan dalam knowledge discovery in database (KDD), yang terdiri dari data cleaning, data integration, data selection, data transformation, data mining, evaluation dan knowledge presentation (Han & Kamber 2006).
2.2.1. Information System dan Decision System
Rough Set menawarkan dua bentuk representasi data yaitu Information Systems (IS) dan Decision System (DS). Information System adalah sebuah Informating System (IS) yang terdiri dari : IS = {U, A}, dimana U = {e1, e2, …, en} dan A = {a1, a2, …, an}
yang merupakan sekumpulan example dan attribute kondisi secara berurutan.
Definisi di atas memperlihatkan bahwa sebuah Information System terdiri dari sekumpulan example, seperti {e1, e2, …, en} dan attribute kondisi, seperti {a1, a2, …,
an}. Sebuah Information System yang sederhana dapat dicontohkan seperti tabel 2.5
Tabel 2.5. Information System
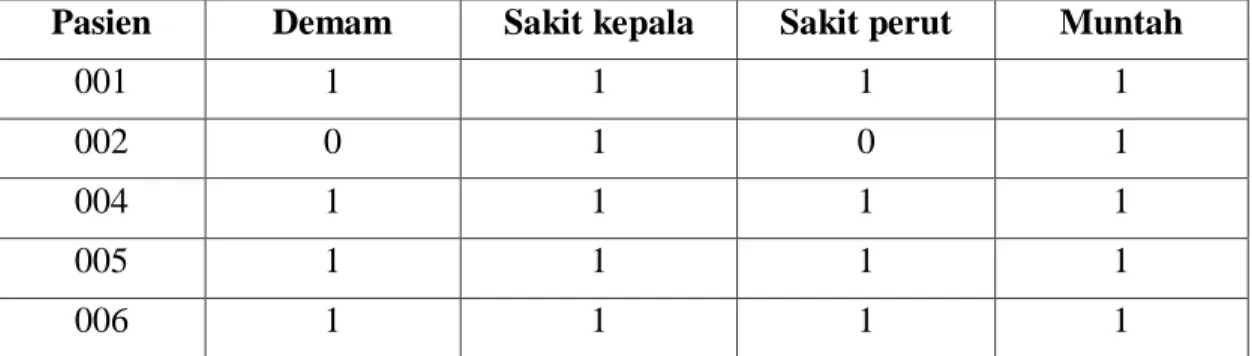
Tabel 2.5 memperlihatkan sebuah Information System yang sederhana. Dalam Information System, tiap-tiap baris mempresentasikan objek sedangkan tiap-tiap kolom mempresentasikan atribut kondisi (A). Tabel 2.4 terdiri dari 5 objek yaitu 001, 002, 004, 005, dan 006, sedangkan atribut kondisinya terdiri dari 4 yaitu demam, sakit kepala, sakit perut, muntah.
Pasien Demam Sakit kepala Sakit perut Muntah
001 1 1 1 1
002 0 1 0 1
004 1 1 1 1
005 1 1 1 1
Dalam banyak aplikasi, sebuah Information System (IS) juga direpresentasikan dengan sebuah Decision Attribute (atribut keputusan), C = {C1, C2, …, Cn }.
Sehingga Information System (IS) menjadi IS = (U, {A,C}). Pada tabel 2.5 dapat dilihat sebuah contoh Information System (IS) yang didalamnya terdapat objek (U), atribut kondisi (A) dan atribut keputusan (C).
Tabel 2.6. Information System Dengan Atribut Keputusan
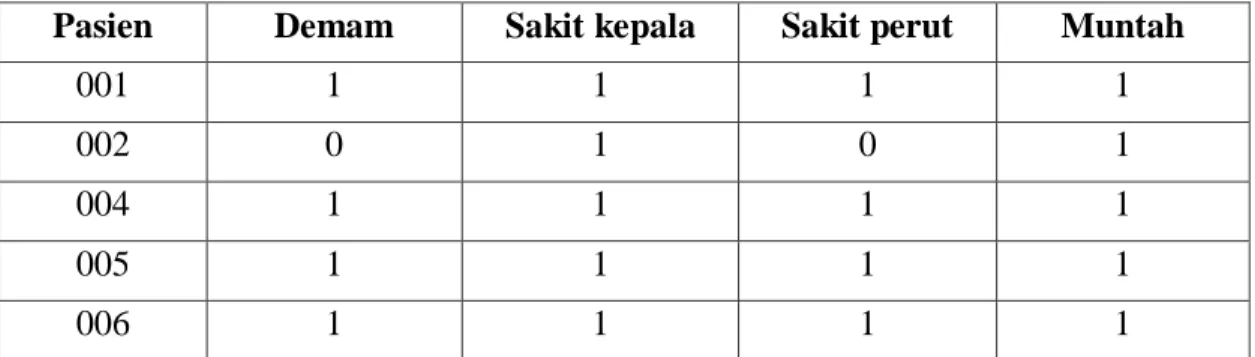
Tabel 2.6 memperlihatkan sebuah Decision System yang sederhana yang terdiri dari 5 objek yaitu, 001, 002, 004, 005, dan 006, 4 atribut kondisi yaitu demam, sakit kepala, sakit perut, muntah, serta 1 atribut keputusan.
2.2.2. Indiscernibility Relation
Dalam decision system, sebuah objek dapat memiliki nilai yang sama untuk sebuah atribut kondisionalnya, hubungan tersebut disebut dengan indiscernibility (tidak dapat dipisahkan (Listiana et al, 2011).
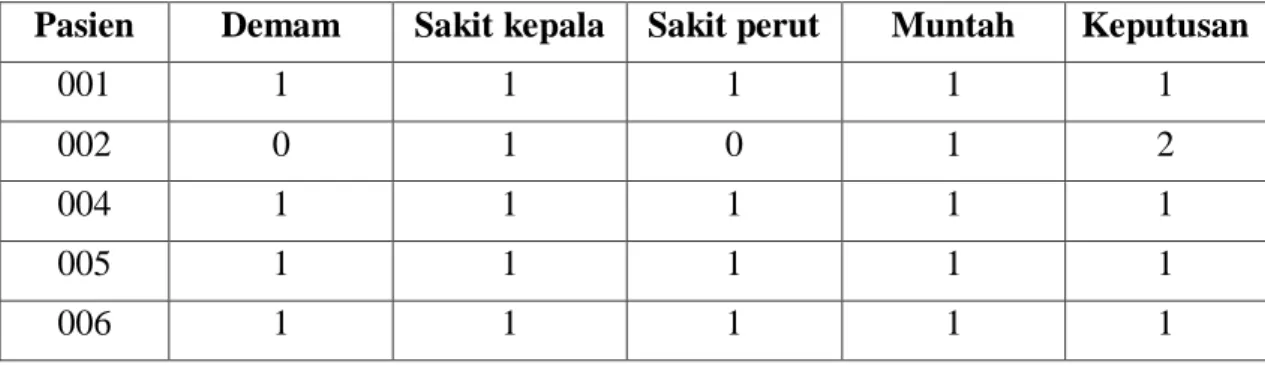
Berdasarkan tabel 2.6 maka didapatkan Indicernibility Relation sebagai berikut:
IND (Demam) = {001, 004, 005, 006} IND (Sakit Kepala) = {001, 002, 004, 005, 006} IND (Sakit Perut) = {001, 004, 005, 006} IND (Muntah) = {001, 002, 004, 005, 006}
Kelas-kelas yang telah dikelompokkan disebut dengan equivalence class.
Pasien Demam Sakit kepala Sakit perut Muntah Keputusan
001 1 1 1 1 1
002 0 1 0 1 2
004 1 1 1 1 1
005 1 1 1 1 1
2.2.3. Equivalence Class
Equivalence Class adalah mengelompokkan objek-objek yang mempunyai nilai atribut yang sama menjadi satu bagian. Seperti dapat dilihat pada tabel 2.6 bahwa beberapa objek mempunyai atribut yang sama sehingga dapat disatukan. Setelah objek yang mempunyai atribut yang sama disatukan, maka akan menghasilkan suatu Equivalence Class (EC1-EC2), seperti digambarkan pada tabel 2.7.
Tabel 2.7. Equivalence Class
2.2.4. Discernibility Matrix
Discernibility Matrix terdiri dari sekumpulan atribut yang berbeda antara object Xi (Kolom Equivalence Class) dan Xj (Baris Equivalence Class). Pada discernibility matrix ini akan dibandingkan isi sebuah atribut antara suatu objek dengan objek lainnya. Dalam proses membandingkan ini, yang diperhatikan hanya atribut kondisinya saja, jika nilai atributnya sama maka tidak akan menghasilkan suatu nilai, tetapi akan memberi suatu nilai jika nilai atribut yang dibandingkan berbeda, seperti dapat dilihat pada tabel 2.8 berikut:
Tabel 2.8. Discernibility Matrix
2.2.5. Discernibility Matrix Modulo D
Sama seperti Discernibility Matrix, pada Discernibility Matrix Modulo D juga terdiri dari sekumpulan atribut yang berbeda antara objek Xi (Kolom Equivalence Class) dan Xj (Baris Equivalence Class). Proses untuk menghasilkan Discernibility Matrix Modulo D ini juga membandingkan isi sebuah atribut suatu objek dengan objek lainnya. Perbedaannya dengan Discernibility Matrix adalah proses Equivalence Class Demam (A) Sakit kepala (B) Sakit perut (C) Muntah (D) Keputusan (E) EC 1 1 1 1 1 1 EC 2 0 1 0 1 2 EC1 EC2 EC1 - AC EC2 - AC
membandingkannya, yang diperhatikan tidak hanya atribut kondisinya saja, tetapi juga atribut keputusannya. Jika nilai atributnya sama maka tidak menghasilkan suatu nilai, tetapi jika nilai atribut yang dibandingkan berbeda maka akan menghasilkan suatu nilai, seperti dapat dilihat pada tabel 2.9 yang merupakan Discernibility Matrix Modulo D.
Tabel 2.9 Discernibility Matrix Modulo D
2.2.6. Reduct
Teknik yang dapat diterapkan untuk mendapatkan representasi volume data set yang jauh lebih kecil disebut dengan Reduct, namun tetap mempertahankan integritas data asli. Artinya pertambangan data set berkurang harus lebih efisien atau sama dengan dengan hasil analisis (Han, et al. 2012)
Discernibility matrix modulo D pada tabel 2.9 dapat ditulis sebagai formula CNF (Conjunctive Normal Form) seperti diperlihatkan pada tabel 2.10.
Tabel 2.10. Reduct
2.2.7. Generating Rule
Generating Rules adalah suatu metode rough set untuk menghasilkan rules/knowledge berdasarkan equivalence class dan reduct. Generating Rules dapat juga dikatakan sebagai suatu algoritma dari Data Mining, yang nantinya dari proses Generating Rules ini akan dihasilkan suatu rules / knowledge yang dapat digunakan dalam sebuah pengambilan keputusan.
Dari hasil reduct yang diperoleh maka didapatkan suatu rules / knowledge. Seperti contoh di atas, rules yang didapatnya adalah :
EC1 EC2
EC1 - AC
EC2 - AC
Class CNF of Boolean Function Prime Implicant Reducts
EC1 A ^ C (A), (C) {A}, {C}
Rules :
A. EC 1 Menghasilkan reduct {A}, {C}, rulenya adalah: Jika demam = 1 dan sakit perut = 1, maka diagnosa = 1 B. EC 2 Menghasilkan reduct {A}, {C}, maka rulenya adalah:
Jika demam = 0 dan sakit perut = 0, maka diagnosa = 2 2.3. Algoritma Apriori
Algoritma apriori menghitung seringnya itemset muncul dalam basis data melalui beberapa iterasi. Setiap iterasi mempunyai dua tahapan menentukan kandidat dan memilih serta menghitung kandidat (Ashok & Sandeep, 2014). Ide dasar dari algoritma ini adalah dengan mengembangkan frequent itemset. Dengan menggunakan satu item dan secara rekursif mengembangkan frequent itemset dengan dua item, tiga item dan seterusnya hingga frequent itemset dengan semua ukuran.
Untuk mengembangkan frequent set dengan dua item, dapat menggunakan frequent set item. Alasannya adalah bila set satu item tidak melebihi support minimum, maka sembarang ukuran itemset yang lebih besar tidak akan melebihi support minimum tersebut. Secara umum, mengembangkan set dengan frecuent – item menggunakan frequent set dengan k – 1 item yang dikembangkan dalam langkah sebelumnya. Setiap langkah memerlukan sekali pemeriksaan ke seluruh isi database.
Dalam asosiasi terdapat istilah antecedent dan consequent, antecedent untuk mewakili bagian “jika” dan consequent untuk mewakili bagian “maka”. Dalam analisis ini, antecedent dan consequent adalah sekelompok item yang tidak punya hubungan secara bersama. Dari jumlah besar aturan yang mungkin dikembangkan, perlu memiliki aturan-aturan yang cukup kuat tingkat ketergantungan antar item dalam antecedent dan consequent. Untuk mengukur kekuatan aturan asosiasi ini, digunakan ukuran support dan confidence. Support adalah rasio antara jumlah transaksi yang memuat antecedent dan consequent dengan jumlah transaksi. Confidence adalah rasio antara jumlah transaksi yang meliputi semua item dalam antecedent dan consequent dengan jumlah transaksi yang meliputi semua item dalam antecedent.
𝐶𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒 =
𝐽𝑢𝑚𝑙𝑎 𝑇𝑟𝑎𝑛𝑠𝑎𝑘𝑠𝑖 𝑀𝑒𝑛𝑔𝑎𝑛𝑑𝑢𝑛𝑔 𝐴 𝑑𝑎𝑛 𝐵𝐽𝑢𝑚𝑙𝑎 𝑇𝑟𝑎𝑛𝑠𝑎𝑘𝑠𝑖 𝑀𝑒𝑛𝑔𝑎𝑛𝑑𝑢𝑛𝑔 𝐴 X 100% ... [2.6]Langkah pertama algoritma apriori adalah, support dari setiap item dihitung dengan men-scan database. Setelah support dari setiap item didapat, item yang memiliki support lebih besar dari minimum support dipilih sebagai pola frekuensi tinggi dengan panjang 1 atau sering disingkat 1-itemset. Singkatan k-itemset berarti satu set yang terdiri dari k item.
Iterasi kedua menghasilkan 2-itemset yang tiap set-nya memiliki dua item. Pertama dibuat kandidat 2-itemset dari kombinasi semua 1-itemset. Lalu untuk tiap kandidat 2-itemset ini dihitung support-nya dengan men-scan database. Support artinya jumlah transaksi dalam database yang mengandung kedua item dalam kandidat 2-itemset. Setelah support dari semua kandidat 2-itemset didapatkan, kandidat 2-itemset yang memenuhi syarat minimum support dapat ditetapkan sebagai 2-itemset yang juga merupakan pola frekuensi tinggi dengan panjang 2. Untuk selanjutnya iterasi iterasi ke-k dapat dibagi lagi menjadi beberapa bagian :
1. Pembentukan kandidat itemset
Kandidat k-itemset dibentuk dari kombinasi (k-1)-itemset yang didapat dari iterasi sebelumnya. Satu ciri dari algoritma apriori adalah adanya pemangkasan kandidat k-itemset yang subset-nya yang berisi k-1 item tidak termasuk dalam pola frekuensi tinggi dengan panjang k-1.
2. Penghitungan support dari tiap kandidat k-itemset
Support dari tiap kandidat k-itemset didapat dengan men-scan database untuk menghitung jumlah transaksi yang memuat semua item di dalam kandidat k-itemset tersebut. Ini adalah juga ciri dari algoritma apriori yaitu diperlukan penghitungan dengan scan seluruh database sebanyak k-itemset terpanjang.
3. Tetapkan pola frekuensi tinggi
Pola frekuensi tinggi yang memuat k item atau k-itemset ditetapkan dari kandidat k-itemset yang support-nya lebih besar dari minimum support. Kemudian dihitung confidence masing-masing kombinasi item.
Iterasi berhenti ketika semua item telah dihitung sampai tidak ada kombinasi item lagi. Secara ringkas algoritma apriori sebagai berikut :
Create L1 = set of supported itemsets of cardinality one Set k to 2
while (Lk−1 _= ∅) {
Create Ck from Lk−1
Prune all the itemsets in Ck that are not supported, to create Lk
Increase k by 1 }
The set of all supported itemsets is L1 ∪ L2 ∪ · · · ∪ Lk
2.3.1. Classification-Based Association
Saat ini, salah satu teknik data mining telah dikembangkan adalah dengan menerapkan konsep association rule mining dalam masalah klasifikasi. Ada beberapa metode yang bisa digunakan, antara lain association rule clustering system (ARCS) dan associative classification (Han, et al. 2012). Metode ARCS melakukan association rule mining didasarkan pada clustering kemudian menggunakan aturan yang dihasilkan untuk klasifikasi. ARCS, melakukan association rule mining dalam bentuk Aquant1 Aquant2 Acat, dimana bentuk Aquant1
dan Aquant2 adalah data test yang atributnya punya rentang nilai, Acat menunjukkan
label kelas untuk atribut kategori yang diberikan dari training data .
Metode associative classification mining menghasilkan aturan dalam bentuk condset (y), dimana condset adalah sekumpulan item dan (y) adalah label kelas. Aturan yang sesuai dengan minimum support tertentu disebut frequent. Rule mempunyai support (s) jika (s %) dari sample dalam data set yang mengandung condset dan memiliki kelas (y). Aturan yang sesuai dengan minimum confidence disebut accurate. Aturan mempunyai confidence (c) jika (c %) dari sample dalam data set yang mengandung condset memiliki kelas (y). Jika beberapa rule mempunyai condset yang sama, maka rule dengan confidence tertinggi dipilih sebagai possible rule (PR). Metode associative classification mining menggunakan algoritma association rule, seperti algoritma Apriori untuk menghasilkan association rule, kemudian memilih sekelompok aturan yang mempunyai kualitas tinggi dan menggunakan aturan tersebut untuk memprediksi data. Associative
classification masih kurang efisien karena seringkali menghasilkan aturan dalam jumlah yang besar (Yin & Han 2003).
2.4. Penelitian Terdahulu
Pada penelitian ini, peneliti menggunakan beberapa penelitian terdahulu yang digunakan sebagai bahan kajian selama proses penelitian, yaitu penelitian yang dilakukan (Adeyemo, et al. 2015), melakukan penelitian tentang diagnosa demam tifoid menggunakan tiga metode yaitu ID3, C45 dan Multilayer Perceptron (MLP), dari hasil penelitian tersebut MLP memiliki tinggi akurasi terbaik dibandingkan dengan kedua metode lainnya, akan tetapi dalam hal kecepatan algoritma C45 ditemukan menjadi yang terbaik dalam data training; (Oguntimilehin, et al. 2013), melakukan sebuah pendekatan untuk diagnosa demam tifoid menggunakan teknik
machine learning yang dikembangkan dalam penelitian ini dan kinerja sistem diukur
pada kedua set pelatihan dan pengujian; (Budiono, et al. 2014) dalam penelitiannya melakukan identifikasi dan pencarian informasi mengenai pola penyakit radang sendi dengan teknik data mining association rule menggunakan algoritma apriori, penelitian ini menampilkan informasi berupa nilai support dan confidence hubungan antara pola penyakit radang sendi dengan atribut umur, jenis kelamin, pekerjaan dan gejala; (Widiastuti & Sofi, 2014) melakukan analisis perbandingan antara algoritma apriori dan fp-growth dalam penelitian ini ditemukan kekurangan pada algoritma apriori terkait dengan kecepatan dalam pencarian frequent itemset karena harus melakukan
scanning database berulang kali untuk setiap kombinasi item, selain itu juga
dibutuhkan generate candidate yang besar untuk mendapatkan kombinasi item dari database sedangkan pada fp-growth menggunakan pembangunan tree dalam pencarian
fruquent item hal tersebut yang menyebabkan algoritma fp-growth lebih cepat. Hasil
Tabel 2.11. Penelitian Terdahulu No. Nama Peneliti dan
Tahun
Metode yang digunakan
Hasil Penelitian
1. Adeyemo, et al. 2015 ID3/C4.5 Decision tree and Multilayer Perceptron Algorithms
Dari hasil perbandingan dua metode tersebut Multilayer Perceptron (MPL) lah yang memiliki tingkat akurasi mencapai 83.62 % dalam memprediksi demam tifoid. 2. Oguntimilehin, et al. 2013 Machine Learning Approach Dengan menggunakan pendekatan machine learning untuk diagnosa demam tifoid tingkat deteksi 95% untuk training set dan 96% untuk set pengujian, tingkat keberhasilan sistem dianggap sangat baik. 3. Widiastuti & Sofi. 2014) Algoritma
Apriori
Algoritma Apriori ditemukan kelemahan dalam hal kecepatan karena melakukan scanning database berulang kali. 4. Budiono, et al. 2014 Algoritma
Apriori
Pengujian terhadap 4 atribut umur, jenis kelamin dan gejala mendapatkan hasil yaitu umur 45, laki-laki, petani, kaku
persendian dengan nilai support 21 % dan confident 3 % dari total 4824 kasus, sehingga dapat membantu Puskesmas setempat untuk dapat memperkirakan persediaan obat dan tenaga medis.
2.5. Perbedaan dengan Penelitian Sebelumnya
Perbedaan penelitian yang peneliti lakukan pada saat ini berdasarkan penelitian yang telah dilakukan sebelumnya, peneliti melakukan Analisis kinerja metode rough set dan algoritma apriori untuk mendapatkan akurasi yang optimal dalam identifikasi pola penyakit demam tifoid.