4 BAB II
TINJAUAN PUSTAKA
2.1 Penelitian Terdahulu
Berikut pada Tabel 1. Merupakan beberapa penelitian terdahulu yang menjadi acuan pada tugas akhir ini.
Tabel 1 Penelitian Terdahulu
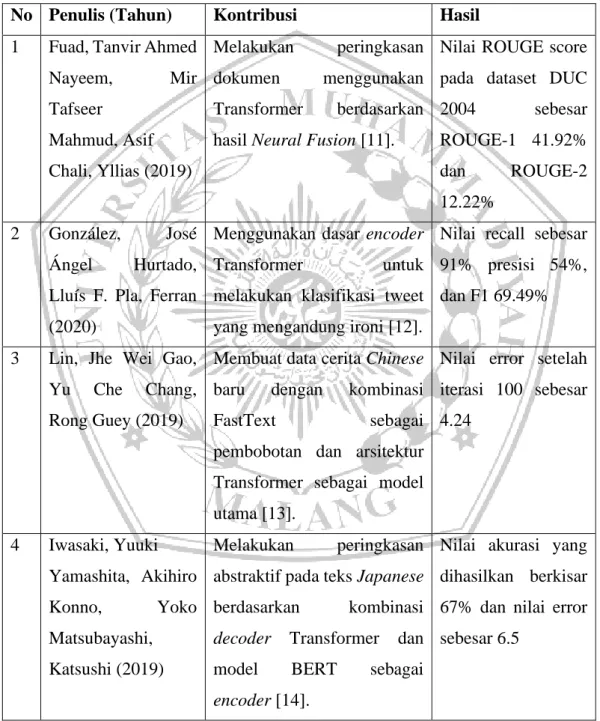
No Penulis (Tahun) Kontribusi Hasil
1 Fuad, Tanvir Ahmed Nayeem, Mir Tafseer Mahmud, Asif Chali, Yllias (2019) Melakukan peringkasan dokumen menggunakan Transformer berdasarkan hasil Neural Fusion [11].
Nilai ROUGE score pada dataset DUC 2004 sebesar ROUGE-1 41.92% dan ROUGE-2 12.22% 2 González, José Ángel Hurtado, Lluís F. Pla, Ferran (2020)
Menggunakan dasar encoder Transformer untuk melakukan klasifikasi tweet yang mengandung ironi [12].
Nilai recall sebesar 91% presisi 54%, dan F1 69.49%
3 Lin, Jhe Wei Gao, Yu Che Chang, Rong Guey (2019)
Membuat data cerita Chinese baru dengan kombinasi
FastText sebagai
pembobotan dan arsitektur Transformer sebagai model utama [13].
Nilai error setelah iterasi 100 sebesar 4.24 4 Iwasaki, Yuuki Yamashita, Akihiro Konno, Yoko Matsubayashi, Katsushi (2019) Melakukan peringkasan abstraktif pada teks Japanese berdasarkan kombinasi decoder Transformer dan model BERT sebagai encoder [14].
Nilai akurasi yang dihasilkan berkisar 67% dan nilai error sebesar 6.5
5 2.2 Peringkasan Teks
Peringkasan teks atau biasa disebut text summarization bertujuan untuk meringkas teks secara otomatis menggunakan algoritma yang sudah dirancang sebelumnya. Hasil teks ringkasan diambil berdasarkan data konten teks pada dokumen-dokumen yang sudah dikumpulkan sebelumnya dan diolah menggunakan model statistik / algoritma. Salah satu teknik yang sering dipakai menggunakan algoritma pembelajaran mesin (machine learning) atau deep learning untuk jumlah kata pada teks yang begitu banyak dan masing-masing kalimat pada data dokumen memiliki konteks informasi tersendiri. Pada penelitian sebelumnya mengenai perbandingan hasil peringkasan teks, hasil penelitian menunjukkan deep learning dapat bekerja lebih baik daripada machine learning dengan selisih skor 10% nilai ROUGE, dimana model deep learning yang digunakan berbasis LSTM dan feed forward neural network [16].
2.3 Deep learning
Deep learning merupakan cara untuk memecahkan masalah kompleks menggunakan komputer dengan memetakan dalam bentuk rangkaian secara bertahap atau biasa disebut lapisan / layer [15]. Deep learning dapat tersusun atas beberapa lapisan bahkan mencapai ratusan lapisan. Pada setiap lapisan terdapat beberapa neuron, dimana tempat transformasi data dilakukan. Umunya neuron tersusun atas fungsi aktivasi, penggunaan fungsi aktivasi bisa beragam seperti ReLU, Softmax, Elu, dan lain sebagainya. Secara sederhana data yang diolah pada deep learning antara lain: input data asli, nilai bobot (weight), bias pada masing-masing neuron, dan hasil perhitungan dari fungsi aktivasi. Pada saat proses komputasi deep learning dilakukan (training) nilai bobot & bias secara bertahap terus mengalami perubahan, perubahan tersebut dilakukan melalui algoritma optimasi (optimizer). Algoritma optimasi melakukan perubahan nilai bobot & bias berdasarkan fungsi error (loss function) yang didapat melalui perbandingan nilai asli output pada data dengan nilai hasil komputasi model deep learning.
2.4 Transformer
Transformer merupakan salah satu arsitektur deep learning yang dapat dimodifikasi. Pada arsitektur Transformer sesuai dengan Gambar 1. Terdapat dua
6
bagian utama yaitu encoder dan decoder, encoder bertugas untuk melakukan mapping setiap word yang terdapat pada teks berita 𝑥 = (𝑥1, … , 𝑥𝑛) ke dalam
bentuk nilai kontinu 𝑧 = (𝑧1, … , 𝑧𝑛), kemudian dari nilai variabel 𝑧, akan diteruskan ke dalam decoder, bersamaan dengan input mapping setiap kata yang terdapat pada ringkasan berita 𝑦 = (𝑦1, … , 𝑦𝑛). Layer encoder dan decoder dapat disusun menjadi beberapa tumpukan 𝑁𝑥.
Gambar 1. Dasar Arsitektur Transformer [10]
2.4.1 Positional Encoding
Setiap kata yang dimasukkan ke dalam arsitektur Transformer dilakukan proses pembobotan kata (word embedding) dan positional encoding. Word embedding bertujuan untuk melakukan encode kata ke dalam bentuk dimensi vektor (𝑑𝑚𝑜𝑑𝑒𝑙) [17]. Bersamaan dengan word
embedding Transformer juga melakukan positional encoding (𝑃𝐸) yang terdapat pada Persamaan 1 & 2. PE yaitu injeksi beberapa informasi terhadap setiap posisi kata yang terdapat dalam kalimat (sequence), PE memiliki ukuran dimensi yang sama seperti 𝑑𝑚𝑜𝑑𝑒𝑙, hasil dari 𝑃𝐸 dan word embedding digabungkan menggunakan penjumlahan matrik. Pada penelitian ini penulis menggunakan Sine-Cosine Positional Encoding sesuai dengan penggunaan pada penelitian arsitektur Transformer sebelumnya.
7 𝑃𝐸(𝑝𝑜𝑠,2𝑖)= sin ( 𝑝𝑜𝑠 10000 2𝑖 𝑑𝑚𝑜𝑑𝑒𝑙 ) (1) 𝑃𝐸(𝑝𝑜𝑠,2𝑖+1) = cos ( 𝑝𝑜𝑠 10000 2𝑖 𝑑𝑚𝑜𝑑𝑒𝑙 ) (2)
pos merupakan posisi, i merupakan dimensi. Persamaan 1 digunakan pada saat nilai ukuran dimensi i habis dibagi 2, sebaliknya persamaan 2 untuk nilai ukuran dimensi i tidak habis dibagi 2.
2.4.2 Encoder-Decoder Stack
Lapisan encoder memiliki dua sublayer antara lain yaitu: multi-head attention dan feed-forward network yang dapat disusukan secara bertumpukan. Input pada layer encoder merupakan teks dokumen berita atau disebut sequence yang terdiri atas beberapa hasil pembobotan kata. Pada saat pertama kali memasuki encoder dilakukan perhitungan Multi-Head Attention kemudian luarannya diteruskan pada sublayer feed-forward network.
Gambar 2. Scaled Dot-Product Attention (Kiri), Multi-Head Attention (Kanan) [10]
Lapisan decoder menerima input dari hasil keluaran encoder dan sequence dari berita yang sudah diringkas sebelumnya. Lapisan decoder terdiri atas 3 sublayer yaitu: Masked Multi-Head Attention, Multi-Head Attention, dan feed-forward Network. Perbedaan mendasar antara Masked Multi-Head Attention dengan Multi-Head Attention adalah beberapa word yang terdapat pada sequence akan dihilangkan secara acak tujuannya untuk melatih model memahami konteks yang terdapat dalam sequence.
8 2.4.3 Softmax
Softmax merupakan fungsi aktivasi untuk menghitung masukan dengan cara melakukan normalisasi pada fungsi exponensial. Hasil dari fungsi softmax merupakan sejumlah probabilitas dari masing-masing label yang ada. Dimana jika probabilitas tersebut dijumlahkan maka secara keseluruhan nilai totalnya sebesar 100%. Secara matematis fungsi softmax dapat dirumuskan seperti yang ada pada Persamaan 3, dimana setiap input (𝑥𝑛) dihitung berdasarkan nilai eksponensial kemudian dibagi sesuai
dengan akumulasi jumlah hasil exponent pada input.
𝑧𝑛 = 𝑒𝑥𝑝(𝑥𝑛)
∑(𝑒𝑥 𝑝(𝑥𝑛)) (3) 2.4.4 Attention
Fungsi attention pada Persamaan 4. Dapat didefinisikan sebagai fungsi yang melakukan mapping query (𝑄) merupakan target sequence, pasangan key (𝐾) dan value (𝑉) berasal dari sequence Setiap 𝑄, 𝐾, 𝑉, dan output mapping definisikan dalam bentuk vektor. Bobot dari setiap nilai yang dihitung merupakan representasi penyesuaian query terhadap key.
𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛(𝑄, 𝐾, 𝑉) = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝑄𝐾𝑇
√𝑑𝑘)𝑉 (4) 2.4.5 Scaled Dot-Product Attention
Input pada bagian Scaled Dot-Product Attention terdiri atas matrix Q, K, dan V. Dimensi query dan key di definisikan sebagai 𝑑𝑘, dan dimensi values sebagai 𝑑𝑣. Secara detail tahapannya dapat dilihat pada Gambar 2.
Dimana setiap query dilakukan perkalian dot product pada semua key, dan dibagi dengan dengan √𝑑𝑘, kemudian diteruskan pada fungsi softmax untuk mendapatkan nilai bobot pada values.
2.4.6 Multi-Head Attention
Bagian Multi-Head Attention menggabungkan beberapa model attention dimensi model dari setiap 𝑄, 𝐾, 𝑉. Dimensi pembobotan dari sequence didefinisikan sebagai 𝑑𝑚𝑜𝑑𝑒𝑙. Pada Multi-Head-Attention semua
9
matrix (concat). Representasi dari Multi-Head Attention dapat dilihat pada Persamaan 5 & 6.
𝑀𝑢𝑙𝑡𝑖𝐻𝑒𝑎𝑑(𝑄, 𝐾, 𝑉) = 𝐶𝑜𝑛𝑐𝑎𝑡(ℎ𝑒𝑎𝑑1, … , ℎ𝑒𝑎𝑑ℎ)𝑊𝑂 (5)
ℎ𝑒𝑎𝑑𝑖 = 𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛(𝑄𝑊𝑖𝑄, 𝐾𝑊𝑖𝐾, 𝑉𝑊𝑖𝑉) (6)
Dimana setiap 𝑊 merupakan parameter dalam bentuk matriks sesuai dengan proyeksi berikut:
𝑊𝑖𝑄 ∈ ℝ𝑑𝑚𝑜𝑑𝑒𝑙×𝑑𝑘, 𝑊
𝑖𝐾 ∈ ℝ𝑑𝑚𝑜𝑑𝑒𝑙×𝑑𝑘, 𝑊𝑖𝑉 ∈ ℝ𝑑𝑚𝑜𝑑𝑒𝑙×𝑑𝑣, 𝑊𝑖𝑉 ∈ ℝℎ𝑑𝑣×𝑑𝑚𝑜𝑑𝑒𝑙 (7)
2.5 Word Embedding
Setiap kata pada sequence yang dimasukkan ke dalam model Transformer dilakukan proses word embedding terlebih dahulu. Pada modifikasi model kali ini penulis menggunakan pre-trained word embedding Global Vector (GloVe) dengan jumlah vocabulary sebesar 2.2M untuk mempresentasikan setiap word dalam bentuk vektor berukuran 300 dimensi [18]. Penelitian sebelumnya menunjukkan hasil perbandingan unsupervised berdasarkan peringkasan teks menggunakan word embedding lebih efektif daripada menggunakan bag of word [19].
2.6 Gaussian Error Linear Unit (GELU)
Pendekatan pada feed-forward network yang diterapkan menggunakan Gaussian Error Linear Unit (GELU). GELU merupakan salah satu fungsi aktivasi pada neural network bekerja secara non-linear dengan secara random menerapkan zero mapping pada bagian input neuron. Eksperimen pengusul fungsi GELU membandingkan dengan fungsi lainnya ReLU dan ELU telah berhasil mengalami peningkatan di bidang NLP [20]. Adapun rumus dari GELU yang peneliti modifikasi sesuai dengan pendekatan yang bisa diterapkan pada NLP dapat dilihat pada Persamaan 8, dimana 𝑥 merupakan input nilai yang ingin di transformasi.
𝑓(𝑥) = 0.5 × 𝑥 × 1 × tanh(𝑥 × 0.7978845608 × (1 + 0.044715 𝑥2)) (8)
2.7 Rectified Linear Unit (ReLU)
Fungsi aktivasi ReLU [21] dapat digambarkan sesuai dengan grafik pada Gambar 7. fungsi ReLU [21] menghasilkan output berupa nilai 0 ketika masukan bernilai < 0 dan menghasilkan nilai secara linear dengan kemiringan 1 ketika
10
masukan bernilai > 0. Rumus dari fungsi ReLU dapat dilihat pada Persamaan 9 [21] dimana x merupakan masukan dan y merupakan luaran.
𝑦 = 𝑚𝑎𝑥(0, 𝑥) (9)
Gambar 3. Grafik ReLU
2.8 Optimasi Adam
Optimasi Adam merupakan optimasi turunan Stochastic Gradient Descent (SGD) menggunakan dasar dari metode estimasi adaptive momen orde pertama dan orde kedua. Menurut penelitian riset dari metode Adam menjelaskan bahwa metode Adam bekerja dengan komputasi efisien, memori yang dibutuhkan kecil, dan cocok digunakan untuk menyelesaikan dengan dataset yang besar [22].
![Gambar 1. Dasar Arsitektur Transformer [10]](https://thumb-ap.123doks.com/thumbv2/123dok/4605667.3361636/3.892.197.738.145.907/gambar-dasar-arsitektur-transformer.webp)
![Gambar 2. Scaled Dot-Product Attention (Kiri), Multi-Head Attention (Kanan) [10]](https://thumb-ap.123doks.com/thumbv2/123dok/4605667.3361636/4.892.209.736.261.891/gambar-scaled-product-attention-kiri-multi-attention-kanan.webp)

