Jurnal Politeknik Caltex Riau
http://jurnal.pcr.ac.id
IMPLEMENTASI TEXT MINING DALAM
KLASIFIKASI JUDUL BUKU PERPUSTAKAAN
MENGGUNAKAN METODE NAIVE BAYES
Siti Amelia Apriyanti 1), Kartina Diah Kesuma Wardhani 2), Istianah Muslim 3)
1Politeknik Caltex Riau, email: [email protected] 2Politeknik Caltex Riau, email: [email protected] 3Politeknik Caltex Riau, email: [email protected]
Abstrak
Setiap buku yang menjadi koleksi di perpustakaan harus diklasifikasikan sesuai DDC. Sehingga petugas perpustakaan harus cermat dan teliti dalam menentukan jenis klasifikasi buku. Banyak buku yang masuk tidak menutup kemungkinan memiliki kemiripan dalam judul buku. Judul buku yang memiliki kemiripan belum tentu berada dalam klasifikasi golongan yang sama, dan petugas dapat melakukan kesalahan dalam klasifikasi buku tersebut. Sehingga dibutuhkan sebuah sistem yang dapat mengklasifikasikan buku berdasarkan dari judulnya. Text mining merupakan sebuah ilmu yang dapat menjawab kebutuhan. Dengan menggunakan konsep text mining menggunakan algoritma naive bayes. Pengklasifikasian menggunakan naive bayes dengan cara melakukan perhitungan peluang dari setiap kata yang ada pada teks judul buku. Perhitungan dilakukan dengan cara menghitung data testing terhadap data latih yang terdahulu. Dari pengujian yang telah dilakukan diperoleh nilai akurasi terbesar dengan klasifikasi menggunakan naive bayes sebesar 80%.
Kata Kunci:
Klasifikasi, DDC, Judul Buku, Text Mining, Naive Bayes, Black Box,
Confusion Matrix
Abstract
Each book that is a collection in the library must be classified according to DDC. So that the librarian should be meticulous in determining the classification of types of books. Many books are sign did not rule have similarities in titles. Titles that have similar classification may not necessarily be in the same group, and the officer can make a mistake in the classification of the book. And so we need a system that can classify a book by its title. Text mining is a science that can answer the needs. Using the concept of text miningmenggunakan Naive Bayes algorithm. Naive Bayes classification used by means calculating the odds of every word in the text books. The calculation is performed by calculating the data testing against previous training data. From the testing that has been done with the greatest accuracy values obtained using a Naive Bayes classification by 80%.
Keywords: Classification, DDC, Book Title, Text Mining, Naive Bayes, Black Box, Confusion
1. Pendahuluan
1.1 Latar Belakang
Klasifikasi berasal dari kata latin “classis” suatu proses pengelompokkan ataupun mengumpulkan sebuah benda dari benda yang berbeda. Klasifikasi merupakan suatu usaha dalam mengelompokkan sejumlah objek, buku, atau golongan berdasarkan ciri yang sama [1]. Dalam kehidupan sehari-hari, klasifikasi sudah banyak dilakukan seperti di perpustakaan dan lainnya. Dalam bidang perpustakaan klasifikasi memiliki pengertian penyusunan sistematis terhadap buku dan bahan pustaka lainnya. Klasifikasi difungsikan untuk tata cara penyusunan buku di rak, dan koleksi pustaka lainnya secara sistematis, sehingga buku yang tersusun sudah masuk ke dalam golongan yang ditentukan.
Setiap buku yang menjadi koleksi dari perpustakaan harus diklasifikasikan berdasarkan dari dewey decimal classification DDC. Sehingga petugas perpustakaan harus cermat dan teliti dalam menentukan klasifikasi buku. Banyak buku yang masuk ke dalam perpustakaan tidak menutup kemungkinan memiliki kemiripan judul buku. Permasalahan yang bisa terjadi adalah buku yang memiliki kemiripan judul, belum bisa dipastikan berada pada klasifikasi golongan buku yang sama. Dengan adanya permasalahan seperti ini petugas harus melakukan pengecekan ulang dan melakukan klasifikasi kembali.
Oleh karena itu, pada penelitian ini dibuatlah sebuah aplikasi untuk pengklasifikasian buku berdasarkan judul buku dengan menggunakan metode naive bayes. Penelitian ini dibuat berdasarkan sumber data yang didapatkan dari perpustakaan Politeknik Caltex Riau PCR). Aplikasi yang akan dibuat dapat melakukan klasifikasi buku secara otomatis dengan training yang diambil dari data terlbih dahulu yang telah di klasifikasi. Naive bayes itu sendiri memiliki kemampuan klasifikasi dengan penghitungan peluang, naive bayes merupakan metode yang sederhana, dengan data latih yang kecil sudah dapat melakukan proses pengklasifikasian dengan akurat [2].
2. Review Penelitian Terdahulu
Pada dasarnya, penelitian mengenai klasifikasi sudah banyak dilakukan baik untuk klasifikasi dokumen dan berita dan lainnya. Klasifikasi untuk bahan perpustakaan itu sendiri sudah banyak dilakukan secara sistem, meski bukan khusus dilakukan klasifikasi untuk melakukan penggolonan buku. Berikut beberapa penelitian yang menggunakan naive bayes:
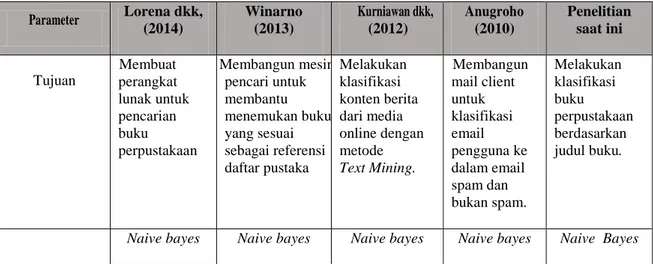
Tabel 1 Perbandingan Penelitian Terdahulu Parameter Lorena dkk, (2014) Winarno (2013) Kurniawan dkk, (2012) Anugroho (2010) Penelitian saat ini Tujuan Membuat perangkat lunak untuk pencarian buku perpustakaan Membangun mesin pencari untuk membantu menemukan buku yang sesuai sebagai referensi daftar pustaka Melakukan klasifikasi konten berita dari media online dengan metode Text Mining. Membangun mail client untuk klasifikasi email pengguna ke dalam email spam dan bukan spam. Melakukan klasifikasi buku perpustakaan berdasarkan judul buku.
Parameter Lorena dkk, (2014) Winarno (2013) Kurniawan dkk, (2012) Anugroho (2010) Penelitian saat ini Metode Klasifikasi Data yang diolah Judul, pengarang, kata kunci
Daftar isi buku Konten berita online
Header dan
body email Judul buku
Bahasa
Pemrograman - - PHP Java Java
Sistem Berbasis
Desktop Berbasis Web Berbasis Web Berbasis Web
Berbasis Desktop
3. Perancangan
Ini adalah gambaran umm dari sistem mulai dari dari sumber awal didapatkannya data judul buku yang akan diklasifikasi.
Gambar 1 Gambaran Umum Sistem
Gambaran sistem ini menejelaskan dari sebuah alur kerja sistem yang dibangun. Alur ini terdiri dari analisis sumber data, judul buku yang diolah, tahapan preprocessing, dan klasifikasi. Tahapan preprocessing terdiri dari empat proses (case folding, tokenizing, filtering,
stemming), tahapan preprocessing adalah tahapan pembersihan dan pengurangan kata dan
dilanjutkan dengan tahapan klasifikasi metode naive bayes. Naive bayes dihitung peluang kata yang sering kemunculannya, untuk mendapatkan nilai dari peluang.
Analisis ini berisikan dari tahapan data yang bertipe .pdf yang akan dilakukan tahapan dari klasifikasi. Namun sebelum tahapan klasifikasi dilakukan maka akan ada proses preprocessing. Di sini akan ada tahapan dari proses tersebut seperti tahapan case folding, tokenizing, filtering, stemming. Setelah tahapan dari preprocessing dilakukan maka dilanjutkan melakukan klasifikasi judul buku.
4. Hasil Perancangan 4.1 Data Training
Klasifikasi termasuk salah satu supervised yang memiliki data latih dan data testing, sehingga sebelum melakukan klasifikasi data testing harus memiliki data pembelajaran terdahulu . Data pembelajaran terdahulu itu sendiri lebih dikenal data latih, data latih sendiri sudah harus memiliki label . Label itu sendiri berfungsi untuk menentukan disaat data testing di klasifikasi. Data latih ini sendiri menggunakan tools RapidMiner. Sebagai berikut langkah klasifikasi menggunakan RapidMiner.
Gambar 2 Data Training menggunakan RapidMiner
4.2 Antarmuka Hasil Perancangan
Tampilan ini digunakan untuk inputan judul buku yang akan di klasifikasi, teks judul buku yang akan diprocessing adalah judul buku berbahasa indonesia, jika buku bukan bahasa indonesia akan tetap ditampilkan tetapi tidak terjadi proses preprocessing. Proses preprocessing akan di lakukan terhadap judul buku baru, atau judul buku baru yang dilakukan klasifikasi. Jika buku yang diinputkan sesuai maka akan diproses dengan metode naive bayes untuk mendapatkan peluang dari judul buku yang diinputkan. Klasifikasi dilakukan dengan tujuan untuk mengetahui peluang dari judul buku tersebut masuk ke dalam golongan buku yang terpilih, hasil dari golongan yang di keluarkan didapat dari peluang terhadap golongan yang paling besar diantara peluang terhadap golongan buku lainnya.
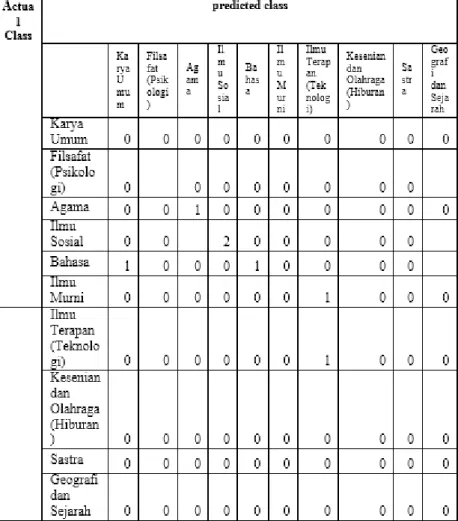
4.3 Confusion Matrix
Pengujian akurasi Naive Bayes bertujuan untuk mengetahui kerja dari algoritma Naive
Bayes dalam mengklasifikasi data ke dalam label yang telah ditentukan. Pengujian ini diperoleh
dari hasil pengamatan user dan hasil dari pengklasifikasian yang dilakukan oleh sistem.
Gambar 4 Confusion Matrix
Akurasi = x100% = 80%
Dari hasil pengujian dapat diketahui nilai akurasi sebesar 80% dan untuk nilai laju error sebesar 20 % dari 10 kali pengujian . Secara umum, hasil dari pengujian menunjukkan nilai akurasi yang baik. Dari hasil akurasi ini didapatkan dari judul buku yang diinputkan dalam sistem sesuai dengan manual, sedangkan untuk laju error didapatkan dengan hasil judul buku dalam sistem dengan manual berbeda. Meski sudah diatur dan lakukan pengklasifikasian untuk mengahasilkan peluang yang tinggi, sistem tetap memiliki kekurangan dalam ke akuratan karena sistem ini mengeluarkan hasil dari perhitungan naive bayes yang berpedoman terhadap data latih dan tidak membedakan data, semua data testing yang masuk akan di hitung peluang terhadap data latih. Semakin banyak data latih maka akan mempengaruhi dari perhitungan peluang data testing. walaupun data tidak 100% akurat tetapi secara kinerja dari naive bayes sudah terlaksanakan dengan baik.
5. Kesimpulan dan Saran
1. Setelah dilakukan pengujian beserta analisa pada proyek akhir ini, maka dapat diambil kesimpulan adalah teknik Klasifikasi naive bayes dapat digunakan untuk mengklasfikasikan Judul buku berdsarkan golongan di perpustakaan PCR. Dari hasil penelitian didapatkan tingkat akurasi tertinggi 80%.Dari kesimpulan penelitian tersebut, adapun saran yang dapat diberikan adalah Memperluas parameter yang digunakan sebagai data yang diklasifikasi dengan menambahkan sinopsis ataupun deskripsi buku.
2. Bisa dikembangkan dengan sistem perhitungan waktu kecepatan dalam klasifikasi. 3. Bisa dikembangkan klasifikasii buku dengan menggunakan teknik klasifikasi lainnya
salah satunya (k-NN).
6. Daftar Pustaka
[1] Subrata, G. (2009). Klasifikasi Bahan Pustaka. Universitas Negeri Malang (UM).
[2] Hamzah, Amir. (2012). Klasifikasi Teks dengan Naive Bayes Classifier (NBC) untuk
Pengelompokan Teks Berita dan Abstract Akademis. Institut Sains dan Teknologi
AKPRIND Yogyakarta.
[3] Feldman, R., Sanger, J. (2006). The Text Mining Handbook:Advanced Approach in
Analyzing Unstructure Data.
[4] Yuliana. (2014). Sistem Pengelolaan Proyek Akhir Menggunakan Text Mining Pada
Politeknik Caltex Riau. Pekanbaru: Politeknik Caltex Riau
[5] Susanto, B. (2013). pengantar Text Mining dan Intelligent Web. Teknik Informatika
UKDW Yogyakarta, 2-10.
[6] Kurniawan, B., Effendi, S., & Sitompul, O. S. (2012). Klasifikasi Konten Berita dengan Text Mining. Jurnal Dunia Teknologi Informasi, 14-19.
[7] Manning, C. D., Raghavan, P., Schutze, H 2008. Introduction of Information Retrieval. New York: Camridge University Press. 253- 287.
[8] Prasetyo , E. (2012). Klasifikasi (Sesion 1) Naive Bayes. Teknik Informatika UPN