PRA-PENGOLAHAN DATA DAN PENERAPAN TEKNIK DIMENSION
REDUCTION MENGGUNAKAN ALGORITMA PRINCIPAL
COMPONENT ANALYSIS (PCA) PADA DATA HIGH-DIMENTIONAL
BIOMEDICAL
Irfan Abbas STMIK Ichsan Gorontalo Email: [email protected]
Abstrak: Dewasa ini data high dimentional biomedical telah menunjukkan peningkatan popularitas dan perhatian, serta telah berkembang dengan cepat selama dua dekade. Data High dimentional biomedical memiliki ribuan atribut serta ribuan jumlah record yang saling berkorelasi (multicolinearity), berskala besar dan kompleks. Teknik pengurangan dimensi merupakan bagian dari pengolahan awal data dan sangat tepat digunakan untuk memecahkan data yang kompleks. Algoritma principal component analysis (P CA) adalah metode teknik pengurangan dimensi yang tergolong dalam kelompok ekstraksi atribut.
Penelitian ini menggunakan Algoritma principal component analysis (P CA) untuk mengurangi dimensi dan membersihkan korelasi antar atribut pada data high dimentional biomedical yang memiliki ribuan atribut
Keywords: Algoritma principal component analysis (PCA), Pengurangan Dimensi, High dimentional biomedical data set,
1. PENDAHULUAN
Data saat ini cenderung multidimensi dan berdimensi tinggi serta lebih kompleks daripada data konvensional, seperti pada data biomedis. Data yang berdimensi tinggi dan multidimensi memerlukan teknik pengurangan dimensi yang merupakan teknik penting dan menjadi teknik mendasar dalam sebagian besar proses data mining ketika menghadapi data yang kompleks [1] [2]. Tujuan dari teknik pengurangan dimensi adalah untuk mendapatkan representasi data baru yang dikelola menjadi dimensi lebih rendah [3]. Representasi data baru ditinjau dari sudut waktu dan kompleksitas komputasi yang jauh lebih efektif untuk pengolahan data berikutnya, misalnya untuk klasifikasi, assosiasi, prediksi, estimasi dan analisis pengelompokan [4]
.
Algoritma pengurangan dimensi yang ada seperti ISOMAP (Isometric Feature Mapping) LLE (Local Linear Embedded) [5] kernelPCA,
aljabar linier dan eigen analysis. Cara kerja PCA adalah menemukan himpunan bilangan orthogonal dengan menggunakan teknik SVD [14]] [15] dari proyeksi matriks vektor pada atribut ekstraksi dengan memaksimalkan variances data, kemudian mengurangi dimensi melalui kombinasi linear dari variabel awal tanpa mengorbankan akurasi [16] [17].
Masalah pada objek penelitian ini adalah data dibidang high dimentional biomedis disebabkan karena data high dimentional biomedis memiliki ribuan atribut serta ribuan jumlah record yang saling berkorelasi (multicolinearity) dan menghasilkan data yang kompleks [18]. Data yang kompleks memiliki banyak kebisingan (noise), anomali (outlier), elemen yang hilang (missing value), tidak konsisten dan juga entitas data tidak berhubungan [17] [19].
Penelitian ini menggunakan algoritma principal component analysis (PCA) untuk mengurangi dimensi dan membersihkan korelasi antar atribut pada data high-dimentional biomedical.
2. PENELITIAN TERKAIT
Penelitian seputar pengurangan dimensi yang pernah dilakukan seperti pada penelitian Soemartini [20] menerapkan algoritma principal componet analysis (PCA) untuk mereduksi dan mengatasi data multikolinieritas. Rahmat Widia Sembiring et al [21] mengusulkan sebuah model untuk memproses data multidimensi untuk pengelompokan database kesehatan. Pada penelitian ini menerapkan empat algoritma untuk pengurangan dimensi antara lain Algoritma SVD, principal component analysis (PCA), Self Organizing Map (SOM) dan FastICA dan membandingkan hasilnya dengan mengunakan atau tanpa algoritma pengurangan dimensi pada pengelompokan data (cluster). Hasil penelitian menunjukkan bahwa pengurangan dimensi secara signifikan mengurangi dimensi dan memperpendek waktu proses dan juga meningkatkan kinerja, pada hasil clister DBSCAN dengan SVD memiliki waktu proses tercepat pada beberapa dataset. Václav kabourek [22] menggunakan algoritma principal component analysis (PCA) untuk mengurangi clutter hidden objects detection pada data Synthetic Aperture Radar (SAR)
2.1KONTRIBUSI PENELITIAN
Kontribusi pada penelitian ini pada metode yang diusulkan, mengukur waktu proses, nilai rata-rata dan nilai varian pada data ekstrak yang dihasilkan dan pada dataset yang diuji, penelitian ini dataset yang duji diambil dari: http://datam.i2r.astar.edu.sg/datasets/krbd/.
3. METODE YANG DIUSULKAN
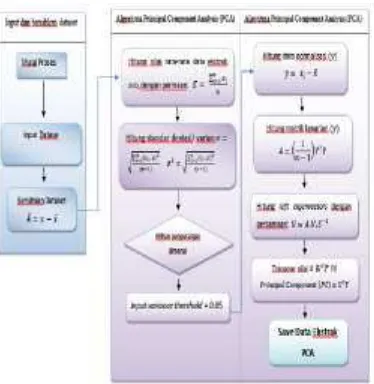
Pada penelitian ini pengurangan dimensi data high dimentional biomedical data set dimulai dengan membersihakan data, membersihkan noise kemudian menormalisasi data, selanjutnya mengurangi dimensi dengan menggunakan algoritma Principal Component Analysis (PCA)
Gambar 1. Metode yang diusulkan
3.1 Data Cleansing
Pembersihan data dimulai dengan proses keterpusatan untuk mengurangi data dengan mencari rata-rata setiap atribut, dengan menggunakan formula ̂ = − ̅ dimana ̂ adalah hasil setelah pemusatan, adalah kolom vektor dan ̅ adalah rata-rata dari kolom yang sesuai. Proses berpusat dilakukan untuk semua rangka dalam, jika nilai null ditemukan, nilai akan diganti dengan nilai rata-rata pada kolom tersebut, hasil dari proses centering dapat digunakan untuk menemukan scetter dengan menggunakan rumus scetter: ̂ ′ ̂ Hasil penyebaran dapat digunakan untuk menemukan nilai kovarian dengan menggunakan rumus
���� =�̂ ′ �̂−1
3.2 Data Denoising
Data denoising menggunakan metode binning [23]. Penelitian ini akan menggunakan metode deteksi outlier dengan � di mana D = jarak, k = tetangga terdekat (nearest neighbour), dan n = titik puncak n. Denoising data outlier dapat dilakukan melalui pencarian dengan ukuran jarak yang sama. Metode ini menyatakan bahwa setiap objek dari kumpulan data dengan jarak terbesar dari k- nearest neighbour disebut outlier.
3.3 Data Normalisasi
Setelah data di denoising langkah berikutnya dinormalisasi. Pada penelitian ini menggunakan fungsi Min to max gunanya untuk mentransformasi variabel jarak (range) yang baru, seperti dari 0 ke 1. digunakan rumus berikut ini [24] [23]
� �′=
�� ��−����� � ��
����� � ���−����� � �� NewMax – � � +
� �
� �′ adalah hasil nilai normalisasi baru. Value adalah variabel nilai asli. Original Min adalah nilai minimum dari variabel asli. Original Max adalah nilai maksimum asli. Nilai Min baru dan Nilai Max baru adalah nilai untuk rentang normal [24] [23].
3.4 Algoritma Principal Component Analysis Kelebihan PCA yaitu mengidentifikasi pola dalam data, dan mengungkapkan data untuk menyorot persamaan dan perbedaan, PCA adalah alat yang ampuh untuk menganalisis data dengan mencari pola-pola dalam data. dengan cara mengurangi dimensi kemudian
mengkompres tanpa kehilangan banyak informasi. [16] [25]. Algoritma Principal Component Analysis (PCA) menggunakan algoritma Singular Value Decompositon (SVD) untuk menemukan himpunan orthogonal [14] [15] yang terbagi dua yaitu right eigenvector � untuk rentang ruang dimensi dan left eigenvector untuk rentang ruang record data yang digunakan untuk menemukan score principal component. Cara kerja PCA mentransformasi � yang memetakan data asli kedalam dimensi data baru, dengan mengurangi dimensi � , yang disebut sebagai Principal Component dari [14] [26].
4. HASIL PENELITIAN DAN
PEMBAHASAN
Sumber data pada penelitian ini diunduh dari http://datam.i2r.astar.edu.sg/datasets/krbd/. Dengan hasil sebagai berikut:
Tabel.1 Eksperiment menggunakan Dataset Breast_Cancer
item result
Process time 5 menit 2 detik keep_variancesce threshold 0.005 Jumlah Atribut 24482 Dimensionality Reduction
Result
14 attribute
Mean 0.000
Variance 0.010
Korelasi Atribut Bersih 100%
Pada uji dataset high dimentional biomedical data set breast cancer atributnya sebanyak 24482, setelah di kurangi dimensi menjadi 14 atribut dengan presentase treshold 0.05 lama proses 5 menit 2 detik
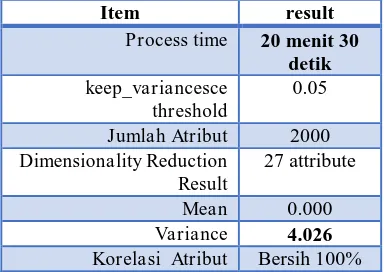
Tabel. 2 Eksperiment menggunakan Dataset Colon_Tumor
Item result
Process time 20 menit 30 detik keep_variancesce
threshold
0.05
Jumlah Atribut 2000 Dimensionality Reduction
Result
27 attribute
Pada uji dataset high dimentional biomedical data set colon tumor atributnya sebanyak 2000, setelah di kurangi dimensi menjadi 27 atribut dengan presentase treshold 0.05 lama proses 20 menit 30 detik .
Tabel. 3 Eksperiment menggunakan Dataset Lunc_Cancer
item result
Process time 1 menit 48 detik keep_variancesce
threshold 0.05 Jumlah Atribut 12534 Dimensionality Reduction
Result 14 attribute Mean 0.000 Variance 3.921 Korelasi Atribut Bersih 100%
Pada uji dataset high dimentional biomedical data set lunch cancer atributnya sebanyak 12534, setelah di kurangi dimensi menjadi 14 atribut dengan presentase treshold 0.05 lama proses 1 menit 48 detik
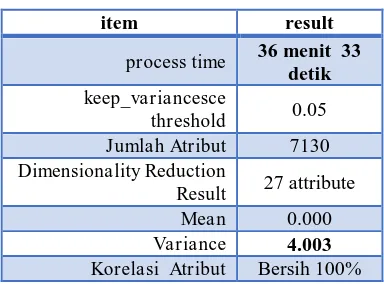
Tabel. 4 Eksperiment pada Dataset Lunc_Michigan
item result
process time 36 menit 33 detik keep_variancesce
threshold 0.05 Jumlah Atribut 7130 Dimensionality Reduction
Result 27 attribute
Mean 0.000
Variance 4.003 Korelasi Atribut Bersih 100%
Pada uji dataset high dimentional biomedical data set lunch michigan atributnya sebanyak 7130, setelah di kurangi dimensi menjadi 27 atribut dengan presentase treshold 0.05 lama proses 36 menit 33 detik
Gambar. 3 data ekstrak Algoritma PCA yang direduksi
& sudah tidak berkorelasi ( dataset Breast_Cancer)
5. KESIMPULAN.
Hasil eksperimen yang dilakukan terbukti bahwa algoritma principal component analysis (PCA) mampu membersihkan 100 % korelasi antar atribut dan mengurangi jumlah atribut dengan presentasi threshold 0.05, nilai rata-rata 0.000 namun nilai varians masih menyebar terbukti dari nilai yang dihasilkan antara 0.010 sampai dengan 4.026, yang artinya hasil data ektraknya belum terpusat dan masih menyebar, waktu prosesnya 1 menit sampai dengan 36 menit. Rencana penelitian selanjutnya akan mengelompokkan (cluster) hasil data ekstrak PCA menggunakan algoritma K-Mean, hasil data ekstrak PCA pada PC1 akan digunakan sebagai titik pusat (cenntroid).
REFERENCES:
[1] Shanwen Zhang; Rongzhi Jing;, “Dimension Reduction Based on Modified Maximum Margin Criterion for Tumor Classification,” dalam Fourth International Conference on Information and Computing, China, 2011.
Engineering (IJCSE), vol. 2 , no. 1, pp. 61-67, 2010.
[3] Longcun Jin; Wanggen Wan; Yongliang Wu; Bin Cui; Xiaoqing Yu; Youyong Wu;, “A Robust High-dimensional Data Reduction Method,” The International Journal of Virtual Reality,, vol. 9, no. 1, pp. 55-60, 2010.
[4] R. Krakovsky; R. Forgac;, “Neural Network Approach to Multidimensional Data Classification via Clustering,” dalam IEEE 9th International Symposium on Intelligent Systems and Informatics , Serbia, 2011.
[5] Panagis Magdalinos; Christos Doulkeridis; Michalis Vazirgiannis;, “Enhancing Clustering Quality through Landmark-Based Dimensionality Reduction,” ACM Transa ctions on Knowledge Discovery from Data, vol. 5, no. 2, pp. 1-44, Februari 2011.
[6] Md. Monjurul Islam; A. S. M. Latiful Hoque;, “Automated Essay Scoring Using Generalized Latent Semantic Analysis,” Journal of Computer, vol. 7, no. 3, pp. 616-626, March 2012.
[7] Altangerel Chagnaa; Cheol-Young Ock; Chang-Beom Lee; Purev Jaimai;, “Feature Extraction of Concepts by Independent Component Analysis,” International Journal of Information Processing Systems, vol. 3, no. 1, pp. 33-37, June 2007.
[8] Ethem Alpaydın, Introduction to Machine Learning, Second penyunt., T. Dietterich, C. Bishop, D. Heckerman dan M. Jorda, Penyunt., London,: Cambridge, Massachusetts, 2010.
[9] Ignacio Gonzalez;Sebastien Dejean;Pascal G. P. Martin;Alain Baccini, “CCA: An R Package to Extend Canonical,” Journal of Statistical Software, vol. 23, no. 12, pp. 1-14, January 2008.
[10] Matthias Scholz; Martin Fraunholz; Joachim Selbig;, “Nonlinear Principal Component Analysis Neural Network Models and Applications,” dalam Federal Ministry of Education and Research (BMBF ), German , 2008.
[11] Liang Sun; Shuiwang J; Shipeng Yu; Jieping Ye;, “On the Equivalence Between Canonical Correlation Analysis
and Orthonormalized Partial Least Squares,” The International journal of Multimedia & Its Applications (IJMA), vol. 2, no. 3, pp. 1230-1235, Agustus 2010.
[12] Neeta Nain; Prashant Gour; Nitish Agarwal; Rakesh P Talawar; Subhash Chandra;, “Face Recognition using PCA and LDA with Singular Value Decomposition(SVD) using 2DLDA,” dalam Proceedings of the World Congress on Engineering, London, U.K, 2008.
[13] Fangzhou Yao; Jeff Coquery; Kim-Anh Lê Cao;, “Independent Principal Component Analysis for biologically meaningful dimension reduction of large biological data sets,” IEEE Transaction On Computational Biology and Bioinformatics, vol. 13, no. 24, pp. 1-15, 2012.
[14] Mario Navas; Carlos Ordonez;, “Efficient computation of PCA with SVD in SQL,” dalam ACM, Paris, 2009.
[15] Rinsurongkawong, Waree; Carlos Ordonez;, “Microarray Data Analysis with PCA in a DBMS,” dalam DTMBIO Napa Valley, California, USA, 2008.
[16] Chang, Cheng-Ding; Wang, Chien-Chih; Jiang, Bernard C;, “Singular Value Decomposition Based Feature Extraction Technique for Physiological Signal Analysis,” Journal of Medical Systems., vol. 36, no. 3, pp. 1769 - 1777, June 2012.
[17] Sanga, S; Chou, T.Y; Cristini, V; Edgerton, M.E;, “Neural Network with K -Means Clustering via PCA for Gene Expression Profile Analysis,” IEEE - Computer Science and Information Engineering, vol. 3, pp. 670-673, April 2009.
[18] Biswas, Shameek; Storey, John D; Akey, Joshua M, “Mapping gene expression quantitativetrait loci by singular value decomposition and independent component analysis,” IEEE Transaction On Computational Biology and Bioinformatics, vol. 5, no. 7, pp. 1-14, May 2008.
(IJAIA),, vol. 1, no. 4, pp. 44-52, October 2010.
[20] Soemartini, “aplikasi principal component analysis (pca) dalam mengatasi multikolinieritas untuk menentukan investasi di indonesia periode 2001.1-2010.4,” jurusan statistika fmipa unpad , Bandung, 2011-2014.
[21] Rahmat Widia Sembiring; Jasni Mohamad Zain; Abdullah Embong;, “Dimension Reduction of Health Data Clustering,” International Journal on New Computer Architectures and Their Applications (IJNCAA), vol. 1, no. 3, pp. 1041-1050, 2011.
[22] Václav Kabourek; Petr Černý; Miloš Mazánek;, “Clutter Reduction Based On Principal Component Analysis Technique For Hidden Objects Detection,” Radioengineering, Vol. 21, No. 1, April 2012, Vol. 21, No. 1, Pp. 464-470, April 2012.
[23] Sembiring , Rahmat Widia; Jasni , Mohamad Zain;, “The Design of Pre -Processing Multidimensional Data Based on Component Analysis,” Computer and Information Science, vol. 4, no. 3, pp. 106-115, May 2011.
[24] Glenn J. Myatt, Making Sense of Data A Practical Guide to Exploratory Data Analysis and Data Mining, Hoboken: John Wiley & Sons, Inc, 2007.
[25] Ribeiro, Marcela X; Ferreira, Mônica R. P. ; Traina Jr., Caetano ;, “Data Pre -processing: A new algorithm for Feature Selection and Data Discretization,” dalam ACM, Cergy-Pontoise, France, 2008. [26] Aditya Krishna Menon; Charles Elkan;,
“Fast Algorithms for Approximating the Singular Value Decomposition,” Transactions on Knowledge Discovery from Data, vol. 5, no. 2, pp. 16-37, Februari 2011.
[27] Hsinchun Chen; Mihail C. Roco;, “Global and Longitudinal Patent and Literature Analysis,” dalam Mapping Nano Technology Innovations and Knowledge, P. R. Sharda dan P. D. Stefan, Penyunt., Tucson, Arizona, Arlington, Virginia, springer.com, 2009, pp. 1-321.
[28] Jiawei Han ; Micheline Kamber;, Data Mining: Concepts and Techniques, Second penyunt., A. Stephan, Penyunt.,
San Francisco: Morgan Kaufmann Publishers is an imprint of Elsevier, 2007.
[29] Karunaratne, Thashmee ; Boström, Henrik; Norinder, Ulf;, “Pre-Processing Structured Data for Standard Machine Learning Algorithms by Supervised Graph Propositionalization - a Case Study with Medicinal Chemistry Datasets,” dalam International Conference on Machine Learning and Applications, Sweden, 2010.
[30] D.Napoleon; S.Pavalakodi;, “A New Method for Dimensionality Reduction using K Means Clustering Algorithm for High Dimensional Data Set,” International Journal of Computer Applications (0975 – 8887), vol. 13, no. 7, pp. 41-46, January 2011.
[31] B. B. Zhao and Y. Q. Chen, “Singular value decomposition (SVD) for extraction of gravity anomaly associated with gold mineralization in Tongshi gold field,Western Shandong Uplifted Block, Eastern China,” Beijing- China, 2011. [32] Jun Yan, Benyu Zhang, Ning Liu;
Shuicheng Yan; Qiansheng Cheng; Weiguo Fan; Qiang Yang; Wensi Xi; Zheng Chen;, “Effective and Efficient Dimensionality Reduction for Large-Scale and Streaming Data Preprocessing,” IEEE Transaction On Knowledge And Data Engineering, vol. 18, no. 2, pp. 1-14, Febbruari 2008.
[33] Ali Shadvar, “Dimension Reduction by Mutual Information discriminant analysis,” International Journal of Artificial Intelligence & Applications (IJAIA), vol. 3, no. 3, pp. 23-35, May 2012.
[34] Taufik Fuadi Abidin; Bustami Yusuf; Munzir Umran;, “Singular Value Decomposition for Dimensionality Reduction in Unsupervised Text Learning Problems,” dalam 2nd International Conference on Education Technology and Computer (ICETC), Banda Aceh - Indonesia, 201O.
[36] Luis M. Ledesma-Carrillo; Eduardo Cabal-Yepez; Rene de J. Romero-Troncoso; Roque A. Osornio-Rios; Tobia D. Carozzi;, “Reconfigurable FPGA -Based Unit for Singular Value Decomposition of Large m × n Matrices,” dalam International Conference on Reconfigurable Computing and FPGAs, Mexico & Sweden, 2011.
[37] Sembiring, Rahmat Widia; Zain, Jasni Mohamad; Embong, Abdullah;, “Dimension Reduction of Health Data Clustering,” International Journal on New Computer Architectures and Their Applications (IJNCAA), vol. 3, no. 1, pp. 1041-1050, 2011.
[38] Taufik Fuadi Abidin ; Bustami Yusuf ; Munzir Umran;, “Singular Value Decomposition for Dimensionality Reduction in Unsupervised Text Learning Problems,” dalam 2nd International Conference on Education Technology and Computer (ICETC), Banda Aceh-Indonesia, 201O.
[39] S.M. Rafizul Haque, “Singular Value Decomposition and Discrete,” Sweden, 2008.
[40] Eko Prasetyo, “Reduksi Dimensi Set Data Dengan Drc Pada Metode Klasifikasi Svm Dengan Upaya Penambahan Komponen Ketiga,” Dalam Snatif Ke-1 Tahun 2014, Surabaya, 2014.
[41] Jha, Sunil K.; R. D. S. Yadava;, “Denoising by Singular Value Decomposition and Its Application to Electronic Nose Data Processing,” IEEE Sensor Journal, vol. 11, no. 1, pp. 35-44, January 2011.
[42] Taufik Fuadi Abidin; Bustami Yusuf; Munzir Umran;, “Singular Value Decomposition for Dimensionality Reduction in Unsupervised Text Learning Problems,” dalam 2nd International Conference on Education Technology and Computer (ICETC), Banda Aceh - Indonesia, 2010.
[43] Stan Lipovetsky;, “PCA and SVD with nonnegative loadings,” GfK Custom Research for excelence, vol. 42, no. 1, pp. 1-30, Januari 2009.
[44] Taro Konda; Yoshimasa Nakamura;, “A new algorithm for singular value decomposition and its parallelization,”
Parallel Computing, vol. 02, no. 001, pp. 1-14, 2009.
[45] C.Venkata Narasimhulu; K.Satya Prasad;, “A Robust Watermarking Technique based on Nonsubsampled Contourlet Transform and SVD,” International Journal of Computer Applications, vol. 16, no. 8, pp. 27-36, February 2011.
[46] Kumar, Nishith; Mohammed Nasser ; Subaran Chandra Sarker;, “A New Singular Value Decomposition Based Robust Graphical Clustering Technique and Its Application in Climatic Data,” Journal of Geography and Geology, vol. 3, no. 1, pp. 227-238, September 2011.
[47] Pritha.D.N; L.Savitha; Shylaja.S.S ;, “Face Recognition by Feedforward Neural Network using Laplacian of Gaussian filter and Singular Value Decomposition,” dalam IEEE International Conference on Data Engineering, India, 2010.
[48] Hu Zhihua, “Binary Image Watermarking Algorithm Based on SVD,” dalam International Conference on Intelligent Human-Machine Systems and Cybernetics, China, 2009.
[49] Satyanarayana Murty. P; M.Uday Bhaskar; P. Rajesh Kumar;, “A Semi-Blind Reference Watermarking Scheme Using DWT-DCT-SVD for Copyright Protection,” International Journal of Computer Science & Information Technology (IJCSIT), vol. 4, no. 2, pp. 69-82, April 2012.
[50] Lailil Muflikhah; Baharum Baharudin;, “Document Clustering using Concept Space and Cosine Simila rity Measurement,” dalam 2009 International Conference on Computer Technology and Development, Malaysia, 2009.