Edgar Weippl
(Eds.)
123
LNCS 9327
20th European Symposium on Research in Computer Security
Vienna, Austria, September 21–25, 2015
Proceedings, Part II
Commenced Publication in 1973 Founding and Former Series Editors:
Gerhard Goos, Juris Hartmanis, and Jan van Leeuwen
Editorial Board
David HutchisonLancaster University, Lancaster, UK Takeo Kanade
Carnegie Mellon University, Pittsburgh, PA, USA Josef Kittler
University of Surrey, Guildford, UK Jon M. Kleinberg
Cornell University, Ithaca, NY, USA Friedemann Mattern
ETH Zurich, Zürich, Switzerland John C. Mitchell
Stanford University, Stanford, CA, USA Moni Naor
Weizmann Institute of Science, Rehovot, Israel C. Pandu Rangan
Indian Institute of Technology, Madras, India Bernhard Steffen
TU Dortmund University, Dortmund, Germany Demetri Terzopoulos
University of California, Los Angeles, CA, USA Doug Tygar
University of California, Berkeley, CA, USA Gerhard Weikum
Edgar Weippl (Eds.)
Computer Security
–
ESORICS 2015
20th European Symposium on Research in Computer Security
Vienna, Austria, September 21
–
25, 2015
Proceedings, Part II
University of Regensburg Regensburg
Germany Peter Y A Ryan
University of Luxembourg Luxembourg
Luxembourg
SBA Research Wien Austria
ISSN 0302-9743 ISSN 1611-3349 (electronic) Lecture Notes in Computer Science
ISBN 978-3-319-24176-0 ISBN 978-3-319-24177-7 (eBook) DOI 10.1007/978-3-319-24177-7
Library of Congress Control Number: 2015948157 LNCS Sublibrary: SL4–Security and Cryptology Springer Cham Heidelberg New York Dordrecht London ©Springer International Publishing Switzerland 2015
This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed.
The use of general descriptive names, registered names, trademarks, service marks, etc. in this publication does not imply, even in the absence of a specific statement, that such names are exempt from the relevant protective laws and regulations and therefore free for general use.
The publisher, the authors and the editors are safe to assume that the advice and information in this book are believed to be true and accurate at the date of publication. Neither the publisher nor the authors or the editors give a warranty, express or implied, with respect to the material contained herein or for any errors or omissions that may have been made.
Printed on acid-free paper
It is our great pleasure to welcome you to the 20thEuropean Symposium on Research in Computer Security (ESORICS 2015).
This year’s symposium continues its tradition of establishing a European forum for bringing together researchers in the area of computer security, by promoting the exchange of ideas with system developers and by encouraging links with researchers in related areas.
The call for papers attracted 293 submissions– a record in the ESORICS series– from 41 countries. The papers went through a careful review process and were eval-uated on the basis of their significance, novelty, technical quality, as well as on their practical impact and/or their level of advancement of the field’s foundations. Each paper received at least three independent reviews, followed by extensive discussion. Wefinally selected 59 papers for thefinal program, resulting in an acceptance rate of 20 %.
The program was completed with keynote speeches by Sushil Jajodia, George Mason University Fairfax, USA and Richard Clayton, University of Cambridge, UK. Putting together ESORICS 2015 was a team effort. Wefirst thank the authors for providing the content of the program. We are grateful to the Program Committee, who worked very hard in reviewing papers (more than 880 reviews were written) and providing feedback for authors. There is a long list of people who volunteered their time and energy to put together and organize the conference, and who deserve special thanks: the ESORICS Steering Committee, and its chair Pierangela Samarati in par-ticular, for their support; Giovanni Livraga, for taking care of publicity; Javier Lopez, as workshop chair, and all workshop co-chairs, who organized workshops co-located with ESORICS; and Yvonne Poul for the local organization and the social events.
Finally, we would like to thank our sponsors, HUAWEI, for thefinancial support and SBA Research, for hosting and organizing ESORICS 2015.
A different country hosts the conference every year. ESORICS 2015 took place in Vienna, Austria at the Vienna University of Technology. We are very happy to have hosted the 20th edition of the symposium in Vienna and we tried to put together a special social program for you, giving you the opportunity to share ideas with other researchers and practitioners from institutions around the world and see all the beautiful sights of Vienna.
We hope that you found this program interesting and thought-provoking and that you enjoyed ESORICS 2015 and Vienna.
July 2015 Günther Pernul
General Chair
Günther Pernul Universität Regensburg, Germany
Program Chairs
Peter Y A Ryan University of Luxembourg, Luxembourg
Edgar Weippl SBA Research & Vienna University of Technology, Austria
Workshops Chair
Javier Lopez University of Malaga, Spain
Program Committee
Alessandro Armando Universitàdi Genova, Italy Vijay Atluri Rutgers University, USA Michael Backes Saarland University, Germany
Feng Bao Security and Privacy Lab, Huawei, China David A. Basin ETH Zurich, Switzerland
Giampaolo Bella Universitàdi Catania, Italy
Carlo Blundo Universitàdegli Studi di Salerno, Italy Stefan Brunthaler SBA Research, Austria
Ran Canetti Tel Aviv University, Israel
Liqun Chen HP Labs, UK
Michael Clarkson Cornell University, USA Jason Crampton University of London, UK Cas Cremers University of Oxford, UK Frédéric Cuppens Télécom Bretagne, France Nora Cuppens-Boulahia Télécom Bretagne, France Sabrina De Capitani
di Vimercati
Universitàdegli Studi di Milano, Italy
Wenliang Du Syracuse University, USA Hannes Federrath University of Hamburg, Germany Simon Foley University College Cork, Ireland Sara Foresti Universitàdegli Studi di Milano, Italy
Felix Freiling Friedrich-Alexander-Universität Erlangen-Nürnberg, Germany
Dieter Gollmann TU Hamburg-Harburg, Germany Dimitris Gritzalis AUEB, Greece
Joshua Guttman MTIRE Corp and Worcester Polytechnic, USA
Feng Hao Newcastle University, UK
Amir Herzberg Bar-Ilan University, Israel Xinyi Huang Fujian Normal University, China Michael Huth Imperial College, UK
Sotiris Ioannidis FORTH, Crete
Sushil Jajodia George Mason University, USA Markus Jakobsson Qualcomm, USA
Sokratis K. Katsikas University of Piraeus, Greece Stefan Katzenbeisser TU Darmstadt, Germany Florian Kerschbaum SAP, Germany
Steve Kremer INRIA Nancy and LORIA, France Adam J. Lee University of Pittsburgh, USA Wenke Lee Georgia Institute of Technology, USA Yingjiu Li Singapore Management University, Singapore Peng Liu Pennsylvania State University, USA
Javier Lopez University of Malaga, Spain
Wenjing Lou Virginia Polytechnic Institute and State University, USA
Haibing Lu Santa Clara University, USA Antonio Maña Univeristy of Malaga, Spain Roy Maxion Carnegie Mellon University, USA Catherine Meadows Naval Research Laboratory, USA
Carroll Morgan University of New South Wales, Australia John C. Mitchell Stanford University, USA
Martin Mulazzani SBA Research, Austria David Naccache ENS, France
Rolf Oppliger eSecurity Technologies, Switzerland Stefano Paraboschi Universitàdegli Studi di Bergamo, Italy Olivier Pereira UCL Crypto Group, Belgium
Günther Pernul University of Regensburg, Germany Bart Preneel Katholieke Universiteit Leuven, Belgium Jean-Jacques Quisquater UCL, Belgium
Kui Ren University at Buffalo, State University of New York, USA
Mark Ryan University of Birmingham, UK Ahmad-Reza Sadeghi TU Darmstadt, Germany
Pierangela Samarati Universitàdegli Studi di Milano, Italy Nitesh Saxena University of Alabama at Birmingham, USA
Andreas Schaad SAP, Germany
Steve Schneider University of Surrey, UK
Jörg Schwenk Ruhr University Bochum, Germany
Einar Snekkenes Gjovik University College, Norway Philip Stark University of California, Berkeley, USA Vanessa Teague University of Melbourne, Australia Jaideep Vaidya Rutgers University, USA
Paulo Verissimo University of Luxembourg, Luxembourg Luca Viganò King’s College London, UK
Michael Waidner TU Darmstadt, Germany
Cong Wang City University of Hong Kong, China Lingyu Wang University of Concordia, Canada Ting Yu North Carolina State University, USA Meng Yu Virginia Commonwealth University, USA
Moti Yung Google, USA
Privacy
FP-Block: Usable Web Privacy by Controlling Browser Fingerprinting . . . 3 Christof Ferreira Torres, Hugo Jonker, and Sjouke Mauw
Mind-Reading: Privacy Attacks Exploiting Cross-App KeyEvent Injections. . . 20 Wenrui Diao, Xiangyu Liu, Zhe Zhou, Kehuan Zhang, and Zhou Li
Enabling Privacy-Assured Similarity Retrieval over Millions
of Encrypted Records . . . 40 Xingliang Yuan, Helei Cui, Xinyu Wang, and Cong Wang
Privacy-Preserving Link Prediction in Decentralized Online
Social Networks . . . 61 Yao Zheng, Bing Wang, Wenjing Lou, and Y. Thomas Hou
Privacy-Preserving Observation in Public Spaces. . . 81 Florian Kerschbaum and Hoon Wei Lim
Privacy-Preserving Context-Aware Recommender Systems: Analysis
and New Solutions . . . 101 Qiang Tang and Jun Wang
Cloud Security
Rich Queries on Encrypted Data: Beyond Exact Matches . . . 123 Sky Faber, Stanislaw Jarecki, Hugo Krawczyk, Quan Nguyen,
Marcel Rosu, and Michael Steiner
Extended Proxy-Assisted Approach: Achieving Revocable Fine-Grained
Encryption of Cloud Data . . . 146 Yanjiang Yang, Joseph K. Liu, Kaitai Liang, Kim-Kwang Raymond
Choo, and Jianying Zhou
Batch Verifiable Computation of Polynomials on Outsourced Data . . . 167 Liang Feng Zhang and Reihaneh Safavi-Naini
CloudBI: Practical Privacy-Preserving Outsourcing of Biometric
Identification in the Cloud . . . 186 Qian Wang, Shengshan Hu, Kui Ren, Meiqi He, Minxin Du,
Protocols and Attribute-Based Encryption
Typing and Compositionality for Security Protocols: A Generalization
to the Geometric Fragment . . . 209 Omar Almousa, Sebastian Mödersheim, Paolo Modesti,
and Luca Viganò
Checking Trace Equivalence: How to Get Rid of Nonces? . . . 230 Rémy Chrétien, Véronique Cortier, and Stéphanie Delaune
Attribute Based Broadcast Encryption with Short Ciphertext
and Decryption Key . . . 252 Tran Viet Xuan Phuong, Guomin Yang, Willy Susilo, and Xiaofeng Chen
Accountable Authority Ciphertext-Policy Attribute-Based Encryption
with White-Box Traceability and Public Auditing in the Cloud . . . 270 Jianting Ning, Xiaolei Dong, Zhenfu Cao, and Lifei Wei
Code Analysis and Side-Channels
DexHunter: Toward Extracting Hidden Code from Packed
Android Applications. . . 293 Yueqian Zhang, Xiapu Luo, and Haoyang Yin
Identifying Arbitrary Memory Access Vulnerabilities in Privilege-Separated
Software . . . 312 Hong Hu, Zheng Leong Chua, Zhenkai Liang, and Prateek Saxena
vBox: Proactively Establishing Secure Channels Between Wireless Devices
Without Prior Knowledge. . . 332 Wei Wang, Jingqiang Lin, Zhan Wang, Ze Wang, and Luning Xia
Detection and Monitoring
Accurate Specification for Robust Detection of Malicious Behavior
in Mobile Environments. . . 355 Sufatrio, Tong-Wei Chua, Darell J.J. Tan, and Vrizlynn L.L. Thing
A Bytecode Interpreter for Secure Program Execution in Untrusted
Main Memory . . . 376 Maximilian Seitzer, Michael Gruhn, and Tilo Müller
Learning from Others: User Anomaly Detection Using Anomalous Samples
from Other Users . . . 396 Youngja Park, Ian M. Molloy, Suresh N. Chari, Zenglin Xu, Chris Gates,
Authentication
Towards Attack-Resistant Peer-Assisted Indoor Localization. . . 417 Jingyu Hua, Shaoyong Du, and Sheng Zhong
Leveraging Real-Life Facts to Make Random Passwords More Memorable. . . . 438 Mahdi Nasrullah Al-Ameen, Kanis Fatema, Matthew Wright,
and Shannon Scielzo
The Emperor’s New Password Creation Policies:: An Evaluation of Leading Web Services and the Effect of Role in Resisting Against
Online Guessing . . . 456 Ding Wang and Ping Wang
Policies
A Theory of Gray Security Policies . . . 481 Donald Ray and Jay Ligatti
Factorization of Behavioral Integrity . . . 500 Ximeng Li, Flemming Nielson, and Hanne Riis Nielson
Checking Interaction-Based Declassification Policies for Android
Using Symbolic Execution . . . 520 Kristopher Micinski, Jonathan Fetter-Degges, Jinseong Jeon,
Jeffrey S. Foster, and Michael R. Clarkson Applied Security
Enhancing Java Runtime Environment for Smart Cards Against
Runtime Attacks . . . 541 Raja Naeem Akram, Konstantinos Markantonakis, and Keith Mayes
Making Bitcoin Exchanges Transparent . . . 561 Christian Decker, James Guthrie, Jochen Seidel, and Roger Wattenhofer
Web-to-Application Injection Attacks on Android: Characterization
and Detection . . . 577 Behnaz Hassanshahi, Yaoqi Jia, Roland H.C. Yap, Prateek Saxena,
and Zhenkai Liang
All Your Voices are Belong to Us: Stealing Voices to Fool Humans
and Machines . . . 599 Dibya Mukhopadhyay, Maliheh Shirvanian, and Nitesh Saxena
Balloon: A Forward-Secure Append-Only Persistent Authenticated
On the Fly Design and Co-simulation of Responses Against
Simultaneous Attacks . . . 642 Léa Samarji, Nora Cuppens-Boulahia, Frédéric Cuppens,
Serge Papillon, Waël Kanoun, and Samuel Dubus
Networks and Web Security
Towards Security of Internet Naming Infrastructure . . . 3 Haya Shulman and Michael Waidner
Waiting for CSP– Securing Legacy Web Applications with JSAgents. . . 23 Mario Heiderich, Marcus Niemietz, and Jörg Schwenk
Analyzing the BrowserID SSO System with Primary Identity Providers
Using an Expressive Model of the Web . . . 43 Daniel Fett, Ralf Küsters, and Guido Schmitz
System Security
A Practical Approach for Adaptive Data Structure Layout Randomization . . . 69 Ping Chen, Jun Xu, Zhiqiang Lin, Dongyan Xu, Bing Mao, and Peng Liu
Trustworthy Prevention of Code Injection in Linux on Embedded Devices . . . 90 Hind Chfouka, Hamed Nemati, Roberto Guanciale, Mads Dam,
and Patrik Ekdahl
Practical Memory Deduplication Attacks in Sandboxed Javascript . . . 108 Daniel Gruss, David Bidner, and Stefan Mangard
Cryptography
Computational Soundness for Interactive Primitives. . . 125 Michael Backes, Esfandiar Mohammadi, and Tim Ruffing
Verifiably Encrypted Signatures: Security Revisited and a New
Construction . . . 146 Christian Hanser, Max Rabkin, and Dominique Schröder
Interleaving Cryptanalytic Time-Memory Trade-Offs on Non-uniform
Distributions. . . 165 Gildas Avoine, Xavier Carpent, and Cédric Lauradoux
Symmetric-Key Based Proofs of Retrievability Supporting Public
Verification . . . 203 Chaowen Guan, Kui Ren, Fangguo Zhang, Florian Kerschbaum,
and Jia Yu
DTLS-HIMMO: Achieving DTLS Certificate Security with Symmetric Key
Overhead . . . 224 Oscar Garcia-Morchon, Ronald Rietman, Sahil Sharma,
Ludo Tolhuizen, and Jose Luis Torre-Arce
Short Accountable Ring Signatures Based on DDH . . . 243 Jonathan Bootle, Andrea Cerulli, Pyrros Chaidos, Essam Ghadafi,
Jens Groth, and Christophe Petit
Updatable Hash Proof System and Its Applications . . . 266 Rupeng Yang, Qiuliang Xu, Yongbin Zhou, Rui Zhang, Chengyu Hu,
and Zuoxia Yu
Server-Aided Revocable Identity-Based Encryption . . . 286 Baodong Qin, Robert H. Deng, Yingjiu Li, and Shengli Liu
Efficient Zero-Knowledge Proofs for Commitments from Learning
with Errors over Rings. . . 305 Fabrice Benhamouda, Stephan Krenn, Vadim Lyubashevsky,
and Krzysztof Pietrzak
MakingAnyIdentity-Based Encryption Accountable, Efficiently . . . 326 Aggelos Kiayias and Qiang Tang
Practical Threshold Password-Authenticated Secret Sharing Protocol . . . 347 Xun Yi, Feng Hao, Liqun Chen, and Joseph K. Liu
On Security of Content-Based Video Stream Authentication . . . 366 Swee-Won Lo, Zhuo Wei, Robert H. Deng, and Xuhua Ding
Oblivious Maximum Bipartite Matching Size Algorithm with Applications
to Secure Fingerprint Identification . . . 384 Marina Blanton and Siddharth Saraph
Practical Invalid Curve Attacks on TLS-ECDH. . . 407 Tibor Jager, Jörg Schwenk, and Juraj Somorovsky
Crypto Applications and Attacks
Challenging the Trustworthiness of PGP: Is the Web-of-Trust Tear-Proof? . . . 429 Alessandro Barenghi, Alessandro Di Federico, Gerardo Pelosi,
Transforming Out Timing Leaks, More or Less . . . 447 Heiko Mantel and Artem Starostin
Small Tweaks Do Not Help: Differential Power Analysis of MILENAGE
Implementations in 3G/4G USIM Cards. . . 468 Junrong Liu, Yu Yu, François-Xavier Standaert, Zheng Guo, Dawu Gu,
Wei Sun, Yijie Ge, and Xinjun Xie
Risk Analysis
Should Cyber-Insurance Providers Invest in Software Security? . . . 483 Aron Laszka and Jens Grossklags
Lightweight and Flexible Trust Assessment Modules for the Internet
of Things . . . 503 Jan Tobias Mühlberg, Job Noorman, and Frank Piessens
Confidence Analysis for Nuclear Arms Control: SMT Abstractions
of Bayesian Belief Networks . . . 521 Paul Beaumont, Neil Evans, Michael Huth, and Tom Plant
Browser Fingerprinting
Christof Ferreira Torres1, Hugo Jonker2(B), and Sjouke Mauw1 1 CSC/SnT, University of Luxembourg, Luxembourg, Luxembourg 2 Open University of the Netherlands, Heerlen, The Netherlands
Abstract. Online tracking of users is used for benign goals, such as detecting fraudulent logins, but also to invade user privacy. We posit that for non-oppressed users, tracking within one website does not have a substantial negative impact on privacy, while it enables legitimate ben-efits. In contrast,cross-domain tracking negatively impacts user privacy, while being of little benefit to the user.
Existing methods to counter fingerprint-based tracking treat cross-domain tracking and regular tracking the same. This often results in ham-pering or disabling desired functionality, such as embedded videos. By distinguishing between regular and cross-domain tracking, more desired functionality can be preserved. We have developed a prototype tool, FP-Block, that counters cross-domain fingerprint-based tracking while still allowing regular tracking. FP-Block ensures that any embedded party will see a different, unrelatable fingerprint for each site on which it is embedded. Thus, the user’s fingerprint can no longer be tracked across the web, while desired functionality is better preserved compared to exist-ing methods.
1
Introduction
Online activities play an ever-growing role in everyday life. Consequently, com-panies are increasingly tracking users online [14]. There may be various rea-sons for such tracking, such as fraud prevention by identifying illegitimate usage attempts [16], suggesting related content, and better targeting advertisements. Where such tracking remains confined to the tracker’s own website, the balance between privacy and functionality is (arguably) satisfied: the website learns a user’s browsing habits on that particular website, which helps to improve the websitefor this user. We will call this type of trackingregular tracking.
However, some companies offer online services that are embedded on a large number of websites. Examples of such services are social sharing buttons, popular JavaScript libraries, and popular web analytics services. Thanks to this ubiqui-tous embedding, such companies can track users over large portions of the web. According to various studies, plenty of different companies are embedded on a sizable1portion of the Web. For example, consider the Facebook “Like” button. 1 E.g. penetration rates for top 1 million sites according to BuiltWith.com(October 2014):DoubleClick.net18.5 %,Facebook Like button15.6 %,Google Analytics46.6 %. c
Springer International Publishing Switzerland 2015
The embedding site includes a piece of code that triggers the user’s browser to contact the Facebook servers to download the button. As browsers are made to explain where a request originated (the HTTPRefererfield), the browser will tell Facebook exactly which URL triggered this request each time. This enables Facebook to track the user across the web [15], irrespective of whether or not the user even has a Facebook account. We will call this type of trackingthird-party tracking.
This tracking can be done using an HTTP cookie, but even if such (third party) cookies are blocked, it is possible to infer a set of attributes (screen resolution, HTTP user agent, time zone, etc.) that are often sufficient to uniquely identify the user [5]. Note that such attributes were intended to benefit the user, e.g. to present her the mobile version of a site when browsing from a phone, or to present the page in the user’s preferred language. Yet even though personalia such as name or age are not explicitly revealed, the tracker can learn far more about the users than one realises2.
Identifying users by such means is called “fingerprinting”. Much like a fin-gerprint belongs to one unique individual, a finfin-gerprint of communication with a server belongs to a unique browser.
Existing countermeasures combat such fingerprint-based tracking with little regard for the impact on the user experience. The goal is then to find an approach that ensures a better balance between user experience (that is: less impact on desired embedded contents) and tracking. We address this with the concept of web identity: the set of fingerprintable browser characteristics. A web identity is generated for the main site visited (e.g.,bbc.com), and that identity is then also used for all interaction with embedded contents on that site (e.g. videos, social media buttons, etc.). If the user visits a different site (e.g.,cnn.com), a different identity is used (the web identity forcnn.com). Thus, a party embedded on both sites will first see the web identity for bbc.com, and later the web identity for cnn.com. As we ensure that the generated identities are distinct, the two visits can no longer be linked by means of their fingerprint. We focus on fingerprinters that aim to re-identify as many users as possible. We do not target tools that are seeking to track any one specific individual.
Contributions. The main contributions of our research are the following: 1. We argue that a distinction be made between regular and cross-domain
track-ing; we observe that current anti-tracking tools do not make this distinction. 2. We introduce the notion of a web identity to generalize the rather dynamic notion of a fingerprint. We proposeseparation of web identitiesas an approach to fingerprint privacy that prevents cross-domain tracking, while allowing regular tracking.
3. We have developed a prototype browser extension, FP-Block, that supports the automatic generation and management of web identities. A user’s web identity remains constant across all his visits to the same domain, while his 2 E.g. by data aggregation, a supermarket can infer if a customer is pregnant, and
web identities for different domains are not related. The tool has a user inter-face that shows which third parties are embedded in the current page, which fingerprintable attributes are requested by the website and how these are spoofed by the tool. This allows the user to fine-tune the tool for individual sites.
4. By deobfuscating the code of the most relevant fingerprinters, we compiled an up-to-date list of the attributes used by current fingerprinters. Further, based on a literature study, we compiled a list of the attributes affected by the most relevant anti-tracking tools. These lists guided our design and helped us to compare our work to existing tools.
5. We have tested our tool against six fingerprinters in two different scenarios: first-party fingerprinting and third-party fingerprinting. In all cases, our tool was successful in affecting the computed fingerprint.
As final validation, we tested our tool against a commercial fingerprinter’s online tracking ID. Again the tool was successful: the tracking ID without the tool was different from the ID when running the tool.
2
Related Work
We distinguish related work between work on fingerprinting and work on coun-termeasures against tracking and fingerprinting.
2.1 Fingerprinting
The possibility of remotely inferring characteristics of devices has been known for some time. E.g. Kohno et al. [6] use TCP clock skew to remotely fingerprint devices. Eckersley [5] was the first to draw significant attention to the problem of fingerprinting web browsers. His fingerprinting algorithm returned a unique fingerprint for 83.6 % of the browsers considered. Subsequent papers established how to fingerprint other aspects such as the user-agent string and IP address [17], the HTML5 “canvas” element [10], the used Javascript engine [9,11], the fonts present [3], etc. Other work has suggested approaches to combine several fin-gerprintable attributes to arrive at unique fingerprints (e.g. [3,17]). Using such techniques only on one site does not constitute a large invasion of privacy. How-ever, as Mayer and Mitchel [8] and Roosendaal [15] have pointed out, social plugins are embedded on many pages, which allows the social network to track users across the Internet. Thanks to fingerprinting, such tracking does not even require an account – anyone with a unique fingerprint can be traced.
In a followup study, Acar et al. [1] investigate the spread of three tracking mecha-nisms, amongst which HTML5 canvas fingerprinting. They propose three heuris-tics to estimate whether a canvas is being used to fingerprint; we adopt these criteria in our tool. This paper also shows that canvas fingerprinting is being used by a popular 3rd party service (AddThis.com). Nikiforakis et al. [13] pro-vide a detailed study of the fingerprinting techniques of three online fingerprint services (BlueCava, Iovation and ThreatMetrix). They found that fingerprinting can be tailored to the detected browser, e.g. when detecting a browser as Inter-net Explorer, the fingerprint would include InterInter-net Explorer-specific attributes. Moreover, Flash was used by all three to enrich the established fingerprint. Flash allows access to many similar attributes as JavaScript, but may give a more detailed response (e.g. including major and minor kernel version number). More-over, Flash ignores a browser’s proxy settings for client-server communication. This allows the fingerprint services to detect if the user is behind a proxy or not, and correlate the IP address of the proxy with that of the user.
2.2 Countermeasures
Several existing plugins directly aim to stop trackers, including commercially developed ones (e.g. Ghostery, AVG Do Not Track, etc.), and academically devel-oped ones, such as FireGloves [3], ShareMeNot [14], PriVaricator [12], etc. Some of these work by blocking trackers, either by using a predefined blacklist or by updating the blacklist on the fly using heuristic rules. Krishnamurthy and Wills [7] argue that blacklists are prone to being incomplete (not all trackers blocked), and therefore ultimately fail at blocking trackers. A similar argument holds against heuristically updated blacklists: the next tracker may well use tracking methods not covered by the heuristics, and so escape notice. More damning, however, Mowery et al. [9] show how an attacker can detect a blacklist and use its content as an additional fingerprintable attribute.
Other plugins work by faking attributes (FireGloves, PriVaricator). As [5,13] point out, such spoofing may lead to inconsistencies that paradoxically make the user stand out more. Indeed, Acar et al. [2] argue this is the case for FireGloves-equipped browsers. Even more strongly, Nikiforakis et al. [13] advice against the use of any user-agent-spoofing extension.
our approach addresses both active and passive fingerprinting, uses real-world browser statistics to generate consistently spoofed fingerprints, and works as a browser extension instead of modifying the browser itself.
The Tor Browser3, widely recognised as providing the best privacy, uses another approach: it aims to keep one single set of attribute values across all its instances. In ideal circumstances, this means that no two Tor Browser instances can be distinguished from each other, however, users can install plugins or tweak settings which undo this protection.
The Tor browser is strongly focused on preserving privacy, providing a level of privacy believed to be sufficient for use under intense state scrutiny. This strong privacy comes at the expense of some usability, most notably, that all data is sent via an onion routing network. We posit that the strong privacy offered by the Tor Browser exceeds the needs of non-oppressed users. Therefore, we will focus on the prevention of third-party tracking.
3
Determining the Fingerprint Surface
In this section, we determine the relevant set of characteristics that are used to fingerprint a user. Determining the full set of characteristics, thefingerprint surface, is not practically possible. For example, as a plugin can change the browser’s behaviour in ways that can be detected, constructing a complete set of characteristics necessarily requires examining all browser plugins. Therefore, we focus pragmatically on that part of the fingerprint surface that is being used by fingerprinters. This implies that we use their definition of identity. As fingerprinters equate a fingerprint of the device with a user identity, we will use this (somewhat imprecise) abstraction as well.
To establish the fingerprint surface, we determine for four major commercial fingerprinters which characteristics they use to fingerprint, i.e., theirfingerprint vector. We also examine four major anti-fingerprint tools and determine which part of the fingerprint surface they consider. Together, this gives us a practical approximation of the fingerprint surface. FP-Block then is built to ensure no two fingerprints are fully coincide within this approximation.
3.1 Limitations of Preventing Fingerprint Tracking
There are two approaches to prevent fingerprint-based tracking: blocking track-ers, and spoofing attribute values. However, neither by itself suffices to prevent tracking, while both impact user experience.
Blocking Fingerprinters. A naive solution is to block any third party content. However, many webpages embed such content, without which the webpage ren-ders incorrectly (e.g. content delivery networks, embedded video). Other third party content helps to sustain and improve the site (counters, advertisers, ana-lytics,. . . ). The impact of blocking all third party content on usability will be
far too great. Blocking known major trackers would provide some protection. However, such a list will remain incomplete [7], irrespective of updates. Thus, blocking by itself cannot fully address third party tracking without impacting on desired functionality.
Spoofing Attribute Values. The attribute values that make up the fingerprint may be faked. This changes the fingerprint, which in turn changes what the tracker infers as the identity. There are many browser plugins that randomise a (sub)set of attributes. However, not all attributes can be faked without substantially impacting user experience (e.g. JavaScript engine speed). Moreover, faked data often makes the user’s fingerprint stand outmore [5,13], making the fingerprint more easy to recognise. Finally, new fingerprintable characteristics keep on being discovered. Thus, it is impossible in practice to determine and spoof the full set of fingerprintable characteristics.
Thus, determining the entire fingerprint surface is impossible. As such, no anti-fingerprint tool can prevent all fingerprinting. This motivates a pragmatic approach: determine which characteristics are used by a set of fingerprinters, and focus on those.
3.2 Fingerprint Vectors
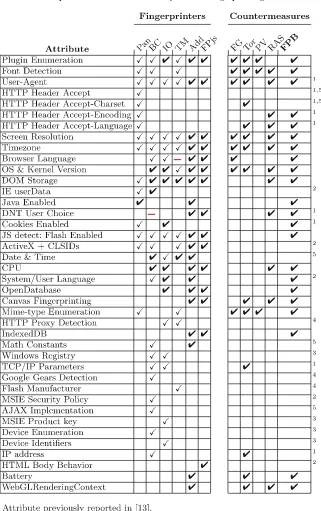
To determine which characteristics are commonly used to fingerprint users, we determine the fingerprint vectors of several widely-used fingerprinters. We ana-lyze three commercial trackers: BlueCava (BC), IOvation (IO), and Threat-Metrix (TM). Note that this part of our analysis builds on and expands the results of [13]. We furthermore analyze one social plugin that fingerprints users: AddThis (Add). We complement this with characteristics gathered from Eckersley’s seminal work [5] (Pan) and from an open source fingerprint library, FingerPrintJS (FPjs). The results are presented in the left part of Table1(legend and footnotes in Table2).
In Table1, each row denotes a fingerprintable characteristic. A√ sign indi-cates that the fingerprinter uses this characteristic in determining a fingerprint. Characteristics marked with were previously reported in [13]; those marked with were reported, but are no longer used.
Recall that in this work we only target the HTTP and JavaScript layer of the communication stack. Fingerprinting can also occur at other layers, e.g. at the TCP/IP layer, or at the Flash layer.
ForFP-Block we only address HTTP and JavaScript characteristics that are used by one ore more of the six analyzed fingerprinters.
3.3 Fingerprint Surface
To determine the minimum set of characteristics that needs to be protected, we investigate four popular anti-fingerprinting tools: FireGloves [3] (FG), the Tor Browser (Tor), PriVaricator [12] (PV), and Random Agent Spoofer4(RAS). For
Table 2.Legend and footnotes for Table1
Fingerprinters Updated from Countermeasures Pan Panopticlick [5] [13] FG FireGloves [3]
BC BlueCava [13] Tor Tor [4] Browser Bundle
IO Iovation [13] PV PriVaricator [12]
TM ThreatMetrix [13] RAS Random Agent Spoofer
Add AddThis new FPB FingerPrint-Block
FPjs FingerPrintJS new
1 Property can be checked passively, i.e., no client-side technology required. 2 Property specific to Internet Explorer.
3Property is determined using a Windows DLL created by the fingerprinting company. 4 Out of scope –FP-Block only targets HTTP and Javascript layers.
5 Blocking or spoofing this attribute would break or limit important functionality.
each, we determine which characteristics are considered. The results are listed on the right side of Table1.
Not all characteristics are equal: some can be used by the fingerprinter with-out using JavaScript (e.g. HTTP headers), some are specific to Internet Explorer, others require additional client-side software (e.g. Windows DLL), etc. For the implementation, we do not focus on these characteristics. Furthermore, some characteristics are intrinsic to the communication or the user experience (HTTP accept header, date & time), and cannot be blocked or spoofed without adverse effects. Taken together, these considerations lead us to formulate the intended fingerprint surface of our tool FP-Block in the rightmost column of Table1. Consequently, FP-Block only generates web identities which are distinct with respect to this fingerprint surface.
4
Design
Our goal is to prevent third-party fingerprint-based tracking. To this end, we generate distinct web identities (i.e., sets of fingerprintable characteristics) and then use these web identities in such a fashion as to be untraceable. More pre-cisely, for each new site visited, we use a freshly generated web identity that is distinct from all previous web identities. This web identity is then used for all interactions due to this site, be they with the site itself or with any of its third parties.
4.1 Balancing Usability vs. Privacy
Fig. 1.Third-party fingerprinting.
does not affect local login processes, nor is it affected by such a process. Moreover, third parties that embed site-specific codes (e.g. of the form http://facebook. com/FROM-SITE-A/) are free to do so. We remark that the defensive paradox, i.e. defenses make the user stand out more, strongly impacts regular tracking. With regards to third-party tracking, however, there is a great difference. Our approach focuses on linkability between different sites, not on distinguishing users on one site. A user that stands out on one website is not necessarily the same person as a user that stands out on another website, even if both stand out due to the defensive paradox. Hence, third-party tracking is affected less severely by the defensive paradox.
The approach of separating web identities thus stays very close to a normal user experience. However, when visiting a different site, a different web identity is used, and the user cannot be tracked to this new site by third-party fingerprint-based tracking. Figure1a depicts the normal functioning of the web: embedded third parties (shown by the dashed arrows) can fingerprint the site’s visitors and match a fingerprint on site A to a fingerprint on site B. Figure1b depicts our approach: each website visited sees another fingerprint. Consider that sites A and C embed a social media plugin of site B. Then when the user visits site A, the web identity as seen by B is IDA. When the user visits site C, however, the web identity as determined by B is IDC. Finally, if the user visits B directly, yet another web identity is used. This allows B to track the user locally on site A and on C, but notfrom site AtoC.
4.2 Generating Web Identities
(changing their characteristics), and fingerprinters need to account for this. Thus, merely ensuring that the set of characteristics of one web identity do not coincide with any other web identity is not sufficient. Moreover, we recall the ing countermeasure paradox: the use of a countermeasure impacts fingerprint- fingerprint-able characteristics in such a way that the resulting set of characteristics is more unique (thus, more traceable) than if no countermeasure was used. An example of this is a client that claims to be an iPhone 2, that is capable of running Flash (real iPhones do not run Flash).
This leads to two design requirements: web identities must be “enough” dif-ferent, and a generated web identity must be “consistent”.
Ensuring Sufficient Difference. Updating a browser affects browser-specific attributes, updating the operating system affects OS-specific attributes, etc. To ensure a freshly generated web identity is sufficiently different from previ-ously generated web identities, accounting for anticipated updates, we group the attributes into the following classes:
– Browser, e.g. user agent, browser name, vendor, accept-encoding. – Language, e.g. language, system language, user language.
– OS/CPU, e.g. platform, cpu class, oscpu. – Screen, e.g. width, height, color depth. – Timezone. i.e. time zone offset.
Ideally, a freshly generated web identity is different in all classes to all previous web identities. This impacts the time required to generate a new web identity. For FP-Block, we chose to require every newly generated web identity to have at least two different attributes from at least two different classes. This allows a decent trade off between time needed to generate a web identity and uniqueness. In future versions, the generation algorithm could be optimised to require more differences.
Consistency of Web Identity. A randomly generated web identity is unlikely to be consistent, that is, have no contradictory attributes (such as Flash running on an iPhone). To ensure consistency, web identities need to be generated using a realistic distribution of attribute values. For instance, the chance that a Fire-fox user is on a Linux computer is greater than the chance that an Internet Explorer user is. In effect, the process to generate a consistent web identity can be modelled as a Markov chain. As usage of different browsers and operating systems varies over time, such a Markov chain needs to be updatable to remain current. To this end, we identified classes of states (operating system, processor, screen properties, etc.). Any Markov chain for a web identity needs to contain these classes. Moreover, these can be ordered (operating system and processor are determined before the user agent is). In this way, we model a construction process for Markov chains generating web identities (see Fig.2).
States and transition probabilities for Markov chains are derived from J. Mealo’s data5, based on actual usage statistics from Wikimedia. An excerpt
Fig. 2.Generic model of Markov chains for web identities.
of this data is shown in Table3, and an example of how this translates into a Markov chain is shown in Fig.3. In this figure, where no weights are indicated, the uniform distribution is implied. Remark that for windows operating systems, one of the attribute values for processor is the empty string ‘’.
Table 3.Example attribute distributions, due to J. Mealo
Win Mac Linux chrome .89 .09 .02 firefox .83 .16 .01 opera .91 .03 .06 safari .04 .96 iexplorer 1.00
Platform Processor string probability
Linux ‘i686’: .5
‘x86 64’: .5
Mac ‘Intel’: .48
‘PPC’: .01
‘U; Intel’: .48 ‘U; PPC’: .01
Windows ‘’: .¯3
‘WOW64’: .¯3 ‘Win64; x64’: .¯3
5
Development and Implementation
5.1 Development
Fig. 3.Partial Markov chain for web identities for the Chrome profile.
cannot consistently pretend to be an Internet Explorer browser. Therefore, FP-Block never pretends to be Internet Explorer. Finally,FP-Block is designed for desktop browsers, and simulates only desktop browsers.
FP-Block is available from http://satoss.uni.lu/software/fp-block/, and is open source6.
5.2 Implementation
FP-Block intercepts and modifies all outgoing requests and incoming responses. This is done by adding observers for the “topics” http-on-modify-request andhttp-on-examine-{cached-}response, respectively. For requests, first the existing web identity for the domain is retrieved, or, if none exists, a fresh web identity is generated and stored. Then HTTP headers likeAccept-Encodingand Accept-Language are set according to the web identity. E-tag headers (which are intended to aid caching) can easily be exploited to track users, and are thus deleted (cf. Table1). Finally, requests for social plugins that are explicitly blocked by user preference are cancelled. Currently,FP-Blockcan block the social plugins of Facebook, Twitter, Google Plus, LinkedIn, Tumblr, and Pinterest.
For incoming responses, the observer evaluates the fingerprint and constructs a Javascript script that enforces the fingerprint. Blocking access to blocked and spoofed attributes is handled by replacing the access functionality of Javascript using navigator. defineGetter (), for attributes such as userAgent, app Name, cookieEnabled,battery,geolocation,oscpu, etc. (cf. Table1). Screen properties are protected analogously using screen. defineGetter (). Detec-tion events are inserted in a similar way to detect when scripts use code that is typically used to fingerprint the user, such as enumerating mimetypes or plug-ins, using DOM storage, font detection, etc. Canvas fingerprinting is thwarted by adding random noise and the FP-Block logo to a random position on the
canvas. This is then stored with the fingerprint to be reused in future visits. Finally, a few lines are added to remove the constructed script after execution, using removeChild() on the script’s parent node. This ensures that the script cannot be found in the source by other scripts.
The thusly constructed script is then injected into the response at the very top, ensuring it is run before any other script sent by the server.
6
Experiments and Validation
We testedFP-Block in two different settings:
– First-party fingerprinting: the visited site uses fingerprinting, and
– Third-party fingerprinting: the visited site embeds a third-party fingerprinter. We ran three main variations of the tests:
1. withoutFP-Block.
This is to verify that the test setup is functioning correctly. 2. withFP-Block,
a. with the test site using an open source fingerprinting script, Finger PrintJS.
This allows us to verify thatFP-Block affects fingerprinting.
b. with the test sites using any one of the four commercial fingerprinting scripts.
This is to test the effectiveness ofFP-Blockagainst real-life fingerprinters. We updated each fingerprinting script to add the fingerprint it computed to the test page. This allows us to execute the tests as described by simply opening the test sites in a browser (see e.g. Fig.4).
Test 1: First-party Fingerprinting. After successfully verifying that the test was set up correctly (Fig.4a), we executed the test shown in Fig.4b using Finger-PrintJS. The result was thatFP-Block correctly ensures that a browser visiting the two sites has a different fingerprint on each site.
Test 2: Embedded Fingerprinting. We created a test page on site A which embeds fingerprinting content from site B, and vice versa (cf. Fig.1). Both test sites also ran the same fingerprint scripts locally. We then visited each page with and without our tool. In both cases, we first tested this set up with the FingerPrintJS script.
Fig. 4.First party fingerprinting tests.
Testing Against Commercial Fingerprinters. We then repeated tests, using the fingerprint scripts of the commercial fingerprinters (BlueCava, IOvation, Threat-Metrix, and AddThis). These scripts all compute a hash which seems to serve as the fingerprint. However, each of them also communicates the entire set of attributes and values used in this fingerprint back to the fingerprinter’s servers. Our tests showed that, withoutFP-Block, the hash as computed by each script does not change – the behaviour is equivalent to that in Fig.1a. WithFP-Block, the hashes were different if they were computed by B’s script embedded on site A, or by the same script of B computed when visiting site B. In short, the tests show that FP-Block successfully affects the fingerprint.
However, affecting the fingerprint does not necessarily mean that tracking is stopped. Given that commercial fingerprinters communicate the determined attribute values back to the fingerprinter, the fingerprinter may match such a set offline to previously seen sets. To test whetherFP-Block is able to prevent such offline fingerprinting, we need to know the web identity which the fingerprinter attributes to us.
BlueCava provides such a service (the BlueCava advertising ID, available on BlueCava’s “opt-out” page). Our final validation was to check our BlueCava advertising ID with and withoutFP-Block. The ID changed, which leads us to conclude that FP-Block successfully prevented BlueCava from tracking us. As can be seen in Table1, BlueCava uses the most attributes for its fingerprint – they are by far the most advanced fingerprinters listed. As such, we believe that success against BlueCava provides a good estimate of success against other offline fingerprint algorithms.
With respect to the commercial fingerprinters: the scripts of BlueCava and AddThis have not changed since we began monitoring them. The scripts for IOvation and ThreatMetrix include time and date of the download, ensuring that every downloaded script is different. Since both scripts are heavily obfus-cated, verifying that there are no changes other than embedded time and date is difficult. However, the file size of IOvation’s script remained constant since September 2014. We take this as an indication that the script has not changed. Finally, ThreatMetrix’ script started changing on 27 October, 2014, and still con-tinues to evolve swiftly. An initial analysis revealed that there are large changes to the code base. Once ThreatMetrix seems to be more stable, we intend to re-analyse the new code.
Stability and Compatibility Testing. To determine the robustness of our plugin, we have been using the plugin in our main browser since June 2014. Where early versions occasionally crashed or gave unexpected results, since October 2014 only Javascript-heavy and Flash pages are noticeably affected.FP-Block blocks Flash to prevent Flash side channels, but Flash can be enabled in FP-Block’s menu. Javascript-heavy pages are slow to load. A refresh solves this.
Lastly, we tested how the plugin cooperates with several popular privacy-focused plugins: AdBlock Plus, Privacy Badger, Ghostery, and Disconnect. FP-Block perfectly cooperates alongside all in default settings. We note two caveats to this. First, Disconnect blocks social media plugins, similar toFP-Block. This functionality is implemented similarly in the two plugins. When both are run-ning, social media plugins are blocked by both. Enabling a social media plugin thus requires enabling it in both plugins. Second, AdBlock Plus is a generic blocking plugin, into which blocklists can be loaded. There exist blocklists for social plugins. Loading such a blocklist inherently causes interference between AdBlock Plus andFP-Block.
7
Conclusions
Ubiquitous tracking on the web is a reality, enabled by the proliferation of embed-ded content and effective fingerprinting techniques. Currently available counter-measures against fingerprinting work by either blocking embedded content or faking a web client’s characteristics. Not only does this break benign applica-tions of fingerprinting (such as detecting session hijacking), but it also reduces the user experience. In order to achieve a more practical balance between pri-vacy and usability, we have introduced the notion of a web identity that allows for re-identification within a web site, while it prevents tracking across websites. Such a web identity is a set of fingerprintable characteristics that can be tweaked on the user side.
The web identities generated by our tool are distinct and consistent. This means that two generated web identities are sufficiently different to prevent being linked by current fingerprint tools and that the attributes are being spoofed in such a way that their combination doesn’t stand out. Consistency is achieved by implementing a Markov model for the generating of attribute values.
Fingerprint tools will be able to re-identify users even after minor changes or regular updates of their computing environment. Therefore, our tool should not generate web identities that can be linked in this way. Our current approach, consisting of classifying attributes, is a rather crude heuristic. We consider a refinement of this approach as interesting future work. Thereto, we propose to collect data on the evolution of client side attributes, in order to build a Markov model that will decide if two generated web identities are sufficiently distinct.
Finally, our prototype implementation only addresses the HTTP and Java Script layers of communication. Given the focus of the current fingerprinting tools, this already provides a significant level of practical privacy. Nevertheless, the arms race between fingerprinters and anti-tracking tools will continue, so we consider extending the current fingerprint vector of our tool as an ongoing activity.
References
1. Acar, G., Eubank, C., Englehardt, S., Ju´arez, M., Narayanan, A., D´ıaz, C.: The web never forgets: Persistent tracking mechanisms in the wild. In: Proceedings of 21st ACM Conference on Computer and Communications Security (CCS 2014), pp. 674–689. ACM Press (2014)
2. Acar, G., Juarez, M., Nikiforakis, N., Diaz, C., G¨urses, S., Piessens, F., Preneel, B.: FPDetective: Dusting the web for fingerprinters. In: Proceedings of 20th ACM SIGSAC Conference on Computer and Communications Security (CCS 2013), pp. 1129–1140. ACM Press (2013)
3. Boda, K., F¨oldes, ´A.M., Guly´as, G.G., Imre, S.: User tracking on the web via cross-browser fingerprinting. In: Laud, P. (ed.) NordSec 2011. LNCS, vol. 7161, pp. 31–46. Springer, Heidelberg (2012)
4. Dingledine, R., Mathewson, N., Syverson, P.: Tor: The second-generation onion router. Technical report, Naval Research Lab Washington (2004)
5. Eckersley, P.: How unique is your web browser? In: Atallah, M.J., Hopper, N.J. (eds.) PETS 2010. LNCS, vol. 6205, pp. 1–18. Springer, Heidelberg (2010) 6. Kohno, T., Broido, A., Claffy, K.: Remote physical device fingerprinting. IEEE
Trans. Dependable Secure Comput.2(2), 93–108 (2005)
7. Krishnamurthy, B., Wills, C.E.: Generating a privacy footprint on the internet. In: Proceedings of 6th ACM SIGCOMM Conference on Internet Measurement (ICM 2006), pp. 65–70. ACM Press (2006)
8. Mitchell, J.C., Mayer, J.R.: Third-party web tracking: Policy and technology. In: Proceedings of IEEE Symposium on Security and Privacy (S&P 2012), pp. 413–427 (2012)
10. Mowery, K., Shacham, H.: Pixel perfect: Fingerprinting canvas in HTML5. In: Proceedings of Web 2.0 Security & Privacy (W2SP 2012). IEEE Computer Society (2012)
11. Mulazzani, M., Reschl, P., Huber, M., Leithner, M., Schrittwieser, S., Weippl, E.R.: Fast and reliable browser identification with Javascript engine fingerprinting. In: Proceedings of Web 2.0 Security & Privacy (W2SP 2013), May 2013
12. Nikiforakis, N., Joosen, W., Livshits, B.: PriVaricator: Deceiving fingerprinters with little white lies. Technical report MSR-TR-2014-26, Microsoft Research, February 2014
13. Nikiforakis, N., Kapravelos, A., Joosen, W., Kruegel, C., Piessens, F., Vigna, G.: Cookieless monster: Exploring the ecosystem of web-based device fingerprinting. In: Proceedings of 34th IEEE Symposium on Security and Privacy (S&P 2013), pp. 541–555. IEEE Computer Society (2013)
14. Roesner, F., Kohno, T., Wetherall, D.: Detecting and defending against third-party tracking on the web. In: Proceedings of 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI 2012), pp. 155–168. USENIX (2012) 15. Roosendaal, A.: We are all connected to facebook ... by facebook!. In: Gutwirth,
S., Leenes, R., De Hert, P., Poullet, P. (eds.) European Data Protection: In Good Health, pp. 3–19. Springer, The Netherlands (2012)
16. Unger, T., Mulazzani, M., Fruhwirt, D., Huber, M., Schrittwieser, S., Weippl, E.R.: SHPF: Enhancing http(s) session security with browser fingerprinting. In: Proceed-ings of Eighth International Conference on Availability, Reliability and Security (ARES 2013), pp. 255–261. IEEE Computer Society (2013)
Cross-App KeyEvent Injections
Wenrui Diao1, Xiangyu Liu1, Zhe Zhou1, Kehuan Zhang1(B), and Zhou Li2 1 Department of Information Engineering, The Chinese University of Hong Kong,
Hong Kong, China
{dw013,lx012,zz113,khzhang}@ie.cuhk.edu.hk
2 IEEE Member, Boston, MA, USA
Abstract. Input Method Editor (IME) has been widely installed on mobile devices to help user type non-Latin characters and reduce the number of key presses. To improve the user experience, popular IMEs integrate personalized features like reordering suggestion list of words based on user’s input history, which inevitably turn them into the vaults of user’s secret. In this paper, we make the first attempt to evaluate the security implications of IME personalization and the back-end infrastruc-ture on Android devices. In the end, we identify a critical vulnerability lying under the Android KeyEvent processing framework, which can be exploited to launch cross-app KeyEvent injection (CAKI) attack and bypass the app-isolation mechanism. By abusing such design flaw, an adversary is able to harvest entries from the personalized user dictionary of IME through an ostensibly innocuous app only asking for common permissions. Our evaluation over a broad spectrum of Android OSes, devices, and IMEs suggests such issue should be fixed immediately. All Android versions and most IME apps are vulnerable and private infor-mation, like contact names, location, etc., can be easily exfiltrated. Up to hundreds of millions of mobile users are under this threat. To miti-gate this security issue, we propose a practical defense mechanism which augments the existing KeyEvent processing framework without forcing any change to IME apps.
Keywords: Mobile security
·
Smart IME·
Privacy leakage·
System flaw1
Introduction
Smartphone is becoming the major device for handling people’s daily tasks like making calls, sending/receiving messages and surfing the Internet. Of partic-ular importance in supporting these features are input devices. Among them,
Responsible disclosure: We have reported the CAKI vulnerability and the corre-sponding exploiting schemes to the Android Security Team on January 7th, 2015. The video demos can be found athttps://sites.google.com/site/imedemo/.
c
Springer International Publishing Switzerland 2015
Fig. 1.Smart IME on Android
Fig. 2.Warning message
keyboard, either hardware keyboard integrated within mobile phone or soft key-board displayed on touch screen, receives a significant volume of users’ input. These keyboards are mostly tailored to users speaking Latin languages. Users in other regions like Chinese and Japanese have to use Input Method Editor (or IME) to type non-Latin characters. In fact, a large number of IME apps1 have
emerged since the advent of smartphone and been installed by enormous pop-ulation. The capabilities of IME are continuously extended to optimize users’ typing experience. The present IME (see Fig.1) is able to learn the words a user has inputted, customize the suggested words, and predict the words the user plans to type. These user-friendly features help the IME gain popularity even among Latin-language users.
The wide adoption of IME, however, does not come without cost. Previ-ous research has raised the privacy concerns withshady IMEs which illegally spy on users’ input [30,34,35,38]. Indeed, they could cause security and privacy issues if installed by common users, but their impact is limited as the major-ity of IMEs are well-behaved and there have been efforts in warning the risk of enabling a new IME (see Fig.2). The question not yet answered is whether legit-imate IMEs are bullet-proof. If the answer is negative, they can be exploited by adversary as stepping stones to breach the privacy of mobile users. In this work, we examine smart IMEs (the ones supporting optimization features) and the back-end framework in an attempt to verify their security implications. We choose Android as a target platform given its popularity and openness.
KeyEvent Processing. We first look into the underlying framework which handles input processing. In short, each key press on hardware keyboard trig-gers a sequence of KeyEvents [11] on Android. As for the purpose of automated
testing, a mobile app can also simulate key presses by directly injecting KeyEvents. Without a doubt, such behavior should be confined to prevent a malicious app from illegally injecting KeyEvents to another victim app. Android consolidates KeyEvent dispatching by ensuring that either the KeyEvent sender app and receiver app are identical or sender app has a system-level permission (INJECT EVENTS) which cannot be possessed by third-party apps. Failing to pass such check will cause KeyEvent being discarded and an exception thrown.
Our Findings. Unfortunately, this seemingly invulnerable framework can be cracked. If a malicious app injects KeyEvents to its owned EditText widget with IME turning on, the KeyEvents will be redirected to the IME, resulting in
cross-app KeyEvent injection (CAKI)attack. Following this trail, attacker can peep into IME dictionary (usually stored in the internal storage protected by app-isolation mechanisms) and know user’s favorite words or even the words taken from other sensitive sources, like phone contact. The root cause of this vulnerability is that Android only performs security checks before KeyEvent is dispatched but misses such when KeyEvent is delivered. For this special case, because of the discrepancy between the point of checking and the point of deliv-ering, IME is turned into the final receiver on the fly when KeyEvent is delivered, therefore the security check at the beginning is bypassed. Since this issue exists in the system layer, all IMEs are potentially under threat.
Attack Against IME. Even knowing this vulnerability, a successful attack against IME is not trivial. The challenges include how to efficiently extract words related to personal information or interest and how to hide the mali-cious activities from user. Towards solving the first challenge, we devise new technique to automatically enumerate the combinations of prefix letters and use differential analysis to infer the words private to user. This technique can be adapted to different language models and all achieve good results. To address the second challenge, we combine several well-founded techniques to make the attack context-aware and executed till user is absent.
We implemented a proof-of-concept malicious app namedDicThief and eval-uated it against 11 very popular IMEs and 7 Android OS versions. The result is quite alarming: all the Android versions we examined are vulnerable and most of the IMEs we surveyed are not immune. The population under threat is at a scale of hundreds of millions (see IME popularity in Table3). Towards mitigating this urgent issue, we propose an origin-checking mechanism which augments the existing Android system without forcing any change to IME apps.
Contributions.We summarize this paper’s contributions as below:
• New Vulnerability.We discovered a fundamental vulnerability in the Android KeyEvent processing framework leading to CAKI attack.
• New Attack Surface.We show by launching CAKI attack, an attacker can steal a variety of private information from IME dictionary. Differing with previous IME-based attacks, our attack is the first to exploit the innocent IMEs.
2
Background and Adversary Model
2.1 IME and Personalized User DictionaryIMEs have emerged to support users speaking different languages like English and Chinese. A smartphone is usually shipped with pre-installed IMEs, but alternatively, users could download and use other IME apps. IME have gained massive popularity: top IMEs like Sogou Mobile IME [16,17] has more than 200 million active users.
The IMEs used today have been evolved from solely soft keyboard to ver-satile input assistant with many new features to improve users’ typing experi-ence. The goals of these new features are to reduce the number of keys a user needs to type. For instance, current mainstream IMEs (such as SwiftKey [18], TouchPal [21], Sogou Mobile IME, etc.) implement features like dynamic sug-gestions order adjustment, contact names sugsug-gestions, next-word prediction and new word saving to provide suggestions for current or subsequent words. Hence, a user could select a word among them without typing the complete text. These features are called “optimization features” and we elaborate them below:
Fig. 3.Dynamic order adjustment – Dynamic Order Adjustment. This
feature adjusts the order of suggested words dynamically according to user’s input history. For example, as shown in Fig.3, two typed characters “ba” lead to different lists of suggested words. “bankruptcy” is the first suggestion in the upper picture while “banquet” is the first suggestion in the lower one.
– Contact Names Suggestion. IME can suggest a name from user’s phone contact when part of the name is typed. In addition, suggestions also pop up when an unknown name is typed for correction. TheREAD CONTACTSpermission needs to be granted to support this feature.
Fig. 4.Next-word prediction – Next-Word Prediction.IME attempts
to predict the next word user wants to input based on the previous words typed. Figure4shows an example that IME gives a prediction “Newcastle” based on the pre-vious input “Fly to”.
– New Word Saving. When a word not existing in the dictionary is typed, IME automatically adds this word to its dictionary.
Table 1.Data sources of mainstream IMEs for optimization features Production name Version Input
history
Contacts Emails/ SMS
Social network
Location
Go Keyboard [7] 2.18 √ √
TouchPal [21] 5.6 √ √ √ √
Adaptxt - Trial [1] 3.1 √ √ √ √ √
Google Keyboard [8] 4.0 √ √ √ √
SwiftKey Keyboard [18] 5.0 √ √ √ √
Swype Keyboard Free [19] 1.6 √ √ √
Fleksy Keyboard Free [5] 3.3 √ √ √ √
Google Pinyin Input [9] 4.0 √ √
Sogou Mobile IME [16] 7.1 √ √ √
Baidu IME [3] 5.1 √ √
QQ IME [14] 4.7 √ √
of mainstream IMEs (each of them has over 1 million installations) in Table1. Apparently, the personalized dictionary should be considered private assets and protected in the safe vault. In fact, most of the IME apps we surveyed keep their dictionaries in the internal storage of mobile phone which is only accessible to the owner app.
2.2 Adversary Model
The adversary we envision here is interested in the dictionary entries of IME deemed private to the user, like contact names, and aims to steal and exfil-trate them to her side. We assume the user has installed a victim IME which is “benign” and “smart”.
1. “Benign” means this IME exercises due diligence in protecting user’s private data. The measures taken include keeping its dictionary in app’s private folder (internal storage). This assumption differs fundamentally from previous IME-based attacks which assume IME itself is malicious.
2. “Smart” means this IME can learn unique word-using habits and build a personalized user dictionary based on user’s input history, contacts, etc.
At the same time, we assume this user has downloaded and installed a malicious app named DicThief aiming to steal entries from victim IME. The default (enabled) IME on the device could be identified through the system class
Settings.Secure[15]. This malware only claims two permissions:INTERNETand
WAKE LOCK. Both permissions are widely claimed by legitimate apps and unlikely to be rejected by users: nearly all apps declare the INTERNET permission, and
Fig. 5.Android KeyEvent processing framework and CAKI vulnerability
attack can be launchedwhen the phone is in sleep mode and locked with password.
3
Vulnerability Analysis
While direct access to the dictionary of IME is prohibited if coming from a dif-ferent and non-system app, our study shows this security guarantee can be vio-lated. By revisiting the keystroke processing framework of Android, we discover a new vulnerability lying under Android OS, allowing us to launch Cross-App
KeyEventInjection (CAKI) attack. In essence, by exploiting such vulnerability, a malicious app can simulate user keystrokes on an IME, and read the suggested words. Below we describe the mechanism of keystroke processing in Android and the new vulnerability we identified.
3.1 Android KeyEvent Processing Flow
The internal mechanism of input processing in Android is quite sophisticated and here we only overview how KeyEvents2are processed. At a high level, when
a key is pressed on hardware (built-in) keyboard, a sequence of KeyEvents will be generated by wrapping the raw input, and then sent to the corresponding handlers (e.g., IME). These two steps are called KeyEvent pre-processing and
KeyEvent dispatching. We illustrate the process in Fig.5and then elaborate the details below3:
2 IME accepts another kind of input event – MotionEvent [12], coming from soft keyboard (see Fig.1). Its processing flow is different and not covered in this paper. 3 Our descriptions are based on Android 4.4.4 r2.0.1 [2]. For other versions, the flows
1 bool c h e c k I n j e c t i o n P e r m i s s i o n (...) { 2 if ( i n j e c t i o n S t a t e
3 && ( w i n d o w H a n d l e == NULL
4 || windowHandle - > getInfo () -> ownerUid != injectionState - > i n j e c t o r U i d )
5 && ! h a s I n j e c t i o n P e r m i s s i o n ( injectionState - > injectorPid , injectionState - > i n j e c t o r U i d ) ) {
6 ... // Code omitted due to space limit
7 return false; // P e r m i s s i o n denied
8 }
9 return true; // Pass c h e c k i n g 10 }
KeyEvent Pre-processing. As soon as a hardware key (e.g., built-in key-board) is pressed, a raw input event is sent to a system thread InputReader
(initiated by WindowManagerService) and encapsulated into an object of type
NotifyKeyArgs. Then, this object is passed to threadInputDispacher(also ini-tiated by WindowManagerService) and aKeyEntryobject is generated. Lastly, this object is converted toEventEntryobject and posted to the message queue (InboundQueue) of InputDispacherto be distributed to right handlers. If a key press is simulated by an app, the corresponding KeyEvents are initiated directly and finally sent to the message queue (in the format of EventEntry).
KeyEvent Dispatching.Before event dispatching, there is a permission check-ing process on the correspondcheck-ingEventEntryto ensure its legitimacy. The code undertaking such check is shown below (excerpted from the Android code repos-itory [24]):
This routine first verifies whether the event is generated by a hardware device (checkinginjectionState). IfinjectionStateisNULL, the check is passed and the event is directly sent to handlers. Otherwise (the event is generated by an app), this routine verifies whether the sender app owns the required permission or if it is identical to the receiver app (we fill in the details in Sect.3.2).
An input event passing the above check will be dispatched via a system IPC mechanism InputChannel to the receiver app, which should run in the fore-ground and take the input focus. In particular, theWindowInputEventReceiver