Analisis Mekanisme
Failover
pada Hyper-V Cluster untuk
Virtual
Server
Artikel Ilmiah
Peneliti :
Hallilintar Arya Pasa Putra (672009020) Teguh Indra Bayu, S.Kom., M.Cs.
Program Studi Teknik Informatika
Fakultas Teknologi Informasi
Universitas Kristen SatyaWacana
Analisis Mekanisme
Failover
pada Hyper-V Cluster
untuk
Virtual
Server
1) Hallilintar Arya Pasa Putra, 2) Teguh Indra Bayu
Fakultas Teknologi Informasi Universitas Kristen Satya Wacana
Jl. Diponegoro 52-60, Salatiga 50711, Indonesia Email: 1) [email protected], 2)[email protected]
Abstract
Virtualization technology has been a trend in IT sector as an effort to reduce the expenditure of server infrastructure development. Virtualization allows multiple servers run as virtual machine (VM) that are built inside single physical machine. As a consequence, if the physical machine experiences a failure, it will also cause failure to the entire VMs inside. In order to maintain services and disaster recovery scenario, a failover technique have to be deployed inside the physical machine. Hyper-V Cluster comes with the feature that needed for the condition. Result of this research is downtime variation analysis which influenced by failover mechanism. Parameters which used for testing are VM amounts that move concurrently and priority level of each VM.
Keywords: Hyper-V Cluster, Failover, Downtime
Abstrak
Teknologi virtualisasi telah menjadi tren dalam bidang IT sebagai usaha untuk menekan pengeluaran dalam pengembangan infrastruktur server. Virtualisasi memungkinkan beberapa server berjalan sebagai mesin virtual (VM) yang dibangun di dalam satu unit mesin fisik. Kerugiannya, jika mesin fisik mengalami kegagalan, akan mengakibatkan kegagalan terhadap seluruh VM di dalamnya. Untuk dapat mempertahankan layanan dan sebagai skenario pemulihan bencana, sebuah teknik failover harus diaplikasikan di dalam mesin fisik. Hyper-V Cluster memiliki fitur yang diperlukan pada kondisi tersebut. Hasil dari penelitian ini adalah analisis terhadap variasi downtime yang dipengaruhi oleh mekanisme failover. Parameter yang digunakan pada proses uji coba adalah jumlah VM yang berpindah secara bersamaan serta tingkatan prioritas dari masing-masing VM.
Kata Kunci: Hyper-V Cluster, Failover, Downtime
1) Mahasiswa Fakultas Teknologi Informasi Jurusan Teknik Informatika, Universitas Kristen
Satya Wacana, Salatiga.
1
1. Pendahuluan
Infrastruktur di bidang teknologi informasi menjadi aset yang penting dan strategis bagi sebuah perusahaan. Tidak dapat dipungkiri, bahwa investasi IT memerlukan anggaran yang cukup besar. Oleh karena itu diperlukan investasi dan perancangan infrastruktur teknologi informasi yang dikembangkan secara strategis untuk dapat mencapai efisiensi dan efektivitas dalam penggunaan serta juga dapat mereduksi pengeluaran. Salah satu potensi pengeluaran yang cukup tinggi adalah pengembangan infrastruktur server. Solusi untuk menekan pengeluaran ini salah satunya adalah dengan melakukan konsolidasi server dengan menggunakan teknologi virtualisasi. Beberapa server yang memiliki utilitas rendah dapat dijadikan sebagai virtualserver yang berjalan di dalam sebuah server fisik.
Seringkali sebuah server dituntut untuk dapat memberikan layanan yang bersifat continue, dengan downtime dan fault tolerance sekecil mungkin untuk mendukung kelangsungan bisnis perusahaan. Padahal, terkadang server memerlukan maintenance, bahkan pada jam sibuk. Ditambah lagi kemungkinan adanya kegagalan maupun error yang dapat terjadi sewaktu-waktu. Disaster recovery perlu dipersiapkan sebagai langkah untuk menjaga layanan dari server. Oleh karena itu, server harus dikonfigurasi sedemikian rupa untuk dapat melakukan penanganan secara otomatis terhadap kegagalan yang terjadi, sehingga server dapat mencapai high availability (ketersediaan tinggi). Salah satu solusinya adalah dengan membangun failover cluster, yang juga dapat diimplementasikan pada lingkungan virtualisasi server. Beberapa server fisik yang menjalankan virtual server secara keseluruhan saling bekerja sama menjadi satu kesatuan cluster. Saat salah satu server fisik mengalami kegagalan, maka sumber daya dari virtual server akan dipindahkan menuju ke server fisik lain yang masih aktif. Dengan demikian, layanan yang diberikan oleh virtual server dapat berjalan secara terus-menerus tanpa terganggu oleh kegagalan maupun error yang terjadi pada server fisiknya.
2. Kajian Pustaka
2
perangkat keras yang ada pada mesin komputer fisik untuk dibagi menjadi beberapa bagian. Setiap bagian tersebut dioperasikan secara mandiri tanpa mengganggu satu sama lain. Bagian ini yang disebut sebagai virtual machine (VM). Sistem operasi yang berjalan pada VM ini disebut sebagai guest dan server fisik disebut sebagai host.
Terdapat tiga jenis pendekatan dalam virtualisasi server, yaitu full virtualization, paravirtualization, dan hardware-assisted virtualization [3]. Pada jenis pendekatan hardware-assisted virtualization, terdapat istilah hypervisor yang merupakan lapisan tambahan yang berada di antara physical hardware dan sistem operasi, yang berfungsi untuk mengelabui setiap sistem operasi agar berpikir bahwa mereka sedang berjalan pada perangkat keras yang sebenarnya. Jenis-jenis hypervisor dapat dibedakan berdasarkan tipe maupun desainnya [4]. Berdasarkan tipenya, terdapat hypervisor dengan jenis bare-metal dan hosted. Bare-metal berjalan langsung di atas hardware, sedangkan tipe hosted berjalan di dalam sistem operasi host-nya. Berdasarkan desainnya terdapat hypervisor dengan struktur monolithic dan microkernelized. Monolithichypervisor membawa driver perangkat kerasnya sendiri yang mengakibatkan attack surface-nya masih signifikan. Sedangkan microkernelized hypervisor tidak memiliki third-party device drivers. Driver yang dibutuhkan oleh perangkat keras dalam berbagi sumber daya terletak pada sistem operasi host, sehingga guest tidak perlu melakukan routing melalui hostpartitiondrivers.
Gambar 1 Strukrur Hypervisor tipe Bare-metal dan Hosted [4]
3
Hyper-V merupakan platform virtualisasi dari Microsoft yang dapat diinstal sebagai standalone application maupun sebagai role dari sistem operasi Microsoft Windows Server 2008 ke atas. Hyper-V menggunakan arsitektur hypervisor tipe bare-metal dengan mengadopsi konsep microkernelized. Hypervisor merupakan jenis software unik yang memungkinkan sebuah komputer dapat menjalankan lebih dari satu sistem operasi. Bare-metal merupakan jenis hypervisor yang berjalan secara langsung di atas perangkat keras fisik dari host-nya, untuk menjadi penjembatan dan sebagai program pengendali antara sistem operasi guest dengan hardware. Sehingga VM memiliki akses langsung terhadap perangkat keras fisik. Sedangkan implementasi dari microkernelized memungkinkan sebuah instance VM berperan sebagai parent partition dan instance lain sebagai child partition. Parent partition merupakan sistem operasi host, sedangkan VM sebagai child partitions. Pada dasarnya, sistem operasi host dan beberapa sistem operasi guest berjalan bersama-sama pada tingkatan yang sama, yaitu di atas hypervisor. Kesemuanya memiliki hak akses yang sama terhadap hardware. Host bertanggung jawab mengelola semua guest yang ada [5]. Selain itu, Hyper-V merupakan platform virtualisasi dengan jenis hardware-assited virtualization, sehingga dibutuhkan prosesor yang mendukung platform virtualisasi tersebut, yaitu dengan menggunakan prosesor Intel VT atau AMD-V. Selain itu, opsi Data Execution Protection (DEP) pada prosesor, atau yang biasa disebut sebagai Intel XD atau AMD NX Bit, juga harus diaktifkan [6].
Gambar 3 Abstraksi Hypervisor pada Hyper-V [5]
Cluster merupakan sekumpulan komputer independen yang beroperasi serta
4
tidak mengalami gangguan, diperlukan solusi high availability untuk melakukan recovery apabila server tersebut mengalami downtime. Sedangkan pada lingkungan virtualisasi, dimana satu unit server fisik menangani beberapa VM sekaligus, apabila terjadi gangguan pada server fisik tersebut tentunya akan berimbas pada gangguan layanan dari seluruh VM yang ada di dalamnya. Untuk mencegah kemungkinan ini, implementasi high availability menjadi hal yang penting dari virtualisasi server.
Implementasi high availability cluster bertujuan untuk meminimalisasi angka downtime dan fault tolerance. Downtime merupakan periode waktu saat layanan yang diberikan oleh sistem tidak tersedia, dikarenakan oleh terjadinya kegagalan dari sistem tersebut [7]. Downtime dapat diakibatkan oleh kesengajaan maupun adanya kegagalan pada sistem. Sehingga, downtime dibagi menjadi dua jenis, yaitu planned downtime dan unplanned downtime [8]. Planned downtime terjadi saat dibutuhkan sebuah pemeliharaan terhadap sistem, antara lain perbaikan atau upgrade hardware maupun software, update dan patching yang memerlukan restart sistem, dan juga deployment aplikasi. Sedangkan unplanned downtime terjadi secara mendadak dan tidak diinginkan, karena disebabkan oleh kegagalan sistem, yang biasanya terjadi karena kesalahan dalam pemakaian (human error), baik oleh administrator maupun oleh user, kerusakan dan malfungsi hardware maupun software, terputusnya jaringan, pemakaian yang melebihi kapasitas, serta dapat pula diakibatkan oleh bencana alam.
5
pada proses copy memory pages secara iteratif dari host sumber menuju host tujuan dan setelah berpindah menuju host tujuan, VM diaktifkan serta akses dari sisi client di-redirect ke VM target [9].
Unplanned downtime pada Hyper-V Cluster di-recovery dengan
menggunakan teknik failover. Recovery ditujukan bagi VM apabila host mengalami kegagalan. Saat terjadi kegagalan pada server host, seluruh VM yang berada di dalam host tersebut akan di-failover dengan cara dipindahkan menuju host lain yang masih aktif. Namun, pada saat host mengalami kegagalan VM kehilangan sumber daya selama beberapa saat, hingga dipindahkan menuju host lain dan di-restart secara otomatis. Sehingga hal ini tetap menyebabkan downtime bagi VM, yang dimulai sejak host asal mengalami kegagalan, dan berakhir pada saat VM aktif setelah proses booting selesai dan service dari VM juga telah aktif.
3. Metode Penelitian
Metode penelitian yang dipakai adalah Network Development Life Cycle (NDLC) yang biasa dipakai dalam perancangan infrastuktur jaringan. Tahapan-tahapan pada metode NDLC dapat dilihat pada Gambar 4.
Gambar 4 Tahapan Network Development Life Cycle [10]
6
oleh client. Jaringan internal untuk komunikasi antar server membutuhkan bandwidth yang besar, karena dikhususkan untuk mendukung proses failover clustering, migrasi VM, dan pertukaran data lain yang menghubungkan seluruh server fisik dan virtual yang ada. Pada penelitian ini jaringan internal didukung dengan penggunaan jaringan dengan bandwidth 1 Gbps. Sedangkan jaringan eksternal menggunakan bandwidth 100 Mbps, untuk koneksi internet, aktivitas manajemen dan remoting, serta akses yang dilakukan oleh client.
Tabel 1 Spesifikasi Hardware
Windows Server 2012 Sistem operasi server fisik dan virtual Hyper-V 3.0 Platform vrtualisasi hypervisor Internet Information Services (IIS) Aplikasi Web server Starwind iSCSI SAN Free Edition v.6 iSCSI SAN
7
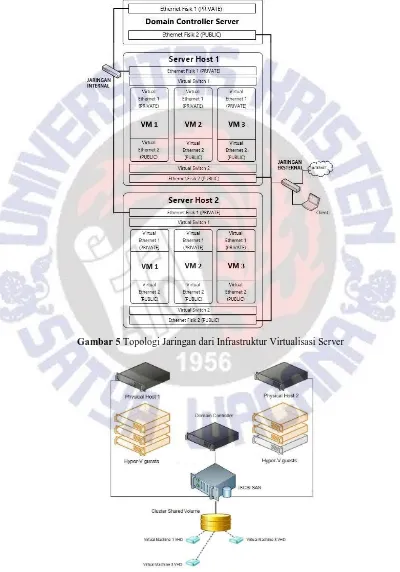
nantinya akan bertugas untuk melayani client secara langsung melalui layanan yang diberikan melalui aplikasi dari tiap-tiap VM tersebut. Topologi jaringan dari setiap server dengan penggunaan dua jaringan yang berbeda ditunjukkan melalui Gambar 5. Sedangkan desain dari sistem cluster ditunjukkan oleh Gambar 6.
Gambar 5 Topologi Jaringan dari Infrastruktur Virtualisasi Server
8
Perancangan desain dari sistem Hyper-V Cluster digambarkan melalui alur kerja dalam Gambar 7. Diawali dengan aktivasi role Failover Clustering pada kedua server node, sehingga muncul fitur Failover Cluster Manager sebagai tool manajemen sistem cluster. Sebelum sistem cluster dibentuk, terlebih dahulu dilakukan validasi untuk melakukan cek validitas dan kompatibilitas dari hardware, jaringan, konfigurasi sistem, dan media penyimpanan terdistribusi yang digunakan. Media penyimpanan Cluster Shared Volume (CSV) digunakan untuk menyimpan seluruh file yang berkaitan dengan VM. Untuk kemudian ketiga VM didaftarkan sebagai role dalam cluster dan juga dilakukan migrasi VM storage menuju CSV.
Gambar 7 Alur Kerja Proses Desain Hyper-V Cluster
Gambar 8 menunjukkan proses alur kerja failover terhadap VM yang terjadi dalam Hyper-V Cluster :
9
Fase simulation prototyping dilakukan dengan mensimulasikan prototpye desain yang telah dirancang dengan menggunakan bantuan perangkat lunak Cisco Packet Tracer. Pada simulasi tersebut, seluruh server fisik dan server virtual diletakkan sejajar dan terhubung langsung dengan jaringan internal dan jaringan eksternal. Hal ini dikarenakan VM yang berdiri di atas lapisan hypervisor memiliki akses langsung dengan jaringan luar, sama seperti server fisik. Meskipun VM menggunakan virtual switch dengan dijembatani oleh ethernet card fisik dari server host-nya, tetapi VM memiliki jaringan mandiri yang tidak memerlukan bridging maupun routing dari ethernet card fisik milik host-nya untuk dapat terhubung dengan jaringan luar. Sedangkan sebuah komputer client ditambahkan pada jaringan eksternal.
Gambar 9 Fase Simulation Prototyping dengan Cisco Packet Tracer
Implementation merupakan penerapan dari perancangan desain sistem virtualisasi dan cluster. Setiap server yang ada harus memiliki alamat IP untuk dapat saling berkomunikasi dan melakukan pertukaran data. Seluruh server memiliki dua ethernet card dengan alamat IP subnet 192.168.2.0/24 untuk jaringan internal dan 192.168.1.0/24 untuk jaringan eksternal. Daftar alamat IP dan hostname dari tiap-tiap server dijelaskan pada Tabel 3. Melalui domain controller server diciptakan sebuah domain pada forest baru dengan nama
“aryapasaputra.net”, untuk kemudian seluruh server yang lain dijadikan sebagai
member dari domain tersebut.
Tabel 3 Daftar Alamat IP dan Hostname
Server IP Internal IP Eksternal Hostname
Domain Controller 192.168.2.100 192.168.1.100 DCS1.aryapasaputra.net Server Host 1 192.168.2.101 192.168.1.101 HVHOST1.aryapasaputra.net Server Host 2 192.168.2.102 192.168.1.102 HVHOST2.aryapasaputra.net
VM 1 192.168.2.111 192.168.1.111 WEB1.aryapasaputra.net
10
Proses instalasi VM dilakukan dengan menggunakan tool Hyper-V Manager yang terdapat pada server host. Konfigurasi dibuat dengan menetapkan resource hardware untuk masing-masing VM yaitu memori sebesar 700 MB dan 50 GB untuk besaran kapasitas hard disk-nya, serta dilakukan aktivasi opsi Processor Compatibility agar VM dapat berpindah antar host dengan prosesor yang berbeda. Hal ini disebabkan karena server HVHOST1 dan HVHOST2 memiliki perbedaan spesifikasi prosesor, meskipun keduanya berasal dari famili Core i3. Setiap VM dibangun dengan menggunakan sistem operasi Windows Server 2012. Layanan dari ketiga VM dirancang dengan menggunakan Internet Information Services (IIS) sebagai aplikasi web server. IIS merupakan role yang sudah tersedia pada sistem operasi Windows Server. Sehingga untuk instalasinya hanya perlu dilakukan aktivasi dari role ini. Halaman web yang akan ditampilkan oleh ketiga VM ini berbeda-beda, oleh karena itu dilakukan pemasangan halaman web custom berupa template HTML pada ketiga VM tersebut. Pada IIS, halaman web beserta dengan seluruh file yang berkaitan dengan web yang akan ditampilkan, disimpan dalam direktori C:\inetpub\wwwroot\.
Sistem cluster juga diimplementasikan berdasarkan desain yang telah dirancang sebelumnya. Cluster diberi nama HVCluster dengan alamat IP 192.168.2.105/24. iSCSI SAN yang berada pada domain controller server dibentuk dengan menggunakan bantuan aplikasi Starwind iSCSI SAN Free Edition versi 6.0, dan dikoneksikan dengan kedua node, melalui fitur iSCSI Initiator. Pada Failover Cluster Manager, iSCSI yang sudah terkoneksi dengan kedua node dikonversikan sebagai Cluster Shared Volume (CSV) untuk menyimpan seluruh file yang berkaitan dengan VM, meliputi file virtual hard disk, file-file konfigurasi VM, dan juga snapshot. Ketiga VM dari kedua node didaftarkan ke dalam sistem cluster agar proses failover dapat diterapkan terhadap VM tersebut. Serta dilakukan pula VM storage migration untuk memindahkan seluruh file yang berkaitan dengan VM menuju ke media penyimpanan CSV. Dengan demikian VM akan memiliki kemampuan untuk melakukan proses failover secara cepat jika terjadi kegagalan pada host-nya, karena file tersimpan di luar dari kedua node. Sehingga, saat terjadi kegagalan yang diperlukan hanya memindahkan VM menuju resource perangkat keras yang baru dari host yang masih aktif.
11
Management, sebagai tahap terakhir melalui pengkajian ulang dengan tujuan untuk mencapai peningkatan kinerja sistem yang optimal dan dapat menyelesaikan permasalahan, serta memastikan bahwa sistem yang dibangun dapat berjalan dengan baik untuk waktu yang lama dan lebih reliabel. Hal yang menjadi kendala dalam infrastruktur cluster yang dibangun adalah terbatasnya hardware dari server host. Masing-masing server host harus mampu menjalankan ketiga VM secara bersamaan. Meskipun dari desain yang dibangun masing-masing host menjalankan 1 dan 2 VM, tetapi saat terjadi kegagalan pada salah satu host, VM yang berada di dalamnya akan berpindah menuju host yang masih aktif. Sehingga ketiga VM akan berjalan pada satu host. Oleh karena itu, pada tahap management dilakukan pengkajian ulang mengenai policy dan beberapa konfigurasi pada sistem. Terutama dalam menetapkan limitasi alokasi hardware resources untuk tiap-tiap VM, sebagai persiapan menghadapi proses failover. Karena kedua host memiliki spesifikasi prosesor dengan 4 logical core dan memori 4 GB, untuk tiap VM ditetapkan prosesor dengan 1 logical core dan memori sebesar 700 MB. Sedangkan pada iSCSI SAN sebagai media penyimpanan dari VM disediakan kapasitas 150 GB. Sehingga virtual hard disk dari tiap VM ditetapkan dengan besaran 50 GB dengan konfigurasi dynamically expanded, sebagai langkah penghematan dalam penggunaan free space pada media penyimpanan fisik, karena besarnya file VHD bergantung dari penggunaan media penyimpanan dalam VM yang bersangkutan.
4. Hasil dan Pembahasan
Setelah infrastruktur Hyper-V Cluster telah terbangun dengan baik, maka perlu dilakukan uji coba untuk mengukur keberhasilannya dalam mencapai tujuan dari virtualisasi server dan penanganan kegagalan dengan failover. Sebuah komputer client diposisikan pada jaringan eksternal dengan alamat IP 192.168.1.200/24 dan didaftarkan ke dalam domain “aryapasaputra.net” dengan
username “user1”. Untuk melakukan uji coba terhadap VM yang telah dirancang
sebelumnya, mula-mula dilakukan uji koneksi dari client menuju IP address dari
ketiga VM dengan menggunakan perintah “ping” melalui command prompt.
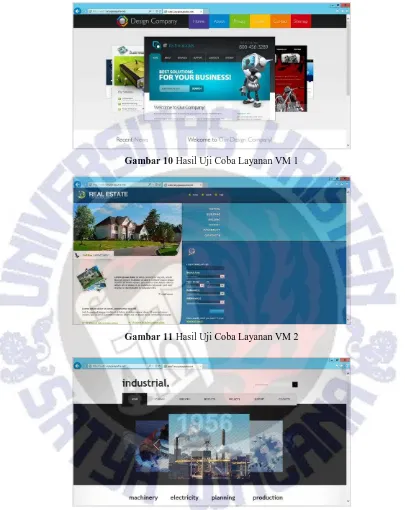
Apabila client sudah terkoneksi dengan ketiga VM, uji coba dilanjutkan terhadap layanan dari VM tersebut.
12
Gambar 10 Hasil Uji Coba Layanan VM 1
Gambar 11 Hasil Uji Coba Layanan VM 2
Gambar 12 Hasil Uji Coba Layanan VM 3
13
digunakan dalam pengujian ini adalah hasil dari besaran downtime yang didapatkan. Untuk melakukan pengujian terhadap kondisi VM, dilakukan monitoring koneksi dengan menggunakan aplikasi PRTG Network Monitoring yang diinstal pada sisi client. Karena ketiga VM merupakan web server dengan layanan HTTP yang didukung oleh aplikasi IIS, sehingga pengukuran downtime dapat dilakukan dengan menggunakan “HTTP Sensor” yang tersedia pada aplikasi PRTG Network Monitoring. Dengan penggunaan HTTP Sensor didapatkan hasil berupa grafik loading time dari layanan HTTP dari web server. Dari grafik tersebut, didapatkan pula durasi downtime yang terjadi.
Uji Coba Simulasi Planned Downtime
Planned downtime dilakukan dengan simulasi migrasi sebagai tindakan saat direncanakan maintenance terhadap server host. Simulasi migrasi yang dilakukan adalah quick migration, dan live migration. Kedua jenis migrasi VM tersebut memiliki fungsi yang sama, yaitu untuk memindahkan hadware resource VM dari satu host menuju ke host yang lain, namun dengan teknik pemindahan yang berbeda. Quick migration terjadi dengan proses save-move-resume, sedangkan live migration terjadi secara live, melalui proses copy memori bitmap secara iteratif.
Quick migration dilakukan dengan memindahkan VM dari server host-nya menuju ke host yang lain secara satu per satu dan dilakukan perhitungan durasi perpindahan dan downtime yang terjadi. VM 1 dipindahkan dari server HVHOST1 menuju ke server HVHOST2, sedangkan untuk VM 2 dan VM 3 dipindahkan dari server HVHOST2 menuju ke server HVHOST1. Hasil perhitungan durasi quick migration dan downtime dari masing-masing VM ditunjukkan oleh Tabel 5. Durasi dari downtime yang terjadi sama dengan durasi dari proses quick migration. Hal ini disebabkan karena pada saat berpindah VM berada pada posisi nonaktif, karena VM terlebih dahulu di-pause dan di-resume saat VM sudah berada pada host tujuan.
Tabel 5 Perbandingan Durasi Quick Migration dengan Durasi Downtime
VM Durasi Quick Migration Durasi Downtime
VM 1 31 detik 31 detik VM 2 29 detik 29 detik VM 3 30 detik 30 detik
14
Tabel 6 Perbandingan Durasi Live Migration dengan Durasi Downtime
VM Durasi Live Migration Durasi Downtime
VM 1 78 detik 3 detik VM 2 68 detik 3 detik VM 3 68 detik 3 detik
Uji Coba Simulasi Unplanned Downtime
Pengujian dengan simulasi unplanned downtime merupakan inti uji coba dalam menganalisis tentang bagaimana Hyper-V Cluster dapat menangani kegagalan dari sebuah server host melalui proses failover. Apabila salah satu server host mengalami kegagalan, seberapa cepat proses failover berlangsung dengan melakukan perpindahan VM menuju host lain yang masih aktif. Pehitungan besaran downtime dilakukan dengan cara yang sama saat dilakukan uji coba planned downtime sebelumnya, yaitu dengan aplikasi PRTG Network Monitoring, dan dengan memanfaatkan penggunaan HTTP Sensor. Pengujian dilakukan dengan cara mematikan power dari salah satu server. Saat salah satu host yang juga berperan sebagai node dimatikan power-nya, maka Heartbeat akan mengenali bahwa node tersebut berada dalam kondisi down, dan secara simultan akan langsung mengirimkan informasi tersebut kepada Cluster Resource Manager untuk melakukan proses failover dengan memindahkan seluruh VM dan juga role lain yang berada pada node yang mengalami kegagalan tersebut menuju node lain yang masih aktif. Proses tersebut berlangsung dalam durasi waktu sekitar 2 detik, tetapi VM yang berpindah akan mengalami proses restart, sehingga terjadi downtime selama beberapa saat, sampai VM berhasil melakukan startup dan berada dalam kondisi standby. Saat VM sudah berhasil melakukan startup, masih diperlukan lagi durasi waktu tambahan untuk menjalankan service IIS, sebagai aplikasi web server. Dari pengujian unplanned downtime yang dilakukan, hasil perhitungan durasi downtime yang didapatkan merupakan durasi waktu yang dimulai pada saat VM tidak aktif karena host-nya mengalami kegagalan, sampai dengan aktifnya layanan IIS setelah VM kembali aktif di dalam host yang lain. Durasi downtime yang bervariasi dipengaruhi oleh beberapa faktor. Pengujian unplanned downtime ini bertujuan untuk melakukan analisis terhadap faktor-faktor yang dapat mempengaruhi variasi dari durasi downtime yang diakibatkan oleh mekanisme failover yang terjadi.
Hipotesis pada uji coba unplanned downtime adalah kemungkinan perbedaan durasi downtime yang diakibatkan oleh faktor jumlah VM yang di-failover pada saat yang bersamaan, dan juga oleh faktor perbedaan priority level dari masing-masing VM. Untuk lebih memastikan hasil kebenaran dari hipotesis, pada tiap-tiap tahap pengkondisian proses failover dilakukan sebanyak 10 kali dan diambil nilai rata-rata dari hasil yang diperoleh sebagai penarikan kesimpulan.
15
kegagalan pada host tersebut. Sehingga dari uji coba ini akan didapatkan hasil berupa nilai downtime yang terjadi saat terdapat 1 VM, 2 VM, dan 3 VM yang berpindah secara bersamaan dari host yang mengalami kegagalan menuju host lain yang masih aktif. Detail besaran nilai rata-rata dari tiap-tiap tahap pengujian ditunjukkan melalui Tabel 7. Dari hasil tersebut didapatkan rata-rata downtime pada perpindahan 1 VM adalah 74,1 detik, 2 VM 126,6 detik, dan 3 VM 187,3 detik.
Tabel 7 Perbandingan Durasi Downtime dengan Perbedaan Jumlah VM
Jumlah VM
yang Berpindah Rata-rata Downtime 1 74,1 detik 2 126,6 detik
3 187,3 detik
Uji coba unplanned downtime yang kedua dikondisikan dengan perbedaan priority level dari masing-masing VM. Pada jendela Failover Cluster Manager, terdapat tiga opsi priority level, yaitu high, medium, low, dan no auto start. VM yang memiliki priority level lebih tinggi akan didahulukan proses recovery-nya saat terjadi kegagalan pada host-nya. Sedangkan dengan opsi no auto start, VM hanya akan dipindahkan menuju host lain yang masih aktif, tetapi dibiarkan tetap dalam keadaan mati. Uji coba ini dilakukan dengan memposisikan ketiga VM dalam satu host yang sama, dan dengan memberikan priority level yang berbeda-beda kepada setiap VM. Kemudian host dimatikan power-nya dan dilakukan analisis mengenai kemungkinan pengaruh priority level terhadap failover dan downtime yang dihasilkan. Uji coba dilakukan dalam tiga tahapan. Setiap tahapan memiliki setingan priority level yang berbeda-beda. Hasil berupa nilai rata-rata downtime dari seluruh tahapan uji coba ini dijelaskan melalui Tabel 8. Rata-rata downtime VM dengan priority high adalah 150,9 detik, medium 174 detik, dan low 198,5 detik.
Tabel 8 Perbandingan Durasi Downtime dengan Perbedaan Priority Level pada VM
16
Total keseluruhan uji coba unplanned downtime adalah sebanyak 60 kali yang dilakukan dalam kondisi yang bervariasi. Dari seluruh uji coba tersebut sistem Hyper-V Cluster mampu menangani seluruh simulasi kegagalan dengan baik. Proses failover dapat terjadi secara sempurna meskipun kegagalan terjadi berulang kali dan terus-menerus.
5. Simpulan
Berdasarkan penelitian yang dilakukan, dapat disimpulkan bahwa perancangan Hyper-V Cluster dapat menjadi salah satu solusi dalam peningkatan ketersediaan pada lingkungan virtualisasi server. Dua host dibangun sebagai node dari cluster yang saling bekerja sama menyediakan sumber daya perangkat keras bagi VM. Sedangkan, seluruh file yang berhubungan dengan VM, seperti file virtual hard disk, configuration file, dan snapshot disimpan di luar dari kedua server host, dengan menggunakan Cluster Shared Volume (CSV) sebagai media penyimpanan terdistribusi. Sehingga, saat terjadi kegagalan pada salah satu host, seluruh VM yang ada di dalamnya dapat secara langsung dipindahkan menuju host lain yang masih aktif. Durasi proses failover dan downtime dipengaruhi oleh faktor jumlah VM yang berpindah secara bersamaan serta oleh prioritylevel dari masing-masing VM. Semakin banyak VM yang berpindah dalam waktu bersamaan mengakibatkan angka downtime yang semakin besar. Sedangkan priority level yang lebih tinggi mengakibatkan downtime yang semakin kecil. Rata-rata downtime saat perpindahan 1 VM adalah 74,1 detik, perpindahan 2 VM 126,6 detik, sedangkan pada perpindahan 3 VM 187,3 detik. Sedangkan pada uji coba dengan priority level yang berbeda-beda, rata-rata angka downtime pada priority level high adalah 150,9 detik, pada level medium 174 detik, sedangkan pada level low 198,5 detik.
Sebagai saran bagi pengembangan penelitian, agar lebih mengoptimalkan infrastruktur Hyper-V yang telah dibangun, perlu disediakan metode backup bagi domain controller server dan juga pemisahan sumber energi primer dan sekunder bagi kedua server node, sehingga apabila terjadi kegagalan yang diakibatkan oleh hilangnya pasokan listrik, tidak akan mengakibatkan padamnya server secara keseluruhan. Selain itu dapat pula ditambahkan implementasi load balancing untuk pembagian beban pada host secara otomatis.
6. Daftar Pustaka
[1] Miller, Lawrence C., 2012, Server Virtualization for Dummies, Oracle Special Edition, Hoboken : John Wiley & Sons, Inc.
[2] Rule, D. & Dittner, R., 2007, The Best Damn Server Virtualization Book Period,Burlington : Syngress.
[3] Anonim, 2007, Understanding Full Virtualization, Paravirtualization, and Hardware Assist, VMware, Inc.
[4] Tulloch, Mitch., 2010, Understanding Microsoft Virtualization Solutions, Second Edition, Washington : Microsoft Press.
17
[6] Tutang, 2013, Instalasi dan Konfigurasi Windows Server 2012 Step By Step. [7] Anonim, 2009, Overview of High Availability, Oracle, Inc.,
http://oracle.su/docs/11g/server.112/e10804/overview.htm (diakses 17 Juni 2013).
[8] Anonim, 2006, Understanding Downtime, A Vision Solutions Whitepaper, Irvine : Visions Solutions, Inc.
[9] Zulkarnain, Bobby I., 2011, Pengantar Virtualization Server dengan Hyper-V dan Presentation Virtualization.
![Gambar 1 Strukrur Hypervisor tipe Bare-metal dan Hosted [4]](https://thumb-ap.123doks.com/thumbv2/123dok/434828.528302/9.595.97.508.178.701/gambar-strukrur-hypervisor-tipe-bare-metal-dan-hosted.webp)
![Gambar 3 Abstraksi Hypervisor pada Hyper-V [5]](https://thumb-ap.123doks.com/thumbv2/123dok/434828.528302/10.595.102.511.111.597/gambar-abstraksi-hypervisor-pada-hyper-v.webp)
![Gambar 4 Tahapan Network Development Life Cycle [10]](https://thumb-ap.123doks.com/thumbv2/123dok/434828.528302/12.595.103.505.283.515/gambar-tahapan-network-development-life-cycle.webp)