1. Pendahuluan
Evaluasi hasil belajar menjadi komponen yang sangat penting dalam proses pembelajaran, karena hasil evaluasi merupakan indikator dari pemahaman siswa terhadap materi ajar yang diberikan. Soal esai merupakan salah satu bentuk dari soal ujian atau evaluasi dimana tidak adanya pilihan jawaban yang disediakan sehingga jawaban dapat bervariasi sesuai dengan pemikiran-pemikiran setiap peserta ujian[1].
Esai dianggap sebagai metode yang paling tepat untuk menilai hasil kegiatan belajar yang kompleks. Namun ternyata esai menimbulkan masalah baru yaitu pemeriksaan esai yang membutuhkan waktu lama serta sifat subjektif dari penilai. Karena itu pengajar membutuhkan sistem yang dapat memeriksa esai secara otomatis.
Tes online adalah sebuah tes yang berbasis komputer. Yang dimaksudkan adalah komputer digunakan sebagai sarana untuk mengadakan tes. Tes online dapat memudahkan pengajar dalam mengoreksi tes karena komputer akan secara otomatis mengoreksinya. Tes online juga dapat menghemat pemakaian kertas karena tidak memerlukan kertas untuk soal dan lembar jawab siswa.
Latent Semantic Analysis (LSA) adalah merupakan sebuah metode statistik yang dapat digunakan untuk menentukan dan merepresentasikan kesamaan makna dari kata-kata dan teks dengan cara melakukan analisis terhadap teks dalam jumlah yang besar. Dengan metode LSA, semantik dari teks dapat ditentukan melalui proses perhitungan semantik similaritas yang merupakan proses keterlibatan beberapa ilmu seperti bahasa, komputer, logika matematika dan domain yang bersangkutan.
Dengan adanya teknologi dan algoritma LSA ini akan diteliti bagaimana membuat sistem tes esai secara online dengan memanfaatkan algoritma LSA. Manfaat yang ingin dicapai didalam penelitian ini adalah agar pengajar dapat dipermudah dalam memeriksa soal berbentuk esai dan mendapatkan patokan bobot nilai yang jelas.
2. Kajian Pustaka
Penelitian terdahulu tentang metode LSA adalah tentang penggunan metode LSA untuk menilai tes esai. Tahap-tahap metode LSA yang dilakukan pada penelitian ini adalah parsing test, pembobotan term dengan TF-IDF, dekomposisi dan reduksi dengan SVD dan perhitungan similarity. Hasil dari penelitian tersebut adalah nilai similarity jawaban kunci dengan jawaban yang lainnya. [2].
Penelitian lain membahas tentang metode LSA dalam pembuatan ringkasan teks dengan menggunakan peringkat dan intisari kalimat dari dokumen asli. Dalam penelitian ini LSA digunakan untuk mengidentifikasi semantik kalimat-kalimat penting dalam pembuatan ringkasan. Sehingga menghasilkan kalimat-kalimat yang mempunyai peringkat tertinggi dan berbeda dari yang lain. Hasil dari penelitian ini dapat membuat ringkasan dokumen dengan cangkupan isi dokumen yang luas dan meminimalisir redundansi [3].
e-leraning. Proses yang dilakukan pada penelitian ini antara lain pencarian sinonim berdasarkan pengukuran similaritas semantik berbasis WordNet dan pemberian skor pada kemiripan objek pada data ontologi. Hasil dari penelitian ini sudah dapat dilakukan perhitungan kemiripan suatu kalimat berdasarkan kedekatan masing-masing katanya dalam struktur database WordNet. Selain itu jawaban akan dilihat hubungannya lagi berdasarkan pada struktur ontologi yang ada pada jawaban di ontologi yang dimasukkan oleh user [4].
Dalam penelitian ini metode LSA juga dimanfaatkan untuk penilaian tes esai dengan penambahan fungsi sinonim kata sehingga kata-kata yang digunakan dalam pembobotan kata lebih spesifik.
Stemming Algoritma Nazief dan Adriani
Stemming merupakan suatu proses yang terdapat dalam sistem Information Retrieval (IR) yang mentransformasi kata-kata yang terdapat dalam suatu dokumen ke kata-kata akarnya (root word) dengan menggunakan aturan-aturan tertentu. Sebagai contoh, kata bersama, kebersamaan, menyamai, akan distem ke root wordnya yaitu “sama”. Proses stemming pada teks berbahasa Indonesia berbeda dengan stemming pada teks berbahasa Inggris. Pada teks berbahasa Inggris, proses yang diperlukan hanya proses menghilangkan sufiks. Sedangkan pada teks berbahasa Indonesia, selain sufiks, prefiks, dan konfiks juga dihilangkan [5].
Algoritma yang dibuat oleh Bobby Nazief dan Mirna Adriani ini memiliki tahap-tahap sebagai berikut:
1. Cari kata yang akan distem dalam kamus. Jika ditemukan maka diasumsikan bahwa kata tesebut adalah root word. Maka algoritma berhenti.
2. Inflection Suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”) dibuang. Jika berupa particles(“-lah”, “-kah”, “-tah” atau “-pun”) maka langkah ini diulangi lagi untuk menghapus Possesive Pronouns (“-ku”, “-mu”, atau “-nya”), jika ada.
3. Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata ditemukan di kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a
a. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “ -k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3b.
b. Akhiran yang dihapus (“-i”, “-an” atau “-kan”) dikembalikan, lanjut ke langkah 4.
4. Hapus Derivation Prefix. Jika pada langkah 3 ada sufiks yang dihapus maka pergi ke langkah 4a, jika tidak pergi ke langkah 4b.
a. Periksa tabel kombinasi awalan-akhiran yang tidak diijinkan. Jika ditemukan maka algoritma berhenti jika tidak pergi ke langkah 4b. b. For i = 1 to 3, tentukan tipe awalan kemudian hapus awalan. Jika root
word belum juga ditemukan lakukan langkah 5, jika sudah maka algoritma berhenti. Catatan: jika awalan kedua sama dengan awalan pertama algoritma berhenti.
6. Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal diasumsikan sebagai root word. Proses selesai.
Tipe awalan ditentukan melalui langkah-langkah berikut:
1. Jika awalannya adalah: “di-”, “ke-”, atau “se-” maka tipe awalannya secara berturut-turut adalah “di-”, “ke-”, atau“se”.
2. Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-” maka dibutuhkan sebuah proses tambahan untuk menentukan tipe awalannya.
3. Jika dua karakter pertama bukan “di-”, “ke-”, “se-”, “te-”, “be-”, “me-”, atau “pe-” maka berhenti.
4. Jika tipe awalan adalah “none” maka berhenti. Jika tipe awalan adalah bukan “none” maka awalan dapat dilihat pada Tabel 2. Hapus awalan jika ditemukan.
Tabel 1. Kombinasi awalan dan akhiran yang tidak diijinkan
Tabel 2. Cara Menentukan Tipe Awalan Kata Yang Diawali Dengan “te-”
Tabel 3. Jenis Awalan Berdasarkan Tipe Awalannya
Untuk mengatasi keterbatasan pada algoritma di atas, maka ditambahkan aturan-aturan dibawah ini:
1. Aturan untuk reduplikasi.
a. Jika kedua kata yang dihubungkan oleh kata penghubung adalah kata yang sama maka root word adalah bentuk tunggalnya, contoh : “buku-buku” root word-nya adalah “buku”.
b. Kata lain, misalnya “bolak-balik”, “berbalas-balasan, dan ”seolah-olah”. Untuk mendapatkan root word-nya, kedua kata diartikan secara terpisah. Jika keduanya memiliki root word yang sama maka diubah menjadi bentuk tunggal, contoh: kata “berbalas-balasan”,“berbalas” dan “balasan” memiliki root word yang sama yaitu “balas”, maka root word “berbalas -balasan” adalah “balas”. Sebaliknya, pada kata “bolak-balik”, “bolak” dan “balik” memiliki root word yang berbeda, maka root word-nya adalah “bolak-balik”
a. Untuk tipe awalan “mem-“, kata yang diawali dengan awalan “memp-” memiliki tipe awalan “mem-”.
b. Tipe awalan “meng-“, kata yang diawali dengan awalan “mengk-” memiliki tipe awalan “meng-”.
Term Frequency-Inverse Document Frequency (TF-IDF)
Metode Term Frequency-Inverse Document Frequency (TF-IDF) adalah cara pemberian bobot hubungan suatu kata (term) terhadap dokumen. Untuk dokumen tunggal tiap kalimat dianggap sebagai dokumen. Metode ini menggabungkan dua konsep untuk perhitungan bobot, yaitu Term frequency (TF) merupakan frekuensi kemunculan kata (t) pada kalimat (d). Document frequency (DF) adalah banyaknya kalimat dimana suatu kata (t) muncul [6].
Frekuensi kemunculan kata di dalam dokumen yang diberikan menunjukkan seberapa penting kata itu di dalam dokumen tersebut. Frekuensi dokumen yang mengandung kata tersebut menunjukkan seberapa umum kata tersebut. Bobot kata semakin besar jika sering muncul dalam suatu dokumen dan semakin kecil jika muncul dalam banyak dokumen.
Adapun rumus umum TF-IDF adalah sebagai berikut:
Dimana:
Wij : bobot kata/term ke-j dan dokumen ke-i
Tfij : jumlah kemuculan kata/term ke-j dalam dokumen ke-i
N : jumlah semua dokumen yang ada dalam basis data n : jumlah dokumen yang mengandung term ke-j
Algoritma Latent Semantic Analysis
Latent Semantic Analysis (LSA) adalah suatu teori atau algoritma untuk mengekstrak dan merepresentasikan kesamaan makna dari kata-kata menggunakan perhitungan statistika yang diterapkan pada keseluruhan teks [7]. LSA menggunakan metode aljabar linear yaitu singular value decomposition (SVD). LSA akan membentuk matriks yang merepresentasikan asosiasi antara term-dokumen yang merupakan semantic space, yakni kata–kata dan dokumen-dokumen yang berasosiasi dekat akan ditempatkan dekat satu sama lain.
Tahapan LSA meliputi 3 tahap utama yaitu: 1. Parsing Text dan Pembobotan dengan TF IDF
a. Tokenizing
Tokenizing merupakan proses mengidentifikasi unit terkecil (token) dari suatu struktur kalimat. Tujuan dilakukannya tokenizing ini adalah untuk mendapatkan term-term yang nantinya akan diindeks. Pengklasifikasian token dilakukan untuk teks yang dipisahkan dengan spasi atau enter adalah suatu dokumen.
b. Filtering
Filtering merupakan proses dimana token-token yang didapat dari proses tokenizing akan diseleksi dari token-token yang dianggap tidak penting (stoplist). Stoplist merupakan kata yang sering muncul dan bisa diabaikan pada proses filtering.
c. Stemming
Stemming adalah suatu proses yang bertujuan untuk mengambil kata dasar dari kata yang berimbuhan atau kata tunggal dari kata bentukan. Hal itu mengurangi jumlah term yang berbeda dalam koleksi.
Setelah proses parsing text dilakukan langkah selanjutnya adalah melakukan pembobotan hasil parsing text dengan menggunakan algoritma TF-IDF.
2. Singular Value Decomposition (SVD)
Singular Value Decomposition (SVD) adalah satu metode untuk memecahkan masalah-masalah matematik linier. Pada SVD, matriks akan didekomposisi menjadi tiga komponen matriks. Komponen matriks pertama mendeskripsikan entitas baris sebagai vektor orthogonal matriks. Komponen matriks kedua mendeskripsikan matriks diagonal yang berisi nilai skalar dan yang ketiga adalah matriks entitas kolom sebagai vektor orthogonal matriks.
Metode SVD berdasarkan pada teori aljabar linier yang menyatakan bahwa suatu matriks A yang berukuran mxn, mempunyai nilai singular yang merupakan akar pangkat dua eigenvalue ATA.
Adapun rumus yang digunakan, yaitu:
Dimana:
A : matriks yang didekomposisi
U : matriks ortogonal U (matriks vektor singular kiri) S : matriks diagonal S (matriks nilai singular)
V : transpose matriks ortogonal V(matriks vektor singular kanan) m : jumlah baris matriks
n : jumlah kolom matriks
Jika nilai-nilai singulir dari matriks S diurutkan berdasarkan nilainya, maka k nilai terbesar dapat tetap disimpan dalam matriks tersebut, dan nilai-nilai lain yang lebih kecil dapat diset menjadi nol. Jika baris dan kolom yang berkaitan pada matriks U dan V juga diset menjadi nol, maka hasil kali dari ketiga matrik ini akan membentuk matriks baru yang merupakan matriks least square approximation.
Dengan menghapus elemen yang tidak menunjukkan arti, berarti menghapus noise yang berada pada vektor pada matriks. Sehingga vektor menjadi lebih pendek dan mengandung elemen yang sangat signifikan dengan data awal saja. Karena tujuan dari LSA bukanlah mendeskripsikan vektor secara verbal tetapi mampu untuk merepresentasikan term, dokumen dan menghasilkan query yang tidak ambigu dan beredundansi dengan sesama term, dimensi nilai k untuk mereduksi matrik bisa menggunakan dua atau tiga vektor saja [9].
3. Pengukuran kemiripan (similarity)
Salah satu pengukuran kemiripan (similarity) adalah dengan menghitung sudut antara dua vector yang bersangkutan, disini antara vector dari permintaan (query) dengan vector dokumen yang akan dinilai (document). Adapun rumus yang digunakan yaitu rumus cosine similarity :
Dimana:
A : vektor A B : vektor B
||A|| : panjang vektor A ||B|| : panjang vektor B
Antara vektor A dan B membentuk sudut α dimana cosinus dari sudut tersebut menunjukkan kemiripan (similarity) dari kedua sudut tersebut, bukan menunjukkan jarak (distance) antara vektor yang satu dengan yang lainnya.
3. Metode dan Perancangan Metode Prototype
Gambar 1 Tahapan-tahapan Metode Prototype [10]
Ketiga proses pada gambar tersebut akan terus berlangsung hingga semua kebutuhan terpenuhi. Proses-proses yang terjadi dalam metode prototype dapat digambarkan, sebagai berikut :
1. Pengumpulan Kebutuhan
Merupakan proses menganalisa kebutuhan yang terdapat pada permasalahan yang dihadapi, pengumpulan data, kemudian bagaimana membangun aplikasi dengan landasan-landasan teori yang ada. Berdasarkan dari penelitian terdahulu, data-data yang dibutuhkan untuk dapat menerapkan algoritma LSA dalam mengolah tes esai adalah kunci jawaban sebagai patokan, jawaban mahasiswa, list kata dasar, stopword list dan skor nilai untuk masing-masing soal. Sehingga nantinya akan diperoleh hasil similaritas antara kunci jawaban dengan jawaban mahasiswa.
2. Perancangan Sistem
Pada tahap ini dilakukan pembuatan desain sistem berdasarkan kebutuhan yang telah dikumpulkan pada tahap pertama. Pembuatan desain dilakukan agar prototype yang nantinya dibuat, dapat menjawab atau memenuhi kebutuhan yang ada. Dengan adanya desain yang jelas maka permbuatan prototype akan lebih terarah. Tahapan ini merupakan proses pembuatan yang meliputi pembuatan UML atau yang lebih spesifik lagi yaitu use case diagram, activity diagram, sequence diagram, dan class diagram. Kemudian setelah UML selesai dibuat maka tahap selanjutnya adalah pembuatan desain antarmuka. Pada tahap ini prototype memang tidak langsung akan menjadi sempurna sesuai dengan apa yang diinginkan, tetapi dengan adanya pengujian dan evaluasi di tahap berikutnya dan beberapa kali pengulangan, prototype akan dapat menjawab kebutuhan.
3. Uji Coba
Perancangan Sistem 4. Hasil dan Pembahasan Pembahasan Aplikasi 1. Halaman Login
Tampilan awal dari sistem tes online adalah halaman login. Halaman login ini meliputi login untuk mahasiswa, dosen dan administrator.
Gambar 7 Halaman Login
Pada Gambar 7 user diharuskan memasukkan id dan password yang valid. Setelah user memasukkan id dan password yang valid, maka sistem akan menampilkan halaman utama.
2. Halaman Pengerjaan Tes
Halaman ini adalah halaman yang menampilkan form pengerjaan tes yang hanya bisa diakses oleh mahasiswa.
Gambar 8 Halaman Pengerjaan Tes
Pada Gambar 8 mahasiswa dapat melihat soal-soal yang ada dalam tes yang sedang dikerjakan dan dapat menginputkan jawaban sesuai dengan soal yang ada. Setiap tes yang ada memiliki batasan lama pengerjaan sesuai dengan kriteria yang telah ditentukan oleh dosen pengampu. Lama pengerjaan tes dapat dilihat dibagian pojok kanan sebagai pengingat mahasiswa. Ketika waktu pengerjaan telah habis, halaman ini akan secara otomatis menyimpan jawaban mahasiswa. Mahasiswa tidak dapat mengerjakan tes yang sama lebih dari sekali.
Halaman ini merupakan halaman yang hanya bisa diakses oleh dosen pengampu. Halaman ini menampilkan form yang dapat diisi oleh dosen pengampu untuk membuat tes matakuliah baru.
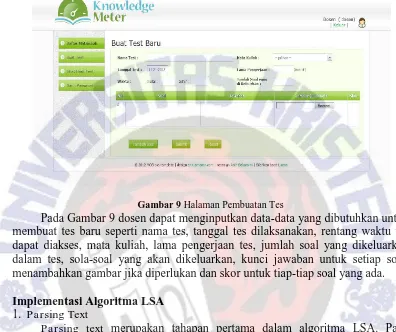
Gambar 9 Halaman Pembuatan Tes
Pada Gambar 9 dosen dapat menginputkan data-data yang dibutuhkan untuk membuat tes baru seperti nama tes, tanggal tes dilaksanakan, rentang waktu tes dapat diakses, mata kuliah, lama pengerjaan tes, jumlah soal yang dikeluarkan dalam tes, sola-soal yang akan dikeluarkan, kunci jawaban untuk setiap soal, menambahkan gambar jika diperlukan dan skor untuk tiap-tiap soal yang ada.
Implementasi Algoritma LSA 1. Parsing Text
Parsing text merupakan tahapan pertama dalam algoritma LSA. Pada tahapan ini jawaban soal dari mahasiswa melakukan proses tokenizing yaitu proses pengidentifikasian term-term dengan menghilangkan tanda baca, spasi dan enter. Setelah itu akan melakukan proses filtering dimana term-term yang dihasilkan dari proses pertama akan diseleksi dari term yang dianggap tidak penting atau yang biasa disebut dengan stopword. Kemudian akan dilakukan penghilangan imbuhan pada term tersebut sehingga menghasilkan kata dasar.
Kode Program 1 menjelaskan tentang fungsi untuk proses parsing text menggunakan algoritma Nazief dan Adriani.
2. Sinonim kata
Setelah proses parsing text selesai dilakukan proses selanjutnya adalah melakukan pencarian sinonim kata, sehingga kata-kata yang digunakan sebagai kata kunci tidak terlalu luas.
Kode Program 2 Perintah untuk sinonim kata
3. Pembobotan dengan TF-IDF
Setelah proses sinonim kata selesai dilakukan proses selanjutnya adalah melakukan pembobotan kata menggunakan algoritma TF-IDF.
Kode Program 3 Perintah untuk menghitung pembobotan kata TF-IDF
Kode program 3 menjelaskan tentang fungsi algoritma TF-IDF yaitu perkalian antara TF yang merupakan frekuensi kemunculan term pada kalimat
1. for($t = 0;$t < count($df);$t++){
2. $query = "select * from sinonim where kata_1 = '".$kata."'";
3. $result = mysql_query($query) or die(mysql_error());
dengan IDF yaitu log hasil pembagian jumlah seluruh dokumen dengan jumlah dokumen yang mengandung term.
4. Singular Value Decomposition (SVD)
Proses selanjutnya adalah SVD yaitu proses mendekomposisikan suatu matrik menjadi tiga komponen matrik.
Kode Program 4 Perintah untuk menghitung SVD
Kode program 4 menjelaskan fungsi SVD dari matrik A menjadi tiga komponen matrik U,S dan V. Dijelaskan juga kode program untuk melakukan aproksimasi matrik S dan V dengan dimensi k = 2. Dimana matrik S merupakan matrik nilai singulir dan matrik V merupakan matrik singular kanan dari matrik A. Perkalian dari kedua matrik V dan S merepresentasikan koordinat dokumen pada semantic space.
5. Cosine Similarity
Langkah terakhir dari algoritma LSA adalah pengukuran kemiripan antar dokumen menggunakan cosine similarity.
Kode Program 5 Perintah untuk menghitung similaritas antar dua dokumen
1. function dotProduct($a, $b){
12. $S2 = new Matrix($So); //S2 merupakan aproksimasi matriks S
13. $V1 = $V->getArray();
19. $V2 = new Matrix($Vo); //V2 merupakan aproksimasi matriks V
Kode program 5 menjelaskan fungsi dari cosine simlarity yaitu perkalian vector a dengan vector b dibagi dengan perkalian length vector a dengan length vector b. Setelah proses ini dilakukan akan menghasilkan nilai similaritas kedua dokumen yang kemudian akan dikalikan dengan skor yang dimiliki oleh soal tersebut.
Pengujian Aplikasi
Pada bagian ini dilakukan pengujian terhadap aplikasi yang telah dibangun. Pengujian ini dilakukan untuk mengetahui sejauh mana aplikasi ini dapat berjalan dan apa saja kekurangan dari aplikasi ini.
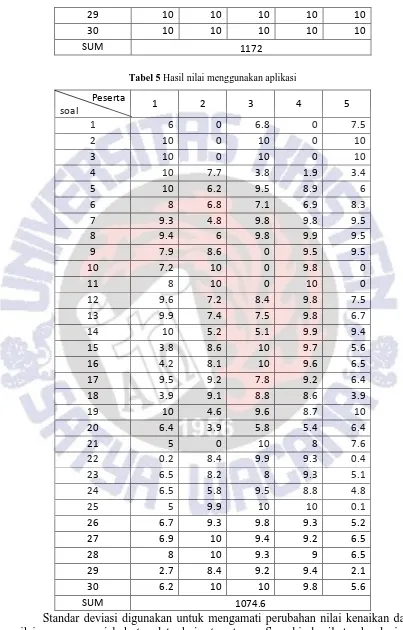
Ujicoba dilakukan dengan 5 peserta dengan 30 soal esai. Tabel 4 Hasil nilai peserta human raters
29 10 10 10 10 10
30 10 10 10 10 10
SUM 1172
Tabel 5 Hasil nilai menggunakan aplikasi
Peserta
soal 1 2 3 4 5
1 6 0 6.8 0 7.5
2 10 0 10 0 10
3 10 0 10 0 10
4 10 7.7 3.8 1.9 3.4
5 10 6.2 9.5 8.9 6
6 8 6.8 7.1 6.9 8.3
7 9.3 4.8 9.8 9.8 9.5
8 9.4 6 9.8 9.9 9.5
9 7.9 8.6 0 9.5 9.5
10 7.2 10 0 9.8 0
11 8 10 0 10 0
12 9.6 7.2 8.4 9.8 7.5
13 9.9 7.4 7.5 9.8 6.7
14 10 5.2 5.1 9.9 9.4
15 3.8 8.6 10 9.7 5.6
16 4.2 8.1 10 9.6 6.5
17 9.5 9.2 7.8 9.2 6.4
18 3.9 9.1 8.8 8.6 3.9
19 10 4.6 9.6 8.7 10
20 6.4 3.9 5.8 5.4 6.4
21 5 0 10 8 7.6
22 0.2 8.4 9.9 9.3 0.4
23 6.5 8.2 8 9.3 5.1
24 6.5 5.8 9.5 8.8 4.8
25 5 9.9 10 10 0.1
26 6.7 9.3 9.8 9.3 5.2
27 6.9 10 9.4 9.2 6.5
28 8 10 9.3 9 6.5
29 2.7 8.4 9.2 9.4 2.1
30 6.2 10 10 9.8 5.6
SUM 1074.6
semakin kecil pula perubahan variabel dari rata-ratanya dan sebaliknya. Standar raters sebesar 3.48 dan untuk hasil nilai menggunakan LSA sebesar 3.08.
Mean Squared Error (MSE) berfungsi untuk membandingkan ketepatan dua atau lebih metode yang berbeda, sebagai alat ukur apakah teknik yang diambil dapa dipercaya atau tidak dan membantu mencari sebuah metode yang optimal.
���= 1
Dari rumus tersebut diperoleh MSE sebesar 10,12.
5. Simpulan
Kesimpulan dari penelitian yang telah dilakukan ini adalah algoritma Latent Semantic Analysis dapat digunakan untuk menilai soal berbentuk esai dengn cara membuat basis data untuk menyimpan data kunci jawaban sebagai patokan, jawaban mahasiswa, list kata dasar, stopword list dan skor nilai. Kemudian melakukan proses stemming, pembobotan kata, memecahkan matriks dan mencari nilai similaritas. Hasil dari penilitian ini adalah standar deviasi hasil nilai human raters sebesar 3.48, standar deviasi untuk hasil nilai menggunakan LSA sebesar 3.08, Mean Square Error (MSE) sebesar 10,12. Saran pengembangan aplikasi ini adalah dengan menambahkan kosakata-kosakata yang lebih luas baik untuk stopword dan kata dasar. Lebih memperhatikan pemilihan kunci jawaban, menyusun daftar persamaan kata kunci jawaban dan pembobotan terhadap posisi kata kunci dalam kalimat.
6. Pustaka
[1] Tarhadi, dkk. 2007. Penggunaan Tes Uraian dibandingkan dengan Tes Pilihan Ganda Terstruktur dan Tes Pilihan Ganda Biasa. Jurnal Pendidikan : Vol. 8 No. 2.
[2] Ardiansyah, Adryan. 2011. Pengembangan Aplikasi Pendeteksi Plagiarisme Menggunakan Metode Latent Semantic Analysis (LSA). Bandung: Universitas Pendidikan Indonesia.
[4] Firdausiah Andi Besse, dkk. 2008. Sistem Penilaian Otomatis Jawaban Essay Menggunakan Ontologi pada Moodle. Surabaya: Institut Teknologi Sepuluh November.
[5] Agusta, Ledy. 2009. Perbandingan Algoritma Stemming Porter dengan Algoritma Nazief & Adriani untuk Stemming Dokumen Teks Bahasa Indonesia. Salatiga: Universitas Kristen Satya Wacana.
[6] Robertson, S., 2004. “Understanding Inverse Document Frequency: On theoretical arguments for IDF”, Journal of Documentation, Vol.60, no.5, pp. 503-520.
[7] Landauer, T. K., Foltz, P. W., & Laham, D. 1998. Introduction to Latent Semantic Analysis. Discourse Processes: 25, 259-284.
[8] Triawati, Chandra. 2009. Metode Pembobotan Statistical Concept Based untuk Klastering dan Kategorisasi Dokumen Berbahasa Indonesia. Institut Teknologi Telkom. Bandung.
[9] S. Deerwester, S. T. Dumais, G. W. Furnas, T. K. Landauer, R. Harshman. 1990. “Indexing by Latent Semantic Analysis”. Journal of the American Society for Information Science: 41 (6), 391-407.
[10] Pressman, Roger. 2001. Rekayasa Perangkat Lunak Pendekatan Praktisi (Buku Satu). Yogyakarta: Andi.

![Gambar 1 Tahapan-tahapan Metode Prototype [10] Ketiga proses pada gambar tersebut akan terus berlangsung hingga semua](https://thumb-ap.123doks.com/thumbv2/123dok/1008796.491864/7.595.102.513.115.685/gambar-tahapan-tahapan-metode-prototype-ketiga-proses-berlangsung.webp)