SEGMENTASI PELANGGAN MENGGUNAKAN
METODE PARTICLE SWARM OPTIMIZATION
DAN K-MEANS
TUGAS AKHIR
Diajukan guna memenuhi sebagian persyaratan dalam rangka menyelesaikan Pendidikan Sarjana Strata Satu (S1) Program Studi Teknologi Informasi
I DEWA AYU AGUNG YUNITA PRIMANDARI NIM: 1204505063
JURUSAN TEKNOLOGI INFORMASI
FAKULTAS TEKNIK
ii
PERNYATAAN
Dengan ini saya menyatakan bahwa dalam Tugas Akhir ini tidak terdapat karya yang pernah diajukan untuk memperoleh gelar kesarjanaan di perguruan tinggi lain, dan sepanjang pengetahuan saya tidak terdapat karya atau pendapat yang pernah ditulis atau diterbitkan oleh orang lain, kecuali yang secara tertulis diacu dalam naskah ini dan disebutkan pada daftar pustaka.
Denpasar, Juni 2016
iii
iv
v
KATA PENGANTAR
Puji dan syukur penulis panjatkan kehadapan Ida Sang Hyang Widhi Wasa/Tuhan Yang Maha Esa, karena atas Asung Kerta Wara Nugraha-Nya, akhirnya penulis dapat menyelesaikan tugas akhir dengan judul “Segmentasi Pelanggan Menggunakan Metode Particle Swarm Optimization dan K-Means”.
Penulis mendapat banyak bimbingan dari berbagai pihak. Ucapan terima kasih penulis sampaikan kepada:
1. Bapak Prof. Ir. Ngakan Putu Gede Suardana, M.T., Ph.D. selaku Dekan Fakultas Teknik Universitas Udayana.
2. Bapak Dr. Eng. I Putu Agung Bayupati, ST., MT, selaku Ketua Jurusan Teknologi Informasi Universitas Udayana.
3. Bapak Prof. Dr. I Ketut Gede Darma Putra, S.Kom., M.T., selaku dosen pembimbing I yang telah banyak memberikan bimbingan dan masukan dalam penyusunan tugas akhir ini.
4. Bapak I Made Sukarsa, S.T., M.T., selaku dosen pembimbing II yang telah banyak memberikan petunjuk dan bimbingan selama penyusunan tugas akhir. 5. Bapak Putu Wira Buana, S.Kom., M.T. selaku dosen pembimbing akademik, yang telah memberikan bimbingan selama menempuh pendidikan di Jurusan Teknologi Informasi Fakultas Teknik Universitas Udayana.
6. Ibu Ayu Supartini, yang telah membantu dalam proses penelitian. Kedua orang tua dan keluarga yang telah memberikan dukungan. Teman-teman yang selalu mau sharing ilmu dan solusi Tio, Maha dan Cinho, Teman-teman seperjuangan selama masa kuliah Utami, Moren, Indah, Tiwi, Teman-teman seperjuangan di HMTI, Resa, Abi, Try serta angkatan 2012 TI telah memberikan dukungan dalam penyusunan tugas akhir ini.
Denpasar, Juni 2016
vi ABSTRAK
Segmentasi pelanggan merupakan salah satu implementasi data mining. Segmentasi pelanggan membagi pelanggan ke dalam beberapa kelas untuk membantu perusahaan memahami karakteristik setiap pelanggannya. Tugas akhir ini menganalisa 33.441 baris data transaksi perusahaan yang ditransformasi ke dalam bentuk Recency, Frequency, dan Monetary (RFM). Metode clustering yang digunakan untuk melakukan segmentasi pelanggan adalah kombinasi dari Metode Particle Swarm Optimization (PSO) dan K-Means. Kombinasi kedua metode tersebut mengambil keunggulan dari masing-masing metode dan menghilangkan kelemahan yang dimiliki. Metode K-Means sangat sensitif dalam menentukan titik pusat karena dilakukan secara acak. Kelemahan pada titik pusat Metode K-Means tersebut dioptimasi dengan Metode PSO sehingga Metode K-Means dapat melakuan clustering secara lebih baik. Penelitian ini menggunakan beberapa jumlah cluster. Berdasarkan metode validasi cluster yang digunakan yaitu Metode Davies-bouldin Index (DBI) dan Silhouette Index cluster terbaik adalah cluster terbaik yang memiliki nilai Indeks DBI sebesar 0.5 dan nilai Indeks Silhouette sebesar 0.83.
vii ABSTRACT
Customer segmentation is an implementation of clustering in the data mining process. Customer segmentation divides customers into certain classes to help a company to understand each customer. This paper analyzed 33,441 rows of a transaction data and transformed it into Recency, Frequency, and Monetary form (RFM) to identify potential customer. Clustering method used was the combination of Particle Swarm Optimization (PSO) and K-Means algorithm. The combination of these algorithms aimed to take advantages of both algorithms and remove their weakness. K-Means is very sensitive to initialize the cluster center because it was done randomly. PSO was used to optimize the cluster center and help K-Means to cluster better. The clustering experiment used several number of cluster. The best number of the cluster for this experiments are two clusters according to Davies-bouldin Index (DBI) method. The second cluster has 0.5 value of DBI’s index and
0.83 value of Silhouette’s index.
viii DAFTAR ISI
HALAMAN DEPAN ... i
PERNYATAAN ... ii
LEMBAR PENGESAHAN TUGAS AKHIR ... iii
BERITA ACARA TUGAS AKHIR ... iv
KATA PENGANTAR ... v
2.3 Hubungan Data Mining dalam Kerangka Kerja CRM ... 11
2.4 Model RFM ... 13
2.5 Normalisasi Data ... 15
2.6 Metode Clustering ... 16
2.7 Metode K-Means ... 16
2.8 Metode Particle Swarm Optimization ... 19
2.8.1 Personal Best dan Global Best Particle Swarm Optimization ... 20
2.8.3 Contoh Perhitungan Particle Swarm Optimization ... 21
2.9 Validasi Cluster ... 23
2.9.1 Validasi Cluster dengan Davies-bouldin Index ... 23
2.9.2 Validasi Cluster dengan Silhouette Index ... 24
2.10 Profil Perusahaan PT. X ... 25
BAB III METODOLOGI PENELITIAN ... 26
3.1 Tempat dan Waktu Penelitian ... 26
3.2 Alur Penelitian ... 26
3.3 Sumber Data ... 27
3.4 Kebutuhan Hardware dan Software ... 27
3.5 Perancangan Sistem ... 28
3.5.1 Gambaran Umum Sistem ... 28
3.5.2 Pemilihan Data ... 30
3.5.4 Transformasi Data ... 35
ix
3.5.6 Optimasi Titik Pusat Cluster Menggunakan PSO ... 44
3.5.7 Clustering Menggunakan K-Means ... 51
3.5.8 Pemodelan Data ... 58
3.5.9 Cluster Validation dengan Davies-bouldin Index ... 61
3.5.10 Cluster Validation dengan Silhouette Index ... 66
3.6 Perancangan Basis Data ... 69
3.7 Interface ... 79
BAB IV PEMBAHASAN DAN ANALISA HASIL ... 85
4.1 Piranti Implementasi Aplikasi ... 85
4.1.1 Kebutuhan Perangkat Lunak Implementasi Aplikasi ... 85
4.1.2 Kebutuhan Perangkat Keras Implementasi Aplikasi ... 85
4.2 Hasil Perancangan Aplikasi ... 86
4.2.1 Tampilan Menu ... 86
4.2.2 Proses Pemilihan Data ... 87
4.2.3 Proses Transformasi Data ... 88
4.2.4 Proses Normalisasi Data ... 90
4.2.5 Proses Optimasi Titik Pusat Cluster dengan Metode Particle Swarm Optimization ... 91
4.2.6 Proses Clustering Menggunakan Metode K-Means ... 92
4.2.7 Proses Validasi Cluster ... 93
4.3 Uji Coba Aplikasi ... 94
4.3.1 Hasil Uji Coba Clustering dengan 2 Cluster ... 95
4.3.2 Hasil Uji Coba Clustering dengan 3 Cluster ... 98
4.3.3 Hasil Uji Coba Clustering dengan 4 Cluster ... 102
4.3.4 Hasil Uji Coba Clustering dengan 5 Cluster ... 106
4.3.5 Hasil Uji Coba Clustering dengan 6 Cluster ... 110
4.4 Analisis Cluster ... 114
4.5 Perbandingan Hasil Clustering Metode K-Means dan Metode PSO+K-Means ... 115
4.6 Perbandingan Kelas Konsumen per Bulan ... 119
BAB V PENUTUP ... 123
5.1 Simpulan ... 123
5.2 Saran ... 124
x
DAFTAR GAMBAR
Gambar 2.1 Diagram Fishbone... 9
Gambar 2.2 Proses KDD ... 10
Gambar 2.3 Skema CRIPS-DM ... 12
Gambar 2.4 Topologi Bintang... 20
Gambar 3.1 Gambaran Umum Sistem ... 28
Gambar 3.2 Relasi Tabel Data Transaksi PT. X ... 31
Gambar 3.3 Skema Pembentukan Nilai RFM ... 35
Gambar 3.4 Skema Penentuan Nilai tb_standar ... 37
Gambar 3.5 Skema Penentuan Nilai tb_rfm ... 38
Gambar 3.6 Screenshoot Data tb_rfm ... 40
Gambar 3.7 Screenshoot Hasil Normalisasi Data tb_rfm ... 44
Gambar 3.8 Flowchart Algoritma PSO ... 46
Gambar 3.9 Hasil Iterasi Pertama Metode PSO ... 49
Gambar 3.10 Hasil Iterasi Kedua Metode PSO ... 51
Gambar 3.11 Flowchart Algoritma K-Means ... 52
Gambar 3.12 Hasil Iterasi Pertama Metode K-Means ... 55
Gambar 3.13 Hasil Iterasi Kedua Metode K-Means ... 57
Gambar 3.14 Flowchart Algoritma Davies-bouldin Index ... 62
Gambar 3.15 Flowchart Algoritma Silhouette ... 67
Gambar 3.16 Rancangan Basis Data Bantu ... 70
Gambar 3.17 Form Home ... 79
Gambar 3.18 Form Transfomasi Monthly Segmentation ... 80
Gambar 3.19 Form Transformasi Data ... 80
Gambar 3.20 Form Pemilihan Titik Pusat ... 81
Gambar 3.21 Form Clustering ... 81
Gambar 3.22 Form Cluster Validation ... 82
Gambar 3.23 Form Hasil Segmentasi ... 83
Gambar 3.24 Form Hasil Segmentasi Per Pelanggan ... 83
Gambar 3.25 Form About ... 84
Gambar 4.1 Tampilan Menu ... 86
Gambar 4.2 Proses Pemilihan Data ... 87
Gambar 4.3 Skema Pembentukan tb_standar ... 88
Gambar 4.4 Skema Transformasi Data ... 88
Gambar 4.5 Proses Normalisasi Data ... 90
Gambar 4.6 Proses Optimasi Titik Pusat Cluster ... 92
Gambar 4.7 Proses Clustering dengan Metode K-Means ... 93
Gambar 4.8 Proses Validasi Cluster ... 94
Gambar 4.9 Proses Pemilihan Titik Pusat dengan 2 Cluster ... 95
Gambar 4.10 Titik Pusat Optimal dengan 2 Cluster ... 96
Gambar 4.11 Hasil Clustering K-Means dengan 2 Cluster ... 96
Gambar 4.12 Hasil Segmentasi Pembentukan 2 Cluster ... 97
Gambar 4.13 Proses Pemilihan Titik Pusat dengan 3 Cluster ... 98
xi
Gambar 4.15 Hasil Clustering K-Means dengan 3 Cluster ... 100
Gambar 4.16 Hasil Segmentasi Pembentukan 3 Cluster ... 101
Gambar 4.17 Proses Pemilihan Titik Pusat dengan 4 Cluster ... 102
Gambar 4.18 Titik Pusat Optimal dengan 4 Cluster ... 103
Gambar 4.19 Hasil Clustering K-Means dengan 4 Cluster ... 104
Gambar 4.20 Hasil Segmentasi Pembentukan 4 Cluster ... 105
Gambar 4.21 Proses Pemilihan Titik Pusat dengan 5 Cluster ... 106
Gambar 4.22 Titik Pusat Optimal dengan 5 Cluster ... 107
Gambar 4.23 Hasil Clustering K-Means dengan 5 Cluster ... 108
Gambar 4.24 Grafik Clustering K-Means dengan 5 Cluster ... 109
Gambar 4.25 Proses Pemilihan Titik Pusat dengan 6 Cluster ... 110
Gambar 4.26 Titik Pusat Optimal dengan 6 Cluster ... 111
Gambar 4.29 Hasil Clustering K-Means dengan 6 Cluster ... 112
Gambar 4.28 Grafik Clustering K-Means dengan 6 Cluster ... 113
Gambar 4.29 Hasil Validasi Cluster ... 115
Gambar 4.30 Perbandingan Hasil Cluster Metode K-Means dan Metode PSO+K-Means ... 116
Gambar 4.30 Grafik Segementasi Pelanggan (Kode Pelanggan = 12100) ... 120
Gambar 4.31 Grafik Segementasi Pelanggan (Kode Pelanggan = 11005) ... 121
Gambar 4.32 Grafik Segementasi Pelanggan (Kode Pelanggan = 12493) ... 121
xii
DAFTAR TABEL
Tabel 2.1 Daftar State of the Art ... 8
Tabel 2.2 Klasifikasi Customer ... 14
Tabel 2.3 Data Sumber ... 17
Tabel 2.4 Titik Pusat Iterasi ke-1 ... 18
Tabel 2.5 Hasil Perhitungan Jarak ... 19
Tabel 3.1 Tabel Pelanggan ... 31
Tabel 3.2 Contoh Tabel tb_pelanggan ... 32
Tabel 3.3 Tabel Produk ... 32
Tabel 3.4 Contoh Tabel tb_produk ... 32
Tabel 3.5 Tabel Sales ... 33
Tabel 3.6 Contoh Tabel Sales ... 33
Tabel 3.7 Tabel Transaksi ... 33
Tabel 3.8 Contoh Tabel Transaksi ... 34
Tabel 3.9 Tabel Detail Transaksi ... 34
Tabel 3.10 Contoh Tabel Detail Transaksi ... 35
Tabel 3.11 Data Pemilihan Atribut Sesuai Model RFM ... 35
Tabel 3.12 Contoh Data pada Tabel Transaksi ... 36
Tabel 3.13 Contoh Data pada tb_standar ... 37
Tabel 3.14 Contoh Data pada tb_rfm ... 39
Tabel 3.15 Contoh Data pada tb_rfm ... 39
Tabel 3.16 Contoh Data Atribut Recency ... 40
Tabel 3.17 Contoh Data Atribut Frequency ... 42
Tabel 3.18 Contoh Data Atribut Monetary ... 43
Tabel 3.19 Hasil Normalisasi Data tb_rfm ... 44
Tabel 3.21 Normalisasi Data tb_rfm ... 47
Tabel 3.21 Contoh Data pada tb_rfm yang Ternormalisasi ... 52
Tabel 3.22 Perhitungan Jarak Iterasi Pertama ... 54
Tabel 3.23 Perhitungan Jarak Iterasi Pertama ... 57
Tabel 3.24 Domain Nilai RFM ... 58
Tabel 3.25 Deskripsi Variabel Linguistik dan Label Konsumen ... 59
Tabel 3.26 Data tb_rfm ... 60
Tabel 3.27 Domain Nilai RFM ... 61
Tabel 3.28 Kelas Cluster ... 61
Tabel 3.29 Normalisasi Data tb_rfm ... 63
Tabel 3.30 Contoh Data Atribut Cluster 1 ... 63
Tabel 3.31 Contoh Data Atribut Cluster 2 ... 64
Tabel 3.32 Normalisasi Data tb_rfm ... 68
Tabel 3.33 Hasil Perhitungan Indeks Silhouette ... 69
Tabel 3.34 Struktur tb_standar ... 70
Tabel 3.35 Contoh Data tb_standar ... 71
xiii
Tabel 3.37 Struktur Data tb_rfm ... 72
Tabel 3.38 Struktur tb_hasil ... 72
Tabel 3.39 Struktur Data tb_hasil ... 72
Tabel 3.40 Struktur tb_range_r ... 73
Tabel 3.41 Struktur Data tb_hasil_r ... 73
Tabel 3.42 Struktur tb_range_f ... 74
Tabel 3.43 Struktur Data tb_hasil_f ... 74
Tabel 3.44 Struktur tb_range_m ... 74
Tabel 3.45 Struktur Data tb_hasil_monetary ... 75
Tabel 3.46 Struktur tb_kelas ... 75
Tabel 3.47 Struktur Data tb_kelas ... 76
Tabel 3.48 Struktur tb_avg ... 76
Tabel 3.49 Struktur Data tb_avg ... 77
Tabel 3.50 Struktur tb_cluster ... 77
Tabel 3.51 Struktur Data tb_cluster ... 77
Tabel 3.52 Struktur tb_hasil_normal ... 78
Tabel 3.53 Struktur Data tb_normal ... 78
Tabel 3.54 Struktur tb_optimasi ... 78
Tabel 3.57 Struktur Data tb_optimasi ... 79
Tabel 4.1 Hasil Optimasi dengan Parameter Cluster =2 dan Iterasi = 20 ... 95
Tabel 4.2 Hasil Segmentasi Pembentukan 2 Cluster ... 97
Tabel 4.3 Hasil Segmentasi Pembentukan 2 Cluster ... 97
Tabel 4.4 Hasil Optimasi dengan Parameter Cluster =3 dan Iterasi = 20 ... 99
Tabel 4.5 Hasil Segmentasi Pembentukan 3 Cluster ... 100
Tabel 4.6 Hasil Segmentasi Pembentukan 3 Cluster ... 100
Tabel 4.7 Hasil Optimasi dengan Parameter Cluster =4 dan Iterasi = 20 ... 103
Tabel 4.8 Hasil Segmentasi Pembentukan 4 Cluster ... 104
Tabel 4.9 Hasil Segmentasi Pembentukan 4 Cluster ... 104
Tabel 4.10 Hasil Optimasi dengan Parameter Cluster = 5 dan Iterasi = 20 ... 107
Tabel 4.11 Hasil Segmentasi Pembentukan 5 Cluster ... 108
Tabel 4.12 Hasil Segmentasi Pembentukan 5 Cluster ... 108
Tabel 4.13 Hasil Optimasi dengan Parameter Cluster = 6 dan Iterasi = 20 ... 111
Tabel 4.14 Hasil Segmentasi Pembentukan 6 Cluster ... 112
Tabel 4.15 Hasil Segmentasi Pembentukan 6 Cluster ... 113
Tabel 4.16 Hasil Segmentasi Pembentukan 6 Cluster ... 117
Tabel 4.17 Waktu Eksekusi Metode ... 118
xiv
DAFTAR KODE PROGRAM
Kode Program 4.1 Stored Procedure Input Nilai RFM ... 89
Kode Program 4.2 Fungsi Normalisasi Data dengan Metode Min and Max ... 90
Kode Program 4.3 Fungsi Metode Particle Swarm Optimization ... 91
Kode Program 4.4 Fungsi Metode K-Means ... 93
Kode Program 4.5 Fungsi Metode DBI ... 93
1 BAB I
PENDAHULUAN
Bab Pendahuluan terdiri dari uraian latar belakang yang mendasari pembuatan tugas akhir, pengenalan masalah yang dibahas didalam tugas akhir, manfaat maupun tujuan penelitian yang ingin dicapai, serta batasan masalah yang membatasi pembahasan yang diuraikan.
1.1 Latar Belakang
Dewasa ini kepuasan pelanggan telah dijadikan aset penting bagi sebagian besar organisasi. Kelangsungan sebuah perusahaan dapat ditunjang dengan mengembangkan hubungan perusahaan dengan pelanggannya. (Ziafat 2014, vol. 4, h. 70). Berdasarkan aturan 20/80, pelanggan berkontribusi sebesar 80 persen dalam penjualan perusahaan, hal ini menunjukkan pentingnya menjaga loyalitas pelanggan untuk meningkatkan pendapatan perusahaan (Aizcorbe, 2007). Loyalitas pelanggan dapat dipertahankan dengan peningkatan pemahaman perusahaan akan kebutuhan mereka sebagai individu dengan melakukan identifikasi pelanggan potensial. Nilai setiap pelanggan perlu untuk diidentifikasi sebelum melakukan berbagai investasi untuk mengembangkan relasi dengan pelanggan (Hyun, 2016, Vol. 10, h. 67).
2
Penelitian mengenai segmentasi pelanggan dengan metode clustering telah beberapa kali dilakukan antara lain penelitian segmentasi pelanggan pada perusahaan furniture (Putri Yuliari, 2015) menggunakan Metode Fuzzy C-Means yang dikombinasikan dengan Fuzzy Recency Frequency Monetary (RFM) dalam menentukan pelanggan potensial. Penelitian lain dilakukan oleh Anindya Santika Devi (2015) dengan menggunakan Metode DBSCAN dan Model RFM dalam melakukan segmentasi pelanggan pada perusahaan perhotelan.
Metode clustering yang digunakan pada penelitian ini yaitu Metode K-Means. Pada penelitian sejenis dinyatakan bahwa Metode K-Means memiliki kemampuan untuk memproses data skala besar secara efisien (Arumawadu et al, 2015, vol. 3, hh. 63-71), namun pada penelitian tersebut dikemukakan juga bahwa pemilihan titik pusat Metode K-Means yang cenderung acak mengakibatkan perbedaan nilai yang cukup besar antar segmennya. Penelitian tersebut kemudian disempurnakan dengan menggunakan metode kombinasi antara Metode K-Means dan Metode Particle Swarm Optimization (Chiu et al, 2009, vol. 36, hh. 4558-4565). Penelitian tersebut menyimpulkan bahwa kekurangan Metode K-Means dalam menentukan titik pusat cluster yang dilakukan secara acak dapat diatasi dengan mengkombinasikan Metode K-Means dan Particle Swarm Optimization sehingga menghasilkan klasifikasi yang lebih akurat dan efisien.
PT. X telah berdiri sejak tahun 1973, dan masuk peringkat sepuluh besar distributor farmasi terbaik di Indonesia dengan jumlah cabang tersebar diseluruh Indonesia sebanyak 31 cabang. PT X cabang Provinsi Bali beroperasi di bidang distribusi produk kesehatan. Ribuan transaksi dicapai oleh PT X. cabang Provinsi Bali dengan jumlah pelanggan yang cukup banyak. Sistem yang dapat melakukan segmentasi pelanggan belum dimiliki oleh PT. X, hal tersebut mempersulit PT. X untuk mengidentifikasi nilai-nilai yang dimiliki oleh konsumennya melalui data transaksi apabila dilakukan secara manual. Implementasi data mining dapat digunakan untuk mengidentifikasi nilai-nilai yang dimiliki konsumen secara lebih cepat dan akurat.
3
RFM, untuk menguji keunggulan Metode Particle Swarm Optimization dalam mengoptimasi Metode K-Means.
1.2 Rumusan Masalah
Berdasarkan latar belakang di atas, dapat dirumuskan rumusan masalah yang menjadi dasar pembuatan tugas akhir yaitu sebagai berikut:
1. Bagaimana menerapkan Metode K-Means dan Particle Swarm Optimization untuk melakukan proses segmentasi pelanggan pada data transaksi perusahaan yang bergerak di bidang distribusi bahan farmasi.
2. Bagaimana hasil dan kinerja Metode K-Means dan Particle Swarm Optimization dalam melakukan proses segmentasi pada data transaksi perusahaan yang bergerak di bidang distribusi bahan farmasi.
1.3 Tujuan Penelitian
Pembuatan dari tugas akhir ini didasari oleh tujuan penelitian sebagai berikut:
1. Menghasilkan aplikasi yang digunakan untuk melakukan segmentasi pelanggan dengan menerapkan Metode K-Means dan Particle Swarm Optimization.
2. Mengetahui hasil dan kinerja dari gabungan Metode K-Means dan Particle Swarm Optimization dalam melakukan proses segmentasi pelanggan.
1.4 Manfaat Penelitian
Manfaat yang diharapkan dapat diperoleh dari hasil penelitian tugas akhir adalah sebagai berikut:
1. Hasil segmentasi pelanggan dengan menggunakan gabungan Metode K-Means dan Particle Swarm Optimization dapat digunakan sebagai dasar pembuatan strategi untuk mengelola pelanggan per kategorinya.
4
3. Menambah wawasan mengenai segmentasi pelanggan dengan menggunakan gabungan Metode K-Means dan Particle Swarm Optimization.
1.5 Batasan Masalah
Melihat luasnya cakupan yang dapat dikaitkan dengan judul tugas akhir ini dan untuk menerapkan keseragaman pemahaman dalam penelitian, maka terdapat batasan-batasan yang perlu diberlakukan pada penelitian ini. Batasan-batasan tersebut adalah sebagai berikut:
1. Segmentasi Pelanggan yang dilakukan menggunakan data transaksi perusahaan yang bergerak di bidang distribusi bahan farmasi yang kemudian diubah ke dalam model RFM (Recency, Frequency, Monetary). 2. Proses segmentasi pelanggan dilakukan dengan menerapkan Metode
K-Means yang dioptimasi Metode Particle Swarm Optimization dan divalidasi menggunakan Metode Davies-bouldin Index dan Silhouette Index.
1.6 Sistematika Penulisan
Sistematika penulisan yang digunakan dalam tugas akhir ini adalah sebagai berikut:
BAB I : PENDAHULUAN
Bab ini berisi tentang pendahuluan yang terdiri dari latar belakang, batasan masalah, tujuan, manfaat serta sistematika penulisan dari tugas akhir ini.
BAB II : TINJAUAN PUSTAKA
5
BAB III : PERANCANGAN SISTEM
Bab ini berisi perancangan sistem, meliputi proses pemilihan data, transformasi data, perancangan sistem, perancangan proses, dan perancangan user interface.
BAB IV : PENGUJIAN DAN ANALISIS SISTEM
Bab ini berisi penjelasan seluruh hasil dan analisa dalam pembuatan tugas akhir ini dan bagaimana proses analisa tersebut dapat ditampilkan ke dalam sebuah program aplikasi.
BAB V : PENUTUP
6 BAB II
KAJIAN PUSTAKA
Sumber-sumber yang digunakan dalam pembuatan tugas akhir, baik yang diambil dari buku, internet, maupun jurnal diuraikan secara terperinci pada Bab Tinjuan Pustaka. Konsep dan definisi dari data mining serta hubungannya dengan customer relationship management melalui atribut recency, frequency dan monetary, penjelasan Metode K-Means dan Particle Swarm Optimization dijelaskan pula pada Bab ini.
2.1 State of the Art
Penelitian mengenai data mining yang berhubungan dengan proses segmentasi pelanggan telah beberepa kali dilakukan. Penelitian segmentasi pelanggan menggunakan Metode Fuzzy C-Means dan Fuzzy Subtractive serta Model Fuzzy Recency Frequency Monetary (RFM) pada perusahaan retail diteliti oleh Yohana Nugraheni. Pada penelitian tersebut diungkapkan bahwa kekurangan dari Algoritma Fuzzy Subratctive, yaitu tidak dapat membentuk cluster yang tergolong dalam label superstar dan golden customer, sehingga dapat dikatakan Algoritma Fuzzy Subtractive Clustering kurang mendukung proses data mining pada perusahaan retail untuk mendapatkan konsumen potensial (Yohana Nugrahaeni 2011, h. 123).
Penelitian sejenis juga dilakukan oleh Ni Putu Putri Yuliari dengan Metode Fuzzy C-Means dan Fuzzy RFM untuk segmentasi pelanggan pada perusahaan furniture. Pada penelitian tersebut diungkapkan bahwa Metode Fuzzy C-Means dapat menghasilkan cluster yang tergolong superstar dengan kombinasi Fuzzy RFM. (Putri Yuliari 2015, h. 107).
7
pada perusahaan perhotelan dilakukan oleh Ni Made Anindya Santika Devi. Pada penelitian tersebut diungkapkan bahwa Metode DBSCAN yang digabungkan dengan Model RFM telah dapat menghasilkan proses segmentasi dengan cukup baik, dapat dilihat dari beragam kelas pelanggan yang dihasilkan (Anindya Santika Devi 2015, h. 114).
Hasil serupa juga diperoleh melalui penelitian yang dilakukan oleh Luh Putu Dian Shavitri Handayani mengenai segmentasi pelanggan pada perusahaan retail dengan Metode ART 2 dan Model RFM. Algoritma ART 2 yang digabungkan dengan model RFM telah dapat melakukan proses segmentasi dengan cukup baik dapat dilihat dari beragam kelas pelanggan yang dihasilkan (Dian Shavitri Handayani 2012, h. 107).
Segmentasi pelanggan pada pelanggan industri telekomunikasi dengan memanfaatkan Metode K-Means dan RFM diteliti oleh Arumawadu, Rathanyaka dan Illangarathne. Pada penelitian tersebut didapat kekurangan dari Metode K-Means dalam menentukan titik pusat cluster sehingga proses clustering menjadi lebih lambat (Arumawadu, Rathnayaka & Illangarathne, 2015, Vol. 3, hh. 63-71). Penelitian mengenai metode kombinasi yang sesuai untuk mengoptimasi Metode K-Means dilakukan oleh Chiu dan kawan-kawan. Metode Particle Swarm Optimization (PSO) diuji coba untuk mengoptimasi Metode K-Means. Pada hasil dari penelitian tersebut dinyatakan bahwa gabungan Metode K-Means dan PSO dapat menghasilkan cluster yang lebih akurat dan efisien (Chiu et al. 2011, vol. 36, hh. 4558-4565).
8
nilai optimal number dari setiap cluster (Komarasamy & Wahi 2011, vol 1, hh. 206-208).
Penelitian mengenai Konsep CRM (Customer Relationship Management) dilakukan oleh Injazz J. Chen dan Karen Popovich. Pada penelitian tersebut diuraikan konsep CRM yang merupakan kombinasi antar manusia, proses dan teknologi. Konsep CRM dapat digunakan untuk memahami karakteristik pelanggan suatu perusahaan melalui pendekatan yang terintegrasi untuk memanajemen hubungan dengan pelanggan (Chen & Popovich 2003, vol. 9, hh. 672-688).
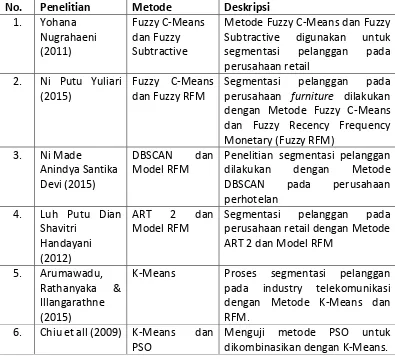
Berikut ini adalah daftar penelitian mengenai data mining yang berkaitan dengan segmentasi pelanggan disajikan dalam Tabel 2.1
Tabel 2.1 Daftar State of the Art
No. Penelitian Metode Deskripsi
1. Yohana
Metode Fuzzy C-Means dan Fuzzy
Subtractive digunakan untuk
segmentasi pelanggan pada
perusahaan retail
2. Ni Putu Yuliari
(2015)
Fuzzy C-Means dan Fuzzy RFM
Segmentasi pelanggan pada
perusahaan furniture dilakukan
dengan Metode Fuzzy C-Means dan Fuzzy Recency Frequency Monetary (Fuzzy RFM)
Penelitian segmentasi pelanggan
dilakukan dengan Metode
DBSCAN pada perusahaan
perhotelan
Segmentasi pelanggan pada
perusahaan retail dengan Metode
K-Means Proses segmentasi pelanggan
pada industry telekomunikasi
9
No. Penelitian Metode Deskripsi
6. G. Komarasamy
Menguraikan konsep CRM untuk data mining
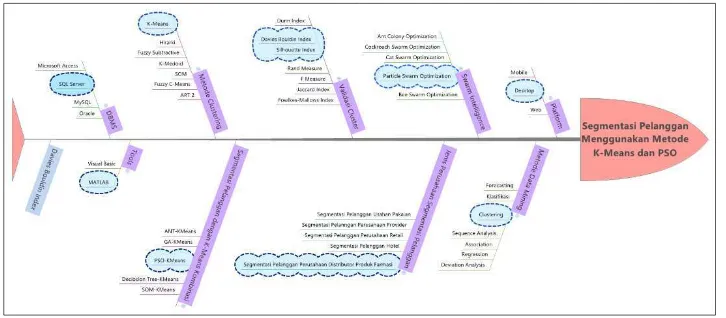
State of the art diatas menguraikan bahwa belum ada penelitian mengenai segmentasi pelanggan dengan Metode K-Means dan PSO serta Model RFM yang digunakan untuk melakukan segmentasi pelanggan pada perusahaan distributor produk farmasi yang mengambil studi kasus di PT. X. State of the art dari judul tugas akhir ini dapat divisualisasikan pada diagram fishbone yang ditunjukkan Gambar 2.1
Gambar 2.1Diagram Fishbone
Pada Gambar 2.1, dapat dijelaskan bahwa judul tugas akhir ini mengambil konsep data mining terutama pada metode clustering data mining, sedangkan platform yang digunakan berbasis desktop. Tools yang digunakan adalah MATLAB
dengan DBMS yang dipilih adalah SQL Server. Jenis metode clustering yang dipilih adalah Metode K-Means, dikombinasikan dengan salah satu jenis swarm intelligence yaitu Particle Swarm Optimization. Segmentasi pelanggan yang pernah
10
produk farmasi. Metode validasi cluster yang akan digunakan adalah Metode Davies-bouldin Index dan Silhouette Index. Diagram fishbone menghasilkan kesimpulan bahwa penelitian mengenai segmentasi pelanggan menggunakan Metode K-Means dan Particle Swarm Optimization belum pernah dilakukan pada perusahaan distributor di bidang produk farmasi.
2.2 Data Mining
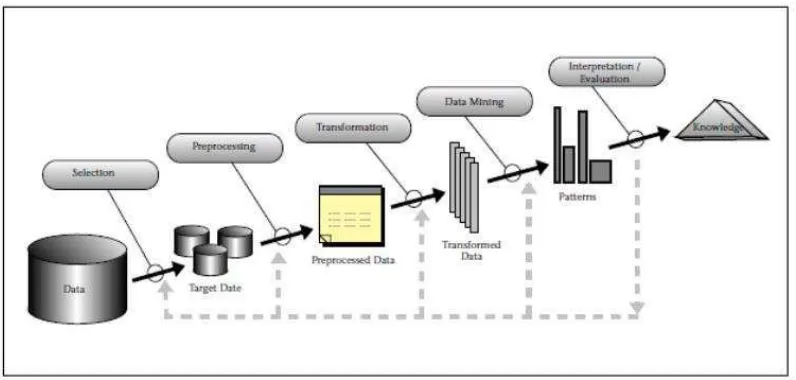
Data dalam skala besar yang diekstrasi untuk mendapat pengetahuan dan informasi yang berguna disebut dengan data mining. Data Mining digunakan untuk menyelesaikan masalah dengan melakukan analisis pada data dalam jumlah besar. (Han and Kamber, 2006). Menurut Sumanthi dan Sivanandam (2006, hh. 1-20), penerapan data mining dapat dilakukan di berbagai bidang industri meliputi bidang keuangan, pelayanan kesehatan, manufaktur, transportasi dan lain sebagainya, juga telah menggunakan data mining untuk mengambil manfaat dari analisis historikal data. Istilah data mining dan knowledge discovery in databases (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Salah satu tahapan dalam keseluruhan proses KDD adalah data mining. Proses KDD secara garis besar dapat dijelaskan sebagai berikut (Fayyad et al, 1996).
11
Gambar 2.2 mengambarkan tahapan KDD. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup proses data selection yaitu pemilihan data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Proses cleaning yaitu proses cleaning pada data yang menjadi fokus KDD.
Proses transformation yaitu transformasi pada data yang telah dipilih, sehingga data tersebut sesuai proses data mining. Proses data mining yaitu proses mencari pola atau informasi menarik dalam data terpilih menggunakan teknik atau metode tertentu. Terakhir, proses interpretation yaitu pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan.
2.3 Hubungan Data Mining dalam Kerangka Kerja CRM
CRM adalah strategi untuk membentuk, menata dan memperkuat loyalitas pelanggan. Kombinasi CRM dan data mining banyak digunakan perusahaan-perusahaan untuk mengidentifikasi pelanggan potensial dengan menggunakan segmentasi pelanggan (Tsiptsis & Charianopoulus, 2009). Data mining dapat digunakan untuk menganalisis pelanggan potensial, teknik data mining yang sering digunakan untuk menganalisi pelanggan adalah clustering dan aturan asosiasi. Inti dari kombinasi antara data mining dalam kerangka kerja CRM adalah memanfaatkan data yang telah dimiliki suatu perusahaan agar berguna bagi masa depan perusahaan itu sendiri.
Kombinasi ini dapat memperolah gambaran atas kebutuhan, selera dan pelayanan yang diinginkan oleh pelanggan (Ziafat, 2014, Vol. 4, h. 72). Implementasi data mining dalam kerangka CRM harus mengikuti skema Cross Industry Standard Process for Data Mining (CRIPS-DM) yang dapat dilihat pada
12
Gambar 2.3 Skema CRIPS-DM Sumber: Ziafat, 2014, h.73
Tahapan dari skema CRIPS-DM antara lain sebagai berikut:
1. Business Understanding, sebuah projek data mining harus memahami proses bisnis secara subjektif, agar dapat mendefinisikan dan merencanakan projek yang akan dikembangkan.
2. Data Understanding, fase ini melibatkan data yang dibutuhkan untuk mengembangkan projek. Fase ini meliputi pengumpulan data dan analisis data untuk menemukan masalah potensial.
3. Data Preparation, fase ini mengidentifikasi data ke dalam model data mining. Fase ini meliputi integrasi data, transformasi format data ke bentuk yang dibutuhkan oleh projek serta proses cleaning data.
4. Modelling, pada fase ini, analis harus memilih model yang sesuai proses bisnis, dimana data akan diubah ke dalam bentuk model yang diinginkan dengan menggunakan algoritma untuk mencapai hasil terbaik.
5. Evaluation, model yang telah dihasilkan kemudian dievaluasi agar sesuai dengan bisnis proses perusahaan.
13
2.4 Model RFM
Menurut Shajahan (2004, hh. 61-62) Model Recency, Frequency dan Monetary adalah sebuah pemodelan bisnis yang dapat diaplikasikan di berbagai situasi yang dapat mengambarkan berbagai tindakan atau prilaku pelanggan dengan melakukan survei tertentu. Pelanggan yang melakukan transaksi pada perusahaan tersebut dapat dihitung komponen recency (R) dan frequentcy (F) serta jumlah transaksi terhadap produk tertantu melalui komponen monetary (M). Menurut Hughes (1994), model RFM dapat diuraikan sebagai berikut:
1. Recency
Recency merepresentasikan jarak diantara transaksi terbaru dengan transaksi sebelumnya. Makin kecil jarak transaksi nilai recency akan semakin besar. 2. Frequency
Frequency merepresentasikan jumlah transaksi yang dilakukan dalam periode
tertentu. Semakin banyak frekuensi yang ada maka nilai frequency akan semakin besar.
3. Monetary
Monetary merepresentasikan jumlah uang yang telah ditransaksikan pada periode tertentu. Semakin besar jumlah transaksi jumlah monetary akan semakin besar.
Implementasikannya recency, frequency dan monetary secara bersama-sama dapat berdampak pada perusahaan untuk mendapatkan indikator dari ketertarikan pelanggan terhadap produk perusahaan tersebut. Asumsi umum dari proses tersebut adalah sebagai berikut:
1. Pelanggan yang baru saja bertransaksi, akan lebih senang bertransaksi kembali dibanding pelanggan yang sudah lama tidak melakukan transaksi.
2. Pelanggan yang bertransaksi secara rutin akan lebih senang bertransaksi daripada pelanggan yang baru saja melakukan satu atau dua transaksi.
3. Pelanggan yang paling banyak bertransaksi secara total akan lebih senang melakukan transaksi.
14
linguistik. Sebagai contoh, atribut recency dideskripsikan dengan bahasa natural long ago (lama) dan very recent (baru saja). Atribut frequency dideskripsikan dengan bahasa natural rare (jarang) dan frequent (sering). Atribut monetary dideskripsikan dengan bahasa natural low value (rendah) dan high value (tinggi).
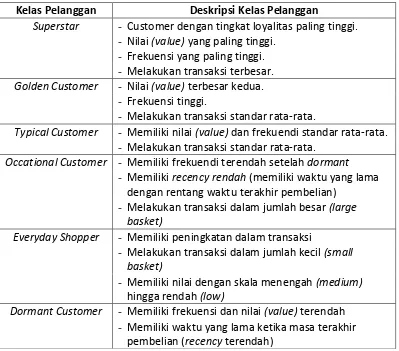
Menurut Tsiptsis dan Chorianopoulos (2009, hh. 344-345) terdapat enam pembagian pelanggan para perusahaan retail berdasarkan nilai RFM yang didefinisian secara lebih spesifik pada Tabel 2.2.
Tabel 2.2 Klasifikasi Customer
Kelas Pelanggan Deskripsi Kelas Pelanggan
Superstar - Customer dengan tingkat loyalitas paling tinggi.
- Nilai (value) yang paling tinggi.
- Frekuensi yang paling tinggi.
- Melakukan transaksi terbesar.
Golden Customer - Nilai (value) terbesar kedua.
- Frekuensi tinggi.
- Melakukan transaksi standar rata-rata.
Typical Customer - Memiliki nilai (value) dan frekuendi standar rata-rata.
- Melakukan transaksi standar rata-rata.
Occational Customer - Memiliki frekuendi terendah setelah dormant
- Memiliki recency rendah (memiliki waktu yang lama
dengan rentang waktu terakhir pembelian)
- Melakukan transaksi dalam jumlah besar (large
basket)
Everyday Shopper - Memiliki peningkatan dalam transaksi
- Melakukan transaksi dalam jumlah kecil (small
basket)
- Memiliki nilai dengan skala menengah (medium)
hingga rendah (low)
Dormant Customer - Memiliki frekuensi dan nilai (value) terendah
- Memiliki waktu yang lama ketika masa terakhir
pembelian (recency terendah)
15
2.5 Normalisasi Data
Proses clustering dapat terdiri dari berbagai interval nilai yang menyebabkan perbedaan jarak antar satu nilai dengan nilai lainnya, diperlukannya proses normaslisasi agar data memiliki nilai rata-rata 0 atau zero mean (Putra, Darma 2010, h.310). Suatu data atau fitur dapat dinormalisasi dengan rumus berikut.
̌ = �−�̅
�� ... (2.1)
Nilai ̌dinyatakan sebagai data atau fitur X yang telah ternormalisasi , ̅ dinyatakan sebagai rata-rata dari X, dan � menyatakan nilai standar deviasi dari X. Sebagai contoh, misalkan vektor data X = (2,3,5,10,15) maka ̅ = , � = . , sehingga vektor X yang telah ternormalisasi adalah sebagai berikut.
̌ = − . , − . , − . , . , .
Setelah dinormalisasi, pada data dapat dilakukan proses scalling agar nilai data berada pada suatu interval tertentu. Proses scalling berfungsi agar suatu fitur memiliki batas atas S dan batas bawah R dapat diperoleh dengan rumus berikut.
̌ = �−�
� max − � ∗ − + ... (2.2)
Data yang telah ternormalisasi di atas diskalakan dengan batas S = 1 dan batas bawah R = 0 maka:
̌ = . − − .− − . ∗ − +
̌ = − . + . , − . + . , − . + . , . + . , . + .. − − . ∗
̌ = , . , . , . , .. = , . , . , . ,
16
2.6 Metode Clustering
Proses dari pengelompokan objek fisik atau abstrak ke dalam kelas yang memiliki kemiripan disebut dengan proses clustering, sedangkan cluster adalah koleksi data yang memiliki kemiripan satu sama lain dengan objek yang berada pada cluster yang sama dan memiliki perbedaan dengan objek yang berada pada cluster yang lain (Han, Kamber & Pei 2007, h. 108). Menurut Kantardzic (2011, h. 250), analisis cluster didasari oleh pengelompokan secara natural, secara pengukuran atau melihat dari segi kesamaan dan perbedaan objek tersebut. Metode K-Means merupakan salah satu jenis metode clustering yang digunakan untuk melakukan pengelompokkan.
2.7 Metode K-Means
Metode clustering yang digunakan dalam tugas akhir ini adalah Metode K-Means. Metode K-Means melakukan pencarian pusat dan batas cluster melalui proses perulangan (iterative). Kedekatan atau kemiripan (similarity) suatu objek dengan objek lain atau dengan pusat cluster dihitung dengan menggunakan perhitungan jarak. Algoritma ini pertama kali diusulkan oleh MacQueen (1967, hh. 281-297) dengan tujuan untuk dapat membagi data point dalam dimensi kedalam sejumlah cluster, dimana proses clustering dilakukan dengan meminimalkan jarak sum squares antara data dengan masing-masing pusat cluster (centroid-based).
Algoritma K-Means dalam penerapannya memerlukan tiga parameter yang seluruhnya ditentukan pengguna yaitu jumlah cluster k, inisialisasi pusat cluster, dan jarak sistem. Tahapan awal, Algoritma K-Means adalah memilih secara acak k buah objek sebagai centroid dalam data, kemudian jarak objek dan centroid dihitung menggunakan Metode Euclidean Distance.
17
Menurut Darma Putra (2010, h. 340), langkah-langkah Algoritma K-Means dijelaskan secara lebih rinci dalam uraian berikut:
1. Inisialisasi K pusat cluster adalah z1(1), z2(2), …, zk(1). Pusat-pusat cluster ini
biasanya dipilih secara acak dari sekumpulan data yang akan dikelompokkan. 2. Pada iterasi ke-k sampel data {x} di antara K domain cluster, dengan
menggunakan hubungan sebagai berikut:
∈ jika ‖ − ‖ < ‖ − ‖ ... (2.3) Untuk semua I = 1, 2, …K, I ≠ j , dengan Sj(k) menyatakan himpunan sampel
dengan pusat cluster adalah zj (k).
3. Hasil pada langkah 2, hitung pusat-pusat cluster baru zj(k+1), j = 1, 2, .., K,
sehingga jumlah seluruh jarak dari semua titik dalam Sj(k) ke pusat cluster yang
baru minimal, dengan kata lain, pusat cluster baru zj(k+1) dihitung sehingga
unjuk kerja indeks: Dengan Nj menyatakan jumlah sampel dalam Sj(k).
4. Bila zj (k+1) = zj (k) untuk j = 1, 2, …, K, maka algoritma telah konvergen dan
proses berakhir. Bila tidak maka kembali ke langkah 2.
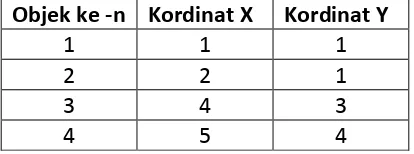
Contoh perhitungan dari MetodeK-Means adalah sebagai berikut. Tabel 2.3 merupakan data sumber yang akan digunakan dalam perhitungan.
18
Tahapan perhitungan adalah sebagai berikut.
1. Banyak cluster yang digunakan adalah dua, jadi k = 2. Banyaknya cluster lebih kecil dari jumlah data atau k < n.
2. Tentukan titik pusat (centroid) setiap cluster. Centroid awal ditentukan secara acak dapat dilihat pada Tabel. 2.4
Tabel 2.4 Titik Pusat Iterasi ke-1
Titik Pusat ke-n Kordinat X Kordinat Y
C1 1 1
C2 2 1
Iterasi selanjutnya tidak menghitung centroid secara acak. Titik pusat ditentukan dengan mencari nilai rata-rata data pada setiap cluster. Jika titik pusat yang didapat berbeda dengan titik pusat sebelumnya maka iterasi tetap dilakukan hingga mendapat titik pusat yang sama dengan iterasi sebelumnya.
3. Menghitung jarak data dengan titik pusat dapat dilakukan dengan tiga cara, yaitu Euclidean Distance, Manhattan / City Block, Minkowski. Perhitungan jarak yang dapat dilakukan pada Metode K-Means adalah dengan
Jarak data dengan titik pusat cluster pertama adalah sebagai berikut.
, = √ − + − = √ − + − =
, = √ − + − = √ − + − =
, = √ − + − = √ − + − = .
, = √ − + − = √ − + − =
19
, = √ − + − = √ − + − =
, = √ − + − = √ − + − =
, = √ − + − = √ − + − = .
, = √ − + − = √ − + − = .
Seterusnya, hitung jarak pada setiap baris data. Hasil perhitungan dapat dilihat pada Tabel 2.5.
Tabel 2.5 Hasil Perhitungan Jarak
Objek ke X Y dc1 dc2 c1 c2
2.8 Metode Particle Swarm Optimization
Menurut Talukder (2011, hh. 10-11), Metode Particle Swarm Optimization (PSO) merupakan algoritma yang memiliki sifat pencarian dengan melibatkan banyak pelaku didalamnya. Pelaku dapat berupa populasi partikel yang merepresentasikan solusi potensial di dalam setiap populasi. Semua partikel melewati ruang pencarian multidimensional yang disesuaikan dengan posisi berdasarkan experience dan tetangga yang dimilikinya. menunjuk vektor dari partikel i di ruang pencarian multidimensional pada tahapan waktu t, lalu posisi setiap partikel diperbaharui di ruang pencarian.
20
partikel diperbaharui dengan kecepatan yang berlaku. Perulangan berhenti dengan aturan yang ditetapkan di awal.
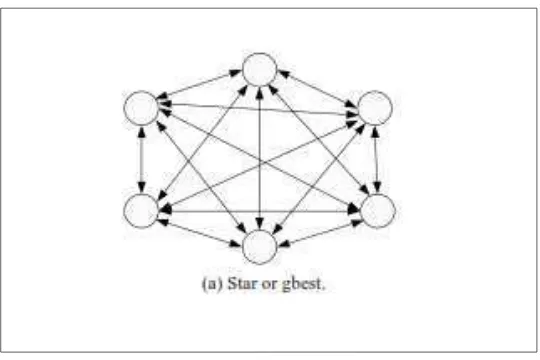
2.8.1 Personal Best dan Global Best Particle Swarm Optimization
Personal Best adalah posisi terbaik setiap individu partikel yang didapat melalui iterasi perubahan kecepatan gerak partikel. Sebaliknya Global Best adalah posisi terbaik yang ditemukan dari nilai Personal Best partikel secara keseluruhan (Talukder 2011, hh. 11-13). Metode ini menggunakan topologi bintang, seperti Gambar 2.4
Gambar 2.4 Topologi Bintang Sumber: Talukder 2011, h. 11
Topologi ini memungkinkan partikel untuk medapatkan informasi secara keseluruhan mengenai keseluruhan partikel. Setiap partikel individu ∈ [ , … , ] dimana n > 1 memiliki posisi terbaru di dalam area pencarian xi dan
kecepatan terbaru vi serta posisi Personal Best Pbest,i. Posisi Personal Best Pbest,i
berkorespondensi dengan posisi di area pencarian dimana partikel i memiliki nilai terkecil yang dipengaruhi oleh fungsi objektif f. Keadaan dimana posisi menghasilkan nilai terkecil diantara posisi Personal Best lainnya maka disebut dengan Global Best yang dinotasikan sebagai Gbest. Posisi Personal Best berikutnya
21
Untuk menghitung kecepatan partikel pada Global Best digunakan rumus berikut:
+ = + [�
,
+ − + ] + [� − ] ... (2.10)
2.8.3 Contoh Perhitungan Particle Swarm Optimization
Menurut Budi Santosa (2011) contoh perhitungan dengan menggunakan Metode Particle Swarm Optimization (PSO) adalah sebagai berikut.
Misal terdapat persoalan optimasi dengan satu variabel.
= −
2. Evaluasi nilai fungsi tujuan untuk setiap partikel untuk j = 1,2,3,4. Dan nyatakan dengan
= = ,
= = ,
= = ,
22
5. Evaluasi nilai fungsi tujuan sekarang pada partikel ,
= = ,
= = ,
= =
= . = .
Sedangkan pada iterasi sebelumnya kita dapatkan
= = ,
= = ,
= = ,
= = ,
Nilai dari f dari iterasi sebelumnya tidak ada yang lebih baik sehingga Pbest untuk masing-masing partikel sama dengan nilai x. Gbest =100.
6. Cek apakah solusi x sudah konvergen, dimana nilai x saling dekat. Jika tidak, tingkatkan ke iterasi berikutnya i = 2. Lanjutkan ke langkah 4.
23
Sedangkan untuk nilai x adalah
= + =
= + =
= − =
= . + = .
8. Evaluasi nilai fungsi tujuan sekarang pada partikel ,
= = ,
= = ,
= = ,
= . = . ,
Jika dibandingkan dengan nilai f dari iterasi sebelumnya, ada nilai yang lebih baik dari nilai f sekarang yaitu = , sehingga � untuk partikel 3 sama berikutnya dengan menghitung kecepatan v dan ulangi langkah-langkah selanjutnya sampai mencapai konvergen.
2.9 Validasi Cluster
Cluster yang dihasilkan terbentuk dari parameter-parameter yang diinputkan. Pembentukan jumlah cluster dapat divalidasi dengan menggunakan metode validasi cluster untuk mengetahui input terbaik dalam pembentukan cluster, Metode validasi cluster yang digunakan antara lain Metode Davies-bouldin Index dan Silhouette Index.
2.9.1 Validasi Cluster dengan Davies-bouldin Index
Davies-24
bouldin Index didapatkan berdasarkan kemiripan dari cluster (Rij) yang merupakan
ukuran dipersi cluster (si) dan ketidakmiripan (dij). Nilai Rij ditentukan dengan menggunakan cara berikut
= + ... (2.12) = ( + ), =| |∑ ∈ , ... (2.13) Sedangkan rumus dari Metode Davies-bouldin Index didefinisikan sebagai berikut:
=
�∑ ,
�
= ... (2.14) = , = … , ≠ ... (2.15)
, = … ... (2.16)
2.9.2 Validasi Cluster dengan Silhouette Index
Menurut Rousseeuw, Peter J (1987) setiap cluster dapat direpresentasikan kedalam sebuah silhouette. Metode Silhouette dapat menunjukkan cluster terbaik untuk setiap objeknya. Rata-rata silhouette dapat digunakan untuk menunjukkan validasi cluster dan jumlah optimal pembentukan cluter. Proses validasi cluster dengan menggunakan Metode Silhouette adalah sebagai berikut.
1. Setiap objek i, dihitung rata-rata jarak dari objek i dengan seluruh objek yang berada dalam satu cluster sehingga didapat nilai rata-rata a(i).
2. Setiap objek i dihitung rata-rata jarak dari objek i dengan objek yang berada di cluster lainnya. Nilai terkecil dari semua rata-rata jarak kemudian digunakan.
Nilai tersebut merupakan nilai dari b(i).
3. Semua variabel kemudian dihitung silhouette coefisien dengan persamaan berikut.
25
2.10 Profil Perusahaan PT. X