BAB 1
PENDAHULUAN
1.1. Latar Belakang
Komputer adalah sebuah alat/mesin yang membantu kita untuk menyelesaikan tugas kita, mempermudah kita mencari informasi. Komputer juga bisa bergerak sebagai penghibur seperti bermain game komputer, menyetel music bahkan video. Akan tetapi komputer tidaklah mengerti bahasa yang kita ucapkan, meskipun begitu kita dapat membuat komputer untuk mengenali/mengerti bahasa yang kita ucapkan. Bagaimana agar komputer dapat mengenali bahasa kita?
Bila komputer dapat mengerti apa yang kita ucapkan, komputer bisa saja melaksanaakan apa saja yang kita ucapkan selama komputer mengerti dan informasi tersedia dalam komputer. Komputerpun akan lebih mempermudah kita dalam melakukan segala aktifitas yang kita lakukan dalam berinteraksi dengan komputer, sejalan dengan itu teknologi pengenalan suara mulai dikembangkan.
Teknologi pengenalan suara adalah teknologi yang menggunakan peralatan dengan sumber masukannya adalah suara, seperti mikrofon untuk menginterpretasikan suara manusia untuk transkripsi atau sebagai metode alternatif interaksi dengan komputer. Teknologi pengenalan suara tidak sama dengan teknologi voice recognition yang hanya mengenali suara sebagai identifikasi keamanan. Walaupun kesuksesan teknologi ini nyata, hanya sedikit orang yang menggunakan sistem pengenalan suara pada komputer. Hal yang terjadi pada kebanyakan pengguna komputer dalam membuat
▸ Baca selengkapnya: akibat adanya konektivitas perangkat, apa saja yang harus diwaspadai terkait data yang kita kirimkan dari perangkat kita
(2)dan mengedit dokumen serta berinteraksi dengan komputer lebih cepat dan nyaman dengan menggunakan peralatan-peralatan input konvensional yaitu keyboard dan mouse, walaupun secara fakta dengan menggunakan teknologi pengenalan suara memungkinkan pengguna untuk berbicara secara langsung, cepat dan efisien daripada harus mengetikkan suatu perintah dengan menggunakan keyboard. Sebenarnya perancangan program disini tidak terbatas untuk 1 perusahaan saja. Akan tetapi penulis melakukan uji coba program pertama kali dilakukan di dapur solo, karena dapur solo memiliki staff IT jadi memudahkan untuk konsultasi program yang diujicobakan. Juga dapur solo tidak jauh dari tempat tinggal penulis sehingga mengurangi kerugian- kerugian yang ditimbulkan bila lokasi jauh.
Suatu lingkungan perkantoran dengan tingkat kebisingan yang tinggi merupakan salah satu lingkungan yang merugikan untuk teknologi pengenalan suara karena dengan begitu suara yang terdengar pada sistem tidak jelas sehingga sistem pengenalan suara tidak dapat bekerja dengan akurat. Pengenalan suara hanya dapat diterima dengan sistem mikrofon yang independent 80%-90% untuk lingkungan yang nyaman dan tidak bising. Sistem pengenalan suara dapat membantu orang-orang yang mengalami kesulitan berinteraksi dengan komputer melalui keyboard contohnya orang yang memiliki carpal tunnel syndrome, serta orang-orang yang memiliki cacat fisik. (Fairley, Grant D.. Computer… Take a Letter... a Speech Recognition Update. 2010)
Maka dibutuhkanlah sebuah software yang sangat mudah digunakan, mampu mengenal suara dengan tepat walaupun dengan tingkat kebisingan yang tinggi, dan mampu membedakan antara intruksi (perintah) atau bukan.
1.2. Perumusan Masalah
Pada penelitian ini, perumusan masalah yang akan dibahas secara rinci beserta solusinya secara lengkap meluputi:
1. Apa yang kita butuhkan agar komputer mendengar suara?
2. Bagaimana agar komputer dapat mengerti apa yang kita ucapkan?
3. Bagaimana bayes dan model markov dalam menganalisa suara terbaik?
1.3. Ruang Lingkup
Agar diperoleh focus sesuai dengan yang diinginkan, maka perlu adanya pembatasan masalah, maka ruang lingkup atas batasan masalah pada penulisan penelitian ini adalah sebagai berikut:
1. Analysis of speech into writing is limited to orders selingkup tested and Indonesian language.
2. Metode yang digunakan dalam analisis adalah bayes dan model markov.
3. Perancangan software menggunakan VC#.
1.4. Tujuan dan Manfaat
Tujuan dari penelitian ini adalah merancang sebuah program komputer yang dapat menganalisis ucapan dan merubahnya kedalam tulisan bahasa Indonesia. Tujuan lainnya adalah Analisis dapat melakukan berbagai proses berdasarkan input suara nantinya.
Adapun manfaat penelitian ini adalah:
1. Bagi peneliti, penelitian ini berguna sebagai ajang pembelajaran pada bayes, model markov, spectrogram dan menambah wawasan serta pengetahuan dalam bidang sains.
2. Bagi pembaca atau pihak lainnya, diharapkan dapat memberikan wawasan dalam bidang komputer mengenal ucapan.
3. Bagi masyarakat, pengoptimalan analisis sehingga mengoptimalkan cara kerja komputer dalam mengenal ucapan.
1.5. Metodologi
Studi lapangan adalah sebuah metode pengumpulan data yang digunakan untuk mencari data-data yang dibutuhkan dalam pembuatan skripsi ini. Hal ini dilakukan secara langsung di tempat objek itu berada. Data-data yang akan dikumpulkan berupa data-data yang bersifat kuantitatif dan merupakan variabel bebas. Observasi, yaitu teknik pengumpulan data dengan mengamati objek-objek secara langsung dan kemudian melakukan pencatatan terhadap objek yang diteliti tersebut. Pengumpulan data juga dilakukan dengan membaca buku-buku yang berhubungan dengan topik skripsi ini. Hal ini dilakukan agar dapat memahami dan menyelesaikan permasalahan yang dihadapi secara tepat dan akurat. Sama seperti studi lapangan, data-data yang didapat dari studi pustaka juga merupakan data-data yang bersifat kuantitatif dan merupakan variabel bebas. Dalam perancangan program menggunakan UML terdiri dari use case, sequence diagram dan diagram alir / flow chart.
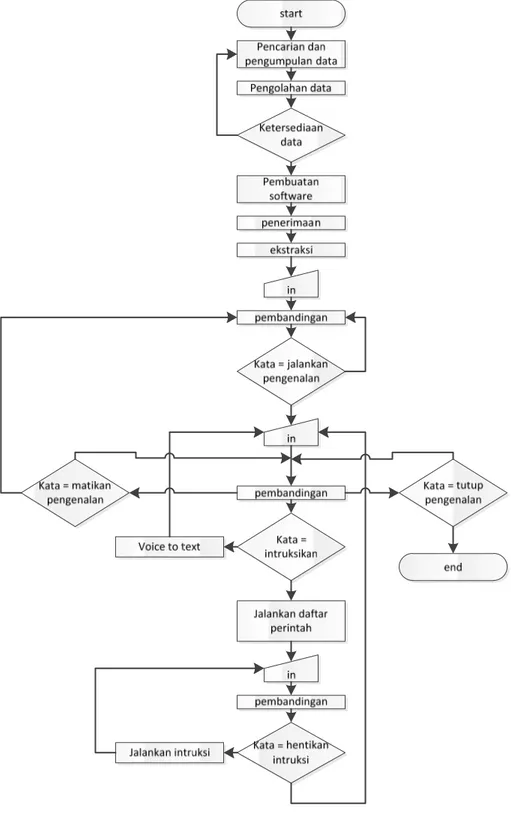
Adapun metode perancangan secara mendasar yang penulis lakukan sesuai pada flowchart berikut:
Gambar 1.1 Flowchart perancangan secara dasar Disini dijelaskan tentang flowchart yang dimaksud, secara lengkap:
Tahap pencarian dan pengumpulan data
Tahap ini adalah tahap pencarian dan pengumpulan data yang digunakan untuk pembuatan program.
Tahap-pengolahan-data
tahap ini dimaksud untuk mengolah data-data untuk digunakan setelah tahap pencarian dan pengumpulan data.
Tahap ketersediaan data
Tahap ini adalah tahap pengecekan saat pembuatan software apakah data tersedia atau kurang tersedia.
Tahap-penerimaan
Masukan berupa kata-kata yang diucapkan lewat mikrofon.
Tahap pengolahan data
Tahap ini adalah tahap dimana data dikelolah dari raw data menjadi data yang siap digunakan.
Tahap in
Tahap ini adalahap menunggu masukkan input suara dari pengguna.
Tahap-ekstraksi
Tahap ini adalah tahap penyimpanaan masukan yang berupa suara sekaligus pembuatan basis data sebagai pola. Proses ekstraksi dilakukan berdasarkan metode Model Markov Tersembunyi atau Hidden Markov Model (HMM).
berdasarkan HMM, proses pengenalan ucapan secara umum menghasilkan keluaran yang dapat dikarakterisasikan sebagai sinyal. Sinyal dapat bersifat diskrit (karakter dalam abjad) maupun kontinu (pengukuran temperatur, alunan
musik). Sinyal dapat pula bersifat stabil (nilai statistiknya tidak berubah terhadap waktu) maupun nonstabil (nilai sinyal berubah-ubah terhadap waktu). Dengan melakukan pemodelan terhadap sinyal secara benar, dapat dilakukan simulasi terhadap masukan dan pelatihan sebanyak mungkin melalui proses simulasi tersebut sehingga model dapat diterapkan dalam sistem prediksi, sistem pengenalan, maupun sistem identifikasi. Secara garis besar model sinyal dapat dikategorikan menjadi dua golongan, yaitu: model deterministik dan model statistikal. Model deterministik menggunakan nilai-nilai properti dari sebuah sinyal seperti: amplitudo, frekuensi, dan fase dari gelombang sinus. Model statistikal menggunakan nilai-nilai statistik dari sebuah sinyal seperti: proses Gaussian, proses Poisson, proses Markov, dan proses Markov Tersembunyi.
Suatu model HMM secara umum memiliki unsur-unsur sebagai berikut:
a. N, yaitu jumlah bagian dalam model. Secara umum bagian tersebut saling terhubung satu dengan yang lain, dan suatu bagian bisa mencapai semua bagian yang lain, serta sebaliknya (disebut dengan model ergodik). Namun hal tersebut tidak mutlak karena terdapat kondisi lain dimana suatu bagian hanya bisa berputar ke diri sendiri dan berpindah ke satu bagian berikutnya.
Hal ini bergantung pada implementasi dari model.
b. M, yaitu jumlah simbol observasi secara unik pada tiap bagiannya, misalnya:
karakter dalam abjad, dimana bagian diartikan sebagai huruf dalam kata.
c. Probabilita Perpindahan Bagian { } = ij A a
d. Probabilita Simbol Observasi pada bagian j, { } () = j Bb k e. Inisial Distribusi Bagian i p p
Setelah memberikan nilai N, M, A, B, dan p, maka proses ekstraksi dapat diurutkan. Berikut adalah tahapan ekstraksi pengenalan ucapan berdasarkan HMM:
1. Tahap-ekstraksi-tampilan
Penyaringan sinyal suara dan pengubahan sinyal suara analog ke digital 2. Tahap-tugas-pemodelan
Pembuatan suatu model HMM dari data-data yang berupa sampel ucapan sebuah kata yang sudah berupa data digital
3. Tahap-sistem-pengenalan-HMM
Penemuan parameter-parameter yang dapat merepresentasikan sinyal suara untuk analisis lebih lanjut.
Tahap-pembandingan
Tahap ini merupakan tahap pencocokan data baru dengan data suara (pencocokan tata bahasa) pada pola. Tahap ini dimulai dengan proses konversi sinyal suara digital hasil dari proses ekstraksi ke dalam bentuk spektrum suara yang akan dianalisa dengan membandingkannya dengan pola suara pada basis data. Sebelumnya, data suara masukan dipilah-pilah dan diproses satu per satu berdasarkan urutannya. Pemilihan ini dilakukan agar proses analisis dapat dilakukan secara paralel. Proses yang pertama kali dilakukan ialah memproses gelombang kontinu spektrum suara ke dalam bentuk diskrit. Langkah berikutnya ialah proses kalkulasi yang dibagi menjadi dua bagian :
1. Transformasi gelombang diskrit menjadi data yang terurut Gelombang diskrit berbentuk masukan berukuran n yang menjadi objek yang akan dibagi pada proses konversi dengan cara pembagian rincian waktu 2. Menghitung frekuensi pada tiap elemen data yang terurut
Selanjutnya tiap elemen dari data yang terurut tersebut dikonversi ke dalam bentuk bilangan biner. Data biner tersebut nantinya akan dibandingkan dengan pola data suara dan kemudian diterjemahkan sebagai keluaran yang dapat berbentuk tulisan ataupun perintah pada perangkat.
Tahap voice to text
Tahap ini akan menkonversi suara ke dalam text yang akan tertera dilayar komputer
Tahap jalankan daftar perintah
Tahap ini akan memasukan program kedalam program perintah dimana software hanya akan melaksanakan perintah sampai hentikan intruksi.
1.6. Sistematika Penulisan
Keterangan masing-masing isi Bab secara ringkas. Gambaran umum tiap bab akan diterangkan pada subbab ini, dengan cara deskriptif:
BAB 1 Pendahuluan
Bab ini berisi latar belakang, perumusan masalah, ruang lingkup, tujuan dan manfaat, metodologi, sistematika penulisan, makalah relevan.
BAB 2 Landasan Teori
Dalam bab ini dibahas mengenai teori-teori pendukung, teori-teori tentang markov dan bayes juga teori untuk metode perancangan program
BAB 3 Perancangan Program Voice Order.
Dalam bab ini diuraikan metode yang dipakai dalam penyusunan program, rancangan program dan hal lain yang terkait.
BAB 4 Hasil dan Pembahasan
Bab ini menampilkan hasil dari program voice order yang dibuat.
BAB 5 Simpulan dan Saran
Bab ini berisi kesimpulan hasil pembahasan program Voice Order ini.
1.7. Makalah Relevan
Disini dituliskan makalah atau penelitian apa saja yang telah dilakukan orang lain yang berkaitan dengan makalah yg akan dibuat :
Zweig, Geoffrey G. (1998). Speech Recognition with Dynamic Bayesian Networks.
California; University of California, Berkeley.
Judul Speech Recognation with Dynamic Bayesian Networks. Menggunakan metode Dynamic Bayesian Networks, memiliki kelebihan rinci membahas mengenai DBN dan mengulas HMM dan Kekurangan lebih banyak mengulas permasalahan, hambatan dan Experiment juga teoritis.
Matthews, James.(2002) How Does Speech Recognition Work?. United Kingdom;
generation5.
Judul How Does Speech Recognition Work?. Menggunakan mnetode Hiden Markov Model, memiliki kelebihan membahas langkah-langkah metode secara ringkas juga padat dan kekurangan : hasil yang masih kurang dari yang diharapkan.
Irfani, Angela dan Amelia, Ratih dan Saptanti, Dyah. (2006). Algoritma Viterbi dalam Metode Hidden Markov Models pada Teknologi Speech Recognition. Bandung; Institut Teknologi Bandung.
Judul Algoritma Viterbi dalam Metode Hidden Markov Models pada Teknologi Speech Recognition. Menggunakan metode Algoritma Viterbi, memiliki kelebihan metode ini menghasilkan ketepatan yang tinggi dengan rangkaian perhitungan mulai dari inisialisasi, rekursif, terminasi dan lintas status dan kekurangan sedikit rumit dan tidak mudah dimengerti, maupun diterapkan. Karena akan membutuhkan source dan memory yang cukup besar.