MODEL FUZZY K-NEAREST NEIGHBOR DENGAN LOCAL MEAN PADA PENGENALAN POLA CITRA TAJWID TESIS HAFIZH AL KAUTSAR AIDILOF
Bebas
69
0
0
Teks penuh
(2) MODEL FUZZY K-NEAREST NEIGHBOR DENGAN LOCAL MEAN PADA PENGENALAN POLA CITRA TAJWID TESIS Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Magister Teknik Informatika. HAFIZH AL KAUTSAR AIDILOF 157038058. PROGRAM STUDI S2 TEKNIK INFORMATIKA FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA MEDAN 2018. Universitas Sumatera Utara.
(3) ii. PERSETUJUAN. Judul. : MODEL FUZZY K-NEAREST NEIGHBOR DENGAN LOCAL MEAN PADA PENGENALAN POLA CITRA TAJWID. Kategori. : ALGORITMA, PENGENALAN POLA. Nama. : HAFIZH AL KAUTSAR AIDILOF. Nomor Induk Mahasiswa : 157038058 Program Studi. : MAGISTER TEKNIK INFORMATIKA. Fakultas. : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA. Komisi Pembimbing. :. Pembimbing 2. Pembimbing 1. Dr. Syahril Efendi, S.Si, M.IT. Prof. Dr. Muhammad Zarlis, M.Sc. Diketahui/disetujui oleh Magister Teknik Informatika Ketua,. Prof. Dr. Muhammad Zarlis, M.Sc 195707011986011003. Universitas Sumatera Utara.
(4) iii. PERNYATAAN. MODEL FUZZY K-NEAREST NEIGHBOR DENGAN LOCAL MEAN PADA PENGENALAN POLA CITRA TAJWID. TESIS. Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.. Medan, 23 Januari 2018. Hafizh Al Kautsar Aidilof 157038058. Universitas Sumatera Utara.
(5) iv. PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS. Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini :. Nama. : Hafizh Al Kautsar Aidilof. NIM. : 157038058. Program Studi. : Magister Teknik Informatika. Jenis Karya Ilmiah. : Tesis. Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalti Free Right) atas tesis saya yang berjudul :. MODEL FUZZY K-NEAREST NEIGHBOR DENGAN LOCAL MEAN PADA PENGENALAN POLA CITRA TAJWID. Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti NonEksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan/atau sebagai pemilik hak cipta.. Demikian pernyataan ini dibuat dengan sebenarnya.. Medan, 23 Januari 2018. Hafizh Al Kautsar Aidilof 157038058. Universitas Sumatera Utara.
(6) v. Telah diuji pada Tanggal : 23 Januari 2018. PANITIA PENGUJI TESIS Ketua. : Prof. Dr. Muhammad Zarlis, M.Sc. Anggota. : 1. Dr. Syahril Efendi, S.Si, M.IT 2. Prof. Dr. Herman Mawengkang 3. Dr. Sutarman, M.Sc. Universitas Sumatera Utara.
(7) vi. RIWAYAT HIDUP. DATA PRIBADI. Nama Lengkap (berikut gelar). : Hafizh Al Kautsar Aidilof, ST. Tempat dan Tanggal Lahir. : Medan, 30 April 1992. Alamat Rumah. : Jl. Pembangunan No. 22 Kebun Lada, Binjai Utara, Kota Binjai. Telepon/Faks/HP. : 082168699025. E-mail. : [email protected] [email protected]. Instansi Tempat Bekerja. :. Alamat Kantor. :. DATA PENDIDIKAN. SD. : SD Negeri No. 33 Banda Aceh. TAMAT : tahun 2004. SMP : SMP Negeri No. 19 Percontohan Banda Aceh. TAMAT : tahun 2007. SMA : SMA Negeri 2 Binjai. TAMAT : tahun 2010. S1. : Teknik Informatika Universitas Malikussaleh. TAMAT : tahun 2015. S2. : Teknik Informatika USU. TAMAT : tahun 2018. 2018. Universitas Sumatera Utara.
(8) vii. UCAPAN TERIMA KASIH. Alhamdulillah Puji dan Syukur penulis ucapkan ke hadirat Allah SWT, zat yang ada sebelum kata ada itu ada, yang Maha Indah dengan segala keindahan-Nya, zat yang Maha Pengasih dengan segala kasih sayang-Nya, yang terlepas dari segala sifat lemah semua makhluk-Nya. Shalawat serta salam mahabbah semoga senantiasa dilimpahkan kepada Nabi Muhammad SAW, sebagai pembawa risalah Allah SWT terakhir dan penyempurnaan seluruh risalah-Nya. Alhamdulillah berkat Rahmat dan Hidayah-Nya penulis mampu menyelesaikan penulisan tesis yang berjudul ”Model Fuzzy K-Nearest Neighbor dengan Local Mean pada Pengenalan Pola Citra Tajwid” yang merupakan salah satu syarat yang harus dipenuhi oleh setiap mahasiswa Magister Teknik Informatika agar dapat lulus dan mendpat ijazah Magister Teknik Informatika pada Universitas Sumatera Utara. Pada kesempatan ini penulis ingin mengucapkan terima kasih yang sebesarbesarnya dan penghargaan yang setinggi-tingginya kepada Ayahanda, Ir. Aidilof, MP dan Ibunda, Dra. Lili Marlaini yang telah membimbing, mendukung, dan mendoakan penulis sejak lahir hingga detik ini. Serta adikku, Talitha Shalsabilla Aidilfilia, S.IAN yang selalu memberikan dukungan dan bantuannya kepada penulis. Pada kesempatan ini tak lupa penulis ucapkan terima kasih yang sebesar-besarnya dan penghargaan yang setinggi-tingginya kepada Bapak Prof. Dr. Muhammad Zarlis, M.Sc dan selaku Pembimbing Utama dan Bapak Dr. Syahril Efendi, S.Si, M.IT selaku Pembimbing Pendamping yang penuh ketulusan, kesabaran, perhatian, dan ketelitian telah meluangkan waktu, tenaga, dan pemikirannya untuk memberikan pengarahan kepada penulis selama penulisan tesis ini. Pada kesempatan ini pula, penulis ingin mengucapkan terima kasih yang sebesarbesarnya kepada : 1.. Bapak Prof. Dr. Runtung Sitepu, SH., M.Hum selaku Rektor Universitas Sumatera Utara.. 2.. Bapak Prof. Dr. Drs. Opim Salim Sitompul, M.Sc selaku Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.. 3.. Bapak Prof. Dr. Muhammad Zarlis, M.Sc selaku Ketua Program Studi Magister Teknik Informatika Universitas Sumatera Utara dan selaku dosen wali penulis.. Universitas Sumatera Utara.
(9) viii. 4.. Bapak Dr. Syahril Efendi, S.Si, M.IT selaku Sekretaris Program Studi Magister Teknik Informatika.. 5.. Bapak Prof. Dr. Herman Mawengkang selaku penguji tesis penulis.. 6.. Bapak Dr. Sutarman, M.Sc selaku penguji tesis penulis.. 7.. Bapak dan Ibu Dosen Program Studi Magister Teknik Informatika Universitas Sumatera Utara.. 8.. Seluruh staff pegawai Program Studi Magister Teknik Informatika Universitas Sumatera Utara. 9.. Teman-teman seperjuangan di KOM C 2015 Magister Teknik Informatika Universitas Sumatera Utara, terimakasih atas kebersamaannya.. 10. Semua pihak yang turut memberikan dukungan dalam penulisan tugas akhir ini yang tidak bisa disebutkan satu per satu. Penulis sadar bahwa dalam penulisan tugas akhir ini masih terdapat banyak kekurangan baik dari segi teknik penyajian penulisan, maupun materi penulisan mengingat keterbatasan ilmu yang dimiliki penulis. Oleh karena itu, penulis sangat mengharapkan segala bentuk saran dan kritik dari semua pihak demi penyempurnaan tugas akhir ini. Akhir kata penulis secara pribadi berharap tulisan tugas akhir ini bisa memberikan manfaat khususnya bagi penulis, dan bagi para pembaca pada umumnya.. Medan, 23 Januari 2018 Penulis,. Hafizh Al Kautsar Aidilof. Universitas Sumatera Utara.
(10) ix. ABSTRAK. K-Nearest Neighbor merupakan salah satu dari 10 algoritma yang sering digunakan dalam data mining (Wu, 2009). Seiring dengan perkembangannya, K-Nearest Neighbor dikombinasikan dengan pendekatan Fuzzy. Fuzzy K-Nearest Neighbor menempatkan derajat keanggotaan –selain jarak euclidian- sebagai ciri kedekatan suatu data terhadap kelas target sehingga Fuzzy K-Nearest Neighbor diketahui dapat meningkatkan hasil klasifikasi ataupun pengenalan pola. Selain menambahkan Fuzzy, K-Nearest Neighbor juga dimodifikasi pada tahap penentuan kelas dengan pendekatan Local Mean. Pada Local Mean based K-Nearest Neighbor, nilai vektor data uji dihitung terhadap masing-masing kelas target sehingga jarak euclidian tidak hanya dihitung antar data tetapi juga antar kelas target. Dalam penelitian ini, dimodelkan vektor dari Local Mean K-Nearest Neighbor dibagi dengan derajat keanggotaan terhadap masing-masing kelas yang dihasilkan oleh Fuzzy K-Nearest Neighbor sehingga dihasilkan vektor yang bernilai lebih kecil. Hal ini akan berpengaruh pada semakin jelasnya rentang nilai kecenderungan suatu data terhadap suatu kelas dibandingkan kelas lainnya dan akan mempermudah algoritma untuk menentukan kelas target dari suatu data. Pengujian model algoritma dilakukan dengan 2 cara. Cara pertama pola citra yang diujikan merupakan pola citra yang termasuk dalam data latih. Sedangkan cara kedua, total keseluruhan pola citra yang berjumlah 84 pola dibagi 2 untuk pola latih dan pola uji dengan perbandingan 2 : 1. Hasil pengujian menunjukkan model algoritma Fuzzy K-Nearest Neighbor dengan Local Mean mendapat akurasi sebesar 96,43 % pada penentuan nilai k = 1. Kata Kunci : FKNN, LMKNN, Pengenalan Pola Citra. Universitas Sumatera Utara.
(11) x. MODEL FUZZY K-NEAREST NEIGHBOR WITH LOCAL MEAN ON PATTERN RECOGNITION OF TAJWEED IMAGE. ABSTRACT. K-Nearest Neighbor is one of 10 algorithms that are often used in data mining (Wu, 2009). Along with its development, K-Nearest Neighbor is combined with Fuzzy approach. Fuzzy K-Nearest Neighbor locates membership degrees - as well as euclidean distance - as a feature of data attachment to the target class so that Fuzzy KNearest Neighbor is known to improve the classification or pattern recognition. In addition to adding Fuzzy, K-Nearest Neighbor is also modified in the class determination stage with Local Mean approach. At Local Mean KNN, the value of the test data vector is calculated against each target class so that the euclidian distance is not only calculated between the data but also between the target classes. In this study, the vector modeled from Local Mean K-Nearest Neighbor is divided by the degree of membership of each class produced by Fuzzy K-Nearest Neighbor resulting in smaller value vectors. This will affect the more clearly the range of values tendency of a data to a class than other classes and will facilitate the algorithm to determine the target class of a data. Testing algorithm model is done in 2 ways. The first way the image pattern is tested is the image pattern included in the training data. While the second way, the total overall pattern of the image of 84 patterns divided by 2 for the pattern of training and test patterns with a ratio of 2: 1. Test results show Fuzzy K-Nearest Neighbor algorithm model with Local Mean gets accuracy of 96.43% on the determination of k=1. Keywords : FKNN, LMKNN, Pattern Recognition. Universitas Sumatera Utara.
(12) xi. DAFTAR ISI Hal. Halaman Judul ................................................................................................. i Persetujuan ....................................................................................................... ii Pernyataan ........................................................................................................ iii Persetujuan Publikasi ....................................................................................... iv Panitia Penguji Tesis ........................................................................................ v Riwayat Hidup ................................................................................................. vi Ucapan Terima Kasih....................................................................................... vii Abstrak ............................................................................................................. ix Abstract ............................................................................................................ x Daftar Isi .......................................................................................................... xi Daftar Tabel ..................................................................................................... xiii Daftar Gambar.................................................................................................. xiv Bab 1. Pendahuluan 1.1. Latar Belakang ............................................................................ 1.2. Rumusan Masalah ....................................................................... 1.3. Batasan Masalah ......................................................................... 1.4. Tujuan Penelitian ........................................................................ 1.5. Manfaat Penelitian ....................................................................... 1 2 3 3 3. Bab 2. Landasan Teori 2.1. Pengenalan Pola Citra Digital ..................................................... 4 2.2. K-Nearest Neighbor .................................................................... 6 2.3. Fuzzy K-Nearest Neighbor ......................................................... 8 2.4. Local Mean ................................................................................. 9 2.5. Hukum Tajwid Al-Quran ............................................................ 10 2.6. Penelitian Terkait ........................................................................ 11. Bab 3. Metodologi Penelitian 3.1. Metodologi Penelitian ................................................................. 3.2. Alur Kerja Penelitian .................................................................. 3.3. Skema Sistem.............................................................................. 3.4. Rencana Tahapan Penelitian ....................................................... 3.5. Local Mean based Fuzzy K-Nearest Neighbor ........................... 3.6. Sampel Pola Citra Tajwid ............................................................ 13 14 14 15 16 16. Hasil Dan Pembahasan 4.1. Hasil Penelitian dan Pengujian ................................................... 4.1.1. Pengujian model algoritma............................................. 4.1.2. Hasil penelitian ............................................................... 4.2. Perbandingan LMFKNN dengan FKNN .................................... 4.3. Analisis Hasil Penelitian dan Pengujian ...................................... 20 20 25 42 42. Bab 4. Universitas Sumatera Utara.
(13) xii. Bab 5. Kesimpulan Dan Saran 5.1. Kesimpulan ................................................................................ 5.1.1. Kesimpulan hasil penelitian ............................................ 5.1.2. Kesimpulan hasil pengujian ............................................ 5.2. Saran ........................................................................................... Daftar Pustaka Lampiran. 45 45 45 45 46 48. Universitas Sumatera Utara.
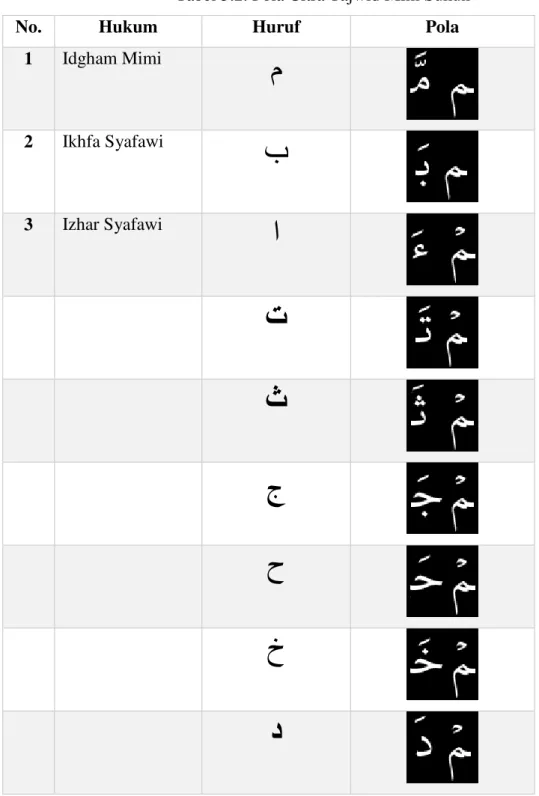
(14) xiii. DAFTAR TABEL. Tabel 2.1. Penelitian Terkait Tabel 3.1. Rencana Tahapan Penelitian Tabel 3.2. Pola Citra Tajwid Mim Sukun Tabel 4.1. Local Mean Vector Tabel 4.2. Vektor Local Mean terhadap Degree of Membership Tabel 4.3. Local Mean Vector Tabel 4.4. Vektor Local Mean terhadap Degree of Membership Tabel 4.5. Perbandingan Akurasi LMFKNN dengan FKNN cara 1 Tabel 4.6. Perbandingan Akurasi LMFKNN dengan FKNN cara 2. Hal. 11 16 17 34 37 38 41 42 42. Universitas Sumatera Utara.
(15) xiv. DAFTAR GAMBAR. Gambar 2.1. Proses Pengolahan Data pada Computer Vision Gambar 2.2. Algoritma Supervised Learnig dan Unsepervised Learning Gambar 3.1. Alur Kerja Penelitian Gambar 3.2. Skema Sistem Gambar 4.1. Akurasi Hasil Pengujian Model Pertama Gambar 4.2. Pengujian dengan k Bernilai 1 dan 2 Gambar 4.3. Pengujian dengan k Bernilai 3 Gambar 4.4. Pengujian dengan k Bernilai > 3 Gambar 4.5. Akurasi Hasil Pengujian Model Kedua Gambar 4.6. Pengujian dengan k Bernilai 1 Gambar 4.7. Pengujian dengan k Bernilai 2 Gambar 4.8. Pengujian dengan k Bernilai > 3. Hal. 6 7 14 14 21 21 22 22 23 24 24 25. Universitas Sumatera Utara.
(16) 1. BAB 1 PENDAHULUAN. 1.1. Latar Belakang K-nearest neighbor diketahui sebagai salah satu algoritma data mining yang tangguh untuk menyelesaikan masalah klasifikasi (Wu, 2009). Tidak hanya masalah klasifikasi, k-nearest neighbor juga banyak diterapkan dalam pengenalan pola dan pengkategorian teks (Bhatia & Vandana. 2010; Jabbar, et al. 2013; Sánchez, et al. 2014). Beberapa kelebihan k-nearest neighbor yaitu sifatnya yang sangat nonlinier, cepat, sederhana dan mudah dipahami serta diterapkan (Wang, et al. 2007; GarcíaPedrajas & Ortiz-Boyer, 2009; Pan, et al. 2017; Ougiaroglou & Evangelidis, 2012; Song, et al. 2017). Disamping beberapa kelebihan, k-nearest neighbor tentu memiliki kelemahan tersendiri. Beberapa kelemahan k-nearest neighbor yaitu harus menggunakan seluruh data latih untuk melakukan identifikasi atau klasifikasi, rentan terhadap data dengan dimensionalitas yang tinggi dan rentang variabel, lambat dalam melakukan komputasi serta ketidakmampuannya dalam menangani missing value (Rosyid, et al. 2013; Raikwal, 2012). Berbagai penelitian dilakukan untuk menyempurnakan k-nearest neighbor. Salah satunya adalah dengan penerapan logika fuzzy untuk menentukan derajat keanggotaan suatu data uji terhadap kelas target. Selain itu upaya untuk memaksimalkan hasil juga dilakukan dengan memodifikasi cara penentuan kelas target sebagai tahap akhir pengklasifikasian ataupun pengenalan pola dari yang awalnya menggunakan vote majority menjadi local mean. Penentuan kelas target menggunakan pendekatan vote majority menentukan kelas sebuah data baru ataupun data uji berdasarkan banyaknya data yang mendominasi salah satu kelas dari sejumlah k kelas yang diambil dan mengabaikan kemiripan ciri ataupun pola antar data yang berada pada kelas berbeda. Berbeda dengan pendekatan local mean dimana jarak antara data uji dengan data latih pada kelas target berbeda juga diperhitungkan sehingga prosesnya akan lebih adil.. Universitas Sumatera Utara.
(17) 2. Dalam sub bidang ilmu computer vision, tahap akhir dari prosesnya adalah klasifikasi ataupun identifikasi. Tahapan ini adalah langkah dimana komputer dapat mengenali pola dan/atau melakukan klasifikasi terhadap objek citra yang diujikan. Pada tahapan ini lah fuzzy k-nearest neighbor yang pada penentuan kelasnya dimodelkan dengan local mean berperan sebagai algoritma yang dapat mengenali pola ataupun menggali informasi dari data melakukan tugasnya. Di sisi lain, penelitian tentang Al-Quran terus berkembang baik dari penggalian informasi dari tafsir dan maknanya, maupun manfaat serta kelebihannya. Dalam bidang ilmu komputer khususnya computer vision, beberapa hal yang dapat diteliti antara lain pengenalan ayat Al-Quran menggunakan suara dan pengenalan pola huruf dan tanda baca Al-Quran. Dalam membaca Al-Quran dikenal hukum tajwid. Hukum tajwid mengatur tata cara membaca Al-Quran sesuai kaidah yang benar, mulai dari bagaimana pengucapan huruf yang sesuai hingga cara membaca Al-Quran itu sendiri. Dengan membaca AlQuran sesuai dengan hukum tajwidnya, maka umat Islam akan diberi ganjaran pahala sebanyak 10 kebaikan dalam setiap hurufnya. Hal ini didasari dari hadist Rasulullah SAW “barang siapa membaca satu huruf Al-Quran maka baginya satu pahala kebaikan dan satu pahala kebaikan akan dilipatgandakan menjadi sepuluh kali. Aku tidak mengatakan Alif Lam Mim itu satu huruf, akan tetapi Alif satu huruf, Lam satu huruf dan Mim satu huruf” (H.R. Tirmidzi no. 2835). Berdasarkan uraian di atas, penulis tertarik mengambil judul “Model Fuzzy KNearest Neighbor dengan Local Mean pada Pengenalan Pola Citra Tajwid”.. 1.2. Rumusan Masalah Berdasarkan uraian di atas, maka masalah yang timbul adalah bagaimana local mean menentukan kelas target untuk data citra berupa pola tajwid Al-Quran yang dilatih dan diuji menggunakan algoritma fuzzy k-nearest neighbor. Dalam klasifikasi menggunakan fuzzy k-nearest neighbor setiap tetangga terdekat diasumsikan memiliki bobot yang sama sehingga kemiripan antar data yang berbeda kelas target diabaikan. Untuk mengakomodir hal tersebut, maka dalam penentuan kelas pada algoritma fuzzy k-nearest neighbor diusulkan menggunakan local mean.. Universitas Sumatera Utara.
(18) 3. 1.3. Batasan Masalah Adapun batasan masalah dalam penelitian ini adalah :. م. a. Sampel citra tajwid yang diambil adalah hukum Mim ( ) sukun yang terdiri dari 3 bagian, yaitu Ikhfa Syafawi, Idgham Mutamatsilain dan Izhar Syafawi.. م. b. Sampel diambil dari pertemuan huruf Mim ( ) dengan huruf hijaiyah lainnya yang berpola terpisah c. Tidak dibahas bagaimana tahapan pre-processing sampel citra.. 1.4. Tujuan Penelitian Penelitian ini bertujuan untuk mengetahui hasil pengenalan pola citra tajwid Al-Quran dengan algoritma fuzzy k-nearest neighbor dimana pada penentuan kelas target menggunakan local mean.. 1.5. Manfaat Penelitian Penelitian ini bermanfaat sebagai : a. Pengembangan algoritma yang dapat digunakan untuk mengenali pola citra tajwid Al-Quran. b. Sebagai kontribusi untuk menutupi kelemahan algoritma fuzzy k-nearest neighbor biasa yang masih menggunakan vote majority.. Universitas Sumatera Utara.
(19) 4. BAB 2 TINJAUAN PUSTAKA. 2.1. Pengenalan Pola Citra Digital Citra digital merupakan representatif dari citra yang diambil oleh mesin dengan bentuk pendekatan berdasarkan sampling dan kuantisasi. Sampling menyatakan besarnya kotak-kotak yang disusun dalam baris dan kolom atau dengan kata lain sampling pada citra menyatakan besar kecilnya ukuran piksel (titik) pada citra, dan kuantisasi menyatakan besarnya nilai tingkat kecerahan yang dinyatakan dalam nilai tingkat keabuan (grayscale) sesuai dengan jumlah bit biner yang digunakan oleh mesin atau dengan kata lain kuantisasi pada citra menyatakan jumlah warna yang ada pada citra (Basuki, 2005). Sedangkan menurut Putra (2010), suatu citra dapat didefinisikan sebagai fungsi f(x,y), berukuran M baris dan N kolom, dimana x dan y adalah koordinat spasial dari citra, sedangkan f(x,y) merupakan intensitas atau tingkat keabuan dari citra pada titik tersebut. Apabila nilai x, y, dan f secara keseluruhan memiliki nilai yang berhingga (finite) dan bernilai diskrit, maka citra tersebut disebut dengan citra digital. Pengolahan citra adalah pengolahan suatu citra dengan menggunakan komputer khusus untuk menghasilkan suatu citra yang lain. Sedangkan computer vision dapat didefinisikan setara dengan pengertian pengolahan citra yang dikaitkan dengan akuisisi citra, pemrosesan, klasifikasi, pengakuan, dan pencakupan keseluruhan, pengembalian keputusan yang diikuti dengan pengidentifikasian citra. (Fadlisyah, 2007). Teknik pengolahan citra digital terbagi menjadi 3 tingkat pengolahan, yaitu : 1. Low-Level Processing (pengolahan tingkat rendah) Pengolahan ini merupakan operasi dasar dalam pengolahan citra. Pengolahan pada tingkatan ini meliputi pengurangan noise, perbaikan citra dan restorasi citra. Input dan Output pada tingkatan ini berupa citra.. Universitas Sumatera Utara.
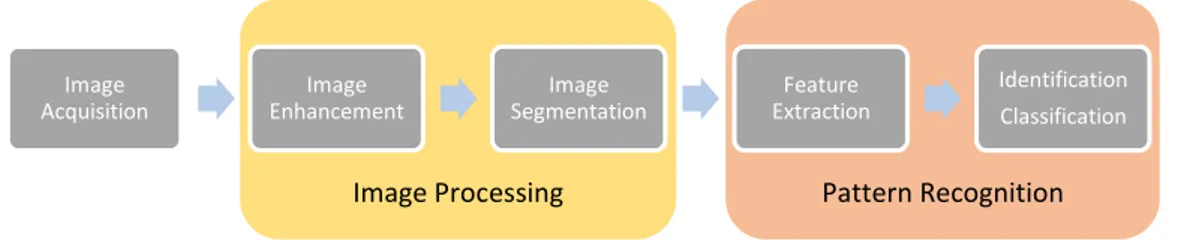
(20) 5. 2. Mid-Level Processing (pengolahan tingkat menengah) Pengolahan inimeliputi segmentasi pada citra, deskripsi objek, dan klasifikasi objek secara terpisah. Pada tingkatan ini input berupa citra sedangkan output sudah berupa fitur citra yang dipisahkan dari citra input. 3. High-Level Processing (pengolahan tingkat tinggi) Salah satu guna pengolahan tingkat tinggi adalah menjadikan objek yang telah dikenali pada tingkat menengah menjadi lebih berguna. Kegiatan pada tingkatan ini berupa analisis citra yang dihasilkan dapat memuat suatu kesimpulan atau pun dapat menjadi masukan untuk pengambilan keputusan. Lebih lanjut, Basuki Ahmad (2005) menguraikannya sebagai berikut : 1. Image Enhacement, berupa proses perbaikan citra dengan meningkatkan kualitas citra baik kontras maupun kecerahan. Salah satu tekniknya adalah dengan cara modifikasi histogram. 2. Image Restoration, proses memperbaiki model citra, biasanya bergubungan dengan bentuk citra yang sesuai. 3. Color Image Processing, suatu proses yang melibatkan citra berwarna, baik berupa image enhacement, image restoration, atau yang lainnya. 4. Wavelet dan Multiresolution Processing, merupakan suatu proses yang menyatakan citra dalam bentuk beberapa resolusi. 5. Image Compression, merupakan proses yang digunakan untuk mengubah ukuran data pada citra. 6. Morphological Processing, merupakan proses untuk memperoleh informasi yang menyatakan deskripsi dari suatu bentuk pada citra. 7. Segmentation, merupakan proses untuk membedakan atau memisahkan objekobjek yang ada dalam suatu citra, seperti memisahkan objek dari latar belakangnya. Salah satu tekniknya adalah dengan menggunakan operasi binerisasi otomatis. 8. Object Recognition, merupakan suatu proses yang dilakukan untuk mengenali objek-objek apa saja yang ada dalam suatu citra.. Universitas Sumatera Utara.
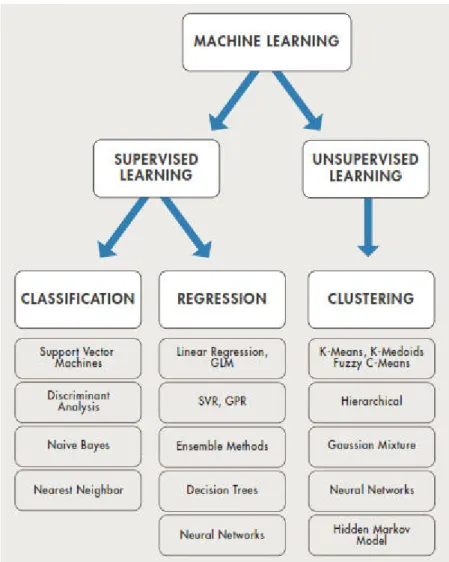
(21) 6. Sedangkan Pengenalan Pola Citra Digital dapat didefinisikan sebagai cabang dari kecerdasan buatan dan pembelajaran mesin yang melakukan identifikasi objek tertentu berupa citra digital atau klasifikasi objek ke dalam kelas tertentu guna menyelesaikan suatu permasalahan. Lebih lanjut, perbedaan pengolahan citra digital dan pengenalan pola citra digital dapat dilihat dari skema berikut :. Image Acquisition. Image Enhancement. Image Segmentation. Image Processing. Feature Extraction. Identification Classification. Pattern Recognition. Gambar 2.1 Proses Pengolahan Data pada Computer Vision. 2.2. K-Nearest Neighbor K-nearest neighbor diperkenalkan pada tahun 1950 dan baru mulai populer digunakan pada tahun 1960 seiring dengan meningkatnya kemampuan komputer (Han, 2012). Knearest neighbor bekerja dengan cara mengkategorikan objek berdasarkan kelas sesuai kemiripan dengan tetangga terdekatnya dalam data latih (Mathworks, 2017). Kinerja klasifikasi k-nearest neighbor ditentukan oleh ketepatan pemilihan k ketetanggaan terdekat dan metode pengukuran jarak yang diterapkan (Mahmoud, et al. 2015). Namun, ketika data terdistribusi secara merata, maka akan sulit untuk menentukan nilai k ketetanggaan terdekat dikarenakan jarak antar sesama data latih terhadap data uji sama. K-Nearest Neighbor merupakan algoritma berbasis pengukuran jarak (distance based algorithms) (Wang, et al. 2007). Distance based algorithms adalah algoritma yang menentukan kemiripan suatu data atau objek berdasarkan kedekatan jarak antara suatu data ke suatu kelas atau kelompok data lainnya (Kataria & Singh, 2013). K-nearest neighbor termasuk algoritma supervised learning dimana kelas target dari suatu data ataupun objek sudah diketahui terlebih dahulu. Untuk lebih jelasnya, pembagian algoritma supervised learning dan unsupervised learning dapat dilihat pada gambar berikut :. Universitas Sumatera Utara.
(22) 7. Gambar 2.2 Algoritma Supervised Learnig dan Unsepervised Learning. Seiring perkembangannya, k-nearest neighbor sering dipakai pada masalah pengenalan pola (Fredj, 2016). Urutan langkah algoritma k-nearest neighbor adalah : 1. Menentukan parameter k (jumlah tetangga paling dekat) 2. Menghitung kuadrat jarak euclidian (euclidean distance) masing-masing objek terhadap data sampel yang diberikan. 𝐸𝑢. 𝑎. ,. = √∑|. Dimana : 𝐸𝑢. 𝑎. ,. 𝑁. =. −. |. : jarak euclidian : record ke i data uji : record ke j data latih. Universitas Sumatera Utara.
(23) 8. 3. Mengurutkan objek-objek tersebut ke dalam kelompok yang mempunyai jarak terkecil 4. Mengumpulkan kategori Y (klasifikasi nearest neighbor) 5. Dengan menggunakan kategori mayoritas,maka dapat diprediksi nilai query instance yang telah dihitung.. 2.3. Fuzzy K-Nearest Neighbor Fuzzy k-nearest neighbor merupakan gabungan antara teknik fuzzy dan klasifikasi knearest neighbor. Teknik fuzzy digunakan untuk mengitung derajat keanggotaan sedangkan k-nearest neighbor sebagai classifier yang menghitung kemiripan suatu objek berdasarkan jarak terdekat dengan dataset. Zbancioc (2012) mengutip dari Keller (-) menuliskan bahwa motivasi menggunakan fuzzy k-nearest neighbor adalah semua vektor dari k-nearest neighbor primitif mempunyai derajat yang setara dalam proses clustering sehingga tidak ada ukuran tingkat kekuatan kepada sebuah kelas target. Dengan adanya penambahan fitur degree of membership pada tiap data uji terhadap masing-masing kelas target maka akan menjadi informasi baru yang memperkuat suatu alasan akan kecenderungan suatu data uji terhadap sebuah kelas target. Hal ini menggambarkan pentingnya peran vektor dalam penentuan kelas final pada fuzzy k-nearest neighbor. Vektor yang bernilai tinggi pada derajat keanggotaan fuzzy akan memiliki nilai bobot yang lebih dalam penetapan kelas target. Hal ini juga menutupi kelemahan k-nearest neighbor primitif dimana akan sulit menetapkan nilai k ketetanggaan terdekat yang ideal jika data tersebar secara merata. Algoritma fuzzy knearest neighbor dijabarkan sebagai berikut (Beyan, 2014) : a. Tentukan nilai data latih dan data uji b. Lakukan normalisasi data jika rentangnya terlalu jauh c. Hitung jarak antara data uji terhadap data latih dengan persamaan euclidian d. Urutkan jarak dari nilai terkecil ke nilai terbesar e. Mengambil data sebanyak nilai k Hitung derajat keanggotaan fuzzy menggunakan persamaan berikut : =. ∑. =. ∑. =. ‖ −. ‖ −. ‖. ‖. − ⁄. − ⁄. −. −. Universitas Sumatera Utara.
(24) 9. Dimana : : nilai keanggotaan fuzzy : nilai keanggotaan data tetangga i terhadap kelas j : banyaknya nilai ketetanggaan terdekat yang diambil −. : selisih data antara data. ke data. dalam. tetangga terdekat. : bobot pangkat yang besarnya m>1. 2.4. Local Mean Local mean adalah sebuah pendekatan yang bekerja dengan cara menghitung vektor dari data uji terhadap tetangga k terdekat dari masing-masing kelas. Penentuan kelas target data uji menggunakan pendekatan local mean akan lebih adil dikarenakan jarak antar data dengan masing-masing kelas target juga dihitung. Berbeda dengan penentuan kelas yang bersifat vote majority dimana klasifier hanya menghitung kedekatan dan mayoritas distribusi pada k kelas terdekat ketetanggaan. Gagasan utama menggunakan local mean adalah untuk mengatasi efek yang ditimbulkan oleh sebuah sampel khusus dari data training (Tu, 2015). Menurut Gou (2012) penggunaan local mean pada k-nearest centroid neighbor berhasil meningkatkan akurasi secara signifikan. Local mean bekerja dengan cara menghitung vektor dari tetangga k terdekat dari masing-masing kelas sehingga pengambilan keputusan akan lebih fair dikarenakan jarak antar data dengan masingmasing kelas juga dihitung. Berbeda dengan pengambilan keputusan vote majority yang hanya menghitung kedekatan dan mayoritas distribusi pada k kelas. Pan (2016) merumuskan langkah-langkah penentuan kelas target untuk data uji baru dengan local mean pada k-nearest neighbor sebagai berikut : 1. Tentukan. data latih dari masing-masing kelas. 2. Hitung vektor local mean. 3. Klasifikasikan. 𝑤𝑗. ∑. =. =. 𝑁𝑁 ,. ke dalam kelas-kelas dimana jarak euclidian berada diantara. vektor local mean dan nilai minimum x 𝜔 = arg. 𝜔. ( ,. 𝜔. ), = , , … , 𝑀. Universitas Sumatera Utara.
(25) 10. 2.5. Hukum Tajwid Al-Quran Secara bahasa, tajwid berarti membaguskan. Sedangkan menurut istilah adalah mengeluarkan setiap huruf dari tempat keluarnya dengan memberi hak dan mustahaknya. Yang dimaksud dengan hak huruf adalah sifat asli yang selalu bersama dengan huruf tersebut, seperti ai jahr, isti'la', istifal dan lain sebagainya. Sedangkan yang dimaksud dengan mustahak huruf adalah sifat yang nampak sewaktu-waktu, seperti tafkhim, tarqiq, ikhfa' dan lain sebagainya. Hukum tajwid dalam membaca Al-Quran terbagi ke dalam 4 bagian, yaitu : a. Hukum Nun sukun dan tanwin b. Hukum Mim sukun Hukum Mim sukun adalah apabila huruf Mim bertanda baca sukun bertemu dengan salah satu huruf hijaiyah. Hukum Mim sukun sendiri terbagi ke dalam 3 bagian, yaitu : 1. Ikhfa Syafawi. م. )بdi. Yaitu jika Mim ( ) bertanda baca sukun bertemu dengan huruf Ba (. depannya. Cara membacanya ialah dengan disamarkan disertai dengung selama 2 harakat. 2. Idgham Mimi (Idgham Mutamatsilain). م. Yaitu jika Mim ( ) yang bertanda baca sukun bertemu dengan huruf Mim (. )مdi depannya. Cara membacanya ialah dengan menekankan huruf Mim selama 2 harakat disertai dengung. 3. Izhar Syafawi Yaitu jika Mim (. )مbertanda baca sukun bertemu dengan huruf Hijaiyah م. )بyaitu : – خ– ح–ج– ث – ت–ا. yang selain Mim ( ) dan Ba (. –ع– ظ – ط –ض – ص – ش – س – ز– ر ذ – د. Universitas Sumatera Utara.
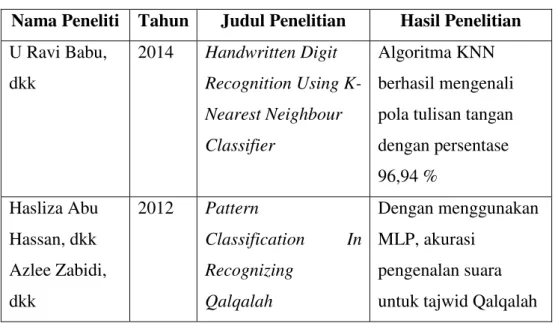
(26) 11. ي–ﮬ–و–ن–ل–ك –ق ف –غ. Cara membacanya ialah dengan memperjelas tanpa disertai dengung. c. Hukum Mad Menurut bahasa, Mad artinya tambahan atau melebihkan. Di dalam istilah ilmu tajwid, Mad adalah memanjangkan bacaan ketika bertemu dengan huruf-huruf yang mengandung hukum Mad. Dapat dikatakan bahwa hukum Mad adalah hukum yang mengatur panjang bacaan di dalam Al-Qur’an. d. Tasydid Tasydid adalah tanda baca (harakat) berbentuk kepala dari huruf Sin (. )س. atau mirip seperti huruf W. Tasydid adalah simbol penekanan pada suatu konsonan ganda, atau sebuah tanda baca yang terjadi karena pertemuan (pengulangan) dari sebuah huruf yang sama. Panjang bacaan untuk huruf bertasydid umumnya adalah 1 alif atau 2 harakat. Namun dapat dibaca lebih panjang lagi, seperti tasydid yang ada di dalam Hukum Ghunnah Musyaddadah. Dan akan lebih tebal (panjang) pantulannya ketika masuk ke dalam Hukum Qolqolah Kubro (qolqolah yang berhenti karena tanda waqof).. 2.6. Penelitian Terkait Beberapa penelitian sebelumnya yang berkaitan dengan dengan usulan penelitian ini antara lain : Tabel 2.1. Penelitian Terkait Nama Peneliti. Tahun. U Ravi Babu,. 2014. dkk. Judul Penelitian Handwritten Digit. Hasil Penelitian Algoritma KNN. Recognition Using K- berhasil mengenali Nearest Neighbour. pola tulisan tangan. Classifier. dengan persentase 96,94 %. Hasliza Abu. 2012. Pattern. Dengan menggunakan. Hassan, dkk. Classification. In MLP, akurasi. Azlee Zabidi,. Recognizing. pengenalan suara. dkk. Qalqalah. untuk tajwid Qalqalah. Universitas Sumatera Utara.
(27) 12. Kubra Pronuncation Kubra sebesar 95 % Using Multilayer Perceptrons Ahsiah, I, dkk. 2013. Tajweed Checking. Sistem pengecekan. System to Support. tajwid dapat. Recitation. membantu para pelajar untuk mengenali hukum tajiwd dengan pengenalan suara. V. Kumar &. 2014. Facial Expression. Aplikasi pengenalan. A. Sikkander. Recognition using. wajah dengan. Ali Basha. Wavelet and K-. algoritma KNN. Nearest Neighbour. berjalan dengan baik dan memuaskan. Auhood. 2013. Alfaries, dkk. Rule Base Annotation Natural Language system to extract. Processing berhasil. Tajweed Rules from. mengenali 100%. Quran. hukum tajwid dalam surat As-Syuraa. Houchine Boubaker, dkk. 2014. Arabic Diacritics. Dalam pengenalan. Detection and Fuzzy. pola tulisan tangan. Representation for. arabic, disulkan. Segmented. menggunakan Fuzzy. Handwriting. Classification. Graphemes Modelling. Universitas Sumatera Utara.
(28) 13. BAB 3 METODOLOGI PENELITIAN. 3.1. Metodologi Penelitian a. Studi Kepustakaan (Library Research) Studi kepustakaan dilakukan untuk mengumpulkan dan mempelajari referensi yang berkaitan dengan pengenalan pola menggunakan algoritma fuzzy k-nearest neighbor dan local mean k-nearest neighbor. Studi kepustakaan dilakukan melalui study literature yang bersumber dari buku, jurnal, tesis dan disertasi terdahulu serta media penunjang lainnya, seperti internet. b. Analisa Permasalahan Pada tahap ini dilakukan analisa terhadap hasil dari study literature. Hasil dari analisa ini nantinya akan dijadikan acuan dari perancangan algoritma yang dimodelkan. c. Perancangan Pada tahap perancangan sistem akan dilakukan perancangan model algoritma, pengumpulan dan normalisasi data, pre-processing citra serta pembagian data untuk tahapan training dan testing. d. Implementasi Pada tahap ini, sistem akan dibangun sesuai dengan hasil perancangan pada tahap sebelumnya. e. Pengujian Tahap pengujian adalah tahap yang akan menentukan hasil. Selain untuk memastikan apakah program berjalan sesuai algoritma dan hasil perancangan, pada tahap ini juga dilakukan pelatihan terhadap sekelompok data yang telah. Universitas Sumatera Utara.
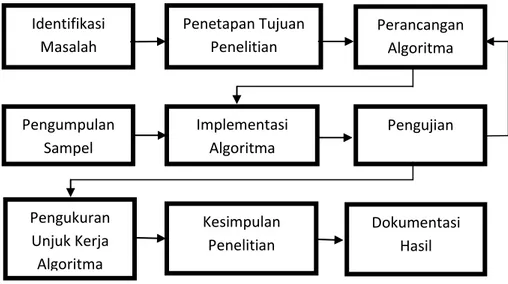
(29) 14. dikumpulkan dan dinormalisasi serta pengujian pada sekelompok data lainnya untuk melihat perbandingan antara kedua algoritma dalam menyelesaikan pengenalan pola tajwid.. f. Dokumentasi Ini adalah tahap akhir dimana hasil dari pengujian akan didokumentasikan untuk kemudian disimpulkan sebagai hasil dari penelitian.. 3.2. Alur Kerja Penelitian Adapun alur kerja penelitian ini ditunjukkan dalam bagan berikut : Identifikasi Masalah. Penetapan Tujuan Penelitian. Perancangan Algoritma. Pengumpulan Sampel. Implementasi Algoritma. Pengujian. Pengukuran Unjuk Kerja Algoritma. Kesimpulan Penelitian. Dokumentasi Hasil. Gambar 3.1. Alur Kerja Penelitian. 3.3. Skema Sistem Adapun skema dari sistem yang akan dibuat adalah :. Aqcuisition. Enhancement Segmentation. Feature Extraction. Identification Recognition. Gambar 3.2.Skema Sistem. Image Acquisition adalah tahapan awal dalam proses pengolahan citra. Pada tahap ini dilakukan pengambilan gambar dan mentransformasikannya menjadi citra digital. Pengambilan data citra dilakukan menggunakan bantuan alat scanner.. Universitas Sumatera Utara.
(30) 15. Image Enhancement adalah tahapan dimana dilakukan pre-processing sebelum sebuah citra digital itu diproses. Pada tahapan ini dilakukan peningkatan kualitas citra guna menonjolkan suatu ciri tertentu yang akan dijadikan sampel dan meperbaiki tampilan pada sampel. Image Segmentation adalah tahapan untuk memisahkan objek yang dipilih dari keseluruhan citra. Segmentasi citra terdiri dari downsampling, pembersihan derau, dan deteksi tepi. Pada tahap downsampling dilakukan pengurangan jumlah piksel dan penghilangan sebagian informasi dari citra yang bertujuan untuk menghasilkan ukuran citra yang lebih kecil atau sering disebut penskalaan ulang (re-scalling). Setelah itu dilakukan pembersihan derau atau noise yang bertujuan untuk membersihkan sampel citra dari derau yang biasanya muncul pada spektrum citra berfrekuensi tinggi. Selain itu pembersihan derau juga dilakukan untuk memisahkan objek yang akan dikenali dengan objek lain pada citra yang tidak terpakai dalam pengenalan pola nantinya. Dalam penelitian ini, objek yang akan diambil adalah tulisan Al-Quran saja sedangkan tulisan latin dan beberapa tulisan lain yang ada dalam lembaran mushaf Al-Quran akan dieliminasi karena dianggap sebagai derau. Selanjutnya adalah tahap feature extraction dimana pada tahap ini dilakukan pengekstrakan informasi dari objek pada citra yang akan dijadikan sebagai data training. Pada akhirnya dilakukan tahapan identification dan recognition. Pada tahap identification dilakukan pelatihan dimana nilai parameter yang didapat dari tahapan ekstraksi fitur dijadikan sebagai masukan untuk kemudian diolah sehingga diperoleh suatu rumusan yang dapat menyimpan informasi untuk mengenali objek. Selanjutnya, tahap classification dimana sekumpulan data testing dipetakan ke masing-masing kelas menggunakan rumusan pada tahap identification. Output pada tahapan ini kemudian dibandingkan dengan target testing sehingga didapat tingkat akurasi pengujian. 3.4. Rencana Tahapan Penelitian Rencana tahapan penelitian dijadwalkan dalam tabel berikut ini : Tabel 3.1. Rencana Tahapan Penelitian. Universitas Sumatera Utara.
(31) 16. 3.5. Local Mean based Fuzzy K-Nearest Neighbor Model algoritma local mean based fuzzy k-nearest neighbor dijabarkan sebagai berikut : a. Menentukan data training dan data testing b. Mengitung distance antara data testing terhadap data training dengan persamaan distance fuzzy berikut : ℎ. ̅, ̅ =. 𝑎 {|̅̅̅ − ̅ |, |̅̅̅𝑟 − ̅̅̅𝑟 |}. c. Mengurutkan distance tiap data dari nilai terkecil ke nilai terbesar d. Mengambil data sebanyak nilai k dari tiap-tiap kelas target yag telah diurutkan. e. Mengitung local mean vector dari sebanyak k data testing ke masing-masing kelas training 𝑤𝑗. =. ∑. 𝑁𝑁 ,. =. f. Menghitung degree of membership dari data testing ke masing-masing kelas training sebanyak k =. ∑. =. ∑. =. (‖ −. (‖ −. ‖. ‖. − ⁄. − ⁄. −. −. ). ). g. Menghitung vector model terhadap masing-masing kelas training sebanyak k 𝑟. =. 𝑤𝑗. h. Penentuan kelas target untuk data testing ditentukan dengan kelas yang memiliki nilai vektor model paling kecil 𝜔 = arg. 𝜔. ,. 𝑟. , = , ,…,𝑀. Universitas Sumatera Utara.
(32) 17. 3.6. Sampel Pola Citra Tajwid Adapun pola citra tajwid yang diambil adalah pola citra tajwid hukum Mim Sukun. م. ( ). Pola disajikan dalam tabel berikut :. Tabel 3.2. Pola Citra Tajwid Mim Sukun No.. Hukum. Huruf. 1. Idgham Mimi. م. 2. Ikhfa Syafawi. ب. 3. Izhar Syafawi. ا. Pola. ت ث ج ح خ د. Universitas Sumatera Utara.
(33) 18. ذ ر ز س ش ص ض ط ظ ع غ ف. Universitas Sumatera Utara.
(34) 19. ق ك ل ن و ﮬ ي. Universitas Sumatera Utara.
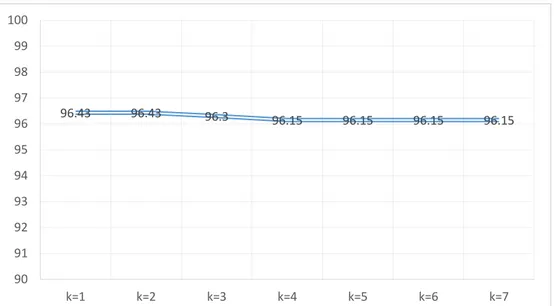
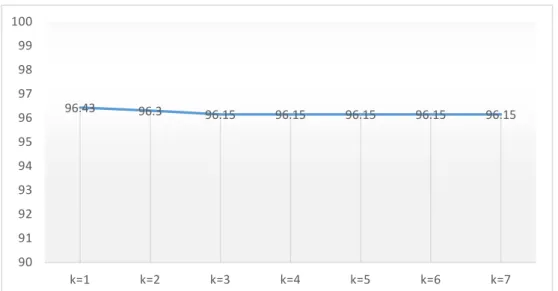
(35) 20. BAB 4 HASIL DAN PEMBAHASAN. 4.1. Hasil Penelitian 4.1.1. Pengujian model algoritma Pengujian dilakukan dengan 2 cara pembagian data. Pertama, pengujian dilakukan menggunakan sekelompok data yang termasuk dalam set data latih. Jumlahnya 1/3 dari jumlah keseluruhan data latih. Hal ini dilakukan untuk mengetahui apakah model algoritma dapat mengenali data yang diujikan dimana sebelumnya data tersebut sudah dilatih terlebih dahulu. Hal ini perlu dilakukan mengingat peranan dari local mean yang mengambil sebanyak k data latih dari masing-masing kelas target dan turut memperhitungkan vektor rata-ratanya sebagai langkah untuk menentukan kelas yang dalam hal ini untuk mengenali pola uji. Dengan adanya pemerataan vektor tersebut maka jarak antara data uji dan data latih tidak lagi bernilai 0 walaupun sebelumnya data tersebut telah dilatih terlebih dahulu. Kedua, keseluruhan data dibagi 2 untuk keperluan pelatihan dan pengujian dengan perbandingan 2 : 1. Artinya, antara data latih dan data uji masing-masing memiliki data yang berbeda walaupun pola antara kedua set data memiliki kemiripan. Untuk cara pertama, digunakan data sebanyak 84 dengan komposisi 28 huruf dan masing-masing huruf menggunakan 3 pola yaitu fattah, kasroh, dan dhommah. Untuk cara ini didapatkan akurasi sebesar 96,43% dengan k bernilai 1 dan 2. Nilai akurasi mengalami penurunan menjadi 96,30 % ketika nilai k diganti menjadi 3. Ketika k diganti menjadi 4 akurasi kembali mengalami penurunan menjadi 96,15 % dan. Universitas Sumatera Utara.
(36) 21. bernilai tetap hingga pengujian pada nilai k=7. Grafik akurasi berdasarkan inputan nilai k dapat dilihat pada gambar berikut :. 100 99 98 97 96. 96.43. 96.43. 96.3. 96.15. 96.15. 96.15. 96.15. k=1. k=2. k=3. k=4. k=5. k=6. k=7. 95 94 93 92 91 90. Gambar 4.1. Akurasi Hasil Pengujian dengan Pembagian Data Cara 1. Sedangkan hasil pengenalan pola dapat dilihat pada grafik berikut :. Universitas Sumatera Utara.
(37) 22. Gambar 4.2. Pengujian dengan k Bernilai 1 dan 2. Universitas Sumatera Utara.
(38) 23. Gambar 4.3. Pengujian dengan k Bernilai 3. Gambar 4.4. Pengujian dengan k Bernilai > 4. Universitas Sumatera Utara.
(39) 24. Cara kedua, keseluruhan data dibagi untuk keperluan pelatihan dan pengujian dengan perbandingan 2 : 1. Total keseluruhan data sama dengan cara pertama dimana data yg digunakan sebanyak 28 huruf dengan masing-masing mempunyai 3 pola yaitu fattah, kasroh, dan dhommah. Untuk model ini didapatkan akurasi sebesar 96,43 % dengan k bernilai 1. Nilai akurasi menurun menjadi 96,30 % ketika nilai k diganti menjadi 2. Ketika k diinputkan bernilai 3 kembali akurasi mengalami penurunan menjadi 96,15 % dan tidak mengalami peningkatan maupun penurunan hingga percobaan k bernilai 7. Akurasi ditampilkan dalam grafik berikut : 100 99 98 97 96. 96.43. 96.3. 96.15. 96.15. 96.15. 96.15. 96.15. k=1. k=2. k=3. k=4. k=5. k=6. k=7. 95 94 93 92 91 90. Gambar 4.5. Akurasi Hasil Pengujian dengan Pembagian Data Cara Kedua. Adapun hasil pengenalan pola dapat dilihat pada gambar berikut :. Universitas Sumatera Utara.
(40) 25. Gambar 4.6. Pengujian dengan k Bernilai 1. Gambar 4.7. Pengujian dengan k Bernilai 2. Universitas Sumatera Utara.
(41) 26. Gambar 4.8. Pengujian dengan k Bernilai > 3. 4.1.2. Hasil penelitian Berdasarkan hasil pengujian yang telah disajikan, penelitian ini menunjukkan model local mean pada fuzzy k-nearest neighbor dapat mengenali pola citra tajwid Mim. م. Sukun ( ) dengan nilai akurasi maksimal 96,43 % pada ketetanggaan terdekat k bernilai 1. Fuzzy distance dari masing-masing pola uji terhadap pola latih sebagai berikut :. Universitas Sumatera Utara.
(42) 27. Pola citra uji 1 sampai 7 terhadap pola citra latih 1 sampai 42. Universitas Sumatera Utara.
(43) 28. Pola citra uji 1 sampai 7 terhadap pola citra latih 43 sampai 84. Universitas Sumatera Utara.
(44) 29. Pola citra uji 8 sampai 14 terhadap pola citra latih 1 sampai 42. Universitas Sumatera Utara.
(45) 30. Pola citra uji 8 sampai 14 terhadap pola citra latih 43 sampai 84. Universitas Sumatera Utara.
(46) 31. Pola citra uji 15 sampai 21 terhadap pola citra latih 1 sampai 42. Universitas Sumatera Utara.
(47) 32. Pola citra uji 15 sampai 21 terhadap pola citra latih 43 sampai 84. Universitas Sumatera Utara.
(48) 33. Pola citra uji 22 sampai 28 terhadap pola citra latih 1 sampai 42. Universitas Sumatera Utara.
(49) 34. Pola citra uji 22 sampai 28 terhadap pola citra latih 43 sampai 84. Local mean vector untuk pembagian data model petama dituliskan dalam tabel berikut :. Universitas Sumatera Utara.
(50) 35. Tabel 4.1. Local Mean Vector k. Local Mean 1. Local Mean 2. Local Mean 3. k=1. 0,0071. 0,0124. 0. k=2. 0,0101. 0,0303. 0. k=3. 0,0124. 0,0393. 1,2326e-32. k=4. 0,0797. 0,0886. 3,8420e-05. k=5. 0,2093. 0,2110. 9,8355e-05. k=6. 0,3330. 0,3314. 1,5368e-04. k=7. 0,4396. 0,4363. 3,9447e-05. Degree of membership dari masing-masing data uji terhadap kelas : k=1. k=2. Universitas Sumatera Utara.
(51) 36. k=3. k=4. Universitas Sumatera Utara.
(52) 37. k=5. k=6. Universitas Sumatera Utara.
(53) 38. k=7. Selanjutnya, vektor dari local mean terhadap terhadap degree of membership dijabarkan dalam tabel berikut : Tabel 4.2. Vektor Local Mean terhadap Degree of Membership k. Dist. LM 1. Dist. LM 2. Dist. LM 3. k=1. 41,0424. 26,9284. 1. k=2. 31,4597. 13,7700. 1. k=3. 0. 0. 8,5484. k=4. 0,0067. 0,0062. 2,0492. k=5. 0,0032. 0,0032. 1,0125. k=6. 2,2812. 2,2895. 724,5002. k=7. 0,0019. 0,0019. 2,0090. Universitas Sumatera Utara.
(54) 39. Sedangkan untuk pembagian data model kedua, local mean vector nya dijabarkan dalam tabel berikut : Tabel 4.3. Local Mean Vector k. Local Mean 1. Local Mean 2. Local Mean 3. k=1. 0,0071. 0,0124. 0. k=2. 0,0117. 0,0303. 0. k=3. 0,1435. 0,1420. 6,8302e-05. k=4. 0,3332. 0,3269. 1,5368e-04. k=5. 0,4867. 0,4791. 1,5805e-05. k=6. 0,6055. 0,5978. 9,6413e-06. k=7. 0,6985. 0,6910. 6,0745e-05. Degree of membership dari masing-masing data uji terhadap kelas : k=1. k=2. Universitas Sumatera Utara.
(55) 40. k=3. k=4. Universitas Sumatera Utara.
(56) 41. k=5. k=6. Universitas Sumatera Utara.
(57) 42. k=7. Selanjutnya, vektor dari local mean terhadap terhadap degree of membership dijabarkan dalam tabel berikut : Tabel 4.4. Vektor Local Mean terhadap Degree of Membership k. Dist. LM 1. Dist. LM 2. Dist. LM 3. k=1. 41,0424. 26,9284. 1. k=2. 28,1154. 13,7700. 1. k=3. 0,0043. 0,0043. 1,3310. k=4. 2,2801. 2,3133. 724,5002. k=5. 0,0017. 0,0017. 3,9894. k=6. 0,0015. 0,0015. 5,7796. k=7. 0,0013. 0,0013. 1,4533. Universitas Sumatera Utara.
(58) 43. 4.2. Perbandingan LMFKNN dengan FKNN Adapun perbandingan akurasi antara model algoritma fuzzy k-nearest neighbor dengan local mean terhadap fuzzy k-nearest neighbor primitif menggunakan pembagian data cara pertama adalah sebagai berikut : Tabel 4.5. Perbandingan Akurasi Model LMFKNN dan FKNN Cara 1 K. LMFKNN. FKNN. k=1. 96,43%. 96,43%. k=2. 96,43%. 96,43%. k=3. 96,30%. 96,30%. k=4. 96,15%. 96,30%. k=5. 96,15%. 96,30%. k=6. 96,15%. 92,59%. k=7. 96,15%. 92,59%. Sedangkan untuk pembagian data dengan cara kedua didapat hasil perbandingan sebagai berikut : Tabel 4.6. Perbandingan Akurasi Model LMFKNN dan FKNN Cara 2 K. LMFKNN. FKNN. k=1. 96,43%. 96,43%. k=2. 96,30%. 96,43%. k=3. 96,15%. 96,30%. k=4. 96,15%. 92,59%. k=5. 96,15%. 92,59%. k=6. 96,15%. 92,59%. k=7. 96,15%. 89,28%. 4.3. Analisis Hasil Penelitian dan Pengujian Model vote majority menentukan kelas target (dalam hal ini pola target) dari sebuah data uji berdasarkan banyaknya suatu kelas yang terpilih dalam k ketetanggaan terdekat. Dalam hal ini, dapat dicontohkan jika diambil k = 5 dan dalam 5 ketetanggaan terdekat terhadap data uji tersebut terdapat suatu kelas target dengan jumlah yang paling banyak maka data uji tersebut akan digolongkan ke dalam kelas yang dominan tersebut. Jika terdapat 2 kelas target (pola target) yang jumlahnya sama,. Universitas Sumatera Utara.
(59) 44. misalnya terdapat 2 data kelas A, 2 data kelas B dan 1 data kelas C, maka pendekatan vote majority akan mengambil kelas dengan jumlah terbanyak yang paling awal muncul. Pendekatan seperti ini kurang adil mengingat suatu data uji tentu memiliki bobot yang berbeda-beda terhadap masing-masing kelas target. Pada fuzzy k-nearest neighbor primitif, penentuan kelas target dilakukan dengan menghitung nilai derajat keanggotaan (degree of membership) dari sebuah pola uji terhadap masing-masing kelas target. Kelas target dengan nilai degree of membership yang paling besar untuk sebuah pola uji akan dipilih sebagai kelas target untuk pola uji tersebut ditempatkan. Pendekatan ini masih mewarisi sifat vote majority karena dalam penentuan kelasnya masih ditetukan oleh. jumlah kelas dominan dari. ketetanggaan terdekat walaupun terdapat degree of membership yang menghitung bobot data uji terhadap tiap kelas target. Pada local mean, penentuan kelas target dilakukan dengan menghitung jarak antara pola uji dengan nilai rata-rata euclidian distance antara pola uji dan pola latih pada masing-masing kelas target dengan pengambilan data sebanyak k ketetanggaan terdekat. Pola uji akan ditempatkan pada kelas target yang memiliki nilai vektor local mean paling tinggi. Model fuzzy k-nearest neighbor dengan local mean menggabungkan kedua teknik penentuan kelas tersebut. Setelah dihitung degree of membership dan vektor local mean dari pola uji terhadap pola latih, maka langkah selanjutnya adalah membagi nilai vektor local mean dengan degree of membership. Pembagian ini dilakukan untuk memperkecil distance vektor antara pola uji dengan masing-masing pola latih maupun dengan kelas target sehingga akan jelas terlihat ke dalam kelas mana suatu pola akan dikenali. Pada penelitian ini tidak didapati perbedaan yang signifikan antara hasil pengenalan pola menggunakan fuzzy k-nearest neighbor primitif dengan fuzzy knearest neighbor dengan local mean dikarenakan data pola citra sampel tidak tersebar merata melainkan tertumpuk pada salah satu pola sehingga kedekatan cirinya sudah terpola dari awal. Namun, pada pengambilan ketetanggaan dengan nilai tinggi dimana jangkauan pengambilan data dari suatu kelas target bisa mengenai data yang dekat pada kelas target lainnya justru fuzzy k-nearest neighbor dengan local mean mendapatkan akurasi yang lebih tinggi daripada fuzzy k-nearest neighbor primitif. Hal. Universitas Sumatera Utara.
(60) 45. ini dikarenakan pendekatan local mean yang menghitung nilai rata-rata dari ekstraksi tiap pola citra dalam suatu kelas target. Pada tabel 4.6 terlihat fuzzy k-nearest neighbor dengan local mean tetap stagnan di akurasi 96,15% baik pada pembagian data cara petama ataupun cara kedua. Local mean berhasil mengenali pola citra dengan tidak memasukkan pola citra lain yang berbeda kelas ke dalam suatu kelas walaupun k ketetanggaan sudah mencapai nilai 7. Berbeda dengan pendekatan vote majority dan degree of membership yang terlihat menurun dengan signifikan setelah k diinputkan bernilai 6 pada cara pertama dan 7 pada cara kedua. Kedua pendekatan ini tetap memasukkan data uji sesuai k ketetanggaan terdekat ke dalam kelasnya kendati data uji tersebut sudah berada pada kelas target lain. Hal inilah yang menjadi kelebihan local mean dalam menentukan kelas target dari suatu data uji. Local mean tidak memasukkan suatu data uji yang cenderung terhadap suatu kelas target ke dalam suatu kelas target lainnya walaupun k ketetanggan ditentukan bernilai besar dan mengambil data dari kelas lainnya.. Universitas Sumatera Utara.
(61) 46. BAB 5 PENUTUP. 5.1. Kesimpulan 5.1.1. Kesimpulan hasil penelitian Berdasarkan hasil penelitian yang telah dibahas pada Bab 4, maka dapat disimpulkan bahwa model fuzzy k-nearest neighbor dengan local mean berhasil mengenali dan mengklasifikasi pola tajwid Al-Quran dengan persentase tertinggi 96,43 % dengan nilai k = 1.. 5.1.2. Kesimpulan hasil pengujian Unjuk kerja model algoritma local mean based fuzzy k-nearest neighbor dengan data uji yang termasuk di dalam data latih berhasil mengenali pola citra tajwid Al-Quran dengan persentase akurasi terendah sebesar 96,15% dengan penentuan nilai k sebesar > 4 dan tertinggi 96,43% dengan pemberian nilai k = 1. Sedangkan pengujian dengan pembagian pada cara kedua dimana total data dibagi untuk keperluan latih dan uji dengan perbandingan 2 : 1 didapat akurasi terendah sebesar 96,15% dengan nilai k > 3 dan akurasi maksimal 96,43% dengan nilai k sebesar 1.. 5.2. Saran Disarankan menggunakan fuzzy k-nearest neighbor dengan local mean jika ingin menguji data dengan pengambilan k ketetanggaan bernilai besar (dalam penelitian ini nilai k > 6) dan bersinggungan dengan data di kelas lain. Adapun kelemahan dari penelitian ini adalah penyebaran data yang tidak merata. Salah satu hukum tajwid Mim Sukun yaitu Izhar Syafawi memiliki jumlah huruf yang lebih banyak dari hukum lainnya. Oleh karena itu, maka pada penelitian selanjutnya disarankan untuk melakukan pengujian pada data citra lainnya yang lebih kompleks maupun bentuk data lain seperti data suara dan data teks ataupun numerik guna mengetahui kekuatan dari model algoritma ini.. Universitas Sumatera Utara.
(62) 46. DAFTAR PUSTAKA. Ahsiah, I., Noor, N.M. & Idris. M.Y.I. 2013. Tajweed Checking System to Support Recitation. ICACSIS 2013, pp. 189-193. Alfaries, Auhood., Albahlal, Manal., Almazrua, Manal. & Almazrua, Amal. 2013. A Rule Based Annotation System to Extract Tajweed Rules from Quran. Taibah University International Conference on Advances in Information Technology for the Holy Quran and Its Sciences, pp. 281-286. Babu, U R., Venkateswarlu, Y. & Chintha, A. K. 2014. Handwritten Digit Recognition Using K-Nearest Neighbour Classifier. World Congress on Computing and Communication Technologies, pp. 60-65. Basuki, Ahmad, dkk. 2005. Pengolahan Citra Digital Menggunakan Visual Basic. Graha Ilmu : Yogyakarta. Baubaker, H., Chaabouni, A. Halima, M.B., Elbaati, A. & Abed, H.E. 2014. Arabic Diacritics Detection and Fuzzy Representation for Segmented Handwriting Graphemes Modeling. International Conference of Soft Computing and Pattern Recognition, pp. 71-76. Beyan, C & Ogul, H. 2014. A Fuzzy K-NN Approach for Cancer Diagnosis with Microarray Gene Expression Data. Bhatia, N. & Vandana., 2010. Survey of Nearest Neighbor Techniques. International Journal of Computer Science and Information Security (IJCSIS) : 302-305. Fadlisyah. 2007. Computer Vision dan Pengolahan Citra. Andi : Yogyakarta. Fredj, I.B. & Ouni, Kais. 2016. Fuzzy K-Nearest Neighbor Applied to Phoneme Recognition. 7𝑡ℎ International Conference of Science of Electronics, Technologies of Information and Telecommunications (SETIT), pp. 422-426. García-Pedrajas, N. & Ortiz-Boyer, D. 2009. Boosting K-Nearest Neighbor Classifier By Means Of Input Space Projection. Expert System With Application : 1057010582. Gou, J., Yi, Z., Du, L. & Xiong, T. 2012. A Local Mean-Based k-Nearest Centroid Neighbor Classifier. The Computer Journal 55 (9) : 1058-1071. Han, J., Kamber, M. & Pei, J. 2012. Data Mining : Concepts and Techniques. Third Edition. Morgan Kaufmann : USA. Hassan, H.A., Nasrudin, N.H., Khalid, M.N.M., Zabidi, A. & Yassin, A.I. 2012. Pattern Classification in Recognizing Qalqalah Kubra Pronuncation using Multilayer Perceptrons. International Symposium on Computer Applications and Industrial Electronics, pp. 209-212. Jabbar, M.A., Deekshatulu, B.L. & Chandra. P. 2013. Classification of Heart Disease Using K- Nearest Neighbor and Genetic Algorithm. International Conference on Computational Intelligence: Modeling Techniques and Applications (CIMTA) : 85-94. Kataria, A. & Singh, M.D. 2013. A Review Data Classification Using K-Nearest Neighbour Algorithm. International Journal of Emerging Technology and Advanced Engineering : 354-360. Keller, J.M., Gray, M.R. & Givens, J.A. A Fuzzy K-Nearest Neighbor Algorithm. IEEE Transactions on Systems, Man, and Cybernetics SMC-15 (4) : 580-585.. Universitas Sumatera Utara.
(63) 47. Kumar, V. & Basha, A.S.A. 2014. Facial Expression Recognition Using Wavelet and K-Nearest Neighbour. 2ⁿͩ International Conference on Current Trends in Engineering and Technology, pp. 48-52. Mahmoud, H.A., Hadad, H.M.E., Mousa, F.A. & Hassanien, A.E. 2015. Cattle Classifications System using Fuzzy K-Nearest Neighbor Classifier. Mathworks Team. 2017. Machine Learning handbook. (section 4), (internet), www.mathworks.com , diakses pada 13 April 2017 pukul 14:21 WIB. McCulloch, J., Wagner, C. & Aickelin, U. 2013. Measuring the Directional Distance Between Fuzzy Set. Ougiaroglou, S. & Evangelidis, G. 2012. Fast and Accuratek-Nearest Neighbor Classification using Prototype Selection by Clustering. Panhellenic Conference on Informatics. Pamungkas, Adi. 2017. K-Nearest Neighbor, (internet), www.pemrogramanmatlab.com , diakses pada 3 Agustus 2017 pukul 21:10 WIB. Pan, Z., Wang, Y. & Ku, W. 2016. A New K-Harmonic Nearest Neighbor Classifier based on the Multi Local Means. Pan, Z., Wang, Y. & Ku, W. 2017. A New General Nearest Neighbor Classification Based On The Mutual Neighborhood Information. Knowledge-Based Systems : 142-152. Putra, Darma. 2010. Pengolahan Citra Digital. ANDI : Yogyakarta. Raikwal, J.S. & Saxena, K. 2012. Performance Evaluation of SVM and K-Nearest Neighbor Algorithm over Medical Dataset. International Journal of Computer Applications 50 (14) : 35-39. Rosyid, H., Prasetyo, E. & Agustin, S. 2013. Perbaikan Akurasi Fuzzy K-Nearest Neighbor In Every Class menggunakan Fungsi Kernel. Seminar Nasional Teknologi Informasi dan Multimedia 2013, pp. 13-18. Sánchez, A.S., Iglesias-Rodríguez, F.J., Fernándes, P.R. & Juez, F.J.de.C. 2015. Applying The K-Nearest Neighbor Technique To The Classification Of Workers According To Their Risk Of Suffering Musculoskeletal Disorders. International Journal of Indsutrial Ergonomics : 1-8. Song, Y., Liang, J., Lu, J. & Zhao, X. 2017. An Efficient Instance Selection Algorithm For K Nearest Neighbor Regression. Neurocomputing : 26-34, Volume : 251. Tu, L., Wei, H. & Ai, L. 2015. Galaxy and Quasar Classificication Based on Local Mean –based K-Nearest Neighbor Method. IEEE, 978-1-4799-7284-5/15. Wang. J., Neskovic . P. & Cooper L.N., 2007. Improving Nearest Neighbor Rule With A Simple Adaptive Distance Measure. Pattern Recognition Letter : 207-213, vol 28. Wu, X. & Kumar, V. 2009. The Top Ten Algorithms in Data Mining. CRC Press : Boca Raton, USA. Zarlis, M., Sitompul, O.S., Sawaluddin, Efendi, S., Sihombing, P. & Nababan, E.B. 2015. Pedoman Penulisan Tesis. Fasilkom-TI USU : Medan. Zbancioc, M. & Feraru, S.M. 2012. Emotion Recognition of the SROL Romanian Database using Fuzzy KNN Algorithm. IEEE, 978-1-4673-1176-2/12.. Universitas Sumatera Utara.
(64) 48. LAMPIRAN. clc;clear;close all; image_folder = 'flatih'; filenames = dir(fullfile(image_folder, '*.gif')); total_images = numel(filenames); area = zeros(1,total_images); perimeter = zeros(1,total_images); metric = zeros(1,total_images); eccentricity = zeros(1,total_images); for n = 1:total_images full_name= fullfile(image_folder, filenames(n).name); our_images = imread(full_name); our_images = bwconvhull(our_images,'objects'); stats = regionprops (our_images,'Area','Perimeter','Eccentricity'); area(n) = stats.Area; perimeter(n) = stats.Perimeter; metric(n) = 4*pi*area(n)/(perimeter(n)^2); eccentricity(n) = stats.Eccentricity; training = [metric;eccentricity]'; end group(1:3,:) = 1; group(4:6,:) = 2; group(7:84,:) = 3; figure, gscatter(metric,eccentricity,group,'rgbk','x',10) grid on hold on image_folder_uji = 'fuji'; filenames_uji = dir(fullfile(image_folder_uji, '*.gif')); total_images_uji = numel(filenames_uji); area_uji = zeros(1,total_images_uji); perimeter_uji = zeros(1,total_images_uji); metric_uji = zeros(1,total_images_uji); eccentricity_uji = zeros(1,total_images_uji); for n = 1:total_images_uji full_name_uji = fullfile(image_folder_uji, filenames_uji(n).name); our_images_uji = imread(full_name_uji); our_images_uji = bwconvhull(our_images_uji,'objects'); stats_uji = regionprops(our_images_uji,'Area','Perimeter','Eccentricity');. Universitas Sumatera Utara.
(65) 49. area_uji(n) = stats_uji.Area; perimeter_uji(n) = stats_uji.Perimeter; metric_uji(n) = (4*pi*area_uji(n))./(perimeter_uji(n).^2); eccentricity_uji(n) = stats_uji.Eccentricity; sample = [metric_uji;eccentricity_uji]'; end group_test(1:1,:) = 1; group_test(2:2,:) = 2; group_test(3:28,:) = 3; for i=1 : size (training,1) for j=1 : size (sample,1) temp = abs(training(i,:)-sample(j,:)); temp = temp.^2; temp = (sum(temp))^(1/2); dist(i,j)=temp; end end k=1; for j=1:size(sample,1) [B,index]=sort(dist(:,j)); n1=1; n2=1; n3=1; for i=1:size(index,1) if((group(index(i))==1) & (n1<(k+1))) tmp1(n1,:)=training(index(i),:); n1=n1+1; elseif((group(index(i))==2) & (n2<(k+1))) tmp2(n2,:)=training(index(i),:); n2=n2+1; elseif((group(index(i))==3) & (n3<(k+1))) tmp3(n3,:)=training(index(i),:); n3=n3+1; end end LM1=[sum(tmp1(:,1)) sum(tmp1(:,2))]./k; LM2=[sum(tmp2(:,1)) sum(tmp2(:,2))]./k; LM3=[sum(tmp3(:,1)) sum(tmp3(:,2))]./k; LM1=abs(LM1-sample(j,:)); LM2=abs(LM2-sample(j,:)); LM3=abs(LM3-sample(j,:)); LM1=LM1.^2; LM2=LM2.^2; LM3=LM3.^2; LM1=sum(LM1); LM2=sum(LM2); LM3=sum(LM3); lmdist(1)=LM1^(1/2); lmdist(2)=LM2^(1/2); lmdist(3)=LM3^(1/2);. Universitas Sumatera Utara.
(66) 50. if(lmdist(1)<lmdist(2) & lmdist(1)<lmdist(3)) prect(j)=1; elseif(lmdist(2)<lmdist(1) & lmdist(2)<lmdist(3)) prect(j)=2; elseif(lmdist(3)<lmdist(1) & lmdist(3)<lmdist(2)) prect(j)=3; end lmdist(1)=(lmdist(1)^(1/2))^(-3/1) lmdist(2)=(lmdist(2)^(1/2))^(-3/1) lmdist(3)=(lmdist(3)^(1/2))^(-3/1) U(j,1)=lmdist(1)/sum(lmdist); U(j,2)=lmdist(2)/sum(lmdist); U(j,3)=lmdist(3)/sum(lmdist); end CF = classperf(prect, group_test); %akurasi akurasi=CF.CorrectRate; gscatter(metric_uji,eccentricity_uji,prect,'rgb','+',10); hold on; legend('Idgham training','Ikhfa training','Izhar training', ... 'Idgham testing','Ikhfa testing','Izhar training','Location','best'); hold off;. Universitas Sumatera Utara.
(67) 51. No. 1. Hukum Idgham Mimi. 2. Ikhfa Syafawi. 3. Izhar Syafawi. Huruf. Pola Fathah. Pola Kasrah. Pola Dhommah. م ب ا ت ث ج ح خ د ذ ر. Universitas Sumatera Utara.
(68) 52. ز س ش ص ض ط ظ ع غ ف ق ك. Universitas Sumatera Utara.
(69) 53. ل ن و ﮬ ي. Universitas Sumatera Utara.
(70)
Gambar
+7
Garis besar
Dokumen terkait
Penelitian ini menggunakan k-Nearest Neighbor (k-NN) untuk identifikasi Freycinetia berdasarkan citra anatomi epidermis daun, yang menjadi input pada klasifikasi ini
Maka dapat disimpulkan bahwa penelitian menggunakan metode Fuzzy K-Nearest Neighbor (FKNN) memiliki kinerja yang baik dalam klasifikasi kualitas cabai di kota Blitar.. Kata kunci
Metode penelitian untuk mengklasifikasikan citra makanan sebelumnya telah dilakukan, yaitu dengan menggunakan K-Nearest Neighbor Classifier dan ekstraksi fitur yang
Tujuan dari penelitian ini adalah untuk menganalisa mengkomparasi Algoritma Scale Invariant Feature Transform (SIFT) dengan Algoritma K-Nearest Neighbor (K-NN) untuk
Salah satu teknik pengolahan citra yang biasa dipakai adalah algoritma K- Nearest Neighbor atau sering disingkat menjadi K-NN yaitu sebuah metode yang sering digunakan
Metode yang diajukan pada penelitian ini adalah Modified k-Nearest Neighbor untuk identifikasi diabetic retinopathy. Sebelum tahap identifikasi dilakukan, citra retina
Pada penelitian sebelumnya pengenalan tulisan tangan huruf Jawa dengan menggunakan Metode K-Nearest Neighbor dan deteksi tepi sobel, dari hasil pengujian pada
ii Skripsi Oleh : ALIF NUZULUR ROHMAN NPM : 18.1.03.02.0179 Judul : PENGENALAN POLA UNTUK IDENTIFIKASI PENYAKIT DAUN PADI MENGGUNAKAN METODE K-NEAREST NEIGHBOR Telah di Setujui
