STATISTIKA DASAR
1. Distribusi Frekuensi
Hasil pengukuran yang kita peroleh disebut dengan data mentah. Besarnya hasil pengukuran yang kita peroleh biasanya bervariasi. Apabila kita perhatikan data mentah tersebut, sangatlah sulit bagi kita untuk menarik kesimpulan yang berarti. Untuk memperoleh gambaran yang baik mengenai data tersebut, data mentah tersebut perlu di olah terlebih dahulu.
Pada saat kita dihadapkan pada sekumpulan data yang banyak, seringkali membantu untuk mengatur dan merangkum data tersebut dengan membuat tabel yang berisi daftar nilai data yang mungkin berbeda (baik secara individu atau berdasarkan pengelompokkan) bersama dengan frekuensi yang sesuai, yang mewakili berapa kali nilai-nilai tersebut terjadi. Daftar sebaran nilai data tersebut dinamakan dengan Daftar Frekuensi atau Sebaran Frekuensi (Distribusi Frekuensi).
Dengan demikian, distribusi frekuensi adalah daftar nilai data (bisa nilai individual atau nilai data yang sudah dikelompokkan ke dalam selang interval tertentu) yang disertai dengan nilai frekuensi yang sesuai.
Pengelompokkan data ke dalam beberapa kelas dimaksudkan agar ciri-ciri penting data tersebut dapat segera terlihat. Daftar frekuensi ini akan memberikan gambaran yang khas tentang bagaimana keragaman data. Sifat keragaman data sangat penting untuk diketahui, karena dalam pengujian-pengujian statistik selanjutnya kita harus selalu memperhatikan sifat dari keragaman data. Tanpa memperhatikan sifat keragaman data, penarikan suatu kesimpulan pada umumnya tidaklah sah.
Sebagai contoh, perhatikan contoh data pada Tabel 1. Tabel tersebut adalah daftar nilai ujian Matakuliah Statistik dari 80 Mahasiswa (Sudjana, 19xx).
Tabel 1. Daftar Nilai Ujian Matakuliah Statistik
63 60 83 82 60 67 89 63
76 63 88 70 66 88 79 75
Sangatlah sulit untuk menarik suatu kesimpulan dari daftar data tersebut. Secara sepintas, kita belum bisa menentukan berapa nilai ujian terkecil atau terbesar. Demikian pula, kita belum bisa mengetahui dengan tepat, berapa nilai ujian yang paling banyak atau berapa banyak mahasiswa yang mendapatkan nilai tertentu. Dengan demikian, kita harus mengolah data tersebut terlebih dulu agar dapat memberikan gambaran atau keterangan yang lebih baik.
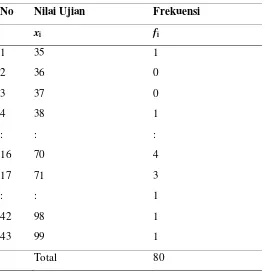
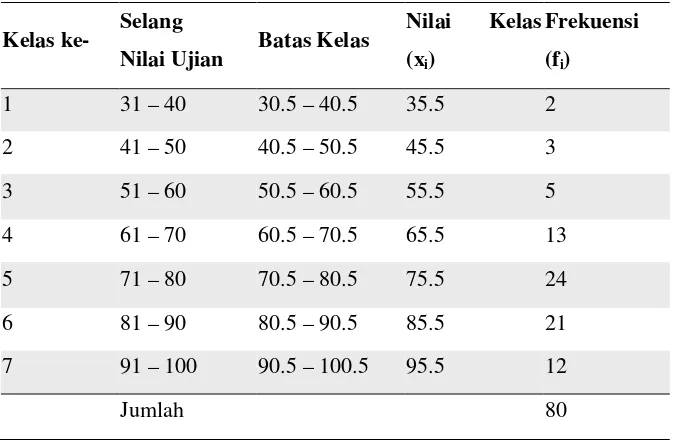
Bandingkan dengan tabel yang sudah disusun dalam bentuk daftar frekuensi (Tabel 2a dan Tabel 2b). Tabel 2a merupakan daftar frekuensi dari data tunggal dan Tabel 2b merupakan daftar frekuensi yang disusun dari data yang sudah di kelompokkan pada kelas yang sesuai dengan selangnya. Kita bisa memperoleh beberapa informasi atau karakteristik dari data nilai ujian mahasiswa.
Tabel 2a.
No Nilai Ujian Frekuensi
Tabel 2b.
Kelas ke- Nilai Ujian Frekuensi fi
1 31 – 40 2 merupakan daftar frekuensi yang sering digunakan. Kita sering kali mengelompokkan data contoh ke dalam selang-selang tertentu agar memperoleh gambaran yang lebih baik mengenai karakteristik dari data. Dari daftar tersebut, kita bisa mengetahui bahwa mahasiswa yang mengikuti ujian ada 80, selang kelas nilai yang paling banyak diperoleh oleh mahasiswa adalah sekitar 71 sampai 80, yaitu ada 24 orang, dan seterusnya. Hanya saja perlu diingat bahwa dengan cara ini kita bisa kehilangan identitas dari data aslinya. Sebagai contoh, kita bisa mengetahui bahwa ada 2 orang yang mendapatkan nilai antara 31 sampai 40. Meskipun demikian, kita tidak akan tahu dengan persis, berapa nilai sebenarnya dari 2 orang mahasiswa tersebut, apakah 31 apakah 32 atau 36 dst. Ada beberapa istilah yang harus dipahami terlebih dahulu dalam menyusun daftar frekuensi. Tabel 3.
Kelas ke- Selang
Nilai Ujian Batas Kelas
Range :
Selisih antara nilai tertinggi dan terendah. Pada contoh ujian di atas, Range = 99 – 35 = 64
Batas bawah kelas:
Nilai terkecil yang berada pada setiap kelas. (Contoh: Pada Tabel 3 di atas, batas bawah kelasnya adalah 31, 41, 51, 61, …, 91)
Batas atas kelas:
Nilai terbesar yang berada pada setiap kelas. (Contoh: Pada Tabel 3 di atas, batas bawah kelasnya adalah 40, 50, 60, …, 100)
Batas kelas (Class boundary):
Nilai yang digunakan untuk memisahkan antar kelas, tapi tanpa adanya jarak antara batas atas kelas dengan batas bawah kelas berikutnya. Contoh: Pada kelas ke-1, batas kelas terkecilnya yaitu 30.5 dan terbesar 40.5. Pada kelas ke-2, batas kelasnya yaitu 40.5 dan 50.5. Nilai pada batas atas kelas ke-1 (40.5) sama dengan dan merupakan nilai batas bawah bagi kelas ke-2 (40.5). Batas kelas selalu dinyatakan dengan jumlah digit satu desimal lebih banyak daripada data pengamatan asalnya. Hal ini dilakukan untuk menjamin tidak ada nilai pengamatan yang jatuh tepat pada batas kelasnya, sehingga menghindarkan keraguan pada kelas mana data tersebut harus ditempatkan. Contoh: bila batas kelas di buat seperti ini:
Kelas ke-1 : 30 – 40
Kelas ke-2 : 40 – 50
dst.
Apabila ada nilai ujian dengan angka 40, apakah harus ditempatkan pada kelas-1 ataukah kelas ke-2?
Panjang/lebar kelas (selang kelas):
lebar kelas = 41 – 31 = 10 (selisih antara 2 batas bawah kelas yang berurutan) atau
lebar kelas = 50 – 40 = 10 (selisih antara 2 batas atas kelas yang berurutan) atau
lebar kelas = 40.5 – 30.5 = 10. (selisih antara nilai terbesar dan terkecil batas kelas pada kelas ke-1)
Nilai tengah kelas:
Nilai kelas merupakan nilai tengah dari kelas yang bersangkutan yang diperoleh dengan formula berikut: ½ (batas atas kelas+batas bawah kelas). Nilai ini yang dijadikan pewakil dari selang kelas tertentu untuk perhitungan analisis statistik selanjutnya. Contoh: Nilai kelas ke-1 adalah ½(31+40) = 35.5
Banyak kelas:
Sudah jelas! Pada tabel ada 7 kelas.
Frekuensi kelas: Banyaknya kejadian (nilai) yang muncul pada selang kelas tertentu. Contoh, pada kelas ke-1, frekuensinya = 2. Nilai frekuensi = 2 karena pada selang antara 30.5 – 40.5, hanya ada 2 angka yang muncul, yaitu nilai ujian 31 dan 38.
2. Teknik pembuatan Tabel Distribusi Frekuensi (TDF)
Distribusi frekuensi dibuat dengan alasan berikut:
• kumpulan data yang besar dapat diringkas
• kita dapat memperoleh beberapa gambaran mengenai karakteristik data, dan • merupakan dasar dalam pembuatan grafik penting (seperti histogram).
Banyak software (teknologi komputasi ) yang bisa digunakan untuk membuat tabel distribusi frekuensi secara otomatis. Meskipun demikian, di sini tetap akan diuraikan mengenai prosedur dasar dalam membuat tabel distribusi frekuensi.
Langkah-langkah dalam menyusun tabel distribusi frekuensi:
• Urutkan data, biasanya diurutkan dari nilai yang paling kecil
• Tentukan range (rentang atau jangkauan)
o Range = nilai maksimum – nilai minimum
• Tentukan banyak kelas yang diinginkan. Jangan terlalu banyak/sedikit, berkisar antara 5 dan 20, tergantung dari banyak dan sebaran datanya.
o Aturan Sturges:
o Banyak kelas = 1 + 3.3 log n, dimana n = banyaknya data • Tentukan panjang/lebar kelas interval (p)
o Panjang kelas (p) = [rentang]/[banyak kelas] • Tentukan nilai ujung bawah kelas interval pertama
Pada saat menyusun TDF, pastikan bahwa kelas tidak tumpang tindih sehingga setiap nilai-nilai pengamatan harus masuk tepat ke dalam satu kelas. Pastikan juga bahwa tidak akan ada data pengamatan yang tertinggal (tidak dapat dimasukkan ke dalam kelas tertentu). Cobalah untuk menggunakan lebar yang sama untuk semua kelas, meskipun kadang-kadang tidak mungkin untuk menghindari interval terbuka, seperti ” 91 ” (91 atau lebih). Mungkin juga ada kelas tertentu dengan frekuensi nol.
Contoh:
Kita gunakan prosedur di atas untuk menyusun tabel distribusi frekuensi nilai ujian mahasiswa (Tabel 1).
Berikut adalah nilai ujian yang sudah diurutkan:
35 38 43 48 49 51 56 59 60 60
Tentukan banyak kelas yang diinginkan.
sekitar 6 atau 7.
Sebagai latihan, kita gunakan aturan Sturges. banyak kelas = 1 + 3.3 x log(n)
5. Tentukan nilai batas bawah kelas pada kelas pertama. Nilai ujian terkecil = 35
Penentuan nilai batas bawah kelas bebas saja,
asalkan nilai terkecil masih masuk ke dalam kelas tersebut. Misalkan: apabila nilai batas bawah yang kita pilih adalah 26, maka interval kelas pertama: 26 – 35, nilai 35 tepat jatuh di batas atas kelas ke-1. Namun apabila kita pilih
nilai batas bawah kelas 20 atau 25, jelas nilai terkecil, 35, tidak akan masuk ke dalam kelas tersebut.
Namun untuk kemudahan dalam penyusunan dan pembacaan TDF, tentunya juga untuk keindahan, he2.. lebih baik kita memilih batas bawah 30 atau 31. Ok, saya tertarik dengan angka 31, sehingga batas bawahnya adalah 31.
Dari prosedur di atas, kita dapat info sebagai berikut: Banyak kelas : 7
Panjang kelas : 10 Batas bawah kelas : 31 Selanjutnya kita susun TDF:
Kelas ke- Nilai Ujian Batas Kelas Frekuensi
atau dalam bentuk yang lebih ringkas:
Kelas ke- Nilai Ujian Frekuensi (fi)
3. Distribusi Frekuensi Relatif dan Kumulatif
Variasi penting dari distribusi frekuensi dasar adalah dengan menggunakan nilai frekuensi relatifnya, yang disusun dengan membagi frekuensi setiap kelas dengan total dari semua frekuensi (banyaknya data). Sebuah distribusi frekuensi relatif mencakup batas-batas kelas yang sama seperti TDF, tetapi frekuensi yang digunakan bukan frekuensi aktual melainkan frekuensi relatif. Frekuensi relatif kadang-kadang dinyatakan sebagai persen.
Contoh: frekuensi relatif kelas ke-1:
fi = 2; n = 80
Frekuensi relatif = 2/80 x 100% = 2.5%
Kelas ke- Nilai Ujian Frekuensi relatif (%) 1 31 – 40 2.50
2 41 – 50 3.75
3 51 – 60 6.25
4 61 – 70 16.25
5 71 – 80 30.00
6 81 – 90 26.25
7 91 – 100 15.00
Jumlah 100.00
4. Distribusi Frekuensi kumulatif
Variasi lain dari distribusi frekuensi standar adalah frekuensi kumulatif. Frekuensi kumulatif untuk suatu kelas adalah nilai frekuensi untuk kelas tersebut ditambah dengan jumlah frekuensi semua kelas sebelumnya.
Nilai Ujian Frekuensi kumulatif kurang dari
kurang dari 100.5 80
atau kadang disusun dalam bentuk seperti ini:
Nilai Ujian Frekuensi kumulatif kurang dari kurang dari 41 2
kurang dari 101 80
Variasi lain adalah Frekuensi kumulatif lebih dari. Prinsipnya hampir sama dengan prosedur di atas.
5. Histogram
6. Poligon Frekuensi
Poligon Frekuensi menggunakan segmen garis yang terhubung ke titik yang terletak tepat di atas nilai-nilai titik tengah kelas. Ketinggian dari titik-titik sesuai dengan frekuensi kelas, dan segmen garis diperluas ke kanan dan kiri sehingga grafik dimulai dan berakhir pada sumbu horisontal.
7. Ogive
menentukan jumlah nilai di bawah nilai tertentu. Sebagai contoh, pada gambar berikut menunjukkan bahwa 68 mahasiswa mendapatkan nilai kurang dari 90.5.
MEDIAN
Median adalah nilai data dari data yang telah diurutkan.
1. Median untuk data ganjil
Keterangan:
Contoh:
Berikut nilai matematika kelas 2 SD: 5,7,6,9,8,8,5,4,10,10,6,6,9. Tentukanlah nilai median dari data ini!
Jawab:
Jadi median data tersebut ada di data ke tujuh setelah data itu di urutkan yaitu 7
2. Median untuk data genap
Keterangan:
Contoh:
Tentukan median dari data berikut: 9,3,5,8,7,4! Jawab:
3,4,5,7,8,9
Jadi median dari data tersebut yaitu 6
3. Median untuk data berkelompok
Keterangan:
Contoh:
Tentukan median dari:
Jawab
Kuartil adalah niali-nilai yang membagi data yang sudah terurut menjadi empat bagian yang sama.
= kuartil tengah = median
= kuartil ketiga = kuartil atas
1. Kuartil data tunggal
Keterangan:
Contoh:
Tentukan kuartil dari data: 11,4,3,8,7,6,2,10,12,14,17! Jawab:
2,3,4,6,7,8,10,11,12,14,17
, yaitu 4
, yaitu 8
, yaitu 12
2. Kuartil data berkelompok
Keterangan:
Contoh:
Tentukan kuartil dari data berikut!
18
Desil
Desil adalah nilai-nilai yang membagi sekumpulan data terurut menjadi sepuluh bagian
yang sama. Terdapat sembilan jenis desil yaitu desil pertama , desil kedua
desil kesembilan . Cara menentukan desil:
a. Susun data menurut urutan b. Tentukan letak desil c. Tentukan nilaki desil
1. Desil Data Tunggal Rumus:
, i=1,2,3…9
Contoh:
Tentukan desil ke-4 dan desil ke-9 dari data berikut:
34, 36, 39, 40, 42, 44, 47, 51, 54, 60, 61, 65, 67 Jawab:
data ke 5,6 yaitu antara data ke-5 dan data ke-6 sebesar 0,6 jauh dari data ke-5
data ke 12,6 yaitu antara data ke-12 dan data ke-13 sebesar 0,6 jauh dari data
19
2. Desil Untuk Data Kelompok Rumus:
Keterangan:
= desil ke-i
=tepi bawah kelas desil ke-i
= jumlah semua frekuensi
= 1,2,3,…,9
= panjang interval kelas desil ke-i
=frekuensi kelas desil ke-i
= jumlah frekuensi sebelum kelas desil ke-i
Contoh:
Tentukan desil ke-3 dan desil ke-7 dari distribusi frekuensi
Panjang (mm) Frekuensi
118-126 3
127-135 5
136-144 9
145-153 12
154-162 5
163-171 4
172-140 2
20
Jawab:
Kelas desil ke-3, jika
Kelas desil ke-7, jika
Diketahui n=40, maka dan
Kelas adalah kelas ke-3 (tepi bawah kelas ke-3)
Kelas adalah kelas ke-4 (tepi bawah kelas ke-4)
=8 =17
C=9
Persentil
Persentil adalah nilai-nilai yang membagi sekumpulan data yang telah berurutan menjadi seratus bagian yang sama. Terdapat smbilan puluh sembilan persentil, yaitu
21
1. Persentil data Tunggal Rumus:
, i=1,2,3…99
Contoh:
Tentukan persentil ke-8 dan persentil ke-54 dari data berikut
11, 13, 14, 16, 17, 19, 21, 22, 23, 25 27, 28, 30, 31, 33, 35, 36, 36, 36 ,36 38, 39, 41, 42, 42, 43, 46, 47, 47, 48 Jawab:
n=30
nilai ke 2,48, yaitu:
nilai ke 16,74, yaitu:
22
Keterangan:
= persentil ke-i
=tepi bawah kelas persentil ke-i
= jumlah semua frekuensi
= 1,2,3,…,99
= panjang interval kelas
=frekuensi kelas persentil ke-i
= jumlah frekuensi sebelum kelas persentil ke-i
Contoh:
Dari daftar distribusi tabel berikut, tentukan dan
BERAT BADAN 100 MAHASISWA UNIV. PGRI PALEMBANG
Berat (kg) F
Kelas persentil ke-37, jika
Kelas persentil ke-87, jika
23
n=100, maka , dan
Kelas adalah kelas ke-3 (tepi bawah kelas ke-3)
Kelas adalah kelas ke-5 (tepi bawah kelas ke-5)
=23 =85
C=5
Modus
Modus adalah nilai data yang paling sering muncul. Dengan kata lain,
modus adalah nilai data yang frekuensinya paling besar.
Berdasrkan banyaknya modus, data dapat dikelompokkan sebagai berikut.
1. Unimodus adalh data yang hanya mempunyai satu modus. 2. Bimodus adalah data yang mempunyai dua modus.
3. Multimodus adalah data yang mempunyai lebih dari dua modus. 4. Data yang tidak mempunyai modus.
Sifat-sifat modus, antara lain sebagai berikut:
24
3. Modus tidak dipengaruhi oleh bilangan-bilangan yang ekstrem, dari suatu distribusi.
4. Letak modus atau nilai modus yang sebenarnya sukar ditentukan, karena itu kebanyakan hanya berdasar taksiran dalam suatu distribusi.
5. Perhitungan modus tidak didasarkan pada seluruh nilai pengamatan, tetapi berdasarkan pada individu yang berada pada titik tempat terjadinya pemusatan yang terjadi.
6. Untuk perhitungan-perhitungan secara aljabar lebih lanjut, modus tidak dapat digunakan.
7. Modus tidak sepopuler ukuran rata-rata hitung atau median.
Hubungan Rata-Rata Hitung, Median, dan Modus
Hubungan rata-rata hitung, median, dan modus akan memberikan gambaran pada kurva data yang bersangkutan. Hubungan antara ketiga ukuran nilai pusat ialah sebagai berikut:
1. Jika rata-rata hitung, median, dan modus memiliki nilai yang sama maka kurvanya berbentuk simetris. Pada kurva simetris sempurna, nilai rata-rata hitung, median, dan modus terletak pada suatu titik ditenah-tengah absis dan ketiga-tiganya berimpitan.
2. Jika nilai rata-rata hitung lebih besar dari pada nilai median dan lebih besar daripada nilai modus maka kurvanya mencing kekanan, karena ujungnya memanjang kearah nilai positif. Jadi distribusi meruncing kearah nilai tinggi. 3. Jika nilai rata-rata hitung lebih kecil dari nilai median dan lebih kecil dari nilai
modus mak kurvanya mencong kekiri. Karena ujungnya memanjang kearah negatif. Jadi distribusi meruncing kearah nilai yang rendah.
25
Jika distribusinya tidak terlalu mencong, hubungan rata-rata hitumg, median, dan modus secara matematis sebagai berikut:
Rata-rata hitung – modus = 3 (rata-rata hitung – median)
Modus = rata-rata hitung – 3(rata-rata hitung – median)
Contoh soal:
26
Penyelesaian:
;