Shortest-Path Problem Solving in the Installation of
Data/Internet Network Using Apriori Algorithm
Ali Akbar
1Faculty of Industrial Technology Gunadarma University
Indonesia [email protected]
Nurul Adhayanti
2Faculty of Computer Science Gunadarma University
Indonesia
Ike Putri Kusumawijaya
3Faculty of Industrial Technology Gunadarma University
Indonesia
Hendri Dwi Putra
4Faculty of Computer Science Gunadarma University
Indonesia [email protected] [email protected]
Abstract—Data network is something highly important in
information development. The commonly occuring problem is how to connect every node or town to make it connected to the network. We develop a softaware tool for solving shortest-path problem with Apriori algorithm to solve problem in the shortest-path in the implementation of internet network. Based on the research results by comparing Apriori Algorithm to genetics, it is found that Apriori Algorithm has advantages from the distance side used. In this case, for an experiment of 10 urban points, a distance of 38 for genetic algorithm is found as compared to 29 using the apriori algorithm and the value increases when 200 points are experimented, resulting in a value of 5931 for genetic and 242.5 (for apriori). From this result, it can then be concluded that apriori algorithm has the advantage in the form of lesser distance than the genetic algorithm hence it can be expected to reduce the costs.
Keywords—Apriori algorithm; Data network ; routing
I. INTRODUCTION
This routing problem can be presented as how to determine the shortest track to find a path between two nodes in such a way that the total weight of its constituent arcs can be as minimum as possible [1]. The shortest-path problems include djikstra algorithm, Floyd-Warshall algorithm and Bellman-Ford algorithm. Meanwhile, according to Rama M Sukaton in his research entitled “Penggunaan Algoritma Genetika Dalam Jalur Terpendek Pada Jaringan Data”, the most appropriate method for shortest-path problem with increasingly greater and more complex number of nodes and tracks is genetic algorithm, since despite the great number of tracks it can still be solved and it moves towards an optimal point when it is followed by increased size of other populations/paths [2]. In this writing, we try to use apriori algorithm to solve shortest-path problem and try to compare it to genetic algorithm.
II. EASE OF USE (LANDASAN TEORI ) A. Routing
A process of finding a path when there is a node in a communication path in computer network is an important task of a router device in a routing operation which is governed in a protocol. There are two types of routing, i.e. static and dynamic. In case of static routing, the path between nodes is determined manually based on certain factors and saved in a routing table [1]. For example, in Rama M Sukaton’s research [2] it is shown router A which has two Ethernet interfaces and one ISDN (Integrated Services Digital Network) interface, where the Ethernet0 (e0) interface is assigned an IP address 10.1.1/24 and the Ethernet1 (e1) interface is assigned an IP address 10.1.2.1/24.
B. Apriori algorithm
Hadoop-Mapreduce which uses apriori algorithm is more efficient than the data search on Hadoop-MapReduce platform with no apriori algorithm.[6] From this, we can conclude that apriori algorithm can increase the efficiency of data calculation analysis. Additionally, another study mentions that apriori-based algorithm has better speed in managing greater data [7].
• Apriori Algorithm Analysis with Router Shortest-Path
Problem
Apriori algorithm belongs to association rule mining, i.e. a data mining technique to find the associative rule between item combinations. An example of associative rule of routing path analysis is to find out the shortest path in a large data network. Using this knowledge, the router can regulate the placement of paths with combination of several existing paths.
In determining an association rule, there is an interestingness measure which is obtained from processing the data using certain calculation. There are generally two measures, namely [4]
• Support (supporting value): a measure which shows
how large an item/itemset’s domination level is over the entire data path. This measure decides whether an item/itemset’s (data path) confidence is worth-finding (for example, out of the entire existing networks, how large is the domination level which shows that the network is used.
• Confidence (certainty/confidence value): a measure
which shows the relationship between 2 paths conditionally (for example, how frequent is path B used if the network is in use).
These two measures would eventually be useful in determining the interesting association rules, i.e. to be compared to a threshold determined by users. This threshold generally consists of min_support and min_confidence, where it is taken using the following ways [4]:
• Finding all frequent itemsets, i.e. the itemsets with
support ≥ minimum support values which is the threshold given by users. Where these itemset are a set of items that is the combined purchased products.
• Finding the association rule which is the confidence of
the obtained frequent itemset.
• Finally, finding the rules which match the obtained
target users of the previous association rule mining process. The obtained rules decribe the itemset combination based on which the conclusion is drawn.
C. Genetic Algorithm
Genetic algorithm is an algorithm of search which depicts biological evolution as a problem solving technique. Genetic algorithm uses heuristic adaptive search technique which finds a set of best solutions of the newly-produced/developing population from the chromosome using an operator such as selection, crossover and mutation. The most suitable is to move the chromosome to the next generation. Weaker candidate have less chance to move to the next generation. This process is repeated until the chromosome has the best
solution which match the given problem. In summary, the average population fitness increases in each iteration, hence by repeating the process for more iterations, a better result is found. Genetic algorithm has been widely studied and experimented in various engineering fields. Genetic algorithm provides an alternative method to solve existing problems which are hard to solve using traditional methods. Genetic algorithm can be applied to non-linear programming such as problem of a moving salesman, minimum spanning tree, scheduling issues and many more.[1]
For genetic algorithm, the basis is as follows:
• generation = 0;
• population [generation] = initializing population
(population);
• evaluating Population (population [generation]); • While isTermination Condition Met () == false do • Parents= choose Parents (population [generation]); • population [generation + 1] = crossover (parents);
• population [generation + 1] = mutating (population
[generation + 1]);
• evaluating Population (population [generation]); • generation ++;
• End of circle;
The pseudo code begins with creating an initial population of genetic algorithm. This population is then evaluated to find the fitness value of individuals. Furthermore, a check is run to decide whether the condition for genetic algorithm termination has been met. If it has not, the genetic algorithm begins the iteration and the population runs through the first cycle of crossover and mutation before it is finally be re-evaluated. From here, the crossover and mutation continue to be applied until the termination condition is met, and the genetic algorithm ends. This pseudo code shows the basic process [8]. In another study it is stated that the Genetic algorithm will be used to optimize the set of items and find the optimal and appropriate association rule.[9] And this algorithm is also used to determine the shortest path in previous studies [2]. Studies using genetic algorithm to solve the shortest-path problems have been conducted by Gihan Nagib and Wahied G. Ali. The research finds that genetic algorithm has similar result as Dijkstra algorithm [10]
Based on the several studies which indicate that apriori algorithm can improve the performance of huge data management, we try to use apriori algorithm to solve the problem of determining the shortest path. It is expected that using apriori algorithm, significant influence in the selection of shortest path can be obtained. As a comparison, we use Genetic algorithm which has been previously used to solve the shortest-path problem in data network.
III. RESEARCH METHOD 3.1. Research Method
In the apriori algorithm explained in this research, the type of representation used is to use support and confidence, using network nodes with positive numbers 1,2,3..,n where is the amount of nodes in network, every amount of nodes serves as input of support and confidence minimum values, thus it can be depicted as a string of codes of nodes in network which does not repeat and represents a sequence or path.
The research design flow method performed in apriori algorithm to determine the shortest path in data communication has the following flow:
• Network traffic data, is a simulation of network points
which are likened to be in an area and town, which will be used as an input of apriori algorithm
• Apriori algorithm is done by turning the traffic data lalu
into input/network. In the initial process, the data will be collected to be a database, then it will be processed to generate a network with apriori iteration to obtain an optimized shortest route of a network traffic data
• Computation is the combination of results from the
traffic data with the design resulting from literature study
• The resulting shortest path is the generated from the
computation containing description of the resulting shortest path with optimized iteration from the achieved shortest path
Figure 3.1 Research Design
The apriori algorithm for this case is as follows:
• Determine the number of network nodes
• Generate connection of each node/network using support
variable
• Determine the value of each connection at each node,
with confidence variable
• find the shortest node by generating the distance,
iteration, cost outputs
• repeat step 2 if you want to use different number of nodes
3.2. Implementation
The implementation of apriori algorithm uses software MATLAB R2013b.
The inputs from the program are:
• File input, containing network data such as number of towns with random values,
• Apriori algorithm parameters, i.e. minimum support (MinSup), minimum confidence (MinConf), number of matching process or nRules, and number of iterations.
Below are the functions used in the program along with their explanations.
• Aporiori_jalurter pendek
An apriori algorithm for shortest path problem in general will be run by the aporiori_jalurterpendek function. This function will summon other functions such as the parameters used in the apriori namely, minimum support, minimum confidence, n rules and iteration
The program summons is done by typing “apriori_jalurterpendek” on the MATLAB Command Window. The program will stop when the predetermined generation limit has been met by users. An example of program summons when entering data and outputs is: Type “aporiori_jalurterpendenk” on the MATLAB command window and press enter. The program will then go through a running process as in figure 3.2
Figure 3.2 Apriori Running Process
The apriori_jalurterpendek process, during the running process will generate output, as in figures 3.3 and 3.4
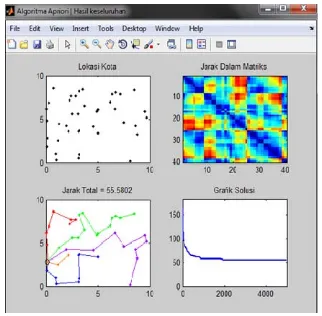
Figure 3.4 Overall Result of Apriori Algorithm
Figures 3.3 and 3.4 are the overall results of apriori algorithm. Figure 3.3 shows the best solution results of apriori algorithm. There are some colored lines indicating paths from data of closest location, and there is a central point which can connect to all location paths, at a total distance of 55.5802 and the number of iterations is 2086 to reach an optimum level.
3.3 Results of Comparison Experiment
The experiments are done by changing the parameter value of minimum confidence and support as well as the iteration for all experiments. The experiment problem using the problem of determining the solution optimality of apriori algorithm will refert to the solution of genetic algorithm, since genetic algorithm is widely used by other researchers in determining the optimal solution to shortest path problem. Below is the table of comparison between apriori algorithm and genetic algorithm [2].
Table 3.1 Comparison Experiment of Genetic and Apriori Algorithms
Algorithm
Numbe r of town points
Source node
Target node
Optimal measure Total
time (second)
iterati on
Dista nce/c ost
Genetic 10 1 10 0.2 10 39
Apriori 10 1 10 2 50 28
In table 3.1, two algorithms related to the material of finding the shortest path with similar test parameters are tested. Using the first test, the number of town points is 10, with source node at 1 point, and target node in all points, i.e. 10 points. The optimum measure is counted from the total time (second), iteration, and distance/cost. In the first table, the genetic algorithm is taken from Rama Sukaton’s, 2011, research which has total time to obtain the shortest path with number of iteration of 10 and distance or cost has a value of 39. Meanwhile, the apriori algorithm delivers total time to obtain the shortest path at 2 seconds, with number of iterations of 36 and distance/cost 26.
Figure 3.5 Best solutin results of apriori algorithm
Figure 3.6 Results of total apriori time
The next experiment result with large data is illustrated in the following data:
Table 3 Comparsion Experiment of Genetic and Apriori Algorithms (continued)
Algorithm
Numbe r of town points
Source node
Target node
Optimal measure Total
time (second)
iterati on
Dista nce/c ost
Genetika 200 1 200 0.259 500 5931
Apriori 200 1 200 58 4978 242.5
Figure 3.6 Result of iteration and distance/cost of apriori algorithm
IV. CONCLUSION AND SUGGESTION
This research proves that from execution time and iteration perspective, genetic algorithm is far more superior, while apriori algorithm is superior in its ability to determine distance/cost. This algorithm can be used particularly to reduce the costs spent to install new data network.
1. Another algorithm can be used to improve the optimum to be a comparison of the more superior algorithm in finding the solutions and shortest path
2. There is a need to add additional algorithms to awaken the provision of support and confidence values to guarantee that the apriori algorithm will not take to much time and computation.
ACKNOWLEDGEMENT
This research was fully supported by Universitas Gunadarma, Jakarta, Indonesia. The authors gratefully acknowledge Universitas Gunadarma for providing research funding and for permission in using the research facilities
REFERENCES
[1] (R.Kumar dan M.Kumar, 2010). “Exploring Genetic Algorithm for Shortest Path Optimization in Data Networks”, Global Journal of Computer Science and Technology. Vol. 10 Issue 11 page 8-12 2010 [2] Rama M Sukaton (2010), “Pengunaan Genetic algorithm Dalam
Masalah Jalur Terpedek Pada Data network”, Universitas Indonesia 2011
[3] R. Agrawal and R. Srikant. “Fast, algorithms for mining association rules in large databases”. Research Report RJ 9839, IBM Almaden Research Center, San Jose, California, June 1994.
[4] Han, Jiawei; Kamber, Micheline; Data Mining: Concepts and Techniques. Morgan Kaufmann, 2001
[5] Sanjay Rathee, et all; R-Apriori : An Efficient Apriori Based Algorithm on Spark. Melbourne, VIC, Australia, October 2015
[6] A.L.Sayeth Saabith, Elankovan Sundararajan, And Azuraliza Abu Bakar. “Parallel Implementation Of Apriori Algorithms On The Hadoop-Mapreduce Platform An Evaluation Of Literature”. In Journal of Theoretical and Applied Information Technology, Vol 85 No.3, 2016. [7] Swami Konakanchi1, V P S Vinay Kumar, Chanda Srinivasarao.
Parallel Mining of Frequent Itemsets Based on MapReduce Approach. In International Journal of Mechanical Engineering and Computer, 372-378, 2015.
[8] J Lee, K Burak, Genetic Algorithms in Java Basics. An Apress Advanced Book, Springer Science & Business Media New York NY: 2015.
[9] Shruti S. Gadgil, L.M.R.J. Lobo. MapReduce to Find Association Rules Representing Social Network Data. In International Journal of Computer Applications. Hal 15-18 . 2016