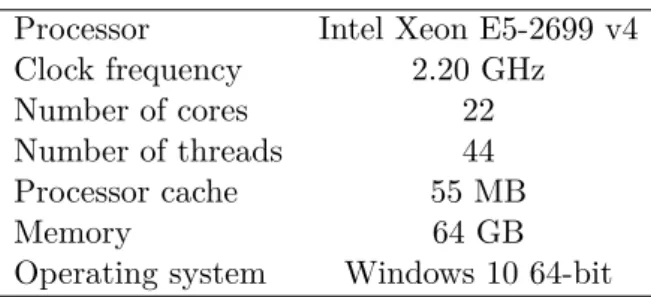
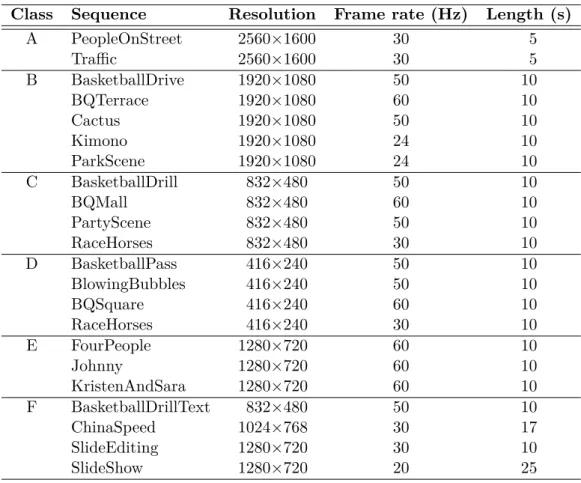
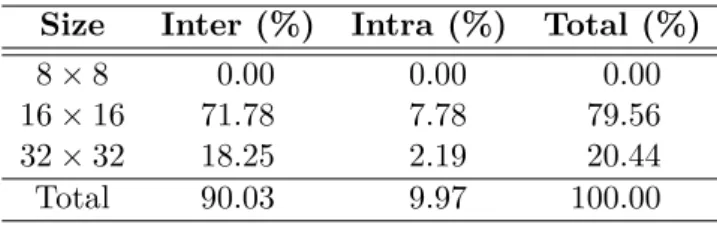
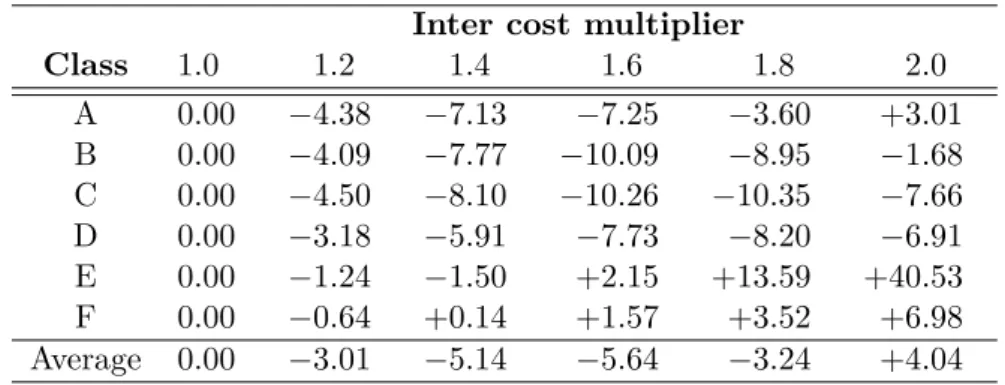
Kvazaar HEVC videokooderin pakkaustehokkuuden ja suorituskyvyn optimointi
Teks penuh
Gambar
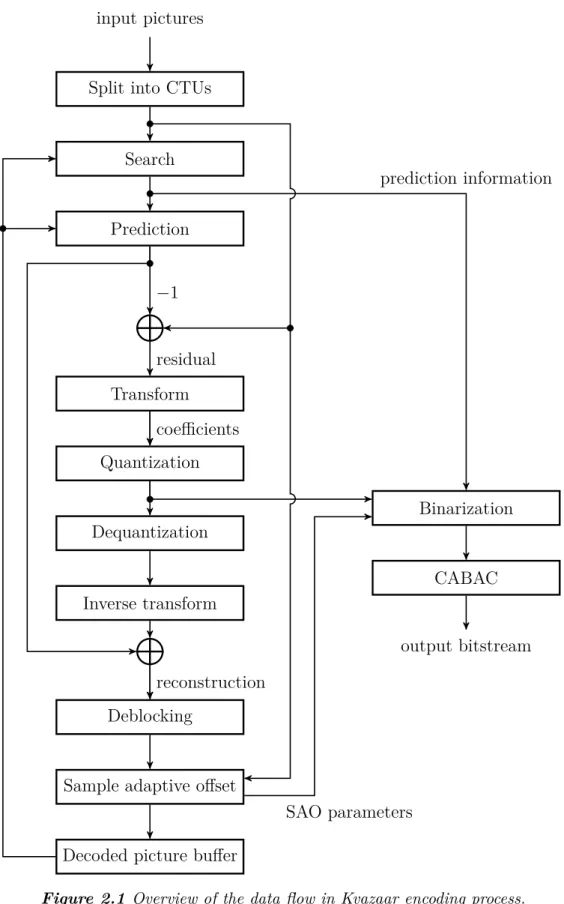
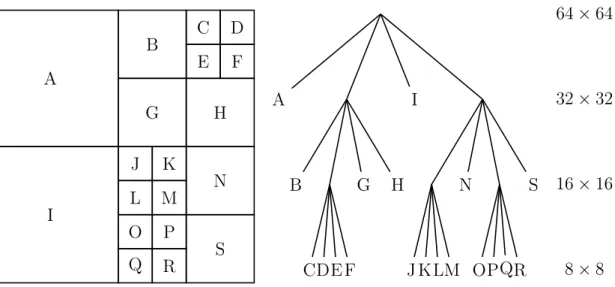
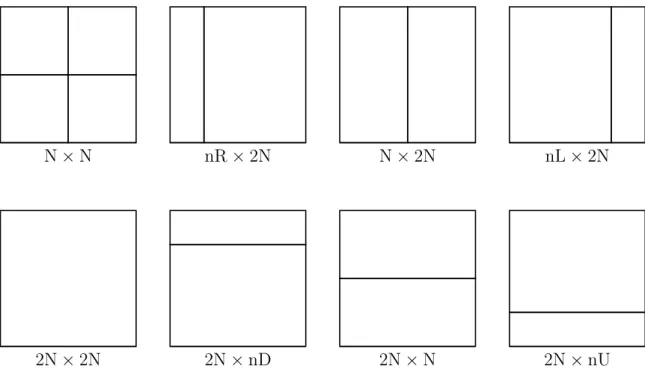
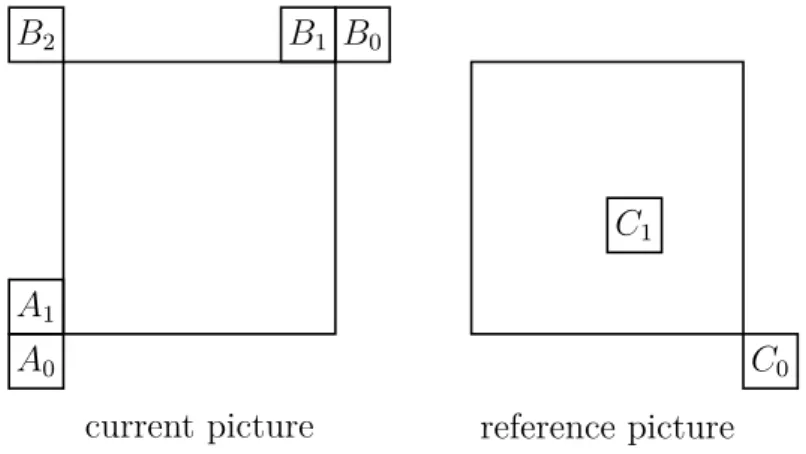

Dokumen terkait
Alex counts the number of students in her class with each hair colour, and summarizes the results in the following table:?. Hair Colour Number of Students
Similar arguments prove that the values of N given in the table in Section 1 are indeed the smallest beginning sequences of 8, 9, 10, 11, 12, and 13 consecutive happy numbers.. Also,
As shown in Table 6, the composition schedule of an increasing production speed on both machines results in a lower weight of the inner layer in the smaller thicknesses on the KM-6
NaCl solution concentration M Property 0.3 0.6 ed, max 0.62 0.56 kd, max m/s 5.710-9 2.210-8 Table 4 Results of k with NaCl solutions under maximum dry density
Table 9 Different test results T-test pretest-posttest control class Data n Average Pretest 31 18.23 Posttest 32 41.84 Confidence level 99.5% 𝒕𝒄𝒐𝒖𝒏𝒕 15.95 𝒕𝒕𝒂𝒃𝒍𝒆 2.659 From
Results of least significance difference test LSD for cortical complete flake length with raw material class between assemblages..., ...207 Table 8.. Frequency and proportion of clast
D Correlation of CSF sIL-2R and CSF cell counts in samples from patients with neurosarcoidosis n = 42.. Results of Spearman’s rank analysis are
The Mann-Whitney U test results of SPS as measured through observation Data N U Uα Experimental Class 20 0,004 0,05 Control Class 20 Table 6 shows that 0.004 < 0.05, it can be
