PENGEMBANGAN METODE EKTRAKSI FITUR DALAM
PENINGKATAN HASIL PERFORMA KLASIFIKASI SENTIMEN
Amalia Anjani A.1)dan Aris Tjahyanto2)
1)Program Studi Magister Sistem Informasi, Institut Teknologi Sepuluh Nopember Jl. Jalan Raya ITS, Sukolilo, Surabaya, 60111, Indonesia
e-mail: [email protected]
2)Jurusan Sistem Informasi, Institut Teknologi Sepuluh Nopember Jl. Jalan Raya ITS, Sukolilo, Surabaya, 60111, Indonesia
e-mail: [email protected]
ABSTRAK
Saat ini jejaring sosial merupakan lumbung informasi bagi banyak pihak. Hal ini dikarenakan masyarakat lebih jujur dalam menyampaikan opininya melalui jejaring sosial yang salah satunya twitter. Hingga saat ini banyak penelitian dilakukan untuk menggali informasi tersebut yang salah satunya adalah klasifikasi sentimen. Dari banyak klasifikasi sentimen yang telah dilakukan, penelitian dengan menggunakan data jejaring sosial berbahasa Indonesia masih sedikit. Selain itu, klasifikasi sentimen pesan jejaring sosial berbahasa indonesia memiliki tantangan tersendiri yakni dari sisi penggunaan bahasa yakni bahasa dalam bentuk tidak baku. Dalam penelitian ini digunakan data pesan dari jejaring sosial twitter yang banyak digunakan oleh masyarakat Indonesia. Penelitian ini terfokus pada metode ekstraksi fitur dari pesan-pesan twitter yang menggunakan bahasa tidak baku. Metode esktraksi fitur ini merupakan kombinasi dari penghapusan stopwords, penghapusan karakter berulang, konversi emoticon, stemming modifikasi untuk bahasa tidak baku, dan konversi bahasa tidak baku menjadi bahasa baku. Metode ekstraksi fitur ini mengolah bahasa dengan struktur tidak baku tersebut menjadi fitur-fitur yang mampu mendukung peningkatan hasil klasifikasi. Pengklasifikasi yang digunakan adalah support vector machine yang telah terkenal keandalannya dalam klasifikasi teks. Dalam penelitian ini, hasil ekstraksi fitur yang dilakukan mampu mendukung hasil klasifikasi hingga akurasi sebesar 94.51%, persisi dan recall sebesar 94.50%, serta ROC Area sebesar 0.914.
Kata kunci: Ekstraksi Fitur, Klasifikasi Sentimen, SVM, Twitter. PENDAHULUAN
Internet telah menjadi bagian bagi hampir sebagian besar masyarakat Indonesia, dibuktikan ditempatinya peringkat ke-enam sebagai pengguna Internet terbesar sedunia. Tingginya pengguna internet ini juga berbanding lurus dengan tingginya pengguna jejaring sosial di Indonesia salah satunya adalah twitter. Pada tahun 2013 tercatat bahwa Indonesia menempati peringkat ketiga di dunia dalam hal penggunaan jejaring media twitter (Tarigan, 2013). Twitter merupakan sistem yang membolehkan penggunanya untuk mengirim pesan yang diunggahnya kepada para followers-nya. Panjang karakter pada pesan yang diunggah dalam twitter hanya terbatas sebanyak 140 karakter (pcmag.com). Pesan yang diunggah tersebut tidak terbatas pada satu topik tertentu. Pengguna twitter dapat menyampaikan mengenai opininya mengenai suatu produk tertentu (Ghiassi, 2013), mengenai layanan pada industri pariwisata (Sotiriadis, 2013), bahkan keadaan emosi yang mereka rasakan (Sari, 2014). Banyaknya informasi yang terkandung ini membuat banyak pihak untuk
melakukan berbagai macam penelitian penggalian informasi yang salah satunya adalah melakukan penggalian informasi mengenai sentimen pengguna yakni dengan cara klasifikasi sentimen.
Tantangan klasifikasi sentimen dengan menggunakan twitter sebagai sumber datanya adalah tatanan bahasa yang digunakan selain keterbatasan panjang karakter yakni sebanyak 140 karakter. Hal ini cukup menyulitkan untuk menggali sentimen seseorang dari konten tweet (da Silva, 2014) terutama dalam pengklasifikasian sentimen. Sumber data seperti berita, dokumen, situs, dan sejenisnya menggunakan bahasa dengan struktur baku berbeda dengan bahasa yang digunakan pada twitter. Bahasa yang digunakan pada twitter memiliki beberapa karakteristik yakni kata yang digunakan tidak mengikuti Kamus Besar Bahasa Indonesia (KBBI), pengulangan karakter yang tidak seharusnya, dan penulisan dengan mengubah karakter huruf menjadi karakter angka. Oleh karenanya perlu dilakukan normalisasi bahasa seperti yang dilakukan oleh Alexander Clark (Clark, 2003) dengan cara memperbaiki kata-kata yang salah ketik atau salah eja. Metode normalisasi yang dirancang oleh Alexander tersebut sayangnya berdasarkan pada teks berbahasa inggris yang berbeda dengan bahasa Indonesia. Penelitian yang dilakukan oleh Naradhipa melakukan pendekatan metode untuk normalisasi bahasa tidak baku berdasarkan bahasa Indonesia yakni dengan cara pengubahan karakter angka menjadi huruf, penghapusan karakter berulang, dan konversi bahasa tidak baku menjadi bahasa baku (Naradhipa, 2012).
Klasifikasi sentimen dengan sumber data berbahasa Indonesia merupakan salah satu topik penelitian yang jumlahnya terbatas. Pada penelitian mengenai klasifikasi sentimen berbahasa Indonesia, para peneliti menggunakan berbagai pendekatan dalam praproses klasifikasi. Praproses klasifikasi merupakan tahap penting dalam klasifikasi (Ma'ady, 2014) yang terbagi menjadi dua yakni ekstraksi fitur dan seleksi fitur (Khan, 2010). Berbagai jenis metode ekstraksi fitur yang salah satunya normalisasi teks dilakukan untuk mengekstrak fitur penting dari pesan dari jejaring sosial berbahasa Indonesia. Berbagai jenis metode tersebut tersebar di berbagai penelitian yang seharusnya saling mendukung satu dengan yang lain. Wijaya melakukan ekstraksi fitur dengan cara menghapus tanda baca, melakukan
tokenization, menghapus karakter yang tidak perlu atau karakter yang berulang (Wijaya,
2013). Sebelumnya Naradhipa juga melakukan hal yang serupa namun menambahkan proses pada tahap normalisasi teks yakni mengubah bahasa informal menjadi bahasa formal (Naradhipa, 2012). Pada penelitian lainnya dilakukan ekstraksi fitur mulai dari menghapus
stopword, menghapus angka dan tanda baca, dan stemming, selain itu emoticon yang ada
tidak dihapus (Sari, 2014). Berbagai metode yang tersebar tersebut dikombinasikan untuk mengekstrak fitur dari pesan-pesan jejaring sosial twitter berbahasa Indonesia.
Hingga saat ini beberapa pengklasifikasi dasar yang umum digunakan dalam penelitian mengenai klasifikasi teks, antara lain naïve bayes classifier (NBC), support vector
model (SVM), logistic regression, maksimum entropy (ME), multinominal random forest,
dan K-nearest neighbor (KNN). Dari berbagai pengklasifikasi dasar tersebut SVM menghasilkan hasil yang lebih baik (Wijaya, 2013; Tan, 2008; Xia & Peng, 2009; Pang, Lee, & Vaithyanathan, 2002). Sebastiani mengutip pernyataan Joachim yang menyatakan bahwa SVM memberikan keuntungan dalam klasifikasi teks, yakni: SVM memiliki kecenderungan untuk memilimalisir kondisi overfitting, selain itu juga memiliki kemampuan untuk menangani fitur dengan dimensi yang besar (Sebastiani, 2002).
Penelitian ini akan terfokus pada tahap ekstraksi fitur dan hasil ekstraksi fitur tersebut akan digunakan dalam proses klasifikasi dengan menggunakan pengklasifikasi SVM. Pada penelitian ini akan dilakukan pengujian kombinasi ekstraksi fitur yakni cleansing,
tokenizing, case folding, stopping, konversi emoticon, stemming, dan konversi kata tidak
baku. Dari hasil pengujian tersebut akan diketahui signifikansi kombinasi metode ekstraksi fitur tersebut dan peran setiap metode ekstraksi fitur.
METODE
Penelitian ini secara umum terbagi menjadi tiga yakni tahap penyiapan data, ekstraksi fitur, dan klasifikasi. Masing-masing tahap tersebut akan dijelaskan sebagai berikut.
Tahap Penyiapan Data
Penelitian ini menggunakan studi kasus penyedia layanan telekomunikasi di Indonesia. Hal ini dikarenakan masing-masing penyedia layanan telekomunikasi tersebut melayani dan berkomunikasi secara aktif melalui twitter. Pengumpulan pesan twitter ini menggunakan Twitter API Stream dengan menggunakan kata kunci: „telkomsel‟,
„indosat‟, „xl axiata‟, „xl‟, „smartfren‟, „telkom‟, „indosatcare‟, „smartfrencare‟,
„xlcare‟, dan „telkomcare‟. Data yang dikumpulkan adalah pesan teks yang mengandung kata kunci tersebut dan pesan yang diambil secara real time. Data yang telah terkumpul kemudian dipilah menjadi dua yakni pesan yang mengandung sentimen dan tidak mengandung sentimen yakni sentimen positif atau negatif. Pesan yang tidak mengandung sentimen tidak digunakan dalam penelitian ini, sedangkan pesan yang mengandung sentimen dipilah kembali menjadi dua kategori yakni sentimen positif dan sentimen negatif. Proses pemilahan pesan-pesan tersebut dilakukan secara manual. Hasil pengumpulan dan pemilahan data ini, terkumpul data sebanyak 1821 tweet dengan jumlah tweet positif sebanyak 1436 tweet dan tweet negatif sebanyak 385 tweet. Contoh pesan mengandung sentimen dan tidak dapat dilihat pada tabel berikut ini.
Tabel 1. Contoh Pesan Twitter Mengandung Sentimen dan Tidak Mengandung Sentimen
Jenis Contoh Tweet
Non-sentimen “Telkomsel Luncurkan Layanan 4G LTE di
Medan
http:\/\/t.co\/rPL3KlMgRp http:\/\/t.co\/RfadXuIF8E”
“@Telkomsel maksudnya *363#? Iya, balasannya tetap sama kayak gitu.”
Sentimen positif “@indosatmania Pake indosat jd makin happy krn sll ada promo-promo yg
menarik seperti HUJAN PULSA :)) #LoveIndosat”
Sentimen negatif “@XLCare ini XL gimana sih? masa udah 2 hari sinyal 3G di rumahku
masih aja berantakan ????? -_-”
Selain pesan twitter yang akan diolah untuk diklasifikasikan, perlu dilakukan penyiapan data lainnya. Data lainnya adalah daftar stopwords yang didapatkan dari penelitian F. Tala yang berjudul “A Study of Stemming Effect on Information Retrieval in Bahasa Indonesia” (Tala, 2003). Daftar stopwords tersebut sedikit dimodifikasi dengan menambahkan daftar stopwords untuk menyesuaikan dengan data yang digunakan pada penelitian ini yang menggunakan bahasa tidak baku misalnya „gue‟, „cuman‟, „kalo‟,
„ih‟, dan sebagainya. Selain itu juga ditambahkan stopwords yang merupakan singkatan dari kata stopword yang umum digunakan, misalnya „klo‟, „ja‟, „dah‟, dan sebagainya. Selain itu, nama penyedia layanan telekomunikasi juga ditambahkan dalam daftar stopword ini. Kata-kata yang ditambahkan pada daftar stopwords tersebut merupakan kata-kata yang tidak memiliki ciri khusus terhadap suatu kategori tertentu.
Selain daftar stopword, juga disipakan daftar kata dasar. Daftar kata dasar ini terbagi menjadi dua yakni daftar kata dasar baku dan daftar kata dasar tidak baku. Daftra kata dasar baku didapatkan dari KBBI, sedangkan daftar kata dasar tidak baku dibuat oleh peneliti. Daftar kata dasar ini digunakan pada proses stemming dan konversi kata tidak baku.
Daftar emoticon juga disiapkan sebelum dilakukan proses ekstraksi fitur. Hal ini karena emoticon pada pesan twitter akan dikonversi menjadi kategori dari emoticon itu
sendiri sehingga meminimalisir keberagaman emoticon yang memiliki maksud yang sama. Daftar emoticon dan ketegorinya dapat dilihat pada Tabel 2 berikut ini.
Tabel 2. Daftar Emoticon
Kategori Emotico
n
Positif :) :-) =) :d ;) ;-) :3 =d ^^ ^_^ xd x-d Negatif :( :-( =( ;( ;-( x_x -_- =_= :| :/
Tahap Ekstraksi Fitur
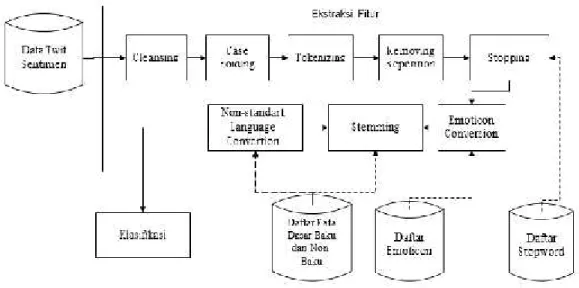
Pada tahap ini dirancang kombinasi berbagai metode ekstraksi fitur yang didapatkan dari berbagai penelitian mengenai klasifikasi teks. Tahap ekstraksi fitur ini dapat dilihat pada Gambar 1.
Gambar 1. Metode Ekstraksi Fitur
Tahap pertama dari metode esktraksi fitur ini adalah noise cleansing yakni menghapus hal-hal yang umum terdapat pada pesan twitter misalnya mention, url, dan sebagainya. tahap berikutnya adalah case folding yang menghapus karakter-karakter selain huruf dan karakter lain yang digunakan pada emoticon, serta mengubah semua karakter yang tersisa menjadi huruf kecil. Tahap ketiga adalah tokenization yang memecah tweet menjadi token yakni kata per kata. Tahap berikutnya adalah menghapus karakter berulang, tahap ini dilakukan sebelum proses kebahasaan (stopping, stemming, konversi kata tidak baku) dan konversi emoticon karena penulisan kata tidak baku pada pesan tweet salah satunya adalah penulisan dengan karakter berulang misalnya „senneeeng‟,
„kezzzeeel‟,„;(((((„, „- -„,dan sebagainya. Pengulangan karakter yang tidak perlu ini perlu dihapus sehingga dapat diolah pada tahap-tahap setelahnya. Tahap kelima adalah
stopping yakni penghapusan stopword dengan membandingkan dengan daftar stopword
yang telah dibuat. Setelah stopword dihapus tahap berikutnya adalah konversi emoticon menjadi kategori emoticon-nya.
Proses berikutnya adalah stemming yakni mengubah kata menjadi bentuk kata dasarnya. Stemming yang digunakan pada penelitian ini adalah stemming yang dirancang khusus untuk masukan kata tidak baku. Stemming ini dibuat dari confix- stripping
menambah aturan rule precedence menyesuaikan tambahan imbuhan, dan menggunakan dua kamus yakni kamus kata dasar bahasa baku dan kamus kata dasar bahasa tidak baku.
Tahap terakhir adalah mengubah token berbentuk kata tidak baku menjadi bentuk kata bakunya. Hal ini karena pada penulisan pesan twitter digunakan kata tidak baku yang bercampur dengan kata baku, sehingga kata-kata tidak baku tersebut perlu diubah menjadi bentuk bakunya sehingga kata yang memiliki maksud yang sama tidak memiliki bentuk yang berbeda-beda.
Tahap Klasifikasi
Klasifikasi dilakukan dengan menggunakan pengklasifikasi SVM dengan kernel linier. Pada penelitian ini evaluasi dilakukan menggunakan k-fold cross-validation yakni
menggunakan 10 folds. Dimana semua data yang terkumpul akan dibagi ke dalam sepuluh kelompok (10 folds) atau dapat disebut sebagai 10-cross-validation (Refaeilzadeh, Tang, & Liu, 2009). Secara bergantian sembilan kelompok akan dijadikan data latih dan satu kelompok akan dijadikan data uji. Pembagian data latih dan uji dilakukan secara acak oleh pengklasifikasi. Data latih tersebut menjadi dasar untuk pembuatan model klasifikasi yang nantinya akan menjadi dasar dalam memprediksikan kelas dari data uji. Evaluasi dilakukan dengan membandingkan hasil prediksi klasifikasi data uji dengan kelas aslinya. Oleh karena evaluasi menggunakan 10-cross-validation maka dari tahap pembagian data hingga tahap perhitungan performa dilakukan sebanyak 10 kali. Hasil evaluasi performa yang dihasilkan merupakan hasil rata-rata dari masing- masing fold.
HASIL DAN PEMBAHASAN
Pada penelitian ini dilakukan delapan jenis uji coba. Pengujian pertama dilakukan tanpa melalui proses ekstraksi fitur. Pengujian kedua dilakukan dengan menggunakan kombinasi metode ekstraksi fitur yang telah dirancang namun dikurangi tahap penghapusan karakter berulang. Hal ini dimaksudkan sama dengan pengujian ketiga hingga keenam sesuai dengan pengurangan tahap yang dapat dilihat pada Tabel 3. Pada pengujian ketujuh dilakukan dengan menggunakan kombinasi metode ekstraksi fitur yang telah dirancang. Pengujian pertama hingga ketujuh dilakukan dengan pengklasifikasi SVM. Hasil evaluasi performa klasifikasi pada masing-masing pengujian dapat dilihat pada Tabel 3.
Dari hasil uji coba pada Tabel 3 dapat diketahui bahwa tahap ekstraksi fitur yang mampu menghasilkan performa hasil klasifikasi terbaik didapatkan dari seluruh kombinasi tahap ekstraksi fitur yakni cleansing, case folding, tokenizing, penghapusan pengulangan karakter, stopping, konversi emoticon, stemming, dan konversi bahasa tidak baku. Hasil evaluasi menunjukkan hasil akurasi yang baik dan jika dinilai dari ROC-Area menghasilkan prediksi akurasi yang tinggi (>0.90).Sedangkan hasil terendah didapatkan jika klasifikasi tidak menggunakan salah satu tahap ekstraksi fitur tersebut. Hasil ini menunjukkan bahwa proses ekstraksi fitur memberikan dampak bagi hasil klasifikasi dengan menghilangkan token-token yang tidak memiliki maksud dan juga menurunkan tingkat keberagaman token. Tabel 3. Hasil Evaluasi Klasifikasi Masing-Masing Pengujian
No Jenis Uji Akurasi Precission Recall F-Measures ROC-Area
1 Tanpa proses ekstraksi fitur 91.65% 91.50% 91.70% 91.50% 0.860 2 Tanpa penghapusan karakter
berulang 93.52% 93.40% 93.50% 93.40% 0.891 3 Tanpa stopping 93.03% 92.90% 93.00% 93.00% 0.886 4 Tanpa konversi emoticon 92.09% 91.90% 92.10% 91.90% 0.862 5 Tanpa stemming 94.12% 94.10% 94.10% 94.10% 0.907
No Jenis Uji Akurasi Precission Recall F-Measures ROC-Area
6 Tanpa konversi kata 91.71% 91.50% 91.70% 91.40% 0.841
7 Dengan seluruh metode ekstraksi 94.51% 94.50% 94.50% 94.50% 0.914 Tahap ekstraksi fitur tanpa tahap konversi bahasa tidak baku menghasilkan perhitungan performa yakni nilai akurasi, presisi, recall, dan f-measures rendah dengan nilai ROC-Area juga terendah dari uji coba lainnya yakni sebesar 0.841 yang berarti akurasi prediksi pada level menengah (0.71-0.90). Sehingga dapat disimpulkan bahwa konversi bahasa tidak baku memiliki peran yang cukup signifikan dalam proses ekstraksi fitur. Hal ini memungkinkan karena satu bahasa baku memiliki berbagai bentuk bahasa tidak baku misalnya kata „lambat‟ memiliki bentuk tidak baku „lemot‟dan „lola‟. Konversi bentuk bahasa tidak baku tersebut menurunkan tingkat keberagaman kata yang berarti juga menurunkan tingkat keberagaman fitur yang memiliki arti yang sama. Untuk posisi ketiga terendah dihasilkan oleh proses ekstraksi fitur tanpa melibatkan tahap konversi
emoticon. Proses konversi emoticon memiliki peran penting dalam proses ekstraksi fitur.
Hal ini memungkinkan karena konversi emoticon yang dilakukan dapat menurunkan tingkat keberagamannya.
Proses ekstraksi fitur yang tidak melibatkan proses stopping berada pada posisi empat terendah yang menghasilkan nilai akurasi, presisi, recall, dan f-measures sebesar 93.03%, 92.90%, 93.00%, dan 93.00% serta ROC Area sebesar 0.886. Proses stopping memang telah dibuktikan pada penelitian mengenai klasifikasi teks bahwa tahap penghapusan stopword
memiliki peran penting dalam proses ekstraksi fitur. Penghapusan stopword tersebut akan mengurangi jumlah fitur yang tidak memiliki ciri khusus terhadap suatu kategori sehingga lebih baik jika dihapus, karena jika dibiarkan stopword tersebut hanya akan membebani pengklasifikasi dan juga dapat menyebabkan salah klasifikasi.
Proses ekstraksi fitur tanpa melibatkan proses stemming rupanya tidak menghasilkan hasil yang berbeda jauh dengan kombinasi seluruh proses ekstraksi fitur, nilai akurasi, presisi, recall, dan f-measures yang dihasilkan hanya sebesar 94.12%, 94.10%, 94.10%, dan 94.10% serta nilai ROC Area diatas 0.90 yakni sebesar 0.907. Dari hasil tersebut dapat dinyatakan bahwa tahap stemming tidak memiliki peran yang cukup signifikan dalam proses ekstraksi fitur pada penelitian ini. Stemming tidak berjalan dengan optimal rupanya dikarenakan oleh tahap sebelumnya yakni tahap penghapusan karakter berulang. Tahap penghapusan karakter berulang akan menghapus pengulangan karakter yang sering digunakan pada penulisan bahasa tidak baku misalnya „seneeeeng‟ atau „luuucccuuuu‟, dan lain sebagainya, tetapi rupanya tahap ini juga akan menghilangkan pengulangan karakter yang semestinya tidak dihilangkan misalnya „maaf‟ sehingga menjadi „maf‟. Jika kata maaf ditambahkan dengan imbuhan misalnya „maafin‟ maka menjadi „mafin‟, dan kata tersebut tidak dapat diproses dengan benar oleh stemmer karena kata maf tidak terdapat dalam kamus. Selain itu, kata yang memiliki karakter berakhiran „n‟ kemudian mendapat imbuhan „nya‟ juga menjadi korban proses ini misalnya „hujannya‟ akan berubah menjadi „hujanya‟. Hal ini tentunya tidak dapat diproses oleh stemmer karena tidak ada imbuhan „ya‟. Hal ini menjadi alasan mengapa tahap stemmer tidak mampu mendorong hasil klasifikasi dengan optimal.Tetapi jika proses penghapusan karakter berulang tidak dilibatkan maka keseluruhan proses ekstraksi fitur tersebut hanya mencapai nilai akurasi, presisi, recall, dan f-measures sebesar 93.52%, 93.40%, 93.50%, dan 93.40% serta nilai ROC Area sebesar 0.891. Tahap penghapusan karakter berulang ini juga tidak dapat dipindahkan posisinya karena jika dipindahkan setelah proses stemming, maka
tetap saja proses stemming tidak dapat berjalan optimal karena kata-kata masukannya memiliki karakter yang berulang misalnya „seneeengkan‟ atau „lembuuuutin‟ dan pada akhirnya tidak dapat diproses oleh stemmer. Selain itu, penghapusan karakter berulang
ini juga memiliki dampak bagi konversi emoticon karena penulisan karakter emoticon banyak yang menggunakan pengulangan karakter ini misalnya „- -„ atau
„;))))‟. Karakter yang diulang-ulang tersebut harus dihilangkan untuk memudahkan proses konversi emoticon.
KESIMPULAN DAN SARAN
1. Kombinasi seluruh metode ekstraksi fitur yang telah dirancang menghasilkan performa klasifikasi terbaik dengan nilai akurasi, presisi, recall, dan f-measures sebesar 94.51%, 94.50%, 94.50%, dan 94.50% serta nilai ROC Area yang baik yakni sebesar 0.914 (level prediksi tinggi). Sedangkan jika data tidak melalui tahap ekstraksi fitur, performa klasifikasi yang dihasilkan memiliki nilai paling rendah.
2. Tahap konversi bahasa tidak baku memiliki peran paling penting dalam ekstraksi fitur yang diikuti oleh tahap konversi emoticon, stopping, dan penghapusan karakter berulang. Stemming memiliki peran terendah dalam peningkatan performa klasifikasi. Hal tersebut dikarenakan tahap stemming tidak mampu bekerja dengan optimal. Akan tetapi dari hasil-hasil ini dapat diketahui bahwa seluruh tahapan dalam proses ekstraksi fitur tersebut saling mendukung untuk menghasilkan performa klasifikasi terbaik. Saran untuk penelitian selanjutnya adalah:
1. Alur atau urutan kombinasi metode yang kurang sempurna, yakni pada tahap penghapusan karakter berulang yang akan berdampak pada tahap-tahap selanjutnya walaupun dampak yang dihasilkan bersifat positif namun juga negative.Oleh karenanya diperlukan modifikasi tertentu pada alur metode ekstraksi fitur.
2. Penelitian ini tidak mengakomodasi singkatan, sehingga perlu ditambahkan tahap untuk mengakomodasi penulisan dalam bentuk singkatan. Hal ini diperlukan karena penulisan beberapa kata berbeda tergantung penulisan singkatan oleh penulis, padahal kata-kata tersebut memiliki bentuk kata yang sama.
DAFTAR PUSTAKA
Asian, J. A. (2007). Stemming Indonesian : a confix-stripping approach. ACM Trnsactions on Asian Language Information Processing (TALIP), 6(4), 1-33.
Clark, A. &. (2003). Pre-Processing Very Noisy Text. In Proc. of Workshop on Shallow Processing of Large Corpora.
da Silva, N. F. (2014). Tweet sentiment analysis with classifier ensembles. Decision Support Systems, 66, 170-179.
Ghiassi, M. S. (2013). Twitter brand sentiment analysis: A hybrid system using n-gram analysis and dynamic artificial neural network. Expert Systems with applications, 40(16), 6266-6282.
Khan, A. B. (2010). A Review of Machine Learning Algorithms for Text-Documents Classification. Journal of Advances in information Technology.
Ma'ady, M. D. (2014). Implementation of Text Classification for Twitter Data Mapping of
Telkomsel Customers in The Form of Heat Map. International Research
Conference on Business, Economics, and Social Science, (pp. 66-76).
Naradhipa, A. R. (2012). Sentiment classification for Indonesian message in social media. In Cloud Computing and Social Networking (ICCCSN) (pp. 1-5). IEEE.
Pang, B., Lee, L., & Vaithyanathan, S. (2002). Thumbs up?: sentiment classification using
machine learning techniques. In Proceedings of the ACL-02 conference on
Empirical methods in natural language processing-Volume 10 (pp. 79-86). Association for Computational Linguistics.
pcmag.com. (n.d.). encyclopedia. Retrieved March 9, 2015, from pcmag.com:
http://www.pcmag.com/encyclopedia/term/57880/twitter
Refaeilzadeh, P., Tang, L., & Liu, H. (2009). Cross-validation. In Encyclopedia of database systems (pp. 532-538). USA: Springer.
Sari, Y. A. (2014). USER EMOTION IDENTIFICATION IN TWITTER USING
SPECIFIC FEATURES: HASHTAG, EMOJI, EMOTICON, AND ADJECTIVE
TERM. Jurnal Ilmu Komputer dan Informasi, 7(1), 18-24.
Sebastiani, F. (2002). Machine Learning in Automated Text Categorization. ACM
computing surveys (CSUR), 34(1), 1-47.
Sotiriadis, M. D. (2013). Electronic word-of-mouth and online reviews in tourism services: the use of twitter by tourists. Electronic Commerce Research, 13(1), 103-124.
Tala, a. Z. (2003). A Study of Stemming Effects on Information Retrieval in Bahasa Indonesia. Netherlands: Master of Logic Project. Institute for Logic, Language and Computation, Universiteit van Amsterdam.
Tan, S. &. (2008). An empirical study of sentiment analysis for chinese documents. Expert System with Applications, 34(4), 2622-2629.
Tarigan, I. A. (2013, November 21). Pengguna Twitter Indonesia Teraktif Ketiga di Dunia.
Retrieved Maret 9, 2015, from Chip Online id:
http://chip.co.id/news/apps-social_media/9030/pengguna_twitter_indonesia_teraktif_ketiga_di_dunia
Wijaya, V. E. (2013). Automatic mood classification of Indonesian tweets using linguistic approach. In Information Technology and Electrical Engineering (ICITEE) (pp. 41-46). IEEE.
Xia, H., & Peng, L. (2009). SVM-Based Comments Classification and Mining of Virtual Community: For Case of Sentiment Classification of Hotel Reviews. Proceedings of the International Symposium on Intelligent Information Systems and Applications (pp. 507-511). Qingdao: Academy Publisher.