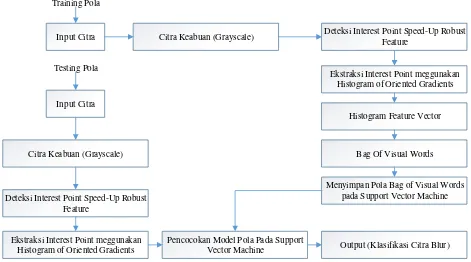
BAB 3
METODOLOGI PENELITIAN
3.1.Alur Kerja Penelitian
Alur Kerja Penelitian ini di ilustrasikan pada gambar 3.1 :
Mengidentifikasi Masalah Melakukan Studi Pustaka Menentukan Tujuan Penelitian Mengumpulkan Data
Merancang dan Mengimplementasi Metode
Menguji Coba Metode Menganalisa dan Mengevaluasi Metode
Menyimpulkan Penelitian
Gambar 3.1 Diagram Alur Kerja Penelitian
Berdasarkan gambar 3.1 dapat dijelaskan bahwa alur kerja penelitian ini dimulai
dengan tahapan mengidentifikasi sebuah masalah yang akan diteliti, kemudian dilakukan
studi pustaka yang berkaitan dengan masalah yang akan diteliti dilanjutkan dengan
menentukan tujuan penelitian agar penelitian tidak menyebar ke ruang lingkup yang lain,
selanjutnya dilakukan pengumpulan data atau sampel yang akan diteliti khususnya citra
blur berdasarkan jenisnya dilanjutkan dengan merancang dan mengimplementasi motode
menggunakan sampel yang telah dikumpulkan dimana perancangan dan
pengimplementasian sesuai dengan tujuan penelitian yang telah ditentukan. Selanjutnya
dilakukan pengujian terhadap metode yang telah dirancang dan diimplementasikan dan
pada tahapan akhir dilakukan analisa dan evaluasi metode sehingga dapat diambil
3.2. Data dan Peralatan Penelitian Yang Digunakan
Data yang digunakan dalam penelitian ini berjumlah 392 citra dengan ukuran 640x480
pixel yang diklassifikasikan menjadi 4 kategori, yaitu average blur, motion blur, gaussian
blur dan citra non blur. Data yang digunakan sebagai training set adalah 60 % dari total
imageset yang digunakan dan 40 % imageset sebagai testing set dimana pembagiannya
ditentukan secara acak. Sedangkan alat yang digunakan dalam penelitian ini adalah matlab
versi 2016b, dan file citra yang digunakan yaitu file yang berformat .jpg . Alasan pemilihan
file citra .jpg adalah untuk menjaga keaslian citra yang diperoleh, dimana citra diperoleh
menggunakan kamera.
3.3. TahapanModikifkasi Speed-up Robust Feature Dengan Histogram of Oriented Gradient
Penelitian ini memodifikasi speed-up robust feature sebagai pendeteksi interest point
dengan histogram of oriented gradient sebagai interest deskriptor. Dengan speed-up robust
feature sebagai interest point detector, mendeteksi interest point pada citra yang blur
dengan skala yang berbeda-beda (multiscale). Setelah interest point diperoleh, maka akan
diextract dengan menggunakan histogram of oriented gradient (HOG). Dengan
mendapatkan intesitas histogram pada deskriptor akan diperoleh pola degradasi pada tiap
interest point. Tahapan modifikasi speed-up robust feature dengan histogram of oriented
23
Input Citra Citra Keabuan (Grayscale) Deteksi Interest Point Speed-Up Robust
Feature
Menyimpan Pola Bag of Visual Words pada Support Vector Machine Deteksi Interest Point Speed-Up Robust
Feature
Ekstraksi Interest Point meggunakan Histogram of Oriented Gradients
Pencocokan Model Pola Pada Support
Vector Machine Output (Klasifikasi Citra Blur)
Gambar 3.2 Tahapan Modifikasi speed-up robust feature dengan histogram of oriented gradient pada skema bag of visual word untuk klassifikasi citra blur.
3.4. Modifikasi Speed-up Robust Feature (SURF) Dengan Histogram of Oriented Gradient (HOG)
Skala pendeteksian interest point pada speed-up robust feature mempengaruhi
klassifikasi citra blur jika dimodifikasikan dengan histogram of oriented gradien sebagai
ekstraksi fiturnya. Hal ini disebabkan oleh proses ekraksi fitur yang berbeda pada kedua
metode ini. Speed-up robust feature mengintegralkan citra dalam proses pendeteksian
keypoint, sedangkan histogram menggunakan cell blok pada citra secara satu per satu atau
single detector. Seperti pada Gambar 3.3, speed-up robust feature sebagai deteksi fitur
menggunakan pengintegralan citra, dengan menggunakan skala invarian pada citra. Proses
ini mendeteksi fitur pada citra dengan membentuk bulatan-bulatan sebagai deteksi fitur
Gambar 3.3 Pendeteksian interest point dengan speed-up robust feature
Bulatan pada citra pada Gambar 3.3 dihasilkan dari integral grid speed-up robust feature
dengan menggunakan fast hessian matrix. Gambar 3.4 akan menunjukkan grid yang telah
dibentuk oleh speed-up robust feature. Pengintegralan grid tersebut dapat mengurangi
waktu komputasi dalam pendeteksian fitur yang diperoleh pada citra. Sedangkan
Histogram of oriented gradient, membentuk Cell block yang menghasilkan gradient
sebagai fitur citra. Gambar 3.5, menunjukkan penggunakan grid oleh Histogram of oriented
gradient yang berbeda dengan speed-up robust feature dalam proses pendeteksian fitur.
Proses pendeteksian Hitogram of oriented gradient, lebih lama waktu komputasinya
dibandingkan dengan speed-up robust feature, hal ini dikarenakan Histogram of oriented
gradient membentuk cell blok terhadap keseluruhan citra dan menghitung gradien sebagai
25
Gambar 3.4 Grid x dan y pada speed-up robust feature mendeteksi fitur dengan membentuk bulatan kecil (blob) terhadap citra.
Dengan memodifikasi Speed-up robust feature dengan Histogram of oriented gradient
menghasilkan pendeteksian fitur seperti yang ditunjukkan pada Gambar 3.6. Dengan
modifikasi ini dapat mengklasifikasikan citra blur berdasarkan tipe blur pada skema bag of
visual word dengan lebih akurat.
Gambar 3.6 Modifikasi Speed-up robust feature dengan Histogram of oriented gradient
3.5. Pembentukan Bag Of Visual Words
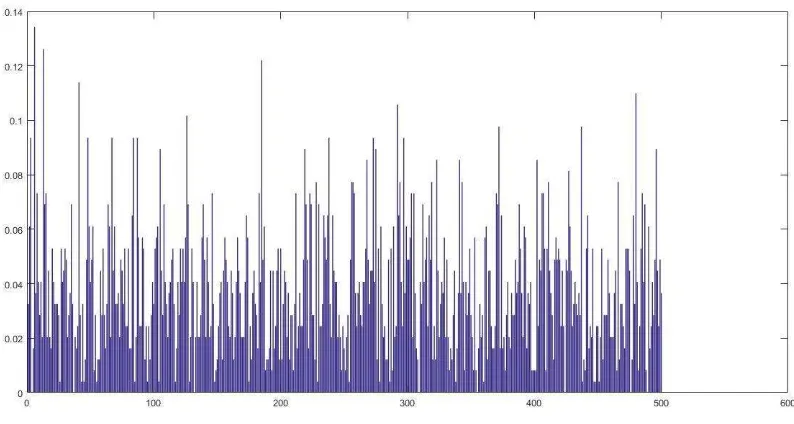
Setelah di dapat fitur dengan menggunakan modifikasi speed-up robust feature dengan histogram of oriented gradients maka fitur-fitur dibentuk bag visual words atau codebook
fitur dari citra blur yang telah diinputkan. Fitur-fitur yang telah didapatkan akan di cluster
menggunakan k-means algorithm, untuk membedakan kelas fitur-fitur tersebut dengan k =
500. Dimana feature vector yang telah di clusterkan ini akan menjadi bag of visual words
atau codebook fitur untuk mengklasifikasikan citra pada training set maupun test set
27
Gambar 3.7 Histogram Feature Vector bag1 dengan K= 500 atau disebut dengan
codebook
3.6. Ukuran Performansi
Pada penelitian ini, pengukuran performansi klassifikasi menggunakan confusion matrix.
Confusion matrix adalah sebuah array 2 dimensi berukuran K x K (dimana K adalah total
jumlah kelas) yang digunakan untuk melaporkan hasil mentah dari eksperimen klasifikasi
(Marques, 2011). Nilai pada baris i, kolom j mengindikasikan berapa kali sebuah objek
yang tergolong benar pada kelas I yang berlabel kelas j. Tabel confusion matrix berisikan
empat kemungkinan keluaran sebagai bahan acuan dalam membandingkan antara kejadian
yang sebenarnya (aktual) dengan kejadian yang terprediksi. Berikut adalah ilustrasinya:
Tabel 3.1 Tabel Confusion Matrix
Prediksi
Average Blur Motion Blur
Aktual Average Blur True Positive (TP) False Negative (FN)
dimana :
True Positive (TP) adalah jumlah data average blur yang diprediksi average blur
False Negative (FN) adalah jumlah data average blur yang diprediksi motion blur
False Positive (FP) adalah jumlah data motion blur yang diprediksi average blur
True Negative (TN) adalah jumlah data motion yang diprediksi motion blur
Untuk menghitung akurasi menggunakan confusion matrix dapat dirumuskan sebagai
berikut:
� � � = (� � ��� + � � �)
Sedangkan untuk menghitung tingkat kesalahan klassifikasi adalah sebagai berikut:
BAB 4
HASIL DAN PEMBAHASAN
4.1.Hasil
Hasil yang dibahas meliputi modifikasi speed-up robust feature dengan histogram of
oriented gradients, pengujian dengan variasi skala speed-up robust feature, perbandingan
modifikasi metode dengan penelitian sebelumnya dan pembahasan.
4.1.1.Sampel pelatihan dan sampel pengujian
Imageset pada penelitian ini terbagi menjadi sampel pelatihan dan sampel pengujian.
Sampel pelatihan yang digunakan dalam penelitian ini berjumlah 236 citra, sedangkan
sampel pengujian terdiri dari 156 citra, yang terdiri dari 4 kategori citra. Yaitu kategori
average blur, citra non blur, gaussian blur dan motion blur, dimana penentuannya dilakukan
secara acak dan ukuran citra pada imageset penelitian ini sebesar 640 width x 480 height
pixel. Berikut adalah 4 contoh citra yang digunakan dalam sampel pelatihan:
Gambar 4.2 Citra 8.jpg pada kategori citra non blur
Gambar 4.3 Citra 8.jpg pada kategori gaussian blur
31
4.1.2.Hasil bag of feature
Setelah menginput training set dan testing set, selanjutnya citra-citra pada training set akan
dideteksi interest pointnya menggunakan speed-up robust feature dan di ekstrak fiturnya
menggunakan histogram of oriented gradients. Bag of feature yang dibentuk pada
trainingSet1 adalah sebagai berikut:
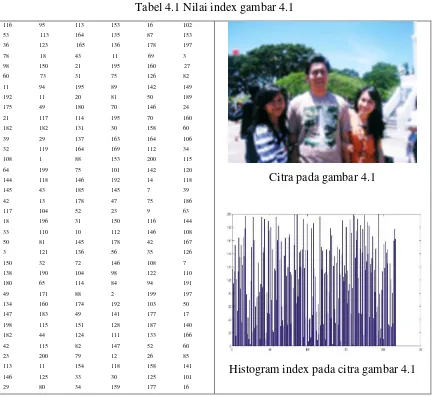
Gambar 4.5 Bag of Feature TrainingSet1
Nilai masing-masing index pada gambar 4.5 menjadi acuan terhadap nilai fitur citra
lainnya. Dimana nilai index diatas merupakan nilai fitur yang telah sudah melalui tahapan
deteksi dan ekstraksi fitur, serta clustering nilai fitur-fitur, yang dikelompokkan menjadi
nilai visual word index. Nilai index tersebut, dapat dilihat pada nilai index masing-masing
citra, dimana nilai index pada gambar 4.1, gambar 4.2, gambar 4.3 dan gambar 4.4 tidak
lebih dari 200. Hal ini sesuai dengan penetapan jumlah index pada bag of feature yang
dibentuk, yaitu K=200. Berikut adalah nilai index gambar 4.1, gambar 4.2, gambar 4.3 dan
Tabel 4.1 Nilai index gambar 4.1
Histogram index pada citra gambar 4.1
Tabel 4.2 Nilai index gambar 4.2
33
35
Tabel 4.3 Nilai index gambar 4.3
116 113 153 16 95 113
177 140 152 167 54 140
37 28 15 163 13 66
180 122 47 111 101 172
166 31 147
Tabel 4.4 Nilai index gambar 4.4
13 95 103 102 1 103
Histogram index citra pada gambar 4.4
4.1.3.Hasil klasifikasi support vector machine
Setelah masing-masing citra didapatkan nilai visual word indexnya, maka akan
diklasifikasikan menggunakan support vector machine. Support vector machine yang
37
16.jpg, citra 18.jpg, citra 19.jpg, dan citra 20.jpg pada kategori average blur merupakan
citra yang termasuk ke dalam testingSet1. Sebelum diklasifikasikan, citra-citra tersebut
merupakan citra yang tergolong ke dalam average blur, namun hasil prediksi klasifikasi
menggunakan support vector machine tidaklah sama. Hasil prediksi klasifikasinya adalah
sebagai berikut:
Tabel 4.5 Hasil Klasifikasi Support Vector Machine
No.
average blur. Support vector machine yang menggunakan fungsi kernel gaussian
menghitung skor terhadap data training, yang menghasilkan skor pada tiap-tiap kategori.
Support vector machine memutuskan klasifikasi kategori citra tersebut berdasarkan nilai
skor yang terbesar. Seperti pada citra nomor 2, skor terbesarnya adalah -0.20611589 pada
kategori gaussian blur, maka support vector machine mengkategorikan citra nomor 2 ke
dalam gaussian blur. Hal ini merupakan klasifikasi yang salah, dimana citra nomor 2
merupakan citra yang tergolong ke dalam average blur. Kesalahan klasifikasi ini
disebabkan oleh tipisnya perbedaan skor antara average blur dan gaussian blur. Support
vector machine sendiri mempunyai 3 fungsi kernel yang sering digunakan dalam
penelitian-penelitan sebelumnya. Kekurangan ini dapat dikembangkan dengan
menggunakan fungsi kernel yang berbeda, ataupun memakai fungsi clustering yang
berbeda. Hal ini dikarenakan bag of feature menggunakan visual word index yang terbentuk
4.1.4.Modifikasi Speed-Up Robust Feature dengan Histogram of Oriented Gradients
Modifikasi speed-up robust feature dengan histogram of oriented gradients dimulai dengan
pembentukan grid untuk menentukan lokasi pendeteksian interest point. Grid Step yang
digunakan ialah 8, grid step ini berfungsi sebagai jarak antara pixel x (width) dan y (height).
Dimana untuk setiap x selanjutnya akan berjarak 8 pixel, pada ukuran citra 480 height dan
640 width akan menghasilkan grid x = 80 dan grid y = 60. Berikut adalah tabel koordinat
39
Pada tabel 4.1 dan tabel 4.2 menampilkan koordinat gridX (1x80) dan gridY (1x60)
yang akan digunakan dalam pendeteksian interest point pada citra. Sehingga menghasilkan
koordinat deteksi interest point dengan ukuran matriks 4800x2, koordinat deteksi interest
point ini diilustrasikan pada Gambar 4.1.
Gambar 4.6 Koordinat deteksi interest point
Kemudian dengan menggunakan koordinat deteksi pada gambar 4.6 akan dilakukan
deteksi interest point menggunakan speed-up robust feature dengan menggunakan 3 skala
pendeteksian pada citra yaitu skala 1.6, 3.2 dan 4.8. Gambar 4.2 adalah hasil pendeteksian
interest point speed-up robust feature dengan menggunakan 3 skala pendeteksian pada citra
Setelah interest point di dapatkan, maka di ekstrak menggunakan hitogram of
oriented gradients, yang menghasilkan ekstraksi seperti pada gambar 4.8 .
Gambar 4.8 Ekstraksi Histogram of Oriented Gradients
Dengan menerapkan modifikasi metode ini, maka di peroleh fitur 83x36 atau 2.988
fitur pada citra 1.jpg. Selanjutnya metode di uji dengan membentuk bag of visual words,
dimana menghasilkan 41.987 fitur pada trainingSet1. Angka fitur ini tidak tetap, mengingat
penentuan training set dan testing set dilakukan secara acak. Sehingga fitur yang ditemukan
berbeda-beda pada tiap citra, hal ini juga dipengaruhi oleh objek yang berbeda pada citra
dan tipe blur yang berbeda pada masing-masing citra.
4.2.Pengujian Dengan Variasi Skala Speed-Up Robust Feature
Pada Pengujian ini skala variasi speed-up robust feature akan di uji cobakan pada 3
model skala level, model pertama menggunakan 3 skala, model kedua dengan
menggunakan 4 skala dan model terakhir menggunakan 5 skala. Berikut adalah hasil
41
Tabel 4.8 Pengujian klassifikasi pada trainingSet1 dengan menggunakan 3 skala deteksi
Average Blur Citra non Blur Gaussian Blur Motion Blur
Average Blur 97 % 0% 3% 0%
Tabel 4.9 Pengujian klassifikasi pada testingSet1 dengan menggunakan 3 skala deteksi
Average Blur Citra non Blur Gaussian Blur Motion Blur
Average Blur 44% 3% 46% 7%
Citra non Blur 0% 90% 2% 8%
Gaussian Blur 69% 0% 26% 5%
Motion Blur 13% 3% 2% 82%
Rata-rata Akurasi 60%
Tabel 4.10 Pengujian klassifikasi pada trainingSet1 dengan menggunakan 4 skala deteksi
Average Blur Citra non Blur Gaussian Blur Motion Blur
Average Blur 100% 0% 0% 0%
Citra non Blur 0% 100% 0% 0%
Gaussian Blur 14% 0% 86% 0%
Motion Blur 0% 0% 0% 100%
Rata-rata Akurasi 97%
Tabel 4.11 Pengujian klassifikasi pada testingSet1 dengan menggunakan 4 skala deteksi
Average Blur Citra non Blur Gaussian Blur Motion Blur
Average Blur 62% 0% 28% 10%
Citra non Blur 0% 95% 0% 5%
Gaussian Blur 69% 0% 18% 13%
Tabel 4.12 Pengujian klassifikasi pada trainingSet1 dengan menggunakan 5 skala deteksi
Average Blur Citra non Blur Gaussian Blur Motion Blur
Average Blur 97% 0% 2% 1%
Citra non Blur 0% 100% 0% 0%
Gaussian Blur 5% 0% 95% 0%
Motion Blur 0% 0% 0% 100%
Rata-rata Akurasi 98%
Tabel 4.13 Pengujian klassifikasi pada testingSet1 dengan menggunakan 5 skala deteksi
Average Blur Citra non Blur Gaussian Blur Motion Blur
Average Blur 56% 0% 31% 13%
Citra non Blur 0% 92% 0% 8%
Gaussian Blur 36% 0% 38% 26%
Motion Blur 3% 0% 5% 92%
Rata-rata Akurasi 70%
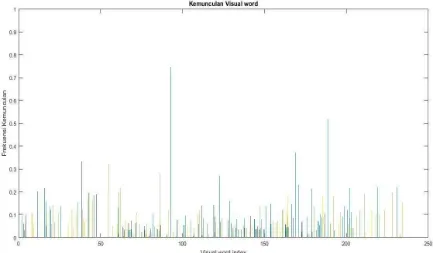
Tabel 4.8 menunjukkan klasifikasi dengan akurasi yang cukup tinggi yaitu 98%, namun
pada tabel 4.9 menunjukkan akurasi klasifikasi yang rendah yaitu 60%. Hal ini
menunjukkan diperlukan pengujian lebih lanjut terhadap skala yang digunakan pada
pendeteksian interest point. Dimana pendeteksian pola blur pada citra kurang dikenali
dengan menggunakan hanya 3 skala pendeteksian interest point. Hal ini juga ditunjukkan
pada bag of feature yang terbentuk, dimana bag of feature yang dihasilkan memiliki rentang
43
Gambar 4.9 Bag of Visual Word yang dibentuk
Pada pengujian yang telah dilakukan pada tabel 4.11 ditemukan peningkatan akurasi
klasifikasi citra blur sebesar 7% dari sebelumnya yaitu pada tabel 4.9. Dimana pada tabel
4.11 menggunakan 4 skala deteksi dan pada tabel 4.9 menggunakan 3 skala deteksi.
Sedangkan pada tabel 4.13 ditemukan peningkatan akurasi klasifikasi citra blur sebesar 3
% dari sebelumnya yaitu pada tabel 4.11. Dimana pada tabel 4.13 menggunakan 5 skala
deteksi dan pada tabel 4.11 menggunakan 4 skala deteksi. Untuk itu diperlukan pengujian
lebih lanjut dengan melakukan 10 kali pengujian terhadap 3, 4 dan 5 skala pendeteksian
pada metode speed-up robust feature sebelum dimodifikasi dengan metode speed-up robust
feature setelah dimodifikasi. Hal ini berfungsi untuk menemukan akurasi yang konsisten
terhadap klasifikasi citra blur sebelum dan sesudah modifikasi, mengingat penentuan
trainingSet dan testingSet dilakukan secara acak. Selain itu pengujian akan dilakukan
dengan mengubah nilai K pada clustering k-means. Hal ini dikarenakan bag of visul words
yang dihasilkan pada pengujian pada tabel 4.10, tabel 4.11, tabel 4.12 dan tabel 4.13 tidak
mencapai 500 index, seperti terlihat pada gambar 4.9. Untuk itu akan dilakukan
Tabel 4.14 Percobaan 1 Menggunakan 3 Skala Pendeteksian Interest Point
Pada percobaan 1 menggunakan 3 skala pendeteksian interest point pada testingSet1
sebelum dimodifikasi speed-up robust feature, menghasilkan nilai akurasi average blur
sebesar 33%, citra non blur sebesar 74 %, gaussian blur sebesar 18 %, motion blur sebesar
77 % dengan rata-rata akurasi sebesar 51 %, seperti terlihat pada tabel 4.9. Selain itu terjadi
banyak miss classification, seperti klasifikasi average blur yang diklasifikasikan ke dalam
citra non blur sebesar 15 %, yang diklasifikasikan ke dalam gaussian blur sebesar 21 %,
dan diklasifikasikan ke dalam motion blur sebesar 31 %. Sedangkan pengujian pada
testingSet1 menggunakan speed-up robust feature yang telah dimodifikasi mengalami
peningkatan nilai akurasi average blur sebesar 44 %. Namun masih terjadi miss
classification terhadap 3 kelas lainnya, untuk itu akan dilakukan 10 kali pengujian menggunakan speed-up robust feature yang belum dimodifikasi dengan speed-up robust
feature yang telah dimodifikasi, untuk mendapatkan nilai akurasi yang konsisten. Hasil
pengujiannya ditunjukkan pada tabel 4.15 dan tabel 4.16.
Percobaan 1 Menggunakan 3 Skala Pendeteksian Interest Point testingSet1 (sebelum modifikasi speed-up robust feature)
Average Blur Citra Non Blur Gaussian Blur Motion Blur
testingSet1 (setelah modifikasi speed-up robust feature )
45
Tabel 4.15 Hasil Keseluruhan 10 Kali Pengujian Pada testingSet1 Sebelum di Modifikasi
Testing Skala yang digunakan 3 Skala 4 Skala 5 Skala
Tabel 4.16 Hasil Keseluruhan 10 Kali Pengujian Pada testingSet1 Setelah di Modifikasi
Testing Skala yang digunakan 3 Skala 4 Skala 5 Skala
Rata-rata Akurasi 64.50% 70.80% 72.30%
Setelah dilakukan 10 kali pengujian pada testingSet1 menggunakan speed-up robust
feature yang belum dimodifikasi dengan speed-up robust feature yang telah dimodifikasi,
Gambar 4.10 Hasil Klasifikasi Citra Blur Sebelum Modifikasi
Gambar 4.11 Hasil Klasifikasi Citra Blur Setelah Modifikasi
Dimana rata-rata akurasi tertinggi menggunakan 3 skala pendeteksian interest point
menggunakan speed-up robust feature yang telah dimodifikasi sebesar 64.5 %, sedangkan
nilai akurasi tertinggi mengggunakan speed-up robust feature yang belum dimodifikasi
sebesar 51.0 % . Rata-rata akurasi tertinggi menggunakan 4 skala pendeteksian interest
point menggunakan speed-up robust feature yang telah dimodifikasi sebesar 70.8 %,
51%
Skala yang digunakan 3 Skala Skala yang digunakan 4 Skala
Skala yang digunakan 5 Skala
Skala yang digunakan 3 Skala Skala yang digunakan 4 Skala
47
sedangkan nilai akurasi tertinggi mengggunakan speed-up robust feature yang belum
dimodifikasi sebesar 49.1 % . Dan rata-rata akurasi tertinggi menggunakan 5 skala
pendeteksian interest point menggunakan speed-up robust feature yang telah dimodifikasi
sebesar 72.3 %, sedangkan nilai akurasi tertinggi mengggunakan speed-up robust feature
yang belum dimodifikasi sebesar 49.6 %. Grafik klasifikasi citra blur sebelum modifikasi
dan sesudah dimodifikasi dapat dilihat pada Gambar 4.10 dan Gambar 4.11.
Setelah dilakukan 10 kali pengujian pada 3 skala yang berbeda yaitu skala 3, 4 dan 5
pendeteksian interest point, maka ditemukan rata-rata akurasi tertinggi klasifikasi citra blur
sebesar 72,3% dengan menggunakan 5 skala pendeteksian seperti yang ditunjukkan pada
tabel 4.16.
4.3.Pembahasan
Hasil keseluruhan pengujian pada tabel 4.15 menunjukkan nilai akurasi terendah dan
tertinggi pada 3 skala pendeteksian interest point sebelum dimodifikasi. Dimana pada tabel
4.15 yaitu hasil keseluruhan 10 kali pengujian pada testingSet1 sebelum dimodifikasi
menunjukkan nilai akurasi terendah menggunakan 3 skala pendeteksian interest point
sebesar 49 % pada percobaan 4 dan percobaan 10, sedangkan akurasi tertinggi
menggunakan 3 skala pendeteksian interest point sebesar 54 % pada percobaan 6. Nilai
akurasi terendah menggunakan 4 skala pendeteksian interest point sebesar 45 % pada
percobaan 6, sedangkan akurasi tertinggi menggunakan 4 skala pendeteksian interest point
sebesar 54 % pada percobaan 9. Nilai akurasi terendah menggunakan 5 skala pendeteksian
interest point sebesar 46 % pada percobaan 2, sedangkan akurasi tertinggi menggunakan 5
skala pendeteksian interest point sebesar 53 % pada percobaan 3, percobaan 8 dan
percobaan 10.
Hasil keseluruhan pengujian pada tabel 4.16 menunjukkan nilai akurasi terendah dan
tertinggi pada 3 skala pendeteksian interest point setelah dimodifikasi. Dimana pada tabel
4.11 yaitu hasil keseluruhan 10 kali pengujian pada testingSet1 setelah dimodifikasi
menunjukkan nilai akurasi terendah menggunakan 3 skala pendeteksian interest point
menggunakan 4 skala pendeteksian interest point sebesar 67 % pada percobaan 1 dan
percobaan 6, sedangkan akurasi tertinggi menggunakan 4 skala pendeteksian interest point
sebesar 75 % pada percobaan 4. Nilai akurasi terendah menggunakan 5 skala pendeteksian
interest point sebesar 69 % pada percobaan 6 dan percobaan 8, sedangkan akurasi tertinggi
menggunakan 5 skala pendeteksian interest point sebesar 77 % pada percobaan 4.
Berdasarkan hasil penelitian yang telah dilakukan, dengan menggunakan 5 skala
pendeteksian interest point pada modifikasi speed-up robust feature dengan histogram of
oriented gradients dapat mengenali pola blur secara konsisten. Seperti yang ditunjukkan
pada tabel 4.16, dimana dalam 10 kali pengujian dalam 8 kali pengujian menghasilkan nilai
akurasi 70%, hanya 2 pengujian yang menghasilkan nilai akurasi dibawah 70%. Hal ini
berkaitan dengan penentuan skala pada interest point citra, yang dijelaskan pada subbab
2.5 dimana menggunakan skala pendeteksian dapat mengenali pola objek pada citra.
Penelitian ini telah membuktikan dengan menggunakan 5 skala pendeteksian interest point
pada modifikasi speed-up robust feature dan histogram of oriented gradients dapat
mengenali pola blur pada citra yang tidak hanya berfokus pada penentuan prediksi model
degradasi citra untuk mengklasifikasikan daerah blur pada citra seperti
penelitian-penelitian sebelumnya. Namun modifikasi metode ini masih sulit untuk mengklasifikasikan
jenis gaussian blur pada citra, dimana pada semua skala yang digunakan dalam pengujian
BAB 5
KESIMPULAN DAN SARAN
5.1.Kesimpulan
Tesis ini menghasilkan beberapa kesimpulan sebagai berikut:
1. Modifikasi speed-up robust feature dan histogram of oriented gradient, dapat
mengenali pola blur secara konsisten dengan rata-rata akurasi tertinggi klasifikasi
citra blur sebesar 72,3% dengan menggunakan 5 skala pendeteksian.
2. Modifikasi metode speed-up robust feature dan histogram of oriented gradient sulit
untuk mengklasifikasikan jenis gaussian blur pada citra. Dimana pada semua skala
yang digunakan dalam pengujian, dimana pada semua skala yang digunakan dalam
pengujian hanya menghasilkan akurasi true positif tertinggi testingSet1 sebesar
56%.
3. Ditemukan peningkatan akurasi klasifikasi citra blur, dimana sebelum
memodifikasi pendeteksian interest point pada speed-up robust feature hanya
menghasilkan akurasi tertinggi sebesar 51%. Sedangkan setelah memodifikasi
pendeteksian interest point pada speed-up robust feature menghasilkan akurasi
tertinggi sebesar 72.3%. Hal ini membuktikan bahwasanya dengan memodifikasi
pendeteksian interest point speed-up robust feature dengan histogram of oriented
gradient menghasilkan akurasi klasifikasi yang lebih baik pada citra blur.
5.2.Saran
Modifikasi metode ini dapat dikembangkan untuk mengenali pola gaussian blur pada
citra blur dengan memodifikasi pendeteksian interest point yang lebih baik dalam