BAB II
LANDASAN TEORI
2.1 Tinjauan Studi
In-Ju Kim, seorang Asisten professor program studi terapan ilmu medis Universitas Dammam, Saudi Arabia pada penelitiannya tahun 2015 yang berjudul “Knowledge Gaps and Research Challenges in the Contemporary Ergonomics” menyatakan bahwa Ergonomi berfokus pada sistem di mana manusia berinteraksi dengan lingkungan mereka dimana lingkungan yang kompleks terdiri tentang fisik, masalah organisasi, dan sosial. Tujuan ergonomi adalah untuk efesiensi dan efektivitas dalam melakukan aktivitas tanpa masukan yang boros, kesalahan, dan kerusakan yang lain. Penelitian ini berkesimpulan bahwa tantangan ergonomi ke depan membutuhkan pengembangan kemampuan yang luas termasuk dalam hal kekuatan teknik dan kompetensi penelitian[6].
Penelitian kali ini didasarkan pada studi data mining beserta aplikasinya. Sesuai studi yang diambil, penelitian kali ini merujuk pada penelitian yang dilakukan oleh S.D.Gheware, A.S.Kejkar, S.M.Tondare pada tahun 2014 yang berjudul “Data Mining: Task, Tools, Techniques and Applications” yang mengungkapkan studi detail dari teknik data mining, alat data mining, serta teknik dalam data mining. Hasilnya, alat-alat yang dibuat dengan konsep data mining ini ternyata dapat memprediksi atau mengklasifikasi label untuk data mendatang[7]. Salah satu terapan dalam studi data mining adalah pengenalan pola. Pengenalan pola didefinisikan sebagai studi kecerdasan buatan yang membuat mesin mampu untuk mengenali pola
secerdas yang dilakukan manusia. Mesin ini jugalah yang mengklasifikasikan pola tersebut kedalam sebuah kelas yang sering disebut label atau target sesuai data set yang ada menggunakan algoritma tertentu.
Kasus pengenalan pola pada data mining dapat diselesaikan dengan berbagai macam teknik serta algoritma di dalamnya seperti teknik klasifikasi, pengelompokan (clustering), prediksi, jaringan saraf, maupun aturan asosiasi seperti penelitian yang dilakukan oleh Tipawan Silwattananusarn, Assoc. Prof. Dr. Kulthida Tuamsuk pada tahun 2012 yang berjudul “Data Mining and Its Applications for Knowledge Management : A Literature Review from 2007 to 2012”. Penelitian ini mendeskripsikan definisi data mining dan fungsinya, manajemen pengetahuan yang didapat dengan data mining setelah diintegrasikan dengan Knowledge management
(KM). Hasilnya, teknik data mining menjadi pengaruh dominan dalam manajemen pengetahuan. Hal tersebut akan menampilkan tantangan yang signifikan untuk penelitian sistem informasi mendatang[8].
Pada April 2013, Priyanka Sharma dan Manavjeet Kaur dengan penelitiannya yang berjudul “Classification in Pattern Recognition: A Review” memperkenalkan konsep dasar pengenalan pola beserta model penelitian terkait seperti klasifikasi dan pengelompokkan (clustering). Hasilnya, pendekatan klasifikasi untuk pengenalan pola menggunakan label training set yang mengklasifikasikan data uji tanpa label ke dalam kategori yang diinginkan. Berbeda dengan klasifikasi, model pengelompokkan (clustering) justru tidak memiliki set berlabel. Pendekatan model ini menggunakan beberapa matrik lain seperti jarak euclidean untuk menempatkan data uji diatur ke dalam kelompokyang benar[3]. Hal ini mendorong teknik klasifikasi untuk dijadikan referensi terbentuknya pengenalan pola dari data mining karena pengenalan pola termasuk didalamnya adalah klasifikasi data set uji yang belum terlabel menjadi terlabeli.
Dalam teknik klasifikasi terdapat beberapa tipe model seperti pohon keputusan (decision tree), naïve bayes, dan SVM. Pada tipe model decision tree
terdapat algoritma ID3 dan C4.5. Penelitian yang dilakukan oleh Nesma Settouti, Mohammed El Amine Bechar and Mohammed Amine Chikh pada tahun 2016 yang berjudul “Statistical Comparisons of the Top 10 Algorithms in Data Mining for Classification Task” bertujuan melakukan uji statistik non-parametrik dengan uji Friedman dengan tes post-hoc sesuai dengan perbandingan beberapa pengklasifikasi pada beberapa set data, menempatkan algoritma C4.5 pada ranking pertama dengan nilai 3.5833 disusul dengan algoritma Begging dengan nilai 3.8333 dan algoritma CART dengan nilai 4.5417[4]. Hasil C4.5 sebagai algoritma dengan ranking tertinggi juga didukung oleh penelitian Masud Karim, Rashedur M. Rahman dengan penelitiannya pada tahun 2013 yang berjudul “Decision Tree and Naïve Bayes Algorithm for Classification and Generation of Actionable Knowledge for Direct Marketing” yang bertujuan membandingkan performa algoritma C4.5 dan Naïve Bayes. Hasil penelitian tersebut menyatakan bahwa algoritma C4.5 memiliki akurasi yang lebih tinggi dan waktu pemrosesan yang lebih cepat jika dibandingkan dengan algoritma lain seperti naïve bayes[9].
Mengacu pada penelitian yang dilakukan oleh Priyanka Sharma dan Manavjeet Kaur yang menyatakan bahwa sebuah pola berhasil dikenali menggunakan teknik klasifikasi juga berdasarkan keakuratan algoritma C4.5 dibandingkan dengan algoritma lain seperti penelitian yang dilakukan Nesma Settouti, Mohammed El Amine Bechar and Mohammed Amine Chikh. Maka penelitian kali ini akan berfokus pada penerapan algoritma C4.5 untuk kasus pengenalan pola.
Tabel 2.1 : Tabel Ringkasan Tinjauan Studi
No Judul Peneliti Tahun Tujuan Hasil
1 Knowledge Gaps and Research Challenges in
In-Ju Kim 2015 Meneliti tantangan perkembangan Tantangan ergonomi kedepan membutuhkan
the Contemporary Ergonomics ergonomi. pengembangan kemampuan yang luas termasuk dalam hal kekuatan teknik dan kompetensi penelitian. 2 Data Mining: Task, Tools, Techniques, and Applications S.D.Gheware , A.S.Kejkar, S.M.Tondare 2014 Mengungkap-kan studi detail dari teknik data mining, alat data mining, serta teknik dalam data mining. Alat-alat yang dibuat dengan konsep data mining dapat memprediksi atau mengklasifikasi label untuk data mendatang. 3 Data Mining and Its Applications for Knowledge Management : A Literature Review from 2007 to 2012 Tipawan Silwattananu sarn, Assoc.Prof. Dr. KulthidaTua msuk 2012 Mendeskripsi-kan definisi data mining dan fungsinya, manajemen pengetahuan yang didapat dengan data mining setelah diintegrasikan dengan Knowledge Teknik data mining menjadi pengaruh dominan dalam manajemen pengetahuan. Hal tersebut akan menampilkan tantangan yang signifikan untuk penelitian sistem informasi
management (KM) mendatang. 4 Classification in Pattern Recognition: A Review Priyanka Sharma dan Manavjeet Kaur 2013 Memperkenal-kan konsep dasar pengenalan pola beserta model penelitian terkait seperti klasifikasi dan klastering Pendekatan klasifikasi untuk pengenalan pola menggunakan label training set yang berfungsi mengklasifikasi-kan data uji tanpa label ke dalam kategori yang diinginkan. Pendekatan model klastering menggunakan beberapa matrik lain seperti jarak euclidean untuk menempatkan data uji diatur ke dalam cluster yang benar. 5 Statistical Comparisons of the top 10 Algorithms in Data Mining Nesma Settouti, Mohammed El Amine Bechar and 2016 Melakukan uji statistik non-parametrik dengan uji Friedman Algoritma C4.5 pada ranking pertama dengan nilai 3.5833. algoritma
for Classification Task Mohammed Amine Chikh dengan tes post-hoc sesuai dengan perbandingan beberapa pengklasifikasi pada beberapa set data. Begging dengan nilai 3.8333 dan algoritma CART dengan nilai 4.5417. 6 Decision Tree and Naïve Bayes Algorithm for Classification and Generation of Actionable Knowledge for Direct Marketing Masud Karim, Rashedur M. Rahman 2013 Membandingk an performa algoritma C4.5 dan Naive Bayes Algoritma C4.5 memiliki akurasi yang lebih tinggi dan waktu pemrosesan yang lebih cepat jika dibandingkan dengan algoritma lain seperti naïve bayes.
2.2 Tinjauan Pustaka
2.2.1 Ergonomi
Masyarakat ergonomi telah mengembangkan pengetahuan dan keterampilan mengenai interaksi antara manusia dan lingkungan mereka. Ergonomi berfokus pada sistem dimana manusia berinteraksi dengan lingkungan mereka. Lingkungan yang
kompleks terdiri dari tentang fisik, organisasi, dan sosial. Tujuan ergonomi adalah untuk efesiensi dan efektivitas dalam melakukan aktivitas tanpa masukan yang boros, kesalahan, dan kerusakan yang lain. Di masa depan ergonomi mempunyai tantangan untuk memperkuat permintaan ergonomi berkualitas tinggi. Solusi untuk tantangan tersebut adalah dengan cara meningkatkan kesadaran akan kebutuhan pemangku kepentingan khususnya untuk ahli sistem dan pembuat keputusan sistem[6].
2.2.2 Sistem Pengenalan Pola
Pola adalah satu paket objek atau konsep yang dapat dikenali untuk membentuk sebuah model yang mirip dengan target model dengan berpatok pada bagaimana ciri target model tersebut. Sebuah pola pada dasarnya adalah pengaturan dengan berbagai unsur yang termuat didalamnya agar membentuk sebuah target model. Gambar 2.1 menampilkan berbagai macam pola dalam kehidupan sehari-hari.
Pengenalan pola didefinisikan sebagai studi kecerdasan buatan yang membuat mesin secerdas manusia untuk mengenali pola tersebut dan mengklasifikasikannya kedalam kategori yang sesuai dengan cirinya. Pengenalan pola mampu mengindikasi data inputan dan mengklasifikasikannya kedalam sebuah label atau target sesuai data yang telah di training dengan menggunakan algoritma tertentu. Didalam dunia teknologi informasi, implementasi pengenalan pola dapat digunakan untuk menentukan kesamaan suatu entitas seperti pola gambar sidik jari, pola tulisan tangan, pola wajah manusia, pola kode bar, pola gelombang suara dan sebagainya.
Gambar 2.1 : Contoh pola: Finger print, gelombang suara, pengenalan wajah, pengenalan wajah, kode bar.
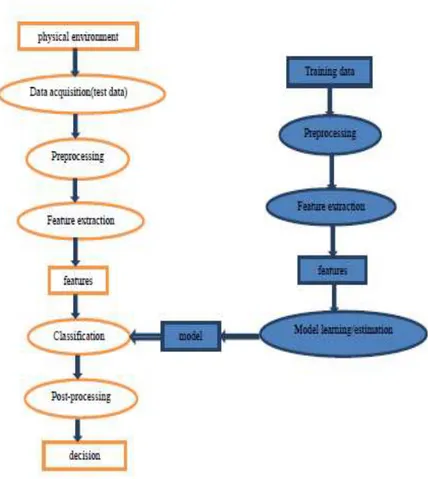
Model desain sistem pengenalan pola pada dasarnya melibatkan tiga langkah berikut: 1) Akuisisi data dan preprocessing: Setelah data dari lingkungan sekitarnya diambil sebagai masukan dan diberikan ke sistem pengenalan pola. Data mentah kemudian diolah dengan baik menghapus noise dari data.
2) Ekstraksi Fitur: fitur yang relevan dari data olahan kemudian diambil. Fitur-fitur yang relevan secara kolektif membentuk badan dari objek yang akan diakui atau diklasifikasikan.
3) Pengambilan keputusan: setelah dilakukan operasi yang diinginkan, klasifikasi atau pengakuan dilakukan pada deskriptor fitur diekstrak.
Gambar 2.2 : Blok Diagram Sistem Pengenalan Pola
2.2.3 Data Mining
Data mining dapat digunakan pada set data yang besar untuk menemukan pola dan hubungan masing-masing atributnya dengan melibatkan metode pada studi kecerdasan buatan, pembelajaran mesin, statistik, dan sistem database. Banyaknya pertumbuhan data yang dapat terjadi dalam sebuah organisasi baik fisik maupun non fisik menyebabkan data memerlukan penataan lebih lanjut. Oleh karena itu, istilah
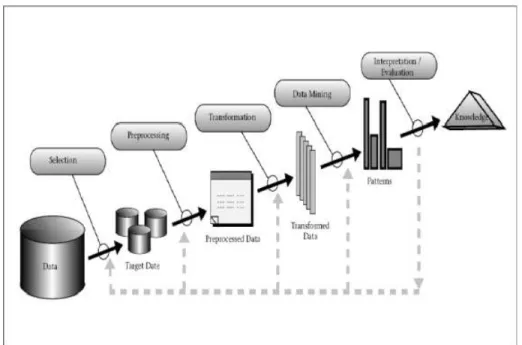
data mining sering kali disebut Knowledge discovery database (KDD)[10]. Secara garis besar proses KDD digambarkan melalui gambar 2.3.
1. Data Selection
Seleksi data dari sekumpulan data operasional sebelum dilakukan tahap penggalian informasi. Data hasil seleksi yang akan digunakan disimpan terpisah dari database
operasional.
2. Cleaning / preprocessing
Proses cleaning ini mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memeperbaiki kesalahan pada data.
3. Transformation
Beberapa teknik data mining membutuhkan format data khusus sebelum diaplikasikan oleh karena itu dilakukan transformasi sehingga data tersebut sesuai untuk proses data mining. Transformasi dan pemilihan data ini juga menentukan kualitas hasil dari data mining.
4. Data Mining
Dengan menggunakan teknik atau metode tertentu yang diaplikasikan pada data terpilih untuk mencari pola atau informasi dari data tersebut.
5. Evaluation / Interpretation
Pola atau informasi yang dihasilkan dari proses data mining ini disajikan dalam bentuk yang mudah dipahami. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya[12].
Gambar 2.3: Proses KDD
2.2.3.1 Algoritma dan Teknik Data Mining
Pendekatan yang dilakukan dalam data mining dapat berupa pendekatan statistik maupun pendekatan mesin pembelajaran[7].
A. Pendekatan Statistik
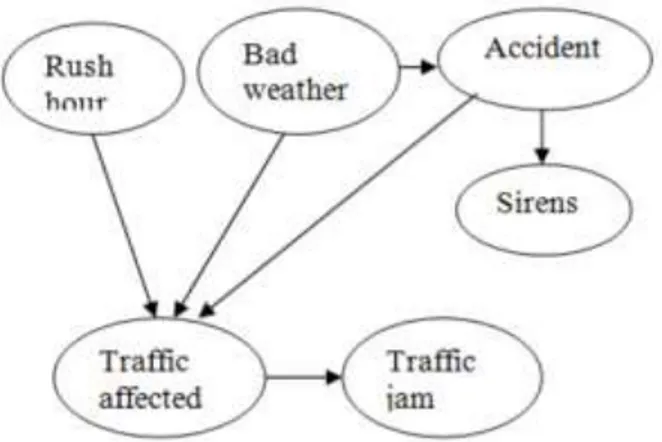
Model statistik yang dibangun dari satu set data pelatihan. Banyak alat statistik telah digunakan untuk data mining termasuk, jaringan saraf, bayesian, analisis korelasi, analisis regresi dan analisis cluster. Misalnya jaringan Bayesian sederhana untuk masalah kemacetan lalu lintas diberikan pada Gambar 2.4. Di node jaringan Bayesian merupakan node atau variabel sementara tepi merupakan dependensi antara node. Dari gambar bisa dilihat bahwa jam sibuk, cuaca buruk atau kecelakaan mempengaruhi lalu lintas yang pada gilirannya menyebabkan kemacetan.
Gambar 2.4 : Contoh Pendekatan Statistik
B. Pendekatan Mesin Pembelajaran
Metode yang paling umum pembelajaran mesin yang digunakan untuk data mining meliputi pembelajaran konseptual,yakni induktif pembelajaran konsep dan induksi pohon keputusan. Dengan mengikuti jalan dari akar ke simpul setiap daun kelas objek dapat menentukan atau memberikan klasifikasi terhadap training set.
Seperti sebuah pohon keputusan sederhana pada di Gambar 2.5 yang menentukan jarak tempuh mobil dari ukuran, jenis transmisi dan berat. Node daun berada di kotak persegi.
Gambar 2.5 : Pohon keputusan
Dalam data mining, terdapat banyak varian algoritma dan teknik seperti klasifikasi, pengelompokkan (clustering), jaringan saraf, aturan asosiasi, prediksi[13] yang semuanya dapat digunakan untuk menemukan pengetahuan dalam basis data yang besar.
A. Clustering
Clustering atau pengelompokkan bisa disebut sebagai identifikasi dari kelas atau objek yang sama. Dengan menggunakan teknik pengelompokan akan dapat lebih lanjut mengidentifikasi daerah padat dan jarang di ruang obyek yang berujung pada penemuan pola distribusi secara keseluruhan dan korelasi antara atribut data.Pendekatan pengelompokkan (clustering) juga dapat digunakan sebagai cara yang efektif dari membedakan kelompok atau kelas dari objek sehingga clustering dapat digunakan sebagai pendekatan preprocessing untuk seleksi atribut bagian dan klasifikasi.
B. Prediksi
Teknik regresi dapat diaplikasikan pada prediksi. Analisis regresi dapat digunakan untuk memodelkan hubungan antara satu atau lebih variabel bebas dan variabel tak bebas. Dalam data mining variabel tak bebas atributnya diketahui dan respon variabel adalah hal yang digunakan untuk memprediksi. Tapi sayangnya, banyak permasalahan di dunia nyata yang tidak hanya prediksi yang menjadi solusinya. Oleh karena itu, teknik yang lebih kompleks seperti regresi logistik, pohon keputusan, atau jaringan saraf mungkin diperlukan untuk nilai prediksi lebih lanjut.
C. Aturan asosiasi
Asosiasi dan korelasi umumnya digunakan untuk menemukan kumpulan frekuensi suatu item diantara data yang besar. Tipe ini membantu pebisnis dalam
membuat keputusan pasar seperti desain katalog, penataan produk, maupun kebiasaan
customer. Algoritma aturan asosiasi dibutuhkan untuk menghasilkan aturan dengan nilai kenyamanan. Akhirnya, karena banyaknya aturan asosiasi yang terbuat maka mengharuskan sebuah perusahaan memiliki gudang data sendiri untuk kemudian digunakan untuk meningkatkan pemasaran produk.
D. Jaringan saraf
Jaringan saraf adalah kumpulan unit input atau output yang saling terkoneksi satu sama lain dengan menggunakan bobot masing-masing koneksi. Selama proses pembelajaran, jaringan akan mengatur bobot untuk dapat memprediksi kelas atau label dari inputan tuple. Jaringan saraf mempunyai kemapuan yang luar biasa dalam memperoleh cara dari data yang kompleks. Jaringan saraf juga mampu untuk meng-ekstrak pola dari inputan yang cukup kompleks.
E. Klasifikasi
Klasifikasi adalah teknik yang paling umum diterapkan dalam data mining. Pendekatan dalam klasifikasi sering menggunakan pohon keputusan yang melibatkan pembelajaran didalamnya. Dalam pembelajaran pelatihan, data dianalisis oleh algoritma klasifikasi dan diuji. Klasifikasi digunakan untuk memperkirakan keakuratan aturan klasifikasi. Jika akurasi diterima aturan dapat diterapkan pada tupel data baru.
2.2.4 Klasifikasi dalam Kasus Pengenalan Pola
Kasus klasifikasi dalam pengenalan pola merujuk pada bagaimana pola inputan dapat kenali. Sebuah pola dapat dikenali melalui petak-petak koordinat dari daerah inputan yang membentuk pola seperti data set yang sudah terbentuk sebelumnya dengan berbagai model klasifikasi yang digunakan.
Tahapan dalam klasifikasi[14]:
1. Setiap tuple / sampel diasumsikan milik kelas yang telah ditetapkan, sebagaimana ditentukan oleh atribut label kelas.
2. Himpunan tupel digunakan untuk konstruksi model: training set.
3. Model ini direpresentasikan sebagai aturan klasifikasi, pohon keputusan, atau rumus matematika.
4. Tingkat Akurasi adalah persentase sampel uji set yang diklasifikasikan dengan benar oleh model.
5. Uji set independen dari training set.
Tipe model klasifikasi:
Klasifikasi oleh Induksi Pohon Keputusan
Klasifikasi Bayesian
Jaringan Saraf
Mesin Pendukung Vektor atau Support Vector Machine (SVM)
Klasifikasi berdasarkan Asosiasi
2.2.5 Pohon Keputusan (Decision Tree)
Pohon keputusan (Decision Tree) adalah tipe model yang mudah diterima dalam teknik klasifikasi. Di antara teknik untuk membangun pohon keputusan, terdapat algoritma yang sering digunakan yakni ID3. Namun sejak C4.5 hadir dan mampu berurusan dengan gangguan data menjadikan ID3 tertinggal dibelakang C4.5. Padahal, keduanya memilih satu atribut sebagai kriteria untuk membangun node pada pohon keputusan. C4.5 digunakan untuk meningkatkan akurasi dan keefektifan sebuah atribut. Dalam membangun pohon keputusan, keberadaan atribut ditunjukkan oleh gain information dan gain ratio. Pada bagian berikut ID3 dan algoritma C4.5 akan dibahas secara rinci[15].
2.2.5.1. ID3
ID3 adalah salah satu algoritma yang membangun pohon keputusan dengan input
dan output data yang bersifat kategoris. Semua kategori atribut dapat diterapkan untuk menghasilkan pohon keputusan ID3.
Pada dasarnya, diperlukan tiga tahapan untuk membangun sebuah pohon:
1. Membuat split dalam berbagai arah. Misalnya untuk semua atribut, sebuah split dibuat dan sub divisi dari split yang diusulkan berujung pada sebuah kategori.
2. Estimasi dari split yang terbesar untuk cabang pohon berdasarkan gain informasi. 3. Pengujian kriteria berhenti, kemudian ulangi langkah-langkah rekursif untuk sub divisi baru.
Ketiga langkah tersebut dilakukan iterasi untuk semua node pohon.
Formula di bawah ini merupakan langkah mendapatkan gain information. S menunjukkan dataset. K menunjukkan jumlah output kelas variabel, dan Pi kemungkinan kelas i. Dalam algoritma ini kualitas perpecahan diwakili oleh gain information.
Entropi(S) = pi log2 pi ... (1)
Gain (S, A) = Entropi (S) - ∑Values (A) Entropi (Sv) ... (2)
Nilai (A) mewakili nilai-nilai kemungkinan atribut A, Sv merupakan subdivisi dari dataset S yang berisi nilai v di S. Entropi (S) menghitung entropi keseluruhan dari masukan atribut A yang memiliki kategori k, Entropi (Sv) adalah entropi sebuah atribut kategori sehubungan dengan atribut output, dan | Sv | / | S | adalah probabilitas kategori Sv dalam S keseluruhan. Perbedaan antara entropi keseluruhan dari node dan
entropi atribut adalah gain information dari atribut. Gain information menunjukkan informasi atribut yang menyampaikan untuk disambiguasi dari kelas.
2.2.5.2. C.4.5
Edisi yang disempurnakan dari algoritma ID3 adalah algoritma C4.5. Data yang digunakan untuk membangun sebuah pohon keputusan dalam algoritma ini dapat bersifat numerik maupun kategoris.
Terdapat 3 langkah untuk membangun pohon berbasis C4.5:
1. Membuat Split untuk atribut kategorikal seperti algoritma ID3.
2. Evaluasi berlangsung pada gain terbesar menurut perolehan rasio matrik.
3.Testing kriteria berhenti, kemudian ulangi langkah-langkah secara rekursif pada subdivisi baru.
Ketiga langkah yang dilakukan iterasi untuk semua node C4.5 menyajikan matrik baru untuk evaluasi perpecahan. Algoritma ini mampu menangani nilai-nilai yang hilang, pemangkasan pohon, pengelompokan nilai atribut. C4.5 adalah algoritma yang paling populer dan yang paling efisien dalam pendekatan berbasis pohon keputusan. Sebuah algoritma pohon keputusan menciptakan model pohon dengan menggunakan nilai-nilai dari atribut yang digunakan. Pada awalnya, terdapat algoritma untuk mengurutkan dataset pada nilai atribut. Kemudian dicari daerah di dataset yang jelas yang hanya berisi satu kelas dan menandai daerah seperti daun. Untuk daerah-daerah yang tersisa yang memiliki lebih dari satu kelas, algoritma ini memilih atribut lain dan melanjutkan proses percabangan dengan hanya jumlah kasus di daerah tersebut sampai pada semua daun atau tidak ada atribut yang dapat digunakan untuk menghasilkan satu atau lebih daun kembali.
2.2.6 Alat yang digunakan
2.2.6.1 Rapid Miner
Sebuah software data mining yang dibangung dengan java platform yang digunakan untuk mengoilah data untuk mendapatkan pengetahuan atau pola data dari pemrosesan data awal (preprocessing) sampai tahap evaluasi. Rapidminer menyediakan berbagai metode data mining yang didasain interaktif (GUI) sehingga memudahkan pemakaian bagi user untuk bereksperimen dalam data mining, mesin pembelajaran (machine learning), text mining, dan analisa prediktif.
2.2.6.2 Eclipse
Eclipse adalah sebuah IDE (Integrated Development Environment) yang sifatnya portable dan open source atau gratis, digunakan untuk membuat aplikasi java platform. Didalamnya, terdapat fasilitas untuk memadukan dengan SDK android untuk pembuatan aplikasi mobile android.
2.3 Kerangka Pemikiran
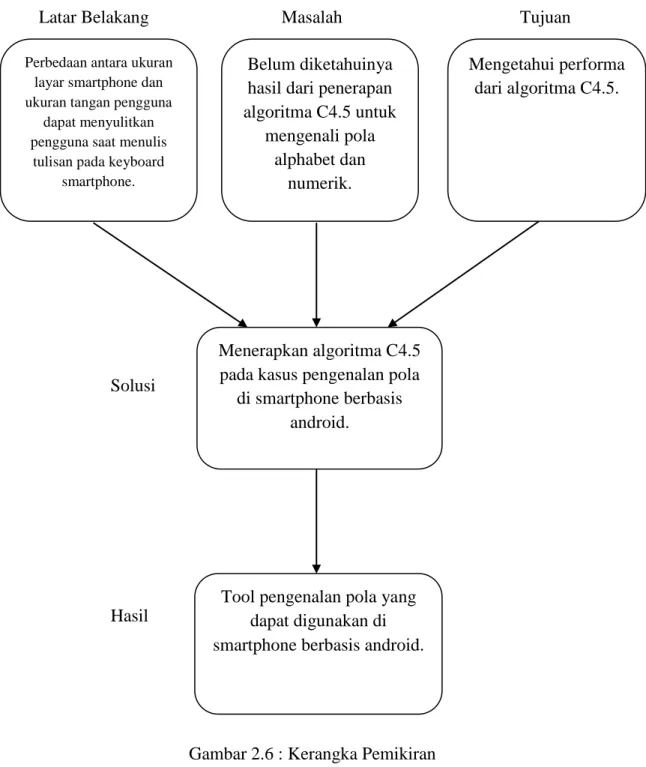
Berikut merupakan kerangka pemikiran dari penelitian yang akan dilakukan:
Latar Belakang Masalah Tujuan
Solusi
Hasil
Gambar 2.6 : Kerangka Pemikiran
Perbedaan antara ukuran layar smartphone dan ukuran tangan pengguna
dapat menyulitkan pengguna saat menulis
tulisan pada keyboard smartphone.
Belum diketahuinya hasil dari penerapan algoritma C4.5 untuk
mengenali pola alphabet dan
numerik.
Menerapkan algoritma C4.5 pada kasus pengenalan pola
di smartphone berbasis android.
Tool pengenalan pola yang dapat digunakan di smartphone berbasis android.
Mengetahui performa dari algoritma C4.5.