5 dikembalikan sebagai top passage dari kueri
pertanyaan yang diberikan. 5. Ekstraksi Jawaban
Top passages yang diperoleh dilakukan perhitungan terhadap jarak kata. Entitas yang memiliki jarak terpendek dengan kata kunci pada kalimat tanya (kueri) akan menjadi entitas jawaban.
Evaluasi Hasil Percobaan
Tahap evaluasi dilakukan secara objektif dari segi:
1. Pasangan jawaban dan dokumen (Responsiveness)
2.
Ketepatan untuk setiap jawaban.
Pemberian nilai dilakukan berdasarkan empat kriteria, yaitu:
1. Wrong (W): jawaban tidak benar.
2. Unsupported (U): jawaban benar tapi dokumen tidak mendukung.
3. Inexact (X): jawaban dan dokumen benar tapi terlalu panjang.
4. Right (R): jawaban dan dokumen benar Lingkungan Pengembangan
Perangkat lunak yang digunakan untuk penelitian yaitu :
1. Windows 7 sebagai sistem operasi,
2. Apache Xampp-win32-1.7.1 sebagai web server,
3. Notepad ++ sebagai editor program.
Perangkat keras yang digunakan untuk penelitian yaitu :
1. Processor Intel Centrino 2.3 GHz, 2. RAM 4 GB,
3. Harddisk kapasitas 250 GB.
HASIL DAN PEMBAHASAN Koleksi Dokumen Pengujian
Dokumen uji yang digunakan adalah dokumen berbahasa Indonesia yang sudah tersedia di Laboratorium Temu Kembali Informasi Departemen Ilmu Komputer IPB. Sumber koleksi dokumen diambil dari media koran, majalah, dan jurnal penelitian. Dokumen ini disimpan dalam satu direktori. Secara umum, nama dokumen diberi nama berdasarkan sumber data dan tanggal data diterbitkan, misalnya suaramerdeka040104.txt yang berarti data berasal dari majalah Suara Merdeka dan diterbitkan oleh Suara Merdeka pada tanggal 04 bulan Januari tahun 2004. Dokumen memiliki ukuran terkecil 1 KB dan terbesar 53 KB. Masing-masing dokumen uji berekstensi teks (*.txt) dan struktur XML di dalamnya. Gambar 5 menunjukkan contoh format strukur dokumen yang digunakan.
<DOC>
<DOCNO> suaramerdeka040104 </DOCNO> <TITLE> Ribuan Bibit untuk Lahan Kritis </TITLE>
<AUTHOR> </AUTHOR>
<DATE> Minggu, 4 Januari 2004 </DATE> <TEXT>
NGALIYAN- Kecamatan Ngaliyan telah mendistribusikan sekitar 30 ribu bibit berbagai jenis tanaman. Sebelumnya, wilayah itu telah menerima bantuan 140.250 bibit tanaman dari Departemen Pertanian. Bibit tanaman yang diberikan adalah petai, durian, rambutan, mangga, sukun, dan jati.
</TEXT> </DOC>
Gambar 5 Struktur dokumen pengujian. Pemrosesan dokumen pada tahap indexing, hanya diambil bagian dokumen yang diapit oleh tag <TITLE> dan <TEXT>, sedangkan untuk pembentukan passages, hanya digunakan bagian dokumen yang diapit oleh tag <TEXT>. Gambar 6 menunjukkan ilustrasi bagian dokumen yang diproses.
<DOC> <DOCNO> </DOCNO> <TITLE> ... </TITLE> <AUTHOR> </AUTHOR> <DATE> </DATE> <TEXT> ... </TEXT> </DOC>
Gambar 6 Ilustrasi bagian dokumen yang digunakan untuk pemrosesan.
6 Pemrosesan Dokumen
Langkah pertama pada pemrosesan dokumen adalah penamaan entitas (named entity) yang disebut tagging pada dokumen dengan menggunakan hasil penelitian dari Citrainingputra (2009). Penamaan entitas dilakukan untuk proses perolehan kandidat jawaban sesuai dengan jenis pertanyaannya. Adapun named entity yang digunakan terdiri dari NAME, ORGANIZATION, NUMBER, PERCENT, CURRENCY, DATE, TIME, dan LOCATION. Pada tahap ini dilakukan dengan memasukkan satu per satu setiap bagian dokumen yang diapit tag <TEXT> ke dalam sistem name entity tagging (Citraningputra 2009). Gambar 7 menunjukkan hasil tagging untuk dokumen suaramerdeka040104.txt. Selanjutnya semua dokumen hasil tagging kemudian disimpan dalam korpus.
NGALIYAN- <LOCATION> Kecamatan Ngaliyan </LOCATION> telah mendistribusikan sekitar <NUMBER>30</NUMBER> ribu bibit berbagai jenis tanaman. Sebelumnya, wilayah itu
telah menerima bantuan <NUMBER>140.250</NUMBER> bibit tanaman dari <ORGANIZATION> Departemen Pertanian </ORGANIZATION>. Bibit tanaman yang diberikan adalah petai, durian, rambutan, mangga, sukun, dan jati.
Gambar 7 Contoh hasil tagging dokumen. Langkah kedua adalah pembacaan terhadap isi file dari korpus. Pembacaan hanya berlaku pada isi file yang berada pada tag <TITLE> dan <TEXT>. Kemudian pada isi file tersebut dilakukan parsing dengan pemisah kata yang tersimpan dalam variabel pemisahKata yang terdiri atas tanda baca [+\/%,.\"\];()\':=`?\[!@]. Tidak semua hasil parsing disimpan, karena hasil parsing diseleksi kembali oleh stopwords yang merupakan kata buangan atau daftar kata umum yang mempunyai fungsi tapi tidak mempunyai arti. File ini tersimpan dalam file stopwords.txt yang terdiri atas 733 kata yang dipisahkan dengan karakter enter, contoh kata tersebut antara lain acapkali, dalam, dan, dapat, sesaat, dari, dan lain-lain. Perhitungan tf-idf
Langkah pertama melakukan perhitungan tf-idf adalah mendapatkan informasi term frequency, dengan memanfaatkan hasil pada tahap pemrosesan dokumen. Term frequency diperoleh dari pasangan dokumen dan hasil parsing (token-token) dari masing-masing file disimpan dalam suatu array pada variabel tf. Variabel ini digunakan untuk menghitung nilai df, idf, dan tf-idf setiap kata.
Langkah selanjutnya adalah mendapatkan document frequency (df). Document frequency adalah jumlah dokumen yang mengadung kata tertentu. Kemudian dari hasil tersebut dapat dihitung nilai invers document frequency (idf). Tujuan dari idf adalah untuk menentukan kata-kata (term) yang merupakan penciri dari suatu dokumen, oleh karena itu dalam penelitian ini hanya kata dengan nilai idf lebih besar sama dengan 0.3 yang disimpan. Hal ini bertujuan untuk menghapus kata-kata yang tidak termasuk dalam stopwords namun bukan penciri dari sebuah dokumen. Hasil idf disimpan dalam fileGenerate/idf.txt dengan menggunakan tanda “>>” sebagai pemisah. Melalui idf dapat diperoleh informasi untuk menghitung nilai tf-idf yang merupakan perkalian antara nilai tf dan idf. Selanjutnya hasil tf-idf kata juga disimpan dalam satu file fileGenerate/tfidf.txt dengan menggunakan tanda “>>” sebagai pemisah. Pembentukan Passages
Tahap awal pembentukan passages adalah dilakukan pembentukan kalimat untuk setiap dokumen dengan menggunakan tanda pemisah antar kalimat yaitu [.?!]. Setiap passage dibentuk dari dua kalimat yang berurutan sehingga passage yang posisinya berdekatan saling overlap. Hasil pembentukan passages ini disimpan dalam satu file . ./fileGenerate/passages.txt. Nilai yang disimpan adalah id passage, nama dokumen, dan passage. Masing-masing variabel dipisahkan dengan tanda “>>”.
Pemrosesan Kueri
Kueri berupa kalimat Tanya yang diawali dengan kata tanya dan diakhiri dengan tanda tanya (?). Kata tanya yang digunakan pada penelitian ini adalah SIAPA, KAPAN, DIMANA, dan BERAPA.
Langkah pertama yang dilakukan pada pemrosesan kueri adalah parsing terhadap kalimat tanya dengan pemisah kata yang tersimpan dalam variabel pemisahKata yang terdiri atas tanda baca [+\/%,.\"\];()\':=`?\[!@].
Kueri di-parsing terlebih dahulu, kemudian dilakukan proses case folding yaitu pengubahan semua huruf menjadi huruf kecil. Selanjutnya dilakukan tokenisasi untuk mendapatkan kata-kata penyusun kueri berupa kata-kata tanya dan keyword (kata-kata selain kata tanya). Hasil tokenisasi disimpan dalam array $query. Melalui $query, kita dapat melakukan
7 identifikasi dan menyimpan kata tanya dari
kueri pertanyaan berupa array dengan index ke-0 atau query[0]. Tujuannya adalah menentukan tipe jawaban yang akan dikembalikan oleh sistem. Tipe jawaban dicirikan dengan tag named entity yang terdapat pada dokumen. Tabel 1 menunjukkan daftar pasangan jenis kata tanya dan named entity yang menjadi acuan dari jawaban yang akan dikembalikan.
Tabel 1 Daftar pasangan kata tanya dan named entity
Kata Tanya Tag Entitas
Siapa NAME, ORGANIZATION
Kapan DATE, TIME
Dimana LOCATION
Berapa NUMBER, CURRENCY
Perolehan dokumen teratas
Dokumen yang digunakan untuk proses perolehan jawaban adalah 10 dokumen dengan bobot kesamaan cosine tertinggi. Dengan memanfaatkan nilai idf dan tf-idf dapat dilakukan perolehan norm dari kueri dan dokumen. Kueri dimasukkan secara manual kemudian dilakukan perhitungan terhadap norm query, tf-idf query, dan norm untuk setiap dokumen. Langkah selanjutnya adalah memasangkan nilai norm query dengan query setiap dokumen untuk menghasilkan nilai dotproduct dan cosine. Setelah diperoleh nilai cosine, dilakukan pengurutan nilai cosine. Dokumen yang diambil untuk memasuki langkah selanjutnya adalah 2 dan 10 dokumen dengan nilai cosine tertinggi.
Selanjutnya dilakukan pemilihan passages pada kamus passage yang termasuk dalam 10 dokumen di atas. Hasil pemilihan passages ini disimpan dalam variabel $passagesDocTop untuk digunakan pada tahap perolehan top passages.
Perolehan Top Passages
Passages yang akan digunakan dalam proses pembobotan adalah passages yang mengandung tag named entity yang dibutuhkan, yang dalam pembahasan kali ini disebut arrayTag. arrayTag merupakan hasil dari identifikasi kata tanya. Misalnya ‘Siapa’ yang mengacu pada PERSON- ORGANIZATION, dan Kapan yang mengacu pada DATE-TIME.
Selanjutnya passage yang disimpan variabel $passagesDocTop kemudian disaring untuk diambil passages yang memiliki TAG sesuai
kata tanya kueri pertanyaan. Selanjutnya dilakukan pembobotan passages menggunakan pembobotan heuristic dan pembobotan menggunakan metode rule-based.
Pembobotan Heuristic
Sesuai dengan tahapan yang terdapat dalam jurnal Ballesteros dan Xiaoyan-Li (2007) serta penelitian Cidhy (2009) yang digunakan sebagai acuan dalam penelitian ini, pembobotan passages terdiri atas :
1. Pembobotan passages berdasarkan hasil dari proses wordmatch sesuai threshold. Hasilnya disimpan dalam variabel count_match.
2. Pembobotan passages berdasarkan urutan nilai dari arrayWordQuestion (kata-kata selain kata tanya pada kueri) dalam passages. Hasilnya bernilai Boolean, disimpan dalam variabel Ord.
3. Pembobotan passages berdasarkan nilai dari arrayWordQuestion dalam passages. Hasilnya bernilai Boolean, disimpan dalam variabel Sm.
4. Pembobotan berdasarkan hasil dari proses wordmatch sesuai threshold berbanding ukuran passage (jumlah kata dalam satu passage).
Setelah diperoleh nilai dari ke-empat variabel di atas kemudian dihitung skor heuristic setiap passage yaitu:
heuristic_score = count_match + count_match/W + Sm*0.5 + Ord*0.5.
Pembobotan Rule-based
Mengacu pada rule yang terdapat dalam Riloff dan Thelen (2000) serta penelitian Sianturi (2008), yang digunakan sebagai acuan dalam penelitian ini pembobotan passages terdiri atas:
1. Fungsi WordMatch. WordMatch adalah nilai perbandingan antara kalimat kueri dengan kalimat pada dokumen. Algoritme WordMatch dilakukan dengan cara membandingkan token-token pada setiap passages dengan token-token pada kalimat kueri. Setiap token yang sama akan menambahkan nilai pada passages tersebut. Hasilnya disimpan dalam variabel WordMatch.
2. Algoritme Rule. Penelitian ini membuat algoritme rule dengan melakukan beberapa modifikasi yang digunakan dalam pembobotan passages. Algoritme rules yang
8 digunakan sebagai acuan dalam penelitian
ini: 1. “SIAPA” Score(S) +=WordMatch (Q,S) If contains(Q,HUMAN) && (S,Human) then Score(S) += slam_dunk
Algoritme rule untuk kueri pertanyaan dengan kata tanya “SIAPA” pada sistem yang dibangun pada penelitian ini berbeda dengan algoritme rule yang telah diimplementasikan oleh Sianturi (2008). Perbedaannya terletak pada penambahan rule dan pemberian nilai score.
2. “KAPAN”
Score(S) +=WordMatch (Q,S)
If contains(S, {saat, ketika, kala,
semenjak, sejak, waktu, setelah,
sebelum}) and contains(S,TIME)
then
Score(S) += slam_dunk
If contains(S,TIME) and contains(Q,TIME) then
Score(S) += confident
If contains(S, {saat, ketika, kala,
semenjak, sejak, waktu, setelah,
sebelum}) or contains(S,TIME)
then
Score(S) += good_clue
Algoritme rule untuk kueri pertanyaan dengan kata tanya “KAPAN” yang dibangun pada penelitian ini dengan algoritme rule yang telah diimplementasikan oleh Sianturi (2008) hanya berbeda pada pemberian nilai score.
3. “DIMANA”
Score(S) +=WordMatch (Q,S) If contains(S, {dalam, dari,
pada}) and contains(S,LOCATION) then
Score(S) += slam_dunk
If contains(S,LOCATION) then Score(S) += good_clue
If contains(S, {dalam, dari, pada }) then
Score(S) += clue
Algoritme rule yang digunakan sama dengan rule yang telah diimplementasikan oleh Sianturi (2008). 4. “BERAPA” Score(S) +=WordMatch (Q,S) If contains(Q,NUMBER) and contains(S,NUMBER) then Score(S) += slam_dunk If contains(S,NUMBER) then Score(S) += confident
Algoritme rule yang digunakan dibuat sendiri oleh penulis.
Fungsi dan notasi yang digunakan dalam rules tersebut adalah sebagai berikut : 1. Notasi S = sentence (kalimat dokumen). 2. Notasi Q = query (kalimat kueri).
3. Fungsi contains adalah fungsi untuk memeriksa kalimat dokumen dan kalimat kueri pertanyaan, apakah mengandung kata yang telah ditentukan.
4. Fungsi WordMatch adalah fungsi untuk memeriksa kesamaan kata.
5. Fungsi score adalah fungsi pemberian nilai pada kalimat dokumen
.
Setelah diperoleh nilai dari Wordmatch dan rule dihitung skor setiap passage.
Pembobotan Heuristic dan Rule-Based Pembobotan passages gabungan heuristic dan rule-based dilakukan berdasarkan nilai hasil dari proses pembobotan heuristic yang diperoleh dari pencocokan kata kueri dengan passages dan nilai pembobotan rule-based diperoleh dari rule yang digunakan. Formula untuk penggabungan kedua metode:
$scoreTotal =
α*$heuristic+(1-α)* $rule-based dengan α=0.5.
Ekstraksi Jawaban
Tahap berikutnya adalah ekstraksi jawaban dari top passages yang diperoleh. Passage yang memiliki nilai tertinggi pada pembobotan passages menjadi top passage. Kata yang menjadi kandidat jawaban adalah kata yang memiliki entitas sesuai dengan kata tanya pada kueri pertanyaan. Yang perlu diperhatikan dalam perolehan entitas jawaban adalah top passage dapat terdiri atas satu atau lebih passage dan setiap passage dapat memiliki satu atau lebih kandidat jawaban. Jawaban akhir setiap passage diperoleh dengan cara menghitung jarak antara setiap kandidat jawaban pada setiap passage dengan masing-masing kata pada $arrayWordMatch. $arrayWordMatch merupakan array yang menampung kumpulan kata hasil pencocokan antara keyword dengan kata-kata pada passage. Kandidat jawaban yang memiliki jarak
9 terpendek dianggap sebagai jawaban yang
paling tepat.
Contoh hasil percobaan menggunakan kueri “Siapa Muwardi P. Simatupang?”, diperoleh 19 passages pada satu dokumen teratas. Setelah diambil passage yang mengandung tag <NAME> atau <ORGANIZATION> diperoleh 12 passage dari 19 passage. TopPassage yang diperoleh dengan heuristic, rule-based serta gabungan heuristic dan rule-based adalah sama. Nilai pembobotan untuk rule-based 5,078 ,heuristic 10 dan gabungan kedua metode adalah 7,53. Top passages yang diperoleh:
Ini mungkin karena pendekatan pembangunan pertanian masih bersifat subsisten kata <ORGANIZATION> Ketua Umum Dewan Pimpinan Pusat Himpunan Alumni Institut Pertanian Bogor </ORGANIZATION> <NAME> Muwardi P Simatupang </NAME> pada acara diskusi 'Membangun Pertanian <LOCATION> Indonesia </LOCATION> Untuk Meningkatkan Pendapatan Petani dan Negara' di <LOCATION> Jakarta </LOCATION> <DATE> Kamis(22/4) </DATE> <NAME>
Muwardi</NAME> mengatakan
pendekatan subsisten merupakan pendekatan yang menitikberatkan pada peningkatan produksi
Kandidat jawaban yang diperoleh hanya ada satu yaitu kata Ketua Umum Dewan Pimpinan Pusat Himpunan Alumni Institut Pertanian Bogor sehingga kata tersebut menjadi jawaban akhir.
Hasil Percobaan
Hasil percobaan dilakukan dengan membandingkan hasil penelitian yang dilakukan oleh penulis dengan hasil penelitian Cidhy (2009). Perbandingan dilakukan dengan melihat perolehan top passage, ketepatan jawaban dan
dokumen yang ditemukembalikan dengan menggunakan tiga pembobotan passages yaitu heuristic (Cidhy 2009), rule-based serta gabungan heuristic dan rule-based dengan menggunakan 10 dokumen teratas.
Jumlah koleksi dokumen yang digunakan sebanyak 106 dokumen dan sebanyak 40 kueri. Kueri tersebut diambil dari penelitian Cidhy (2009). Proses dokumentasi evaluasi kueri dicatat dalam bentuk tabel yang terdiri atas sumber dokumen, pertanyaan (kueri), perolehan passages, ketepatan dokumen, ketepatan jawaban, dan koreksi. Kemudian dilakukan pencocokan antara hasil pencarian yang diperoleh terhadap pasangan dokumen dan kueri pertanyaan yang seharusnya. Berdasarkan kesesuaian pasangan jawaban dan dokumen, penilaian dibedakan menjadi 4 jenis yaitu : right, wrong, unsupported, dan null. Persentase evaluasi hasil percobaan yang dilakukan oleh Cidhy dan penulis dapat dilihat pada Tabel 2. Berikut pembahasan untuk masing-masing percobaan :
1. Perbandingan Hasil Percobaan Untuk Kata Tanya SIAPA
Berdasarkan 10 kueri pertanyaan yang diuji, diambil contoh kueri pertanyaan Siapa Bungaran Saringgih ?. Hasil penelitian Cidhy (2009) dan penulis mengembalikan 10 dokumen teratas yang sama, namun mengembalikan top passage dan jawaban yang berbeda. Top passage yang diperoleh pada penelitian Cidhy (2009) :
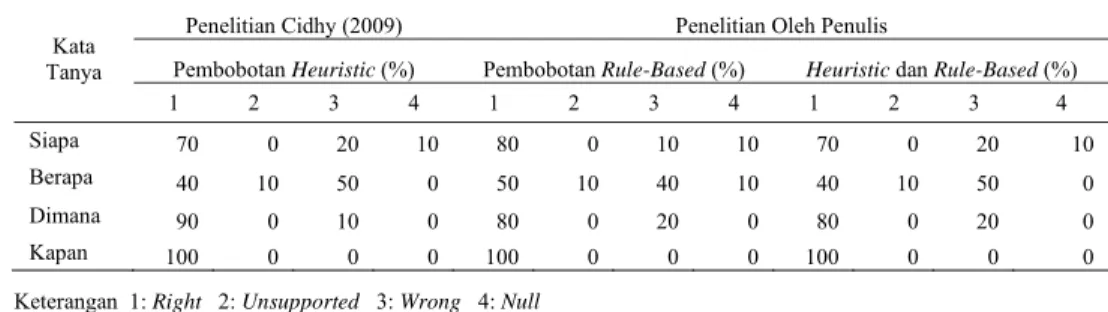
Tabel 2 Persentase perolehan jawaban oleh Cidhy (2009) dan penulis menggunakan 10 dokumen teratas
Kata Tanya
Penelitian Cidhy (2009) Penelitian Oleh Penulis
Pembobotan Heuristic (%) Pembobotan Rule-Based (%) Heuristic dan Rule-Based (%)
1 2 3 4 1 2 3 4 1 2 3 4
Siapa 70 0 20 10 80 0 10 10 70 0 20 10
Berapa 40 10 50 0 50 10 40 10 40 10 50 0
Dimana 90 0 10 0 80 0 20 0 80 0 20 0
Kapan 100 0 0 0 100 0 0 0 100 0 0 0
10 Menurut <NAME> Bungaran Saragih
</NAME>, hal tersebut wajar dengan keadaan setiap penyalur pupuk, dimana mereka memerlukan waktu dalam proses pengepakan kembali. Mengenai kelangkaan pupuk di <LOCATION> Cirebon </LOCATION> yang hanya terjadi di beberapa kecamatan, <NAME> Bungaran Saragih </NAME> menegaskan bahwa produsen pupuk setempat telah menutupi kelangkaan tersebut dengan pengiriman pupuk dari luar wilayah <LOCATION> Cirebon </LOCATION>.
Top passage di atas diperoleh dari dokumen indosiar260504.txt. Berdasarkan hasil top passage, tidak diperoleh kandidat jawaban sehingga jawaban yang dikembalikan null.
Dengan menggunakan kueri pertanyaan yang sama, penelitian yang dilakukan menggunakan rule-based menghasilkan kriteria right yaitu Menteri Pertanian. Jawaban ini diperoleh setelah sistem mengembalikan top passage sebagai berikut :
Dalam acara yang dihadiri <ORGANIZATION> Menteri Pertanian </ORGANIZATION> <NAME>Bungaran Saragih</NAME>, <ORGANIZATION> Menteri Kelautan dan Perikanan </ORGANIZATION> <NAME> Rokhmin Dahuri </NAME>, serta Menakertrans <NAME> Jacob Nuwa Wea </NAME>, <NAME> Presiden Megawati </NAME> menyampaikan rasa terima kasihnya kepada masyarakat <LOCATION> Gorontalo </LOCATION> yang telah bekerja keras menanam dan memproduksi jagung. Dalam pidato tanpa teks, <NAME>Mega</NAME> mengatakan, ''Saya melihat potensi menanam jagung di <LOCATION> Gorontalo</LOCATION> memang bisa digerakkan, bahkan bisa menjadi satu potensi yang sangat luar biasa.
Top passage di atas diperoleh dari dokumen indosiar260504.txt.
Masih menggunakan kueri pertanyaan yang sama, penelitian yang dilakukan menggunakan gabungan heuristic dan rule-based juga menghasilkan kriteria null yaitu tidak mengembalikan jawaban. Hal ini disebabkan top passage yang dihasilkan sama dengan top passage pada penelitian Cidhy (2009).
Jawaban yang diperoleh dengan rule-based lebih tepat dibanding metode yang lain. Hal ini disebabkan oleh top passage yang dihasilkan rule-based lebih relevan dibanding metode yang lain.
Persentase ketepatan jawaban untuk kata tanya SIAPA pada penelitian Cidhy (2009) menghasilkan persentase kriteria right sebesar 70%, wrong 20% dan null 10%, sedangkan hasil penelitian penulis menghasilkan persentase kriteria right sebesar 80%, wrong 10% dan null 10% untuk rule-based dan kriteria right sebesar 70%, wrong 20% dan null 10% untuk gabungan heuristic dan rule-based. Daftar kueri pertanyaan dan evaluasi untuk kata tanya SIAPA dapat dilihat pada Lampiran 4. 2. Perbandingan Hasil Percobaan Untuk
Kata Tanya KAPAN
Berdasarkan 10 kueri pertanyaan yang diuji, diambil contoh kueri pertanyaan Kapan dilakukan penelitian di rumah kaca Balitro?. Hasil penelitian Cidhy (2009) dan penulis mengembalikan 10 dokumen teratas, top passage dan jawaban yang dihasilkan pada ketiga percobaan adalah sama. Jawaban yang diperoleh adalah 1998/1999. Berikut top passage yang bersumber dari dokumen balaipenelitian000000-009.txt:
Penelitian ini bertujuan untuk menguji potensi agensi hayati dalam menekan perkembangan penyakit layu bakteri jahe. Untuk itu telah dilakukan penelitian di <LOCATION>rumah kaca Balittro Bogor
</LOCATION> pada tahun <DATE>1997/1998 </DATE> dan di lanjutkan penelitian di lapang di <LOCATION> IP Sukamulya (Sukabumi)</LOCATION> pada tahun <DATE>1998/1999</DATE>.
Persentase ketepatan jawaban untuk kata tanya KAPAN merupakan yang paling tinggi dibanding kata tanya yang lain. Baik penelitian Cidhy maupun yang dilakukan penulis, menghasilkan persentase kriteria right sebesar 100%. Hal ini disebabkan kedua penelitian menghasilkan top passage yang sama dengan tepat sehingga diperoleh jawaban yang sama. Daftar kueri pertanyaan dan evaluasi untuk kata tanya KAPAN dapat dilihat pada Lampiran 5. 3. Perbandingan Hasil Percobaan Untuk
Kata Tanya DIMANA
Berdasarkan 10 kueri pertanyaan yang diuji, diambil contoh kueri pertanyaan Dimana terjadi kekeringan dengan jumlah terbanyak?. Hasil penelitian Cidhy (2009) dan penulis mengembalikan 10 dokumen teratas yang sama, namun mengembalikan top passage dan jawaban yang berbeda. Top passage yang diperoleh pada penelitian Cidhy (2009) terdapat
11 pada dokumen mediaindonesia270308.txt.
Adapun top passages yang dihasilkan:
Mereka yang terkena dampak kekeringan khususnya pada kebutuhan rumah tangga itu terdapat di wilayah <LOCATION> Kabupaten Gunungkidul</LOCATION>, <LOCATION> Sleman, dan Kulonprogo </LOCATION>. Jumlah yang terkena kekeringan terbanyak di wilayah <LOCATION> Kabupaten Gunungkidul</LOCATION> yang mencapai lebih dari <NUMBER> 100
ribu jiwa </NUMBER>.
Berdasarkan hasil top passage, diperoleh kriteria right dengan kandidat jawaban Sleman, dan Kulonprogo.
Dengan menggunakan kueri pertanyaan yang sama, penelitian yang dilakukan menggunakan rule-based menghasilkan kriteria wrong yaitu Kabupaten Rembang. Jawaban ini diperoleh setelah sistem mengembalikan top passage yang kurang tepat sebagai berikut :
Provinsi <LOCATION> Jateng </LOCATION> menghadapi kekeringan tahun ini telah memprioritaskan pembuatan embung-embung air agar dapat mengairi lahan pertanian yang dilanda kekeringan. "Kita tengah mempercepat pembuatan embung di <LOCATION>Kabupaten
Rembang</LOCATION> pada tahun <DATE>2005</DATE>, agar lahan pertanian di <LOCATION>Kabupaten Rembang</LOCATION> yang sering dilanda kekeringan dapat terairi," katanya.
Masih menggunakan kueri pertanyaan yang sama, penelitian yang dilakukan menggunakan gabungan heuristic dan rule-based juga menghasilkan kriteria wrong yaitu Kabupaten Rembang. Hal ini disebabkan top passage yang dihasilkan sama dengan top passage pada rule-based.
Persentase ketepatan jawaban untuk kata tanya DIMANA pada penelitian Cidhy (2009) lebih baik dari metode yang lain, karena menghasilkan persentase kriteria right sebesar 90% dan wrong 10%, sedangkan hasil penelitian penulis dengan rule-based dan untuk gabungan heuristic dan rule-based menghasilkan persentase yang sama dengan kriteria right sebesar 80% dan wrong 20%. Daftar kueri pertanyaan dan evaluasi untuk kata tanya DIMANA dapat dilihat pada Lampiran 6
.
4. Perbandingan Hasil Percobaan Untuk Kata Tanya BERAPA
Berdasarkan 10 kueri pertanyaan yang diuji, diambil contoh kueri pertanyaan Berapa luas wilayah yang ditanami tanaman padi di Kalimantan Timur?. Hasil penelitian Cidhy (2009) dan penulis mengembalikan 10 dokumen teratas yang sama, namun mengembalikan top passage dan jawaban yang berbeda. Top passage yang diperoleh pada penelitian Cidhy (2009) maupun gabungan heuristic dan rule-based mengembalikan kriteria wrong dengan jawaban 6 kecamatan. Adapun top passage yang diperoleh dari dokumen indosiar031203.txt, yaitu :
Dari catatan <ORGANIZATION>Dinas Pertanian dan Tanaman Pangan Provinsi Jambi</ORGANIZATION>, rusaknya tanaman pertanian akibat banjir yang terjadi pada tanaman padi, cabe, kacang tanah, dan jeruk. Hal itu terjadi di <NUMBER>6 kecamatan</NUMBER> yang ada di <LOCATION>Kabupaten
Kerinci</LOCATION>, seperti tanaman padi seluas <NUMBER>11,87 hektar</NUMBER> tergenang air, dan sebanyak <NUMBER>148 hektar</NUMBER> mengalami puso.
Pada kueri pertanyaan yang sama, penelitian yang dilakukan menggunakan rule-based mengembalikan jawaban yang benar yaitu 11,5 juta dengan top passage sebagai berikut :
Semua pelaku usaha perbenihan
masih mengonsentrasikan pemasarannya di <LOCATION> Pulau
Jawa </LOCATION> yang dinilai sudah maju dalam usaha tanaman pangan, sedangkan di luar <LOCATION> Pulau Jawa </LOCATION> belum banyak disentuh atau dimanfaatkan produsen benih sehingga produktivitas padi yang dihasilkannya pun masih rendah. <NAME> Susena </NAME> mengatakan, peluang pemasaran benih padi unggul saat ini masih terbuka lebar karena dari areal tanaman padi sekira <NUMBER>11,5 juta</NUMBER> ha, hanya sekira <NUMBER> 4 juta </NUMBER> ha yang menggunakan benih padi unggul.
Jawaban yang diperoleh dengan rule-based lebih tepat dibanding metode yang lain. Hal ini disebabkan oleh top passage yang dihasilkan rule-based lebih relevan dibanding metode yang lain.
12 Persentase ketepatan jawaban untuk kata
tanya BERAPA merupakan yang paling rendah dibanding kata tanya yang lain. Dengan metode rule-based menghasilkan persentase kriteria right sebesar 50%, unsupported 10%, dan wrong 40%, sedangkan penelitian Cidhy (2009) maupun metode gabungan menghasilkan persentase kriteria right sebesar 40%, unsupported 10%, dan wrong 50%. Hal ini disebabkan pada panamaan entitas (Name-Entity-Tagger) untuk Kata Tanya BERAPA masih dalam ruang lingkup yang kecil, yaitu hanya menggunakan tangging <NUMBER>, <CURRENCY>, dan <PERCENT> sedangkan penulisan teks dan informasi untuk jawaban BERAPA seringkali disajikan dengan cara lebih variatif. Seperti adanya penulisan dalam bentuk rincian untuk jumlah, luas dan lain-lain.
Daftar kueri pertanyaan dan evaluasi untuk kata tanya BERAPA dapat dilihat pada Lampiran 7.
5. Perbandingan Hasil Percobaan untuk keseluruhan Kata Tanya
Percobaan dilakukan dengan membandingkan ketepatan passage dan jawaban yang ditemukembalikan pada keseluruhan Kata Tanya menggunakan tiga metode pembobotan passages.
Perbandingan Hasil Percobaan menggunakan 10 Dokumen Teratas
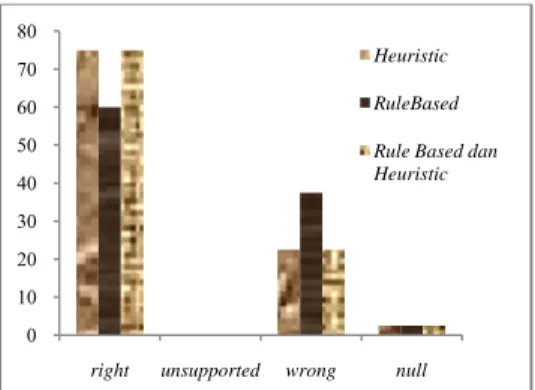
Persentase ketepatan jawaban yang ditemukembalikan dari hasil percobaan dapat dilihat pada Gambar 8.
Gambar 8 Grafik hasil percobaa keseluruhan kata tanya menggunakan 10 dokumen teratas.
Berdasarkan Gambar 8 dapat dilihat bahwa metode pembobotan rule-based menghasilkan persentase kriteria right yang tinggi dibanding metode yang lain. Persentase untuk kriteria right untuk rule-based sebesar 77,5%, heuristic persentasenya lebih rendah daripada rule-based
sebesar 75%, dan untuk penggabungan kedua metode hasil persentasenya lebih kecil dari masing-masing metode sebesar persentase 72,5%.
Perbandingan Hasil Percobaan menggunakan 2 Dokumen Teratas
Persentase ketepatan jawaban yang ditemukembalikan dari hasil percobaan dapat dilihat pada Gambar 9.
Gambar 9 Grafik hasil percobaan keseluruhan kata tanya menggunakan 2 dokumen teratas.
Berdasarkan Gambar 9 dapat dilihat bahwa metode pembobotan heuristic serta gabungan heuristic dan rule-based menghasilkan persentase kriteria right yang tinggi dibanding metode rule-based. Persentase heuristic dan penggabungan kedua metode hasil persentasenya sebesar 75% sedangkan persentase untuk kriteria right untuk rule-based sebesar 60%.
Dengan menggunakan keseluruhan Kata Tanya yang diambil dari 10 dokumen teratas, metode rule-based lebih banyak mengembalikan top passages dan jawaban yang tepat. Diambil dari 2 dokumen teratas, metode heuristic serta gabungan heuristic dan rule-based yang lebih banyak mengembalikan top passages dan jawaban yang tepat. Dengan demikian, dilihat untuk masing-masing pembobotan dapat mengembalikan jawaban yang tepat namun tergantung pada banyaknya dokumen yang digunakan. Untuk pembobotan dengan metode rule-based berpengaruh pada banyaknya dokumen namun tergantung pada rule yang digunakan dalam menemukembalikan jawaban berdasarkan tipe pertanyaan kueri, sedangkan pembobotan heuristic berpengaruh pada banyaknya dokumen dan keterkaitan informasi dan urutan susunan kata pada kueri dengan passages. 0 10 20 30 40 50 60 70 80 90
right unsupported wrong null Heuristic
RuleBased
Rule Based dan Heuristic 0 10 20 30 40 50 60 70 80
right unsupported wrong null Heuristic
RuleBased
Rule Based dan Heuristic