MODUL PRAKTIKUM
METODE STATISTIKA I
Oleh:
Dr. Suci Astutik, S.Si., M.Si.
Darmanto, S.Si.
PRODI STATISTIKA
JURUSAN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS BRAWIJAYA
PRAKTIKUM I
STATISTIKA DESKRIPTIF I
1. Tujuan Umum
Mahasiswa mampu menghitung dan menginterpretasikan ukuran pemusatan dan penyebaran dari suatu data.
2. Tujuan Khusus
Mahasiswa mampu :
1. menghitung nilai mean, median, jangkauan, variansi dan simpangan baku serta menginterpretasikannya.
2. menjelaskan pengaruh outlier terhadap mean dan median. 3. menjelaskan hubungan antara jangkauan dan simpangan baku. 3. Teori
Beberapa Pengertian:
a. Rata-rata hitung (mean) yaitu jumlah data dibagi banyaknya data (ukuran data) atau dapat ditulis
n 1 i i x n 1 xdi mana x mean , n= ukuran data dan xi data ke i. b. Median
Sebelum menentukan nilai median, data diurutkan terlebih dulu.
Jika banyaknya data ganjil maka median merupakan nilai tengah suatu data sedangkan jika banyaknya data genap maka median merupakan rata-rata dari dua nilai tengah suatu data.
c. Rentang/range/jangkauan : Selisih antara data maksimum dan minimum. d. Variansi dari suatu data sampel x1, x2, …, xn adalah
1 n x x s n 1 i 2 i 2
s2 = notasi variansi sampel
Simpangan baku = akar positif variansi. 4. Metodologi
Perintah:
Terdapat tiga cara untuk membuka dan membuat worksheet pada software GenStat a. Data yang akan digunakan diinputkan ke Microsoft excel simpan dengan format
*xls. Buka Genstat dan klik icon Microsoft excel untuk menginput data, diperoleh kotak dialog sebagai berikut:
Pilih file data yang akan digunakan, klik icon “Set as Working Directory”, kemudian klik Open. Selanjutnya muncul kotak dialog sebagai berikut:
Klik Next, muncul kotak dialog sebagai berikut:
Pada Selection of Cells in the Worksheet to be used in the Spreadsheet, pilih Specified Range. Kemudian isi dengan A2:A13, yang menjelaskan posisi data di Excel. Selanjutnya, klik Finish. Kemudian muncul data sebagai berikut:
b. Copy data yang ada di Excel. Kemudian buka Genstat, klik Spread > New > From Clipboard. Kemudian muncul kotak dialog sebagai berikut:
Beri centang pada Drop empty rows, Data contains Variates & factors only, Set as Active Sheet, pada Column names in first row, pilih Yes if All labels. Klik OK. Muncul kotak dialog berikut:
Klik Yes. Kemudian muncul:
Kemudian pada kotak dialog dengan nama Genstat, klik Yes. Kemudian ganti nama C2 dengan cara bawa cursor ke arah C2 sampai keluar gambar tangan, kemudian klik kanan, pilih Rename. Ganti C2 dengan Data. Kemudian klik OK.
c. Buka Genstat. Klik Spread > New > Create . Kemudian muncul kotak dialog sebagai berikut:
Isi Rows dengan banyaknya sampel. Isi Columns dengan banyaknya variabel. Beri centang pada Set as Active Sheet. Klik OK. Kemudian muncul sebagai berikut:
Kemudian pada kotak dialog dengan nama Genstat, klik Yes. Kemudian masukkan data dan ganti nama C3 dengan cara bawa cursor ke arah C3 sampai keluar gambar tangan, kemudian klik kanan, pilih Rename. Ganti C3 dengan Data. Kemudian klik OK. Sehingga didapatkan:
Sedangkan untuk menampilkan statistika deskriptif
Klik Stats > Summary Statistics > Summarize Contents of Variates. Kemudian muncul kotak dialog sebagai berikut:
Masukkan data dari Available data ke kolom Variates kemudian centang statistik yang diinginkan
Klik OK maka akan diperoleh hasil sebagai berikut:
5. Percobaan
1. Ambil suatu data sampel berukuran 12 yang nilainya antara 30 – 40.
2. Masukkan data tersebut ke spreadsheet dengan ketiga cara. Beri nama Data. 3. Lakukan langkah 1 dan 2. Ubah nilai data ke-1 menjadi 65. Beri nama Data_65. 4. Lakukan langkah 1 dan 2. Ubah nilai data ke-1 menjadi 130. Beri nama
Data_130.
5. Lakukan langkah 1 dan 2. Ubah nilai data ke-1 menjadi 10. Beri nama Data_10. 6. Lakukan langkah 1 dan 2. Ubah nilai data ke-1 menjadi 25. Beri nama Data_25. 7. Hitung nilai mean, median dan simpangan baku data kelima data tersebut
8. Buat kolom baru kemudian tambahkan setiap data dengan 29. Beri nama Data+29.
9. Buat kolom baru kemudian kalikan setiap data dengan 16. Beri nama Data*16. 10. Hitung nilai simpangan baku untuk Data, Data+29 dan Data* dengan
menggunakan GenStat.
11. Print hasil percobaan saudara, lalu buatlah analisisnya berdasarkan pertanyaan berikut:
a. Hitung nilai mean, median, simpangan baku dan jangkauan secara manual. b. Bandingkan mean dan median hasil 2, 3, 4, 5, 6, 11a. Kesimpulan apa yang
dapat saudara ambil.
c. Hitung nilai jangkauan untuk data kolom Data, Data_65,Data130, Data_10 dan Data_25. Adakah hubungan antara jangkauan dan simpangan bakunya? Jelaskan jawaban saudara.
d. Hitung pula nilai variansinya. Bandingkan variansi, simpangan baku hasil 10 dan 11a. Kesimpulan apa yang dapat saudara ambil.
PRAKTIKUM II
STATISTIKA DESKRIPTIF II
1. Tujuan Umum
Mahasiswa mampu menyajikan data dalam bentuk tabel, diagram atau grafik serta mampu menganalisis dan menginterpretasikannya.
2. Tujuan Khusus
Mahasiswa mampu :
1. menyusun tabel distribusi frekuensi, membuat grafik histogram dari suatu data serta mampu menganalisis dan menginterpretasikannya.
2. membuat diagram stem-and-leaf (diagram batang-dan-daun) dari suatu data serta mampu menganalisis dan menginterprestasikannya.
3. memberi argumentasi jika terdapat perbedaan antara hasil interpretasi 1 dan 2.
3. Teori
Bila data yang ada banyak jumlahnya, maka untuk memudahkan dalam analisis data perlu disusun distribusi frekuensi. Distribusi frekuensi kuantitatif yaitu penyusunan data menurut besarnya (kuantitatifnya).
Cara menyusun distribusi kuantitatif yaitu:
Menentukan banyak dan lebar interval kelas. Banyak interval kelas yang efisien biasanya antara 5 dan 15.Rumus banyak interval kelas (H.A Struges, 1925) adalah k = 1 + 3, 322 log n dan
Lebar interval =
k
range Jangkauan( )
Interval-interval tersebut diletakkan dalam suatu kolom, diurutkan dari interval kelas terendah pada kolom paling atas dan seterusnya.
Data diperiksa dan dimasukkan ke dalam interval kelas yang sesuai. Frekuensi interval kelas yaitu banyak data dalam suatu interval kelas.
Nilai mean dan median dari data yang disajikan dalam distribusi frekuensi dapat dihitung menggunakan rumus sebagai berikut :
mean data = n x f f x f f f f x f x f x f x k i i i k i i k i i i k k k
1 1 1 2 1 2 2 1 1 ... ...di mana fi = frekuensi interval kelas ke- i.
xi = nilai tengah interval kelas ke- i.
k = banyaknya interval kelas
c f F L Md Median Md n Md 2
di mana : LMd = Batas bawah interval median
n = banyak data
F = jumlah frekuensi interfal sebelum interval median fMd = frekuensi interval median
c = Lebar interval
Di samping data disajikan dalam bentuk tabel frekuensi dapat juga disajikan dalam bentuk grafik. Grafik yang akan dibahas di sini adalah histogram dan stem-and-leaf. Cara menggambarkan histogram distribusi frekuensi yaitu dengan meletakkan interval
kelas pada sumbu-x dan frekuensi pada sumbu-y. Selanjutnya untuk keperluan beberapa analisis, kita juga dapat menyajikan data berupa histogram distribusi frekuensi kumulatif, histogram persen, histogram persen kumulatif.
Suatu diagram stem-and-leaf mempunyai tampilan yang serupa dengan histogram, tetapi menggunakan data yang sebenarnya (bukan interval) untuk membuat tampilan. Misal 60,81,48,70,72,63,54,50 adalah sekumpulan data fiktif. Slah satu tampilan diagram stem-and-leaf yaitu :
Stem-and-leaf of C2 N = 8 Leaf Unit = 1.0 1 4 8 3 5 04 3 5 N= (2) 6 03 3 6 3 7 02 1 7 1 8 1 stem leaf 4. Metodologi
Perintah untuk membuat tampilan diagram stem-and-leaf : Graphics Stem and Leaf
Muncul dialog box, isikan pada kotak Data nama kolom yang akan dibuat tampilannya. Pada options Digits per Leaf :menunjukkan jumlah digit satuan yang diinginkan dan Stem unit menunjukkan satuan unit untuk data awal (10,100,1000 dst).
Klik Ok
Perintah untuk membuat grafik histogram : Graphics Histogram
Muncul dialog box, pada kotak Select Data diisi nama kolom yang akan dibuat grafiknya. Klik Next untuk pengaturan histogram yang lebih lanjut, seperti memberi
judul pada histogram, memberi batas atas dan batas bawah. Jika batasan yang digunakan hanya data yang kita pilih maka klik Use data values. Klik Finish Finish.
Maka akan diperoleh hasil sebagai berikut:
5. Percobaan
Data : 86, 75, 68, 66, 60, 45, 92, 82, 76, 66, 73, 61, 51, 28, 30, 55, 62, 71, 69, 80, 83, 32, 56, 63, 74.
1. Isilah data di dalam spreadsheet GenStat pada kolom C1, beri nama datastat. 2. Kalikan datastat dengan 2, isikan pada kolom C2 dan beri nama datastat_*2. 3. Kalikan datastat dengan 5, isikan pada kolom C3 dan beri nama datastat_*5. 4. Kalikan datastat dengan 10, isikan pada kolom C4 dan beri nama datastat_*10. 5. Gunakan GenStat untuk membuat tampilan stem-and-leaf dari datastat, datastat_*2,
datastat_*5, datastat_*10.
6. Gunakan Genstat untuk membuat tampilan histogram frekuensi untuk datastat. 7. Ulangi percobaan 6 untuk datastat_*5 .
8. Ulangi percobaan 6 untuk datastat_*10.
9. Print hasil percobaan saudara lalu buatlah analisisnya berdasarkan pertanyaan berikut :
a. Berdasarkan diagram stem-and-leaf datastat.
Tentukan mean, median,data terendah dan data tertinggi. Berapa banyak data yang mempunyai nilai tujuhpuluhan.
Berapa banyak data yang mempunyai nilai di bawah 65, di bawah mean, di atas 65, di atas mean.
b. Bandingkan hasil-hasil tampilan percobaan 5.
c. Susunlah tabel distribusi frekuensi dari Data dengan banyak interval kelas menurut rumus H.A Sturges dan gambarkan grafiknya secara manual.
PRAKTIKUM III
PENGANTAR PELUANG
1. Tujuan Umum
Mampu menjelaskan teori peluang sebagai dasar pengembangan statistika. 2. Tujuan khusus
Mahasiswa mampu :
1. menghitung jumlah anggota ruang contoh.
2. mentranformasi ruang contoh ke peubah acak dan menghitung peluang peubah acak.
3. Teori
Percobaan statistika adalah proses yang menghasilkan data. Suatu contoh yang amat sederhana adalah lantunan mata uang logam. Seluruh kemungkinan hasil yang dapat terjadi dari percobaan statistika disebut ruang contoh (S). Prinsip dasar perhitungan titik contoh dikenal dengan analisa kombinatorika yang terdiri dari teorema dasar (perkalian), permutasi dan kombinasi.
Teorema Dasar (Perkalian):
Bila suatu operasi dapat dilakukan dengan n1 cara, dan bila untuk tiap cara ini
operasi kedua dapat dikerjakan dengan n2 cara, maka kedua operasi itu dapat
dikerjakan bersama-sama dengan n1n2cara.
Permutasi:
Banyak permutasi n benda berlainan bila diambil r sekaligus adalah
n! nPr =
---( n – r )!
Kombinasi:
Jumlah kombinasi dari n benda yang berlainan bila diambil sebanyak r adalah
n n!
( ) =
---r ---r! ( n – ---r )!
Sering yang menarik perhatian bukan titik contoh dari ruang contoh, melainkan gambaran numerik dari hasil. Bilangan tersebut dapat dipandang sebagai peubah acak x. Peubah acak adalah suatu fungsi bernilai real yang harganya ditentukan oleh tiap anggota dalam ruang contoh. Suatu peubah acak mendapat tiap nilai dengan peluang tertentu.
4. Metodologi Teori
Dua uang logam dilantunkan 1 kali. Tentukan S. Teori kombinatorika apa yang digunakan untuk menghitung S. Jika X adalah peubah acak banyaknya gambar yang muncul, tentukan nilai peubah acak X dan peluang masing-masing peubah acak X. Gambar histogram peluangnya.
5. Percobaan Percobaan 1.
Ambil 2 uang logam dan lantunkan sebanyak 4 kali. Daftarkan hasilnya. Apakah sudah sesuai dengan teori. Jika belum sesuai teori lakukan lagi lantunan sampai ruang contoh sesuai dengan teori dan daftarkan masing-masing frekuensinya. Berapa kali lantunan yang diperlukan supaya percobaan lantunan sesuai dengan teori. Gambar histogram peluangnya. Percobaan 2.
Kumpulkan hasil percobaan dari seluruh temanmu dan daftarkan seluruh frekuensinya. Jika x adalah peubah acak banyaknya gambar yang muncul, maka tentukan peluang peubah acak tersebut berdasarkan frekuensi relatifnya. Gambar histogram peluangnya. Tarik kesimpulan berdasar histogram peluang dari teori, percobaan 1 dan percobaan 2.
PRAKTIKUM IV
SEBARAN PELUANG KHUSUS
1. Tujuan Umum
Mahasiswa mampu menjelaskan bentuk sebaran khusus peubah acak diskrit dan peubah acak kontinyu
2. Tujuan Khusus
Mahasiswa mampu :
1. menjelaskan bentuk sebaran Binomial dengan parameter tertentu, dan mampu menghitung peluang dari sebaran Binomial.
2. menjelaskan bentuk sebaran Normal dengan parameter tertentu, dan mampu menghitung peluang dari sebaran Normal.
3. Teori
Sebaran Binomial
1. Peubah acak binomial adalah peubah acak diskrit yang menyatakan jumlah sukses yang diperoleh dari n percobaan yang masing-masing hanya memiliki dua kemungkinan, sukses dan gagal, dengan p sebagai peluang sukses.
2. Fungsi peluang dari X ~Bin
n,p adalah:
p
p
x n x n x X P x1 n x untuk 0,1,2,..., 3. Pusat dari sebaran ini adalah nilai harapannya sebesar: np. 4. Fungsi peluang kumulatif bagi sebaran ini adalah:
1
0
x j j n j p p j n x X P x F , sehingga P
X x
1F
x .5. Peluang X yang berada di antara selang tertentu:
1
. 1 a F b F p p j n b X a P b a j j n j
6. Invers dari fungsi kumulatif dengan peluang tertentu adalah, nilai x yang bersesuaian dengan fungsi kumulatif dengan nilai peluang yang diinginkan:
1
maka x F x F Sebaran Normal1. Peubah acak yang menyebar normal adalah peubah acak kontinyu yang mempunyai fungsi kepekatan peluang:
untuk - ,- , 0 2 1 2 2 1 x e x f x , umumnya dinyatakan sebagai
2, ~N
X .
2. menyatakan pusat dari sebaran normal dan menyatakan ketersebaran dari sebaran ini.
3. Peubah acak Z yang menyebar normal baku: Z~ N
0,1 , diperoleh dari peubah acak
2, ~N
X yang telah ditransformasi dengan hubungan:
X
Z .
x dx x f x X P x F , sehingga P
X x
1F
x .5. Peluang di antara dua nilai tertentu:
a X b
Pa X b
Pa X b
Pa X b
F
b F aP
6. Invers dari fungsi kumulatif dengan peluang tertentu adalah, nilai x yang bersesuaian dengan fungsi kumulatif dengan nilai peluang yang diinginkan
1
maka x F x F . 4. Metodologi:1. Membangkitkan data dengan sebaran tertentu dengan langkah: Click: Data > Generate Random sample.
Maka akan muncul dialog box seperti berikut:
Isilah
Distribution : distribusi yang diinginkan
Size of Sample : banyak data yang ingin dibangkitkan Save In : kolom yang diinginkan
Seed : 0
Properties
Mean : rata-rata dari data yang ingin dibangkitkan Variance : ragam dari data yang dibangkitkan
Beri tanda pada Display In spreadsheet. Klik OK
2. Melihat bentuk dan pusat sebaran dengan cara: Click: GraphicsHistogram.
Dari dialog box yang muncul, diisi kolom letak data yang akan dibuat histogramnya (misal: Normal)
Klik Finish
3. Menghitung frekuensi relatif dari nilai tertentu (misal: X=2), atau frekuensi relatif dari nilai-nilai pada selang tertentu (misal: -1<X<1), untuk data hasil bangkitan, dengan langkah:
Dari dialog box yang muncul isikan letak kolom untuk menyimpan hasil perhitungan (jangan di kolom yang sudah ada isinya), letak kolom yang berisi data bangkitan, dan ekspresi operasi matematika untuk mencari nilai yang diinginkan (Mis: X=2, -1<X<1 dll)
Misal: Untuk menentukan nilai-nilai yang memenuhi -1<X<1 isian pada kotak pertama adalah:
Pada kolom letak hasil perhitungan (C2) akan diperoleh kode 0 dan 1. Kode 1 berpasangan dengan nilai-nilai yang bersesuaian dengan -1<X<1, atau selang dan nilai lain yang diinginkan
Frekuensi dari nilai yang pada selang tersebut dihitung dengan cara menjumlahkan seluruh nilai pada kolom baru tersebut (C2), dengan cara: Data Calculations Klik Functions, sampai muncul dialog box seperti berikut:
yang diisi dengan function : Cumulative sum dan X: Data yang ingin dijumlahkan. Klik OK.
Frekuensi relatif dari nilai pada selang yang diinginkan adalah hasil dari perhitungan tersebut dibagi dengan jumlah angka yang telah dibangkitkan (misal: 50, 100 atau 1000).
Frekuensi relatif ini pada dasarnya adalah menghitung peluang suatu nilai tertentu, atau peluang nilai pada selang tertentu secara empiris.
4. Menghitung peluang secara teoritis, dengan langkah: Untuk Sebaran Kontinyu
Maka akan muncul dialog box:
Untuk sebaran kontinyu (Normal) dari dialog box yang muncul dapat diisikan parameter dari sebaran tersebut dan dapat dipilih:
Distribution : Pilih distribusi yang dicari peluangnya Parameter of Distribution : Parameter yang ingin digunakan Calculation : Pilih peluang yang ingin dicari Misal :
Cumulative Lower probability : Peluang kumulatif yang dicari, maka yang dimasukkan adalah X deviate
Critical value (one sided) : Nilai kritis dari peluang yang dicari, maka yang dimasukkan adalah confidence level (alpha)
Klik OK
Untuk sebaran diskrit,
Untuk sebaran diskret (Binomial) dari dialog box yang muncul dapat diisikan parameter dari sebaran tersebut dan dapat dipilih:
Distribution : Pilih distribusi yang dicari peluangnya Parameter of Distribution : Parameter yang ingin digunakan Calculation : Pilih peluang yang ingin dicari Misal :
Cumulative Lower probability : Peluang kumulatif yang dicari, maka yang dimasukkan adalah X deviate
Critical value (one sided) : Nilai kritis dari peluang yang dicari, maka yang dimasukkan adalah confidence level (alpha)
Klik OK. 5. Percobaan
Sebaran Binomial:
1. Bangkitkan data sebanyak 100 nilai dari sebaran Binomial dengan parameter: a. n10 dan p 0.1
b. n10 dan p0.5 c. n10 dan p0.9
2. Buat histogram dari data bangkitan pada 1a, 1b, dan 1c. Bandingkan bentuk dan pusat sebaran dari histogram tersebut!
3. Dari masing-masing data bangkitan pada 1a, 1b, 1c, hitunglah frekuensi relatif dariX 5,X 4,X 6,4 X 6, dengan menggunakan metode empirik. 4. Hitunglah peluang berikut ini secara teoritis bagi sebaran binomial dengan
menggunakan parameter pada 1a, 1b dan 1c:
X 5
P ,P
X 4
,P
X 6
,P
4 X 6
. Bandingkan hasil yang diperoleh dengan hasil pada soal no 3.Sebaran Normal
1. Bangkitkan data sebanyak 100 nilai dari sebaran Normal dengan parameter: a. 50dan2 1
b. 75dan2 1 c. 50dan2 10 d. 75dan2 10
2. Buat histogram dari data bangkitan pada 1a, 1b, 1c dan 1d.
a. Bandingkan pusat sebaran dari histogram tersebut untuk data 1a dan 1b
b. Bandingkan rentang nilai maksimum dan minimum untuk data 1a dan 1c, 1b dan 1d!
3. Pada data bangkitan 1a dan 1c, hitunglah frekuensi relatif berikut ini: 51
X , X 49, dan 49 X 51.
4. Hitunglah peluang secara teoritis untuk sebaran normal dengan menggunakan parameter-parameter pada 1a dan 1c:
X 51
P , P
X 49
, dan P
49 X 51
. Bandingkan hasilnya dengan hasil pada soal no 3!PRAKTIKUM V
SELANG KEPERCAYAAN UNTUK SATU POPULASI
( Rata-rata, Ragam dan Proporsi )1. Tujuan Umum
Mahasiswa mampu membuat, memahami dan menginterpretasikan secara benar problematika pada pendugaan parameter rata-rata dan ragam untuk satu populasi dengan selang kepercayaan.
2. Tujuan Khusus
Mahasiswa mampu :
1. Menghitung selang kepercayaan untuk rata-rata, ragam dan proporsi untuk satu populasi
2. Menganalisis perubahan-perubahan yang terjadi pada selang kepercayaan satu populasi jika besaran-besaran selang kepercayaan berubah-ubah.
3. Menginterpretasi dengan benar hasil selang kepercayaan bagi rata-rata, ragam dan proporsi untuk satu populasi
3. Teori
- Salah satu sistem pendugaan parameter populasi berdasarkan statistik sampel
adalah dengan selang kepercayaan (Interval Confidence) di mana sistem ini menghasilkan dugaan parameter yang representatif terhadap parameternya
dibandingkan sistem pendugaan titik.
- Pada umumnya parameter satu populasi yang ingin diduga adalah : 1. Untuk data kuantitatif : dan 2
2. Untuk data kualitatif : proporsi (p)
- Rumus untuk menghitung selang kepercayaan dan 2satu populasi : Jika2diketahui :
P(xz/2 / n xz/2/ n)(1) Jika2tak diketahui :
P(xt/2s/ n xt/2s/ n)(1) dengan selang kepercayaan2:
P(( 1) ( (11)/2) ) (1 ) ) 1 ( 2 2 2 / ) 1 ( 2 n n s n s n
- Rumus untuk menghitung selang kepercayaan proporsi (P) satu populasi : P(ˆ /2 ˆ(1 ˆ) ˆ /2 ˆ(1 ˆ))(1) n p p z p p n p p z p 4. Metodologi
4.1.Analisis GenStat untuk selang kepercayaan satu populasi dengan 2diketahui(1 Sample Z)
Dilakukan perhitungan secara manual
Cari nilai rata-rata dari Data. Klik Stats > Summary Statistics > Summarize
Klik dua kali pada Data, sehingga Variates akan berisi Tinggi. Kemudian beri centang pada Arithmetic Mean. Klik OK. Sehingga didapatkan hasil sebagai berikut:
Cari batas atas selang kepercayaan.
Klik Data > Calculations. Kemudian muncul kotak dialog:
Tulis perhitungan batas atas untuk selang kepercayaan pada tempat yang disediakan untuk menulis formula kalkulasi. Pastikan pada Available Data terdapat centang pada Variates. Beri centang pada Print in Output. Klik OK. Dengan mengasumsikan simpangan baku=14, dapat dihasilkan sebagai berikut:
Cari batas bawah selang kepercayaan.
Langkah-langkah yang dilakukan seperti halnya pada perhitungan batas atas. Yang berbeda hanya pada proses perhitungan, batas bawah menggunakan nilai “-“.Dengan mengasumsikan simpangan baku=14, dapat dihasilkan sebagai berikut:
Summary statistics for Data
Mean = 72.20 BA=72.20+(1.96*(14/sqrt(10))) BA 80.88 BB=72.20-(1.96*(14/sqrt(10))) BA 63.52
Contoh : (Data yang akan dianalisis bernama data dengan=5% berarti level 95) data
85 75 62 61 55 53 78 87 81 85
Berdasarkan hasil tersebut didapatkan batas atas selang kepercayaan 95% untuk µ sebesar 80.88 dan batas bawah yang diperoleh 63.52, Maka didapatkan selang kepercayaan 95% untuk µ adalah sebagai berikut:
Artinya : Nilai duga untuk rata-rata populasi berkisar
antara 63.52 sampai dengan 80.88 dengan
tingkat kebenaran pendugaan sebesar 95% dan tingkat kesalahan pendugaan sebesar 5%.
4.2. Analisis GenStat untuk selang kepercayaan satu populasi dengan 2tak diketahui
- Menu yang harus dipilih : Stats > Statistical Tests > One and two sample t-tests - Pada dialog boxnya isilah : Test: Pilih One sample
Data set: isi dengan judul data coloumn
Confidence Limit(%): bisa dirubah 99, 90 atau yang lain tergantung kepada yang diketahui Klik Options centang summary and confidence levels >OK
OK : tekan OK untuk melakukan analisis
Contoh : (Data yang akan dianalisis bernama data dengan=5% berarti level 95)
data
85 75 62 61 55 53 78 87 81 85 Printout GenStat :
*** Summary ***
Sample Size Mean Variance Standard Standard error
deviation of mean
Data 10 72.20 173.3 13.16 4.163
95% confidence interval for mean: (62.78, 81.62)
Artinya : P(62.78<<81.62)=0.95, Nilai duga untuk rata-rata populasi berkisar antara 62.78 sampai dengan 81.62 dengan tingkat kebenaran pendugaan sebesar 95% dan tingkat kesalahan pendugaan sebesar 5%.
Sedangkan cara mencari penduga bagi2nya adalah : - Menu yang harus dipilih : Data> Calculations - Pada dialog boxnya isilah rumus dari batas bawah
Ulangi sekali lagi proses ini untuk mendapatkan nilai batas atas rumus pendugaan bagi2dengan mengganti BB dengan BA. Berarti dalam hal ini BB berisi nilai batas bawahnya dan BA berisi nilai batas atasnya. Nilai BB dan BA telah tercetak pada output.
4.3. Analisis GenStat untuk selang kepercayaan proporsi (P) satu populasi - Menu yang harus dipilih : Statistical Tests > One and Two Sample
Binomial tests
Maka akan muncul dialog box
- Pada dialog boxnya isilah :
Test : One-sample
Data Arrangement : Summary Value
Number of Successes : Banyaknya kejadian sukses (proporsi*Sample size) Sample Size (N) : Ukuran sampel
Proportion of Success : 0.5 Confidence limit : 1-α
Method : Normal approximation
Type of test : Selang kepercayaan yang diinginkan Klik Options > Centang Summary dan Confidence Interval
Contoh : Suatu karakteristik diketahui mempunyai proporsi 30% dari 20 pengamatan yang dilakukan. Dengan =5%, terntukan proporsi populasi bagi karakteristik tersebut!
Dengan langkah-langkah sebagaimana di atas diperoleh hasil sebagai berikut :
***** One-sample binomial test *****
*** Summary ***
Sample Size Successes Proportion 20 6 0.3
Approx s.e. of proportion: 0.1
95% confidence interval for proportion: (0.09916, 0.5008)
Artinya : P(0.09916<P<0.5008)=0.95, Nilai duga
untuk proporsi populasi berkisar antara
0.09916 sampai dengan 0.5008 dengan tingkat kebenaran pendugaan sebesar 95% dan tingkat kesalahan pendugaan sebesar 5%.
E. Percobaan
I. 1. Kumpulkan data kuantitatif dan kualitatif satu populasi di sekitar saudara sekarang ini!
2. Cek data kuantitatif hasil pengamatan saudara tersebut untuk mengetahui data outlier!
3. Jika ada outlier, apa yang harus saudara lakukan? Jelaskan! 4. Apa yang disebut taraf nyata ()? Jelaskan!
5. Bagaimanakah cara menentukan taraf nyata ()? Jelaskan! II. Berdasarkan data pada bagian I,
1. Dugalah parameter rata-rata, ragam dan proporsi dengan selang kepercayaan pada taraf nyata () 1%, 5% dan 10%! Apa kesimpulan saudara? Jelaskan!
2. Apa pengaruh perubahan taraf nyata () yang digunakan terhadap hasil pendugaan parameter dengan selang kepercayaan? Jelaskan secara terapannya!
3. Taraf nyata () manakah yang harus dipilih pada kasus saudara ini? Jelaskan!
III. Berdasarkan data pada bagian I,
1. Ambil 10 data, 20 data, 35 data dan (n-1) data secara acak!
2. Berdasarkan data hasil 1 tersebut, dugalah parameter rata-rata, ragam dan proporsi dengan selang kepercayaan pada taraf nyata () 5%. Apa kesimpulan saudara? Jelaskan!
3. Berdasarkan hasil 1. dan 2., apa kaitan antara sampel dengan populasinya dikaitkan dengan banyaknya sampel yang dilibatkan dalam selang kepercayaan? Jelaskan!
IV. Bentuk 3 kelompok untuk mempresentasikan masalah I s/d III di atas dengan spesifikasi data sebagai berikut :
1. Kelompok 1 sebagai penyaji materi data kuantitatif rata-rata untuk satu populasi
2. Kelompok 2 sebagai penyaji materi data kuantitatif ragam untuk satu populasi
3. Kelompok 3 sebagai penyaji materi data kualitatif proporsi untuk satu populasi
Pembahasan dan materi yang disajikan sesuaikan dengan pertanyaan I, II dan III di atas. Apabila kelompok I sebagai penyaji, maka kelompok yang lain sebagai pengkritik, pelengkap dan menyempurnakan materi penyaji. Dalam hal ini, asisten praktikum sebagai perangkum akhir dan membuat kesimpulan semua hasil diskusi yang telah dilakukan oleh seluruh kelompok penyaji.
PRAKTIKUM VI
SELANG KEPERCAYAAN UNTUK DUA POPULASI
( Rata-rata dan Proporsi )1. Tujuan Umum
Mahasiswa mampu membuat, memahami dan menginterpretasikan secara benar problematika pada pendugaan parameter rata-rata dan proporsi untuk dua populasi dengan selang kepercayaan.
2. Tujuan Khusus Mahasiswa mampu :
1. Menghitung selang kepercayaan untuk rata-rata dan proporsi untuk dua populasi. 2. Menganalisis perubahan-perubahan yang terjadi pada selang kepercayaan dua
populasi jika besaran-besaran selang kepercayaan berubah-ubah.
3. Menginterpretasi dengan benar hasil selang kepercayaan bagi rata-rata, ragam dan proporsi untuk dua populasi.
3. Teori
- Salah satu sistem pendugaan parameter populasi berdasarkan statistik sampel adalah dengan selang kepercayaan (Interval Confidence) di mana sistem ini menghasilkan dugaan parameter yang representatif terhadap parameternya dibandingkan sistem pendugaan titik.
- Pada umumnya parameter dua populasi yang ingin diduga adalah : 1. Untuk data kuantitatif : (1-2)
2. Untuk data kualitatif : proporsi (p1-p2)
- Rumus untuk menghitung selang kepercayaan (1-2) dua populasi tak berpasangan
(independent) :
Jika12dan22 diketahui :
P(( ) ( ) ) (1 ) 2 2 2 1 2 1 2 / 2 1 2 1 2 2 2 1 2 1 2 / 2 1 n n z x x n n z x x
Jika salah satu2tak diketahui dengan kedua2tak sama :
P(( ) ( ) ) (1 ) 2 2 2 1 2 1 2 / 2 1 2 1 2 2 2 1 2 1 2 / 2 1 n s n s t x x n s n s t x x v v
dengan v adalah derajat bebas efektif (pendekatan) yang mempunyai rumus :
)] 1 /( ) / [( )] 1 /( ) / [( ) / / ( 2 2 2 2 2 1 2 1 2 1 2 2 2 2 1 2 1 n n s n n s n s n s v
Jika salah satu2tak diketahui dengan kedua2sama :
P(( ) (1 1 ) ( ) (1 1 )) (1 ) 2 1 2 2 / 2 2 1 2 1 2 1 2 2 / 2 2 1 1 2 1 2 n n s t x x n n s t x x n n gabung n n gabung dengan 2 ) 1 ( ) 1 ( 2 1 2 2 2 2 1 1 2 n n s n s n sgabung
- Rumus untuk menghitung selang kepercayaan D (beda) dua populasi berpasangan (dependent) : P( / /2 / ) (1 ) 1 2 / 1 tn sD nD D D tn sD nD D D D
dengan D adalah selisih populasi 1 dan populasi 2 atau sebaliknya. nDadalah banyaknya sampel berpasangan.
- Rumus untuk menghitung selang kepercayaan proporsi (p1-p2) dua populasi :
P((ˆ ˆ ) ˆ (1 ˆ ) ˆ (1 ˆ ) (ˆ ˆ ) ˆ (1 ˆ ) ˆ (1 ˆ )) (1 ) 2 2 2 1 1 1 2 / 2 1 2 1 2 2 2 1 1 1 2 / 2 1 n p p n p p z p p P P n p p n p p z p p 4. Metodologi
4.1. Analisis Genstat untuk selang kepercayaan selisih dua populasi dengan kedua 2diketahui
- Menu yang harus dipilih : Data > Calculations
Tulis perhitungan batas atas untuk selang kepercayaan pada tempat yang disediakan untuk menulis formula kalkulasi. Pastikan pada Available Data terdapat centang pada Variates. Beri centang pada Print in Output. Klik OK. Dengan mengasumsikan dan , dapat dihasilkan sebagai berikut:
Ulangi sekali lagi proses ini untuk mendapatkan nilai batas bawah rumus pendugaan bagi 2dengan mengganti BA dengan BB. Berarti dalam hal ini BB berisi nilai batas bawahnya dan BA berisi nilai batas atasnya. Nilai BB dan BA telah tercetak pada output.
Contoh : (Data yang akan dianalisis bernama data1 dan data2 dengan =5% berarti level 95) data1 : dengan 1=15 85 75 62 61 55 53 78 87 81 85 data2 : dengan 2=20 75 80 65 65 78 87 56 77 88 86 BA= (72.2-75.7)+(1.96*(225/10+400/10)**0.5) BA 12.00 P(-19.00 ≤ µ ≤ 12.00) = 0.95
Artinya:Nilai duga untuk selisih rata-rata dua
populasi melewati nilai 0 (batas bawah - dan batas
atas +) sehingga disimpulkan bahwa kedua populasi
mempunyai rata-rata yang sama dengan tingkat
kebenaran pendugaan sebesar 95%.
4.2. Analisis GenStat untuk selang kepercayaan selisih dua populasi dengan 2 tak diketahui dan diasumsikan2 kedua populasi tak sama
- Menu yang harus dipilih : Stats > Statistical Tests > One and two sample t-tests - Pada dialog boxnya isilah : Test: Pilih Two-sample (unpaired)
Data set1: isi dengan judul data column data1 Data set2: isi dengan judul data column data2 Confidence Limit(%): bisa dirubah 99, 90 atau yang lain tergantung kepada yang diketahui
Data Arrangement pilih Two Sets
Klik Options pada box display centang summary and confidence levels >OK Pada box Estimate of variance pilih separate
OK : tekan OK untuk melakukan analisis
Contoh : (Data yang akan dianalisis bernama data1 dan data2 dengan=5% berarti level 95) data1 : 85 75 62 61 55 53 78 87 81 85 data2 : 75 80 65 65 78 87 56 77 88 86 Printout GenStat :
** Test for equality of sample variances ***
Test statistic F = 1.52 on 9 and 9 d.f.
Probability (under null hypothesis of equal variances) = 0.54
*** Summary ***
Sample Size Mean Variance Standard Standard error deviation of mean Data1 10 72.20 173.3 13.16 4.163 Data2 10 75.70 114.2 10.69 3.380
Standard error for difference of means 5.362
95% confidence interval for difference in means: (-14.80, 7.800)
Berarti Confidence Intervals untuk selisih dua nilai tengahnya adalah : P(-14.80 <data1-data2< 7.80)=0.95
Artinya: Nilai duga untuk selisih rata-rata dua populasi melewati nilai 0 (batas bawah - dan batas atas +) sehingga disimpulkan bahwa kedua populasi mempunyai rata-rata yang sama dengan tingkat kebenaran pendugaan sebesar 95%.
4.3. Analisis GenStat untuk selang kepercayaan selisih dua populasi dengan 2 tak diketahui dan diasumsikan2 kedua populasi sama
- Menu yang harus dipilih : Stats > Statistical Tests > One and two sample t-tests
- Pada dialog boxnya isilah : Test: Pilih Two-sample (unpaired)
Data set1: isi dengan judul data column data1 Data set2: isi dengan judul data column data2 Confidence Limit(%): bisa dirubah 99, 90 atau yang lain tergantung kepada yang diketahui
Data Arrangement pilih Two Sets
Klik Options pada box display centang summary and confidence levels >OK Pada box Estimate of variance pilih pooled
OK : tekan OK untuk melakukan analisis
Contoh : (Data yang akan dianalisis bernama data1 dan data2 dengan=5% berarti level 95) data1 : 85 75 62 61 55 53 78 87 81 85 data2 : 75 80 65 65 78 87 56 77 88 86 Printout GenStat:
*** Test for equality of sample variances ***
Test statistic F = 1.52 on 9 and 9 d.f.
Probability (under null hypothesis of equal variances) = 0.54
*** Summary ***
Sample Size Mean Variance Standard Standard error deviation of mean Data1 10 72.20 173.3 13.16 4.163 Data2 10 75.70 114.2 10.69 3.380
Standard error for difference of means 5.362
95% confidence interval for difference in means: (-14.77, 7.765)
Berarti Confidence Intervals untuk selisih dua nilai tengahnya adalah : P(-14.77 <data1-data2< 7.765)=0.95
Artinya : Nilai duga untuk selisih rata-rata dua populasi melewati nilai 0 (batas bawah - dan batas atas +) sehingga disimpulkan bahwa kedua populasi mempunyai rata-rata yang sama dengan tingkat kebenaran pendugaan sebesar 95%.
4.4. Analisis GenStat untuk selang kepercayaan selisih dua populasi berpasangan - Menu yang harus dipilih : Stats > Statistical Tests > One and two sample
t-tests
- Pada dialog boxnya isilah : Test: Pilih Two-sample (paired)
Data set1: isi dengan judul data column sebelum Data set2: isi dengan judul data column sesudah Confidence Limit(%): bisa dirubah 99, 90 atau yang lain tergantung kepada yang diketahui
Klik Options pada box display centang summary and confidence levels >OK OK : tekan OK untuk melakukan analisis
Contoh : (Data yang akan dianalisis bernama sebelum dan sesudah dengan=5% berarti level 95%)
sebelum :(tekanan darah sebelum berlari) 85 75 62 61 55 53 78 87 81 85
sesudah : (tekanan darah sesudah berlari) 100 120 130 110 125 115 120 100 95 110 Printout GenStat :
***** One-sample T-test ***** Variate: Y[1].
*** Summary ***
Sample Size Mean Variance Standard Standard error deviation of mean Sebelum- Sesudah 10 -40.30 503.6 22.44
7.096
95% confidence interval for mean: (-56.35, -24.25)
Berarti Confidence Intervals untuk selisih dua nilai tengahnya adalah : P(-56.35 <data1-data2< -24.25)=0.95
Artinya : Nilai duga untuk selisih rata-rata dua populasi
tak melewati nilai 0 (batas bawah - dan batas
atas -) sehingga disimpulkan bahwa kedua populasi mempunyai rata yang berbeda di mana rata-rata tekanan darah sesudah berlari lebih tinggi daripada sebelum berlari dengan tingkat kebenaran pendugaan sebesar 95%.
4.5. Analisis GenStat untuk selang kepercayaan selisih dua proporsi (P1-P2) populasi
- Menu yang harus dipilih : Statistical Tests > One and Two Sample Binomial tests
Maka akan muncul dialog box
- Pada dialog boxnya isilah :
Test : Two-sample
Data Arrangement : Summary Value
Number of Successes(Y1) : Banyaknya kejadian sukses data 1 (proporsi1*Sample size1)
Sample Size (N1) : Ukuran sampel data 1
Number of Successes(Y2) : Banyaknya kejadian sukses data 2 (proporsi2*Sample size2)
Sample Size (N2) : Ukuran sampel data 2 Confidence limit : 1-α
Method : Normal approximation
Type of test : Selang kepercayaan yang diinginkan Klik Options > Centang Summary dan Confidence Interval
Contoh : Suatu karakteristik dua populasi diketahui mempunyai proporsi 30% dan 20% dari 20 pengamatan yang dilakukan. Dengan =5%, tentukan selisih dua proporsi populasi bagi karakteristik tersebut! Dengan langkah-langkah sebagaimana di atas diperoleh hasil sebagai berikut :
***** Two-sample binomial test *****
*** Summary ***
Sample Size Successes Proportion 1 20 6 0.3 2 20 4 0.2
Approx s.e. of difference between proportions: 0.1
95% confidence interval for difference between proportions: (-0.1666, 0.3666)
Artinya : P(-0.1666<P1-P2<0.3666)=0.95
Sehingga dapat dikatakan bahwa proporsi kedua populasi sama dengan tingkat kebenaran
5. Percobaan
I. 1. Kumpulkan data kuantitatif dan kualitatif dua populasi di sekitar saudara sekarang ini baik data berpasangan maupun tak berpasangan! 2. Cek data kuantitatif hasil pengamatan saudara tersebut untuk
mengetahui data outlier!
3. Jika ada outlier, apa yang harus saudara lakukan? Jelaskan! 4. Apa yang disebut taraf nyata ()? Jelaskan!
5. Bagaimanakah cara menentukan taraf nyata ()? Jelaskan! II. Berdasarkan data pada bagian I,
1. Dugalah selisih parameter rata-rata dan proporsi dengan selang kepercayaan pada taraf nyata () 1%, 5% dan 10%! Apa kesimpulan saudara? Jelaskan!
2. Apa pengaruh perubahan taraf nyata () yang digunakan terhadap hasil pendugaan parameter dengan selang kepercayaan? Jelaskan secara terapannya!
3. Taraf nyata () manakah yang harus dipilih pada kasus saudara ini? Jelaskan!
III. Berdasarkan data pada bagian I,
1. Ambil 10 data, 20 data, 35 data dan (n1-1), (n2-1) data secara acak!
2. Berdasarkan data hasil 1 tersebut, dugalah selisih parameter rata-rata dan proporsi dengan selang kepercayaan pada taraf nyata () 5%. Apa kesimpulan saudara? Jelaskan!
3. Berdasarkan hasil 1. dan 2., apa kaitan antara sampel dengan
populasinya dikaitkan dengan banyaknya sampel yang dilibatkan dalam selang kepercayaan? Jelaskan!
IV. Bentuk 3 kelompok untuk mempresentasikan masalah I s/d III di atas dengan spesifikasi data sebagai berikut :
1. Kelompok 1 sebagai penyaji materi data kuantitatif selisih rata-rata untuk dua populasi tak berpasangan!
2. Kelompok 2 sebagai penyaji materi data kuantitatif selisih rata-rata untuk dua populasi berpasangan!
3. Kelompok 3 sebagai penyaji materi data kualitatif selisih dua populasi proporsi!
Pembahasan dan materi yang disajikan sesuaikan dengan pertanyaan I, II dan III di atas. Apabila kelompok I sebagai penyaji, maka kelompok yang lain sebagai pengkritik, pelengkap dan menyempurnakan materi penyaji. Dalam hal ini, asisten praktikum sebagai perangkum akhir dan membuat kesimpulan semua hasil diskusi yang telah dilakukan oleh seluruh kelompok penyaji.
PRAKTIKUM VII
UJI HIPOTESIS SATU POPULASI
1. Tujuan Umum
Mahasiswa mampu menyusun hipotesis apabila dipunyai satu sampel random dan membuktikan apakah hipotesis tersebut didukung atau tidak oleh data hasil pengamatan sampel tersebut.
2. Tujuan Khusus Mahasiswa mampu :
1. menyusun hipotesis satu parameter, dengan hipotesis alternatif dua sisi, satu sisi ke kiri dan ke kanan.
2. memilih statistik uji berdasarkan parameter yang diuji, pada langkah (1) dan menghitung nilainya berdasarkan data sampel, untuk menentukan apakah hipotesis nol atau alternatif yang diterima.
3. mencari nilai kritis dari tabel statistik yang sesuai dengan tingkat nyata yang dipilih (0,01 <<0,1).
4. mengambil kesimpulan berdasarkan nilai statistik uji dan nilai kritis. 3. Teori
Hipotesis adalah anggapan sementara yang akan dibuktikan kebenarannya berdasarkan hasil pengamatan sampel. Hipotesis selalu menguji tentang parameter populasi yang melibatkan nilai tengah, ragam dan proporsi “Sukses”. Dalam hubungannya dengan pengujian, hipotesis ada dua, hipotesis nol dan alternatif, yang bersifat saling
melengkapi. Artinya, bila data sampel mendukung hipotesis nol, maka hipotesis ini diterima dan hipotesis alternatif ditolak. Dan sebaliknya. Yang perlu diperhatikan dalam setiap pengujian adalah : mendeskripsikan hipotesis, memilih statistik uji dan
menentukan tingkat nyata yang diinginkan.
Rumus-rumus statistik uji :
Parameter Hipotesis Statistik uji
H0: = 0 Z (t)hitung= (X -0)/sx
P H0: p = p0 Z-hitung= (X/n – p0)/sp
2
H0:2=20 2-hitung= (n-1)s2/20
4. Metodologi
Langkah-langkah pengujian hipotesis menggunakan GenStat untuk : (i) Rata-rata satu populasi di mana ragam populasi tidak diketahui : 1. Buka GenStat dan masukkan data dalam spreadsheet sebagai berikut :
diperoleh :
3. Pada kolom test pilih One-sample 4. Masukkan
Data set : data yang digunakan Test Mean : rata-rata
Confidence Limit(%) : Type of Test :
One-sided (y1<y2), jika hipotesis yang digunakan “<” One-sided (y1>y2), jika hipotesis yang digunakan “>” Two sided, jika hipotesis yang digunakan “≠”
5. Klik OK
6. Percobaan Percobaan 1
Misalnya dimiliki data tentang nilai mata kuliah Statistika mahasiswa Fakultas “AA” yang diambil pada Semester Pendek sebagai berikut :
65 59 67 40 79 66 84 64 59 80 48 68 74 91 58 47 58 57 52 83 79 68 73 60 48 77 58 61 73 80 64 64 72 88 92 53 56 76
Sistim pengajaran yang digunakan oleh dosen tersebut adalah dengan pembahasan soal-soal yang dibawa oleh mahasiswa, baik soal-soal-soal-soal kuis, ujian tengah semester maupun soal-soal ujian akhir semester, sehingga soal tersebut mencakup materi yang ada dala matakuliah Statistika. Disamping itu dosen juga mempunyai catatn tentang rata-rata nilai Statistika mahasiswa yang diambil dari bagian pengajaran Fakultas “AA”. Pertanyaannya adalah apakah sistim pengajaran yang digunakan oleh dosen tersebut mampu :
(a) memperbaiki nilai Statistika mahasiswa?
(b) menurunkan proporsi mahasiswa yang mendapatkan nilai <=C (c) menaikkan homogenitas nilai mahasiswa.
Suhubungan dengan pertanyaan tersebut maha hipotesis yang diuji adalah (a). H0: = 60 versus H1: > 60
(b). H0: p = 0,25 versus H1: p < 0,25
(c). H0:2= 225 versus H1:2< 225
Percobaan 2
Seluruh anggota praktikum dibagi 3 kelompok dengan banyaknya anggota yang relatif sama dan masing-masing kelompok dianggap sebagai suatu sampel random yang diambil dari suatu populasi. Masing-masing kelompok mencatat banyaknya uang yang ada dibawa para anggotanya kelompok Data ini untuk selanjutnya digunakan untuk pengujian semua hipotesis. Dan pada setiap kelompok lakukan :
(1). Pengujian nilai tengah populasi
a. tulis hipotesis yang diuji, baik satu sisi maupun dua sisi b. cari rata-rata dan ragam sampel
c. hitung salah baku rata-rata sampel , s2x= [ragam sampel/n]0,5
d. cari statistik uji, t-hitung
e. dari tabel t-student, cari nilai kritis untuk yang telah dipilih, t-tabel
f. Bandingkan nilai statistik uji dengan nilai kritisnya, dan ambil kesimpulan yang bias saudara peroleh.
(2). Pengujian ragam populasi
a. deskripsikan hipotesis yang diuji, dua sisi maupun satu sisi. b. Hitung (n-1)s2
c. Hitung statistik uji2hitung
d. Dari tabel2, cari nilai kritis,2tabel
e. Bandingkan 2hitungdengan2, dan ambil kesimpulan yang saudara peroleh.
(3). Pengujian proporsi “Sukses” populasi
a. deskripsikan hipotesis yang diuji, dua sisi maupun satu sisi b. Hitung nilai X/n ( X- banyaknya “Sukses”; n –ukuran sample) c. Hitung statistik uji t-hitung
d. Dari table t-student, cari nilai kritis sesuai dengan tingkat nyata yang saudara gunakan ().
e. Bandingkan nilai statistik t dengan nilai kritis, dan ambil kesimpulan yang saudara peroleh.
PRAKTIKUM VIII
UJI HIPOTESIS DUA POPULASI
1. Tujuan Umum
Mahasiswa mampu menyusun hipotesis apabila dipunyai dua sampel random dan membuktikan apakah hipotesis tersebut didukung atau tidak oleh data hasil pengamatan sampel tersebut.
2. Tujuan Khusus Mahasiswa mampu :
a. menyusun hipotesis dua parameter, dengan hipotesis alternatif dua sisi, satu sisi ke kiri dan ke kanan.
b. memilih statistik uji berdasarkan parameter yang diuji, pada langkah (a) dan menghitung nilainya berdasarkan data sampel, untuk menentukan apakah hipotesis nol atau alternatif yang diterima
c. mencari nilai kritis dari tabel statistik yang sesuai dengan tingkat nyata yang dipilih (0,01 <<0,1)
d. mengambil kesimpulan berdasarkan nilai statistik uji dan nilai kritis. 3. Teori
Hipotesis adalah anggapan sementara yang akan dibuktikan kebenarannya berdasarkan hasil pengamatan sampel. Dan hipotesis selalu menguji tentang parameter populasi yang melibatkan nilai tengah, ragam dan proporsi “Sukses”. Dalam hubungannya dengan pengujian, hipotesis ada dua, hipotesis nol dan alternatif, yang bersifat saling
melengkapi. Artinya, bila data sampel mendukung hipotesis nol, maka hipotesis ini diterima dan hipotesis alternatif ditolak. Dan sebaliknya. Yang perlu diperhatikan dalam setiap pengujian adalah : mendeskripsikan hipotesis, memilih statistik uji dan
menentukan tingkat nyata yang didinginkan.
Rumus-rumus statistik uji adalah sbb.:
1-2 H0:1-2=0 Z(t)-hitung= [(X1- X2) -0]/sx1-x2
P1-p2 H0; p1-p2= p0 Z-hitung= [(X1/n1– X2/n2)- p0]/sp1-p2
2
1=22 H0:21=22 F-hitung= s21/s22
4. Metodologi
Untuk menguji hipotesis digunakan soft-ware Minitab.
Misalnya dimiliki data nilai Statistika mahasiswa Fakultas “AA” dan Fakultas “BB” yang diajar oleh dosen yang sama.
Fakultas Nilai MK “Statistika”
AA 65 59 67 40 79 66 84 64 59 80 48 68 74 91 58 47 58 BB 83 45 66 59 89 60 52 67 44 90 75 57 88 40 36 78 84 Dosen tersebut ingin mengetahui
a. apakah respon mahasiswa terhapap pemahaman materi kuliah yang diberikan pada dua fakultas tersebut sama atau tidak.
b. apakah sama atau tidak variabilitas kemampuan mahasiswa pada mata kuliah tersebut pada kedua fakultas.
c. Bila dosen tersebut selalu menggunakan aturan bahwa mahasiswa akan mendapatkan nilai mutu A apabila nilai angka paling tidak 80. Apakah prosentase mahasiswa yang mendapatkan nilai A berbeda pada kedua fakultas tersebut ? Sehubungan dengan keinginan dosen tersebut maka hipotesis yang diuji adalah : (a). H0:1=2versus H1:1 2
(b). H0:21=22versus H1:21 22
(c). H0: p1= p2versus H1: p1 p1
Langkah-langkah pemakaian Minitab
(i). Uji rata-rata 2 populasi di mana ragam populasi tidak diketahui 1. Buka GenStat dan masukkan data dalam spreadsheet sebagai berikut :
2. Klik stat > basic statistics > 2 sample t,sebagai berikut :
3. Pada kolom test pilih Two-sample unpaired (digunakan jika data tidak berpasangan) dan pilih Two-sample paired (digunakan jika data berpasangan) 4. Masukkan
Data arrangement : two sets (jika data yang digunakan beda kolom) dan one set with group (jika data yang digunakan satu kolom dibedakan berdasarkan group)
Data set 1 : data pertama yang digunakan Data set 2 : data kedua yang digunakan Confidence Limit(%) :
Type of Test :
One-sided (y1<y2), jika hipotesis yang digunakan “<” One-sided (y1>y2), jika hipotesis yang digunakan “>” Two sided, jika hipotesis yang digunakan “≠”
5. Klik Options maka akan muncul dialog box sebagai berikut:
Pada kotak Estimate of variance klik automatic maka software GenStat akan melakukan estimasi ragam sesuai hasil yang diperoleh pada uji F.
E. Percobaan
Hasil percobaan pada pengujian satu sampel digunakan untuk pengujian dua sampel. (1). Pengujian dua nilai tengah populasi
a. tulis hipotesis yang diuji, baik satu sisi maupun dua sisi b. cari rata-rata dan ragam sampel
c. hitung salah baku beda rata-rata sampel d. cari statistik uji, t-hitung
e. dari tabel t-student, cari nilai kritis untuk yang telah dipilih, t-tabel
f. Bandingkan nilai statistik uji dengan nilai kritisnya, dan ambil kesimpulan yang bias saudara peroleh.
(2). Pengujian ragam populasi
a. deskripsikan hipotesis yang diuji, dua sisi maupun satu sisi. b. Hitung ragam sampel
c. Hitung statistik F-hitung( ragam kecil sebagai penyebut)
d. Dari tabel F , cari nilai kritis
e. Bandingkan F-hitung dengan nilai kritis, dan ambil kesimpulan yang
saudara peroleh.
(3). Pengujian proporsi “Sukses” populasi
a. deskripsikan hipotesis yang diuji, dua sisi maupun satu sisi
b. Hitung nilai X/n (X-banyaknya “Sukses”; n–ukuran sampel) kedua sampel.
c. Hitung statistik uji t-hitung
d. Dari table t-student, cari nilai kritis sesuai dengan tingkat nyata yang saudara gunakan ().
PRAKTIKUM IX
REGRESI DAN KORELASI LNEAR SEDERHANA
1. Tujuan Umum
Mahasiswa mampu membuat model regresi linear sederhana dan menentukan korelasinya.
2. Tujuan Khusus
Mahasiswa mampu :
1. Menentukan peubah respon dan peubah penjelas dari suatu data percobaan. 2. Membuat diagram pencar dari data percobaan.
3. Menghitung koefisien regresi dari model regresi linear sederhana dan memeriksa ketepatan model regresi linear secara parsiil (Uji t), secara serentak (Uji F) serta menentukan koefisien determinasi (R2).
4. Menggambarkan model regresi linear sederhana.
5. Menentukan dan menguji (uji t) koefisien korelasi linear pada model regresi linear sederhana.
3. Teori
Persamaan regresi adalah hubungan antara peubah bebas dengan peubah respon yang dicocokkan pada data percobaan. Peubah bebas adalah peubah yang dikendalikan dalam percobaan. Peubah bebas x1,x2,…,xkbukanlah peubah acak, tapi k besaran yang ditentukan
sebelumnya oleh peneliti dan tidak mempunyai sifat-sifat distribusi. Sedangkan peubah respon adalah peubah yang bergantung pada satu atau lebih peubah bebas.
3.1.Regresi Linear Sederhana
Persamaan regresi Linier sederhana :
x
Y
0 1Penduga untuk persamaan regresi Linier sederhana :
x
b
b
Y
ˆ
0
1di mana : b0adalah penduga bagi
0dan b1adalah penduga bagi
1Dengan MKT, diperoleh penduga untuk koefisien regresi :
XX XY n i i n i n i i n i i n i i i i i n i i i
S
S
n
X
X
n
Y
X
Y
X
X
X
Y
Y
X
X
b
i
2 1 1 2 1 1 1 1 2 1 1 1)
(
)
)(
(
ˆ
X
b
Y
b
0 1 0ˆ
Pemeriksaan ketepatan Garis Regresi
1. Menguji koefisien regresi secara parsiil (uji t) (i) uji 1 0 : 1 0 : 0 1 1 H H
statistik uji : xx S s b t / 1 tolak H0 jika /22 tn t (ii) uji 0 0 : 1 0 : 0 0 0 H H statistik uji : xx n i i nS x s b t
1 2 0 tolak H0 jika /22 tn tSelang prediksi untuk Y0:
Misal diperoleh model regresi linier bx
a yˆ
Berapa nilai y0jika x=x0diketahui ? :
Selang Kepercayaan (1)100% untuk y0adalah :
1 1 ( ) ˆ 1 1 ( ) 1 ˆ 2 0 2 / 2 0 0 2 0 2 / 2 0 xx n xx n S x x n s t y y S x x n s t y P di mana :
n i i i xy n i i yy n i i xx y y x x S y y S x x S 1 1 2 1 2 ) )( ( ) ( ) ( 2 n KT s G2. Uji koefisien regresi serentak (Uji F)
0
:
0
:
1 1 0 0
H
H
Analisis ragam SK db JK KT Fhit Regresi 1
n i i RY
Y
JK
1 2ˆ
1
R RJK
KT
G RKT
KT
Galat n-2
n i i i GY
Y
JK
1 2ˆ
2
n
JK
KT
G G Total n-1
n i i TY
Y
JK
1 2 KeputusanJika
Fhit
F
(1,n2)maka tolak HoArtinya terdapat jumlah keragaman yang berarti dalam respon Y yang disebabkan/diterangkan oleh model.
3. Persentase Keragaman yang dijelaskan (R2)
Mengukur proporsi keragaman /variasi total di sekitar nilai tengah yang
Y
yang dapat dijelaskan oleh regresi tersebut.T R
JK
JK
R
2
3.2. Korelasi antara peubah respon (Y) dengan peubah penjelas (X) Mengukur keeratan hubungan linier antar X dan Y
Y X XY
S
S
b
r
1 di mana :S
X
S
XX danS
Y
S
YYUntuk regresi Linier sederhana berlaku
2
R
r
XY
Uji hipotesis untuk koefisien korelasi :
0 : 1 0 : 0 H H
statistik uji yang digunakan sama seperti pengujian hipotesis 0 , yaitu :
2 1 2 r n r t
tolak H0 jika t tn/22, artinya hubungan antara dua peubah tersebut tidak linear. 4. Percobaan
4.1. Percobaan 1
Kadar air campuran basah suatu produk diperkirakan berpengaruh pada kepadatan produk akhirnya. Dalam suatu percobaan, kadar air campuran dikendalikan dan kemudian kepadatan produk akhirnya diukur. Data yang diperoleh adalah sebagai berikut :
Kadar air campuran (%) 4.7 5.0 5.2 5.2 5.9 4.7 5.9 5.2 5.3 5.9 5.6 5.0 Kepadatan (%) 3 3 4 5 10 2 9 3 7 6 6 4
4.2. Percobaan 2.
Mahasiswa dibagi beberapa kelompok, di mana setiap kelompok terdiri dari 10-15 orang. Setiap anggota kelompok dicatat berat badan (kg) dan tinggi badannya (cm).
5. Metodologi
5.1.Menentukan Peubah respon dan peubah penjelas
Peubah respon adalah peubah yang bergantung pada satu atau lebih peubah penjelas. Sedangkan peubah penjelas adalah peubah yang dikendalikan dalam percobaan. Peubah penjelas x1,x2,…,xk bukanlah peubah acak, tapi k besaran yang ditentukan
sebelumnya oleh peneliti dan tidak mempunyai sifat-sifat distribusi. 5.2.Membuat diagram pencar dari data percobaan.
1. Masukkan data pada spreadsheet GenStat
2. Klik Graphics Create Graph muncul dialog sebagai berikut:
3. Pilih 2D scatter plotlik Next muncul dialog sebagai berikut:
Isikan:
Type of plot: Single XY
Select Y :Masukkan peubah respon Select X : Masukkan peubah penjelas
Jika ingin memberi nama pada scatter plot (diagram pencar) kli Next
5.3. Menghitung koefisien regresi dari model regresi linear sederhana dan memeriksa ketepatan model regresi linear secara parsiil (Uji t), secara serentak (Uji F) serta menentukan koefisien determinasi (R2).
1. Klik StatsRegression Analysis Linear Models, sebagai berikut :
akan muncul :
2. Pilih Simple Linear Regression
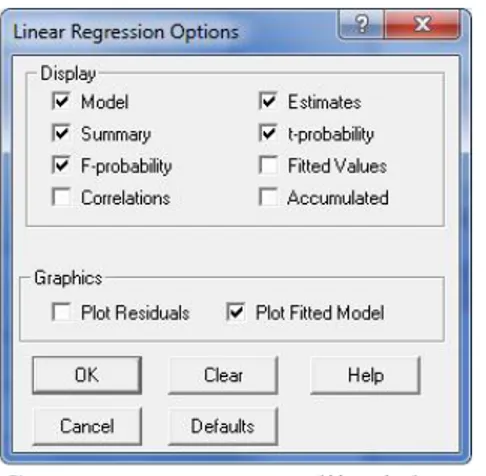
Isikan: Response Variate : peubah respon Explanatory Variate :peubah penjelas Groups : banyaknya group 3. Klik OptionsMuncul kotak dialog box :
Centang output yang diinginkanKlik OK
Centang Plot Fitted Model untuk menggambarkan model regresi linear sederhana
5.5. Menentukan koefisien korelasi linear pada model regresi linear sederhana. 1. Klik Stats Summary statistics Correlations, sebagai berikut :
Maka akan muncul dialog box sebagai berikut: