BAB II
TINJAUAN LITERATUR
2.1. Database
Basis data atau database merupakan kumpulan dari data yang saling
berhubungan satu sama lain, tersimpan di perangkat keras komputer secara
terstruktur sehingga memberikan kemudahan dalam akses kembali. Database
dapat dikatakan sebagai salah satu komponen yang penting dalam sistem
informasi karena merupakan basis data dalam menyediakan informasi bagi para
pengguna.
Rainer dan Turban (2009, 412) mendefinisikan “Database adalah sekelompok file yang berhubungan secara logika yang menyimpan data dan saling berkaitan”. Sedangkan William dan Sawyer (2011, 164) menjelaskan “Database
merupakan koleksi data yang disimpan secara elektronik dalam sistem komputer”. Apabila melihat dari kedua definisi di atas, dapat disimpulkan bahwa
database merupakan sekelompok file yang berhubungan secara logika dan
disimpan secara elektronik dan terkomputerisasi sehingga dapat diakses dengan
mudah dan cepat.
Prinsip utama database adalah sebagai pengaturan data dengan tujuan
utama fleksibilitas dan kecepatan pada saat pengambilan data kembali. Aurino
(2007) menjabarkan lebih detail lagi mengenai gambaran sebuah database yaitu
Sekumpulan mengenai data yang saling berhubungan. Hubungan antar data dapat ditunjukan dengan adanya field/kolom kunci dari tiap file/tabel yang ada. Dalam satu file atau tabel terdapat record yang sejenis, sama besar, sama bentuk, yang merupakan satu kumpulan entitas yang seragam. Satu record (umumnya digambarkan sebagai baris data) terdiri dari field yang saling berhubungan menunjukan bahwa field tersebut dalam satu pengertian yang lengkap dan disimpan dalam satu record.
Telah dijelaskan oleh Aurino lebih detail bagaimana bentuk fisik dari
sebuah database yang terdiri dari satu baris data (record)yang sejenis, sama besar
dan sama bentuk yang terdapat dalam satu tabel (file) yang saling berhubungan.
kolom yang satu dengan kolom yang lainnya dan memiliki satu pengertian
lengkap yang disimpan dalam satu record.
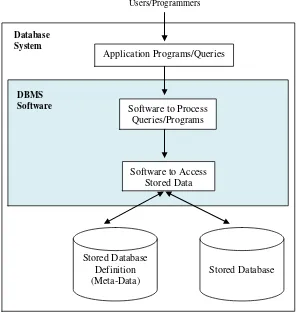
Berikut merupakan gambaran mengenai lingkup sistem database secara
sederhana menurut Elmasri dan Navathe.
Gambar 2.1 Lingkup Sistem Database Secara Sederhana
Sumber: Elmasri dan Navathe 2011, 1
Gambar di atas memperlihatkan bahwa sebuah database tidak hanya
disimpan begitu saja, tetapi diolah dan dikelola oleh sebuah sistem database yang
disebut Database Management System (DBMS). Database ini menggunakan
perangkat lunak (software) tertentu untuk memanipulasinya yang merupakan
bagian dari program aplikasi komputer (computer application programs). Jadi
meski data yang diolah sangat besar, namun dapat tetap tersusun dan terstruktur
untuk meningkatkan kecepatan dalam akses data. Dan dapat diketahui bahwa Application Programs/Queries
Stored Database Definition (Meta-Data)
Stored Database
Users/Programmers
Database System
Software to Process Queries/Programs
Software to Access Stored Data DBMS
metadata-lah yang mengontrol dan menjadikan data terstruktur serta terkendali
untuk kepentingan database tersebut.
2.1.1. Tujuan Penggunaan Database
Dalam penerapan suatu sistem pasti mempunyai suatu tujuan tertentu.
Seperti yang telah disebutkan sebelumnya, database diorganisasikan sedemikian
rupa untuk menemukan kemudahan dalam mengakses data yang dibutuhkan.
Menurut Wardhani (2007) tujuan dari penggunaan database adalah
sebagai berikut:
1. Kecepatan dan kemudahan (speed); dimaksudkan agar user dapat menyimpan, memanipulasi, dan menampilkan kembali data lebih cepat dan mudah daripada cara biasa.
2. Efisiensi ruang penyimpanan (space); dapat mengurangi redundancy, misalnya dengan pengkodean dan membuat relasi.
3. Keakuratan (accuracy); dimaksudkan agar data sesuai dengan aturan dan batasan tertentu.
4. Ketersediaan (availability); yaitu agar data dapat diakses oleh setiap user yang membutuhkan.
5. Kelengkapan (completeness); yaitu dengan menambahkan field pada tabel.
6. Keamanan (security); yaitu pembedaan hak akses untuk setiap user terhadap data yang dapat dibaca atau proses yang dapat dilakukan yang bertujuan agar data yang rahasia tidak jatuh ke tangan user yang tidak berhak, misalnya dengan pengkodean atau membuat akun (username dan password).
7. Kebersamaan (shareability); yaitu mendukung lingkungan multiuser, menghindari inkonsistensi data dan deadlock.
Dari tujuan yang telah dijabarkan di atas, dapat diketahui bahwa database
memiliki kecepatan, kemudahan, keakuratan dan efisiensi dalam menyimpan data
sesuai dengan kebutuhan user; serta memiliki keamanan dan ketersediaan dalam
hal akses dan penyimpanan.
Keuntungan yang diperoleh dari penerapan sebuah database untuk
memenuhi tujuan dari suatu sistem seperti dikemukakan oleh Subekti (2004, 7)
sebagai berikut:
1. Kontrol terpusat data operasional,
5. Penerapan standardisasi,
6. Penerapan pembatasan keamanan data (security), 7. Integritas data dapat dipelihara,
8. Kebutuhan yang berbeda dapat diselaraskan, dan 9. Independensi data/program.
Dari penerapan database ini diharapkan mampu menghindari atau
meminimalisir ketidak konsistenan data, sehingga data dapat terkontrol secara
terpusat dan integritas data juga dapat dipelihara. Kebutuhan pengguna yang
berbeda juga dapat diselaraskan, serta keamanan dalam pembatasan pengggunaan
data dapat diterapkan (Karyatin 2012, 11).
Mengarah kepada integritas yang tertera pada salah satu keuntungan
penerapan database yang dikemukakan oleh Subekti pada penjelasan di atas,
dalam penelitian ini penulis memfokuskan untuk membahas masalah integrasi
berdasarkan rancangan struktur metadata pada database bibliografis Perpustakaan
USU, yaitu OPAC dan IR.
2.1.2. Struktur pada Database
Sebelum menjabarkan mengenai konten atau komponen metadata dari
database yang diperlukan untuk memulai tahapan integrasi, ada baiknya terlebih
dahulu mengetahui akan tingkatan data dalam sebuah struktur database seperti
yang dijelaskan oleh Widiarti sebagai berikut:
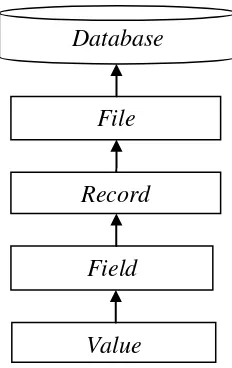
Gambar 2.2 Hierarki/Tingkatan Data dalam Sebuah Struktur Database
Sumber: Widiarti 2008, 39
Database
File
Record
Field
Lebih lanjut, Widiarti (2008, 39) mengemukakan penjelasan mengenai
lima tingkatan data dalam sebuah struktur database yang telah diketahui pada
gambar di atas, yaitu:
1. Database : merupakan kumpulan dari tabel (file) yang saling berhubungan, database menduduki urutan tertinggi karena di dalamnya semua data disimpan.
2. File : sering disebut entitas. File terdiri atas record yang menggambarkan kesatuan data yang sejenis.
3. Record : merupakan kumpulan kolom (field) yang membentuk suatu record. Satu record menggambarkan informasi tentang individu tertentu.
4. Field : merupakan atribut dari record yang menunjukan suatu value/item data.
5. Value : jenjang terkecil yang merupakan isi dari field yang berupa karakter, huruf, dan angka.
Dapat dilihat bahwa jenjang dari tingkatan sebuah data pada database,
dimulai tingkatan yang paling terkecil adalah value yang berupa karakter,
kemudian menyusul field/kolom yang berisi dari kumpulan value, kemudian
record yang merupakan kumpulan dari field, serta file yang menggambarkan
kesatuan data yang sejenis yang terangkum dalam hierarki struktur database.
Value yang merupakan tingkatan paling terkecil dalam hierarki struktur
database memuat informasi berupa struktur metadata yang digunakan sebagai
format/standar untuk pengumpulan data. Penyeragaman metadata pada database
penting untuk dilakukan agar integrasi dapat berjalan. Pada pembahasan
selanjutnya akan dijelaskan mengenai metadata dan integrasi database.
2.1.3. Relational Database Management System (RDMS)
“Dalam basis data (database), terdapat tiga istilah penting yang berkaitan erat satu sama lain yaitu entitas, atribut, dan relationship” (Connolly 2010, 65;
dalam Muliady dkk 2013, 8). Lebih lanjut, Connolly menjelaskan bahwa yang
dimaksud dengan entitas, atribut, dan relationship adalah
Dan relationship adalah asosiasi atau kumpulan keterhubungan yang mempunyai arti (meaningful association) antar tipe entitas (Conolly 2010, 65).
Konstruksi utama untuk merepresentasikan data dalam model relational
database adalah relasi. Relasi terdiri dari contoh relasi yang berupa tabel, dan
skema relasi yang berupa deskripsi kepala kolom (primary key) dari tabel.
Dalam mendesain sebuah relasi (relational database) perlu dilakukan
identifikasi hubungan tiap-tiap entitas. Adapun solusi untuk menganalisa dan
mengidentifikasi hubungan pada entitas database tersebut adalah dengan
menggunakan Relational Database Management Systems (RDMS). RDMS dapat
mengelola relasi-relasi yang merupakan sekumpulan entitas yang saling berkaitan
pada suatu basis data, dan relasi ini juga akan menggambarkan atau menjelaskan
hubungan antara satu entitas dengan entitas lain.
Adapun yang dimaksud dengan relational database pada RDMS seperti
yang diungkapkan oleh Jae Jin Koh (2007) dalam International Forum on
Strategic Technology IEEE bahwa “Relational database is a group of tables, also
called relations in the database community”.
Sejalan dengan definisi di atas, Suri dan Sharma (2011, 116) dalam
International Journal of Database Management Systems juga menambahkan bahwa “A relational database is a database that comforms to the relational model and could also be defined as a set of relations or a database built in an RDMS”.
Dari dua pendapat di atas, dapat dikatakan bahwa relational database
merupakan database yang berisi dua atau lebih tabel yang saling berhubungan dan
memungkinkan untuk menjelaskan hubungan antara semua data struktur.
Adapun tujuan utama dari desain relational database pada RDMS
menurut Connolly (2010, 418) adalah untuk “mengelompokkan atribut-atribut ke
dalam relasi-relasi sehingga meminimalisasi redundansi data atau mengurangi
penggunaan tempat penyimpanan yang dibutuhkan oleh sebuah relasi dasar”.
Menurut Simarmata dan Paryudi (2006, 59) “Relasi entitas (entity
relational) didasarkan pada persepsi terhadap dunia nyata yang tersusun atas
Setiap relasi entitas pasti memiliki suatu batasan. Batasan utama pada relational entity disebut multiplicity, yaitu jumlah (range) dari kejadian yang mungkin terjadi pada suatu entitas yang terhubung ke satu kejadian dari entitas lain yang berhubungan melalui suatu relationship. Relationship yang paling umum dikenal adalah binary relationship (Connolly 2010, 382).
Adapun macam-macam binary relationship yang dipaparkan Connolly
(2010, 382-389) adalah sebagai berikut:
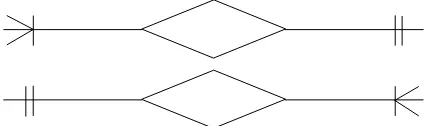
1. One to one relationship
Jika sebuah entitas A berhubungan paling banyak dengan satu entitas B dan sebuah entitas B berhubungan paling banyak dengan satu entitas A.
Gambar 2.3 Simbol Relasi One to One
2. One to many dan many to one relationship
Jika sebuah entitas A berhubungan dengan lebih dari satu entitas B dan sebuah entitas B berhubungan dengan paling banyak satu entitas A, atau sebaliknya.
Gambar 2.4 Simbol Relasi One to Many dan Many to One
3. Many to many relationship
Jika sebuah entitas A berhubungan dengan lebih dari satu entitas B dan sebuah entitas B berhubungan dengan lebih dari satu entitas A.
Gambar 2.5 Simbol Relasi Many to Many
2.2. Metadata
manajemen pangkalan data” (Haynes 2004). Dalam pengertiannya, metadata sering disebut data tentang data atau informasi tentang suatu informasi.
Perpustakaan sudah lama menciptakan metadata dalam bentuk
pengatalogan koleksi yang bertujuan untuk memudahkan pendeskripsian sumber
informasi dari objek data. Metadata merupakan pilar atau dasar dalam
membangun database pada perpustakaan digital, dimana metadata bukan hanya
sekedar data melainkan data yang berisikan data ataupun informasi data dan data
informasi. Informasi kecil yang cukup representatif dalam suatu metadata akan
memberikan kemudahan dalam pencarian informasi yang dibutuhkan.
Menurut National Information Standards Organization (NISO 2004, 1) “Metadata is key to ensuring that resources will survive and continue to be accessible into the future”. (Metadata adalah kunci untuk memastikan bahwa
sumberdaya akan bertahan dan dapat terus diakses di masa depan).
Dalam hal ini, metadata memberikan kesempatan bagi pustakawan untuk
membuat suatu kerangka metadata yang efektif dan cocok untuk penggunaan
jangka panjang sehingga memungkinkan untuk kemudahan penelusuran (access)
dalam melayankan berbagai jenis sumber informasi kepada pengguna
perpustakaan.
Munculnya perpustakaan digital dan perkembangan informasi di Intenet dan WWW (World Wide Web) semakin memperbesar rasa urgensi untuk membuat standar atau skema metadata (metadata scheme) yang tidak saja cocok untuk description dan discovery sumber-sumber digital (digital resources) tetapi juga untuk keperluan lain seperti pengelolaan, pelestarian, dan penilaian (Aditirto 2006, 2).
Menurut Caplan (2003, 3) dari bagian pengenalan tentang metadata memberikan definisi bahwa “Metadata is here used to mean structured information about an information resources of any media type of format”.
Senada dengan pernyataan di atas, National Information Standards Organization (NISO 2004, 1) melengkapi bahwa “Metadata is structured information that describes, explains, locates, or otherwise makes it easier to
Dari kedua definisi yang dipaparkan di atas, dapat diambil kesimpulan
bahwa metadata adalah bentuk pengidentifikasian, penjelasan suatu data, atau
diartikan sebagai struktur dari sebuah data yang fungsinya untuk mengelola
sumberdaya elektronik serta memudahkan dalam penemuan informasi yang
relevan.
Lebih lanjut, NISO mengemukakan tiga jenis metadata yang dikutip oleh
Rachmat, yaitu:
1. Metadata deskriptif
Yaitu metadata yang menjelaskan suatu record data dengan tujuan untuk identifikasi atau pencarian data. Beberapa elemen yang bisa masuk dalam metadata ini adalah judul (title), penulis (author), abstraksi (abstract), dan kata kunci (keywords).
2. Metadata struktural
Yaitu metadata yang memberikan informasi tambahan terhadap suatu obyek lain. Contohnya: halaman pada buku yang membentuk suatu bab buku.
3. Metadata administratif
Yaitu metadata yang memberikan informasi tambahan terhadap suatu data dengan tujuan untuk pengelolaan record data. Contohnya: kapan dan bagaimana data itu diciptakan, tipe/jenis file, serta informasi mengenai pengguna yang diizinkan untuk mengakses. Jadi, tipe metadata ini tidak langsung berkaitan dengan informasi datanya, melainkan ke pengelolaan. Ada dua tipe metadata administratif, yaitu rights management metadata dan preservation metadata (NISO 2004, 1; dalam Rachmat 2014, 2-3).
Telah dijelaskan oleh NISO lebih detail bahwa jenis-jenis metadata
terbagi atas deskriptif, struktural, dan administratif. Metadata deskriptif digunakan
untuk identifikasi atau pencarian data, metadata struktural digunakan untuk
informasi tambahan berupa metode pendukung untuk pencarian data, dan yang
terakhir metadata administratif digunakan untuk informasi lengkap yang
digunakan dalam pengelolaan record data.
2.2.1. Fungsi Penggunaan Metadata
Metadata dibuat agar mempermudah pengguna dalam melakukan
pencarian data yang relevan, membantu pengguna dalam mengorganisasikan
informasi (data), memudahkan interoperabilitas (multi sistem operasi) sehingga
digital (mirip dengan digital signature), serta membantu dalam pengarsipan
(archiving) dan pelestarian (preservation) (NISO 2004).
Haynes mengemukakan beberapa fungsi metadata seperti yang dikutip
oleh Prasetya sebagai berikut:
1. Sumber informasi (resources description)
Ini merupakan fungsi yang paling fundamental dari sebuah metadata. Karena sebuah data dapat diidentifikasi sebagai satu kesatuan berbeda dari data lainnya sehingga dapat ditemukan dengan menggunakan suatu pendekatan unik yang ada dalam metadata tersebut.
2. Temu kembali informasi (information retrieval)
Metadata digunakan untuk memasukkan suatu istilah pada semacam konteks semantik, memberitahukan mesin pencari atau aplikasi lain bagaimana memperlakukan suatu unsur metadata sehingga suatu sumber informasi dapat ditemukan dengan istilah tersebut.
3. Pengelolaan informasi (management of information)
Dengan adanya metadata, dapat ditentukan bagaimana melakukan pengelolaan informasi mengenai penyimpanan dan penemuan kembali sumberdaya informasi.
4. Manajemen hak cipta, kepemilikan dan otentisitas (right management, ownership and authenticity)
Mendorong perkembangan metadata dalam dunia penerbitan khususnya media tercetak dan elektronik, menjadi suatu kebutuhan untuk mengelola hak intelektual tersebut dengan baik. Fungsi ini merupakan salah satu fungsi yang menjadi fokus utama untuk menghindari plagiarisme dan melindungi hak cipta atas suatu sumber informasi.
5. Interoperabilitas (interoperability)
Merupakan kemampuan pertukaran data dalam berbagai sistem menggunakan perangkat lunak dan perangkat keras, serta struktur data. Dengan menggunakan metadata, sebuah sistem dapat mengidentifikasi informasi terstruktur yang kemudian sumber informasi tersebut menampilkan informasi sesuai dengan ketentuan tertentu (Haynes 2004; dalam Prasetya 2010, 10-12).
Dapat dilihat bahwa fungsi metadata seperti yang dijabarkan oleh
Haynes, dapat memenuhi berbagai hal yaitu sebagai sumber informasi, temu
kembali informasi, pengelolaan informasi, manajemen hak cipta, kepemilikan dan
2.2.2. Standar Metadata di Perpustakaan
Seperti yang telah diketahui pada pembahasan sebelumnya, metadata
memiliki standar yang digunakan untuk pengumpulan data.
Beragam standar metadata yang digunakan akan menjadi masalah pada saat integrasi dilakukan. Pada implementasinya, harus digunakan satu jenis metadata yang dapat menyatukan seluruh metadata yang akan digunakan sebagai format standar untuk pengumpulan data. Pemetaan metadata dapat digunakan untuk transformasi elemen yang terdapat pada satu jenis metadata ke jenis metadata lainnya (Gunawan 2011, 8).
Standar metadata yang umum digunakan di perpustakaan adalah MARC
(Machine Readable Cataloging), METS (Metadata Encoding and Transmission
Standard), MODS (Metadata Object Description Standard), dan Dublin Core.
Sesuai dengan ruang lingkup penelitian, pembahasan standar metadata dalam
penelitian ini dibatasi pada Dublin Core dan MARC yang merupakan standar dari
struktur (konten) OPAC dan IR Perpustakaan USU.
2.2.2.1. Standar Metadata MARC dan IndoMARC
MARC merupakan salah satu hasil dan juga sebagai salah satu standar
untuk penulisan katalog koleksi bahan perpustakaan, contohnya pada penerapan
struktur data OPAC. Dalam penerapannya, MARC memiliki standar metadata
yang memiliki elemen lengkap dibandingkan standar metadata lainnya. “Dengan
menggunakan metadata MARC, sebuah dokumen dapat direpresentasikan secara mendetail” (Gunawan 2011, 9).
Dalam situs Library of Congress (LC) dinyatakan bahwa standar
metadata katalog perpustakaan ini dikembangkan pertama kali oleh mereka pada
pertengahan tahun 1960 dan diprakarsai oleh Henriette Avram yang juga seorang
anggota dari LC. Format LC MARC diketahui sangat besar manfaatnya bagi
penyebaran data katalogisasi bahan pustaka ke berbagai perpustakaan di Amerika
Serikat. Keberhasilan ini membuat negara lain turut mengembangkan format
MARC bagi kepentingan nasionalnya masing-masing.
pendidikan dan pekerjaan di bidang perpustakaan, sehingga MARC dianggap mampu mewakili kebutuhan dunia perpustakaan terhadap sebuah standar metadata. Bahasa yang digunakan MARC terdiri atas angka, huruf, dan karakter sehingga MARC terkadang hanya dimengerti oleh orang-orang yang berada dalam lingkup dunia perpustakaan (Primadesi 2012, 7-11).
Menurut Library of Congress (LC 2008, 1) “A MARC record is composed of three elements: the record structure, the content designation, and the data
content of the record”. (Rekod MARC terdiri dari 3 unsur, yaitu: struktur rekod,
penunjukan konten, dan konten data dari rekod).
Lebih lanjut, LC (2008, 1) menjelaskan lebih detail ketiga unsur yang
merupakan bagian dari rekod MARC diantaranya:
1. Struktur rekod
Merupakan implementasi dari standar internasional Format for Information Exchange (ISO 2709) dari Amerika, dan Bibliographic Information Interchange (ANSI/NISO Z39.2).
2. Penunjukan konten
Kode dan konvensi yang ditetapkan secara eksplisit untuk mengidentifikasi dan mencirikan elemen data dalam catatan dan untuk mendukung manipulasi data yang didefinisikan oleh masing-masing format MARC.
3. Konten data atau isi
Isi dari elemen data yang terbentuk dari rekod MARC biasanya diartikan oleh sebuah standar tertentu. Contohnya adalah International Standard Bibliographic Description (ISBD), Anglo-American Cataloguing Rules (AACR), Library of Congress Subject Headings (LCSH), Tesaurus Subjek, atau peraturan katalogisasi lainnya.
Masing-masing negara mengembangkan format MARC sendiri sesuai
dengan kebutuhan spesifik dari negara tersebut, sebagai contoh: Indonesia
mengembangkan IndoMARC, Inggris mengembangkan UKMARC, Rusia
mengembangkan RUSMARC, dan Malaysia mengembangkan MALMARC.
Menurut Taylor (2004), format MARC menjadi berbeda penerapannya di
beberapa negara karena beberapa hal diantaranya:
1. MARC merupakan pengembangan sistem katalogisasi, 2. Adanya perbedaan subject control dan sistem klasifikasi, 3. Perbedaan bahasa resmi yang digunakan,
5. Perbedaan set karakter dan kode, dan
6. Beberapa perbedaan teknik yang pada umumnya disesuaikan dengan kebutuhan pengembang konsep MARC tersebut.
IndoMARC merupakan implementasi dari International Standard
Organization (ISO) 2709 untuk Indonesia, yang merupakan format untuk
tukar-menukar informasi bibliografi melalui format digital atau media terbacakan mesin
(machine-readable). Informasi bibliografi biasanya mencakup pengarang, judul,
subjek, catatan, data penerbitan dan deskripsi fisik (Suharyanto 2012, 2).
IndoMARC menguraikan format cantuman bibliografi yang sangat
lengkap terdiri dari 700 elemen dan dapat mendeskripsikan dengan baik objek
fisik sumber pengetahuan, seperti monograf (BK); manuskrip (AM); dan terbitan
berseri (SE) termasuk buku pamflet, lembar tercetak, atlas, skripsi, tesis dan
disertasi (baik diterbitkan ataupun tidak), dan jurnal buku langka (LC 2008, 2).
Lebih lanjut, LC (2008) mengemukakan metadata MARC yang terdiri
atas beberapa ruas dan elemen dengan dilengkapi kode tengara, sebagai berikut:
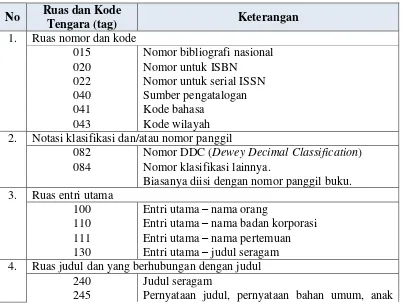
Tabel 2.1 Unsur Metadata MARC
No Ruas dan Kode
Tengara (tag) Keterangan
1. Ruas nomor dan kode
015 Nomor bibliografi nasional 020 Nomor untuk ISBN
022 Nomor untuk serial ISSN 040 Sumber pengatalogan 041 Kode bahasa
043 Kode wilayah 2. Notasi klasifikasi dan/atau nomor panggil
082 Nomor DDC (Dewey Decimal Classification) 084 Nomor klasifikasi lainnya.
Biasanya diisi dengan nomor panggil buku. 3. Ruas entri utama
100 Entri utama – nama orang
110 Entri utama – nama badan korporasi 111 Entri utama – nama pertemuan 130 Entri utama – judul seragam 4. Ruas judul dan yang berhubungan dengan judul
240 Judul seragam
judul, judul paralel, pernyataan tanggung jawab 246 Bentuk variasi judul/judul lain
5. Ruas edisi, impresium, dan sebagainya 250 Pernyataan edisi
255 Data matematik bahan kartografi 256 Karakteristik berkas komputer
260 Publikasi, distribusi, dan sebagainya (tempat, penerbit, dan tahun)
6. Ruas deskripsi fisik
300 Deskripsi fisik
306 Waktu putar (rekaman suara, film, rekaman radio) 310 Frekuensi publikasi mutakhir
362 Tanggal publikasi dan/atau rancangan urutan 7. Ruas pernyataan seri
440 Pernyataan seri/entri tambahan judul 490 Pernyataan seri (tanpa entri tambahan) 8. Ruas catatan
521 Catatan kelompok pembaca 538 Catatan rincian sistem 9. Ruas akses subjek
600 Entri tambahan subjek – nama orang
610 Entri tambahan subjek – nama badan korporasi 611 Entri tambahan subjek – nama pertemuan 630 Entri tambahan subjek – judul seragam 650 Entri tambahan subjek – topik
651 Entri tambahan subjek – wilayah 10. Ruas entri tambahan
700 Entri tambahan – nama orang
710 Entri tambahan – nama badan korporasi 711 Entri tambahan – nama pertemuan
740 Entri tambahan – judul analitik atau judul lain 11. Ruas entri tambahan seri
800 Entri tambahan seri – nama orang
810 Entri tambahan seri – nama badan korporasi 811 Entri tambahan seri – nama pertemuan 830 Entri tambahan seri – judul seragam 14. Ruas kepemilikan, lokasi, dan sebagainya
Contoh metadata MARC seperti yang dipaparkan oleh Hagen adalah sebagai
berikut:
Gambar 2.6 Contoh Metadata MARC
Sumber: Hagen 2013, 9
2.2.2.2. Standar Metadata Dublin Core
Dublin Core Metadata Element Set (DCMES) atau yang biasa disebut
sebagai Dublin Core merupakan standar metadata yang sangat terkenal dan
dipakai secara luas di berbagai bidang ilmu termasuk salah satunya perpustakaan,
yaitu pada USU-IR. “Standar metadata Dublin Core memiliki elemen yang sederhana, namun efektif untuk merepresentasikan berbagai sumber daya” (Gunawan 2011, 6).
008 050621s2005 wvu bm s000 0 eng d 035__ |a (OCoLC)ocm60695171 040__ |a WVU |c WVU
043__ |a n-us-wv
099__ |a Electronic |a Thesis |a 2005 |a Burns, S. 1001_ |a Burns, Shirley Stewart.
24510 |a Bringing down the mountains |h [electronic resource] : |b the impact of mountaintop removal surface coal mining on
southern West Virginia communities, 1970-2004 / |c Shirley L. Stewart Burns.
24630 |a Impact of mountaintop removal surface coal mining on southern West Virginia communities, 1970-2004
260__ |a Morgantown, W. Va. : |b [West Virginia University Libraries], |c c2005.
500__ |a Title from document title page.
500__ |a Document formatted into pages; contains x, 232 p. : ill. (some col.), maps.
500__ |a Includes abstract.
502__ |a Thesis (Ph. D.)--West Virginia University, 2005. 504__ |a Includes bibliographical references (p. 210-225). 530__ |a WVU users: Also available in print for a fee.
538__ |a System requirements: World Wide Web browser and PDF reader. 650_0 |a Mountaintop removal mining |z West Virginia.
650_0 |a Strip mining |z West Virginia. 650_0 |a Coal trade |z West Virginia.
7102_ |a West Virginia University. |t Theses. History.
National Information Standards Organization (NISO 2004, 3)
menyatakan bahwa Dublin Core muncul sejak tahun 1995 tepatnya di kota
Dublin, Ohio. Dengan dukungan dari Online Computer Library Center (OCLC)
dan National Center for Supercomputing Applications (NCSA), metadata Dublin
Core dibangun berdasarkan 15 unsur yang bertujuan untuk mendeskripsikan
kumpulan elemen yang dibuat oleh suatu mesin pengendali informasi berbasis
web.
Lebih lanjut, NISO mengemukakan metadata Dublin Core yang terdiri
atas 15 unsur tersebut, yaitu sebagai berikut:
Tabel 2.2 Unsur Metadata Dublin Core
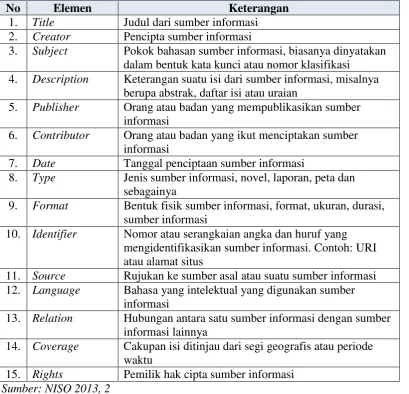
No Elemen Keterangan
1. Title Judul dari sumber informasi
2. Creator Pencipta sumber informasi
3. Subject Pokok bahasan sumber informasi, biasanya dinyatakan dalam bentuk kata kunci atau nomor klasifikasi
4. Description Keterangan suatu isi dari sumber informasi, misalnya berupa abstrak, daftar isi atau uraian
5. Publisher Orang atau badan yang mempublikasikan sumber
informasi
6. Contributor Orang atau badan yang ikut menciptakan sumber informasi
7. Date Tanggal penciptaan sumber informasi
8. Type Jenis sumber informasi, novel, laporan, peta dan
sebagainya
9. Format Bentuk fisik sumber informasi, format, ukuran, durasi, sumber informasi
10. Identifier Nomor atau serangkaian angka dan huruf yang mengidentifikasikan sumber informasi. Contoh: URI atau alamat situs
11. Source Rujukan ke sumber asal atau suatu sumber informasi 12. Language Bahasa yang intelektual yang digunakan sumber
informasi
13. Relation Hubungan antara satu sumber informasi dengan sumber informasi lainnya
14. Coverage Cakupan isi ditinjau dari segi geografis atau periode waktu
15. Rights Pemilik hak cipta sumber informasi
Dublin Core merupakan salah satu skema metadata yang digunakan untuk
web resource description and discovery. Lima belas elemen Dublin Core yang
telah dijelaskan dalam standar ini adalah bagian dari metadata kosakata dan
spesifikasi teknis yang dikelola oleh Dublin Core Metadata Initiative (DCMI).
Seperti yang dikemukakan oleh Ajie (2011, 3) metadata Dublin Core
memiliki beberapa kekhususan sebagai berikut:
1. Memiliki deskripsi yang sangat sederhana,
2. Semantic atau arti kata yang mudah dikenali secara umum, dan
3. Bersifat expandable yang memiliki potensi untuk dikembangkan lebih lanjut.
Contoh metadata Dublin Core seperti yang dipaparkan oleh Greenberg, yaitu:
Gambar 2.7 Contoh Metadata Dublin Core
Sumber: Greenberg 2010, 8
2.3. Database Bibliografis Perpustakaan Perguruan Tinggi 2.3.1. Pengertian dan Konsep Katalog Perpustakaan
Katalog perpustakaan lahir dari konsep sistem temu balik informasi yang
merupakan salah satu unsur vital dalam kegiatan penelusuran di perpustakaan.
Dalam perkembangannya katalog perpustakaan telah mengalami perubahan dari
segi fisik, pemanfaatan, serta kemudahan akses yang dilakukan oleh pengguna
dalam pencarian sumberdaya informasi di perpustakaan.
Zahiruddin dan Ahmed (2007, 4) dalam artikelnya mengatakan bahwa
pengembangan Web OPAC sebagai katalog generasi keempat pada pertengahan
tahun 1990 memberikan kenyamanan kepada pengguna, karena dilengkapi dengan <dc:title>Godiva Chocolatier</dc:title>
<dcterms:alternative>Godiva store</dcterms:alternative> <dc:creator>Nancy Confection</dc:creator>
<dc:creator>Confection, Nancy</dc:creator> <dc:subject>Chocolate</dc:subject>
<dc:subject xsi:type="dcterms:lcsh">Truffles (Confectionery)</dc:subject>
<dcterms:created xsi:type=“dcterms.W3CDTF">
2008--6--28</dcterms:created>
<dc:identifier>http://www.godiva.com</dc:identifier> <dcterms:abstract>Provides access to
kemampuan untuk menelusur katalog secara online melalui desain antar muka
(interface) yang menarik dan mudah digunakan.
Menurut Supriyanto dan Muhsin (2008, 134) “OPAC (Online Public Access Catalog) adalah sebuah fitur yang digunakan untuk memfasilitasi
pengunjung untuk mencari katalog koleksi perpustakaan yang dapat diakses oleh umum”.
Tedd seperti yang dikutip oleh Hasugian (2009, 154) menyatakan hal
yang sama namun lebih mendetail bahwa OPAC adalah
Sistem katalog terpasang yang dapat diakses secara umum, dan dapat dipakai pengguna untuk menelusur pangkalan data katalog, untuk memastikan apakah perpustakaan menyimpan karya tertentu, untuk mendapatkan informasi tentang lokasinya, dan jika sistem katalog dihubungkan dengan sistem sirkulasi, maka pengguna dapat mengetahui apakah bahan pustaka yang sedang dicari sedang tersedia di perpustakaan atau sedang dipinjam.
Dari definisi di atas dapat diketahui bahwa OPAC atau disebut juga
sebagai katalog perpustakaan (library catalog) merupakan sebuah databaseonline
berupa cantuman bibliografi yang dibangun oleh suatu perpustakaan yang
ditujukan untuk pengguna perpustakaan dalam menelusur pangkalan data
sumberdaya informasi (koleksi) yang dimiliki perpustakaan.
“Kebutuhan pengguna berkomunikasi dengan sistem komputer dalam rangka memecahkan suatu pertanyaan atau permintaan (query), merupakan aspek paling penting pada OPAC” (Hasugian 2003, 4).
Menurut Archives Library Information Center (ALIC) pada website
kelembagaan National Archives and Records Administration (NARA 2014),
disebutkan bahwa OPAC memungkinkan pencarian dengan kombinasi penulis
(author), judul (title), subjek/kata kunci (subject/keyword), tanggal publikasi
(publication date), serta format fisik (physical format).
Penggunaan OPAC di suatu perpustakaan tentunya memiliki suatu tujuan
tertentu bagi pengguna. Menurut Kusmayadi dan Andriaty (2006, 53) beberapa
tujuan yang ingin dicapai dalam pemanfaatan OPAC adalah:
2. Mengurangi beban biaya dan waktu yang diperlukan dan yang harus dikeluarkan oleh pengguna dalam mencari informasi.
3. Mengurangi beban pekerjaan dalam pengelolaan pangkalan data sehingga dapat meningkatkan efisiensi tenaga kerja.
4. Mempercepat pencarian informasi.
5. Dapat melayani kebutuhan informasi masyarakat dalam jangkauan yang luas.
Dengan demikian, dapat diambil kesimpulan bahwa tujuan utama dari
pemanfaatan OPAC di perpustakaan adalah untuk membantu pengguna dalam
kemudahan penelusuran sumber informasi yang tersedia di perpustakaan. Salah
satu tujuan lainnya dari penggunaan OPAC ini yaitu sebagai sarana temu kembali
informasi yang biasa digunakan oleh sejumlah perpustakaan agar dapat saling
bertukar data bibliografis.
2.3.2. Pengertian dan Konsep Repositori Institusi Perguruan Tinggi
Repositori Institusi atau dalam bahasa Inggris dikenal sebagai
Institusional Repository (disingkat IR) merupakan sebuah media penyimpanan
data-data digital hasil penelitian akademik dalam suatu lingkungan perguruan
tinggi. Keberadaan IR telah menjadi suatu infrastruktur penting bagi perguruan
tinggi dengan menyediakan akses penuh dan terbuka untuk hasil-hasil penelitian
civitas akademikanya.
Dalam sejarahnya, keberadaan IR tidak terlepas dari fenomena Open
Archives Initiative (OAI) yang berkembang di tahun 1990-an.
Pada mulanya hasil karya intelektual di lembaga disimpan secara lokal dan hanya melibatkan ilmuwan di satu jurusan saja. Namun, setelah OAI muncul dan memperkenalkan protokol untuk harvesting, maka mulai ada kesempatan untuk saling bertukar koleksi antar departemen/jurusan yang kemudian meluas hingga ke seluruh institusi. Dari sinilah lahir konsep dan praktik simpanan kelembagaan untuk hasil karya intelektual institusi (Pendit 2008, 139).
“Simpanan kelembagaan untuk hasil karya intelektual institusi saat ini telah dilayankan kepada publik dalam bentuk database berbasis website” (Ware
2004, 3). Hal ini dilakukan karena adanya tuntutan perkembangan zaman yang
mengharuskan perpustakaan untuk mengolah seluruh koleksi dan aset yang
pengguna (user). Kebutuhan akan pemrosesan data yang cepat dan akurat, secara
tidak langsung menuntut perpustakaan untuk melakukan pengembangan dalam
bidang teknologi guna mendukung proses operasional di dalam perpustakaan.
Dalam pandangan inilah, akhirnya repositori digital muncul dan mulai berkembang sejak tahun 2003 pada saat Massachusetts Institute of Technology (MIT) dan Hewlett Packard Corporation bekerjasama mengembangkan DSpace yang menjadi program aplikasi dalam pembangunan dan pengelolaan IR (Lynch 2003, 1).
Dikutip dalam jurnal Association of Research Library (ARL), Lynch (2003, 2) mengemukakan bahwa IR diartikan sebagai “a set of services that a university offers to the members of its community for the management and
dissemination of digital materials created by the institution and its community
members”.
Dari definisi di atas, dapat dikatakan bahwa IR merupakan serangkaian
pelayanan yang disediakan oleh perguruan tinggi kepada pengguna atau civitas
akademika sebagai media pengelolaan dan penyebaran bahan digital yang
dihasilkan oleh lembaga maupun civitas akademika itu sendiri.
Hal selaras juga dikemukakan Suprayitno yang dikutip dalam Hasan
(2012, 3) disebutkan bahwa “Repositori Institusional merupakan sebuah konsep
untuk mengumpulkan, mengelola, menyebarkan dan melestarikan karya-karya
ilmiah civitas perguruan tinggi yang hasil karya tersebut dikelola dalam bentuk
digital untuk dimanfaatkan kembali dalam menunjang kegiatan akademik”.
Pada umumnya kegiatan hasil penelitian dinilai akan terus mengalami
perkembangan dan meningkat setiap tahunnya, sehingga mengharuskan
perpustakaan untuk beralih menggunakan alternatif lain dalam mengolah dan
menyajikan koleksi karya ilmiah (tercetak) ke dalam bentuk/media digital yang
bertujuan untuk pelestarian jangka panjang sehingga tidak terbatas ruang dan
waktu dalam hal kemudahan akses dan lokasi penyimpanan.
Dalam segi bentuk dan pemanfaatannya, Ware (2004, 3) mendefinisikan
IR sebagai berikut
sehingga dapat mengumpulkan, menyimpan, dan menyebarkan luaskan yang merupakan bagian dari proses komunikasi ilmiah.
Lain halnya dengan Bailey (2005), yang berfokus pada keragaman bahan
digital IR yang mencakup
A variety of materials produced by scholars from many units, such as e-prints, technical reports, theses and dissertations, data sets, and teaching materials. Some institutional repositories are also being used as electronic presses, publishing e-books and e-journals.
Dari berbagai definisi mengenai IR yang telah dikembangkan
berdasarkan konsep dan maknanya seperti yang terangkum dalam beberapa
definisi di atas, dapat diambil kesimpulan bahwa IR merupakan media
penyimpanan data-data digital akademik (hasil penelitian) seperti disertasi, tesis,
skripsi, kertas karya, dan karya ilmiah lainnya yang dihasilkan oleh suatu civitas
akademika (mahasiswa, dosen, peneliti) dalam sebuah lingkungan perguruan
tinggi yang kemudian disebarkan serta dipelihara dalam sistem elektronik
(database berbasis website).
Adanya IR dalam lingkungan perguruan tinggi memudahkan pengguna
terutama civitas akademika dalam menelusur informasi ilmiah agar dapat dengan
mudah ditemukan (information retrieval) sekaligus juga sebagai sarana promosi
untuk perguruan tinggi dalam hal penyampaian hasil-hasil penelitian yang
dilakukan oleh civitas akademika perguruan tinggi tersebut.
2.4. Integrasi Online Public Access Catalog Perpustakaan dengan
Institusional Repository
Dalam perkembangannya sebagai media penyedia informasi, sebuah
perpustakaan dituntut untuk lebih dinamis, mudah, cepat, dan akurat dalam segala
hal terutama dari segi pelayanan maupun fasilitas penelusuran sumber informasi
yang disajikan kepada penggunanya. Dikatakan demikian agar keberadaan
perpustakaan dapat dipertahankan ditengah banyaknya persaingan global penyedia
informasi yang semakin canggih dan tentu saja hal ini menjadi kompetitor bagi
Telah diketahui bahwa OPAC dan IR sama-sama memegang peranan
penting dalam sistem temu kembali (information retrieval system) yang menjadi
unsur penting dalam kegiatan penelusuran informasi di perpustakaan. Dewasa ini
terlihat bahwa pengguna memiliki keterbatasan waktu dalam melakukan
pencarian dan penelusuran informasi yang tersebar di situs web Perpustakaan
(OPAC dan IR) dalam bentuk publikasi elektronik (digital publishing) maupun
sumber informasi bibliografis bahan tercetak (printed materials). Hal ini terjadi
karena para pengguna harus melakukan penelusuran dengan database yang
berbeda untuk mengakses sumber informasi yang dibutuhkan, sehingga akan
dapat menyulitkan beberapa pengguna yang memiliki keterbatasan waktu dalam
menelusur dan memanfaatkan informasi. Jika ditinjau lebih jauh lagi, hal ini
secara perlahan akan mengakibatkan penurunan efisiensi serta kinerja dari layanan
organisasi perpustakaan.
Mannino (2007) menyebutkan bahwa database itu bersifat interrelated
yang artinya saling berhubungan, data yang awalnya disimpan sebagai unit
terpisah dapat dikoneksikan satu sama lain sesuai dengan hubungan (relationship)
yang dibangun. Pernyataan ini didukung oleh Fathansyah (2007) yang
menyatakan bahwa sistem database dapat mengintegrasikan sekumpulan data
yang saling berhubungan satu dengan lainnya dan membuatnya ke dalam
beberapa aplikasi yang diterapkan dalam suatu organisasi.
Layanan OPAC dan IR di perpustakaan sudah menjadi kebutuhan dalam
penelusuran informasi bagi penggunanya, sehingga menuntut perpustakaan untuk
mengolah seluruh koleksi dan aset yang dimilikinya dalam hal pemanfaatan serta
kemudahan akses yang dilakukan oleh pengguna (user). Kebutuhan akan
pemrosesan data yang cepat dan akurat, secara tidak langsung menuntut
perpustakaan untuk melakukan pengembangan dalam bidang teknologi guna
mendukung proses operasional di dalam perpustakaan.
Dalam hal inilah integrasi database bibliografis perpustakaan penting
untuk dilakukan karena seringkali pengguna memiliki keterbatasan waktu dalam
pencarian informasi yang tersebar di berbagai database perpustakaan dalam
Diperlukan suatu sistem yang terintegrasi antar database perpustakaan seperti
integrasi OPAC dengan IR agar dapat mempermudah pengguna dalam melakukan
penelusuran informasi.
Seperti yang diungkapkan oleh Lenzirini (2002) dalam Aisa (2012) bahwa “Integrasi database merupakan suatu proses menggabungkan atau menyatukan data yang berasal dari sumber berbeda agar dapat membantu pengguna untuk melihat kesatuan data”. Dengan demikian, tujuan integrasi kedua database bibliografis tersebut diketahui sangat besar manfaatnya pada pelayanan
sebuah perpustakaan yang bertujuan untuk efektivitas dan efisiensi pengguna
dalam menelusur sumber informasi atau koleksi yang dimiliki perpustakaan agar
tidak lagi berpindah database dalam mencari sumber informasi yang sama.
Adapun manfaat integrasi database adalah untuk efisiensi pengguna,
beberapa diantaranya yaitu:
1. Pengguna tidak perlu lagi berpindah antara satu situs ke situs lainnya saat
menelusur informasi.
2. Pengguna tidak perlu mengetikan query yang sama sebanyak dua kali
dalam penelusuran di situs/database yang dituju.
3. Pengguna dapat melihat dan memperoleh hasil pencarian sekaligus dalam
satu interface.
4. Menghemat waktu dalam menelusur informasi terkait sehingga
penelusuran informasi yang relevan tidak memakan waktu yang lama.
5. Meningkatkan kepuasan pengguna dalam memanfaatkan layanan
informasi perpustakaan.
Tse (2004) menyebutkan bahwa setidaknya terdapat 3 model dalam
integrasi, yaitu:
1. Integrasi presentasi
Gambar 2.8 Integrasi Presentasi
Keuntungan dari model integrasi presentasi adalah resiko dan biaya rendah, teknologi yang tersedia relatif stabil, mudah untuk dilakukan, cepat untuk diimplementasikan, dan tidak perlu merubah data sumber. Sedangkan kelemahan ada pada performan, persepsi, dan tidak adanya interkoneksi antara aplikasi dan data.
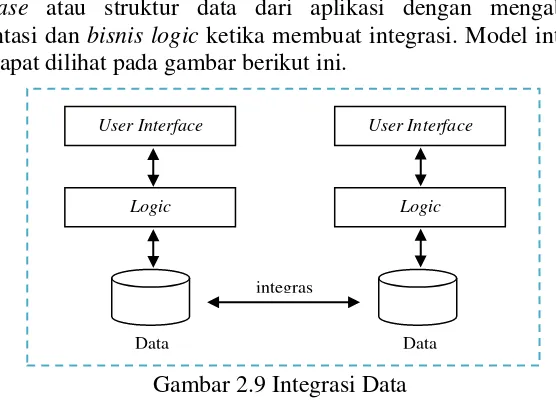
2. Integrasi data
Merupakan suatu model integrasi data yang dilakukan langsung pada database atau struktur data dari aplikasi dengan mengabaikan presentasi dan bisnis logic ketika membuat integrasi. Model integrasi data dapat dilihat pada gambar berikut ini.
Gambar 2.9 Integrasi Data
Keunggulan dari model integrasi data ada pada fleksibilitas yang lebih baik dari model presentasi dan memungkinkan data dapat digunakan oleh aplikasi lain. Namun jika ada perubahan model data, maka integrasi tidak dapat berfungsi lagi.
Data Data
Common Presentation
Presentation
Package Aplication Presentation
Legacy Aplication
User Interface
integras
Data Data
User Interface
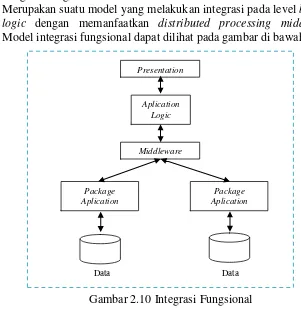
3. Integrasi fungsional
Merupakan suatu model yang melakukan integrasi pada level business logic dengan memanfaatkan distributed processing middleware. Model integrasi fungsional dapat dilihat pada gambar di bawah ini.
Gambar 2.10 Integrasi Fungsional
Keunggulan dari integrasi fungsional ada pada kemampuan integrasi yang kuat diantara model integrasi yang lain. Selain itu, model integrasi fungsional menggunakan true code reuse infrastructure untuk beberapa aplikasi pada enterprise.
Penelitian ini menggunakan model integrasi presentasi sesuai dengan
tema penelitian yaitu membahas tentang perancangan struktur metadata (konten)
dan user interface untuk integrasi OPAC dan USU-IR. Namun kendala yang
sering terjadi adalah format metadata pada interface penelusuran yang tidak
seragam sehingga dapat menyulitkan penelusur untuk mengakses informasi pada
database tersebut. Diperlukan adanya keseragaman antara OPAC dan USU-IR
yang memungkinkan pengguna untuk mengakses informasi secara cepat walaupun
berbeda format metadata sehingga perlu ditinjau kembali bagaimana sistem
terintegrasi agar tidak ada lagi database yang terpisah dan penelusuran informasi
yang relevan juga tidak memakan waktu yang lama. Middleware
Package Aplication
Data Data
Presentation
Package Aplication Aplication
2.4.1. Pengalaman Perpustakaan dalam Integrasi OPAC Perpustakaan
dengan Repository
Pengalaman perpustakaan atau rangkuman penelitian terdahulu yang
dilakukan oleh peneliti sebelumnya sangat penting untuk dipelajari dan dipahami
sebagai bahan acuan dan referensi bagi penulis dalam melakukan penelitian ini. “Seorang peneliti harus belajar dari peneliti lain, untuk menghindari duplikasi dan pengulangan penelitian atau kesalahan yang sama seperti yang dibuat oleh peneliti sebelumnya” (Masyhuri dan Zainuddin 2008, 100).
Adapun pengalaman peneliti sebelumnya yang telah melakukan dan
menerapkan pengintegrasian kedua database bibliografis perpustakaan perguruan
tinggi (katalog koleksi dengan repository/konten lokal) akan dijelaskan melalui
tabel di bawah ini.
Tabel 2.3 Informasi Penelitian Terdahulu
Tahun Nama Peneliti Judul Penelitian Hasil Penelitian
2007 Mutsikiwa
Dari hasil penelitian, terbukti bahwa
ETD dapat terintegrasi dengan web
OPAC dalam satu tampilan antar
muka (interface). Penelusuran
terintegrasi diterapkan pada situs
web OPAC Perpustakaan UZ untuk
mengakses data fulltext publikasi
elektronik yang terdapat dalam UZ
ETD.
Dari tabel di atas, dapat diketahui bahwa Admire (2007) melakukan penelitian dengan judul “Integrating UZ ETD with Web OPAC” studi kasus pada Perpustakaan University of Zimbabwe (UZ), South Africa. Dalam penelitian yang
disampaikan pada Innopac Users Group South Africa Conference di Pretoria
tersebut, Admire memberi gagasan untuk mengintegrasikan ETD (Electronic
Theses and Dissertations) dengan web OPAC, sehingga web OPAC dapat
Dalam laporan tersebut diketahui bahwa ETD untuk publikasi bahan
elektronik di Perpustakaan UZ mengalami statistik penelusuran yang cukup
rendah, namun untuk akses katalog koleksi perpustakaan statistiknya cenderung
tinggi. Berbeda jauh jika kita lihat pada Perpustakaan USU dengan statistik
penelusuran bahan publikasi elektronik yang cukup tinggi dan untuk statistik
penelusuran katalog koleksi perpustakaan cenderung rendah. Namun kedua hal ini
bukan menjadi pertimbangan atau inti dari permasalahan yang akan dibahas dalam
penelitian ini, mengingat bahwa integrasi itu penting dilakukan agar pengguna
dapat lebih mudah untuk mengakses sumber informasi atau koleksi yang dimiliki
perpustakaan secara efektif dan efisien.
Lebih lanjut, Admire memaparkan desain akhir struktur metadata web
OPAC yang akan digunakan untuk integrasi kedua database. Admire mengekspor
metadata yang terdapat pada UZ ETD menggunakan software Millennium Server
untuk mengubah format metadata Dublin Core sehingga menghasilkan format
rekod MARC untuk diimplementasikan ke dalam struktur web OPAC.
Berikut adalah hasil akhir struktur data (konten) yang terdapat dalam web
OPAC yang telah terintegrasi dengan ETD pada situs web Perpustakaan UZ.
Tabel 2.4 Struktur Data Integrasi OPAC dengan UZ-ETD
Sumber: Situs web Perpustakaan UZ
Adapun struktur metadata seperti yang dipaparkan pada menu MARC
Display situs web integrasi OPAC UZ adalah sebagai berikut:
LEADER 00000ntm 2200205uu 4500
No Kategori OPAC
(Struktur Data/Konten)
Kode Tag Metadata MARC
Kode Tag Keterangan
1. Author 100 Entri utama untuk nama orang
2. Title 245 Area judul
3. Publication Info 260 Keterangan publikasi
4. Connect to Fulltext Article 856 Lokasi file dan akses informasi
5. Call Number 090 Nomor panggil koleksi
6. Thesis 502 Catatan disertasi
7. Bibliography 504 Catatan bibliografi
8. Subject 650 Entri tambahan subjek – topik
090 TD195.W295 MAS 100 1 Masocha, Mhosisi.
245 10 Solid Waste Disposal in Victoria Falls Town: |bSpatial Dynamics, Environmental Impacts, Health Threats and Socioeconomic Benefits. / |cMhosisi Masocha. -2004. 260 Not Published.
502 Thesis (MPHIL) - - University of Zimbabwe, 2004. 504 Includes bibliographical references.
650 0 Waste disposal.
650 0 Environmental management.
700 1 Tevera, Daniel S (Prof.) |eSupervisor. 710 2 Geography |bUniversity of Zimbabwe.
856 40 |zFull-Text Article Accessible Only On Campus
|uhttp://ethesis.uz.ac.zw/theses/available/etd-09242004-113058/
Berikut adalah tampilan (user interface) konten struktur web OPAC
setelah diintegrasikan dengan data fulltext UZ ETD yang dapat diakses melalui
situs web uzlibsys.uz.ac.zw.
Gambar 2.11 User Interface Konten Web Integrasi OPAC dengan UZ-ETD
Sumber: Situs web Perpustakaan UZ
Dengan demikian, hasil penelitian Admire menunjukkan bahwa
Adapun persamaan dan perbedaan penelitian terdahulu dengan penelitian
saat ini, yaitu:
1. Persamaan Penelitian:
a. Sama-sama melakukan penelitian mengenai integrasi database
bibliografis perguruan tinggi, yaitu katalog koleksi dan konten lokal
(repository).
b. Data primer penelitian sama-sama menggunakan metadata Dublin
Core dan MARC, karena pada dasarnya semua perpustakaan di
dunia telah menerapkan standar metadata tersebut untuk
pengidentifikasian sumber informasi database bibliografis
perpustakaan. Seperti layaknya Perpustakaan UZ, IR pada
Perpustakaan USU juga menggunakan standar metadata Dublin
Core dan pada web OPAC-nya menggunakan standar metadata
MARC.
2. Perbedaan Penelitian:
a. Jika pada penelitian Admire (2007) dilakukan pada database
Perpustakaan UZ Afrika Selatan, pada penelitian ini dilakukan pada
database Perpustakaan Universitas Sumatera Utara (USU)
Indonesia.
b. Jika pada penelitian Admire (2007) Perpustakaan UZ menggunakan
ETD untuk penyimpanan konten lokalnya, dalam penelitian ini
Perpustakaan USU menggunakan IR untuk penyimpanan konten
lokalnya.
c. Penelitian Admire (2007) dilatarbelakangi oleh laporan atau data
statistik penelusuran yang cukup rendah untuk akses publikasi
bahan elektronik pada database ETD, namun untuk akses informasi
bibliografi bahan tercetak pada database katalog koleksi terlihat
cukup tinggi, sehingga perpustakaan perlu menggunakan alternatif
lain dalam meningkatkan statistik penelusuran database ETD
tersebut salah satunya adalah dengan melakukan integrasi database
membangun latar belakang penelitian berdasarkan peningkatan
pelayanan kepada pengguna agar lebih efektif dan efisien dalam
melakukan penelusuran dengan kedua database (OPAC dan
USU-IR) sehingga dapat membantu beberapa pengguna yang memiliki
keterbatasan waktu dalam menelusur dan memanfaatkan informasi
yang dibutuhkan.
2.4.2. Perbandingan Metadata OPAC Perpustakaan dengan Repository
Dalam penerapannya, OPAC dan IR menggunakan format metadata yang
berbeda. IR menggunakan format metadata Dublin Core sedangkan katalog
koleksi (OPAC) menggunakan format metadata MARC.
Berikut akan dijabarkan mengenai perbedaan format metadata pada
struktur database IR dan OPAC.
Tabel 2.5 Pemetaan Format Metadata IR dan OPAC
Metadata Format Bibliografis
IR (Dublin Core) OPAC (MARC)
dc.title 245a (pernyataan judul)
dc.title.alternative 246 (judul alternatif) dc.title.translated 242 (judul terjemahan)
dc.creator 100a (pengarang/entri utama nama orang) dc.subject 650a (topik judul/entri tambahan subjek) dc.subject 653a (subjek kosakata terkendali) dc.description.abstract 520a (abstrak)
dc.description.note 504 (catatan bibliografi)
dc.publisher 260a+b (tempat publikasi dan nama institusi) dc.contributor 720a (nama penanggung jawab) dc.contributor role 720e (penunjukan: pemandu/pengawas)
dc.date 008 (tanggal penyerahan)
dc.type 655 (tipe dokumen)
dc.identifier 856u (lokasi file dan akses informasi)
dc.language 008 (bahasa)
thesis.degree.name 502a (catatan disertasi) thesis.degree.level 502a (gelar Doctoral/Master) thesis.degree.discipline 710b (entri tambahan nama subjek)
Lebih detail lagi, Gunawan menjabarkan mengenai pemetaan metadata
MARC dan Dublin Core seperti yang tertera pada tabel di bawah ini.
Tabel 2.6 Pemetaan Format Metadata IR dan OPAC
IR (Dublin
Core) OPAC (MARC)
Contributor 100, 110, 111, 700, 710, 711, 720
Coverage 651, 662
Creator 751, 752
Date 008/07-10 260$c$g
Description 500-599, except 506, 530, 540, 546
Format 340, 856$q
Identifier 020$a, 022$a, 024$a, 856$u
Language 008/35-37, 041$a$b$d$e$f$g$h$j, 546
Publisher 260$a$b
Relation 530, 760-787$o$t
Rights 506, 540
Source 534$t, 786$o$t
Subject 050, 060, 080, 082, 600, 610, 611, 630, 650, 653
Title 245, 246
Type Leader06, Leader07, 655
Sumber: Gunawan 2011, 7
Pemetaan metadata ini akan digunakan sebagai dasar perancangan
struktur data (cantuman data bibliografi) spesifik pada OPAC dan IR untuk
memasukkan item data. Kerangka struktur data yang telah dijabarkan pada tabel
di atas telah disesuaikan menurut daftar dan nomor kode bidang yang terdapat