BAB 2
LANDASAN TEORI
2.1 Algoritma
Algoritma berasal dari nama ilmuwan muslim dari Uzbekistan, Abu Ja’far Muhammad bin Musa Al-Khuwarizmi (780-846M). Pada awalnya kata algoritma adalah istilah yang merujuk kepada aturan-aturan aritmetika untuk menyelesaikan persoalan dengan menggunakan bilangan numerik arab. Pada abad ke-18, istilah ini berkembang menjadi algoritma, yang mencakup semua prosedur atau urutan langkah yang jelas dan diperlukan untuk menyelesaikan suatu permasalahan. Pemecahan sebuah masalah pada hakikatnya adalah menemukan langkah-langkah tertentu yang jika dijalankan efeknya akan memecahkan masalah tersebut [7].
Algoritma adalah urutan langkah-langkah logis penyelesaian masalah yang disusun secara sistematis dan logis. Kata logis merupakan kata kunci dalam algoritma. Langkah-langkah dalam algoritma harus logis dan harus dapat ditentukan bernilai salah atau benar [8].
Ada beberapa tipe masalah algoritma, antara lain [2]: 1. Pengurutan
Masalah pengurutan berhubungan dengan bagaimana mengurutkan kembali unsur-unsur dari suatu daftar yang diberikan.
2. Pencarian
Masalah pencarian berhubungan dengan bagaimana menemukan suatu nilai yang disebut kunci pencarian (search key) dalam suatu himpunan (set).
3. Pemrosesan String
Salah satu masalahnya yaitu mencari kata tertentu dalam teks yang disebut pencocokan
4. Masalah Grafik
string.
Dalam algoritma, masalah grafik mencakup graph traversal algorithms dan
shortest-path algorithms. 5. Masalah Kombinatoris
Prespektik abstrak, masalah traveling salesman, dan masalah pewarnaan grafik merupakan contoh dari masalah kombinatorik.
6. Masalah Geometris
Masalah ini berhubungan dengan objek geometris, seperti titik, garis, dan poligon.
7. Masalah Numerik
Algoritma ini banyak dikembangkan pada masalah yang mencakup objek matematis yang bersifat menyelesaikan persamaan dan sistem persamaan, menghitung integral tertentu, dan mengevaluasi sebuah fungsi.
2.2 Algoritma Pencarian
Pengertian string menurut Dictionary of Algorithms and Data Structures, National Institute of Standards and Technology (NIST) adalah susunan dari karakter-karakter (angka, alfabet atau karakter yang lain) dan biasanya direpresentasikan sebagai struktur data array. String dapat berupa kata, frase, atau kalimat [9].
Algoritma pencarian adalah algoritma untuk mencari nilai dalam struktur data [9]. Pencocokan string merupakan bagian penting dari sebuah proses pencarian string
(string searching) dalam sebuah dokumen. Hasil dari pencarian sebuah string dalam dokumen tergantung dari teknik atau cara pencocokan string yang digunakan.
Untuk mengukur performansi metode pencarian, terdapat empat kriteria yang dapat digunakan [1] :
1. Completeness : apakah metode tersebut menjamin penemuan solusi jika
2. Time complexity : berapa lama waktu yang diperlukan, 3. Space complexity : berapa banyak memori yang diperlukan,
4. Optimality : apakah metode tersebut menjamin menemukan solusi yang terbaik jika terdapat beberapa solusi berbeda.
2.3 Algoritma Pencarian Linear
Algoritma Pencarian Linear (Linear Search) adalah algoritma yang digunakan untuk mencari nilai pada sebuah array atau daftar nilai dengan cara memeriksa satu per satu [9]. Linear Search atau yang juga dikenal sebagai Sequential Search (Pencarian Beruntun) bekerja dengan memeriksa setiap elemen dari sebuah list sampai sebuah kecocokan ditemukan. Pencarian Linear tidak membutuhkan pengurutan data terlebih dahulu.
Kelebihan dari algoritma Linear Search antara lain: 1.
2.
Algoritma pencarian sekuensial ini cocok untuk pencarian nilai tertentu pada sekumpulan data terurut maupun tidak.
3.
Keunggulan algoritma ini adalah dalam mencari sebuah nilai dari sekumpulan kecil data.
Termasuk algoritma yang sederhana dan cepat karena tidak memerlukan proses persiapan data (misalnya: pengurutan).
Sedangkan kelemahan algoritma Linear Search adalah bahwa dalam kasus terburuk (nilai tidak ditemukan), pembandingan nilai dilakukan sebanyak jumlah data dalam kumpulan nilai. Dengan demikian, proses pencarian akan bertambah lambat secara linear dengan bertambahnya banyaknya jumlah data.
2.3.1 Karakteristik Algoritma Pencarian Linear
Karakteristik algoritma Pencarian Linear
1. Pencarian dapat dilakukan di struktur data apapun yang dapat diakses secara sekuensial (misalnya array, linked list), sementara sebagian algoritma lain
kadang hanya bisa digunakan pada struktur data yang bisa diakses secara random (misalnya binary search)
2. Data tidak harus terurut
3. Worst case dan expected cost untuk pencarian linear adalah O(n)
2.3.2 Cara Kerja Algoritma Pencarian Linear
Algoritma pencarian linear dapat dituliskan sebagai berikut : 1. i⇽ 0
2. Ketemu ⇽ false
3. Selama (tidak ketemu) dan (i<=N) kerjakan baris 4
4. Jika (data[i] = x) maka ketemu ⇽ true, jikan tidak i ⇽ i + 1
5. Jika (ketemu) maka i adalah indeks dari data yang dicari, jika tidak data tidak ditemuka n.
2.3.3 Pseudocode Algoritma Pencarian Linear
Pseudocode algoritma Pencarian Linear adalah:
ketemu false {belum ketemu }
n 1 { mulai dari elemen pertama }
while ((n < ukuran) and (not ketemu)) do
if (array[n] = kunci) then { dibandingkan } ketemu true { data ketemu }
i n { pada posisi ke-i, posisi disimpan } endif
else n n+1 { cek data berikutnya } endwhile
if ketemu then pencarianLinier I { data ketemu pada posisi ke-i } else pencarianLinier -1 { data tidak ketemu }
endif end
2.3.4 Kompleksitas Algoritma Pencarian Linear
Jika linear search dimulai dari kiri, maka posisi berawal dari elemen ke-1 dan membandingkannya sampai ketemu. Kemungkinan terbaik (best case) dari algoritma ini adalah jika data yang dicari terletak di indeks array terdepan (elemen array
pertama) sehingga waktu yang dibutuhkan untuk pencarian data sangat sebentar (minimal). Kemungkinan terburuk (worst case) adalah jika data yang dicari terletak di indeks array terakhir (elemen array terakhir) sehingga waktu yang dibutuhkan untuk pencarian data sangat lama (maksimal). Kompleksitas dari algoritma ini sebanyak n pebandingan untuk kasus terburuk (data tidak ditemukan atau berada di posisi terakhir). Bila rata-rata posisi data ada ditengah, maka kompleksitas menjadi 1/2 n.
Penelitian yang dilakukan Sabdifha, 2010 menggunakan algoritma Depth-First
Search pada permainan Word Scramble. Kotak-kotak pada papan permainan
direpresentasikan sebagai simpul sehingga setiap kotak akan memiliki indeks. Program akan mengacak huruf dengan menggunakan frekuensi dari Hidden Markov
Models (HMM) untuk selanjutnya kotak tersebut akan diisi dengan huruf acak.
Selanjutnya komputer akan mencari kata yang dapat dibentuk dari huruf-huruf tersebut sebagai jawaban yang valid dengan menggunakan algoritma DFS. Kemudian permainan oleh user (pemain). Pemain diberi waktu untuk menebak kata yang dapat dibentuk dari huruf-huruf yang ada pada papan permainan sebanyak mungkin. Jawaban pemain akan dicocokkan dengan jawaban valid dari komputer. Jika jawaban pemain benar maka pemain akan memperoleh nilai berdasarkan jumlah huruf dari kata-kata yang diperolehnya. Permainan akan berakhir ketika waktu habis.
2.4 Pengacakan Huruf
Proses ini berfungsi sebagai pengacak huruf yang akan keluar di setiap kotak pada papan permainan. Huruf-huruf pada setiap kotak diacak sedemikian rupa agar huruf acak yang diperoleh adalah huruf-huruf yang memiliki frekuensi kemunculan yang tinggi, sehingga lebih mudah untuk mendapatkan campuran yang baik antara vokal dan konsonan. Oleh karena itu, dibutuhkan suatu daftar frekuensi huruf yang paling sering muncul dalam bahasa Inggris.
Frase mnemonik “ETAOIN SHRDLU” sering digunakan untuk mengingat 12 buah huruf yang paling sering muncul di dalam teks Bahasa Inggris [4].
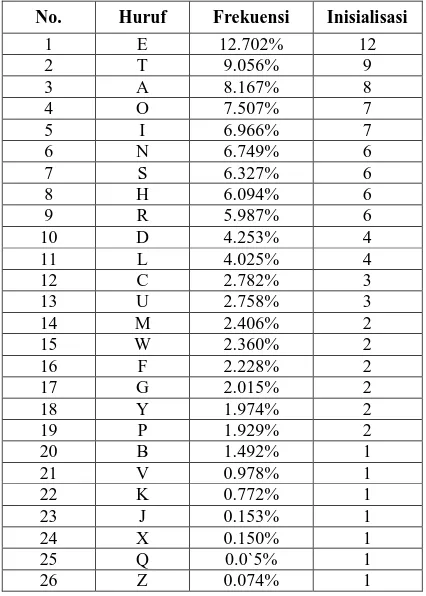
Tabel 2.1 Daftar Nilai Frekuensi Huruf yang Akan Diacak No. Huruf Frekuensi Inisialisasi
1 E 12.702% 12 2 T 9.056% 9 3 A 8.167% 8 4 O 7.507% 7 5 I 6.966% 7 6 N 6.749% 6 7 S 6.327% 6 8 H 6.094% 6 9 R 5.987% 6 10 D 4.253% 4 11 L 4.025% 4 12 C 2.782% 3 13 U 2.758% 3 14 M 2.406% 2 15 W 2.360% 2 16 F 2.228% 2 17 G 2.015% 2 18 Y 1.974% 2 19 P 1.929% 2 20 B 1.492% 1 21 V 0.978% 1 22 K 0.772% 1 23 J 0.153% 1 24 X 0.150% 1 25 Q 0.0`5% 1 26 Z 0.074% 1 (Robert Lewand, 2000)
Menurut table di atas, jumlah seluruh inisialisasinya adalah 100, maka dapat didefinisikan sebuah array dengan interval 0 sampai 99 seperti ini:
alfabet[0] = [0-7] (Huruf A memiliki nilai frekuensi 0 sampai 7)
alfabet[1] = [8] (Huruf B memiliki nilai frekuensi 8)
...
alfabet[24] = [97-98] (Huruf Y memiliki nilai frekuensi 97 sampai 98)
alfabet[25] = [99] (Huruf Z memiliki nilai frekuensi 99)
Kemudian saat proses generalisasi angka acak frekuensi pada interval 0 hingga 99, program hanya mencari dalam interval array dan mendapatkan huruf yang terdapat pada interval tersebut.
alfabet = "A","B","C","D","E","F","G","H","I","J","K","L","M","N", "O","P","Qu","R","S","T","U","V","W","X","Y","Z"]
frek ← random()*99
if 0<= frek and frek <=7 then begin
alfabet[0] end
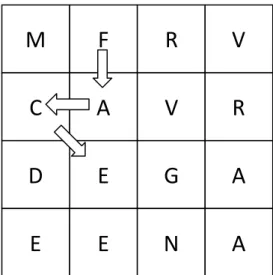
2.5 Word Scramble
Scramble merupakan pengembangan dari permainan scrabble yang sangat inspiratif. Pola permainannya yang menjadi inspirasi dalam mengerjakan tugas akhir ini. Permainan ini dimulai dengan mengacak huruf dengan tingkat frekuensi yang berbeda-beda untuk diisi pada papan berukuran 4x4 kotak, masing-masing kotak diisi dengan huruf berbeda atau sama tergantung nilai acak yang diperoleh. Selanjutnya pemain harus mencari kata yang bisa dibentuk dari huruf yang sudah terisi pada papan. Pemain akan diberikan waktu untuk menebak dan harus mencari kata sebanyak mungkin. Pemain akan mendapatkan nilai sesuai dengan jumlah huruf pada setiap kata valid yang berhasil ditebak.
2.5.1 Aturan Permainan Word Scramble
Aturan permainan Word Scramble secara umum adalah sebagai berikut:
1. Pemain mencari kata sebanyak-banyaknya dari huruf acak yang terdapat pada papan permainan. Huruf-huruf tersebut harus terhubung secara vertikal, horizontal atau diagonal.
2. Setiap kotak hanya bisa digunakan satu kali dalam satu kata. 3. Jawaban minimal terdiri dari tiga huruf.
4. Permainan berakhir ketika waktu habis.
Gambar 2.1 Papan Permainan Word Scramble
2.6 Penilaian Kualitas Aplikasi
Untuk menghitung penilaian kualitas dari aplikasi ini dapat dihitung dengan menggunakan rumus (2.1) dan rumus (2.2):
Pk = (f/N) * Ikb P ... ... (2.1) total = ∑ Pk / n ... ... (2.2) Dimana: Pk
dan sangat baik
= persentase untuk k kondisi dalam hal tidak baik, kurang baik, baik,
f = total respon dalam k kondisi N = jumlah responden
Ikb
baik 50%, baik 75%, dan sangat baik 100%)
= interpretasi k kondisi terbesar (dalam hal ini tidak baik 25%, kurang
Ptotal
n = banyak pertanyaan
= persentase untuk jumlah keseluruhan persentase pertanyaan