STUDI KOMPARASI METODE MULTICLASS SUPPORT VECTOR
MACHINE UNTUK MASALAH ANALISIS SENTIMEN PADA TWITTER
Mohammad Luthfi Pratama1. Hendri Murfi2
Departemen Matematika, FMIPA UI, Kampus UI Depok, 16424, Indonesia
E-mail: [email protected],
Abstrak
Perkembangan teknologi informasi khususnya internet di Indonesia terbilang sangat pesat. Media sosial hadir sebagai sarana baru dalam berkomunikasi dengan perantara internet. Salah satu media sosial pemicu hal tersebut adalah twitter. Banyak sekali variasi topik yang dihasilkan para pengguna twitter. Setiap topik yang dihasilkan memiliki nilai sentimen. Nilai sentimen dibagi menjadi positif, negatif, dan netral. Untuk mengetahui nilai sentimen, digunakanlah analisis sentimen. Namun dengan banyaknya pengguna twitter, akan memakan waktu banyak untuk mengetahui nilai sentimen. Sehingga digunakanlah Support Vector Machine (SVM). Tetapi SVM hanya bisa mengklasifikasikan 2 kelas. Sehingga diperlukan pendekatan Multiclass. terdapat dua cara dalam melakukan pendekatan Multiclass, yaitu pendekatan One Vs One dan One Vs All.
Comparative Study of Multiclass Support Vector Machine Method for Sentiment
Analysis Problem on twitter
Abstract
The growth of information technology, especially the Internet in Indonesia, is rapidly increasing. Social media is the new way to communicate with other users on the internet. Twitter is one of the social media that contribute the growth. There are many topics that are generated by the users. Each topic that is generated by the users has the sentiment value. The sentiment value is divided into positive, negative, and neutral. To determine the value of the sentiment, we need to use the sentiment analysis. However, with so many twitter users, it will take a lot of time. That is why we use Support Vector Machine (SVM). However, SVM can only classify two classes. Therefore, we need multiclass approach. There are two ways of doing multiclass approach: One Vs One and One vs All. Keyword : Sentiment Analysis, Support Vector Machine, twitter, Multiclass, One Vs One, One Vs All
1. Pendahuluan
Perkembangan teknologi informasi khususnya internet di Indonesia terbilang sangat pesat. Media sosial hadir sebagai sarana baru dalam berkomunikasi dengan perantara internet. Setiap pengguna media sosial bebas mengungkapkan opini dalam menanggapi permasalahan yang berlangsung. Oleh karena itu terjadi pergerakan arus informasi yang sangat besar. Salah satu media sosial pemicu hal tersebut adalah twitter. Twitter adalah salah satu media sosial yang memungkinkan penggunanya untuk saling berkirim pesan yang dibatasi dengan 140
karakter, yang dikenal sebagai tweet. Pengguna twitter di Indonesia menempati posisi kelima sebagai negara yang memiliki akun terbanyak yaitu sebesar 30 juta akun terhitung Juli 20121.
Banyak sekali variasi topik yang dihasilkan para pengguna twitter. Topik tersebut bisa merupakan tanggapan dari suatu kejadian, produk, tokoh, kampanye politik, dan lainnya. Dengan tingginya pergerakan arus informasi yang sangat besar, hal ini merupakan ladang emas yang sangat berharga jika dapat diolah dengan baik. Salah satu cara mengolah tweet tersebut adalah dengan melihat sentimen dari apa yang para pengguna twitter ungkapkan. Jika topik tersebut memiliki sentimen yang negatif, para pengguna twitter cenderung tidak setuju, menolak, atau tidak menyukai topik tersebut. Sebaliknya, Jika topik tersebut memiliki sentimen yang positif, para pengguna twitter cenderung setuju, mendukung, atau menyukai topik tersebut.
Salah satu metode yang digunakan dalam analisis sentimen adalah Support Vector Machine (SVM). Namun SVM hanya dapat mengklasifikasikan data menjadi 2 kelas saja. Sedangkan tweet yang dihasilkan oleh para pengguna twitter memiliki sentimen yang positif, negatif, dan netral. Sehingga digunakanlah metode Multiclass SVM. Terdapat 2 cara yang digunakan untuk mengklasifikasikan data yang mempunyai lebih dari 2 kelas dengan menggunakan SVM yaitu pendekatan One Vs One dan One Vs All.
2. Support Vector Machine
Support Vector Machine (SVM) merupakan salah satu metode machine learning untuk pattern recognition, yang lebih khususnya dalam penelitian ini adalah text recognition.
Algoritma SVM sendiri pertama kalinya dikembangkan oleh Vladimir Vapnik (Bishop, 2006). SVM termasuk ke dalam supervised learning yang dapat digunakan untuk permasalahan klasifikasi. SVM mengklasifikasikan data menjadi dua kelas berbeda dengan cara membuat decision boundary atau biasa disebut juga hyperplane. Konsep dasar dari SVM adalah mencari hyperplane yang memaksimumkan margin.
Berikut model linier secara umum yang dipakai dalam SVM untuk menghasilkan hyperplane
! = !"#$(!!! + !) 1
di mana ! ∈ ℝ! adalah vektor yang dimensinya bergantung dari n banyaknya fitur. variabel
! ∈ {−1,1} merupakan nilai target dari vektor !, sedangkan ! ∈ ℝ! merupakan vektor yang
menjadi parameter bobot, dan ! ∈ ℝ merupakan bias atau error yang berupa skalar.
Hyperplane yang dihasilkan membagi data menjadi dua kelas, yaitu kelas positif dan kelas negatif yang dimodelkan sebagai berikut:
!!! !+ ! ≥ 1 , untuk !! bernilai 1 !!! !+ ! ≤ −1 untuk !! bernilai − 1 (2) (3) dapat diformulasikan sebagai berikut
!! !!!
!+ ! ≥ 1 (4)
Hyperplane optimal yang dihasilkan merupakan hyperplane yang memaksimalkan jarak minimum antara kedua hyperplane diatas. Sehingga didaat persamaan sebagai berikut:
min !,! ! ! 2 (5) Dengan syarat : !!(!!! !+ !) ≥ 1
Bentuk optimasi pada persamaan (5) akan menghasilkan klasifikator yang bersifat hard margin. Hard margin adalah suatu klasifikator yang memisahkan dua kelas secara sempurna. Namun akan sangat sulit menemukan data yang bisa dipisahkan oleh hard margin, kerena belum tentu semua data dapat dipisahkan secara linier dengan sempurna. Sehingga perlu ditambahkan sedikit perubahan pada permasalahan optimasi (5). Ide dasarnya memperbolehkan beberapa data berada di sisi hyperplane yang tidak sesuai dengan kelasnya. Pada persamaan (5) ditambahkan variabel slack (ξ! ≥ 0) sehingga menjadi:
min !,! 1 2 ! !+ ! ξ! ! !!! (6) Dengan syarat : !! !!! !+ ! ≥ 1 − ξ! ξ! ≥ 0 (7) (8)
variabel C merupakan Tradeoff dari margin dan variabel slack. Dalam bentuk dual, persamaan akan berbentuk sebagai berikut:
max ! = !! −1 2 !!!!!!!!!!!!! ! !!! ! !!! ! !!! (9) Dengan syarat 0 ≤ !! ≤ !, ! = 1, … , ! !!!! = 0 ! !!! 10 (11)
Pada kasus di kehidupan sehari-hari akan sulit mencari Hyperplane yang dapat membagi data secara linier, walaupun sudah menggunakan Soft Margin. Sehingga digunakanlah kernel Round Basis Function (RBF) yang diharapkan dapat memisahkan data-data tersebut secara linier. Konsep dari kernel RBF adalah memetakan data ke dimensi yang lebih tinggi. Alasan pemilihan RBF sebagai kernel karena RBF memiliki parameter yang lebih sedikit dari kernel yang lain. Alasan lainnya adalah operasi numerik relatif lebih mudah dibandingkan fungsi kernel yang lain.
Setiap perkalian !!!!
! akan diubah menjadi ! !!, !! yang memiliki bentuk sebagai
berikut:
! !!, !! = exp −! !!− !! , ! > 0 (12)
Gunakan fungsi kernel RBF pada persamaan (9), sehingga permasalahan optimasi menjadi seperti berikut: max ! ! = !! − 1 2 !!!!!!!!!(!!, !!) ! !!! ! !!! ! !!! (13) Dengan syarat, 0 ≤ !! ≤ !, ! = 1, … , ! !!!! = 0 ! !!! 14 (15)
Namun SVM hanya dapat melakukan klasifikasi pada dua kelas, pada kenyataannya banyak kasus menggunakan lebih dari dua kelas. Sehingga digunakanlah metode Multiclass SVM. Pada penelitian ini digunakan pendekatan One Vs One (OVO) dan One Vs All (OVA).
Pada pendekatan OVO, misalkan permasalahan yang ditemui terdiri dari N kelas. Sehingga akan dibuat N(N-1)/2 decision boundary. Decision boundary yang dihasilkan merupakan hasil dari pencarian hyperplane dari setiap kelas dengan setiap satu kelas yang lainnya.
Pada pendekatan OVA, misalkan permasalahan yang ditemui terdiri dari N kelas. Sehingga akan dibuat N decision boundary. Decision boundary yang dihasilkan merupakan hasil dari pencarian hyperplane dari setiap kelas ke i dengan kelas sisa yang lainnya.
3. Simulasi
Pada bagian ini dibahas mengenai simulasi metode Multiclass SVM One Vs One dan metode Multiclass SVM One Vs All pada analisis Sentimen Calon Presiden Republik Indonesia periode 2014-2019. Data teks yang digunakan berasal dari twitter. Untuk dapat menganalisis metode-metode tersebut, diperlukan beberapa tahap. Dimulai dengan akuisisi data lalu diteruskan dengan penyaringan data, pelabelan data, ekstraksi fitur, model selection, dan diakhiri dengan evaluasi.
3.1 Akuisisi Data
Data yang digunakan dalam penelitian kali ini berupa teks yang disebut tweet. Tweet merupakan pesan teks yang terdiri dari 140 karakter yang dihasilkan pengguna media sosial twitter. Akuisisi data dibantu dengan Software Online Discovertext.com. Akuisisi data dilakukan dari Agustus 2013 hingga Februari 2014. Data terkumpul sebanyak 11731 tweet.
Tweet diakuisisi dengan menggunakan keyword “calon presiden” beserta nama tokoh yang kemungkinan besar maju pada pemilu presiden 2014 yaitu Aburizal Bakrie, Dahlan Iskan, Hatta Rajasa, Jussuf Kalla, Joko Widodo, Mahfud MD, Megawati Soekarno Putri, Prabowo Subianto, Surya Paloh, dan Wiranto.
Data disimpan dalam format .csv sehingga dapat diproses selanjutnya dengan menggunakan python.
3.2 Penyaringan Data
Setelah data terkumpul oleh proses sebelumnya, yang dilakukan selanjutnya adalah
RT. Retweet atau RT merupakan suatu pilihan dalam twitter yang dapat mengirim ulang tweet yang sudah ada dan dapat juga menambah suatu komentar pendek. Dengan ada pilihan retweet atau RT tersebut akan menyebabkan banyaknya tweet yang hampir mirip dalam jumlah banyak dalam data training. Banyaknya data yang mirip tersebut tidak memberi pengaruh pada
pembentukan fungsi klasifikator. Sehingga digunakanlah algoritma Levenshtein. Algoritma tersebut dapat menghilangkan tweet yang mirip. Pada penelitian ini, dua data tweet akan diasumsikan mirip jika memiliki perbedaan hingga lima belas karakter.
Setelah melalui proses eliminasi tweet, selanjutnya adalah menghilangkan hashtag, nama akun pengguna twitter, dan nama kandidat presiden, karena nama tidak memiliki nilai sentimen dan pemakaian hashtag tidak begitu berpengaruh dalam memberi nilai sentiment dikarenakan hashtag lebih difokuskan dalam pembuatan topik. Terdapat simbol @ sebelum nama pengguna twitter disebutkan. Begitu juga dengan hashtag, hashtag memiliki simbol # sebelum kata. Ketiga hal tersebut akan dimasukan kedalam tabel stopwords, sehingga tidak digunakan diproses
selanjutnya. Stopwords adalah tabel kata atau fitur yang tidak dihilangkan. Selain itu juga terdapat link suatu website dalam tweet yang diakuisisi. Link juga perlu dihapuskan, karena link tidak mempunyai muatan nilai sentimen. Sehingga kata yang mengandung ‘http://’ diawal akan dihapus.
Langkah selanjutnya adalah menghilangkan simbol yang biasa digunakan para pengguna twitter. Simbol yang dimaksud di antaranya karakter “+”, “-”, dan lain-lain. begitu juga
kombinasi dari simbol-simbol tersebut yang digunakan pengguna twitter sebagai emoticon dalam mengekspresikan emosi saat menghasilkan tweet tersebut. Hal tersebut dikarenakan mesin menggunakan pembacaan karakter sistem utf8.
3.3 Pelabelan Data
Pelabelan data adalah proses pemberian nilai target pada tweet. Pelabelan data dilakukan secara manual kepada tweet yang sudah melalui proses penyaringan. Tweet dibagi menjadi tiga kelas. Tweet yang bersentimen negatif dilabelkan dengan ‘-1’, yang bersentimen positif
dilabelkan dengan ‘1’, yang berupa pertanyaan atau fakta dikategorikan sebagai tweet yang bersentimen netral dan dilabelkan dengan ‘0’.
3.4 Ekstraksi Fitur
Ekstraksi Fitur adalah suatu proses mengubah data tweet yang bersifat teks menjadi numerik, sehingga dapat diolah oleh mesin untuk memperoleh fungsi klasifikator. Proses pada ekstraksi fitur diantaranya adalah tokenisasi, pembobotan, dan pemilihan fitur.
3.4.1 Tokenisasi
Proses ini mengubah setiap kata yang ada pada data teks/ tweet menjadi suatu fitur. Proses ekstraksi fitur ini membedakan data teks berdasarkan spasi dan tanda baca. Setiap fitur bersifat unik, kata teks yang sudah terdaftar menjadi fitur sebelumnya tidak diambil menjadi fitur ke depannya.
3.4.2 Pembobotan
Metode ini merupakan proses penghitungan bobot banyaknya kata yang terdapat pada teks sesuai fitur yang ada. Metode ini disebut Term Frequency (TF). Namun pembobotan dengan TF menghasilkan beberapa fitur yang kurang penting seperti subjek, preposisi, dll memiliki
representasi numerik yang besar dikarenakan kata-kata tersebut sering muncul, sehingga menutupi fitur penting yang memiliki bobot kecil. Hal ini mengakibatkan mesin akan menghasilkan fungsi klasifikator yang buruk. Sehingga dilanjutkan dengan metode Inverse Document Frequency (IDF).
Berikut proses pembobotan yang dilakukan oleh TF. Misal sebuah dokumen ! =
(!!, !!, … , !!), di mana !! merupakan kata ke-j dalam dokumen d dan m adalah banyaknya kata fitur dalam d, maka tahap TF akan melakukan pembobotan data tweet sebagai berikut.
!!! ! = !! (16)
!! merepresentasikan banyaknya kemunculan kata !! dalam dokumen d (Manning, Raghavan, &
Schütze, 2009).
Setelah data dibobotkan dengan metode TF, dilanjutkan dengan metode IDF. Persamaan dituliskan sebagai berikut:
!" ×!"# (17)
Dengan !" adalah vektor hasil TF, dan !"# merupakan vektor hasil berikut:
!"#! = log!" !
!"! (18)
N merupakan banyaknya seluruh dokumen tweet, dan !"!merupakan banyaknya tweet dari
keseluruhan dokumen yang memuat kata j (Manning, Raghavan, & Schütze, 2009). 3.4.3 Penskalaan Fitur
Penskalaan fitur merupakan tahap yang penting sebelum data dimasukan kedalam SVM. Keuntungan dari penggunaan penskalaan fitur adalah menghindari fitur yang memiliki nilai range yang besar mendominasi dibanding fitur yang memiliki nilai range yang lebih kecil. Selain
itu penskalaan fitur juga dapat digunakan untuk menghindari kesulitan numerik selama proses perhitungan (Hsu, Chang, & Lin, 2010).
Metode yang digunakan dalam penskalaan fitur ini adalah metode Max Scaler. Min-Max Scaler adalah metode yang melakukan penskalaan fitur yang bergantung pada bobot maksimum fitur dan bobot minimum fitur dari suatu vektor numerik. Berikut metode Min-Max Scaler:
!!! = !!− !!"#
!!"#− !!"# (19)
di mana !!! merupakan bobot fitur ke-j yang sudah dilakukan penskalaan fitur dengan metode
Min-Max Scaler, !! merupakan bobot fitur ke-j yang belum dilakukan penskalaan fitur, !!"#
merupakan bobot fitur yang memiliki nilai bobot terkecil, dan !!"# merupakan bobot fitur yang memiliki nilai bobot terbesar.
3.4.4 Seleksi Fitur
Fitur yang dihasilkan dalam proses ekstraksi data sangat banyak dan tidak semua data mempunyai pengaruh yang besar dalam pembentukan fungsi klasifikator, dan tidak menutup kemungkinan beberapa fitur dapat mengurangi akurasi yang dihasilkan. Sehingga digunakanlah feature selection untuk memilih fitur-fitur yang berpengaruh dalam pembuatan fungsi
klasifikator yang baik. Dalam penelitian ini digunakan beberapa metoe dari feature selection yaitu Univariate Chi Square, Variance Threshold, dan Extra Tree Classifier.
3.4.4.1 Univariate Chi Square
Univariate Chi Square merupakan salah satu metode dalam Feature selection yang menggunakan pendekatan statistik. Metode Univariate Chi Square menggunakan Chi Square dalam melakukan seleksi fitur. Metode Univariate mencari suatu fitur yang memiliki fitur yang berpengaruh dengan data numerik yang telah dihasilkan. Berikut model yang diberikan :
!! !, ! = ! !" − !" !
! + ! ! + ! ! + ! ! + !
(18)
A adalah banyaknya tweet dalam kelas c yang mengandung kata t. B adalah banyaknya tweet yang bukan dalam kelas c namun mengandung kata t. C adalah banyaknya tweet dalam kelas c tetapi tidak mengandung kata t. D adalah banyaknya tweet yang bukan dalam kelas c dan tidak mengandung kata t. N merupakan total keseluruhan dokumen. (Sun, C.,Wang, X., dan Xu, Ju. 2009)
Fitur akan dipilih berdasarkan hasil yang dilakukan pada persamaan diatas. Semakin besar nilai yang dihasilkan akan menentang nilai !!, dengan kata lain fitur yang bersangkutan
memiliki hubungan yang erat dengan banyak tweet. Pada metode Univariate akan dicari k banyaknya fitur dengan nilai Chi Square tertinggi.
3.4.4.2 Extra Tree Classifier
ETC merupakan algoritma yang menggunakan Tree pada proses seleksi fitur.
Mengeliminasi fitur-fitur yang berada dibawah bobot yang ditentukan sesuai dengan algoritma berikut:
Pseudo-code dari algoritma Extra Trees (Geurts, Ernst, & Wehenkel, 2006)
Build_an_extra_tree_ensemble (S) . Input: himpunan data training S.
Output: ensemble tree ! = !!, !!, … , !!
– Untuk i = 1 sampai M
Hasilkan sebuah tree !! : Build_an_extra_tree (S) ; – Return T.
Build_an_extra_tree (S) . Input: himpunan data training . Output: sebuah tree .
– Return sebuah label leaf yaitu jumlah data dengan kelas terbanyak (atau rata-rata output untuk regresi) pada S jika:
(i) |S | < !!"# , atau
(ii) Semua kandidat fitur bernilai konstan pada S , atau (iii) Variabel output pada S bernilai konstan
–Selain itu:
1. Pilih K fitur secara random, {!!, !!, … , !!}, tanpa replacement, di antara (yang tidak
bernilai konstan di S ) kandidat fitur;
(!, !!).Untuk i =1,.., K
3. Pilih sebuah split !∗, sedemikian sehingga Score (!∗, !) = max !"#$% (!∗, !) ;
4. Split S menjadi subhimpunan !! dan !! berdasarkan !∗ ;
5. Buat !! = Build_an_extra_tree (Sl) dan !! = Build_an_extra_tree (Sr)
dari subhimpunan tersebut;
6. Buat sebuah node dengan split !∗ , jadikan !! dan !! sebagai subtree kanan dan kiri dari node tersebut dan return tree t yang dihasilkan Pick_a_random_split (S,a)
Input: himpunan data training S dan sebuah fitur a . Output: sebuah split.
– Jika fitur a memiliki tipe data kontinu:
(i) Hitung nilai minimal dan maksimal dari a pada himpunan S , dinotasikan sebagai !!"#! dan !
!"# ! ;
(ii) Ambil sebuah cut-point !! secara uniform dalam !!"#! , !!"#! ;
(iii) Return split [! < !!] .
di mana K adalah banyaknya fitur yang diambil secara random pada setiap node, dan !!"# adalah banyaknya sample minimum untuk melakukan pemisahan node. !"#$% (!∗, !), dalam penelitian ini dihitung dengan menggunakan persamaan sebagai berikut:
!"#$% !!, ! = 2 !!!(!) !! ! + !!(!) (19) dengan !!! ! = ! ! ! − !!|! ! !! ! = 1 − !! ! ! !∈!,! !! ! = 1 − !!! !∈(!!,!) !!|!(!) = ! !(! !, !!) !(!!) !∈(!,!) !∈! (20) (21) (22) (23)
di mana p merupakan probabilitas. 3.4.4.3 Variance Threshold
Metode Variance Threshold adalah metode yang mengeliminasi fitur yang memiliki variansi dibawah batas yang sudah ditentukan.
!"#$"%&$ !"#$% = !! − ! !
! !!!
!
(24)
di mana !! merupakan nilai bobot pada suatu fitur di tweet ke-!, ! merupakan rata-rata dari
seluruh bobot di fitur tesebut, dan N merupakan banyaknya jumlah tweet.
Variansi yang tinggi pada seuatu fitur menandakan keberagaman yang tinggi pada bobotnya di setiap tweet, sedangkan variansi yang rendah menandakan keberagaman yang rendah pada bobotnya di setiap tweet.
3.5 Model Selection
Pada tahap ini mesin akan diberikan data training. Data training terdiri dari tweet yang sudah diberikan target pada proses pelabelan yang kemudian akan berfungsi memberikan pemahaman untuk mesin sehingga dapat mengklasifikasikan tweet yang bernilai negatif, positif, atau netral. Data training akan diproses menggunakan SVM dengan radial basis function sebagai fungsi basis.
Proses Model Selection menggunakan SVM dengan fungsi kernel RBF mencari dua parameter yaitu parameter C dan γ. Parameter C merupakan parameter pengatur Tradeoff dari kesalahan pengklasifikasian data. Semakin kecil nilai C, fungsi klasifikator yang terbentuk akan bersifat soft margin. Sedangkan jika nilai C semakin besar, fungsi klasifikator yang terbentuk akan bersifat hard margin. Sedangkan nilai γ akan merepresentasikan tingkat kepentingan sebagian data training terhadap data training lainnya. Nilai yang besar berarti sebagian data training akan semakin berpengaruh pada bagian lain dari data training.
Pemilihan kombinasi dari C dan γ akan mempengaruhi kinerja SVM. Grid Search digunakan untuk mendapatkan kombinasi yang optimal antara C dan γ (Hsu, Chang, & Lin, 2010). Proses untuk melakukan Grid Search secara lengkap memerlukan waktu yang sangat lama sehingga penelitian ini akan menggunakan metode pembagian Grid Search menjadi dua tahap.
Pertama adalah Loose grid Search, pencarian ini mencari nilai parameter C dengan ! = 2!
dengan nilai ! = −5, −3, … , 15. dan parameter ! = 2! dengan ! = −15, −13, … , 3. Setelah
kecil pada titik yang ditemukan pada proses sebelumnya, pencarian ini dinamakan Fine Grid
Search. pencarian ini mencari nilai parameter C dengan ! = 2!!!! dengan nilai
!! = −2, −1.75, … , 2. dan parameter ! = 2!!!! dengan !! = −2, −1.75, … , 2.
3.6 Evaluasi Model
Setelah diperoleh model fungsi klasifikator SVM yang terbaik, dilakukan evaluasi terhadap model tersebut. Hal ini dilakukan untuk mengetahui keakuratan model fungsi klasifikator dalam memprediksi data baru yang bukan termasuk dalam data training. K-Fold Cross Validation digunakan untuk menghitung akurasi model fungsi klasifikator terhadap data baru.
K-Fold Cross Validation pertama-tama dilakukan dengan membagi data training menjadi K bagian yang sama besar. Lalu K-1 bagian tadi dijadikan data training baru dan bagian lain data dijadikan sebagai data testing. Proses ini dilakukan sebanyak K pengulangan pada setiap
kombinasi data testing dan data training yang berbeda.
Untuk menyajikan hasil dari K-Fold Cross Validation ini digunakan confusion matrix dengan isi sebagai berikut:
Gambar 1 Confusion Matriks
Dari confusion matrix, menurut Tom Fawcet (2006) satuan akurasi kinerja dari model bisa dilihat dengan:
!"#$%&' = !!!+ !!!+ !!!
!!!+ !!"+ !!"+ !!"+ !!!+ !!"+ !!"+ !!"+ !!!
Dengan kata lain untuk mencari akurasi cukup melakukan penjumlahan diagonal dari confusion matrix, lalu dibagi jumlah data yang digunakan.
4. Hasil dan Pembahasan
Setelah melalui proses akuisisi, filter data, dan pelabelan manual. Data tweet yang diperoleh sebanyak 1124 tweet bersentimen positif, 1467 tweet bersentimen netral, dan 766 tweet bersentimen negatif. Ben Aisen (2005) menggunakan 500 data teks disetiap kelasnya yang bertujuan untuk mendapatkan proporsi yang sama setiap kelasnya. Pada penelitian ini
menggunakan 700 data di setiap kelas agar memberikan proporsi yang sama dan dapat
memberikan pengetahuan yang lebih pada mesin dan memperkaya fitur yang akan dijadikan data training. Sehingga total tweet yang digunakan pada data training berjumlah 2100 tweet.
Pembobotan menggunakan metode TF-IDF lalu dilakukan proses seleksi fitur. Setelah itu menggunakan Penskalaan fitur dengan metode Min-Max .
Tujuan dilakukannya simulasi pada penelitian ini yaitu membandingkan akurasi dengan metode seleksi fitur pada masing masing metode Multiclass One Vs One (OVO) dan metode Multiclass One Vs All (OVA) dengan SVM. Metode seleksi fitur terdiri dari Extra Tree Classifier (ETC), Univariate Chi Square (UCS), dan Variance Threshold (VT).
Pada proses pencarian akurasi, digunakan 5 – Fold Cross Validation untuk pengukuran kinerja setiap metode.
4.1 Akurasi Pendekatan One Vs One (OVO)
Saat melakukan simulasi pendekatan OVO tanpa metode seleksi fitur, menghasilkan akurasi sebesar 76,1905% dan jumlah fitur sebesar 5149 fitur. Dengan banyaknya fitur yang dihasikan, akan dicari fitur-fitur mana saja yang penting yang berguna dalam menghasilkan akurasi yang lebih tinggi. Sehingga untuk mereduksi fitur-fitur yang kurang penting,
digunakanlah metode seleksi fitur . metode seleksi fitur terdiri dari Extra Tree Classifier (ETC), Univariate Chi Square (UCS), dan Variance Threshold (VT).
Pada metode seleksi fitur ETC menghasilkan akurasi sebesar 78,381% dengan jumlah fitur sebanyak 1223 buah fitur.
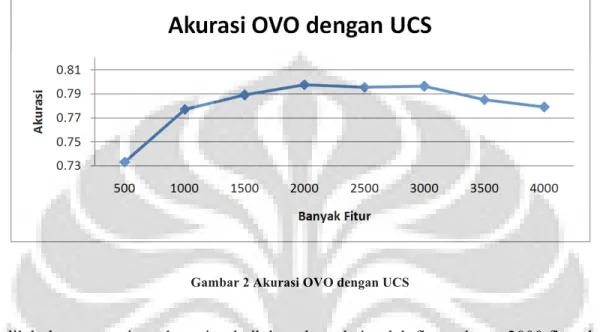
Pada metode seleksi fitur UCS, belum adanya suatu cara untuk mendapatkan berapa nilai tertinggi optimum pada proses seleksi fitur. Sehingga pencarian dilakukan pada jumlah fitur sebanyak 500, 1000, …, 4000 fitur.
Gambar 2 Akurasi OVO dengan UCS
setelah dilakukan pencarian, akurasi terbaik berada pada jumlah fitur sebesar 2000 fitur dengan akurasi 79,7619%.
Pada metode seleksi fitur VT, belum adanya suatu cara untuk mendapatkan batas nilai tertinggi optimum pada proses seleksi fitur, sehingga akan dilihat akurasi di sekitar nilai rata-rata dari variansi setiap fitur. Misalkan nilai rata-rata dari variansi masing-masing fitur bernilai V, dilakukan pencarian dengan batas-batas sebagai berikut 0.5!, 0.55!, … , 1.5!.
Gambar 3 Akurasi OVO dengan VT
setelah dilakukan pencarian, akurasi terbaik berada pada koefisien 1 dan menghasilkan akurasi sebesar 76,4286% dengan jumlah 1237 fitur.
Berikut ditunjukan hasil simulasi program, Tabel 4.1 menunjukan jumlah fitur yang dipakai dan akurasi yang dihasilkan dengan metode seleksi fitur ETC, UCS, dan VT pada pendekatan OVO.
Tabel 1 Perbandingan Akurasi Seleksi Fitur pada pendekatan OVO
No Metode Seleksi Fitur Jumlah Fitur Akurasi
1 Tanpa seleksi fitur 5149 76,1905 %
2 ETC 1223 78,3810 %
3 UCS 2000 79,7619 %
4 VT 1237 76,4286 %
Berdasarkan Tabel 1terlihat beberapa hasil sebagai berikut:
• Secara umum penggunaan metode seleksi fitur meningkatkan akurasi kinerja mesin pada pendekatan OVO.
• Metode seleksi fitur ETC pada pendekatan OVO mengeliminasi fitur terbanyak, sehingga menjadi 1223 fitur dari 5149 fitur yang ada.
• Metode seleksi fitur UCS merupakan metode seleksi fitur yang menghasilkan akurasi terbaik dibandingkan dengan metode seleksi fitur yang lain. dengan akurasi sebesar 79,7619% dengan jumlah fitur sebanyak 2000 fitur
Sehingga pada penelitian ini, metode seleksi fitur UCS merupakan metode terbaik ketika menggunakan pendekatan OVO.
4.2 Akurasi Metode pendekatan One Vs All (OVA)
Saat melakukan simulasi pendekatan OVA tanpa metode seleksi fitur, menghasilkan akurasi sebesar 76,1905% dan jumlah fitur sebesar 5149 fitur. Dengan banyaknya fitur yang dihasikan, akan dicari fitur-fitur mana saja yang penting yang berguna dalam menghasilkan akurasi yang lebih tinggi. Sehingga untuk mereduksi fitur-fitur yang kurang penting,
digunakanlah metode seleksi fitur . metode seleksi fitur terdiri dari Extra Tree Classifier (ETC), Univariate Chi Square (UCS), dan Variance Threshold (VT).
Pada metode seleksi fitur ETC mengahasilkan akurasi sebesar 78,5238% dengan jumlah fitur sebanyak 1223 buah fitur.
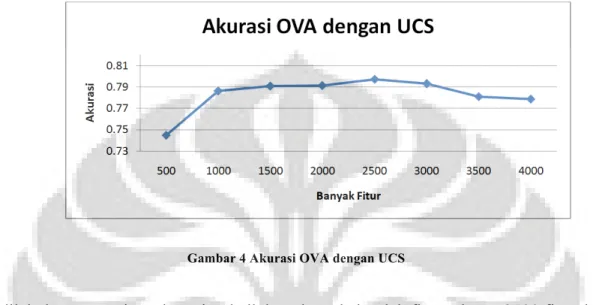
Pada metode seleksi fitur UCS, belum adanya suatu cara untuk mendapatkan berapa nilai tertinggi optimum pada proses seleksi fitur. Sehingga pencarian dilakukan pada jumlah fitur sebanyak 500, 1000, …, 4000 fitur.
Gambar 4 Akurasi OVA dengan UCS
setelah dilakukan pencarian, akurasi terbaik berada pada jumlah fitur sebesar 2500 fitur dengan akurasi 79,7143%.
Pada metode seleksi fitur VT, belum adanya suatu cara untuk mendapatkan batas nilai tertinggi optimum pada proses seleksi fitur, sehingga akan dilihat akurasi di sekitar nilai rata-rata dari variansi setiap fitur. Misalkan nilai rata-rata dari variansi masing-masing fitur bernilai V, dilakukan pencarian dengan batas-batas sebagai berikut 0.5!, 0.55!, … , 1.5!.
Gambar 5 Akurasi OVA dengan VT
setelah dilakukan pencarian, akurasi terbaik berada pada koefisien 0.7 dan menghasilkan akurasi sebesar 76,6667% dengan jumlah 1788 fitur.
Berikut ditunjukan hasil simulasi program, Tabel 4.2 menunjukan jumlah fitur yang dipakai dan akurasi yang dihasilkan dengan metode seleksi fitur ETC, UCS, dan VT pada pendekatan OVA.
Tabel 2 Perbandingan Akurasi Seleksi Fitur pada pendekatan OVA
No Metode Seleksi Fitur Jumlah Fitur Akurasi
1 Tanpa seleksi fitur 5149 76,1905 %
2 ETC 1223 78,5238 %
3 UCS 2500 79,7143 %
4 VT 1788 76,6667%
Berdasarkan Tabel 2terlihat beberapa hasil sebagai berikut:
• Secara umum penggunaan metode seleksi fitur meningkatkan akurasi kinerja mesin pada pendekatan OVA.
• Metode seleksi fitur ETC mengeliminasi fitur terbanyak, sehingga menjadi 1223 fitur dari 5149 fitur yang ada.
• Metode seleksi fitur UCS merupakan metode seleksi fitur yang menghasilkan akurasi terbaik dibandingkan dengan metode seleksi fitur yang lain. dengan akurasi sebesar 79,7143% dengan jumlah fitur sebanyak 2500 fitur
Sehingga pada penelitian ini, metode seleksi fitur UCS merupakan metode terbaik ketika menggunakan pendekatan OVA.
4.3 Perbandingan hasil simulasi pendekatan OVO dan OVA
Setelah mendapatkan hasil terbaik dari masing-masing metode Multiclass dengan seleksi fiturnya, selanjutnya ditunjukan metode Multiclass yang memberikan hasil terbaik dalam melakukan analisis sentiment. Berikut hasil terbaik dari masing-masing metode Multiclass:
Tabel 3 Perbandingan Akurasi Seleksi Fitur terbaik pada OVO dan OVA
no Metode Multiclass Metode Seleksi Fitur
Banyaknya Fitur Akurasi
1 OVO UCS 2000 79.7619%
Pada Tabel 3 terlihat bahwa pendekatan OVO dengan seleksi fitur UCS menggunakan 2000 fitur menghasilkan akurasi lebih besar jika dibandingkan dengan pendekatan OVA dengan seleksi fitur UCS yang menggunakan 2500 fitur.
Sehingga pendekatan OVO dengan metode seleksi fitur Univariate Chi Square (UCS) merupakan metode terbaik dalam menyelesaikan masalah Multiclass dalam kasus sentiment pada twitter.
5. Kesimpulan
Berdasarkan hasil simulasi program analisis sentimen twitter dengan menggunakan metode Multiclass Support Vector Machine (SVM) untuk pendekatan One Vs One dan One Vs All pada studi kasus calon presiden Republik Indonesia periode 2014-2019 pada bab 4 dalam skripsi ini, maka dapat ditarik beberapa kesimpulan, yaitu:
1. Pada metode Multiclass SVM untuk pendekatan One Vs One dan One Vs All, proses seleksi fitur berhasil mengurangi fitur yang tidak berguna tanpa mengurangi akurasi.
2. Pada metode Multiclass SVM untuk pendekatan One Vs One dan One Vs All dengan Seleksi Fitur dapat meningkatkan kinerja mesin dalam hal akurasi.
3. Pada metode Multiclass SVM untuk pendekatan One Vs One, metode seleksi fitur dengan Univariate Chi Square menghasilkan akurasi yang terbaik dengan
menggunakan 2000 fitur.
4. Pada metode Multiclass SVM untuk pendekatan One Vs All, metode seleksi fitur dengan Univariate Chi Square menghasilkan akurasi yang terbaik dengan
menggunakan 2500 fitur.
5. Pada metode Multiclass SVM untuk pendekatan One Vs One dan One VS All, Metode seleksi fitur Extra Tree Classifier mengeliminasi fitur terbanyak, sehingga hanya 1223 fitur yang digunakan dari total 5149 fitur.
6. Pendekatan One Vs One dengan menggunakan Seleksi Fitur Univariate Chi Square memiliki Akurasi yang lebih tinggi dibandingkan pendekatan One Vs All dengan menggunakan Seleksi Fitur Univariate Chi Square walau akurasi terpaut sangat kecil, yaitu dengan selisih sebesar 0.0476 %. Selain itu pemakaian fitur juga lebih sedikit, dengan selisih sebesar 500 fitur.
6. Saran
Berikut saran-saran yang diberikan penulis dalam penelitian ini, yang diharapkan dapat berguna untuk penelitian-penelitian selanjutnya yang membahas Analisis Sentimen dengan Multiclass SVM:
1. Agar dapat menghemat waktu penelitian. Diperlukannya metode Model Selection yang lebih baik dari pada Loose grid Search dan Fine Grid Search untuk mencari
parameter C dan γ. Pencarian parallel pada kedua parameter tersebut juga sangat disarankan.
2. Agar dapat menghemat waktu penelitian. Diperlukannya suatu metode yang efektif dalam memilih parameter k banyaknya fitur dengan nilai Chi Square tertinggi pada Seleksi Fitur Univariate Chi Square dan parameter batas variansi yang optimal pada seleksi fitur Variance Threshold.
3. Agar penelitian ini dapat diaplikasikan dalam kehidupan sehari-hari, diperlukan prosedur yang lebih layak dalam proses Akuisisi data, Filter data, dan Pelabelan data.
7. Daftar Referensi
Aisen, B (2006). A comparison of Multiclass SVM method.
http://courses.media.mit.edu/2006fall/mas622j/Projects/aisen-project Diakses pada : 1 Oktober 2014, 13.48 WIB
Bazaraa, M. S., Sherali, H. D., dan Shetty, C. M. (2006).Nonlinear Programming Theory and Algorithms (3rd ed.). USA : John Wiley & Sons, Inc.
Bishop, C. H. (2006). Pattern Recognition and Machine Learning. Singapore:Springer. Burden, R. L. dan Fairies. J. D. (2001). Numerical Analysis (7th ed). USA : Brooks/Cole
Publishing Co.
Cristianini, N. dan Shawe, T. J. (2000). An Introduction to Support Vector Machines. UK : Cambridge University Press.
Elizindo, D. (2006). The Linear Separability Problem: Some Testing Methods. IEEE Transactions on Neural Networks, vol.17(2).
Feldman, R. (2013). Techniques and applications for sentiment analysis. Communication of the ACM, vol. 56 (4), 82-89.
Geurts, P., Ernst, D., dan Wehenkel, L. (2006). Extremely randomized trees. Springer Science+Business Media, Inc.
Hogg, R. V., McKean, J., & Craig, A. T. (2012). Introduction to Mathematical Statistics (7th ed.). Pearson
Hsu, C. W., Chang, C. C., dan Lin, C. J (2010). A Practical Guide to Support Vector
Classification. http://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf. Diakses: diakses 20 Oktober 2014, 21.30 WIB
Manning, C. D., Raghavan, P., & Schütze, H. (2009). An Introduction to Information Retrieval. Cambridge: Cambridge University Press.
Mitchell, T. M. (1997). Machine Learning. USA : McGraw Hill.
Platt, J. C. (1998). Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines. Microsoft Research. Microsoft Research.
Sun, C.,Wang, X., dan Xu, Ju. (2009). Study on Feature Selection in Finance Text
Categorization. IEEE International Conference on Systems, Man, and Cybernetics, 5077-5082.
Winston, W. (2004). Operation Research Applications and Algorithms (4th ed.). USA : Brooks/Cole Publishing Co.