BAB 3.
METODOLOGI PENELITIAN
3.1. Bagan Alir Penelitian
Vergidis et al. (2007) mengusulkan dua langkah dasar dari framework
multi-objective optimisasi untuk perancangan proses bisnis. Langkah pertama adalah
membuat konstruksi model dengan cara model dirumuskan dalam bentuk matematis untuk memastikan formalitas, konsistensi dan ketelitiannya. Langkah kedua adalah mencari solusi model dengan menerapkan algoritma optimisasi pada model proses bisnis dengan menggunakan KEA Tool-box. KEA Tool-box merupakan software
optimisasi yang dikembangkan oleh Bartz-Beielstein et al., 2004 yang menggunakan algoritma NSGA-II (Non Dominated Sorting in Genetic Algorithm II), SPEA2 (Strength
Pareto Evolutionary Algorithm 2), MOPSO (Multi-Objective Particle Swarm
Optimisation)dengan penyelesaiannya menggunakan KEA-Software. Ketiga algoritma ini digunakan karena dapat mengoptimisasi model proses bisnis yang multi-objective. NSGA-II dan SPEA2 lebih popular dibandingkan dengan algoritma MOPSO. NSGA-II banyak diaplikasikan dalam berbagai penelitian karena menggunakan pendekatan elitist, sedikit parameter dan memberikan perkembangan solusi yang signifikan. SPEA2 juga merupakan evolutionary algorithms yang menggunakan pendekatan elitist yang lain. MOPSO memberikan hasil yang lebih baik apabila digunakan dalam permasalahan yang membutuhkan pencarian solusi yang kontinu. Dari hasil analisis secara umum diketahui bahwa algoritma NSGA-II memberikan solusi yang lebih optimal dibandingkan dengan algoritma SPEA2 dan MOPSO. Dengan desain proses bisnis yang kompleks, secara umum kemampuan dari NSGA-II dapat dikarakteristikkan baik dan memiliki elitism
yang dimana NSGA-II menyimpan solusi optimum dari setiap generasi dan membandingkan solusi tersebut dengan solusi antar setiap generasi, sehingga memungkinkan untuk mengidentifikasikan feasible solutions. Sesuai dengan informasi yang diterima dari Bartz-Beielstein bahwa software optimisasi KEA Tool-box tidak di rawat lagi untuk jangka waktu yang tidak terbatas, sehingga dalam penelitian ini tidak akan menggunakan software tersebut.
Pada framework multi-objective optimisasi yang diusulkan oleh Vergidis et al. tidak menggunakan metodologi pemodelan proses yang jelas untuk menggambarkan proses bisnis yang terjadi, sehingga tidak memberikan penjelasan yang lebih rinci mengenai proses yang terjadi dan tidak menunjukkan logika proses dari model. Sementara itu Kusiak et al. (2000) mengatakan bahwa metodologi pemodelan proses secara umum didasarkan pada simbol yang tidak formal dan secara kualitatif sehingga sulit untuk dianalisis.
Pada bagian ini akan diformulasikan model perbaikan proses bisnis yang multi-objective secara kuantitatif menggunakan algoritma NSGA-II (Non Dominated Sorting in Genetic Algorithm. Berdasarkan uraian di atas bahwa pemodelan proses hanya sedikit menggunakan model matematis dan perbaikan proses bisnisnya hanya bersifat kualitatif, maka dalam penelitian ini akan melakukan perbaikan proses bisnis secara kuantitatif dengan merepresentasikan secara matematis model proses bisnis dan penyelesaiannya menggunakan pendekatan algoritma NSGA-II. Kekurangan dalam pemodelan yang dilakukan oleh peneliti sebelumnya akan ditutupi dengan menggunakan metodologi IDEF3 (Integrated Definition Methodology 3) yang memiliki kemampuan mengakomodasi hubungan-hubungan atau ketergantungan antar proses dalam proses bisnis dan memberikan gambaran yang jelas mengenai deskripsi sistem. IDEF3 merupakan tool pemodelan dengan representasi terstruktur dari sebuah sistem dengan cara meng-capture perilaku dari sistem yang dibahas mengenai urut-urutan terjadinya proses, proses apa yang menyebabkan proses apa, dan bagaimana keputusan diambil.
Vergidis et al. (2007) menguraikan bahwa penelitian pada proses bisnis yang kompleks, NSGA-II (Non Dominated Sorting in Genetic Algorithm II) mempunyai kemampuan yang lebih baik secara keseluruhan dan menunjukkan adanya elitisim.
Untuk itulah, maka pada penelitian ini hanya akan mengembangkan algoritma NSGA-II pada proses bisnis. Penelitian ini pada tahap awalnya akan mendefinisikan variabel dengan menggunakan model matematis. Penyelesaian model matematis ini menggunakan pendekatan modifikasi algoritma NSGA-II. Model yang terbentuk dianalisis sehingga diperoleh karakteristik dari proses bisnisnya, aktivitas-aktivitas yang
tersebut, kemudian akan digunakan sebagai input untuk mencari pilihan suatu set aktivitas yang optimal yang mempunyai kriteria minimum biaya dan durasi. Hasil yang diperoleh dari penerapan algoritma optimisasi adalah beberapa alternatif solusi yang saling trade-off antara kriteria tujuan yang ingin dicapai. Untuk dapat memilih solusi akhir dari beberapa alternatif solusi yang diberikan maka diperlukan keterlibatan pihak pengambil keputusan untuk memilih solusi tersebut
Untuk memudahkan penelitian yang akan dilakukan, maka perlu direncanakan tahapan–tahapan yang akan menjadi pedoman dan arahan bagi penelitian ini. Tahapan-tahapan proses tersebut dapat dilihat pada gambar 3.1 berikut ini :
• Business Process Modelling
• Multiobjective Optimization
• Single Objective Optimization
• IDEF3
• Algoritma Genetika
• Algoritma NSGA-II
• Penentuan Variabel dan Kriteria tujuan
• IDEF3
• Model Matematika
• Contoh Numerik 1 : Proses di Travel Agents
• Contoh Numerik 2 : Proses Pembelian Bahan Baku di PT.X
• Contoh Numerik 3 : Proses
Rekrutmen Siswa di Tempat Pelatihan Y
Deb et al. (2000),
”A fast elitist non-dominated sorting genetic algorithm for multiobjective optimization:
NSGA-II”
Kajian Penelitian dalam jurnal
K. Vergidisa, A. Tiwaria, B. Majeedb, R. Roya (2007) Optimisation of business process designs:
3.1.1 Kajian Penelitian dalam jurnal
Tahap kajian penelitian jurnal merupakan awal dalam penelitian ini yaitu mencari permasalahan-permasalahan yang muncul dalam desain proses bisnis. Kajian ini dilakukan dengan cara mencari, meng-explore, dan mengkaji permasalahan proses bisnis dan multi-objective optimisation. Penelitian-penelitian ini terdiri dari Vergidis et al. (2007), Aguilar-Saven (2004), Bititci et al. (1997), Hofacker and Vetschera (2001), dan Deb et al. (2000).
3.1.2 Formulasi Masalah
Formulasi masalah merupakan proses identifikasi dan perumusan masalah yang muncul untuk melakukan perbaikan proses bisnis seperti bentuk representasi proses bisnis yang multi-objective secara kuantitatif, tools yang digunakan dan karakteristik-karakteristik dari pendekatan analitik yang diusulkan untuk mengevaluasi usulan perbaikan proses bisnis.
3.1.3 Penetapan Tujuan Penelitian
Tujuan penelitian adalah merupakan arah yang digunakan oleh peneliti untuk mencapai sasaran yang dikehendaki oleh penulis. Tujuan yang dikehendaki berdasarkan penyelesaian permasalahan-permasalahan yang muncul pada tahap formulasi masalah adalah menganalisis model proses bisnis secara kuantitatif sehingga mendapatkan perbaikan proses bisnis yang lebih baik dibandingkan dengan perbaikan secara kualitatif, mengembangkan tools untuk membantu proses analisis yang lebih formal bagi model perbaikan sebuah proses bisnis yang multi-objective, dan menganalisis model kuantitatif optimisasi proses bisnis dengan mengunakan contoh numerik untuk mengetahui karakteristik dari model bisnis.
3.1.4 Studi Literatur
Studi literatur dilakukan dengan mempelajari literatur yang berhubungan dengan penelitian, yaitu topik-topik mengenai:
• Penelitian-penelitian yang berkaitan
• Business Proses Modelling
• Multi-objective optimisation
• Single-objective optimisation
• IDEF3 (Integrated Definition Methodology 3) • Algoritma Genetika Sederhana
• Algoritma NSGA-II (Non Dominated Sorting in Genetic Algorithm II)
3.1.5 Pengembangan Model
Pengembangan dan perancangan model dalam penelitian ini merupakan salah satu tahapan yang penting dalam melakukan penelitian ini. Pada tahapan ini akan diidentifikasikan variabel-variabel apa saja yang mempengaruhi kelancaran pelayanan pada proses bisnis dan didasarkan pada tujuan penelitian yang telah didefinisikan. Pada tahapan ini di bangun kerangka pengembangan model yaitu mendefinisikan variabel optimisasi dan tujuan optimisasi dalam proses bisnis, merumuskan suatu model matematis dasar untuk memastikan formalitas, konsistensi dan ketelitian, setelah itu melakukan pemodelan proses dengan menggunakan IDEF3 (Integrated Definition
Methodology 3), dan menggambarkan pengembangan model dengan menggunakan
contoh numerik. Penjelasan dari komponen ini dapat dilihat pada subbab 3.2.
3.1.6 Pengembangan Algoritma NSGA-II
Model yang telah digambarkan pada tahap sebelumnya akan menjadi dasar pemikiran dan penyelesaiannya dengan menggunakan pendekatan algoritma NSGA-II.
yang multi-objective. Seperti yang kita ketahui bahwa dalam penelitian ini adalah mencari set urutan alternatif aktivitas yang terbaik dalam desain proses bisnis sesuai dengan variabel dan kriteria tujuan yang ingin dicapai, sehingga populasi yang
di-generate memiliki kendala. Untuk itu maka diperlukan perubahan dalam original
NSGA-II dalam men-generate populasi, seleksi dan mutasi, sehingga perlu adanya modifikasi algoritma NSGA-II. Untuk selanjutnya, algoritma yang akan dikembangkan dalam penelitian ini akan disebut modifikasi algoritma NSGA-II.
3.1.7 Uji Coba Algoritma
Uji Coba Algoritma ini digunakan sebagai pendekatan pemecahan masalah dengan menggunakan modifikasi algoritma NSGA-II (Non Dominated Sorting in
Genetic Algorithm II). Tahapan ini bertujuan untuk mengetahui kelebihan dan
kelemahan dari pendekatan pemecahan masalah yang dikembangkan. Pengujian ini akan dilakukan dengan menggunakan contoh data numerik yang bersifat hipotetik.
3.1.8 Validasi Model
Validasi merupakan model proses penentuan apakah model memiliki makna dan dapat merepresentasikan secara akurat suatu sistem nyata. Salah satu cara yang dapat dilakukan untuk memvalidasi model adalah membandingkan model dengan model yang lain. Modifikasi algoritma NSGA-II yang dikembangkan dalam penelitian ini akan divalidasi dengan menggunakan Metoda Enumerasi. Metoda Enumerasi melakukan pencarian nilai-nilai fungsi objektif satu demi satu secara berurutan pada setiap titik dalam ruang solusi.
3.1.9 Analisis dan Pembahasan
Pada tahapan ini akan diuraikan tentang proses analisis solusi yang telah diperoleh dengan modifikasi algoritma, pengujian validasi dari model algoritma NSGA-II (Non Dominated Sorting in Genetic Algorithm II), dan analisis pemakaian model usulan.
3.1.10 Kesimpulan dan Saran
Kesimpulan pada penelitian ini diharapkan mampu memberikan suatu masukan mengenai cara mengoptimalkan proses bisnis yang memiliki beberapa alternatif aktivitas dalam urutan aktivitasnya di dalam proses bisnisnya, menghasilkan kerangka pemodelan proses bisnis secara kuantitatif dengan menggunakan langkah-langkah yang diusulkan, dan memodifikasi algoritma multi-objective NSGA-II (Non Dominated Sorting in Genetic Algorithm II) untuk optimisasi proses bisnis dengan menggunakan contoh numerik. Selain itu dirumuskan saran-saran seperti saran untuk penelitian selanjutnya.
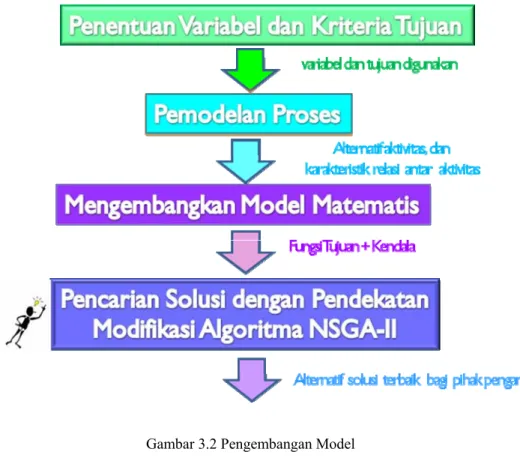
3.2Pengembangan Model
Kerangka pengembangan model penelitian yang diusulkan ini dibangun dari empat komponen utama, yaitu mendefinisikan variabel optimisasi dan kriteria tujuan yang ingin dicapai, melakukan pemodelan proses menggunakan IDEF3 (Integrated Definition Methodology 3) melalui analisis contoh numerik, setelah itu merumuskan suatu model matematis dasar untuk memastikan formalitas, konsistensi dan ketelitian, sehingga didapatkan gambaran model dan fungsi tujuan yang akan digunakan pada uji coba modifikasi algoritma NSGA-II (Non Dominated Sorting in Genetic Algorithm II). Hubungan keempat komponen ini dapat dilihat pada gambar 3.2 di bawah ini :
Gambar 3.2 Pengembangan Model
3.2.1 Penentuan Variabel dan Kriteria Tujuan dalam Model.
Seperti yang telah dijelaskan sebelumnya, bahwa langkah pertama yang harus dilakukan adalah menjelaskan framework yang terkait dengan konstruksi model proses bisnis dan kebutuhan yang terkait bagi gambaran formal suatu proses bisnis.
Suatu model proses bisnis yang akan dioptimisasi harus didefinisikan terlebih dahulu model variabel optimisasi dan tujuannya seperti yang dijelaskan pada gambar 3.3. Variabel optimisasi dari model proses bisnis adalah activities dan starting times. Tujuannya adalah menghasilkan penyempurnaan proses dengan minimasi dua tujuan, yaitu durasi waktu proses dan biaya pelayanan dalam sebuah sistem. Untuk masing-masing desain proses, terdapat beberapa alternatif calon aktivitas dengan atribut seperti durasi aktivitas dan biaya. Suatu aktivitas didefinisikan berdasarkan resources input dan
resources output serta memiliki atribut durasi dan biaya. Beberapa aktivitas yang mempunyai kebutuhan yang yang sama dalam kaitan dengan resources masukan dan keluarannya dapat saling dipertukarkan dalam sebuah desain proses bisnis. Pertukaran aktivitas dalam sebuah desain proses bisnis secara langsung mempengaruhi total durasi dan biaya proses bisnis. Untuk mengoptimalkan desain proses bisnis maka dibutuhkan pilihan suatu set aktivitas yang men-generate minimum biaya dan durasi (Vergidis et al.,2007).
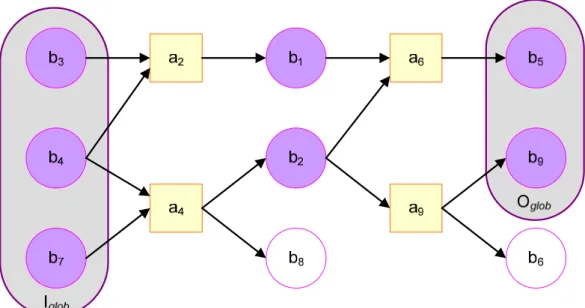
Gambar 3.4 menggambarkan desain proses bisnis yang feasible menggunakan 2 konsep yaitu : activities dan resources. (Bititci and Muir, 1997). Bititci dan Muir menyatakan bahwa aktivitas yang dilakukan dalam suatu bisnis ikut berpartisipasi dalam membentuk tujuan dari suatu proses bisnis. Desain proses bisnis pada gambar 3.4 memiliki dua set resources yaitu initial (Iglob) dan final (Oglob) resources. Initial resouces merupakan resources yang sudah tersedia pada awal proses bisnis, sementara
final resources terbentuk pada hasil akhir. Resources mengalir sepanjang proses dan termasuk dalam dua kategori yang utama yaitu fisik dan informasi resources. Aktivitas merupakan langkah-langkah perubahan di dalam proses yang menggunakan beberapa
resources sebagai masukan dan memproduksinya sebagai keluaran. Dalam desain proses yang feasible, semua aktivitas digambarkan secara berurutan, resources haruslah cukup dan yang sangat penting resources final dihasilkan dengan adanya partisipasi aktivitas.
Gambar 3.4 Desain proses bisnis yang feasible dengan menggunakan activities dan resources (Hofacker and Vetschera ,2001)
Activities and resources dapat digambarkan sebagai nodes dan arcs pada grafik.
Actvities digambarkan dengan nodes, sedangkan input dan output digambarkan dengan
arcs, yang menghubungkan suatu aktivitas dengan aktivitas yang lain. Setiap aktivitas menggunakan satu atau lebih inputs dan men-generate satu atau lebih output. Dalam uraian oriented models dari proses bisnis seperti halnya dalam model penjadwalan dalam manufaktur, aktivitas pendahulu (precedence of activities) diasumsikan given.
Untuk memodelkan hubungan antara activities dan resources menjadi lebih realistis, maka resources yang ada dibedakan menjadi 2 tipe yaitu physical resources dan
information resources. Sumber daya fisik dapat bertindak sebagai input hanya untuk satu aktivitas yang mengkonsumsinya. Sumber daya informasi yang dibuat sekali, dapat digunakan oleh sejumlah aktivitas manapun yang mengikutinya. Masing-masing aktivitas ditandai oleh atribut seperti durasi, biaya, atau aspek kualitas. Hubungan antara aktivitas dan sumber daya didasarkan pada tiga asumsi (Hofacker and Vetschera,2001) yaitu :
1) Masing-Masing aktivitas mengkonsumsi persisnya satu unit dari tiap sumber daya di dalam Ii dan menghasilkan persisnya satu unit dari tiap sumber daya di dalam Oi.
2) Semua masukan (input) harus tersedia sebelum suatu aktivitas dapat dijalankan/dilaksanakan (yaitu input yang terkait oleh suatu hubungan AND
daripada OR).
3) Semua keluaran (output) di dalam Oi dihasilkan ketika aktivitas ai dijalankan/dilaksanakan (yaitu ouput yang juga terkait oleh AND).
Suatu desain proses adalah feasible jika kedua kondisi di bawah ini dipenuhi (Hofacker and Vetschera,2001):
1. Untuk semua aktivitas ai yang termasuk dalam desain proses, semua sumber daya di dalam Ii adalah salah satunya termasuk dalam Iglob atau dihasilkan oleh beberapa aktivitas ai, di mana pj<pi. Untuk sumber daya fisik, tidak ada aktivitas lain yang harus mengkonsumsi unit yang sama dari sumber daya.
2. Semua sumber daya di dalam Oglob dihasilkan oleh beberapa aktivitas ai dalam suatu desain proses dan sumber daya fisik harus tidak dikonsumsi oleh aktivitas yang lain.
Pada Gambar 3.4, menggambarkan suatu desain proses yang feasible. Sumber daya
b3,b4 dan b7 adalah tersedia pada awal proses. Aktivitas a2 digunakan untuk
menghasilkan b1 dari b3 dan b4. Aktivitas a4 juga menggunakan sumber daya informasi
b4 seperti halnya b7 untuk menghasilkan b2 dan b8. b1 dan b2 digunakan oleh a6 untuk
menghasilkan b5, b2 juga digunakan oleh a9 untuk menghasilkan b9 dan b6. Hanya b5 dan
b9 merupakan global outputs dari proses tersebut, sedangkan b6 dan b8 tidak digunakan.
3.2.2 Pemodelan Proses
Model proses adalah proses yang disederhanakan dalam bentuk model sehingga lebih mudah, aman, murah dan tidak beresiko. Model merepresentasikan sistem, obyek, atau persoalan. Melalui model akan diperoleh gambaran mengenai sistem, analisis dan evaluasi terhadap performansi sistem, dan dapat dilakukan perbaikan-perbaikan dan evaluasi terhadap usulan perbaikan.
Seperti yang diuraikan sebelumnya bahwa penelitian ini menggunakan model yang dibangun oleh Vergidis et al. (2007), akan tetapi pemodelan tersebut masih terdapat kekurangan seperti tidak memberikan penjelasan yang lebih rinci mengenai proses yang ada dalam sistem dan tidak menunjukkan logika proses dari model. Kekurangan ini dapat ditutupi dengan menggunakan metodologi IDEF3 yang memiliki kemampuan mengakomodasi hubungan-hubungan atau ketergantungan antar proses dan memberikan gambaran secara jelas tentang deskripsi sistem.
IDEF3 (Integrated Definition Methodology 3) merupakan tool pemodelan untuk menghasilkan model atau representasi terstruktur dari sebuah sistem, yang dilakukan dengan cara meng-capture perilaku dari sistem yang dibahas seperti urut-urutan terjadinya proses, proses apa yang menyebabkan proses apa, dan bagaimana keputusan diambil. Alasan menggunakan IDEF3 adalah dikarenakan kemampuannya dalam deskripsi proses bisnis yang semakin dapat dipertajam melalui dekomposisi proses yaitu dengan cara menyederhanakan proses melalui tingkatan abstraksi modul yang berbeda-beda. Pada dasarnya pada setiap tingkatan dekomposisi diperoleh deskripsi proses yang lebih rinci, sehingga dengan menggunakan metode IDEF3 kita dapat mencari lokalisasi masalah yang lebih rinci dari proses bisnis yang besar. Dengan adanya lokalisasi masalah dalam proses bisnis yang sangat besar, kita dapat memperbaiki secara fokus keterkaitan antara satu jenis proses dengan jenis proses dalam proses bisnis yang memiliki masalah. Seperti yang dijelaskan sebelumnya bahwa IDEF3 nantinya akan menghasilkan deskripsi proses dalam sistem secara terstruktur sehingga dapat menjadi
knowledge base untuk mengkonstruksi model analitis, selain itu dapat memberikan penjelasan yang lebih rinci mengenai proses yang ada dalam sistem dan memiliki karakteristik sequence yang mampu menunjukkan aktivitas predecessor dan successor. IDEF3 memodelkan proses dengan menggunakan diagram yang disebut diagram proses. Diagram proses memiliki tiga elemen dasar yaitu proses (atau disebut UOBs = Unit of Behaviours), Links, dan Junction. UOBs menggambarkan proses aktual yang dijelaskan dengan kotak persegi panjang, Links yang menghubungkan kotak-kotak dan menggambarkan hubungan di antara UOBs, dan Junction menggambarkan logika dari
Pada saat menggambarkan model proses yang menjelaskan urutan aktivitas-aktivitas dan yang memberikan identifikasi bagi peningkatan prosesnya. Penggunaan prosedur sangat penting di dalam membangun model proses yang berskala besar. Adapun prosedur di dalam membangun model proses adalah sebagai berikut (Adaptasi dari Kusiak, 1999):
1. Mendefinisikan skenario
2. Mengidentifikasi dan menetapkan aktivitas yang tepat 3. Menyusun aktivitas dalam urutan yang bertahap 4. Mengidentifikasi dan menentukan input dan output
5. Menetapkan object life cycle
6. Menetapkan logical junctions
Seperti yang dijelaskan oleh Kusiak (1999) bahwa terdapat dua tipe analisis yang dapat dilakukan untuk perbaikan proses, yaitu: analisis observasi (manual) dan analisis computational. Dan karena merupakan model proses yang kualitatif pada dasarnya, analisis sering dilakukan berdasarkan analisis observasi yang memungkinkan analisis untuk mengidentifikasikan kurang sempurnanya area dalam suatu model dengan cara mengaplikasikan model IDEF3 (Integrated Definition Methodology 3). Sedangkan analisis computational dilakukan untuk merekayasa model proses. Analisis struktur model dilakukan pada model IDEF3 yang telah ditransfer ke dalam bentuk matriks. Analisis computational merupakan analisis yang memanipulasi elemen-elemen dalam matriks sesuai dengan tujuan yang diinginkan. Berdasarkan kelebihan masing-masing dari analisis tersebut, maka penulis akan menggabungkan kedua analisis tersebut dalam penelitian ini yaitu pertama kali melakukan analisis observasi dengan cara menggambarkan aktivitas-aktivitas yang ada dalam suatu sistem, dan kemudian melakukan analisis computational dengan cara merepresentasikannya dalam bentuk
matriks yang nantinya akan digunakan unuk men-generate populasi dalam set aktivitas pada proses bisnis di dalam algoritma NSGA-II (Non Dominated Sorting in Genetic Algorithm II).
3.2.3 Pengembangan Model Matematis
Model proses bisnis dibatasi oleh suatu rangkaian kendala matematis yang mendefinisikan kendala yang mungkin dari suatu proses bisnis dan juga mendefinisikan kumpulan fungsi tujuan yang terdiri dari berbagai variasi dari tujuan proses bisnis yang diinginkan. Hal yang penting yang harus diketahui bahwa framework bekerja secara independen dari jumlah proses tujuan. Durasi proses dan biaya dipilih sebagai kriteria dua tujuan umum untuk perbaikan proses bisnis. Berikut ini adalah notasi yang digunakan dalam pengembangan model matematis yaitu :
ci = ongkos pelaksanaan aktivitas ai;
xi = variabel biner yang menandai (adanya) apakah suatu calon aktivitas ai mengambil bagian di desain proses bisnis;
yj = variabel biner yang menandai apakah sumber daya informasi bj adalah yang tersedia sepanjang proses bisnis;atau menjadi
ti,j = matriks variabel biner yang menghubungkan aktivitas dengan output sumber daya; rij = matriks dari variabel biner yang menandai jika suatu unit dari sumber daya fisik bj
gij = binary konstan dengan 1 dimensi yang menandai adanya sumber daya bj ada di global input;
goj = binary konstan dengan 1 dimensi yang menandai adanya sumber daya bj ada di global
ouput;
M = konstanta yang sangat besar sekali yang mengindikasikan bahwa sumber daya fisik berisikan
global input yang tersedia dalam jumlah yang tidak terbatas; pi = waktu mulai aktivitas ai;
dj = waktunya sumber daya bj menjadi tersedia;
δI = durasi aktivitas ai;
λij = variabel biner yang menunjukkan bahwa aktivitas ai digunakan untuk menciptakan sumber daya bj ;
Ii/Oi = set sumber daya input/output dari aktivitas ai; BP/BI = set sumber daya fisik dan informasi bj.
∀ = untuk semua anggota
Model matematis mendefinisikan tujuan optimisasi yang ingin dicapai dengan dua fungsi tujuan dan memastikan proses bisnis yang konsisten dan feasible dengan menggunakan ketiga belas kendala (constraints). Model matematis terdiri dari sejumlah variabel biner dan matriks variabel biner yang memiliki dampak dalam desain proses bisnis yang feasible. Model Matematis yang dijelaskan di atas adalah sebagai berikut (Hofacker and Vetschera,2001) :
( )
P( )
dj j bj gojf1 =max →min, ∀ : ∈
Fungsi tujuan yang pertama (f1) dari model adalah mengkalkulasi durasi proses bisnis, yaitu total durasi dari awal proses sampai akhir proses melayani customer yang dimana global output dihasilkan
( )
1 min2 P =∑ci xi →
f
sedangkan fungsi tujuan kedua (f2) mengkalkulasikan biaya yang dikeluarkan dari proses bisnis
yaitu penjumlahan semua biaya untuk semua aktivitas yang berpartisipasi.
Kendala (constraints) pada model matematis dapat memastikan bahwa model yang dihasilkan adalah proses bisnis yang feasible dari pengujian berbagai aspek dari model proses bisnis. Tabel 3.1 di bawah ini memperlihatkan penjelasan singkat mengenai masing-masing kendala (constraints) dari model matematis. Model matematis di atas terdiri dari banyak variabel biner diskrit yang secara signifikan menambah kompleksitas dari terjadinya desain proses dalam pencarian solusi yang feasible.
, , : , , j i j p ij i r i j b I b B x ≤ ∀ ∈ ∈ (1)
Semua masukan sumber daya fisik dari suatu aktivitas harus tersedia ( rij = 1) pada kondisi tertentu dari suatu proses jika aktivitas sedang berpartisipasi ( xi= 1).
, , : , , j i j I j i y i j b I b B x ≤ ∀ ∈ ∈ (2)
Semua masukan sumber daya informasi ( yj) dari suatu aktivitas harus tersedia pada kondisi tertentu dari suatu proses jika aktivitas sedang berpartisipasi. ( xi= 1).
∑
∑
≤ + ∀ ∈ + i P j i ij j i ij i r Mgi t x j b B go , : , (3), : ,
∑
∀ ∈ + ≤ i I j i ij j j gi t x j b B y (4)Suatu sumber daya informasi (yj) dapat tersedia pada awal proses-seperti initial resource (gij)-atau sebagai output resources dari aktivitas yang sedang berpartisipasi.
, j j go
y ≥ (5)
Suatu sumber daya ( yj) tidak bisa menjadi bagian dari output tanpa pertama menjadi yang tersedia pada kondisi tertentu dari proses ( goj).
(
1 i)
, , : j i,j
i d M x i j b I
p ≥ − − ∀ ∈ (6)
Dalam kaitan dengan waktu, aktivitas yang berpartisipasi dapat dimulai ( pi) jika hanya setelah waktu semua sumber daya masukan nya sudah tersedia.
(
i)
j i i i j p M x i b O d ≤ +δ + 1− , ∀ : ∈ (7)(
1 i)
(
1 ij)
, : j i, i i j p M x M i b O d ≥ +δ − − − −λ ∀ ∈ (8)Dalam kaitan dengan waktu, suatu sumber daya keluaran harus menjadi yang tersedia persisnya ketika aktivitas yang di- generate telah diselesaikan (qj= pi).
, : , , j i i ij ≤x ∀i j b ∈O λ (9)
Suatu aktivitas tanpa penyertaan ( xi= 1) tidak bisa mempunyai sumber daya keluaran( ij= 1)
(
1)
, : , 0 : = ∀ − − + ≥∑
∑
∈Oi P j bj i i j j ij ij r go M y j B gi λ (10)Ketika suatu sumber daya fisik yang bukan merupakan sumber daya awal (initial), maka harus dihasilkan sepanjang proses sejumlah yang sama atau lebih besar bagi sumber daya masukan yang diperlukan dari aktivitas yang sedang berpartisipasi.
(
1)
, : , 0 1 : = ∈ ∀ − − ≥∑
∈Oi j P j bj i i ij M y j b B gi λ (11)Masing-Masing sumber daya fisik yang bukan merupakan sumber daya awal (initial) tetapi muncul di output dari suatu aktivitas yang sedang berpartisipasi harus diproduksi sedikitnya satu kali.
{ }
ixi∈ 0,1, ∀ (12)
Variabel x ( menandakan aktivitas yang berpartisipasi) harus biner.
{ }
0,1, , : j i,ij∈ ∀i j b ∈O
λ (13)
Variabel λ ( menandakan output sumber daya j dari aktivitas i) harus biner.
Persamaan model matematis di atas dapat dituliskan kembali sebagai berikut :
( )
P( )
dj j bj gojf1 =max →min, ∀ : ∈ (3.1)
s.t , , : , , j i j p ij i r i j b I b B x ≤ ∀ ∈ ∈ (3.3) , , : , , j i j I j i y i j b I b B x ≤ ∀ ∈ ∈ (3.4)
∑
∑
≤ + ∀ ∈ + i ij i j P j i ij i r Mgi t x j b B go , : , (3.5) , : ,∑
∀ ∈ + ≤ i I j i ij j j gi t x j b B y (3.6) , j j go y ≥ (3.7)(
1 i)
, , : j i, j i d M x i j b I p ≥ − − ∀ ∈ (3.8)(
i)
j i i i j p M x i b O d ≤ +δ + 1− , ∀ : ∈ (3.9)(
1 i)
(
1 ij)
, : j i, i i j p M x M i b O d ≥ +δ − − − −λ ∀ ∈ (3.10) , : , , j i i ij ≤x ∀i j b ∈O λ (3.11)(
1)
, : , 0 : = ∀ − − + ≥∑
∑
∈Oi P j bj i i j j ij ij r go M y j B gi λ (3.12)(
1)
, : , 0 1 : = ∈ ∀ − − ≥∑
∈Oi j P j bj i ij i gi B b j y M λ (3.13){ }
i xi∈ 0,1, ∀ (3.14){ }
0,1, , : j i, ij∈ ∀i j b ∈O λ (3.15)3.2.4 Modifikasi Algoritma NSGA-II
Berdasarkan penelitian yang dilakukan Vergidis et al. (2007) bahwa algoritma
multi-objective optimization seperti NSGA-II (Non Dominated Sorting in Genetic Algorithm II), SPEA2 (Strength Pareto Evolutionary Algorithm 2), dan MOPSO
(Multi-Objective Particle Swarm Optimisation) dapat digunakan untuk mengoptimalkan suatu model proses bisnis. Seleksi ini berdasarkan pada persyaratan seperti fragmented search space dan constraints. Menurut Deb, 2001 bahwa NSGA-II dan SPEA2 lebih popular karena ketahanan dalam menyelesaikan permasalahan fragmented search space.
NSGA-IIdan SPEA2 banyak digunakandan saling bersaing antar satu sama lainnya di dalam memberikan kualitas hasil yang dihasilkan pada domain yang berbeda.
Non-dominated Sorting Genetic Algorithm II (NSGA-II) merupakan multi-objective evolutionary algorithms. Versi yang pertama adalah NSGA (Deb.et al., 2000) yang banyak menerima kritikan karena sama seperti algoritma genetika yang lain yang memiliki non-dominated shorting and sharing, yaitu memiliki kompleksitas dalam perhitungannya. Untuk itulah, maka dikembangkan lagi NSGA-II dengan perhitungannya yang lebih sedikit dibandingkan dengan NSGA (Deb,2001). NSGA-II juga melakukan pengembangan dalam hal elitist dan menggunakan parameter yang lebih sedikit. NSGA-II lebih popular dan banyak diterapkan pada berbagai masalah dalam area penelitian. Dalam studi yang dilakukan oleh Zitzler (1999) terbukti jelas bahwa elitism dapat membantu pencapaian pemusatan solusi terbaik di dalam MOEAs
(Multi-objective Evolutionary Algorithms). Berdasarkan penelitian yang dilakukan oleh Vergidis et al. (2007), secara keseluruhan tampak bahwa NSGA-II memberikan kepuasan dalam pareto-optimal solutions melalui lima test desain berdasarkan evaluasi rasio sukses. Karena hal di atas, maka penulis memutuskan untuk berfokus pada algoritma NSGA-II (Non Dominated Sorting in Genetic Algorithm II) saja dalam penelitian ini.
3.2.4.1A Fast non-dominated sortingdari NSGA-II
Dalam rangka pengurutan populasi yang berukuran N menurut tingkatan non-domination, setiap solusi harus dibandingkan dengan setiap solusi yang lain dalam populasi untuk menemukan solusi mana yang di dominasi. Hal ini akan memerlukan perbandingan O (mN) untuk setiap solusi, dimana m adalah jumlah fungsi tujuan dan N adalah ukuran populasi. Ketika proses ini di lanjutkan untuk menemukan individu-individu mana yang pertama kali yang mendominasi dalam populasi awal, maka total kompleksitas yang dibutuhkan adalah O (mN2). Pada tahapan ini akan diperoleh semua individu yang mendominasi pada front yang pertama. Dalam rangka memperoleh individu-individu yang lain pada front yang berikutnya, solusi pada front yang pertama
terburuk sekali pun, dalam rangka memperoleh front yang kedua juga akan memerlukan komputasi O (mN2). Prosedur ini akan diulang untuk memperoleh front-front yang berikutnya.
3.2.4.2Representasi Kromosom
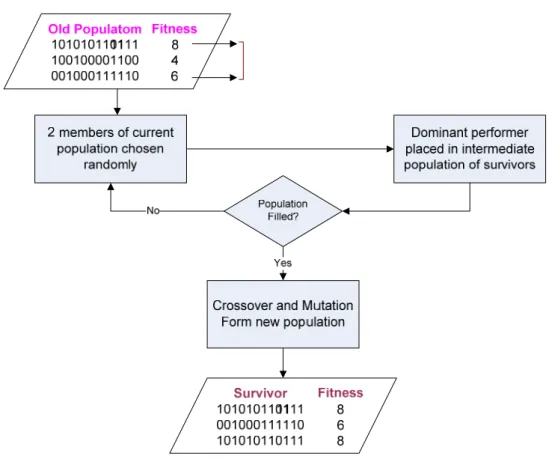
Gen merupakan bagian dari kromosom. Satu gen disini akan mewakili satu variabel. Gen direpresentasikan dalam bentuk string bit yang akan digunakan dalam implementasi pada operator genetika. Representasi kromosom bertujuan untuk mendekodekan sebuah kromosom yang berisi bilangan biner menjadi individu x yang menyatakan aktivitas tersebut ikut berpartisipasi atau tidak yang dimana bilangan biner 0 menyatakan aktivitas tersebut tidak ikut berpartisipasi dan 1 menyatakan aktivitas tersebut ikut berpartisipasi.
Kromosom adalah sebuah matriks berukuran 1 x jumlah gen atau biasanya disebut vektor baris. Keluaran dari fungsi ini adalah sebuah individu yang menyatakan alternatif aktivitas mana saja yang ikut berpartisipasi dalam set aktivitas proses bisnis.
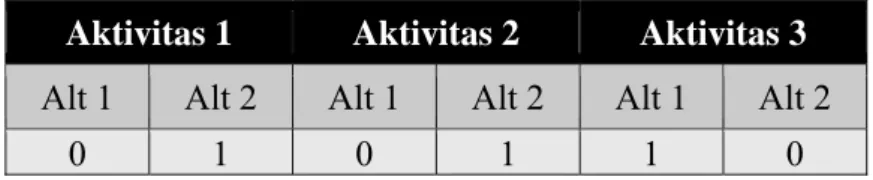
Berikut ini akan diuraikan sebuah contoh untuk memperjelas pemodelan representasi di atas. Representasi kromosom pada tabel 3.1 memiliki arti bahwa aktivitas 1 dengan alternatif 1 tidak ikut berpartisipasi dalam set aktivitas proses bisnis, sedangkan aktivitas 1 dengan alternatif 2 ikut berpartisipasi dalam set aktivitas proses bisnis.
Tabel 3.1 Contoh Representasi Kromosom
Aktivitas 1 Aktivitas 2 Aktivitas 3
Alt 1 Alt 2 Alt 1 Alt 2 Alt 1 Alt 2
3.2.4.3Inisialisasi Populasi
Ukuran populasi tergantung pada masalah yang akan dipecahkan dan jenis operator genetika yang akan diimplementasikan. Setelah ukuran populasi ditentukan, kemudian harus dilakukan inisialisasi terhadap kromosom yang terdapat pada populasi tersebut. Inisialisasi kromosom dilakukan secara acak, namun demikian harus tetap memperhatikan domain solusi dan kendala permasalahan yang ada.
Tujuan dari fungsi ini adalah membangkitkan sebuah populasi yang berisi sejumlah kromosom. Setiap kromosom berisi sejumlah gen. Masukkan untuk fungsi ini adalah jumlah kromosom dan jumlah gen, sedangkan keluaran dari fungsi ini adalah variabel populasi yang berupa matriks dua dimensi berukuran ukuran populasi x jumlah gen yang bernilai biner (0 dan 1). Proses pembangkitan kromosom dilakukan gen per gen, dengan cara melihat kondisi bilangan acak yang dibangkitkan secara acak. Populasi dibangkitkan berdasarkan pada range dan pembatas masalah jika ada. Dari gambar model IDEF3 (Integrated Definition Methodology), maka kita akan men-generate
segala kemungkinan populasi yang berasal dari set aktivitas bisnis dalam proses bisnis yang mungkin secara random. Inisialisasi populasi ini akan direperesentasikan dalam bentuk matrik yang direpresentasikan dalam bentuk string bit. Inisialisasi populasi ini perlu sebagai suatu set aktivitas awal dalam melakukan proses elitism, crossover dan mutasi. Tujuan dari fungsi ini adalah membangkitkan sebuah populasi yang berisi sejumlah kromosom. Setiap kromosom berisi sejumlah gen. Masukkan untuk fungsi ini adalah jumlah kromosom dan jumlah gen.
3.2.4.4Non-Dominated Sort
Seperti yang dijelaskan bahwa dalam permasalahan multi-objective optimization
solusi terbaik ditentukan oleh dominance. Menurut Deb, (2001) bahwa non-dominated solution set adalah merupakan suatu set solusi, yang merupakan solusi yang tidak didominasi oleh solusi manapun dari kumpulan anggota solusi yang ada. Pareto-Optimal set adalah kumpulan solusi yang tidak dikuasai (Non-dominated solution set) di
yang digambarkan dengan kumpulan semua titik-titik yang dipetakan dari Pareto-Optimal set disebut Pareto-Optimal Front. Sasaran dari multi-objective optimization
(MOOP) adalah menemukan suatu set solusi yang sedekat mungkin dengan Pareto Optimal Front dan menemukan set solusi yang berbeda sebisa mungkin
Pertama-tama, untuk setiap solusi , kita menghitung dua entitas yaitu (i)
n
i, yangmerupakan jumlah solusi yang mendominasi solusi i, dan (ii) Si yang merupakan set
solusi i yang mendominasi. Perhitungan dari kedua entitas ini memerlukan perbandingan O (mN2). Untuk pertama kalinya, kita akan mengidentifikasikan semua point sama dengan 0 yaitu
n
i,= 0 dan masukkan solusi-solusi yang mendominasi tersebut dalam F1 (disebut current front). Setelah itu untuk setiap solusi pada current front, kitateliti setiap individu (j) dalam set Sidengan mengurangi nilai
n
i, dengan nilai 1. Ketikanilai individu j menjadi sama dengan nol, maka kita akan memasukkan dalam list yang terpisah yaitu H. Setelah semua individu pada current front telah diperiksa, maka kita akan mengumumkan semua anggota individu yang termasuk dalam list F1 sebagai
anggota dalam front yang pertama. Kemudian proses akan dilanjutkan dengan menggunakan identifikasi baru front H sebagai current front sebagai front berikutnya.
Setiap iterasi membutuhkan komputasi O (N), dan proses ini akan berlanjut sampai semua front telah diidentifikasikan. Oleh karena itu paling banyak front yang terjadi adalah sebanyak N. Pada kasus terburuk sekalipun kompleksitas dari loop ini adalah O (N2). Secara keseluruhan , kompleksitas dari algoritma ini adalah O (mN2) +
O (N2) atau O (mN2). Pada algoritma NSGA-II, komputasi telah berkurang menjadi O
(mN2) dari O (mN3).
Prosedur fast non-dominated sorting ditunjukkan pada populasi P untuk mendapatkan list solusi yang mendominasi pada front F ditunjukkan pada tabel 3.2 berikut ini :
Tabel 3.2 Prosedur dari Fast-nondominated-sort (P)
For each p Є P For each q Є P
If (p p q) then jika p mendominasi q maka Sp = Sp ∪{q} masukkan q di dalam Sp
else if (q p p) then jika p didominasi oleh q maka np = np + 1 tambahkan np
if np = 0 then jika tidak ada solusi yeng mendominasi p maka
F 1 = F 1∪{p} p merupakan anggota pada front pertama
i = 1
While F i ≠ Ø
H = Ø
For each p Є F I Untuk setiap anggota p di dalam F i
For each q Є Sp Ubah setiap anggota dari kumpulan Sp
nq = nq - 1 lakukan pengurangan nq
if nq = 0 then H =H ∪{q} Jika nq=0, q merupakan anggota dariH
i = i + 1
F i = H front sekarang dibentuk dari semua anggota dari H
3.2.4.5Estimasi Kepadatan Solusi
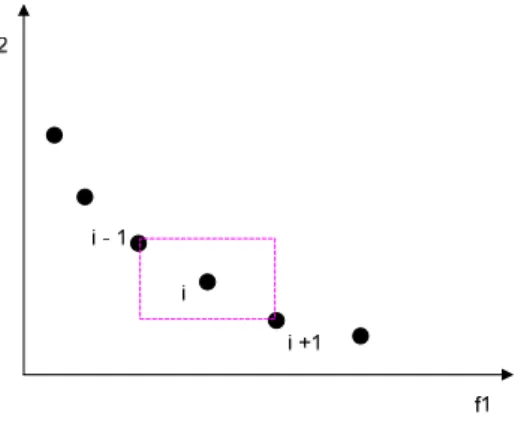
Untuk mendapatkan estimasi dari kepadatan solusi di sekeliling titik tertentu di dalam populasi, maka digunakan rata-rata jarak (distance) dari kedua titik yang berada disebelahnya. Banyaknya i distance menyajikan estimasi ukuran kotak terbesar yang
memasukkan titik i tanpa melibatkan titik-titik lain di dalam populasi itu. (jarak ini disebut crowding distance). Pada gambar 3.4 di bawah ini, crowding distance dari solusi ke-i dalam front-nya adalah jarak rata-rata sisi dari kotak (garis yang membentuk kotak). Algoritma untuk menghitung crowding distance ditunjukkan pada tabel 3.4 di bawah ini.
Gambar 3.5 Perhitungan Crowding distance
Tabel 3.3 Prosedur dari perhitungan Crowding-distance Perhitungan Crowding-distance (I)
l= I Jumlah solusi di dalam I Untuk setiap i, I [i]distance = 0 inisialisasi jarak
Untuk setiap fungsi tujuan m
I = sort (I, m) diurutkan menggunakan nilai pada setiap fungsi tujuan
I[1] distance= I [l] distance = ∞ sehingga setiap batasan selalu dipilih
for i = 2 to (l - 1) untuk semua nilai poin
I[i] distance = I[i] distance + (I[i+1]. m - I[i-1]. m)
Dimana I[i].m adalah nilai individu ke-i dalam set I dari nilai fungsi tujuan yang ke-m. Kompleksitas dari prosedur ini diatur berdasarkan algoritma pengurutan terlebih dahulu. Pada keadaan yang terburuk, pengurutan ini akan membutuhkan perhitungan O(mN log N).
3.2.4.6Crowded comparison Operator
Tournament Based Selection adalah salah satu cara memilih kromosom induk dari populasi awal. Metode ini akan langsung memilih k induk kromosom dengan nilai
fitness yang paling baik, di mana k lebih kecil dari ukuran populasi. Pada metode seleksi dengan turnamen ini, akan ditetapkan suatu nilai tour untuk individu-individu yang
kelompok ini akan diseleksi sebagai induk. Parameter yang digunakan pada metode ini adalah ukuran tour yang bernilai 2 sampai N (jumlah individu dalam suatu populasi).
Gambar 3.6 Seleksi Turnamen
Crowded comparison Operator (≥n) akan menuntun pada proses seleksi pada
berbagai tingkatan dari algoritma dengan mengarahkan penyebaran yang uniform dari
pareto-optimal front. Setelah setiap individu i di dalam populasi memiliki dua atribut, yaitu Non-domination rank (irank) dan local crowding distance (idistance), maka crowded
comparison Operator dilakukan jika :
i ≥n j if (irank < jrank) or ((irank = jrank) and (idistance > jdistance))
Apabila dua solusi memiliki nilai rank non-domination yang berbeda , maka akan dipilih nilai rank yang lebih kecil. Sebaliknya, jika kedua titik berada pada front yang sama, maka nilai crowding distance yang akan terpilih.
3.2.4.7 Crossover dengan menggunakan One-point crossover.
Crossover (penyilangan) dilakukan terhadap 2 kromosom induk (parents) yang dipilih berdasarkan binary tournament selection untuk menghasilkan kromosom anak (offspring). Kromosom anak yang terbentuk akan mewarisi sebagian sifat kromosom induknya (parents).
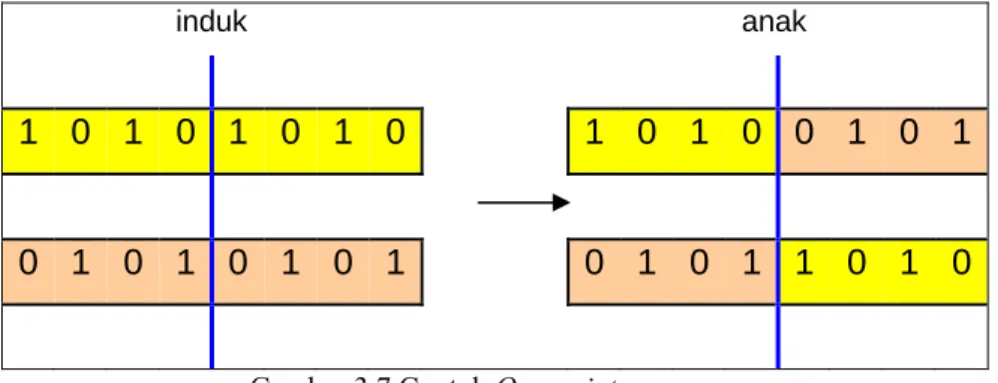
Pada penyilangan satu titik, posisi penyilangan k (k=1,2,……,W) dengan W adalah panjang kromosom (jumlah gen) diseleksi secara random. Agar penentuan titik
crossover dapat dilakukan secara random dan tidak merusak kromosom yang
merepresentasikan partisipasi alternatif untuk aktivitas dalam desain proses bisnis, maka perlu didefinisikan jumlah alternatif untuk setiap aktivitas (tci). Contoh :
• Jumlah alternatif untuk aktivitas 1 = 2 • Jumlah alternatif untuk aktivitas 2 = 2 • Jumlah alternatif untuk aktivitas 3 = 2 • Jumlah alternatif untuk aktivitas 4 = 2
Maka perlu dihitung kumulatif tc [ 2 4 6 8], kemudian angka tersebut akan diacak untuk menentukan posisi penyilangan yang akan dipilih misalkan posisi penyilangan yang terpilih adalah 4, maka variabel-variabel ditukar antar kromosom pada titik tersebut untuk menghasilkan keturunan (Child) seperti yang ditunjukkan pada gambar 3.7 di bawah ini :
induk anak 1 0 1 0 1 0 1 0 1 0 1 0 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 1 0 1 0
Gambar 3.7 Contoh One-point crossover
Semakin besar pc, maka semakin cepat string baru diperkenalkan ke dalam populasi.
Jika nilai pc, yang diberikan terlalu besar, string yang merupakan kandidat solusi terbaik
mungkin dapat hilang lebih cepat dari seleksi. Pada modifikasi NSGA-II , probabilitas
crossover yang digunakan dalam penelitian ini adalah 0.8 (Freschi and Repetto, 2005), berarti bahwa diharapkan terdapat 80 kromosom dari 100 kromosom (0.8 x 100) yang ada pada populasi tersebut akan mengalami crossover.
3.2.4.8Mutasi
Mutasi yang digunakan pada modifikasi algoritma NSGA-II ini adalah mutasi biner, yang pada dasarnya akan mengubah secara acak nilai suatu bit pada posisi tertentu dengan mengganti bit 1 dengan 0, atau mengganti bit 0 menjadi 1. Pada mutasi ini sangat dimungkinkan munculnya kromosom baru yang semula belum muncul dalam populasi awal.
1 0 1 0 0 1 0 1
Pada aktivitas 3 terkena mutasi pada gen 5 dan 6 (alternatif dari aktivitas 3), diperoleh 1 0 1 0 1 0 0 1
Gambar 3.8 Contoh Mutasi Biner
Pada mutasi ini terdapat satu parameter yang sangat penting yaitu peluang mutasi (pm). Peluang mutasi menunjukkan presentasi jumlah total gen pada populasi yang akan mengalami mutasi. Peluang mutasi mengendalikan banyaknya gen baru yang akan dimunculkan untuk dievaluasi. Jika peluang mutasi terlalu kecil, banyak gen yang mungkin berguna tidak pernah dievaluasi. Akan tetapi bila peluang mutasi terlalu besar, maka akan terlalu banyak gangguan acak, sehingga anak (offspring) akan kehilangan kemiripan dari induknya (parents). Mutasi ini berperan untuk menggantikan gen yang hilang dari populasi akibat proses seleksi yang memungkinkan munculnya kembali nilai gen yang tidak muncul pada inisialisasi populasi. Untuk melakukan mutasi, terlebih
mutasi (gen ke berapa pada kromosom ke berapa). Pada modifikasi NSGA-II , probabilitas mutasi yang digunakan adalah 0.2 (Freschi and Repetto, 2005), berarti bahwa diharapkan terdapat (0.2 x 100 (jumlah populasi N)) 20 gen yang akan mengalami mutasi pada setiap generasinya.
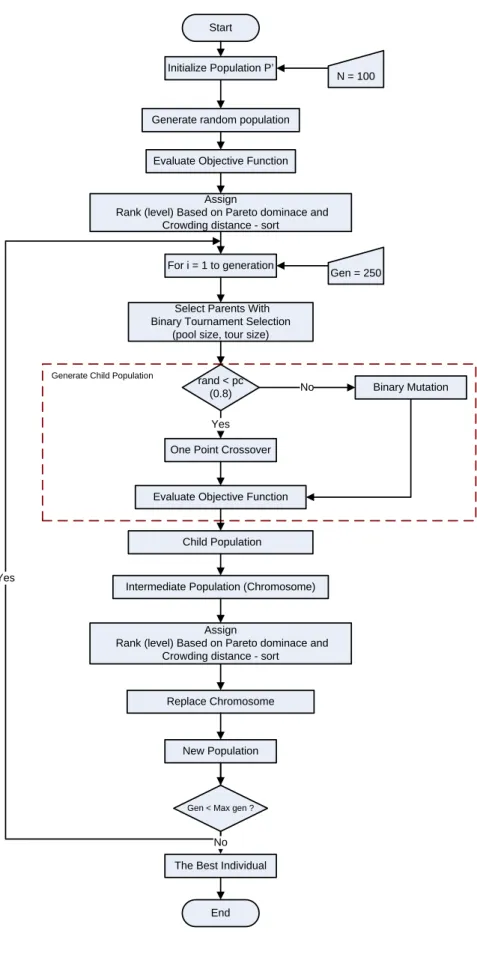
3.2.4.9Main Loop Modifikasi Algoritma NSGA-II
Pertama-tama, dibangkitkan secara acak populasi induk Po. Populasi itu kemudian diurutkan berdasarkan yang non-domination (didominasi). Setiap solusi dihitung nilai fitness-nya menurut level non-domination dimana 1 merupakan level yang terbaik. Binary tournament selection, Rekombinasi, dan Mutasi digunakan untuk menciptakan populasi keturunan Qodari jumlah N. Pada generasi berikutnya, terdapat prosedur dimana terdapat elitism untuk t ≥ 1 dan untuk generasi yang berikutnya ditunjukkan sebagai berikut :
Tabel 3.4 Main Loop Algoritma NSGA-II
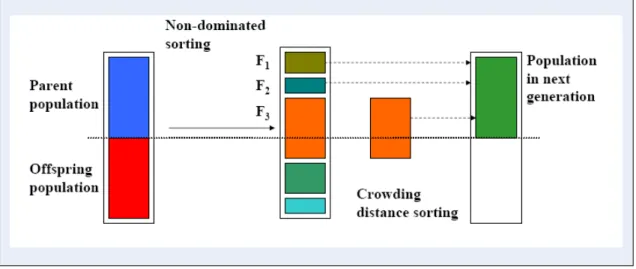
Rt = Pt ∪ Qt Menggabungkan populasi induk dan anak
F = fast-nondominated-sort (Rt) F = (F1 , F2 , ……..), Semua fronts yang mendominasi dari Rt.
Until Pt+1 < N Sampai populasi induk dipenuhi Crowding-distance-assignment (F i) Hitung crowding distance di dalam F i
Pt+1 = Pt+1 ∪ F i Tambahkan front mendominasi ke- i dalam
populasi induk
Sort (Pt+1, ≥n) Urutkan secara menurun menggunakan ≥n
Pt+1= Pt+1 [0 : N] Pilih elemen 1 dari Pt+1
Qt+1=make-new-pop (Pt+1) Gunakan seleksi, crossover dan mutasi
untuk membentuk populasi baru Qt+1
Pertama, kombinasi populasi dari Rt = Pt ∪ Qt dilakukan, sehingga populasi Rt
akan menjadi dua kali lipat yaitu 2N. Kemudian populasi Rt diurutkan berdasarkan
non-domination. Populasi induk yang baru Pt+1 dibentuk dengan menambahkan solusi-solusi
dari front pertama sampai jumlahnya melebihi N. Sesudah itu, solusi-solusi yang berada pada front yang terakhir akan diurutkan nilai crowding distance-nya (≥n) dan titik
crossover, dan mutasi untuk menciptakan populasi baru Qt+1 dari jumlah N. Hal penting
yang harus diketahui adalah kita menggunakan binary tournamentselection , akan tetapi kriteria pemilihannya di dasarkan pada kedalaman crowded comparison Operator (≥n).
Seperti yang kita lihat bahwa secara keseluruhan kompleksitas dari algoritma NSGA-II adalah O (mN2). Keanekaragaman di antara solusi yang non-dominated
diperlihatkan dengan menggunakan prosedur crowding comparison yang mana digunakan binary tournament selection. Secara keseluruhan algoritma NSGA-II ditunjukkan pada flowchart berikut ini.
Binary Mutation Initialize Population P’
N = 100 Start
One Point Crossover Evaluate Objective Function Generate random population
Assign
Rank (level) Based on Pareto dominace and Crowding distance - sort
Generate Child Population
rand < pc (0.8)
Child Population Select Parents With Binary Tournament Selection
(pool size, tour size)
New Population Evaluate Objective Function
Intermediate Population (Chromosome) For i = 1 to generation
Assign
Rank (level) Based on Pareto dominace and Crowding distance - sort
Replace Chromosome Gen = 250 Yes No Yes End The Best Individual
Gen < Max gen ?
No
Gambar 3.10 Flow diagram yang menunjukkan cara bekerjanya Modifikasi Algoritma NSGA-II
Pada gambar 3.7 di atas, Pt adalah populasi induk (parents) dan Qt merupakan populasi
anak (offspring) pada generasi t. F1 adalah solusi terbaik dari kombinasi
populasi-populasi (parents dan offspring). F2 adalah solusi terbaik yang kedua dan seterusnya.
3.2.4.10 Parameter yang digunakan
Parameter yang digunakan dalam Algoritma NSGA-II adalah sebagai berikut (Freschi and Repetto, 2005) :
• Population size = 100
• Generation = 250
• Mutation probability = 0.2 • Crossover probability = 0.8
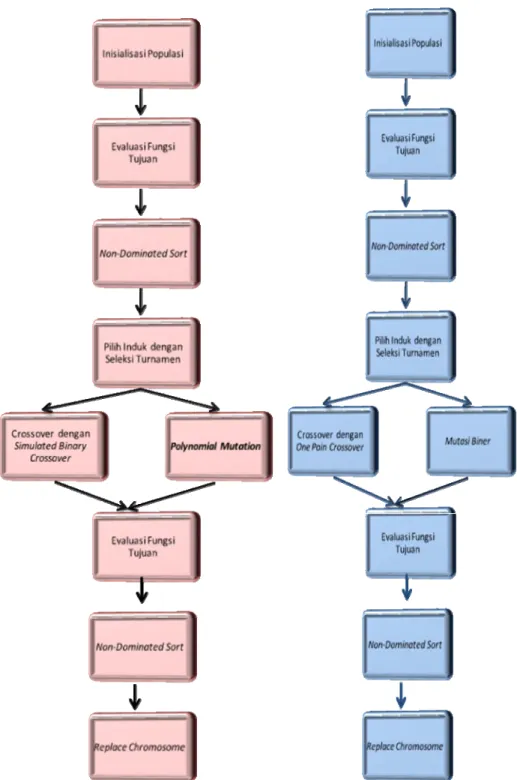
3.2.4.11 Perbedaan Original Algoritma NSGA-II dengan Modifikasi
Algoritma NSGA-II
Original algoritma NSGA-II (Non Dominated Sorting in Genetic Algorithm II)
proses bisnis yang memiliki sejumlah alternatif aktivitas. Seperti yang kita ketahui bahwa dalam penelitian ini adalah mencari set urutan alternatif aktivitas yang terbaik dalam desain proses bisnis sesuai dengan variabel dan kriteria tujuan yang ingin dicapai, sehingga populasi yang di-generate memiliki kendala. Variabel yang digunakan dalam contoh numerik pada penelitian ini adalah activities dan starting times. Untuk itu maka diperlukan perubahan dalam original NSGA-II dalam men-generate populasi, seleksi dan mutasi, sehingga perlu adanya modifikasi algoritma NSGA-II. Untuk selanjutnya, algoritma yang akan dikembangkan dalam penelitian ini akan disebut modifikasi algoritma NSGA-II. Adapun perbedaan prosedurnya adalah pada saat melakukan inisialisasi populasi, crossover dan mutasi seperti ditunjukkan pada gambar 3.7 di berikut ini.
Inisialisasi populasi pada original NSGA-II dilakukan secara acak, sedangkan pada modifikasi algoritma NSGA-II dilakukan sesuai dengan variabel yang ditentukan sejak awal pada saat pengembangan model yaitu activities dan starting times yang digunakan pada penelitian ini. Untuk menghasilkan keturunan yang lebih baik pada setiap generasi, maka perlu dilakukan proses crossover dan mutasi. Crossover pada
original NSGA-II dilakukan dengan menggunakan cara simulated binary crossover
yang ditunjukkan pada persamaan 2.9 sampai persamaan 2.14, sedangkan pada modifikasi algoritma NSGA-II dilakukan dengan menggunakan one-point crossover.
Mutasi pada original NSGA-II dilakukan dengan menggunakan cara polynomial mutation yang ditunjukkan pada persamaan 2.15 sampai persamaan 2.17, sedangkan pada modifikasi algoritma NSGA-II dilakukan dengan menggunakan binary mutation.