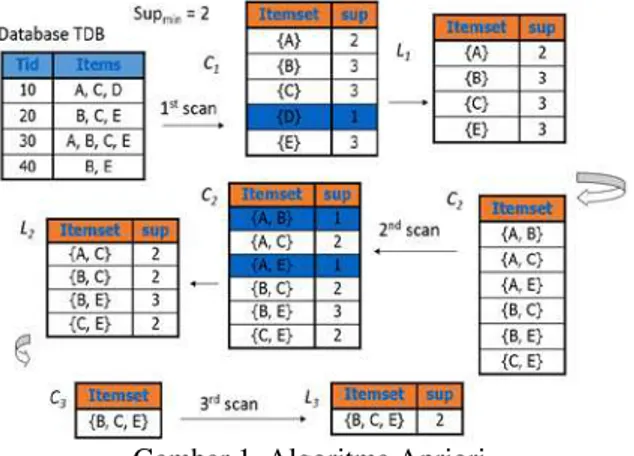
Penerapan Algoritma Apriori untuk Menemukan Hubungan Data Murid dengan Nilai Sekolah
Teks penuh
Gambar
Dokumen terkait
selaku Sekretaris Jurusan Administrasi Bisnis Politeknik Negeri Sriwijaya dan Dosen Pembimbing II yang telah membantu, mengarahkan dan membimbing penulis
a) Transaksi swap valas adalah transaksi pertukaran dua valas melalui pembelian atau penjualan tunai ( spot ) dengan penjualan atau pembelian kembali secara berjangka ( forward
(1991) yang mengestimasi parameter lokasi dan skala dari distribusi extreme value tipe 2 berdasarkan sampel tersensor; Sadik (1999) yang mengidentifikasi curah
Selain nilai-nilai budaya tersebut ada factor lain yang mendorong masyarakat Hindu Bali dapat berintergrasi dengan baik dengan masyarakat Tionghoa penganut Buddha, yaitu
Tetapi pada saat yang sama, dia juga mengambil kuliah di Fakultas Hukum
Keuangan Syariah , (Jakarta: Sinar Grafika, 2013), h.173.. dilakukan dalam jangka waktu tertentu, dengan bagi hasil yang keun tungannya berdasarkan kesepakatan bersama.
Peserta didik dibagi menjadi beberapa kelompok yang terdiri dari 4 siswa untuk melakukan analisa soal tentang percepatan, kecepatan, dan kelajuan dalam gerak lurus
Keragaman genetika yang cukup tinggi dapat di- deteksi dari empat belas aksesi kentang yang diguna- kan dalam penelitian ini.. Sebanyak 60 alel terdeteksi berdasarkan 12
