BAB 2
LANDASAN TEORI
2.1 Information Retrieval
Information Retrieval atau sering disebut “temu kembali infromasi” adalah suatu
sistem yang mampu melakukan penyimpanan, pencarian, dan pemeliharaan informasi. Informatian retrieval merupakan ilmu yang mempelajari prosedur-prosedur dan metode-metode untuk menemukan kembali informasi yang tersimpan dari berbagai sumber yang relevan atau koleksi sumber informasi yang dicari atau dibutuhkan. Dengan tindakan index panggilan (searching), pemanggilan data kembali . (Kowalski, G. 1997)
Dalam pencarian data, beberapa jenis data dapat ditemukan diantaranya texts, table, image, video, audio. Adapun tujuan dari Infromation Retrieval ialah untuk
memenuhi informasi pengguna dengan cara meretrieve dokumen yang relevan atau menguragi dokumen pencarian yang tidak relevan. (Kowalski, G. 1997)
Information Retrieval memiliki kegunaan yang banyak untuk user. Kita bisa melihat
fungsinya di mesin pencari untuk mencari informasi, atau di perpustakaan, di apotik dan lain sebagainya. Itu semua adalah karena jasa Information Retrieval. Information Retrieval mempunyai peran untuk:
1) Menganalisis isi sumber informasi dan pertanyaan pengguna.
2) Mempertemukan pertanyaan pengguna dengan sumber informasi untuk mendapatkan dokumen yang relevan.
2.2 String Matching
1) Memindai teks dengan bantuan sebuah window yang ukurannya sama dengan panjang pattern.
2) Menempatkan window pada awal teks.
3) Membandingkan karakter pada window dengan karakter dari pattern. Setelah pencocokan (baik hasilnya cocok atau tidak cocok) dilakukan pergeseran ke kanan pada window. Prosedur ini dilakukan berulang-ulang sampai window berada pada akhir teks. Mekanisme ini disebut mekanisme sliding window.
Algoritma string matching mempunyai tiga komponen utama (Effendi, D. et al. 2013), yaitu:
1) Pattern, yaitu deretan karakter yang akan dicocokkan dengan teks, dinyatakan dengan , panjang pattern dinyatakan dengan .
2) Teks, yaitu tempat pencocokan pattern dilakukan. Dinyatakan dengan
, panjang teks dinyatakan dengan .
3) Alfabet, berisi semua simbol yang digunakan oleh bahasa pada teks dan pattern, dinyatakan dengan dengan ukuran dinyatakan ASIZE.
2.3 Cara Kerja String Matching
Pattern adalah solusi umum yang dapat digunakan kembali pada permasalahan umum
yang sering terjadi pada software design. Design pattern bukan desain final yang dapat ditransformasikan secara langsung kedalam kode. Ini hanyalah deskripsi atau template untuk mengetahui bagaimana menyelesaikan permasalahan yang dapat digunakan pada berbagai macam situasi yang berbeda.
Cara yang jelas untuk mencari pattern yang cocok dengan teks adalah dengan mencoba mencari di setiap posisi awal dari teks dan mengabaikan pencarian secepat mungkin jika karakter yang salah ditemukan (Knuth, D.E. et al. 1977). Proses pertama adalah menyelaraskan bagian paling kiri dari pattern dengan teks. Kemudian dibandingkan karakter yang sesuai dari teks dan pattern. Setelah seluruhnya cocok maupun tidak cocok dari pattern, window digeser ke kanan sampai posisi
pada teks. Menurut Singh, R. & Verma, H.N. (2011), efisiensi dari algoritma terletak pada dua tahap:
2) Tahap pencarian, pattern dibandingkan dengan window dari kanan ke kiri atau kiri ke kanan sampai kecocokan atau ketidakcocokan terjadi.
2.4 Klasifikasi Algoritma String Matching
Algoritma string matching dapat diklasifikasikan menjadi tiga bagian menurut arah pencariannya (Charras, C. & Lecroq, T. 1997), yaitu:
1) Dari kiri ke kanan (left to right), algoritma yang termasuk dalam kategori ini adalah algoritma Brute Force, algoritma Morris dan Pratt yang kemudian dikembangkan menjadi algoritma Knuth-Morris-Pratt.
2) Dari kanan ke kiri (right to left) yang biasanya menghasilkan hasil terbaik secara partikal. Contoh algoritma ini adalah algoritma Boyer-Moore, yang kemudian banyak dikembangkan menjadi algoritma Tuned Boyer-Moore, algoritma Turbo Boyer-Moore, algoritma Zhu Takaoka dan algoritma Horspool.
3) Dari arah yang ditentukan secara spesifik oleh algoritma tersebut (in a spesific order), arah ini menghasilkan hasil terbaik secara teoritis. Algoritma yang
termasuk kategori ini adalah algoritma Colussi dan algoritma Chrocemorre-Perrin.
2.5 Teknik Algoritma String Matching
Menurut Singla, N. & Garg, D. (2012), ada dua teknik utama dalam algoritma string matching, yaitu:
1) Exact string matching
Exact string matching, merupakan pencocokan string secara tepat dengan susunan karakter dalam string yang dicocokkan memiliki jumlah maupun urutan karakter dalam string yang sama. Beberapa algoritma exact string matching antara lain:
a. Knuth-Morris-Pratt, metode ini mencari kehadiran sebuah kata dalam teks dengan melakukan observasi awal (preprocessing) dengan cara mengecek ulang kata sebelumnya. Algoritma ini melakukan pencocokan dari kiri ke kanan.
pencocokan karakter yang dimulai dari kanan ke kiri. Karena sifatnya yang sangat efisien, Boyer-Moore memiliki banyak variasi penyederhanaannya. Salah satunya adalah algoritma Horspool yang akan digunakan dalam penelitian ini dan akan dijelaskan pada poin berikutnya.
2) Approximate string matching atau Fuzzy string matching
Fuzzy string matching merupakan pencocokan string secara samar, maksudnya pencocokan string dimana string yang dicocokkan memiliki kemiripan memiliki susunan karakter yang berbeda (mungkin jumlah atau urutannya), tetapi string tersebut memiliki kemiripan baik kemiripan tekstual/penulisan (approximate string matching) atau kemiripan ucapan (phonetic string matching).
2.6 Algoritma Not So Naive
Algoritma Not So Naive pertama kali dipublikasikan oleh Christophe Hancart tahun 1992. Algoritma Not So Naive merupakan variasi turunan dari algoritma Naive atau yang sering disebut algoritma Brute Force. Cara kerja algoritma ini adalah dengan memiliki fase pencarian mengecek teks dan pola dari kiri ke kanan. Lalu, algoritma Not So Naive akan mengidentifikasi terlebih dahulu dua kasus yang dimana di setiap
akhir fase pencocokan pergeseran dapat dilakukan sebanyak 2 posisi ke kanan, tidak seperti algoritma Naive yang dimana pergeseran tetaplah sebanyak 1 posisi ke kanan.
Kita asumsikan bahwa P[0] ≠ P[1]. Jika P[0] = T[s] dan P[1] = T[s+1], maka di akhir fase pencocokan pergeseran s bisa dilakukan sebanyak 2 posisi. Karena P[0] ≠ P[1] = T[s+1]. Dan jika P[0] = P[1]. Jika P[0] = T[s] tapi P[1] ≠ T[s+1]. Maka sekali lagi pergeseran s dapat dilakukan sebanyak 2 posisi (Cantone & Faro,2004) dimana P adalah Pattern,T adalah Teks dan s adalah nilai posisi.
Saat fase pencarian dari Algoritma Not So Naive perbandingan karakter dilakukan dengan posisi pola mengikuti urutan 1, 2, ..., m-2, m-1, 0 dimana m adalah panjang pattern. Di setiap percobaan dimana “jendela” diposisikan di teks faktor y[i..j+m-1].
jika x[0] = x[1] dan x[1] y[ j+1] atau jika x[0] x[1] dan x[1] = y[j+1] polanya akan digeser sebanyak 2 posisi di setiap akhir percobaan dan sebanyak 1 posisi jika kondisi di atas tidak terpenuhi (Alapati & Mannava, 2011) dimana y adalah teks dan x adalah pattern.
mengalami kesamaan (x[0] != x[1]) maka nilai variabel k akan diinisialisasi dengan nilai 1 dan nilai variabel ell akan diinisialisasi dengan nilai 2 dimana kedua variabel tersebut akan digunakan untuk nilai pergeseran pada proses pencocokan.
Contoh
Teks : NURUL HASANAH HARAHAP
Pattern : ARAH
Tabel 1.1 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Satu
N U R U L H A S A N A H H A R A H A P 1
A R A H
Pada Tabel 1.1 perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 1.2 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Dua
N U R U L H A S A N A H H A R A H A P 1 2
A R A H
Pada Tabel 1.2 perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 2 posisi sesuai dengan nilai variable ell.
Tabel 1.3 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Tiga
N U R U L H A S A N A H H A R A H A P 1
A R A H
Tabel 1.4 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Empat N U R U L H A S A N A H H A R A H A P
1
A R A H
Pada Tabel 1.4 perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 1.5 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Lima N U R U L H A S A N A H H A R A H A P
1
A R A H
Pada Tabel 1.5, perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 1.6 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Enam
N U R U L H A S A N A H H A R A H A P 1
A R A H
Pada Tabel 1.6 perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 1.7 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Tujuh
N U R U L H A S A N A H H A R A H A P 1
A R A H
Tabel 1.8 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Delapan N U R U L H A S A N A H H A R A H A P
1
A R A H
Pada Tabel 1.8 perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 1.9 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Sembilan N U R U L H A S A N A H H A R A H A P
1
A R A H
Pada Tabel 1.9 perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 1.10 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Sepuluh
N U R U L H A S A N A H H A R A H A P 1
A R A H
Pada Tabel 1.10 perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 1.11 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Sebelas
N U R U L H A S A N A H H A R A H A P 1
A R A H
Tabel 1.12 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Dua Belas
N U R U L H A S A N A H H A R A H A P 1
A R A H
Pada Tabel 1.12 perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 1.13 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Tiga Belas
N U R U L H A S A N A H H A R A H A P 1
A R A H
Pada Tabel 1.13 perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 1.14 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Empat Belas
N U R U L H A S A N A H H A R A H A P 1
A R A H
Pada Tabel 1.14 perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k.
Tabel 1.15 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Lima Belas
Pada Tabel 1.15 perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 2 posisi sesuai dengan nilai variabel ell.
Tabel 1.16 Proses Pencocokan Algoritma Not So Naive Pada Percobaan Enam Belas
N U R U L H A S A N A H H A R A H A P 1 A R A H
Pada Tabel 1.16 perbandingan karakter pertama (x[1] != y[j+1]) sudah mengalami ketidakcocokan. Maka akan dilakukan percobaan selanjutnya dengan posisi pola digeser sebanyak 1 posisi sesuai dengan nilai variabel k. Namun dikarenakan sisa Teks lebih kecil daripada pola maka fase pencarian berhenti disini.
2.7 Algoritma Two Way
Algoritma Two Way Algorithm atau Algoritma Dua Arah dipublikasikan Maxime Crochemore dan Dominique Perrin pada tahun 1991. Algoritma ini memfaktorkan pattern menjadi dua bagian patternkiri, dan patternkanan sehingga pattern=patternkiripatternkanan. Fase pencocokan pada algoritma ini terdiri dari dua
bagian, pertama mencocokkan karakter patternkanan dari kiri ke kanan, lalu mencocokkan karakter patternkiri dari kanan ke kiri [CHA01]. Hal ini diilustrasikan pada Gambar 21. Fase inisialisasi pada algoritma ini menghitung faktorisasi yang baik dari pattern atas patternkiri dan patternkanan. Jika (u, v) merupakan sebuah faktorisasi dari pattern, maka sebuah pengulangan di (u, v) adalah sebuah kata w, sehingga dua persyaratan ini terpenuhi:
1. w adalah akhiran dari u atau u adalah akhiran dari w 2. w adalah awalan dari v atau v adalah awalan dari w
periode lokal dan periode global akan sama. Algoritma Crochemore-Perrin memilih faktorisasi kritis (patternkiri, patternkanan) sehingga |patternkiri| < per(x) dan |patternkiri| mempunyai nilai minimal. (Crochemore, M & Perrin, D. 1991)
Fase inisialisasi pada algoritma ini mempunyai kompleksitas waktu dan ruang O (n), sedang fase pencocokan dapat dilakukan dengan kompleksitas waktu O (m), dan pada kasus terburuk, algoritma ini melakukan 2m-n pencocokan karakter.
Contoh:
Teks : NURUL HASANAH HARAHAP
Pattern : ARAH
Tabel 2.1 Proses Pencocokan Algoritma Two Way Pada Percobaan Satu
N U R U L H A S A N A H H A R A H A P 1
A R A H
Terlihat perbedaan pada index R sehingga geser pattern sebanyak 1
Tabel 2.2 Proses Pencocokan Algoritma Two Way Pada Percobaan Dua N U R U L H A S A N A H H A R A H A P
1 A R A H
Terlihat perbedaan pada index U sehingga geser pattern sebanyak 1
Tabel 2.3 Proses Pencocokan Algoritma Two Way Pada Percobaan Tiga N U R U L H A S A N A H H A R A H A P
1 A R A H
Terlihat perbedaan pada index L sehingga geser pattern sebanyak 1
Tabel 2.4 Proses Pencocokan Algoritma Two Way Pada Percobaan Empat
N U R U L H A S A N A H H A R A H A P 1
A R A H
Tabel 2.5 Proses Pencocokan Algoritma Two Way Pada Percobaan Lima N U R U L H A S A N A H H A R A H A P
1 A R A H
Terlihat perbedaan pada index H sehingga geser pattern sebanyak 1
Tabel 2.6 Proses Pencocokan Algoritma Two Way Pada Percobaan Enam
N U R U L H A S A N A H H A R A H A P 1 2
A R A H
Terlihat persamaan pada index A dan terlihat perbedaan pada index S sehingga geser pattern sebanyak 2
Tabel 2.7 Proses Pencocokan Algoritma Two Way Pada Percobaan Tujuh
N U R U L H A S A N A H H A R A H A P 1 2
A R A H
Terlihat persamaan pada index A dan terlihat perbedaan pada index N sehingga geser pattern sebanyak 2
Tabel 2.8 Proses Pencocokan Algoritma Two Way Pada Percobaan Delapan N U R U L H A S A N A H H A R A H A P
3 4 1 2 A R A H
Terlihat persamaan pada index A, H, A dan terlihat perbedaan pada index N sehingga geser pattern sebanyak 2
Tabel 2.9 Proses Pencocokan Algoritma Two Way Pada Percobaan Sembilan
N U R U L H A S A N A H H A R A H A P 1 2
A R A H
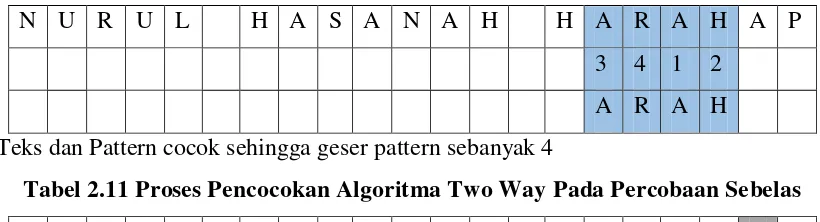
Tabel 2.10 Proses Pencocokan Algoritma Two Way Pada Percobaan Sepuluh N U R U L H A S A N A H H A R A H A P
3 4 1 2 A R A H Teks dan Pattern cocok sehingga geser pattern sebanyak 4
Tabel 2.11 Proses Pencocokan Algoritma Two Way Pada Percobaan Sebelas
N U R U L H A S A N A H H A R A H A P 1 A R A H Pada pola ini tidak perlu dilakukan pergeseran karena sudah pada indeks terakhir.
2.8 Kompleksitas Algoritma
Suatu masalah dapat mempunyai banyak algoritma penyelesaian. Algoritma yang digunakan tidak saja harus benar, namun juga harus efisien. Efisiensi suatu algoritma dapat diukur dari waktu eksekusi algoritma dan kebutuhan ruang memori. Algoritma yang efisien adalah algoritma yang meminimumkan kebutuhan waktu dan ruang. Dengan menganalisis beberapa algoritma untuk suatu masalah, dapat diidentifikasi satu algoritma yang paling efisien. Besaran yang digunakan untuk menjelaskan model pengukuran waktu dan ruang ini adalah kompleksitas algoritma.
Kompleksitas dari suatu algoritma merupakan ukuran seberapa banyak komputasi yang dibutuhkan algoritma tersebut untuk menyelesaikan masalah. Secara informal, algoritma yang dapat menyelesaikan suatu permasalahan dalam waktu yang singkat memiliki kompleksitas yang rendah, sementara algoritma yang membutuhkan waktu lama untuk menyelesaikan masalahnya mempunyai kompleksitas yang tinggi. Kompleksitas algoritma terdiri dari dua macam yaitu kompleksitas waktu dan kompleksitas ruang.
dapat ditentukan laju peningkatan waktu atau ruang yang diperlukan algoritma, seiring dengan meningkatnya ukuran masukan ( n ).
Kecenderungan saat ini, ruang (memori utama) yang disediakan semakin besar yang artinya kapasitas data yang diproses juga semakin besar. Namun, waktu yang diperlukan untuk menjalankan suatu algoritma harus semakin cepat. Karena kompleksitas waktu menjadi hal yang sangat penting, maka analisis kompleksitas algoritma deteksi tepi akan dilakukan terhadap running time algoritma tersebut.
2.9 Notasi O (Big-O)
Notasi O menyatakan running time dari duatu algoritma untuk kemungkinan kasus terburuk. Notasi memiliki dari beberapa bentuk. Notasi O dapat berupa salah satu bentuk maupun kombinasi dari bentuk-bentuk tersebut. Bentuk O (1) memiliki arti bahwa algoritma yang sedang dianalisis merupakan algoritma konstan. Hal ini mengindikasikan bahwa running time algoritma tersebut tetap, tidak bergantung pada n.
O (n) berarti bahwa algoritma tersebut merupakan algoritma linier. Artinya, bila n menjadi 2n maka running time algoritma akan menjadi dua kali running time semula.
O ( ) berarti bahwa algoritma tersebut merupakan algoritma kuadratik. Algoritma kuadratik biasanya hanya digunakan untuk kasus dengan n yang berukuran kecil. Sebab, bila n dinaikkan menjadi dua kali semula, maka running time algoritma akan menjadi empat kali semula.
O ( ) berarti bahwa algoritma tersebut merupakan algoritma kubik. pada algoritma kubik, bila n dinaikkan menjadi dua kali semula, maka running time algoritma akan menjadi delapan kali semula.
O ( ) Bentuk berarti bahwa algoritma tersebut merupakan algoritma eksponensial. Pada kasus ini, bila n dinaikkan menjadi dua kali semula, maka running time algoritma akan menjadi kuadrat kali semula.
persoalan besar dengan mentransformasikannya menjadi beberapa persoalan yang lebih kecil dengan ukuran sama. Basis algoritma tidak terlalu penting, sebab bila misalkan n dinaikkan menjadi dua kali semula, meningkat sebesar jumlah tetapan.
Bentuk O (n ) terdapat pada algoritma yang membagi persoalan menjadi beberapa persoalan yang lebih kecil, menyelesaikan setiap persoalan secara independen, kemudian menggabungkan solusi masing- masing persoalan.
Sedangkan O (n ) berarti bahwa algoritma tersebut merupakan algoritma faktorial. Algoritma jenis ini akan memproses setiap masukan dan menghubungkannya dengan n-1 masukan lainnya. Bila n menjadi dua kali semula, maka running time algoritma akan menjadi faktorial dari 2n
Kompleksitas algoritma yang akan diuji adalah kompleksitas Algoritma Not So Naive dan Algoritma Two Way. Seperti dijelaskan pada Tabel 4.7 dan Tabel 4.8 berikut
2.10 Penelitian yang relevan
Berikut ini beberapa penelitian yang terkait dengan Algoritma Not So Naive dan Two Way :
1. Cantone, D. & Faro, S. (2004) Menjelaskan bahwa Algoritma Not So Naive merupakan variasi simpel dari Algoritma Naive yang ternyata cukup efisien dalam beberapa kasus. Proses searching dari Algoritma Not So Naive dilakukan dengan mencocokan teks dan pola dari kiri ke kanan. Namun, Algoritma Not So Naive mempunyai dua kasus yang jikalau terpenuhi maka akhir dari pencocokan, pola bisa bergeser sebanyak 2 posisi ke kanan, daripada 1 posisi yang terdapat di Algoritma Not So Naive.