BAB 2
TINJAUAN PUSTAKA
Pada bab ini akan dibahas tinjauan pustaka untuk mendukung penulisan skripsi ini. Teori yang dibahas yaitu mengenai search engine, focused crawler, stemming, Porter stemmer, bahasa pemrograman PHP dan databaseMySQL dan beberapa subpokok pembahasan lainnya yang menjadi landasan teori pada skripsi ini.
Semua dasar teori dalam tinjauan pustaka ini, diambil dari buku, jurnal, laporan dan internet.
2.1.Search Engine
Search engine (mesin pencari)merupakan fasilitas yang digunakan untuk mengeksplorasi berbagai data, informasi, dan pengetahuan yang ada di internet. Search engine adalah sebuah program yang dapat diakses melalui internet yang berfungsi untuk membantu pengguna komputer dalam mencari berbagai hal yang ingin diketahuinya (Indrajit R.E. et al.). TheAmerican Heritage Dictionary mendefinisikan search engine sebagai sebuah program perangkat lunak (software) yang menelusur, menjaring, dan menampilkan informasi dari pangkalan data.
2.1.1.Sejarah search engine
Search engine pertama kali diciptakan pada tahun 1990 oleh Emtage mahasiswa Universitas McGill di Montreal Canada. Dia menciptakan alat bantu untuk melakukan pencarian bernama Archie.Aplikasi berguna untuk mencari file saja.
Gambar 2.2 Hasil pencarian dari Archie (Sumber: archie.icm.edu.pl)
Pada tahun 1991, Mark McCahilldari Universitas Minnesota menemukan search engine yang lebih canggih.Aplikasi ini bernama Gopher dan berguna untuk mencari teks di internet.Gopher mengindeks dokumen teks yang akhirnya berkembang menjadi dunia website atau www. Kemudian diciptakan sebuah program bernama Veronica singkatan dari software bernama Very Easy Rodent Oriented Net-wide Index to Computerized Archieves.Setelah Veronica, diciptakan website yang
disebut Jungheadyang merupakan singkatan dari Jony’z Universal Gopher Hierarchy Excavation and Display yang merupakan software untuk mencari teks yang tersimpan di sistem indeks dari Gopher.
Tahun 1993, munculsearch engine baru bernama wandex yang dikembangkan oleh Matthew Gray.Wandex bekerja dengan cara mengindeks dan mencari index dari halaman. Semenjak saat itu muncul search engine seperti Excite, Yahoo!, Google,Lycos, Ask.com dan yang lainnya (Wahana Komputer, 2009).
2.1.2.Prinsip umum search engine
Prinsip umum dari search engine (Febrian, 2007), yaitu: 1. Spider
halaman yang dikunjungi untuk disimpan ke dalam database yang dimiliki oleh search engine.
2. Crawler
Crawler merupakan program yang dimiliki oleh search engine untuk melacak dan menemukan link yang terdapat dari setiap halaman yang ditemuinya. Crawler berfungsi untuk menentukan spider harus pergi kemana dan mengevaluasi link berdasarkan alamat yang ditentukan dari awal.
3. Indexer
Indexer berfungsi untuk melakukan aktivitas untuk menguraikan masing-masing halaman dan meneliti berbagai unsur seperti teks, header, struktur, atau fitur dari gaya penulisan, tag HTML khusus, dan yang lainnya.
4. Database
Database merupakan tempat standar untuk menyimpan data-data dari halaman yang telah dikunjungi, diunduh dan sudah dianalisis.
5. Result Engine
Result engine merupakan mesin yang melakukan penggolongan dan penentuan
peringkat dari hasil pencarian pada search engine. Result engine berfungsi untuk menentukan halaman mana yang menemui kriteria terbaik dari hasil pencarian berdasarkan permintaan penggunaannya dan bagaimana bentuk penampilan yang akan ditampilkan.
6. Web Server
Web Server merupakan komputer yang melayani permintaan dan memberikan respon balik dari permintaan tersebut. Web Server menghasilkan informasi atau dokumen dalam format HTML.
2.1.3.Cara kerja search engine
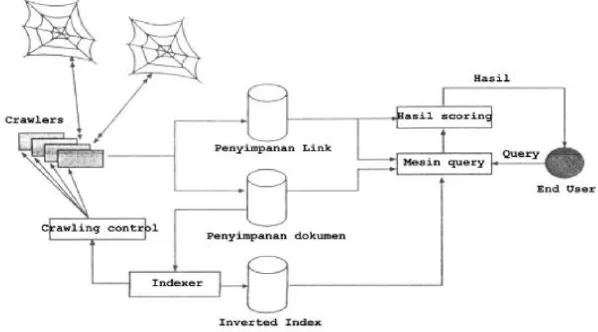
Untuk menentukan halaman potensial, mereka mengacu pada link yang terdapat pada halaman yang telah disimpan di dalam database. Jika suatu halaman web tidak pernah di-link dari halaman lainnya, maka spider dari search engine tidak akan menemukan halaman tersebut. Mereka hanya memantau dari database yang dimiliki.Seperti pada Gambar 2.3.
Gambar 2.3 Arsitektur Search Engine (Falani, 2010)
2.1.4.Sifat search engine
Ditinjau dari mekanisme kerjanya, search engine dibagi menjadi 3 tipe (Wahana Komputer, 2009), yaitu:
1. Search Engine Bersifat Crawler
Google menggunakan software agen otomatis yang disebut crawler untuk mengunjungi website, membaca, dan mengindeks website tersebut.Semua informasi yang dikumpulkan oleh crawlerakandisimpan di lokasi terpusat.Crawlerakan mengunjungi website berulang kali secara periodik dengan periode yang ditentukan oleh administratorsearch engine.
2. Search Engine dengan Campur Tangan Manusia
Search engine ini mengindeks dengan cara campur tangan manusia. Dimana, pemilik situs mengirimkan data yang akan diindeks dan setelah diindeks akan ditampilkan sebagai hasil pencarian. Contoh: Yahoo!.
3. Search Engine Hibrida
mengirimkan crawler untuk mengindeks website. Dengan menggunakan campur tangan manusia maka search engine bisa menghindari spammer.
2.1.5.Algoritma umum dalam search engine
Algoritma menentukan bagaimana prosedur pengambilan data dan pengumpulannya. Algoritma umum yang dipakai oleh search engine (Wahana Komputer, 2009), yaitu: 1. Pencarian List
Algoritma yang melakukan pencarian dengan cara mencari satu kunci, dan pencarian dilakukan secara linier. Kekurangan dari algoritma ini yaitu sangat lama karena pencariannya yang linier.Kelebihannya yaitu hasilnya sedikit sehingga lebih tersaring yang benar-benar relevan terhadap hasil pencarian. 2. Pencarian Tree
Algoritma ini mencari data dari dataset yang paling luas kemudian menyempit hingga sampai ke bagian yang lebih detail.Satu dataset bisa memiliki cabang yang lebih kecil dan menyempit.Pencarian tree lebih bagus hasilnya dari pencarian list.Kekuranganya yaitu pencariannya bertingkat sehingga untuk bisa melakukan pencarian harus dari akar, batang, dan ranting sesuai dengan ranking yang dimiliki dataset.
3. Pencarian SQL
Pencarian SQL menggunakana databasestructured query language yang memungkinkan data untuk diambil secara tidak linier. Data langsung bisa diambil dari subset dari keseluruhan dataset yang ada.
4. Pencarian Informed
Algoritma ini bertujuan mencari jawaban yang spesifik dari dataset. Pencarian ini tidak selalu jadi solusi terbaik karena umumnya yang dicari oleh pengunjung search engine adalah jawaban dari pencarian.
5. Pencarian Adversarial
Algoritma yang mencari semua solusi dari masalah. Algoritma ini kurang efektif untuk pencarian web karena jumlah solusinya akan sangat banyak di www sehingga boros sumber daya yang ada.
6. Pencarian Berdasar Batasan
2.2.Focused Crawler
Pada tahun 1999, Soumen Chakrabarti memperkenalkan focused crawler. Focused crawler berfungsi untuk menelusuri link yang mengarah pada page target dan berusaha semaksimal mungkin menghindari link yang tidak mengarah padapagetarget (Maimunah & Kuspriyanto, 2008). Focused crawler adalah teknik untuk mengunduhurldan konten dari halaman web. Pada penelitian ini url dan konten yang sudah diunduh akan secara otomatis masuk ke dalam database.
Setelah selesai proses crawling,focused crawler juga akan menghitung bobot dan relevansi. Relevansi yang didapat akan menentukan jurnal terkait masing-masing jurnal. Hal tersebut akan menghemat penggunaan waktu dan sumber daya ketika melakukan pencarian jurnal. Apabila dalam suatu halaman web terdapat kata yang sesuai dengan kata kunci, maka halaman dianggap memiliki kecocokan dengan apa yang dicari oleh user (Sulastri & Zuliarso, 2010).
Relevant Page Database Seed URL
URL Queue
Web Page Downloader
Irrelevant Table
Parser & Extractor
Relevance Calculator
Topic Filter
Topic Spesific Weight Table
Irrelevant Relevant
Internet
Keterangan :
1. SeedURLs dan URL Queue
Seed URLs (bibit URL) akan dimasukkan ke dalam antrian URL yang disebut URLQueue. Dalam antrian (URL Queue) akan dilakukan proses pengurutan berdasakan nilai link tertinggi pada URL yang didapat. URLakan dihapus jika proses crawling selesai. Proses ini berlanjut hingga URL dan URL Queue kosong. 2. Web Page Downloader
Halaman yang ada pada URL Queue akan diunduh olehweb page downloader melalui internet. Halaman tersebut akan disimpan sementara di dalam cache. 3. Parser dan Extractor
Halaman yang tersimpan dalam cache akan mengalami proses penguraian (parser) yaitu penghapusan tag html. Setelah itu dilakukan proses penghilangan imbuhan bentuk kata dasar oleh Porter Stemmer. Kata yang memiliki kata dasar yang sama kan digabungkan.
4. Topic Spesific Weight Table
Topic Spesific Weight Table berfungsi sebagai pembanding untuk mendapatkan relevansi suatu halaman.Rumus menghitung bobot stem untuk mendapatkan Topic Spesific Weight Table yaitu:
w (weight) = Bobot keyword wi= Bobot dari stem
wmax= Nilai tertinggi dari bobot stem
5. Relevance Calculator
Rumus untuk menghitung relevansi suatu halaman, yaitu:
√ √ Keterangan :
6. Topic Filter
Jika suatu halaman relevant, maka akan dimasukkan ke dalam relevant page database. Jika tidak relevant maka akan masuk ke dalam irrelevant table.
7. Relevant Page Database
Relevant Page Database berisi halaman URL yang relevant. Halaman yang relevant akan dimasukkan ke dalam URLqueue.Bobot atau nilai dari URL yaitu nilai dari relevansi halaman tersebut.
8. Irrelevant Table
Jika suatu halaman tidak relevant, maka akan dimasukkan ke dalam irrelevant table. Halaman yang tidak memiliki relevansi pada irrelevant table tidak akan melakukan proses crawling lagi.
2.3.Algoritma Porter Stemmer
Stemming adalah proses menghapus variasi kata untuk mendapatkan kata dasar yang mengacu pada morfologi kata. Stemming khusus bahasa Inggris ditemukan oleh Martin Porter pada tahun 1980.
Algoritma Porter stemmer adalah proses penghilangan akhiran morphological dan inflexional yang umumnya terdapat dalam bahasa Ingris (Porter, 1980). Algoritma ini mencari kata dasar dari suatu kata yang berimbuhan dengan membuang imbuhan-imbuhan (akhiran) pada kata-kata bahasa Inggris karena bahasa Inggris tidak mengenal awalan.
Kondisi stem (akar kata) pada algoritma Porterstemmer:
1. Ukuran (measure), dinotasikan dengan m, dari sebuah stem berdasarkan pada urutan vokal-konsonan.
m = 0, contoh : TR, EE, TREE, Y, BY
2. *<X>berarti stem berakhir dengan huruf X 3. *v*berarti stem mengandung sebuah vokal 4. *d berarti stem diakhiri dengan konsonan double
5. *o berarti stem diakhiri dengan konsonan – vokal – konsonan secara berurutan dimana konsonan akhir bukan w, x, atau y.
Pada sebagian kondisi mungkin juga terdapat ekspresi dengan, and, or and not, seperti:
1. (m>1 and (*S or *T)) Pada bagian m>1 dengan berakhir di s atau t.
2. (*d and not (*L or *S or *Z))stem diakhiri dengan konsonan double, tidak akhiran L atau S atau Z
Aturan-aturan dalam proses stemming pada algoritma Porterstemmer(http://tartarus.org/martin/PorterStemmer/def.txt):
1. Langkah 1
Langkah 1a: remove plural suffixation, yaitu mengganti atau menghapus
akhiran kata berbentuk jamak hingga mendapatkan stem.
Tabel 2.1 Aturan Stemming Step 1a(http://tartarus.org/martin/PorterStemmer/def.txt)
Conditions Suffix Replacement Examples
NULL SSES SS caresses caress
NULL IES I ponies poni
ties ti
NULL SS SS caress caress
NULL S NULL cats cat
Tabel 2.2 Aturan Stemming Step
1b(http://tartarus.org/martin/PorterStemmer/def.txt) Conditions Suffix Replacement Examples
(m>0) EED EE feed feed
agreed agree
(*v*) ED NULL plastered plaster
bled bled
(*v*) ING NULL motoring motor
singing sing
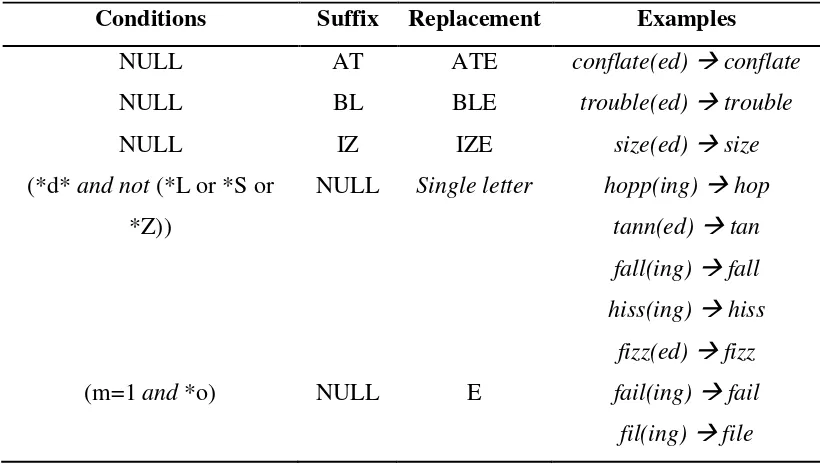
Continued for ed and ing rules, merupakan tahap selanjutnya pada akhiran -ed dan -ing. Kata yang diakhiri oleh double konsonan (tidak berakhir oleh huruf l, s, z) maka kata tersebut akan diganti dengan satu huruf konsonan saja. Suatu kata akan ditambahkan e, jika kata diakhiri oleh huruf konsonan-vokal-konsonan secara berurutan (konsonan-vokal-konsonan akhir bukan w ,x, y) dan hanya memiliki satu urutan vokal-konsonan didalamnya.
Tabel 2.3 Continued for –ed and –ing
rules(http://tartarus.org/martin/PorterStemmer/def.txt) Conditions Suffix Replacement Examples
NULL AT ATE conflate(ed) conflate
NULL BL BLE trouble(ed) trouble
NULL IZ IZE size(ed) size
(*d* and not (*L or *S or *Z))
NULL Single letter hopp(ing) hop tann(ed) tan fall(ing) fall hiss(ing) hiss
fizz(ed) fizz
(m=1 and *o) NULL E fail(ing) fail
Langkah 1c: -y dan -i, jika dalam sebuah kata terdapat huruf vokal, maka
akhiran y diganti dengan -i.
Tabel 2.4 Aturan Stemming Step 1c(http://tartarus.org/martin/PorterStemmer/def.txt) Conditions Suffix Replacement Examples
(*v*) Y I happy happi
sky sky
2. Langkah 2: peel one suffix off for multiple suffixes yaitu sebuah kata memiliki sebuah huruf vokal-konsonan secara berurutan.
Tabel 2.5 Aturan Stemming Step 2 (http://tartarus.org/martin/PorterStemmer/def.txt)
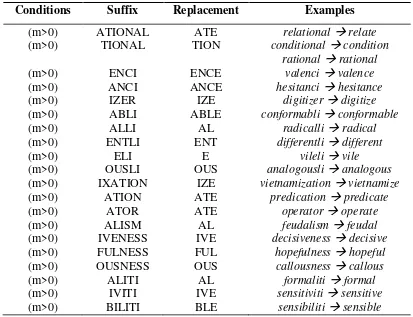
Conditions Suffix Replacement Examples
(m>0) ATIONAL ATE relational relate (m>0) TIONAL TION conditional condition
rational rational
(m>0) ENCI ENCE valenci valence
(m>0) ANCI ANCE hesitanci hesitance (m>0) IZER IZE digitizer digitize (m>0) ABLI ABLE conformabli conformable
(m>0) ALLI AL radicalli radical
(m>0) ENTLI ENT differentli different
(m>0) ELI E vileli vile
(m>0) OUSLI OUS analogousli analogous (m>0) IXATION IZE vietnamization vietnamize (m>0) ATION ATE predication predicate
(m>0) ATOR ATE operator operate
(m>0) ALISM AL feudalism feudal
(m>0) IVENESS IVE decisiveness decisive (m>0) FULNESS FUL hopefulness hopeful (m>0) OUSNESS OUS callousness callous
(m>0) ALITI AL formaliti formal
(m>0) IVITI IVE sensitiviti sensitive (m>0) BILITI BLE sensibiliti sensible
Tabel 2.6 Aturan Stemming Step
3(http://tartarus.org/martin/PorterStemmer/def.txt)
Conditions Suffix Replacement Examples (m>0) ICATE IC triplicate triplic
(m>0) ATIVE NULL formative form
(m>0) ALIZE AL formalize formal
(m>0) ICITI IC electriciti electric (m>0) ICAL IC electrical electric
(m>0) FULL NULL hopeful hope
(m>0) NESS NULL goodness good
4. Langkah 4: delete last suffix. Sebuah akhiran akan dihapus jika kata tersebut memiliki dua huruf vokal-konsonan secara berurutan.
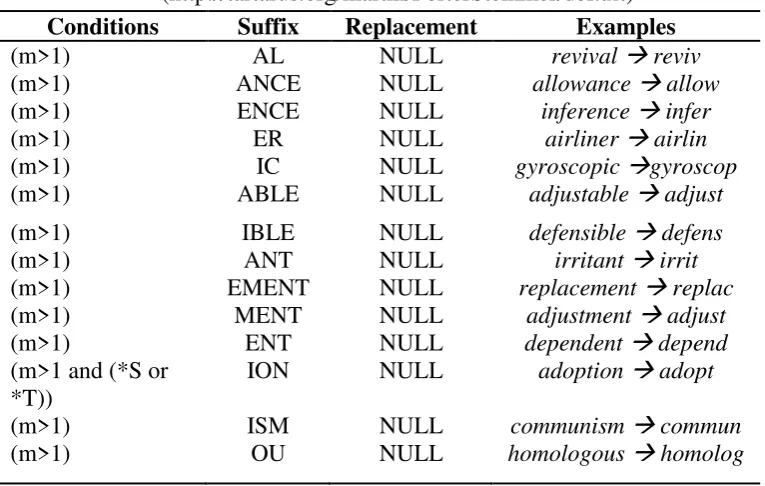
Tabel 2.7 Aturan Stemming Step 4 (http://tartarus.org/martin/PorterStemmer/def.txt) Conditions Suffix Replacement Examples
(m>1) AL NULL revival reviv
(m>1) ANCE NULL allowance allow
(m>1) ENCE NULL inference infer
(m>1) ER NULL airliner airlin
(m>1) IC NULL gyroscopic gyroscop
(m>1) ABLE NULL adjustable adjust
(m>1) IBLE NULL defensible defens
(m>1) ANT NULL irritant irrit
(m>1) EMENT NULL replacement replac
(m>1) MENT NULL adjustment adjust
Tabel 2.7 Aturan Stemming Step 4 (lanjutan) (http://tartarus.org/martin/PorterStemmer/def.txt)
Conditions Suffix Replacement Examples
(m>1) OUS NULL homologous homolog (m>1) IVE NULL effective effect (m>1) IZE NULL bowdlerize bowdler
5. Langkah 5 :
Langkah 5a: remove e. Akhiran –eakan dihapus jika kata tersebut memiliki dua
vokal-konsonan berurutan (konsonan akhir tidak w, x, y) dan tidak diakhiri konsonan-vokal-konsonan secara berurutan.
Tabel 2.8 Aturan Stemming Step 5a (http://tartarus.org/martin/PorterStemmer/def.txt)
Conditions Suffix Replacement Examples
(m>1) E NULL probate probat
rate rate
(m=1 and not *o) E NULL cease ceas
Langkah 5b: reduction. Akhiran akan diganti menjadi satu huruf konsonan
jika, kata memiliki sebuah vokal-konsonan berurutan dan tidak berakhir dengan double konsonan.
Tabel 2.9 Stemming Step 5b
(http://tartarus.org/martin/PorterStemmer/def.txt)
Conditions Suffix Replacement Examples (m>1 and *d an *L) NULL Single Letter controll control
roll roll
2.4.Bahasa Pemrograman PHP
PHP merupakan software open sourceyang disebarkan dan dilisensikan secara gratis serta dapat diunduhsecara bebas dari system resminya.Penggunaan PHP memungkinakan web dapat dibuat dinamis sehingga maintenance situs web tersebut menjadi lebih mudah dan efisien (Kasiman, 2006).
Databaseyang dapat didukung oleh PHP, yaitu MySQL, Adabas D, d Base, Direct MS-SQL, Empress, FilePro, FrontBase, Hyperwave, IBM DB2, Informx dan lain sebagainya.
2.5.DatabaseMySQL
MySQL termasuk dalam kategori database management system, yaitu suatu database yang terstruktur dalam pengolahan dan penampilan datanya.MySQL merupakan database yang bersifat client server.MySQL dapat juga dikatakan sebagai Relational Database Management System (RDBMS), yaitu hubungan antar tabel yang berisi data-data pada suatu data-database sehinga mempercepat pencaria suatu data-data.
Kelebihan database MySQL (Sugiri dan Harris, 2008), yaitu :
1. MySQL merupakan database yang memiliki kecepatan tinggi dalam pemrosesan data, dapat diandalkan, mudah digunakan dan mudah dipelajari.
2. MySQL mendukung banyak bahasa pemrograman seperti C, C++, Perl, Phython, Java dan PHP. Bahasa pemrograman tersebut dapat digunakan untuk berinteraksi maupun berkomunikasi dengan dengan MySQL server.
3. Koneksi, kecepatan, dan keamanannya membuat MySQL sangat cocok diterapkan untuk pengaksesan database melalui internet dengan menggunakan bahasa pemrograman Perl atau PHP sebagai interfacenya.
4. MySQL dapat menangani database dengan skala sangat besar, dengan jumlah record lebih dari 50 juta, 60 ribu tabel, dan bisa menampung 5 milyar basis data. 5. Multiuser, yaitu dalam satu databaseserver pada MySQL dapat diakses oleh
beberapa user dalam waktu yang sama tanpa mengalami konflik atau crash. 6. MySQL merupakan software database yang bersifat free atau gratis.
2.6.Penelitian Terdahulu
Penelitian yang dilakukan oleh Pal Anshika et al. (2009) yaitu Effective Focused Crawler Based on Content and Link Structure Analysis.Hasil dari penelitian ini yaitu pendekatan yang diteliti memiliki kinerja yang lebih baik daripada Breadth-FirstSearch (BFS) crawler.
Focused Crawler Optimization Using Genetic Algorithm oleh Yohannes et al. (2011). Hasil dari penelitian ini menunjukkan bahwa Genetic Algorithm (GA) dalam proses crawling dapat melintasi ruang pencarian web yang lebih komprehensif dibandingkan focused crawler tradisional.
Thenmalar & Geetha (2011) melakukan penelitian mengenai Concept Based Focused Crawling Using Ontology.Pada penelitian ini, algoritma ontology memiliki kemampuan untuk memecahkan masalah utama dari proses crawling dalam menentukan relevant pages. Penggunaan dari gabungan seed concept vector untuk menentukan peringkat masing-masing dokumen.
Implementasi Focused Crawler dengan Menggunakan Content Similarity dan Link Structure Analysis oleh Herdiansyah Rendy (2012). Penelitian yang dilakukan yaitu mengimplementasikan focused crawler dengan menggunakan metode cosine similarity, link score, dantraverse irrelevant page. Hasil dari penelitian ini menunjukkan bahwa focused crawlerakan mendapatkan nilai precision rate yang optimal dengan menggunakan metode traverse irrelevant page dengan kedalaman level 0.
digunakan sangat mempengaruhi hasil stemming. Semakin lengkap kamus yang digunakan maka semakin akurat pula hasil stemming.
Algoritma Porter Stemmer for bahasa Indonesia untuk Pre-ProcessingText Mining Berbasis Metode Market Basket Analysis oleh Budhi et al. (2006). Hasil dari penelitian ini yaitu algoritma Porter Stemmer for Bahasa Indonesia dapat digunakan pada proses stemmer saat merubah sebuah data teks dalam bahasa Indonesia menjadi bentuk Compact Transaction. Pada penelitian ini, hasil dari proses tidak selalu benar sehingga masih diperlukan pemeriksaan manual.
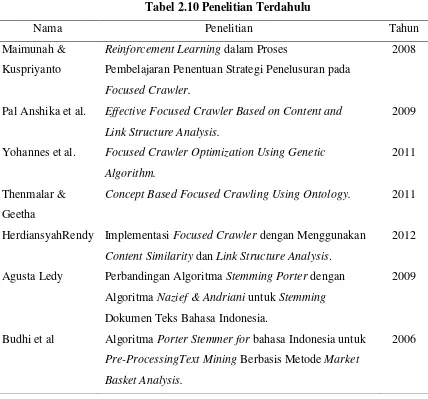
Tabel 2.10 Penelitian Terdahulu
Nama Penelitian Tahun
Maimunah & Kuspriyanto
Reinforcement Learning dalam Proses
Pembelajaran Penentuan Strategi Penelusuran pada Focused Crawler.
2008
Pal Anshika et al. Effective Focused Crawler Based on Content and Link Structure Analysis.
2009
Yohannes et al. Focused Crawler Optimization Using Genetic Algorithm.
2011
Thenmalar & Geetha
Concept Based Focused Crawling Using Ontology. 2011
HerdiansyahRendy Implementasi Focused Crawler dengan Menggunakan Content Similarity dan Link Structure Analysis.
2012
Agusta Ledy Perbandingan Algoritma Stemming Porter dengan Algoritma Nazief & Andriani untuk Stemming Dokumen Teks Bahasa Indonesia.
2009
Budhi et al Algoritma Porter Stemmer for bahasa Indonesia untuk Pre-ProcessingText Mining Berbasis Metode Market
Basket Analysis.