Fakultas Ilmu Komputer
4462
Implementasi Naive Bayes Pada Proxy Server Untuk Klasifikasi Pengguna
Internet
Siwi Rahmat Januar1, Rakhmadhany Primananda2, Mochammad Hannats Hanafi Ichsan3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Penggunaan akses jaringan internet di seluruh dunia mempunyai perkembangan yang sangat pesat. Banyak informasi yang diambil dengan sangat mudah. keberadaaan internet dapat memiliki dampak buruk dan memiliki dampak baik bagi penggunanya. Dengan adanya permasalahan tersebut, diperlukan suatu langkah untuk menganalisa jumlah perkembangan kriteria pengguna internet dengan cara mengumpulkan semua aktivitas informasi yang diminta oleh penggunanya dengan menggunakan squid server yang nantinya dapat melakukan Klasifikasi pengelompokan jenis karakter pengguna internet dengan menggunakan algoritme naive bayes. Naive Bayes Classifier (NBC) dapat membentuk tabel probabilitas sebagai dasar proses klasifikasi yang dapat memprediksi dan memberikan rekomendasi untuk proses yang diolah dengan nilai optimal. Hasil pengujian akan berpengaruh dengan faktor data klasifikasi yang diambil dalam menentukan hasil dari klasifikasinya. Setelah ditemukan nilai dari kategori naïve bayes, maka pada router mikrotik akan dilakukan pemblokiran website yang mengandung konten negatif. Dari hasil penelitian dan pengujian penentuan pengelompokan dapat menghasilkan nilai algoritma Naive Bayes dengan tingkat akurasi sampai dengan nilai maksimal 98,2%.
Kata kunci: Pengguna, Klasifikasi, Squid, Naive Bayes
Abstract
The use of internet network access around the world has a very rapid development. A lot of information is taken very easily. the existence of the internet can have adverse impact and have a good impact for its users. With this problem, we need a step to analyze the amount of development criteria internet users by collecting all the information activities requested by users by using a squid server that will be able to Classify the grouping of Internet user character types using naive bayes algorithm. The Naive Bayes Classifier (NBC) can form a probability table as the basis of a classification process that can predict and provide recommendations for processes processed with optimum value. Test results will affect the data classification factors taken in determining the results of the classification. Once found the value of the category naïve bayes, then the mikrotik router will be blocking websites containing negative content. From the results of research and testing the determination of clustering can yield the value of Naive Bayes algorithm with accuracy level up to a maximum value of 98.2%.
Keywords: User, Classification, Squid, Naive Bayes
1. PENDAHULUAN
Penggunaan akses jaringan internet di seluruh dunia mempunyai perkembangan yang sangat pesat. Menurut pengumpulan data yang diperoleh dari Asosiasi Penyelengara Jasa Internet Indonesia (APJII) sejak tahun 2013 sampai 2014, penetrasi angka pengguna di indonesia terus mengalami peningkatan yang tinggi sebesar 71,19 juta penggunaan internet diindonesia pada awal 2013 hingga dengan
Informasi (MenKomInfo) dalam memblokir sejumlah Uniform Resource Locator (URL) yang dianggap tidak pantas dalam menampilkan informasi yang merugikan penggunanya. Dengan adanya permasalahan tersebut, diperlukan suatu langkah untuk menganalisa jumlah perkembangan kriteria pengguna, dengan cara mengumpulkan semua aktivitas kegiatan aktivitas akses pengguna internet.
Pendekatan dalam pengambilan capture
Data pada aktivitas pengguna dilakukan dengan menyisipkan perangkat Router Mikrotik pada suatu jaringan internet di suatu lingkungan dengan menggunakan web proxy. Fungsi dari web proxy menjadi perantara antara pengguna dengan server squid itu sendiri, sehingga data aktivitas pengguna internet dapat dikumpulkan. Pengambilan jenis kriteria pengguna diambil dengan metode Naive Bayes. Ide dasar dari Naive Bayes adalah machine learning yang menggunakan perhitungan probabilitas data yang ada, dalam arti dapat melakukan pengelompokan pada data data yang didapat. Berdasarkan dari latar belakang yang telah dipaparkan, dapat disimpulkan bahwa metode naive bayes dapat melakukan pengelompokan jenis Karakter pengguna internet dengan mengambil data melalui squid server sebagai data mentah yang dapat dijadikan data berkualitas.
2. PERSAMAAN MATEMATIKA
2. 1 Karakteristik Pengguna
Karakteristik pengguna merupakan pergerakan aktifitas pengguna yang memiliki nilai pembanding antara pengguna satu dengan pengguna lainnya yang disebabkan oleh informasi yang selalu berkembang setiap waktunya. Apalagi Website saat ini salah satu sumber infirmasi yang membantu penggunannya dalam mendapatkan informasi yang diinginkan secara cepat.
2. 2 Squid Analysis Report Generator
Squid Analysis Report Generator (SARG) aplikasi tersetruktur yang dibutuhkan untuk merekam seluruh kegiatan aktifitas pengguna. Kebutuhan penting dalam menggunakan SARG (Squid Analysis Report Generator) adalah : 1. Proxy : berguna sebagai perangkat
pendukung yang bertindak sebagai pelayan atau gateway kepada sumber informasi untuk mendapatkan sumber yang dibutuhkan.
2. Squid (software) : aplikasi pada aplikasi proxy server pada linux/ubuntu yang befungsi mempercepat tingkat permintaan data yang diminta sebelumnya tersimpan pada webcache.
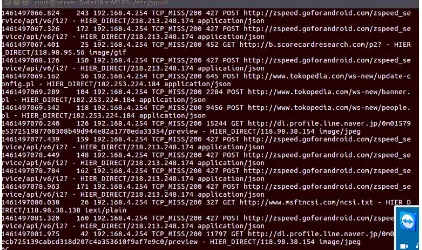
Pada Gambar 1 proses saat aplikasi Squid Server saat berjalan dengan merekam POST dan
GET link Uniform Resource Locator(URL)yang diambil dari aktifitas penggunanya.
Gambar 1.Aplikasi SARG (Squid Analysis Report Generator)
2. 3 Preprocessing
Preprocessing adalah langkah untuk membuat suatu informasi data mentah untuk dijadikan data yang berkualitas. Untuk dapat melakukan pemrosesan text, maka yang dapat dilakukan preprocessing sebagai berikut : 1. Tokenisasi : proses untuk dapat memecah
sekumpulan text simbol berupa karakter
whitespace, seperti enter, tabulasi, spasi, dan lain-lain.
2. Filtering : proses filtering untuk
menghapus text simbol. Proses stopword
dilakukan dengan pencocokan kalimat
apakah masuk stopword yang dicariatau
tidak. Apabila sebuah kata masuk didalam
daftar stopword maka kata tesebut akan
diproses dan dilanjutkan pada proses pencarian berikutnya.
3. Reguler Expression (REGEX) : tehnik yang digunakan dalam memasukkan data string simbol, text, angka untuk mencocokkan simbol yang memiliki kesamaan dari text yang dicari.
2. 4 Data Proccesing
dilakukan untuk melakukan fungsi-fungsi seperti membantu dalam klasifikasi, menandai kepemilikan, batas-batas notting, dan menunjukkan identitas online. Berikut adalah yang dapat digunakan dalam Metadata :
1. Titel biasa juga disebut dengan judul pada suatu website. Pada sebuah sourcecode dari Tabel 1 dapat ditentukan dengan format seperti :
Tabel 1. Metadata Tag Titel
Metadata <title>Meta Tags Example</title>
2. Keyword dapat disebut dengan bentuk data terpenting yang masih memiliki arti yang luas Didalamnnya. Pada sebuah sourcecode
dari Tabel 2 keyword dapat ditentukan dengan format seperti ini :
Tabel 2. Metadata Tag Keyword
Metadata <meta name="keywords"content="HTML, Meta Tags, Metadata"/>
3. Decription sebagai suatu penjelasan tentang website tersebut. Pada Decription dapat ditentukan dengan format seperti:
Tabel 3. Metadata Tag Description
Metadata <metaname="description"content="Learnin g about Meta Tags."/>
2. 5 Naive Bayes Algorithm
Naive Bayes merupakan suatu cara untuk dapat menentukan dalam pengambilan keputusan dalam menentukan kelas pada suatu data yang melum diketahui nilainnya metode probabilitas yang terstruktur yang dikembangkan oleh ilmuwan Inggris Thomas Bayes. Rumus dari Teorema Bayes adalah sebagai berikut :
𝑃(𝐻|𝑋) =𝑃(𝑋|𝑃(𝑋)𝐻).𝑃(𝐻) (1) Berdasarakan kondisi X (posterior Probabilitas)
P(H) : Nilai dari Probabilitas Hiptesis H
(Prior Probabilitas)
P(X|H) : Nilai dari Probabilitas X dengan kondisi berdasarkan hipotesis H. P(X) : Nilai dari probabilitas X
Untuk mencari hasil data pengelompokan dapat diselesaikan dengan menggunakan langkah-langkah berikut :
1. Data latih : diambil melalui suatu contoh yang sudah memiliki hasil. Pengambilan datalatih bisa berupa angka ataupun text yang bertolak ukur sebagai pengukur hasil dari perhitungan keberhasilan klasifikasi menggunakan metode Naive Bayes. 2. Term Frequency – Inverse Document
Frequency (TF-IDF) : Mempermudah dalam pencarian informasi dengan pengukuran tingkat similaritas karena dapat mempresentasikan hasil informasi secara terurut berdasarkan kemiripan antara query dengan informasi yang ada pada dokumen karya ilmiah.
𝑇𝐹 = {0 ,𝑓𝑡𝑚𝑑=01+𝑙𝑜𝑔10 (𝑓𝑡,𝑑),𝑓𝑡,𝑑>0 (2)
Keterangan:
Ft : Frekuensi Term d : Dokumen
3. Probabilitas awal (Prior) : diambil dari nilai rata rata pada data latih.Prior dapat dihiting dengan menghitung nilai dari rata rata dengan cara sebagai berikut:
𝜇 =𝑋1+𝑋2+𝑋3+⋯+𝑋𝑛𝑛 (3) dihitung nilai dari likehood untuk mengetahui nilai dari pembanding antara kategori. Rumus likelihood dinotasikan sebagai berikut:
terbesar dari seluruh kategori. Rumus posterior dinotasikan sebagai:
𝑃𝑜𝑠𝑡𝑒𝑟𝑖𝑜𝑟 = 𝑝𝑟𝑖𝑜𝑟𝑥𝑙𝑖𝑘𝑒ℎ𝑜𝑜𝑑𝑒𝑣𝑖𝑑𝑒𝑛𝑐𝑒 (6)
Keterangan :
Prior : Nilai rata rata Likehood : Nilai maksimum
Evidence : Perbandingan dengan kelas lainnya
2. 6 Pengujian
Pengujian dilakukan dengan menggunakan aplikasi yaitu wireshark software dan riwayat
browser dimana berfungsi sebagai tolak ukur dimana mencari jumlah kecocokan antara system dengan tools yang ada.
1. Pengujian Analisis uji coba pencarian Metadata Tag dilakukan menggunakan aplikasi Meta Tag Analizer dimana berfungsi untuk tolak ukur dalam mencari data metadata tag deskripsi yang dapat dilihat jumlah kecocokan antara system dengan tools yang ada.
2. Pengujian Conffusion Matrix
Tabel 4. Tabel Pengujian Conffusion Matrix
Nilai Sebenarnnya
Nilai Prediksi
Data Benar
TP (True Positive)
FP (False Positive)
Data Salah
FN (False Negative)
TN (True Negative)
- Precision berfungsi sebagai salah satu cara untuk mengetahui tingkar akurasi dan ketepatan antara informasi hasil dari pengguna dan di bandingkan dengan sistem.
Precision = 𝑇𝑃
𝑇𝑃+𝐹𝑃 (7) Keterangan :
TP : True Positif (Pengguna Positif hasil sesuai)
FP : False Positif(Pengguna Positif hasil Tidak sesuai)
- Recall adalah metode dalam mengukur tingkat keberhasilan sistem dengan sebuah informasi kemungkinan pada pengujian
Recall = 𝑇𝑃+𝐹𝑁𝑇𝑃 (8)
Keterangan :
TP : True Positif (Pengguna Positif hasil sesuai)
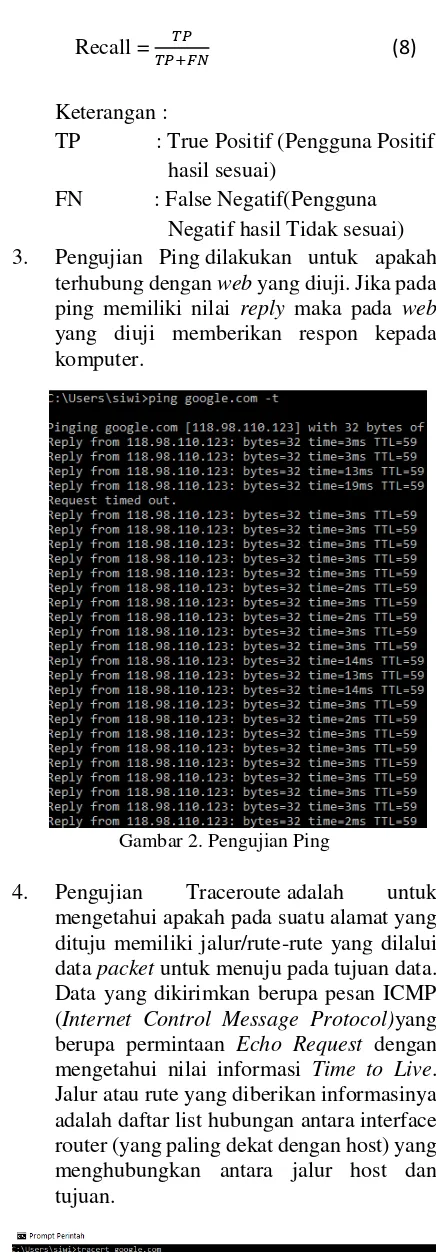
FN : False Negatif(Pengguna Negatif hasil Tidak sesuai) 3. Pengujian Ping dilakukan untuk apakah
terhubung dengan web yang diuji. Jika pada ping memiliki nilai reply maka pada web
yang diuji memberikan respon kepada komputer.
Gambar 2. Pengujian Ping
4. Pengujian Traceroute adalah untuk mengetahui apakah pada suatu alamat yang dituju memiliki jalur/rute-rute yang dilalui data packet untuk menuju pada tujuan data. Data yang dikirimkan berupa pesan ICMP (Internet Control Message Protocol)yang berupa permintaan Echo Request dengan mengetahui nilai informasi Time to Live. Jalur atau rute yang diberikan informasinya adalah daftar list hubungan antara interface router (yang paling dekat dengan host) yang menghubungkan antara jalur host dan tujuan.
5. Pengujian nslookup menguji permintaan informasi mengenai alamat ip public yang dapat diakses tanpa menggunakan nama domain . jika pada domain memiliki ip public lainnya maka domain tersebut dapat terhubung dengan cara melakukan ping/melakukan browsing secara satu per satu.
Gambar 4.Pengujian Nslookup
6. Pengujian akses browser dilakukan dengan cara manual dan tidak efisien dimana pengguna akan memasukkan alamat Url yang di tuju . dalam pengujian ini jika pada alamat url yang dituju dapat memberikan informasi maka alamat URL tersebut dapat terhubung.
Gambar 5 .Pengujian Browser
7. Pengujian Proxy menggunakan perantara dengan system komputer komputer lain yang bertindak sebagai perantara permintaan dari client untuk mencari sumber daya dari suatu website yang di blokir.
Gambar 6. Pengujian Proxy
3. PERANCANGAN
Perancangan dilakukan sesudah didapatkan seluruh data dari analisis kebutuhan yag sudah terkumpul. Dalam pembuatan sistem ini fokus dari perancangannya adalah antara router board, Web Proxy dan Squid Server. Gambar 7 merupakan perencanaan topologi yang akan di buat:
Internet Service Provide
Squid Server Router Board Mikrotik
Switch 5 Port Akses Point 1
Akses Point 2
Akses Point 3 User/Pengguna
Gambar 7. Topologi Jaringan
Gambar 8. Tampilan System
Gambar 9. Tampilan Blacklist
4. PENGUJIAN DAN ANALISIS
Tahap pengujian proses uji yang dilakukan adalah melalui cara pencocokan terhadap hasil perhitungan sistem. Tahap uji ini dilakukan dengan cara yang tidak efektif. Dimana pengujian dilakukan dengan meliputi pengujian seperti PengujianSquid Server, metadata tag, akurasi, dan Uji Akses.
4. 1Hasil dan Analisis Uji Squid
Gambar 10. Pengujian Squid Server
Dari Gambar.10 terjadi peningkatan yang berbeda dengan menggunakan pengumpulan data squid server, wireshark dan history browser dimana data yang paling banyak ditangkap adalah pada history browser yang diambil melalui aktifitas client/pengguna dimana pada browser semua aktifitas akan di rekam dan di simpan kedalam riwayat akses pada komputer client. Pada hasil grafik gambar 10 disimpulkan nilai pengujian terbaik adalah dengan menggunakan squid server karena data URL yang masuk tidak berulang ulang seperti pengujian History Browser. Hasil dari pola grafik tesebut dapat disimpulkan bahwa proses dalam pencarian informasi metadata deskripsi memiliki nilai integritas yang berbeda dari masing masing pengujian tersebut.
4. 2Hasil dan Analisis Uji Coba Metadata tag
Gambar 11. Pengujian Metadata
Dari Gambar 11 terjadi peningkatan yang berbeda dengan menggunakan pengumpulan data squid server, wireshark dan history browser
dimana data yang paling banyak ditangkap adalah pada history browser yang diambil melalui aktifitas client/pengguna pada
browser.Semua aktifitas akan direkam dan disimpan kedalam riwayat akses pada komputer
client. Pada hasil grafik Gambar 11 disimpulkan nilai pengujian terbaik adalah dengan menggunakan squid server karena data URL yang masuk tidak berulang seperti pengujian
History Browser. Hasil dari pola grafik tesebut dapat disimpulkan bahwa proses dalam pencarian informasi metadata deskripsi memiliki nilai integritas yang berbeda dari pengujian tersebut.
4. 3Hasil Pengujian Akurasi
0 200 400
10
…
20
…
40
…
80
…
15
0…
ANALISIS SQUID
Squid Server
Wireshar k
0 500 1000
10 20 40 80
15
0
Uji Coba Pencarian
Metadata Tag
System NBC
Gambar 12. Pengujian Akurasi
Pada grafik Gambar 12 dilihat bahwa setiap skenario memiliki nilai Precision, Reccal, Accuracy, dan Error-rate yang berbeda beda yang saling terhimpit dengan garis frekuensi kategori dan frekuensi error yang menghasilkan kategori sangat baik dalam penentuan akurasinnya dan hal tersebut dapat diambil kesimpulan bahwa penentuan penetapan akurasi kategori naive bayes memenuhi syarat dari sudut pandang pengujian akurasi yang dihasilkan untuk penentuan system.
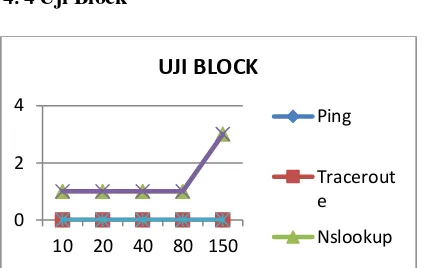
4. 4Uji Block
Gambar 13. Pengujian Block
Jika dilihat pada Gambar 13 terhadap percobaan uji akses Ping, Traceroute, Nslookup, Akses Browser, Proxy dapat ditarik sebuah kesimpulan bahwa uji coba pemblokiran yang berhasil keseluruhannya pada Nslookup, Akses. Hal ini terbukti dari Gambar 13yang memiliki hasil yang sama. Hal ini dapat membuktikan jenis link url yang diizinkan oleh system untuk tidak dapat melakukan akses permintaan akses content web.
5. HASIL DAN PEMBAHASAN
Hasil dari perancangan, analisis, implementasi, pengujian dan analisis hasil maka dalam penelitian ini dapat disimpulkan:
1. Pengumpulan data URL (Uniform Resource Locator) Dilakukan selama squid server berjalan dengan melakukan perintah pada terminal pada linux yang disimpan
kedalam log squid dengan nama default access.log.
2. Metode naïve bayes mempunyai syarat memiliki data latih dan data uji. Pengumpulan data latih diambil dari website Kamus Besar Bahasa Indonesia (KBBI) dan website kamus inggris versi
oxford learner dictionaries. Untuk dapat mengambil data uji pada proxy squid server
diharuskan mencari informasi mengenai
metadata tag deskripsi pada suatu Web
yang terdaftar sebelumnya di dalam list
SARG. Hasil di tentukan oleh algoritma naïve bayes berpengaruh pada data latih dan nilai dari likepriornnya.
3. Cara pemblokiran Uniform Resource Locator (URL) dilakukan ketika proses mulai dari pengumpulan data URL (Uniform Resource Locator) sampai dengan hasil dari naïve bayes di temukan Pemblokiran akses akan dilakukan melalui pernagkat router mikrotik dengan cara
memanfaatkan API
(applicationprogramminginterface )mengg unakan perintah CLI (Command line) yang dapat dilakukan printah secara terprogram. 4. Pengujian dilakukan dengan cara manual, dengan melihat hasil perbedaan dengan
tools yang digunakan .
6. DAFTAR PUSTAKA
Adam Mohammed Saliu & Mohammed Idris Kolo.,2013. Internet authentication and billing (hotspot) system using MikroTik router operating system. International Journal of Wireless Communications and Mobile Computing, 1(1): 51-57.
Andrew McCallum & Kamal Nigam.,2015 A Comparison of Event Models for Naive Bayes Text Classi_cation. Darpa HPKB program under contract F30602-97-1-0215
Ashur Harmadi dan Budi Hermana.,2005. Analisis Karakteristik Individu Dan Prilaku Pengguna Internet Banking: Realibilitas Dan Validitas Instrumen Pengukuran. ISBN: 979-756-061-6.
Asosiasi Penyelenggara JasaInternet Indonesia., 2013. Profil Pengguma Internet Indonesia 2014.
Amir Hamzah., 2012.Klasidikasi Teks Dengan Naive Bayes Classifier (NBC) Untuk Pengelompokan Teks Berita Dan Abstract Akademis. Prosiding Seminar Nasional Aplikasi Sains & Teknologi (SNAST) Periode III.
Andy Rachman., 2011. Rancang Bangun Proxy Server Dan Analisis Pemakai Internet Dengan Menggunakan SARG(Studi Kasus di BMKG Juanda Surabaya).
AzwarRhosyied, dan& Bambang Wijanarko Otok., 2014. Analisa Pengaruh Pengguna Internet Sebagai Media Belajar, Motivasi Belajar Dan Kreativitas Terhadap Prestasi Belajar Siswa Dengan Menggunakan Structural Equation Modeling.
Biswanath Dutta & Durgesh Nandini., 2015. MOD: Metadata for Ontology Description and Publication. Proc. Int’l Conf. on Dublin Core and Metadata Applications.
Chi-Wing Lo &Qin Lu and Kwun-Tak Ng. 2002 Character-Image Search Engine. IEEE SMC TPlE2.
Dr. S. Vijayarani& Ms. J. Ilamathi, 2012.Preprocessing Techniques for Text Mining - An Overview. Dr.S.Vijayarani et al , International Journal of Computer Science & Communication Networks,Vol 5(1),7-16.
Dr.S.Kannan, Vairaprakash Gurusamy,. 2014. Preprocessing Techniques for ext Mining. Available from: Vairaprakash Gurusamy Retrieved on: 22 February 2016
Evangelos P. Markatos, Dionisios N. Pnevmatikatos., 2002Web-Conscious Storage Management for Web Proxies. IEEE/ACM TRANSACTIONS ON NETWORKING, VOL. 10, NO. 6.
Edikoston ferreira. Mikrotik com Squid3 proxy rápido e fácil. Tersedia di: <http://shoiem.blogspot.co.id/2010/04/s
ejarah-internet-Perkembangannya.html> [Diakses 25Februari 2016]
Gencho Stoitsov&Vasil Rangelov.,2014 .One implementation of API interface for RouterOS.TEM Journal – Volume 3 / Number 2 / 2014.
Hidayatul Rahman. Naive Bayes Algorithm. Tersedia di: <http://education-programmer.blogspot.co.id/2013/01/nai ve-bayes-algorithm_22.html
> [Diakses 1 Februari 2016]
Idayatul Rahman. Naive Bayes Algorithm. Tersedia di: <
https://www.youtube.com/watch?v=laOkbwUx 0ws> [Diakses 25Februari 2016]
Jamal Muhlis. Konfigurasi Mikrotik dan Squid Proxy. Tersedia di:
<https://www.academia.edu/4739436/K onfigurasi_Mikrotik_dan_Squid_Proxy > [Diakses 25Februari 2016]
Kanchana Ihalagedara., 2015 Feasibility of Using Machine Learning to Access Control in Squid Proxy Server. Proceedings of the Fourth Engineering Students’ Conference at Peradeniya 2015 (ESCaPe’15).
kbbi.web.id. Kamus Besar Bahasa Indonesia
(KBBI). Tersedia di:
<http://kbbi.web.id/karakter> [Diakses 25Februari 2016]
Lin Lv& Yu-Shu Liu.,2008. Research Of Research Of English Text Classification Methods Based On Semantic Meaning. Lina Noviandari. Naive Bayes Algorithm.
Tersedia di:
<https://id.techinasia.com/talk/statistik- pengguna-internet-dan-media-sosial-terbaru-2015> [Diakses 20Februari 2016]
Margus Veanes & Peli de Halleux.,2009. Rex: Symbolic Regular Expression Explorer. Microsoft Research Technical Report MSR-TR-2009-137.
Statistic Based Spam Filter. First International Workshop on Education Technology and Computer Science.
Mochamad Rizki., 2011. Kontrol Ekspresi Wajah Berdasarkan Klasifikasi Teks Menggunakan Metode Naïve Bayes.
Tersedia di :
<http://repo.pens.ac.id/497/> [Diakses : 03- Maret 2016].
Mr.S.V.Gumaste..2013.Proxy Server Experiment and the Behavior of the Web.Volume4,NO.2 ,ISSN No. 0976-5697.
Prof. Rahul Patil..2014. A Hybrid Model to Detect Phishing-Sites using Clustering and Bayesian Approach. International Conference for Convergence of Technology.
Russ Cox .,2007. Regular Expression Matching Can Be Simple And Fast
(but is slow in Java, Perl, PHP, Python, Ruby,).
Rizky Agung . Penjelasan Web Proxy Mikrotik .
Tersedia di:
<http://mikrotikindo.blogspot.co.id/201
3/04/penjelasan-web-proxy-mikrotik.html> [Diakses 20Februari 2016]
RN. Tri Hardianto, S.Kom,.2015. Analisis unjuk Kerja Pengaruh Hit Ratio pada Squid Proxy Terhadap Sumber Daya Komputer Server.
Santanu Santra& Pinaki Pratim Acharjya.,2013.A Study And Analysis on Computer Network Topology For Data Communication. ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 1.
Sang-Bum Kim &Kyoung-Soo Han.,2006.Some Effective Techniques for Naive Bayes Text Classification. IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 18, NO. 11.
Selvia Lorena Br Ginting,S.Si., M. Pengguna Metode Naive Bayes Classifier Pada Aplikasi Perpustakaan.Tersedia di:
<http://elib.unikom.ac.id/files/disk1/63 2/jbptunikompp-gdl-reggypasya-31586-11-unikom_r-l.pdf> [Diakses 16Februari 2016]
Silvia Ari santhy., 2013. Sistem Deteksi Pengunaan Tunneling Software.
Tersedia di :
http://webcache.googleusercontent.com /search?q=cache:l7OZUrI69OkJ:ptiik.u b.ac.id/doro/download/article/file/DR00 094201412+&cd=1&hl=id&ct=clnk&gl =id [Diakses 03 Maret 2016].
Simon Holm Jensen. Modeling the HTML DOM and Browser API in Static Analysis of JavaScript Web Applications. Tersedia di:
<https://cs.au.dk/~amoeller/papers/dom /paper.pdf> [Diakses 20Februari 2016]