Creating a
Fine-Grained Corpus for
Chinese Sentiment
Analysis
Yanyan Zhao, Bing Qin, and Ting Liu, Harbin Institute of Technology
Existing corpora
are almost
sentence-level works that
ignore important
global sentiment
information in other
sentences. Given
the rise of advanced
applications, more
fine-grained corpora
are needed, especially
for Chinese.
However, browsing the extensive collection of reviews and finding useful information is a time-consuming and tedious task. Con-sequently, sentiment analysis and opinion mining have attracted significant attention in recent years, paving the way for auto-matic analysis of reviews and extraction of the information most relevant to users.
Sentiment analysis entails several interest-ing and challenginterest-ing tasks. A fundamental one is polarity classification—determining the po-larity of a sentence or a document—but this sort of task is coarse-grained and can’t pro-vide detailed information.1–3 Recently, there
has been a shift toward fine-grained tasks that not only search for opinionated text but also analyze its polarity (positive, neu-tral, negative) and intensity (weak, medium, strong, extreme), identifying the associated source or opinion holder, as well as the topic, target entity, or aspect of the opinion.4–7
Many of these tasks are based on statistical and machine learning algorithms, making an-notated, fine-grained corpora necessary for measuring algorithm performance and as
training data for supervised machine learning algorithms.8
Some public corpora exist for fine-grained tasks.7,9–11 Although they provide more
de-tailed sentiment information than their coarse-gained counterparts (which con-tain polarity labels only), their annotation schemes are generally at the sentence or ex-pression level. But not all useful information can co-occur in the same sentence, meaning these schemes ignore important global senti-ment information. For example, in the sen-timent sentence, “The image quality is so good,” “image quality” can be labeled as an aspect, but the owner of this “image quality” isn’t mentioned. Such information is more im-portant in practical applications and might be found in other sentences in the document.
Unfortunately, useful sentence-level senti-ment information hasn’t drawn special atten-tion or been annotated in the existing public corpora. For example, most of the current cor-pora annotate the aspect-opinion pair, but more than 25 percent of aspects can’t find their corre-sponding opinion words. Sentences containing
T
he Web holds a considerable amount of user-generated content
de-scribing the opinions of customers on products and services through
reviews, blog, tweets, and so on. These reviews are valuable for customers
in the annotation process or incorrectly treated as non-sentiment. Take the sen-timent sentence, “The lens is a piece of work,” as an example: it has no aspect-opinion pair but can clearly show the opinion for the aspect “lens.” Today, quite a few researchers have mentioned this problem, but they haven’t treated it as an independent task—proposed methods are very simple and not ideal.12
In this article, we discuss the problems underlying the existing product review corpus, briefly survey the research area, and propose a new annotation scheme that’s more fine-grained than existing ones and can provide global sentiment information that’s more useful and im-portant in advanced applications. More importantly, from analyzing our anno-tated corpus, we can explore vital but ignored tasks to provide useful hints about future research directions. As a case study, we present a Chinese cor-pus on two kinds of products—a digital camera and a mobile phone.
Analysis of Existing
Sentiment Analysis Corpora Coarse-grained tasks have many public corpora. Cornell Movie Review Data (MRD; www.cs.cornell.edu/people/ pabo/movie-review-data), for example, is a commonly used sentiment analy-sis corpus that includes three datas-ets—sentiment polarity datasets, senti-ment scale datasets, and subjectivity da-tasets—that are all used for sentiment classification tasks. Stanford’s Large Movie Review Dataset (LMRD; http:// ai.stanford.edu/~amaas/data/sentiment) is used for binary sentiment classifica-tion and contains more substantial data compared with previous benchmark da-tasets. Coarse-grained sentiment analy-sis tasks, such as classifying a sentence or document into several polarities or ratings, are generally training mod-els based on these corpora. However, many practical applications pay more
attention to the product or the particu-lar aspect to which the poparticu-larity is linked. This necessitates fine-grained tasks and corresponding fine-grained corpora.
A basic fine-grained task is to ex-tract an aspect in a text and identify its polarity. In the sentence, “The picture quality is good,” for example, we can extract “picture quality” as the aspect and recognize “positive” as the polar-ity tag. Product Review Data (PRD)7
includes several product review datas-ets that are annotated with the product aspect and its polarity and intensity in every sentence. Another Movie Review Data9 is labeled with aspect-opinion
pairs (such as <picture quality, good>). Another corpus in the literature10 is
an-notated at both sentence and expres-sion levels, filtering individual sentences according to whether they’re an opin-ion and identifying opinopin-ion expressopin-ions including the opinion holder, modifiers, and so on at the expression level. Dif-fering from product or movie reviews, the multiperspective question-answer-ing (MPQA; http://mpqa.cs.pitt.edu) opinion corpus contains news articles from a wide variety of sources manu-ally annotated for opinions and other private states (beliefs, emotions, senti-ments, speculations, and so on). This dataset annotates the agent, expressive-subjectivity, target entity, attitude, and other fine-grained elements.
Compared with these abundant Eng-lish resources, Chinese sentiment anal-ysis corpora are limited. The most popular one is from the Chinese Opin-ion Analysis EvaluatOpin-ion (COAE),11
which contains product, movie, and fi-nance reviews and is annotated with
aspect-opinion pairs and their polari-ties. Although these fine-grained corpora can provide more detailed sentiment in-formation than the coarse-gained ones, their annotation schemes are gener-ally at the sentence or expression levels. A primary problem is thus the omis-sion of important information outside the sentence. In most cases, the aspect’s target entity might not be in the same sentence. We call this the “target entity ignoring” problem—for example, in the first line of Table 1, the two sentiment sentences are annotated with the aspect-opinion pair, <appearance, beautiful> and <screen, great>, but the target en-tity that corresponds to the aspect (“ap-pearance” or “screen”) isn’t annotated. Obviously, target entity is an important element for sentiment analysis and opin-ion mining, and should be included in the annotation scheme, but statistics in-dicate that about 90 percent of aspects don’t appear with the target entity in the same sentence, with two to three target entities present in each review. Hence, recognizing the corresponding target en-tity for each aspect is a necessary task that also requires appropriate corpora. Moreover, several useful sentence-level sentiment elements haven't drawn spe-cial or enough attention, nor have they been annotated in the public existing corpora. We illustrate some representa-tive ones as follows.
Implicit Polarity
Existing corpora are mostly anno-tated with aspect-opinion pairs. How-ever, among the sentiment sentences, not all aspects are modified by polar-ity words. The second line in Table 1 is
3
S E N T I M E N T A N A L Y S I S
an example: the sentence doesn’t con-tain an aspect-opinion pair, but actu-ally shows the opinion as “positive” for the aspect “color.”
As mentioned earlier, more than 25 percent of aspects can’t identify their corresponding opinion words and will be discarded in the annotation procedure; they’re also often ignored in practical applications. Moreover, sentiment sentences containing this problem are always incorrectly con-sidered as non-sentiment sentences, which might affect sentiment analy-sis performance. Today, quite a few researchers have mentioned this prob-lem12 but haven’t treated it as an
in-dependent task. Besides, no corpora annotate these kinds of elements.
Here, we call the aforementioned problem implicit polarity. This term
refers to a kind of aspect that’s modi-fied without a corresponding polarity word but that shows polarity. We call the sentiment sentences that have this problem implicit sentiment sentences. Given the proportion of implicit sen-timent sentences in the corpus, this element should be annotated.
Implicit aspect
Implicit aspect doesn’t explicitly oc-cur in the sentence but is implied in the polarity word. In the third line of Table 1, for example, the polarity word “expensive” implies the aspect “price.” Another similar example is “quick” implying “speed.” Although this problem has aroused the interests of a few researchers,7,13 no existing
corpora annotate this kind of element to provide a platform.
Annotation Guidelines To make the corpus adequate for solv-ing the problems presented in Table 1, we designed a new annotation scheme. Although it’s also organized in a sen-tence unit, it can’t be easily treated as a sentence-level annotation because it includes cross-sentence and global in-formation. It also enhances the existing annotation scheme by proposing sev-eral useful elements in sentences.
Inspired by practical applications, this annotation guideline is suitable for many common sentiment analysis tasks. For a given sentence, it not only classifies the polarity but also extracts a more complete and fine-grained struc-tured representation. The new elements in this scheme can also generate new and interesting sentiment analysis tasks.
Based on these principles, we de-signed the following sentiment elements for annotation:
• Target entity refers to the main topic. In product reviews, it might be the product or brand discussed in a given sentence. In Figure 1, for example, the target entity for each sentence is “NEX-5N.” However, target entity doesn’t always appear with the aspect in the same sentence, such as the sec-ond and third sentences in Figure 1. Hence, recognizing the corresponding target entity for each aspect in a given sentence is a challenging and new meaningful task in sentiment analysis. • Aspect refers to a component or at-tribute of a certain product. In the first sentence of Figure 1, “appear-ance” is tagged as an aspect. Aspect recognition is a hot research topic in sentiment analysis. Here, aspect is exactly present in the given sentence. • Implicit aspect is explained in the
preceding section. Compared with common aspect, it’s implied, hence, not occurring in a given sentence— see, for example, the third sentence of Figure 1, where the implicit aspect is
implied in the polarity words. Recog-nizing implicit aspect is an interesting task, the results of which can enhance the findings of sentiment analysis. • Polarity expression is the word or
phrase that modifies the aspect and indicates sentiment orientation, such as the word “beautiful” in the first sentence of Figure 1. More spe-cifically, in this article, polarity ex-pression refers to the polarity word, which is tagged during annotation. • Modifier refers to the word
modify-ing the polarity word, such as “very” in the first sentence of Figure 1. • Negation is the word that can
re-verse the polarity of the polarity word, such as “no” or “not.” It plays a special role in sentiment analysis. • Polarity refers to the sentiment
ori-entation of a given target entity/ aspect/implicit aspect. In this arti-cle, we consider only three polarity tags, namely, “positive,” “nega-tive,” and “neural.”
• Transition words are always lo-cated at the beginning of the sen-tence, such as the word “but” in the third sentence of Figure 1. A sentence containing a transition word can show opposite polarity with the sentence before or after it. • Compare is used to evaluate whether
the given sentence is comparative. A comparative sentence contains comparative words, such as the word “than” in the third sentence of Figure 1. Comparative sentiment analysis can be considered as a characteristic task and has recently gained extensive attention.
Each sentiment sentence is annotated in XML to represent every element. Fig-ure 1 shows an XML representation for several sentiment sentences extracted from the digital camera domain.
Three main elements are mostly rele-vant in sentiment analysis tasks: <object,
description, polarity>. Object refers to the main and complete topic; descrip-tion refers to the words or phrases de-scribing the object; and polarity refers to the sentiment orientation of <object, description>. In our annotation scheme, the combination of elements (1)–(3) is the complete object, that of elements (4)–(6) is the description of the object, and elements (7)–(9) can be used to compute polarity.
Among the aforementioned elements, “target entity” and “polarity” can’t be tagged with “NULL” under any con-dition. Other elements can be tagged with “NULL” in the absence of an ap-propriate word or phrase. If a sentence contains more than one target entity or aspect, all of them will be annotated, and different <object, description, po-larity> units will be constructed.
A Fine-Grained Corpus and Analysis
We present the Chinese product review corpus as a case study for the issues proposed in previous sections.
Data Collection
We manually collected online customer reviews from several famous Chinese fo-rum sites—namely, ww.xitek.com and www.fengniao.com for the digital cam-era, and http://bbs.dospy.com and http:// bbs.cnmo.com for the mobile phone.
The raw corpus contained 400 doc-uments, in which 200 were for the dig-ital camera and 200 documents were for the mobile phone. Every document included the post’s main body and ti-tle. We asked two experts to anno-tate them manually, which came to 8,042 sentences for the digital camera domain and 9,530 sentences for the mobile phone domain. According to
Cohen’s κ score, the agreement calcu-lated was satisfactory, that is, κ= 0.71 for the digital camera domain and
κ= 0.73 for the mobile phone domain. To extend our corpus, inspired by pre-vious works14,15 we applied a third
independent annotation where incon-sistency was detected. Then, the cases where inconsistency persisted, such as when experts selected different tags, were discarded as too ambiguous to be annotated. Ultimately, 2,020 and 2,144 sentences were annotated for the digital camera and mobile phone domains, respectively. Table 2 presents the corpus statistics, which we’ll dis-cuss in the following subsection.
This corpus was domain-oriented and not very large because the anno-tation procedure was complex and manual: it might be time-consum-ing to manually build a large corpus, which can cover all the general do-mains, based on the proposed annota-tion schema. In the future, to enlarge the corpus and also easily build other domain corpora, we can use a semiau-tomatic annotation procedure. First, we can automatically annotate some elements according to existing senti-ment resources. Of course, the auto-matic annotation isn’t perfect and can lead to some incorrect annotations or miss some elements. Thus, we might need to then manually correct some of the annotations. But clearly, this semi-automatic annotation will require less work than fully manual annotation. We can use the most frequent target entity in a document as the “target en-tity” for each sentence and annotate the “aspect” or “polarity-expression” by matching an aspect or polarity ex-pression dictionary. Similar annota-tions, such as “modifier,” “negation,”
Avg. no. of sentences in each review 40.21 47.65
S E N T I M E N T A N A L Y S I S
“transition word,” and “compare word” can also be annotated using corresponding dictionaries.
analysis and Exploitation for the Corpus
To obtain relevant ideas for the po-tential future use of the corpus, we performed in-depth analysis and ex-ploitation from which we could mine new sentiment analysis tasks.
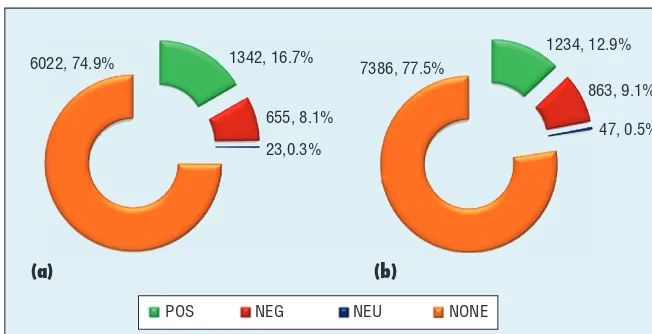
Polarity distribution in the sentiment analysis corpus. Table 2 shows that each review contains an average of 40 to 50 sentences, in which approx-imately 10 to 11 are sentiment tences. Hence, the ratio between sen-timent and non-sensen-timent sentences is 1:3, of which the non-sentiment sentences are the main part. Figure 2,
which shows the polarity distribution statistics separately for the digital camera and mobile phone domains, also reflects this phenomenon.
Classifying a sentence as either sen-timent or non-sensen-timent is a necessary step in sentiment analysis. However, at present, not much work focuses on this traditional task except for some meth-ods proposed16,17 in the preliminary
stage of sentiment analysis. Therefore, we should pay more attention to this old but important task in the future.
Figure 2 also shows the distribution of three different polarities, with the neutral one just a minimal part of sen-timent sentences that can be simply ig-nored. Note that the neutral sentences are different from non-sentiment sen-tences here because they still show the sentiment orientation “neutral,”
although the neutral and non-senti-ment sentences are always joined in one class in previous work.18
Target entity distribution in the senti-ment analysis corpus. Target entity is an important element in sentiment analy-sis.19–21 Without recognizing the
tar-get entity, other fine-grained elements, such as aspect or polarity, become al-most useless in practical applications. Table 3 shows target entity distribu-tion statistics.
The low ratios (especially for the mobile phone domain) shown in row A-1 illustrate that just a few aspects and their corresponding target enti-ties are co-occurring in the same sen-tence. The ratios of A-2 indicate that most reviews have more than one tar-get entity, and approximately two to three target entities are in each review, as shown in A-3. These statistics im-ply that for most aspects, we should explore their target entities in other sentences and choose the proper one from the target entity candidates.
However, most public product re-view corpora ignore the annotation of the target entity, and few studies focus on target entity recognition, especially the “target entity aspect” (“target as-pect” for short in the following sec-tions) pair extraction tasks. Thus, by analyzing the target entity distribution statistics, we can propose a new and important task: target-aspect pair ex-traction to solve the “target entity ig-noring” problem in Table 1. Moreover, developing the sentiment analysis cor-pora with target entity tags is vital, as they can be used for the algorithm re-search of these tasks.
Aspect-opinion pair distribution in the sentiment analysis corpus. Aspect-opinion pair extraction is one of the most important tasks in sentiment analysis.7,22,23 Table 4 illustrates the
statistics for aspect-opinion pair
distri-Table 3. Target entity distribution statistics for the digital camera and mobile phone domains.*
No. Types Examples Digital camera Mobile phone
A-1 Ratio indicating that target entity and aspectco-occur in the same sentence
√: GF3
(the appearanceof GF3
is very beautiful) ×:
(the appearanceis very
beautiful)
11.24% 7.23%
A-2 Ratio of the reviews that only contain one target entity
— 27% 36.5%
A-3 Average no. of target entities for each review
— 2.82 2.37
*The green text indicates target entity.
POS NEG NEU NONE
1342, 16.7%
655, 8.1%
23,0.3%
7386, 77.5%
1234, 12.9%
863, 9.1%
47, 0.5%
(a) (b)
6022, 74.9%
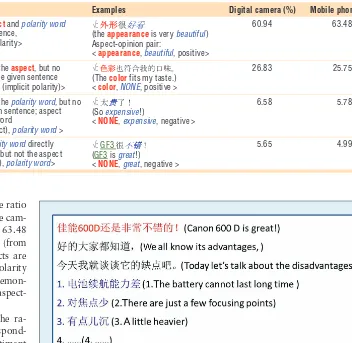
bution for the two domains. The ratio of the aspect-opinion pair for the cam-era domain is 60.94 percent and 63.48 percent for the phone domain (from B-1), indicating that most aspects are modified by corresponding polarity words. This finding can also demon-strate the importance of the aspect-opinion pair recognition task.
B-2 in Table 4 shows that the ra-tios of aspects without correspond-ing polarity word but with sentiment orientation (such as the examples in B-2) aren’t low: 26.83 percent for the digital camera and 25.75 percent for the mobile phone. Many researchers have studied algorithms for the aspect-opinion pair extraction task, but most of them have ignored the aspects with-out corresponding polarity words. Sentences containing this problem of implicit polarity are always confused with some non-sentiment sentences because both do not contain polarity words. The difference, however, is that implicit polarity sentences actually show polarities. In addition, the ratio of this kind of aspects isn’t minimal. As such, we should focus on the prob-lem of implicit polarity. Here, we pro-pose a new task—implicit polarity rec-ognition—that can distinguish implicit sentiment sentences from the non-sen-timent sentence as well as improve the aspect-opinion recognition results.
Table 4 shows that the ratios of sentiment sentences containing
aspects are about 88 percent (60.94 + 26.83) for the digital camera domain and 89 percent (63.48 + 25.75) for the mobile phone domain. Thus, more than 10 percent of sentiment sentences don’t contain aspects for each domain. These sentiment sentences have two cases: the implicit aspect implied in the polarity word (B-3), and the polarity word that directly modifies the target entity but not the aspect (B-4).
Table 4 shows that the implicit aspect ratio for the camera domain is 6.58 per-cent and 5.78 perper-cent for the mobile phone domain, which occupies a cer-tain proportion. Implicit aspect recog-nition can be retreated as an important task from this exploitation. B-4 shows that the ratio of the polarity word di-rectly modifying the target entity is 5.64
percent for the camera and 4.99 percent for phone, which also occupies a cer-tain proportion. In previous studies, re-searchers treated both target entity and aspect as the same and used similar ap-proaches to distinguish them. However, target-opinion and aspect-opinion pairs can be used in different applica-tions. The former can be considered as the conclusion of a product, whereas the latter is the detailed attribute de-scription for a product.
For example, in Figure 3, the itali-cized sentence, “Canon 600D is great!” containing a target-opinion pair is a conclusion for the product “Canon 600D.” The author fully recom-mends this product despite numerous negative underlined sentences contain-ing aspect-opinion pairs. Therefore,
<aspect, polarity> Aspect-opinion pair:
<appearance, beautiful, positive> B-2 Ratio indicating that only the aspect, but no
polarity word, occurs in the given sentence <aspect, NO polarity word(implicit polarity)>
√:
(The colorfits my taste.) <color, NONE, positive >
26.83 25.75
B-3 Ratio indicating that only the polarity word, but no aspect, occurs in the given sentence; aspect is implied in the polarity word
<NO aspect (implicit aspect), polarity word >
√:
(So expensive!)
<NONE, expensive, negative >
6.58 5.78
B-4 Ratio indicating that polarity worddirectly modifies the target entity, but not the aspect < NO aspect (target entity), polarity word>
√: GF3
(GF3 is great!)
<NONE, great, negative >
5.65 4.99
S E N T I M E N T A N A L Y S I S
extracting this kind of conclusion sen-tences with target-opinion pairs is im-portant, as they’re useful in product recommendation.
We also analyzed comparative senti-ment sentences. Statistics indicate that comparative sentences occupy a cer-tain proportion: 8.27 percent for the camera domain and 6.95 percent for the mobile phone domain. Given that comparative sentences always compare two target entities or one aspect of two target entities, they entail numerous in-teresting applications.
F
rom our observations of the fine-grained corpus, we propose two new sentiment analysis tasks, thus generating relevant ideas for future di-rections: target-aspect pair extraction and implicit polarity recognition.To explore a completely structured representation of each sentiment sen-tence, a new scheme is necessary that can encompass the global information to solve the problem on the original sentence-level scheme. Target entity is one of the most important pieces of global information. Recognizing the corresponding target entity for each aspect is necessary in practical appli-cations, thus target-aspect pair extrac-tion can be treated as a new sentiment analysis task and should receive ad-ditional attention. Similarly, a certain percentage of aspects don’t contain corresponding polarity words. Senti-ment sentences containing these kinds of aspects are always confused with non-sentiment sentences. Recognizing this kind of aspect and searching its polarity are important and interesting future tasks as well.
In the future, we’ll annotate more customer reviews to extend our cor-pus. We’ll also explore algorithms for new sentiment analysis tasks proposed in this article and improve the exist-ing algorithms with inspiration from
the corpus to address the old sentiment analysis tasks.
Acknowledgments
This work was supported by the National Nat-ural Science Foundation of China (NSFC) via grants 61300113, 61133012, and 61273321, the Ministry of Education Research of So-cial Sciences Youth funded projects via grant 12YJCZH304, and the Fundamental Research Funds for the Central Universities via grant HIT.NSRIF.2013090.
References
1. B. Pang and L. Lee, “Opinion Mining and Sentiment Analysis,” Foundations and Trends in Information Retrieval, vol. 2, 2008.
2. B. Liu, Sentiment Analysis and Opinion Mining, Morgan and Claypool, 2012. 3. E. Cambria et al., “New Avenues
in Opinion Mining and Sentiment Analysis,” IEEE Intelligent Systems, vol. 28, no. 2, 2013, pp. 15–21. 4. T. Wilson, “Fine-Grained Subjectivity
and Sentiment Analysis: Recognizing the Intensity, Polarity, and Attitudes of Private States,” PhD dissertation, Dept. Computer Science, Univ. Pittsburgh, 2008.
5. A. Mukherjee and B. Liu, “Aspect Extraction through Semi-Supervised Modeling,” Proc. Assoc. Computational Linguistics (ACL), 2012, pp. 339–348. 6. G. Qiu et al., “OpinionWord Expansion
and Target Extraction through Double Propagation,” Computational Linguistics, vol. 37, no. 1, 2011, pp. 9–27.
7. M. Hu and B. Liu, “Mining and Summarizing Customer Reviews,” Proc. ACM SIGKDD Int’l Conf. Knowledge Discovery and Data Mining (KDD), 2004, pp. 168–177.
8. C. Bosco, V. Patti, and A. Bolioli, “Developing Corpora for Sentiment Analysis and Opinion Mining: The Case of Irony and Senti-TUT,” IEEE Intelligent Systems, vol. 28, no. 2, 2013, pp. 55–63.
9. L. Zhuang, F. Jing, and X. Zhu, “Movie Review Mining and Summarization,”
Proc.15th ACM Int’l Conf. Information and Knowledge Management (CIKM), 2006, pp. 43–50.
10. T. Cigdem, J. Niklas, and G. Iryna, “Sentence and Expression Level Annotation of Opinions in User-Generated Discourse,” Proc. Assoc. Computational Linguistics (ACL), 2010, pp. 575–584. 11. J. Zhao et al., Overview of Chinese Opinion Analysis Evaluation 2008, tech. report, China Conf. Information Retrieval, 2008.
12. Y. Zhao, B. Qin, and T. Liu,
“Integrating Intra- and Inter- Document Evidences for Improving Sentence Sentiment Classification,” Acta Automatica Sinica, vol. 36, no. 10, 2010, pp. 1417–1425.
13. Q. Su et al., “Hidden Sentiment Association in Chinese Web Opinion Mining,” Proc. World Wide Web Conf. (WWW), 2008, pp. 959–968.
14. L. Devillers, I. Vasilescu, and L. Lamel, “Annotation and Detection of Emotion in a Task-oriented Human-Human Dialog Corpus,” Proc. Isle Workshop on Dialogue Tagging, 2002; http://citeseerx.ist.psu.edu/viewdoc/ summary?doi=10.1.1.12.5524. 15. X. Cao et al., “The Use of
Categorization Information in Language Models for Question Retrieval,” Proc.18th ACM Int’l Conf. Information and Knowledge Management (CIKM), 2009, pp. 265–274.
16. B. Pang and L. Lee, “A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts,” Proc. Assoc. Computational Linguistics (ACL), 2004, pp. 271−278.
17. H. Yu and V. Hatzivassiloglou, “Towards Answering Opinion Questions: Separating Facts from Opinions and Identifying the Polarity of Opinion Sentences,” Proc. Conf. Empirical Methods in Natural Language Processing (EMNLP), 2003, pp. 129−136.
Semantics, 2013, pp. 380−383.
19. W. Wei and J. Gulla, “Sentiment Learning on Product Reviews via Sentiment Ontology Tree,” Proc. Assoc. Computational Linguistics (ACL), 2010, pp. 404–413. 20. J. Yu and Z. Zha, “Domain-Assisted Product
Aspect Hierarchy Generation: Towards Hierarchical Organization of Unstructured Consumer Reviews,” Proc. Conf. Empirical Methods in Natural Language Processing (EMNLP), 2011, pp. 140–150.
21. X. Ding, B. Liu and L. Zhang, “Entity Discovery and Assignment for Opinion Mining Applications,” Proc. ACM SIGKDD Int’l Conf. Knowledge Discovery and Data Mining (KDD), 2009, pp. 1125–1134.
22. K. Bloom, N. Garg and S. Argamon, “Extracting Appraisal Expressions,” Proc. North Am. Assoc. Computational Linguistics (NAACL), 2007, pp. 308–315.
23. S. Li, R. Wang, and G. Zhou, “Opinion Target Extraction Using a Shallow Semantic Parsing Framework,” Assoc. Advancement of Artificial Intelligence (AAAI), 2012, pp. 1671–1677.
of the Association for Computation Linguistics (ACL) and the China Computer Federation (CCF). Contact her at [email protected].
bing Qin is a professor in the Department of Computer Science and Technology at Harbin Institute of Technology. Her interests include text mining and natural language processing. Qin has a PhD in computer science from Harbin Institute of Technology. She’s a member of the Association for Computation Linguistics (ACL) and the China Computer Federation (CCF). Contact her at [email protected].
Ting Liu, the corresponding author, is a professor in the Department of Computer Science and Technology at Harbin Institute of Technology. His interests include information retrieval, natural language processing, and social computing. Liu has a PhD in computer science from Harbin Institute of Technology. He’s a member of the Association for Computation Linguis-tics (ACL) and the China Computer Federation (CCF). Contact him at [email protected].
Experimenting with your hiring process?
Finding the best computing job or hire shouldn’t be left to chance.
IEEE Computer Society Jobs is your ideal recruitment resource, targeting over 85,000 expert researchers and qualified top-level managers in software engineering, robotics, programming, artificial intelligence, networking and communications, consulting, modeling, data structures, and other computer science-related fields worldwide. Whether you’re looking to hire or be hired, IEEE Computer Society Jobs provides real results by matching hundreds of
relevant jobs with this hard-to-reach audience each month, inComputer
magazine and/or online-only!