BAB II
LANDASAN TEORI
2.1 Data Kategorik
Data statistik yang diperhatikan dalam setiap analisis atau penelitian pada umumnya memuat banyak variabel numerik maupun variabel kategorik. Sehingga analisis data juga dapat dilakukan dengan memakai kedua macam ukuran variabel tersebut. Akan tetapi, dengan mentransformasikan semua variabel numerik menjadi variabel kategorik (ordinal) maka kita akan mempunyai suatu data baru dengan semua variabel kategorik, yang akan disebut data kategorik. Manfaat atau keuntungan yang dapat diperoleh dengan memakai data kategorik antara lain:
a) Ruang yang diperlukan untuk menyimpan data menjadi sangat sempit/kecil dibandingkan dengan data aslinya atau data primernya
b) Waktu yang diperlukan untuk melakukan analisis data akan menjadi jauh lebih singkat daripada memakai data primer menjadi sangat kecil
c) Akhirnya, hasil analisis data kategorik dapat dilakukan atau dipertanggungjawabkan atas dasar pemikiran sebagai berikut
1. Pada dasarnya, analisis statistik dilakukan dengan tujuan untuk mempelajari perbedaan atau kesamaan kelompok-kelompok individu yang dibentuk berdasarkan kategori sebuah variabel atau lebih, antara lain perbedaan proporsi (persentase), prevalensi atau insiden suatu peristiwa tertentu antara kelompok individu yang ditinjau.
2. mempelajari asosiasi ganda antar variabel kategorik dengan menerapkan model log linier, atau model regresi logistik yang meliputi penerapan statistik Rasio Kesamaan atau Rasio Kecenderungan (RK) 3. Model asosiasi (korelasi) antara variabel kategorik, seperti model
regresi logistik t dinyatakan telah mempunyai pola yang standard atau baku. Sehingga lebih mudah dapat dipahami dan diulang kembali dengan memakai berbagai macam data kategorik sesuai dengan bidangnya masing-masing.
4. di pihak lain, kesimpulan yang diperoleh berdasarkan model asosiasi (empiris) antara variabel numerik kerap kali tidak dapat dipertanggungjawabkan, karena data yang dipakai pada umumnya bukanlah data yang sesuai.
Data sering terdiri dari sejumlah objek yang terhitung dengan atribut tertentu yang dimiliki oleh kategori-kategori tertentu yang disusun dalam tabel satu dimensi, dua dimensi, tiga dimensi atau bahkan dalam tabel berdimensi lebih tinggi lagi, biasanya disebut tabel kontingensi satu arah, dua arah dan tiga arah. Masing-masing dimensi atau arah berhubungan dengan sebuah klasifikasi dalam kategori-kategori yang menyajikan satu atribut.
Tabel satu arah, pengkategoriannya mungkin tidak relevan untuk setiap analisis statistik. Seseorang dapat memisalkan pernyataan yang dibuat-buat bahwa datanya merupakan sampel acak dan memperoleh sebuah perkiraan dari median atau rata-rata tetapi hasilnya tidak informatif atau sah karena datanya tidak dipilih secara acak, disini kurang pengacakan juga dapat menimbulkan pertanyaan bagaimana (dalam arti statistik) setiap kesimpulan populasi yang diterapkan. Pengujian ini sebenarnya bukan non parametrik jika pengujiannya mengenai sebuah parameter p yang merinci frekuensi terjadinya setiap angka. Ini adalah sebuah uji kecocokan dan goodness of fit test.
Tabel dua arah, sama formatnya tetapi berbeda dalam status logikanya. Datanya terdiri dari dua sampel bebas. Namun demikian dalam dua kasus tersebut masih digambarkan bahwa pembedaannya dapat diabaikan untuk ukuran sampel yang cukup yang besar, dan dapat digunakan uji untuk sampel besar yang sama tanpa memandang apakah pemilihannya menetapkan hanya jumlah keseluruhan yang akan diambil sampelnya dan kemudian mencatat jumlah masing-masing kelas. Pada suatu keadaan, kita hanya menetapkan total keseluruhannya pada keadaan lain kita menetapkan tabel keseluruhan dan total baris. Hal ini juga mungkin untuk menetapkan total keseluruhan dan total kolom, dan sama dengan pertukaran baris dan kolom. Pendekatan uji sampel besar untuk kebebasan antara klasifikasi baris dan kolom adalah sama pada seluruh
keadaan tersebut, dan merupakan uji terpenting yang tergantung pada total baris dan kolom pengamatan. Uji sampel besar yang cocok digunakan adalah uji Q Cochran
Tabel multiarah, bila tabel dua arah dengan mudah disajikan pada kertas, tabel tiga arah atau lebih paling baik disajikan dengan subtabel-subtabel dan lebih dari satu penyajian selalu mungkin. Setelah data tersebut diberikan dalam tabel lebih baik untuk analisis selanjutnya dengan memasukkan tabel marginal yang ditunjukkan. Pembaca dapat menyusun data ini dengan susunan logika yang berbeda meskipun pengujian untuk kebebasan dapat diperluas dari tabel dua arah sampai multi arah, dan uji berpasangan mengenai kebebasan dapat digunakan, sehingga analisisnya biasanya tidak cukup( tidak efisien) dan kita sering tertarik dalam menguji dengan lebih mengembangkan hipotesis-hipotesis, atau bahkan serangkaian hipotesis.
Banyak eksperimen secara simultan mempelajari lebih dari dua independen variabel atau lebih dari dua faktor. Misalnya eksperimen bias melibatkan dua kategori atau dua tingkatan dari satu faktor, tiga kategori dari faktor yang kedua, 5 kategori atau lima tingkat dari faktor yang ketiga, dengan sejumlah n subjek yang ditarik secara acak dari masing-masing 2x3x5 kelompok eksperimen tersebut. Ekperimen seperti itu dikenal dengan nama ‘2x3x5 faktorial eksperimen’. Data yang diperoleh dari eksperimen seperti itu dapat dikonseptualisasikan sebagai kubus bertiga dimensi, yang terdiri dari 2 baris, 3 kolom dan 5 lapis, dengan masing-masing n subjek dari 30 sel yang berbeda dalam eksperimen tersebut.
Analisis dan interpretasi dari data yang dihasilkan dari eksperimen seperti itu adalah merupakan perluasan langsung dari analisis dan interpretasi dari klasifikasi dua arah. Dalam suatu eksperimen dua-faktor dengan n subjek dalam setiap sel, jumlah kuadrat total terbagi dalam empat bagian, yaitu: jumlah kuadrat antar baris, jumlah kuadrat antar kolom, jumlah kuadrat interaksi dan jumlah kuadrat sel dalam. Setiap jumlah kuadrat mempunyai sebuah angka yang menjadi angka derajat kebebasan. Jumlah kuadrat dibagi dengan angka derajat kebebasan untuk memperoleh taksiran variansi
atau rata-rata kuadrat yang digunakan untuk menguji signifikansi pengaruh utama dan interaksi.
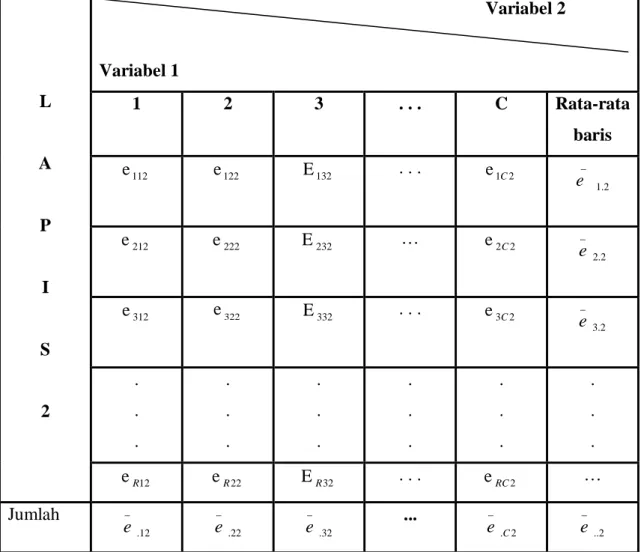
Umpamakan sejumlah eksperimen yang melibatkan sejumlah R tingkatan dari faktor pertama, sejumlah C tingkatan dari faktor kedua, dan sejumlah L tingkatan dari faktor ketiga. Jumlah sel menjadi sebanyak RxCxL yang disingkat menjadi RCL. Misalkan khusus dalam kasus ini kita mempunyai satu alat pengukuran untuk setiap kombinasi RCL, jumlah total hasil pengukuran menjadi N. data untuk lapis pertama dari angka-angka hasil pengukuran itu dapat dituliskan sebagai berikut:
Tabel 2.1 Tabel Data Untuk Lapis Pertama L A P I S 1 Variabel 2 Variabel 1 1 2 3 . . . C Rata-rata baris e111 e121 E131 . . . e1C1 _ e 1.1 e211 e221 E231 . . . e2C1 _ e 2.1 e311 e321 E331 . . . e3C1 _ e 3.1 . . . . . . . . . . . . . . . . . . eR11 eR21 ER31 . . . eRC1 … Jumlah _ e .11 _ e.21 _ e.31 . . . _ e.C1 _ e..1
Dalam subskrip di atas diidentifikasikan, yang pertama sebagai baris, yang kedua sebagai kolom dan yang ketiga sebagai lapis. Dengan demikian, misalnya e321
menunjukkan observasi pada baris ketiga kolom kedua dari lapis pertama.
_
e .11 adalah
rata-rata dari kolom pertama dari lapis petama, sedang
_
e ..1rata-rata dari semua observasi yang ada pada lapis pertama.
Adapun notasi pada lapis kedua adalah sebagai berikut: Tabel 2.2 Tabel Data Untuk Lapis Kedua
L A P I S 2 Variabel 2 Variabel 1 1 2 3 . . . C Rata-rata baris e112 e122 E132 . . . e1C2 _ e 1.2 e212 e222 E232 … e2C2 _ e 2.2 e312 e322 E332 . . . e3C2 _ e 3.2 . . . . . . . . . . . . . . . . . . eR12 eR22 ER32 . . . eRC2 … Jumlah _ e .12 _ e.22 _ e.32 ... _ e .C2 _ e..2 Keterangan: C= Column (kolom) R=Row (baris) L= Layer (lapis)
Demikian juga halnya dapat ditunjukkan lapis yang ketiga, keempat sampai lapis yang ke-L. secara umum erc1 menunjukkan yang menunjukkan hasil pengukuran baris yang ke-r, pada kolom yang ke-c dan pada baris yang ke-1.harus dipahami bahwa R menunjukkan angka dari baris, C merupakan angka dari kolom dan L merupakan angka dari lapis. Jumlah r menunjukkan baris yang ke-r, dimana r bias saja berupa angka 1, 2,…R. demikian juga dengan c dan 1 menunjukkan kolom yang ke c dan lapis yang ke-1.
Rata-rata dari semua RCL= N adalah ... _
Χ jumlah kuadrat simpangan total dari rata-rata umum tadi dapat dituliskan:
2 1 1 1 ...) (Xrcl X L l C c R r −
∑
∑
∑
= = =2.2 Analisis Berdasarkan Tabel IxJxK
Berdasarkan data trivariat (V1, V2,V3) dengan berbagai skala ukuran, selalu dapat dibentuk tabel berdimensi tiga, termasuk tabel 2x2x2. Dengan sendirinya langkah pertama yang harus dilakukan adalah mentransformasikan atau mengubah ketiga variabel yang ditinjau menjadi variabel kategorik, berdasarkan kriteria yang disepakati atau ditentukan.
Disini akan diperhatikan tiga variabel satu-nol, dimana simbol Y dipakai untuk menyatakan variabel tak bebas atau variabel respon dan kedua variabel lainnya sebagai variabel bebas yang akan dinyatakan dengan simbol X1 dan X2. Penentuan
variabel tak bebas dan variabel bebas diantara komponen trivariat (V1,V2,V3) haruslah didukung oleh landasan teori dan substansi, karena pola asosiasi antar variabel ditentukan secara teoritis. Dipihak lain, secara statistik koefisien asosiasi atau korelasi antara variabel selalu dapat dihitung walaupun variabel tersebut tidak berasosiasi secara substansi. Sehingga, analisis statistika berdasarkan data trivariat mempunyai tujuan antara lain untuk menentukan model kuantitatif atau model
statistik yang sesuai dengan pola hubungan teoritis antar ketiga variabel yang ditinjau, yang akan disebut model teoritis.
2.3 Ukuran Asosiasi Berdasarkan Tabel 2x2x2 2.3.1 Selisih Prevalensi atau Proporsi Bersyarat
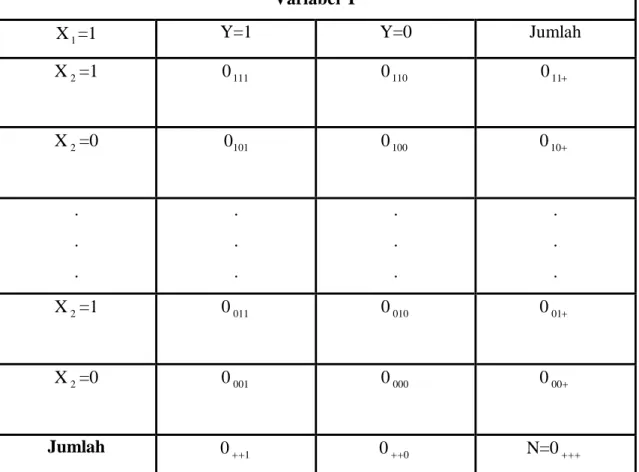
Tabel berikut menunjukkan suatu bentuk tabel 2x2x2. tabel ini menyajikan banyaknya observasi menurut variabel X1,X2 dan Y yang masing-masing merupakan variabel satu- nol. Perhatikanlah tabel ini mempunyai empat buah baris dan dua buah kolom dan banyaknya observasi dalam tiap-tiap sel dinyatakan dengan simbol Oijk untuk setiap i, j dan k sama dengan satu atau nol
Tabel 2.3 Banyaknya Responden Menurut Variabel X1, X2 dan X3
Variabel Y
X1=1 Y=1 Y=0 Jumlah
X2=1 0111 0110 011+ X2=0 0101 0100 010+ . . . . . . . . . . . . X2=1 0011 0010 001+ X2=0 0001 0000 000+ Jumlah 0++1 0++0 N=0+++
Sebenarnya tabel ini menggambarkan ruang bedimensi –tiga (kubus) dengan sumbu X1, X2 dan Y, yang dibagi menjadi 8 (2x2x2) buah kubus kecil yang membentuk delapan buah sel yang dikemukakan di atas.
2.4 Model Log Linier
Dalam kategorik bivariat dimana diperoleh nilai statistik Chi-kuadrat dari pearson (Pearson Chi-Kuadrat) dan Rasio Kesamaan. Akan tetapi untuk mempelajari pola asosiasi ganda berdasarkan data trivariat atau lebih harus diterapkan Model Log Linier, terlebih-lebih jika model yang ditinjau secara teoritis menunjukkan hubungan antara demikian banyaknya variabel. Model statistik Model Log Linier akan dipakai untuk mempelajari apakah data sampel yang akan dipakai mendukung atau tidak mendukung model asosiasi ganda yang dihipotesiskan dinyatakan atau diasumsikan berlaku untuk ketiga variabel yang ditinjau.
Analisis yang lebih terinci mengenai tabel kontingensi tiga dimensi atau yang biasanya menggunakan pengujian pasangan yang tidak sederhana dari kebebasan yang dapat dilakukan pada bagian-bagian dari tabel-tabel dua arah. Sejumlah besar dari model-model yang berbeda adalah mungkin dan teknik analitik yang modern sering didasarkan pada model log-linier. Dalam sebuah buku dasar-dasar statistik, hal ini cocok hanya untuk memberikan pengenalan singkat untuk model dan pengujian, dan dijelaskan dengan satu contoh sederhana. Teknik-teknik analitik adalah data diskrit yang analog dengan analisis varians untuk data kontinu. Pembaca yang belum kenal dengan analisis varians model linier untuk rancangan percobaan dengan struktur percobaan faktorial mungkin sulit untuk mengikuti bagian ini, tetapi diharapkan sebuah penjelasan yang mendasar akan memberikan beberapa indikasi tentang kekuatan model linier sebagai sebuah alat analitik. Penerapan yang lebih sulit dari metode ini membutuhkan pengetahuan yang luas mengenai statistik dan tersedianya program komputer yang cocok.
Misalkan {mijk} merupakan frekuensi harapan, dugalah semua mijk>0 dan misalkan
ijk ijk =logm
η . Tanda dot dibawah merupakan rata-rata, seperti: η.jk =(
∑
iηijk)/I... η µ = ... .. η η λ = i − x i , λ =η.j. −η... Y j , λ =η..k −η... Z k ... . . .. . η η η η λXY = ij − i − j + ij ... .. .. . η η η η λXZ = ik − i − k + ik ... .. . . . η η η η λ = jk − j − k + YZ jk ... .. . . .. . . . η η η η η η η η λ = ijk − ij − ik − jk + i + j + k − XYZ ijk
Jumlah semua parameter di atas sama dengan nol, yaitu:
∑
=∑
=∑
=∑
=∑
= =∑
= i j k i j k XYZ ijk XY ij XY ij Z k Y j x i λ λ λ λ ... λ 0 λSehingga bentuk umum model log linier untuk tabel kontingensi tiga dimensi, adalah:
XYZ ijk YZ jk XZ ik XY ij Z k Y j X i ijk m =µ +λ +λ +λ +λ +λ +λ +λ log
Dalam hal pengujian ini juga sama dengan analisis variansi tiga dimensi. Beberapa model log linier untuk tabel tiga dimensi:
Model log-linier simbol
Z k Y j X i ijk m =µ +λ +λ +λ log (X,Y,Z) XY ij Z k Y j X i ijk m =µ +λ +λ +λ +λ log (XY,Z) YZ jk XY ij Z k Y j X i ijk m =µ +λ +λ +λ +λ +λ log (XY,YZ) XZ ik YZ jk XY ij Z k Y j X i ijk m =µ +λ +λ +λ +λ +λ +λ log (XY,YZ,XZ) XYZ ijk XZ ik YZ jk XY ij Z k Y j X i ijk m =µ +λ +λ +λ +λ +λ +λ +λ log (XYZ)
Untuk menunjukkan model log-linier kita cari bentuk marginal dan partialnya dengan menggunakan odds ratios. X-Y tabel marginal {πij+} dengan (I-1)(J-1) odds ratios, bentuknya: + + + + + + + + = , , , , 1 . 1 , 1 i j i j i j i ij XY ij π π π π θ , 1≤i≤I −1,1≤ j ≤J −1
Dengan k dalam Z, hubungan odds ratiosnya:
k j i k j i k j i ijk k ij , , 1 , 1 , , 1 , 1 ) ( + + + + = π π π π θ , 1≤i≤ I−1,1≤ j≤J −1
Menunjukkan hubungan X-Y. Sama halnya antara X dan Y didapatkan dari (I-1)(K-1) Odds ratios {θi(j)k}untuk setiap J pada Y, dan hubungan antara Y dan Z didapatkan dari (J-1)(K-1) odds ratios {θ(i)jk} untuk setiap I pada X.
Untuk tabel tiga dimensi logmijkdalam log odds ratios, didapat:
= = = 11 ) 2 ( 11 ) 1 ( 1 ) 2 ( 1 1 ) 1 ( 1 ) 2 ( 11 ) 1 ( 11 111 log 8 1 log 8 1 ) log( 8 1 θ θ θ θ θ θ λXYZ
Dengan jumlah nol batasannya {λijkXYZ}. Masing-masing {λijkXYZ} adalah nol ketika odds ratios antara dua variabel sama dengan tiga variabel. Bentuk umumnya
} 0
{λijkXYZ = dalam tabel 2x 2x K, ketika θ11(1) =...=θ11(k), sehingga:
) ( 11 11 log 4 1 k XY θ λ = untuk k=1…K
Seperti dalam kasus dua dimensi parameternya sebanding pada log odds ratios. Model Log linier dapat dikenal dengan menggunakan hubungan odds ratios. Dalam hal hubungan independent antara X dan Y equivalent terhadap
} ,..., 1 , 1 ,..., 1 , 1 ,..., 1 1 {θij(k) = i= I− j= J − k = K
Kenudian kita berikan satu keadaan yang cukup terhadap X-Y odds ratios menjadi sama dalam tabel parsial seperti pada tabel marginal. Ketika keadaan sama kita dapat mempelajari gabungan X-Y dengan cara menyederhanakan menyelesaikan dimensi Z. selanjutnya, Z akan menjadi variabel tunggal atau multidimensi.
) ( ) 2 ( ) 1 ( ij .. ijk ij XY ij θ θ θ θ = = = = , 11≤i≤I −1,1≤ j≤J −1 , 1 ) (jk = i θ 1≤i≤ I−1,1≤ j≤J −1,1≤k ≤K−1 , 1 ) (i jk = θ 1≤i≤ I−1,1≤ j≤J −1,1≤k ≤K−1
Dengan kata lain, gabungan marginal da parsial X-Y disamakan jika Z dan X bebas (i.e, disimbolkan dengan (XY,YZ)terikat), atau jika Z danY bebas (i.e, bentuknya (XY,XZ)terikat)
2.4.1 Penerapan Model Log Linier Data Trivariat
Dalam sebuah tabel kontingensi dua dimensi, nilai harapan e untuk sel ij dengan ij
hipotesis kebebasan atau tidak ada asosiasi adalah eij= N
n ni )( j)
( + +
ini selanjutnya
mengikuti e11e22 =(n1+n+1n2+n+2)/N2 =e12e21 yaitu bahwa produk silang atau diagonal adalah sama, atau
1 21 12 22 11 = e e e e
Sifat perkalian dan harapan untuk kebebasan ini dapat dibandingkan dengan sifat harapan aditif bila tidak ada interaksi dalam model liniernya. Sebenarnya ada kesamaan model-model jika kita mengambil logaritma eij dan menulis x lneij
~
= ini merupakan dasar model log linier karena persamaan
1 21 12 22 11 = e e e e
adalah sebuah kondisi yang diperlukan untuk kebebasan, maka selanjutnya
setiap hipotesis yang menyebutkan ketergantungan menyatakan sebuah hubungan yang lebih umum
1 21 12 22 11 = e e e e k 1≠
Dengan mengambil logaritmanya kita mempunyai analog model yang berinteraksi. Perluasan untuk tabel tiga dimensi, modelnya dapat diperluas untuk tabel r x c dan lebih penting untuk tabel multi arah. Pertama, kita membuat perluasan dari model linier untuk tiga faktor masing-masing dengan dua level dalam konteks analisis varians. Pengukuran interaksi telah diperkenalkan dalam model dua faktor yang disebut sebuah orde pertama atau kadang-kadang disebut sebuah interaksi dua faktor. Jika kita mempunyai tiga faktor masing-masing pada dua level, kita dapat menyajikan hasil yang diharapkan dalam sebuah perluasan yang jelas dari notasi xijk
~
i, j, k = 1,2 .
Jika kita mempertimbangkan dua faktor pertama pada level pertama dari faktor ketiga (ditunjukkan dengan k=1) kita akan mempunyai sebuah interaksi pertama antara
faktor 1 dan faktor 2 pada level tetap faktor 3 ini jika x111+x221−x121−x211 =Ι,Ι≠0 sebagai tambahan, jika kita mempunyai sebuah interaksi orde pertama antara faktor 1 dan faktor 2 pada level kedua dari faktor 3 ( k= 2 ), ini menyatakan
~ x112+ ~ x 222 -~ x122 -~
x 212= J, J=0. jika I≠ J kita katakana tidak ada interaksi orde kedua antara ketiga
faktor. Jika I≠ J kita katakan tidak ada sebuah interaksi orde kedua atau orde ketiga. Jika I= J= 0 mempunyai model tidak ada interaksi. Dalam konteks dari model log-linier dimana kita tulis
~
x ijk=lneijk dimana eijk adalah harapan untuk level ke-i klasifikasi 1, untuk level ke-j klasifikasi 2, untuk level ke-k klasifikasi 3, model dengan tidak ada interaksi berhubungan dengan kebebasan dan eijk menjadi:
1 ) ( ) ( ) ( ) ( 212 122 222 112 211 121 221 111 = = e e e e e e e e
Ketergantungan dapat menjadi orde pertama atau kedua (ditunjukkan untuk interaksi orde pertama atau kedua dalam model log-linier). Untuk interaksi model pertama:
k e e e e e e e e = = ) ( ( ) ( ) ( 212 122 222 112 211 121 221 111
Dimana k ≠1, dan untuk model interaksi orde kedua:
) ( ) ( ) ( ) ( 212 122 222 112 211 121 221 111 e e e e e e e e ≠
Model log-linier mengizinkan pengujian untuk menentukan apakah data dapat menjadi cocok digambarkan oleh beberapa model tertentu. Untuk contoh ilustrasi, kita mengikuti prosedur yang relevan untuk pengujian model interaksi orde pertama. Dalam kasus dalam sebuah tabel kontingensi tiga dimensi, penduga maksimum likelihood darieijk, yang akan dinotasikan dengan
^
e ijk harus memenuhi kondisi:
(ẽ111ẽ221)/(ẽ121ẽ211)= (ẽ112ẽ222)/(ẽ122ẽ212)
Dengan batasan bahwa
^
e ijk harus juga jumlah untuk total marginal yang diamati setiap akhiran. Pada umumnya, penduga maksimum likelihood hanya dapat diperoleh dengan metode yang berulang-ulang( salah satunya dikenal dengan iterative scaling procedure); akan tetapi dalam kasus khusus dari tabel tiga dimensi dengan model interaksi orde pertama, perhitungan pertama adalah langsung. Sekali
^
e ijk telah dihitung, statistik T atau T1untuk tabel tiga dimensi digunakan untuk pengujian nyata. T1sering lebih disukai karena dari sifat aditif tertentu yang memungkinkan terbagi kedalam komponen-komponen, analog dengan cara yang dilakukan untuk jumlah kuadrat orthogonal dalam analisis varians.
Suatu penelitian yang meneliti tiga faktor ( X, Y dan Z ) yang masing-masing dicobakan dalam berbagai tingkatan. Faktor X dalam x tingkatan, faktor Y dalam y
tingkatan dan faktor Z dalam z tingkatan. Percobaan tersebut merupakan percobaan faktorial xxyxz. Dengan demikian banyak perlakuan yang dicobakan adalah t=xyz. Andaikan bahwa tiap perlakuan diulang dengan ulangan yang sama sebanyak n (ukuran contohnya n). tentu saja pada percobaan demikian, data yang diperoleh akan beragam yang dapat dikaitkan dengan tingkat masing-masing faktornya. Dengan demikian dapat dituliskan:
ijkl ijk jk ik ij k j i ijkl X =µ +α +β +Γ +(αβ) +(αΓ) +(βΓ) +(αβΓ) +ε Dengan: = ijkl
X pengamatan ke 1 (1=1,2,…,n) untuk faktor X yang ke i (i=1,2,…,n), faktor Y yang ke j (j=1,2,…,b), dan faktor z yang ke k (k=1,2,…,c)
=
µ rata-rata =
i
α pengaruh faktor X yang ke i
=
j
β pengaruh faktor Y yang ke j =
Γk pengaruh faktor Z yang ke k
=
ij
)
(αβ interaksi faktor X yang ke i dengan faktor Y yang ke j =
Γ)ik
(α interaksi faktor X yang ke i dengan faktor Z yang ke k (βΓ)jk = interaksi faktor Y yang ke j dengan faktor Z yang ke k
(αβΓ)ijk = interaksi faktor X yang ke i, faktor Y yang ke j dengan faktor Z yang ke k
=
ijkl
ε sesatan pengamatan yang bersangkutan
Penduga masing-masing komponen dalam model di atas diduga dengan cara yang sama seperti yang sudah biasa dilakukan. Penduga yang didapat adalah:
^ µ = ...X− ^ i α = .. _ _ ... X Xi − j ^ β = ... _ . . _ X X j − k _ Γ = .... _ ... _ X X −
( )ij = ^ αβ ... _ . . _ .. _ . _ X X X Xij − i − j− ( )ik ^ Γ α = __ ... . . _ .. _ . _ X X X Xik− i − k − ( Γ jk = ^ ) β ... _ . . _ . . _ . _ X X X X jk− j− k− ( ^ )ijk Γ αβ = ... _ . . _ . . _ .. _ . _ . . _ . _ _ X X X X X X X Xijk− ij − ik − jk+ i − j − k − = ^ jkl ε ... _ _ X Xijkl−
Berbagai penduga ini dengan mudah dapat kita peroleh apabila kita lihat pola untuk mendapatkannya. Penduga pengaruh suatu tingkat suatu faktor merupakan selisih antara rerata tingkat faktor tersebut dengan rata-rata keseluruhan data. Perhatikan notasinya yang ternyata berupa satu indeks saja yang lainnya titik ( i atau j atau k saja, yang lainnya berupa titik) dan pengurangnya mempunyai indeks yang berupa titik semua. Pada interaksi dua faktor, penduganya didapat dengan jalan mengurangi rata-rata gabungan tingkat kedua faktornya dengan rata-rata-rata-rata tingkat masing-masing faktor dan kemudian ditambah dengan rata-rata keseluruhan data. Menyimak indeksnya, penduga interaksi dua faktor ini didapat dengan jalan mengurangi rata-rata yang berindeks dua ( i dan j, i dan k, atau j dan k sedangkan lainnya berupa titik) dengan rata-rata yang berindeks satu yang persis dengan indeks duanya dan kemudian ditambah rata-rata keseluruhan data yang semua indeksnya berupa titik.
Seperti halnya dengan analisis varian yang terdahulu, berbagai jumlah kuadrat didapat tidak dengan menggunakan berbagai penduga diatas tetapi dalam bentuk yang telah disederhanakan terlebih dahulu. Untuk jumlah kuadrat X
JKX = 2 _ .. _ ...) (Xi −X Σ = yzn 2 ... ... 2 _ .. _ _ 2 .. _ X xyzn X X yzn Xi − Σ i + Σ = yzn .... 2 _ 2 .. _ X xyzn Xi − Σ
Karena ... _ .. _ X x Xi = Σ sehingga JKX = FK yzr Xi − Σ 2.. dengan FK = xyzn X ...2
perhatikan bahwa JKX didapat dengan menjumlahkan kuadrat jumlah masing-masing tingkat faktor X (dijumlah terhadap i) yang dibagi dengan sesuatu yang besarnya sama dengan batas indeks yang berubah menjadi titik. Dalam hal ini indeks yang berubah menjadi titik adalah j, k, dan l yang mempunyai batas nilai y, z dan n. perhatikan bahwa rumus untuk jumlah kuadrat ini bertalian dengan rumus untuk penduganya. Penduga untuk pengaruh X yang ke i adalah rata-rata dengan indeks i ( yang lainnya berupa titik) dikurangi dengan rata-rata dengan semua indeksnya berupa titik rumus JKX juga mempunyai indeks i yang dikurangi dengan sesuatu yang tanpa indeks, yaitu FK. Maka dengan mudah diperoleh JKY dan JKZ, sebagai berikut:
JKY = FK yzr X j − Σ 2 . . JKZ = FK yzr X k − Σ ..2.
Sekarang akan kita lihat bagaimana penyederhanaan jumlah kuadrat interaksi dua faktor. Kita akan simak terlebih untuk interaksi antara X dan Y:
JKXY = 2 _ . . _ .. _ .. ...) (Xij −Xi −X j+ X ΣΣ −
Yang apabila disederhanakan akan diperoleh:
JKXY = ... . 2 _ 2 . . 2 .. 2 . X xy xzn X yzn X zn X j j i i ij −Σ −Σ + ΣΣ
Dalam kaitannya dengan rumus untuk penduganya, lihat keterkaitan antara rumus penduga dan jumlah kuadrat suatu komponen. Rumus penduga komponen interaksi XY didapat dengan mengurangi rata-rata berindeks dua ( yaitu i dan j untuk X dan Y) dengan rata-rata berindeks satu untuk X dan berideks satu untuk Y, dan akhirnya ditambah dengan rata-rata yang semua indeksnya berupa titik ( tidak berindeks). Penyederhanaan lebih lanjut akan menghasilkan:
JKXY = FK JKX JKY zn Xij − − − ΣΣ 2 ..
Perhatikan bahwa jumlah kuadrat interaksi X dan Y didapat dengan menjumlahkan semua jumlah pada kombinasi X dan Y yang dibagi dengan sesuatu yang merupakan nilai batas indeks yang berupa titik dalam hal ini indeks yang berupa titik adalah untuk k dan l yang mempunyai batas z dan n sehingga sebagai pembagi adalah zn, dikurangi dengan faktor koreksi dan dikurangi lagi dengan jumlah kuadrat faktor-faktor yang menyusun interaksinya.
Jumlah kuadrat interaksi tiga faktornya didapat dari:
JKXYZ = 2 _ .. _ . . _ .. _ . _ . _ . _ _ ...) X X X X X X X Xijk− ij− ik− jk+ i + j+ k− ΣΣΣ
Yang apabila disederhanakan akan menghasilkan:
JKXYZ = 2 _ 2 .. 2 .. 2 .. 2 . 2 . 2 . 2 X xyzn xyn X xzn X yzn X xn X yn X zn X n X k k j j i i jk k j k i k i ij j i ijk − Σ + Σ + Σ + Σ Σ − Σ Σ − Σ Σ − ΣΣΣ
JKXYZ = JKX JKY JKZ JKXY JKXZ JKYZ
n Xijk − − − − − − ΣΣΣ 2
Derajat bebas berbagai jumlah kuadrat diatas dapat dengan mudah diperoleh dengan memperhatikan beberapa kali pengkuadratan yang kita jumlahkan dan kurangkan. Untuk faktor X, kita mengkuadrat a kali yang dijumlahkan dan mengkuadratkan
sekali untuk memperoleh faktor koreksi yang kemudian kita gunakan untuk mengurangi. Dengan demikian derajat bebas X adalah ( x-1). Analogi dengan X adalah untuk Y dan Z.
Untuk interaksi dua faktor, XY misalnya kita mengkuadratkan sebanyak xy kali yang kemudian kita jumlahkan, kemudian dikurangi dengan FK (yang diperoleh dengan sekali mengkuadratkan) dan dikurangi lagi dengan JKX dan JKB yang mempunyai derajat bebas (x-1) dan (y-1). Dengan demikian derajat bebas XY adalah:
xy-1-(x-1)-(y-1)=(x-1)(y-1)
dengan cara yang sama kita dapatkan bahwa interaksi XZ mempunyai derajat bebas (x-1)(z-1) dan interaksi YZ mempunyai derajat bebas (y-1)(z-1). Derajat bebas interaksi tiga faktor XY pun diperoleh dengan cara yang sama. Suku pertama pada rumus jumlah kuadrat XYZ menunjukkan bahwa kita harus mengkuadratkan xyz kali, sedangkan derajat bebas suku-suku pengurangannya telah kita ketahui. Dengan demikian derajat bebas untuk interaksi XYZ adalah:
xyz-1-(x-1)(y-1)-(x-1)(z-1)-(y-1)(z-1)-(x-1)-(y-1)-(z-1) yang telah disederhanakan akan berubah menjadi (x-1)(y-1)(z-1)