Intisari
Jumlah berita
online
semakin hari semakin meningkat. Hal ini akan menyulitkan
editor
berita
dalam mengkategorikan dokumen berita secara manual. Oleh karena itu, dibutuhkan proses
pengkategorian berita secara otomatis menggunakan klasifikasi. Klasifikasi adalah salah satu bagian
dari
data mining
yang digunakan untuk menentukan kelas dari suatu objek yang belum diketahui
kelasnya. Salah satu metode klasifikasi adalah K-Nearest Neighbor (K-NN), yaitu metode untuk
menghitung jarak terdekat dari dua buah objek kemudian mengelompokan objek yang berdekatan ke
dalam satu kelas. Pada penelitian ini, dilakukan perbandingan metode untuk menghitung jarak
dokumen terdekat yaitu Cosine Similarity dan
ℓ
2𝑑
istance
pada klasifikasi menggunakan metode
K-NN.
Dari dari penelitian yang telah dilakukan, metode
Cosine Similarity
memberikan hasil yang
lebih baik daripada metode
ℓ
2𝑑
istance
. Nilai
precision
terbesar untuk metode
Cosine Similarity
adalah 0.97 dan nilai
recall
sebesar 0.97. Sementara itu, untuk metode
ℓ
2𝑑
istance
, nilai
precision
yang didapatkan yaitu 0.81 dan nilai
recall
sebesar 0.41.
Abstract
The number of online news is increasing day by day. It is not easy for the news editor to
categorize the news article manually. Therefore, an automatic news category classifier is needed.
Classification is a part of data mining that is used to determine the class of unclassified object. One
of the classification methods is K-Nearest Neighbor (K-NN), which is a method to calculate the
distance between two objects and put the objects whose closest distance into one class. In this
research, two distance calculation methods, Cosine Similarity and
ℓ
2d
istance are compared in
classification using K-NN.
My experimental results show that Cosine similarity outperforms the
ℓ
2d
istance. With the
precision and recall for Cosine Similarity are 0.97 and 0.97 respectively. For the
ℓ
2d
istance, it reaches
0.81 and 0.41 respectively.
Klasifikasi Berita Menggunakan Metode
K-Nearest Neighbor (K-NN)
(
News Classification using K-Nearest Neighbor
(K-NN))
Baiq Pratiwi Komalasari
[1], Budi Irmawati
[1], Ario Yudo Husodo
[1][1]Program Studi Teknik Informatika, Fakultas Teknik, Universitas Mataram
Jl. Majapahit 62, Mataram, Lombok NTB, INDONESIA
Email: baiqpratiwikomalasari@gmail.com, yzakodek@gmail.com, ario@unram.ac.id
Abstract The number of online news is increasing day by day. It is not easy for the news editor to categorize the news article manually. Therefore, an automatic news category classifier is needed. Classification is a part of data mining that is used to determine the class of unclassified object. One of the classification methods is K-Nearest Neighbor (K-NN), which is a method to calculate the distance between two objects and put the objects whose closest distance into one class. In this research, two distance calculation methods, Cosine Similarity and 𝓵𝟐𝐝istance are compared in classification using K-NN.
My experimental results show that Cosine similarity outperforms the 𝓵𝟐𝐝istance. With the precision and recall for Cosine Similarity are 0.97 and 0.97 respectively. For the
𝓵𝟐𝐝istance, it reaches 0.81 and 0.41 respectively.
Key words:Document classification, k-NN, VSM, Cosine Similarity, 𝓵𝟐𝒅istance.
I.PENDAHULUAN
Secara umum, berita dapat dikelompokkan menjadi beberapa kategori seperti berita nasional, internasional, ekonomi, teknologi, kesehatan, dan lain-lain. Sejauh ini pengelompokan berita masih menggunakan tenaga manusia atau manual. Sebelum artikel berita di-publish, editor harus mengetahui isi berita secara keseluruhan untuk selanjutnya dikelompokkan. Jika jumlah artikel berita yang akan di-publish semakin banyak, hal ini akan menghabiskan banyak waktu, terlebih jika dokumen tersebut memiliki kategori yang beragam. Permasalahan lain yaitu ketika dokumen yang dikelompokkan memiliki kemiripan isi, misalnya: untuk kategori teknologi bisa juga memiliki hubungan dengan kategori ilmu pengetahuan dan juga kategori kesehatan. Hal ini dibutuhkan ketelitian dan waktu yang tidak sebentar bagi editor untuk dapat mengelompokkannya.
Oleh karena itu, dibutuhkan suatu proses untuk mengklasifikasikan berita secara otomatis sesuai dengan kategori berita yang ada. Salah satu cara yang digunakan yaitu dengan metode K-Nearest Neighbor (K-NN) sebagai metode klasifikasinya. Metode K-NN merupakan metode dalam klasifikasi berita yang menggunakan perhitungan jarak terdekat antara dokumen latih dan dokumen uji.
Sehingga pada penelitian ini digunakan perbandingan metode Cosine Similarity dengan metode ℓ2distance untuk mendapatkan hasil terbaik dalam melakukan perhitungan jarak dokumen.
II.TINJAUANPUSTAKA
Palinoan [1] melakukan penelitian tentang sistem klasifikasi dokumen bahasa Jawa dengan metode k-NN. Pada penelitian ini, input nilai k memiliki pengaruh penting dalam proses klasifikasi. Jika nilai k yang dipilih sangat kecil, maka kategori dokumen uji hanya bergantung pada beberapa dokumen latih sehingga belum mewakili karakteristik data secara general. Akibatnya pemilihan dokumen yang menjadi data latih akan sangat mempengaruhi hasil klasifikasi. Hasil penelitian ini memperoleh nilai akurasi tertinggi yaitu 95% dengan kesalahan klasifikasi 5% pada 3 fold dengan k=4.
Purwanti [2] melakukan penelitian tentang klasifikasi jurnal bahasa Inggris menggunakan metode k-NN. Ia menggunakan data latih sebanyak 160 dokumen dan data uji sebanyak 20 dokumen untuk 4 kategori yang dipilih. Pada penelitian ini, dilakukan tiga kali percobaan dengan nilai k= {37, 41, 43}. Tingkat keberhasilan yang cukup baik didapat dalam klasifikasi dokumen pada nilai k=43 dengan memperoleh nilai F-Measure sebesar 0.539, nilai precision sebesar 0.519, dan nilai recall sebesar 0.501.
dianggap tidak perlu pada tahap proses preprocessing untuk meningkatkan hasil klasifikasi dokumen.
Hamzah [4] melakukan penelitian tentang klasifikasi teks berita dan tulisan ilmiah dengan Naïve Bayes
Classifier (NCB). Ia menggunakan 1000 dokumen berita
dengan berbagai kategori sebagai dokumen uji dan dokumen latih. Untuk dokumen akademik, digunakan 450 dokumen. Ia memperoleh nilai akurasi 91% untuk klasifikasi artikel berita dan 82% untuk klasifikasi tulisan ilmiah.
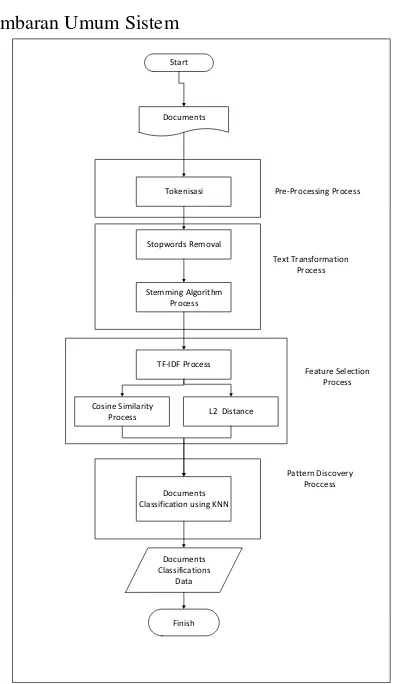
Gambar 1. Gambaran umum sistem.
Gambar 1 merupakan gambaran umum sistem pada saat klasifikasi menggunakan metode k-NN. Berikut tapahan pengerjaannya:
1. Proses input data
Data latih dan data uji yang dimasukkan untuk klasifikasi adalah berita bahasa Inggris dengan format txt. 2. Tokenisasi
Pada tahap ini terdapat proses pengubahan huruf pada teks dokumen menjadi huruh kecil (case folding), kemudian terdapat penghilangan karakter selain huruf
‘a’…’z’, kemudian yang terakhir adalah memecah kata
-kata dari string penyusunnya.
3. Stopwods removal
Menghilangkan kata-kata umum yang tidak mempengaruhi hasil klasifikasi.
4. Stemming
Proses mengubah kata bentukan menjadi kata dasarnya dengan menghilangkan akhiran (suffixes) dari kata aturannya.
5. TF-IDF
Proses ini memberikan bobot kata pada tiap dokumen latih berdasarkan dokumen uji sebagai masukan.
6. Cosine Similarity dan ℓ2distance
Cosine similarity dan ℓ2distance merupakan proses menghitung kedekatan antara dokumen uji dan dokumen latih berdasarkan perhitungan bobot kata pada TF-IDF. 7. k-NN
Proses klasifikasi penentuan kategori dokumen berdasarkan kelas terdekat pada dokumen latih berdasarkan nikai k yang sudah ditentukan.
B. Teknik Pengujian
Teknik pengujian yang digunakan untuk mengukur kualitas retrieval, yaitu dengan menggunakan perhitungan recall, precision, dan waktu pengujian sistem.
Berikut persamaan untuk menghitung nilai recall dan
precision, menggunakan Persamaan 1 dan persamaan 2.
𝑅𝑒𝑐𝑎𝑙𝑙 = |𝑅𝑎||𝑅| dimana:
|Ra |= Jumlah dokumen relevan yang ditemukembalikan. |R| = Jumlah dokumen relevan.
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = |𝑅𝑎| |𝐴| dimana:
|Ra| = Jumlah dokumen relevan yang ditemukembalikan. |A| = Jumlah hasil temu kembali.
IV. HASILDANPEMBAHASAN
Dalam penelitian ini data yang digunakan sebanyak 1000 dokumen yaitu 200 dokumen mewakili masing-masing kategori. Pengujian yang dilakukan pada penelitian ini menggunakan cross validation dengan nilai k fold=5.
Pengujian dilakukan sebanyak lima kali, yaitu: dengan masukan nilai k pada k-NN =1, 3, 5, 7, 9, 11, 13, 15, dan 17. Berikut hasil pengujian yang telah dilakukan:
1. Percobaan 1
Pengujian percobaan 1 dilakukan dengan nilai k=1 pada masukan nilai k-NN, sehingga didapatkan hasil pengujian yang ditunjukkan pada Tabel 1.
Tabel 1. Pengujian menggunakan nilai k=1
Berikut hasil waktu komputasi menggunakan metode Cosine Similarity dan ℓ2distance yang ditunjukkan pada Tabel 2.
Tabel 2.Waktu perhitungan menggunakan nilai k=1.
2. Percobaan 2
Pengujian percobaan 2 dilakukan dengan nilai k=3 pada masukan nilai k-NN, sehingga didapatkan hasil pengujian yang ditunjukkan pada Tabel 3.
Tabel 3. Pengujian menggunakan nilai k=3.
Berikut hasil waktu komputasi menggunakan metode Cosine Similarity dan ℓ2distance yang ditunjukkan pada Tabel 4.
Tabel 4. Waktu perhitungan menggunakan nilai k=3.
3. Percobaan 3
Pengujian percobaan 3 dilakukan dengan nilai k=5 pada masukan nilai k-NN, sehingga didapatkan hasil pengujian yang ditunjukkan pada Tabel 5.
Tabel 5. Pengujian menggunakan nilai k=5.
Berikut hasil waktu komputasi menggunakan metode Cosine Similarity dan ℓ2distance yang ditunjukkan pada Tabel 6.
Tabel 6. Waktu perhitungan menggunakan nilai k=5.
4. Percobaan 4
Pengujian percobaan 4 dilakukan dengan nilai k=7 pada masukan nilai k-NN, sehingga didapatkan hasil pengujian yang ditunjukkan pada Tabel 7.
Tabel 7. Pengujian menggunakan nilai k=7.
Tabel 8. Waktu pengujian menggunakan nilai k=7.
5. Percobaan 5
Pengujian percobaan 5 dilakukan dengan nilai k=9 pada masukan nilai k-NN, sehingga didapatkan hasil pengujian yang ditunjukkan pada Tabel 9.
Tabel 9. Perhitungan menggunakan nilai k=9.
Berikut hasil waktu komputasi menggunakan metode Cosine Similarity dan ℓ2distance yang ditunjukkan pada Tabel 10.
Tabel 10. Waktu perhitungan menggunakan nilai k=9.
6. Percobaan 6
Pengujian percobaan 5 dilakukan dengan nilai k=11 pada masukan nilai k-NN, sehingga didapatkan hasil pengujian yang ditunjukkan pada Tabel 11.
Tabel 11. Perhitungan menggunakan nilai k=11.
Berikut hasil waktu komputasi menggunakan metode Cosine Similarity dan ℓ2distance yang ditunjukkan pada Tabel 12.
Tabel 12. Waktu perhitungan menggunakan nilai k=11.
7. Percobaan 7
Pengujian percobaan 5 dilakukan dengan nilai k=13 pada masukan nilai k-NN, sehingga didapatkan hasil pengujian yang ditunjukkan pada Tabel 13.
Tabel 13. Perhitungan menggunakan nilai k=13.
Berikut hasil waktu komputasi menggunakan metode Cosine Similarity dan ℓ2distance yang ditunjukkan pada Tabel 13.
Tabel 13. Waktu perhitungan menggunakan nilai k=13.
8. Percobaan 8
Tabel 14. Perhitungan menggunakan nilai k=15.
Berikut hasil waktu komputasi menggunakan metode Cosine Similarity dan ℓ2distance yang ditunjukkan pada Tabel 15.
Tabel 15. Waktu perhitungan menggunakan nilai k=15.
9. Percobaan 9
Pengujian percobaan 5 dilakukan dengan nilai k=17 pada masukan nilai k-NN, sehingga didapatkan hasil pengujian yang ditunjukkan pada Tabel 15.
Tabel 15. Perhitungan menggunakan nilai k=17.
Berikut hasil waktu komputasi menggunakan metode Cosine Similarity dan ℓ2distance yang ditunjukkan pada Tabel 16.
Tabel 16. Waktu perhitungan menggunakan nilai k=17.
Nilai precision dari tiap-tiap percobaan menggunakan metode Cosine Similarity dan ℓ2𝑑istance akan dijelaskan padaGambar 2.
Gambar 2. Nilai precision pengujian menggunakan cross validation.
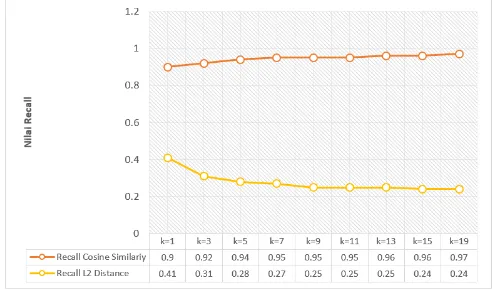
Nilai recall dari tiap-tiap percobaan menggunakan metode Cosine Similarity dan ℓ2𝑑istance akan dijelaskan pada Gambar 3.
Gambar 3. Nilai recall pengujian menggunakan cross validation.
Tabel 16. Waktu perhitungan metode Cosine Similarity dan ℓ2𝑑istance menggunakan cross validation.
A. Pembahasan
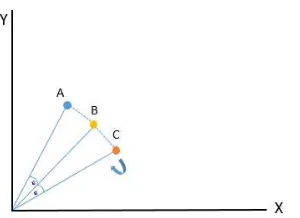
Hasil dari pengujian yang dilakukan, diketahui bahwa metode Cosine Similariy mendapatkan nilai precision dan recall yang lebih tinggi daripada metode ℓ2𝑑istance. Hal ini dikarenakan prinsip perhitungan menggunakan kedua metode tersebut. Misalnya, terdapat vektor A, Vektor B, dan Vektor C dengan nilai tertentu yang akan digambarkan pada koordinat kartesius pada Gambar 4.
Gambar 4. Koordinat Kartesius Vektor A, Vektor B, dan Vektor C.
Dari koordinat kartesian diatas, berdasarkan dot product pada metode Cosine Similarity, sudut antara A ke B dan B ke C sama besar, maka bisa dikatakan bahwa vektor A dan vektor C memiliki tingkat kemiripan yang sama dengan vektor B, jika diputar secara perlahan sampai
360˚ sudutnya tidak akan berubah. Berbeda halnya ketika
menggunakan panjang vektor pada metode ℓ2𝑑istance, akan menghasilkan jarak yang berbeda pada saat panjang
vektor tersebut diputar secara perlahan hingga 360˚. Inilah
yang menyebabkan hasil klasifikasi menggunakan metode Cosine Similarity lebih baik atau bagus dibandingkan metode ℓ2𝑑istance pada klasifikasi teks.
Waktu komputasi menggunakan metode Cosine Similarity menunjukkan waktu proses yang lebih lama
dibandingkan metode ℓ2𝑑istance. Hal tersebut dikarenakan metode Cosine Similarity memiliki tahapan perhitungan yang lebih lama dari metode ℓ2𝑑istance, yaitu sebelum melakukan perhitungan klasifikasi terlebih dahulu dilakukan perhitungan untuk mencari jarak query, jarak dokumen dan juga perhitungan inner product.
Dari Hasil pengujian yang dilakukan, dapat disimpulkan bahwa perhitungan jarak menggunakan metode Cosine Similarity lebih cocok atau baik digunakan daripada metode ℓ2𝑑istance untuk klasifikasi teks dokumen. Hal ini dilihat dari pengujian dengan metode
Cosine Similarity yang memperoleh nilai precision
terbesar yaitu 0.97 atau 97% dan nilai recall sebesar 0.97 atau 97% yang didapatkan pada pengujian menggunakan nilai k=17. Sedangkan untuk pengujian menggunakan metode ℓ2𝑑istance mendapatkan nilai precision terbesar yaitu 0.81 atau 81% pada nilai k=3 dan nilai recall terbesar pada nilai k=1 yaitu 0.41 atau 41%.
V.KESIMPULANDANSARAN
A. Kesimpulan
Melalui penelitian yang dilakukan, dapat disimpulkan bahwa:
1. Metode Cosine Similarity lebih baik digunakan dalam proses perhitungan jarak dokumen dibandingkan dengan metode ℓ2distance.
2. Hasil pengujian tertinggi menggunakan metode Cosine Similarity memperoleh nilai precision = 0.96 atau 96% dan recall = 0.96 atau 96%, sedangakan untuk metode ℓ2distance memperoleh nilai precision = 0.04 atau 4% dan nilai recall = 0.2 atau 20%.
3. Waktu komputasi menggunakan metode ℓ2distance lebih singkat dibandingkan dengan metode Cosine Similarity.
B. Saran
1. Metode untuk menghitung jarak dokumen juga dapat menggunakan metode perhitungan yang lainnya, seperti: metode Jaccard, Tanimoto Coefficient, ataupun metode Manhattan untuk membandingkan hasil dari pengujian menggunakan metode Cosine Similarity dan metode ℓ2𝑑istance.
2. Penggunaan proses klasifikasi dengan metode k-NN dapat menggunakan metode klasifikasi yang lainnya, seperti: Naïve Bayes Classifier (NBC), Support Vector
Machine (SVM), atau Neural Network (NN).
sangat berpengaruh pada masukan jumlah nilai k pada hasil akhir klasifikasi.
DAFTARPUSTAKA
[1] Palinoan, V. W., 2014, Sistem Klasifikasi Dokumen Bahasa Jawa Menggunakan Metode K-Nearest Neighbor, Universitas Sanata Dharma, Yogyakarta.
[2] Purwanti, E., 2015, Klasifikasi Dokumen Temu Kembali Informasi dengan K-Nearest Neighbor, Record and Library Journal, Vol. 01, No. 2, p.137.
[3] Chandra, D. N., Indrawan, G. & Sukajaya, I. N., 2016,
Klasifikasi Berita Lokal Radar Malang Menggunakan Metode Naive Bayes dengan Fitur N-Gram, Jurnal Ilmiah Teknologi dan Informasi ASIA, Vol. 10, No. 1, p. 19. [4] Hamzah, A., 2010, Klasifikasi Teks dengan Naive Bayes