Analisa Penjualan Barang Menggunakan Metode Clustering K-Means Untuk Perencanaan Penjualan Pada Hawaii Swalayan
Fionda ,Warnia Nengsih dan Memen Akbar
Jurnal Aksara Komputer Terapan
Politeknik Caltex Riau
Website : https://jurnal.pcr.ac.id/index.php/jakt/about/index
Email : [email protected]
Analisa Penjualan Barang Menggunakan Metode
Clustering K-Means Untuk Perencanaan Penjualan
Pada Hawaii Swalayan
Fionda 1) Warnia Nengsih 2) Memen Akbar3)
1)Program Studi Sistem Informasi, Politeknik Caltex Riau, email:[email protected] 2)Program Studi Sistem Informasi, Politeknik Caltex Riau, email: [email protected] 3)Program Studi Teknik Komputer, Politeknik Caltex Riau, email: [email protected]
Abstrak
Swalayan Hawaii merupakan salah satu perusahaan retail berskala menengah ke atas yang berada di Pekanbaru, Riau. Data-data penjualan yang dimiliki oleh Swalayan Hawaii dapat diolah dan dianalisa untuk menghasilkan data barang yang laris dan tidak laris dengan
menerapkan teknik data mining metode clustering k-means. Data barang laris dan tidak laris
berguna untuk menjadi pertimbangan oleh pihak manajemen untuk perencanaan penjualan di event yang sama berikutnya. Pada penelitian ini event yang akan diuji adalah event ramadhan, natal, waisak, dan imlek dalam rentang tanggal dari 1 Mei 2009 sampai dengan 28 Februari 2013. Berdasarkan hasil penelitian, penerapan aplikasi clustering k-means ini membantu dalam melakukan analisa yang dapat memberikan informasi berupa barang yang laris dan tidak laris pada event yang ditentukan. Aplikasi data mining ini dapat membedakan kelompok barang laris dan tidak laris dengan selisih ketelitian sekitar 2.052% dibandingkan dengan perhitungan pihak swalayan Hawaii dari 16 event yang diuji.
Kata kunci: Data Mining, Clustering K-Means, Swalayan Hawaii
Abstract
Hawaii Store is one of middle and upper scale retail in Pekanbaru, Riau. Selling data of Hawaii Store can be processed and analyzed to determine best selling goods and not best selling goods in easier way using data mining technique with clustering k-means method. That data used as consideration of management for sales planning for the next same event. In this research the events being tested are Ramadhan, Christmas, Waisak, and Chinese New Year, in the date range of May 1, 2009 until February 28, 2013. Based on this research, the application of k-means clustering application helps the analysis that can provide information in the form of best selling and not best selling goods on that particular event. This data mining application can determine best selling and not best selling goods with about 2.052% difference in accuracy compared with Hawaii Store manual calculation in 16 events that tested.
Analisa Penjualan Barang Menggunakan Metode Clustering K-Means Untuk Perencanaan Penjualan Pada Hawaii Swalayan
Fionda ,Warnia Nengsih dan Memen Akbar 1. Pendahuluan
Sebagai sebuah perusahaan yang semakin besar dan memiliki data yang besar PT Hawaii Retail Indonesia (Swalayan Hawaii) saat ini memang sudah berkewajiban memanfaatkan data mining untuk dapat bersaing dalam kancah bisnis khususnya didalam bagian penjualan produk-produknya, yaitu busana dan barang kebutuhan primer dan sekunder terhadap kompetitornya. Perusahaan besar sekalipun akan mengalami kesulitan dalam bisnisnya jika tidak mampu menganalisa dengan tepat untuk perencanaan terhadap prospek bisnisnya ke depan. Dengan menggunakan
data mining tentu saja hal ini bisa diatasi.
Salah satu teknik yang terdapat dalam data mining yang digunakan dalam penelitian ini adalah pengelompokkan (Clustering) dimana pada clustering terdapat metode k-means. Metode ini mampu mengidentifikasi objek yang memiliki kesamaan karakteristik tertentu, dan kemudian menggunakan karakteristik tersebut sebagai “vektor karakteristik” atau “centroid”.
Tujuan penelitian ini membangun aplikasi analisa penjualan barang menggunakan metode clustering k-means untuk mempermudah pihak manajemen Swalayan Hawaii dalam mengetahui barang laris dan tidak laris pada event tertentu. Sehingga pihak manajemen dipermudah dalam menganalisa barang laris dan tidak laris tersebut yang dapat menjadi pertimbangan oleh pihak manajemen untuk perencanaan penjualan pada event yang sama berikutnya.
2. Landasan Teori 2.1 Hawaii
Didirikan oleh Afdirman, PT Hawaii Retail Indonesia merupakan salah satu perusahaan retail berskala menengah ke atas yang berada di Riau. Perseroan ini
memulai operasinya pada tahun 1992. Berawal dengan nama toko Hawaii Busana yang memasarkan pakaian-pakaian secara grosir, perusahaan ini kemudian bertransformasi nama menjadi Hawaii Busana-Retail di tahun 2004. Sejak saat itu, perusahaan ini dikenal masyarakat sebagai pemasar berbagai produk berkualitas dengan harga ekonomis.
2.2 Data Mining
Data mining merupakan salah satu
proses yang terdapat dalam Knowledge
Discovery in Database, dimana proses
tersebut bertujuan mencari pola-pola baru dan tersembunyi dari suatu kumpulan data yang berukuran besar yang tersimpan dalam suatu basis data, data warehouse, atau tempat penyimpanan data lainnya[3].
Menurut Sumanthi dan Sivandham [2], data mining juga didefinisikan sebagai bagian dari proses penggalian pengetahuan dalam database yang sering disebut dengan istilah Knowledge Discovery in Database (KDD). KDD merupakan suatu area yang mengintegrasikan berbagai metode, yang meliputi statistik, basis data, kecerdasan buatan (Artificial Intelligence), machine
learning, pengenalan pola (Pattern
Recognition), pemodelan yang menangani
ketidakpastian, visualisasi data, optimasi, Sistem Informasi Manajemen (SIM), dan sistem berbasis pengetahuan (knowledge
based-system). Sebagai bagian dari proses
yang ada di dalam KDD, maka data mining didahului dengan proses pemilihan data, pembersihan data, preprocessing, dan transformasi data.
Analisa Penjualan Barang Menggunakan Metode Clustering K-Means Untuk Perencanaan Penjualan Pada Hawaii Swalayan
Fionda ,Warnia Nengsih dan Memen Akbar Tahapan proses KDD terdiri dari : a. Data Selection
Pada proses ini dilakukan pemilihan himpunan data, menciptakan himpunan data target, atau memfokuskan pada subset variabel (sampel data) dimana penemuan (discovery) akan dilakukan. Hasil seleksi disimpan dalam suatu berkas yang terpisah dari basis data operasional.
b. Pre-Processing dan Cleaning Data Pre-Processing dan Cleaning Data dilakukan membuang data yang tidak konsisten dan noise, duplikasi data, memperbaiki kesalahan data, dan bisa diperkaya dengan data eksternal yang relevan.
c. Transformation
Proses ini mentransformasikan atau menggabungkan data ke dalam yang lebih tepat untuk melakukan proses mining dengan cara melakukan peringkasan (agregasi). d. Data Mining
Proses data mining yaitu proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik, metode atau algoritma tertentu sesuai dengan tujuan dari proses KDD secara keseluruhan.
e. Interpretation / Evaluasi
Proses untuk menerjemahkan pola-pola yang dihasilkan dari data mining. Mengevaluasi (menguji) apakah pola atau informasi yang ditemukan bersesuaian atau bertentangan dengan fakta atau hipotesa sebelumnya. Pengetahuan yang diperoleh dari pola-pola yang terbentuk dipresentasikan dalam bentuk visualisasi.
2.2.1 Clustering K-Means
K-means termasuk dalam partitioning clustering yaitu setiap data harus masuk
dalam cluster tertentu dan memungkinkan bagi setiap data yang termasuk dalam
cluster tertentu pada suatu tahapan proses,
pada tahapan berikutnya berpindah ke
cluster yang lain. K-means memisahkan
data ke k daerah bagian yang terpisah, dimana k adalah bilangan integer positif. Algoritma k-means sangat terkenal karena kemudahan dan kemampuannya untuk mengklasifikasi data besar dan outlier dengan sangat cepat.
2.2.2 Proses Clustering Algoritma K-Means
Langkah-langkah yang dilalui oleh
clustering algoritma K-means memuat
bagian-bagian sebagai berikut [1]:
1. N data : Data set yang akan diolah sebanyak N data dimana N data tersebut terdiri dari atribut-atributnya N.
2. K centroid : Inisialisasi dari pusat
cluster data adalah sebanyak K dimana
pusat-pusat awal tersebut digunakan sebagai banyaknya kelas yang akan tercipta. Centroid didapatkan secara random dari N data set yang ada. 3. Euclidian Distance : Merupakan jarak
yang didapat dari perhitungan antara semua N data dengan K centroid dimana akan memperoleh tingkat kedekatan dengan kelas yang terdekat dengan populasi tersebut.
Jarak euclidian untuk menandai adanya persamaan antar tiap
cluster dengan jarak minimum dan
mempunyai persamaan yang lebih tinggi.
Euclidian matrik antara titik x = dan titik y = adalah : d(x,y)= = Dimana :
x : Titik data pertama y : Titik data kedua
Analisa Penjualan Barang Menggunakan Metode Clustering K-Means Untuk Perencanaan Penjualan Pada Hawaii Swalayan
Fionda ,Warnia Nengsih dan Memen Akbar n : Jumlah karakteristik (attribut) dalam terminologi datamining
d(x,y) : Euclidian distance yaitu jarak antara data pada titik x dan titik yang menggunakan kalkulasi matematika.
4. Pengelompokkan data : Setelah sejumlah populasi data tersebut menemukan kedekatan dengan salah satu centroid yang ada maka secara otomatis populasi data tersebut masuk kedalam kelas yang memiliki centroid yang bersangkutan.
5. Update centroid baru : Tiap kelas yang telah tercipta tadi melakukan update
centroid baru. Hal ini dilakukan
dengan menghitung nilai rata-rata dari kelas masing-masing. Apabila belum memenuhi optimal hasil proses pengukuran ecluidian distance
dilakukan kembali.
3. Metodologi Penelitian 3.1 Usecase Diagram
Perancangan usecase diagram dimaksudkan untuk mempresentasikan fungsionalitas yang disediakan oleh sistem.
Pada sistem ini pengguna hanya terdapat satu, yakni EDP (Entri Data Processor).
Gambar 3. Usecase Diagram
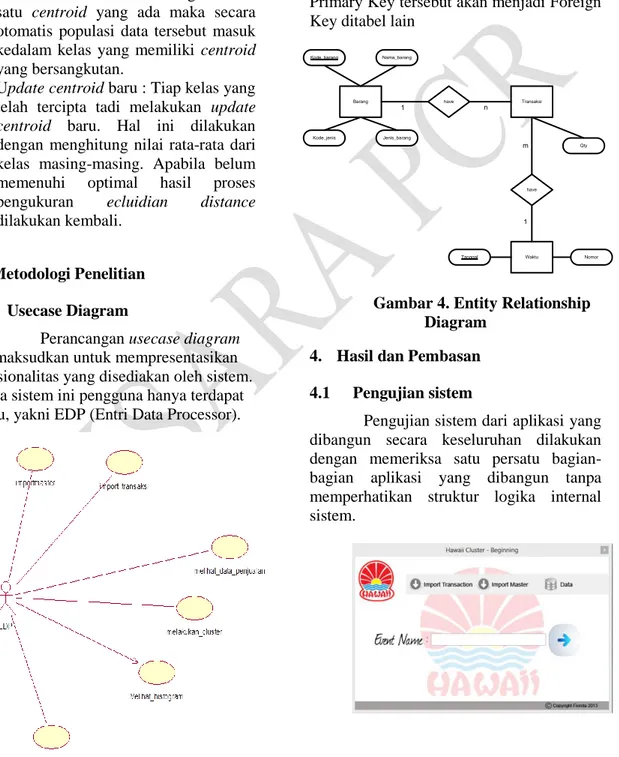
3.2 Entity Relationship Diagram Gambar 3.11 berikut merupakan
Entity Relational Diagram (ERD) dari database yang nantinya akan digunakan
oleh aplikasi. Setiap tabel memiliki Primary Key yang menjadi ciri khas pada tabel berikut. Primary Key tersebut juga dapat digunakan untuk merelasikan suatu tabel dengan tabel lainnya sehingga nantinya Primary Key tersebut akan menjadi Foreign Key ditabel lain
Kode_barang Barang Waktu Nama_barang Kode_jenis Jenis_barang Transaksi Qty Tanggal Nomor have have 1 n 1 m
Gambar 4. Entity Relationship Diagram
4. Hasil dan Pembasan 4.1 Pengujian sistem
Pengujian sistem dari aplikasi yang dibangun secara keseluruhan dilakukan dengan memeriksa satu persatu bagian-bagian aplikasi yang dibangun tanpa memperhatikan struktur logika internal sistem.
Analisa Penjualan Barang Menggunakan Metode Clustering K-Means Untuk Perencanaan Penjualan Pada Hawaii Swalayan
Fionda ,Warnia Nengsih dan Memen Akbar
5(a). Jendela Awal
5(b). Import Transactoin
5(c). Import Master
5(d). Cluster
5(e). Hasil Cluster
5(f). Details Barang
4.2 Pengujian K-Means
Dari data-data barang di swalayan Hawaii, diambil 14 sampel barang dengan kategori perawatan rambut yang dipilih secara random berdasarkan brand dari tanggal 1 Desember 2009 sampai dengan 7 Desember 2009 sebagai contoh untuk penerapan algoritma k-means dalam menentukan barang laris dan barang tidak laris. Percobaan dilakukan dengan menggunakan parameter-parameter berikut: Jumlah cluster (laris dan tidak laris): 2 Jumlah data (item barang) :14 Jumlah attribut (hari) : 7
Pada perhitungan manual diperoleh hasil sebagai berikut :
Analisa Penjualan Barang Menggunakan Metode Clustering K-Means Untuk Perencanaan Penjualan Pada Hawaii Swalayan
Fionda ,Warnia Nengsih dan Memen Akbar Anggota cluster pertama adalah data ke-8 dan data ke-11 yaitu:
1. PANTENE SHP TOTAL
DAMAGE 170+80
2. PANTENE COND PRO&CARE HAIRMASK90
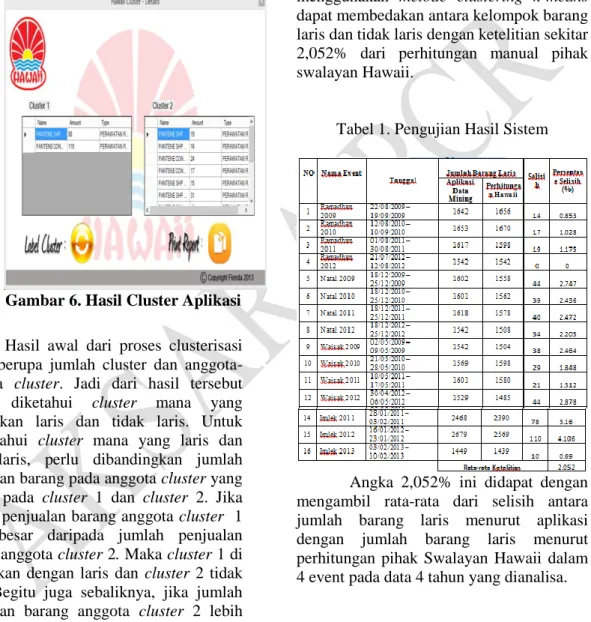
Sedangkan perhitungan dari aplikasi memperoleh hasil sebagai berikut :
Gambar 6. Hasil Cluster Aplikasi Hasil awal dari proses clusterisasi masih berupa jumlah cluster dan anggota-anggota cluster. Jadi dari hasil tersebut belum diketahui cluster mana yang dinyatakan laris dan tidak laris. Untuk mengetahui cluster mana yang laris dan tidak laris, perlu dibandingkan jumlah penjualan barang pada anggota cluster yang berada pada cluster 1 dan cluster 2. Jika jumlah penjualan barang anggota cluster 1 lebih besar daripada jumlah penjualan barang anggota cluster 2. Maka cluster 1 di asumsikan dengan laris dan cluster 2 tidak laris. Begitu juga sebaliknya, jika jumlah penjualan barang anggota cluster 2 lebih besar daripada jumlah penjualan barang anggota cluster 1. Maka cluster 2 di asumsikan dengan laris dan cluster 1 tidak laris. Pada gambar 4, dapat dilihat bahwa cluster 1 merupakan cluster yang laris dengan barang PANTENE SHP TOTAL DAMAGE 170+80 dan PANTENE COND PRO&CARE HAIRMASK90.
4.3 Pengujian Hasil sistem
Pada penelitian pengujian dilakukan dengan menggunakan 4 event, yaitu ; Ramadhan, Natal, Waisak, Imlek. Setelah memberikan angket perbandingan jumlah data barang laris menurut pihak swalayan Hawaii berdasarkan jumlah penjualan barang, dapat diambil kesimpulan bahwa aplikasi data mining yang dibangun menggunakan metode clustering k-means dapat membedakan antara kelompok barang laris dan tidak laris dengan ketelitian sekitar 2,052% dari perhitungan manual pihak swalayan Hawaii.
Tabel 1. Pengujian Hasil Sistem
Angka 2,052% ini didapat dengan mengambil rata-rata dari selisih antara jumlah barang laris menurut aplikasi dengan jumlah barang laris menurut perhitungan pihak Swalayan Hawaii dalam 4 event pada data 4 tahun yang dianalisa.
5. Kesimpulan dan saran 5.1 Kesimpulan
Setelah dilakukan pengujian beserta analisa pada proyek akhir ini, maka dapat diambil kesimpulan sebagai berikut : 1. Aplikasi data mining dengan
k-Analisa Penjualan Barang Menggunakan Metode Clustering K-Means Untuk Perencanaan Penjualan Pada Hawaii Swalayan
Fionda ,Warnia Nengsih dan Memen Akbar
means berhasil dibangun pada
Swalayan Hawaii.
2. Penerapan aplikasi clustering
k-means ini membantu dalam melakukan analisa yang dapat memberikan informasi berupa barang yang laris dan tidak laris pada event tertentu.
3. Berdasarkan hasil angket yang diberikan aplikasi data mining yang dibangun menggunakan metode
clustering k-means ini dapat membedakan antara kelompok barang laris dan tidak laris dengan ketelitian aplikasi data mining sekitar 2,052% dari perhitungan manual pihak Swalayan Hawaii.
5.2 Saran
1. Menggabungkan dengan metode pengklasteran yang lain seperti
GA-KMeans atau Fast Genetic Algorithm – Kmeans, untuk mendapatkan titik pusat awal klaster yang bagus.
2. Menambahkan atribut lain, bukan hanya jumlah penjualan saja. Dengan begitu hasil data mining yang di dapat lebih variatif.
3. Menggabungkan dengan bidang ilmu lain seperti marketing untuk mendapatkan perhitungan nilai deviasi persentase keakuratan kemunculan barang untuk perencanaan penjualan
Daftar Pustaka
[1] Prayitno (2009), Penentuan Bidang
Konsentrasi Studi Tugas Akhir Berdasarkan Nilai Matakuliah Dengan Klasterisasi Kmeans. Jurnal
untuk Proyek Akhir Teknik Informatika, Politeknik Elektronika Negeri Semarang.
[2] Sumathi, S., Sivanandam, S.N. 2006. Introduction to Data Mining and its Applications. Spinger, Verlag Berlin Heidelberg.
[3] Tan, P., Steinbach, M., Kumar, V., (2006). Introduction to Data Mining. Pearson Addison-Wesley Inc.