HASIL DAN PEMBAHASAN
4.1. Formulasi Masalah dan Penentuan Tujuan.
Dalam bagian ini dibahas tentang formulasi masalah dan penentuan tujuan yang akan dicapai, diperlukan tahapan-tahapan analisis yang akan timbul selama proses optimisasi query dijalankan.
Aspek utama pemilihan strategi query untuk sistem basis data terdistribusi terletak dalam penentuan strategi operasi join. Strategi operasi join dapat menggunakan fasilitas optimizer yang terdapat dalam DBMS, antara lain : Metode Nested-Loops-Join, Block–Nested-Loops-Join, Sort-Merge-Join dan Hash Join. Tetapi tidak semua DBMS dapat melakukan strategi dengan metode-metode tersebut. Dalam penelitian ini penulis mencoba membahas secara spesifik optimisasi join query sesuai dengan karakteristik basis data dan spesifikasi komputer yang digunakan.
Untuk memformulasi masalah terdapat beberapa faktor yang harus dipertimbangkan dalam sistem terdistribusi, antara lain :
• Biaya / waktu untuk transmisi data dan biaya operasi join.
• Potensi peningkatan unjuk kerja karena adanya sejumlah simpul yang dapat melaksanakan query secara paralel.
• Karakteristik basis data.
Biaya / waktu transfer data dalam jaringan dan transfer data ke dan dari disk, sangat berbeda-beda tergantung pada tipe jaringan yang dipilih dan kecepatan akses dari disk yang digunakan. Sementara unjuk kerjanya akan sangat tergantung pada desain basis data terdistribusi yang kita terapkan serta strategi DBMS dalam melakukan transformasi setiap perintah query.
Ambil sebuah contoh perintah query sederhana, “ tampilkan semua baris data dalam tabel pst_ke1 “. Pemrosesan query tersebut menjadi tidak sederhana, jika tabel tersebut telah direplikasi atau difragmentasi atau sekaligus direplikasi dan difragmentasi. Jika tabel pst_ke1 tersebut ternyata telah direplikasi, maka dapat dengan mudah untuk memenuhi query tersebut dengan memilih salah satu simpul tempat tabel pst_ke1 berada, dan kemudian mengeksekusi query. Jika
tabel tersebut tidak difragmentasi, pemilihan simpul didasarkan pada simpul yang memberikan ongkos transmisi data paling rendah. Akan tetapi jika tabel pst_ke1 tersebut difragmentasi dan ditempatkan di berbagai simpul yang berbeda, maka harus melakukan operasi join atau union untuk merekontruksi isi seluruh tabel pst_ke1.
Penerapan operasi di atas disamping tergantung pada bentuk perintah query, tergantung pada jenis fragmentasi yang diterapkan pada tabel terlibat. Jika tabel pst_ke1 telah difragmentasi horizontal, perlu rekonstruksi dengan menggunakan operasi union, tetapi jika fragmentasi dilakukan vertikal , maka rekonstruksi operasi natural join yang harus digunakan. Dalam berbagai kasus dan berbagai keadaan banyak pilihan strategi dan metode yang harus dipetimbangkan, tetapi besar kemungkinan akan memperberat upaya optimisasi query yang kadang-kadang menjadi tidak praktis untuk diterapkan.
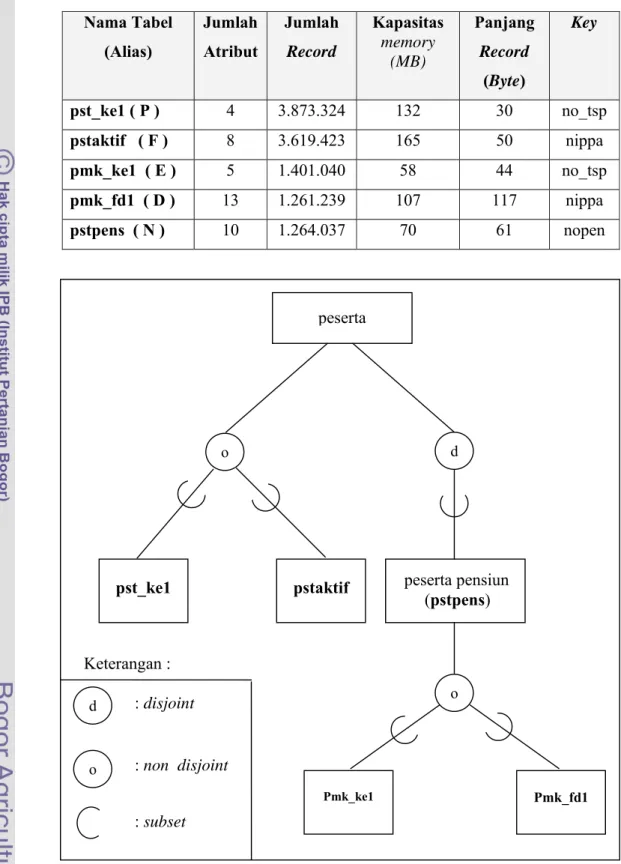
Percobaan dilakukan untuk menganalisis permasalahan menggunakan tabel peserta asuransi, dengan tabel hasil fragmentasi dari peserta didekomposisi (spesialisasi) menjadi tabel pst_ke1 dan tabel pstaktif, tabel peserta pensiun (pstpens) didekomposisi menjadi tabel pmk_ke1 dan tabel pmk_fd1. Tabel-tabel yang digunakan dalam percobaan hanya menggunakan 5 buah tabel yang terdiri dari tabel pstaktif, pst_ke1, pstpens, pmk_ke1 dan pmk_fd1. Hal ini dilakukan dengan pertimbangan efisiensi ruang penyimpanan. Untuk lebih jelasnya situasi tabel secara keseluruhan dapat dilihat pada kamus data di bawah ini dan Diagram E-R ditunjukkan pada Gambar 5.
Kamus data dari 5 buah tabel yang dianalisis antara lain : a. pst_ke1 ( no_tsp, tgl_lhr, tmt_pst, kd_bup)
b. pstaktif ( nippa, tgl_lhr, tmt_pst, sex, gaji_pokok, blth_gapok, suskel, pangkat)
c. pmk_ke1 ( no_tsp, tmt_pst, tglhr_ymk, tgl_kej, kd_kej,)
d. pmk_fd1 ( nippa, tmt_pst, kd_kej, tgl_klim, tgl_trans, pangkat, gaji_pokok, thp, suskel, nama_ymk, tglhr_ymk, rp_hak)
e. pstpens ( nopen, jenis, kp030, kp040, kp080, kp180, kp380, kp570, kp550, kp710).
Tabel 8 : Tabel informasi data tabel relasi Nama Tabel (Alias) Jumlah Atribut Jumlah Record Kapasitas memory (MB) Panjang Record (Byte) Key pst_ke1 ( P ) 4 3.873.324 132 30 no_tsp pstaktif ( F ) 8 3.619.423 165 50 nippa pmk_ke1 ( E ) 5 1.401.040 58 44 no_tsp pmk_fd1 ( D ) 13 1.261.239 107 117 nippa pstpens ( N ) 10 1.264.037 70 61 nopen
Gambar 5 : Diagram E-R dari keseluruhan tabel peserta peserta peserta pensiun (pstpens) pst_ke1 pstaktif Pmk_ke1 Pmk_fd1 o d o Keterangan : o d : disjoint : non disjoint : subset
Tanda ‘d’ dalam konektor lingkaran menunjukkan dekomposisi (spesialisasi) disjoint dan tidak terdapat relasi spesialisasi antar tabel, dan tanda ‘o’ menunjukkan non disjoint dan terdapat relasi spesialisasi antar tabel dan menunjukkan perbedaan tiap entitas, tanda ‘ С ‘ menunjukkan subset (Begg C. 1996). 5 buah tabel yang digunakan dalam percobaan lebih dijelaskan pada Diagram E-R Gambar 6 dan Gambar 7.
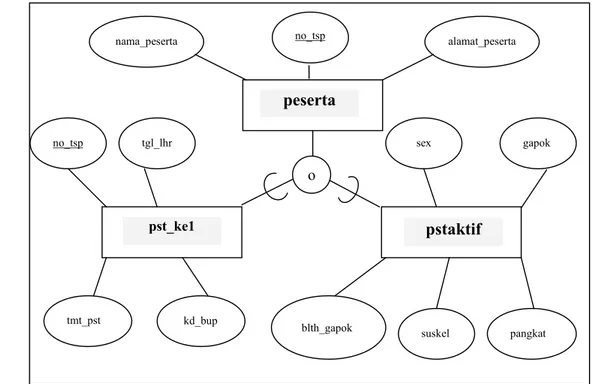
Gambar 6 : Diagram E-R tabel peserta spesialisasi menjadi tabel pst_ke1 dan tabel pstaktif.
pstaktif pst_ke1 o no_tsp tgl_lhr kd_bup gapok blth_gapok suskel sex pangkat peserta nama_peserta alamat_peserta tmt_pst no_tsp
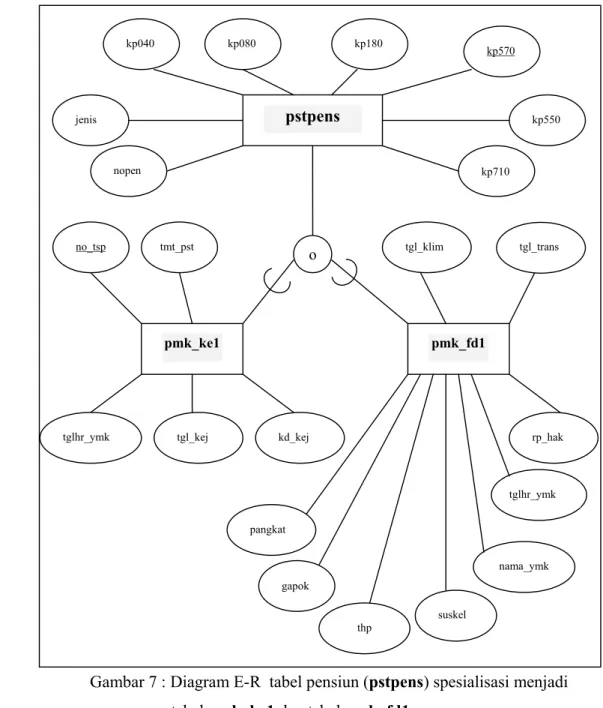
Gambar 7 : Diagram E-R tabel pensiun (pstpens) spesialisasi menjadi tabel pmk_ke1 dan tabel pmk_fd1.
4.2. Formulasi Optimisasi Query. pstpens pmk_fd1 pmk_ke1 o jenis kp040 kp080 kp180 kp570 kp550 kp710 no_tsp tmt_pst
tglhr_ymk tgl_kej kd_kej
gapok pangkat tgl_trans tgl_klim thp nama_ymk tglhr_ymk suskel nopen rp_hak
Pada bagian ini bagaimana proses query diformulasi, dianalisis dan dievaluasi. Data deskriptif atau metadata disimpan dalam tabel khusus yang disebut katalog sistem yang digunakan untuk menemukan cara terbaik dalam mengevaluasi query. Secara umum query tersusun dari beberapa operator, algoritma pada operator relasi dapat dikombinasikan dengan berbagai cara untuk mengevaluasi query. Setiap perintah query sebaiknya dievaluasi dengan melalui formulasi tree aljabar relasional. Keterangan pada masing-masing node menggambarkan metode akses untuk masing-masing tabel dan metode implementasi untuk tiap operator relasional.
Penulis mencoba mempertimbangkan contoh dengan menggunakan skema berikut :
a. pst_ke1 (no_tsp, tgl_lhr, tmt_pst, kd_bup)
b. pstaktif (nippa, tgl_lhr, tmt_pst, sex, gaji_pokok, blth_gapok, suskel, pangkat)
Tabel di atas masing-masing record dari pst_ke1 panjangnya 30 byte, dengan asumsi sebuah halaman yang akan masuk dalam buffer dapat menangani 100 record pst_ke1, maka dalam pst_ke1 terdapat 3.873.324 record akan mempunyai 38.730 halaman dalam buffer, demikian juga bahwa masing-masing record dari pstaktif panjangnya 50 byte, mempunyai 3.619.423 record, sebuah halaman dapat menangani 80 record pstaktif, sehingga mempunyai 45.242 halaman.
Perhatikan query SQL berikut ini :
SELECT F. tmt_pst
FROM pst_ke1 P, pstaktif F WHERE P.no_tsp = F.nippa
AND P. kd_bup= ‘100’ AND F. pangkat >= ‘3A’
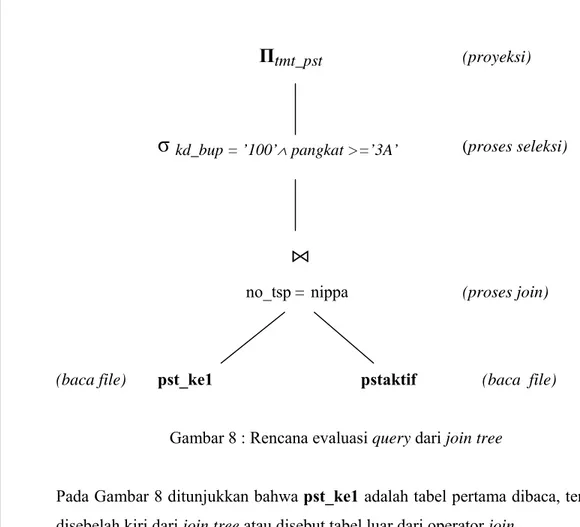
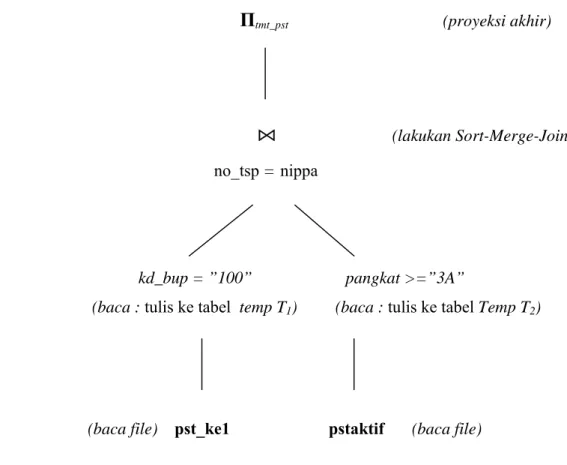
Query di atas dapat dinyatakan dalam aljabar relasional seperti berikut : Πtmt_pst (σkd_bup = ’100’ ∧ pangkat >=’3A’(pst_ke1 ⋈no_tsp= nippa pstaktif)
Pernyataan di atas dapat dinyatakan dalam bentuk join tree pada Gambar 8. Sebagian pernyataan aljabar dapat menentukan bagaimana mengevaluasi query pertama, join dihitung secara alami dari pst_ke1 dan pstaktif, kemudian melakukan seleksi dan akhirnya memproyeksikan atribut tmt_pst. Untuk proses evaluasi harus dijelaskan implementasi untuk masing-masing operasi aljabar yang terlibat. Sebagai contoh dapat digunakan page-oriented dari nested-loop-join yang sederhana dengan pst_ke1 sebagai tabel pertama yang dibaca, dan mengaplikasikan seleksi dan proyeksi untuk masing-masing record pada hasil join, hasil dari join tersebut sebelum seleksi dan proyeksi tidak disimpan seluruhnya.
Π
tmt_pst (proyeksi)σ
kd_bup = ’100’∧ pangkat >=’3A’ (proses seleksi)⋈
no_tsp= nippa (proses join)
(baca file) pst_ke1 pstaktif
(baca file)
Gambar 8 : Rencana evaluasi query dari join treePada Gambar 8 ditunjukkan bahwa pst_ke1 adalah tabel pertama dibaca, terletak disebelah kiri dari join tree atau disebut tabel luar dari operator join.
Mendahulukan operasi seleksi sebelum operasi join
Untuk melakukan operasi Join secara heuristik sebaiknya tabel dibuat dengan ukuran sekecil mungkin, dan operasi seleksi dilakukan lebih awal. Sebagai contoh seleksi kd_bup =”100” hanya melibatkan atribut dari pst_ke1 dan dapat diaplikasikan pada pst_ke1 sebelum join. Sama halnya dengan seleksi pangkat >= ”3A” hanya melibatkan atribut dari pstaktif, dapat diaplikasikan pada pstaktif sebelum join.
Andaikan bahwa seleksi didahulukan dengan menggunakan scan file, hasil dari masing-masing seleksi ditulis ke tabel temporer pada disk, selanjutnya tabel temporer digabung menggunakan metode sort-merge-join seperti ditunjukkan pada Gambar 9. Hasil eksekusi menunjukkan perbedaan waktu yang cukup signifikan, untuk jumlah record masing-masing 10.000 record eksekusi medahulukan seleksi lebih cepat dari pada eksekusi mendahulukan join. Penurunan waktu eksekusi mencapai 37,45 %
Πtmt_pst
(proyeksi akhir)
⋈
(lakukan Sort-Merge-Join)
no_tsp = nippa
kd_bup = ”100” pangkat >=”3A”
(baca : tulis ke tabel temp T1) (baca : tulis ke tabel Temp T2)
(baca file) pst_ke1 pstaktif (baca file)
4.2.1. Analisis Selectivity Factor dari Karakteristik Basis Data.
Dalam hal ini penulis mengemukakan statistik basis data sesuai dengan karateristiknya, yaitu relasi yang digunakan berupa tabel basis data dengan nilai kardinalitas cukup besar.
Statistik basis data dengan operasi Join untuk tabel relasi difragmentasi dengan jumlah record 10.000 per tabel pada tabel (pst_ke1 dan pstaktif, serta pmk_ke1 dan pmk_fd1), berdasarkan persamaan (2.3) adalah:
card( P
⋈
F ) card(P⋈
no_tsp=nippaF) = card(F)a. SF1 (P, F) = --- = --- card( P ) * card( F ) card( P ) * card( F )
283 =--- --- = 0,00000283 10,000 * 10,000 card( E
⋈
D ) b. SF1 (E, D) = --- card( E ) * card( D ) card(E⋈
no_tsp=nippaD) = --- card( E ) * card( D ) 240 = --- 10.000*10.000 = 0,0000024Untuk Selectivity Factor operasi Selection berdasarkan persamaan (2.4) adalah :
card(σ F (R)) = SF σ (F) *card(R) dimana
1 S F σ (A = value) = --- card(∏A (R)) 1 1 S F σ
(
kodebup = “100”=1) = --- = ---= 0,000102
card(∏kodebup(P)) 9776Dari hasil perhitungan Selectivity Factor menghasilkan angka 0,00000283 dan 0,0000024 dan 0,000102, menunjukkan bahwa operasi join dan operasi seleksi di atas cukup baik, karena nilai selectivity-nya mendekati 0, dan jumlah record tabel-tabel di atas secara spesifik tidak berpengaruh terhadap nilai selectivity factor
4.2.2. Analisis Optimisasi Secara Spesifik.
Perintah query menggunakan operator relasional sebenarnya mempunyai banyak persamaan (ekivalen). Beberapa teknik yang sederhana dapat digunakan untuk mengembangkan algoritma dari masing-masing operator yaitu :
• Indektasi : Jika syarat seleksi atau join telah ditentukan, maka gunakan indek untuk memeriksa record yang memenuhi syarat saja.
• Iterasi : Proses secara iterasi yaitu memeriksa semua record dalam tabel input satu per satu, jika kita hanya memerlukan beberapa field dari masing-masing record dan terdapat indek yang key-nya berisi semua field tersebut akan diambil.
• Partisi : Mempartisi record pada sort key, memungkinkan dekomposisi sebuah operasi menjadi serangkaian operasi partisi yang lebih tidak mahal. Sorting dan hashing merupakan dua teknik yang umum digunakan.
Dalam menganalisis proses optimisasi secara spesifik operasi query dijalankan menggunakan algoritma dengan partisi relasi-relasi menggunakan metode-metode Nested-Loops-Join, Block-nested-loops-join, Sort-Merge-Join, dan Hash Join.
Penulis mencoba membahas tentang operasi join dari sebuah contoh kasus sederhana di bawah ini:
SELECT *
FROM pst_ke1 P, pstaktif F WHERE P. no_tsp = F. nippa
Gambar 10 : Contoh Perintah Join
Query ini dapat dinyatakan sebagai operasi ( P
⋈
F ) dan perintahnya sangat sederhana, meskipun join dapat didefinisikan sebagai cross product yang diikuti oleh seleksi dan proyeksi, join lebih sering muncul dalam praktek dibandingkan dengan cross product murni. Cross product biasanya lebih besar daripada hasil join. Dalam hal ini sangat penting untuk mengimplementasikan join tanpa menampilkan cross product. Untuk mengimplementasikan join dapat digunakan algoritma simple-nested-loops-join dan block-nested-loops-join, yang pada dasarnya menghitung semua record dalam cross product dan membuang record yang tidak memenuhi syarat join. Selanjutnya menghindari perhitungan cross product dengan menggunakan partisi. Secara intuitif jika syarat join terdiri dari equality, maka record dalam dua relasi dapat dianggap tercakup dalam partisi, sehingga hanya record yang berada dalam partisi yang sama yang dapat join satu sama lain atau record dalam partisi tersebut berisi nilai yang sama dalam kolom join. Indeks nested-loops-join men-scan salah satu relasi, untuk masing-masing record didalamnya, dengan menggunakan indeks pada kolom join dari relasi kedua untuk menemukan record yang berada dalam partisi yang sama. Jadi hanya subset relasi kedua yang dibandingkan dengan record tertentu dari relasi pertama, seluruh cross-product tidak dihitung.Penulis mencoba membahas join dari dua relasi P dan F, dengan syarat join Pi = Fj, menggunakan tanda posisional. Diasumsikan M halaman dalam P
dengan PP ( page P) record per halaman M, dan N halaman dalam F dengan PF (page F) record per halaman dalam N, dimana P adalah tabel relasi pst_ke1 dan F adalah tabel relasi pstaktif.
4.2.3.1Nested-Loops-Join
Algoritma yang paling sederhana adalah record pada saat dievaluasi nested loops. Algoritma men-scan relasi P tabel relasi pertama, untuk tiap record p∈P, kemudian men-scan semua relasi kedua dalam F . Biaya men-scan P adalah M I/O, dimana M adalah jumlah halaman dalam P, kemudian men-scan F sebanyak PP M kali, dan tiap scanning biayanya N I/O, dimana N adalah jumlah halaman dalam F (Raghu 2003), jadi biaya totalnya adalah :
M + PP.M.N ...(4.1).
Dimana : pP : adalah jumlah record per halaman dari M M: jumlah halaman dari relasi P
N : jumlah halaman dari relasi F Algoritmanya dapat dinyatakan sebagai berikut :
For eachrecordp ∈ Pdo For eachrecordf∈ Fdo
ifpi == fj then
add (p,f) to result
Gambar 11 : Algoritma Simple-Nested-Loops-Join (Raghu 2003)
Algoritma Simple-Nested-Loops-Join tidak memanfaatkan fasilitas buffer. Andaikan memilih P menjadi pst_ke1 dan F menjadi pstaktif , maka nilai M adalah 38.730 halaman dan pP adalah 100, kemudian nilai N adalah 45.242 PF adalah 80. Menurut Ramakrishna Raghu & Gehrke Johanes (2003) merujuk ke rumus (4.1.), biaya simple-nested-loops-join adalah :
38.730 + 100 * 38.730 * 45.242 halaman I/O
ditambah biaya penulisan hasil yang dalam hal ini diabaikan, maka besarnya biaya paling sedikit :
38.730 + 100 * 38.730 * 45.242 = 175.222.304.730
= 175.222.340.730 halaman I/O
Biaya tersebut sangat mengejutkan, apabila biaya I/O 10 ms ( setara dengan 0,001666667 detik atau 1/360000 jam = 0,0000028 jam ) per halaman pada perangkat keras terbaru, maka join ini akan memerlukan waktu :
175.222.340.730 * 0,001666667 = 292.037.293 detik 292.037.293 / 60 = 4.867.288,216 menit 4.867.288,216 / 60 = 81121,470 jam 81.121,470 / 24 = 3380,061 hari 3.380,061261 / 365 = 9,260 tahun
Biaya tersebut sangat tidak realistik, mungkin dapat diperbaiki dengan menggunakan join-page-at-a-time. Untuk tiap halaman P, kita dapat mengambil halaman F dan mengisi record (p,f) untuk semua record yang memenuhi syarat p ∈ P halaman dan f∈ F halaman. Atas dasar tersebut biaya M untuk men-scan P, seperti sebelumnya, akan tetapi F hanya di-scan M kali.
Jadi biaya total adalah : M + M * N, maka perbaikan page-at-a-time memberikan perkembangan faktor PF. Dalam contoh join dari relasi pst_ke1 dan pstaktif, biaya dapat dikurangi, yaitu :
38.733 + 38.733 * 45.242 = 1.752.397.119 halaman I/O 1.752.397.119 * 0,0000028 = 4867,769775 jam
4867,769775 / 24 = 202,9 hari
Perkembangan ini menekankan pentingnya partisi yang ditunjukkan pada operasi page-at-a-time dan dapat meminimalkan disk I/O, sehingga terjadi perubahan yang signifikan.
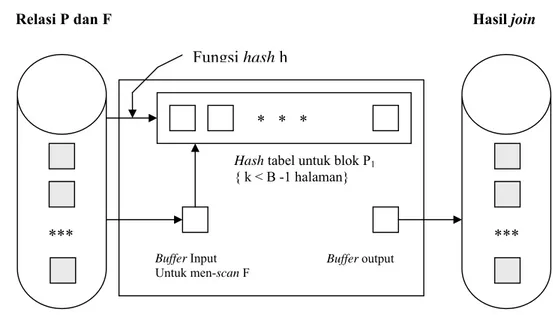
4.2.3.2 Block-Nested-Loops-Join
Algoritma simple-nested-loops-join tidak memanfaatkan halaman buffer B secara efektif. Andaikan CPU mempunyai memory yang cukup untuk mempertahankan relasi P, diasumsikan paling sedikit terdapat dua halaman buffer ( B-2) ekstra yang tersisa. Kemudian menggunakan salah satu dari halaman buffer ekstra untuk men-scan relasi F. Untuk tiap record f ∈ F, memeriksa P dan menghasilkan record ( p, f ) untuk record f yang memenuhi syarat (misalnya, pi=fj ). Halaman buffer ekstra kedua digunakan sebagai buffer output. Tiap relasi hanya di scan sekali, sehingga biaya total : I/O M + N .
Berikutnya mempartisi relasi P menjadi blok yang dapat masuk ke halaman buffer, kemudian men-scan semua F untuk tiap blok P. P adalah relasi
pertama, cukup di-scan sekali, dan F adalah relasi kedua dan di-scan banyak kali. Jika memori tersedia sebanyak B halaman buffer, maka P dapat masuk kedalam B-2, dan men-scan relasi dalam F dengan menggunakan satu dari dua halaman yang masih ada. Kita dapat menulis record (p, f), dimana p ∈ P blok, f ∈ F halaman, dan pi = fj dengan menggunakan halaman buffer terakhir untuk menulis output.
Cara yang efisien untuk menemukan pasangan record yang cocok (misalnya record yang memenuhi syarat join pi = fj ) adalah membentuk main memory hash tabel ( yaitu tabel sementara hasil join tersimpan dalam memori utama) untuk blok P. Karena hash tabel melibatkan pertukaran ukuran blok P yang efektif, dalam hal ini jumlah record per blok dikurangi.
Algoritma block-nested-loops dideskripsikan pada Gambar 12 dan penggunaan buffer dalam algoritma diilustrasikan pada Gambar 13.
foreach block of B-2 pages of P do
foreach page of F do
{ for all maching in-memory record p ∈ P block dan f ∈ F –page,
add (p,f) to result }
Gambar 12. : Algoritma Block-nested-loops-Join (Raghu 2003)
Biaya strategi ini adalah M I/O untuk membaca P (scan sekali), F di-scan sebanyak ⎢⎢⎡ ⎥⎥⎤
−2 B
M
kali, ini diperlukan berkenaan dengan in-memory hash tabel (yaitu tabel yang akan dibuat sementara dalam memori utama berisi tabel hasil join), dan biaya tiap scan N I/O.
Jadi biaya totalnya adalah = ⎢⎢⎡ ⎥⎥⎤ − + 2 * B M N M ... (4.2). dimana : M : Jumlah halaman pada tabel relasi pertama P
N : Jumlah halaman pada tabel relasi kedua F B : Blok halaman buffer
Gambar 13: Penggunaan buffer Block-nested-loops-Join (Raghu 2003 )
Relasi pst_ke1 adalah relasi pertama P dan pstaktif adalah relasi kedua F. Asumsikan bahwa kita mempunyai buffer yang cukup untuk menahan in-memory hash tabel untuk 100 halaman pst_ke1, sehingga harus men-scan pst_ke1 dengan biaya 38.730 I/O. Untuk tiap 100 halaman blok pst_ke1, harus di-scan pstaktif. Oleh karena itu akan menampilkan 10 halaman scan dari pstaktif, yang masing-masing biayanya adalah 45.242 I/O, maka biaya totalnya adalah :
38.730 + 10 * 45.242 = 491.150 halaman I/O
jika tersedia buffer yang cukup untuk menahan 90 halaman pst_ke1, maka harus men-scan pstaktif 38.730 / 90 = 430 kali, dan biaya total akan menjadi :
38.730 + 430 * 45.242 = 19.509.380 halaman I/O
Jika kemampuan perangkat keras I/O mempunyai kecepatan 10ms, maka total biaya di atas adalah :
19.509.380 * 0,0000028 = 54,2 jam 542 / 24 = 2,26 hari.
Hasilnya menunjukkan lebih baik dari metode nested-loops-join yang tidak memanfaatkan blok buffer.
* * *
*** ***
Buffer Input
Untuk men-scanF Buffer output
Hash tabel untuk blok P1
{ k < B -1 halaman}
Relasi P dan F Hasil join
4.2.3.3 Sort- Merge-Join
Dasar pemikiran dari Sort-Merge-Join adalah mengurutkan kedua relasi pada atribut yang akan melakukan join, lalu mencari record yang memenuhi syarat p ∈ P dan f∈ F , dengan menggabungkan dua relasi. Langkah pengurutan mengelompokkan semua record yang mempunyai nilai sama dalam kolom join, untuk memudahkan dalam mengidentifikasi partisi, atau grup record dengan nilai sama dalam kolom join. Sort-Merge-Join memanfaatkan partisi dengan membandingkan record P dalam partisi hanya dengan record F dalam partisi yang sama (dengan semua record F), dengan demikian dapat menghindari perhitungan cross-product P dan F. (Pendekatan secara spesifik hanya bekerja untuk syarat equality join).
Jika relasi telah diurutkan berdasarkan atribut join, selanjutnya memproses penggabungan secara terperinci. Pertama scanning relasi P dan F untuk mencari record yang memenuhi syarat (misalnya, record Tp dalam P dan Tf , dalam F sehingga Tpi=Tfj). Kedua, scanning dimulai pada record pertama dalam tiap relasi dan scan P selama record P terbaru kurang dari record F terbaru (mengacu pada nilai atribut join ). Ketiga, scan F selama record F terbaru kurang dari record P terbaru, dan memilih sampai menemukan P record Tp dan F record Tf dengan syarat Tp i = Tf j.
Pada saat menemukan record Tp dan Tf yaitu Tp i = Tf j, hasilnya perlu dikeluarkan. Tetapi pada kenyataannya dapat terjadi beberapa record P dan beberapa record F mempunyai nilai yang sama. Disini mengacu pada record tersebut sebagai partisi P terbaru dan partisi F terbaru. Untuk tiap record p dalam partisi P terbaru, scan semua record f dalam partisi F terbaru yang akan menghasilkan record hasil join ( p, f ), kemudian dilanjutkan scan P dan F, mulai dengan record pertama dan mengikuti partisi yang baru diproses.
Algoritma Sort-Merge-Join ditunjukkan pada Gambar 14 menetapkan nilai record pada variable Tp, Tf dan Gf, menggunakan nilai eof untuk menandai bahwa tidak ada record lagi dalam relasi yang sedang di-scan. Subscripts mengidentifikasi field, Tpi menyatakan atribut ke i dari record Tp. jika Tp mempunyai nilai eof, maka setiap perbandingan yang melibatkan TPi didefinisikan
untuk mengevaluasi kondisi false, dengan syarat join yang menjadi equality pada atribut no_tsp.
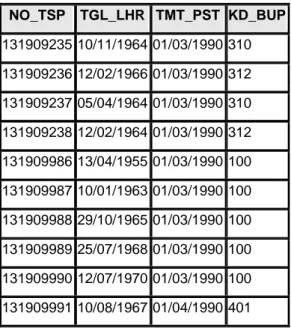
Relasi pst_ke1 diurutkan pada no_tsp, relasi pstaktif diurutkan pada atribut nippa. Tahap penggabungan pada algoritma sort-merge-join mulai dengan scan pada record pertama pada masing-masing relasi. Dahulukan scan pst_ke1, karena nilai no_tsp = ‘131909235’ pada pst_ke1, pada contoh segmen tabel pst_ke1 (lihat Tabel 9), kurang dari nilai nippa = ‘131909236’ pada pstaktif. Record kedua pst_ke1 mempunyai nilai ‘131909236’, sama dengan nilai nippa record pstaktif terbaru, pada pstaktif (lihat Tabel 10). Hasil join mendapatkan sepasang record, satu dari pst_ke1 dan satu dari pstaktif, dalam partisi terbaru (berisi nippa = no_tsp =’131909236’). Karena hanya mempunyai satu record pst_ke1 dengan nilai no_tsp=’131909236’ dan satu record dari pstaktif, maka selanjutnya menuliskan satu record hasil pada partisi keluaran. Tahap selanjutnya pemposisikan scan pstaktif pada record pertama dengan nippa = ‘131909237’. Sama halnya dalam memposisikan scan sebelumnya, karena record kedua tersebut mempunyai nilai yang sama dengan no_tsp record ketiga yaitu '131909237' dari pst_ke1, maka jika telah ditemukan partisi yang cocok, tulis lagi record yang dihasilkan oleh partisi ini pada partisi keluaran. Atribut no_tsp dan nippa sama-sama key sehingga paling banyak hanya satu record yang cocok dalam partisi. Selanjutnya scanning pada pst_ke1 diposisikan pada no_tsp=’131909238’, scanning pstaktif diposisikan pada record nippa=’131909238’, tahap penggabungan selanjutnya dilakukan dengan cara yang sama.
Proc smjoin( P, F, ‘Pi = Fj )
if P not sorted on atribut i, sort it;
if F not sorted on atribut j, sort it;
Tp = first record in P; // range over P
Tf = first record in F; // range over F
Gf = first record in F; // start of current F-partition
while Tp≠ eof and Gf≠ eof do{
while Tpi < Gfjdo
Tp = next record in P after Tp; // continue scan of P
while Tpi > Gfjdo
Gf = next record in F after Gf; // continue scan of F
Tf = Gf ; // needed in case Tpi≠ Gfj
while Tpi = = Gfjdo { // process current P partition
Tf =Gf ; // reset F partition scan
while Tfj = Tpi do { // process current P record
add (Tp, Tf) to result; // output joined records
Tf = next record in F after Tf ; } // advance F partition scan
Tp =next record in P after Tp; // advanced scan of P
} // done with current P partition
Gf = Tf ; // initialize search for next F partition
}
Tabel 9 : Contoh Segmen Tabel pst_ke1 NO_TSP TGL_LHR TMT_PST KD_BUP 131909235 10/11/1964 01/03/1990 310 131909236 12/02/1966 01/03/1990 312 131909237 05/04/1964 01/03/1990 310 131909238 12/02/1964 01/03/1990 312 131909986 13/04/1955 01/03/1990 100 131909987 10/01/1963 01/03/1990 100 131909988 29/10/1965 01/03/1990 100 131909989 25/07/1968 01/03/1990 100 131909990 12/07/1970 01/03/1990 100 131909991 10/08/1967 01/04/1990 401
Tabel 10 : Contoh segmen Tabel pstaktif
NIPPA TGL_LHR TMT_PST SEX GAJI_POKOK BLTH_GAPOK SUSKEL PANGKAT
13190923613/02/196601/03/1990 L 901500 012001 100 3C 13190923705/04/196401/03/1990 L 828200 082001 101 3B 13190923812/02/196401/03/1990 L 870100 012001 103 3B 13190923907/05/196601/03/1990 P 891900 072002 000 3B 13190924008/02/196701/03/1990 P 870100 082001 101 3B 13190924128/12/196701/03/1990 L 839800 082001 102 3A 13190924303/08/196201/03/1990 P 914200 082001 101 3B 13190924431/03/196401/03/1990 L 870100 082001 102 3B 13190924505/04/196401/03/1990 L 848900 082001 101 3B 13190924612/10/196501/03/1990 L 901500 082001 102 3C
Secara umum, algoritma harus men-scan partisi record dalam relasi kedua dalam F sesering jumlah record dalam partisi yang sesuai dengan relasi pertama P
4.2.3.4Biaya Sort-Merge-Join
Biaya sorting P adalah O(M log M) dan biaya sorting F adalah O(N logN). Biaya dari tahap penggabungan adalah M + N jika tidak terdapat partisi F di-scan beberapa kali (atau halaman yang diperlukan ditemukan dalam buffer setelah tahap pertama). Pendekatan ini sangat menarik jika setidaknya terdapat satu relasi yang telah disortir pada atribut join atau mempunyai clustered indek pada atribut join.
Perhatikan join dari relasi pst_ke1 dan pstaktif, asumsikan bahwa kita mempunyai 100 halaman buffer, kemudian dapat mengurutkan pstaktif dalam dua tahap. Tahap pertama menghasilkan 10 run tiap 100 halaman yang diurutkan secara internal. Tahap kedua menggabungkan 10 run tersebut untuk menghasilkan relasi yang disortir. Karena membaca dan menulis dalam tiap tahap biaya sortingnya adalah :
2 * 2 * 38.730 = 154..920 halaman I/O
Sama halnya kita dapat menyortir pstaktif dalam dua tahap dengan biaya 2 * 2 * 45.242 = 180.968 halaman I/O
Selain itu tahap kedua algoritma sort-merge-join meminta scan tambahan kedua relasi , jadi total biaya adalah :
154.920 + 180.968 + 38.730 + 45.242 = 419.860 halaman I/O. Apabila kecepatan perangkat keras 10 ms, maka :
419.860 * 0,0000028 = 1,166277778 jam
4.2.3.5Hash Join
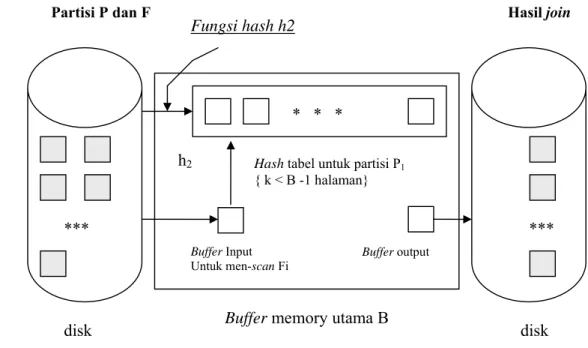
Algoritma Hash join, seperti algoritma sort-merge-join, yaitu mengidentifikasi partisi dalam P dan F dalam tiap partisi dan dalam tahap equality berikutnya membandingkan record dalam partisi P hanya dengan record dalam F yang sesuai untuk menguji syarat equality join. Berbeda dengan sort-merge-join, hash join menggunakan hashing untuk mengidentifikasi partisi dalam pengurutan. Tahap partisi ini dapat disebut juga sebagai building dari hasil hash join serupa dengan partisi dalam proyeksi hash based dan diilustrasikan dalam Gambar 15, dan tahap equality atau disebut matching diilustrasikan dalam Gambar 16.
Gambar 15: Tahap Partisi Proyeksi Hash-Based. (Raghu 2003)
Gambar di atas menandakan bahwa jika terdapat sejumlah besar (misalkan B halaman buffer relatif) dengan jumlah halaman P, maka pendekatan hash-based sangat perlu, karena terdapat dua tahap pekerjaan yaitu : partisi dan eliminasi duplikat.
Dalam tahap partisi dipunyai satu halaman buffer input dari B-1 halaman buffer output. Relasi P dibaca ke dalam halaman buffer input, setiap satu halaman. Halaman input diproses sebagai berikut : Untuk tiap record, diproyeksikan sesuai atribut yang diinginkan, dan kemudian mengaplikasikan fungsi hash h pada kombinasi dari semua atribut yang ada. Fungsi h dipilih sehingga record didistribusikan secara seragam pada satu B-1 partisi; dan terdapat satu halaman output per partisi. Setelah proyeksi record diisi ke halaman buffer output yang di hash menurut h.
Pada akhir tahap partisi, mempunyai B-1 partisi, masing-masing berisi kumpulan record menggunakan nilai hash umum (dihitung dengan mengaplikasikan h pada semua field, dan hanya mempunyai field yang diinginkan. Dua record yang tercakup dalam partisi yang berbeda dijamin tidak menjadi duplikat karena mereka mempunyai nilai hash yang berbeda. Jadi jika
* * *
*** * * *
Input
Fungsi hash
h
Partisi Orisinil Partisi
disk Buffer memory utama B disk
B-1 1 2 B-1 1 2
dua record merupakan duplikat, maka mereka berada dalam partisi yang sama. Dalam tahap eliminasi duplikat dibaca B-1 partisi satu per satu untuk menghilangkan duplikat, dasar pemikirannya adalah membentuk in-memory hash tabel seperti memproses record untuk mendeteksi duplikat. Untuk tiap partisi dihasilkan dalam tahap pertama :
1. Baca partisi satu halaman per satu waktu. Hash tiap record dengan mengaplikasikan fungsi hash h2 ( ≠ h ) pada kombinasi dari semua field dan kemudian menyisipkannya ke dalam in-memory hash tabel. Jika record baru meng-hash nilai yang sama seperti beberapa record yang ada, maka bandingkan keduanya untuk memeriksa apakah record baru tersebut merupakan duplikat, buang duplikat saat ditemukan.
2. Setelah semua partisi telah dibaca, tulis record dalam hash tabel (dimana tidak terdapat duplikat) ke file hasil, kemudian bersihkan in-memory hash tabel untuk mempersiapkan partisi berikutnya.
Untuk persoalan join idenya adalah meng-hash kedua relasi pada atribut join, menggunakan fungsi hash h yang sama. Jika meng-hash tiap relasi (idealnya secara seragam) ke dalam k partisi, maka yakin bahwa record P dalam partisi i hanya dapat join dengan record F dalam partisi j yang sama. Pengamatan ini dapat digunakan untuk pengaruh yang baik, yaitu dapat membaca dalam partisi secara lengkap dari relasi P yang lebih kecil dan hanya men-scan partisi sesuai dengan F untuk kesesuaian. Dan selanjutnya tidak perlu memperhatikan record P dan F lagi. Jadi setelah P dan F di partisi, maka dapat dilakukan join dengan hanya membaca P dan F sebanyak satu kali saja. Dan menyediakan memory yang cukup diperkenankan untuk menyimpan semua record dalam partisi P tertentu.
Dalam praktek sistem membentuk in-memory hash tabel untuk partisi P, menggunakan fungsi hash h2 yang berbeda dari h ( karena h2 dimaksudkan untuk mendistribusi record dalam partisi yang berdasarkan h ), untuk mengurangi biaya CPU. Hal ini sangat memerlukan memory yang cukup untuk memegang hash tabel, yang sedikit lebih besar daripada partisi P itu sendiri.
Gambar 16: Tahap equality join menggunakan Hash-Join.(Raghu 2003)
Algoritma hash join dipresentasikan pada Gambar 17, perhatikan biaya algoritma hash join. Dalam tahap partisi harus men-scan P dan F sekali dan menulisnya sekali. Oleh karena itu biaya tahap ini adalah 2 ( M + N ). Pada tahap kedua men-scan tiap partisi sekali, dengan asumsi bahwa tidak terdapat partisi overflow, dengan besar biayanya adalah :
( M + N ) I/O
sehingga dengan demikian biaya total adalah : 3 ( M + N )
dengan asumsi bahwa tiap partisi dapat dimasukkan dalam memory pada tahap kedua. Pada contoh join dari pst_ke1 dan pstaktif biaya total adalah :
3 * ( 38.733 + 45.242) = 251.925 halaman I/O.
Apabila unjuk kerja komputer diasumsikan 10 ms per I/O, hash join memerlukan waktu sebesar:
251.925 * 0,0000028 = 0,699791667 jam
hal tersebut dikarenakan algoritma hash join memanfaatkan buffer ekstra (in-memory) dan menggunakan variabel dinamis dimana memory yang sudah tidak digunakan dapat dibersihkan.
* * *
*** ***
Buffer Input
Untuk men-scanFi Buffer output
Hash tabel untuk partisi P1
{ k < B -1 halaman}
Partisi P dan F Hasil join
disk Buffer memory utama B disk
Fungsi hash h2
Dari hasil analisis di atas jelas terlihat bahwa algoritma mem-partisi tabel-tabel relasi dengan menggunakan metode hash join secara parsial dapat menunjukkan unjuk kerja query secara signifikan. Tetapi prinsip Hash Based harus dirancang sebelum aplikasi digunakan, karena tabel-tabel relasi harus berupa “hash tabel” yang mana terdapat fungsi hash berupa variabel pointer yang dapat menunjuk langsung pada alamat tertentu sesuai keperluan yang dilakukan dalam hash join,
// partition P into k partitions foreach record p ∈ P do
read p and it to buffer page h(pi); // flushed as page fills // Partition F into k partitions
foreach record f ∈ F do
read f and it to buffer page h(fj); // flushed as page fills // Probing phase
for l=1,... , k do {
// build in memory hash tabel for Pi, using h2 foreach tuple p ∈ Partition Pi do
read p and insert into hash table using h2(pi); // Scan Fl and Probe for matching Pi record
foreach record f ∈ Partition Fj do { read f and probe tabel using h2 ( fj ); for matching P record p, output (p,f) } clear hash tabel to prepare for next partition; }
Gambar 17. Algoritma Hash-Join (Raghu 2003)
4.2.3. Analisis Signifikansi Optimisasi Query.
Proses scanning relasi yang berulang kali dari sebuah partisi akan memerlukan biaya yang mahal. Untuk meningkatkan kesempatan suatu partisi dapat masuk kedalam memory yang tersedia dalam tahap equality, besaran partisi harus diminimalkan dengan memaksimalkan jumlah partisi. Dalam tahap partisi,
untuk mem-partisi P (sama halnya dengan F) ke dalam k partisi memerlukan k buffer output dan satu buffer input. Misalkan terdapat B halaman buffer, jumlah maksimum partisi k = B-1, dengan asumsi bahwa ukuran partisi sama, maka ukuran tiap partisi P adalah
1
−
B M
(M adalah jumlah halaman P). Jumlah halaman
dalam (in-memory hash tabel) partisi terbentuk selama tahap equality adalah
1 − B
cM
, dimana c adalah nilai konstanta yang digunakan untuk meningkatkan ukuran antara partisi dan hash tabel.
Dalam tahap equality selain hash tabel untuk partisi P diperlukan halaman buffer untuk scanning partisi F dan halaman buffer untuk keluaran. Maka buffer yang diperlukan sebanyak 2
1 . + − > B M c
B , dan buffer B> c.M , agar algoritma hash join dapat dilakukan dengan baik.
Partisi P diharapkan sesuai dengan tersedianya buffer, sehingga buffer B 1 − > B M
, maka jumlah halaman buffer yang diperlukan lebih kecil daripada
M c
B> . . Resiko akan timbul jika fungsi hash h tidak mempartisi P secara seragam, maka hash tabel untuk satu partisi P atau lebih mungkin tidak dapat masuk ke dalam memory selama tahap equality. Situasi ini secara signifikan dapat menurunkan unjuk kerja.
Proyeksi Hash-based adalah salah satu cara untuk menangani masalah overflow partisi, yaitu mengaplikasikan teknik hash join secara berulang pada join partisi P yang overflow dengan partisi F yang bersangkutan. Pertama membagi partisi P dan F ke dalam subpartisi, berikutnya melakukan join subpartisi secara berpasangan. Semua subpartisi P masuk ke dalam memory dengan mengaplikasikan teknik hash join secara berulang, seperti tertulis dalam algoritma pada Gambar 17.
Memori ekstra adalah memori yang tersedia dalam memori utama berupa RAM atau chace memori dan metode hybrid hash join adalah salah satu metode yang memanfaatkan memori ekstra. Jika tersedia lebih banyak memory, maka hybrid hash join dapat digunakan.
Andaikan bahwa ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ > k M c
B . , k adalah jumlah partisi yang dapat
dibentuk. Jika P dibagi menjadi k partisi ukuran ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ k M
, in-memory hash tabel dapat dibentuk untuk tiap partisi. Untuk partisi P ( sama halnya dengan F) menjadi k partisi dibutuhkan k buffer output dan satu buffer input, yaitu k+1 halaman, dan akan menyisakan sebanyak B-(k+1) halaman ekstra selama tahap
partisi. Jika ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ > + − k M c k
B ( 1) . , berarti mempunyai cukup memory ekstra selama tahap partisi. Metode hybrid hash join adalah membentuk in-memory hash tabel untuk partisi pertama P selama tahap partisi, yang berarti bahwa dapat menulis partisi ke disk. Sama halnya saat mempartisi F, dapat langsung melakukan equality dalam in-memory hash tabel dengan partisi P pertama. Pada akhir tahap partisi telah menyelesaikan equality join, selanjutnya algoritma bekerja seperti dalam hash join.
Penghematan melalui hybrid hash join yaitu menghindari untuk menulis partisi pertama P dan F ke disk selama tahap partisi, dan membacanya kembali selama tahap equality. Apabila dilihat contoh pada pst_ke1 yang terdapat 38.730 halaman dalam relasi P lebih kecil dari 45.242 dari relasi F. Jika buffer tersedia B=300 halaman, maka dapat dengan mudah membentuk in-memory hash tabel untuk partisi P pertama saat mempartisi P menjadi dua partisi. Selama tahap partisi P algoritma dapat membaca P dan menulis satu partisi, biayanya adalah:
38.730 + 19.366 = 58.096 halaman I/O
Jika diasumsikan bahwa partisi mempunyai ukuran yang sama, kemudian selanjutnya membaca F dan menulis satu partisi, biayanya adalah :
45.242 + 38.730 = 83.972 halaman I/O
Pada tahap equality membaca partisi kedua P dan F, biayanya adalah : 19.366 + 38.730 = 58.096 halaman I/O
Biaya totalnya adalah :
58.096 + 83.972 + 58.096 = 200.164 halaman I/O.
Jika kecepatan 1 halaman I/O memakan waktu 10 ms, maka kecepatan totalnya adalah :
200.164 * 0,0000028 = 0,556 jam
Dilihat dari hasil perhitungan, terdapat penurunan waktu runtime yang signifikan antara algoritma hash join dengan nilai 0,69 jam dan algoritma hybrid hash join sebesar 0,56 jam , yaitu sebesar ( 0, 69 jam – 0,56 jam = 0,13 jam).
Jika mempunyai cukup memori untuk menyimpan in-memory hash tabel untuk semua P, maka penghematannya akan lebih besar. Misalkan jika B> c.N+2, yaitu k = 1, maka dapat membentuk hash tabel ini dan membaca F sekali untuk menyelidiki hash tabel P sehingga biayanya menjadi :
38730 + 45242 = 83.972 I/O.
Apabila unjuk kerja komputer mempunyai kecepatan I/O 10 ms, yaitu : 83.972 * 0,0000028 = 0,233 jam
Metode hybrid hash join, saat ini untuk DBMS komersial terdapat dalam Oracle, IBM DB2, dan Informix.
Analisis perhitungan optimisasi query dengan metode hybrid-hash-join, hasilnya menunjukkan bahwa proses optimisasi query dapat dicapai secara signifikan apabila memory CPU dapat menampung sejumlah buffer dan bucket-bucket (in-memory hash tabel dengan sejumlah halaman) yang sedang diproses. Apabila hash tabel tidak dapat dibentuk, maka selama tahap partisi dan tahap equality, hasil query akan selalu ditulis ke disk yang tentunya akan memakan waktu yang cukup lama.
Untuk mengatasi proses query yang cukup lama dan menghindari partisi overflow dapat dilakukan fragmentasi horizontal sesuai dengan rentang atau kriteria tertentu, hasil fragmentasi disebar dibeberapa server dan diasumsikan penyebaran data seragam.
4.2.4. Analisis Optimisasi query optimizer DBMS MySQL
DBMS MySQL Oprimizer dapat memberikan perkiraan unjuk kerja pecarian dari disk. Untuk tabel-tabel yang kecil dapat mencari baris dalam satu disk secara berurutan. Jika tabel-tabel cukup besar, dapat diperkirakan dengan menggunakan B++ tree index, akan diperlukan langkah pencarian sebanyak i : log(row_count) / log(index_block_length / 3 * 2 / (index_length + data_pointer_length)) + 1 seeks to find a row ... (4.3) dan memerlukan buffer sebanyak :
row_count * (index_length + data_pointer_length)*3/2 ... (4.4) Dalam MySQL banyak indek dalam block adalah 1024 bytes dan panjang data pointer 4 bytes dan panjang indek 3 bytes. Jika diaplikasikan pada tabel pst_ke1 yang mempunyai record sebanyak 3.873.324, maka dalam tabel pst_ke1 dengan mempunyai panjang data pointer 4 bytes dan panjang indek 3 bytes, berdasarkan persamaan (4.3) akan didapat nilai pencarian sebesar :
log(3.873.324 )/log(1024/3*2/(3+4)) + 1 = (6.58880 / 0.07167 ) + 1 = 93 kali pencarian.
dan berdasarkan persamaan (4.4), memerlukan buffer sebanyak 3.873.324 * 7 * 3/2 = 40,6 MB
Untuk tabel pstaktif mempunyai jumlah record sebesar 3.619.423, akan mempunyai nilai pencarian sebesar :
log(3.619.423 )/log(1024/3*2/(3+4)) + 1 = (6.55863 / 0.07167 ) + 1 = 92 kali pencarian dan memerlukan buffer sebanyak
3.619.423 * 7 * 3/2 = 38 MB
Proses pencarian satu indek dalam tabel pst_ke1 diperlukan 93 langkah dan memerlukan memori sebanyak 40,6 MB, sedangkan untuk tabel pstaktif pencarian indek diperlukan 92 langkah dengan memerlukan memori sebanyak 38MB. Diasumsikan buffer index digunakan sebanyak 2/3, normalnya proses pencarian dilakukan 2 kali, yaitu untuk update indek dan menulis baris.
Proses selanjutnya melakukan join setelah record mempunyai indek yang sesuai, dan kemudian dilakukan equality join.
Untuk menghitung biaya join diperlukan ii : a. Jumlah blok sebesar :
bP =r / bfr ... (4.5) dimana : r = jumlah record
bfr = blocking factor (jumlah record per blok)
b. Selection cardinality, yaitu :
Satribut = rP / datribut ... (4.6) dimana : rP = jumlah record dalam tabel pertama
datribut = distinct value tabel kedua
c. Biaya algoritma nested loop :
Cost = bP + ( bP * bF) + [ ( js * rP * rF) / bfrF ] ... (4.7) dimana : bp = jumlah blok dalam tabel pertama
bF = jumlah blok tabel kedua
js = join selectivity sebesar (1/jumlah record tabel kedua) rP = jumlah record dalam tabel pertama
rF = jumlah record dalam tabel kedua
bfrF = blocking factor dari tabel kedua
d. Biaya algoritma B++ tree indek structure :
Cost = bP + (rP * ( XatributF + SatributP))+[ (js*rP * rF) / bfrF ] ... (4.8) dimana : bp = jumlah blok dalam tabel pertama
rP = jumlah record dalam tabel pertama
XatributF = primary index tabel kedua
SatributP = Selection cardinality tabel pertama
js = join selectivity sebesar (1/jumlah record tabel kedua) rF = jumlah record dalam tabel kedua
bfrF = blocking factor dari tabel kedua
ii
Contoh kasus sebelumnya perintah join query yaitu:
SELECT *
FROM pst_ke1 P, pstaktif F WHERP P. no_tsp = F. no_tsp
Tabel pst_ke1 P mempunyai 3.873.324 record. Jadi rp = 3.873.324 ( rP adalah
record dalam P ). Diasumsikan jumlah record pst_ke1 per-halaman dalam satu disk blok adalah 100. Jadi bfrP= 100. Jika b adalah jumlah blok yang diperlukan untuk menyimpan tabel, maka jumlah blok dalam tabel P adalah bP, berdasarkan persamaan (4.5) blocking factor dari tabel P adalah :
bP =rP / bfrP
= 3.873.324 / 100 = 38.733
Untuk membedakan nilai indek diperlukan sebuah secondary index pada no_tsp dengan Xno_tsp = 2. Jangkauan atribut no_tsp terhadap nippa dari tabel pstaktif diperlukan 3.619.423 distinct value untuk no_tsp. Jadi dno_tsp= 3.619.423
Berdasarkan persamaan (4.6), nilai selection cardinality tabel P dari no_tsp adalah:
Sno_tsp = rP / dno_tsp
= 3.873.324 / 3.619.423 = 1,07
Tabel pstaktif mempunyai 3.619.423 record. Jadi rF = 3.619.423 dengan
Blocking factor dari pstaktif adalah bfrF= 80, maka nilai blok untuk pstaktif F
adalah bF = 45242. Primary index pada nippa adalah tunggal, maka Xnippa = 1
Berdasarkan asumsi-asumsi di atas, Join Selectivity (js) adalah 1 / 3.619.423. dan untuk mendapatkan harga yang minimum, dapat dilakukan perhitungan berdasarkan persamaan (4.7) untuk nested loop, dan persamaan (4.8) untuk index structure yaitu :
1. Menggunakan nested loop dengan pst_ke1 pada bagian luar : Cost = bP + ( bP * bF) + [ ( js * rP * rF) / bfrF ]
= 38733 + ( 38733 * 45242 ) + [ (1 / 3.619.423 * 3.873.324 * 3.619.423 ) / 80 ] = 38733 + 1752358386 + 48416,55
= 1752445536 blok
Apabila kecepatan I/O komputer mencapai 10ms, maka biaya di atas menjadi : = 1752445536 * 0,0000028, hasilnya setara dengan
= 4906,85 jam = 204,5 hari
2. Menggunakan nested loop dengan pstaktif pada bagian luar : Cost = bF + ( bF * bP) + [ ( js * rP * rF) / bfrF ]
= 45242 + (45242 * 38733 ) + [ ( 1 / 3.619.423 * 3.873.324 * 3.619.423 ) / 80 ] = 45242 + 1752358386 + 48416,55
= 1752452027,55 blok , jika kecepatan I/O komputer mencapai 10ms, maka, = 1752452027,55 * 0,0000028, hasilnya setara dengan
= 4906,86 jam = 204 hari
3. Menggunakan index structure pada nippa dengan pst_ke1 pada bagian luar. Cost = bP + ( rP * ( Xnippa + Sno_tsp) ) + [ ( js * rP * rF) / bfrF ]
= 38733 + ( 3.873.324*(1 + 1)) + [(1/3.619.423 * 3.873.324 * 3.619.423) / 80 ] = 38733 + 7746648 + 48416,55
= 7833797,55 blok, jika kecepatan I/O komputer mencapai 10ms, maka, = 7833797,55 * 0,0000028, hasilnya setara dengan
= 21,935 jam = 0,91395 hari
4. Menggunakan index structure pada nippa dengan pstaktif pada bagian luar. Cost = bF + ( rF * ( Xno_tsp + Sno_tsp ) ) + [ ( js * rP * rF) / bfrF ]
= 45242+ (3.619.423*(2+1,07 ))+ [(1/3.619.423 * 3.873.324 * 3.619.423) /80] = 45242 + 11111628,61 + 48416,55
= 11205287,16 blok , jika kecepatan I/O komputer mencapai 10ms, maka, = 11205287,16 * 0,0000028, hasilnya setara dengan
= 31,3748 jam = 1,37 hari
Dari hasil perhitungan menunjukkan bahwa persamaan ketiga mempunyai biaya 21,935 jam adalah nilai yang paling rendah, sehingga optimizer akan memilih eksekusi menggunakan persamaan yang ketiga. Biaya keempat proses di atas tidak termasuk proses pencarian yang dilakukan sebelum operasi join, untuk proses pencarian biaya dapat diabaikan karena proses pencarian dilakukan didalam buffer.
Fasilitas optimizer dari DBMS MySQL, menggunakan index structure biaya query lebih rendah dibandingkan dengan biaya menggunakan nested loops, MySQL optimizer akan memilih dan menggunakan index structure, dengan persyaratan spesifikasi minimum untuk tabel yang besar harus dipenuhi , sebagai berikut iii :
Processor Intel Pentium IV Set Up Buffer : Key_buffer = 384 M max_allowed_packet = 1 M table_cache = 512 M Sort_buffer_size = 2 M read_buffer_size = 2 M MyISAM_sort_buffer_size = 64 M thread_cache_size = 32 M iii
4.3. Percobaan
Penulis melaksanakan percobaan menggunakan fasilitas jaringan komputer yang berada di Kampus FMIPA UNPAD Jatinangor (” sebagian peta network dapat dilihat pada Gambar 23 ”), fasilitas tersebut menggunakan arsitektur client-server dengan spesifikasi antara lain :
- Client : Processor Intel Pentium IV Core Duo 2,66 GHZ Memory 512 MB, Harddisk 60 GB
Processor Intel Pentium IV 1,7 GHZ Memory 256 MB, Harddisk 40 GB Sistem Operasi Windows XP
- Server : Processor Intel Pentium IV Core Duo 2,66 GHZ Memory 2 GB, Harddisk 80 GB
Sistem Operasi Linux Redhat - Software DBMS: Mysql 4.0.3 win
My ODBC 3.51.06 My SQL-Front_2.5
My-SQL Administrator 1.0.5
Dalam melakukan perintah-perintah query terdapat karakteristik dari DBMS dan arsitektur client server antara lain :
1. Client dan server dapat melakukan komputasi, client dapat menerima bagian dari jawaban query.
2. Server melakukan replikasi kepada client secara real time dimana server sebagai server master dan client sebagai server slave.
3. Client akan merubah data transaksi pada server sebelum koneksi ke server di tutup.
Dalam skenario yang memiliki 3 karakteristik ini minimasi waktu akses dan transfer data menjadi sangat penting, sehingga masalah minimasi ongkos yang dikeluarkan dalam transfer hasil query dapat menjadi lebih murah.
Ada beberapa cara yang mungkin untuk mendekomposisi query kedalam hasil views, rencana terbaik yaitu mempunyai ukuran minimum dan pada basis data di server.
Sebuah keuntungan dari pendekatan ini adalah bahwa menggunakan metoda formal, untuk memilih optimisasi secara global yang terdapat dalam DBMS dapat diperhitungkan dan dapat dibuktikan pada saat yang sama efisiensi metoda-metoda yang men-dekomposisi query kedalam views, dengan kata lain untuk sebuah query yang diberikan dari sebuah client ke server. Dalam percobaan dengan ketiga skenario di atas ongkos komunikasi tidak dapat diabaikan dan akan berpengaruh pada total perhitungan waktu, kemudian hasilnya dapat dievaluasi dalam berbagai kasus query tersebut.
Dalam percobaan ini data relasi disimpan pada client (server slave) dan server (server master), situasinya dapat dilihat pada Gambar 23, masing-masing pst_ke1 dan pstaktif disimpan dalam client (server slave), sedangkan, pmk_ke1, pmk_fd1 dan pstpens disimpan dalam server (server master).
Dalam DBMS yang penulis gunakan client terkoneksi dengan database server, dan server melakukan replikasi pada client. Replikasi yang dijalankan yaitu dari server master ke server slave, transfer data (selama replikasi) antar server apabila query menggunakan MySQL kecepatannya mencapai 0,0002 detik dalam keadaan kondisi jaringan normal.
Untuk percobaan yang dilakukan tabel-tabel yang diuji masih berupa tabel dengan tipe file masih ber-ekstensi .dbf, tabel tersebut dikonversi kedalam tabel Microsoft Access, setelah menjadi file Microsoft Access kemudian dikonversi lagi kedalam database MySQL, hal ini dilakukan karena karakteristik database tersebut banyak mengandung duplikasi dan banyak kesalahan dari tipe data yang tidak sesuai dengan isi data, begitu pula untuk field yang tidak null banyak yang tidak dipenuhi, sehingga apabila data berupa file .dbf tersebut langsung di konversi kedalam database MySQL sulit dapat diterima.
Dari hasil pengamatan dalam proses query yang dilakukan terdapat hasil analisis dari beberapa output runtime antara lain :
1. Perintah-perintah query yang tidak melakukan join tidak terdapat masalah walaupun jumlah record cukup besar dengan rata-rata lebih dari satu juta record dengan kapasitas memori tabel di atas 100 MB.
2. Perintah-perintah query dengan menggunakan proses optimisasi menggunakan kriteria tertentu baik dalam satu relasi atau lebih dari satu
relasi, perbedaan kecepatan join query sangat signifikan, walaupun dalam DBMS sendiri sudah mempunyai fasilitas optimizer.
3. Proses optimisasi dengan mendahulukan proses seleksi sebelum melakukan join, proses eksekusi waktunya lebih cepat dari pada melakukan join lebih dahulu kemudian melakukan seleksi.
4. Perubahan-perubahan hasil proses optimisasi sangat terlihat dalam jumlah record diatas 100.000, demikian juga untuk spesifikasi komputer yang berbeda, perbedaan runtime terlihat pada record diatas 100.000.
5. Fragmentasi sangat diperlukan dalam jumlah record lebih dari satu juta, karena proses join tersebut dapat memakan waktu lebih dari satu hari. Perintah-perintah query yang dilaksanakan dalam kasus ini pertama kali adalah perintah query yang dilakukan untuk menguji bahwa tabel betul-betul layak uji dan tidak terdapat error data dalam field sehingga tidak perlu melakukan join terlebih dahulu, kemudian perintah query selanjutnya dilakukan seleksi dan join, perintah-perintah query tersebut adalah :
Q1. Perintah-perintah query tanpa optimisasi pada satu tabel relasi, hal ini
untuk melihat seluruh isi tabel layak uji dan melihat unjuk kerja I/O komputer, yaitu : 1 SELECT * FROM pst_ke1; 2 SELECT * FROM pstaktif; 3 SELECT * FROM pmk_ke1; 4 SELECT * FROM pmk_fd1; 5 SELECT * FROM pstpens;
Q2 Perintah-perintah query dengan optimisasi seleksi satu kriteria dari atribut tertentu pada tabel satu relasi, yaitu :
1 SELECT * FROM pst_ke1 WHERE no_tsp = 131653793; 2 SELECT * FROM pstaktif WHERE nippa = 131653793; 3 SELECT * FROM pmk_ke1 WHERE tmt_pst = “1970/01/01”; 4 SELECT * FROM pmk_fd1 WHERE tmt_pst = “1970/01/01”; 5 SELECT * FROM pstpens WHERE kp180=”1997/11/01”;
Tabel 11 . Running time query tabel satu relasi tanpa join, Q1 tanpa optimisasi Q2
dengan optimisasi satu kriteria.
TABEL/QUERY P IV Core Duo
512 MB
pmk_ke1 pstpens pmk_fd1 pst_ke1 pstaktif 58 MB 1,4 juta record 70 MB 1,26 juta record 107 MB 1,26 juta record 132 MB 3,87 juta record 165 MB 3,62 juta record Q1 10,84 14,69 19,26 22,75 29,66 Q2 0,8 2,81 3,05 7,49 7,73
Query Tanpa Join
0
5
10
15
20
25
30
35
1,4 juta record 1,26 juta record 1,26 juta record 3,87 juta record 3,62 juta record
58 MB
70 MB
107 MB
132 MB
165 MB
Jumlah Record
Run
ti
m
e
(
de
ti
k
)
Q1: Query Tanpa Optimisasi
Q2: Query dengan Optimisasi
Gambar 18. Running time query satu relasi tanpa join, Q1 tanpa optimisasi, Q2 dengan optimisasi satu kriteria.
Perintah-perintah join query Q3, Q4 dan Q5 di bawah ini digunakan untuk
membandingkan perintah tanpa optimisasi dan perintah dengan optimisasi, perintah query tersebut yaitu :
Q3 : SELECT *
FROM pst_ke1 P, pstaktif F WHERE P. no_tsp = F. nippa;
Q4 : SELECT P.no_tsp, P.tgl_lhr, P.tmt_pst, F.pangkat
FROM pst_ke1 P, pstaktif F WHERE P.no_tsp = F. nippa;
Q1
Q5 : SELECT P.no_tsp, P.tgl_lhr, P.tmt_pst, F.pangkat
FROM pst_ke1 P, pstaktif F WHERE P.no_tsp = F. nippa
AND F.gaji_pokok >= 500000 AND F.pangkat >='3A';
Hasil eksekusi perintah-perintah query tersebut ditunjukkan dalam Tabel 12 dan Gambar 19.
Tabel 12. :Perbandingan join query tidak dioptimisasi dan dioptimisasi Query /Kardinalitas 1000 record 10000 record 20000 record 30000 record 40000 record 50000 record Q3: Join Query tidak dioptimisasi 0,72 45,59 192,02 426,67 776,41 1213,43 Q4: Join Query dioptimisasi satu kriteria 0,44 41,88 166 372,13 659,58 1028,84 Q5: Join Query dioptimisasi tiga kriteria 0,22 32,25 135,55 275,95 466,08 689,17
Optimisasi Join Query 0,00 200,00 400,00 600,00 800,00 1000,00 1200,00 1400,00 1000 10000 20000 30000 40000 50000 Jumlah Record R u n ti m e ( d et ik)
Q3:Join Query tidak dioptimisasi Q4:Join Query dioptimisasi 1 kriteria Q5:Join Query dioptimisasi 3 kriteria
Gambar 19 . Perbandingan join query Q3 tidak dioptimisasi dan Q4 , Q5
dioptimisasi
Salah satu teknik perintah optimisasi dapat dilakukan dengan mendahulukan operasi seleksi sebelum melakukan operasi join, hasil eksekusi secara signifikan lebih cepat dari pada mendahulukan operasi join sebelum melaksanakan operasi seleksi, hal ini ditunjukkan pada perintah query Q6 dan Q7, dan hasil eksekusi ditunjukkan pada Tabel 13 dan Gambar 20.
Q6 : SELECT P.no_tsp, P.tgl_lhr, P.tmt_pst, F.gaji_pokok, F.pangkat
FROM pst_ke1 P, pstaktif F
WHERE F.gaji_pokok >= 500000 AND
F.pangkat >='3A' AND P.no_tsp = F. nippa;
Q7 : SELECT P.no_tsp, P.tgl_lhr, P.tmt_pst, F.gaji_pokok, F.pangkat
FROM pst_ke1 P, pstaktif F WHERE P.no_tsp = F. nippa AND
gaji_pokok >= 500000 AND F.pangkat >='3A' ;
Q3
Q4
Tabel 13 : Running time query, Q6 mendahukan operasi join sebelum seleksi dan
Q7 mendahulukan operasi seleksi sebelum operasi join
Query/Kardinalitas 1000 record 10000 record 20000 record 30000 record 40000 record 50000 record Q6 : mendahulukan join 0,38 51,56 202,75 468,2 742,39 1044,31 Q7 : mendahulukan seleksi 0,22 32,25 135,55 275,95 466,08 689,17
Mendahulukan Join atau Seleksi
0,00 200,00 400,00 600,00 800,00 1000,00 1200,00 1000 10000 20000 30000 40000 50000 Jumlah Record Ru n ti m e ( d et ik)
Q6: Mendulukan Join Q7: Mendahulukan Seleksi
Gambar 20 . Running time query, Q6 mendahulukan operasi join sebelum seleksi
dan Q7 mendahulukan operasi seleksi sebelum operasi join.
Perintah-perintah query untuk melakukan join dan seleksi satu atau beberapa kriteria lebih dari satu tabel dengan atribut yang sama dari tabel yang telah difragmentasi ditunjukkan pada Tabel 14 dan Gambar 21.
Q6
Perintah join query Q8 dan Q9 di bawah ini untuk melakukan join dan
seleksi dengan tiga kriteria dari tabel pst_ke1 (3.873.333 record) dan pstaktif (3.619.4230 record ), untuk Tabel 14 dan Gambar 21 jumlah record pst_ke1 dan pstaktif difragmentasi antara 1000 s/d 100.000 record. Q8 fragmentasi dilakukan
setelah proses join query berjalan, dan Q9 fragmentasi dilakukan sebelum proses
join query dilakukan dari 1000 s/d 100.000 record.
Q8 : SELECT *
FROM pst_ke1 P, pstaktif F WHERE P.no_tsp = F. nippa AND
P. kd_bup=’100’ AND F.pangkat >='3A' LIMIT 1000; Q9 : SELECT *
FROM pst_ke1 P, pstaktif F WHERE P.no_tsp = F. nippa AND
P. kd_bup=’100’ AND F.pangkat >='3A';
Tabel 14 : Perbandingan Runtime fragmentasi setelah proses join query dan fragmentasi sebelum proses join query.
Join / Kardinalitas
P IV 256 MB
1000
(record)
10.000
(record) (50.000 record) 100.000 (record)
Q8 : fragmentasi setelah proses query 85,3 1.246,09 31.250 155.556,5 Q9 : fragmentasi sebelum proses query 0,42 31,98 325,2 1.245,48
Fragmentasi Join Query
0 50000 100000 150000 200000 1000 10000 50.000 100000 Jumlah Record Ru n ti m e ( d et ik ) Q8 Q9Gambar 21 : Perbandingan Runtime Q8 : fragmentasi setelah proses query
Q9 : fragmentasi sebelum proses query
Perintah-perintah query untuk melakukan join dan seleksi satu atau beberapa kriteria lebih dari satu tabel dengan atribut yang sama dengan spesifikasi client yang berbeda, ditunjukkan pada Tabel 15 dan Gambar 22.
Q10 SELECT P.no_tsp, P.tgl_lhr, F.tmt_pst, F.gaji_pokok, F.pangkat
FROM pst_ke1 P, pstaktif F WHERE P.no_tsp = F.nippa
AND P.tgl_lhr = F.tgl_lhr AND P.kd_bup ="100" AND F.pangkat >="3A" AND P.gaji_pokok >=700000;
Q8
Tabel 15. Perbadingan Running time client berbeda spesifikasi Join / Kardinalitas 1000 (record) 10.000 (record) 50.000 (record) 100.000 (record) 200.000 (record) P1 : Query pada P IV 256 MB 0,42 31,98 325,20 1245,48 12110,03 P2 : Query pada P IV Core Duo 512 MB 0,02 17,11 169,33 699,31 6177,05
Perbedaan Runtime Query Berbeda
Client
0 5000 10000 15000 1000 10000 50000 100000 200000 Jumlah Record R u n ti m e ( d et ik ) P1 : Query pada P IV 256 MBP2: Query pada P IV Core Duo 512 MB
Gambar 22: Perbandingan Runtime client yang berbeda, P1 Pentium
IV 256 MB P2 Pentium IV Core Duo 512 MB, P1
Gambar 23: Konfigurasi sebagian peta MIPA-NETWORK ( FMIPA-UNPAD 2007 ) switch switch switch hub hub hub hub Dekanat client Lab. Penelitian (slave) router Dekanat 192.168.0.1 router hotspot DataBase server 192.168.0.2 (master) ROUTER OMNI FMIPA web server mail server DNS server Proxy server point to point FMIPA 192.168.203.2 management server point to point FMIPA-Jalawave SBP & Akademik Perpustakaan ROUTER FMIPA-PTBS