Pembuatan Tugas Akhir ini didasari oleh beberapa teori penunjang yang saya ambil dari berbagai sumber, sebagai berikut :
a. Jaccard’s Coefficient b. Multiset
c. Cosine Similarity Measurement d. Recall dan Precision
e. Stemming Bahasa Indonesia f. Stemming Bahasa Inggris
g. Entity Relationship Diagram (ERD) h. Data Flow Diagram (DFD)
i. IndoMARC
2.1 Jaccard’s Cofficient
Jaccard’s Coefficient adalah perhitungan statistik yang digunakan untuk membandingkan kemiripan dan perbedaan dari sebuah contoh set (Wikipedia, 2008). Misal ingin dicari kemiripan dari A dan B, maka rumus Sim(A,B) dengan menggunakan Jaccard’s Coefficient didefinisikan sebagai
Sim(A,B) =
|
|
|
| B A
B A
∪
∩ (2.1)
di mana A dan B adalah suatu multiset terhadap Universe.
2.2 Multiset
Multiset adalah generalisasi dari suatu set, di mana kehadiran 1 anggota dari suatu set bisa dinyatakan berkali-kali (Wikipedia, 2008). Total keanggotaan dari suatu multiset, termasuk kehadiran anggota yang sama yang berulang-ulang, adalah kardinalitas dari sutau multiset. Sedangkan jumlah kehadiran 1 anggota dalam suatu mutiset adalah multiplicity dari anggota tersebut. Sebagai contoh
dalam suatu multiset {a, a, b, b, b, c, c} mutiplicity dari a, b, c adalah 2, 3, dan 1, sedangkan kardinalitas dari multiset itu adalah 6.
2.3 Cosine Similarity Measurement
Metode pemberian bobot yang paling umum adalah produk dari 2 faktor : term frequency (tf) dan inverse document frequency (idf) (Garcia E, 2006):
wij = tfij *IDFij (2.2)
Kata frequency mempunyai arti jumlah kata yang dicocokkan dibagi dengan jumlah semua kata yang terdapat pada dokumen. Kata yang sering muncul dalam suatu dokumen mempunyai kaitan yang lebih erat dengan dokumen itu daripada kata yang lebih jarang muncul di dokumen tersebut. Inverse document frequency menunjukkan hubungan keeratan suatu kata dengan seluruh dokumen yang ada. Semakin sedikit jumlah dokumen yang mengandung kata itu semakin unik kata itu bagi suatu dokumen yang akan menambah bobot dari kata itu.
Konsep ini ditunjukkan pada persamaan 2.2. Sedangkan IDFij dijabarkan pada Persamaan 2.3 di bawah :
IDFij = log
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡ dfj
D (2.3)
Persamaan 2.2 dan Persamaan 2.3 dijelaskan sebagai berikut : tfij adalah jumlah term j yang terdapat pada metadata koleksi i, dfj adalah jumlah metadata yang mengandung term j, dan D adalah jumlah total koleksi. Wi,j akan direlasikan dengan kata tambahan mulai dari peringkat paling atas (Atom, Energi, Knowledge, dan Information) dengan cara mengalikan konstanta kemiripan yang dihasilkan saat pencarian extended keyword dengan wi,j dari kata yang sama untuk menghasilkan wi,j yang baru.
Dengan memanfaatkan wij yang telah didapat dari Persamaan 2.2, untuk mendapatkan Similarity Measure, wQj yang menyatakan bobot term dalam query perlu dihitung.
wQ,j=tfQ,j*log
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡ dfj
D (2.4)
di mana sama dengan Persamaan 2.3, dfij adalah jumlah jumlah koleksi yang mengandung term j, D adalah jumlah total koleksi, sedangkan tfQj adalah jumlah term j yang terdapat pada query Q.
Persamaan untuk mendapatkan kemiripan antara query dengan dokumen adalah :
Sim(Q,Di)=
∑ ∑
∑
i j i j
j Q i
j i j Q
w w
w w
2, 2 ,
, ,
(2.5)
Contoh data untuk perhitungan Cosine Similarity Measurement dapat dilihat di Tabel 2.1
Tabel 2.1 Contoh data untuk perhitungan Cosine Similarity Measurement TERM VECTOR MODEL BASED ON wi=tfij*IDFij
Query Q : “gold silver truck”
D1 : “Shipment of gold damaged in a fire”
D2 : “Delivery of silver arrived in a silver truck”
D3 : “Shipment of gold arrived in a truck”
Counts, tfij Weight, wij=tfij*IDFij
Terms Q D1 D2 D3 dfj D/dfj IDFij Q D1 D2 D3
a 0 1 1 1 3 3/3=1 0 0 0 0 0 arrived 0 0 1 1 2 3/2=1.5 0.18 0 0 0.18 0.18 damaged 0 1 0 0 1 3/1=3 0.48 0 0.48 0 0 delivery 0 0 1 0 1 3/1=3 0.48 0 0 0.48 0 fire 0 1 0 0 1 3/1=3 0.48 0 0.48 0 0 gold 1 1 0 1 2 3/2=1.5 0.18 0.18 0.18 0 0.18 in 0 1 1 1 3 3/3=1 0 0 0 0 0 of 0 1 1 1 3 3/3=1 0 0 0 0 0 silver 1 0 2 0 1 3/1=3 0.48 0.48 0 0.95 0 shipment 0 1 0 1 2 3/2=1.5 0.18 0 0.18 0 0.18 truck 1 0 1 1 2 3/2=1.5 0.18 0.18 0 0.18 0.18
Seperti terlihat pada Tabel 2.1, term yang tergolong stop word seperti a, in, dan of diikutkan dalam perhitungan di atas. Sebenarnya ke3 term tersebut termasuk dalam stop word, yaitu daftar kata-kata yang umum dipakai dan tidak menunjukkan keunikan dalam suatu dokumen, sehingga tidak perlu diikutkan dalam perhitungan. tfij pada kolom 3-5 menunjukkan jumlah keberadaan suatu
term dalam setiap dokumen. IDF dihitung di kolom 8, dan weight pada kolom 9- 12 merupakan perhitungan dari tfij dikalikan dengan IDFij.
Selanjutnya perlu dihitung nilai absolut dari tiap dokumen dengan Persamaan :
|Di| =
∑
i j
w2i, (2.6)
D1 = 0.482 +0.482 +0.182 +0.182 = 0.72 D2 = 0.182 +0.482 +0.952 +0.182 = 1.09 D3 = 0.182 +0.182 +0.182 +0.182 = 0.36
|Q| adalah perhitungan berikutnya dengan rumus
|Q| =
∑
i j
w2Q, (2.7)
|Q| = 0.182 +0.482 +0.182 = 0.54
Berikutnya kita menghitung semua dot product (angka 0 tidak ikut dihitung) dengan rumus
Q●Di =
∑
i
j i j
Q w
w , , (2.8)
Q●D1 = 0.18 * 0.18 = 0.032
Q●D2 = (0.48 * 0.95) + (0.18 * 0.18) = 0.488 Q●D3 = (0.18 * 0.18) + (0.18 * 0.18) = 0.064 Pada akhirnya Sim(Q,Di) dihitung dengan rumus
CosineӨDi = Sim(Q,Di)
Sim(Q,Di)=
∑ ∑
∑
i j i j
j Q i
j i j Q
w w
w w
2, 2 ,
, ,
CosineOD1 =
|
|
*
|
| 1
1
D Q
D Q•
= 0.5382*1.0955 4862 .
0 = 0.8246
CosineOD2 =
|
|
*
|
| 2
2
D Q
D Q•
= 0.5382*0.7192 031 .
0 = 0.0801
CosineOD3 =
|
|
*
|
| 3
3
D Q
D Q•
= 0.5382*0.3522 062 .
0 = 0.3271
Sehingga ranking dokumen berdasarkan hasil perhitungan Similaritynya adalah sebagai berikut :
Urutan ke 1 : Doc 2 = 0.8246 Urutan ke 2 : Doc 3 = 0.3271 Urutan ke 3 : Doc 1 = 0.0801
2.4 Recall dan Precision
Recall dan Precision adalah pengukuran yang sering digunakan untuk mengukur kualitas dari hasil proses seperti Information Retrieval dan Statistical Classification (Wikipedia, 2008). Secara singkat, Precision dapat dianggap sebagai ukuran ketepatan / ketelitian, sedangkan Recall adalah ukuran kesempurnaan. Dalam penggunaannya pada Information Retrieval, nilai Precision yang sempurna (1) berarti semua hasil yang keluar adalah relevan. Nilai Recall yang sempurna (1) berarti semua dokumen yang relevan telah berhasil didapatkan.
Bagaimanapun juga, ada hubungan saling berkebalikan antara nilai Recall dan Precision, di mana nilai Recall dapat dinaikkan, tapi akan mengurangi nilai Precision. Sebagai contoh, pada Search Engine seperti yang dibuat dalam Tugas Akhir (TA) ini, nilai Recall dapat dinaikkan dengan memperbanyak jumlah dokumen yang didapat, tapi sebagai akibatnya dokumen tidak relevan yang didapat juga semakin banyak sehingga nilai Precision semakin kecil. Rumus Recall dan Precision ditunjukkan pada Persamaan 2.9 dan Persamaan 2.10
(2.9) (2.10) Seperti terlihat pada Persamaan 2.9, nilai Recall merupakan dokumen relevan yang didapatkan sebagai hasil pencarian dibagi dengan total dokumen relevan dari database. Sedangkan nilai Precision adalah jumlah dokumen relevan yang ditemukan dibagi dengan total dokumen yang didapatkan sebagai hasil pencarian.
2.5 Stemming Bahasa Indonesia
Stemming adalah proses untuk mendapatkan kata dasar sebuah term dengan menghilangkan segala kata imbuhan yang terdapat dalam term tersebut (http:// citeseerx.ist.psu.edu/ viewdoc/ summary? doi=10.1.1.5.5224 , 2005).
Stemming yang digunakan dalam TA ini adalah stemming bahasa Indonesia dan bahasa Inggris. Pembuatannya menggunakan rule based stemmer (stemmer berdasarkan aturan). Stemming Indonesia yang dipakai di TA ini berdasarkan paper yang disajikan Fadillah Z Tala dengan judul ‘A Study of Stemming Effects on Information Retrieval in Bahasa Indonesia’.
Dalam proses stemming bahasa Indonesia ini terdapat beberapa tahap.
Sebuah kata akan dites dengan menggunakan rule yang dibuat pada setiap tahap.
Pada setiap tahap, sebuah kata yang memenuhi kondisi untuk rule pada tahap itu maka kata tersebut akan diganti dengan kata baru yang dibentuk dengan substitution rule (aturan pengganti).
Kata
Eliminasi Partikel Kata
Gambar 2.1 Arsitektur Proses Stemming Bahasa Indonesia, Fadillah Z Tala A Study of Stemming Effects on Information Retrieval in Bahasa Indonesia (21
Februari 2008) figure 2.1. http://citeseerx.ist.psu.edu/ viewdoc/ summary?
doi=10.1.1.5.5224
Eliminasi Prefiks Pertama Eliminasi Possessive
Pronouns
Kata Dasar Eliminasi
Prefiks Kedua
Eliminasi Sufiks
Eliminasi Sufiks
Eliminasi Prefiks Kedua Semua rule
tidak cocok Rule dijalankan
Rule dijalankan
Semua rule tidak cocok
Ada beberapa kondisi yang digunakan pada setiap rule. Salah satu kondisi yang digunakan yaitu minimum length yang disebut measure. Measure yang digunakan untuk bahasa Indonesia yaitu jumlah suku kata yang ada pada sebuah kata. Jumlah suku kata diperoleh dengan menghitung banyak huruf vokal yang terdapat pada kata tersebut. Perhitungan suku kata sebagai measure dilakukan pada sebuah kata tanpa termasuk imbuhan yang diduga, contoh kata
“mencari’ maka hanya bagian kata “cari” yang dihitung jumlah suku katanya.
Kondisi lain yang digunakan untuk kondisi sebuah rule yaitu pengecekan huruf pertama berupa huruf vokal atau konsonan dan beberapa kondisi lain.
Arsitektur proses stemming untuk bahasa Indonesia dapat dilihat pada Gambar 2.1. Tahap pertama yang dilakukan adalah menghilangkan partikel kata kemudian menghilangkan possesive pronouns. Baru setelah itu dilakukan proses untuk menghilangkan prefiks pertama dari kata tersebut. Jika kata tersebut memiliki prefiks pertama maka proses selanjutnya yang dipilih adalah proses menghilangkan sufiks dan kemudian menghilangkan prefiks kedua. Namun jika kata tersebut tidak memiliki sufiks maka proses langsung dihentikan. Jika kata tersebut tidak memiliki prefiks pertama maka proses selanjutnya adalah menghilangkan prefiks kedua barulah kemudian menghilangkan sufiks.
Tabel 2.2 menunjukkan daftar rule yang digunakan untuk menghilangkan partikel kata dalam sebuah kata yaitu lah, kah, dan pun. Kondisi, jumlah suku kata, dan rule pengganti ketiga rule tersebut sama. NULL (kosong) pada kolom rule pengganti berarti sufiks yang dibuang tidak diganti dengan karakter atau kata lain. Sedangkan NULL pada kolom kondisi berarti tidak ada kondisi lain yang dicek selain jumlah suku kata yaitu sebanyak 2 suku kata.
Tabel 2.2 Rule Eliminasi Partikel Kata
Sufiks Pengganti Suku Kata Kondisi Contoh
lah NULL 2 NULL diakah Æ dia
kah NULL 2 NULL barulah Æ baru
pun NULL 2 NULL meskipun Æ meski
Tabel 2.3 menunjukkan proses kedua yang dilakukan setelah partikel kata dihilangkan yaitu eliminasi sufiks possessive pronouns. Ada 3 rule yang
digunakan dalam proses ini dan semua rule pengganti, jumlah suku kata, kondisi semuanya sama
Tabel 2.3 Rule Eliminasi Possessive Pronouns
Sufiks Pengganti Suku Kata Kondisi Contoh
ku NULL 2 NULL rumahku Æ rumah
mu NULL 2 NULL kertasmu Æ kertas
nya NULL 2 NULL obatnya Æ obat
Tabel 2.4 di bawah merupakan daftar rule yang digunakan untuk membuang prefiks pertama. Tanda * pada didepan prefiks menandakan bahwa rule tersebut adalah rule tambahan yang diberikan selain dari paper yang disajikan Fadillah Z. Talla. Jika rule pengganti tidak bernilai NULL berarti kata yang dihasilkan akan ditambah dengan karakter pada rule pengganti. Simbol “V”
sebagai simbol huruf vokal dan simbol “K” untuk huruf konsonan. Kondisi “V*”
berarti kata diawali huruf vokal sedangkan kondisi “K*” berarti kata diawali huruf konsonan. Pada kondisi rule prefiks me yaitu “not KK*” berarti kata setelah prefiks me tidak boleh diawali oleh 2 konsonan yang sama, contoh kondisi yang tidak terpenuhi : me-rdeka, setelah prefiks me diawali 2 konsonan r dan d. Semua rule yang ada dicek secara berurutan, jika rule pertama tidak cocok maka dicoba rule kedua, dan seterusnya. Jika semua rule tidak ada yang cocok maka kata tersebut dianggap tidak memiliki prefiks pertama dan proses eliminasi kedua dilakukan.
Tabel 2.4 Rule Eliminasi Prefiks Pertama
Prefiks Pengganti Suku Kata Kondisi Contoh
*meng k 2 e* mengejar Æ kejar
meng NULL 2 NULL mengangkatÆ angkat
meny s 2 V* menyapa Æ sapa
*men t 2 V* menumpang Æ tumpang
men NULL 2 NULL mendapat Æ dapat
mem p 2 V* memilah Æ pilah
mem NULL 2 NULL membuat Æ buat
*me NULL 2 not KK* merusak Æ rusak
peng NULL 2 NULL pengasah Æ asah
*peny s 2 V* penyuplai Æ suplai
*pen t 2 V* penari Æ tari
pen NULL 2 NULL penduga Æ duga
*pem p 2 V* pemilih Æ pilih
Tabel 2.4 Rule Eliminasi Prefiks Pertama (Sambungan)
pem NULL 2 NULL pemberi Æ beri
di NULL 2 NULL diukur Æ ukur
ter NULL 2 NULL terbilang Æ bilang
ke NULL 2 NULL kekasih Æ kasih
Tabel 2.5 merupakan daftar rule yang digunakan untuk menghilangkan prefiks kedua. Proses ini hanya dilakukan setelah eliminasi prefiks pertama jika kata tersebut tidak memiliki prefiks pertama. Jika kata tersebut memiliki prefiks pertama maka proses ini dilakukan setelah eliminasi sufiks. Prefiks yang dapat ditangani diantaranya yaitu ber, bel, be, per, pel, dan pe. Semua rule pengganti untuk eliminasi prefiks kedua memang berupa NULL artinya sufiks tidak diganti dengan apapun. Kondisi seperti “K*er” berarti kata yang berawalan dengan huruf konsonan dan diakhiri dengan “er” saja yang dianggap memenuhi kondisi.
Tabel 2.5 Rule Eliminasi Prefiks Kedua
Prefiks Pengganti Suku Kata Kondisi Contoh
ber NULL 2 NULL bermain Æ main
bel NULL 2 ajar belajar Æ ajar
be NULL 2 K*er bekerja Æ kerja
per NULL 2 NULL perjelas Æ jelas
pel NULL 2 ajar pelajar Æ ajar
pe NULL 2 NULL pelaut Æ laut
Tabel 2.6 merupakan daftar rule yang digunakan untuk membuang sufiks yang ada. Tanda * di depan sufiks berarti bahwa rule ini merupakan rule modifikasi yang diberikan selain dari paper yang disajikan Fadillah Z. Talla Sufiks yang dapat ditangani diantaranya yaitu kan, an, dan i. Kondisi-kondisi yang menjadi syarat pada eliminasi sufiks agak berbeda dengan eliminasi prefiks.
Kondisi seperti pada rule eliminasi sufiks “kan” berarti rule tersebut dijalankan jika kata yang bersangkutan tidak memiliki prefiks berupa ke, peng, peny, pen, pem, per, pel, atau pe. Begitu juga kondisi untuk rule eliminasi sufiks “an” berarti kata yang bersangkutan tidak boleh diawali dengan prefiks di, meng, atau ter.
Sedangkan kondisi untuk rule eliminasi i yaitu tidak diawali oleh prefiks ber, ke, ataupun peng.
Tabel 2.6 Rule Eliminasi Sufiks
Sufiks Pengganti Suku Kata Kondisi Contoh
*kan NULL 2 prefiks є {ke, peng, peny, pen, pem, per, pel, pe}
(meng)ambilkan Æ ambil
pertunjukan Æ tunjuk
dipertunjukkan Æ tunjuk
an NULL 2 prefiks є {di, meng,
ter}
makanan Æ makan
i NULL 2 prefiks є {ber, ke,
peng}
tandai Æ tanda pantai Æ panta Bagaimanapun, stemming Indonesia yang diterapkan dalam TA ini masih mempunyai kelemahan. Kelemahan yang pertama adalah, dalam bahasa Indonesia dikenal adanya diphthongs yaitu adanya sederetan huruf vokal yang tidak dapat dipisahkan pemakaiannya dalam sebuah kata, contohnya ai, au, oi. Beberapa kesalahan ditemukan pada kata-kata yang mengandung diphthongs seperti kata
“pantai” yang menjadi “panta”. Kelemahan kedua adalah kata seperti ‘berelasi’
akan di-stem berdasarkan rule eliminasi prefiks kedua menjadi ‘elasi’, yang seharusnya adalah ‘relasi’.
2.6 Stemming Bahasa Inggris
Stemming bahasa Inggris yang digunakan dalam TA ini adalah Porter Stemmer, yang banyak digunakan dalam sistem Information Retrieval (The Porter Stemming Algorithm, n.d. ). Algoritma Porter Stemmer untuk keperluan TA ini ditampilkan di bawah.
Konsonan adalah huruf selain dari A, E, I, O, U, dan selain dari Y yang didahului oleh sebuah konsonan. Jadi dalam kata ‘toy’ konsonannya adalah ‘t’
dan ‘y’, dan pada kata ‘syzygy’ konsonannya adalah ‘s’, ‘z’, dan ‘g’. Jika suatu huruf bukan konsonan maka huruf itu adalah vowel.
Sebuah konsonan akan dilambangkan dengan c dan sebuah vowel akan disebut dengan v. ccc… berurutan dengan jumlah > 0 dilambangkan dengan C, dan vvv… dengan jumlah > 0 disebut dengan V. Sehingga semua kata mempunyai salah satu dalam 4 bentuk ini :
CVCV … C
CVCV … V VCVC … C VCVC … V
Semua ini dapat direpresentasikan dengan 1 macam bentuk [C]VCVC ... [V]
di mana kurung siku menunjukkan bahwa yang berada di dalamnya bisa ada dan bisa tidak ada. Dengan menggunakan (VC)m untuk menunjukkan VC yang diulang m kali, bentuk di atas dapat ditulis sebagai
[C](VC)m[V]
m dapat dianggap sebagai ukuran dari suatu kata dalam bentuk ini. m = 0 menunjukkan kata yang kosong (null word). Berikut diberikan contohnya :
Tabel 2.7 Contoh perhitungan m m=0 TR, EE, TREE, Y, BY.
m=1 TROUBLE, OATS, TREES, IVY.
m=2 TROUBLES, PRIVATE, OATEN, ORRERY.
Aturan untuk menghilangkan sufiks diberikan dengan bentuk (kondisi) S1 -> S2
Ini berarti jika suatu kata berakhiran dengan sufiks S1, dan stem sebelum S1 memenuhi kondisi, S1 diganti dengan S2. Kondisi biasanya diberikan dalam bentuk m, contoh
(m > 1) EMENT ->
Pada contoh di atas S1 adalah ‘EMENT’ dan S2 adalah null. Dengan ini
‘REPLACEMENT’ akan diganti dengan ‘REPLAC’, karena ‘REPLACEMENT’
mempunyai m = 2.
Kondisi lainnya diberikan di bawah
Tabel 2.8 Daftar kondisi untuk Stemming Inggris
*S - stem-nya berakhiran dengan S (berlaku juga untuk huruf lainnya).
*v* - stem-nya mengandung paling sedikit 1 vowel.
*d - stem-nya berakhiran dengan dobel konsonan (cth : -TT, -SS).
*o - stem-nya berakhiran dengan cvc, di mana c yang kedua bukan W, X atau Y (cth : -WIL, -HOP).
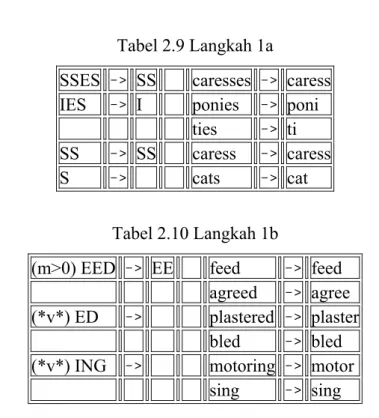
Dan kondisi dapat juga mengandung ekspresi seperti and, or, dan not. Dalam 1 set aturan yang ditulis di bawah yang lain, hanya 1 saja yang dijalankan, yaitu S1 yang cocok dan terpanjang. Contoh, dengan aturan pada Langkah 1a
‘CARESSES’ diubah menjadi ‘CARESS’ karena ‘SSES’ adalah S1 yang cocok dan terpanjang. Sedangkan ‘CARESS’ menjadi ‘CARESS’ dan ‘CARES’ to
‘CARE’
Tabel 2.9 Langkah 1a
SSES -> SS caresses -> caress IES -> I ponies -> poni
ties -> ti
SS -> SS caress -> caress
S -> cats -> cat
Tabel 2.10 Langkah 1b
(m>0) EED -> EE feed -> feed agreed -> agree (*v*) ED -> plastered -> plaster
bled -> bled (*v*) ING -> motoring -> motor
sing -> sing
Jika langkah kedua atau ketiga dari langkah 1b berhasil, maka langkah berikut di bawah ini dijalankan :
Tabel 2.11 Langkah 1b kedua
AT -> ATE conflat(ed) -> conflate
BL -> BLE troubl(ed) -> trouble
IZ -> IZE siz(ed) -> size
(*d and not (*L or *S or
*Z)) ->
single
letter hopp(ing) -> hop tann(ed) -> tan fall(ing) -> fall hiss(ing) -> hiss fizz(ed) -> fizz (m=1 and *o) -> E fail(ing) -> fail
fil(ing) -> file
-E diberikan pada –AT, -BL, dan –IZ agar sufiks –ATE, -BLE, dan –IZE bisa dikenali di langkah berikutnya. E ini akan dihapus pada langkah 4.
Tabel 2.12 Langkah 1c (*v*) Y -> I happy -> happi
sky -> sky
Langkah 1 berhubungan dengan plurals dan past participles.
Tabel 2.13 Langkah 2
(m>0) ATIONAL -> ATE relational -> relate (m>0) TIONAL -> TION conditional -> condition
rational -> rational (m>0) ENCI -> ENCE valenci -> valence (m>0) ANCI -> ANCE hesitanci -> hesitance (m>0) IZER -> IZE digitizer -> digitize (m>0) ABLI -> ABLE conformabli -> conformable (m>0) ALLI -> AL radicalli -> radical (m>0) ENTLI -> ENT differentli -> different (m>0) ELI -> E vileli -> vile (m>0) OUSLI -> OUS analogousli -> analogous (m>0) IZATION -> IZE vietnamization -> vietnamize (m>0) ATION -> ATE predication -> predicate (m>0) ATOR -> ATE operator -> operate (m>0) ALISM -> AL feudalism -> feudal (m>0) IVENESS -> IVE decisiveness -> decisive (m>0) FULNESS -> FUL hopefulness -> hopeful (m>0) OUSNESS -> OUS callousness -> callous (m>0) ALITI -> AL formaliti -> formal (m>0) IVITI -> IVE sensitiviti -> sensitive (m>0) BILITI -> BLE sensibiliti -> sensible
Tabel 2.14 Langkah 3
(m>0) ICATE -> IC triplicate -> triplic (m>0) ATIVE -> formative -> form (m>0) ALIZE -> AL formalize -> formal (m>0) ICITI -> IC electriciti -> electric (m>0) ICAL -> IC electrical -> electric (m>0) FUL -> hopeful -> hope
Tabel 2.14 Langkah 3 (Sambungan) (m>0) NESS -> goodness -> good
Tabel 2.15 Langkah 4
(m>1) AL -> revival -> reviv (m>1) ANCE -> allowance -> allow (m>1) ENCE -> inference -> infer (m>1) ER -> airliner -> airlin (m>1) IC -> gyroscopic -> gyroscop (m>1) ABLE -> adjustable -> adjust (m>1) IBLE -> defensible -> defens (m>1) ANT -> irritant -> irrit (m>1) EMENT -> replacement -> replac (m>1) MENT -> adjustment -> adjust (m>1) ENT -> dependent -> depend (m>1 and (*S or *T)) ION -> adoption -> adopt (m>1) OU -> homologou -> homolog (m>1) ISM -> communism -> commun (m>1) ATE -> activate -> activ (m>1) ITI -> angulariti -> angular (m>1) OUS -> homologous -> homolog (m>1) IVE -> effective -> effect (m>1) IZE -> bowdlerize -> bowdler
Sekarang sufiks telah dihilangkan.
Tabel 2.16 Langkah 5a
(m>1) E -> probate -> probat rate -> rate (m=1 and not *o) E -> cease -> ceas
Tabel 2.17 Langkah 5b
(m > 1 and *d and *L) -> single letter controll -> control roll -> roll
2.7 Entity Relationship Diagram (ERD)
Entity Relationship Diagram mengandung informasi yang berharga mengenai arsitektur dari database relasional). ERD memodelkan suatu sistem
dengan cara menentukan data apa saja yang ada pada sebuah entity dan bagaimana entity yang satu berhubungan dengan entity yang lain. Simbol – simbol yang digunakan dalam penggambaran ERD yaitu :
Relationship_1
Entity_1 Entity_2
Gambar 2.2 Relasi One to One
Gambar 2.2 menggambarkan bentuk hubungan one to one. Hubungan ini ditandai dengan adanya garis tunggal yang menempel pada kedua sisi entity.
Relationship_2
Entity_3 Entity_4
Gambar 2.3 Relasi One to Many
Gambar 2.3 menggambarkan bentuk hubungan one to many. Hubungan ini ditandai dengan adanya garis dengan cabang 3 pada sisi entity yang bersifat many.
Relationship_3
Entity_5 Entity_6
Gambar 2.4 Relasi many to many
Gambar 2.4 menggambarkan bentuk hubungan many to many. Hubungan ini ditandai dengan adanya garis dengan cabang 3 pada kedua sisi entity.
Relationship_4
Entity_7 Entity_8
Gambar 2.5 Relasi one to many mandatory
Gambar 2.5 menggambarkan mandatory. Sebuah entity dikatakan mandatory bila garis yang berada di dekatnya ada tanda “|”. Entity_8 adalah contoh mandatory. Entity_7 bukan mandatory karena garis di dekatnya terdapat tanda “O”. Istilah mandatory disebut juga dengan “obligatory” dan non- mandatory disebut juga dengan “non-obligatory”.
Relationship_5
Entity_9 Entity_10
Gambar 2.6 Relasi one to many dependent
Gambar 2.6 menggambarkan dependent, terlihat bahwa Entity_9 (sisi kanan) merupakan dependent dari Entity_10 (sisi kiri)
2.8 Data Flow Diagram (DFD)
Data Flow Diagram atau yang dikenal sebagai process model, adalah sebuah teknik analisis untuk mengikuti alur data dari input sistem sampai ke outputnya dalam bentuk gambar.
Beberapa simbol yang digunakan untuk menggambarkan DFD digambarkan sebagai berikut :
External Entity
Gambar 2.7 External Entity
Seperti terlihat pada Gambar 2.7, external entity adalah simbol yang mewakili elemen yang berada di luar sistem, namun memiliki interaksi dengan sistem.
.
1 Proses
Gambar 2.8 Proses
Proses adalah serangkaian kegiatan yang dilakukan untuk menghasilkan output yang diminta seperti terlihat pada Gambar 2.8
data store
Gambar 2.9 Data Store
Data Store menggambarkan tempat penyimpanan data seperti terlihat pada Gambar 2.9.
Gambar 2.10 Data Flow
Data Flow merupakan simbol yang mewakili arah aliran data seperti terlihat pada Gambar 2.10.
Pemodelan dengan menggunakan DFD dilakukan dengan menggambarkan proses secara umum yang dikenal dengan context diagram / DFD level 0 kemudian tiap proses yang masih mempunyai fungsi yang lebih spesifik akan dipecah lagi menjadi DFD level 1 dan seterusnya hingga sebuah proses tidak dapat dijabarkan lagi lebih lanjut.
2.9 IndoMARC
Format IndoMARC merupakan implementasi International Standard Format ISO 2709 untuk Indonesia, sebuah format untuk tukar-menukar informasi bibliografi melalui pita magnetik (magnetic tape) atau media yang terbacakan mesin (machine-readeable) lainnya. Informasi bibliografi biasanya mencakup pengarang, judul, subyek, catatan, data penerbitan dan deskripsi fisik.
Cantuman (record) adalah kumpulan ruas yang memberikan informasi mengenai karya yang dikatalog secara terpisah.
Ruas (field) berisi satu atau lebih unsur data. Tiap ruas mempunyai nama yang menggambarkan isi ruas tersebut. Misalnya ruas deskripsi fisik, ruas edisi.
Panjang ruas dapat tetap atau tidak tetap.
Unsur data (data element) adalah unit informasi terkecil pada format untuk maksud manipulasi, pemilahan, dan sebagainya, misalnya, tempat terbit, bahasa.
Ruas tetap (fixed field) terdiri dari satu atau lebih unsur data yang selalu dinyatakan dengan jumlah karakter yang sama isinya, sehingga panjang ruas tetap selalu sama.
Ruas tidak tetap (variable field) panjangnya bervariasi sesuai dengan karya yang dideskripsikan. Ruas tidak tetap dapat berisi lebih dari satu unsur data, misalnya, ruas publikasi dan distribusi biasanya berisi tempat terbit, penerbit, dan tahun terbit.
Tengara (tag) adalah kode tiga digit yang mengidentifikasikan tiap ruas data bibliografi dalam suatu cantuman, misalnya, tengara 2600 selalu digunakan sebagai ruas publikasi dan distribusi.
Subruas (subfield) adalah unsur data dalam ruas tidak tetap. Tiap subruas diidentifikasi dengan kode subruas terpisah yang terdiri dari lambang karakter pembatas (delimiter) (dalam pedoman ini digunakan lambang dollar [$]) diikuti dengan huruf kecil atau mungkin juga angka. Misalnya, pada ruas publikasi sebagai subruas, yaitu $a, tempat terbit; $b, penerbit; $c, tahun terbit. Subruas yang pertama pada sebuah ruas biasanya disebut subruas $a. Beberapa ruas hanya memiliki satu subruas, misalnya ruas catatan disertasi (tengara 502) hanya berisi subruas $a. Kode subruas tidak harus dimasukkan secara abjad. Selain itu, urut- urutan kode-kode subruas tertentu bisa berbeda-beda setiap kali ruasnya digunakan, tergantung pada sifat dari data bibliografinya.
Penjelasan ruas-ruas IndoMARC dapat dilihat pada Tabel 2.18 Tabel 2.18 Penjelasan ruas-ruas IndoMARC
IndoMARC Penjelasan K008/35-37 Bahasa yang digunakan secara umum oleh koleksi
K020a ISBN
K041a Bahasa terjemahan
K041h Bahasa asli dari koleksi K099a Nomor panggil lokal
K099b Tiga huruf pertama entri utama K099c Huruf pertama judul koleksi K099d Tahun
K100a Entri utama: Pengarang bila individu
K110a Entri utama: Pengarang bila berupa perusahaan / organisasi K111a Entri utama: Pengarang bila sebuah seminar / konferensi K130a Entri utama: Judul seragam koleksi (misalnya: Ensiklopedi) K245a Judul utama koleksi (misalnya: Enabling Knowledge Creation) K245b Judul tambahan koleksi (misalnya: How to Unlock the Mistery
of Their Knowledge) K245c Pernyataan tanggung jawab K245n Nomor bagian koleksi
K245h Jenis media dari koleksi (AV, CD, DVD, Peta, dll.) K250a Edisi dari koleksi
K250b Pernyataan tambahan dari edisi koleksi
Tabel 2.18 Penjelasan ruas-ruas IndoMARC (Sambungan)
IndoMARC Penjelasan K255a Skala
K260a Tempat penerbitan
RowID_Pene rbit
Nama Penerbit
K260c Tanggal penerbitan
K534a Pengarang asli
K534t Judul asli
K650a Subyek dari koleksi K700a Pengarang individu tambahan K710a Pengarang perusahaan tambahan
K730a Judul tambahan