www.elsevier.com/locate/eja
Development of a crop knowledge base for Europe
G. Russell
a,
*, R.I. Muetzelfeldt
a
, K. Taylor
a
, J.-M. Terres
b
aInstitute of Ecology and Resource Management, the University of Edinburgh, West Mains Road, Edinburgh EH9 3JG, UK bJoint Reseach Centre — Space Applications Institute, I-21020, Ispra (VA), Italy
Accepted 19 April 1999
Abstract
This paper describes the development of a Crop Knowledge Base System for use in crop modelling and yield forecasting. The inherent limitations of databases can cause problems for dealing effectively with geo-referenced data sets. The system described here includes all the normal database operations but also handles richer types of data. Values of queried attributes can be deduced through the use of heritability within hierarchies and by the application of rules that summarise sets of empirical observations. The system is able to reason about similar locations, so that where no information exists in the knowledge base for a particular location, then an alternative location, subject to similar meteorological and agricultural conditions, will be sought. © 1999 Elsevier Science B.V. All rights reserved.
Keywords:Database; Knowledge base; Model; Phenology; Yield forecasting
1. Introduction large sub-national regions, in order to manage the
cereal market and to adjust the Common
The aim of the project entitledEstablishment of Agricultural Policy. Yield forecasts and
informa-computerised crop knowledge base was ‘to design tion on crop condition are provided from
deter-and implement a working, computer-based crop ministic Agrometeorological Crop Growth
knowledge base’. The work was funded by the Simulation models (Supit, 1997) using
meteorolog-Agriculture Information System group of the Joint ical data, soil characteristics from the European
Research Centre of the European Commission, soil map ( King et al., 1995) and crop-specific
Ispra, Italy, as a means of rationalising existing parameters (Boons-Prins et al., 1993). During the
holdings of information in reports and databases monitoring period, which runs from February to
within the MARS (Monitoring Agriculture with October, the model is run monthly to provide a
Remote Sensing) project (Genovese, 1998). A yield forecast for the main annual crops. The
detailed account of the work is given in Russell model outputs and auxiliary information are then
et al. (1997). analysed and integrated by a multi-disciplinary
Since 1993, the European Commission has oper- team, including agronomists and statisticians,
ated through the MARS project, a European yield- before the final figures are released to the
custom-forecasting system at the level of countries and ers. During the analysis process, the model
predic-tions are sometimes refined using expert agronomic knowledge to take account of factors not included
* Corresponding author. Tel.:+44-131-535 4063;
in the models. The Crop Knowledge Base System
fax+44-131-229-2601
E-mail address:[email protected] (G. Russell ) was seen as a tool that could aid this activity by
to the guidelines of Debenham (1989). This
$ the need for extensive modifications when
com-ponent maps and associated databases are involved a series of stages (see below)
correspond-ing to the procedures in Fig. 1, each of which was updated by changing boundaries or adding
new fields. characterised by the production of a document,
data files, or software. In practice, these stages are Knowledge bases can include all the functions
of a relational database (Black, 1986) but are able not independent, and an element of iteration was
required. Broadly, the knowledge base was devel-to handle information in a more flexible manner.
They can deduce values for an attribute using the oped in two phases: (1) development of the
operat-ing shell usoperat-ing a small knowledge base, which concept of heritability within a hierarchy, by
apply-ing a rule that summarises empirical observations, included a representative set of information and
associated data dictionary, and (2) fine-tuning the or by using transfer rules ( King et al., 1995; Batjes,
1996) that relate the required attribute to a known shell and expanding the amount of information
held in the knowledge base and data dictionary. attribute. The extended knowledge database for
interpreting the 1:1 000 000 EU soil map ( Van
Ranst et al., 1995) is a type of knowledge base 2.2.1. Task specification
Potential users from a range of disciplines and that uses rules to deduce soil properties from other
information held in the system. Although this rule- organisations were consulted by questionnaire and
personal interview to identify the tasks that the based approach for estimating unknown values
could be incorporated as a function within a crop system should be able to perform. The
question-naire was structured so that the respondent was model, there is a strong argument for separating
models from their data sources, not least because offered a choice of options but could add
addi-tional options. the derived data may be required by several
models.
2.2.2. Application Model
The Application Model is the formal specifica-tion of the knowledge to be included in the knowl-2. Methodology
edge base. In the present case, it consists of a small number of generic templates in stylised or quasi-2.1. Components of the system
natural language, representing the different types of knowledge to be incorporated into the system. The components of the Crop Knowledge Base
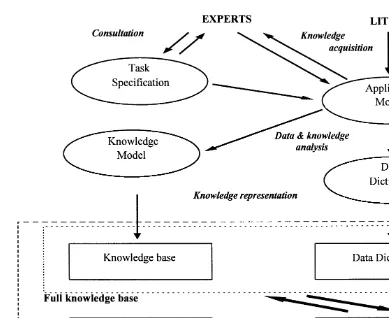
System and their relationships are shown in the Sentences and tables from a set of representative
Fig. 1. Project procedures, goals and communications links. Thin arrows show the procedures linking different stages. Thick arrows show the flow of information linking the different components in the completed Knowledge Base System.
et al., 1993; Russell and Wilson, 1994) were ana- details, so that each piece of information was
understandable on its own; lysed by dividing them into atomic statements and
re-writing them in simple English. Atomic state- 5. classify and group types of information to
pro-duce a small number of generic templates. ments are simplified and unambiguous sentences
consisting of a subject and object that are
recog-nised entities, a verb that describes the relationship 2.2.3. Knowledge Model
Knowledge modelling is the formal representa-between them, and any conditional clauses. The
procedure followed was to: tion in a computer language of the statements
derived from the process of knowledge acquisition 1. identify tables and sentences from the sample
texts which contain relevant information; such that the semantics are made clear and
accessible to the automated inference mechanism 2. select within these tables and sentences items of
information that were either considered typical whose reasoning will utilise the knowledge content
of these formal representations. Each element of of the agronomy domain or represented
particu-lar challenges; the Knowledge Model is associated with one of
the Application Model templates. Construction
3. translate the information into simplified
English; of the Knowledge Model depends on the process
of knowledge acquisition. 4. add ancillary information (meta-information),
were tested for accuracy and functionality. These the knowledge base would be to connect the system
were the software shell (i.e. the inference engine to external databases using knowledge base rules
plus the user interface) and the knowledge base. that include the field names. Such links would be
Unit testing of the software shell was carried out particularly advantageous for databases that have
in phase 1 of the development and a workshop to be updated regularly, such as those of
agricul-was held in phase 2 to test the system and identify tural statistics, and for those specifying the regional
any errors. distribution of climates and soil types. The system
At all stages of development of the system, the was therefore connected to a small external test
information in the knowledge base was routinely database, and an investigation was carried out into
tested against the four criteria suggested by Walker whether a reliable link could also be made to
and Sinclair (1995):
externally maintained databases. $
validity of representation, relevance, ambiguity
and utility associated with individual
2.2.4. Data Dictionary statements;
The Data Dictionary defines the attributes used $ repetition of, and contradictions between,
in the Knowledge Model. The definitions resemble statements;
encyclopaedia entries more than dictionary entries $ completeness of the knowledge base as a whole;
since they include synonyms, units, maximum and $ consistency in the use of terms.
minimum values and other information required The results of the tests were compared with the
to establish the full meaning of the knowledge appropriate data files in the knowledge base and
statements. All items in the Data Dictionary were any anomalies were assessed from the aspect of
designed to be accessible to the reasoning process, both system operation and the representation and
e.g. to allow the identification of values outside validity of the data. Error tracing was facilitated
the permitted range and to convert from one set by the inclusion of an option, a proof tree, for
of units to another. As the dictionary was compiled listing the rules used to satisfy each query. The
from a wide range of sources, it was important to continuous assessment and correction procedure
check that all the definitions were applicable was designed to minimise the risk of errors aff
ect-throughout Europe. ing the further development of the system.
2.2.5. Inference engine 2.4. Software issues The inference engine infers solutions to user
queries by applying rules contained in the knowl- Prolog (Bratko, 1990), which is one of the two
Intelligence, was used to represent relationships within the system. The table templates in particular were found to be a versatile format for representing and rules in the knowledge base and for
program-ming the inference engine of the operating shell. the data, as many of the sources favoured tabular
formats. Even when this was not the case, it was Its features, such as pattern matching, tree-based
data structuring and automatic backtracking, pro- often possible to manipulate the data to fit the
templates. However, care had to be taken to ensure vide a powerful and flexible framework for solving
problems that involve data items and the relation- that the sense of the actual facts was not altered
when doing this. ships between them. The version used was Logic
Programming Associates WinPro Version 3.1,
which provided interfacing with the Microsoft 3.3. Knowledge model
Windows environment.
3.3.1. Attribute-value statements
This general-purpose statement was able to
3. Results represent a large proportion of the facts within the
knowledge base: 3.1. Task specification
att_val(Attribute, Value, Place, Time)
The potential users identified four main tasks The argument, Attribute, is used to specify
to be carried out by the Crop Knowledge Base the attribute of a crop, an object, or a process to
System: which the statement can be applied. TheValue
1. to specify where ( location or environment) a argument gives the value for the attribute
appro-particular crop species is or could be grown; priate for the combination of circumstances given
2. to identify situations (soil, weather) in which by the final two arguments.Placeand Time
crop yields are significantly reduced below the specify the location and the year, season or
pheno-water-limited potential; logical stage to which the information applies. The
3. to generate the input files needed to run crop value of an attribute can be given as a word, lines
models; of text, a number or a list of items. Facts can be
4. to act as an encyclopaedia to store information turned into rules by making their truth conditional
about crops. on the truth of other att_val statements. In the
All these goals are achievable, although not all example given below, theValueargument
speci-were fully implemented in the current version of fies which particular object of the category ‘crop’
the Crop Knowledge Base System. the information applies to at location ‘Scotland’,
at ‘any time’. This type of formulation would be 3.2. Application model used as a conditional clause attached to another att_val statement, for example giving the earliest
An example of the output from this process is date of harvest:
shown in Fig. 2. Although several hundred
state-att_val(crop, ‘common winter wheat’ ,
ments were examined, it was found that almost all
‘Scotland’ , ‘any time’). could be allocated to one of four classes:
$ statements about the values of attributes of
an object; 3.3.2. Hierarchical statements
Attribute-value statements are linked to crop,
$ statements about position in a taxonomic
hierarchy; location and soil taxonomies included in the Crop
Knowledge Base. If there is no direct match to a
$ tables of values; and
$ references to time. query, the system is able to use its hierarchical
structures to find solutions at other levels of aggre-These four basic unitary knowledge statement
types were found to be sufficient to represent the gation. A simplified crop hierarchy is given in
Fig. 2. Example showing (a) an extract from Narciso et al. (1992), page 33, and (b) part of the results of the knowledge extraction process. The indices in the remarks section of the document refer to entries in a legend that has not been presented here. QU: qualifying information; CT: contextual information; DD: data dictionary information; RF: the reference from which the item of knowledge was extracted; SO: the source of knowledge, if different from the reference.
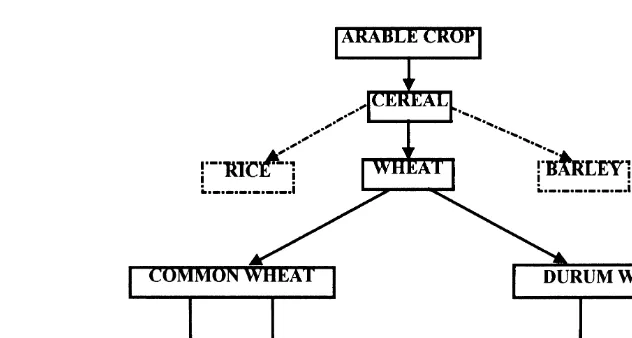
for the location and soil taxonomies. If the user relating either to common wheat or durum wheat
and so on down to the lowest level of the hierarchy. queries the system about wheat, and the knowledge
base does not contain the information specifically However, if information is still not found, the
Fig. 3. Part of the crop hierarchy showing cereal and wheat types.
ments about first cereals then arable crops. The crossed the boundaries of the physiographic
region, the agricultural part of the former could crop hierarchy is essentially botanical and is
broadly compatible with the classification adopted usually be allocated entirely to one of the latter
regions. The division of Europe into grouped areas by EUROSTAT for the collection of agricultural
statistics. The division between winter and spring was only partially implemented since there is no
general agreement about their appropriate bound-crops is actually between autumn and spring
sow-ings since biological spring types can be sown in aries, although river basins would make a good
starting point. The system also contained a table autumn, and the classes are defined in terms of
the date of sowing. This classification implies that of latitudes and longitudes of the centroid of the
agricultural area of each NUTS I region or coun-winter and spring wheat have more in common
than winter wheat and winter barley. try, for places outside the EU.
Soils were classified according to the modified Location is specified in terms of administrative
regions in the NUTS (Nomenclature des Unite´s FAO classification adopted for the 1:1 000 000
Soil Map Of the European Communities (CEC, Territoriales Statistiques) scheme of EUROSTAT
expanded with primary administrative regions for 1985)
countries outside the EU. Although each NUTS
region has a code number, this has been revised 3.3.3. Table references entries
An example of a general template used in the more than once, and it was felt that it would be
better to use the name of each region as the knowledge base for the table entries is
identifier. Unfortunately, in several cases, the same
table(CropType, AgriculturalPractice,
region name is used for more than one country.
LocationList, ListofRelatedInformation).
To overcome this and to improve the search effi
-ciency, each region name was linked directly to The Knowledge Model representation of the
data given in Fig. 2 is shown as an instance of a the top region of its hierarchy.
The system can take account of the disparity table entry in Fig. 4. This table entry only covers
the optimal conditions for a clay soil type. Similar that there often is between the boundaries of
administrative regions and of agro-ecological table entries give the data for loam and sandy
loam soils, which are also mentioned in the zones. A number of searchable physiographic
regions, such as the Po valley of northern Italy, extracted information. Other sets of tables in the
knowledge base cover the information relating to were defined as aggregations of NUTS III regions.
Fig. 4. Example of a knowledge base table entry for optimal agricultural practices relating to skim ploughing for a common wheat crop in Italy, Spain or Greece using information from Narciso et al. (1992).
those that result in crop failure, and crop depend on context, and this was not always stated
explicitly. For example, since the list of factors calendars.
significantly affecting wheat yield varies with cli-mate and soil, it is important to specify exactly 3.3.4. Reference to time
Time refers to any temporal indication including which region an author’s statements refer to.
Some publications contained useful compila-day, month, year or phenological stage and is
represented by the statement: tions of data from primary sources although
inad-vertent or deliberate changes had occasionally been
temp_reason(TimeOfInterest,
made in the process. No data were entered into a ListOfValidTimes).
data file without checking the accuracy of content and spelling. The latter is particularly important This predicate should perhaps be considered the
temporal equivalent of the spatial hierarchies. It is when it is used as a search term. Typographical
errors were often found in the source literature. used to signify whether a given time occurs within
a longer period and is called upon to perform a For example, the phrase ‘forbed and sprangled
roots’ appeared in one description of sugar beet check on the temporal applicability of the
informa-tion requested by the user. in place of ‘forked and strangled roots’. Dubious
terms like this can be spotted by an alert operator and referred to a dictionary or an agronomist for 3.3.5. Knowledge acquisition
Crop data relevant to Europe, i.e. west of the resolution. More difficult to spot are errors in
numbers unless the error is in the position of a Ural Mountains, and North Africa were extracted
from 30 documents covering the major crops, decimal point. In other cases, data sources were
found to quote different values for the same attri-although the extent of the coverage varied with
crop. Data acquisition was carried out by an bute. This problem was overcome by first seeking
expert advice to determine whether one should be operator without specialised agronomic
knowl-edge, and, although agronomists were always preferred or, if not, giving both with qualifying
comments. Problems were encountered where available to assist, this help was rarely required. It
was sometimes difficult to correctly interpret state- terms were inadequately defined in the source
cereals may exclude the area of the leaf sheaths, 3.5. Inference engine and soil water content can be expressed
volumetri-cally or gravimetrivolumetri-cally. Where terms were defined, Prolog itself includes an inference engine that
can be used for reasoning with a knowledge base. it was usually possible to convert to a single scale.
This was often the case with phenological stages, However, it has to be expanded, as described below,
to allow more complex queries to be addressed. for which several descriptions of development are
currently in use (Landes & Porter, 1989).
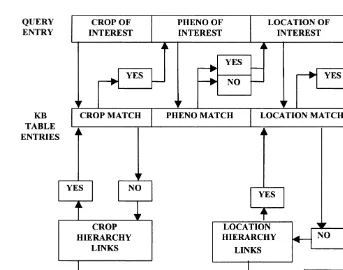
The system includes information about the 3.5.1. Data matching
Fig. 5 shows how the system attempts to match parameters required to run the WOFOST ( Van
Diepen et al., 1989) crop model. Parameter values a query to the information in a table of type:
for other models can be derived manually from
table_name(CropType, PhenologicalStage,
these or from other information in the system.
LocationList, ListofRelatedInformation). The system was interfaced successfully with an
external database. However, this could only be The user inputs crop, phenological phase and
location, and the system works from left to right done reliably when there was a formal link between
the field names in the database and the attributes to attempt a direct match with the knowledge in
the knowledge base. Problems were encountered known to the system, even though the Crop
Knowledge Base System could read the database in reasoning with phenological stages, and these
are explained later. field names. This was partly because database
management systems have restrictive rules for
naming fields and partly because there is no guar- 3.5.2. Hierarchical searches
One of the important features provided by the antee that the definition of field names is the same
in both systems. Thus, the completed prototype Crop Knowledge Base system is its ability to infer
a solution if there is no direct match with informa-did not include a facility for interfacing with
external systems. tion in the knowledge base. In a conventional
database, if any one of the first three arguments By the end of the project, enough information
had been included to demonstrate the potential of (i.e. fields in a database) of the table did not match
the input query, the system would fail to produce the system.
a solution. However, in the Crop Knowledge Base System, the inference engine searches for solutions 3.4. Data Dictionary
to related queries. Thus, an unsatisfied query about ‘common wheat’ would automatically be directed Construction of the Data Dictionary was
gen-erally straightforward, although there are terms to ‘common winter wheat’ and ‘common spring
wheat’, and, failing this, ‘wheat’ itself. If only one such as Leaf Area Index that can be defined in
more than one way. This problem was overcome of the three arguments finds no direct match, then
the appropriate hierarchical search is carried out by including a warning in the entry. The main
difficulty experienced was ensuring completeness. until a solution is found. However, if more than
one argument fails to match, a decision has to be This task could be made easier by automatically
generating a pro forma every time a new term is made about the order in which the matches are
sought. If the crop of interest can be matched to added to the system. Two types of entry can be
distinguished, those referring to attribute names data in the knowledge base, whether directly or
hierarchically, then the system tries to match the and those referring to terms used in qualifying
information or in the data dictionary definition phenological stage. If no match is found, then a
solution will be sought for any phenological stage. themselves. Ideally, a restricted and consistent
vocabulary would be used for all entries. In either case, a search is then made to match the
location of interest. In the table entries, the loca-Compound terms were treated as single entries
although it would be better to index the root term tions for which the information is valid are
Fig. 5. Matching an input query to information held in a table. PHENO: phenological stage.
a direct match, and if none is found, the system candidate region must both be either inside or
outside the Mediterranean zone, which is defined attempts to link the query to a location for which
information is held using the location hierarchy. in a rule as a set of NUTS regions and countries.
The Mediterranean zone was identified for special Should this be unsuccessful, further inferences are
made with regard to nearby regions, as described treatment because the climate imposes constraints
on agriculture that have led to the development of in Section 3.5.3.
It is important to recognise that these search similar farming systems across the whole area and
which differ from those elsewhere. The next step
paths and criteria are themselves rules developed
from expert knowledge and that other formula- is to identify NUTS I regions whose centroid lies
within a rectangle centred on the centroid of the tions could equally well have been included.
region for which information is required. For regions outside the Mediterranean zone, the search 3.5.3. Inferring alternative locations
Users querying the knowledge base specify the is initially restricted to one of four quadrants
(north or south of latitude 50°N; east or west of
geographical region of interest. If there is no exact
match, the system first tries to find a solution for longitude 20° E ). These divisions were chosen
subjectively to separate northern and southern a region above or below the area of interest in the
location hierarchy up to the level of the primary farming systems and eastern and western farming
systems. Latitude is not used in the search rules administrative region of a country. If this
pro-cedure does not produce a solution, a proximity for the Mediterranean zone because the seasonal
cycle of photoperiod is less marked at these south-search is invoked to find regions that are
consid-ered similar to the region of interest. The first erly latitudes, and millennia of selection have
tied to a growing season defined in terms of water attribute, value, and location and time of interest. Associated with each task is a list of relevant availability rather than temperature and solar
radi-ation. Finally, if no solution is found, the search attributes ( Fig. 6), which are selected from a
drop-down list-box. The user then fills the remaining is extended to the whole knowledge base.
slots. The time slot is usually filled by ‘any time’, but exists for the few cases where information is 3.6. User interface
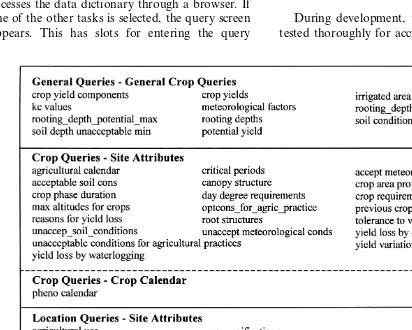
only relevant for a particular period of time. The screen also allows the help and encyclopaedia The main screen presents the user with a menu
bar with file, tasks and help menus. The file and functions to be accessed so that descriptions of the
attributes can be obtained. If further information help facilities include standard utilities, and the
task menu provides options related to the tasks is required from the user, an additional
informa-tion screen is displayed, which has the same format specified in Section 3.1. Task1 is divided into three,
thus giving a total of six options. Two of these as the query screen.
tasks are sub-divided, and further drop-down
menus are displayed. The encyclopaedia query task 3.7. Results of testing the knowledge base
accesses the data dictionary through a browser. If
one of the other tasks is selected, the query screen During development, the knowledge base was
tested thoroughly for accuracy in its retrieval and appears. This has slots for entering the query
series of direct matches where the value varies sets of parameters, those that are constant for a particular crop and those that vary geographically. within the location of interest or where there are
conflicting views in the literature, an inferred solu- Fig. 8 shows the results of a query about the initial
crop specifications for emergence of winter wheat. tion or a related solution.
The query produces values for the parameters TBASEM (the threshold temperature for calculat-3.7.1. Crop queries — site attributes
The first example query is ‘‘how much winter ing thermal time to emergence), TEFFMX (the
maximum daily increment in thermal time), and wheat yield is lost to pathogens in France?’’. This
is a crop query to which the answer varies with TSUMEM (the thermal time from sowing to
emer-gence) and gives the reference to the source mate-site, i.e. location. The task menu offers four
attri-butes relevant to yield loss ( Fig. 6): reasons for rial. These results were checked to ensure that they
accurately reflected the original material. Although yield loss; yield variation factors; yield loss by
disease; yield loss by waterlogging. Fig. 7 shows this example involves a direct match, the same
procedure would be used to derive values for a an extract from the results for a query on yield
loss by disease. The full display gives information crop for which information was unknown.
Parameters that vary geographically can also be on all the diseases known to the system that can
affect winter wheat in France. Although there was found on a region-by-region basis. In many cases,
the information is incomplete or has previously nothing relating directly to winter wheat,
informa-tion was found for common wheat, which occurs been derived by interpolation. The current version
of the knowledge base can only reason hierarchi-at the next level in the crop hierarchy. Both the
binomial and common name are given for the cally or by proximity, although it would be possible
to develop a form of intelligent interpolation based pathogen along with the recorded yield loss
associ-ated with it. Additional information associassoci-ated on the degree of similarity between regions (see
Section 4.2). There is currently no facility to with the disease and the yield loss are given as a
comment. In this case, the information does not automatically output the model parameter files
themselves. Although this could be done, some come from a primary source, but the reference
allows the user to carry out a further investigation. mechanism would be needed to reconcile any
conflicting values. In some cases, further information would be
avail-able using the alarms and hazards task. Although
there is a logical distinction between the two tasks, 3.7.3. Location queries — site attributes
The next query is about the form of agriculture they are clearly related. However, although rules
Fig. 8. Results of a query about the WOFOST parameters relating to the initial crop specifications.
region of Portugal. The solution is given in Fig. 9 3.7.4. Crop queries — crop calendar
Fig. 11 gives three solutions to the query ‘‘when together with some qualifying information. The
proof tree that is used to show the chain of is winter wheat sown in Oost-Nederland?’’ The
second solution is for Gelderland, which is part of reasoning involved is given in Fig. 10. It can be
seen that the solution has been derived from the Oost-Nederland. Thus, queries about a region also
retrieve solutions for the constituent regions. If rules that limited arable farming takes place on
these soils in Italy and Portugal and that Pinhal the query had been posed for the Netherlands,
solutions would also have been found for Oost-Litoral is a part of Portugal. From the associated
comment, it can be seen that the type of farming Groningen (NUTS III ) and Overig-Zeeland
(NUTS III ) but not for the Netherlands in this suggested does not imply that other types of
farm-ing are not possible. This distinction between a case. Queries at country level can sometimes
pro-duce very large numbers of solutions, and so the null and a missing value is a recurring problem in
any knowledge base or database. If the system system is currently set up to limit the solutions to
ten. If ten solutions are produced, the user should were connected to an external regional statistical
database, it would be possible to develop more restrict the search.
A comparison of the first two queries also shows complex rules for allocating land use to
Fig. 9. Results of a query about the type of agriculture carried out on Eutric Regosols in Pinhal Litoral, Portugal.
later in the large region than in one of its constitu- to the specification right up to the end of the
project. Although the project has now finished,
ents. This may be a genuine difference of opinion
due to differences in the primary sources. However, subsequent experience in using the system will
prove valuable in assessing its functionality in the term ‘earliest’ does not refer to the absolute
earliest date ever recorded but to the ten percentile practice and in drawing up a specification for
further developments. value averaged over a 5-year period. This is an
expert interpretation of the data given in the The tests showed that the system could perform
the tasks specified in Section 3.1 and highlighted original source. It is thus theoretically possible,
although unlikely in this case, for both statements some of the benefits of using this approach rather
than normal database operations. For example: to be true. The first and third solutions also differ.
These come from independent sources, and the 1. The system can infer solutions to a query where
there is no direct match. user must decide which to accept.
2. Conditional information, qualifying the validity of the information found, is given with each solution.
4. Discussion
3. Conflicting solutions can be presented together with the associated information that should The novelty of the system meant that the final
form of the knowledge base shell evolved over allow the user to decide which is preferred.
4. Proof trees allow the train of reasoning leading time. Frequent meetings and discussions with the
Fig. 10. Proof tree for the query of Fig. 9.
The work raised several interesting epistemological ment are widely recognised by crop physiologists
and there is general agreement about the broad issues, of which three are discussed below.
phenological stages, the actual phenological stages at which farming operations are carried out or 4.1. Reasoning with phenological information
when the crop is vulnerable to particular hazards are often not specified using standard terminology. It was initially thought that the crop
phenologi-cal phases could be structured in a shallow hierar- The names for analogous phases may also differ
from crop to crop. This is important, as facts chy with sub-divisions of major phases. However,
it soon became apparent that the terms used in added to the knowledge base must use terms that
are recognised by it if they are to be used in the the literature would not fit neatly into such a
different in these two regions, and a model of
mation was available for different phases of maize production would thus require di
fferent
development or when the same phase went by parameters.
different names, for example ear emergence and During the development of the Crop Knowledge
heading of cereals. Base, a utility was developed for identifying similar
We now feel that the best approach would be
regions on the basis of objective geographical to use a hybrid approach in which the original
attributes. These attributes, which included lati-names are used but additional rules are developed
tude, longitude, lowest altitude, river basin, and to relate them to a generic scheme of phenological
selected climatic data, were chosen because of their
description, such as the extended BBCH
effect on phenology or farming system type. After
(Biologische Bundesanstalt Bundessortenamt and
a check that these attributes could be considered Chemical industry) scheme described by Meier
independent, a cumulative score was calculated in (1997), which enables the temporal relationship of
which a one or zero was given for each attribute one stage to another to be deduced. However,
depending on whether or not the value lay within even reasoning with a monotonically increasing
a pre-defined range. Regions with high scores were numerical system as internally consistent as BBCH
very much like the regions of interest. The utility is complicated by the scale not being
mathemati-successfully grouped NUTS III regions in two test cally continuous, and by phases proceeding in
areas, a transect from the north Sea to Bavaria parallel or even not in their strict sequence.
and northern Italy. However, it was recognised that the degree of similarity between two regions 4.2. Reasoning by similarity
might vary with crop and indeed with crop attri-bute and that economic factors operating at the Some important crop attributes vary
geographi-country scale could lead to significant changes in cally. These are mainly those related to phenology
farming practice at frontiers, even though there and those that influence the ratio between actual
was no difference in the physical environment.
and potential production. The latter category
There was insufficient time either to investigate
includes factors related to farming system, such as
this aspect further or indeed to create the large crop rotation and cultivar. An important feature
database of attributes of the agricultural parts of of the Crop Knowledge Base is that the inference
the regions that would be required to implement
engine is able to offer answers to queries about
the utility. The approach allows more flexibility attributes like these where there is no direct
solu-than a simple agroclimatic classification and would tion for the region of interest. As explained in
Knowledge Base with a Geographic Information improved by using problem-specific information to decide on the most promising way to proceed System.
As explained earlier, the current system contains at each stage of the search. This has the effect of
targeting the search process towards a goal, avoid-a simplified version of this type of reavoid-asoning in
which nearness of one region to another is the ing fruitless paths. Algorithms that use these
heuristic methods already exist (Bratko, 1990). main criterion.
Temporal reasoning should be expanded to enable the system to reason with the concept of time such 4.3. Alarm warnings
as ‘during’, ‘before’ and ‘after’. The system, for example, should know that agricultural practice of Whereas some query attributes ( Fig. 6) are easy
to represent, others, such as those related to factors ploughing takes place before sowing.
At the moment, it is relatively easy to add extra responsible for yield reduction below the potential,
posed considerable problems. One of the difficul- information to an existing template in the
knowl-edge base. However, adding new rules requires ties with representing crop warnings effectively was
that there is very little consistent information about specialist knowledge of Prolog. Further
develop-ment should include utilities, i.e. a knowledge base the threshold levels of environmental factors
beyond which yield losses become significant. This editor, to make these operations easier and to
provide checks on the integrity of the system. It problem is compounded by variation of thresholds
with phenological stage, and the dependence of would be worthwhile developing normalisation
rules, such as those used in database development, the consequences on previous conditions and the
possibility of recovery. Consequently, crop warn- to facilitate making problem-free additions,
modi-fications or deletions to the data (Rothwell, 1993). ing information is described in many different ways
in the literature and incorporation into the The data dictionary should also be expanded to
include permitted values for attributes to allow Knowledge Model was not easy. The major
limita-tion is not actually in the programming but in the automatic flagging of dubious entries.
knowledge possessed by experts, which tends to be empirical and location-specific. Authors used a wide range of ways of describing these effects and,
since it had been decided to include information 5. Conclusion
as close to the original form as possible, many
separate attributes had to be used, although it is The Crop Knowledge Base System software is
now (August 1998) in test use at the Joint Research clear that many are related. In practice, an
experi-enced user learns to search the whole set of attri- Centre of the European Commission at Ispra in
Italy. The current version contains information butes that might be relevant. Nevertheless, it would
be possible to include higher level rules in the about the main field crops of Europe, with an
emphasis on wheat, grape vines, olives and orchard system to group related attributes and to allow
deduction of the consequences for yield of a factor crops. All the countries of Europe west of the Ural
Mountains, together with the Maghreb, have been influencing one of the constituent processes of
crop growth. included in the system.
There seem to be no real barriers to developing the concept further by increasing the knowledge 4.4. Suggestions for future developments
content, improving the user interface, expanding the associated utilities and allowing information There is scope for improving the inference
engine to support more complex forms of reason- to be input and output from external systems. The
concept has been successfully tested, and the tech-ing. Further expert knowledge could be
incorpo-rated so that the system could make associative niques developed are widely applicable to the
problem of storage and reasoning with information inferences between different data sets. It is thought
Knowledge-base of Wheat in Europe. Commission of the Nostrand Reinhold, Wokingham, UK. 159 pp
Boons-Prins, E.R., de Koning, G.H.J., van Diepen, C.A., Pen- European Communities, Luxembourg. 160 pp. EUR 15789 EN
ning de Vries, F.W.T., 1993. Crop Specific Simulation
Parameters for Yield Forecasting across the European Com- Russell, G., Muetzelfeldt, R., Taylor, K., 1997. Crop Knowl-edge Base System. European Commission, Luxemburg. munity. Simulation Reports No. 32. CABO-DLO,
The Netherlands. 172 pp. EUR 17697 EN
Supit, I., 1997. Predicting national wheat yields using a crop Bratko, I., 1990. Prolog — Programming for Artificial
Intelli-gence. 2nd edition, Addison-Wesley, Wokingham, UK. simulation and trends model. Agric. For. Meteorol. 88, 199–214.
597 pp
CEC, 1985. Soil Map of the European Communities, 1:1 000 Van Diepen, C.A., Wolf, J., van Keulen, H., Rappoldt, C., 1989. WOFOST: a simulation model of crop production. Soil Use 000. Explanatory Text. Commission of the European
Com-munities, Luxemburg. 516 pp. EUR 17735 EN and Management 5, 16–24.
Van Ranst, E., Vanmechelen, L., Thomasson, A.J., Daroussin, Debenham, J.K., 1989. Knowledge Systems Design.
Prentice-Hall, New York. J., Hollis, J.M., Jones, R.J.A., Jamagne, M., King, D., 1995. Elaboration of an extended knowledge database to interpret Genovese, G., 1998. The methodology, the results and the
eval-uation of the MARS crop yield forecasting ‘system’. In: the 1: 1 000 000 EU soil map for environmental purposes. In: King, D., Jones, R.J.A., Thomasson, A.J. ( Eds.), Euro-Rijks, D., Terres, J.M., Vossen, P. ( Eds.),
Agrometeorologi-cal Applications for Regional Crop Monitoring and Pro- pean Land Information Systems for Agro-environmental Monitoring. European Commission, Luxemburg, duction Assessment. European Commission, Luxemburg,
516 pp. EUR 17735 EN pp. 71–84.
Walker, D.H., Sinclair, F.L., 1995. A knowledge-based system King, D., Le Bas, C., Daroussin, A.J., Thomasson, A.J., Jones,
R.J.A., 1995. The EU map of soil water available for plants. approach to agroforestry research and extension. AI Applic. 9, 61–72.