BAB 2
TINJAUAN PUSTAKA
2.1 Pengolahan Citra
Pengolahan Citra Digital adalah teknologi menerapkan sejumlah algoritma komputer untuk memproses gambar digital. Hasil dari proses ini dapat berupa gambar atau suatu set perwakilan karakteristik atau properti dari gambar asli. Tujuan utama dari pengolahan citra digital adalah untuk memungkinkan manusia untuk mendapatkan gambar berkualitas tinggi atau karakteristik deskriptif dari gambar asli (Zhou et al. 2010).
2.2 Distribusi pixel (Histogram)
Sebuah histogram citra adalah alur dari frekuensi relatif dari peristiwa masing-masing nilai pixel yang diizinkan pada citra terhadap nilai-nilai itu sendiri (Salomon & Breckon, 2011). Jika kita menormalkan sebuah alur frekuensi, sehingga total jumlah semua entri frekuensi selama rentang yang diperbolehkan adalah satu, kita dapat memperlakukan histogram citra sebagai fungsi probabilitas diskrit kepadatan yang mendefinisikan kemungkinan nilai pixel yang terjadi di dalam citra.
Histogram memberikan deskripsi global utama dalam citra (Acharya & Ray, 2005). Sebagai contoh histogram citra greyscale, jika histogram citra sempit, maka dapat diartikan bahwa citra terlihat kurang baik (secara visual) karena perbedaan level grey yang ada pada citra umumnya rendah. Sedangkan jika histogram citra lebar, maka dapat diartikan hampir semua level grey, kontras dan visibilitas citra meningkat.
2.3 Deteksi Tepi (Edge detection)
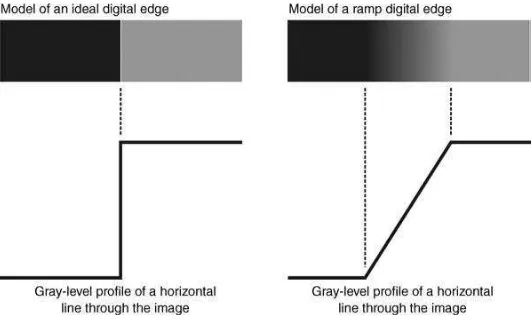
warna dan tekstur) (Marques, 2011). Seperti pada citra greyscale , yang biasanya berhubungan dengan variasi yang tajam dari intensitas di bagian citra. Gambar 2.1 mengilustrasikan konsep ini dan menunjukkan perbedaan antara tepi ideal (transisi tajam) dan tepi lereng (transisi bertahap antara daerah gelap dan terang pada citra).
Deteksi tepi biasanya bergantung pada perhitungan turunan pertama atau kedua sepanjang tampilan intensitas citra (Marques, 2011). Turunan pertama memiliki sifat berbanding lurus dengan perbedaan intensitas di tepi, sehingga turunan pertama dapat digunakan untuk mendeteksi keberadaan tepi pada titik tertentu dalam citra. Turunan kedua dapat digunakan untuk menentukan apakah pixel terletak pada sisi gelap atau terang pada tepi. Selain itu persimpangan nol antara puncak positif dan negatif dapat digunakan untuk menemukan pusat pada tepi yang tebal. Berikut adalah ilustrasi tepi :
Gambar 2.1 Ilustrasi tepi ideal dan tepi lereng pada citra (Marques, 2011).
2.3.1 Turunan Pertama deteksi tepi (First-order derivative)
Pada dasarnya, batas suatu objek adalah langkah perubahan dalam tingkat intensitas. Untuk mendeteksi posisi tepi dapat digunakan diferensiasi ordo pertama, diferensiasi ordo pertama tidak memberikan respon ketika diterapkan pada perubahan intensitas yang tidak berubah, sebuah perubahan intensitas dapat diungkapkan oleh perbedaan titik yang berdekatan (Nixon & Aguado, 2008).
horizontal karena perbedaannya adalah nol. Ketika diterapkan pada citra � aksi detector-tepi horizontal membentuk perbedaan antara dua titik horizontal yang berdekatan, seperti mendeteksi tepi vertikal , , seperti berikut: (Nixon & Aguado, 2008)
, = |�, − � + , | ∀ , � − ; , � (2.1)
untuk mendeteksi tepi horizontal dibutuhkan detektor-tepi vertikal yang membedakan poin vertikal yang berdekatan. Hal ini akan menentukan perubahan intensitas horizontal, tetapi tidak yang vertikal, sehingga detektor-tepi vertikal mendeteksi tepi horisontal, , seperti berikut:
, = |�, − � , + | ∀ , �; , � − (2.2)
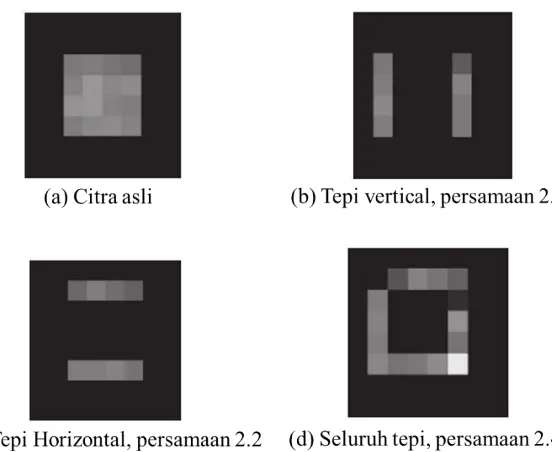
gambar 2.2 (b) dan (c) menampilkan aplikasi operator vertikal dan horizontal pada citra persegi pada gambar 2.2 (a).
tepi kiri vertikal pada gambar 2.2 (b) muncul pada samping persegi (citra asli) yang disebabkan oleh proses diferensiasi. Demikian juga dengan tepi atas pada gambar 2.2(c) muncul diatas persegi (citra asli).
Mengkombinasikan kedua operator E yang dapat mendeteksi tepi vertikal dan horizontal secara bersamaan, yaitu,
, = |�, − �+ , + �, − � , + | ∀ , , � − (2.3)
menghasilkan
, = | �, − �+ , − �, + | ∀ , , � − (2.4)
persamaan 2.4 memberikan koefisien diferensiasi yang dapat konvolusikan dengan gambar untuk mendeteksi semua poin tepi, seperti yang ditunjukkan pada gambar 2.2 (d). Titik cerah di sudut kanan bawah dari tepi pada Gambar 2.2 (d) jauh lebih terang dari titik-titik lainnya. Hal ini karena itu adalah satu-satunya titik yang dideteksi sebagai tepi oleh kedua operator vertikal dan horizontal dan karena itu jauh lebih terang dari titik tepi lainnya. Sebaliknya, titik sudut kiri atas tidak terdeteksi oleh kedua operator sehingga tidak muncul di gambar 2.2 (d).
2.3.2 Turunan kedua deteksi tepi (Second-order derivative)
, = �2 ,
� 2 +
�2 ,
� 2 (2.5)
Dimana turunan kedua deteksi tepi :
�2 ,
� 2 = + , + − , − , (2.6)
Dan
�2 ,
� 2 = , + + , − − , (2.7)
yang menghasilkan ekspresi laplacian yang dinyatakan sebagai jumlah produk :
, = + , + − , + , − − 4 , (2.8)
2.4 Bag of visual words
Bag of words merupakan suatu skema yang digunakan untuk kategorisasi teks dan pencarian teks. Dalam penelitian ini bag of words digunakan untuk pembangunan
codebook, yaitu kosakata visual dimana pola yang paling representative (codified) di dalam codebook sebagai kosakata visual. Kemudian representasi gambar yang dihasilkan melalui analisis frekuensi sederhana setiap codeword dalam citra. Representasi ini telah digunakan dalam berbagai jenis klassifikasi citra diantaranya dalam penelitian Cruz-Roa et al. (2009) menganalisis pola visual histopathology menggunakan bag of word. Penelitian tersebut mengidentifikasi koleksi citra menggunakan bag of word yang berhubungan dengan konsep semantik gambar histopatologi. Raza et al. (2011) menganalisis pengaruh skala dan rotasi invariant descriptor dalam skema bag of word.
Terdapat tiga langkah utama dalam skema bag of word, diantaranya adalah deteksi fitur dan deskrispi citra, cluster fitur, dan pembangunan kantong fitur (bag of feature). Gambar 2.3 akan menunjukkan langkah-langkah bag of visual words:
Citra Keabuan (Grayscale) Deteksi Interest Point Menggunakan Speed-Up Robust Feature
2.5 Deteksi skala (scale detection)
Representasi ruang skala adalah serangkaian citra yang diwakili pada tingkat resolusi yang berbeda (Mikolajczyk & Schmid, 2001). Resolusi yang berbeda dibentuk dengan konvolusi menggunakan kernel Gaussian (Mikolajczyk & Schmid, 2001):
� , = ∗ (2.9)
dimana I adalah citra dan x = (x,y). Dengan demikian dapat direpresentasikan fitur (seperti tepi atau sudut) pada resolusi yang berbeda dengan menerapkan fungsi yang sesuai (kombinasi turunan) pada skala yang berbeda.
Derivatif Amplitudo spasial, secara umum, menurun berdasarkan skala. Dalam kasus bentuk invarian skala, derivatif harus konstan atas skala. Untuk mempertahankan nilai invarian fungsi skala turunan harus dinormalisasi sehubungan dengan observasi skala. Skala yang dinormalisasikan derivatif D atas orde m didefenisikan sebagai berikut (Mikolajczyk & Schmid, 2001):
……. = � ……. , = ……. ∗ (2.10)
Derivatif yang dinormalisasi berjalan baik pada skala pola intensitas. Pertimbangkan dua gambar dan dicitrakan pada skala yang berbeda. Hubungan antara dua gambar ini kemudian didefinisikan = ′ ′ , dimana ′ = . Derivatif citra kemudian terkait sebagai berikut (Mikolajczyk & Schmid, 2001):
……. ∗ = ……. ∗ ′ (2.11)
kemudian untuk derivatif yang dinormalisasikan, didapatkan : (Mikolajczyk & Schmid, 2001)
…… , = ′ …… , (2.12)
Dengan nilai-nilai yang sama diperoleh pada skala relatif yang sesuai. Untuk menjaga perubahan informasi yang seragam antara tingkat resolusi yang berurut dan factor skala harus didistribusikan secara eksponensial.
yang tidak mempunyai nilai maximum. Titik-titik ini terletak pada daerah yang homogen dan tidak mempunyai nilai maximum dalam jangkauan jarak yang dianggap dalam skala. Skala yang dipilih untuk titik adalah benar jika rasio antara skala karakteristik dalam poin yang sesuai adalah sama dengan faktor skala dalam citra. Titik yang sesuai ditentukan oleh proyeksi dengan perkiraan transformasi matrik. Dalam beberapa kasus skala maxima, titik dianggap benar, jika salah satu dari maxima sesuai dengan rasio yang benar. Titik dengan skala yang benar ditampilkan dalam titik putih.
Gambar 2.4 Titik karakteristik pada citra (Mikolajczyk & Schmid, 2001).
2.6 Deteksi fitur Speed-up Robust Feature (SURF)
Untuk mendeteksi fitur pada citra, digunakan SURF dalam bag of visual words. SURF mengambil interest point pada citra, dimana interest point ini adalah deskripsi pada setiap bagian citra.
Penentuan interest point SURF feature menggunakan matrix hessian, dimana matrix hessian didefenisikan sebagai berikut: (Bay et al. 2006).
�, � = [� �, � �� �, � � �, � �, � ] (2.13)
sangat cepat menggunakan citra yang dintegralkan. Seperti yang ditunjukkan pada gambar 2.5 dengan menggunakan filter kotak 9x9 memperkirakan orde kedua derivative Gaussian dengan skala (�=1.2) .
Gambar 2.5 Orde kedua gaussian yang terdiskrit dan dikelompokkan secara derivatif parsial dalam arah y dan arah xy, (diambil dari Bay et al. 2006).
Dengan pendekatan perkiraan adalah , , dan , dimana determinan hessian (diambil dari Bay et al. 2006)
|� , |�||� 9 |�
|� , |�||� 9 |�=0.912..≅0.9, (2.14)
dimana || |� adalah norma frobenius yang menghasilkan (diambil dari Bay et al. 2006)
( � ) = − .9 (2.15)
Gambar 2.6 100 Interest point tertinggi yang diwakilkan dengan bulatan (blob) pada citra.
Pada gambar 2.6 memperlihatkan deteksi dengan menggunakan 4 skala, dimana bulatan terkecil menunjukkan pendeteksian pada skala yang terkecil yaitu 1.6. pendeteksian ini merupakan pendeteksian fitur pada citra dengan menggunakan skala invarian, seperti yang dijelaskan pada bagian 2.5.
2.7 Histogram of Oriented Gradient (HOG)
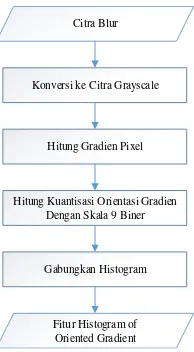
Metode histogram of oriented gradient didasarkan pada evaluasi histogram lokal yang dinormalisasi dari orientasi gradien gambar dalam grid (Dalal & Triggs, 2005).Tahapan histogram of orientated gradient dapat digambarkan seperti berikut:
Hitung Kuantisasi Orientasi Gradien Dengan Skala 9 Biner
Gabungkan Histogram Konversi ke Citra Grayscale
Hitung Gradien Pixel Citra Blur
Fitur Histogram of Oriented Gradient
2.7.1.Konversi Citra Warna ke Citra Greyscale
Konversi greyscale merupakan tahap pertama dalam banyak algoritma analisis citra. Walaupun citra greyscale memuat informasi yang lebih sedikit dibandingkan dengan citra warna, mayoritas penting pada citra tetap terjaga. Seperti tepi, region, dan gumpalan citra tetap ada.
Citra RGB dikonversikan ke citra greyscale menggunakan transformasi berikut: (Salomon & Breckon. 2011)
� � − �� � , = � � , , + � � , , + � � , , (2.16)
dimana (n,m) individual index pixel dari citra greyscale dan (n,m,c) adalah individual chanel pada lokasi pixel (n,m) pada citra warna untuk chanel c, merah untuk chanel r, biru chanel b, dan hijau chanel g. dengan koefisien standar NTSC =0.2989, =0.587 dan
=0.1140.
2.7.2. Menghitung Gradien Pixel
Setelah citra blur dikonversikan menjadi citra greyscale, maka akan dihitung gradien secara vertical dan horizontal (memusatkan). Lalu akan dihitung arah sudut dengan membagi citra
menjadi region yang lebih kecil (“cells"). Pada gambar 2.8 akan ditunjukkan tahap penentuan nilai gradien, dimana gradien dihitung secara vertikal dan horizontal dengan penentuan arah yang ditunjukkan pada gambar 2.9. Kemudian gradien akan dihitung satu-persatu dengan menggunakan cell block (grid) dengan memindahkan grid secara overlapping seperti yang ditunjukkan pada gambar 2.10. Tahap perhitungannya adalah seperti berikut (diadoptasi dari Dalal & Triggs, 2005):
Gradien vertical dan horizontal :
-1
0
1
-1 0 1
Derajat : = √ + Orientasi: � =
Gambar 2.9 Arah orientasi gradien
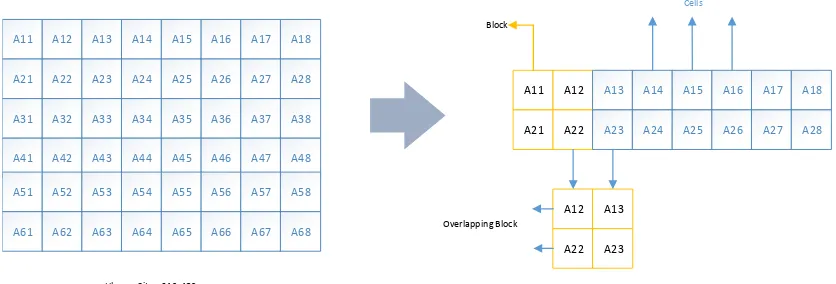
Untuk menentukan pixel mana yang harus dihitung, HOG menggunakan cells block dan overlapping terhadap citra, tahapannya dapat digambarkan sebagai berikut:
A11 A12 A13 A14
Gambar 2.10 Block grid dengan ukuran 2x2 dan overlapping sebesar 50% dari block sebelumnya.
2.7.3.Menghitung Kuantisasi Orientasi Biner dengan skala 9 bin (0-180)
= , maka �=85 digolongkan kepada �=90, dapat diilustrasikan sebagai berikut (diadoptasi
Gambar 2.11 Contoh tahap kuantisasi orientasi biner dengan skala 9 bin (0-180)
2.7.4.Menggabungkan Histogram
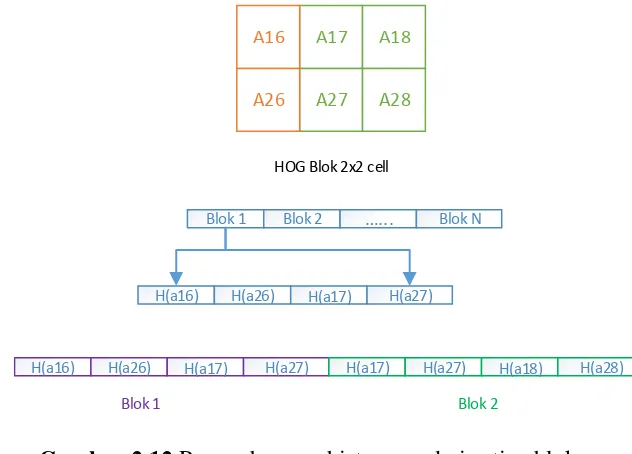
Hasil perhitungan kuantisasi pada tiap blok yang dibentuk, akan digabungkan untuk menghasilkan histogram setiap cell pada blok. Tahap penggabungan histogram dapat digambarkan sebagai berikut (diadoptasi dari Dalal & Triggs, 2005):
A17 A18
H(a16) H(a26) H(a17) H(a27) H(a17) H(a27) H(a18) H(a28)
Blok 1 Blok 2
HOG Blok 2x2 cell
Gambar 2.12 Penggabungan histogram dari setiap blok.
merupakan block cells yang berisikan cell A17,A18,A27 dan A28. A17 dan A18 dihitung pada blok 1 dan blok 1, hal ini dikarenakan oleh overlapping block sebesar 50%, yang artinya setengah nilai cell blok pada blok sebelumnya tetap digunakan untuk menghitung setengah nilai cell blok di depannya. Maka masing-masing blok tersebut dihitung nilai histogramnya dan digabungkan berdasarkan blok yang telah dibentuk.
2.8. K-means Clustering
K-means bertujuan meminimalkan fungsi tujuan kuadrat kesalahan sederhana secara iteratif dalam bentuk (Salomon & Breckon, 2011):
� = ∑ = ∑� | − | , in class j (2.17)
Dimana menyatakan koordinat vektor dari jth kluster dan { } adalah point yang
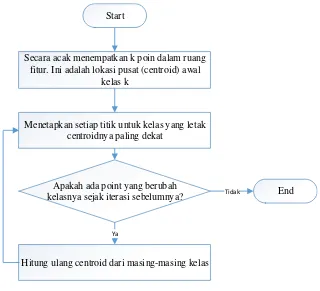
ditetapkan kepada jth kluster. Tahapan algoritma k-means clustering dapat dilihat pada Gambar 2.13 (diadoptasi dari Salomon & Breckon, 2011):
Secara acak menempatkan k poin dalam ruang fitur. Ini adalah lokasi pusat (centroid) awal
kelas k
Menetapkan setiap titik untuk kelas yang letak centroidnya paling dekat
Hitung ulang centroid dari masing-masing kelas Apakah ada point yang berubah
kelasnya sejak iterasi sebelumnya? Tidak
Ya
Start
End
Gambar 2.14 Algoritma k-means (diadoptasi dari Salomon & Breckon, 2011).
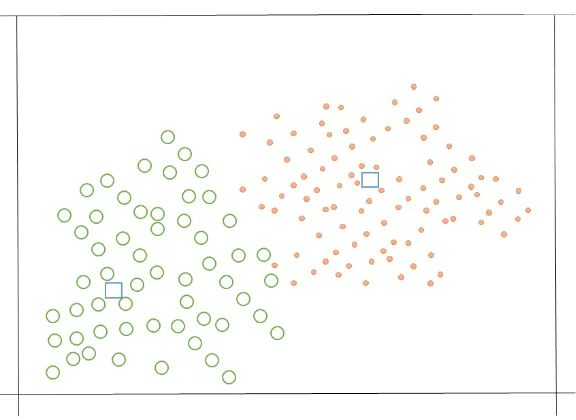
Penjelasan k-means clustering dapat di lihat pada gambar 2.14, dimana secara konseptual untuk mempartisi sebuah data set ke dalam beberapa jumlah kluster k. pada gambar tersebut ditetapkan k=2. Yang berarti menetapkan 2 centroid sebagai pusat pembedaan antara 2 kelas pada gambar tersebut. Penetapan data atau titik vector pada gambar 2.14 disekitar centroid, menggunakan fungsi jarak. Fungsi jarak yang digunakan pada umumnya adalah menggunakan jarak euclidean.
2.9. Support Vector Machine (SVM)
Support vector machine menggunakan pemetaan nonlinear untuk mengubah data pelatihan asli ke dimensi yang lebih tinggi. Dalam dimensi baru ini, akan mencari hyperplane
Support vector machine mencari jarak margin maximum dari hyperplane, untuk memisahkan 2 kelas yang berbeda. Support vector machine dapat dilustrasikan sebagai berikut :
Gambar 2.15 Support vector machine dan hyperplane (diadoptasi dari Han & Kamber, 2006).
bobot dapat disesuaikan sehingga hyperplane mendefinisikan sisi margin dari data training yang ada, formulasinya dapat ditulis sebagai berikut (Han & Kamber, 2006):
: + + + = + , dan
: + + − = −
maka dari itu, data manapun yang setara atau diatas tergolong ke dalam kelas +1, dan data manapun yang setara atau dibawah tergolong ke dalam kelas -1.
2.10 Klasifikasi
Klasifikasi merupakan tahapan analisa data untuk menentukan label atau kelas data dengan menggunakan suatu model atau klasifier (Han & Kamber, 2006). Klasifikasi data dilakukan dengan 2 tahapan. Tahapan pertama menggunakan klasifier untuk suatu set kelas atau konsep data atau yang disebut learning step (training phase). Dimana algoritma klasifikasi
dari tupel database dan label kelas terkait. Tahap pertama klassifikasi digambarkan pada
Input Data Training Output (Klasifier yang telah di training)
Gambar 2.16 Tahap pertama klasifikasi.
Tahap kedua model digunakan untuk klasifikasi. pertama keakuratan prediksi dari classifier diperkirakan. jika kita menggunakan training set untuk mengukur keakuratan classifier, perkiraan ini kemungkinan akan optimis, karena classifier cenderung overfit data
(dalam “pembelajaran data” memungkinkan untuk menggabungkan beberapa anomali tertentu dari training data yang tidak ada dalam data set secara keseluruhan). Oleh karena itu, satu set tes digunakan, terdiri dari tupel tes dan label kelas. Tupel tersebut dipilih secara acak dari kumpulan data umum. Tupel tersebut independen dari tupel pelatihan, yang berarti bahwa tidak digunakan untuk membangun classifier. Keakuratan classifier pada set tes yang diberikan adalah persentase dari uji set tupel yang diklasifikasikan dengan benar oleh classifier. Tahap kedua klassifikasi dapat digambarkan pada Gambar 2.17.