5
BAB II
TEORI PENUNJANG
Pada bagian ini akan dijelaskan mengenai beberapa teori yang berkenaan dengan penelitian Tugas Akhir ini. Subbab 2.1, menjelaskan mengenai perkembangan dari teknik dalam melakukan Content Based
Image retrieval (CBIR). Penjelasan lebih lanjut mengenai CBIR akan
dijelaskan pada subbab 2.2 tentang beberapa metode yang biasa digunakan dalam melakukan visual content decriptions. Kemudian pada subbab 2.3 akan dijelaskan tentang metode clustering. Pada subbab 2.4 akan dijelaskan tentang analisa cluster dan pada subbab 2.5 akan dijelaskan tentang identifikasi pola pergerakan varian.
2.1
Content Based Image retrieval (CBIR)[11]Content Based Image retrieval (CBIR), teknik yang
mengunakan fitur gambar (visual contents) dalam melakukan pencarían gambar dalam database gambar gambar yang besar.
Penelitian dan pengembangan image retrieval dimulai pada sekitar 1970-an. Pada tahun 1979, sebuah konferensi mengenai
Database Tehcniques for Pictorial Application diadakan di Florida.
Sejak itu aplikasi dalam melakukan manajemen database gambar menarik perhatian para peneliti. Awalnya teknik yang dipakai bukan mencari fitur gambar melainkan berdasarkan penambahan deskripsi mengenai gambar dalam bentuk teks. Dengan kata lain pertama gambar diberi teks berdasarkan gambar tersebut kemudian dilakukan pencarian berdasarkan teks (text based) mengunakan sistem database manajemen tradisional. Namun karena pembangkitan teks secara otomatis, mengenai deskripsi spektrum gambar, secara detail sulit untuk dilakukan kebanyakan aplikasi text-based image retrieval saat itu melakukan pemberian teks deskripsi gambar secara manual. Pemberian deskripsi gambar berdasarkan teks merupakan usaha yang merepotkan dan mahal bila diaplikasikan dalam database gambar yang sangat besar dan selain itu sering bersifat subjektif, bersifat kontekstual (context-sensitive) dan mendeskripsikan gambar secara tidak lengkap (incomplete). Hasilnya,
text-based image retrieval tradisonal sulit untuk mampu mendukung
Pada awal 1990-an perkembangan teknologi internet dan teknologi sensor image digital terjadi dengan sangat pesat. Sebagai hasilnya jumlah produksi gambar digital oleh para peneliti, akademisi, militer, industri, kesehatan dan para penguna lainnya berkembang dengan sangat pesat. Sedangkan pencarian gambar berdasarkan teks sudah tidak mampu lagi secara optimal menyelesaikan permasalahan ini. Sehingga diperlukan suatu metode baru dalam melakukan image
retrieval. Pada tahun 1992, National Science Foundation of the United
States mengadakan workshop mengenai pengembangan metode baru dalam image database management system. Dalam seminar itu dikemukan metode baru yang lebih efekfif dan presisi dalam merepresentasikan informasi dari fitur gambar yaitu berdasarkan properti atau fitur yang terkandung dalam gambar itu sendiri. Sejak tahun 1997 penelitian dan publikasi dibidang content-based image
retrieval seperti ekstraksi fitur, indexing, image database manajemen
berkembang dengan pesat, contohnya QBIC produk IBM, Virage produk Virage Inc, Netra produk Synapse dan beberapa teknik dan sistem mengenai aplikasi CBIR lainnya.
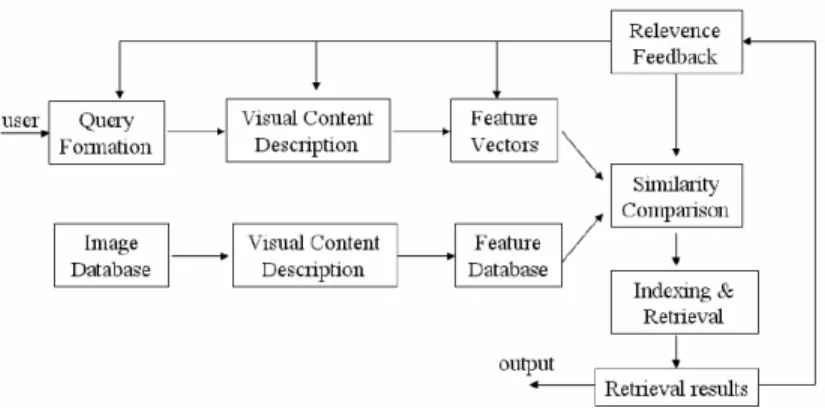
CBIR, mengunakan fitur gambar seperti warna, bentuk, tekstur dan dan informasi spasial untuk merepresentasikan dan mengindekskan gambar. Dalam sistem aplikasi CBIR secara umum (gambar) fitur visual dari kumpulan gambar dalam database gambar diekstraksi dan didekripsikan dalam bentuk vektor fitur multi-dimensi. Fitur ini disimpan dalam database fitur. Untuk mencari gambar dalam database, user memerlukan gambar query. Gambar query ini kemudian diekstraksi fitur visual-nya dan direpresentasikan dalam bentuk vektor fitur. Kemiripan atau jarak antara vektor fitur dari gambar model dan gambar
query dihitung oleh proses indexing. Proses indexing diperlukan untuk
melakukan proses pencarian yang cepat dan efisien. Feedback dari user merupakan modifikasi dari proses pencarian gambar untuk menghasilkan pencarian gambar yang lebih presisi. Dalam bagian ini akan dijelaskan mengenai teknik – teknik yang dipakai dalam melakukan ekstraksi fitur gambar.
Gambar 2.1 Diagram dari Content-Based Image retrieval.
2.2
Ekstraksi Fitur GambarBerbicara mengenai fitur gambar, secara umum ada dua fitur gambar yaitu visual dan semantic (tekstual). Fitur visual adalah fitur yang terdapat dalam gambar itu sendiri. Fitur visual dibagi menjadi dua yaitu general dan domain spesifik. General visual content termasuk warna, bentuk, tekstur dan relasi spasial. Domain spesific content contohnya seperti wajah manusia. Sematic content adalah penambahan deskripsi secara tekstual berdasarkan ekstraksi fitur gambar. Pada penelitian tugas akhir ini difokuskan pada pembahasan mengenai
General visual content selanjutnya akan ditulis sebagai fitur gambar.
Ekstraksi fitur gambar yang dapat dilakukan untuk citra digital adalah merubah citra/image input a[m,n] menjadi sebuah image output b[m,n] (atau dengan representasi lain) dapat dikelompokan kedalam tiga kategori sebagaimana ditunjukan dalam tabel 2.1.
Tabel 2.1 Tipe dari ekstraksi fitur gambar. Ukuran citra = N x N; ukuran neighborhood= P x P. Sebagai catatan bahwa complexitas dikhususkan
untuk operasi per pixel.
Operasi Karakteristik Kompleksi-tas/Pixel
*Point Nilai output pada koordinat tertentu hanya tergantung pada nilai input pada kordinat yang sama.
Operasi Karakteristik Kompleksi-tas/Pixel
* Local Nilai output pada koordinat tertentu tergantung pada nilai input pada neighborhood
(ketetanggaan) dari koordinat yang sama.
P2
* Global Nilai ouput pada koordinat
terntentu tergantung pada semua nilai input image.
N2
Gambar 2.2 Ilustrasi dari tipe-tipe pengoperasian citra.
Pada bagian ini akan dijelaskan mengenai beberapa teknik yang digunakan secara luas dalam melakukan ekstraksi fitur gambar
2.2.1 Warna (Color)
Warna merupakan fitur gambar yang paling banyak digunakan dalam berbagai aplikasi CBIR. Sebelum menjelaskan mengenai beberapa teknik mengenai ekstraksi fitur warna, akan dijelaskan terlebih dahulu mengenai ruang warna (space color).
2.2.1.1 Ruang Warna
Setiap piksel dalam gambar dapat direpresentasikan sebagai sebuah titik dalam suatu ruang warna 3D. Umumnya yang mengunakan ruang warna untuk image retrieval termasuk RGB, Munsell, CIE
L*a*b*, CIE L*u*v, HSV (or HSL, HSB) dan opponent color. Salah satu
karakteristik yang diinginkan dari ruang warna dalam image retrieval adalah karena sifatnya yang uniform.
Ruang warna RGB dalam pengelolahan gambar (citra) terdiri dari 3 (tiga) warna utama, yaitu merah (R), hijau (G), dan biru (B). Jika
warna-warna pokok tersebut digabungkan, maka akan menghasilkan warna lain. Penggabungan tersebut bergantung pada warna pokok yang tiap-tiap warna memiliki nilai 256 (8 bit). Jika dilihat dari pemetaan model warna RGB yang berbentuk cube ( kubus ) seperti gambar dibawah ini.
Gambar 2.3 Pemetaan RGB cube dengan sumbu x,y,z
Pada bagian ini, selanjutnya akan dibahas mengenai teknik ekstraksi fitur warna dengan color histogram.
2.2.1.2 Color histogram
Color histrogram merupakan hubungan dari intensitas tiga
macam warna. Dimana setiap gambar mempunyai distribusi warna tertentu. Distribusi warna ini dimodelkan dengan color histogram. Color
histogram tersebut didefinisikan sebagai berikut :
HR,G,B[r,g,b] = N.Prob { R=r, G=g, B=b }……… (2.1)
dimana R,G,B merupakan tiga macam warna dan N adalah jumlah piksel pada gambar.
Color histogram dihitung dengan cara mendiskretkan warna
dalam gambar dan menghitung jumlah dari tiap-tiap pixel pada gambar (image). Karena jumlah dari tiap-tiap warna terbatas, maka untuk lebih tepatnya dengan cara mengubah 3 Histogram ke dalam single variable
Pada gambar RGB, salah satu transformnya didefinisikan sebagai berikut :
m = r+Nr g+NrNgb(2.2) ……… (2.2)
dimana Nr, Ng, dan Nb merupakan jumlah nilai biner dari warna merah, biri, dan hijau secara berturut-turut. Untuk mendapatkan Color histo-gram menggunakan persamaan sebagai berikut :
}
,
,
|
)
,
,
{(
, ,r
g
b
r
I
g
I
b
I
H
rgb=
⊂
⊂
⊂
……… (2.3) Keterangan : R = warna merah G = warna hijau B = warna biruHr,g,b = Data untuk menampung nilai probabilitas warna RGB Contoh Histogram warna :
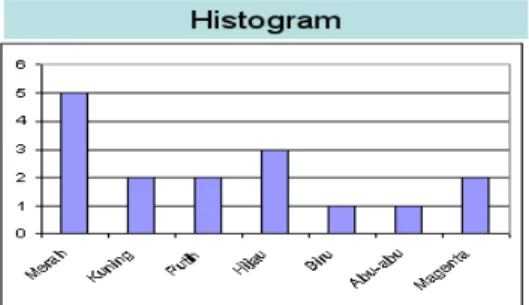
Gambar 2.4 Warna pada tiap pixel.
Gambar diatas menjelaskan bahwa warna merah mempunyai jumlah 5, Kuning = 2, Hijau = 3, Biru = 1, Abu-abu = 1, Pink = 2 dan Putih = 2. Dari jumlah tersebut maka akan ditampilkan dalam bentuk Histogram seperti gambar dibawah ini.
Gambar 2.5 Grafik Histogram warna
• Probability Density Function
image b g r b g r
N
H
P
(, , )=
( , , ) ……… (2.4)Gambar 2.6 Grafik probability density function
• Normalisasi Histogram
)
(
(, , ) ) , , ( ) , , ( b g r b g r b g rH
Max
H
P
=
……… (2.5) 2.2.2 TeksturTekstur adalah salah satu fitur gambar yang sangat penting. Pengunaan fitur tekstur digunakan secara luas oleh peneliti pada pengenalan pola (pattern recognition) dan computer vision. Pada dasarnya, metode representasi tekstur dapat diklasisfikasikan menjadi
dua, yaitu: structural dan statistical. Metode structural termasuk
morphological operator dan adjacency graph, mendifinisikan tekstur
dengan cara melakukan identifikasi struktur primitifnya dan aturan penempatan pola. Metode ini efektif digunakan pada gambar dengan tekstur yang sangat umum. Metode statistik, termasuk diantaranya :
Fourier power spectra, co-occurrence matrices, shift-invariant principal component analysis (SPCA), Tamura feature, Wold decomposition, Markov random field, fractal model, dan teknik multi-resolution filtering seperti Gabor and wavelet transform.
Langkah awal pada peneletian sebelumnya adalah memuat semua gambar pembelajaran sebagai model dan disimpan dengan menggunakan bentuk array, setelah itu setiap gambar diekstraksi fitur warna dan teksturnya. Untuk fitur warna akan terbentuk suatu nilai numerik, begitu juga dengan fitur tekstur akan terbentuk suatu nilai numerik, semua nilai yang merupakan hasil dari ekstraksi fitur ini berupa data array.
2.2.2.1 Filter Gabor
Sejak penemuan kelompok garis kristal dari korteks visual utama dari otak mamalia ±30 tahun yang lalu oleh Hubel dan Wiesel, dan sejumlah besar eksperimen dan penelitian terhadap berbagai teori dengan luas menambah pengetahuan kita terhadap bidang ini dan berbagai respon positif muncul untuk sel-sel ini. Secara teori sebuah wawasan penting telah dikembangkan oleh Marcelja dan Daugman bahwa sel-sel sederhana pada korteks visual dapat dibentuk dengan fungsi gabor. Fungsi Gabor yang di perkenalkan oleh Daugman adalah berupa band-pass filter yang bekerja lokal spasial yang mencapai limit teorinya untuk resolusi conjoint(penggabungan) dari informasi dalam domain spasial 2D dan domain frekuensi 2D.
Fungsi Gabor pertama kali diperkenakan oleh Denis Gabor sebagai tool untuk deteksi sinyal dalam noise. Gabor menunjukan bahwa terdapat prinsip kuantum “quantum principal” untuk informasi. Gabungan domain frekuensi dan domain waktu dan frekuensi untuk ID sinyal harus diperbaiki dengan baik sehingga tidak ada sinyal atau filter yang menempatinya kurang dari area minimum tertentu di dalamnya. Bagaimanapun ada sebuah pertukaran antara resolusi waktu dan frekuensi. Gabor menemukan bahwa dengan modulasi eksponensial kompleks Gaussian akan menghasilkan pertukaran yang terbaik. Untuk misalnya suatu kasus, Fungsi Gabor diperoleh dari sebuah fungsi
Gaussian yang diperbaiki dengan frekuensi modulasi geombang yang bervariasi.
Daugman mengembangkan kerja Gabor kedalam filter dua dimensi (Daugman 1980,1985). Dia menunjukan bahwa perluasan dari kriteria optimasi hubungan ke dua dimensi telah dipenuhi dengan kelompok fungsi-fungsi yang dapat dinyatakan sebagai filter spasial terdiri dari gelombang rataan sinusoidal dengan dua dimensi ellips
envelope Gaussian. Transformasi Fourier yang bersesuaian berisi ellips
Gaussian dipindahkan dari sumbu asal ke bidang spasial dari envelope Gaussian. Fungsi tersebut, berikutnya lebih dikenal dengan Gabor
Elementary function (GEF) dapat didesain pada frekuensi tinggi maupun
rendah, atau dengan kata lain GEF merupakan filter bandpass. Persamaan untuk GEF diberikan sebagai berikut,
)] ( 2 exp[ ) ' , ' ( ) , (x y g x y j Ux Vy h = π + ……… (2.6)
(x’,y’)=(x cos θ+y sin θ, -x sin θ +y cos θ) menyatakan koordinat garis lurus dari domain spasial yang dirotasikan, (U,V) mewakili frekuensi 2D tertentu fungsi g(x,y) merupakan Gaussian 2D,
+ − = 2 2 2 1 exp 2 2 1 ) , ( y y x x y x g σ σ πσ ………… (2.7)dimana σx dan σy menyatakan luas spasial dan bandwidth dari filter.
Dengan mengasumsikan σx= σy=σ dan parameter θ tidak dibutuhkan,
persamaan GEF pada 2.13 disederhanakan menjadi,
(
x y)
[
j(
Ux Vy)
]
y x h = − + +
π σ πσ 2 2 exp 2 2 2 exp 2 2 1 ) , ( ……… (2.8)dan untuk fungsi Gaussian menjadi,
(
)
2 2 2 2 22
1
)
,
(
σπσ
y xe
y
x
g
+ −=
……… (2.9)dari persamaan matematika diatas dapat kita lihat bahwa respon impuls dari GEF diperoleh dari perkalian fungsi Gaussian dengan fungsi kompleks.
Ciri tekstur yang dipakai sebagai attribut dalam pembentukan cluster adalah nilai mean
µ
mndan standard deviasiσ
mndari magnitude hasil transformasi gabor pada masing-masing skala dan orientasi m,n.( )
=
∑∑
( )
x y mnx
y
G
n
m
E
,
,
……… (2.11)( )
PxQ
n
m
E
mn,
=
µ
……… (2.12)( )
(
)
PxQ
y
x
G
x y mn mn mn∑∑
−
=
2,
µ
σ
……… (2.13)2.3
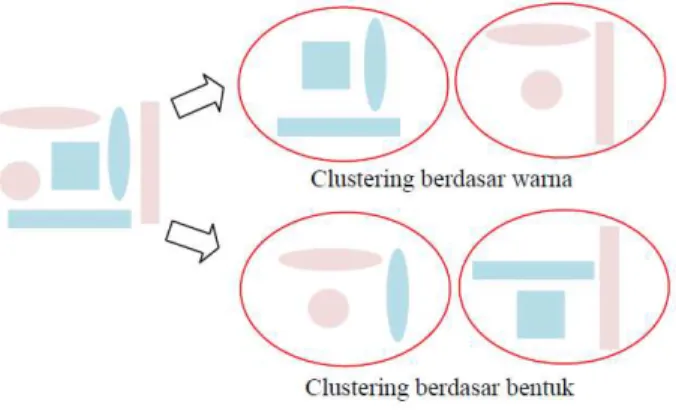
Clustering[1]Clustering adalah proses pengelompokan objek ke dalam kelompok-kelompok yang anggota-anggotanya mempunyai kesamaan tertentu. Contohnya adalah sebagai berikut:
Gambar 2.7 Clustering berdasarkan kedekatan jarak
Karakteristik clustering dibagi menjadi 4, yaitu : 1. Partitioning clustering
Partitioning clustering disebut juga exclusive clustering, dimana
setiap data harus termasuk ke cluster tertentu. Karakteristik tipe ini juga memungkinkan bagi setiap data yang termasuk cluster tertentu
pada suatu tahapan proses, pada tahapan berikutnya berpindah ke
cluster yang lain.
Contoh : K-Means, residual analysis. 2. Hierarchical clustering
Pada hierarchical clustering, Setiap data harus termasuk ke cluster tertentu. Dan suatu data yang termasuk ke cluster tertentu pada suatu tahapan proses, tidak dapat berpindah ke cluster lain pada tahapan berikutnya.
Contoh: Single Linkage, Centroid Linkage,Complete Linkage,
Average Linkage.
3. Overlapping clustering
Dalam overlapping clustering, setiap data memungkinkan termasuk ke beberapa cluster. Data mempunyai nilai keanggotaan (membership) pada beberapa cluster.
Contoh: Fuzzy C-means, Gaussian Mixture. 4. Hybrid
Karakteristik hybrid adalah mengawinkan karakteristik dari
partitioning, overlapping dan hierarchical.
2.3.1 Algoritma Clustering
Ada beberapa algoritma yang sering digunakan dalam
clustering, yaitu :
1. K-Means
Termasuk partitioning clustering yang memisahkan data ke k daerah bagian yang terpisah. K-means algorithm sangat terkenal karena kemudahan dan kemampuannya untuk clustering data besar dan data outlier dengan sangat cepat. Sesuai dengan karakteristik
partitioning clustering. Setiap data harus termasuk ke cluster
tertentu dan Memungkinkan bagi setiap data yang termasuk cluster tertentu pada suatu tahapan proses, pada tahapan berikutnya berpindah ke cluster yang lain.
Algoritma K-Means :
1. Menentukan k sebagai jumlah cluster yang ingin dibentuk
2. Membangkitkan k centroids (titik pusat cluster) awal secara random
3. Menghitung jarak setiap data ke masing-masing
centroids
5. Menentukan posisi centroids baru dengan cara menghitung nilai rata-rata dari data-data yang memilih pada centroid yang sama.
6. Kembali ke langkah 3 jika posisi centroids baru dengan centroids lama tidak sama.
Gambar 2.8 Ilustrasi Algoritma K-Means
Karakteristik K-Means:
• K-means sangat cepat dalam proses clustering
• K-means sangat sensitif pada pembangkitan centroids
awal secara random
• Memungkinkan suatu cluster tidak mempunyai anggota
• Hasil clustering dengan K-means bersifat tidak unik (selalu berubah-ubah) - terkadang baik, terkadang jelek.
• K-means sangat sulit untuk mencapai global optimum.
Gambar 2.9 Ilustrasi kelemahan Algoritma K-Means
2. Hierarchical Clustering
Dengan metode ini, data tidak langsung dikelompokan ke dalam beberapa cluster dalam 1 tahap, tetapi dimulai dari 1 cluster yang mempunyai kesamaan, dan berjalan seterusnya selama beberapa iterasi, hingga terbentuk beberapa cluster tertentu.
Arah hierarchical clustering dibagi 2, yaitu : a) Divisive
• Dari 1 cluster ke k cluster
• Pembagian dari atas ke bawah (top to down division) b) Agglomerative
• Dari N cluster ke k cluster
• Penggabungan dari bawah ke atas (down to top merge). Algoritma Hierarchical clustering :
1. Menentukan k sebagai jumlah cluster yang ingin dibentuk
2. Setiap data dianggap sebagai cluster. Kalau N = jumlah data dan c=jumlah cluster, berarti ada c=N.
3. Menghitung jarak antar cluster
4. Cari 2 cluster yang mempunyai jarak antar cluster yang paling minimal dan gabungkan (berarti c=c-1).
5. Jika c>k, kembali ke langkah 3.
Ilustrasi dari hierarchical clustering adalah sebagai berikut:
Gambar 2.10 Ilustrasi Algoritma Hierarchical Clustering
Penghitungan jarak antar obyek, maupun antar cluster-nya dilakukan dengan Euclidian distance, khususnya untuk data numerik. Untuk data 2 dimensi, digunakan persamaan sebagai berikut:
( )
∑
=−
=
n i i iy
x
y
x
d
1 2|
|
,
………(2.14)Pada proyek akhir ini akan menggunakan Single Linkage
Hierarchical Method dan Centroid Linkage Hierarchical Method.
Gambar 2.11 Ilustrasi clustering 2.3.2 Hierarchical Clustering
Pada tahap pengindeksan ini karakteristik fitur yang telah diekstraksi dimasukan dalam database. Kemudian vektor fitur dari hasil ekstraksi fitur gambar ini akan dikelompokan (cluster) berdasarkan nilai kedekatan dari vektor fitur. Dalam proses pengelompokan fitur vektor gambar ini bisa direpresentasikan dengan mengunakan algoritma dari hierarchical clustering.
Hierarchical clustering adalah suatu metode clustering dimana
data tidak langsung dikelompokan dalam beberapa cluster dalam 1 tahap, tetapi dimulai dari 1 cluster yang mempunyai kesamaan dan berjalan seterusnya selama beberapa iterasi hingga terbentuk beberapa cluster tertentu.
Algoritma Single Linkage Hierarchical Clustering: 1. Diasumsikan setiap data dianggap sebagai
cluster. Jika n=jumlah data dan c=jumlah cluster, berarti ada c=n.
2. Menghitung jarak antar cluster dengan
Euclidian distance.
3. Mencari 2 cluster yang mempunyai jarak minimum antar cluster yang paling minimal dan digabungkan (merge) kedalam cluster baru (sehingga c=c-1)
4. Kembali ke langkah 3, dan diulangi sampai dicapai cluster yang diinginkan.
Gambar 2.12 Ilustrasi Algoritma Single Hierarchical Clustering
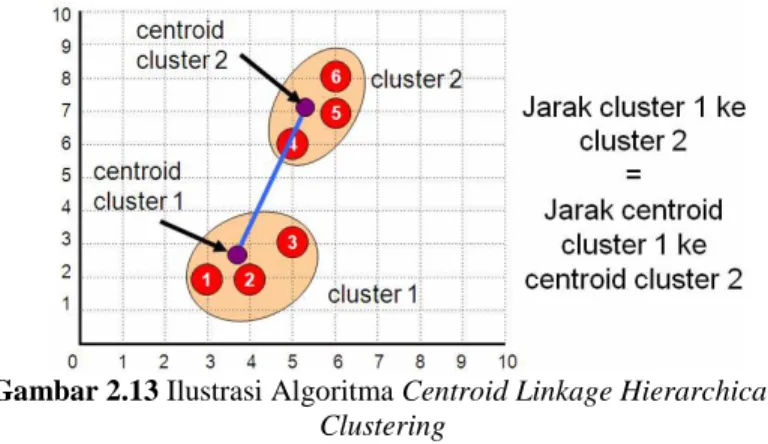
Algoritma dari Centroid Linkage Hierarchical clustering 1. Tentukan k sebagai jumlah cluster yang ingin
dibentuk
2. Setiap data dianggap sebagai cluster.
Kalau N=jumlah data dan c=jumlah cluster
cluster, berarti ada c=N.
3. Hitung jarak antar cluster
4. Cari 2 cluster yang mempunyai jarak antar centroid yang paling minimal dan gabungkan (berarti c=c-1)
Gambar 2.13 Ilustrasi Algoritma Centroid Linkage Hierarchical
Clustering
Dimisalkan n adalah jumlah gambar dalam suatu database, dan belum dilakukan penghitungan persamaan/kedekatan bentuk diantara gambar-gambar tersebut. Suatu hierarchical clustering dilakukan sebagai berikut :
1. Suatu n gambar dalam database, dikelompokan kedalam n
cluster. cluster ini diindekskan kedalam
{C1,C2,C3,…<Cn}. Untuk suatu cluster ke-k, Ek
merupakan gambar – gambar apa saja yang masuk dalam suatu cluster dan Nk menandakan banyaknya jumlah
gambar dalam suatu cluster.
Ek ={k}dan Nk = 1 untuk k = 1,2,…,n
2. Dua cluster Ck dan Cl dikelompokan berdasarkan
pengukuran persamaan/kedekatan Sk,l dengan nilai
kemiripan yang paling besar. Dua cluster ini digabung dalam suatu cluster baru Cn+1. Ini mengurangi jumlah total
dari unmerged cluster dengan satu. En+1 menjadi En+1 = {
Ek U El } dan Nn+1 menjadi Nn+1 = Nk + Nl. Suatu Cn+1
terbentuk dari dua anak yang merupakan gabungan dari dua unmerged cluster, yang pertama right child = RCn+1 =
k dan yang kedua left child LCn+1 = l. Pengukuran
persamaan/kedekatan diantara suatu cluster baru Cn+1 dan
unmerged cluster lainnya dibahas lebih lanjut dibawah.
3. Langkah 2 dan 3 diulangi sampai jumlah cluster telah mencapai jumlah cluster yang diinginkan atau jumlah nilai persamaan/kedekatan terbesar antar cluster telah mencapai nilai threshold terendah.
Gambar 2.14 menunjukan contoh sederhana dari hierarchical
clustering dengan mengunakan 8 gambar. Clustering ini berhenti
setelah mencapai 2 cluster. Dalam contoh ini diketahui, N14 = 5, N12
= 3, E14 = {1,2,3,4,5} dan E12 = {6,7,8}. Selain itu RC14 = 5 dan
LC14 = 13. Masing – masing cluster mempunyai tree yang saling
terhubung.
Gambar 2.14 Contoh sederhana proses pengabungan cluster dengan
hierarchical clustering
Pengukuran persamaan/kedekatan antara dua gambar sudah dijelaskan pada bagian sebelumnya. Pengukuran persamaan/kedekatan, Sk,l, diantara dua cluster, Ck dan Cl , adalah digambarkan sebagai
pengukuran persamaan/kedekatan antara gambar – gambar yang terdapat dalam kedua cluster tersebut, yang dijelaskan sebagai berikut :
) ( , , ,
),
(
l k N N j i l k i j l kP
jS
i
E
E
S
+∑
∈
∪
≠
=
……… (2.15)Dimana adalah pengukuran persamaan/kedekatan antara gambar i dan gambar j. adalah elemen gambar apa saja yang masuk dalam cluster dan adalah jumlah gambar dalam cluster , adalah jumlah pasangan dari gambar dalam suatu cluster dengan n gambar :
2
)
1
(
n
n
P
n=
−
1 2 3 4 5 6 7 8 10 9 13 14 11 12Dengan kata lain merupakan rata – rata persamaan antara semua pasangan gambar yang ada dalam suatu cluster yang diperoleh dengan cara mengabungkan antara Ck dan Cl. Karena persamaan antar
cluster telah dijelaskan dapat diperoleh dengan pengukuran persamaan
gambar – gambar yang ada dalam cluster, jadi tidak perlu dilakukan penghitungan titik tengah dari masing – masing cluster bila dua cluster akan digabungkan.
Ketika dua cluster Ck dan Cl digabungkan untuk membentuk
cluster baru Cm, kemudian diperlukan penghitungan persamaan cluster
ini dengan semua cluster yang lain seperti yang dijelaskan pada rumus 2.15. Maka ini akan menjadi perhitungan yang cukup rumit seperti yang ditujukan rumus dibawah. Untuk setiap cluster Ct pengukuran
persamaan Cm dan Ct adalah :
) ( , , , , ,
,
,
},
{
t l k N N N i l k t ij j i t j i k l j i t mP
S
E
j
E
E
jS
i
E
j
i
E
E
S
+ +∑
∈
∪
≠
+
∑
∈
≠
+
∑
∈
∪
∈
=
……… (2.16) danS
m,m adalah sama denganS
k,lSuatu metode rekursi sederhana untuk dapat mencapai hal yang sama diperoleh mengunakan kaitan pada rumus (2.16) dengan menguraikan rumus pertama sama dengan
j l t l k N N S N
P
, ) ( + + kemudianrumus ke-dua diperoleh t t t S N
P
, )( dan yang ketiga sama dengan
t t N k k N l l N t k N N t l N N
S
P
S
P
S
P
S
P
S
P
t k l t k t l ) , ( ) , ( ) , ( ) , ( ) , ( ++
+−
−
−
2
Sehingga demikian sehingga pengukuran persamaan
S
m,tdapat diperoleh dari
S
l,k,
S
l,t,
S
k,t,
S
t,t,
S
l,l,
danS
k,k Berikut rumus untuk memperoleh pengukuran persamaan dengan proses komputasi yang lebih mudah dibandingkan cara – cara sebelumnya :) ( , ) ( , ) ( , ) ( , ) ( , ) ( , ) ( , t l K t k l k l t k t l N N N t t N k k N l l N k l N N t k N N t l N N t m
P
S
P
S
P
S
P
S
P
S
P
S
P
S
+ + + + ++
+
−
−
−
=
……… (2.17)Pada rumus (2.16),
S
m,tdihitung dengan menjumlahkanpengukuran persamaan dari semua pasangan gambar didalam Cm dan Ct
dan karenanya komputasi yang dihasilkan merupakan kuadrat dari jumlah gambar yang ada dalam dua cluster. Penghitungan dalam rumus (2.17), adalah tidak terikat pada jumlah gambar – gambar dalam cluster. Pada awal setiap clustering untuk semua cluster
S
i,jsama denganj i
S
, danS
i,isama dengan nol.2.4
Analisa ClusterAnalisa cluster adalah suatu teknik analisa multivariate (banyak variabel) untuk mencari dan mengorganisir informasi tentang variabel tersebut sehingga secara relatif dapat dikelompokan dalam bentuk yang homogen dalam sebuah cluster. Secara umum, bisa dikatakan sebagai proses menganalisa baik tidaknya suatu proses pembentukan cluster. Analisa cluster bisa diperoleh dari kepadatan
cluster yang dibentuk (cluster density). Kepadatan suatu cluster bisa
ditentukan dengan variance within cluster (Vw) dan variance between
cluster (Vb).
Varian tiap tahap pembentukan cluster bisa dihitung dengan rumus :
∑
=−
−
=
n i c i c Cy
y
n
V
1 2 2)
(
1
1
……… (2.18) Dimana,Vc2 = varian pada cluster c
c = 1..k, dimana k = jumlah cluster n
c = jumlah data pada cluster c
yi = data ke-i pada suatu cluste
yi = rata-rata dari data pada suatu cluster
Selanjutnya dari nilai varian diatas, kita bisa menghitung nilai variance
within cluster (Vw) dengan rumus :
∑
=−
−
=
c i i i wn
V
c
N
V
1 2).
1
(
1
……… (2.19) Dimana,N = Jumlah semua data n
Vi= Varian pada cluster i
Dan nilai variance between cluster (Vb) dengan rumus :
∑
=−
−
=
n i i i bn
y
y
c
V
1 2)
(
1
1
……… (2.20) Dimana, y= rata-rata dari iySalah satu metode yang digunakan untuk menentukan cluster yang ideal adalah batasan variance , yaitu dengan menghitung kepadatan cluster berupa variance within cluster (Vw) dan variance between cluster (Vb).
Cluster yang ideal mempunyai Vw minimum yang merepresentasikan internal homogenity dan maksimum Vb yang menyatakan external homogenity. b w
V
V
V
=
……… (2.21)Meskipun minimum Vw menunjukan nilai cluster yang ideal, tetapi pada beberapa kasus kita tidak bisa menggunakannya secara langsung untuk mencapai global optimum. Jika kita paksakan, maka solusi yang dihasilkan akan jatuh pada local optima.
2.5
Identifkasi Pola Pergerakan VarianIdentifikasi pola pergerakan varian merupakan metode untuk memperoleh cluster yang mencapai global optimum, yang mampu mengatasi masalah dari minimum V. Gambar 2.15 menunjukan pergerakan varian pada tiap tahap pembentukan cluster, dimana dari gambar tersebut terlihat bahwa global optimum berada pada tahap ke 15, dengan 6 total cluster.
Gambar 2.15 Pergerakan Variance pada tiap Tahap Pembentukan
Berikut tahap untuk menemukan global optimum dari tahap pembentukan cluster :
a) Mendeskripsikan semua pola dari pergerakan varian, seperti gambar 2.15 diatas.
b) Menganalisa kemungkinan global optimum yang berada pada tempat yang tepat.
c) Melihat posisi dari global optimum yang mungkin.
Posisi yang mungkin untuk menemukan global optimum pada pergerakan varian, dikelompokan menjadi 2, yaitu :
1) Hill-climbing Pada Hill-climbing didefinisikan bahwa
kemungkinan mencapai global optimum terletak pada tahap ke-i, jika memenuhi persamaan berikut :
i i
a
v
v
+1>
.
……… (2.22)Dimana, α adalah nilai tinggi.
Nilai tinggi digunakan untuk menentukan seberapa mungkin metode ini mencapai global optimum. Nilai α yang biasa digunakan adalah 2,3, dan 4.
Persamaan diatas diperoleh berdasar analisa pergerakan varian pola Hill-climbing berikut:
Gambar 2.16 Pola nilai beda Hill-climbing
2) Valley-tracing Pada Valley-tracing didefinisikan bahwa
kemungkinan mencapai global optimum terletak pada tahap ke-i, jika memenuhi persamaan berikut :
)
(
)
(
v
i−1≥
v
i∩
v
i+1>
v
i ……… (2.23) Dimana i = 1…n, dan n tahap terakhir pembentukan cluster. Persamaan diatas, diperoleh berdasar analisa pergerakan varian pola Valley-tracing berikut :Gambar 2.17 Pola nilai beda Valley-tracing
Berikut tabel yang menunjukan pola-pola Valley-tracing yang mungkin mencapai global optimum. Pola yang mungkin ditandai dengan simbol √.
Tabel 2.2. Tabel kemungkinan pola
Selanjutnya, baik dengan pendekatan metode valley-tracing maupun hill-climbing dilakukan identifikasi perbedaan nilai tinggi (∂) pada tiap tahap, yang didefinisikan dengan :
(
v
i 1−
v
i) (
+
v
i 1−
v
i) (
=
v
i 1−
v
i 1)
−
(
2
×
v
i)
=
∂
+ − + − ………… (2.24)Nilai ∂ digunakan untuk menghindari local optima, dimana persamaan ini diperoleh dari maksimum ∂ yang dipenuhi pada persamaan 2.24. Untuk membentuk cluster secara otomatis, yaitu cluster yang mencapai
global optima, digunakan nilai λ sebagai threshold, sehingga cluster
secara otomatis terbentuk ketika memenuhi : max (∂) ≥ λ
Untuk mengetahui keakuratan dari suatu metode pembentukan cluster pada hierarchical method, baik menggunakan valley-tracing maupun
hill-climbing, digunakan persamaan sebagai berikut :
)
max(
)
max(
∂
∂
=
terdekat
nilai
ϕ
……… (2.25)Dimana nilai terdekat ke max adalah nilai kandidat max(∂) sebelumnya. Nilai φ yang lebih besar dari 2, menunjukan cluster yang terbentuk merupakan cluster yang well-separated (terpisah dengan baik).