BAB II
KAJIAN PUSTAKA
2.1 State Of The Art Review
Beberapa penelitian yang berkaitan dengan desain sistem semantic data
warehouse dengan menggunakan metode ontology diantara lain penelitian yang
dilakukan oleh Banu dkk. (2011) dengan judul penelitian “Semantic – Based Querying
Using Ontology in Relational Database of Library Management System”. Pada
penelitian ini dijelaskan bahwa bahwa web tradisional termasuk sebagian besar dari
relational database (RDB) yang mendukung penataan data pada dasar sintak (code).
Mengkonversi data yang disimpan dalam database relasional ke format RDF sangat susah dan sering terjadi kesalahan. Maka dibangun sebuah relasi database dengan
format RDF dengan desain ontology. Jadi pendekatan ini untuk penggalian ontology
dari RDB dan memungkinkan pengguna untuk melakukan query semantic dan menerjemahkannya ke dalam RDF bahasa query atau sering disebut dengan SPARQL. SPARQL bisa digunakan untuk mengekspresikan query di sumber data yang beragam.
Penelitian yang lain tentang semantic data juga dilakukan oleh Airinei dan Berta (2012) dengan judul “Semantic Business Intelligence – a New Generation of Business
Intelligence”. Menjelaskan perkembangan generasi baru solusi business Intelligence
yang akan digunakan oleh perusahaan untuk mengelola dan menganalisis data untuk memberikan sebuah informasi yang mendukung keputusan yang tepat. Dalam konteks
semantic data perkembangan untuk mengintegrasikan data semantic yang tidak
terstruktur, membuat solusi business intelligence yang akan didesain untuk dapat
menganalisis, memproses dan memahami data dalam bentuk terstruktur maupun tidak terstruktur.
Selanjutnya penelitian Kakish dan Kraft (2012) dengan judul penelitian “ETL
Evolution for Real-Time Data Warehousing”. Dalam penelitian ini dijelakan metode
yang digunakan dipenelitian ini adalah Change Data Capture (CDC) yang diintegrasikan dengan tool ETL sehingga proses ETL dapat efisien dan real-time. CDC adalah pendekatan inovasi untuk integrasi data, berdasarkan identifikasi, menangkap, dan mengirimkan perubahan yang dibuat oleh data sumber. Dengan memproses hanya perubahannya, CDC membuat proses integrasi data lebih efisien. Integrasi CDC dengan
tool ETL yang ada menyediakan pendekatan terintegrasi untuk mengurangi jumlah
informasi yang dikirimkan sambil meminimalisasi kebutuhan sumber daya dan memaksimalkan kecepatan dan efisiensi ke data warehouse secara real- time.
Penelitian Thenmozhi1 dan Vivekanandan (2013) dengan judul “A Tool For Data
Warehouse Multidimensional Schema Design Using Ontology” menjelaskan tentang
data warehouse telah menjadi komponen yang diperlukan untuk analisis yang efektif usaha besar. Hal ini diterima secara luas bahwa data warehouse harus terstruktur sesuai dengan model multidimensi untuk memudahkan analisis OLAP. Metode yang digunakan untuk perancangan data warehouse dipenelitian ini adalah dengan menggunakan ontology. Ontology memanfaatkan domain pengetahuan pada data
warehouse yang digunakan untuk proses pencarian sumber-sumber rancangan informasi
yang relevan sesuai dengan yang diinginkan. Pembuatan desain ontology dilakukan untuk membuat konsep pengetahuan tentang database yang berasal dari sumber data yang berbeda.
Penelitian Yadav dan Srivastava (2014) dengan judul “Semantic Web Data
Mining & Analysis”. Dalam penelitian ini hanya menjelaskan tentang penggunaan semantic web mining yang menggabungkan dua bidang penelitian yaitu semantic web
dan web mining. Dalam hubungan ini, kehebatan penelitian ini adalah untuk meningkatkan pencarian informasi pada web dengan strategi semantic yang membuatnya cepat dan akurat dalam menggali informasi. Dengan perkembangan yang luar biasa dari WWW, itu membuat halaman web yang banyak dapat menghabiskan waktu cukup lama untuk pengguna dalam mencari informasi yang dibutuhkan. Oleh karena itu menggali informasi dengan web semantic telah menjadi sangat diperlukan agar informasi yang penting bisa dicari dengan cepat dan tepat. Strategi semantic web dan web mining bila diterapkan dengan penggalian informasi web akan memberikan hasil yang baru dan efisien bagi permintaan pengguna. Hal ini akan membantu untuk memberikan kepuasan yang lebih baik bagi pengguna yang kurang paham didalam mencari informasi pada website.
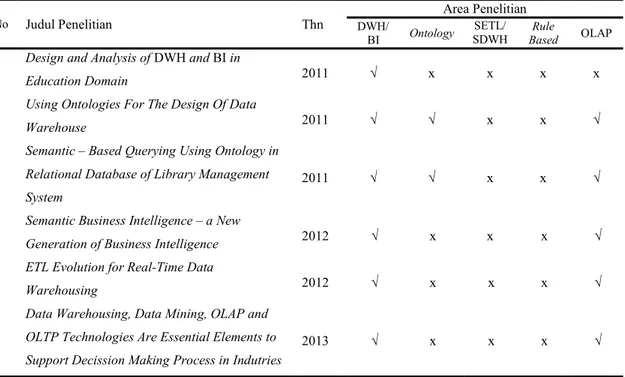
Tabel 2.1 Daftar Penelitian yang Dijadikan Acuan
No Judul Penelitian Thn
Area Penelitian DWH/
BI Ontology SDWH SETL/ Based Rule OLAP
1 Design and Analysis of DWH and BI in
Education Domain 2011 √ x x x x
2 Using Ontologies For The Design Of Data
Warehouse 2011 √ √ x x √
3
Semantic – Based Querying Using Ontology in Relational Database of Library Management System
2011 √ √ x x √
4 Semantic Business Intelligence – a New
Generation of Business Intelligence 2012 √ x x x √ 5 ETL Evolution for Real-Time Data
Warehousing 2012 √ x x x √
6
Data Warehousing, Data Mining, OLAP and OLTP Technologies Are Essential Elements to Support Decission Making Process in Indutries
7 A Tool For Data Warehouse Multidimensional
Schema Design Using Ontology 2013 √ √ x x x
8 Semantic Web Data Mining & Analysis 2014 √ √ x x √
9 Data Warehouse Design of Students Profile
from XYZ University 2014 √ x x x √
10 Toward An Ontology Based Approach For
Data Warehouse 2014 √ √ x x √
11
Desain Sistem Semantic Data Warehouse Untuk Mengolah Data Akademik dengan Menggunakan Metode Ontology dan Rule Based
2015 √ √ √ √ √
2.2 Konsep Data Warehouse
Menurut Turban dkk. (2011), data warehouse adalah kumpulan data yang dihasilkan untuk mendukung pengambilan keputusan. Data warehouse juga merupakan tempat penyimpanan data saat ini dan data historis dari kepentingan manager diseluruh organisasi. Menurut Laudon dan Laudon (2010), data warehouse adalah database yang menyimpan data penting saat ini dan historis dari kebutuhan informasi untuk manager dalam perusahaan.
Berdasarkan pengertian yang dijabarkan oleh para ahli diatas dapat disimpulkan bahwa pengertian data warehouse adalah kumpulan data atau database yang digunakan sebagai tempat penyimpanan data saat ini dan data historis dari kebutuhan informasi untuk manager diseluruh organisasi untuk mendukung pengambilan keputusan.
2.3 Karakteristik Data Warehouse
Karakteristik data warehouse terdiri dari subject oriented, integrated, time
variant, dan non volatile. Karakteristik Data Warehouse menurut Turban dkk. (2011),
a) Subject Oriented
Data tersusun berdasarkan subyek yang detil, seperti sales, product, atau
customers, hanya mengandung informasi yang relevan untuk mengambil
keputusan. Subject Oriented tidak hanya dapat membantu user untuk menentukan bagaimana proses bisinis mereka berjalan tetapi juga membantu dalam menentukan mengapa proses bisnis mereka berjalan.
b) Integrated
Integrasi berhubungan erat dengan subject orientation. Data warehouse harus menempatkan data dari sumber yang berbeda ke dalam format yang konsisten untuk melakukannya, mereka harus menghadapi konflik penamaan dan perbedaan di antara satuan ukuran.
c) Time Variant
Data warehouse menyimpan data historical. Data yang tidak selalu memberikan
status. Mereka mendeteksi tren, penyimpangan dan hubungan jangka panjang untuk melakukan peramalan dan perbandingan, yang mengarah kepada pengambilan keputusan. Setiap data warehouse mempunyai kualitas yang sementara. Waktu adalah satu-satunya dimensi yang penting yang semua data
warehouse harus bisa mendukung.
d) Nonvolatile
Setelah data dimasukan ke dalam data warehouse, user tidak bisa mengganti atau meng-update data. Data yang lama dibuang dan perubahan data disimpan sebagai data yang baru.
2.4 Model Dimensional Data Warehouse
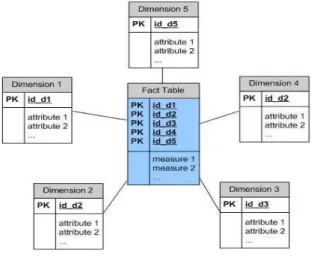
Menurut Connolly dan Begg (2010), dimensionality modeling adalah sebuah teknik desain logika yang bertujuan untuk menampilkan data dalam bentuk standar, intuitif yang memungkinkan akses cepat. Dimensionality modeling menggunakan konsep model Entity-Relationship (ER) dengan beberapa batasan penting. Setiap model dimensi terdiri dari satu tabel dengan satu composite primary key yang disebut fact table dan memiliki kumpulan dari tabel yang lebih sederhana yang disebut tabel dimensi (dimension table). Tiap tabel dimensi memiliki primary key (non composite) yang akan berkorespondensi tepat satu dengan komponen pada composite key dalam fact table.
a) Star Schema
Menurut Connolly dan Begg (2010), star schema adalah model data dimensional yang mempunyai fact table di bagian tengah, dikelilingi oleh tabel dimensi yang terdiri dari data reference (yang bisa di-denormalized). Star schema mengambil karakteristik dari factual data yang di-generate oleh event yang terjadi dimasa lampau.
Gambar 2.1 Star Schema (Sumber: Connolly dan Begg, 2010)
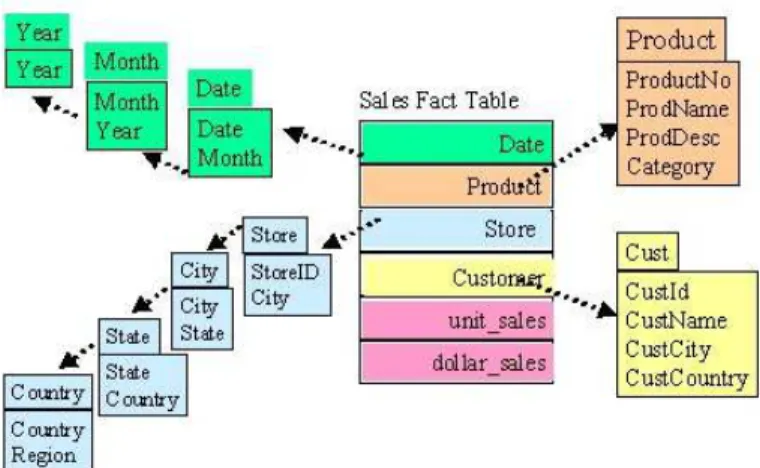
b) Snowflake
Menurut Connolly dan Begg (2010), Snowflake adalah jenis dari star schema dimana tabel dimensinya tidak mengandung denormalisasi.
Gambar 2.2 Snowflake (Sumber: Connolly dan Begg, 2010) c) Starflake
Menurut Connolly dan Begg (2010), Starflake adalah struktur gabungan yang mengandung campuran dari star schema dan snowflake. Berdasarkan dari kutipan pengertian ketiga schema diatas, dapat disimpulkan bahwa tabel fakta pada star schema dikelilingi oleh banyak dimensi dengan hubungan
one-to-many, sedangkan pada snowflake tabel fakta terhubung banyak ke tabel dimensi,
yang dimana dimensi tersebut dapat dihubungkan ke tabel dimensi lain, sedangkan starflake schema merupakan gabungan antara star schema dengan
2.5 Web Semantic
Menurut Jhon Markoff, web semantic adalah sekumpulan teknologi yang menawarkan cara baru yang efisien dalam membantu komputer mengorganisasi dan menarik kesimpulan dari data online. Melalui web semantic inilah berbagai perangkat lunak akan mampu mencari, membagi, dan mengintegrasi informasi dengan cara yang lebih mudah. Web Semantic adalah sekumpulan informasi yang dikumpulkan dengan metode tertentu agar dapat dengan mudah diproses oleh mesin, dalam skala yang besar. Ini seperti cara yang efisien dari representasi data pada World Wide Web, atau sebagai
database global yang saling terhubung. Web semantic terdiri dari seperangkat
prinsip-prinsip desain, kelompok kerja kolaboratif, dan berbagai teknologi. Beberapa elemen dari web semantic yang dinyatakan sebagai calon masa depan dan unsur-unsur lain dari
web semantic disajikan dalam spesifikasi formal dimaksudkan untuk memberikan
deskripsi formal konsep, istilah, dan hubungan dalam satu domain tertentu. Istilah web
semantic itu sendiri diperkenalkan oleh Tim Berners-Lee, penemu World Wide Web.
Sekarang, prinsip web semantic disebut-sebut akan muncul pada Web 3.0, generasi ketiga dari World Wide Web. Bahkan Web 3.0 itu sendiri sering disamakan dengan web
semantic. Web semantic menggunakan XML, XMLS (XML Schema), RDF, RDFS
(Resources Description Framework Schema) dan OWL.
2.6 ETL Berbasis Semantic
Menurut Rainardi (2008), ETL adalah suatu proses mengambil dan mengirim data dari sumber data ke data warehouse. Dalam proses pengambilan data, data harus bersih agar didapat kualitas data yang baik. Contohnya ada nomor telepon yang invalid, ada kode buku yang tidak eksis lagi, ada beberapa data yang null, dan lain sebagainya. Pendekatan tradisional pada proses ETL mengambil data dari data sumber, meletakkan
pada staging area, dan kemudian mentransformasi dan meng-load ke data warehouse. Pada ETL berbasis semantic ini, prosesnya hampir sama denga ETL tradisional hanya perbedaan pada transfrom yang akan menerapkan metode ontology dengan rule based. Proses Extrac Transform Loading (ETL) berbasis semantic terbagi menjadi 3, yaitu:
1. Extract
Extract adalah proses penentuan source yang akan digunakan sebagai sumber
data bagi data warehouse. Di sini kita bisa menentukan data apa saja yang diperlukan, tabel apa saja yang dijadikan sumber. Langkah pertama pada proses ETL adalah mengekstrak data dari sumber-sumber data. Kebanyakan proyek
data warehouse menggabungkan data dari sumber-sumber yang berbeda. Pada
hakekatnya, proses ektraksi adalah proses penguraian, pembersihan dari data diekstrak untuk mendapatkan struktur atau pola data yang diharapkan.
2. Transform
Setelah source ditentukan, maka data tersebut diubah agar sesuai dengan
standard yang ada pada data warehouse. Tahapan transformasi menggunakan
serangkaian aturan atau fungsi untuk mengekstrak data dari sumber dan selanjutnya dimasukkan dalam data warehouse. Dibawah ini hal-hal yang dilakukan dalam tahapan transformasi, yaitu:
a) Hanya memilih kolom tertentu saja untuk dimasukkan ke dalam data
warehouse.
b) Menterjemahkan nilai-nilai yang berupa kode, misalnya sumber
database menyimpan nilai 1 untuk laki-laki dan nilai 2 untuk perempuan,
tetapi data warehouse yang telah ada menyimpan A untuk dewasa dan C untuk anak-anak, maka ini disebut juga dengan automated data cleaning
(tidak ada pembersihan secara manual yang ditunjukkan selama proses ETL).
c) Proses transformasi dari OLTP fisik ke data model mapping dengan pendekatan ontology dan rule based yang menghasilkan bentuk model RDFS logic. Dari RDFS logic ini akan ditransformasikan kebentuk SDWH fisik dengan model dimensional schema.
3. Loading
Loading adalah proses memasukkan data-data yang sudah di transformasi ke
dalam data warehouse untuk disimpan sebagai summary atau archieve. Fase
load merupakan tahapan yang berfungsi untuk memasukkan data ke dalam
target akhir, yang biasanya ke dalam suatu data warehouse. Jangka waktu proses ini tergantung pada kebutuhan organisasi. Beberapa data warehouse dapat setiap minggu menulis keseluruhan informasi yang ada secara kumulatif, data diubah, sementara data warehouse yang lain satau bagian lain dari data warehouse yang sama dapat menambahkan data baru dalam suatu bentuk historical, contohnya setiap jam. Waktu dan jangkauan untuk mengganti atau menambah data tergantung dari perancangan data warehouse pada waktu menganalisis keperluan informasi.
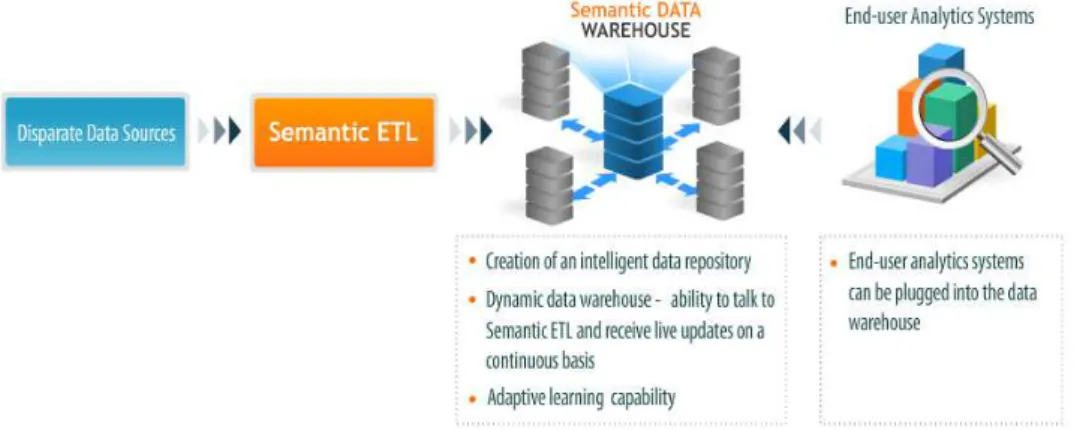
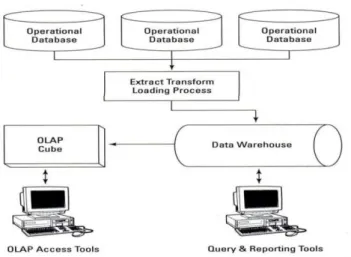
2.7 Semantic Data Warehouse
Semantic data warehouse adalah repositori data yang cerdas yang diciptakan
dalam proses ETL berbasis semantic. Memiliki sifat yang sangat dinamis karena kemampuannya untuk mengolah semantic ETL dan menerima update langsung secara terus menerus. Semantic data warehouse juga merupakan pengembangan data
lebih baik yang memungkinkan komputer dan pengguna dapat bekerja sama. Semantic
data warehouse bertujuan agar informasi pada data warehouse yang diekpresikan di
dalam bahasa alami yang dimengerti manusia dan perangkat lunak (software). Melalui
semantic data warehouse inilah, berbagai perangkat lunak akan mampu mencari,
membagi, dan mengintegrasikan informasi dengan cara yang lebih mudah dan cepat.
Gambar 2.3 Alur Semantic Data Warehouse (Sumber : TAS Information Intelligence)
2.8 OLTP dan OLAP
2.8.1 OLTP (Online Transaction Processing)
Menurut Stair dkk. (2010), OLTP adalah suatu bentuk pengolahan data dimana setiap transaksi diproses dengan segera, tanpa penundaan mengumpulkan transaksi ke dalam batch. Memiliki karakteristik dengan jumlah data yang besar namun transaksi yang dilakukan cukup sederhana seperti insert, update, dan delete. Hal utama yang menjadi perhatian dari sistem yang dilakukan OLTP adalah melakukan
1.8.2 OLAP (Online Analytical Processing)
1.8.2.1 Pengertian OLAP (Online Analytical Processing)
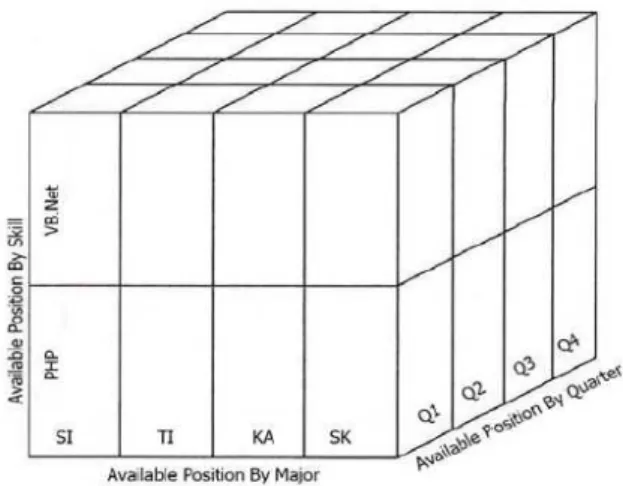
Menurut Turban dkk. (2011) struktur operasional utama dalam OLAP didasarkan pada konsep yang disebut kubus (cube). Kubus (cube) didalam OLAP adalah struktur data multidimensional (actual atau virtual) yang memungkinkan analisis data yang cepat. Juga dapat didefinisikan sebagai kemampuan dari memanipulasi dan menganalisis data secara efisien dari berbagai perspektif. Susunan data ke dalam kubus bertujuan untuk mengatasi keterbatasan database relational. Database relational tidak cocok untuk analisis yang cepat dan dekat dari sejumlah besar data. Sebaliknya, mereka lebih cocok untuk memanipulasi
record (menambahkan, menghapus, dan memperbarui data) yang
mewakili serangkaian transaksi.
Gambar 2.4 Online Analytical Processing (Sumber: Scheps, 2008)
Berdasarkan pengertian yang dijabarkan oleh para ahli diatas dapat disimpulkan bahwa pengertian Online Analytical
Processing (OLAP) adalah sebuah konsep data multidimensional
yang mendukung kegiatan mulai dari self service reporting dan analisis data yang cepat dan efisien dari berbagai perspektif. 1.8.2.2 Arsitektur OLAP
Menurut Scheps (2008), Sistem OLAP mempunyai dua kategori, yaitu:
a) OLAP Cube
Di lingkungan OLAP, cube adalah penyimpan data terspesialisasi dirancang secara spesifik untuk menangani data ringkasan multidimensional (multidimentional summary
data). Data cube disimpan di cell dan strukturnya seperti 3D spreadsheet.
Gambar 2.5 Cube (Sumber: Scheps, 2008)
b) OLAP Access Tools
Lingkungan client yang memungkinkan pengguna untuk memanipulasi data cube dan akhirnya menghasilkan Business
Intelligence yang berarti dari berbagai sudut pandang dan
dapat lebih dari satu sudut pandang.
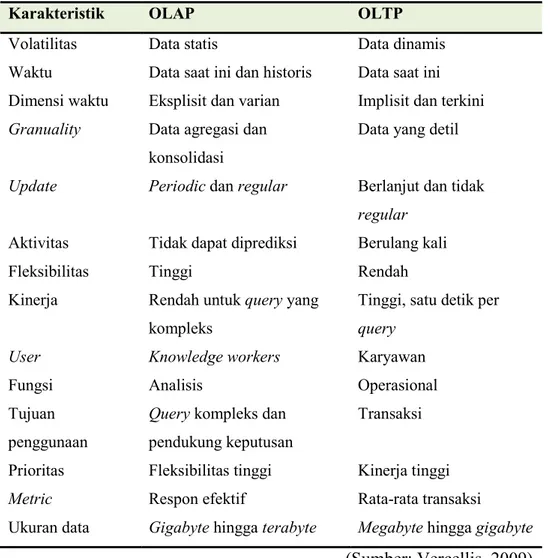
1.8.3 Perbedaan OLAP dan OLTP
Menurut Vercellis (2009) terdapat perbedaan antara OLAP dan OLTP, antara lain dapat dilihat pada tabel dibawah ini :
Tabel 2.2 Perbedaan Antara OLTP dan OLAP
Karakteristik OLAP OLTP
Volatilitas Data statis Data dinamis Waktu Data saat ini dan historis Data saat ini Dimensi waktu Eksplisit dan varian Implisit dan terkini
Granuality Data agregasi dan
konsolidasi
Data yang detil
Update Periodic dan regular Berlanjut dan tidak
regular
Aktivitas Tidak dapat diprediksi Berulang kali
Fleksibilitas Tinggi Rendah
Kinerja Rendah untuk query yang kompleks
Tinggi, satu detik per
query
User Knowledge workers Karyawan
Fungsi Analisis Operasional
Tujuan penggunaan
Query kompleks dan
pendukung keputusan
Transaksi
Prioritas Fleksibilitas tinggi Kinerja tinggi
Metric Respon efektif Rata-rata transaksi
Ukuran data Gigabyte hingga terabyte Megabyte hingga gigabyte
1.9 Data Mining
Menurut Han dan Kamber (2011), data mining adalah proses menemukan pola yang menarik dan pengetahuan dari data yang berjumlah besar. Menurut Vercellis (2009), data mining adalah aktivitas yang menggambarkan sebuah proses analisis yang terjadi secara iteratif pada database yang besar, dengan tujuan mengekstrak informasi dan knowledge yang akurat dan berpotensial berguna untuk knowledge workers yang berhubungan dengan pengambilan keputusan dan pemecahan masalah.
Aktivitas data mining dapat dipisahkan menjadi 2, berdasarkan tujuan dari analisis yaitu:
a) Interpretasi
Tujuan dari interpretasi adalah untuk mengetahui pola dari data dan menghasilkannya dalam bentuk aturan dan kriteria yang dapat dimengerti eksekutif.
b) Prediksi
Tujuan dari prediksi adalah untuk mengestimasikan kejadian-kejadian yang terjadi di masa depan. Contohnya, perusahaan retail dapat menggunakan data
mining untuk memprediksikan penjualan dari produk mereka di masa depan
dengan menggunakan data-data yang telah didapatkan dari beberapa minggu. Berdasarkan pengertian yang dijabarkan oleh para ahli diatas dapat disimpulkan bahwa pengertian data mining adalah sebuah proses analisis yang terjadi secara interatif dan menemukan pola yang menarik, serta pengetahuan dari data yang berjumlah besar.
1.10 BI (Business Intelligence)
2.10.1 Pengertian Business Intelligence
Menurut Scheps (2008), Business Intelligence adalah segala aktivitas, tool, atau proses yang digunakan untuk mendapatkan informasi yang terbaik untuk mendukung proses pembuatan keputusan. Menurut Vercellis (2009), Business
Intelligence adalah kumpulan model metematika dan metodologi analisa yang
secara sistematik menghasilkan data untuk menghasilkan suatu informasi dan pengetahuan yang berguna untuk mendukung proses pengambilan keputusan yang kompleks. Tujuan utama dari business intelligence adalah untuk menyediakan alat dan metodologi bagi knowledge workers untuk membuat keputusan yang efektif dan tepat waktu.
a) Keputusan yang efektif
Aplikasi dari metode analisa yang butuh ketelitian tinggi membuat pengambil keputusan harus mengandalkan informasi dan pengetahuan mana yang dapat diandalkan. Hasilnya, mereka dapat membuat keputusan yang lebih baik dan membuat suatu perencanaan yang dapat membuat tujuan mereka tercapai dengan efektif.
b) Keputusan yang tepat waktu
Perusahaan beroperasi dalam lingkungan ekonomi yang berkarakterisasi oleh tingkatan kompetisi dan dinamisme yang tinggi. Konsekuensinya, kemampuan untuk bereaksi dengan pesaing dan kondisi pasar baru merupakan faktor penting dalam kesuksesan ataupun kelangsungan hidup perusahaan.
Berdasarkan pengertian yang dijabarkan oleh para ahli diatas dapat disimpulkan bahwa pengertian Business Intelligence (BI) adalah kumpulan aktivitas, tool, atau proses yang digunakan, dan metodologi analisa yang secara sistematis dapat menghasilkan suatu informasi dan pengetahuan yang berguna untuk mendukung proses pembuatan keputusan yang kompleks.
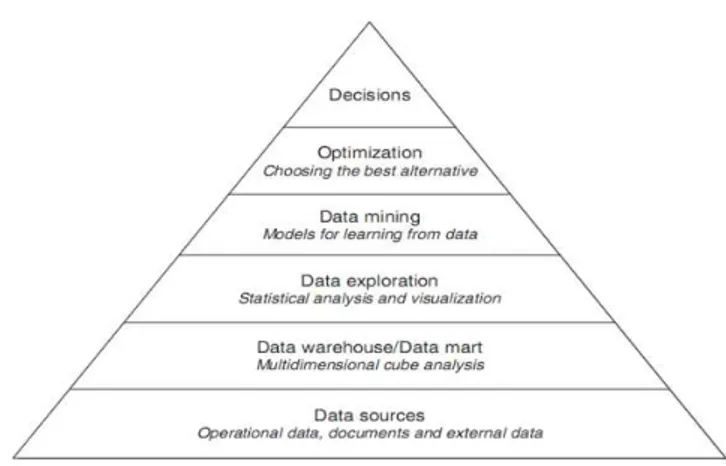
2.10.2 Arsitektur Business Intelligence
Menurut Vercellis (2009), arsitektur dari sebuah business intelligence system, terdiri dari enam komponen utama yaitu:
a) Data sources
Pada tahap pertama, diperlukan suatu proses untuk mengumpulkan dan mengintegrasikan data-data yang disimpan dalam berbagai sumber yang bervariasi, yang mana saling berbeda baik itu asal maupun jenisnya. Sumber ini kebanyakan berasal dari data-data yang terdapat pada
operational systems, tetapi bisa juga berasal dari dokumen yang tidak
terstruktur seperti email dan data-data yang dikirimkan oleh pihak luar. b) Data Warehouse dan Data Marts
Dengan menggunakan extraction dan transformation tools yang dikenal sebagai ETL (extract, transform, load), data yang berasal dari berbagai sumber yang berbeda disimpan ke dalam database yang ditujukan untuk mendukung analisis business intelligence. Database inilah yang biasanya dikenal dengan sebutan data warehouse dan data marts.
c) Data Exploration
Pada level ketiga ini, tools-tools yang berfungsi untuk keperluan analisis
business intelligence pasif digunakan. Tools-tools ini terdiri dari query
dan reporting systems, serta statistical methods. Metodologi ini bersifat pasif karena para pengambil keputusan harus mengambil keputusan berdasarkan hipotesa mereka sendiri atau mendefinisikan kriteria dari
data extraction, kemudian menggunakan tools analisis untuk
menemukan jawaban dan mencocokkannya dengan hipotesa awal mereka.
d) Data Mining
Level keempat ini terdiri dari sejumlah metodologi business intelligence
yang bersifat aktif yang tujuannya adalah untuk mengekstrak informasi dan pengetahuan dari data. Metodologi ini berisi sejumlah model matematika untuk pengenalan pola, pembelajaran mesin, dan teknik data
mining. Tidak seperti tools yang digunakan pada level sebelumnya,
model dari business intelligence yang bersifat aktif ini tidak mengharuskan para pengambil keputusan untuk mengeluarkan hipotesa apapun.
e) Optimization
Pada level ini, solusi terbaik harus dipilih dari sekian alternative yang ada, yang biasanya sangat banyak dan beragam.
f) Decisions
Pada level terakhir ini yang menjadi persoalan utama adalah bagaimana menentukan keputusan akhir yang akan diambil yang dikenal sebagai
decision making process. Walaupun metodologi business intelligence
berhasil diterapkan, pilihan untuk mengambil sebuah keputusan ada pada para pengambil keputusan. Pertimbangkan untuk mengambil keputusan ini biasanya diambil juga dari informasi yang tidak terstruktur serta tidak formal dan memodifikasi rekomendasi serta kesimpula yang dicapai melalui penggunaan model matematika.
Gambar 2.6 Komponen Business Intelligence (Sumber: Vercellis, 2009)
2.10.3 Siklus Hidup Business Intelligence
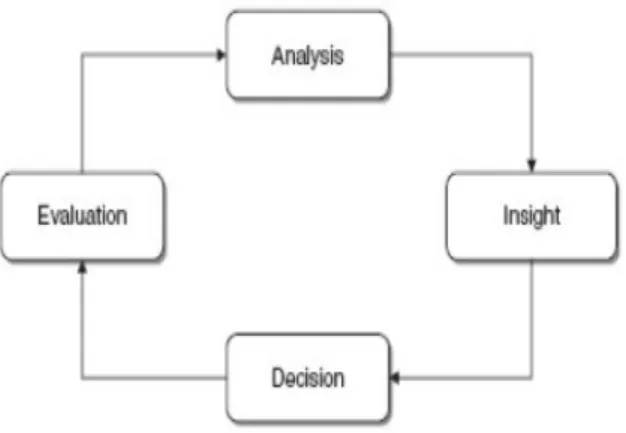
Menurut Vercellis (2009), ada 4 siklus hidup business intelligence, yaitu: a) Analysis
Saat fase analisis, sangat penting untuk mengenali masalah luar maupun dalam. Pengambil keputusan harus membuat representasi dari kejadian yang sedang dianalisis, dengan mengidentifikasikan faktor penting yang paling relevan dengan masalah.
b) Insight
Fase kedua membuat pengambil keputusan mengerti lebih dalam mengenai masalah, biasanya dalam tingkatan kausal. Sebagai contoh,
jika analisis dalam fase pertama menunjukkan bahwa banyak pelanggan yang tidak lagi melanjutkan asuransi mereka, dalam fase kedua sangat penting untuk mengidentifikasi profil dan karakteristik yang dimiliki oleh pelanggan. Informasi yang didapat dari fase pertama ditransformasikan kedalam fase kedua.
c) Decision
Saat fase ketiga, pengetahuan yang didapat dari fase kedua diubah menjadi suatu keputusan yang akan diikuti dengan ksi. Metodologi
business intelligence memungkinkan fase analisis dan pendalaman
dieksekusi berkali-kali agar keputusan yang efektif dan tepat waktu dalam dibuat untuk memenuhi prioritas strategis suatu perusahaan. d) Evaluation
Fase terakhir dari Business Intelligence meliputi pengukuran kinerja dan evaluasi. Dengan menunjukkan indikator kinerja yang dapat digunakan untuk mengevaluasi kinerja dari perusahaan.
Gambar 2.7 Siklus Hidup Business Intelligence (Sumber: Vercellis, 2009)
2.10.4 Keuntungan Business Intelligence
Menurut Khan (2012) dalam jurnalnya mengatakan bahwa sementara dunia bisnis berubah dengan cepat dan proses bisnis menjadi lebih dan lebih kompleks sehingga lebih sulit bagi manager untuk memiliki yang komprehensif pemahaman lingkungan bisnis. Faktor globalisasi, deregulasi, merger dan akuisisi, kompetisi dan inovasi teknologi, telah memaksa perusahaan untuk memikirkan kembali strategi bisnis mereka dan hanya perubahan besar telah menggunakan teknik Business
Inteligence (BI) untuk membantu mereka memahami dan mengendalikan proses
bisnis untuk mendapatkan keuntungan kompetitif. BI terutama digunakan untuk meningkatkan ketepatan waktu dan kualitas informasi, dan memungkinkan manager lebih memahami posisi perubahan mereka dibandingkan dengan pesaing.
Aplikasi dan Teknologi BI ini membantu perusahaan untuk menganalisis perubahan tren dalam pangsa pasar, perubahan perilaku pelanggan dan pengeluaran pola, preferensi pelanggan, kemampuan perusahaan dan kondisi pasar. Hal ini digunakan untuk membantu analisis dan manager menentukan penyesuaian yang paling mungkin untuk merespon perubahan tren. Ia telah muncul sebagai sebuah konsep untuk menganalisis data yang dikumpulkan dengan tujuan untuk membantu unit pengambilan keputusan mendapatkan pengetahuan yang lebih baik yang komprehensif dari sebuah operasi, organisasi dan dengan demikian membuat keputusan bisnis lebih baik.
2.10.5 Komponen Business Intelligence
Menurut Kapoor (2010) dalam jurnalnya mengatakan bahwa komponen
Business Intelligence terdiri dari 4 (empat) sub-system, yaitu:
a) The Data Management Sub-System
Mencakup komponen yang berkaitan dengan data warehouse, data mart, dan Online Analytical Processing (OLAP). Orang-orang yang bekerja terutama di daerah ini adalah "teknologi", yang mengkhususkan diri dalam Ilmu Komputer, Sistem Informasi Manajemen (MIS), atau disiplin terkait.
b) The Advanced Analytics Sub-System
Meliputi analisis fungsi berdasarkan statistik, data mining, peramalan, pemodelan prediktif, analisis prediktif, dan optimasi. Orang-orang yang bekerja terutama di daerah ini adalah super user, yang mengkhususkan diri dalam Matematika, Statistik, Ilmu Manajemen atau disiplin yang terkait.
c) The Business Performance Management Sub-System
Terdiri dari proses untuk tujuan strategis dan tujuan, pengukuran kinerja dan mentoring, menganalisis kinerja dan membuat keputusan untuk meningkatkan kinerja bisnis.
d) The Information Delivery Sub-System
Memberikan pengguna bisnis kemampuan untuk mengakses laporan dan terus memantau kinerja organisasi pada perusahaan dan tingkat yang lebih rendah. Menurut perannya sebagai teknokrat, super user, manager menengah, manager eksekutif, atau pengguna operasional, ia akan diberi
peran berbasis hak untuk mengakses laporan yang relevan dalam ringkasan dan atau format rinci. Pengguna akhir juga mampu memantau kegiatan kunci seperti tren, metrik, dan KPI dalam mudah untuk memahami desain, seperti portal informasi dikonfigurasi, Scorecard dan
dashboard. Tergantung pada peran individu dan tanggung jawab,
disajikan dengan tren, metrik, dan KPI pada tingkat agregasi yang sesuai dengan keamanan untuk memblokir non-hak istimewa item.
2.11 Metode Ontology
Metode ontology digunakan untuk pemodelan bentuk dari konseptual data
warehouse yang akan dirancang. Metode ontology ini memiliki beberapa tahapan (rule based) didalam perancangan. Untuk lebih jelasnya akan didefinisikan dibawah ini.
2.11.1 Definisi Ontology
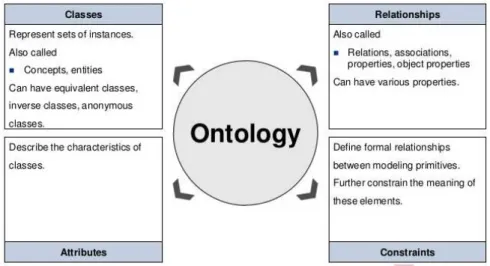
Metode ontology adalah suatu konseptual yang formal dari sebuah domain tertentu. Ontology juga merupakan teori tentang makna dari suatu obyek, properti dari suatu obyek, serta relasi obyek tersebut yang mungkin terjadi pada suatu domain pengetahuan. Ontology sangat penting karena dapat digunakan menerangkan tentang struktur suatu database. Secara teknis sebuah ontology direpresentasikan dalam bentuk
classes, properties, slots, dan instans.
a. Class, menerangkan konsep (atau makna) suatu domain. Class adalah kumpulan dari elemen dengan properti yang sama. Suatu class dapat mempunyai turunan subclass yang menerangkan konsep yang lebih spesifik. b. Properti, menerangkan konsep nilai-nilai, status, terukur yang mungkin ada
c. Slot, merupakan representasi dari kerangka pengetahuan atau relasi yang menerangkan properti dari class dan instant.
d. Instant, adalah individu yang telah dibuat (diciptakan). Instant dari sebuah
subclass merupakan instant dari suatu superclass.
Gambar 2.8 Model Ontology
(Sumber: www.ontology.com, 2014) 2.11.2 Bahasa Ontology
Ontologi sendiri mempunyai struktur bahasa yang formal (terdefinisi), agar dapat digunakan. Beberapa struktur bahasa yang menyusun ontology antara lain :
a. XML (Extensible Markup Langguage)
Struktur mirip HTML yang tag-nya dapat didefiniskan sendiri. b. XML Schema
Bahasa yang membatasi struktur yang didefinisikan pada dokumen XML. c. RDF (Resource Description Framework)
Model data untuk objek (resources) dan relasi diantaranya, menyediakan
semantic yang sederhana untuk model data tersebut, dan data model ini dapat
d. RDF Schema
Adalah kosakata untuk menjelaskan properties dan classes dari sumber RDF, dengan sebuah semantics untuk hirarki penyamarataan dari properties dan
classes.
e. OWL (Ontology Web Langguage)
Menambahkan beberapa kosakata untuk menjelaskan properties dan classes, antara lain: relasi antara classes (misalkan disjointness), kardinalitas (misalkan tepat satu), equality, berbagai tipe dari properties, karakteristik dari
properties (misalkan symmetry), menyebutkan satu persatu classes .
2.12 Metode Rule Based
Aturan atau rule merupakan sebuah konsep yang menjadi acuan pada suatu model
ontology dan proses pencarian informasi dengan query menggunakan bahasa alami
(Natural Language Processing).
2.12.1 Ontology Rule Based
Suatu model ontology dimungkinkan terdiri dari sebuah rule bahkan lebih dari satu rule. Banyaknya rule yang digunakan atau diterapkan pada sebuah model ontology dipengaruhi oleh banyak faktor seperti komplektivitas permasalahan, keragaman data yang digunakan, hubungan antar objek dalam permasalahan, dan lain sebagainya. Rule digunakan untuk mengatur relasi atau hubungan antar elemen-elemen penyusun
ontology seperti relasi antar class, relasi class dengan data type, relasi antar instance
2.12.2 Query Rule Based
Query Rule Based merupakan sebuah aturan yang menjadi acuan pada proses
pencarian informasi dengan kata kunci bahasa alami (natural language) indonesia. Tipe
query yang digunakan untuk acuan implementasi ini dengan penyusunan aturan
produksi (production rule). Berdasarkan identifikasi yang telah dilakukan Andayani yang digunakan pada penelitian Wibisono (2013) , terdapat tujuh tipe query sebagai berikut:
1. Tipe q _ a (query – atribut)
Tipe query ini hanya berisi satu atribut pada kalimat yang berfungsi sebagai pertanyaan atau pernyataan.
2. Tipe q _ a _ a (query – atribut – atribut)
Tipe query ini berisi beberapa atribut yang akan ditampilkan. 3. Tipe q _ a _ opr (query – atribut – operator)
Tipe query berisi satu atribut yang akan ditampilkan dan mempunyai satu kondisi.
4. Tipe q _ a _ a _ opr (query – atribut – atribut – operator – atribut – operator) Tipe query berisi beberapa atribut yang akan ditampilkan dan beberapa kondisi.
5. Tipe q _ a _ opr _ data (query – atribut – operator – <data>)
Tipe query berisi beberapa atribut yang akan ditampilkan dan kondisi operator ‘lebih’, ‘kurang’, ‘sebelum’ atau ‘sesudah’.
6. Tipe q _ a _ bukan (query – atribut – bukan – data)
Tipe query berisi sebuah atribut yang akan ditampilkan dan kondisi operator ‘bukan’ atau ‘tidak’ atau ‘selain’.
7. Tipe q _ a _ a _ bukan (query – atribut – atribut – bukan – data)
Tipe query berisi beberapa atribut yang akan ditampilkan dan kondisi operator ‘bukan’ atau ‘tidak’ atau ‘selain’.
2.13 Metode Nine Step Kimball
Metodologi yang digunakan perancangan basis data untuk semantic data warehouse adalah metodologi sembilan langkah atau tahap (Nine-Step Methodology) yang dikemukan oleh Kimball. Kesembilan langkah tersebut meliputi:
1. Pemilihan Proses (Choosing the process)
Pada tahap ini yang dilakukan adalah data mart yang pertama kali dibangun haruslah data mart yang dapat dikirim tepat waktu dan dapat menjawab semua pertanyaan bisnis yang penting.
2. Pemilihan Sumber (Choosing the grain)
Pemilihan sumber data untuk memutuskan secara pasti apa yang diwakili atau direpresentasikan oleh sebuah tabel fakta. Misal, jika sumber data dari sebuah tabel fakta properti sale adalah properti sale individual maka sumber dari sebuah dimensi pelanggan berisi rincian pelanggan yang membeli properti utama. 3. Mengidentifikasi Dimensi (Identifying and conforming the dimensions)
Pada tahap identifikasi dimensi ini yang dilakukan adalah:
a. Set dimensi yang dibangun dengan baik, memberikan kemudahan untuk memahami dan menggunakan data mart.
b. Dimensi ini penting untuk menggambarkan fakta-fakta yang terdapat pada tabel fakta.
c. Jika ada dimensi yang muncul pada dua data mart, kedua data mart tersebut harus berdimensi sama, atau paling tidak salah satunya berupa subset matematis dari yang lainnya.
d. Jika sebuah dimensi digunakan pada dua data mart atau lebih, dan dimensi ini tidak disinkronisasi, maka keseluruhan data warehouse akan gagal, karena dua data mart tidak bisa digunakan secara bersama-sama.
4. Pemilihan Fakta (Choosing the facts)
Pada tahap pemilahan fakta yang dilakukan adalah:
a. Sumber dari sebuah tabel fakta menentukan fakta mana yang bisa digunakan dalam data mart.
b. Semua fakta harus diekspresikan pada tingkat yang telah ditentukan oleh sumber.
5. Menyimpan Pre-kalkulasi di Tabel Fakta (Storing pre-calculations in the fact
table)
Tabel fakta merupakan tabel utama dalam data warehouse, semua informasi yang ingin dicapai lewat data warehouse melalui tabel fakta. Banyak proses kalkulasi dilakukan terhadap tabel fakta, dan untuk memudahkan dalam implementasi ke data warehouse perlu menyimpan hasil pre-kalkulasi tersebut. 6. Melengkapi Tabel Dimensi (Rounding out the dimension tables)
Pada tahap ini yang kita lakukan adalah:
a. Menambahkan keterangan selengkap-lengkapnya pada tabel dimensi. b. Keterangannya harus bersifat intuitif dan mudah dipahami oleh
7. Pemilihan Durasi Basis Data (Choosing the duration of the database)
Berdasarkan kegunaan dari basis data yang dibuat maka pada tahap ini ditentukan berapa lama data tersebut tersimpan.
8. Menelusuri Perubahan Dimensi Secara Perlahan (Tracking slowly changing
dimensions)
Ada tiga tipe perubahan dimensi yang perlahan, yaitu : a. Atribut dimensi yang telah berubah tertulis ulang
b. Atribut dimensi yang telah berubah menimbulkan sebuah dimensi baru c. Atribut dimensi yang telah berubah menimbulkan alternatif sehingga
nilai atribut lama dan yang baru dapat diakses secara bersama pada dimensi yang sama.
9. Menentukan Prioritas dan Mode Query (Deciding the query priorities and the
query modes)
Setelah langkah 1 sampai dengan 8 dilalui, maka pada tahap ini kita menggunakan perancangan fisik. Tahap perancangan fisik ini menghasilkan data
warehouse yang siap diimplementasikan. Untuk itu perlu dibuat sebuah sistem
atau aplikasi yang didalamnya berisi query-query yang digunakan untuk dapat menampilkan data yang diinginkan oleh pengguna.
2.14 PHP (PHP: Hypertext Preprocessor)
2.14.1 Pengantar PHP (PHP:Hypertext Preprocessor)
PHP adalah bahasa atau script yang dijalankan pada sisi server yang diciptakan khusus untuk pengembangan web. Di dalam halaman HTML kita dapat menambahkan kode PHP yang akan dijalankan pada saat halaman dikunjungi. Kode PHP yang
ditanamkan akan dijalankan oleh web server dan men-generate HTML atau output lain yang akan dilihat oleh pengunjung.
PHP dibuat pada tahun 1994 oleh Rasmus Lerdorf. Kemudian dikembangkan oleh para ahli di seluruh dunia. Pada Januari 2001, PHP digunakan hampir sekitar lima juta domain di seluruh dunia dan terus berkembang dengan pesatnya. Kebanyakan dari
sintaks PHP dipinjam Perl, C, dan Java dengan beberapa penambahan corak spesial
PHP. PHP biasanya sering digunakan bersama web server apache diberagam sistem operasi. PHP dikembangkan sepenuhnya untuk bahasa skrip server-side programming. PHP bersifat open source, kita dapat mengakses langsung ke source code PHP dan dapat digabungkan dengan berbagai server yang berbeda-beda. PHP mempunyai kemampuan mengakses database dan diintegrasikan dengan HTML. PHP semakin populer karena memiliki beberapa kelebihan, antara lain :
a. Mudah dibuat dan dijalankan.
b. Mampu berjalan pada web server dengan sistem operasi yang berbeda-beda, seperti sistem operasi UNIX, keluarga windows, dan macintosh.
c. PHP bisa didapatkan secara gratis.
d. Dapat berjalan pada web server yang berbeda, seperti Microsoft Personal Web
Server, Apache, IIS, Xitami, dll.
2.14.2 Framework Codeigniter
Codeigniter merupakan framework PHP yang diklaim memiliki eksekusi
tercepat dibandingkan dengan framework yang lainnya (Saputra, 2011). Codeigniter bersifat open source dan menggunakan model basis MVC (Model Veiw Controller), yang merupakan model konsep modern framework yang digunakan saat ini. Dengan
konsep MVC ini, segala macam logika dan layout telah dipisahkan, sehingga si
programmer dan designer dapat mengerjakan masing-masing tugasnyan secara fokus.
Konsep MVC juga dapat menuntun para pembuat program untuk membangun web dengan cara yang terstruktur. Dilihat dari cara kerjanya, framework codeigniter menekankan pada MVC. Untuk alurnya dapat dilihat pada Gambar 2.9 dibawah ini.
Gambar 2.9 Konsep MVC (Sumber : Saputra, 2011)
1. Model, digunakan sebagai presentasi database. Berbeda dengan framework CadePHP. Dalam Codeigniter, segala macam perintah-perintah query SQL diletakkan dalam file model, seperti insert, edit, delete, dan select. Karena semuanya berhubungan dengan database.
2. Controller, digunakan sebagai pengendali (control) antara view dan model melalui permintaan dari HTTP.
3. View, suatu halaman khusus yang digunakan untuk menyajikan informasi kepada client. Secara definisi, segala macam permintaan yang dikelola oleh
controller dan model, akan dikembalikan kepada view sesuai hasi permintaan
Alur kerjanya dapat dilihat pada Gambar 2.10 berikut ini.
Gambar 2.10 Alur Kerja MVC (Sumber: Saputra, 2011) Dari gambar 2.2 dapat dijelaskan sebagai berikut:
1. Index.php merupakan controller awal yang menginiliasisakan kebutuhan untuk menjalankan Codeigniter.
2. Router/Routing merupakan bagian yang menentukan kegiatan yang harus dilakukan ketika ada request/permintaan dari client/browser.
3. Caching merupakan bagian yang mengcek apakah data sudah pernah diminta atau belum. Jika cache dalam keadaan aktif, maka akan langsung dikirimkan kepada client/browser dengan mengabaikan alur kerja normal.
4. Security, sebelum apalikasi dikirimkan, maka akan terlebih dahulu data tersebut difilter sebagai keamanan.
5. Controller merupakan pengendali dari jalannya aplikasi dan akan segera
memproses sesuai request/permintaan yang diminta, yaitu models, libraries,
helpers, plugins, dan scripts.
6. View merupakan bagian dari menyajikan suatu informasi ke client/browser sesuai dengan permintaan yang diminta (setelah melewati tahap 1 s/d 5).
2.15 Database MySQL
MySQL merupakan database yang populer digunakan karena kemudahannya, kecepatan kinerja, dan memenuhi kebutuhan database perusahaan-perusahaan skala menengah kecil. Keuntungan lainnya adalah bahwa software ini sudah open source, yang berarti dapat dipergunakan dan didistribusikan baik untuk pribadi maupun komersial secara bebas. MySQL dikenal sebagai database yang pertama kali didukung oleh bahasa pemrograman skrip untuk internet, misal PHP dan Perl. MySQL dan PHP dianggap sebagai pasangan software pengembangan aplikasi berbasis web yang ideal.
Antar muka untuk aplikasi database MySQL dapat menggunakan bahasa pemrograman umum seperti Java, C/C++, MS Visual Basic ataupun Borland Delphi. Hasil akhir dari model aplikasi yang dihasilkan adalah aplikasi Client/Server. Umumnya akses kepada database MySQL dari bahasa pemrograman yang disebutkan di atas jika di lingkungan Windows menggunakan MyODBC, driver koneksi database dengan menggunakan standar ODBC. Paket distribusi software MySQL terdiri atas komponen:
1. Server SQL merupakan komponen yang menjadi inti dari MySQL, sebagai
engine, dan menyediakan akses kepada database.
2. Program client untuk mengakses server program interaktif yang memungkinkan kita untuk melakukan query dan manipulasi data kemudian melihat hasilnya secara langsung, program untuk administratif dan utilitas. Hanya satu utilitas yang digunakan untuk melakukan pengendalian server, lainnya untuk mengekspor, impor data, memeriksa hak akses dan lain-lainnya. 3. Sekumpulan library untuk menulis program untuk mengakses server
merupakan kumpulan library fungsi yang dapat digunakan untuk membuat program client sendiri dengan menggunakan bahasa C, karena library yang
disediakan menggunakan C, sebenarnya bisa juga untuk digunakan oleh bahasa pemrograman lain.
2.16 Teknik Pengujian Sistem 2.16.1 Pengujian Black Box
Menurut Luqman (2012), pengujian black box merupakan tahap yang berfokus pada pernyataan fungsional perangkat lunak. Test case ini bertujuan untuk menunjukan fungsi perangkat lunak tentang cara beroperasinya. Apakah pemasukan data telah berjalan sebagaimana mestinya dan apakah informasi yang tersimpan dapat dijaga kemutahirannya. Selain itu juga black box adalah pengujian yang dilakukan hanya mengamati hasil eksekusi melalui data uji dan memeriksa fungsional dari perangkat lunak. Jadi dianalogikan seperti melihat suatu kotak hitam, hanya bisa melihat penampilan luarnya saja, tanpa tau ada apa dibalik bungkus hitam nya. Pengujian black
box berfokus pada pengujian persyaratan fungsional perangkat lunak, untuk
mendapatkan serangkaian kondisi input yang sesuai dengan persyaratan fungsional suatu program. Dengan demikian, pengujian black box memungkinkan pembuat perangkat lunak mandapatkan serangkaian kondisi input yang sepenuhnya menggunakan semua persyaratan fungsional untuk suatu program. Pengujian black box berusah menemukan kesalahan dalam beberapa hal yaitu:
a. Fungsi-fungsi yang tidak benar atau salah. b. Kesalahan interface.
c. Kesalahan dalam struktur data atau akses database. d. Kesalahan kinerja, analisa, dan kesalahan terminasi.
2.16.2 Teknik Angket
Kuesioner atau angket merupakan teknik pengumpulan data yang dilakukan dengan cara memberi seperangkat pertanyaan atau pernyataan tertulis kepada responden untuk dijawabnya (Sugiyono, 2013). Sedangkan menurut Sutoyo (2012), kuesioner atau angket merupakan sejumlah pertanyaan atau pernyataan tertulis tentang data faktual atau opini yang berkaitan dengan diri responden, yang dianggap fakta atau kebenaran yang diketahui dan perlu dijawab oleh responden. Kuesioner cocok apabila digunakan pada responden yang jumlahnya cukup besar dan tersebar di wilayah yang luas.